Hi Ben, On Mon, 04 Apr 2016 19:53:36 +0100 "Ben Avison" <[email protected]> wrote:
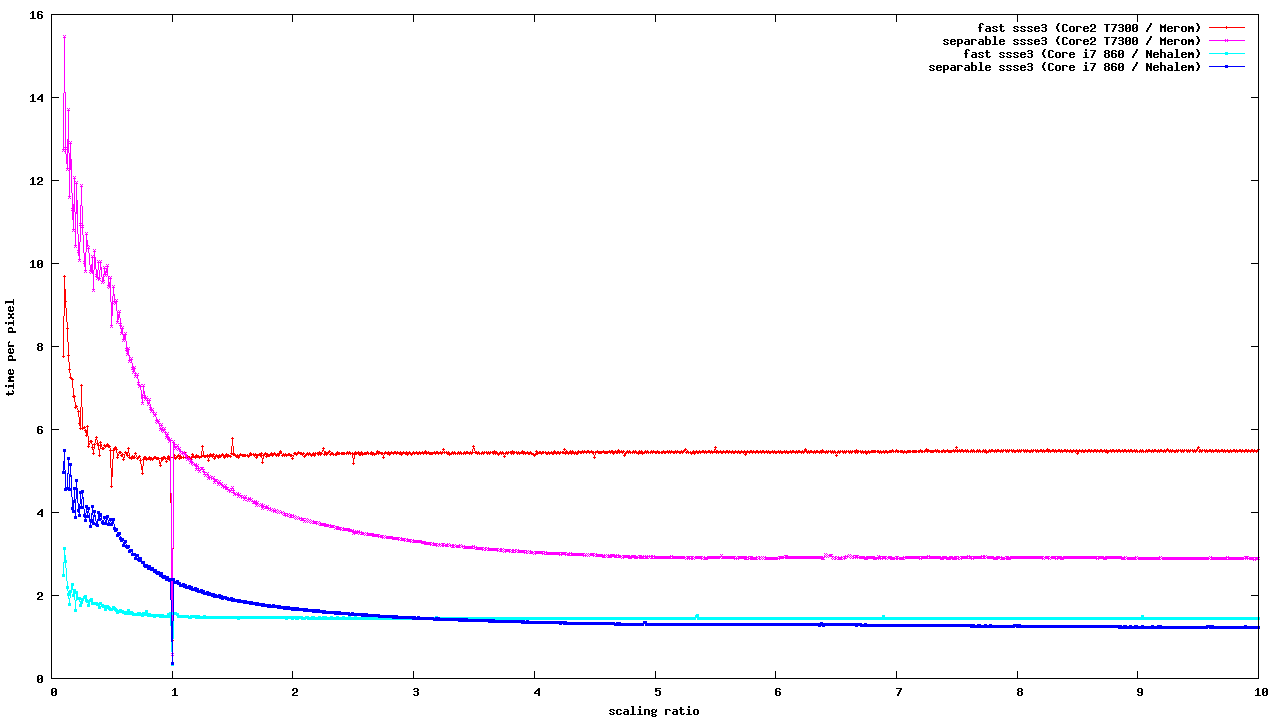
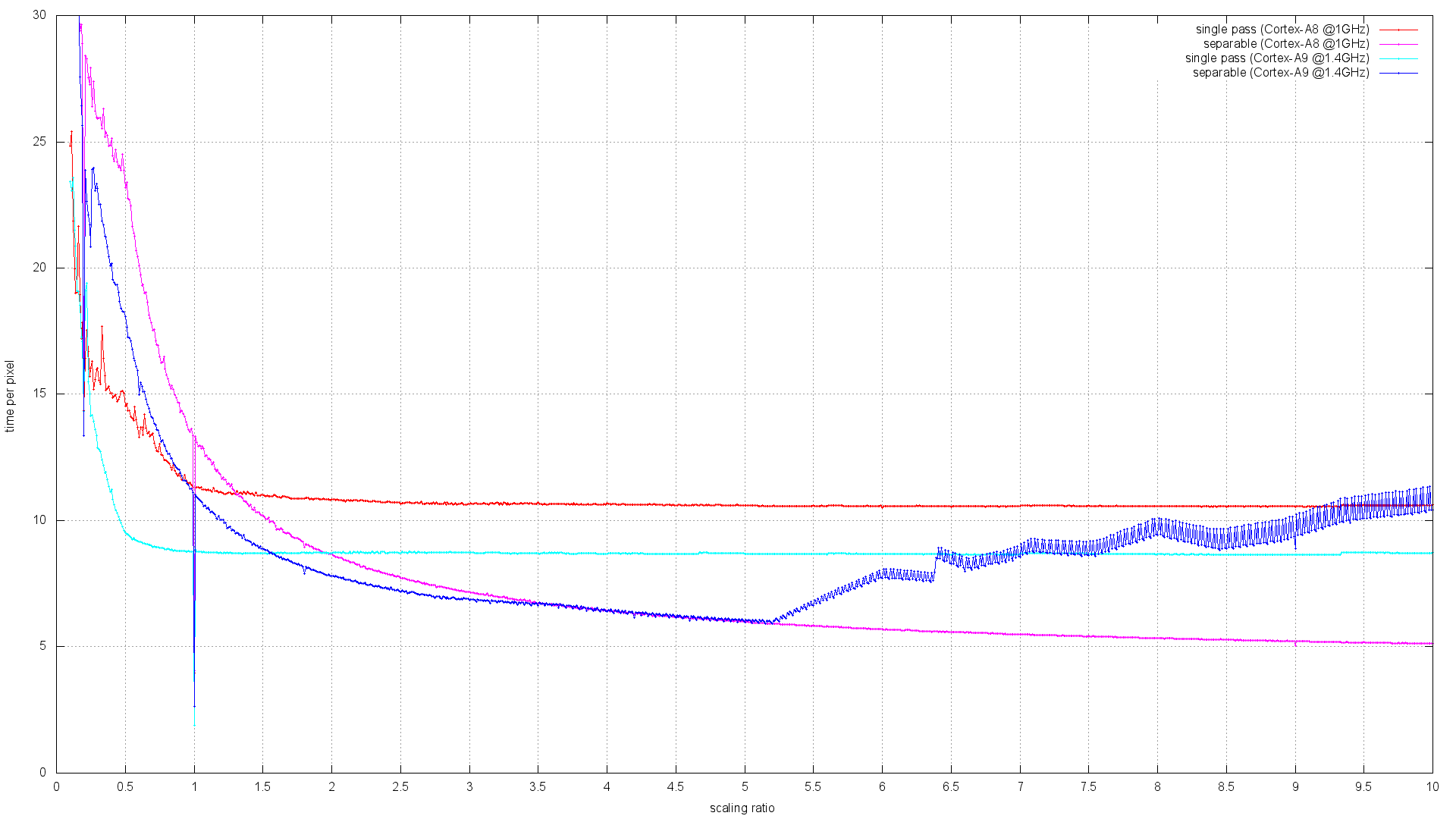
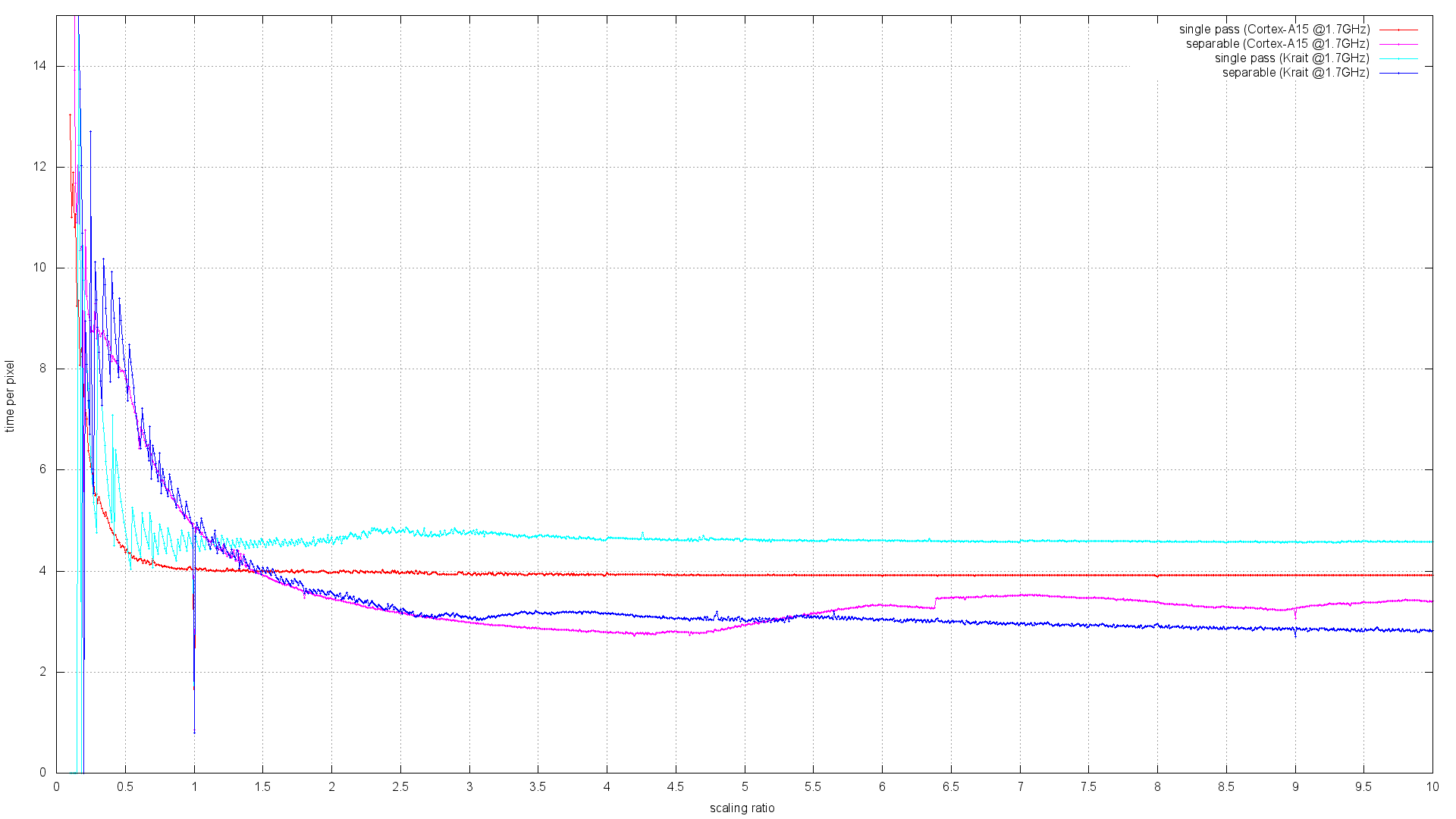
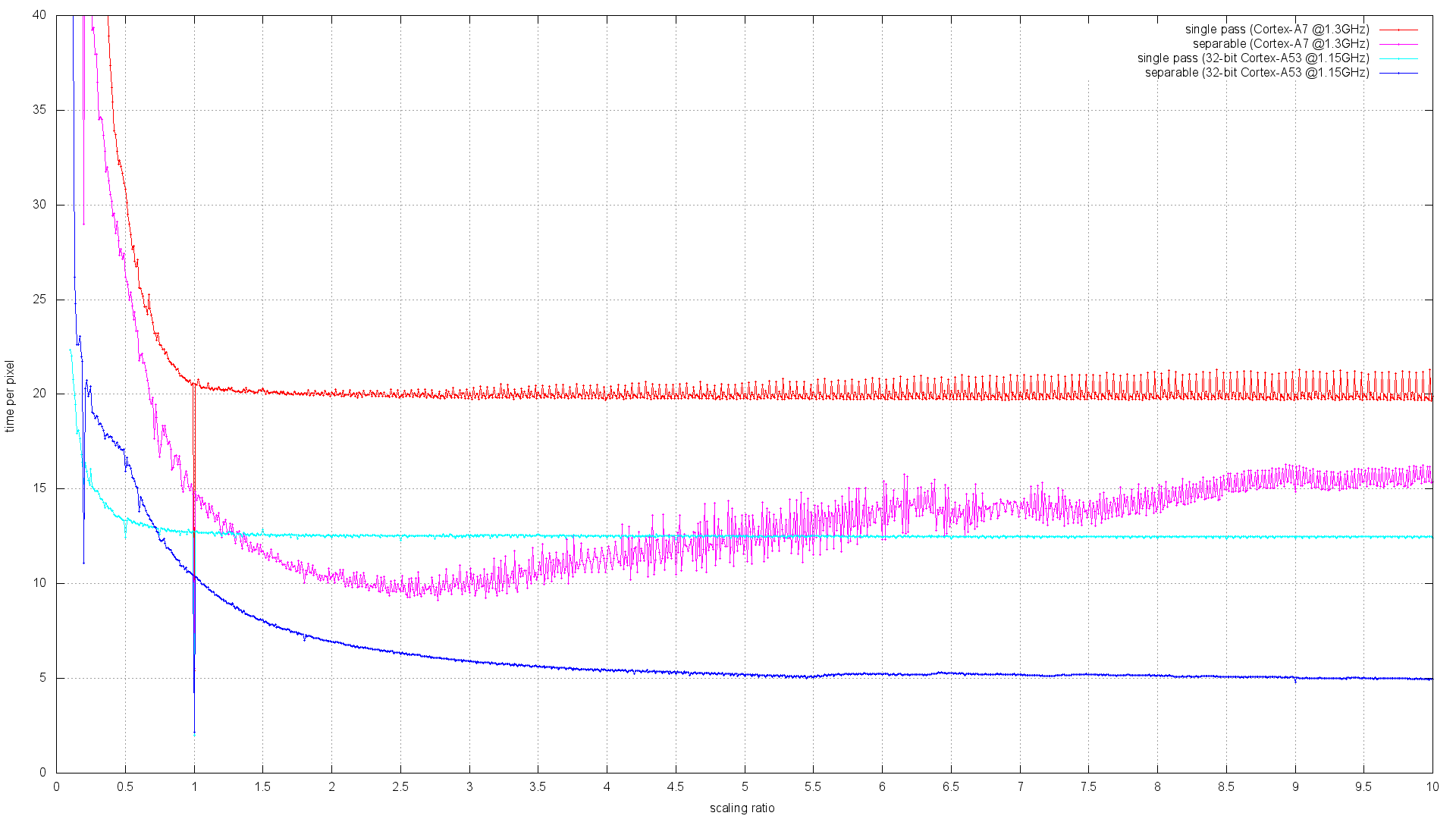
> On Sat, 02 Apr 2016 13:30:58 +0100, Mizuki Asakura <[email protected]> wrote: > > This patch only contains STD_FAST_PATH codes, not scaling (nearest, > > bilinear) codes. > > Hi Mizuki, > > It looks like you have used an automated process to convert the AArch32 > NEON code to AArch64. Will you be able to repeat that process for other > code, or at least assist others to repeat your steps? > > The reason I ask is that I have a large number of outstanding patches to > the ARM NEON support. The process of getting them merged into the > FreeDesktop git repository has been very slow because there aren't many > people on this list with the time and ability to review them, however my > versions are in many cases up to twice the speed of the FreeDesktop > versions, and it would be a shame if AArch64 couldn't benefit from them. It is always possible to find time for fixing bugs and reviewing the code, which is doing something obviously useful. > If your AArch64 conversion is a one-time thing, it will make make it > extremely difficult to merge my changes in. Yes, the way how we are going to keep the 32-bit and 64-bit code in sync is one of the concerns that have to be addressed. But you don't need to worry about this right now. Let's focus at one task at a time. So it's probably best to use the current pixman code for the initial AArch64 conversion round. And at the same time we can try to look at integrating your patches as 32-bit code first. > > After completing optimization this patch, scaling related codes should be > > done. > > One of my aims was to implement missing "iter" routines so as to accelerate > scaled plots for a much wider combination of pixels formats and Porter-Duff > combiner rules than the existing limited selection of fast paths could > cover. If you look towards the end of my patch series here: > > https://github.com/bavison/pixman/commits/arm-neon-release1 > > you'll see that I discovered that I was actually outperforming Pixman's > existing bilinear plotters so consistently that I'm advocating removing > them entirely, Please hold your horses! I did give this branch a try. And I'm not sure if you genuinely did not notice this fact, but with your runs of "lowlevel-blt-bench -b" tests, you are actually benchmarking a special code path for horizontal-only scaling against the code that is doing scaling in both directions. That's an obvious flaw in the benchmark itself, which gives you misleading results! I have already sent a fix for this problem: https://lists.freedesktop.org/archives/pixman/2016-April/004511.html And I have also pushed your patches with this lowlevel-blt-bench fix to the following git branch: https://cgit.freedesktop.org/~siamashka/pixman/log/?h=20160405-arm-neon-release1-from-bavison Reverting your removal of the existing bilinear plotters allows us to benchmark the implementations against each other via setting the PIXMAN_DISABLE=wholeops environment variable. Here are the results that I got: =========================== == ARM Cortex-A7 @1.3GHz == =========================== $ ./lowlevel-blt-bench -b ... (old NEON bilinear fast paths) src_8888_8888 = L1: 51.40 L2: 43.62 M: 48.08 ( 35.48%) HT: 32.84 VT: 31.14 R: 27.95 RT: 14.12 ( 102Kops/s) src_8888_0565 = L1: 48.61 L2: 44.98 M: 46.56 ( 25.72%) HT: 32.31 VT: 32.22 R: 26.04 RT: 13.08 ( 98Kops/s) over_8888_8888 = L1: 40.44 L2: 34.28 M: 34.44 ( 25.39%) HT: 22.75 VT: 22.67 R: 19.45 RT: 9.56 ( 82Kops/s) $ PIXMAN_DISABLE=wholeops ./lowlevel-blt-bench -b ... (new separable NEON iterators) src_8888_8888 = L1: 45.32 L2: 56.91 M: 47.55 ( 34.96%) HT: 34.17 VT: 29.90 R: 26.83 RT: 10.79 ( 80Kops/s) src_8888_0565 = L1: 38.08 L2: 47.27 M: 48.13 ( 26.61%) HT: 31.18 VT: 25.89 R: 23.72 RT: 8.87 ( 70Kops/s) over_8888_8888 = L1: 36.15 L2: 34.68 M: 33.45 ( 24.66%) HT: 24.91 VT: 20.88 R: 19.38 RT: 8.23 ( 68Kops/s) $ PIXMAN_DISABLE=wholeops ./lowlevel-blt-bench -bh ... (new separable NEON iterators, only horizontal) src_8888_8888 = L1: 92.51 L2: 74.43 M: 65.66 ( 47.27%) HT: 40.34 VT: 33.82 R: 30.02 RT: 11.76 ( 84Kops/s) src_8888_0565 = L1: 71.68 L2: 63.86 M: 58.99 ( 32.20%) HT: 36.19 VT: 28.96 R: 26.57 RT: 9.68 ( 74Kops/s) over_8888_8888 = L1: 61.80 L2: 44.28 M: 40.05 ( 29.13%) HT: 27.69 VT: 22.71 R: 21.11 RT: 8.86 ( 71Kops/s) ============================= === ARM Cortex-A9 @1.4GHz === ============================= $ ./lowlevel-blt-bench -b ... (old NEON bilinear fast paths) src_8888_8888 = L1: 115.82 L2: 113.35 M:107.33 (117.45%) HT: 57.95 VT: 48.20 R: 39.86 RT: 20.75 ( 140Kops/s) src_8888_0565 = L1: 105.67 L2: 104.18 M: 99.80 ( 82.02%) HT: 54.40 VT: 46.61 R: 37.24 RT: 19.10 ( 134Kops/s) over_8888_8888 = L1: 80.68 L2: 79.07 M: 75.95 ( 83.09%) HT: 38.69 VT: 29.25 R: 26.37 RT: 13.79 ( 112Kops/s) $ PIXMAN_DISABLE=wholeops ./lowlevel-blt-bench -b ... (new separable NEON iterators) src_8888_8888 = L1: 52.17 L2: 69.91 M: 49.56 ( 54.43%) HT: 43.70 VT: 36.51 R: 31.96 RT: 16.02 ( 112Kops/s) src_8888_0565 = L1: 43.51 L2: 61.72 M: 47.09 ( 38.76%) HT: 37.19 VT: 31.19 R: 27.30 RT: 12.64 ( 97Kops/s) over_8888_8888 = L1: 44.85 L2: 52.69 M: 25.41 ( 27.85%) HT: 24.53 VT: 21.33 R: 20.29 RT: 11.73 ( 94Kops/s) $ PIXMAN_DISABLE=wholeops ./lowlevel-blt-bench -bh ... (new separable NEON iterators, only horizontal) src_8888_8888 = L1: 99.47 L2: 87.14 M: 63.50 ( 69.66%) HT: 48.91 VT: 40.11 R: 35.05 RT: 17.69 ( 118Kops/s) src_8888_0565 = L1: 81.97 L2: 76.98 M: 61.69 ( 50.79%) HT: 40.95 VT: 33.84 R: 29.54 RT: 13.74 ( 102Kops/s) over_8888_8888 = L1: 82.53 L2: 62.73 M: 29.01 ( 31.82%) HT: 26.11 VT: 22.32 R: 21.50 RT: 12.67 ( 99Kops/s) ============================ The accuracy of measurements is not perfect, but it is good enough to easily see the pattern. Your implementations are providing better performance on ARM Cortex-A7 for the special case of horizontal-only scaling. But when we are doing general purpose scaling (for example the same scale factor for the x and y axes), the performance is more or less comparable between the existing bilinear fast paths and your new implementation. And if we take a different processor, for example ARM Cortex-A9, then everything changes. Now the general purpose scaling is much slower with your code. And even the horizontal-only special case is somewhat slower than the old fast paths which run general purpose bilinear scaling. I would say that rather than dropping the existing bilinear scaling code, it might be worth trying to implement the horizontal-only and the vertical-only special cases to see how much faster it can get. However if we try to do a really fair comparison, then we need to get rid of the redundant memcpy for the bilinear src_8888_8888 operation in the iterators based implementation. I had some old patches for this: https://lists.freedesktop.org/archives/pixman/2013-September/002879.html These patches were used in an old git branch: https://cgit.freedesktop.org/~siamashka/pixman/log/?h=ssse3-bilinear-fast-path-test which I used for comparing the fast path based SSE2/SSSE3 bilinear scaling implementation with the separable SSSE3 implementation on two x86 processors: Core2 T7300 (Merom) and Core i7 860 (Nehalem): https://lists.freedesktop.org/archives/pixman/2013-September/002892.html https://people.freedesktop.org/~siamashka/files/20130905/ssse3-scaling-bench.png It shows that on x86 processors, the straightforward single pass implementation works faster for downscaling, but becomes worse than the separable SSSE3 scaling code on upscaling. There is a crossover point, which may be different for different processors. Now I have rebased all this old code on a current pixman master branch, applied your patches with the separable NEON bilinear scaling implementation and have done pretty much the same benchmarks. This git branch is here: https://cgit.freedesktop.org/~siamashka/pixman/log/?h=20160405-separable-neon-bilinear-test This particular change makes your implementation faster by getting rid of the redundant memcpy: https://cgit.freedesktop.org/~siamashka/pixman/commit/?h=20160405-separable-neon-bilinear-test&id=c8c12d62098bf5b22828f851a035b6c4ecf0fc0b And here are the results from different ARM processors (all the benchmark scripts are also included): https://people.freedesktop.org/~siamashka/files/20160405-arm-bilinear/ It appears that the existing bilinear scaling code (src_8888_8888 ARM NEON fast path) works faster for downscaling on Cortex-A8, Cortex-A9, Cortex-A15 and Qualcomm Krait: https://people.freedesktop.org/~siamashka/files/20160405-arm-bilinear/neon-scaling-bench-a8-a9.png https://people.freedesktop.org/~siamashka/files/20160405-arm-bilinear/neon-scaling-bench-a15-krait.png Also your separable implementation is always faster for both upscaling/downscaling on ARM Cortex-A7, while the crossover point for ARM Cortex-A53 is currently around ~0.7x scaling factor, which is not exactly great: https://people.freedesktop.org/~siamashka/files/20160405-arm-bilinear/neon-scaling-bench-a7-a53.png > with the additional advantage that it simplifies the code > base a lot. So you might want to consider whether it's worth bothering > converting those to AArch64 in the first place. I'll try to tune the single-pass bilinear scaling code for Cortex-A53 to see if it can become more competitive. There are some obvious performance problems in it. For example, Cortex-A53 wants the ARM and NEON instructions to be interleaved in perfect pairs, so we can't have separate chunks of ARM and NEON code anymore: https://cgit.freedesktop.org/pixman/tree/pixman/pixman-arm-neon-asm.S?id=pixman-0.34.0#n3313 Now the instructions need to be mixed. Cortex-A8 had separate deep queue for NEON instructions, so it did not mind. As a side effect, now the "advanced prefetch" instructions sequence in the 32-bit ARM code needs to be carefully interleaved with the NEON instructions if we want it to run fast on Cortex-A53. Another problem is that now there is at least 1 cycle stall between vshll.u16 and vmlsl.u16 here: vshll.u16 q2, d20, #BILINEAR_INTERPOLATION_BITS vmlsl.u16 q2, d20, d30 vmlal.u16 q2, d21, d30 Cortex-A8 could run this instructions sequence in 3 cycles without stalls. Maybe there is something else. I have a sample code here if anyone cares to experiment: https://gist.github.com/ssvb/343379ceeb6d017c0023424b70fc90e2 Anyway, I'll try to make a Cortex-A53 optimized version and also a special horizontal scaling shortcut. Let's see how fast it can be :-) > I would maybe go so far as to suggest that you try converting all the iters > first and only add fast paths if you find they do better than the iters. > One of the drawbacks of using iters is that the prefetch code can't be as > sophisticated - it can't easily be prefetching the start of the next row > while it is still working on the end of the current one. But since hardware > prefetchers are better now and conditional execution is hard in AArch64, > this will be less of a drawback with AArch64 CPUs. > > I'll also repeat what has been said, that it's very neat the way the > existing prefetch code sneaks calculations into pipeline stalls, but it was > only ever really ideal for Cortex-A8. With Cortex-A7 (despite the number, > actually a much more recent 32-bit core) I noted that it was impossible to > schedule such complex prefetch code without adding to the cycle count, at > least when the images were already in the cache. Yes, Cortex-A7 is a pretty awful processor. It had the NEON unit cut in half (can process only 64 bits of data per cycle) and also its automatic hardware prefetcher can track just a single stream, which is not good enough for pixman. This is an oddball hardware, which differs a lot from most of the other ARM processors. I have not had any experience with any Cortex-A5 based device though, probably it may be roughly the same or even worse. Regarding your patches in general. It would be great to have more comments about the algorithm details, registers layout documentation and other stuff. It would be great not to regress performance on non Cortex-A7 processors (we probably need runtime detection and multiple implementations). It would be also great to have your new iterators framework eventually shared between ARM, x86 and other architectures to avoid unnecessary code duplication. Thanks for you work. -- Best regards, Siarhei Siamashka _______________________________________________ Pixman mailing list [email protected] https://lists.freedesktop.org/mailman/listinfo/pixman
{kind=link}
{kind=link}
{kind=link}
{kind=link}