Team,
Reaching out the community as we are applying some parts of resiliency
changes for the first time.
A discussion of working resource limits will benefit the community and the
log pods - in both directions
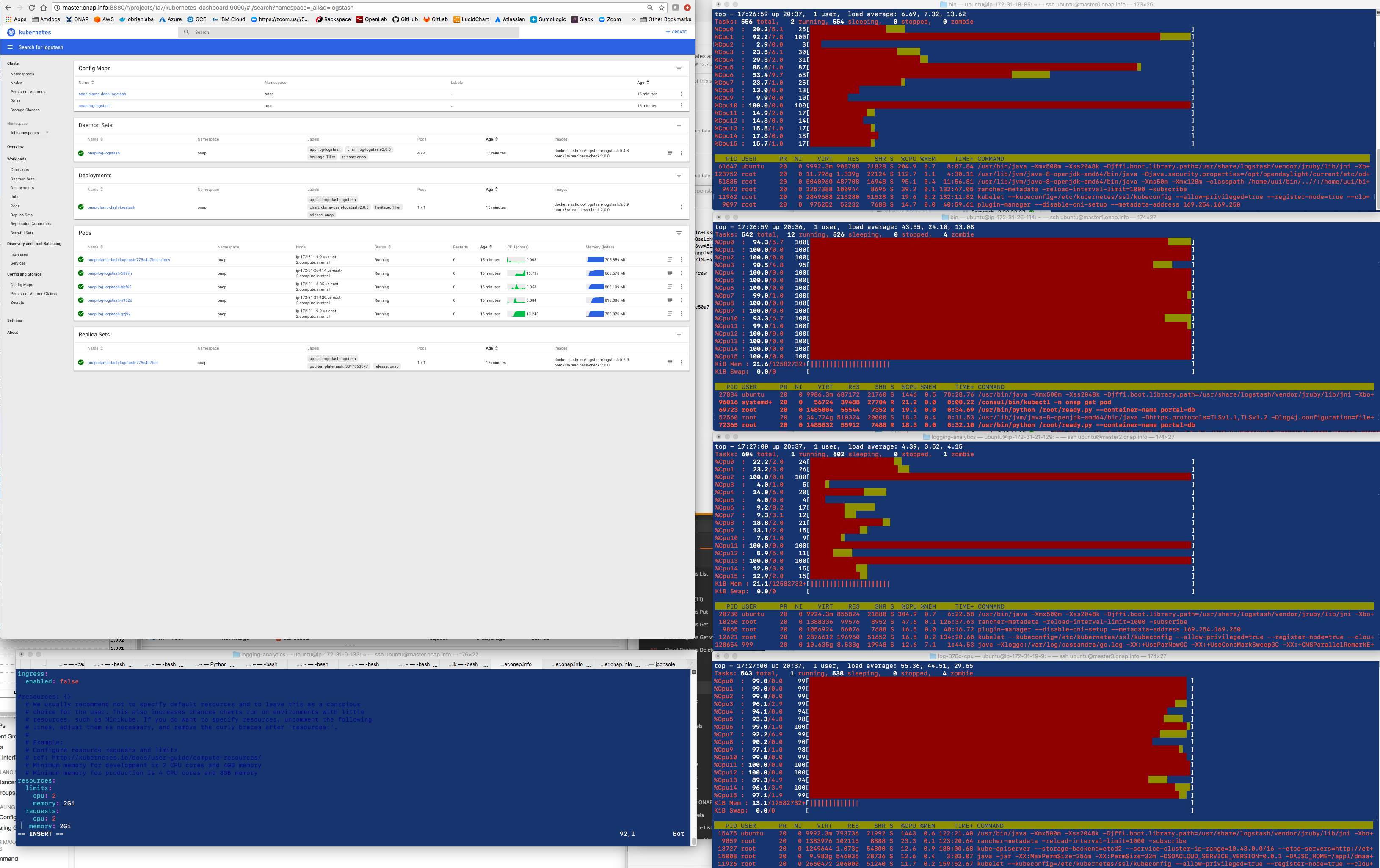
I am having difficulty getting cpu limits applied to a particular pod -
collaborating with the community in case anyone else is bringing in resource
requirements - I found another override in mariadb-galera but looking at the
rendered yaml In the k8s dashboard - shows an empty resources section there as
well - same issue.
Ideally we all (PTL's) do this together (There is a hierarchy in progress)
as we will need to decide on who get allocated from 2/4/8/16/32 cores on a
particular cluster VM flavor.
If anyone has implemented %percentage allocations let us know. We can
answer questions on what happens if multiple requests for 2 cores on a 2 core
vm occur for example.
The following patch looks straightforward - but it does not
actually have any effect yet (with/without quotes) - I am going over overrides
above and attempting to hardcode the values in the deployment.yaml to at least
work backwards from a working override.
https://gerrit.onap.org/r/#/c/49553/1/kubernetes/log/charts/log-logstash/values.yaml
resources:
limits:
cpu: "2"
requests:
cpu: "2"
Background:
-------------------
LOG-376 deals with a runaway logstash container where it will take (n-1)
vCores on 1 to 2 VMs on a 4-12 node cluster - I have seen 7 and 15 core
saturation.
https://jira.onap.org/browse/LOG-376
an example of a runaway pod that takes over 50% of the vCPU capacity of a 4
node 64core/256g cluster
https://jira.onap.org/secure/attachment/11827/Screenshot%202018-05-30%2013.26.34.png
The root cause southbound/northbound is the main issue and being looked at
- but for now I would like to limit the
The ELK stack had logstash clustered into a ReplicaSet with periodic
success and last week into a DaemonSet (1 container per VM) - however load
balancing is still asymmetric - likely due to misuse of the LB service -
looking into all of this - the current patch above is just to get the cluster
back to a working state
This issue with the ELK stack is at least 3 weeks old.
Thank you
/michael
This message and the information contained herein is proprietary and
confidential and subject to the Amdocs policy statement,
you may review at https://www.amdocs.com/about/email-disclaimer
<https://www.amdocs.com/about/email-disclaimer>
_______________________________________________
onap-discuss mailing list
[email protected]
https://lists.onap.org/mailman/listinfo/onap-discuss
{kind=link}