[spark] branch master updated: [SPARK-37925][DOC] Update document to mention the workaround for YARN-11053
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 74ebef2 [SPARK-37925][DOC] Update document to mention the workaround for YARN-11053 74ebef2 is described below commit 74ebef243c18e7a8f32bf90ea75ab6afed9e3132 Author: Cheng Pan AuthorDate: Sat Feb 5 09:47:15 2022 -0600 [SPARK-37925][DOC] Update document to mention the workaround for YARN-11053 ### What changes were proposed in this pull request? Update document "Running multiple versions of the Spark Shuffle Service" to mention the workaround for YARN-11053 ### Why are the changes needed? User may stuck when they following the current document to deploy multi-versions Spark Shuffle Service on YARN because of [YARN-11053](https://issues.apache.org/jira/browse/YARN-11053) ### Does this PR introduce _any_ user-facing change? User document changes. ### How was this patch tested?  Closes #35223 from pan3793/SPARK-37925. Authored-by: Cheng Pan Signed-off-by: Sean Owen --- docs/running-on-yarn.md | 9 ++--- 1 file changed, 6 insertions(+), 3 deletions(-) diff --git a/docs/running-on-yarn.md b/docs/running-on-yarn.md index c55ce86..63c0376 100644 --- a/docs/running-on-yarn.md +++ b/docs/running-on-yarn.md @@ -916,9 +916,12 @@ support the ability to run shuffle services within an isolated classloader can coexist within a single NodeManager. The `yarn.nodemanager.aux-services..classpath` and, starting from YARN 2.10.2/3.1.1/3.2.0, `yarn.nodemanager.aux-services..remote-classpath` options can be used to configure -this. In addition to setting up separate classpaths, it's necessary to ensure the two versions -advertise to different ports. This can be achieved using the `spark-shuffle-site.xml` file described -above. For example, you may have configuration like: +this. Note that YARN 3.3.0/3.3.1 have an issue which requires setting +`yarn.nodemanager.aux-services..system-classes` as a workaround. See +[YARN-11053](https://issues.apache.org/jira/browse/YARN-11053) for details. In addition to setting +up separate classpaths, it's necessary to ensure the two versions advertise to different ports. +This can be achieved using the `spark-shuffle-site.xml` file described above. For example, you may +have configuration like: ```properties yarn.nodemanager.aux-services = spark_shuffle_x,spark_shuffle_y - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Contribution guide to document actual guide for pull requests
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 991df19 Contribution guide to document actual guide for pull requests 991df19 is described below commit 991df1959e2381dfd32dadce39cbfa2be80ec0c6 Author: khalidmammadov AuthorDate: Fri Feb 4 17:07:55 2022 -0600 Contribution guide to document actual guide for pull requests Currently contribution guide does not reflect actual flow to raise a new PR and hence it's not clear (for a new contributors) what exactly needs to be done to make a PR for Spark repository and test it as per expectation. This PR addresses that by following: - It describes in the Pull request section of the Contributing page the actual procedure and takes a contributor through a step by step process. - It removes optional "Running tests in your forked repository" section on Developer Tools page which is obsolete now and doesn't reflect reality anymore i.e. it says we can test by clicking “Run workflow” button which is not available anymore as workflow does not use "workflow_dispatch" event trigger anymore and was removed in https://github.com/apache/spark/pull/32092 - Instead it documents the new procedure that above PR introduced i.e. contributors needs to use their own GitHub free workflow credits to test new changes they are purposing and a Spark Actions workflow will expect that to be completed before marking PR to be ready for a review. - Some general wording was copied from "Running tests in your forked repository" section on Developer Tools page but main content was rewritten to meet objective - Also fixed URL to developer-tools.html to be resolved by parser (that converted it into relative URI) instead of using hard coded absolute URL. Tested imperically with `bundle exec jekyll serve` and static files were generated with `bundle exec jekyll build` commands This closes https://issues.apache.org/jira/browse/SPARK-37996 Author: khalidmammadov Closes #378 from khalidmammadov/fix_contribution_workflow_guide. --- contributing.md| 21 +++-- developer-tools.md | 17 - images/running-tests-using-github-actions.png | Bin 312696 -> 0 bytes site/contributing.html | 18 +- site/developer-tools.html | 19 --- site/images/running-tests-using-github-actions.png | Bin 312696 -> 0 bytes 6 files changed, 28 insertions(+), 47 deletions(-) diff --git a/contributing.md b/contributing.md index d5f0142..b127afe 100644 --- a/contributing.md +++ b/contributing.md @@ -322,9 +322,16 @@ Example: `Fix typos in Foo scaladoc` Pull request +Before creating a pull request in Apache Spark, it is important to check if tests can pass on your branch because +our GitHub Actions workflows automatically run tests for your pull request/following commits +and every run burdens the limited resources of GitHub Actions in Apache Spark repository. +Below steps will take your through the process. + + 1. https://help.github.com/articles/fork-a-repo/";>Fork the GitHub repository at https://github.com/apache/spark";>https://github.com/apache/spark if you haven't already -1. Clone your fork, create a new branch, push commits to the branch. +1. Go to "Actions" tab on your forked repository and enable "Build and test" and "Report test results" workflows +1. Clone your fork and create a new branch 1. Consider whether documentation or tests need to be added or updated as part of the change, and add them as needed. 1. When you add tests, make sure the tests are self-descriptive. @@ -355,14 +362,16 @@ and add them as needed. ... ``` 1. Consider whether benchmark results should be added or updated as part of the change, and add them as needed by -https://spark.apache.org/developer-tools.html#github-workflow-benchmarks";>Running benchmarks in your forked repository +Running benchmarks in your forked repository to generate benchmark results. 1. Run all tests with `./dev/run-tests` to verify that the code still compiles, passes tests, and -passes style checks. Alternatively you can run the tests via GitHub Actions workflow by -https://spark.apache.org/developer-tools.html#github-workflow-tests";>Running tests in your forked repository. +passes style checks. If style checks fail, review the Code Style Guide below. +1. Push commits to your branch. This will trigger "Build and test" and "Report test results" workflows +on your forked repository an
[spark] branch master updated (7a613ec -> 54b11fa)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7a613ec [SPARK-38100][SQL] Remove unused private method in `Decimal` add 54b11fa [MINOR] Remove unnecessary null check for exception cause No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/spark/network/shuffle/ErrorHandler.java | 4 ++-- .../org/apache/spark/network/shuffle/RetryingBlockTransferor.java | 2 +- 2 files changed, 3 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37984][SHUFFLE] Avoid calculating all outstanding requests to improve performance
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f8ff786 [SPARK-37984][SHUFFLE] Avoid calculating all outstanding
requests to improve performance
f8ff786 is described below
commit f8ff7863e792b833afb2ff603878f29d4a9888e6
Author: weixiuli
AuthorDate: Sun Jan 23 20:23:20 2022 -0600
[SPARK-37984][SHUFFLE] Avoid calculating all outstanding requests to
improve performance
### What changes were proposed in this pull request?
Avoid calculating all outstanding requests to improve performance.
### Why are the changes needed?
Follow the comment
(https://github.com/apache/spark/pull/34711#pullrequestreview-835520984) , we
can implement a "has outstanding requests" method in the response handler that
doesn't even need to get a count,let's do this with PR.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Exist unittests.
Closes #35276 from weixiuli/SPARK-37984.
Authored-by: weixiuli
Signed-off-by: Sean Owen
---
.../apache/spark/network/client/TransportResponseHandler.java | 10 --
.../apache/spark/network/server/TransportChannelHandler.java | 3 +--
2 files changed, 9 insertions(+), 4 deletions(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
b/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
index 576c088..261f205 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java
@@ -140,7 +140,7 @@ public class TransportResponseHandler extends
MessageHandler {
@Override
public void channelInactive() {
-if (numOutstandingRequests() > 0) {
+if (hasOutstandingRequests()) {
String remoteAddress = getRemoteAddress(channel);
logger.error("Still have {} requests outstanding when connection from {}
is closed",
numOutstandingRequests(), remoteAddress);
@@ -150,7 +150,7 @@ public class TransportResponseHandler extends
MessageHandler {
@Override
public void exceptionCaught(Throwable cause) {
-if (numOutstandingRequests() > 0) {
+if (hasOutstandingRequests()) {
String remoteAddress = getRemoteAddress(channel);
logger.error("Still have {} requests outstanding when connection from {}
is closed",
numOutstandingRequests(), remoteAddress);
@@ -275,6 +275,12 @@ public class TransportResponseHandler extends
MessageHandler {
(streamActive ? 1 : 0);
}
+ /** Check if there are any outstanding requests (fetch requests + rpcs) */
+ public Boolean hasOutstandingRequests() {
+return streamActive || !outstandingFetches.isEmpty() ||
!outstandingRpcs.isEmpty() ||
+!streamCallbacks.isEmpty();
+ }
+
/** Returns the time in nanoseconds of when the last request was sent out. */
public long getTimeOfLastRequestNs() {
return timeOfLastRequestNs.get();
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
b/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
index 275e64e..d197032 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/server/TransportChannelHandler.java
@@ -161,8 +161,7 @@ public class TransportChannelHandler extends
SimpleChannelInboundHandler
requestTimeoutNs;
if (e.state() == IdleState.ALL_IDLE && isActuallyOverdue) {
- boolean hasInFlightRequests =
responseHandler.numOutstandingRequests() > 0;
- if (hasInFlightRequests) {
+ if (responseHandler.hasOutstandingRequests()) {
String address = getRemoteAddress(ctx.channel());
logger.error("Connection to {} has been quiet for {} ms while
there are outstanding " +
"requests. Assuming connection is dead; please adjust" +
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37934][BUILD] Upgrade Jetty version to 9.4.44
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 2e95c6f [SPARK-37934][BUILD] Upgrade Jetty version to 9.4.44 2e95c6f is described below commit 2e95c6f28d012c88c691ccd28cb04674461ff782 Author: Sajith Ariyarathna AuthorDate: Wed Jan 19 12:19:57 2022 -0600 [SPARK-37934][BUILD] Upgrade Jetty version to 9.4.44 ### What changes were proposed in this pull request? This PR upgrades Jetty version to `9.4.44.v20210927`. ### Why are the changes needed? We would like to have the fix for https://github.com/eclipse/jetty.project/issues/6973 in latest Spark. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? CI Closes #35230 from this/upgrade-jetty-9.4.44. Authored-by: Sajith Ariyarathna Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 4 ++-- pom.xml | 2 +- 3 files changed, 4 insertions(+), 4 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index 0227c76..09b01a3 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -145,7 +145,7 @@ jersey-hk2/2.34//jersey-hk2-2.34.jar jersey-server/2.34//jersey-server-2.34.jar jetty-sslengine/6.1.26//jetty-sslengine-6.1.26.jar jetty-util/6.1.26//jetty-util-6.1.26.jar -jetty-util/9.4.43.v20210629//jetty-util-9.4.43.v20210629.jar +jetty-util/9.4.44.v20210927//jetty-util-9.4.44.v20210927.jar jetty/6.1.26//jetty-6.1.26.jar jline/2.14.6//jline-2.14.6.jar joda-time/2.10.12//joda-time-2.10.12.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index afa4ba5..b7cc91f 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -133,8 +133,8 @@ jersey-container-servlet/2.34//jersey-container-servlet-2.34.jar jersey-hk2/2.34//jersey-hk2-2.34.jar jersey-server/2.34//jersey-server-2.34.jar jettison/1.1//jettison-1.1.jar -jetty-util-ajax/9.4.43.v20210629//jetty-util-ajax-9.4.43.v20210629.jar -jetty-util/9.4.43.v20210629//jetty-util-9.4.43.v20210629.jar +jetty-util-ajax/9.4.44.v20210927//jetty-util-ajax-9.4.44.v20210927.jar +jetty-util/9.4.44.v20210927//jetty-util-9.4.44.v20210927.jar jline/2.14.6//jline-2.14.6.jar joda-time/2.10.12//joda-time-2.10.12.jar jodd-core/3.5.2//jodd-core-3.5.2.jar diff --git a/pom.xml b/pom.xml index 5087113..4f53da0 100644 --- a/pom.xml +++ b/pom.xml @@ -138,7 +138,7 @@ 10.14.2.0 1.12.2 1.7.2 -9.4.43.v20210629 +9.4.44.v20210927 4.0.3 0.10.0 2.5.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4c59a83 -> 0841579)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4c59a83 [SPARK-37921][TESTS] Update OrcReadBenchmark to use Hive ORC reader as the basis add 0841579 [SPARK-37901] Upgrade Netty from 4.1.72 to 4.1.73 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 28 ++-- dev/deps/spark-deps-hadoop-3-hive-2.3 | 28 ++-- pom.xml | 2 +- 3 files changed, 29 insertions(+), 29 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37876][CORE][SQL] Move `SpecificParquetRecordReaderBase.listDirectory` to `TestUtils`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 7614472 [SPARK-37876][CORE][SQL] Move
`SpecificParquetRecordReaderBase.listDirectory` to `TestUtils`
7614472 is described below
commit 7614472950cb57ffefa0a51dd1163103c5d42df6
Author: yangjie01
AuthorDate: Sat Jan 15 09:01:55 2022 -0600
[SPARK-37876][CORE][SQL] Move
`SpecificParquetRecordReaderBase.listDirectory` to `TestUtils`
### What changes were proposed in this pull request?
`SpecificParquetRecordReaderBase.listDirectory` is used to return the list
of files at `path` recursively and the result will skips files that are ignored
normally by MapReduce.
This method is only used by tests in Spark now and the tests also includes
non-parquet test scenario, such as `OrcColumnarBatchReaderSuite`.
So this pr move this method from `SpecificParquetRecordReaderBase` to
`TestUtils` to make it as a test method.
### Why are the changes needed?
Refactoring: move test method to `TestUtils`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #35177 from LuciferYang/list-directory.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../src/main/scala/org/apache/spark/TestUtils.scala | 15 +++
.../parquet/SpecificParquetRecordReaderBase.java| 21 -
.../benchmark/DataSourceReadBenchmark.scala | 11 ++-
.../orc/OrcColumnarBatchReaderSuite.scala | 4 ++--
.../datasources/parquet/ParquetEncodingSuite.scala | 11 ++-
.../datasources/parquet/ParquetIOSuite.scala| 6 +++---
.../execution/datasources/parquet/ParquetTest.scala | 3 ++-
.../spark/sql/test/DataFrameReaderWriterSuite.scala | 5 ++---
8 files changed, 36 insertions(+), 40 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/TestUtils.scala
b/core/src/main/scala/org/apache/spark/TestUtils.scala
index d2af955..505b3ab 100644
--- a/core/src/main/scala/org/apache/spark/TestUtils.scala
+++ b/core/src/main/scala/org/apache/spark/TestUtils.scala
@@ -446,6 +446,21 @@ private[spark] object TestUtils {
current ++ current.filter(_.isDirectory).flatMap(recursiveList)
}
+ /**
+ * Returns the list of files at 'path' recursively. This skips files that
are ignored normally
+ * by MapReduce.
+ */
+ def listDirectory(path: File): Array[String] = {
+val result = ArrayBuffer.empty[String]
+if (path.isDirectory) {
+ path.listFiles.foreach(f => result.appendAll(listDirectory(f)))
+} else {
+ val c = path.getName.charAt(0)
+ if (c != '.' && c != '_') result.append(path.getAbsolutePath)
+}
+result.toArray
+ }
+
/** Creates a temp JSON file that contains the input JSON record. */
def createTempJsonFile(dir: File, prefix: String, jsonValue: JValue): String
= {
val file = File.createTempFile(prefix, ".json", dir)
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
index e1a0607..07e35c1 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
@@ -19,10 +19,8 @@
package org.apache.spark.sql.execution.datasources.parquet;
import java.io.Closeable;
-import java.io.File;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
-import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
@@ -122,25 +120,6 @@ public abstract class SpecificParquetRecordReaderBase
extends RecordReader listDirectory(File path) {
-List result = new ArrayList<>();
-if (path.isDirectory()) {
- for (File f: path.listFiles()) {
-result.addAll(listDirectory(f));
- }
-} else {
- char c = path.getName().charAt(0);
- if (c != '.' && c != '_') {
-result.add(path.getAbsolutePath());
- }
-}
-return result;
- }
-
- /**
* Initializes the reader to read the file at `path` with `columns`
projected. If columns is
* null, all the columns are projected.
*
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/DataSourceReadBenchmark.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/DataSourceReadBenchmark.scala
index 31cee48..5094cdf 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/DataSo
[spark] branch master updated: [SPARK-37862][SQL] RecordBinaryComparator should fast skip the check of aligning with unaligned platform
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8ae9707 [SPARK-37862][SQL] RecordBinaryComparator should fast skip
the check of aligning with unaligned platform
8ae9707 is described below
commit 8ae970790814a0080713857261a3b1c2e2b01dd7
Author: ulysses-you
AuthorDate: Sat Jan 15 08:59:56 2022 -0600
[SPARK-37862][SQL] RecordBinaryComparator should fast skip the check of
aligning with unaligned platform
### What changes were proposed in this pull request?
`RecordBinaryComparator` compare the entire row, so it need to check if the
platform is unaligned. #35078 had given the perf number to show the benefits.
So this PR aims to do the same thing that fast skip the check of aligning with
unaligned platform.
### Why are the changes needed?
Improve the performance.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
Pass CI. And the perf number should be same with #35078
Closes #35161 from ulysses-you/unaligned.
Authored-by: ulysses-you
Signed-off-by: Sean Owen
---
.../java/org/apache/spark/sql/execution/RecordBinaryComparator.java | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/RecordBinaryComparator.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/RecordBinaryComparator.java
index 1f24340..e91873a 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/RecordBinaryComparator.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/RecordBinaryComparator.java
@@ -24,6 +24,7 @@ import java.nio.ByteOrder;
public final class RecordBinaryComparator extends RecordComparator {
+ private static final boolean UNALIGNED = Platform.unaligned();
private static final boolean LITTLE_ENDIAN =
ByteOrder.nativeOrder().equals(ByteOrder.LITTLE_ENDIAN);
@@ -41,7 +42,7 @@ public final class RecordBinaryComparator extends
RecordComparator {
// we have guaranteed `leftLen` == `rightLen`.
// check if stars align and we can get both offsets to be aligned
-if ((leftOff % 8) == (rightOff % 8)) {
+if (!UNALIGNED && ((leftOff % 8) == (rightOff % 8))) {
while ((leftOff + i) % 8 != 0 && i < leftLen) {
final int v1 = Platform.getByte(leftObj, leftOff + i);
final int v2 = Platform.getByte(rightObj, rightOff + i);
@@ -52,7 +53,7 @@ public final class RecordBinaryComparator extends
RecordComparator {
}
}
// for architectures that support unaligned accesses, chew it up 8 bytes
at a time
-if (Platform.unaligned() || (((leftOff + i) % 8 == 0) && ((rightOff + i) %
8 == 0))) {
+if (UNALIGNED || (((leftOff + i) % 8 == 0) && ((rightOff + i) % 8 == 0))) {
while (i <= leftLen - 8) {
long v1 = Platform.getLong(leftObj, leftOff + i);
long v2 = Platform.getLong(rightObj, rightOff + i);
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37854][CORE] Replace type check with pattern matching in Spark code
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c7c51bc [SPARK-37854][CORE] Replace type check with pattern matching
in Spark code
c7c51bc is described below
commit c7c51bcab5cb067d36bccf789e0e4ad7f37ffb7c
Author: yangjie01
AuthorDate: Sat Jan 15 08:54:16 2022 -0600
[SPARK-37854][CORE] Replace type check with pattern matching in Spark code
### What changes were proposed in this pull request?
There are many method use `isInstanceOf + asInstanceOf` for type
conversion in Spark code now, the main change of this pr is replace `type
check` with `pattern matching` for code simplification.
### Why are the changes needed?
Code simplification
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #35154 from LuciferYang/SPARK-37854.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/TestUtils.scala| 36 ++--
.../main/scala/org/apache/spark/api/r/SerDe.scala | 12 ++--
.../spark/internal/config/ConfigBuilder.scala | 18 +++---
.../scala/org/apache/spark/rdd/HadoopRDD.scala | 64 +++---
.../main/scala/org/apache/spark/rdd/PipedRDD.scala | 7 ++-
core/src/main/scala/org/apache/spark/rdd/RDD.scala | 8 ++-
.../main/scala/org/apache/spark/util/Utils.scala | 38 ++---
.../storage/ShuffleBlockFetcherIteratorSuite.scala | 10 ++--
.../org/apache/spark/util/FileAppenderSuite.scala | 17 +++---
.../scala/org/apache/spark/util/UtilsSuite.scala | 19 ---
.../apache/spark/examples/mllib/LDAExample.scala | 11 ++--
.../spark/mllib/api/python/PythonMLLibAPI.scala| 12 ++--
.../expressions/aggregate/Percentile.scala | 14 ++---
.../apache/spark/sql/catalyst/trees/TreeNode.scala | 7 +--
.../sql/catalyst/encoders/RowEncoderSuite.scala| 11 ++--
.../sql/execution/columnar/ColumnAccessor.scala| 10 ++--
.../spark/sql/execution/columnar/ColumnType.scala | 50 +
.../sql/execution/datasources/FileScanRDD.scala| 19 ---
.../org/apache/spark/sql/jdbc/H2Dialect.scala | 30 +-
.../spark/sql/SparkSessionExtensionSuite.scala | 57 +--
.../sql/execution/joins/BroadcastJoinSuite.scala | 13 ++---
.../apache/spark/sql/streaming/StreamTest.scala| 6 +-
.../sql/hive/client/IsolatedClientLoader.scala | 12 ++--
.../spark/streaming/scheduler/JobGenerator.scala | 10 ++--
.../org/apache/spark/streaming/util/StateMap.scala | 21 +++
25 files changed, 263 insertions(+), 249 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/TestUtils.scala
b/core/src/main/scala/org/apache/spark/TestUtils.scala
index 20159af..d2af955 100644
--- a/core/src/main/scala/org/apache/spark/TestUtils.scala
+++ b/core/src/main/scala/org/apache/spark/TestUtils.scala
@@ -337,22 +337,26 @@ private[spark] object TestUtils {
connection.setRequestMethod(method)
headers.foreach { case (k, v) => connection.setRequestProperty(k, v) }
-// Disable cert and host name validation for HTTPS tests.
-if (connection.isInstanceOf[HttpsURLConnection]) {
- val sslCtx = SSLContext.getInstance("SSL")
- val trustManager = new X509TrustManager {
-override def getAcceptedIssuers(): Array[X509Certificate] = null
-override def checkClientTrusted(x509Certificates:
Array[X509Certificate],
-s: String): Unit = {}
-override def checkServerTrusted(x509Certificates:
Array[X509Certificate],
-s: String): Unit = {}
- }
- val verifier = new HostnameVerifier() {
-override def verify(hostname: String, session: SSLSession): Boolean =
true
- }
- sslCtx.init(null, Array(trustManager), new SecureRandom())
-
connection.asInstanceOf[HttpsURLConnection].setSSLSocketFactory(sslCtx.getSocketFactory())
- connection.asInstanceOf[HttpsURLConnection].setHostnameVerifier(verifier)
+connection match {
+ // Disable cert and host name validation for HTTPS tests.
+ case httpConnection: HttpsURLConnection =>
+val sslCtx = SSLContext.getInstance("SSL")
+val trustManager = new X509TrustManager {
+ override def getAcceptedIssuers: Array[X509Certificate] = null
+
+ override def checkClientTrusted(x509Certificates:
Array[X509Certificate],
+ s: String): Unit = {}
+
+ override def checkServerTrusted(x509Certificates:
Array[X509Certificate],
+ s: String): Unit = {}
+}
+val verifier = new HostnameVerifier() {
+ override def verify(hostname: String, session: SSLSession): Boolean
= true
+}
+sslCtx.init(null, Array(trust
[spark] branch master updated (c68dcef -> f3eedaf4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c68dcef [SPARK-37418][PYTHON][ML] Inline annotations for pyspark.ml.param.__init__.py add f3eedaf4 [SPARK-37805][TESTS] Refactor `TestUtils#configTestLog4j` method to use log4j2 api No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/TestUtils.scala| 30 -- .../test/scala/org/apache/spark/DriverSuite.scala | 2 +- .../org/apache/spark/deploy/SparkSubmitSuite.scala | 4 +-- .../WholeStageCodegenSparkSubmitSuite.scala| 2 +- .../spark/sql/hive/HiveSparkSubmitSuite.scala | 20 +++ 5 files changed, 30 insertions(+), 28 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (c68dcef -> f3eedaf4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c68dcef [SPARK-37418][PYTHON][ML] Inline annotations for pyspark.ml.param.__init__.py add f3eedaf4 [SPARK-37805][TESTS] Refactor `TestUtils#configTestLog4j` method to use log4j2 api No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/TestUtils.scala| 30 -- .../test/scala/org/apache/spark/DriverSuite.scala | 2 +- .../org/apache/spark/deploy/SparkSubmitSuite.scala | 4 +-- .../WholeStageCodegenSparkSubmitSuite.scala| 2 +- .../spark/sql/hive/HiveSparkSubmitSuite.scala | 20 +++ 5 files changed, 30 insertions(+), 28 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (c68dcef -> f3eedaf4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c68dcef [SPARK-37418][PYTHON][ML] Inline annotations for pyspark.ml.param.__init__.py add f3eedaf4 [SPARK-37805][TESTS] Refactor `TestUtils#configTestLog4j` method to use log4j2 api No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/TestUtils.scala| 30 -- .../test/scala/org/apache/spark/DriverSuite.scala | 2 +- .../org/apache/spark/deploy/SparkSubmitSuite.scala | 4 +-- .../WholeStageCodegenSparkSubmitSuite.scala| 2 +- .../spark/sql/hive/HiveSparkSubmitSuite.scala | 20 +++ 5 files changed, 30 insertions(+), 28 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (c68dcef -> f3eedaf4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c68dcef [SPARK-37418][PYTHON][ML] Inline annotations for pyspark.ml.param.__init__.py add f3eedaf4 [SPARK-37805][TESTS] Refactor `TestUtils#configTestLog4j` method to use log4j2 api No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/TestUtils.scala| 30 -- .../test/scala/org/apache/spark/DriverSuite.scala | 2 +- .../org/apache/spark/deploy/SparkSubmitSuite.scala | 4 +-- .../WholeStageCodegenSparkSubmitSuite.scala| 2 +- .../spark/sql/hive/HiveSparkSubmitSuite.scala | 20 +++ 5 files changed, 30 insertions(+), 28 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37256][SQL] Replace `ScalaObjectMapper` with `ClassTagExtensions` to fix compilation warning
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3faced8 [SPARK-37256][SQL] Replace `ScalaObjectMapper` with
`ClassTagExtensions` to fix compilation warning
3faced8 is described below
commit 3faced8b2ab922c2a3f25bdf393aa0511d87ccc8
Author: yangjie01
AuthorDate: Tue Jan 11 09:25:49 2022 -0600
[SPARK-37256][SQL] Replace `ScalaObjectMapper` with `ClassTagExtensions` to
fix compilation warning
### What changes were proposed in this pull request?
There are some compilation warning log like follows:
```
[WARNING] [Warn]
/spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/RebaseDateTime.scala:268:
[deprecation
org.apache.spark.sql.catalyst.util.RebaseDateTime.loadRebaseRecords.mapper.$anon
| origin=com.fasterxml.jackson.module.scala.ScalaObjectMapper |
version=2.12.1] trait ScalaObjectMapper in package scala is deprecated (since
2.12.1): ScalaObjectMapper is deprecated because Manifests are not supported in
Scala3
```
Refer to the recommendations of `jackson-module-scala`, this PR use
`ClassTagExtensions` instead of `ScalaObjectMapper` to fix this compilation
warning
### Why are the changes needed?
Fix compilation warning
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes #34532 from LuciferYang/fix-ScalaObjectMapper.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/sql/catalyst/util/RebaseDateTime.scala | 4 ++--
.../org/apache/spark/sql/catalyst/util/RebaseDateTimeSuite.scala | 4 ++--
.../spark/sql/execution/streaming/state/RocksDBFileManager.scala | 4 ++--
3 files changed, 6 insertions(+), 6 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/RebaseDateTime.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/RebaseDateTime.scala
index 72bb43b..dc1c4db 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/RebaseDateTime.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/RebaseDateTime.scala
@@ -25,7 +25,7 @@ import java.util.Calendar.{DAY_OF_MONTH, DST_OFFSET, ERA,
HOUR_OF_DAY, MINUTE, M
import scala.collection.mutable.AnyRefMap
import com.fasterxml.jackson.databind.ObjectMapper
-import com.fasterxml.jackson.module.scala.{DefaultScalaModule,
ScalaObjectMapper}
+import com.fasterxml.jackson.module.scala.{ClassTagExtensions,
DefaultScalaModule}
import org.apache.spark.sql.catalyst.util.DateTimeConstants._
import org.apache.spark.sql.catalyst.util.DateTimeUtils._
@@ -273,7 +273,7 @@ object RebaseDateTime {
// it is 2 times faster in DateTimeRebaseBenchmark.
private[sql] def loadRebaseRecords(fileName: String): AnyRefMap[String,
RebaseInfo] = {
val file = Utils.getSparkClassLoader.getResource(fileName)
-val mapper = new ObjectMapper() with ScalaObjectMapper
+val mapper = new ObjectMapper() with ClassTagExtensions
mapper.registerModule(DefaultScalaModule)
val jsonRebaseRecords = mapper.readValue[Seq[JsonRebaseRecord]](file)
val anyRefMap = new AnyRefMap[String, RebaseInfo]((3 *
jsonRebaseRecords.size) / 2)
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/util/RebaseDateTimeSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/util/RebaseDateTimeSuite.scala
index 428a0c0..0d3f681c 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/util/RebaseDateTimeSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/util/RebaseDateTimeSuite.scala
@@ -252,7 +252,7 @@ class RebaseDateTimeSuite extends SparkFunSuite with
Matchers with SQLHelper {
import scala.collection.mutable.ArrayBuffer
import com.fasterxml.jackson.databind.ObjectMapper
-import com.fasterxml.jackson.module.scala.{DefaultScalaModule,
ScalaObjectMapper}
+import com.fasterxml.jackson.module.scala.{ClassTagExtensions,
DefaultScalaModule}
case class RebaseRecord(tz: String, switches: Array[Long], diffs:
Array[Long])
val rebaseRecords = ThreadUtils.parmap(ALL_TIMEZONES, "JSON-rebase-gen",
16) { zid =>
@@ -296,7 +296,7 @@ class RebaseDateTimeSuite extends SparkFunSuite with
Matchers with SQLHelper {
}
val result = new ArrayBuffer[RebaseRecord]()
rebaseRecords.sortBy(_.tz).foreach(result.append(_))
-val mapper = (new ObjectMapper() with ScalaObjectMapper)
+val mapper = (new ObjectMapper() with ClassTagExtensions)
.registerModule(DefaultScalaModule)
.writerWithDefaultPrettyPrinter()
mapper.writeValue(
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/st
[spark] branch master updated: [SPARK-37796][SQL] ByteArrayMethods arrayEquals should fast skip the check of aligning with unaligned platform
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 8c6d312 [SPARK-37796][SQL] ByteArrayMethods arrayEquals should fast skip the check of aligning with unaligned platform 8c6d312 is described below commit 8c6d3123086cf4def7e8be61214dfc9286578169 Author: ulysses-you AuthorDate: Wed Jan 5 09:30:05 2022 -0600 [SPARK-37796][SQL] ByteArrayMethods arrayEquals should fast skip the check of aligning with unaligned platform ### What changes were proposed in this pull request? The method `arrayEquals` in `ByteArrayMethods` is critical function which is used in `UTF8String.` `equals`, `indexOf`,`find` etc. After SPARK-16962, it add the complexity of aligned. It would be better to fast sikip the check of aligning if the platform is unaligned. ### Why are the changes needed? Improve the performance. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? Pass CI. Run the benchmark using [unaligned-benchmark](https://github.com/ulysses-you/spark/commit/d14d4bfcfeddcf90ccfe7cc3f6cda426d6d6b7e5), and here is the benchmark result: [JDK8](https://github.com/ulysses-you/spark/actions/runs/1639852573) ``` byte array equals OpenJDK 64-Bit Server VM 1.8.0_312-b07 on Linux 5.11.0-1022-azure Intel(R) Xeon(R) Platinum 8272CL CPU 2.60GHz Byte Array equals:Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative Byte Array equals fast 1322 NaN121.0 8.3 1.0X Byte Array equals 3378 3381 3 47.4 21.1 0.4X ``` [JDK11](https://github.com/ulysses-you/spark/actions/runs/1639853330) ``` byte array equals OpenJDK 64-Bit Server VM 11.0.13+8-LTS on Linux 5.11.0-1022-azure Intel(R) Xeon(R) Platinum 8272CL CPU 2.60GHz Byte Array equals:Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative Byte Array equals fast 1860 1891 15 86.0 11.6 1.0X Byte Array equals 2913 2921 8 54.9 18.2 0.6X ``` [JDK17](https://github.com/ulysses-you/spark/actions/runs/1639853938) ``` byte array equals OpenJDK 64-Bit Server VM 17.0.1+12-LTS on Linux 5.11.0-1022-azure Intel(R) Xeon(R) Platinum 8171M CPU 2.60GHz Byte Array equals:Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative Byte Array equals fast 1543 1602 39103.7 9.6 1.0X Byte Array equals 3027 3029 1 52.9 18.9 0.5X ``` Closes #35078 from ulysses-you/SPARK-37796. Authored-by: ulysses-you Signed-off-by: Sean Owen --- .../spark/unsafe/array/ByteArrayMethods.java | 2 +- .../ByteArrayBenchmark-jdk11-results.txt | 10 .../ByteArrayBenchmark-jdk17-results.txt | 10 sql/core/benchmarks/ByteArrayBenchmark-results.txt | 10 .../execution/benchmark/ByteArrayBenchmark.scala | 66 +- 5 files changed, 83 insertions(+), 15 deletions(-) diff --git a/common/unsafe/src/main/java/org/apache/spark/unsafe/array/ByteArrayMethods.java b/common/unsafe/src/main/java/org/apache/spark/unsafe/array/ByteArrayMethods.java index f3a59e3..5a7e32b 100644 --- a/common/unsafe/src/main/java/org/apache/spark/unsafe/array/ByteArrayMethods.java
[spark] branch master updated (4caface -> 88c7b6a)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4caface [MINOR] Remove unused imports in Scala 2.13 Repl2Suite add 88c7b6a [SPARK-37719][BUILD] Remove the `-add-exports` compilation option introduced by SPARK-37070 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 +- mllib-local/pom.xml | 5 + mllib/pom.xml | 5 + pom.xml | 20 ++-- project/SparkBuild.scala | 6 +- 6 files changed, 23 insertions(+), 17 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4fd1a0c -> 9b94081)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4fd1a0c [SPARK-37739][BUILD] Upgrade Arrow to 6.0.1 add 9b94081 [MINOR][DOCS] Update pandas_pyspark.rst No new revisions were added by this update. Summary of changes: python/docs/source/development/contributing.rst| 2 +- .../source/user_guide/pandas_on_spark/best_practices.rst | 14 +++--- .../source/user_guide/pandas_on_spark/from_to_dbms.rst | 2 +- .../source/user_guide/pandas_on_spark/pandas_pyspark.rst | 2 +- .../source/user_guide/pandas_on_spark/transform_apply.rst | 8 5 files changed, 14 insertions(+), 14 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (805e3fb -> 64c79a7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 805e3fb [SPARK-37462][CORE] Avoid unnecessary calculating the number of outstanding fetch requests and RPCS add 64c79a7 [SPARK-37718][MINOR][DOCS] Demo sql is incorrect No new revisions were added by this update. Summary of changes: docs/sql-ref-null-semantics.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (f6be769 -> 805e3fb)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from f6be769 [SPARK-37668][PYTHON] 'Index' object has no attribute 'levels' in pyspark.pandas.frame.DataFrame.insert add 805e3fb [SPARK-37462][CORE] Avoid unnecessary calculating the number of outstanding fetch requests and RPCS No new revisions were added by this update. Summary of changes: .../java/org/apache/spark/network/server/TransportChannelHandler.java | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (57ca75f -> 6511dbb)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 57ca75f [SPARK-37695][CORE][SHUFFLE] Skip diagnosis ob merged blocks from push-based shuffle add 6511dbb [SPARK-37628][BUILD] Upgrade Netty from 4.1.68 to 4.1.72 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 16 +++- dev/deps/spark-deps-hadoop-3-hive-2.3 | 16 +++- pom.xml | 76 ++- project/SparkBuild.scala | 4 +- 4 files changed, 106 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37493][CORE] show gc time and duration time of driver in executors page
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c2df895 [SPARK-37493][CORE] show gc time and duration time of driver
in executors page
c2df895 is described below
commit c2df895a8cbdfcbffc320e837ad1826933685912
Author: zhoubin11
AuthorDate: Mon Dec 13 08:47:01 2021 -0600
[SPARK-37493][CORE] show gc time and duration time of driver in executors
page
### What changes were proposed in this pull request?
show driver's gc time & duration time(equivalent to application time) of
driver in both driver side and history side UI
### Why are the changes needed?
help user to config driver's resource more appropriately
### Does this PR introduce _any_ user-facing change?
yes,user will see driver's gc time & duration time in executors page .
when `spark.eventLog.logStageExecutorMetrics` is enabled driver's gc time
can be logged.
before this change,user always get zero


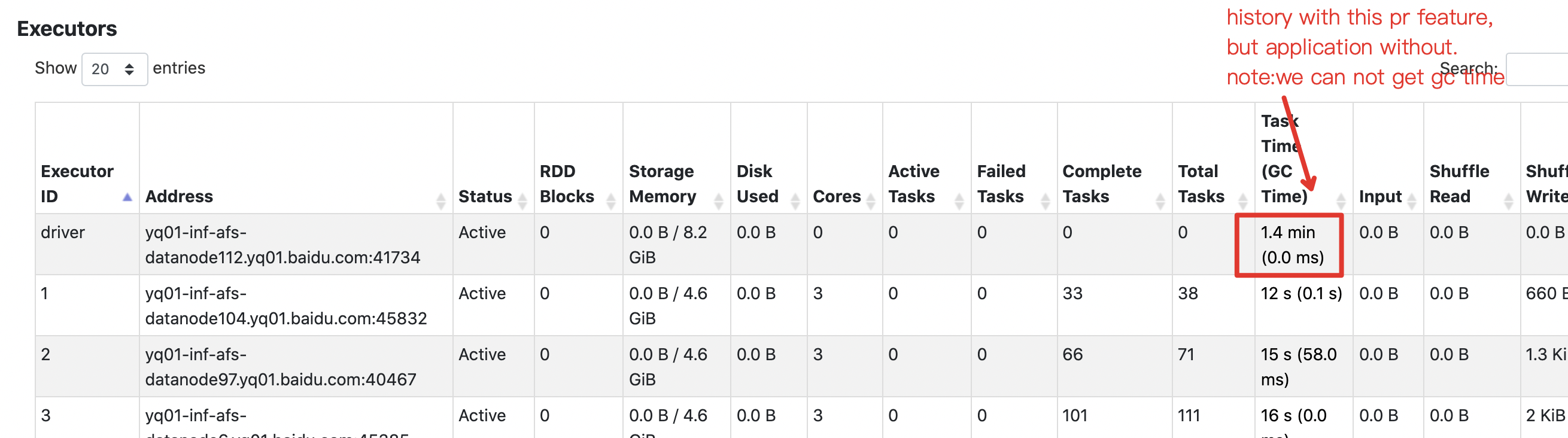
### How was this patch tested?
unit tests
Closes #34749 from summaryzb/SPARK-37493.
Authored-by: zhoubin11
Signed-off-by: Sean Owen
---
.../apache/spark/metrics/ExecutorMetricType.scala | 9 ++--
.../org/apache/spark/status/AppStatusStore.scala | 54 +++-
.../complete_stage_list_json_expectation.json | 9 ++--
.../excludeOnFailure_for_stage_expectation.json| 9 ++--
...xcludeOnFailure_node_for_stage_expectation.json | 18 ---
.../executor_list_json_expectation.json| 7 +--
...ist_with_executor_metrics_json_expectation.json | 14 --
.../executor_memory_usage_expectation.json | 32 ++--
...executor_node_excludeOnFailure_expectation.json | 40 ---
...e_excludeOnFailure_unexcluding_expectation.json | 14 --
.../executor_resource_information_expectation.json | 2 +-
.../failed_stage_list_json_expectation.json| 3 +-
..._json_details_with_failed_task_expectation.json | 6 ++-
.../one_stage_attempt_json_expectation.json| 6 ++-
.../one_stage_json_expectation.json| 6 ++-
.../one_stage_json_with_details_expectation.json | 6 ++-
.../stage_list_json_expectation.json | 12 +++--
...age_list_with_accumulable_json_expectation.json | 3 +-
.../stage_list_with_peak_metrics_expectation.json | 9 ++--
.../stage_with_accumulable_json_expectation.json | 6 ++-
.../stage_with_peak_metrics_expectation.json | 9 ++--
...stage_with_speculation_summary_expectation.json | 17 ---
.../stage_with_summaries_expectation.json | 12 +++--
.../scheduler/EventLoggingListenerSuite.scala | 58 +++---
.../org/apache/spark/util/JsonProtocolSuite.scala | 36 +-
25 files changed, 260 insertions(+), 137 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/metrics/ExecutorMetricType.scala
b/core/src/main/scala/org/apache/spark/metrics/ExecutorMetricType.scala
index 76e2813..a536919 100644
--- a/core/src/main/scala/org/apache/spark/metrics/ExecutorMetricType.scala
+++ b/core/src/main/scala/org/apache/spark/metrics/ExecutorMetricType.scala
@@ -109,7 +109,8 @@ case object GarbageCollectionMetrics extends
ExecutorMetricType with Logging {
"MinorGCCount",
"MinorGCTime",
"MajorGCCount",
-"MajorGCTime"
+"MajorGCTime",
+"TotalGCTime"
)
/* We builtin some common GC collectors which categorized as young
generation and old */
@@ -136,8 +137,10 @@ case object GarbageCollectionMetrics extends
ExecutorMetricType with Logging {
}
override private[spark] def getMetricValues(memoryManager: MemoryManager):
Array[Long] = {
-val gcMetrics = new Array[Long](names.length) // minorCount, minorTime,
majorCount, majorTime
-ManagementFactory.getGarbageCollectorMXBeans.asScala.foreach { mxBean =>
+val gcMetrics = new Array[Long](names.length)
+val mxBeans = ManagementFactory.getGarbageCollectorMXBeans.asScala
+gcMetrics(4) = mxBeans.map(_.getCollectionTime).sum
+mxBeans.foreach { mxBean =>
if (youngGenerationGarbageCollector.contains(mxBean.getName)) {
gcMetrics(0) = mxBean.getCollectionCount
gcMetrics(1) = mxBean.getCollectionTime
diff --git a/core/src/main/scala/org/apache/spark/status/AppStatusStore.scala
b/core/src/main/scala/org/apache/spark/status/AppStatusStore.scala
index
[spark] branch branch-3.2 updated: [SPARK-37594][SPARK-34399][SQL][TESTS] Make UT more stable
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 0bd2dab [SPARK-37594][SPARK-34399][SQL][TESTS] Make UT more stable
0bd2dab is described below
commit 0bd2dab53baaf1ad19a4389e5bcbeb388693d11f
Author: Angerszh
AuthorDate: Fri Dec 10 10:53:31 2021 -0600
[SPARK-37594][SPARK-34399][SQL][TESTS] Make UT more stable
### What changes were proposed in this pull request?
There are some GA test failed caused by UT ` test("SPARK-34399: Add job
commit duration metrics for DataWritingCommand") ` such as
```
sbt.ForkMain$ForkError: org.scalatest.exceptions.TestFailedException: 0 was
not greater than 0
at
org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:472)
at
org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:471)
at
org.scalatest.Assertions$.newAssertionFailedException(Assertions.scala:1231)
at
org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:1295)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.$anonfun$new$87(SQLMetricsSuite.scala:810)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withTable(SQLTestUtils.scala:305)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withTable$(SQLTestUtils.scala:303)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.withTable(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.$anonfun$new$86(SQLMetricsSuite.scala:800)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.org$apache$spark$sql$test$SQLTestUtilsBase$$super$withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf(SQLTestUtils.scala:246)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf$(SQLTestUtils.scala:244)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.$anonfun$new$85(SQLMetricsSuite.scala:800)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at
org.apache.spark.sql.execution.adaptive.DisableAdaptiveExecutionSuite.$anonfun$test$5(AdaptiveTestUtils.scala:65)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.org$apache$spark$sql$test$SQLTestUtilsBase$$super$withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf(SQLTestUtils.scala:246)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf$(SQLTestUtils.scala:244)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.execution.adaptive.DisableAdaptiveExecutionSuite.$anonfun$test$4(AdaptiveTestUtils.scala:65)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at
org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190)
at
org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224)
at
org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at
org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236)
at
org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218)
at
org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62)
at
org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
at
org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62)
at
org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$
[spark] branch master updated: [SPARK-37594][SPARK-34399][SQL][TESTS] Make UT more stable
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 471a5b5 [SPARK-37594][SPARK-34399][SQL][TESTS] Make UT more stable
471a5b5 is described below
commit 471a5b55b80256ccd253c93623ff363add5f1985
Author: Angerszh
AuthorDate: Fri Dec 10 10:53:31 2021 -0600
[SPARK-37594][SPARK-34399][SQL][TESTS] Make UT more stable
### What changes were proposed in this pull request?
There are some GA test failed caused by UT ` test("SPARK-34399: Add job
commit duration metrics for DataWritingCommand") ` such as
```
sbt.ForkMain$ForkError: org.scalatest.exceptions.TestFailedException: 0 was
not greater than 0
at
org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:472)
at
org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:471)
at
org.scalatest.Assertions$.newAssertionFailedException(Assertions.scala:1231)
at
org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:1295)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.$anonfun$new$87(SQLMetricsSuite.scala:810)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withTable(SQLTestUtils.scala:305)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withTable$(SQLTestUtils.scala:303)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.withTable(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.$anonfun$new$86(SQLMetricsSuite.scala:800)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.org$apache$spark$sql$test$SQLTestUtilsBase$$super$withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf(SQLTestUtils.scala:246)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf$(SQLTestUtils.scala:244)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.$anonfun$new$85(SQLMetricsSuite.scala:800)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at
org.apache.spark.sql.execution.adaptive.DisableAdaptiveExecutionSuite.$anonfun$test$5(AdaptiveTestUtils.scala:65)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
at
org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.org$apache$spark$sql$test$SQLTestUtilsBase$$super$withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf(SQLTestUtils.scala:246)
at
org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf$(SQLTestUtils.scala:244)
at
org.apache.spark.sql.execution.metric.SQLMetricsSuite.withSQLConf(SQLMetricsSuite.scala:44)
at
org.apache.spark.sql.execution.adaptive.DisableAdaptiveExecutionSuite.$anonfun$test$4(AdaptiveTestUtils.scala:65)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at
org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190)
at
org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224)
at
org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at
org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236)
at
org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218)
at
org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62)
at
org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
at
org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62)
at
org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuite
[spark] branch master updated (12d3517 -> 16d1c68)
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git.
from 12d3517 [SPARK-34332][SQL][TEST][FOLLOWUP] Remove unnecessary test
for ALTER NAMESPACE .. SET LOCATION
add 16d1c68 [SPARK-37474][R][DOCS] Migrate SparkR docs to pkgdown
No new revisions were added by this update.
Summary of changes:
.github/workflows/build_and_test.yml | 5 +-
R/create-docs.sh | 14 +
R/pkg/.Rbuildignore| 3 +
R/pkg/.gitignore | 1 +
R/pkg/R/DataFrame.R| 31 +-
R/pkg/R/SQLContext.R | 29 +-
R/pkg/R/functions.R| 17 +-
R/pkg/R/jobj.R | 1 +
R/pkg/R/schema.R | 2 +
R/pkg/R/utils.R| 1 +
R/{ => pkg}/README.md | 0
R/pkg/pkgdown/_pkgdown_template.yml| 311 +
.../pkg/pkgdown/extra.css | 43 ++-
R/pkg/vignettes/sparkr-vignettes.Rmd | 175 ++--
dev/create-release/spark-rm/Dockerfile | 3 +
docs/README.md | 2 +
docs/_plugins/copy_api_dirs.rb | 7 +-
17 files changed, 503 insertions(+), 142 deletions(-)
create mode 100644 R/pkg/.gitignore
rename R/{ => pkg}/README.md (100%)
create mode 100644 R/pkg/pkgdown/_pkgdown_template.yml
copy
sql/catalyst/src/main/java/org/apache/spark/sql/connector/distributions/OrderedDistribution.java
=> R/pkg/pkgdown/extra.css (60%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-37556][SQL] Deser void class fail with Java serialization
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new 113f750 [SPARK-37556][SQL] Deser void class fail with Java
serialization
113f750 is described below
commit 113f75058f99465281cd2065c22c0456c344be71
Author: Daniel Dai
AuthorDate: Tue Dec 7 08:48:23 2021 -0600
[SPARK-37556][SQL] Deser void class fail with Java serialization
**What changes were proposed in this pull request?**
Change the deserialization mapping for primitive type void.
**Why are the changes needed?**
The void primitive type in Scala should be classOf[Unit] not classOf[Void].
Spark erroneously [map
it](https://github.com/apache/spark/blob/v3.2.0/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala#L80)
differently than all other primitive types. Here is the code:
```
private object JavaDeserializationStream {
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
"char" -> classOf[Char],
"short" -> classOf[Short],
"int" -> classOf[Int],
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
"void" -> classOf[Void]
)
}
```
Spark code is Here is the demonstration:
```
scala> classOf[Long]
val res0: Class[Long] = long
scala> classOf[Double]
val res1: Class[Double] = double
scala> classOf[Byte]
val res2: Class[Byte] = byte
scala> classOf[Void]
val res3: Class[Void] = class java.lang.Void <--- this is wrong
scala> classOf[Unit]
val res4: Class[Unit] = void < this is right
```
It will result in Spark deserialization error if the Spark code contains
void primitive type:
`java.io.InvalidClassException: java.lang.Void; local class name
incompatible with stream class name "void"`
**Does this PR introduce any user-facing change?**
no
**How was this patch tested?**
Changed test, also tested e2e with the code results deserialization error
and it pass now.
Closes #34816 from daijyc/voidtype.
Authored-by: Daniel Dai
Signed-off-by: Sean Owen
(cherry picked from commit fb40c0e19f84f2de9a3d69d809e9e4031f76ef90)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala | 4 ++--
.../test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
index 077b035..3c13401 100644
--- a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
@@ -87,8 +87,8 @@ private object JavaDeserializationStream {
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
-"void" -> classOf[Void]
- )
+"void" -> classOf[Unit])
+
}
private[spark] class JavaSerializerInstance(
diff --git
a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
index 6a6ea42..03349f8 100644
--- a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
@@ -47,5 +47,5 @@ private class ContainsPrimitiveClass extends Serializable {
val floatClass = classOf[Float]
val booleanClass = classOf[Boolean]
val byteClass = classOf[Byte]
- val voidClass = classOf[Void]
+ val voidClass = classOf[Unit]
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-37556][SQL] Deser void class fail with Java serialization
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 2816017 [SPARK-37556][SQL] Deser void class fail with Java
serialization
2816017 is described below
commit 281601739de100521de6009b4a65efc3e922622a
Author: Daniel Dai
AuthorDate: Tue Dec 7 08:48:23 2021 -0600
[SPARK-37556][SQL] Deser void class fail with Java serialization
**What changes were proposed in this pull request?**
Change the deserialization mapping for primitive type void.
**Why are the changes needed?**
The void primitive type in Scala should be classOf[Unit] not classOf[Void].
Spark erroneously [map
it](https://github.com/apache/spark/blob/v3.2.0/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala#L80)
differently than all other primitive types. Here is the code:
```
private object JavaDeserializationStream {
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
"char" -> classOf[Char],
"short" -> classOf[Short],
"int" -> classOf[Int],
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
"void" -> classOf[Void]
)
}
```
Spark code is Here is the demonstration:
```
scala> classOf[Long]
val res0: Class[Long] = long
scala> classOf[Double]
val res1: Class[Double] = double
scala> classOf[Byte]
val res2: Class[Byte] = byte
scala> classOf[Void]
val res3: Class[Void] = class java.lang.Void <--- this is wrong
scala> classOf[Unit]
val res4: Class[Unit] = void < this is right
```
It will result in Spark deserialization error if the Spark code contains
void primitive type:
`java.io.InvalidClassException: java.lang.Void; local class name
incompatible with stream class name "void"`
**Does this PR introduce any user-facing change?**
no
**How was this patch tested?**
Changed test, also tested e2e with the code results deserialization error
and it pass now.
Closes #34816 from daijyc/voidtype.
Authored-by: Daniel Dai
Signed-off-by: Sean Owen
(cherry picked from commit fb40c0e19f84f2de9a3d69d809e9e4031f76ef90)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala | 4 ++--
.../test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
index 077b035..3c13401 100644
--- a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
@@ -87,8 +87,8 @@ private object JavaDeserializationStream {
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
-"void" -> classOf[Void]
- )
+"void" -> classOf[Unit])
+
}
private[spark] class JavaSerializerInstance(
diff --git
a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
index 6a6ea42..03349f8 100644
--- a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
@@ -47,5 +47,5 @@ private class ContainsPrimitiveClass extends Serializable {
val floatClass = classOf[Float]
val booleanClass = classOf[Boolean]
val byteClass = classOf[Byte]
- val voidClass = classOf[Void]
+ val voidClass = classOf[Unit]
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37556][SQL] Deser void class fail with Java serialization
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new ce414f8 [SPARK-37556][SQL] Deser void class fail with Java
serialization
ce414f8 is described below
commit ce414f82eb69a1888f0a166ce8f3bd3f209b15a6
Author: Daniel Dai
AuthorDate: Tue Dec 7 08:48:23 2021 -0600
[SPARK-37556][SQL] Deser void class fail with Java serialization
**What changes were proposed in this pull request?**
Change the deserialization mapping for primitive type void.
**Why are the changes needed?**
The void primitive type in Scala should be classOf[Unit] not classOf[Void].
Spark erroneously [map
it](https://github.com/apache/spark/blob/v3.2.0/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala#L80)
differently than all other primitive types. Here is the code:
```
private object JavaDeserializationStream {
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
"char" -> classOf[Char],
"short" -> classOf[Short],
"int" -> classOf[Int],
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
"void" -> classOf[Void]
)
}
```
Spark code is Here is the demonstration:
```
scala> classOf[Long]
val res0: Class[Long] = long
scala> classOf[Double]
val res1: Class[Double] = double
scala> classOf[Byte]
val res2: Class[Byte] = byte
scala> classOf[Void]
val res3: Class[Void] = class java.lang.Void <--- this is wrong
scala> classOf[Unit]
val res4: Class[Unit] = void < this is right
```
It will result in Spark deserialization error if the Spark code contains
void primitive type:
`java.io.InvalidClassException: java.lang.Void; local class name
incompatible with stream class name "void"`
**Does this PR introduce any user-facing change?**
no
**How was this patch tested?**
Changed test, also tested e2e with the code results deserialization error
and it pass now.
Closes #34816 from daijyc/voidtype.
Authored-by: Daniel Dai
Signed-off-by: Sean Owen
(cherry picked from commit fb40c0e19f84f2de9a3d69d809e9e4031f76ef90)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala | 4 ++--
.../test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
index 077b035..3c13401 100644
--- a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
@@ -87,8 +87,8 @@ private object JavaDeserializationStream {
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
-"void" -> classOf[Void]
- )
+"void" -> classOf[Unit])
+
}
private[spark] class JavaSerializerInstance(
diff --git
a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
index 6a6ea42..03349f8 100644
--- a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
@@ -47,5 +47,5 @@ private class ContainsPrimitiveClass extends Serializable {
val floatClass = classOf[Float]
val booleanClass = classOf[Boolean]
val byteClass = classOf[Byte]
- val voidClass = classOf[Void]
+ val voidClass = classOf[Unit]
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37556][SQL] Deser void class fail with Java serialization
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new fb40c0e [SPARK-37556][SQL] Deser void class fail with Java
serialization
fb40c0e is described below
commit fb40c0e19f84f2de9a3d69d809e9e4031f76ef90
Author: Daniel Dai
AuthorDate: Tue Dec 7 08:48:23 2021 -0600
[SPARK-37556][SQL] Deser void class fail with Java serialization
**What changes were proposed in this pull request?**
Change the deserialization mapping for primitive type void.
**Why are the changes needed?**
The void primitive type in Scala should be classOf[Unit] not classOf[Void].
Spark erroneously [map
it](https://github.com/apache/spark/blob/v3.2.0/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala#L80)
differently than all other primitive types. Here is the code:
```
private object JavaDeserializationStream {
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
"char" -> classOf[Char],
"short" -> classOf[Short],
"int" -> classOf[Int],
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
"void" -> classOf[Void]
)
}
```
Spark code is Here is the demonstration:
```
scala> classOf[Long]
val res0: Class[Long] = long
scala> classOf[Double]
val res1: Class[Double] = double
scala> classOf[Byte]
val res2: Class[Byte] = byte
scala> classOf[Void]
val res3: Class[Void] = class java.lang.Void <--- this is wrong
scala> classOf[Unit]
val res4: Class[Unit] = void < this is right
```
It will result in Spark deserialization error if the Spark code contains
void primitive type:
`java.io.InvalidClassException: java.lang.Void; local class name
incompatible with stream class name "void"`
**Does this PR introduce any user-facing change?**
no
**How was this patch tested?**
Changed test, also tested e2e with the code results deserialization error
and it pass now.
Closes #34816 from daijyc/voidtype.
Authored-by: Daniel Dai
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala| 2 +-
.../test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala| 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
index 9d76611..95d2bdc 100644
--- a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
@@ -99,7 +99,7 @@ private object JavaDeserializationStream {
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
-"void" -> classOf[Void])
+"void" -> classOf[Unit])
}
diff --git
a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
index 77226af..6a35fd0 100644
--- a/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/serializer/JavaSerializerSuite.scala
@@ -69,5 +69,5 @@ private class ContainsPrimitiveClass extends Serializable {
val floatClass = classOf[Float]
val booleanClass = classOf[Boolean]
val byteClass = classOf[Byte]
- val voidClass = classOf[Void]
+ val voidClass = classOf[Unit]
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (bde47c8 -> 116255d)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from bde47c8 [SPARK-37546][SQL] V2 ReplaceTableAsSelect command should qualify location add 116255d [SPARK-37506][CORE][SQL][DSTREAM][GRAPHX][ML][MLLIB][SS][EXAMPLES] Change the never changed 'var' to 'val' No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/deploy/ClientArguments.scala | 2 +- .../main/scala/org/apache/spark/rdd/CoalescedRDD.scala | 2 +- .../main/scala/org/apache/spark/status/LiveEntity.scala | 3 +-- .../spark/storage/ShuffleBlockFetcherIterator.scala | 2 +- .../scala/org/apache/spark/deploy/SparkSubmitSuite.scala | 2 +- .../org/apache/spark/deploy/SparkSubmitUtilsSuite.scala | 2 +- .../org/apache/spark/scheduler/TaskSetManagerSuite.scala | 2 +- .../org/apache/spark/examples/MiniReadWriteTest.scala| 8 .../spark/sql/kafka010/KafkaOffsetReaderAdmin.scala | 2 +- .../spark/sql/kafka010/KafkaOffsetReaderConsumer.scala | 2 +- .../org/apache/spark/graphx/util/GraphGenerators.scala | 2 +- .../scala/org/apache/spark/ml/linalg/BLASBenchmark.scala | 16 .../scala/org/apache/spark/mllib/feature/Word2Vec.scala | 2 +- .../org/apache/spark/ml/feature/InteractionSuite.scala | 4 ++-- .../org/apache/spark/ml/recommendation/ALSSuite.scala| 2 +- .../src/main/scala/org/apache/spark/sql/Row.scala| 2 +- .../spark/sql/catalyst/expressions/jsonExpressions.scala | 2 +- .../apache/spark/sql/catalyst/util/DateTimeUtils.scala | 2 +- .../columnar/compression/compressionSchemes.scala| 2 +- .../execution/datasources/BasicWriteStatsTracker.scala | 2 +- .../test/scala/org/apache/spark/sql/SubquerySuite.scala | 2 +- .../datasources/parquet/ParquetColumnIndexSuite.scala| 2 +- .../sql/streaming/test/DataStreamReaderWriterSuite.scala | 4 ++-- .../apache/spark/sql/hive/client/HiveClientImpl.scala| 2 +- .../spark/streaming/ReceivedBlockTrackerSuite.scala | 4 ++-- 25 files changed, 38 insertions(+), 39 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37286][DOCS][FOLLOWUP] Fix the wrong parameter name for Javadoc
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f570d01 [SPARK-37286][DOCS][FOLLOWUP] Fix the wrong parameter name
for Javadoc
f570d01 is described below
commit f570d01c0d009bb035d3c89d77661a5432f982cb
Author: Kousuke Saruta
AuthorDate: Fri Dec 3 11:16:39 2021 -0600
[SPARK-37286][DOCS][FOLLOWUP] Fix the wrong parameter name for Javadoc
### What changes were proposed in this pull request?
This PR fixes an issue that the Javadoc generation fails due to the wrong
parameter name of a method added in SPARK-37286 (#34554).
https://github.com/apache/spark/runs/4409267346?check_suite_focus=true#step:9:5081
### Why are the changes needed?
To keep the build clean.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
GA itself.
Closes #34801 from sarutak/followup-SPARK-37286.
Authored-by: Kousuke Saruta
Signed-off-by: Sean Owen
---
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala
b/sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala
index fcc2be2..9a647e5 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala
@@ -196,7 +196,7 @@ abstract class JdbcDialect extends Serializable with
Logging{
/**
* Converts aggregate function to String representing a SQL expression.
- * @param aggregate The aggregate function to be converted.
+ * @param aggFunction The aggregate function to be converted.
* @return Converted value.
*/
@Since("3.3.0")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Fix the link of SPARK-24554 in Spark 3.1.1 release note
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 81ab561 Fix the link of SPARK-24554 in Spark 3.1.1 release note 81ab561 is described below commit 81ab561dcb9da5983674a9f8b090e54908cc97e7 Author: Hyukjin Kwon AuthorDate: Wed Dec 1 08:52:50 2021 -0600 Fix the link of SPARK-24554 in Spark 3.1.1 release note SPARK-24554 has to link to https://issues.apache.org/jira/browse/SPARK-24554 but it's linked to https://issues.apache.org/jira/browse/SPARK-33748. This PR fixes the link. Author: Hyukjin Kwon Closes #370 from HyukjinKwon/typo-jira. --- releases/_posts/2021-03-02-spark-release-3-1-1.md | 2 +- site/releases/spark-release-3-1-1.html| 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/releases/_posts/2021-03-02-spark-release-3-1-1.md b/releases/_posts/2021-03-02-spark-release-3-1-1.md index 2126301..59010ea 100644 --- a/releases/_posts/2021-03-02-spark-release-3-1-1.md +++ b/releases/_posts/2021-03-02-spark-release-3-1-1.md @@ -222,7 +222,7 @@ Please read the migration guides for each component: [Spark Core](https://spark. - Support getCheckpointDir method in PySpark SparkContext ([SPARK-33017](https://issues.apache.org/jira/browse/SPARK-33017)) - Support to fill nulls for missing columns in unionByName ([SPARK-32798](https://issues.apache.org/jira/browse/SPARK-32798)) - Update cloudpickle to v1.5.0 ([SPARK-32094](https://issues.apache.org/jira/browse/SPARK-32094)) -- Add MapType support for PySpark with Arrow ([SPARK-24554](https://issues.apache.org/jira/browse/SPARK-33748)) +- Add MapType support for PySpark with Arrow ([SPARK-24554](https://issues.apache.org/jira/browse/SPARK-24554)) - DataStreamReader.table and DataStreamWriter.toTable ([SPARK-33836](https://issues.apache.org/jira/browse/SPARK-33836)) **Changes of behavior** diff --git a/site/releases/spark-release-3-1-1.html b/site/releases/spark-release-3-1-1.html index 8fafba3..b0c9786 100644 --- a/site/releases/spark-release-3-1-1.html +++ b/site/releases/spark-release-3-1-1.html @@ -424,7 +424,7 @@ Support getCheckpointDir method in PySpark SparkContext (https://issues.apache.org/jira/browse/SPARK-33017";>SPARK-33017) Support to fill nulls for missing columns in unionByName (https://issues.apache.org/jira/browse/SPARK-32798";>SPARK-32798) Update cloudpickle to v1.5.0 (https://issues.apache.org/jira/browse/SPARK-32094";>SPARK-32094) - Add MapType support for PySpark with Arrow (https://issues.apache.org/jira/browse/SPARK-33748";>SPARK-24554) + Add MapType support for PySpark with Arrow (https://issues.apache.org/jira/browse/SPARK-24554";>SPARK-24554) DataStreamReader.table and DataStreamWriter.toTable (https://issues.apache.org/jira/browse/SPARK-33836";>SPARK-33836) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37461][YARN] YARN-CLIENT mode client.appId is always null
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new db9a982 [SPARK-37461][YARN] YARN-CLIENT mode client.appId is always
null
db9a982 is described below
commit db9a982a1441810314be07e2c3b7cc77d1f1
Author: Angerszh
AuthorDate: Sun Nov 28 08:53:25 2021 -0600
[SPARK-37461][YARN] YARN-CLIENT mode client.appId is always null
### What changes were proposed in this pull request?
In yarn-client mode, `Client.appId` variable is not assigned, it is always
`null`, in cluster mode, this variable will be assigned to the true value. In
this patch, we assign true application id to `appId` too
### Why are the changes needed?
1. Refactor the code to avoid define different id in each function, we can
just use this variable.
2. In client mode, user can use this value to get the application id.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manuel tested.
We have a internal proxy server to replace yarn tracking url, here use
`appId`, with this patch it's not null.
```
21/11/26 12:38:44 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to
Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: user_queue
start time: 1637901520956
final status: UNDEFINED
tracking URL:
http://internal-proxy-server/proxy?applicationId=application_1635856758535_4209064
user: user_name
```
Closes #34710 from AngersZh/SPARK-37461.
Authored-by: Angerszh
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/deploy/yarn/Client.scala| 13 +
1 file changed, 5 insertions(+), 8 deletions(-)
diff --git
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
index 7787e2f..e6136fc 100644
---
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
+++
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
@@ -169,7 +169,6 @@ private[spark] class Client(
def submitApplication(): ApplicationId = {
ResourceRequestHelper.validateResources(sparkConf)
-var appId: ApplicationId = null
try {
launcherBackend.connect()
yarnClient.init(hadoopConf)
@@ -181,7 +180,7 @@ private[spark] class Client(
// Get a new application from our RM
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
- appId = newAppResponse.getApplicationId()
+ this.appId = newAppResponse.getApplicationId()
// The app staging dir based on the STAGING_DIR configuration if
configured
// otherwise based on the users home directory.
@@ -207,8 +206,7 @@ private[spark] class Client(
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
-
- appId
+ this.appId
} catch {
case e: Throwable =>
if (stagingDirPath != null) {
@@ -915,7 +913,6 @@ private[spark] class Client(
private def createContainerLaunchContext(newAppResponse:
GetNewApplicationResponse)
: ContainerLaunchContext = {
logInfo("Setting up container launch context for our AM")
-val appId = newAppResponse.getApplicationId
val pySparkArchives =
if (sparkConf.get(IS_PYTHON_APP)) {
findPySparkArchives()
@@ -971,7 +968,7 @@ private[spark] class Client(
if (isClusterMode) {
sparkConf.get(DRIVER_JAVA_OPTIONS).foreach { opts =>
javaOpts ++= Utils.splitCommandString(opts)
- .map(Utils.substituteAppId(_, appId.toString))
+ .map(Utils.substituteAppId(_, this.appId.toString))
.map(YarnSparkHadoopUtil.escapeForShell)
}
val libraryPaths = Seq(sparkConf.get(DRIVER_LIBRARY_PATH),
@@ -996,7 +993,7 @@ private[spark] class Client(
throw new SparkException(msg)
}
javaOpts ++= Utils.splitCommandString(opts)
- .map(Utils.substituteAppId(_, appId.toString))
+ .map(Utils.substituteAppId(_, this.appId.toString))
.map(YarnSparkHadoopUtil.escapeForShell)
}
sparkConf.get(AM_LIBRARY_PATH).foreach { paths =>
@@ -1269,7 +1266,7 @@ private[spark] class Client(
* throw an appropriate SparkException.
*/
def run(): Unit = {
-this.appId = submitApplication()
+submitApplication()
if (!launcherBackend.isConnected() && fireAndForget) {
val report = getApplicati
[spark] branch master updated: [SPARK-37437][BUILD] Remove unused hive profile and related CI test
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f399d0d [SPARK-37437][BUILD] Remove unused hive profile and related
CI test
f399d0d is described below
commit f399d0d748dc72740ba0b3f662d658546215c71d
Author: Angerszh
AuthorDate: Sat Nov 27 08:50:46 2021 -0600
[SPARK-37437][BUILD] Remove unused hive profile and related CI test
### What changes were proposed in this pull request?
Since we only support hive-2.3, we should remove the unused profile and
related GA test.
`-Phive-2.3` still works after removing the profile
### Why are the changes needed?
Remove unused profile
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes #34679 from AngersZh/SPARK-37437.
Authored-by: Angerszh
Signed-off-by: Sean Owen
---
dev/create-release/release-build.sh | 2 +-
dev/run-tests-jenkins.py| 3 ---
dev/run-tests.py| 23 +--
dev/test-dependencies.sh| 8 +++-
pom.xml | 5 -
5 files changed, 5 insertions(+), 36 deletions(-)
diff --git a/dev/create-release/release-build.sh
b/dev/create-release/release-build.sh
index 96b8d4e..44baedd 100755
--- a/dev/create-release/release-build.sh
+++ b/dev/create-release/release-build.sh
@@ -192,7 +192,7 @@ SCALA_2_12_PROFILES="-Pscala-2.12"
HIVE_PROFILES="-Phive -Phive-thriftserver"
# Profiles for publishing snapshots and release to Maven Central
# We use Apache Hive 2.3 for publishing
-PUBLISH_PROFILES="$BASE_PROFILES $HIVE_PROFILES -Phive-2.3
-Pspark-ganglia-lgpl -Pkinesis-asl -Phadoop-cloud"
+PUBLISH_PROFILES="$BASE_PROFILES $HIVE_PROFILES -Pspark-ganglia-lgpl
-Pkinesis-asl -Phadoop-cloud"
# Profiles for building binary releases
BASE_RELEASE_PROFILES="$BASE_PROFILES -Psparkr"
diff --git a/dev/run-tests-jenkins.py b/dev/run-tests-jenkins.py
index f24e702..67d0972 100755
--- a/dev/run-tests-jenkins.py
+++ b/dev/run-tests-jenkins.py
@@ -174,9 +174,6 @@ def main():
os.environ["AMPLAB_JENKINS_BUILD_PROFILE"] = "hadoop2.7"
if "test-hadoop3.2" in ghprb_pull_title:
os.environ["AMPLAB_JENKINS_BUILD_PROFILE"] = "hadoop3.2"
-# Switch the Hive profile based on the PR title:
-if "test-hive2.3" in ghprb_pull_title:
-os.environ["AMPLAB_JENKINS_BUILD_HIVE_PROFILE"] = "hive2.3"
# Switch the Scala profile based on the PR title:
if "test-scala2.13" in ghprb_pull_title:
os.environ["AMPLAB_JENKINS_BUILD_SCALA_PROFILE"] = "scala2.13"
diff --git a/dev/run-tests.py b/dev/run-tests.py
index 55c65ed..25df8f6 100755
--- a/dev/run-tests.py
+++ b/dev/run-tests.py
@@ -345,24 +345,6 @@ def get_hadoop_profiles(hadoop_version):
sys.exit(int(os.environ.get("CURRENT_BLOCK", 255)))
-def get_hive_profiles(hive_version):
-"""
-For the given Hive version tag, return a list of Maven/SBT profile flags
for
-building and testing against that Hive version.
-"""
-
-sbt_maven_hive_profiles = {
-"hive2.3": ["-Phive-2.3"],
-}
-
-if hive_version in sbt_maven_hive_profiles:
-return sbt_maven_hive_profiles[hive_version]
-else:
-print("[error] Could not find", hive_version, "in the list. Valid
options",
- " are", sbt_maven_hive_profiles.keys())
-sys.exit(int(os.environ.get("CURRENT_BLOCK", 255)))
-
-
def build_spark_maven(extra_profiles):
# Enable all of the profiles for the build:
build_profiles = extra_profiles + modules.root.build_profile_flags
@@ -616,7 +598,6 @@ def main():
build_tool = os.environ.get("AMPLAB_JENKINS_BUILD_TOOL", "sbt")
scala_version = os.environ.get("AMPLAB_JENKINS_BUILD_SCALA_PROFILE")
hadoop_version = os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE",
"hadoop3.2")
-hive_version = os.environ.get("AMPLAB_JENKINS_BUILD_HIVE_PROFILE",
"hive2.3")
test_env = "amplab_jenkins"
# add path for Python3 in Jenkins if we're calling from a Jenkins
machine
# TODO(sknapp): after all builds are ported to the ubuntu workers,
change this to be:
@@ -627,14 +608,12 @@ def main():
build_tool = "sbt"
scala_version = os.environ.get("SCALA_PROFILE")
hadoop_version = os.environ.get("HADOOP_PROFILE", "hadoop3.2")
-hive_version = os.environ
[spark] branch master updated: [MINOR][DOCS] Update scaladoc of KnownSizeEstimation
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 6c73cee [MINOR][DOCS] Update scaladoc of KnownSizeEstimation 6c73cee is described below commit 6c73cee8108731414bb56be5f52bd2dffd1eb6d5 Author: Cheng Pan AuthorDate: Wed Nov 24 09:11:06 2021 -0600 [MINOR][DOCS] Update scaladoc of KnownSizeEstimation ### What changes were proposed in this pull request? Followup #9813 ### Why are the changes needed? Fix scaladoc. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #34692 from pan3793/SPARK-11792. Authored-by: Cheng Pan Signed-off-by: Sean Owen --- core/src/main/scala/org/apache/spark/util/SizeEstimator.scala | 8 +++- 1 file changed, 3 insertions(+), 5 deletions(-) diff --git a/core/src/main/scala/org/apache/spark/util/SizeEstimator.scala b/core/src/main/scala/org/apache/spark/util/SizeEstimator.scala index 85e1119..9ec9307 100644 --- a/core/src/main/scala/org/apache/spark/util/SizeEstimator.scala +++ b/core/src/main/scala/org/apache/spark/util/SizeEstimator.scala @@ -33,11 +33,9 @@ import org.apache.spark.util.collection.OpenHashSet /** * A trait that allows a class to give [[SizeEstimator]] more accurate size estimation. - * When a class extends it, [[SizeEstimator]] will query the `estimatedSize` first. - * If `estimatedSize` does not return `None`, [[SizeEstimator]] will use the returned size - * as the size of the object. Otherwise, [[SizeEstimator]] will do the estimation work. - * The difference between a [[KnownSizeEstimation]] and - * [[org.apache.spark.util.collection.SizeTracker]] is that, a + * When a class extends it, [[SizeEstimator]] will query the `estimatedSize`, and use + * the returned size as the size of the object. The difference between a [[KnownSizeEstimation]] + * and [[org.apache.spark.util.collection.SizeTracker]] is that, a * [[org.apache.spark.util.collection.SizeTracker]] still uses [[SizeEstimator]] to * estimate the size. However, a [[KnownSizeEstimation]] can provide a better estimation without * using [[SizeEstimator]]. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new 7ba340c [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` 7ba340c is described below commit 7ba340c952fec83f59b6d0111c849ed8afbe99f1 Author: yangjie01 AuthorDate: Sun Nov 21 19:11:40 2021 -0600 [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### What changes were proposed in this pull request? `YarnShuffleIntegrationSuite`, `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` will failed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`, the fail reason is `java.lang.NoClassDefFoundError: breeze/linalg/Matrix`. The above UTS can succeed when using `hadoop-2.7` profile without `assembly/target/scala-%s/jars` because `KryoSerializer.loadableSparkClasses` can workaroud when `Utils.isTesting` is true, but `Utils.isTesting` is false when using `hadoop-3.2` profile. After investigated, I found that when `hadoop-2.7` profile is used, `SPARK_TESTING` will be propagated to AM and Executor, but when `hadoop-3.2` profile is used, `SPARK_TESTING` will not be propagated to AM and Executor. In order to ensure the consistent behavior of using `hadoop-2.7` and ``hadoop-3.2``, this pr change to manually propagate `SPARK_TESTING` environment variable if it exists to ensure `Utils.isTesting` is true in above test scenario. ### Why are the changes needed? Ensure `YarnShuffleIntegrationSuite` releated UTs can succeed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test `YarnShuffleIntegrationSuite`. `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` can be verified in the same way. Please ensure that the `assembly/target/scala-%s/jars` directory does not exist before executing the test command, we can clean up the whole project by executing follow command or clone a new local code repo. 1. run with `hadoop-3.2` profile ``` mvn clean install -Phadoop-3.2 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service *** FAILED *** FAILED did not equal FINISHED (stdout/stderr was not captured) (BaseYarnClusterSuite.scala:227) Run completed in 48 seconds, 137 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` Error stack as follows: ``` 21/11/20 23:00:09.682 main ERROR Client: Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (localhost executor 1): java.lang.NoClassDefFoundError: breeze/linalg/Matrix at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:216) at org.apache.spark.serializer.KryoSerializer$.$anonfun$loadableSparkClasses$1(KryoSerializer.scala:537) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.serializer.KryoSerializer$.loadableSparkClasses$lzycompute(KryoSerializer.scala:535) at org.apache.spark.serializer.KryoSerializer$.org$apache$spark$serializer$KryoSerializer$$loadableSparkClasses(KryoSerializer.scala:502) at org.apache.spark.serializer.KryoSerializer.newKryo(KryoSerializer.scala:226) at org.apache.spark.serializer.KryoSerializer$$anon$1.create(KryoSerializer.scala:102) at com.esotericsoftware.kryo.pool.KryoPoolQueueImpl.borrow(KryoPoolQueueImpl.java:48) at org.apache.spark.serializer.KryoSerializer$PoolWrapper.borrow(KryoSerializer.scala:109) at org.apache.spark.serializer.KryoSerializerInstance.borrowKryo(KryoSerializer.scala:346) at org.apache.spark.serializer.KryoSerializationStream.(KryoSerializer.scala:266) at org.apache.spark.serializer.KryoSerializerInstance.serializeStream(KryoSerializer.scala:432) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.open(ShufflePartitionPairsWriter.scala:76) at
[spark] branch branch-3.1 updated: [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.1 by this push: new a1851cb [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` a1851cb is described below commit a1851cb8087eb3acd6b1d894148babe54eb3aa53 Author: yangjie01 AuthorDate: Sun Nov 21 19:11:40 2021 -0600 [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### What changes were proposed in this pull request? `YarnShuffleIntegrationSuite`, `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` will failed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`, the fail reason is `java.lang.NoClassDefFoundError: breeze/linalg/Matrix`. The above UTS can succeed when using `hadoop-2.7` profile without `assembly/target/scala-%s/jars` because `KryoSerializer.loadableSparkClasses` can workaroud when `Utils.isTesting` is true, but `Utils.isTesting` is false when using `hadoop-3.2` profile. After investigated, I found that when `hadoop-2.7` profile is used, `SPARK_TESTING` will be propagated to AM and Executor, but when `hadoop-3.2` profile is used, `SPARK_TESTING` will not be propagated to AM and Executor. In order to ensure the consistent behavior of using `hadoop-2.7` and ``hadoop-3.2``, this pr change to manually propagate `SPARK_TESTING` environment variable if it exists to ensure `Utils.isTesting` is true in above test scenario. ### Why are the changes needed? Ensure `YarnShuffleIntegrationSuite` releated UTs can succeed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test `YarnShuffleIntegrationSuite`. `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` can be verified in the same way. Please ensure that the `assembly/target/scala-%s/jars` directory does not exist before executing the test command, we can clean up the whole project by executing follow command or clone a new local code repo. 1. run with `hadoop-3.2` profile ``` mvn clean install -Phadoop-3.2 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service *** FAILED *** FAILED did not equal FINISHED (stdout/stderr was not captured) (BaseYarnClusterSuite.scala:227) Run completed in 48 seconds, 137 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` Error stack as follows: ``` 21/11/20 23:00:09.682 main ERROR Client: Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (localhost executor 1): java.lang.NoClassDefFoundError: breeze/linalg/Matrix at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:216) at org.apache.spark.serializer.KryoSerializer$.$anonfun$loadableSparkClasses$1(KryoSerializer.scala:537) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.serializer.KryoSerializer$.loadableSparkClasses$lzycompute(KryoSerializer.scala:535) at org.apache.spark.serializer.KryoSerializer$.org$apache$spark$serializer$KryoSerializer$$loadableSparkClasses(KryoSerializer.scala:502) at org.apache.spark.serializer.KryoSerializer.newKryo(KryoSerializer.scala:226) at org.apache.spark.serializer.KryoSerializer$$anon$1.create(KryoSerializer.scala:102) at com.esotericsoftware.kryo.pool.KryoPoolQueueImpl.borrow(KryoPoolQueueImpl.java:48) at org.apache.spark.serializer.KryoSerializer$PoolWrapper.borrow(KryoSerializer.scala:109) at org.apache.spark.serializer.KryoSerializerInstance.borrowKryo(KryoSerializer.scala:346) at org.apache.spark.serializer.KryoSerializationStream.(KryoSerializer.scala:266) at org.apache.spark.serializer.KryoSerializerInstance.serializeStream(KryoSerializer.scala:432) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.open(ShufflePartitionPairsWriter.scala:76) at
[spark] branch branch-3.2 updated: [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new b27be1f [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` b27be1f is described below commit b27be1fe956f4ce7bef6a0d96e7b4402c4998887 Author: yangjie01 AuthorDate: Sun Nov 21 19:11:40 2021 -0600 [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### What changes were proposed in this pull request? `YarnShuffleIntegrationSuite`, `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` will failed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`, the fail reason is `java.lang.NoClassDefFoundError: breeze/linalg/Matrix`. The above UTS can succeed when using `hadoop-2.7` profile without `assembly/target/scala-%s/jars` because `KryoSerializer.loadableSparkClasses` can workaroud when `Utils.isTesting` is true, but `Utils.isTesting` is false when using `hadoop-3.2` profile. After investigated, I found that when `hadoop-2.7` profile is used, `SPARK_TESTING` will be propagated to AM and Executor, but when `hadoop-3.2` profile is used, `SPARK_TESTING` will not be propagated to AM and Executor. In order to ensure the consistent behavior of using `hadoop-2.7` and ``hadoop-3.2``, this pr change to manually propagate `SPARK_TESTING` environment variable if it exists to ensure `Utils.isTesting` is true in above test scenario. ### Why are the changes needed? Ensure `YarnShuffleIntegrationSuite` releated UTs can succeed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test `YarnShuffleIntegrationSuite`. `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` can be verified in the same way. Please ensure that the `assembly/target/scala-%s/jars` directory does not exist before executing the test command, we can clean up the whole project by executing follow command or clone a new local code repo. 1. run with `hadoop-3.2` profile ``` mvn clean install -Phadoop-3.2 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service *** FAILED *** FAILED did not equal FINISHED (stdout/stderr was not captured) (BaseYarnClusterSuite.scala:227) Run completed in 48 seconds, 137 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` Error stack as follows: ``` 21/11/20 23:00:09.682 main ERROR Client: Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (localhost executor 1): java.lang.NoClassDefFoundError: breeze/linalg/Matrix at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:216) at org.apache.spark.serializer.KryoSerializer$.$anonfun$loadableSparkClasses$1(KryoSerializer.scala:537) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.serializer.KryoSerializer$.loadableSparkClasses$lzycompute(KryoSerializer.scala:535) at org.apache.spark.serializer.KryoSerializer$.org$apache$spark$serializer$KryoSerializer$$loadableSparkClasses(KryoSerializer.scala:502) at org.apache.spark.serializer.KryoSerializer.newKryo(KryoSerializer.scala:226) at org.apache.spark.serializer.KryoSerializer$$anon$1.create(KryoSerializer.scala:102) at com.esotericsoftware.kryo.pool.KryoPoolQueueImpl.borrow(KryoPoolQueueImpl.java:48) at org.apache.spark.serializer.KryoSerializer$PoolWrapper.borrow(KryoSerializer.scala:109) at org.apache.spark.serializer.KryoSerializerInstance.borrowKryo(KryoSerializer.scala:346) at org.apache.spark.serializer.KryoSerializationStream.(KryoSerializer.scala:266) at org.apache.spark.serializer.KryoSerializerInstance.serializeStream(KryoSerializer.scala:432) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.open(ShufflePartitionPairsWriter.scala:76) at
[spark] branch master updated: [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new a7b3fc7 [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` a7b3fc7 is described below commit a7b3fc7cef4c5df0254b945fe9f6815b072b31dd Author: yangjie01 AuthorDate: Sun Nov 21 19:11:40 2021 -0600 [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### What changes were proposed in this pull request? `YarnShuffleIntegrationSuite`, `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` will failed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`, the fail reason is `java.lang.NoClassDefFoundError: breeze/linalg/Matrix`. The above UTS can succeed when using `hadoop-2.7` profile without `assembly/target/scala-%s/jars` because `KryoSerializer.loadableSparkClasses` can workaroud when `Utils.isTesting` is true, but `Utils.isTesting` is false when using `hadoop-3.2` profile. After investigated, I found that when `hadoop-2.7` profile is used, `SPARK_TESTING` will be propagated to AM and Executor, but when `hadoop-3.2` profile is used, `SPARK_TESTING` will not be propagated to AM and Executor. In order to ensure the consistent behavior of using `hadoop-2.7` and ``hadoop-3.2``, this pr change to manually propagate `SPARK_TESTING` environment variable if it exists to ensure `Utils.isTesting` is true in above test scenario. ### Why are the changes needed? Ensure `YarnShuffleIntegrationSuite` releated UTs can succeed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test `YarnShuffleIntegrationSuite`. `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` can be verified in the same way. Please ensure that the `assembly/target/scala-%s/jars` directory does not exist before executing the test command, we can clean up the whole project by executing follow command or clone a new local code repo. 1. run with `hadoop-3.2` profile ``` mvn clean install -Phadoop-3.2 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service *** FAILED *** FAILED did not equal FINISHED (stdout/stderr was not captured) (BaseYarnClusterSuite.scala:227) Run completed in 48 seconds, 137 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` Error stack as follows: ``` 21/11/20 23:00:09.682 main ERROR Client: Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (localhost executor 1): java.lang.NoClassDefFoundError: breeze/linalg/Matrix at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:216) at org.apache.spark.serializer.KryoSerializer$.$anonfun$loadableSparkClasses$1(KryoSerializer.scala:537) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.serializer.KryoSerializer$.loadableSparkClasses$lzycompute(KryoSerializer.scala:535) at org.apache.spark.serializer.KryoSerializer$.org$apache$spark$serializer$KryoSerializer$$loadableSparkClasses(KryoSerializer.scala:502) at org.apache.spark.serializer.KryoSerializer.newKryo(KryoSerializer.scala:226) at org.apache.spark.serializer.KryoSerializer$$anon$1.create(KryoSerializer.scala:102) at com.esotericsoftware.kryo.pool.KryoPoolQueueImpl.borrow(KryoPoolQueueImpl.java:48) at org.apache.spark.serializer.KryoSerializer$PoolWrapper.borrow(KryoSerializer.scala:109) at org.apache.spark.serializer.KryoSerializerInstance.borrowKryo(KryoSerializer.scala:346) at org.apache.spark.serializer.KryoSerializationStream.(KryoSerializer.scala:266) at org.apache.spark.serializer.KryoSerializerInstance.serializeStream(KryoSerializer.scala:432) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.open(ShufflePartitionPairsWriter.scala:76) at
[spark] branch master updated (32054e1 -> ff2608c)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 32054e1 [SPARK-37339][K8S] Add `spark-version` label to driver and executor pods add ff2608c [SPARK-37335][ML] Flesh out FPGrowth docs No new revisions were added by this update. Summary of changes: docs/ml-frequent-pattern-mining.md | 14 +++--- 1 file changed, 11 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7cd4259 -> 06bdea0)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7cd4259 [SPARK-37243][SQL][DOC] Fix the format of the document add 06bdea0 [MINOR][INFRA] Explicitly specify Java version for lint test on GA No new revisions were added by this update. Summary of changes: .github/workflows/build_and_test.yml | 4 1 file changed, 4 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4011dd6 -> 7cd4259)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4011dd6 [SPARK-36895][SQL][FOLLOWUP] Use property to specify index type add 7cd4259 [SPARK-37243][SQL][DOC] Fix the format of the document No new revisions were added by this update. Summary of changes: docs/sql-ref-syntax-dml-insert-table.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ddf27bd -> 1047708)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ddf27bd [SPARK-37223][SQL][TESTS] Fix unit test check in JoinHintSuite add 1047708 [SPARK-37207][SQL][PYTHON] Add isEmpty method for the Python DataFrame API No new revisions were added by this update. Summary of changes: python/docs/source/reference/pyspark.sql.rst | 1 + python/pyspark/sql/dataframe.py | 16 2 files changed, 17 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37223][SQL][TESTS] Fix unit test check in JoinHintSuite
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ddf27bd [SPARK-37223][SQL][TESTS] Fix unit test check in JoinHintSuite
ddf27bd is described below
commit ddf27bd3af4cee733b8303c9cde386861e87c449
Author: Cheng Su
AuthorDate: Sun Nov 7 07:48:31 2021 -0600
[SPARK-37223][SQL][TESTS] Fix unit test check in JoinHintSuite
### What changes were proposed in this pull request?
This is to fix the unit test where we should assert on the content of log
in `JoinHintSuite`.
### Why are the changes needed?
Improve test.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Changed test itself.
Closes #34501 from c21/test-fix.
Authored-by: Cheng Su
Signed-off-by: Sean Owen
---
.../test/scala/org/apache/spark/sql/JoinHintSuite.scala| 14 --
1 file changed, 8 insertions(+), 6 deletions(-)
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/JoinHintSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/JoinHintSuite.scala
index 91cad85..99bad40 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/JoinHintSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/JoinHintSuite.scala
@@ -612,8 +612,9 @@ class JoinHintSuite extends PlanTest with
SharedSparkSession with AdaptiveSparkP
val logs = hintAppender.loggingEvents.map(_.getRenderedMessage)
.filter(_.contains("is not supported in the query:"))
-assert(logs.size == 2)
-logs.forall(_.contains(s"build left for
${joinType.split("_").mkString(" ")} join."))
+assert(logs.size === 2)
+logs.foreach(log =>
+ assert(log.contains(s"build left for
${joinType.split("_").mkString(" ")} join.")))
}
Seq("left_outer", "left_semi", "left_anti").foreach { joinType =>
@@ -640,8 +641,9 @@ class JoinHintSuite extends PlanTest with
SharedSparkSession with AdaptiveSparkP
}
val logs = hintAppender.loggingEvents.map(_.getRenderedMessage)
.filter(_.contains("is not supported in the query:"))
-assert(logs.size == 2)
-logs.forall(_.contains(s"build right for
${joinType.split("_").mkString(" ")} join."))
+assert(logs.size === 2)
+logs.foreach(log =>
+ assert(log.contains(s"build right for
${joinType.split("_").mkString(" ")} join.")))
}
Seq("right_outer").foreach { joinType =>
@@ -689,8 +691,8 @@ class JoinHintSuite extends PlanTest with
SharedSparkSession with AdaptiveSparkP
}
val logs = hintAppender.loggingEvents.map(_.getRenderedMessage)
.filter(_.contains("is not supported in the query:"))
-assert(logs.size == 2)
-logs.forall(_.contains("no equi-join keys"))
+assert(logs.size === 2)
+logs.foreach(log => assert(log.contains("no equi-join keys")))
}
test("SPARK-36652: AQE dynamic join selection should not apply to non-equi
join") {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ec6a3ae -> b78167a)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ec6a3ae [SPARK-37176][SQL] Sync JsonInferSchema#infer method's exception handle logic with JacksonParser#parse method add b78167a [SPARK-37066][SQL] Improve error message to show file path when failed to read next file No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/avro/AvroLogicalTypeSuite.scala | 2 +- .../apache/spark/sql/errors/QueryExecutionErrors.scala| 8 .../spark/sql/execution/datasources/FileScanRDD.scala | 13 ++--- .../execution/datasources/v2/FilePartitionReader.scala| 15 +++ .../execution/datasources/FileSourceStrategySuite.scala | 4 ++-- .../spark/sql/execution/datasources/csv/CSVSuite.scala| 4 ++-- .../datasources/parquet/ParquetSchemaSuite.scala | 6 ++ 7 files changed, 24 insertions(+), 28 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (70fde44 -> 11de0fd)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 70fde44 [SPARK-37062][SS] Introduce a new data source for providing consistent set of rows per microbatch add 11de0fd [MINOR][DOCS] Add import for MultivariateGaussian to Docs No new revisions were added by this update. Summary of changes: python/pyspark/ml/stat.py | 1 + 1 file changed, 1 insertion(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37102][BUILD] Removed redundant exclusions in `hadoop-cloud` module
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 6906328 [SPARK-37102][BUILD] Removed redundant exclusions in `hadoop-cloud` module 6906328 is described below commit 6906328dc49560e460f2c0eddbf60c9c3d279236 Author: Vasily Malakhin AuthorDate: Sat Oct 30 11:23:35 2021 -0500 [SPARK-37102][BUILD] Removed redundant exclusions in `hadoop-cloud` module ### What changes were proposed in this pull request? Redundant exclusions were removed for hadoop-cloud module so the build output contains required dependency for hadoop-azure artifact (ackson-mapper-asl). ### Why are the changes needed? Currently Hadoop ABFS connector (for Azure Data Lake Storage Gen2) is broken due to missing dependency. So required dependencies for hadoop-azure artifact should be included into distribution output if hadoop-cloud module enabled. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unfortunately Microsoft does not provide support for Data Lake Storage Gen2 within azurite emulator - so the change was tested manually and the diff was checked to see if anything else was picked up for build outputs (before and after the change). So the only change is inclusion of jackson-mapper-asl-1.9.13.jar. Closes #34383 from vmalakhin/SPARK-37102. Lead-authored-by: Vasily Malakhin Co-authored-by: vmalakhin <49170798+vmalak...@users.noreply.github.com> Signed-off-by: Sean Owen --- hadoop-cloud/pom.xml | 16 1 file changed, 16 deletions(-) diff --git a/hadoop-cloud/pom.xml b/hadoop-cloud/pom.xml index fe62443..2e95b57 100644 --- a/hadoop-cloud/pom.xml +++ b/hadoop-cloud/pom.xml @@ -86,14 +86,6 @@ commons-logging - org.codehaus.jackson - jackson-mapper-asl - - - org.codehaus.jackson - jackson-core-asl - - com.fasterxml.jackson.core jackson-core @@ -185,10 +177,6 @@ hadoop-common - org.codehaus.jackson - jackson-mapper-asl - - com.fasterxml.jackson.core jackson-core @@ -272,10 +260,6 @@ hadoop-common - org.codehaus.jackson - jackson-mapper-asl - - com.fasterxml.jackson.core jackson-core - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36627][CORE] Fix java deserialization of proxy classes
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 90fe41b [SPARK-36627][CORE] Fix java deserialization of proxy classes
90fe41b is described below
commit 90fe41b70a9d0403418aa05a220d38c20f51c6f9
Author: Samuel Souza
AuthorDate: Thu Oct 28 18:15:38 2021 -0500
[SPARK-36627][CORE] Fix java deserialization of proxy classes
## Upstream SPARK-X ticket and PR link (if not applicable, explain)
https://issues.apache.org/jira/browse/SPARK-36627
## What changes were proposed in this pull request?
In JavaSerializer.JavaDeserializationStream we override resolveClass of
ObjectInputStream to use the threads' contextClassLoader. However, we do not
override resolveProxyClass, which is used when deserializing Java proxy
objects, which makes spark use the wrong classloader when deserializing
objects, which causes the job to fail with the following exception:
```
Caused by: org.apache.spark.SparkException: Job aborted due to stage
failure: Task 0 in stage 1.0 failed 4 times, most recent failure: Lost task 0.3
in stage 1.0 (TID 4, , executor 1): java.lang.ClassNotFoundException:
Signed-off-by: Sean Owen
---
.../apache/spark/serializer/JavaSerializer.scala | 50 +++---
.../spark/serializer/ContainsProxyClass.java | 50 ++
.../spark/serializer/JavaSerializerSuite.scala | 26 ++-
3 files changed, 108 insertions(+), 18 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
index 077b035..9d76611 100644
--- a/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala
@@ -28,8 +28,10 @@ import org.apache.spark.internal.config._
import org.apache.spark.util.{ByteBufferInputStream, ByteBufferOutputStream,
Utils}
private[spark] class JavaSerializationStream(
-out: OutputStream, counterReset: Int, extraDebugInfo: Boolean)
- extends SerializationStream {
+out: OutputStream,
+counterReset: Int,
+extraDebugInfo: Boolean)
+extends SerializationStream {
private val objOut = new ObjectOutputStream(out)
private var counter = 0
@@ -59,9 +61,10 @@ private[spark] class JavaSerializationStream(
}
private[spark] class JavaDeserializationStream(in: InputStream, loader:
ClassLoader)
- extends DeserializationStream {
+extends DeserializationStream {
private val objIn = new ObjectInputStream(in) {
+
override def resolveClass(desc: ObjectStreamClass): Class[_] =
try {
// scalastyle:off classforname
@@ -71,6 +74,14 @@ private[spark] class JavaDeserializationStream(in:
InputStream, loader: ClassLoa
case e: ClassNotFoundException =>
JavaDeserializationStream.primitiveMappings.getOrElse(desc.getName,
throw e)
}
+
+override def resolveProxyClass(ifaces: Array[String]): Class[_] = {
+ // scalastyle:off classforname
+ val resolved = ifaces.map(iface => Class.forName(iface, false, loader))
+ // scalastyle:on classforname
+ java.lang.reflect.Proxy.getProxyClass(loader, resolved: _*)
+}
+
}
def readObject[T: ClassTag](): T = objIn.readObject().asInstanceOf[T]
@@ -78,6 +89,7 @@ private[spark] class JavaDeserializationStream(in:
InputStream, loader: ClassLoa
}
private object JavaDeserializationStream {
+
val primitiveMappings = Map[String, Class[_]](
"boolean" -> classOf[Boolean],
"byte" -> classOf[Byte],
@@ -87,13 +99,15 @@ private object JavaDeserializationStream {
"long" -> classOf[Long],
"float" -> classOf[Float],
"double" -> classOf[Double],
-"void" -> classOf[Void]
- )
+"void" -> classOf[Void])
+
}
private[spark] class JavaSerializerInstance(
-counterReset: Int, extraDebugInfo: Boolean, defaultClassLoader:
ClassLoader)
- extends SerializerInstance {
+counterReset: Int,
+extraDebugInfo: Boolean,
+defaultClassLoader: ClassLoader)
+extends SerializerInstance {
override def serialize[T: ClassTag](t: T): ByteBuffer = {
val bos = new ByteBufferOutputStream()
@@ -126,6 +140,7 @@ private[spark] class JavaSerializerInstance(
def deserializeStream(s: InputStream, loader: ClassLoader):
DeserializationStream = {
new JavaDeserializationStream(s, loader)
}
+
}
/**
@@ -141,20 +156,23 @@ class JavaSerializer(conf: SparkConf) extends Serializer
with Externalizable {
private var counterReset = conf.get(SERIALIZER_OBJECT_STREAM_RESET)
private var extraDebugInfo = conf.get(SERIALIZER_EXTRA_DEBUG_INFO)
- protected def this() = thi
[spark] branch master updated (7ed7afe -> 09ec7ca)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7ed7afe [SPARK-37136][SQL] Remove code about hive buildin function but not implement in spark add 09ec7ca [SPARK-37118][PYTHON][ML] Add distanceMeasure param to trainKMeansModel No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/mllib/api/python/PythonMLLibAPI.scala | 4 +++- python/pyspark/mllib/clustering.py| 8 ++-- 2 files changed, 9 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37071][CORE] Make OpenHashMap serialize without reference tracking
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3319361 [SPARK-37071][CORE] Make OpenHashMap serialize without
reference tracking
3319361 is described below
commit 3319361ca67212d2ae373bb46c5b6f2d80d792a4
Author: Emil Ejbyfeldt
AuthorDate: Wed Oct 27 08:58:37 2021 -0500
[SPARK-37071][CORE] Make OpenHashMap serialize without reference tracking
### What changes were proposed in this pull request?
Change the anonymous functions in OpenHashMap to member methods. This avoid
having a member which captures the OpenHashMap object in its closure. This
fixes so that OpenHashMap instances can be serialized with Kryo with reference
tracking turned off.
I am not sure why the original implementation had the anonymous function
members in the first place. But if it was implemented that way for performance
reason another possible fix is just to mark the `grow` and `move` members as
transient.
### Why are the changes needed?
User might want to turn off referenceTracking in kryo since it has
performance benefits, but currently this will unnecessary and unexpectedly
prevent them from using some features of spark that uses OpenHashMap internally.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests and a new test in the `KryoSerializerSuite`.
Closes #34351 from
eejbyfeldt/SPARK-37071-make-open-hash-map-serialize-without-reference-tracking.
Authored-by: Emil Ejbyfeldt
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/util/collection/OpenHashMap.scala | 9 ++---
.../spark/util/collection/PrimitiveKeyOpenHashMap.scala | 9 ++---
.../org/apache/spark/serializer/KryoSerializerSuite.scala | 11 +++
.../util/collection/GraphXPrimitiveKeyOpenHashMap.scala | 9 ++---
4 files changed, 17 insertions(+), 21 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/util/collection/OpenHashMap.scala
b/core/src/main/scala/org/apache/spark/util/collection/OpenHashMap.scala
index 1200ac0..79e1a35 100644
--- a/core/src/main/scala/org/apache/spark/util/collection/OpenHashMap.scala
+++ b/core/src/main/scala/org/apache/spark/util/collection/OpenHashMap.scala
@@ -149,17 +149,12 @@ class OpenHashMap[K : ClassTag, @specialized(Long, Int,
Double) V: ClassTag](
}
}
- // The following member variables are declared as protected instead of
private for the
- // specialization to work (specialized class extends the non-specialized one
and needs access
- // to the "private" variables).
- // They also should have been val's. We use var's because there is a Scala
compiler bug that
- // would throw illegal access error at runtime if they are declared as val's.
- protected var grow = (newCapacity: Int) => {
+ private def grow(newCapacity: Int): Unit = {
_oldValues = _values
_values = new Array[V](newCapacity)
}
- protected var move = (oldPos: Int, newPos: Int) => {
+ private def move(oldPos: Int, newPos: Int): Unit = {
_values(newPos) = _oldValues(oldPos)
}
}
diff --git
a/core/src/main/scala/org/apache/spark/util/collection/PrimitiveKeyOpenHashMap.scala
b/core/src/main/scala/org/apache/spark/util/collection/PrimitiveKeyOpenHashMap.scala
index 7a50d85..69665aa 100644
---
a/core/src/main/scala/org/apache/spark/util/collection/PrimitiveKeyOpenHashMap.scala
+++
b/core/src/main/scala/org/apache/spark/util/collection/PrimitiveKeyOpenHashMap.scala
@@ -117,17 +117,12 @@ class PrimitiveKeyOpenHashMap[@specialized(Long, Int) K:
ClassTag,
}
}
- // The following member variables are declared as protected instead of
private for the
- // specialization to work (specialized class extends the unspecialized one
and needs access
- // to the "private" variables).
- // They also should have been val's. We use var's because there is a Scala
compiler bug that
- // would throw illegal access error at runtime if they are declared as val's.
- protected var grow = (newCapacity: Int) => {
+ private def grow(newCapacity: Int): Unit = {
_oldValues = _values
_values = new Array[V](newCapacity)
}
- protected var move = (oldPos: Int, newPos: Int) => {
+ private def move(oldPos: Int, newPos: Int): Unit = {
_values(newPos) = _oldValues(oldPos)
}
}
diff --git
a/core/src/test/scala/org/apache/spark/serializer/KryoSerializerSuite.scala
b/core/src/test/scala/org/apache/spark/serializer/KryoSerializerSuite.scala
index 229ef69..dd2340a 100644
--- a/core/src/test/scala/org/apache/spark/serializer/KryoSerializerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/serializer/KryoSerializerSuite.scala
@@ -39,6 +39,7 @@ impor
[spark] branch master updated (5c28b6e -> 74d974a)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 5c28b6e Revert "[SPARK-37103][INFRA] Switch from Maven to SBT to build Spark on AppVeyor" add 74d974a [SPARK-37037][SQL] Improve byte array sort by unify compareTo function of UTF8String and ByteArray No new revisions were added by this update. Summary of changes: .../org/apache/spark/unsafe/types/ByteArray.java | 36 + .../org/apache/spark/unsafe/types/UTF8String.java | 25 +-- .../apache/spark/unsafe/array/ByteArraySuite.java | 19 + .../expressions/codegen/CodeGenerator.scala| 2 +- .../apache/spark/sql/catalyst/util/TypeUtils.scala | 11 --- .../org/apache/spark/sql/types/BinaryType.scala| 4 +- .../spark/sql/catalyst/util/TypeUtilsSuite.scala | 18 - .../ByteArrayBenchmark-jdk11-results.txt | 16 sql/core/benchmarks/ByteArrayBenchmark-results.txt | 16 .../execution/benchmark/ByteArrayBenchmark.scala | 86 ++ 10 files changed, 178 insertions(+), 55 deletions(-) create mode 100644 sql/core/benchmarks/ByteArrayBenchmark-jdk11-results.txt create mode 100644 sql/core/benchmarks/ByteArrayBenchmark-results.txt create mode 100644 sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/ByteArrayBenchmark.scala - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37056][CORE] Remove unused code in HistoryServer'ss unit test
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 8f6af64 [SPARK-37056][CORE] Remove unused code in HistoryServer'ss unit test 8f6af64 is described below commit 8f6af642bc5c48db04c8c99b5897ec052c1ae15e Author: Angerszh AuthorDate: Sat Oct 23 10:02:19 2021 -0500 [SPARK-37056][CORE] Remove unused code in HistoryServer'ss unit test ### What changes were proposed in this pull request? Remove unused code in HistoryServer 's unit test. Since `HistoryServer.initialize()` is called when construct the object, we should remove the call in unit test. ### Why are the changes needed? Fix ut code ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existed UT Closes #34327 from AngersZh/SPARK-37056. Authored-by: Angerszh Signed-off-by: Sean Owen --- .../test/scala/org/apache/spark/deploy/history/HistoryServerSuite.scala | 2 -- .../apache/spark/deploy/history/RealBrowserUIHistoryServerSuite.scala | 1 - 2 files changed, 3 deletions(-) diff --git a/core/src/test/scala/org/apache/spark/deploy/history/HistoryServerSuite.scala b/core/src/test/scala/org/apache/spark/deploy/history/HistoryServerSuite.scala index 71ab9e7..10900dd 100644 --- a/core/src/test/scala/org/apache/spark/deploy/history/HistoryServerSuite.scala +++ b/core/src/test/scala/org/apache/spark/deploy/history/HistoryServerSuite.scala @@ -91,7 +91,6 @@ class HistoryServerSuite extends SparkFunSuite with BeforeAndAfter with Matchers val securityManager = HistoryServer.createSecurityManager(conf) server = new HistoryServer(conf, provider, securityManager, 18080) -server.initialize() server.bind() provider.start() port = server.boundPort @@ -413,7 +412,6 @@ class HistoryServerSuite extends SparkFunSuite with BeforeAndAfter with Matchers } server = new HistoryServer(myConf, provider, securityManager, 0) -server.initialize() server.bind() provider.start() val port = server.boundPort diff --git a/core/src/test/scala/org/apache/spark/deploy/history/RealBrowserUIHistoryServerSuite.scala b/core/src/test/scala/org/apache/spark/deploy/history/RealBrowserUIHistoryServerSuite.scala index 4a5c34f..ba8bd8d 100644 --- a/core/src/test/scala/org/apache/spark/deploy/history/RealBrowserUIHistoryServerSuite.scala +++ b/core/src/test/scala/org/apache/spark/deploy/history/RealBrowserUIHistoryServerSuite.scala @@ -87,7 +87,6 @@ abstract class RealBrowserUIHistoryServerSuite(val driverProp: String) val securityManager = HistoryServer.createSecurityManager(conf) server = new HistoryServer(conf, provider, securityManager, 18080) -server.initialize() server.bind() provider.start() port = server.boundPort - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8fbd1fb -> ca861eb)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 8fbd1fb [SPARK-37086][R][ML][TESTS] Fix the R test of FPGrowthModel for Scala 2.13 add ca861eb [SPARK-37013][SQL] Forbid `%0$` usage explicitly to ensure `format_string` has same behavior when using Java 8 and Java 17 No new revisions were added by this update. Summary of changes: docs/sql-migration-guide.md | 2 ++ .../sql/catalyst/expressions/stringExpressions.scala| 17 + .../resources/sql-tests/results/postgreSQL/text.sql.out | 5 +++-- 3 files changed, 22 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Add Scala 2.13 build download link
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 84f9e1f Add Scala 2.13 build download link
84f9e1f is described below
commit 84f9e1f1a00601b0f97ed985ca58ee1127d556f4
Author: Sean Owen
AuthorDate: Wed Oct 20 20:12:25 2021 -0500
Add Scala 2.13 build download link
We have a Scala 2.13 build for Hadoop 3.3 - add it as an option to download
Author: Sean Owen
Closes #364 from srowen/320Scala213.
---
js/downloads.js | 3 ++-
site/js/downloads.js | 3 ++-
2 files changed, 4 insertions(+), 2 deletions(-)
diff --git a/js/downloads.js b/js/downloads.js
index 57003bb..7d9a1a1 100644
--- a/js/downloads.js
+++ b/js/downloads.js
@@ -16,6 +16,7 @@ var hadoopFree = {pretty: "Pre-built with user-provided
Apache Hadoop", tag: "wi
var hadoop2p7 = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2.7"};
var hadoop3p2 = {pretty: "Pre-built for Apache Hadoop 3.2 and later", tag:
"hadoop3.2"};
var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3.2"};
+var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3.2-scala2.13"};
var scala2p12_hadoopFree = {pretty: "Pre-built with Scala 2.12 and
user-provided Apache Hadoop", tag: "without-hadoop-scala-2.12"};
// 3.0.0+
@@ -23,7 +24,7 @@ var packagesV10 = [hadoop2p7, hadoop3p2, hadoopFree, sources];
// 3.1.0+
var packagesV11 = [hadoop3p2, hadoop2p7, hadoopFree, sources];
// 3.2.0+
-var packagesV12 = [hadoop3p3, hadoop2p7, hadoopFree, sources];
+var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7, hadoopFree,
sources];
addRelease("3.2.0", new Date("10/13/2021"), packagesV12, true);
addRelease("3.1.2", new Date("06/01/2021"), packagesV11, true);
diff --git a/site/js/downloads.js b/site/js/downloads.js
index 57003bb..7d9a1a1 100644
--- a/site/js/downloads.js
+++ b/site/js/downloads.js
@@ -16,6 +16,7 @@ var hadoopFree = {pretty: "Pre-built with user-provided
Apache Hadoop", tag: "wi
var hadoop2p7 = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2.7"};
var hadoop3p2 = {pretty: "Pre-built for Apache Hadoop 3.2 and later", tag:
"hadoop3.2"};
var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3.2"};
+var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3.2-scala2.13"};
var scala2p12_hadoopFree = {pretty: "Pre-built with Scala 2.12 and
user-provided Apache Hadoop", tag: "without-hadoop-scala-2.12"};
// 3.0.0+
@@ -23,7 +24,7 @@ var packagesV10 = [hadoop2p7, hadoop3p2, hadoopFree, sources];
// 3.1.0+
var packagesV11 = [hadoop3p2, hadoop2p7, hadoopFree, sources];
// 3.2.0+
-var packagesV12 = [hadoop3p3, hadoop2p7, hadoopFree, sources];
+var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7, hadoopFree,
sources];
addRelease("3.2.0", new Date("10/13/2021"), packagesV12, true);
addRelease("3.1.2", new Date("06/01/2021"), packagesV11, true);
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (64eabb6 -> eda3fd0)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 64eabb6 [SPARK-37048][PYTHON] Clean up inlining type hints under SQL module add eda3fd0 [SPARK-37025][BUILD] Update RoaringBitmap version to 0.9.22 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2.7-hive-2.3 | 4 ++-- dev/deps/spark-deps-hadoop-3.2-hive-2.3 | 4 ++-- pom.xml | 2 +- 3 files changed, 5 insertions(+), 5 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (db89320 -> 3849340)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from db89320 [SPARK-37057][INFRA] Fix wrong DocSearch facet filter in release-tag.sh add 3849340 [SPARK-36796][BUILD][CORE][SQL] Pass all `sql/core` and dependent modules UTs with JDK 17 except one case in `postgreSQL/text.sql` No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/SparkContext.scala | 19 + .../apache/spark/launcher/JavaModuleOptions.java | 47 ++ .../spark/launcher/SparkSubmitCommandBuilder.java | 2 + pom.xml| 20 - project/SparkBuild.scala | 14 ++- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- 7 files changed, 101 insertions(+), 5 deletions(-) create mode 100644 launcher/src/main/java/org/apache/spark/launcher/JavaModuleOptions.java - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ee2647e -> f9cc7fb)
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git.
from ee2647e [SPARK-37008][SQL][TEST] Replace `UseCompressedOops` with
`UseCompressedClassPointers` to pass `WholeStageCodegenSparkSubmitSuite` with
Java 17
add f9cc7fb [SPARK-36992][SQL] Improve byte array sort perf by unify
getPrefix function of UTF8String and ByteArray
No new revisions were added by this update.
Summary of changes:
.../org/apache/spark/unsafe/types/ByteArray.java | 36
.../org/apache/spark/unsafe/types/UTF8String.java | 38 +
.../{LongArraySuite.java => ByteArraySuite.java} | 39 +-
3 files changed, 54 insertions(+), 59 deletions(-)
copy
common/unsafe/src/test/java/org/apache/spark/unsafe/array/{LongArraySuite.java
=> ByteArraySuite.java} (53%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (cf43623 -> ee2647e)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from cf43623 [SPARK-36900][SPARK-36464][CORE][TEST] Refactor `: size returns correct positive number even with over 2GB data` to pass with Java 8, 11 and 17 add ee2647e [SPARK-37008][SQL][TEST] Replace `UseCompressedOops` with `UseCompressedClassPointers` to pass `WholeStageCodegenSparkSubmitSuite` with Java 17 No new revisions were added by this update. Summary of changes: .../execution/WholeStageCodegenSparkSubmitSuite.scala | 17 ++--- 1 file changed, 14 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36900][SPARK-36464][CORE][TEST] Refactor `: size returns correct positive number even with over 2GB data` to pass with Java 8, 11 and 17
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new cf43623 [SPARK-36900][SPARK-36464][CORE][TEST] Refactor `: size
returns correct positive number even with over 2GB data` to pass with Java 8,
11 and 17
cf43623 is described below
commit cf436233072b75e083a4455dc53b22edba0b3957
Author: yangjie01
AuthorDate: Sat Oct 16 09:10:06 2021 -0500
[SPARK-36900][SPARK-36464][CORE][TEST] Refactor `: size returns correct
positive number even with over 2GB data` to pass with Java 8, 11 and 17
### What changes were proposed in this pull request?
Refactor `SPARK-36464: size returns correct positive number even with over
2GB data` in `ChunkedByteBufferOutputStreamSuite` to reduce the total use of
memory for this test case, then this case can pass with Java 8, Java 11 and
Java 17 use `-Xmx4g`.
### Why are the changes needed?
`SPARK-36464: size returns correct positive number even with over 2GB data`
pass with Java 8 but OOM with Java 11 and Java 17.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
- Pass the Jenkins or GitHub Action
- Manual test
```
mvn clean install -pl core -am -Dtest=none
-DwildcardSuites=org.apache.spark.util.io.ChunkedByteBufferOutputStreamSuite
```
with Java 8, Java 11 and Java 17, all tests passed.
Closes #34284 from LuciferYang/SPARK-36900.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../spark/util/io/ChunkedByteBufferOutputStreamSuite.scala| 11 ++-
1 file changed, 6 insertions(+), 5 deletions(-)
diff --git
a/core/src/test/scala/org/apache/spark/util/io/ChunkedByteBufferOutputStreamSuite.scala
b/core/src/test/scala/org/apache/spark/util/io/ChunkedByteBufferOutputStreamSuite.scala
index 29443e2..0a61488 100644
---
a/core/src/test/scala/org/apache/spark/util/io/ChunkedByteBufferOutputStreamSuite.scala
+++
b/core/src/test/scala/org/apache/spark/util/io/ChunkedByteBufferOutputStreamSuite.scala
@@ -121,12 +121,13 @@ class ChunkedByteBufferOutputStreamSuite extends
SparkFunSuite {
}
test("SPARK-36464: size returns correct positive number even with over 2GB
data") {
-val ref = new Array[Byte](1024 * 1024 * 1024)
-val o = new ChunkedByteBufferOutputStream(1024 * 1024, ByteBuffer.allocate)
-o.write(ref)
-o.write(ref)
+val data4M = 1024 * 1024 * 4
+val writeTimes = 513
+val ref = new Array[Byte](data4M)
+val o = new ChunkedByteBufferOutputStream(data4M, ByteBuffer.allocate)
+(0 until writeTimes).foreach(_ => o.write(ref))
o.close()
assert(o.size > 0L) // make sure it is not overflowing
-assert(o.size == ref.length.toLong * 2)
+assert(o.size == ref.length.toLong * writeTimes)
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36915][INFRA] Pin actions to a full length commit SHA
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 00b87c9 [SPARK-36915][INFRA] Pin actions to a full length commit SHA
00b87c9 is described below
commit 00b87c967ff8217b64e597400f3248c375a74879
Author: Hyukjin Kwon
AuthorDate: Sat Oct 16 08:53:19 2021 -0500
[SPARK-36915][INFRA] Pin actions to a full length commit SHA
### What changes were proposed in this pull request?
Pinning github actions to a SHA
### Why are the changes needed?
Pinning an action to a full length commit SHA is currently the only way to
use an action as
an immutable release. Pinning to a particular SHA helps mitigate the risk
of a bad actor adding a
backdoor to the action's repository, as they would need to generate a SHA-1
collision for
a valid Git object payload.
https://docs.github.com/en/actions/security-guides/security-hardening-for-github-actions#using-third-party-actions
https://github.com/ossf/scorecard/blob/main/docs/checks.md#pinned-dependencies
### Does this PR introduce _any_ user-facing change?
Running github action and checking the SHA with the existing repository
### How was this patch tested?
Running the GitHub action
Closes #34163 from naveensrinivasan/naveen/feat/pin-github-actions.
Lead-authored-by: Hyukjin Kwon
Co-authored-by: naveen <172697+naveensriniva...@users.noreply.github.com>
Signed-off-by: Sean Owen
---
.github/workflows/cancel_duplicate_workflow_runs.yml | 2 +-
.github/workflows/labeler.yml| 2 +-
.github/workflows/notify_test_workflow.yml | 2 +-
.github/workflows/publish_snapshot.yml | 6 +++---
.github/workflows/stale.yml | 2 +-
.github/workflows/test_report.yml| 4 ++--
.github/workflows/update_build_status.yml| 2 +-
7 files changed, 10 insertions(+), 10 deletions(-)
diff --git a/.github/workflows/cancel_duplicate_workflow_runs.yml
b/.github/workflows/cancel_duplicate_workflow_runs.yml
index 1077371..525c7e7 100644
--- a/.github/workflows/cancel_duplicate_workflow_runs.yml
+++ b/.github/workflows/cancel_duplicate_workflow_runs.yml
@@ -29,7 +29,7 @@ jobs:
name: "Cancel duplicate workflow runs"
runs-on: ubuntu-latest
steps:
- - uses:
potiuk/cancel-workflow-runs@953e057dc81d3458935a18d1184c386b0f6b5738 # @master
+ - uses:
potiuk/cancel-workflow-runs@4723494a065d162f8e9efd071b98e0126e00f866 # @master
name: "Cancel duplicate workflow runs"
with:
cancelMode: allDuplicates
diff --git a/.github/workflows/labeler.yml b/.github/workflows/labeler.yml
index 98855f4..88d17bf 100644
--- a/.github/workflows/labeler.yml
+++ b/.github/workflows/labeler.yml
@@ -44,7 +44,7 @@ jobs:
#
# However, these are not in a published release and the current `main`
branch
# has some issues upon testing.
-- uses: actions/labeler@2.2.0
+- uses: actions/labeler@5f867a63be70efff62b767459b009290364495eb #
pin@2.2.0
with:
repo-token: "${{ secrets.GITHUB_TOKEN }}"
sync-labels: true
diff --git a/.github/workflows/notify_test_workflow.yml
b/.github/workflows/notify_test_workflow.yml
index cc2b7a2..08c50cc 100644
--- a/.github/workflows/notify_test_workflow.yml
+++ b/.github/workflows/notify_test_workflow.yml
@@ -33,7 +33,7 @@ jobs:
runs-on: ubuntu-20.04
steps:
- name: "Notify test workflow"
-uses: actions/github-script@v3
+uses: actions/github-script@f05a81df23035049204b043b50c3322045ce7eb3 #
pin@v3
if: ${{ github.base_ref == 'master' }}
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
diff --git a/.github/workflows/publish_snapshot.yml
b/.github/workflows/publish_snapshot.yml
index 46f4f7a..bd75e26 100644
--- a/.github/workflows/publish_snapshot.yml
+++ b/.github/workflows/publish_snapshot.yml
@@ -36,18 +36,18 @@ jobs:
- branch-3.1
steps:
- name: Checkout Spark repository
- uses: actions/checkout@master
+ uses: actions/checkout@61b9e3751b92087fd0b06925ba6dd6314e06f089 #
pin@master
with:
ref: ${{ matrix.branch }}
- name: Cache Maven local repository
- uses: actions/cache@v2
+ uses: actions/cache@c64c572235d810460d0d6876e9c705ad5002b353 # pin@v2
with:
path: ~/.m2/repository
key: snapshot-maven-${{ hashFiles('**/pom.xml') }}
restore-keys: |
snapshot-maven-
- name: Install Java 8
- uses: actions/setup-java@v1
+ uses: actions/setup-java@d202f5dbf7256730fb690ec59f6381650114feb2 #
pin@v1
with:
java-version: 8
- name: Publish snapshot
diff
[spark] branch branch-3.2 updated: [SPARK-36900][TESTS][BUILD] Increase test memory to 6g for Java 11
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 29ebfdc [SPARK-36900][TESTS][BUILD] Increase test memory to 6g for
Java 11
29ebfdc is described below
commit 29ebfdcdff74af72c6900fa0856ada3ab07f8de1
Author: Sean Owen
AuthorDate: Sun Oct 10 18:08:37 2021 -0500
[SPARK-36900][TESTS][BUILD] Increase test memory to 6g for Java 11
### What changes were proposed in this pull request?
Increase JVM test memory from 4g to 6g.
### Why are the changes needed?
Running tests under Java 11 fails consistently on a few tests without more
memory. The tests do legitimately grab a lot of memory, I believe. It's not
super clear why memory usage is different in Java 11, but, also seems fine to
just give comfortably more heap to tests for now.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests, run manually with Java 11.
Closes #34214 from srowen/SPARK-36900.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 6ed13147c99b2f652748b716c70dd1937230cafd)
Signed-off-by: Sean Owen
---
pom.xml| 6 +++---
project/SparkBuild.scala | 4 ++--
resource-managers/kubernetes/integration-tests/pom.xml | 2 +-
sql/catalyst/pom.xml | 2 +-
sql/core/pom.xml | 2 +-
sql/hive/pom.xml | 2 +-
6 files changed, 9 insertions(+), 9 deletions(-)
diff --git a/pom.xml b/pom.xml
index d9c10ee..bd8ede6 100644
--- a/pom.xml
+++ b/pom.xml
@@ -2640,7 +2640,7 @@
-Xss128m
-Xms4g
- -Xmx4g
+ -Xmx6g
-XX:MaxMetaspaceSize=2g
-XX:ReservedCodeCacheSize=${CodeCacheSize}
@@ -2690,7 +2690,7 @@
**/*Suite.java
${project.build.directory}/surefire-reports
--ea -Xmx4g -Xss4m -XX:MaxMetaspaceSize=2g
-XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
+-ea -Xmx6g -Xss4m -XX:MaxMetaspaceSize=2g
-XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
- -da -Xmx4g -XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
+ -da -Xmx6g -XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36900][TESTS][BUILD] Increase test memory to 6g for Java 11
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6ed1314 [SPARK-36900][TESTS][BUILD] Increase test memory to 6g for
Java 11
6ed1314 is described below
commit 6ed13147c99b2f652748b716c70dd1937230cafd
Author: Sean Owen
AuthorDate: Sun Oct 10 18:08:37 2021 -0500
[SPARK-36900][TESTS][BUILD] Increase test memory to 6g for Java 11
### What changes were proposed in this pull request?
Increase JVM test memory from 4g to 6g.
### Why are the changes needed?
Running tests under Java 11 fails consistently on a few tests without more
memory. The tests do legitimately grab a lot of memory, I believe. It's not
super clear why memory usage is different in Java 11, but, also seems fine to
just give comfortably more heap to tests for now.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests, run manually with Java 11.
Closes #34214 from srowen/SPARK-36900.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
---
pom.xml| 6 +++---
project/SparkBuild.scala | 4 ++--
resource-managers/kubernetes/integration-tests/pom.xml | 2 +-
sql/catalyst/pom.xml | 2 +-
sql/core/pom.xml | 2 +-
sql/hive/pom.xml | 2 +-
6 files changed, 9 insertions(+), 9 deletions(-)
diff --git a/pom.xml b/pom.xml
index 5c6d3a8..1ef33e1 100644
--- a/pom.xml
+++ b/pom.xml
@@ -2657,7 +2657,7 @@
-Xss128m
-Xms4g
- -Xmx4g
+ -Xmx6g
-XX:MaxMetaspaceSize=2g
-XX:ReservedCodeCacheSize=${CodeCacheSize}
@@ -2707,7 +2707,7 @@
**/*Suite.java
${project.build.directory}/surefire-reports
--ea -Xmx4g -Xss4m -XX:MaxMetaspaceSize=2g
-XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
+-ea -Xmx6g -Xss4m -XX:MaxMetaspaceSize=2g
-XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
- -da -Xmx4g -XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
+ -da -Xmx6g -XX:ReservedCodeCacheSize=${CodeCacheSize}
-Dio.netty.tryReflectionSetAccessible=true
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Fix remotes URLs to point to apache/spark
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 3cff519 Fix remotes URLs to point to apache/spark 3cff519 is described below commit 3cff5195eb37664b3f6c4cd7ae664ceb45cf07aa Author: zero323 AuthorDate: Sat Oct 9 16:00:47 2021 -0500 Fix remotes URLs to point to apache/spark How to Merge a Pull Request section describes process of working with main Spark repositiory. However, `git remote` links in the How to Merge a Pull Request point to apache/spark-website. Author: zero323 Closes #358 from zero323/fix-setting-up-remotes. --- committers.md| 12 ++-- site/committers.html | 12 ++-- 2 files changed, 12 insertions(+), 12 deletions(-) diff --git a/committers.md b/committers.md index ad12fa9..4bb255c 100644 --- a/committers.md +++ b/committers.md @@ -179,12 +179,12 @@ After cloning your fork of Spark you already have a remote `origin` pointing the contains at least these lines: ``` -apache g...@github.com:apache/spark-website.git (fetch) -apache g...@github.com:apache/spark-website.git (push) -apache-github g...@github.com:apache/spark-website.git (fetch) -apache-github g...@github.com:apache/spark-website.git (push) -origin g...@github.com:[your username]/spark-website.git (fetch) -origin g...@github.com:[your username]/spark-website.git (push) +apache g...@github.com:apache/spark.git (fetch) +apache g...@github.com:apache/spark.git (push) +apache-github g...@github.com:apache/spark.git (fetch) +apache-github g...@github.com:apache/spark.git (push) +origin g...@github.com:[your username]/spark.git (fetch) +origin g...@github.com:[your username]/spark.git (push) ``` For the `apache` repo, you will need to set up command-line authentication to GitHub. This may diff --git a/site/committers.html b/site/committers.html index 4e93005..93bdd5c 100644 --- a/site/committers.html +++ b/site/committers.html @@ -626,12 +626,12 @@ into the official Spark repo just by specifying your fork in the origin pointing there. So if correct, your git remote -v contains at least these lines: -apache g...@github.com:apache/spark-website.git (fetch) -apache g...@github.com:apache/spark-website.git (push) -apache-github g...@github.com:apache/spark-website.git (fetch) -apache-github g...@github.com:apache/spark-website.git (push) -origin g...@github.com:[your username]/spark-website.git (fetch) -origin g...@github.com:[your username]/spark-website.git (push) +apache g...@github.com:apache/spark.git (fetch) +apache g...@github.com:apache/spark.git (push) +apache-github g...@github.com:apache/spark.git (fetch) +apache-github g...@github.com:apache/spark.git (push) +origin g...@github.com:[your username]/spark.git (fetch) +origin g...@github.com:[your username]/spark.git (push) For the apache repo, you will need to set up command-line authentication to GitHub. This may - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4f825aa -> 7468cd7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4f825aa [SPARK-36839][INFRA][FOLLOW-UP] Respect Hadoop version configured in scheduled GitHub Actions jobs add 7468cd7 [SPARK-36804][YARN] Support --verbose option in YARN mode No new revisions were added by this update. Summary of changes: .../org/apache/spark/deploy/yarn/ClientArguments.scala | 14 +- 1 file changed, 13 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Remove duplicated command instruction from developer-tools
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 436c173 Remove duplicated command instruction from developer-tools 436c173 is described below commit 436c1733a13f965d6a99c1eeac1274d17df39a82 Author: Yuto Akutsu AuthorDate: Fri Oct 8 18:05:06 2021 -0500 Remove duplicated command instruction from developer-tools I'm not so sure if it is intended but `build/sbt compile` is duplicated in developer-tools. Author: Yuto Akutsu Closes #357 from yutoacts/asf-site. --- developer-tools.md| 2 -- site/developer-tools.html | 2 -- 2 files changed, 4 deletions(-) diff --git a/developer-tools.md b/developer-tools.md index bf3ee6e..51260dd 100644 --- a/developer-tools.md +++ b/developer-tools.md @@ -25,8 +25,6 @@ $ export SPARK_PREPEND_CLASSES=true $ ./bin/spark-shell # Now it's using compiled classes # ... do some local development ... # $ build/sbt compile -# ... do some local development ... # -$ build/sbt compile $ unset SPARK_PREPEND_CLASSES $ ./bin/spark-shell diff --git a/site/developer-tools.html b/site/developer-tools.html index 81d64c7..c7b819e 100644 --- a/site/developer-tools.html +++ b/site/developer-tools.html @@ -217,8 +217,6 @@ $ export SPARK_PREPEND_CLASSES=true $ ./bin/spark-shell # Now it's using compiled classes # ... do some local development ... # $ build/sbt compile -# ... do some local development ... # -$ build/sbt compile $ unset SPARK_PREPEND_CLASSES $ ./bin/spark-shell - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-36717][CORE] Incorrect order of variable initialization may lead incorrect behavior
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new 74fddec [SPARK-36717][CORE] Incorrect order of variable
initialization may lead incorrect behavior
74fddec is described below
commit 74fddec656a8a24d35a6c394738a7f49541a3686
Author: daugraph
AuthorDate: Fri Oct 8 07:11:26 2021 -0500
[SPARK-36717][CORE] Incorrect order of variable initialization may lead
incorrect behavior
### What changes were proposed in this pull request?
Incorrect order of variable initialization may lead to incorrect behavior,
related code: TorrentBroadcast.scala , TorrentBroadCast will get wrong
checksumEnabled value after initialization, this may not be what we need, we
can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
Supplement:
Snippet 1
```scala
class Broadcast {
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
var checksumEnabled = false
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
false
```
Snippet 2
```scala
class Broadcast {
var checksumEnabled = false
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
true
```
### Why are the changes needed?
we can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes #33957 from daugraph/branch0.
Authored-by: daugraph
Signed-off-by: Sean Owen
(cherry picked from commit 65f6a7c1ecdcf7d6df798e30c9fc03a5dbe0b047)
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala| 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
index 1024d9b..e35a079 100644
--- a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
+++ b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
@@ -73,6 +73,10 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Size of each block. Default value is 4MB. This value is only read by
the broadcaster. */
@transient private var blockSize: Int = _
+
+ /** Whether to generate checksum for blocks or not. */
+ private var checksumEnabled: Boolean = false
+
private def setConf(conf: SparkConf): Unit = {
compressionCodec = if (conf.get(config.BROADCAST_COMPRESS)) {
Some(CompressionCodec.createCodec(conf))
@@ -90,8 +94,6 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Total number of blocks this broadcast variable contains. */
private val numBlocks: Int = writeBlocks(obj)
- /** Whether to generate checksum for blocks or not. */
- private var checksumEnabled: Boolean = false
/** The checksum for all the blocks. */
private var checksums: Array[Int] = _
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-36717][CORE] Incorrect order of variable initialization may lead incorrect behavior
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 758b370 [SPARK-36717][CORE] Incorrect order of variable
initialization may lead incorrect behavior
758b370 is described below
commit 758b3706d0b9fa4468caa6648a4b04cbc311365c
Author: daugraph
AuthorDate: Fri Oct 8 07:11:26 2021 -0500
[SPARK-36717][CORE] Incorrect order of variable initialization may lead
incorrect behavior
### What changes were proposed in this pull request?
Incorrect order of variable initialization may lead to incorrect behavior,
related code: TorrentBroadcast.scala , TorrentBroadCast will get wrong
checksumEnabled value after initialization, this may not be what we need, we
can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
Supplement:
Snippet 1
```scala
class Broadcast {
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
var checksumEnabled = false
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
false
```
Snippet 2
```scala
class Broadcast {
var checksumEnabled = false
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
true
```
### Why are the changes needed?
we can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes #33957 from daugraph/branch0.
Authored-by: daugraph
Signed-off-by: Sean Owen
(cherry picked from commit 65f6a7c1ecdcf7d6df798e30c9fc03a5dbe0b047)
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala| 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
index 1024d9b..e35a079 100644
--- a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
+++ b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
@@ -73,6 +73,10 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Size of each block. Default value is 4MB. This value is only read by
the broadcaster. */
@transient private var blockSize: Int = _
+
+ /** Whether to generate checksum for blocks or not. */
+ private var checksumEnabled: Boolean = false
+
private def setConf(conf: SparkConf): Unit = {
compressionCodec = if (conf.get(config.BROADCAST_COMPRESS)) {
Some(CompressionCodec.createCodec(conf))
@@ -90,8 +94,6 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Total number of blocks this broadcast variable contains. */
private val numBlocks: Int = writeBlocks(obj)
- /** Whether to generate checksum for blocks or not. */
- private var checksumEnabled: Boolean = false
/** The checksum for all the blocks. */
private var checksums: Array[Int] = _
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-36717][CORE] Incorrect order of variable initialization may lead incorrect behavior
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 8e60d6e [SPARK-36717][CORE] Incorrect order of variable
initialization may lead incorrect behavior
8e60d6e is described below
commit 8e60d6e7a9dcc9712deffd519709592e40771086
Author: daugraph
AuthorDate: Fri Oct 8 07:11:26 2021 -0500
[SPARK-36717][CORE] Incorrect order of variable initialization may lead
incorrect behavior
### What changes were proposed in this pull request?
Incorrect order of variable initialization may lead to incorrect behavior,
related code: TorrentBroadcast.scala , TorrentBroadCast will get wrong
checksumEnabled value after initialization, this may not be what we need, we
can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
Supplement:
Snippet 1
```scala
class Broadcast {
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
var checksumEnabled = false
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
false
```
Snippet 2
```scala
class Broadcast {
var checksumEnabled = false
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
true
```
### Why are the changes needed?
we can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes #33957 from daugraph/branch0.
Authored-by: daugraph
Signed-off-by: Sean Owen
(cherry picked from commit 65f6a7c1ecdcf7d6df798e30c9fc03a5dbe0b047)
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala| 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
index 1024d9b..e35a079 100644
--- a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
+++ b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
@@ -73,6 +73,10 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Size of each block. Default value is 4MB. This value is only read by
the broadcaster. */
@transient private var blockSize: Int = _
+
+ /** Whether to generate checksum for blocks or not. */
+ private var checksumEnabled: Boolean = false
+
private def setConf(conf: SparkConf): Unit = {
compressionCodec = if (conf.get(config.BROADCAST_COMPRESS)) {
Some(CompressionCodec.createCodec(conf))
@@ -90,8 +94,6 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Total number of blocks this broadcast variable contains. */
private val numBlocks: Int = writeBlocks(obj)
- /** Whether to generate checksum for blocks or not. */
- private var checksumEnabled: Boolean = false
/** The checksum for all the blocks. */
private var checksums: Array[Int] = _
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36717][CORE] Incorrect order of variable initialization may lead incorrect behavior
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 65f6a7c [SPARK-36717][CORE] Incorrect order of variable
initialization may lead incorrect behavior
65f6a7c is described below
commit 65f6a7c1ecdcf7d6df798e30c9fc03a5dbe0b047
Author: daugraph
AuthorDate: Fri Oct 8 07:11:26 2021 -0500
[SPARK-36717][CORE] Incorrect order of variable initialization may lead
incorrect behavior
### What changes were proposed in this pull request?
Incorrect order of variable initialization may lead to incorrect behavior,
related code: TorrentBroadcast.scala , TorrentBroadCast will get wrong
checksumEnabled value after initialization, this may not be what we need, we
can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
Supplement:
Snippet 1
```scala
class Broadcast {
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
var checksumEnabled = false
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
false
```
Snippet 2
```scala
class Broadcast {
var checksumEnabled = false
def setConf(): Unit = {
checksumEnabled = true
}
setConf()
}
println(new Broadcast().checksumEnabled)
```
output:
```scala
true
```
### Why are the changes needed?
we can move L94 front of setConf(SparkEnv.get.conf) to avoid this.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes #33957 from daugraph/branch0.
Authored-by: daugraph
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala| 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
index 1024d9b..e35a079 100644
--- a/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
+++ b/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala
@@ -73,6 +73,10 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Size of each block. Default value is 4MB. This value is only read by
the broadcaster. */
@transient private var blockSize: Int = _
+
+ /** Whether to generate checksum for blocks or not. */
+ private var checksumEnabled: Boolean = false
+
private def setConf(conf: SparkConf): Unit = {
compressionCodec = if (conf.get(config.BROADCAST_COMPRESS)) {
Some(CompressionCodec.createCodec(conf))
@@ -90,8 +94,6 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj: T,
id: Long)
/** Total number of blocks this broadcast variable contains. */
private val numBlocks: Int = writeBlocks(obj)
- /** Whether to generate checksum for blocks or not. */
- private var checksumEnabled: Boolean = false
/** The checksum for all the blocks. */
private var checksums: Array[Int] = _
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36929][SQL] Remove Unused Method EliminateSubqueryAliasesSuite#assertEquivalent
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 7f6d0ce [SPARK-36929][SQL] Remove Unused Method
EliminateSubqueryAliasesSuite#assertEquivalent
7f6d0ce is described below
commit 7f6d0ceb44235d1af34793cf33607bc41145a765
Author: leesf
AuthorDate: Fri Oct 8 07:09:38 2021 -0500
[SPARK-36929][SQL] Remove Unused Method
EliminateSubqueryAliasesSuite#assertEquivalent
### What changes were proposed in this pull request?
Remove Unused method in EliminateSubqueryAliasesSuite
### Why are the changes needed?
Remove Unused method to simplify the codebase.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Covered by existing tests.
Closes #34175 from leesf/SPARK-36929.
Authored-by: leesf
Signed-off-by: Sean Owen
---
.../sql/catalyst/optimizer/EliminateSubqueryAliasesSuite.scala | 7 ---
1 file changed, 7 deletions(-)
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/EliminateSubqueryAliasesSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/EliminateSubqueryAliasesSuite.scala
index 4df1a14..780423d 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/EliminateSubqueryAliasesSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/EliminateSubqueryAliasesSuite.scala
@@ -20,7 +20,6 @@ package org.apache.spark.sql.catalyst.optimizer
import org.apache.spark.sql.catalyst.analysis
import org.apache.spark.sql.catalyst.analysis.EliminateSubqueryAliases
import org.apache.spark.sql.catalyst.dsl.expressions._
-import org.apache.spark.sql.catalyst.dsl.plans._
import org.apache.spark.sql.catalyst.expressions._
import org.apache.spark.sql.catalyst.expressions.Literal.TrueLiteral
import org.apache.spark.sql.catalyst.plans.PlanTest
@@ -34,12 +33,6 @@ class EliminateSubqueryAliasesSuite extends PlanTest with
PredicateHelper {
val batches = Batch("EliminateSubqueryAliases", Once,
EliminateSubqueryAliases) :: Nil
}
- private def assertEquivalent(e1: Expression, e2: Expression): Unit = {
-val correctAnswer = Project(Alias(e2, "out")() :: Nil,
OneRowRelation()).analyze
-val actual = Optimize.execute(Project(Alias(e1, "out")() :: Nil,
OneRowRelation()).analyze)
-comparePlans(actual, correctAnswer)
- }
-
private def afterOptimization(plan: LogicalPlan): LogicalPlan = {
Optimize.execute(analysis.SimpleAnalyzer.execute(plan))
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR][DOCS] Typo fix in cloud-integration.md
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 25db6b4 [MINOR][DOCS] Typo fix in cloud-integration.md 25db6b4 is described below commit 25db6b45c7636a1c62b6fd6ad189836b019374a3 Author: Dmitriy Fishman AuthorDate: Fri Oct 1 11:26:21 2021 -0500 [MINOR][DOCS] Typo fix in cloud-integration.md ### What changes were proposed in this pull request? Typo fix ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #34129 from fishmandev/patch-1. Authored-by: Dmitriy Fishman Signed-off-by: Sean Owen --- docs/cloud-integration.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/docs/cloud-integration.md b/docs/cloud-integration.md index 22925a5..d65616e 100644 --- a/docs/cloud-integration.md +++ b/docs/cloud-integration.md @@ -188,7 +188,7 @@ directories called `"_temporary"` on a regular basis. 1. For AWS S3, set a limit on how long multipart uploads can remain outstanding. This avoids incurring bills from incompleted uploads. 1. For Google cloud, directory rename is file-by-file. Consider using the v2 committer -and only write code which generates idemportent output -including filenames, +and only write code which generates idempotent output -including filenames, as it is *no more unsafe* than the v1 committer, and faster. ### Parquet I/O Settings - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36550][SQL] Propagation cause when UDF reflection fails
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d003db3 [SPARK-36550][SQL] Propagation cause when UDF reflection fails
d003db3 is described below
commit d003db34c4c5c52a8c99ceecf7233a9b19a69b81
Author: sychen
AuthorDate: Wed Sep 29 08:30:50 2021 -0500
[SPARK-36550][SQL] Propagation cause when UDF reflection fails
### What changes were proposed in this pull request?
When the exception is InvocationTargetException, get cause and stack trace.
### Why are the changes needed?
Now when UDF reflection fails, InvocationTargetException is thrown, but it
is not a specific exception.
```
Error in query: No handler for Hive UDF 'XXX':
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native
Method)
at
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
manual test
Closes #33796 from cxzl25/SPARK-36550.
Authored-by: sychen
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/sql/hive/HiveSessionCatalog.scala | 7 ++-
1 file changed, 6 insertions(+), 1 deletion(-)
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionCatalog.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionCatalog.scala
index 7cbaa8a..56818b5 100644
--- a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionCatalog.scala
+++ b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionCatalog.scala
@@ -17,6 +17,7 @@
package org.apache.spark.sql.hive
+import java.lang.reflect.InvocationTargetException
import java.util.Locale
import scala.util.{Failure, Success, Try}
@@ -87,7 +88,11 @@ private[sql] class HiveSessionCatalog(
udfExpr.get.asInstanceOf[HiveGenericUDTF].elementSchema
}
} catch {
- case NonFatal(e) =>
+ case NonFatal(exception) =>
+val e = exception match {
+ case i: InvocationTargetException => i.getCause
+ case o => o
+}
val errorMsg = s"No handler for UDF/UDAF/UDTF
'${clazz.getCanonicalName}': $e"
val analysisException = new AnalysisException(errorMsg)
analysisException.setStackTrace(e.getStackTrace)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-36712][BUILD] Make scala-parallel-collections in 2.13 POM a direct dependency (not in maven profile)
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 2e75837 [SPARK-36712][BUILD] Make scala-parallel-collections in 2.13
POM a direct dependency (not in maven profile)
2e75837 is described below
commit 2e7583799ebd2cecabdd7bd0271ad129f852c569
Author: Lukas Rytz
AuthorDate: Mon Sep 13 11:06:50 2021 -0500
[SPARK-36712][BUILD] Make scala-parallel-collections in 2.13 POM a direct
dependency (not in maven profile)
As [reported on
`devspark.apache.org`](https://lists.apache.org/thread.html/r84cff66217de438f1389899e6d6891b573780159cd45463acf3657aa%40%3Cdev.spark.apache.org%3E),
the published POMs when building with Scala 2.13 have the
`scala-parallel-collections` dependency only in the `scala-2.13` profile of the
pom.
### What changes were proposed in this pull request?
This PR suggests to work around this by un-commenting the
`scala-parallel-collections` dependency when switching to 2.13 using the the
`change-scala-version.sh` script.
I included an upgrade to scala-parallel-collections version 1.0.3, the
changes compared to 0.2.0 are minor.
- removed OSGi metadata
- renamed some internal inner classes
- added `Automatic-Module-Name`
### Why are the changes needed?
According to the posts, this solves issues for developers that write unit
tests for their applications.
Stephen Coy suggested to use the
https://www.mojohaus.org/flatten-maven-plugin. While this sounds like a more
principled solution, it is possibly too risky to do at this specific point in
time?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally
Closes #33948 from lrytz/parCollDep.
Authored-by: Lukas Rytz
Signed-off-by: Sean Owen
(cherry picked from commit 1a62e6a2c119df707f15101b03ecff0c3dee62f5)
Signed-off-by: Sean Owen
---
core/pom.xml| 15 ++-
dev/change-scala-version.sh | 12
external/avro/pom.xml | 17 ++---
external/kafka-0-10-sql/pom.xml | 17 ++---
external/kafka-0-10/pom.xml | 18 ++
mllib/pom.xml | 18 ++
pom.xml | 16 +++-
sql/catalyst/pom.xml| 18 ++
sql/core/pom.xml| 15 ++-
sql/hive-thriftserver/pom.xml | 17 ++---
sql/hive/pom.xml| 15 ++-
streaming/pom.xml | 17 ++---
12 files changed, 75 insertions(+), 120 deletions(-)
diff --git a/core/pom.xml b/core/pom.xml
index d2b4616..2229a95 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -35,6 +35,12 @@
+
org.apache.avro
avro
@@ -639,15 +645,6 @@
-
- scala-2.13
-
-
- org.scala-lang.modules
-
scala-parallel-collections_${scala.binary.version}
-
-
-
diff --git a/dev/change-scala-version.sh b/dev/change-scala-version.sh
index 48b7f64..e17a224 100755
--- a/dev/change-scala-version.sh
+++ b/dev/change-scala-version.sh
@@ -54,11 +54,15 @@ sed_i() {
sed -e "$1" "$2" > "$2.tmp" && mv "$2.tmp" "$2"
}
-export -f sed_i
-
BASEDIR=$(dirname $0)/..
-find "$BASEDIR" -name 'pom.xml' -not -path '*target*' -print \
- -exec bash -c "sed_i 's/\(artifactId.*\)_'$FROM_VERSION'/\1_'$TO_VERSION'/g'
{}" \;
+for f in $(find "$BASEDIR" -name 'pom.xml' -not -path '*target*'); do
+ echo $f
+ sed_i 's/\(artifactId.*\)_'$FROM_VERSION'/\1_'$TO_VERSION'/g' $f
+ sed_i 's/^\([[:space:]]*\)\(\)/\1\2/'
$f
+ sed_i 's/^\([[:space:]]*\)/\1\)/\1-->\2/' $f
+done
# dependency:get is workaround for SPARK-34762 to download the JAR file of
commons-cli.
# Without this, build with Scala 2.13 using SBT will fail because the help
plugin used below downloads only the POM file.
diff --git a/external/avro/pom.xml b/external/avro/pom.xml
index 92b8b73..6dbfc68 100644
--- a/external/avro/pom.xml
+++ b/external/avro/pom.xml
@@ -70,22 +70,17 @@
org.apache.spark
spark-tags_${scala.binary.version}
+
org.tukaani
xz
-
-
- scala-2.13
-
-
- org.scala-lang.modules
-
scala-parallel-collections_${scala.binary.version}
-
-
-
-
target/scala-${scala.binary.version}/classes
target/scala-${scala.binary.version}/test-classes
diff --git a/exte
[spark] branch master updated: [SPARK-36712][BUILD] Make scala-parallel-collections in 2.13 POM a direct dependency (not in maven profile)
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1a62e6a [SPARK-36712][BUILD] Make scala-parallel-collections in 2.13
POM a direct dependency (not in maven profile)
1a62e6a is described below
commit 1a62e6a2c119df707f15101b03ecff0c3dee62f5
Author: Lukas Rytz
AuthorDate: Mon Sep 13 11:06:50 2021 -0500
[SPARK-36712][BUILD] Make scala-parallel-collections in 2.13 POM a direct
dependency (not in maven profile)
As [reported on
`devspark.apache.org`](https://lists.apache.org/thread.html/r84cff66217de438f1389899e6d6891b573780159cd45463acf3657aa%40%3Cdev.spark.apache.org%3E),
the published POMs when building with Scala 2.13 have the
`scala-parallel-collections` dependency only in the `scala-2.13` profile of the
pom.
### What changes were proposed in this pull request?
This PR suggests to work around this by un-commenting the
`scala-parallel-collections` dependency when switching to 2.13 using the the
`change-scala-version.sh` script.
I included an upgrade to scala-parallel-collections version 1.0.3, the
changes compared to 0.2.0 are minor.
- removed OSGi metadata
- renamed some internal inner classes
- added `Automatic-Module-Name`
### Why are the changes needed?
According to the posts, this solves issues for developers that write unit
tests for their applications.
Stephen Coy suggested to use the
https://www.mojohaus.org/flatten-maven-plugin. While this sounds like a more
principled solution, it is possibly too risky to do at this specific point in
time?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally
Closes #33948 from lrytz/parCollDep.
Authored-by: Lukas Rytz
Signed-off-by: Sean Owen
---
core/pom.xml| 15 ++-
dev/change-scala-version.sh | 12
external/avro/pom.xml | 17 ++---
external/kafka-0-10-sql/pom.xml | 17 ++---
external/kafka-0-10/pom.xml | 18 ++
mllib/pom.xml | 18 ++
pom.xml | 16 +++-
sql/catalyst/pom.xml| 18 ++
sql/core/pom.xml| 15 ++-
sql/hive-thriftserver/pom.xml | 17 ++---
sql/hive/pom.xml| 15 ++-
streaming/pom.xml | 17 ++---
12 files changed, 75 insertions(+), 120 deletions(-)
diff --git a/core/pom.xml b/core/pom.xml
index be44964..dbde22f 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -35,6 +35,12 @@
+
org.apache.avro
avro
@@ -639,15 +645,6 @@
-
- scala-2.13
-
-
- org.scala-lang.modules
-
scala-parallel-collections_${scala.binary.version}
-
-
-
diff --git a/dev/change-scala-version.sh b/dev/change-scala-version.sh
index 48b7f64..e17a224 100755
--- a/dev/change-scala-version.sh
+++ b/dev/change-scala-version.sh
@@ -54,11 +54,15 @@ sed_i() {
sed -e "$1" "$2" > "$2.tmp" && mv "$2.tmp" "$2"
}
-export -f sed_i
-
BASEDIR=$(dirname $0)/..
-find "$BASEDIR" -name 'pom.xml' -not -path '*target*' -print \
- -exec bash -c "sed_i 's/\(artifactId.*\)_'$FROM_VERSION'/\1_'$TO_VERSION'/g'
{}" \;
+for f in $(find "$BASEDIR" -name 'pom.xml' -not -path '*target*'); do
+ echo $f
+ sed_i 's/\(artifactId.*\)_'$FROM_VERSION'/\1_'$TO_VERSION'/g' $f
+ sed_i 's/^\([[:space:]]*\)\(\)/\1\2/'
$f
+ sed_i 's/^\([[:space:]]*\)/\1\)/\1-->\2/' $f
+done
# dependency:get is workaround for SPARK-34762 to download the JAR file of
commons-cli.
# Without this, build with Scala 2.13 using SBT will fail because the help
plugin used below downloads only the POM file.
diff --git a/external/avro/pom.xml b/external/avro/pom.xml
index d9d3583..7e414be 100644
--- a/external/avro/pom.xml
+++ b/external/avro/pom.xml
@@ -70,22 +70,17 @@
org.apache.spark
spark-tags_${scala.binary.version}
+
org.tukaani
xz
-
-
- scala-2.13
-
-
- org.scala-lang.modules
-
scala-parallel-collections_${scala.binary.version}
-
-
-
-
target/scala-${scala.binary.version}/classes
target/scala-${scala.binary.version}/test-classes
diff --git a/external/kafka-0-10-sql/pom.xml b/external/kafka-0-10-sql/pom.xml
index 8d505cf..7bedcee 100644
--- a/external/kafka-0-10-sql/po
[spark] branch branch-3.0 updated (72e48d2 -> 6b804c7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git. from 72e48d2 [SPARK-36685][ML][MLLIB] Fix wrong assert messages add 6b804c7 [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/LocalSparkCluster.scala | 5 - 1 file changed, 4 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.1 by this push: new c11b66d [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision c11b66d is described below commit c11b66d5f728dfd4b61b7e20bbc45a91cf716549 Author: yangjie01 AuthorDate: Sun Sep 12 09:57:06 2021 -0500 [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision ### What changes were proposed in this pull request? As described in SPARK-36636,if the test cases with config `local-cluster[n, c, m]` are run continuously within 1 second, the workdir name collision will occur because appid use format as `app-MMddHHmmss-` and workdir name associated with it in test now, the related logs are as follows: ``` java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-/1 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 21/09/08 22:44:32.266 dispatcher-event-loop-0 INFO Worker: Asked to launch executor app-20210908074432-/0 for test 21/09/08 22:44:32.266 dispatcher-event-loop-0 ERROR Worker: Failed to launch executor app-20210908074432-/0 for test. java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-/0 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Since the default value of s`park.deploy.maxExecutorRetries` is 10, the test failed will occur when 5 consecutive cases with local-cluster[3, 1, 1024] are completed within 1 second: 1. case 1: use worker directories: `/app-202109102324-/0`, `/app-202109102324-/1`, `/app-202109102324-/2` 2. case 2: retry 3 times then use worker directories: `/app-202109102324-/3`, `/app-202109102324-/4`, `/app-202109102324-/5` 3. case 3: retry 6 times then use worker directories: `/app-202109102324-/6`, `/app-202109102324-/7`, `/app-202109102324-/8` 4. case 4: retry 9 times then use worker directories: `/app-202109102324-/9`, `/app-202109102324-/10`, `/app-202109102324-/11` 5. case 5: retry more than **10** times then **failed** To avoid this issue, this pr change to use tmp workdir in test with config `local-cluster[n, c, m]`. ### Why are the changes needed? Avoid UT failures caused by continuous workdir name collision. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA or Jenkins Tests. - Manual test: `build/mvn clean install -Pscala-2.13 -pl core -am` or `build/mvn clean install -pl core -am`, with Scala 2.13 is easier to reproduce this problem **Before** The test failed error logs as follows and randomness in test failure: ``` - SPARK-33084: Add jar support Ivy URI -- test exclude param when transitive=true *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104
[spark] branch branch-3.2 updated: [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new 90c4cf3 [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision 90c4cf3 is described below commit 90c4cf3cf3b574e593e163951935196cf58a5d4e Author: yangjie01 AuthorDate: Sun Sep 12 09:57:06 2021 -0500 [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision ### What changes were proposed in this pull request? As described in SPARK-36636,if the test cases with config `local-cluster[n, c, m]` are run continuously within 1 second, the workdir name collision will occur because appid use format as `app-MMddHHmmss-` and workdir name associated with it in test now, the related logs are as follows: ``` java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-/1 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 21/09/08 22:44:32.266 dispatcher-event-loop-0 INFO Worker: Asked to launch executor app-20210908074432-/0 for test 21/09/08 22:44:32.266 dispatcher-event-loop-0 ERROR Worker: Failed to launch executor app-20210908074432-/0 for test. java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-/0 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Since the default value of s`park.deploy.maxExecutorRetries` is 10, the test failed will occur when 5 consecutive cases with local-cluster[3, 1, 1024] are completed within 1 second: 1. case 1: use worker directories: `/app-202109102324-/0`, `/app-202109102324-/1`, `/app-202109102324-/2` 2. case 2: retry 3 times then use worker directories: `/app-202109102324-/3`, `/app-202109102324-/4`, `/app-202109102324-/5` 3. case 3: retry 6 times then use worker directories: `/app-202109102324-/6`, `/app-202109102324-/7`, `/app-202109102324-/8` 4. case 4: retry 9 times then use worker directories: `/app-202109102324-/9`, `/app-202109102324-/10`, `/app-202109102324-/11` 5. case 5: retry more than **10** times then **failed** To avoid this issue, this pr change to use tmp workdir in test with config `local-cluster[n, c, m]`. ### Why are the changes needed? Avoid UT failures caused by continuous workdir name collision. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA or Jenkins Tests. - Manual test: `build/mvn clean install -Pscala-2.13 -pl core -am` or `build/mvn clean install -pl core -am`, with Scala 2.13 is easier to reproduce this problem **Before** The test failed error logs as follows and randomness in test failure: ``` - SPARK-33084: Add jar support Ivy URI -- test exclude param when transitive=true *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104
[spark] branch master updated: [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 0e1157d [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision 0e1157d is described below commit 0e1157df06ba6364ca57be846194996327801ded Author: yangjie01 AuthorDate: Sun Sep 12 09:57:06 2021 -0500 [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision ### What changes were proposed in this pull request? As described in SPARK-36636,if the test cases with config `local-cluster[n, c, m]` are run continuously within 1 second, the workdir name collision will occur because appid use format as `app-MMddHHmmss-` and workdir name associated with it in test now, the related logs are as follows: ``` java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-/1 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 21/09/08 22:44:32.266 dispatcher-event-loop-0 INFO Worker: Asked to launch executor app-20210908074432-/0 for test 21/09/08 22:44:32.266 dispatcher-event-loop-0 ERROR Worker: Failed to launch executor app-20210908074432-/0 for test. java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-/0 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Since the default value of s`park.deploy.maxExecutorRetries` is 10, the test failed will occur when 5 consecutive cases with local-cluster[3, 1, 1024] are completed within 1 second: 1. case 1: use worker directories: `/app-202109102324-/0`, `/app-202109102324-/1`, `/app-202109102324-/2` 2. case 2: retry 3 times then use worker directories: `/app-202109102324-/3`, `/app-202109102324-/4`, `/app-202109102324-/5` 3. case 3: retry 6 times then use worker directories: `/app-202109102324-/6`, `/app-202109102324-/7`, `/app-202109102324-/8` 4. case 4: retry 9 times then use worker directories: `/app-202109102324-/9`, `/app-202109102324-/10`, `/app-202109102324-/11` 5. case 5: retry more than **10** times then **failed** To avoid this issue, this pr change to use tmp workdir in test with config `local-cluster[n, c, m]`. ### Why are the changes needed? Avoid UT failures caused by continuous workdir name collision. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA or Jenkins Tests. - Manual test: `build/mvn clean install -Pscala-2.13 -pl core -am` or `build/mvn clean install -pl core -am`, with Scala 2.13 is easier to reproduce this problem **Before** The test failed error logs as follows and randomness in test failure: ``` - SPARK-33084: Add jar support Ivy URI -- test exclude param when transitive=true *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104
[spark] branch branch-3.0 updated (35caf2d -> 55f050c)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git. from 35caf2d Revert "[SPARK-35011][CORE][3.0] Avoid Block Manager registrations when StopExecutor msg is in-flight" add 55f050c [SPARK-36704][CORE] Expand exception handling to more Java 9 cases where reflection is limited at runtime, when reflecting to manage DirectByteBuffer settings No new revisions were added by this update. Summary of changes: .../java/org/apache/spark/unsafe/Platform.java | 87 +- 1 file changed, 51 insertions(+), 36 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-36704][CORE] Expand exception handling to more Java 9 cases where reflection is limited at runtime, when reflecting to manage DirectByteBuffer settings
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 62dfa14 [SPARK-36704][CORE] Expand exception handling to more Java 9
cases where reflection is limited at runtime, when reflecting to manage
DirectByteBuffer settings
62dfa14 is described below
commit 62dfa14ff20b114c42ec6357a0b3d18f8eeaaa10
Author: Sean Owen
AuthorDate: Sat Sep 11 13:38:10 2021 -0500
[SPARK-36704][CORE] Expand exception handling to more Java 9 cases where
reflection is limited at runtime, when reflecting to manage DirectByteBuffer
settings
### What changes were proposed in this pull request?
Improve exception handling in the Platform initialization, where it
attempts to assess whether reflection is possible to modify DirectByteBuffer.
This can apparently fail in more cases on Java 9+ than are currently handled,
whereas Spark can continue without reflection if needed.
More detailed comments on the change inline.
### Why are the changes needed?
This exception seems to be possible and fails startup:
```
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make
private java.nio.DirectByteBuffer(long,int) accessible: module java.base does
not "opens java.nio" to unnamed module 71e9ddb4
at
java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:357)
at
java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at
java.base/java.lang.reflect.Constructor.checkCanSetAccessible(Constructor.java:188)
at
java.base/java.lang.reflect.Constructor.setAccessible(Constructor.java:181)
at org.apache.spark.unsafe.Platform.(Platform.java:56)
```
### Does this PR introduce _any_ user-facing change?
Should strictly allow Spark to continue in more cases.
### How was this patch tested?
Existing tests.
Closes #33947 from srowen/SPARK-36704.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit e5283f5ed5efa5bf3652c3959166f59dc5b5daaa)
Signed-off-by: Sean Owen
---
.../java/org/apache/spark/unsafe/Platform.java | 87 +-
1 file changed, 51 insertions(+), 36 deletions(-)
diff --git a/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
b/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
index dc8d6e3..1286762 100644
--- a/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
+++ b/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
@@ -45,30 +45,20 @@ public final class Platform {
private static final boolean unaligned;
- // Access fields and constructors once and store them, for performance:
-
- private static final Constructor DBB_CONSTRUCTOR;
- private static final Field DBB_CLEANER_FIELD;
- static {
-try {
- Class cls = Class.forName("java.nio.DirectByteBuffer");
- Constructor constructor = cls.getDeclaredConstructor(Long.TYPE,
Integer.TYPE);
- constructor.setAccessible(true);
- Field cleanerField = cls.getDeclaredField("cleaner");
- cleanerField.setAccessible(true);
- DBB_CONSTRUCTOR = constructor;
- DBB_CLEANER_FIELD = cleanerField;
-} catch (ClassNotFoundException | NoSuchMethodException |
NoSuchFieldException e) {
- throw new IllegalStateException(e);
-}
- }
-
// Split java.version on non-digit chars:
private static final int majorVersion =
Integer.parseInt(System.getProperty("java.version").split("\\D+")[0]);
+ // Access fields and constructors once and store them, for performance:
+ private static final Constructor DBB_CONSTRUCTOR;
+ private static final Field DBB_CLEANER_FIELD;
private static final Method CLEANER_CREATE_METHOD;
+
static {
+// At the end of this block, CLEANER_CREATE_METHOD should be non-null iff
it's possible to use
+// reflection to invoke it, which is not necessarily possible by default
in Java 9+.
+// Code below can test for null to see whether to use it.
+
// The implementation of Cleaner changed from JDK 8 to 9
String cleanerClassName;
if (majorVersion < 9) {
@@ -77,28 +67,53 @@ public final class Platform {
cleanerClassName = "jdk.internal.ref.Cleaner";
}
try {
- Class cleanerClass = Class.forName(cleanerClassName);
- Method createMethod = cleanerClass.getMethod("create", Object.class,
Runnable.class);
- // Accessing jdk.internal.ref.Cleaner should actually fail by default in
JDK 9+,
- // unfortunately, unless the user has allowed access with something like
- // --add-opens java.base/java.lang=ALL-UNNA
[spark] branch branch-3.2 updated: [SPARK-36704][CORE] Expand exception handling to more Java 9 cases where reflection is limited at runtime, when reflecting to manage DirectByteBuffer settings
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 043dd53 [SPARK-36704][CORE] Expand exception handling to more Java 9
cases where reflection is limited at runtime, when reflecting to manage
DirectByteBuffer settings
043dd53 is described below
commit 043dd531a0a23b836d6f3795e4e5e949d4cdee7c
Author: Sean Owen
AuthorDate: Sat Sep 11 13:38:10 2021 -0500
[SPARK-36704][CORE] Expand exception handling to more Java 9 cases where
reflection is limited at runtime, when reflecting to manage DirectByteBuffer
settings
### What changes were proposed in this pull request?
Improve exception handling in the Platform initialization, where it
attempts to assess whether reflection is possible to modify DirectByteBuffer.
This can apparently fail in more cases on Java 9+ than are currently handled,
whereas Spark can continue without reflection if needed.
More detailed comments on the change inline.
### Why are the changes needed?
This exception seems to be possible and fails startup:
```
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make
private java.nio.DirectByteBuffer(long,int) accessible: module java.base does
not "opens java.nio" to unnamed module 71e9ddb4
at
java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:357)
at
java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at
java.base/java.lang.reflect.Constructor.checkCanSetAccessible(Constructor.java:188)
at
java.base/java.lang.reflect.Constructor.setAccessible(Constructor.java:181)
at org.apache.spark.unsafe.Platform.(Platform.java:56)
```
### Does this PR introduce _any_ user-facing change?
Should strictly allow Spark to continue in more cases.
### How was this patch tested?
Existing tests.
Closes #33947 from srowen/SPARK-36704.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit e5283f5ed5efa5bf3652c3959166f59dc5b5daaa)
Signed-off-by: Sean Owen
---
.../java/org/apache/spark/unsafe/Platform.java | 87 +-
1 file changed, 51 insertions(+), 36 deletions(-)
diff --git a/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
b/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
index dc8d6e3..1286762 100644
--- a/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
+++ b/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
@@ -45,30 +45,20 @@ public final class Platform {
private static final boolean unaligned;
- // Access fields and constructors once and store them, for performance:
-
- private static final Constructor DBB_CONSTRUCTOR;
- private static final Field DBB_CLEANER_FIELD;
- static {
-try {
- Class cls = Class.forName("java.nio.DirectByteBuffer");
- Constructor constructor = cls.getDeclaredConstructor(Long.TYPE,
Integer.TYPE);
- constructor.setAccessible(true);
- Field cleanerField = cls.getDeclaredField("cleaner");
- cleanerField.setAccessible(true);
- DBB_CONSTRUCTOR = constructor;
- DBB_CLEANER_FIELD = cleanerField;
-} catch (ClassNotFoundException | NoSuchMethodException |
NoSuchFieldException e) {
- throw new IllegalStateException(e);
-}
- }
-
// Split java.version on non-digit chars:
private static final int majorVersion =
Integer.parseInt(System.getProperty("java.version").split("\\D+")[0]);
+ // Access fields and constructors once and store them, for performance:
+ private static final Constructor DBB_CONSTRUCTOR;
+ private static final Field DBB_CLEANER_FIELD;
private static final Method CLEANER_CREATE_METHOD;
+
static {
+// At the end of this block, CLEANER_CREATE_METHOD should be non-null iff
it's possible to use
+// reflection to invoke it, which is not necessarily possible by default
in Java 9+.
+// Code below can test for null to see whether to use it.
+
// The implementation of Cleaner changed from JDK 8 to 9
String cleanerClassName;
if (majorVersion < 9) {
@@ -77,28 +67,53 @@ public final class Platform {
cleanerClassName = "jdk.internal.ref.Cleaner";
}
try {
- Class cleanerClass = Class.forName(cleanerClassName);
- Method createMethod = cleanerClass.getMethod("create", Object.class,
Runnable.class);
- // Accessing jdk.internal.ref.Cleaner should actually fail by default in
JDK 9+,
- // unfortunately, unless the user has allowed access with something like
- // --add-opens java.base/java.lang=ALL-UNNA
[spark] branch master updated: [SPARK-36704][CORE] Expand exception handling to more Java 9 cases where reflection is limited at runtime, when reflecting to manage DirectByteBuffer settings
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e5283f5 [SPARK-36704][CORE] Expand exception handling to more Java 9
cases where reflection is limited at runtime, when reflecting to manage
DirectByteBuffer settings
e5283f5 is described below
commit e5283f5ed5efa5bf3652c3959166f59dc5b5daaa
Author: Sean Owen
AuthorDate: Sat Sep 11 13:38:10 2021 -0500
[SPARK-36704][CORE] Expand exception handling to more Java 9 cases where
reflection is limited at runtime, when reflecting to manage DirectByteBuffer
settings
### What changes were proposed in this pull request?
Improve exception handling in the Platform initialization, where it
attempts to assess whether reflection is possible to modify DirectByteBuffer.
This can apparently fail in more cases on Java 9+ than are currently handled,
whereas Spark can continue without reflection if needed.
More detailed comments on the change inline.
### Why are the changes needed?
This exception seems to be possible and fails startup:
```
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make
private java.nio.DirectByteBuffer(long,int) accessible: module java.base does
not "opens java.nio" to unnamed module 71e9ddb4
at
java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:357)
at
java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at
java.base/java.lang.reflect.Constructor.checkCanSetAccessible(Constructor.java:188)
at
java.base/java.lang.reflect.Constructor.setAccessible(Constructor.java:181)
at org.apache.spark.unsafe.Platform.(Platform.java:56)
```
### Does this PR introduce _any_ user-facing change?
Should strictly allow Spark to continue in more cases.
### How was this patch tested?
Existing tests.
Closes #33947 from srowen/SPARK-36704.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
---
.../java/org/apache/spark/unsafe/Platform.java | 87 +-
1 file changed, 51 insertions(+), 36 deletions(-)
diff --git a/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
b/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
index dc8d6e3..1286762 100644
--- a/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
+++ b/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java
@@ -45,30 +45,20 @@ public final class Platform {
private static final boolean unaligned;
- // Access fields and constructors once and store them, for performance:
-
- private static final Constructor DBB_CONSTRUCTOR;
- private static final Field DBB_CLEANER_FIELD;
- static {
-try {
- Class cls = Class.forName("java.nio.DirectByteBuffer");
- Constructor constructor = cls.getDeclaredConstructor(Long.TYPE,
Integer.TYPE);
- constructor.setAccessible(true);
- Field cleanerField = cls.getDeclaredField("cleaner");
- cleanerField.setAccessible(true);
- DBB_CONSTRUCTOR = constructor;
- DBB_CLEANER_FIELD = cleanerField;
-} catch (ClassNotFoundException | NoSuchMethodException |
NoSuchFieldException e) {
- throw new IllegalStateException(e);
-}
- }
-
// Split java.version on non-digit chars:
private static final int majorVersion =
Integer.parseInt(System.getProperty("java.version").split("\\D+")[0]);
+ // Access fields and constructors once and store them, for performance:
+ private static final Constructor DBB_CONSTRUCTOR;
+ private static final Field DBB_CLEANER_FIELD;
private static final Method CLEANER_CREATE_METHOD;
+
static {
+// At the end of this block, CLEANER_CREATE_METHOD should be non-null iff
it's possible to use
+// reflection to invoke it, which is not necessarily possible by default
in Java 9+.
+// Code below can test for null to see whether to use it.
+
// The implementation of Cleaner changed from JDK 8 to 9
String cleanerClassName;
if (majorVersion < 9) {
@@ -77,28 +67,53 @@ public final class Platform {
cleanerClassName = "jdk.internal.ref.Cleaner";
}
try {
- Class cleanerClass = Class.forName(cleanerClassName);
- Method createMethod = cleanerClass.getMethod("create", Object.class,
Runnable.class);
- // Accessing jdk.internal.ref.Cleaner should actually fail by default in
JDK 9+,
- // unfortunately, unless the user has allowed access with something like
- // --add-opens java.base/java.lang=ALL-UNNAMED If not, we can't really
use the Cleaner
- // hack below. It doesn't break, just means the us
[spark] branch master updated: [SPARK-36613][SQL][SS] Use EnumSet as the implementation of Table.capabilities method return value
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new bdb73bb [SPARK-36613][SQL][SS] Use EnumSet as the implementation of Table.capabilities method return value bdb73bb is described below commit bdb73bbc277519f0c7ffa3ab856cf87515c12934 Author: yangjie01 AuthorDate: Sun Sep 5 08:23:05 2021 -0500 [SPARK-36613][SQL][SS] Use EnumSet as the implementation of Table.capabilities method return value ### What changes were proposed in this pull request? The `Table.capabilities` method return a `java.util.Set` of `TableCapability` enumeration type, which is implemented using `java.util.HashSet` now. Such Set can be replaced `with java.util.EnumSet` because `EnumSet` implementations can be much more efficient compared to other sets. ### Why are the changes needed? Use more appropriate data structures. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA or Jenkins Tests. - Add a new benchmark to compare `create` and `contains` operation between `EnumSet` and `HashSet` Closes #33867 from LuciferYang/SPARK-36613. Authored-by: yangjie01 Signed-off-by: Sean Owen --- .../spark/sql/kafka010/KafkaSourceProvider.scala | 4 +- .../EnumTypeSetBenchmark-jdk11-results.txt | 104 .../benchmarks/EnumTypeSetBenchmark-results.txt| 104 .../spark/sql/connector/catalog/V1Table.scala | 3 +- .../CreateTablePartitioningValidationSuite.scala | 3 +- .../connector/catalog/EnumTypeSetBenchmark.scala | 176 + .../sql/connector/catalog/InMemoryTable.scala | 5 +- .../datasources/noop/NoopDataSource.scala | 6 +- .../sql/execution/datasources/v2/FileTable.scala | 2 +- .../execution/datasources/v2/jdbc/JDBCTable.scala | 2 +- .../spark/sql/execution/streaming/console.scala| 4 +- .../spark/sql/execution/streaming/memory.scala | 3 +- .../streaming/sources/ForeachWriterTable.scala | 4 +- .../streaming/sources/RateStreamProvider.scala | 4 +- .../sources/TextSocketSourceProvider.scala | 3 +- .../sql/execution/streaming/sources/memory.scala | 3 +- .../spark/sql/connector/JavaSimpleBatchTable.java | 5 +- .../connector/JavaSimpleWritableDataSource.java| 6 +- .../spark/sql/connector/DataSourceV2Suite.scala| 4 +- .../connector/FileDataSourceV2FallBackSuite.scala | 5 +- .../spark/sql/connector/LocalScanSuite.scala | 5 +- .../sql/connector/SimpleWritableDataSource.scala | 2 +- .../sql/connector/TableCapabilityCheckSuite.scala | 8 +- .../spark/sql/connector/V1ReadFallbackSuite.scala | 4 +- .../spark/sql/connector/V1WriteFallbackSuite.scala | 4 +- .../sources/StreamingDataSourceV2Suite.scala | 17 +- .../streaming/test/DataStreamTableAPISuite.scala | 7 +- .../sql/streaming/util/BlockOnStopSource.scala | 4 +- 28 files changed, 433 insertions(+), 68 deletions(-) diff --git a/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSourceProvider.scala b/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSourceProvider.scala index 4a75ab0..640996d 100644 --- a/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSourceProvider.scala +++ b/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSourceProvider.scala @@ -408,8 +408,8 @@ private[kafka010] class KafkaSourceProvider extends DataSourceRegister // ACCEPT_ANY_SCHEMA is needed because of the following reasons: // * Kafka writer validates the schema instead of the SQL analyzer (the schema is fixed) // * Read schema differs from write schema (please see Kafka integration guide) - Set(BATCH_READ, BATCH_WRITE, MICRO_BATCH_READ, CONTINUOUS_READ, STREAMING_WRITE, -ACCEPT_ANY_SCHEMA).asJava + ju.EnumSet.of(BATCH_READ, BATCH_WRITE, MICRO_BATCH_READ, CONTINUOUS_READ, STREAMING_WRITE, +ACCEPT_ANY_SCHEMA) } override def newScanBuilder(options: CaseInsensitiveStringMap): ScanBuilder = diff --git a/sql/catalyst/benchmarks/EnumTypeSetBenchmark-jdk11-results.txt b/sql/catalyst/benchmarks/EnumTypeSetBenchmark-jdk11-results.txt new file mode 100644 index 000..4c961c1 --- /dev/null +++ b/sql/catalyst/benchmarks/EnumTypeSetBenchmark-jdk11-results.txt @@ -0,0 +1,104 @@ +OpenJDK 64-Bit Server VM 11+28 on Linux 4.14.0_1-0-0-42 +Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz +Test contains use empty Set: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative + +Use HashSet
[spark] branch master updated (6bd491e -> 3584838)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 6bd491e [SPARK-36643][SQL] Add more information in ERROR log while SparkConf is modified when spark.sql.legacy.setCommandRejectsSparkCoreConfs is set add 3584838 [SPARK-36602][COER][SQL] Clean up redundant asInstanceOf casts No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/api/r/RBackendHandler.scala| 2 +- core/src/main/scala/org/apache/spark/rdd/RDD.scala | 2 +- .../src/main/scala/org/apache/spark/scheduler/InputFormatInfo.scala | 4 ++-- core/src/main/scala/org/apache/spark/util/Utils.scala | 2 +- core/src/test/scala/org/apache/spark/rdd/RDDSuite.scala | 2 +- .../org/apache/spark/storage/ShuffleBlockFetcherIteratorSuite.scala | 2 +- core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala| 2 +- .../org/apache/spark/streaming/kinesis/KinesisStreamSuite.scala | 5 ++--- .../src/test/scala/org/apache/spark/ml/linalg/BLASSuite.scala | 2 +- .../src/test/scala/org/apache/spark/ml/linalg/MatricesSuite.scala | 6 +++--- .../scala/org/apache/spark/mllib/api/python/PythonMLLibAPI.scala| 2 +- mllib/src/test/scala/org/apache/spark/mllib/linalg/BLASSuite.scala | 2 +- .../test/scala/org/apache/spark/mllib/linalg/MatricesSuite.scala| 6 +++--- .../pmml/export/BinaryClassificationPMMLModelExportSuite.scala | 2 +- .../apache/spark/mllib/pmml/export/KMeansPMMLModelExportSuite.scala | 2 +- .../main/scala/org/apache/spark/sql/catalyst/ScalaReflection.scala | 2 +- .../apache/spark/sql/catalyst/expressions/SpecificInternalRow.scala | 2 +- .../org/apache/spark/sql/catalyst/expressions/arithmetic.scala | 2 +- .../spark/sql/catalyst/expressions/ExpressionEvalHelper.scala | 2 +- .../sql/catalyst/expressions/xml/ReusableStringReaderSuite.scala| 6 +++--- .../spark/sql/catalyst/expressions/xml/UDFXPathUtilSuite.scala | 2 +- .../apache/spark/sql/catalyst/util/ArrayDataIndexedSeqSuite.scala | 4 ++-- .../apache/spark/sql/catalyst/util/CaseInsensitiveMapSuite.scala| 2 +- sql/core/src/main/scala/org/apache/spark/sql/api/r/SQLUtils.scala | 2 +- .../spark/sql/execution/datasources/v2/ContinuousScanExec.scala | 2 +- .../sql/execution/streaming/continuous/ContinuousExecution.scala| 4 ++-- sql/core/src/test/scala/org/apache/spark/sql/QueryTest.scala| 2 +- .../org/apache/spark/sql/execution/joins/HashedRelationSuite.scala | 2 +- .../src/test/scala/org/apache/spark/sql/streaming/StreamSuite.scala | 2 +- .../apache/spark/sql/streaming/StreamingQueryListenerSuite.scala| 2 +- .../spark/sql/streaming/sources/StreamingDataSourceV2Suite.scala| 2 +- sql/hive/src/main/scala/org/apache/spark/sql/hive/TableReader.scala | 3 +-- .../scala/org/apache/spark/streaming/BasicOperationsSuite.scala | 4 ++-- 33 files changed, 44 insertions(+), 46 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: Update Spark key negotiation protocol
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-2.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.4 by this push:
new 4be5660 Update Spark key negotiation protocol
4be5660 is described below
commit 4be566062defa249435c4d72eb106fe7b933e023
Author: Sean Owen
AuthorDate: Wed Aug 11 18:04:55 2021 -0500
Update Spark key negotiation protocol
---
common/network-common/pom.xml | 4 +
.../spark/network/crypto/AuthClientBootstrap.java | 6 +-
.../apache/spark/network/crypto/AuthEngine.java| 420 +
.../{ServerResponse.java => AuthMessage.java} | 56 ++-
.../spark/network/crypto/AuthRpcHandler.java | 6 +-
.../spark/network/crypto/ClientChallenge.java | 101 -
.../java/org/apache/spark/network/crypto/README.md | 217 ---
.../spark/network/crypto/AuthEngineSuite.java | 182 ++---
.../spark/network/crypto/AuthMessagesSuite.java| 46 +--
dev/deps/spark-deps-hadoop-2.6 | 1 +
dev/deps/spark-deps-hadoop-2.7 | 1 +
dev/deps/spark-deps-hadoop-3.1 | 1 +
pom.xml| 6 +
13 files changed, 432 insertions(+), 615 deletions(-)
diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml
index cd57c43..d585185 100644
--- a/common/network-common/pom.xml
+++ b/common/network-common/pom.xml
@@ -85,6 +85,10 @@
org.apache.commons
commons-crypto
+
+ com.google.crypto.tink
+ tink
+
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
index 737e187..1586989 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
@@ -98,15 +98,15 @@ public class AuthClientBootstrap implements
TransportClientBootstrap {
String secretKey = secretKeyHolder.getSecretKey(appId);
try (AuthEngine engine = new AuthEngine(appId, secretKey, conf)) {
- ClientChallenge challenge = engine.challenge();
+ AuthMessage challenge = engine.challenge();
ByteBuf challengeData = Unpooled.buffer(challenge.encodedLength());
challenge.encode(challengeData);
ByteBuffer responseData =
client.sendRpcSync(challengeData.nioBuffer(),
conf.authRTTimeoutMs());
- ServerResponse response = ServerResponse.decodeMessage(responseData);
+ AuthMessage response = AuthMessage.decodeMessage(responseData);
- engine.validate(response);
+ engine.deriveSessionCipher(challenge, response);
engine.sessionCipher().addToChannel(channel);
}
}
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
index 64fdb32..078d9ce 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
@@ -17,134 +17,216 @@
package org.apache.spark.network.crypto;
+import javax.crypto.spec.SecretKeySpec;
import java.io.Closeable;
-import java.io.IOException;
-import java.math.BigInteger;
import java.security.GeneralSecurityException;
import java.util.Arrays;
import java.util.Properties;
-import javax.crypto.Cipher;
-import javax.crypto.SecretKey;
-import javax.crypto.SecretKeyFactory;
-import javax.crypto.ShortBufferException;
-import javax.crypto.spec.IvParameterSpec;
-import javax.crypto.spec.PBEKeySpec;
-import javax.crypto.spec.SecretKeySpec;
-import static java.nio.charset.StandardCharsets.UTF_8;
import com.google.common.annotations.VisibleForTesting;
import com.google.common.base.Preconditions;
import com.google.common.primitives.Bytes;
-import org.apache.commons.crypto.cipher.CryptoCipher;
-import org.apache.commons.crypto.cipher.CryptoCipherFactory;
-import org.apache.commons.crypto.random.CryptoRandom;
-import org.apache.commons.crypto.random.CryptoRandomFactory;
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
-
+import com.google.crypto.tink.subtle.AesGcmJce;
+import com.google.crypto.tink.subtle.Hkdf;
+import com.google.crypto.tink.subtle.Random;
+import com.google.crypto.tink.subtle.X25519;
+import io.netty.buffer.ByteBuf;
+import io.netty.buffer.Unpooled;
+import static java.nio.charset.StandardCharsets.UTF_8;
import org.apache.spark.network.util.TransportConf;
/**
- * A helper class for abstracting authentication and key negotiation details.
This is used by
- * both client and server sides, since the operations are basically
[spark] branch branch-3.0 updated (95ae41e -> 74d0115)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git. from 95ae41e [SPARK-36532][CORE][3.1] Fix deadlock in CoarseGrainedExecutorBackend.onDisconnected to avoid executorsconnected to avoid executor shutdown hang shutdown hang add 74d0115 Updates AuthEngine to pass the correct SecretKeySpec format No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/spark/network/crypto/AuthEngine.java | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: Updates AuthEngine to pass the correct SecretKeySpec format
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new dadb08b Updates AuthEngine to pass the correct SecretKeySpec format
dadb08b is described below
commit dadb08b2129d5dcd7c2bc14a47c2b5a5a878a19c
Author: sweisdb <60895808+swei...@users.noreply.github.com>
AuthorDate: Fri Aug 20 08:31:39 2021 -0500
Updates AuthEngine to pass the correct SecretKeySpec format
AuthEngineSuite was passing on some platforms (MacOS), but failing on
others (Linux) with an InvalidKeyException stemming from this line. We should
explicitly pass AES as the key format.
### What changes were proposed in this pull request?
Changes the AuthEngine SecretKeySpec from "RAW" to "AES".
### Why are the changes needed?
Unit tests were failing on some platforms with InvalidKeyExceptions when
this key was used to instantiate a Cipher.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests on a MacOS and Linux platform.
Closes #33790 from sweisdb/patch-1.
Authored-by: sweisdb <60895808+swei...@users.noreply.github.com>
Signed-off-by: Sean Owen
(cherry picked from commit c441c7e365cdbed4bae55e9bfdf94fa4a118fb21)
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/spark/network/crypto/AuthEngine.java | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
index aadf2b5..078d9ce 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
@@ -213,7 +213,7 @@ class AuthEngine implements Closeable {
transcript, // Passing this as the HKDF salt
OUTPUT_IV_INFO, // This is the HKDF info field used to differentiate
IV values
AES_GCM_KEY_SIZE_BYTES);
-SecretKeySpec sessionKey = new SecretKeySpec(sharedSecret, "RAW");
+SecretKeySpec sessionKey = new SecretKeySpec(sharedSecret, "AES");
return new TransportCipher(
cryptoConf,
conf.cipherTransformation(),
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: Updates AuthEngine to pass the correct SecretKeySpec format
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 243bfaf Updates AuthEngine to pass the correct SecretKeySpec format
243bfaf is described below
commit 243bfafd5cb58c1d3ae6c2a1a9e2c14c3a13526c
Author: sweisdb <60895808+swei...@users.noreply.github.com>
AuthorDate: Fri Aug 20 08:31:39 2021 -0500
Updates AuthEngine to pass the correct SecretKeySpec format
AuthEngineSuite was passing on some platforms (MacOS), but failing on
others (Linux) with an InvalidKeyException stemming from this line. We should
explicitly pass AES as the key format.
### What changes were proposed in this pull request?
Changes the AuthEngine SecretKeySpec from "RAW" to "AES".
### Why are the changes needed?
Unit tests were failing on some platforms with InvalidKeyExceptions when
this key was used to instantiate a Cipher.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests on a MacOS and Linux platform.
Closes #33790 from sweisdb/patch-1.
Authored-by: sweisdb <60895808+swei...@users.noreply.github.com>
Signed-off-by: Sean Owen
(cherry picked from commit c441c7e365cdbed4bae55e9bfdf94fa4a118fb21)
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/spark/network/crypto/AuthEngine.java | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
index aadf2b5..078d9ce 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
@@ -213,7 +213,7 @@ class AuthEngine implements Closeable {
transcript, // Passing this as the HKDF salt
OUTPUT_IV_INFO, // This is the HKDF info field used to differentiate
IV values
AES_GCM_KEY_SIZE_BYTES);
-SecretKeySpec sessionKey = new SecretKeySpec(sharedSecret, "RAW");
+SecretKeySpec sessionKey = new SecretKeySpec(sharedSecret, "AES");
return new TransportCipher(
cryptoConf,
conf.cipherTransformation(),
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (5c0762b -> c441c7e)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 5c0762b [SPARK-36448][SQL] Exceptions in NoSuchItemException.scala have to be case classes add c441c7e Updates AuthEngine to pass the correct SecretKeySpec format No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/spark/network/crypto/AuthEngine.java | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Use ASF mail archives not defunct nabble links
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new dc9faff Use ASF mail archives not defunct nabble links dc9faff is described below commit dc9faff4a121070d58fc0f145d8f0a3521074fb3 Author: Sean Owen AuthorDate: Wed Aug 18 12:58:05 2021 -0500 Use ASF mail archives not defunct nabble links Nabble archive links appear to not work anymore. Use ASF pony mail links instead for archives. Author: Sean Owen Closes #355 from srowen/Nabble. --- community.md| 16 faq.md | 2 +- site/community.html | 16 site/faq.html | 2 +- 4 files changed, 18 insertions(+), 18 deletions(-) diff --git a/community.md b/community.md index e8f2cf7..ebc438a 100644 --- a/community.md +++ b/community.md @@ -24,8 +24,8 @@ Some quick tips when using StackOverflow: - Search StackOverflow's https://stackoverflow.com/questions/tagged/apache-spark";>`apache-spark` tag to see if your question has already been answered - - Search the nabble archive for - http://apache-spark-user-list.1001560.n3.nabble.com/";>u...@spark.apache.org + - Search the ASF archive for + https://lists.apache.org/list.html?u...@spark.apache.org";>u...@spark.apache.org - Please follow the StackOverflow https://stackoverflow.com/help/how-to-ask";>code of conduct - Always use the `apache-spark` tag when asking questions - Please also use a secondary tag to specify components so subject matter experts can more easily find them. @@ -42,16 +42,16 @@ project, and scenarios, it is recommended you use the u...@spark.apache.org mail -http://apache-spark-user-list.1001560.n3.nabble.com";>u...@spark.apache.org is for usage questions, help, and announcements. +https://lists.apache.org/list.html?u...@spark.apache.org";>u...@spark.apache.org is for usage questions, help, and announcements. mailto:user-subscr...@spark.apache.org?subject=(send%20this%20email%20to%20subscribe)">(subscribe) mailto:user-unsubscr...@spark.apache.org?subject=(send%20this%20email%20to%20unsubscribe)">(unsubscribe) -http://apache-spark-user-list.1001560.n3.nabble.com";>(archives) +https://lists.apache.org/list.html?u...@spark.apache.org";>(archives) -http://apache-spark-developers-list.1001551.n3.nabble.com";>d...@spark.apache.org is for people who want to contribute code to Spark. +https://lists.apache.org/list.html?d...@spark.apache.org";>d...@spark.apache.org is for people who want to contribute code to Spark. mailto:dev-subscr...@spark.apache.org?subject=(send%20this%20email%20to%20subscribe)">(subscribe) mailto:dev-unsubscr...@spark.apache.org?subject=(send%20this%20email%20to%20unsubscribe)">(unsubscribe) -http://apache-spark-developers-list.1001551.n3.nabble.com";>(archives) +https://lists.apache.org/list.html?d...@spark.apache.org";>(archives) @@ -60,8 +60,8 @@ Some quick tips when using email: - Prior to asking submitting questions, please: - Search StackOverflow at https://stackoverflow.com/questions/tagged/apache-spark";>`apache-spark` to see if your question has already been answered - - Search the nabble archive for - http://apache-spark-user-list.1001560.n3.nabble.com/";>u...@spark.apache.org + - Search the ASF archive for + https://lists.apache.org/list.html?u...@spark.apache.org";>u...@spark.apache.org - Tagging the subject line of your email will help you get a faster response, e.g. `[Spark SQL]: Does Spark SQL support LEFT SEMI JOIN?` - Tags may help identify a topic by: diff --git a/faq.md b/faq.md index af57f26..0275c18 100644 --- a/faq.md +++ b/faq.md @@ -71,4 +71,4 @@ Please also refer to our Where can I get more help? -Please post on StackOverflow's https://stackoverflow.com/questions/tagged/apache-spark";>apache-spark tag or http://apache-spark-user-list.1001560.n3.nabble.com";>Spark Users mailing list. For more information, please refer to https://spark.apache.org/community.html#have-questions";>Have Questions?. We'll be glad to help! +Please post on StackOverflow's https://stackoverflow.com/questions/tagged/apache-spark";>apache-spark tag or https://lists.apache.org/list.html?u...@spark.apache.org";>Spark Users mailing list. For more information, please refer to https://spark.apache.org/community.html#have-questions";>Have Questions?. We'll be glad to help! diff --git a/site/community.html b/site/community.html index b779d37..f4e1fcf 100644 --- a/site/community.html +++ b/site/community.html @@ -219,8 +219,8 @@
[spark] branch master updated (707eefa -> 1859d9b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 707eefa [SPARK-36428][SQL][FOLLOWUP] Simplify the implementation of make_timestamp add 1859d9b [SPARK-36407][CORE][SQL] Convert int to long to avoid potential integer multiplications overflow risk No new revisions were added by this update. Summary of changes: .../shuffle/checksum/ShuffleChecksumHelper.java| 2 +- .../org/apache/spark/util/collection/TestTimSort.java | 18 +- .../spark/sql/execution/UnsafeKVExternalSorter.java| 2 +- 3 files changed, 11 insertions(+), 11 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (281b00a -> a1ecf83)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 281b00a [SPARK-34309][BUILD][FOLLOWUP] Upgrade Caffeine to 2.9.2 add a1ecf83 [SPARK-36451][BUILD] Ivy skips looking for source and doc pom No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 6 ++ 1 file changed, 6 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated (763a25a -> ae07b63)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git. from 763a25a Update Spark key negotiation protocol add ae07b63 [HOTFIX] Add missing deps update for commit protocol change No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2.7-hive-1.2 | 1 + 1 file changed, 1 insertion(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated (dc0f1e5 -> 763a25a)
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a change to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git.
from dc0f1e5 [SPARK-36500][CORE] Fix temp_shuffle file leaking when a task
is interrupted
add 763a25a Update Spark key negotiation protocol
No new revisions were added by this update.
Summary of changes:
common/network-common/pom.xml | 4 +
.../spark/network/crypto/AuthClientBootstrap.java | 6 +-
.../apache/spark/network/crypto/AuthEngine.java| 420 +
.../{ServerResponse.java => AuthMessage.java} | 56 ++-
.../spark/network/crypto/AuthRpcHandler.java | 6 +-
.../spark/network/crypto/ClientChallenge.java | 101 -
.../java/org/apache/spark/network/crypto/README.md | 217 ---
.../spark/network/crypto/AuthEngineSuite.java | 182 ++---
.../spark/network/crypto/AuthMessagesSuite.java| 46 +--
dev/deps/spark-deps-hadoop-2.7-hive-2.3| 1 +
dev/deps/spark-deps-hadoop-3.2-hive-2.3| 1 +
pom.xml| 8 +-
12 files changed, 432 insertions(+), 616 deletions(-)
rename
common/network-common/src/main/java/org/apache/spark/network/crypto/{ServerResponse.java
=> AuthMessage.java} (53%)
delete mode 100644
common/network-common/src/main/java/org/apache/spark/network/crypto/ClientChallenge.java
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: Update Spark key negotiation protocol
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 1cb0f7d Update Spark key negotiation protocol
1cb0f7d is described below
commit 1cb0f7db88a4aea20ab95cb07825d13f8e0f25aa
Author: Sean Owen
AuthorDate: Wed Aug 11 18:04:55 2021 -0500
Update Spark key negotiation protocol
---
common/network-common/pom.xml | 4 +
.../spark/network/crypto/AuthClientBootstrap.java | 6 +-
.../apache/spark/network/crypto/AuthEngine.java| 420 +
.../{ServerResponse.java => AuthMessage.java} | 56 ++-
.../spark/network/crypto/AuthRpcHandler.java | 6 +-
.../spark/network/crypto/ClientChallenge.java | 101 -
.../java/org/apache/spark/network/crypto/README.md | 217 ---
.../spark/network/crypto/AuthEngineSuite.java | 182 ++---
.../spark/network/crypto/AuthMessagesSuite.java| 46 +--
dev/deps/spark-deps-hadoop-2.7-hive-2.3| 1 +
dev/deps/spark-deps-hadoop-3.2-hive-2.3| 1 +
pom.xml| 6 +
12 files changed, 431 insertions(+), 615 deletions(-)
diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml
index 0dd6619..2233100 100644
--- a/common/network-common/pom.xml
+++ b/common/network-common/pom.xml
@@ -92,6 +92,10 @@
commons-crypto
+ com.google.crypto.tink
+ tink
+
+
org.roaringbitmap
RoaringBitmap
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
index 4428f0f..b555410 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
@@ -105,15 +105,15 @@ public class AuthClientBootstrap implements
TransportClientBootstrap {
String secretKey = secretKeyHolder.getSecretKey(appId);
try (AuthEngine engine = new AuthEngine(appId, secretKey, conf)) {
- ClientChallenge challenge = engine.challenge();
+ AuthMessage challenge = engine.challenge();
ByteBuf challengeData = Unpooled.buffer(challenge.encodedLength());
challenge.encode(challengeData);
ByteBuffer responseData =
client.sendRpcSync(challengeData.nioBuffer(),
conf.authRTTimeoutMs());
- ServerResponse response = ServerResponse.decodeMessage(responseData);
+ AuthMessage response = AuthMessage.decodeMessage(responseData);
- engine.validate(response);
+ engine.deriveSessionCipher(challenge, response);
engine.sessionCipher().addToChannel(channel);
}
}
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
index c2b2edc..aadf2b5 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
@@ -17,134 +17,216 @@
package org.apache.spark.network.crypto;
+import javax.crypto.spec.SecretKeySpec;
import java.io.Closeable;
-import java.io.IOException;
-import java.math.BigInteger;
import java.security.GeneralSecurityException;
import java.util.Arrays;
import java.util.Properties;
-import javax.crypto.Cipher;
-import javax.crypto.SecretKey;
-import javax.crypto.SecretKeyFactory;
-import javax.crypto.ShortBufferException;
-import javax.crypto.spec.IvParameterSpec;
-import javax.crypto.spec.PBEKeySpec;
-import javax.crypto.spec.SecretKeySpec;
-import static java.nio.charset.StandardCharsets.UTF_8;
import com.google.common.annotations.VisibleForTesting;
import com.google.common.base.Preconditions;
import com.google.common.primitives.Bytes;
-import org.apache.commons.crypto.cipher.CryptoCipher;
-import org.apache.commons.crypto.cipher.CryptoCipherFactory;
-import org.apache.commons.crypto.random.CryptoRandom;
-import org.apache.commons.crypto.random.CryptoRandomFactory;
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
-
+import com.google.crypto.tink.subtle.AesGcmJce;
+import com.google.crypto.tink.subtle.Hkdf;
+import com.google.crypto.tink.subtle.Random;
+import com.google.crypto.tink.subtle.X25519;
+import io.netty.buffer.ByteBuf;
+import io.netty.buffer.Unpooled;
+import static java.nio.charset.StandardCharsets.UTF_8;
import org.apache.spark.network.util.TransportConf;
/**
- * A helper class for abstracting authentication and key negotiation details.
This is used by
- * both client and server sides, since the operations are basically the same.
+ * A helper class for abstract
[spark] branch branch-3.2 updated: Update Spark key negotiation protocol
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new b8c1014 Update Spark key negotiation protocol
b8c1014 is described below
commit b8c1014e2375b6960bc715ba818d171b643817ba
Author: Sean Owen
AuthorDate: Wed Aug 11 18:04:55 2021 -0500
Update Spark key negotiation protocol
---
common/network-common/pom.xml | 4 +
.../spark/network/crypto/AuthClientBootstrap.java | 6 +-
.../apache/spark/network/crypto/AuthEngine.java| 420 +
.../{ServerResponse.java => AuthMessage.java} | 56 ++-
.../spark/network/crypto/AuthRpcHandler.java | 6 +-
.../spark/network/crypto/ClientChallenge.java | 101 -
.../java/org/apache/spark/network/crypto/README.md | 217 ---
.../spark/network/crypto/AuthEngineSuite.java | 182 ++---
.../spark/network/crypto/AuthMessagesSuite.java| 46 +--
dev/deps/spark-deps-hadoop-2.7-hive-2.3| 1 +
dev/deps/spark-deps-hadoop-3.2-hive-2.3| 1 +
pom.xml| 6 +
12 files changed, 431 insertions(+), 615 deletions(-)
diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml
index 0318f60..c7cfa12 100644
--- a/common/network-common/pom.xml
+++ b/common/network-common/pom.xml
@@ -92,6 +92,10 @@
commons-crypto
+ com.google.crypto.tink
+ tink
+
+
org.roaringbitmap
RoaringBitmap
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
index 4428f0f..b555410 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthClientBootstrap.java
@@ -105,15 +105,15 @@ public class AuthClientBootstrap implements
TransportClientBootstrap {
String secretKey = secretKeyHolder.getSecretKey(appId);
try (AuthEngine engine = new AuthEngine(appId, secretKey, conf)) {
- ClientChallenge challenge = engine.challenge();
+ AuthMessage challenge = engine.challenge();
ByteBuf challengeData = Unpooled.buffer(challenge.encodedLength());
challenge.encode(challengeData);
ByteBuffer responseData =
client.sendRpcSync(challengeData.nioBuffer(),
conf.authRTTimeoutMs());
- ServerResponse response = ServerResponse.decodeMessage(responseData);
+ AuthMessage response = AuthMessage.decodeMessage(responseData);
- engine.validate(response);
+ engine.deriveSessionCipher(challenge, response);
engine.sessionCipher().addToChannel(channel);
}
}
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
index c2b2edc..aadf2b5 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/crypto/AuthEngine.java
@@ -17,134 +17,216 @@
package org.apache.spark.network.crypto;
+import javax.crypto.spec.SecretKeySpec;
import java.io.Closeable;
-import java.io.IOException;
-import java.math.BigInteger;
import java.security.GeneralSecurityException;
import java.util.Arrays;
import java.util.Properties;
-import javax.crypto.Cipher;
-import javax.crypto.SecretKey;
-import javax.crypto.SecretKeyFactory;
-import javax.crypto.ShortBufferException;
-import javax.crypto.spec.IvParameterSpec;
-import javax.crypto.spec.PBEKeySpec;
-import javax.crypto.spec.SecretKeySpec;
-import static java.nio.charset.StandardCharsets.UTF_8;
import com.google.common.annotations.VisibleForTesting;
import com.google.common.base.Preconditions;
import com.google.common.primitives.Bytes;
-import org.apache.commons.crypto.cipher.CryptoCipher;
-import org.apache.commons.crypto.cipher.CryptoCipherFactory;
-import org.apache.commons.crypto.random.CryptoRandom;
-import org.apache.commons.crypto.random.CryptoRandomFactory;
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
-
+import com.google.crypto.tink.subtle.AesGcmJce;
+import com.google.crypto.tink.subtle.Hkdf;
+import com.google.crypto.tink.subtle.Random;
+import com.google.crypto.tink.subtle.X25519;
+import io.netty.buffer.ByteBuf;
+import io.netty.buffer.Unpooled;
+import static java.nio.charset.StandardCharsets.UTF_8;
import org.apache.spark.network.util.TransportConf;
/**
- * A helper class for abstracting authentication and key negotiation details.
This is used by
- * both client and server sides, since the operations are basically the same.
+ * A helper class for abstract
[spark-website] branch asf-site updated: Additional typo fixes
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 2c6581b Additional typo fixes
2c6581b is described below
commit 2c6581ba8830cf097ac38e2b3e650205f668e3ca
Author: fredster33 <64927044+fredste...@users.noreply.github.com>
AuthorDate: Sat Aug 14 08:54:52 2021 -0500
Additional typo fixes
Note: there's a typo in my commit, it's supposed to spell "fixes".
Author: fredster33 <64927044+fredste...@users.noreply.github.com>
Closes #354 from fredster33/asf-site.
---
README.md | 8
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index f19ddd7..ea34048 100644
--- a/README.md
+++ b/README.md
@@ -14,7 +14,7 @@ Using Jekyll via `bundle exec jekyll` locks it to the right
version.
So after this you can generate the html website by running `bundle exec jekyll
build` in this
directory. Use the `--watch` flag to have jekyll recompile your files as you
save changes.
-In addition to generating the site as HTML from the markdown files, jekyll can
serve the site via
+In addition to generating the site as HTML from the Markdown files, jekyll can
serve the site via
a web server. To build the site and run a web server use the command `bundle
exec jekyll serve` which runs
the web server on port 4000, then visit the site at http://localhost:4000.
@@ -38,14 +38,14 @@ project's `/docs` directory.
## Rouge and Pygments
-We also use [Rouge](https://github.com/rouge-ruby/rouge) for syntax
highlighting in documentation markdown pages.
+We also use [Rouge](https://github.com/rouge-ruby/rouge) for syntax
highlighting in documentation Markdown pages.
Its HTML output is compatible with CSS files designed for
[Pygments](https://pygments.org/).
-To mark a block of code in your markdown to be syntax highlighted by `jekyll`
during the
+To mark a block of code in your Markdown to be syntax highlighted by `jekyll`
during the
compile phase, use the following syntax:
{% highlight scala %}
-// Your scala code goes here, you can replace scala with many other
+// Your Scala code goes here, you can replace Scala with many other
// supported languages too.
{% endhighlight %}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Grammar fix, improve PR template
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 2dbffae Grammar fix, improve PR template 2dbffae is described below commit 2dbffae2a8de20452d4d61810d6238cb641ae528 Author: fredster33 <64927044+fredste...@users.noreply.github.com> AuthorDate: Fri Aug 13 18:11:10 2021 -0500 Grammar fix, improve PR template By commenting it out, it will still appear when somebody starts a PR, but then they do not need to remove it, as it will be gone after saving (but it is still visible when editing). Author: fredster33 <64927044+fredste...@users.noreply.github.com> Closes #353 from fredster33/asf-site. --- .github/PULL_REQUEST_TEMPLATE.md | 2 +- README.md| 4 ++-- 2 files changed, 3 insertions(+), 3 deletions(-) diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md index ae08529..9e1ffb3 100644 --- a/.github/PULL_REQUEST_TEMPLATE.md +++ b/.github/PULL_REQUEST_TEMPLATE.md @@ -1 +1 @@ -*Make sure that you generate site HTML with `bundle exec jekyll build`, and include the changes to the HTML in your pull request also. See README.md for more information. Please remove this message.* + diff --git a/README.md b/README.md index 3fad336..f19ddd7 100644 --- a/README.md +++ b/README.md @@ -4,7 +4,7 @@ In this directory you will find text files formatted using Markdown, with an `.m Building the site requires [Jekyll](http://jekyllrb.com/docs) [Rouge](https://github.com/rouge-ruby/rouge). -The easiest way to install the right version of these tools is using the +The easiest way to install the right version of these tools is using [Bundler](https://bundler.io/) and running `bundle install` in this directory. See also https://github.com/apache/spark/blob/master/docs/README.md @@ -38,7 +38,7 @@ project's `/docs` directory. ## Rouge and Pygments -We also use [rouge](https://github.com/rouge-ruby/rouge) for syntax highlighting in documentation markdown pages. +We also use [Rouge](https://github.com/rouge-ruby/rouge) for syntax highlighting in documentation markdown pages. Its HTML output is compatible with CSS files designed for [Pygments](https://pygments.org/). To mark a block of code in your markdown to be syntax highlighted by `jekyll` during the - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (a47ceaf -> 46f56e6)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a47ceaf [SPARK-32920][CORE][FOLLOW-UP] Fix string interpolator in the log add 46f56e6 [SPARK-36487][CORE] Modify exit executor log logic No new revisions were added by this update. Summary of changes: .../org/apache/spark/executor/CoarseGrainedExecutorBackend.scala| 6 +- 1 file changed, 5 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (aff1b55 -> 3b0dd14)
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git.
from aff1b55 [SPARK-36482][BUILD] Bump orc to 1.6.10
add 3b0dd14 Update Spark key negotiation protocol
No new revisions were added by this update.
Summary of changes:
common/network-common/pom.xml | 4 +
.../spark/network/crypto/AuthClientBootstrap.java | 6 +-
.../apache/spark/network/crypto/AuthEngine.java| 420 +
.../{ServerResponse.java => AuthMessage.java} | 56 ++-
.../spark/network/crypto/AuthRpcHandler.java | 6 +-
.../spark/network/crypto/ClientChallenge.java | 101 -
.../java/org/apache/spark/network/crypto/README.md | 217 ---
.../spark/network/crypto/AuthEngineSuite.java | 184 ++---
.../spark/network/crypto/AuthMessagesSuite.java| 44 +--
dev/deps/spark-deps-hadoop-2.7-hive-2.3| 1 +
dev/deps/spark-deps-hadoop-3.2-hive-2.3| 1 +
pom.xml| 6 +
12 files changed, 432 insertions(+), 614 deletions(-)
rename
common/network-common/src/main/java/org/apache/spark/network/crypto/{ServerResponse.java
=> AuthMessage.java} (53%)
delete mode 100644
common/network-common/src/main/java/org/apache/spark/network/crypto/ClientChallenge.java
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-20384][SQL] Support value class in nested schema for Dataset
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 33c6d11 [SPARK-20384][SQL] Support value class in nested schema for
Dataset
33c6d11 is described below
commit 33c6d1168c077630a8f81c1a4e153f862162f257
Author: Mick Jermsurawong
AuthorDate: Mon Aug 9 08:47:35 2021 -0500
[SPARK-20384][SQL] Support value class in nested schema for Dataset
### What changes were proposed in this pull request?
- This PR revisits https://github.com/apache/spark/pull/22309, and
[SPARK-20384](https://issues.apache.org/jira/browse/SPARK-20384) solving the
original problem, but additionally will prevent backward-compat break on schema
of top-level `AnyVal` value class.
- Why previous break? We currently support top-level value classes just as
any other case class; field of the underlying type is present in schema. This
means any dataframe SQL filtering on this expects the field name to be present.
The previous PR changes this schema and would result in breaking current usage.
See test `"schema for case class that is a value class"`. This PR keeps the
schema.
- We actually currently support collection of value classes prior to this
change, but not case class of nested value class. This means the schema of
these classes shouldn't change to prevent breaking too.
- However, what we can change, without breaking, is schema of nested value
class, which will fails due to the compile problem, and thus its schema now
isn't actually valid. After the change, the schema of this nested value class
is now flattened
- With this PR, there's flattening only for nested value class (new), but
not for top-level and collection classes (existing behavior)
- This PR revisits https://github.com/apache/spark/pull/27153 by handling
tuple `Tuple2[AnyVal, AnyVal]` which is a constructor ("nested class") but is a
generic type, so it should not be flattened behaving similarly to `Seq[AnyVal]`
### Why are the changes needed?
- Currently, nested value class isn't supported. This is because when the
generated code treats `anyVal` class in its unwrapped form, but we encode the
type to be the wrapped case class. This results in compile of generated code
For example,
For a given `AnyVal` wrapper and its root-level class container
```
case class IntWrapper(i: Int) extends AnyVal
case class ComplexValueClassContainer(c: IntWrapper)
```
The problematic part of generated code:
```
private InternalRow If_1(InternalRow i) {
boolean isNull_42 = i.isNullAt(0);
// 1) The root-level case class we care
org.apache.spark.sql.catalyst.encoders.ComplexValueClassContainer
value_46 = isNull_42 ?
null :
((org.apache.spark.sql.catalyst.encoders.ComplexValueClassContainer) i.get(0,
null));
if (isNull_42) {
throw new NullPointerException(((java.lang.String)
references[5] /* errMsg */ ));
}
boolean isNull_39 = true;
// 2) We specify its member to be unwrapped case class
extending `AnyVal`
org.apache.spark.sql.catalyst.encoders.IntWrapper value_43 = null;
if (!false) {
isNull_39 = false;
if (!isNull_39) {
// 3) ERROR: `c()` compiled however is of type
`int` and thus we see error
value_43 = value_46.c();
}
}
```
We get this errror: Assignment conversion not possible from type "int" to
type "org.apache.spark.sql.catalyst.encoders.IntWrapper"
```
java.util.concurrent.ExecutionException:
org.codehaus.commons.compiler.CompileException:
File 'generated.java', Line 159, Column 1: failed to compile:
org.codehaus.commons.compiler.CompileException: File 'generated.java', Line
159, Column 1: Assignment conversion not possible from type "int" to type
"org.apache.spark.sql.catalyst.encoders.IntWrapper"
```
From [doc](https://docs.scala-lang.org/overviews/core/value-classes.html)
on value class: , Given: `class Wrapper(val underlying: Int) extends AnyVal`,
1) "The type at compile time is `Wrapper`, but at runtime, the
representation is an `Int`". This implies that when our struct has a field of
value class, the generated code should support the underlying type during
runtime execution.
2) `Wrapper` "must be instantiated... when a value class is used as a type
argument". This implies that `scala.Tuple[Wrapper, ...], Seq[Wrapper],
Map[String, Wrapper], Option[Wrapper]` will still contain Wrapper as-is in
during runtime instead of `Int`.