[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2
that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612499511
Hi @vinothchandar base on your branch, there are mainly the following
updates:
- Rebase branch
- Add TestHoodieBloomIndexV2.java
- Add DeltaTimer.java
- Fix an implicit bug which causes input record duplication.
**Bug fix**
In the stage of double
check(`HoodieBloomIndexV2.LazyKeyChecker#computeNext`),
when the target file doesn't contains the record key, should return
`Option.empty()`.
**Previous**
```
Option> ret = fileIdOpt.map(fileId -> {
...
Option location =
currHandle.containsKey(record.getRecordKey())
? Option.of(new HoodieRecordLocation(currHandle.getBaseInstantTime(),
currHandle.getFileId()))
: Option.empty();
return Option.of(getTaggedRecord(record, location));
}).orElse(Option.of(record));
```
**Changes**
```
Option> recordOpt = fileIdOpt.map((Function>>) fileId -> {
...
if (currHandle.containsKey(record.getRecordKey())) {
HoodieRecordLocation recordLocation = new
HoodieRecordLocation(currHandle.getBaseInstantTime(), currHandle.getFileId());
return Option.of(getTaggedRecord(record, recordLocation));
} else {
return Option.empty();
}
}).orElse(Option.of(record));
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612552933 > how many files did your bulk_insert create. Actually, I did `upsert` operation twice directly, IMO `bulk_insert` will get the same result, There are about `41` parquet files, total size: `418MB` in my env. ``` dcadmin-imac:hudi_mor_table dcadmin$ ll -lh /tmp/hudi_mor_table/2020-03-19 total 844928 -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 05484246-8655-4045-b31b-45f6ff4b5765-0_37-47-674_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 06272cc1-337c-4ea1-9e5b-aa1b1d6b479f-0_17-47-654_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 0c9875b3-6ea3-4dfa-bc1d-ecc83de8440e-0_30-47-667_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 0fc36101-c1e9-41e2-b356-d680a17dc468-0_22-47-659_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:57 1329dfae-a324-438d-9606-6deb9d65fdb7-0_0-47-637_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:57 17417d4f-13d2-4d3f-94e6-c4f713575b58-0_5-47-642_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 1c5199eb-04b7-48c8-ba64-b66c41fe7f88-0_35-47-672_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 1f1f8a06-b6bb-4491-8f1e-c2203106aacd-0_23-47-660_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 230859c6-3ffe-4efc-813e-079bea14abe9-0_8-47-645_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 252c73ae-6912-481d-b0d2-356f9796b073-0_38-47-675_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:57 3173646f-47d2-4b70-bed5-c867045b6da7-0_3-47-640_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 341a530d-d7c9-4ab3-bbca-38cc276b4c17-0_32-47-669_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 352facd1-cdd1-4ea9-b38a-c36af74674c1-0_40-47-677_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 40cdb651-29b4-4b16-b8e7-26470f98c966-0_21-47-658_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 429d3ace-459a-4e55-903a-3a7cc6b35511-0_15-47-652_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 47e21491-f4cd-4f1d-82a5-ae8516846f47-0_19-47-656_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:57 4853078d-d120-49e5-abc1-622e6963324b-0_1-47-638_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 4c1d4a60-b2dd-4cdd-b98d-bbb216a838cb-0_31-47-668_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 4f49aaf4-6a74-425c-b5a8-29b3f311caae-0_13-47-650_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 5361ec26-6fce-4d95-96c4-e2811135d9d2-0_26-47-663_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 5815a649-0b09-4bce-aaff-82ac8428c1a7-0_14-47-651_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 60672e15-9477-42aa-aa79-d3a340feb9d6-0_20-47-657_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 740775dd-01d7-4147-a00a-805862599eed-0_24-47-661_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 78ff0cb1-6c8a-4c4b-bf47-01f1c56d5fd5-0_27-47-664_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 8710662b-66a7-4b0d-a818-e5cd6584a14f-0_34-47-671_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 8e21464e-cadb-4ab3-8ef6-198b138e2f0d-0_18-47-655_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 9b6accdc-e3f9-43b8-9d43-9e2306cafbab-0_12-47-649_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 a4bcc9e9-29c5-470b-8a8c-539e4ffa8f51-0_16-47-653_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 aa2dcc86-79f0-479f-92a4-886566e75219-0_10-47-647_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 b699bc5f-9786-44dd-90f9-57f9e68f85a2-0_25-47-662_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:57 b8941692-e240-4dc4-a47a-9adcedb86db6-0_4-47-641_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 b9a70bca-7fe4-4fa3-83e7-eb4a063ff56b-0_36-47-673_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58 c2d799e5-edf0-4c3b-9e6d-1473489489e9-0_39-47-676_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:57 db1d8409-75d3-45ef-8f57-3b1040a473ad-0_6-47-643_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.6M Apr 12 10:58 db7cd3a8-cd27-436a-b2df-f2e4b6ae0e79-0_28-47-665_20200412105332.parquet -rw-r--r-- 1 dcadmin wheel 9.7M Apr 12 10:58
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612552933 > how many files did your bulk_insert create. Actually, I did `upsert` operation twice directly, IMO `bulk_insert` will get the same result, There are about `xxx` parquet files. ``` recalculating ``` > can you help review the SimpleIndex Sure, will review that pr, : ) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612552933 > how many files did your bulk_insert create. Actually, I did `upsert` operation twice directly, IMO `bulk_insert` will get the same result, There are about `329` parquet files. ``` dcadmin-imac:incubator-hudi dcadmin$ ll -lh /tmp/hudi_mor_table/2020-03-19/ total 6758152 -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 17:36 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_26-21-122_20200411173245.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:28 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_31-17-166_20200411212041.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:37 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_31-17-166_20200412032957.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 09:05 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_31-17-166_20200412085802.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 02:05 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_32-17-167_20200412015545.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:20 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_32-21-308_20200412025315.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 08:48 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_32-26-563_20200412082503.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:53 019e47df-aa9f-49e9-81a6-1aa572e1cb11-0_32-47-477_20200411214153.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 17:36 1021eafc-9346-47c9-bb76-e3ece4436f96-0_13-21-109_20200411173245.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 02:05 1021eafc-9346-47c9-bb76-e3ece4436f96-0_33-17-168_20200412015545.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 08:48 1021eafc-9346-47c9-bb76-e3ece4436f96-0_33-26-564_20200412082503.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:53 1021eafc-9346-47c9-bb76-e3ece4436f96-0_33-47-478_20200411214153.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:28 1021eafc-9346-47c9-bb76-e3ece4436f96-0_34-17-169_20200411212041.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:37 1021eafc-9346-47c9-bb76-e3ece4436f96-0_34-17-169_20200412032957.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 09:06 1021eafc-9346-47c9-bb76-e3ece4436f96-0_34-17-169_20200412085802.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:20 1021eafc-9346-47c9-bb76-e3ece4436f96-0_34-21-310_20200412025315.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:27 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-17-149_20200411212041.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 02:04 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-17-149_20200412015545.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:36 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-17-149_20200412032957.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 09:04 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-17-149_20200412085802.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:19 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-21-290_20200412025315.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 08:47 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-26-545_20200412082503.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:49 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_14-47-459_20200411214153.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 17:36 1837cc2d-1cea-401a-8227-ddbb775a48c7-0_29-21-125_20200411173245.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 17:36 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_15-21-111_20200411173245.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:27 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_7-17-142_20200411212041.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 02:03 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_7-17-142_20200412015545.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 09:04 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_7-17-142_20200412085802.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 08:46 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_7-26-538_20200412082503.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 11 21:48 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_7-47-452_20200411214153.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:36 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_8-17-143_20200412032957.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:18 20289d4b-91c1-46d8-9d76-fb0e6cc31d0f-0_8-21-284_20200412025315.parquet -rw-r--r-- 1 dcadmin wheel10M Apr 11 17:36 29eb3b7b-b127-40f0-94f0-77e1aa6406bc-0_27-21-123_20200411173245.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 09:03 29eb3b7b-b127-40f0-94f0-77e1aa6406bc-0_3-17-138_20200412085802.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 03:18 29eb3b7b-b127-40f0-94f0-77e1aa6406bc-0_3-21-279_20200412025315.parquet -rw-r--r-- 1 dcadmin wheel 9.9M Apr 12 08:46 29eb3b7b-b127-40f0-94f0-77e1aa6406bc-0_3-26-534_20200412082503.parquet
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2
that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612499511
Hi @vinothchandar base on your branch, there are mainly the following
updates:
- Rebase master branch
- Add TestHoodieBloomIndexV2.java
- Add DeltaTimer.java
- Fix an implicit bug which causes repeat input record
**Bug fix**
In the stage of double
check(`HoodieBloomIndexV2.LazyKeyChecker#computeNext`),
when the target file doesn't contains the record key, should return
`Option.empty()`.
**Previous**
```
Option> ret = fileIdOpt.map(fileId -> {
if (currHandle == null || !currHandle.getFileId().equals(fileId)) {
currHandle = new HoodieKeyLookupHandle<>(config, table,
Pair.of(record.getPartitionPath(), fileId));
}
Option location =
currHandle.containsKey(record.getRecordKey())
? Option.of(new HoodieRecordLocation(currHandle.getBaseInstantTime(),
currHandle.getFileId()))
: Option.empty();
return Option.of(getTaggedRecord(record, location));
}).orElse(Option.of(record));
```
**Changes**
```
Option> recordOpt = fileIdOpt.map((Function>>) fileId -> {
DeltaTimer deltaTimer = new DeltaTimer();
if (currHandle == null || !currHandle.getFileId().equals(fileId)) {
currHandle = new HoodieKeyLookupHandle<>(config, table,
Pair.of(record.getPartitionPath(), fileId));
}
totalReadTimeMs += deltaTimer.deltaTime();
if (currHandle.containsKey(record.getRecordKey())) {
HoodieRecordLocation recordLocation = new
HoodieRecordLocation(currHandle.getBaseInstantTime(), currHandle.getFileId());
return Option.of(getTaggedRecord(record, recordLocation));
} else {
return Option.empty();
}
}).orElse(Option.of(record));
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2
that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612500968
Also, index performance has been greatly improved, your idea and design is
amazing @vinothchandar
I tested `upsert` 500, records, `bulk_insert` first, then do `upsert`
operation with the same dataset
1. Download CSV data with 5M records
```
https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
```
2. Run demo command
```
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--packages
org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4
\
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--jars `ls
packaging/hudi-spark-bundle/target/hudi-spark-bundle_*.*-*.*.*-SNAPSHOT.jar` \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_table"
val basePath = "file:///tmp/hudi_mor_table"
var inputDF = spark.read.format("csv").option("header",
"true").load("file:///work/hudi-debug/2.csv")
val hudiOptions = Map[String,String](
"hoodie.insert.shuffle.parallelism" -> "10",
"hoodie.upsert.shuffle.parallelism" -> "10",
"hoodie.delete.shuffle.parallelism" -> "10",
"hoodie.bulkinsert.shuffle.parallelism" -> "10",
"hoodie.datasource.write.recordkey.field" -> "tds_cid",
"hoodie.datasource.write.partitionpath.field" -> "hit_date",
"hoodie.table.name" -> tableName,
"hoodie.datasource.write.precombine.field" -> "hit_timestamp",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.memory.merge.max.size" -> "200485760",
"hoodie.index.type" -> "BLOOM_V2",
"hoodie.bloom.index.v2.buffer.max.size" -> "1020"
)
inputDF.write.format("org.apache.hudi").
options(hudiOptions).
mode("Append").
save(basePath)
spark.read.format("org.apache.hudi").load(basePath +
"/2020-03-19/*").count();
```
### Performance comparison
`HoodieBloomIndex`: cost about 20min
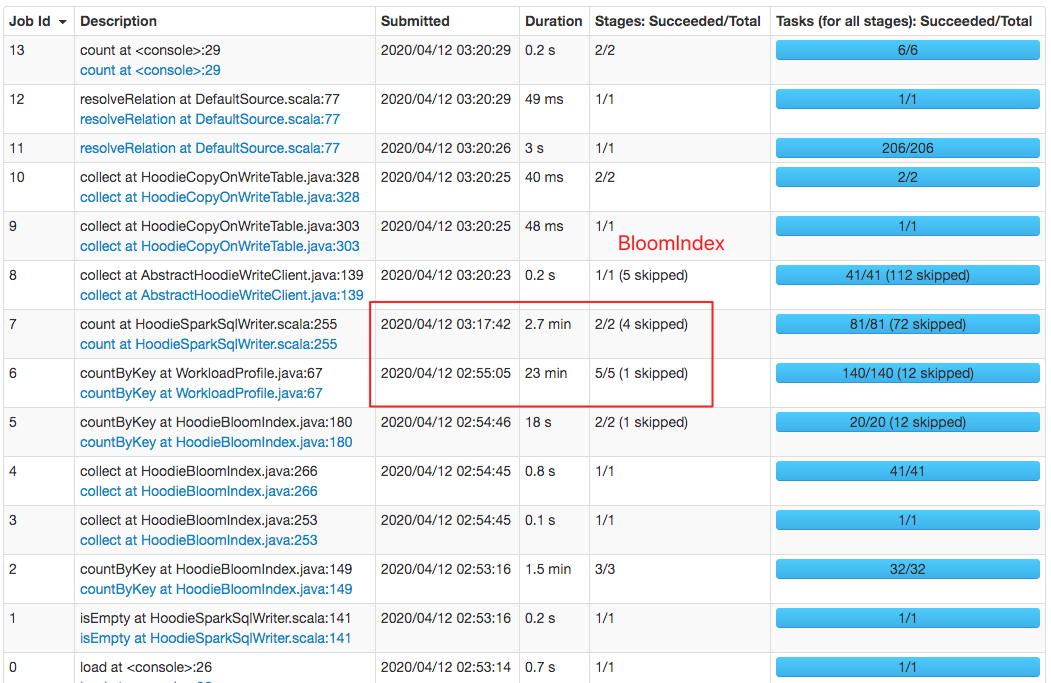
`HoodieBloomIndexV2`: cost about 3min
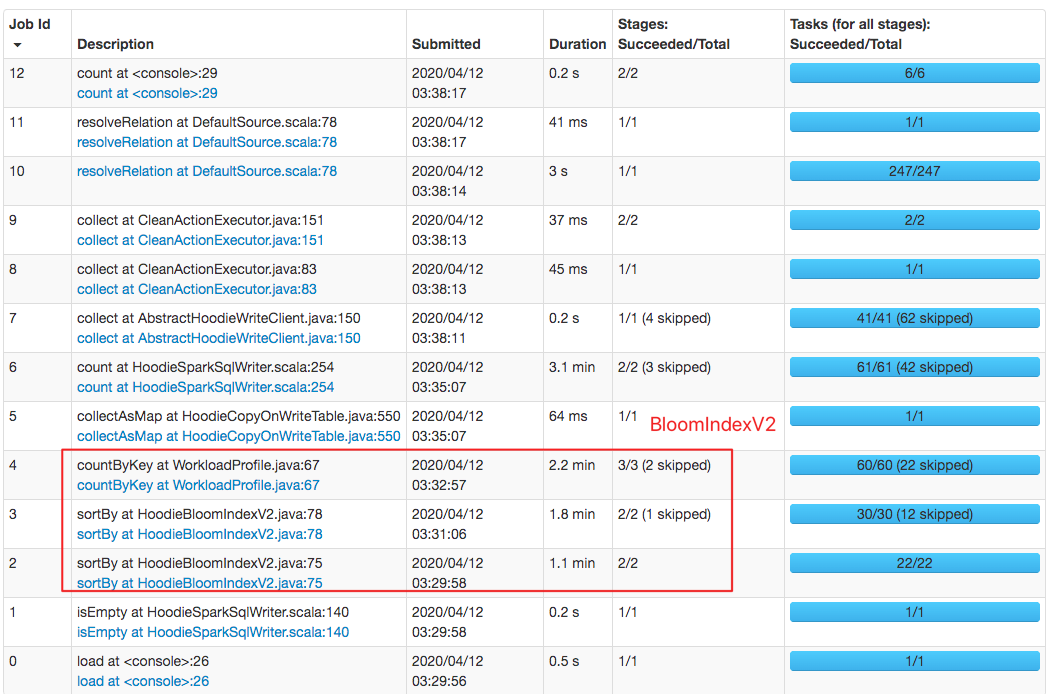
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2
that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612499511
Hi @vinothchandar base on your branch, there are mainly the following
updates:
- Rebase master branch
- Add TestHoodieBloomIndexV2.java
- Add DeltaTimer.java
- Fix an implicit bug which causes repeat input record
**Bug fix**
In the stage of double
check(`HoodieBloomIndexV2.LazyKeyChecker#computeNext`),
when the target file doesn't contains the record key, should return
`Option.empty()`.
**Previous**
```
Option> ret = fileIdOpt.map(fileId -> {
if (currHandle == null || !currHandle.getFileId().equals(fileId)) {
currHandle = new HoodieKeyLookupHandle<>(config, table,
Pair.of(record.getPartitionPath(), fileId));
}
Option location =
currHandle.containsKey(record.getRecordKey())
? Option.of(new HoodieRecordLocation(currHandle.getBaseInstantTime(),
currHandle.getFileId()))
: Option.empty();
return Option.of(getTaggedRecord(record, location));
}).orElse(Option.of(record));
```
**Changes**
```
Option> recordOpt = fileIdOpt.map((Function>>) fileId -> {
DeltaTimer deltaTimer = new DeltaTimer();
if (currHandle == null || !currHandle.getFileId().equals(fileId)) {
currHandle = new HoodieKeyLookupHandle<>(config, table,
Pair.of(record.getPartitionPath(), fileId));
}
totalReadTimeMs += deltaTimer.deltaTime();
if (currHandle.containsKey(record.getRecordKey())) {
HoodieRecordLocation recordLocation = new
HoodieRecordLocation(currHandle.getBaseInstantTime(), currHandle.getFileId());
return Option.of(getTaggedRecord(record, recordLocation));
} else {
return Option.empty();
}
}).orElse(Option.of(record));
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2
that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612499511
Hi @vinothchandar base on your branch, there are mainly the following
updates:
- Rebase branch
- Add TestHoodieBloomIndexV2.java
- Add DeltaTimer.java
- Fix an implicit bug which causes repeat input record
**Bug fix**
In the stage of double
check(`HoodieBloomIndexV2.LazyKeyChecker#computeNext`),
when the target file doesn't contains the record key, should return
`Option.empty()`.
**Previous**
```
Option> ret = fileIdOpt.map(fileId -> {
if (currHandle == null || !currHandle.getFileId().equals(fileId)) {
currHandle = new HoodieKeyLookupHandle<>(config, table,
Pair.of(record.getPartitionPath(), fileId));
}
Option location =
currHandle.containsKey(record.getRecordKey())
? Option.of(new HoodieRecordLocation(currHandle.getBaseInstantTime(),
currHandle.getFileId()))
: Option.empty();
return Option.of(getTaggedRecord(record, location));
}).orElse(Option.of(record));
```
**Changes**
```
Option> recordOpt = fileIdOpt.map((Function>>) fileId -> {
DeltaTimer deltaTimer = new DeltaTimer();
if (currHandle == null || !currHandle.getFileId().equals(fileId)) {
currHandle = new HoodieKeyLookupHandle<>(config, table,
Pair.of(record.getPartitionPath(), fileId));
}
totalReadTimeMs += deltaTimer.deltaTime();
if (currHandle.containsKey(record.getRecordKey())) {
HoodieRecordLocation recordLocation = new
HoodieRecordLocation(currHandle.getBaseInstantTime(), currHandle.getFileId());
return Option.of(getTaggedRecord(record, recordLocation));
} else {
return Option.empty();
}
}).orElse(Option.of(record));
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612543458 > @lamber-ken thanks for the update.. from the UI, it seems like the difference was only in `countByKey/WorkloadProfile` which has nothing to do with indexing? The above shows the spark job page, a job is a sequence of stages which triggered by an action such as .count(), collect(), read() and etc. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2 that does not depend on memory caching
lamber-ken edited a comment on issue #1469: [HUDI-686] Implement BloomIndexV2
that does not depend on memory caching
URL: https://github.com/apache/incubator-hudi/pull/1469#issuecomment-612500968
Also, index performance has been greatly improved, your idea and design is
amazing @vinothchandar
I tested `upsert` 500, records, `bulk_insert` first, then do `upsert`
operation with the same dataset
1. Download CSV data with 5M records
```
https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
```
2. Run demo command
```
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--packages
org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4
\
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--jars `ls
packaging/hudi-spark-bundle/target/hudi-spark-bundle_*.*-*.*.*-SNAPSHOT.jar` \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_table"
val basePath = "file:///tmp/hudi_mor_table"
var inputDF = spark.read.format("csv").option("header",
"true").load("file:///work/hudi-debug/2.csv")
val hudiOptions = Map[String,String](
"hoodie.insert.shuffle.parallelism" -> "10",
"hoodie.upsert.shuffle.parallelism" -> "10",
"hoodie.delete.shuffle.parallelism" -> "10",
"hoodie.bulkinsert.shuffle.parallelism" -> "10",
"hoodie.datasource.write.recordkey.field" -> "tds_cid",
"hoodie.datasource.write.partitionpath.field" -> "hit_date",
"hoodie.table.name" -> tableName,
"hoodie.datasource.write.precombine.field" -> "hit_timestamp",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.memory.merge.max.size" -> "200485760",
"hoodie.index.type" -> "BLOOM_V2",
"hoodie.bloom.index.v2.buffer.max.size" -> "1020"
)
inputDF.write.format("org.apache.hudi").
options(hudiOptions).
mode("Append").
save(basePath)
spark.read.format("org.apache.hudi").load(basePath +
"/2020-03-19/*").count();
```
### Performance comparison
`HoodieBloomIndex`: cost about 20min

`HoodieBloomIndexV2`: cost about 3min

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services