[GitHub] [incubator-druid] terry19850829 opened a new issue #8062: druid segments not used
terry19850829 opened a new issue #8062: druid segments not used URL: https://github.com/apache/incubator-druid/issues/8062 druid coordinator not load old interval segments after I changed load rules from P10D to P1M. ### Affected Version 0.11.0 ### Description rule config and loaded interval segments only has latest 2 days . 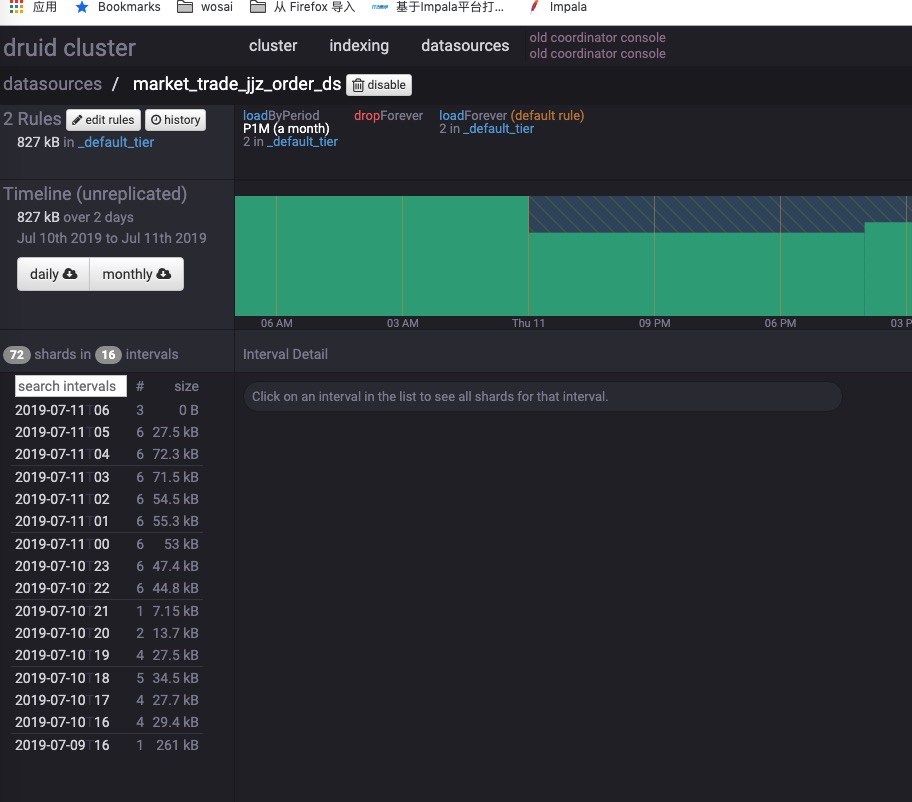 metadata interval and hdfs files: 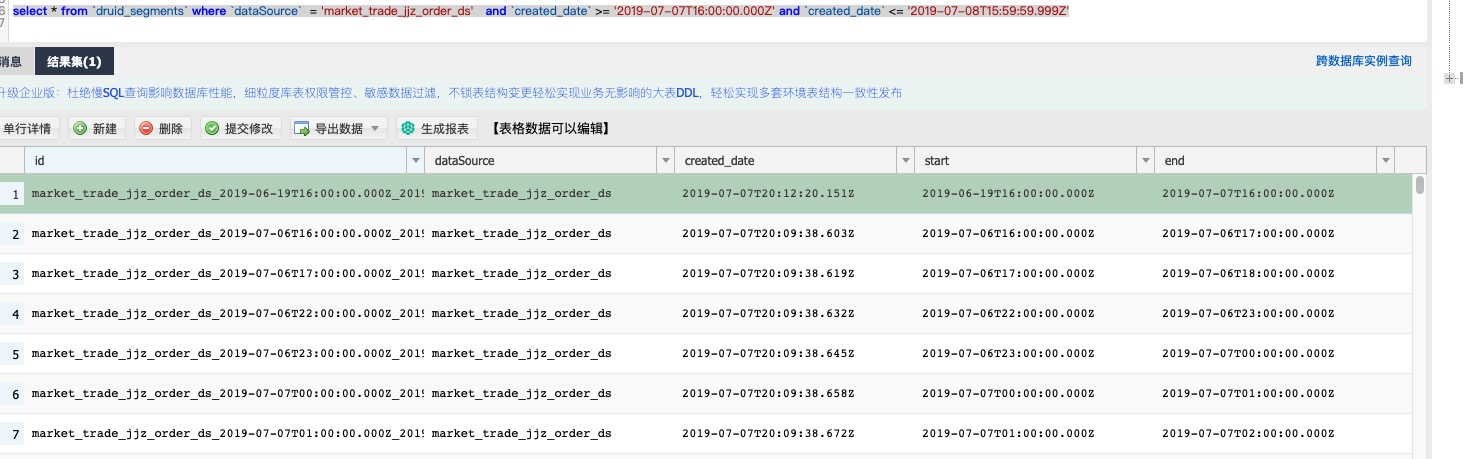  when I start a index_hadoop task , it failed. message is interval not exists.  The interval segments exists, but the mysql metadata column `used` is 0. Any one had same problem ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] sashidhar commented on issue #8038: Making optimal usage of multiple segment cache locations
sashidhar commented on issue #8038: Making optimal usage of multiple segment cache locations URL: https://github.com/apache/incubator-druid/pull/8038#issuecomment-510305954 @jihoonson , @himanshug , thanks for your inputs. Should I raise a separate proposal PR or modify this PR to make it a proposal ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on issue #8056: Add inline firehose
ccaominh commented on issue #8056: Add inline firehose URL: https://github.com/apache/incubator-druid/pull/8056#issuecomment-510270472 Manual test: 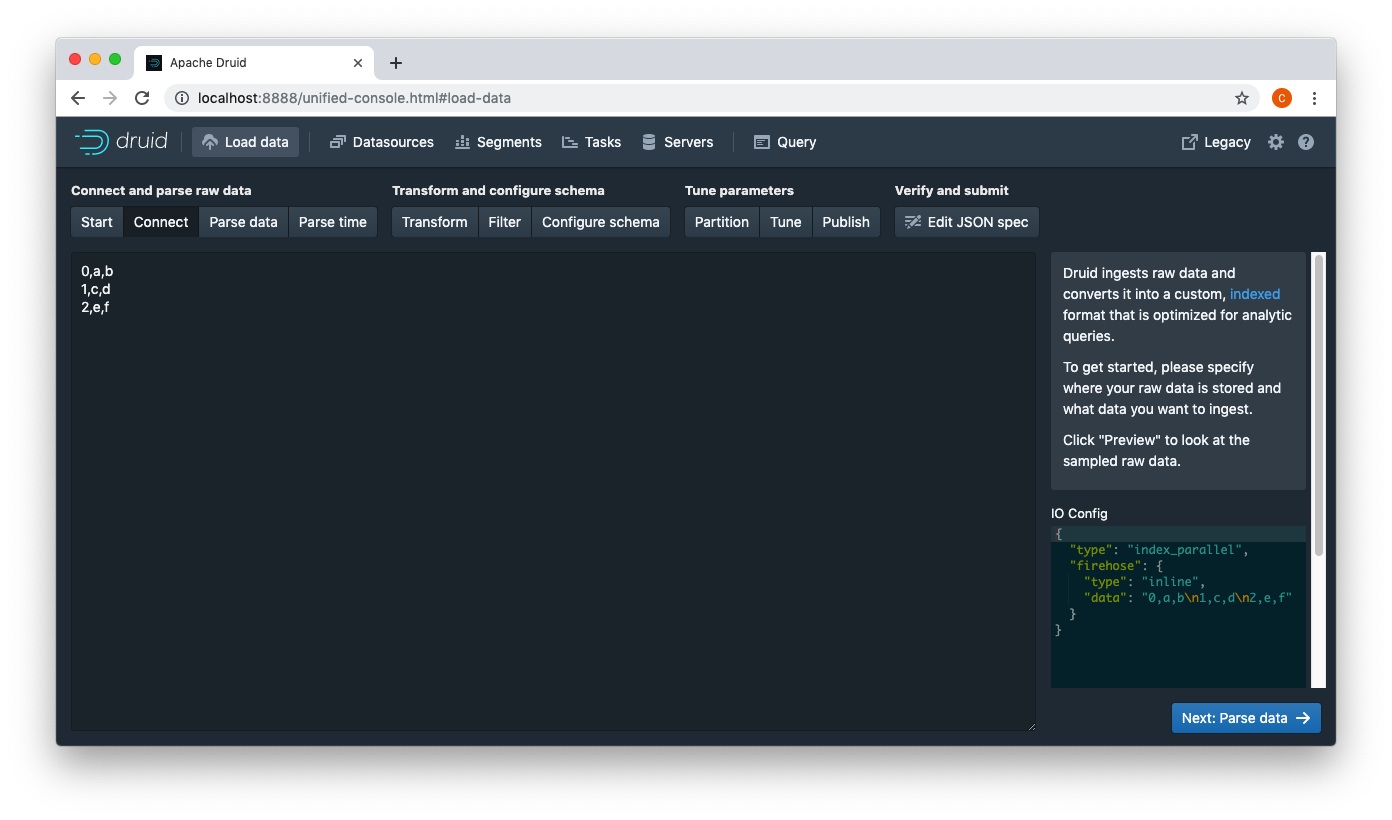 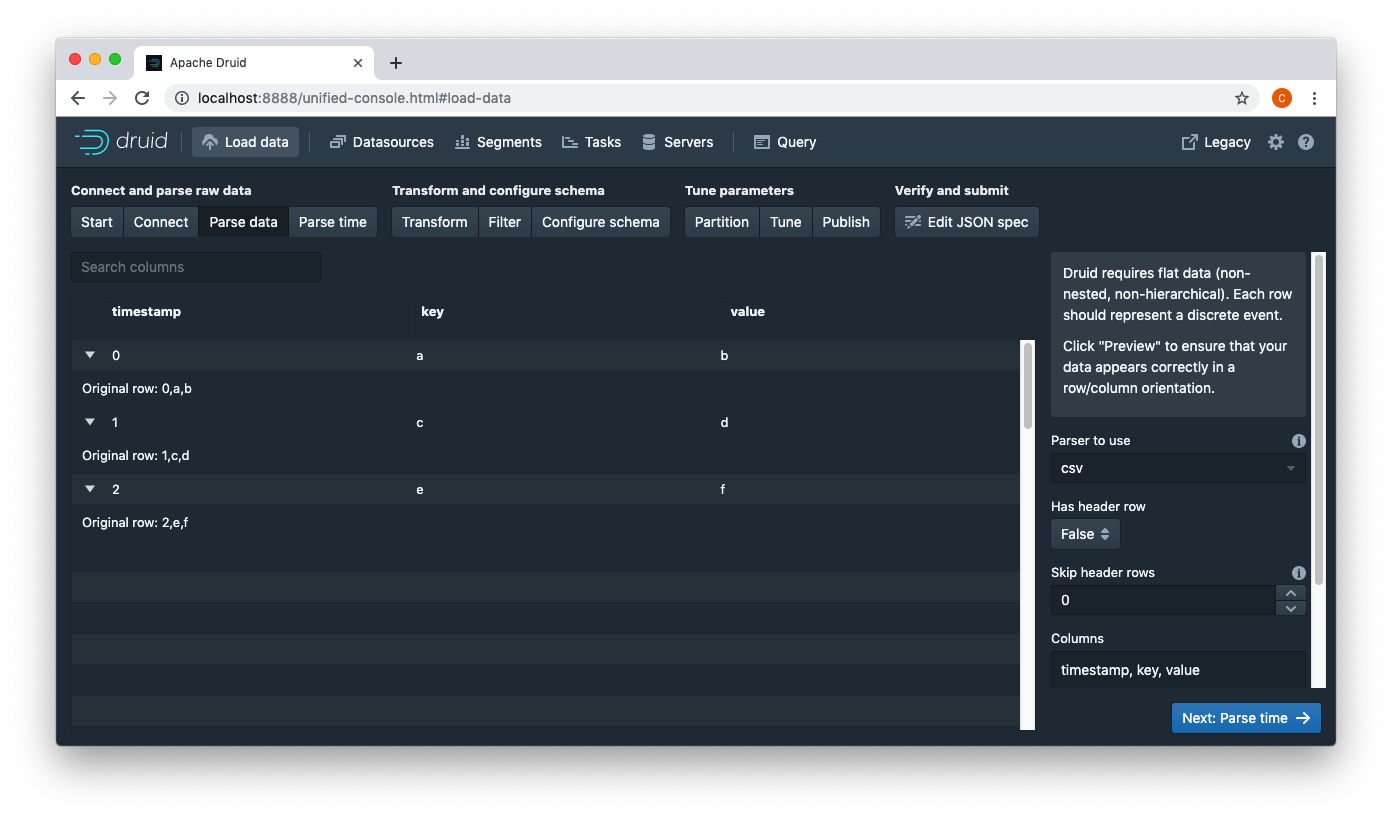 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson opened a new issue #8061: Native parallel batch indexing with shuffle
jihoonson opened a new issue #8061: Native parallel batch indexing with shuffle
URL: https://github.com/apache/incubator-druid/issues/8061
### Motivation
General motivation for native batch indexing is described in
https://github.com/apache/incubator-druid/issues/5543.
We now have the parallel index task, but it doesn't support perfect rollup
yet because of lack of the shuffle system.
### Proposed changes
I would propose to add a new mode for parallel index task which supports
perfect rollup with two-phase shuffle.
Two phase partitioning with shuffle
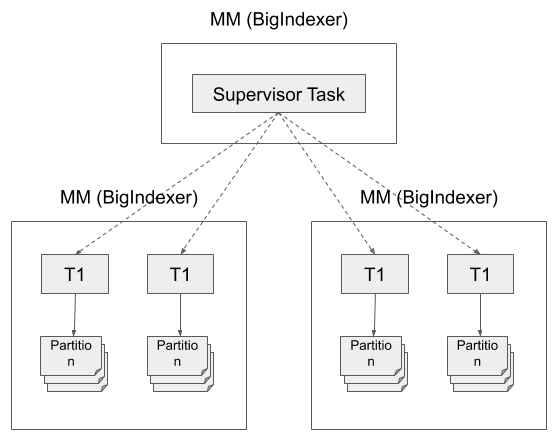
Phase 1: each task partitions data by segmentGranularity and then by hash or
range key of some dimensions.
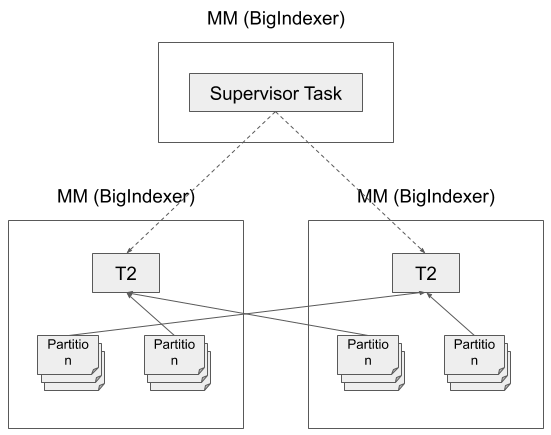
Phase 2: each task reads a set of partitions created by the tasks of Phase 1
and creates a segment per partition.
`PartitionsSpec` support for `IndexTask` and `ParallelIndexTask`
`PartitionsSpec` is the way to define the secondary partitioning and is
currently being used by `HadoopIndexTask`. This interface should be adjusted to
be more general as below.
```java
public interface PartitionsSpec
{
@Nullable
Integer getNumShards();
@Nullable
Integer getMaxRowsPerSegment(); // or getTargetRowsPerSegment()
@Nullable
List getPartitionDimensions();
}
```
Hadoop tasks can use an extended interface which is more specialized for
Hadoop.
```java
public interface HadoopPartitionsSpec extends PartitionsSpec
{
Jobby getPartitionJob(HadoopDruidIndexerConfig config);
boolean isAssumeGrouped();
boolean isDeterminingPartitions();
}
```
`IndexTask` currently provides duplicate configurations for partitioning in
its tuningConfig such as `maxRowsPerSegment`, `maxTotalRows`, `numShards`, and
`partitionDimensions`. These configurations will be deprecated and the
indexTask will support `PartitionsSpec` instead.
To support `maxRowsPerSegment` and `maxTotalRows`, a new partitionsSpec
could be introduced.
```java
/**
* PartitionsSpec for best-effort rollup
*/
public class DynamicPartitionsSpec implements PartitionsSpec
{
private final int maxRowsPerSegment;
private final int maxTotalRows;
}
```
This partitionsSpec will be supported as a new configuration in the
tuningConfig of `IndexTask` and `ParallelIndexTask`.
New parallel index task runner to support secondary partitioning
`ParallelIndexSupervisorTask` is the supervisor task which orchestrates the
parallel ingestion. It's responsible for spawning and monitoring sub tasks, and
publishing created segments at the end of ingestion.
It uses `ParallelIndexTaskRunner` to run single-phase parallel ingestion
without shuffle. To support two-phase ingestion, we can add a new
implementation of `ParallelIndexTaskRunner`, `TwoPhaseParallelIndexTaskRunner`.
`ParallelIndexSupervisorTask` will choose the new runner if partitionsSpec in
tuningConfig is `HashedPartitionsSpec` or `RangePartitionsSpec`.
This new taskRunner does the followings:
- Add `TwoPhasesParallelIndexTaskRunner` as a new runner for the supervisor
task
- Spawns tasks for determining partitions (if `numShards` is missing in
tuningConfig)
- Spawns tasks for building partial segments (phase 1)
- When all tasks of the phase 1 finish, spawns new tasks for building the
complete segments (phase 2)
- Each Phase 2 task is assigned one or multiple partitions
- The assigned partition is represented as an HTTP URL
- Publish the segments reported by phase 2 tasks.
- Triggers intermediary data cleanup when the supervisor task is finished
regardless of its last status.
The supervisor task provides an additional configuration in its
tuningConfig, i.e., `numSecondPhaseTasks` or `inputRowsPerSecondPhaseTask`, to
support control of parallelism of the phase 2. This will be improved to
automatically determine the optimal parallelism in the future.
New sub task types
# Partition determine task
- Similar to what indexTask or HadoopIndexTask do.
- Scan the whole input data and collect `HyperLogLog` per interval to
compute approximate cardinality.
- numShards could be computed as below:
```java
numShards = (int) Math.ceil(
(double) numRows / Preconditions.checkNotNull(maxRowsPerSegment,
"maxRowsPerSegment")
);
```
# Phase 1 task
- Read data via the given firehose
- Partition data by segmentGranularity by hash or range (and aggregates if
rollup)
- Should be able to access by (supervisorTaskId, timeChunk, partitionI
[GitHub] [incubator-druid] stale[bot] commented on issue #7218: google-extensions: upgrade google-http-client, fix "logs (last 8kb)"
stale[bot] commented on issue #7218: google-extensions: upgrade google-http-client, fix "logs (last 8kb)" URL: https://github.com/apache/incubator-druid/pull/7218#issuecomment-510266531 This pull request has been marked as stale due to 60 days of inactivity. It will be closed in 1 week if no further activity occurs. If you think that's incorrect or this pull request should instead be reviewed, please simply write any comment. Even if closed, you can still revive the PR at any time or discuss it on the d...@druid.apache.org list. Thank you for your contributions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] SandishKumarHN edited a comment on issue #8060: 6855 add Checkstyle for constant name static final
SandishKumarHN edited a comment on issue #8060: 6855 add Checkstyle for constant name static final URL: https://github.com/apache/incubator-druid/pull/8060#issuecomment-510265717 @leventov took some time to come up with this PR! a lot of patience was required! all tests were passed locally! could not squash the commits into one! sorry about that! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] SandishKumarHN commented on issue #8060: 6855 add Checkstyle for constant name static final
SandishKumarHN commented on issue #8060: 6855 add Checkstyle for constant name static final URL: https://github.com/apache/incubator-druid/pull/8060#issuecomment-510265717 @leventov took some time to come up with this PR! a lot of patience was required! all tests were passed locally This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis opened a new issue #5882: Coordinator load queue imbalance
clintropolis opened a new issue #5882: Coordinator load queue imbalance URL: https://github.com/apache/incubator-druid/issues/5882 Based on behavior observed on a coordinator on a test cluster, I believe an unintended consequence of #5532, which modified coordinator segment assignment logic to no longer continuously tell historical nodes to load a segment until it became available, is that now there can be scenarios where primary assignment can become incorrectly lumped into a deep load queue while other nodes have availability leading to longer than necessary segment unavailability and blocking realtime handoff. I think this was in fact an issue before the fix was added and may explain some of the needlessly long load queues encountered with the coordinator from time to time, but is now perhaps more apparent than was previously. The agitator of the problem is that nothing is ever removed from a load queue so this needs to be taken into consideration _somehow_, because of the fact that the environment can change between when the decision to place a segment in a particular load queue is made and subsequent runs. Consider a canary style deployment to update machine images in a cloud provider, where a new historical node is provisioned, observed, and if all is well, the remaining historical nodes are also replaced. If the coordinator were to run at a point where there is only a single historical announced, the fix of #5532 will result in this single node getting assigned ALL unavailable segments, and new historicals that appear later to hang around with near idle load queues, because the segment is already 'being loaded' somewhere, dragging out the time it takes for full availability and causing a large cluster imbalance (that does eventually right itself). # relevant log snippet ``` 18516004-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorBalancer - [_default_tier]: Segments Moved: [44] Segments Let Alone: [0] 18516179-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - [_default_tier] : Assigned 2 segments among 5 servers 18516344-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - [_default_tier] : Dropped 0 segments among 5 servers 18516508-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - [_default_tier] : Moved 44 segment(s) 18516657-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - [_default_tier] : Let alone 0 segment(s) 18516809:2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Load Queues: 18516933-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Server[ip-172-31-7-66.ec2.internal:8283, historical, _default_tier] has 36 left to load, 0 left to drop, 991,994,042 bytes queued, 48,377,883,776 bytes served. 18517204-2018-06-13T23:44:54,626 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Server[ip-172-31-12-20.ec2.internal:8283, historical, _default_tier] has 1 left to load, 0 left to drop, 14,313 bytes queued, 92,762,210,971 bytes served. 18517470-2018-06-13T23:44:54,627 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Server[ip-172-31-8-78.ec2.internal:8283, historical, _default_tier] has 5 left to load, 0 left to drop, 1,378,762,871 bytes queued, 99,371,506,890 bytes served. 18517742-2018-06-13T23:44:54,627 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Server[ip-172-31-3-9.ec2.internal:8283, historical, _default_tier] has 1 left to load, 0 left to drop, 1,925,142 bytes queued, 101,943,239,778 bytes served. 18518010-2018-06-13T23:44:54,627 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Server[ip-172-31-11-223.ec2.internal:8283, historical, _default_tier] has 1 left to load, 0 left to drop, 43,619,569,242 bytes queued, 117,176,111,771 bytes served. 28201415-2018-06-14T00:43:00,627 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorBalancer - [_default_tier]: One or fewer servers found. Cannot balance. 28201590-2018-06-14T00:43:00,627 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - [_default_tier] : Assigned 20692 segments among 1 servers 28201759:2018-06-14T00:43:00,627 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Load Queues: 28201883-2018-06-14T00:43:00,628 INFO [Coordinator-Exec--0] io.druid.server.coordinator.helper.DruidCoordinatorLogger - Server[ip-172-31-7-66.ec2.internal:8283, historical, _d
[GitHub] [incubator-druid] clintropolis commented on issue #5882: Coordinator load queue imbalance
clintropolis commented on issue #5882: Coordinator load queue imbalance URL: https://github.com/apache/incubator-druid/issues/5882#issuecomment-510264621 This is still relevant This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] stale[bot] commented on issue #5882: Coordinator load queue imbalance
stale[bot] commented on issue #5882: Coordinator load queue imbalance URL: https://github.com/apache/incubator-druid/issues/5882#issuecomment-510264634 This issue is no longer marked as stale. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] stale[bot] commented on issue #5882: Coordinator load queue imbalance
stale[bot] commented on issue #5882: Coordinator load queue imbalance URL: https://github.com/apache/incubator-druid/issues/5882#issuecomment-510264631 This issue is no longer marked as stale. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] SandishKumarHN opened a new pull request #8060: 6855 add Checkstyle for constant name static final
SandishKumarHN opened a new pull request #8060: 6855 add Checkstyle for
constant name static final
URL: https://github.com/apache/incubator-druid/pull/8060
Add check style check that static final field names are all uppercase
Fixes #6855.
(Replace with the id of the issue fixed in this PR. Remove the above
line if there is no corresponding
issue. Don't reference the issue in the title of this pull-request.)
(If you are a committer, follow the PR action item checklist for committers:
https://github.com/apache/incubator-druid/blob/master/dev/committer-instructions.md#pr-and-issue-action-item-checklist-for-committers.)
### Description
Describe the goal of this PR, what problem are you fixing. If there is a
corresponding issue (referenced above), it's
not necessary to repeat the description here, however, you may choose to
keep one summary sentence.
Describe your patch: what did you change in code? How did you fix the
problem?
If there are several relatively logically separate changes in this PR,
create a mini-section for each of them. For
example:
Fixed the bug ...
Renamed the class ...
Added a forbidden-apis entry ...
In each section, please describe design decisions made, including:
- Choice of algorithms
- Behavioral aspects. What configuration values are acceptable? How are
corner cases and error conditions handled, such
as when there are insufficient resources?
- Class organization and design (how the logic is split between classes,
inheritance, composition, design patterns)
- Method organization and design (how the logic is split between methods,
parameters and return types)
- Naming (class, method, API, configuration, HTTP endpoint, names of
emitted metrics)
It's good to describe an alternative design (or mention an alternative name)
for every design (or naming) decision point
and compare the alternatives with the designs that you've implemented (or
the names you've chosen) to highlight the
advantages of the chosen designs and names.
If there was a discussion of the design of the feature implemented in this
PR elsewhere (e. g. a "Proposal" issue, any
other issue, or a thread in the development mailing list), link to that
discussion from this PR description and explain
what have changed in your final design compared to your original proposal or
the consensus version in the end of the
discussion. If something hasn't changed since the original discussion, you
can omit a detailed discussion of those
aspects of the design here, perhaps apart from brief mentioning for the sake
of readability of this PR description.
Some of the aspects mentioned above may be omitted for simple and small
changes.
This PR has:
- [ ] been self-reviewed.
- [ ] using the [concurrency
checklist](https://github.com/apache/incubator-druid/blob/master/dev/code-review/concurrency.md)
(Remove this item if the PR doesn't have any relation to concurrency.)
- [ ] added documentation for new or modified features or behaviors.
- [ ] added Javadocs for most classes and all non-trivial methods. Linked
related entities via Javadoc links.
- [ ] added comments explaining the "why" and the intent of the code
wherever would not be obvious for an unfamiliar reader.
- [ ] added unit tests or modified existing tests to cover new code paths.
- [ ] added integration tests.
- [ ] been tested in a test Druid cluster.
Check the items by putting "x" in the brackets for the done things. Not all
of these items apply to every PR. Remove the
items which are not done or not relevant to the PR. None of the items from
the checklist above are strictly necessary,
but it would be very helpful if you at least self-review the PR.
For reviewers: the key changed/added classes in this PR are `MyFoo`,
`OurBar`, and `TheirBaz`.
(Add this section in big PRs to ease navigation in them for reviewers.)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] surekhasaharan opened a new pull request #8059: Refactoring to use `CollectionUtils.mapValues`
surekhasaharan opened a new pull request #8059: Refactoring to use `CollectionUtils.mapValues` URL: https://github.com/apache/incubator-druid/pull/8059 ### Description This PR has some follow-ups changes left from #7595. Some minor doc updates and code updates to use `CollectionUtils.mapValues` and `CollectionUtils.mapKeys` utility methods. This PR has: - [x] been self-reviewed. - [x] added Javadocs for most classes and all non-trivial methods. Linked related entities via Javadoc links. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #8056: Add inline firehose
vogievetsky commented on issue #8056: Add inline firehose URL: https://github.com/apache/incubator-druid/pull/8056#issuecomment-510256851 ❤️ ❤️ ❤️ ❤️ ❤️ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh removed a comment on issue #8056: Add inline firehose
ccaominh removed a comment on issue #8056: Add inline firehose URL: https://github.com/apache/incubator-druid/pull/8056#issuecomment-510238083 Blocked by #8057 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] AlexanderSaydakov commented on issue #8055: force native order when wrapping ByteBuffer
AlexanderSaydakov commented on issue #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055#issuecomment-510250285 > Would you please add a unit test? Unfortunately I don't have a unit test. The bug leads to sporadic failures. I could not find a small use case to reproduce it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: fix master branch build (#8057)
This is an automated email from the ASF dual-hosted git repository. cwylie pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git The following commit(s) were added to refs/heads/master by this push: new 349b743 fix master branch build (#8057) 349b743 is described below commit 349b743ce0a066e3fb3f9f2b2542bdd66b05905b Author: Clint Wylie AuthorDate: Wed Jul 10 14:58:10 2019 -0700 fix master branch build (#8057) --- .../org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java | 1 + 1 file changed, 1 insertion(+) diff --git a/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java b/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java index e8e46ad..6474c22 100644 --- a/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java +++ b/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java @@ -294,6 +294,7 @@ public class KafkaSupervisorTest extends EasyMockSupport null, null, null, +null, null ), null - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] capistrant opened a new pull request #7562: Enable ability to toggle SegmentMetadata request logging on/off
capistrant opened a new pull request #7562: Enable ability to toggle SegmentMetadata request logging on/off URL: https://github.com/apache/incubator-druid/pull/7562 Relates to #7115 and #5320 In reference to @gianm comment in #5320: I held off on making this a more involved enhancement that would allow ignoring only internal SegmentMetadata queries as opposed to all SegmentMetadata queries because I wasn't sure of the value add from doing that versus a blanket ignore of this type. I am certainly open to revisiting that and making this more than an on/off switch. (something like `druid.request.logging.logSegmentMetadataQueries` with the options `all, none, internal_only, external_only` that then leverages the identity in the query -- defaulting to logging all SegmentMetadata queries in clusters not using security and the config is not set to none) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] stale[bot] commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off
stale[bot] commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off URL: https://github.com/apache/incubator-druid/pull/7562#issuecomment-510239038 This pull request/issue is no longer marked as stale. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off
gianm commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off URL: https://github.com/apache/incubator-druid/pull/7562#issuecomment-510239071 Reopened!! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on issue #8056: Add inline firehose
ccaominh commented on issue #8056: Add inline firehose URL: https://github.com/apache/incubator-druid/pull/8056#issuecomment-510238083 Blocked by #8057 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] alonshoshani opened a new issue #8058: Graphite Emitter Issue Druid 0.14
alonshoshani opened a new issue #8058: Graphite Emitter Issue Druid 0.14
URL: https://github.com/apache/incubator-druid/issues/8058
I'm using Druid 0.14 and try sending metrics to graphite.
I'm using the following configuration in the common file and the graphite
metrics **Are not sent** I try it in the coordinator and the historicals
service and still nothing is being sent.
Important to say that we worked with graphite emitter in druid 0.9 and
everything worked smoothly.
Attached the logs and my configuration! thx!
When the service is up it wrote this lines to the log file
```
2019-07-10T20:32:00,666 INFO [main] org.apache.druid.guice.JsonConfigurator
- Skipping druid.emitter.graphite.hostname property: one of it's prefixes is
also used as a property key. Prefix: druid
2019-07-10T20:32:00,666 INFO [main] org.apache.druid.guice.JsonConfigurator
- Skipping druid.emitter.graphite.port property: one of it's prefixes is also
used as a property key. Prefix: druid
2019-07-10T20:32:00,666 INFO [main] org.apache.druid.guice.JsonConfigurator
- Skipping druid.emitter.graphite.alertEmitters property: one of it's prefixes
is also used as a property key. Prefix: druid
2019-07-10T20:32:00,667 INFO [main] org.apache.druid.guice.JsonConfigurator
- Skipping druid.emitter.graphite.eventConverter property: one of it's prefixes
is also used as a property key. Prefix: druid
```
My configuration
```
# Monitoring
druid.monitoring.monitors=["org.apache.druid.java.util.metrics.JvmMonitor"]
druid.monitoring.emissionPeriod=PT10s
druid.emitter=graphite
druid.emitter.logging.logLevel=info
# Graphite configuration
druid.emitter.graphite.hostname=my.graphite.domain
# Text port = 2003, Pickle port = 2004. Graphite emitter uses Pickle protocol
druid.emitter.graphite.port=2004
druid.emitter.graphite.eventConverter={"type":"all", "namespacePrefix":
"app-druid-014",
# in milliseconds
druid.emitter.graphite.flushPeriod=1
druid.emitter.graphite.alertEmitters=["logging"]
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis opened a new pull request #8057: fix master branch build
clintropolis opened a new pull request #8057: fix master branch build URL: https://github.com/apache/incubator-druid/pull/8057 master build is broken due to non-conflicting merge incompatibility from #7919 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on issue #8038: Making optimal usage of multiple segment cache locations
himanshug commented on issue #8038: Making optimal usage of multiple segment cache locations URL: https://github.com/apache/incubator-druid/pull/8038#issuecomment-510214132 I think, ideally in all cases, we want to minimize `variance(location1_usedSpace, location2_usedSpace, location3_usedSpace )` and `LeastBytesUsed` should achieve that. Can't think of use cases that wouldn't want that. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh opened a new pull request #8056: Add inline firehose
ccaominh opened a new pull request #8056: Add inline firehose URL: https://github.com/apache/incubator-druid/pull/8056 ### Description To allow users to quickly parsing and schema, add a firehose that reads data that is inlined in its spec. This PR has: - [x] been self-reviewed. - [x] added documentation for new or modified features or behaviors. - [x] added Javadocs for most classes and all non-trivial methods. Linked related entities via Javadoc links. - [x] added comments explaining the "why" and the intent of the code wherever would not be obvious for an unfamiliar reader. - [x] added unit tests or modified existing tests to cover new code paths. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint
clintropolis commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint URL: https://github.com/apache/incubator-druid/pull/8039#discussion_r302243505 ## File path: docs/content/operations/api-reference.md ## @@ -162,15 +162,15 @@ Returns a list of datasource names found in the cluster. * `/druid/coordinator/v1/datasources?simple` -Returns a list of JSON objects containing the name and properties of datasources found in the cluster. Properties include segment count, total segment byte size, minTime, and maxTime. +Returns a list of JSON objects containing the name and properties of datasources found in the cluster. Properties include segment count, total segment byte size, replicated total segment byte size, minTime and maxTime. Review comment: Heh, indeed, that's why i called it a 'nit', but oxford comma is the one true way imo! 😅 Thanks for fixing :+1: This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] a2l007 commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint
a2l007 commented on a change in pull request #8039: Include replicated segment
size property for datasources endpoint
URL: https://github.com/apache/incubator-druid/pull/8039#discussion_r302239098
##
File path: docs/content/operations/api-reference.md
##
@@ -162,15 +162,15 @@ Returns a list of datasource names found in the cluster.
* `/druid/coordinator/v1/datasources?simple`
-Returns a list of JSON objects containing the name and properties of
datasources found in the cluster. Properties include segment count, total
segment byte size, minTime, and maxTime.
+Returns a list of JSON objects containing the name and properties of
datasources found in the cluster. Properties include segment count, total
segment byte size, replicated total segment byte size, minTime and maxTime.
* `/druid/coordinator/v1/datasources?full`
Returns a list of datasource names found in the cluster with all metadata
about those datasources.
* `/druid/coordinator/v1/datasources/{dataSourceName}`
-Returns a JSON object containing the name and properties of a datasource.
Properties include segment count, total segment byte size, minTime, and maxTime.
+Returns a JSON object containing the name and properties of a datasource.
Properties include segment count, total segment byte size, replicated total
segment byte size, minTime and maxTime.
Review comment:
Fixed
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] a2l007 commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint
a2l007 commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint URL: https://github.com/apache/incubator-druid/pull/8039#discussion_r302239053 ## File path: docs/content/operations/api-reference.md ## @@ -162,15 +162,15 @@ Returns a list of datasource names found in the cluster. * `/druid/coordinator/v1/datasources?simple` -Returns a list of JSON objects containing the name and properties of datasources found in the cluster. Properties include segment count, total segment byte size, minTime, and maxTime. +Returns a list of JSON objects containing the name and properties of datasources found in the cluster. Properties include segment count, total segment byte size, replicated total segment byte size, minTime and maxTime. Review comment: Thanks for reviewing. It turns out both are grammatically correct: https://www.grammarly.com/blog/comma-before-and/ Regardless, I've added the comma back :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug edited a comment on issue #8055: force native order when wrapping ByteBuffer
himanshug edited a comment on issue #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055#issuecomment-510199593 this is unfortunate (discussed in https://github.com/apache/incubator-druid/pull/6381#discussion_r224541279 as well ) . I wish there could be a better solution to handle this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on issue #8055: force native order when wrapping ByteBuffer
himanshug commented on issue #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055#issuecomment-510199593 this is unfortunate (discussed in https://github.com/apache/incubator-druid/pull/6381#discussion_r224541279 well ) . I wish there could be a better solution to handle this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8055: force native order when wrapping ByteBuffer
jihoonson commented on issue #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055#issuecomment-510198207 There is a helper method called `AggregatiohnTestHelper.runRelocateVerificationTest()` which could facilitate writing unit tests for this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8055: force native order when wrapping ByteBuffer
jihoonson commented on issue #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055#issuecomment-510197721 Would you please add a unit test? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] AlexanderSaydakov commented on issue #8055: force native order when wrapping ByteBuffer
AlexanderSaydakov commented on issue #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055#issuecomment-510197501 This was already forced every time a ByteBuffer from Druid is wrapped for use with Datasketches library, except this one instance that was missed by mistake. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint
clintropolis commented on a change in pull request #8039: Include replicated
segment size property for datasources endpoint
URL: https://github.com/apache/incubator-druid/pull/8039#discussion_r302234863
##
File path: docs/content/operations/api-reference.md
##
@@ -162,15 +162,15 @@ Returns a list of datasource names found in the cluster.
* `/druid/coordinator/v1/datasources?simple`
-Returns a list of JSON objects containing the name and properties of
datasources found in the cluster. Properties include segment count, total
segment byte size, minTime, and maxTime.
+Returns a list of JSON objects containing the name and properties of
datasources found in the cluster. Properties include segment count, total
segment byte size, replicated total segment byte size, minTime and maxTime.
* `/druid/coordinator/v1/datasources?full`
Returns a list of datasource names found in the cluster with all metadata
about those datasources.
* `/druid/coordinator/v1/datasources/{dataSourceName}`
-Returns a JSON object containing the name and properties of a datasource.
Properties include segment count, total segment byte size, minTime, and maxTime.
+Returns a JSON object containing the name and properties of a datasource.
Properties include segment count, total segment byte size, replicated total
segment byte size, minTime and maxTime.
Review comment:
same nit about comma
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint
clintropolis commented on a change in pull request #8039: Include replicated segment size property for datasources endpoint URL: https://github.com/apache/incubator-druid/pull/8039#discussion_r302234797 ## File path: docs/content/operations/api-reference.md ## @@ -162,15 +162,15 @@ Returns a list of datasource names found in the cluster. * `/druid/coordinator/v1/datasources?simple` -Returns a list of JSON objects containing the name and properties of datasources found in the cluster. Properties include segment count, total segment byte size, minTime, and maxTime. +Returns a list of JSON objects containing the name and properties of datasources found in the cluster. Properties include segment count, total segment byte size, replicated total segment byte size, minTime and maxTime. Review comment: nit: lost a comma, > minTime, and maxTime. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: add config to optionally disable all compression in intermediate segment persists while ingestion (#7919)
This is an automated email from the ASF dual-hosted git repository. himanshug pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git The following commit(s) were added to refs/heads/master by this push: new 14aec7f add config to optionally disable all compression in intermediate segment persists while ingestion (#7919) 14aec7f is described below commit 14aec7fceca90dfaf9b2ce4dae68186d04ffcc47 Author: Himanshu AuthorDate: Wed Jul 10 12:22:24 2019 -0700 add config to optionally disable all compression in intermediate segment persists while ingestion (#7919) * disable all compression in intermediate segment persists while ingestion * more changes and build fix * by default retain existing indexingSpec for intermediate persisted segments * document indexSpecForIntermediatePersists index tuning config * fix build issues * update serde tests --- .../development/extensions-core/kafka-ingestion.md | 3 +- .../extensions-core/kinesis-ingestion.md | 3 +- docs/content/ingestion/hadoop.md | 3 +- docs/content/ingestion/native_tasks.md | 10 ++ .../MaterializedViewSupervisorSpec.java| 1 + .../indexing/kafka/KafkaIndexTaskTuningConfig.java | 4 +++ .../kafka/supervisor/KafkaSupervisorSpec.java | 1 + .../supervisor/KafkaSupervisorTuningConfig.java| 3 ++ .../druid/indexing/kafka/KafkaIndexTaskTest.java | 1 + .../kafka/KafkaIndexTaskTuningConfigTest.java | 12 ++- .../kafka/supervisor/KafkaSupervisorTest.java | 2 ++ .../KafkaSupervisorTuningConfigTest.java | 8 - .../TestModifiedKafkaIndexTaskTuningConfig.java| 2 ++ .../kinesis/KinesisIndexTaskTuningConfig.java | 3 ++ .../kinesis/supervisor/KinesisSupervisorSpec.java | 1 + .../supervisor/KinesisSupervisorTuningConfig.java | 3 ++ .../indexing/kinesis/KinesisIndexTaskTest.java | 1 + .../kinesis/KinesisIndexTaskTuningConfigTest.java | 3 ++ .../kinesis/supervisor/KinesisSupervisorTest.java | 2 ++ .../TestModifiedKinesisIndexTaskTuningConfig.java | 3 ++ .../druid/indexer/HadoopDruidIndexerConfig.java| 5 +++ .../apache/druid/indexer/HadoopTuningConfig.java | 14 .../apache/druid/indexer/IndexGeneratorJob.java| 2 +- .../druid/indexer/BatchDeltaIngestionTest.java | 1 + .../indexer/DetermineHashedPartitionsJobTest.java | 1 + .../druid/indexer/DeterminePartitionsJobTest.java | 1 + .../indexer/HadoopDruidIndexerConfigTest.java | 2 ++ .../druid/indexer/HadoopTuningConfigTest.java | 2 ++ .../druid/indexer/IndexGeneratorJobTest.java | 1 + .../org/apache/druid/indexer/JobHelperTest.java| 1 + .../indexer/path/GranularityPathSpecTest.java | 1 + .../index/RealtimeAppenderatorTuningConfig.java| 12 +++ .../indexing/common/index/YeOldePlumberSchool.java | 2 +- .../druid/indexing/common/task/IndexTask.java | 40 +- .../parallel/ParallelIndexSupervisorTask.java | 1 + .../batch/parallel/ParallelIndexTuningConfig.java | 4 ++- .../SeekableStreamIndexTaskTuningConfig.java | 13 +++ .../AppenderatorDriverRealtimeIndexTaskTest.java | 1 + .../indexing/common/task/CompactionTaskTest.java | 6 .../druid/indexing/common/task/IndexTaskTest.java | 4 +++ .../common/task/RealtimeIndexTaskTest.java | 1 + .../druid/indexing/common/task/TaskSerdeTest.java | 3 ++ .../ParallelIndexSupervisorTaskKillTest.java | 1 + .../ParallelIndexSupervisorTaskResourceTest.java | 1 + .../ParallelIndexSupervisorTaskSerdeTest.java | 1 + .../parallel/ParallelIndexSupervisorTaskTest.java | 2 ++ .../parallel/ParallelIndexTuningConfigTest.java| 1 + .../druid/indexing/overlord/TaskLifecycleTest.java | 4 +++ .../SeekableStreamSupervisorStateTest.java | 1 + .../segment/indexing/RealtimeTuningConfig.java | 14 .../realtime/appenderator/AppenderatorConfig.java | 2 ++ .../realtime/appenderator/AppenderatorImpl.java| 4 +-- .../segment/realtime/plumber/RealtimePlumber.java | 5 +-- .../segment/indexing/RealtimeTuningConfigTest.java | 10 -- .../appenderator/AppenderatorPlumberTest.java | 1 + .../realtime/appenderator/AppenderatorTester.java | 1 + .../DefaultOfflineAppenderatorFactoryTest.java | 1 + .../plumber/RealtimePlumberSchoolTest.java | 1 + .../druid/segment/realtime/plumber/SinkTest.java | 2 ++ .../druid/cli/validate/DruidJsonValidatorTest.java | 1 + 60 files changed, 215 insertions(+), 25 deletions(-) diff --git a/docs/content/development/extensions-core/kafka-ingestion.md b/docs/content/development/extensions-core/kafka-ingestion.md index c070e46..ec1d046 100644 --- a/docs/content/development/extensions-core/kafka-ingestion.md +++ b/docs/content/development/extensions-core/kafka-ingestion.md @@ -139,7 +139,8 @@ The tuni
[GitHub] [incubator-druid] himanshug merged pull request #7919: add config to optionally disable all compression in intermediate segment persists while ingestion
himanshug merged pull request #7919: add config to optionally disable all compression in intermediate segment persists while ingestion URL: https://github.com/apache/incubator-druid/pull/7919 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] AlexanderSaydakov opened a new pull request #8055: force native order when wrapping ByteBuffer
AlexanderSaydakov opened a new pull request #8055: force native order when wrapping ByteBuffer URL: https://github.com/apache/incubator-druid/pull/8055 Fixes #8032 ### force native order when wrapping ByteBuffer since Druid might have it set incorrectly This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on issue #7919: add config to optionally disable all compression in intermediate segment persists while ingestion
himanshug commented on issue #7919: add config to optionally disable all compression in intermediate segment persists while ingestion URL: https://github.com/apache/incubator-druid/pull/7919#issuecomment-510194149 @clintropolis @jihoonson thanks for the build fix. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on issue #8031: remove unnecessary synchronization overhead from complex Aggregators
himanshug commented on issue #8031: remove unnecessary synchronization overhead from complex Aggregators URL: https://github.com/apache/incubator-druid/issues/8031#issuecomment-510193661 @pdeva this proposal is not about removing/modifying synchronizations where there is real concurrency. aggregator implementors are free to handle that independently using their preferred way. this is about removing the synchronization overhead when aggregator is only accessed by single thread , but it appears that wouldn't be worth it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] santoshdvn opened a new issue #8054: Issue installing using Docker build
santoshdvn opened a new issue #8054: Issue installing using Docker build URL: https://github.com/apache/incubator-druid/issues/8054 Hi , Trying to install the Apache Druid using docker . `docker build -t druid:tag -f distribution/docker/Dockerfile .` I am getting below error > [ERROR] Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.2.1:exec (generate-license) on project distribution: Command execution failed.: Process exited with an error: 127 (Exit value: 127) -> [Help 1] Can anyone help me with this ? Thanks, Santosh This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis closed issue #4638: SQL: Multi-value column support
clintropolis closed issue #4638: SQL: Multi-value column support URL: https://github.com/apache/incubator-druid/issues/4638 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #4638: SQL: Multi-value column support
clintropolis commented on issue #4638: SQL: Multi-value column support URL: https://github.com/apache/incubator-druid/issues/4638#issuecomment-510189362 resolved by the additions from proposal #7525 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] Caroline1000 commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off
Caroline1000 commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off URL: https://github.com/apache/incubator-druid/pull/7562#issuecomment-510187490 +1 for reviving. Having the `all, none, internal_only, external_only` options might be useful but not sure it's necessary. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8038: Making optimal usage of multiple segment cache locations
jihoonson commented on issue #8038: Making optimal usage of multiple segment cache locations URL: https://github.com/apache/incubator-druid/pull/8038#issuecomment-510180832 This sounds like a PR which needs a proposal to me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #7933: #7858 Throwing UnsupportedOperationException from ImmutableDruidDataSource's equals() and hashCode() methods
jihoonson commented on a change in pull request #7933: #7858 Throwing UnsupportedOperationException from ImmutableDruidDataSource's equals() and hashCode() methods URL: https://github.com/apache/incubator-druid/pull/7933#discussion_r302215099 ## File path: server/src/test/java/org/apache/druid/server/http/DataSourcesResourceTest.java ## @@ -182,9 +182,9 @@ public void testGetFullQueryableDataSources() Set result = (Set) response.getEntity(); Assert.assertEquals(200, response.getStatus()); Assert.assertEquals(2, result.size()); -Assert.assertEquals( - listDataSources.stream().map(DruidDataSource::toImmutableDruidDataSource).collect(Collectors.toSet()), -new HashSet<>(result) +TestUtils.assertEqualsImmutableDruidDataSource( + listDataSources.stream().map(DruidDataSource::toImmutableDruidDataSource).collect(Collectors.toList()), Review comment: The "equality" is checked differently for `ArrayList` and `HashSet`. Set is not an ordered collection, so ordering is not considered when comparing two sets while List is an ordered one. Please check the code of `ArrayList.equals()` and `HashSet.equals()` for details. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson edited a comment on issue #6849: [Proposal] Consolidated segment metadata management
jihoonson edited a comment on issue #6849: [Proposal] Consolidated segment metadata management URL: https://github.com/apache/incubator-druid/issues/6849#issuecomment-510175689 @capistrant as @gianm said, you don't have to. `KillTask` will remove them automatically. Also please note that `KillTask` will fail in 0.14.0 or earlier if `descriptor.json` file is missing. It means, once you remove those files, it might be hard for you to roll back to an earlier version. This issue exists only for HDFS deep storage. The roll back should be fine with other types of deep storage. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #6849: [Proposal] Consolidated segment metadata management
jihoonson commented on issue #6849: [Proposal] Consolidated segment metadata management URL: https://github.com/apache/incubator-druid/issues/6849#issuecomment-510175689 @capistrant as @gianm said, you don't have to. `KillTask` will remove them automatically. Also please note that `KillTask` will fail in 0.14.0 or earlier if `descriptor.json` file is missing. It means, once you remove those files, it might be hard for you to roll back to an earlier version. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #6849: [Proposal] Consolidated segment metadata management
gianm commented on issue #6849: [Proposal] Consolidated segment metadata management URL: https://github.com/apache/incubator-druid/issues/6849#issuecomment-510123193 They don't _need_ to be manually removed, but you can if you want to. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on a change in pull request #6794: Query vectorization.
gianm commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302138402
##
File path:
processing/src/main/java/org/apache/druid/segment/QueryableIndexCursorSequenceBuilder.java
##
@@ -0,0 +1,638 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.segment;
+
+import com.google.common.annotations.VisibleForTesting;
+import com.google.common.base.Function;
+import com.google.common.base.Preconditions;
+import com.google.common.collect.ImmutableList;
+import com.google.common.collect.Lists;
+import org.apache.druid.collections.bitmap.ImmutableBitmap;
+import org.apache.druid.java.util.common.granularity.Granularity;
+import org.apache.druid.java.util.common.guava.Sequence;
+import org.apache.druid.java.util.common.guava.Sequences;
+import org.apache.druid.java.util.common.io.Closer;
+import org.apache.druid.query.BaseQuery;
+import org.apache.druid.query.filter.Filter;
+import org.apache.druid.query.monomorphicprocessing.RuntimeShapeInspector;
+import org.apache.druid.segment.column.BaseColumn;
+import org.apache.druid.segment.column.ColumnHolder;
+import org.apache.druid.segment.column.NumericColumn;
+import org.apache.druid.segment.data.Offset;
+import org.apache.druid.segment.data.ReadableOffset;
+import org.apache.druid.segment.historical.HistoricalCursor;
+import org.apache.druid.segment.vector.BitmapVectorOffset;
+import org.apache.druid.segment.vector.FilteredVectorOffset;
+import org.apache.druid.segment.vector.NoFilterVectorOffset;
+import
org.apache.druid.segment.vector.QueryableIndexVectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorCursor;
+import org.apache.druid.segment.vector.VectorOffset;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+
+import javax.annotation.Nullable;
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+public class QueryableIndexCursorSequenceBuilder
+{
+ /**
+ * At this threshold, timestamp searches switch from binary to linear. See
+ * {@link #timeSearch(NumericColumn, long, int, int, int)} for more details.
+ */
+ private static final int TOO_CLOSE_FOR_MISSILES = 15000;
Review comment:
See this comment from the `timeSearch` method:
> The idea is to avoid too much decompression buffer thrashing. The default
value `TOO_CLOSE_FOR_MISSILES` is chosen to be similar to the typical number of
timestamps per block.
I moved the sentence about choice of default value to the javadoc for
`TOO_CLOSE_FOR_MISSILES`, and kept the "idea" comment in the javadoc for
`timeSearch`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on a change in pull request #6794: Query vectorization.
gianm commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302135190
##
File path:
processing/src/main/java/org/apache/druid/segment/QueryableIndexCursorSequenceBuilder.java
##
@@ -0,0 +1,618 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.segment;
+
+import com.google.common.base.Function;
+import com.google.common.base.Preconditions;
+import com.google.common.collect.ImmutableList;
+import com.google.common.collect.Lists;
+import org.apache.druid.collections.bitmap.ImmutableBitmap;
+import org.apache.druid.java.util.common.granularity.Granularity;
+import org.apache.druid.java.util.common.guava.Sequence;
+import org.apache.druid.java.util.common.guava.Sequences;
+import org.apache.druid.java.util.common.io.Closer;
+import org.apache.druid.query.BaseQuery;
+import org.apache.druid.query.filter.Filter;
+import org.apache.druid.query.monomorphicprocessing.RuntimeShapeInspector;
+import org.apache.druid.segment.column.BaseColumn;
+import org.apache.druid.segment.column.ColumnHolder;
+import org.apache.druid.segment.column.NumericColumn;
+import org.apache.druid.segment.data.Offset;
+import org.apache.druid.segment.data.ReadableOffset;
+import org.apache.druid.segment.historical.HistoricalCursor;
+import org.apache.druid.segment.vector.BitmapVectorOffset;
+import org.apache.druid.segment.vector.FilteredVectorOffset;
+import org.apache.druid.segment.vector.NoFilterVectorOffset;
+import
org.apache.druid.segment.vector.QueryableIndexVectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorCursor;
+import org.apache.druid.segment.vector.VectorOffset;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+
+import javax.annotation.Nullable;
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+public class QueryableIndexCursorSequenceBuilder
+{
+ // At this threshold, timestamp searches switch from binary to linear. The
idea is to avoid too much decompression
+ // buffer thrashing. The default value is chosen to be similar to the
typical number of timestamps per block.
+ private static final int TOO_CLOSE_FOR_MISSILES = 15000;
+
+ private final QueryableIndex index;
+ private final Interval interval;
+ private final VirtualColumns virtualColumns;
+ @Nullable
+ private final ImmutableBitmap filterBitmap;
+ private final long minDataTimestamp;
+ private final long maxDataTimestamp;
+ private final boolean descending;
+ @Nullable
+ private final Filter postFilter;
+ private final ColumnSelectorBitmapIndexSelector bitmapIndexSelector;
+
+ public QueryableIndexCursorSequenceBuilder(
+ QueryableIndex index,
+ Interval interval,
+ VirtualColumns virtualColumns,
+ @Nullable ImmutableBitmap filterBitmap,
+ long minDataTimestamp,
+ long maxDataTimestamp,
+ boolean descending,
+ @Nullable Filter postFilter,
+ ColumnSelectorBitmapIndexSelector bitmapIndexSelector
+ )
+ {
+this.index = index;
+this.interval = interval;
+this.virtualColumns = virtualColumns;
+this.filterBitmap = filterBitmap;
+this.minDataTimestamp = minDataTimestamp;
+this.maxDataTimestamp = maxDataTimestamp;
+this.descending = descending;
+this.postFilter = postFilter;
+this.bitmapIndexSelector = bitmapIndexSelector;
+ }
+
+ public Sequence build(final Granularity gran)
+ {
+final Offset baseOffset;
+
+if (filterBitmap == null) {
+ baseOffset = descending
+ ? new SimpleDescendingOffset(index.getNumRows())
+ : new SimpleAscendingOffset(index.getNumRows());
+} else {
+ baseOffset = BitmapOffset.of(filterBitmap, descending,
index.getNumRows());
+}
+
+// Column caches shared amongst all cursors in this sequence.
+final Map columnCache = new HashMap<>();
+
+final NumericColumn timestamps = (NumericColumn)
index.getColumnHolder(ColumnHolder.TIME_COLUMN_NAME).getColumn();
+
+final Closer closer = Closer.create();
+closer.register(timestamps);
+
+Iterable i
[GitHub] [incubator-druid] gianm commented on a change in pull request #6794: Query vectorization.
gianm commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302135190
##
File path:
processing/src/main/java/org/apache/druid/segment/QueryableIndexCursorSequenceBuilder.java
##
@@ -0,0 +1,618 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.segment;
+
+import com.google.common.base.Function;
+import com.google.common.base.Preconditions;
+import com.google.common.collect.ImmutableList;
+import com.google.common.collect.Lists;
+import org.apache.druid.collections.bitmap.ImmutableBitmap;
+import org.apache.druid.java.util.common.granularity.Granularity;
+import org.apache.druid.java.util.common.guava.Sequence;
+import org.apache.druid.java.util.common.guava.Sequences;
+import org.apache.druid.java.util.common.io.Closer;
+import org.apache.druid.query.BaseQuery;
+import org.apache.druid.query.filter.Filter;
+import org.apache.druid.query.monomorphicprocessing.RuntimeShapeInspector;
+import org.apache.druid.segment.column.BaseColumn;
+import org.apache.druid.segment.column.ColumnHolder;
+import org.apache.druid.segment.column.NumericColumn;
+import org.apache.druid.segment.data.Offset;
+import org.apache.druid.segment.data.ReadableOffset;
+import org.apache.druid.segment.historical.HistoricalCursor;
+import org.apache.druid.segment.vector.BitmapVectorOffset;
+import org.apache.druid.segment.vector.FilteredVectorOffset;
+import org.apache.druid.segment.vector.NoFilterVectorOffset;
+import
org.apache.druid.segment.vector.QueryableIndexVectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorCursor;
+import org.apache.druid.segment.vector.VectorOffset;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+
+import javax.annotation.Nullable;
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+public class QueryableIndexCursorSequenceBuilder
+{
+ // At this threshold, timestamp searches switch from binary to linear. The
idea is to avoid too much decompression
+ // buffer thrashing. The default value is chosen to be similar to the
typical number of timestamps per block.
+ private static final int TOO_CLOSE_FOR_MISSILES = 15000;
+
+ private final QueryableIndex index;
+ private final Interval interval;
+ private final VirtualColumns virtualColumns;
+ @Nullable
+ private final ImmutableBitmap filterBitmap;
+ private final long minDataTimestamp;
+ private final long maxDataTimestamp;
+ private final boolean descending;
+ @Nullable
+ private final Filter postFilter;
+ private final ColumnSelectorBitmapIndexSelector bitmapIndexSelector;
+
+ public QueryableIndexCursorSequenceBuilder(
+ QueryableIndex index,
+ Interval interval,
+ VirtualColumns virtualColumns,
+ @Nullable ImmutableBitmap filterBitmap,
+ long minDataTimestamp,
+ long maxDataTimestamp,
+ boolean descending,
+ @Nullable Filter postFilter,
+ ColumnSelectorBitmapIndexSelector bitmapIndexSelector
+ )
+ {
+this.index = index;
+this.interval = interval;
+this.virtualColumns = virtualColumns;
+this.filterBitmap = filterBitmap;
+this.minDataTimestamp = minDataTimestamp;
+this.maxDataTimestamp = maxDataTimestamp;
+this.descending = descending;
+this.postFilter = postFilter;
+this.bitmapIndexSelector = bitmapIndexSelector;
+ }
+
+ public Sequence build(final Granularity gran)
+ {
+final Offset baseOffset;
+
+if (filterBitmap == null) {
+ baseOffset = descending
+ ? new SimpleDescendingOffset(index.getNumRows())
+ : new SimpleAscendingOffset(index.getNumRows());
+} else {
+ baseOffset = BitmapOffset.of(filterBitmap, descending,
index.getNumRows());
+}
+
+// Column caches shared amongst all cursors in this sequence.
+final Map columnCache = new HashMap<>();
+
+final NumericColumn timestamps = (NumericColumn)
index.getColumnHolder(ColumnHolder.TIME_COLUMN_NAME).getColumn();
+
+final Closer closer = Closer.create();
+closer.register(timestamps);
+
+Iterable i
[GitHub] [incubator-druid] gianm commented on a change in pull request #6794: Query vectorization.
gianm commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302135101
##
File path:
processing/src/main/java/org/apache/druid/query/filter/vector/ReadableVectorMatch.java
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.query.filter.vector;
+
+import javax.annotation.Nullable;
+
+/**
+ * The result of calling {@link VectorValueMatcher#match}.
+ *
+ * @see VectorMatch, the implementation, which also adds some extra mutation
methods.
+ */
+public interface ReadableVectorMatch
+{
+ /**
+ * Returns an array of indexes into the current batch. Only the first
"getSelectionSize" are valid.
+ *
+ * Even though this array is technically mutable, it is very poor form to
mutate it if you are not the owner of the
+ * VectorMatch object.
+ */
+ int[] getSelection();
Review comment:
I added this sentence:
> Potential optimizations could include making it easier for the JVM to use
CPU-level vectorization, avoid method calls, etc.
I'm not 100% sure that the CPU level vectorization will _actually_ be
triggered, but it could theoretically be, which is the point. Even if it isn't
today, it might be in future JVMs. (And it might be today, I just haven't
checked.)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] capistrant commented on issue #6849: [Proposal] Consolidated segment metadata management
capistrant commented on issue #6849: [Proposal] Consolidated segment metadata management URL: https://github.com/apache/incubator-druid/issues/6849#issuecomment-51071 @jihoonson This was a cool change. I have a question regarding the existing descriptor.json files after the upgrade. Do they need to be manually removed? We use HDFS as a deep store so it would be nice to reduce the file count from Druid after upgrade validation. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: Add IS_INCREMENTAL_HANDOFF_SUPPORTED for KIS backward compatibility (#8050)
This is an automated email from the ASF dual-hosted git repository.
fjy pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-druid.git
The following commit(s) were added to refs/heads/master by this push:
new fcf56f2 Add IS_INCREMENTAL_HANDOFF_SUPPORTED for KIS backward
compatibility (#8050)
fcf56f2 is described below
commit fcf56f23300a32f14a0e34ed2c330c490f95b867
Author: Jihoon Son
AuthorDate: Wed Jul 10 08:29:37 2019 -0700
Add IS_INCREMENTAL_HANDOFF_SUPPORTED for KIS backward compatibility (#8050)
* Add IS_INCREMENTAL_HANDOFF_SUPPORTED for KIS backward compatibility
* do it for kafka only
* fix test
---
.../indexing/kafka/supervisor/KafkaSupervisor.java | 4 ++
.../kafka/supervisor/KafkaSupervisorTest.java | 47 ++
.../kinesis/supervisor/KinesisSupervisorTest.java | 1 -
.../supervisor/SeekableStreamSupervisor.java | 3 +-
4 files changed, 53 insertions(+), 2 deletions(-)
diff --git
a/extensions-core/kafka-indexing-service/src/main/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisor.java
b/extensions-core/kafka-indexing-service/src/main/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisor.java
index cdf1336..c769617 100644
---
a/extensions-core/kafka-indexing-service/src/main/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisor.java
+++
b/extensions-core/kafka-indexing-service/src/main/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisor.java
@@ -240,6 +240,10 @@ public class KafkaSupervisor extends
SeekableStreamSupervisor
final String checkpoints =
sortingMapper.writerFor(CHECKPOINTS_TYPE_REF).writeValueAsString(sequenceOffsets);
final Map context = createBaseTaskContexts();
context.put(CHECKPOINTS_CTX_KEY, checkpoints);
+// Kafka index task always uses incremental handoff since 0.16.0.
+// The below is for the compatibility when you want to downgrade your
cluster to something earlier than 0.16.0.
+// Kafka index task will pick up LegacyKafkaIndexTaskRunner without the
below configuration.
+context.put("IS_INCREMENTAL_HANDOFF_SUPPORTED", true);
List> taskList = new ArrayList<>();
for (int i = 0; i < replicas; i++) {
diff --git
a/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
b/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
index aff5639..05242da 100644
---
a/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
+++
b/extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
@@ -19,6 +19,7 @@
package org.apache.druid.indexing.kafka.supervisor;
+import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.base.Optional;
import com.google.common.collect.ImmutableList;
@@ -256,6 +257,52 @@ public class KafkaSupervisorTest extends EasyMockSupport
}
@Test
+ public void testCreateBaseTaskContexts() throws JsonProcessingException
+ {
+supervisor = getTestableSupervisor(1, 1, true, "PT1H", null, null);
+final Map contexts = supervisor.createIndexTasks(
+1,
+"seq",
+objectMapper,
+new TreeMap<>(),
+new KafkaIndexTaskIOConfig(
+0,
+"seq",
+new SeekableStreamStartSequenceNumbers<>("test",
Collections.emptyMap(), Collections.emptySet()),
+new SeekableStreamEndSequenceNumbers<>("test",
Collections.emptyMap()),
+Collections.emptyMap(),
+null,
+null,
+null,
+null
+),
+new KafkaIndexTaskTuningConfig(
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null,
+null
+),
+null
+).get(0).getContext();
+final Boolean contextValue = (Boolean)
contexts.get("IS_INCREMENTAL_HANDOFF_SUPPORTED");
+Assert.assertNotNull(contextValue);
+Assert.assertTrue(contextValue);
+ }
+
+ @Test
public void testNoInitialState() throws Exception
{
supervisor = getTestableSupervisor(1, 1, true, "PT1H", null, null);
diff --git
a/extensions-core/kinesis-indexing-service/src/test/java/org/apache/druid/indexing/kinesis/supervisor/KinesisSupervisorTest.java
b/extensions-core/kinesis-indexing-service/src/test/java/org/apache/druid/indexing/kinesis/supervisor/KinesisSupervisorTest.java
index 9b6f893..e6bb39c 100644
---
a/extensions-core/kinesis-indexing-service/src/test/java/org/apache/druid/indexin
[GitHub] [incubator-druid] fjy merged pull request #8050: Add IS_INCREMENTAL_HANDOFF_SUPPORTED for KIS backward compatibility
fjy merged pull request #8050: Add IS_INCREMENTAL_HANDOFF_SUPPORTED for KIS backward compatibility URL: https://github.com/apache/incubator-druid/pull/8050 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: remove IRC badge from readme (#8052)
This is an automated email from the ASF dual-hosted git repository. fjy pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git The following commit(s) were added to refs/heads/master by this push: new 4e3314f remove IRC badge from readme (#8052) 4e3314f is described below commit 4e3314f675add979d2a8eea92178441a19d5dd04 Author: Vadim Ogievetsky AuthorDate: Wed Jul 10 08:29:19 2019 -0700 remove IRC badge from readme (#8052) --- README.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/README.md b/README.md index 4d5f065..68d168b 100644 --- a/README.md +++ b/README.md @@ -17,7 +17,7 @@ ~ under the License. --> -[](https://travis-ci.org/apache/incubator-druid) [](https://teamcity.jetbrains.com/viewType.html?buildTypeId=OpenSourceProjects_Druid_Inspections) [](https://coverall [...] +[](https://travis-ci.org/apache/incubator-druid) [](https://teamcity.jetbrains.com/viewType.html?buildTypeId=OpenSourceProjects_Druid_Inspections) [](https://coverall [...] ## Apache Druid (incubating) - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy merged pull request #8052: Remove IRC badge from readme
fjy merged pull request #8052: Remove IRC badge from readme URL: https://github.com/apache/incubator-druid/pull/8052 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: added replicated size (#8043)
This is an automated email from the ASF dual-hosted git repository.
fjy pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-druid.git
The following commit(s) were added to refs/heads/master by this push:
new 1712158 added replicated size (#8043)
1712158 is described below
commit 17121587342f03be78ec3551d0521276ea01adb0
Author: Vadim Ogievetsky
AuthorDate: Wed Jul 10 08:29:05 2019 -0700
added replicated size (#8043)
---
.../__snapshots__/datasource-view.spec.tsx.snap | 9 +
web-console/src/views/datasource-view/datasource-view.tsx| 12
2 files changed, 21 insertions(+)
diff --git
a/web-console/src/views/datasource-view/__snapshots__/datasource-view.spec.tsx.snap
b/web-console/src/views/datasource-view/__snapshots__/datasource-view.spec.tsx.snap
index c2f33f2..b619181 100755
---
a/web-console/src/views/datasource-view/__snapshots__/datasource-view.spec.tsx.snap
+++
b/web-console/src/views/datasource-view/__snapshots__/datasource-view.spec.tsx.snap
@@ -30,6 +30,7 @@ exports[`data source view matches snapshot 1`] = `
"Retention",
"Compaction",
"Size",
+ "Replicated size",
"Num rows",
"Actions",
]
@@ -145,6 +146,14 @@ exports[`data source view matches snapshot 1`] = `
},
Object {
"Cell": [Function],
+ "Header": "Replicated size",
+ "accessor": "replicated_size",
+ "filterable": false,
+ "show": true,
+ "width": 100,
+},
+Object {
+ "Cell": [Function],
"Header": "Num rows",
"accessor": "num_rows",
"filterable": false,
diff --git a/web-console/src/views/datasource-view/datasource-view.tsx
b/web-console/src/views/datasource-view/datasource-view.tsx
index 9a4ae18..8297a71 100644
--- a/web-console/src/views/datasource-view/datasource-view.tsx
+++ b/web-console/src/views/datasource-view/datasource-view.tsx
@@ -57,6 +57,7 @@ const tableColumns: string[] = [
'Retention',
'Compaction',
'Size',
+ 'Replicated size',
'Num rows',
ActionCell.COLUMN_LABEL,
];
@@ -100,6 +101,7 @@ interface DatasourceQueryResultRow {
num_segments_to_load: number;
num_segments_to_drop: number;
size: number;
+ replicated_size: number;
num_rows: number;
}
@@ -138,6 +140,7 @@ export class DatasourcesView extends React.PureComponent<
COUNT(*) FILTER (WHERE is_published = 1 AND is_overshadowed = 0 AND
is_available = 0) AS num_segments_to_load,
COUNT(*) FILTER (WHERE is_available = 1 AND NOT ((is_published = 1 AND
is_overshadowed = 0) OR is_realtime = 1)) AS num_segments_to_drop,
SUM("size") FILTER (WHERE (is_published = 1 AND is_overshadowed = 0) OR
is_realtime = 1) AS size,
+ SUM("size" * "num_replicas") FILTER (WHERE (is_published = 1 AND
is_overshadowed = 0) OR is_realtime = 1) AS replicated_size,
SUM("num_rows") FILTER (WHERE (is_published = 1 AND is_overshadowed = 0) OR
is_realtime = 1) AS num_rows
FROM sys.segments
GROUP BY 1`;
@@ -201,6 +204,7 @@ GROUP BY 1`;
num_segments_to_load: segmentsToLoad,
num_segments_to_drop: 0,
size: d.properties.segments.size,
+replicated_size: -1,
num_rows: -1,
};
},
@@ -762,6 +766,14 @@ GROUP BY 1`;
show: hiddenColumns.exists('Size'),
},
{
+ Header: 'Replicated size',
+ accessor: 'replicated_size',
+ filterable: false,
+ width: 100,
+ Cell: row => formatBytes(row.value),
+ show: hiddenColumns.exists('Replicated size'),
+},
+{
Header: 'Num rows',
accessor: 'num_rows',
filterable: false,
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy merged pull request #8043: Web console: added replicated size to datasources view
fjy merged pull request #8043: Web console: added replicated size to datasources view URL: https://github.com/apache/incubator-druid/pull/8043 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] sashidhar edited a comment on issue #8038: Making optimal usage of multiple segment cache locations
sashidhar edited a comment on issue #8038: Making optimal usage of multiple segment cache locations URL: https://github.com/apache/incubator-druid/pull/8038#issuecomment-510046061 @dclim , @nishantmonu51 Here's what I'm thinking. As discussed, the segment cache location selector strategy should be configurable. There could be 3 possible strategies currently. 1. Round-robin selector strategy 2. Least bytes used selector strategy 3. Current behaviour Questions: 1. Default strategy - Should this be the current behaviour which is there right now in production or one of round-robin or least bytes used ? 2. Property name for the new configuration - how does this sound **druid.segmentCache.locationSelectorStrategy**. ? 3. Possible values for the above property - **round-robin**, **least-bytes-used** ? Other things to note: 1. This PR will have to introduce an optional new Historical runtime property. 2. Documentation for the same and mention in the release notes. @gianm FYI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] capistrant commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off
capistrant commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off URL: https://github.com/apache/incubator-druid/pull/7562#issuecomment-510086321 @gianm @Caroline1000 Any interest in reviving this PR to address the related issue regarding the logging here? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] egor-ryashin commented on a change in pull request #6794: Query vectorization.
egor-ryashin commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302070676
##
File path:
processing/src/main/java/org/apache/druid/segment/QueryableIndexCursorSequenceBuilder.java
##
@@ -0,0 +1,618 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.segment;
+
+import com.google.common.base.Function;
+import com.google.common.base.Preconditions;
+import com.google.common.collect.ImmutableList;
+import com.google.common.collect.Lists;
+import org.apache.druid.collections.bitmap.ImmutableBitmap;
+import org.apache.druid.java.util.common.granularity.Granularity;
+import org.apache.druid.java.util.common.guava.Sequence;
+import org.apache.druid.java.util.common.guava.Sequences;
+import org.apache.druid.java.util.common.io.Closer;
+import org.apache.druid.query.BaseQuery;
+import org.apache.druid.query.filter.Filter;
+import org.apache.druid.query.monomorphicprocessing.RuntimeShapeInspector;
+import org.apache.druid.segment.column.BaseColumn;
+import org.apache.druid.segment.column.ColumnHolder;
+import org.apache.druid.segment.column.NumericColumn;
+import org.apache.druid.segment.data.Offset;
+import org.apache.druid.segment.data.ReadableOffset;
+import org.apache.druid.segment.historical.HistoricalCursor;
+import org.apache.druid.segment.vector.BitmapVectorOffset;
+import org.apache.druid.segment.vector.FilteredVectorOffset;
+import org.apache.druid.segment.vector.NoFilterVectorOffset;
+import
org.apache.druid.segment.vector.QueryableIndexVectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorCursor;
+import org.apache.druid.segment.vector.VectorOffset;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+
+import javax.annotation.Nullable;
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+public class QueryableIndexCursorSequenceBuilder
+{
+ // At this threshold, timestamp searches switch from binary to linear. The
idea is to avoid too much decompression
+ // buffer thrashing. The default value is chosen to be similar to the
typical number of timestamps per block.
+ private static final int TOO_CLOSE_FOR_MISSILES = 15000;
+
+ private final QueryableIndex index;
+ private final Interval interval;
+ private final VirtualColumns virtualColumns;
+ @Nullable
+ private final ImmutableBitmap filterBitmap;
+ private final long minDataTimestamp;
+ private final long maxDataTimestamp;
+ private final boolean descending;
+ @Nullable
+ private final Filter postFilter;
+ private final ColumnSelectorBitmapIndexSelector bitmapIndexSelector;
+
+ public QueryableIndexCursorSequenceBuilder(
+ QueryableIndex index,
+ Interval interval,
+ VirtualColumns virtualColumns,
+ @Nullable ImmutableBitmap filterBitmap,
+ long minDataTimestamp,
+ long maxDataTimestamp,
+ boolean descending,
+ @Nullable Filter postFilter,
+ ColumnSelectorBitmapIndexSelector bitmapIndexSelector
+ )
+ {
+this.index = index;
+this.interval = interval;
+this.virtualColumns = virtualColumns;
+this.filterBitmap = filterBitmap;
+this.minDataTimestamp = minDataTimestamp;
+this.maxDataTimestamp = maxDataTimestamp;
+this.descending = descending;
+this.postFilter = postFilter;
+this.bitmapIndexSelector = bitmapIndexSelector;
+ }
+
+ public Sequence build(final Granularity gran)
+ {
+final Offset baseOffset;
+
+if (filterBitmap == null) {
+ baseOffset = descending
+ ? new SimpleDescendingOffset(index.getNumRows())
+ : new SimpleAscendingOffset(index.getNumRows());
+} else {
+ baseOffset = BitmapOffset.of(filterBitmap, descending,
index.getNumRows());
+}
+
+// Column caches shared amongst all cursors in this sequence.
+final Map columnCache = new HashMap<>();
+
+final NumericColumn timestamps = (NumericColumn)
index.getColumnHolder(ColumnHolder.TIME_COLUMN_NAME).getColumn();
+
+final Closer closer = Closer.create();
+closer.register(timestamps);
+
+Ite
[GitHub] [incubator-druid] egor-ryashin commented on a change in pull request #6794: Query vectorization.
egor-ryashin commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302069843
##
File path:
processing/src/main/java/org/apache/druid/segment/QueryableIndexCursorSequenceBuilder.java
##
@@ -0,0 +1,638 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.segment;
+
+import com.google.common.annotations.VisibleForTesting;
+import com.google.common.base.Function;
+import com.google.common.base.Preconditions;
+import com.google.common.collect.ImmutableList;
+import com.google.common.collect.Lists;
+import org.apache.druid.collections.bitmap.ImmutableBitmap;
+import org.apache.druid.java.util.common.granularity.Granularity;
+import org.apache.druid.java.util.common.guava.Sequence;
+import org.apache.druid.java.util.common.guava.Sequences;
+import org.apache.druid.java.util.common.io.Closer;
+import org.apache.druid.query.BaseQuery;
+import org.apache.druid.query.filter.Filter;
+import org.apache.druid.query.monomorphicprocessing.RuntimeShapeInspector;
+import org.apache.druid.segment.column.BaseColumn;
+import org.apache.druid.segment.column.ColumnHolder;
+import org.apache.druid.segment.column.NumericColumn;
+import org.apache.druid.segment.data.Offset;
+import org.apache.druid.segment.data.ReadableOffset;
+import org.apache.druid.segment.historical.HistoricalCursor;
+import org.apache.druid.segment.vector.BitmapVectorOffset;
+import org.apache.druid.segment.vector.FilteredVectorOffset;
+import org.apache.druid.segment.vector.NoFilterVectorOffset;
+import
org.apache.druid.segment.vector.QueryableIndexVectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorColumnSelectorFactory;
+import org.apache.druid.segment.vector.VectorCursor;
+import org.apache.druid.segment.vector.VectorOffset;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+
+import javax.annotation.Nullable;
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+public class QueryableIndexCursorSequenceBuilder
+{
+ /**
+ * At this threshold, timestamp searches switch from binary to linear. See
+ * {@link #timeSearch(NumericColumn, long, int, int, int)} for more details.
+ */
+ private static final int TOO_CLOSE_FOR_MISSILES = 15000;
Review comment:
Just wonder how that value was chosen?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] egor-ryashin commented on a change in pull request #6794: Query vectorization.
egor-ryashin commented on a change in pull request #6794: Query vectorization.
URL: https://github.com/apache/incubator-druid/pull/6794#discussion_r302061881
##
File path:
processing/src/main/java/org/apache/druid/query/filter/vector/ReadableVectorMatch.java
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.query.filter.vector;
+
+import javax.annotation.Nullable;
+
+/**
+ * The result of calling {@link VectorValueMatcher#match}.
+ *
+ * @see VectorMatch, the implementation, which also adds some extra mutation
methods.
+ */
+public interface ReadableVectorMatch
+{
+ /**
+ * Returns an array of indexes into the current batch. Only the first
"getSelectionSize" are valid.
+ *
+ * Even though this array is technically mutable, it is very poor form to
mutate it if you are not the owner of the
+ * VectorMatch object.
+ */
+ int[] getSelection();
Review comment:
Could you mention `HotSpot vectorization` term in the comment?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] sashidhar commented on issue #8038: Making optimal usage of multiple segment cache locations
sashidhar commented on issue #8038: Making optimal usage of multiple segment cache locations URL: https://github.com/apache/incubator-druid/pull/8038#issuecomment-510046061 @dclim , @nishantmonu51 Here's what I'm thinking. As discussed, the segment cache location selector strategy should be configurable. There could be 3 possible strategies currently. 1. Round-robin selector strategy 2. Least bytes used selector strategy 3. Current behaviour Questions: 1. Default strategy - Should this be the current behaviour which is there right now in production or one of round-robin or least bytes used ? 2. Property name for the new configuration - how does this sound **druid.segmentCache.locations.selector.strategy**. ? 3. Possible values for the above property - **round-robin**, **least-bytes-used** ? Other things to note: 1. This PR will have to introduce an optional new Historical runtime property. 2. Documentation for the same and mention in the release notes. @gianm FYI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] niravmehta commented on issue #8015: full-text search
niravmehta commented on issue #8015: full-text search URL: https://github.com/apache/incubator-druid/issues/8015#issuecomment-510008691 Druid has a nice [Search API](https://druid.apache.org/docs/latest/querying/searchquery.html). There are also some options to [refine how searches are performed](https://druid.apache.org/docs/latest/querying/searchqueryspec.html). It won't do stemming / stop word removal etc. Neither will it highlight matches in results. But I found it to be very useful implementation because: it's fast and even returns the dimensions where match occurred. Word highlighting can be easily implemented in your front-end app. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] duanxuelin commented on issue #8025: PagingIdentifiers are not right when query data with select query
duanxuelin commented on issue #8025: PagingIdentifiers are not right when query data with select query URL: https://github.com/apache/incubator-druid/issues/8025#issuecomment-509997974 >The major difference between the two is that the Scan query does not support pagination. However, the Scan query type is able to return a virtually unlimited number of results even without pagination, making it unnecessary in many cases. @vogievetsky Documents show that scan query does not support pagination. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] dclim commented on issue #8038: Making optimal usage of multiple segment cache locations
dclim commented on issue #8038: Making optimal usage of multiple segment cache locations URL: https://github.com/apache/incubator-druid/pull/8038#issuecomment-509948508 Ah interesting - I thought I remembered the behavior used to select the least filled disk! Looks like a regression at some point. @sashidhar I do still think there's value in making the selector strategy configurable to something like round-robin for the reason you mentioned. An example - I was setting up a Druid cluster that had two volumes mounted (let's say they were each 10G and called /mnt and /mnt1). I was also using /mnt for other stuff - as a general scratch drive, storing intermediate indexing files, log files, etc. so I needed to reserve some space for this - let's say I reserved 2G. I had 8G left, so I set the size of the segment cache for /mnt to 8G. Now, what do I set the size of the segment cache for /mnt1 to? If I set it to 10G to fully utilize the volume and at a point in time have less than 2G of data, it would all be on /mnt1 and potentially wouldn't be maximizing the I/O throughput available. I could instead set it to 8G to be the same as /mnt and that would evenly distribute the segments, but I'd lose those 2G unnecessarily just to coax the algorithm to utilize both locations. A round-robin strategy (or one that selects the location that has the least bytes used in absolute terms instead of relative to the capacity) would have been what I wanted. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] CalvinSchulze opened a new issue #8053: Kafka Ingestion Loop
CalvinSchulze opened a new issue #8053: Kafka Ingestion Loop URL: https://github.com/apache/incubator-druid/issues/8053 ### Affected Version 0.15.0 ### Description I'm running the micro quicktest and ingest data via supervisor task from Kafka. When I tried to push 100 million files into druid, the task crashed with an out of memory exception (GC overhead limit exceeded). Of course I need to upscale the JVM, but I was waiting for 3 days now for druid to catch up on this error. But instead it regularly starts new tasks, which load parts of the data I ingested. They crash again and the loaded data is gone again. This has been looping and probably will be looping forever. All of these tasks are just running for about a minute. I'll not change any druid setting now and I won't delete the data. Feel free to ask for logs, if needed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org