On Sun, Jul 20, 2008 at 9:06 AM, Iljitsch van Beijnum <[EMAIL PROTECTED]> wrote: > I don't see that. > > If I want to shrink my routing tables I can filter out any Canadian more > specifics all over the world except in Canada, and instead put in an > aggregate that covers the address space used in Canada.
Iljitsch, As you recall, I refuted a geoaggregation approach you described on ARIN PPML last year using arguments similar to the recent discussion with Heiner. I understand your current proposal is different: it takes those arguments into account. To wit: 1. Assignment of addresses to organizations by some geographical basis is mandatory. When assigning addresses, registries should choose from a block reserved for the closest geographical match for that organization. 2. Aggregation of routes by geography is strictly opportunistic. Routes are distributed via BGP as now. If a particular router finds that most or RIB entries for a given geography take the same exit from the router, it may aggregate the routes that take that exit before passing them on. Any routes which don't take that exit are passed on as more-specific cutouts within the aggregated prefix. Is that correct? Take a look at http://bill.herrin.us/network/geoag.gif . Let's sever the link between F and G. A backhoe took it out. This should sever nodes E and F from nodes G and H. Until the link is repaired, those two node sets should be unable to communicate with each other. >From your plan, the RIBs look something like this: Node B: B local, propagate to F, A. C A via A, propagate to F, C F via F, propagate to A E via F, propagate to A C via C, aggregate in {right area} D via C, aggregate in {right area} G via C, aggregate in {right area} H via C, aggregate in {right area} {right area} via C propagate to A Node C: C local, propagate to B, D, G A via B, aggregate in {left area} B via B, aggregate in {left area} D via D, propagate to B, G G via G, propagate to D, B H via G, propagate to D, B {left area} via B, propagate to D, G Node G: G local, propagate to C, H (F link is down) {left area} via C, propagate to H C via C, propagate to H (F link is down) D via C, propagate to H (F link is down) H via H, propagate to C (F link is down) Okay, so the first thing we notice is that we get no meaningful benefit in nodes B and C. The RIBs there are as large or larger than they are with plain old BGP. The next thing we notice is that there is still a path from H to E: H->G (left area known via G) G->C (left area known via C) C->B (left area was aggregated via B) B->F (E known via F) F->E (E known via E) This is a permission violation! There does not appear to be a reverse path. Packets can not travel from E to H because neither F nor E have a route to {right area}. However, F may be able to cheat by placing a static route to {right area} via B, If we restore the link between F and G, F *can* cheat by receiving routes from G but not sending any routes. If F's traffic is predominantly inbound, this will save him some money at B and C's expense. In today's networks, this would be prevented by installing traffic filters at the peering points so that F may only send packets to B that are destined to B or A. But because of the aggregation, that filter is no longer effective. I suppose you could filter packets from B to F that don't originate from A or B but that adds complexity and consumes the same kind of router resources that the FIB does. Anyway, my concern is this: if it's that close to a full breach of the permission constraint in an 8-node system, what does it look like in a 50-node system? There are some other weaknesses in the plan as well but lets look at this one for now. Regards, Bill Herrin -- William D. Herrin ................ [EMAIL PROTECTED] [EMAIL PROTECTED] 3005 Crane Dr. ...................... Web: <http://bill.herrin.us/> Falls Church, VA 22042-3004 -- to unsubscribe send a message to [EMAIL PROTECTED] with the word 'unsubscribe' in a single line as the message text body. archive: <http://psg.com/lists/rrg/> & ftp://psg.com/pub/lists/rrg
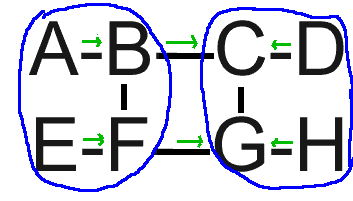{kind=link}