On Thu, 29 Aug 2013 13:02:51 -0400 "Søren Sandmann Pedersen" <[email protected]> wrote:
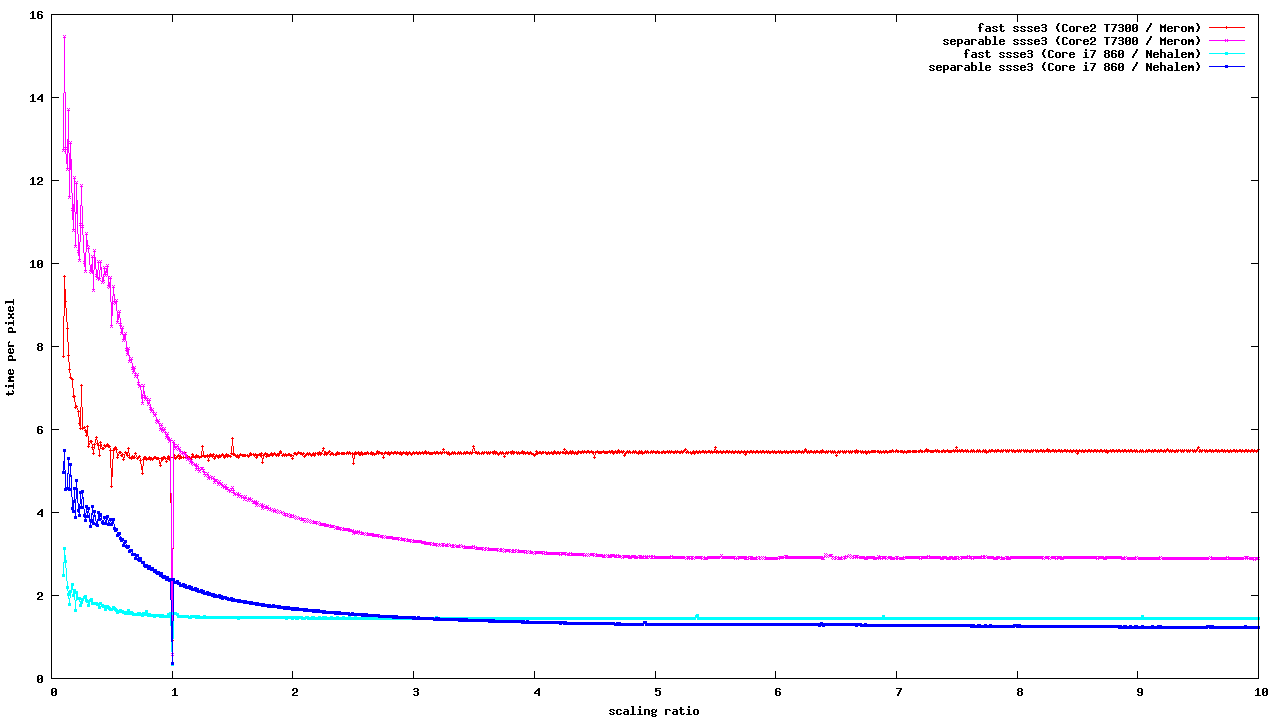
> The following patches add a new SSSE3 implementation and an iterator > for separable bilinear scaling. As expected, the new iterator is > clearly faster than the C iterator. > > Unfortunately or fortunately, when combined with the SSE2 combiner, it > is also clearly faster than the existing SSE2 fast paths. This is a > problem because the fast paths will be chosen ahead of the general > implementation and therefore of the new iterator. > > This is an instance of a more general problem that we have had for a > long time and which will only get worse as we add new iterators and > fast path. The following assumptions that we are making: > > - That a fast path is always better than iterators + combiners > - That newer SIMD is always better than older (e.g., SSE2 > MMX) > > are both wrong. The SSSE3 iterator demonstrates that the first is > wrong FWIW, the SIMD bilinear fast paths have been always slower compared to doing scaled fetch followed by unscaled combine (if looking at the CPU cycles alone). The fundamental problem here is that having one big loop stresses the registers allocation a lot more, the compiler generates worse code, we get spills to stack, etc. The less complex individual loops can be usually optimized much better, even though we have some additional load/store overhead for handling the temporary data. A good idea is to make sure that each loop can allocate all the important variables in registers. And if the loops are becoming too complex, then split them. I myself was not very enthusiastic about abusing the bilinear scaling code for implementing large all-in-one fast paths since the very beginning. But Taekyun Kim added a bunch of them, because it was a quick and simple tweak, and it clearly improved performance compared to having no fast path at all: http://cgit.freedesktop.org/pixman/commit/?id=81050f2784407b26 http://cgit.freedesktop.org/pixman/commit/?id=4dcf1b0107334857 And he even actually proved me wrong in the end :-) Because Taekyun Kim's bilinear fast paths for ARM NEON turned out to provide good performance in the limited memory bandwidth conditions: http://lists.freedesktop.org/archives/pixman/2012-July/002159.html Yes, the big unified fast paths needs more CPU cycles. However, if some of the separate loops are memory performance limited (the CPU is mostly waiting for the data from memory), while the other loops keep the memory controller idle, then the overall performance may be worse. Let's see if we can get really close to the memory bandwidth limits for the operations involving bilinear scaling on x86. The separable bilinear fetcher has a stage, where it only works with the data in the L1 cache (vertical interpolation). I guess that bilinear scaled add_8888_8888 might work better as a single pass fast path if compared to a separable bilinear fetcher and a combiner. And the non-separable bilinear code still seems to be somewhat competitive for dowscaling. But the scaling ratio, where the separable implementation becomes faster, differs for different generations of hardware: http://people.freedesktop.org/~siamashka/files/20130905/ http://people.freedesktop.org/~siamashka/files/20130905/ssse3-scaling-bench.png http://cgit.freedesktop.org/~siamashka/pixman-g2d/log/?h=ssse3-bilinear-fast-path-test As Chris Wilson suggested, it makes sense to add multiple variants of optimized bilinear fetch implementations and calibrate them to find the best separable/non-separable pair and the crossover point on different hardware (and also take into account 32-bit vs. 64-bit mode). The CPUID information should be sufficient to identify them at run time, but we would need to find volunteers to run tests on different hardware and populate the tables :-) > and the second could be wrong for example if we had an MMX fast > path specialized for scaling and an SSE2 one specialized for general > bilinear transformation. Both could handle a scaling operation, but > it's quite likely that the MMX one would be faster. Yes, this is ugly. And it's definitely difficult to keep track of all this stuff if it is done manually. > It's not the first time this has come up: > > http://lists.freedesktop.org/archives/pixman/2011-January/000949.html > http://lists.freedesktop.org/archives/pixman/2011-January/000950.html > http://lists.freedesktop.org/archives/pixman/2011-February/000957.html > > but no clear solution has been found so far. > > I still don't have a good answer; all ideas welcome. For the start, we can just try to get rid of as many redundant fast paths as possible. The simple format conversions and bilinear fast paths would be the first candidates. -- Best regards, Siarhei Siamashka _______________________________________________ Pixman mailing list [email protected] http://lists.freedesktop.org/mailman/listinfo/pixman
{kind=link}