[GitHub] spark pull request #21422: [Spark-24376][doc]Summary:compiling spark with sc...
Github user gentlewangyu closed the pull request at: https://github.com/apache/spark/pull/21422 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21422: [Spark-24376][doc]Summary:compiling spark with scala-2.1...
Github user gentlewangyu commented on the issue: https://github.com/apache/spark/pull/21422 @HyukjinKwon @jerryshao ok , thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21422: [Spark-24376][doc]Summary:compiling spark with scala-2.1...
Github user gentlewangyu commented on the issue: https://github.com/apache/spark/pull/21422 @HyukjinKwon thanks for your answer! I have tested it by using the command (build/mvn clean package install deploy -DskipTests -Pscala-2.10) 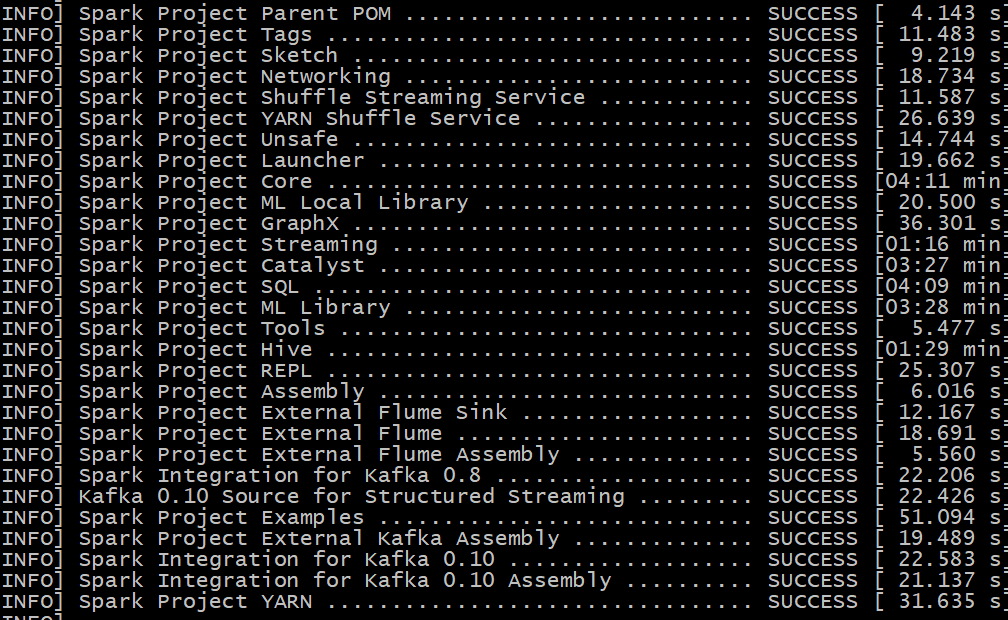 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21422: [Spark-24376][doc]Summary:compiling spark with sc...
Github user gentlewangyu commented on a diff in the pull request: https://github.com/apache/spark/pull/21422#discussion_r190541918 --- Diff: docs/building-spark.md --- @@ -92,10 +92,10 @@ like ZooKeeper and Hadoop itself. ./build/mvn -Pmesos -DskipTests clean package ## Building for Scala 2.10 -To produce a Spark package compiled with Scala 2.10, use the `-Dscala-2.10` property: +To produce a Spark package compiled with Scala 2.10, use the `-Pscala-2.10` property: ./dev/change-scala-version.sh 2.10 -./build/mvn -Pyarn -Dscala-2.10 -DskipTests clean package +./build/mvn -Pyarn -scala-2.10 -DskipTestsP clean package --- End diff -- sorry , It's -Pscala-2.10 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21422: [Spark-24376][doc]Summary:compiling spark with scala-2.1...
Github user gentlewangyu commented on the issue: https://github.com/apache/spark/pull/21422 I have verified this patch --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21422: [Spark-24376][doc]Summary:compiling spark with sc...
GitHub user gentlewangyu opened a pull request: https://github.com/apache/spark/pull/21422 [Spark-24376][doc]Summary:compiling spark with scala-2.10 should use the -P parameter instead of -D What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/gentlewangyu/spark SPARK-24376 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21422.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21422 commit d5167ed3dd3ce87a8904c2444eaf6c839ea541d3 Author: wangyu Date: 2018-05-24T08:06:47Z git config --global user.email "wan...@cmss.chinamobile.com" git config --global user.name "gentlewangyu" --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21421: Myfeature
Github user gentlewangyu closed the pull request at: https://github.com/apache/spark/pull/21421 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21421: Myfeature
GitHub user gentlewangyu opened a pull request:
https://github.com/apache/spark/pull/21421
Myfeature
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a
pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/gentlewangyu/spark myfeature
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21421.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21421
commit 9949fed1c45865b6e5e8ebe610789c5fb9546052
Author: Corey Woodfield
Date: 2017-07-19T22:21:38Z
[SPARK-21333][DOCS] Removed invalid joinTypes from javadoc of
Dataset#joinWith
## What changes were proposed in this pull request?
Two invalid join types were mistakenly listed in the javadoc for joinWith,
in the Dataset class. I presume these were copied from the javadoc of join, but
since joinWith returns a Dataset\, left_semi and left_anti are
invalid, as they only return values from one of the datasets, instead of from
both
## How was this patch tested?
I ran the following code :
```
public static void main(String[] args) {
SparkSession spark = new SparkSession(new SparkContext("local[*]",
"Test"));
Dataset one = spark.createDataFrame(Arrays.asList(new Bean(1), new
Bean(2), new Bean(3), new Bean(4), new Bean(5)), Bean.class);
Dataset two = spark.createDataFrame(Arrays.asList(new Bean(4), new
Bean(5), new Bean(6), new Bean(7), new Bean(8), new Bean(9)), Bean.class);
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"inner").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"cross").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"full").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"full_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"right").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"right_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_semi").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_anti").show();} catch (Exception e) {e.printStackTrace();}
}
```
which tests all the different join types, and the last two (left_semi and
left_anti) threw exceptions. The same code using join instead of joinWith did
fine. The Bean class was just a java bean with a single int field, x.
Author: Corey Woodfield
Closes #18462 from coreywoodfield/master.
(cherry picked from commit 8cd9cdf17a7a4ad6f2eecd7c4b388ca363c20982)
Signed-off-by: gatorsmile
commit 88dccda393bc79dc6032f71b6acf8eb2b4b152be
Author: Dhruve Ashar
Date: 2017-07-21T19:03:46Z
[SPARK-21243][CORE] Limit no. of map outputs in a shuffle fetch
For configurations with external shuffle enabled, we have observed that if
a very large no. of blocks are being fetched from a remote host, it puts the NM
under extra pressure and can crash it. This change introduces a configuration
`spark.reducer.maxBlocksInFlightPerAddress` , to limit the no. of map outputs
being fetched from a given remote address. The changes applied here are
applicable for both the scenarios - when external shuffle is enabled as well as
disabled.
Ran the job with the default configuration which does not c
[GitHub] spark pull request #21419: Branch 2.2
Github user gentlewangyu closed the pull request at: https://github.com/apache/spark/pull/21419 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21419: Branch 2.2
GitHub user gentlewangyu opened a pull request:
https://github.com/apache/spark/pull/21419
Branch 2.2
## What changes were proposed in this pull request?
compiling spark with scala-2.10 should use the -P parameter instead of -D
## How was this patch tested?
./build/mvn -Pyarn -Pscala-2.10 -DskipTests clean package
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/apache/spark branch-2.2
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21419.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21419
commit 9949fed1c45865b6e5e8ebe610789c5fb9546052
Author: Corey Woodfield
Date: 2017-07-19T22:21:38Z
[SPARK-21333][DOCS] Removed invalid joinTypes from javadoc of
Dataset#joinWith
## What changes were proposed in this pull request?
Two invalid join types were mistakenly listed in the javadoc for joinWith,
in the Dataset class. I presume these were copied from the javadoc of join, but
since joinWith returns a Dataset\, left_semi and left_anti are
invalid, as they only return values from one of the datasets, instead of from
both
## How was this patch tested?
I ran the following code :
```
public static void main(String[] args) {
SparkSession spark = new SparkSession(new SparkContext("local[*]",
"Test"));
Dataset one = spark.createDataFrame(Arrays.asList(new Bean(1), new
Bean(2), new Bean(3), new Bean(4), new Bean(5)), Bean.class);
Dataset two = spark.createDataFrame(Arrays.asList(new Bean(4), new
Bean(5), new Bean(6), new Bean(7), new Bean(8), new Bean(9)), Bean.class);
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"inner").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"cross").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"full").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"full_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"right").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"right_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_semi").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_anti").show();} catch (Exception e) {e.printStackTrace();}
}
```
which tests all the different join types, and the last two (left_semi and
left_anti) threw exceptions. The same code using join instead of joinWith did
fine. The Bean class was just a java bean with a single int field, x.
Author: Corey Woodfield
Closes #18462 from coreywoodfield/master.
(cherry picked from commit 8cd9cdf17a7a4ad6f2eecd7c4b388ca363c20982)
Signed-off-by: gatorsmile
commit 88dccda393bc79dc6032f71b6acf8eb2b4b152be
Author: Dhruve Ashar
Date: 2017-07-21T19:03:46Z
[SPARK-21243][CORE] Limit no. of map outputs in a shuffle fetch
For configurations with external shuffle enabled, we have observed that if
a very large no. of blocks are being fetched from a remote host, it puts the NM
under extra pressure and can crash it. This change introduces a configuration
`spark.reducer.maxBlocksInFlightPerAddress` , to limit the no. of map outputs
being fetched from a given remote address. The changes applied here are
applicable for both the scenarios - when external shuffle is enabled as well as
disabled.
Ran the job with the default configuration which does not change the
existing behavior and ran it with few configurations of lower values
-10,20,50,100. The job ran fine and there is no change in the output. (I will
update the metrics related to NM in some ti
[GitHub] spark pull request #21418: Branch 2.2
Github user gentlewangyu closed the pull request at: https://github.com/apache/spark/pull/21418 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21417: Branch 2.0
Github user gentlewangyu closed the pull request at: https://github.com/apache/spark/pull/21417 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21418: Branch 2.2
GitHub user gentlewangyu opened a pull request:
https://github.com/apache/spark/pull/21418
Branch 2.2
## What changes were proposed in this pull request?
compiling spark with scala-2.10 should use the -p parameter instead of -d
## How was this patch tested?
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/apache/spark branch-2.2
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21418.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21418
commit 9949fed1c45865b6e5e8ebe610789c5fb9546052
Author: Corey Woodfield
Date: 2017-07-19T22:21:38Z
[SPARK-21333][DOCS] Removed invalid joinTypes from javadoc of
Dataset#joinWith
## What changes were proposed in this pull request?
Two invalid join types were mistakenly listed in the javadoc for joinWith,
in the Dataset class. I presume these were copied from the javadoc of join, but
since joinWith returns a Dataset\, left_semi and left_anti are
invalid, as they only return values from one of the datasets, instead of from
both
## How was this patch tested?
I ran the following code :
```
public static void main(String[] args) {
SparkSession spark = new SparkSession(new SparkContext("local[*]",
"Test"));
Dataset one = spark.createDataFrame(Arrays.asList(new Bean(1), new
Bean(2), new Bean(3), new Bean(4), new Bean(5)), Bean.class);
Dataset two = spark.createDataFrame(Arrays.asList(new Bean(4), new
Bean(5), new Bean(6), new Bean(7), new Bean(8), new Bean(9)), Bean.class);
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"inner").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"cross").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"full").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"full_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"right").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"right_outer").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_semi").show();} catch (Exception e) {e.printStackTrace();}
try {two.joinWith(one, one.col("x").equalTo(two.col("x")),
"left_anti").show();} catch (Exception e) {e.printStackTrace();}
}
```
which tests all the different join types, and the last two (left_semi and
left_anti) threw exceptions. The same code using join instead of joinWith did
fine. The Bean class was just a java bean with a single int field, x.
Author: Corey Woodfield
Closes #18462 from coreywoodfield/master.
(cherry picked from commit 8cd9cdf17a7a4ad6f2eecd7c4b388ca363c20982)
Signed-off-by: gatorsmile
commit 88dccda393bc79dc6032f71b6acf8eb2b4b152be
Author: Dhruve Ashar
Date: 2017-07-21T19:03:46Z
[SPARK-21243][CORE] Limit no. of map outputs in a shuffle fetch
For configurations with external shuffle enabled, we have observed that if
a very large no. of blocks are being fetched from a remote host, it puts the NM
under extra pressure and can crash it. This change introduces a configuration
`spark.reducer.maxBlocksInFlightPerAddress` , to limit the no. of map outputs
being fetched from a given remote address. The changes applied here are
applicable for both the scenarios - when external shuffle is enabled as well as
disabled.
Ran the job with the default configuration which does not change the
existing behavior and ran it with few configurations of lower values
-10,20,50,100. The job ran fine and there is no change in the output. (I will
update the metrics related to NM in some time.)
Author: Dhruve Ashar
Closes #18487 from dhruv
[GitHub] spark pull request #21417: Branch 2.0
GitHub user gentlewangyu opened a pull request: https://github.com/apache/spark/pull/21417 Branch 2.0 ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/apache/spark branch-2.0 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21417.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21417 commit 050b8177e27df06d33a6f6f2b3b6a952b0d03ba6 Author: cody koeninger Date: 2016-10-12T22:22:06Z [SPARK-17782][STREAMING][KAFKA] alternative eliminate race condition of poll twice ## What changes were proposed in this pull request? Alternative approach to https://github.com/apache/spark/pull/15387 Author: cody koeninger Closes #15401 from koeninger/SPARK-17782-alt. (cherry picked from commit f9a56a153e0579283160519065c7f3620d12da3e) Signed-off-by: Shixiong Zhu commit 5903dabc57c07310573babe94e4f205bdea6455f Author: Brian Cho Date: 2016-10-13T03:43:18Z [SPARK-16827][BRANCH-2.0] Avoid reporting spill metrics as shuffle metrics ## What changes were proposed in this pull request? Fix a bug where spill metrics were being reported as shuffle metrics. Eventually these spill metrics should be reported (SPARK-3577), but separate from shuffle metrics. The fix itself basically reverts the line to what it was in 1.6. ## How was this patch tested? Cherry-picked from master (#15347) Author: Brian Cho Closes #15455 from dafrista/shuffle-metrics-2.0. commit ab00e410c6b1d7dafdfabcea1f249c78459b94f0 Author: Burak Yavuz Date: 2016-10-13T04:40:45Z [SPARK-17876] Write StructuredStreaming WAL to a stream instead of materializing all at once ## What changes were proposed in this pull request? The CompactibleFileStreamLog materializes the whole metadata log in memory as a String. This can cause issues when there are lots of files that are being committed, especially during a compaction batch. You may come across stacktraces that look like: ``` java.lang.OutOfMemoryError: Requested array size exceeds VM limit at java.lang.StringCoding.encode(StringCoding.java:350) at java.lang.String.getBytes(String.java:941) at org.apache.spark.sql.execution.streaming.FileStreamSinkLog.serialize(FileStreamSinkLog.scala:127) ``` The safer way is to write to an output stream so that we don't have to materialize a huge string. ## How was this patch tested? Existing unit tests Author: Burak Yavuz Closes #15437 from brkyvz/ser-to-stream. (cherry picked from commit edeb51a39d76d64196d7635f52be1b42c7ec4341) Signed-off-by: Shixiong Zhu commit d38f38a093b4dff32c686675d93ab03e7a8f4908 Author: buzhihuojie Date: 2016-10-13T05:51:54Z minor doc fix for Row.scala ## What changes were proposed in this pull request? minor doc fix for "getAnyValAs" in class Row ## How was this patch tested? None. (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Author: buzhihuojie Closes #15452 from david-weiluo-ren/minorDocFixForRow. (cherry picked from commit 7222a25a11790fa9d9d1428c84b6f827a785c9e8) Signed-off-by: Reynold Xin commit d7fa3e32421c73adfa522adfeeb970edd4c22eb3 Author: Shixiong Zhu Date: 2016-10-13T20:31:50Z [SPARK-17834][SQL] Fetch the earliest offsets manually in KafkaSource instead of counting on KafkaConsumer ## What changes were proposed in this pull request? Because `KafkaConsumer.poll(0)` may update the partition offsets, this PR just calls `seekToBeginning` to manually set the earliest offsets for the KafkaSource initial offsets. ## How was this patch tested? Existing tests. Author: Shixiong Zhu Closes #15397 from zsxwing/SPARK-17834. (cherry picked from commit 08eac356095c7faa2b19d52f2fb0cbc47eb7d1d1) Signed-off-by: Shixiong Zhu commit c53b8374911e801ed98c1436c384f0aef076eaab Author: Davies Liu Date: 2016-10-14T21:45:20Z [SPARK-17863][SQL] should not add column into Distinct ## What changes were proposed in this pull request? We are trying to resolve the attribute in sort by pulling up some column for grandchild into ch