Hi Lisa, Le 10/07/2014 15:40, Lisa a écrit : > Hi Joe, > > we know the Amazon's hot market is based on a economic model. Suppose to > assign to each group a virtual money amount for renting hot instances. > So, the money may reflect the "share" concept in our model. This means that a > big money amount may rent potentially more resources (actually it depends by > the current resource price, the offer, etc). > As in the real World, this economic model emphasizes the difference between > rich and poor. So a rich group may rent all resources available for long time. > For sure this approach maximizes the resource utilization but it is not so > fair. It should guarantees that the usage of the resources is fairly > distributed among users and teams according to their mean number of VMs they > have got by considering the portion of the resources allocated to them (i.e. > share) and the evaluation of the effective resource usage consumed in the > recent past. > Probably this issue may be solved by defining fair lease contracts between > the user and the resource provider. What do you think? > To make it more clear, for simplicity let's say that we have only two teams, > "A" and "B" who are undertaking activities of Type3. The site administrator > assigns 1000$ to the group "A" and just 100$ to "B". Suppose "A" and "B" need > both more resources at the same time. So, for sure "B" will be able to rent > something only when "A" releases its resources or when "A" becomes poor. > Instead, with a fair-share algorithm, "B" would be able to rent some > resources because the purchasing power of "A" is adjusted by the recent > trading. > At the moment I'm still not really sure that this approach can cover this use > case.
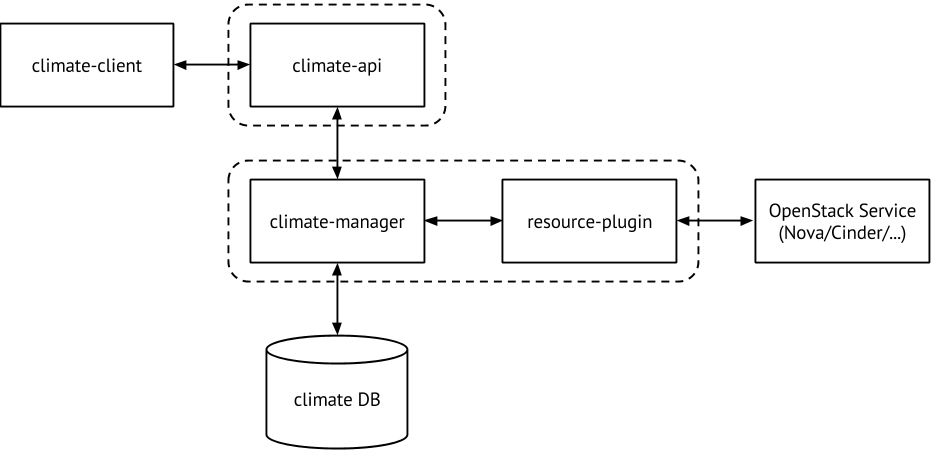
The idea behind what you mention is that there are possibly different policies for overcommitting the resources, but the contract remains the same : by accepting a Type 3 lease, users from either group A or group B accepts that an external event can terminate its lease. >From what is coming the event, and how the event is triggered is a question of policy to me. Ideally, it should be operator-driven thanks to a choice in the policies he wants to play with. In any way, that doesn't change how the workflow is made, nor the contract (ie. the API, as Joe said). -Sylvain > thanks a lot. > Cheers, > Lisa > > > > > On Tue, Jul 8, 2014 at 4:18 AM, Lisa <lisa.zangrando at pd.infn.it > <http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev>> wrote: > > >/ Hi Sylvain, > />/ > />/ > />/ On 08/07/2014 09:29, Sylvain Bauza wrote: > />/ > />/ Le 08/07/2014 00:35, Joe Gordon a écrit : > />/ > />/ > />/ On Jul 7, 2014 9:50 AM, "Lisa" <lisa.zangrando at pd.infn.it > <http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev>> wrote: > />/ > > />/ > Hi all, > />/ > > />/ > during the last IRC meeting, for better understanding our proposal (i.e > />/ the FairShareScheduler), you suggested us to provide (for the tomorrow > />/ meeting) a document which fully describes our use cases. Such document is > />/ attached to this e-mail. > />/ > Any comment and feedback is welcome. > />/ > />/ The attached document was very helpful, than you. > />/ > />/ It sounds like Amazon's concept of spot instances ( as a user facing > />/ abstraction) would solve your use case in its entirety. I see spot > />/ instances as the general solution to the question of how to keep a cloud > at > />/ full utilization. If so then perhaps we can refocus this discussion on the > />/ best way for Openstack to support Amazon style spot instances. > />/ > />/ > />/ > />/ > />/ Can't agree more. Thanks Lisa for your use-cases, really helpful for > />/ understand your concerns which are really HPC-based. If we want to > />/ translate what you call Type 3 in a non-HPC world where users could > compete > />/ for a resource, spot instances model is coming to me as a clear model. > />/ > />/ > />/ our model is similar to the Amazon's spot instances model because both try > />/ to maximize the resource utilization. The main difference is the mechanism > />/ used for assigning resources to the users (the user's offer in terms of > />/ money vs the user's share). They differ even on how they release the > />/ allocated resources. In our model, the user, whenever requires the > creation > />/ of a Type 3 VM, she has to select one of the possible types of "life time" > />/ (short = 4 hours, medium = 24 hours, long = 48 hours). When the time > />/ expires, the VM is automatically released (if not explicitly released by > />/ the user). > />/ Instead, in Amazon, the spot instance is released whenever the spot price > />/ rises. > />/ > />/ > /I think you can adapt your model your use case to the spot instance model > by allocating different groups 'money' instead of a pre-defined share. If > one user tries to use more then there share they will run out of 'money.' > Would that fully align the two models? > > Also why pre-define the different life times for type 3 instances? > > > >/ > />/ > />/ > />/ I can see that you mention Blazar in your paper, and I appreciate this. > />/ Climate (because that's the former and better known name) has been > kick-off > />/ because of such a rationale that you mention : we need to define a > contract > />/ (call it SLA if you wish) in between the user and the platform. > />/ And you probably missed it, because I was probably unclear when we > />/ discussed, but the final goal for Climate is *not* to have a start_date > and > />/ an end_date, but just *provide a contract in between the user and the > />/ platform* (see > />/ https://wiki.openstack.org/wiki/Blazar#Lease_types_.28concepts.29 ) > />/ > />/ Defining spot instances in OpenStack is a running question, each time > />/ discussed when we presented Climate (now Blazar) at the Summits : what is > />/ Climate? Is it something planning to provide spot instances ? Can Climate > />/ provide spot instances ? > />/ > />/ I'm not saying that Climate (now Blazar) would be the only project > />/ involved for managing spot instances. By looking at a draft a couple of > />/ months before, I thought that this scenario would possibly involve Climate > />/ for best-effort leases (see again the Lease concepts in the wiki above), > />/ but also the Nova scheduler (for accounting the lease requests) and > />/ probably Ceilometer (for the auditing and metering side). > />/ > />/ Blazar is now in a turn where we're missing contributors because we are a > />/ Stackforge project, so we work with a minimal bandwidth and we don't have > />/ time for implementing best-effort leases but maybe that's something we > />/ could discuss. If you're willing to contribute to an Openstack-style > />/ project, I'm personnally thinking Blazar is a good one because of its > />/ little complexity as of now. > />/ > />/ > />/ > />/ Just few questions. We read your use cases and it seems you had some > />/ issues with the quota handling. How did you solved it? > />/ About the Blazar's architecture ( > />/ https://wiki.openstack.org/w/images/c/cb/Climate_architecture.png): the > />/ resource plug-in interacts even with the nova-scheduler? > />/ Such scheduler has been (or will be) extended for supporting the Blazar's > />/ requests? > />/ Which relationship there is between nova-scheduler and Gantt? > />/ > />/ It would be nice to discuss with you in details. > />/ Thanks a lot for your feedback. > />/ Cheers, > />/ Lisa > />/ > />/ > /> > > > _______________________________________________ > OpenStack-dev mailing list > [email protected] > http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev
{kind=link}
_______________________________________________ OpenStack-dev mailing list [email protected] http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev