[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17005128#comment-17005128 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569581591 Thanks @lresende This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Spark-2.4.0 > > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17005127#comment-17005127 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569581591 Thank @lresende This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Spark-2.4.0 > > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[
https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17004574#comment-17004574
]
ASF subversion and git services commented on BAHIR-213:
---
Commit d036820c0efa1b2e9b8021506164b67582352dff in bahir's branch
refs/heads/master from abhishekd0907
[ https://gitbox.apache.org/repos/asf?p=bahir.git;h=d036820 ]
[BAHIR-213] Faster S3 file Source for Structured Streaming with SQS (#91)
Using FileStreamSource to read files from a S3 bucket has problems
both in terms of costs and latency:
Latency: Listing all the files in S3 buckets every micro-batch can be both
slow and resource-intensive.
Costs: Making List API requests to S3 every micro-batch can be costly.
The solution is to use Amazon Simple Queue Service (SQS) which lets
you find new files written to S3 bucket without the need to list all the
files every micro-batch.
S3 buckets can be configured to send a notification to an Amazon SQS Queue
on Object Create / Object Delete events. For details see AWS documentation
here Configuring S3 Event Notifications
Spark can leverage this to find new files written to S3 bucket by reading
notifications from SQS queue instead of listing files every micro-batch.
This PR adds a new SQSSource which uses Amazon SQS queue to find
new files every micro-batch.
Usage
val inputDf = spark .readStream
.format("s3-sqs")
.schema(schema)
.option("fileFormat", "json")
.option("sqsUrl", "https://QUEUE_URL";)
.option("region", "us-east-1")
.load()
> Faster S3 file Source for Structured Streaming with SQS
> ---
>
> Key: BAHIR-213
> URL: https://issues.apache.org/jira/browse/BAHIR-213
> Project: Bahir
> Issue Type: New Feature
> Components: Spark Structured Streaming Connectors
>Affects Versions: Spark-2.4.0
>Reporter: Abhishek Dixit
>Priority: Major
>
> Using FileStreamSource to read files from a S3 bucket has problems both in
> terms of costs and latency:
> * *Latency:* Listing all the files in S3 buckets every microbatch can be
> both slow and resource intensive.
> * *Costs:* Making List API requests to S3 every microbatch can be costly.
> The solution is to use Amazon Simple Queue Service (SQS) which lets you find
> new files written to S3 bucket without the need to list all the files every
> microbatch.
> S3 buckets can be configured to send notification to an Amazon SQS Queue on
> Object Create / Object Delete events. For details see AWS documentation here
> [Configuring S3 Event
> Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html]
>
> Spark can leverage this to find new files written to S3 bucket by reading
> notifications from SQS queue instead of listing files every microbatch.
> I hope to contribute changes proposed in [this pull
> request|https://github.com/apache/spark/pull/24934] to Apache Bahir as
> suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi]
> [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17004573#comment-17004573 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on pull request #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17004075#comment-17004075 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569241249 @abhishekd0907 Thanks, I will wait a day or so in case @steveloughran can say something, otherwise, I will go ahead and merge this and we can iterate on master when @steveloughran is better and available. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003564#comment-17003564 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569030710 > @abhishekd0907 could you please rebase to latest master to make sure we get a green build. Otherwise, looks ok to me. @lresende I have rebased to latest master & the build is green now. Can we go ahead with the next steps now? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16987877#comment-16987877 ] ASF GitHub Bot commented on BAHIR-213: -- steveloughran commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-561650867 I'm not directly ignoring you, just some problems are stop me doing much coding right now. I had hoped to do a PoC what this would look like against hadoop-3.2.1 I'm so drive whatever changes needed to be done there to help this (e.g delegation tokens to support the SQS), plus some tests. But its not going to happen this year -sorry. Similarly, I'm cutting back on approximately all my reviews. Anything involving typing basically. I do think it's important -and I also think somebody needs to look at spark streaming checkpointing -against S3 put-with-overwrite works the way rename doesn't. Just not going to be me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16986278#comment-16986278 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-560538377 > @abhishekd0907 could you please rebase to latest master to make sure we get a green build. Otherwise, looks ok to me. @lresende i see that master build is also failing https://travis-ci.org/apache/bahir/builds/584684002?utm_source=github_status&utm_medium=notification probably due to this `Detected Maven Version: 3.5.2 is not in the allowed range 3.5.4. ` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16985188#comment-16985188 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-559875628 @abhishekd0907 could you please rebase to latest master to make sure we get a green build. Otherwise, looks ok to me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16966315#comment-16966315 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-549194053 ping @steveloughran This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16921083#comment-16921083 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-527259701 @steveloughran could you please review this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16919860#comment-16919860 ] Abhishek Dixit commented on BAHIR-213: -- [~lresende] [~ste...@apache.org] This PR for new extension has been open for quite some time with no reviews or reviewers assigned. Can you please review or assign a reviewer? Do I need to send an email to Bhair Mailing List for that? > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16902384#comment-16902384 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on pull request #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[
https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16902385#comment-16902385
]
ASF GitHub Bot commented on BAHIR-213:
--
abhishekd0907 commented on pull request #91: [BAHIR-213] Faster S3 file Source
for Structured Streaming with SQS
URL: https://github.com/apache/bahir/pull/91
## What changes were proposed in this pull request?
Using FileStreamSource to read files from a S3 bucket has problems both in
terms of costs and latency:
- **Latency**: Listing all the files in S3 buckets every microbatch can be
both slow and resource intensive.
- **Costs**: Making List API requests to S3 every microbatch can be costly.
The solution is to use Amazon Simple Queue Service (SQS) which lets you find
new files written to S3 bucket without the need to list all the files every
microbatch.
S3 buckets can be configured to send notification to an Amazon SQS Queue on
Object Create / Object Delete events. For details see AWS documentation here
[Configuring S3 Event
Notifications](https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html)
Spark can leverage this to find new files written to S3 bucket by reading
notifications from SQS queue instead of listing files every microbatch.
This PR adds a new SQSSource which uses Amazon SQS queue to find new files
every microbatch.
## Usage
`val inputDf = spark
.readStream
.format("s3-sqs")
.schema(schema)
.option("fileFormat", "json")
.option("sqsUrl", "https://QUEUE_URL";)
.option("region", "us-east-1")
.load()`
## Implementation Details
We create a scheduled thread which runs asynchronously with the streaming
query thread and periodically fetches messages from the SQS Queue. Key
information related to file path & timestamp is extracted from the SQS messages
and the new files are stored in a thread safe SQS file cache.
Streaming Query thread gets the files from SQS File Cache and filters out
the new files. Based on the maxFilesPerTrigger condition, all or a part of the
new files are added to the offset log and marked as processed in the SQS File
Cache. The corresponding SQS messages for the processed files are deleted from
the Amazon SQS Queue and the offset value is incremented and returned.
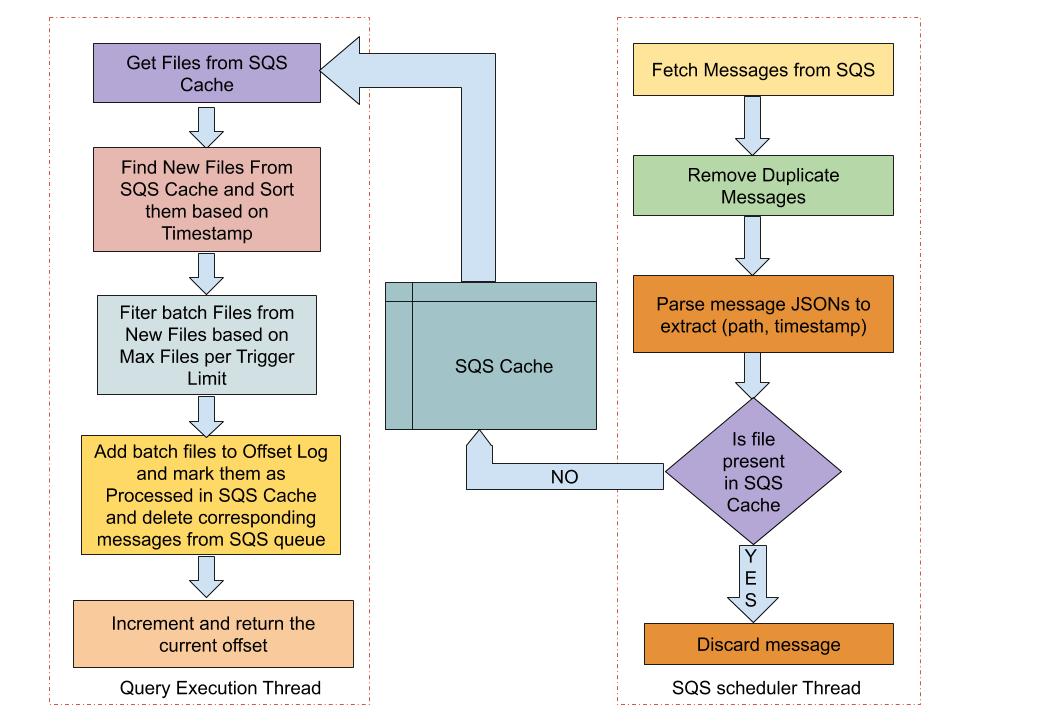
## How was this patch tested?
Added new unit tests in SqsSourceOptionsSuite which test various
SqsSourceOptions. Will add more tests after some initial feedback on design
approach and functionality.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Faster S3 file Source for Structured Streaming with SQS
> ---
>
> Key: BAHIR-213
> URL: https://issues.apache.org/jira/browse/BAHIR-213
> Project: Bahir
> Issue Type: New Feature
> Components: Spark Structured Streaming Connectors
>Affects Versions: Spark-2.4.0
>Reporter: Abhishek Dixit
>Priority: Major
>
> Using FileStreamSource to read files from a S3 bucket has problems both in
> terms of costs and latency:
> * *Latency:* Listing all the files in S3 buckets every microbatch can be
> both slow and resource intensive.
> * *Costs:* Making List API requests to S3 every microbatch can be costly.
> The solution is to use Amazon Simple Queue Service (SQS) which lets you find
> new files written to S3 bucket without the need to list all the files every
> microbatch.
> S3 buckets can be configured to send notification to an Amazon SQS Queue on
> Object Create / Object Delete events. For details see AWS documentation here
> [Configuring S3 Event
> Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html]
>
> Spark can leverage this to find new files written to S3 bucket by reading
> notifications from SQS queue instead of listing files every microbatch.
> I hope to contribute changes proposed in [this pull
> request|https://github.com/apache/spark/pull/24934] to Apache Bahir as
> suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi]
> [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130]
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16896997#comment-16896997 ] Abhishek Dixit commented on BAHIR-213: -- I see that Pull Request is not linked in the issue. Please find the pull request here: [[BAHIR-213] Faster S3 file Source for Structured Streaming with SQS|[https://github.com/apache/bahir/pull/91]] > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by @[gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[
https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16896994#comment-16896994
]
Abhishek Dixit commented on BAHIR-213:
--
* *Issue of FNFE when querying file:* I checked the behavior of the existing
implementation of FileStreamSource for this scenario, i.e. if the file gets
listed in the _getOffset_ phase but gets deleted before file read happens in
_getBatch,_ Spark catches the FNFE and the following warning is thrown
{code:java}
The directory $path was not found. Was it deleted very recently?{code}
I have gone with similar behavior in SqsSource. Let me know if you have any
concerns about mimicking FileStreamSource Behavior for this scenario.
* *Issue of File State Update:* In case of fo FileStreamSource, files are
listed in _getOffset_ phase and if the contents of the same file change before
the file is actually read in the _getBatch_ phase, then the initial content of
the file is lost & not processed. Only the latest content of file available
during _getBatch_ is processed & similar will be the behavior of SQS Source.
* *Issue of Double Update:* On the other hand, if the file is processed in
_getBatch_ and then later updated, FileStreamSource considers the file as
seen/processed and doesn't read it again unless the file is aged. SQS Source
also behaves, in the same way, i.e. if an SQS message pertaining to an already
processed file comes again, it is simply ignored.
*
*Issue of Messages arriving out of order:* By default, the new/unprocessed file
list obtained from SQS File Cache is sorted based on timestamp (of file
updation) to avoid the issue of messages arriving out of order. In case some
messages arrive very late, they will be processed in succeeding micro-batches.
In any case, we can't guarantee to process files in the order of timestamp
because of the distributed nature of SQS.
[~ste...@apache.org] Let me know if you have any concerns with any of the above
points and want me to change the implementation in some way.
> Faster S3 file Source for Structured Streaming with SQS
> ---
>
> Key: BAHIR-213
> URL: https://issues.apache.org/jira/browse/BAHIR-213
> Project: Bahir
> Issue Type: New Feature
> Components: Spark Structured Streaming Connectors
>Affects Versions: Spark-2.4.0
>Reporter: Abhishek Dixit
>Priority: Major
>
> Using FileStreamSource to read files from a S3 bucket has problems both in
> terms of costs and latency:
> * *Latency:* Listing all the files in S3 buckets every microbatch can be
> both slow and resource intensive.
> * *Costs:* Making List API requests to S3 every microbatch can be costly.
> The solution is to use Amazon Simple Queue Service (SQS) which lets you find
> new files written to S3 bucket without the need to list all the files every
> microbatch.
> S3 buckets can be configured to send notification to an Amazon SQS Queue on
> Object Create / Object Delete events. For details see AWS documentation here
> [Configuring S3 Event
> Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html]
>
> Spark can leverage this to find new files written to S3 bucket by reading
> notifications from SQS queue instead of listing files every microbatch.
> I hope to contribute changes proposed in [this pull
> request|https://github.com/apache/spark/pull/24934] to Apache Bahir as
> suggested by @[gaborgsomogyi|https://github.com/gaborgsomogyi]
> [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130]
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16895999#comment-16895999 ] Steve Loughran commented on BAHIR-213: -- BTW, because of the delay between S3 change and event being processed, there's a risk of changes in the store happening before the stream handler sees it 1. POST path 2. event #1 queued 3. DELETE path 4. event #2 queued 5. event #1 received 5. FNFE when querying file Also: double update 1. POST path 2. event #1 queued 3. POST path 4. event #2 queued 5. event #1 received 6.. contents of path are at state (3) 7. event #2 received even though state hasn't changed there's also two other issues * the risk of events arriving out of order. * the risk of a previous state of the file (contents or tombstone) being seen in processing event #1 What does that mean? I think it means that you need to handle * file potentially missing when you receive the event...but you still need to handle the possibility that a tombstone was cached before the post #1 operation, so may want to spin a bit awaiting its arrival. * file details when processing event different from that in the event data the best thing to do here is demand that every file uploaded MUST have a unique name, while making sure that the new stream source is resilient to changes (i.e downgrades if the source file isn't there...), without offering any guarantees of correctness > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by @[gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16893718#comment-16893718 ] Steve Loughran commented on BAHIR-213: -- I've thought about doing this for a while. Note that the event queue is itself inconsistent; you still need to scan for changes sporadically. The other cloud infras provide similar event queues (at least Azure does); be good to design this to be somewhat independent. Testing will be fun. > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.3.0, Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by @[gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian JIRA (v7.6.14#76016)