svn commit: r24311 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_18_22_01-541dbc0-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 06:14:47 2018 New Revision: 24311 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_18_22_01-541dbc0 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24308 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_18_20_01-568055d-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 04:15:02 2018 New Revision: 24308 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_18_20_01-568055d docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when casting PythonUserDefinedType to String.
Repository: spark
Updated Branches:
refs/heads/branch-2.3 225b1afdd -> 541dbc00b
[SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when casting
PythonUserDefinedType to String.
## What changes were proposed in this pull request?
This is a follow-up of #20246.
If a UDT in Python doesn't have its corresponding Scala UDT, cast to string
will be the raw string of the internal value, e.g.
`"org.apache.spark.sql.catalyst.expressions.UnsafeArrayData"` if the
internal type is `ArrayType`.
This pr fixes it by using its `sqlType` casting.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN
Closes #20306 from ueshin/issues/SPARK-23054/fup1.
(cherry picked from commit 568055da93049c207bb830f244ff9b60c638837c)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/541dbc00
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/541dbc00
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/541dbc00
Branch: refs/heads/branch-2.3
Commit: 541dbc00b24f17d83ea2531970f2e9fe57fe3718
Parents: 225b1af
Author: Takuya UESHIN
Authored: Fri Jan 19 11:37:08 2018 +0800
Committer: Wenchen Fan
Committed: Fri Jan 19 11:38:37 2018 +0800
--
python/pyspark/sql/tests.py | 11 +++
.../org/apache/spark/sql/catalyst/expressions/Cast.scala | 2 ++
.../org/apache/spark/sql/test/ExamplePointUDT.scala | 2 ++
3 files changed, 15 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/541dbc00/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index 2548359..4fee2ec 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -1189,6 +1189,17 @@ class SQLTests(ReusedSQLTestCase):
]
)
+def test_cast_to_string_with_udt(self):
+from pyspark.sql.tests import ExamplePointUDT, ExamplePoint
+from pyspark.sql.functions import col
+row = (ExamplePoint(1.0, 2.0), PythonOnlyPoint(3.0, 4.0))
+schema = StructType([StructField("point", ExamplePointUDT(), False),
+ StructField("pypoint", PythonOnlyUDT(), False)])
+df = self.spark.createDataFrame([row], schema)
+
+result = df.select(col('point').cast('string'),
col('pypoint').cast('string')).head()
+self.assertEqual(result, Row(point=u'(1.0, 2.0)', pypoint=u'[3.0,
4.0]'))
+
def test_column_operators(self):
ci = self.df.key
cs = self.df.value
http://git-wip-us.apache.org/repos/asf/spark/blob/541dbc00/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
index a95ebe3..79b0516 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
@@ -282,6 +282,7 @@ case class Cast(child: Expression, dataType: DataType,
timeZoneId: Option[String
builder.append("]")
builder.build()
})
+case pudt: PythonUserDefinedType => castToString(pudt.sqlType)
case udt: UserDefinedType[_] =>
buildCast[Any](_, o =>
UTF8String.fromString(udt.deserialize(o).toString))
case _ => buildCast[Any](_, o => UTF8String.fromString(o.toString))
@@ -838,6 +839,7 @@ case class Cast(child: Expression, dataType: DataType,
timeZoneId: Option[String
|$evPrim = $buffer.build();
""".stripMargin
}
+ case pudt: PythonUserDefinedType => castToStringCode(pudt.sqlType, ctx)
case udt: UserDefinedType[_] =>
val udtRef = ctx.addReferenceObj("udt", udt)
(c, evPrim, evNull) => {
http://git-wip-us.apache.org/repos/asf/spark/blob/541dbc00/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
b/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
index a73e427..8bab7e1 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
@@ -34,6 +34,8 @@ private[sql] class ExamplePoint(val x: Double, val y: Double)
extends Serializab
case that: ExamplePoint => this.x == that.x && this.y == that.y
case _ => false
}
+
+ override def toString(): Stri
spark git commit: [SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when casting PythonUserDefinedType to String.
Repository: spark
Updated Branches:
refs/heads/master 6121e91b7 -> 568055da9
[SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when casting
PythonUserDefinedType to String.
## What changes were proposed in this pull request?
This is a follow-up of #20246.
If a UDT in Python doesn't have its corresponding Scala UDT, cast to string
will be the raw string of the internal value, e.g.
`"org.apache.spark.sql.catalyst.expressions.UnsafeArrayData"` if the
internal type is `ArrayType`.
This pr fixes it by using its `sqlType` casting.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN
Closes #20306 from ueshin/issues/SPARK-23054/fup1.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/568055da
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/568055da
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/568055da
Branch: refs/heads/master
Commit: 568055da93049c207bb830f244ff9b60c638837c
Parents: 6121e91
Author: Takuya UESHIN
Authored: Fri Jan 19 11:37:08 2018 +0800
Committer: Wenchen Fan
Committed: Fri Jan 19 11:37:08 2018 +0800
--
python/pyspark/sql/tests.py | 11 +++
.../org/apache/spark/sql/catalyst/expressions/Cast.scala | 2 ++
.../org/apache/spark/sql/test/ExamplePointUDT.scala | 2 ++
3 files changed, 15 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/568055da/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index 2548359..4fee2ec 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -1189,6 +1189,17 @@ class SQLTests(ReusedSQLTestCase):
]
)
+def test_cast_to_string_with_udt(self):
+from pyspark.sql.tests import ExamplePointUDT, ExamplePoint
+from pyspark.sql.functions import col
+row = (ExamplePoint(1.0, 2.0), PythonOnlyPoint(3.0, 4.0))
+schema = StructType([StructField("point", ExamplePointUDT(), False),
+ StructField("pypoint", PythonOnlyUDT(), False)])
+df = self.spark.createDataFrame([row], schema)
+
+result = df.select(col('point').cast('string'),
col('pypoint').cast('string')).head()
+self.assertEqual(result, Row(point=u'(1.0, 2.0)', pypoint=u'[3.0,
4.0]'))
+
def test_column_operators(self):
ci = self.df.key
cs = self.df.value
http://git-wip-us.apache.org/repos/asf/spark/blob/568055da/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
index a95ebe3..79b0516 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
@@ -282,6 +282,7 @@ case class Cast(child: Expression, dataType: DataType,
timeZoneId: Option[String
builder.append("]")
builder.build()
})
+case pudt: PythonUserDefinedType => castToString(pudt.sqlType)
case udt: UserDefinedType[_] =>
buildCast[Any](_, o =>
UTF8String.fromString(udt.deserialize(o).toString))
case _ => buildCast[Any](_, o => UTF8String.fromString(o.toString))
@@ -838,6 +839,7 @@ case class Cast(child: Expression, dataType: DataType,
timeZoneId: Option[String
|$evPrim = $buffer.build();
""".stripMargin
}
+ case pudt: PythonUserDefinedType => castToStringCode(pudt.sqlType, ctx)
case udt: UserDefinedType[_] =>
val udtRef = ctx.addReferenceObj("udt", udt)
(c, evPrim, evNull) => {
http://git-wip-us.apache.org/repos/asf/spark/blob/568055da/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
b/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
index a73e427..8bab7e1 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/test/ExamplePointUDT.scala
@@ -34,6 +34,8 @@ private[sql] class ExamplePoint(val x: Double, val y: Double)
extends Serializab
case that: ExamplePoint => this.x == that.x && this.y == that.y
case _ => false
}
+
+ override def toString(): String = s"($x, $y)"
}
/**
-
To unsu
svn commit: r24306 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_18_18_01-225b1af-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 02:14:38 2018 New Revision: 24306 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_18_18_01-225b1af docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [DOCS] change to dataset for java code in structured-streaming-kafka-integration document
Repository: spark
Updated Branches:
refs/heads/branch-2.3 acf3b70d1 -> 225b1afdd
[DOCS] change to dataset for java code in
structured-streaming-kafka-integration document
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example
for Kafka integration is using `DataFrame`, shouldn't it be changed to
`DataSet`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark
2.2.1 with Kafka 1.0
Author: brandonJY
Closes #20312 from brandonJY/patch-2.
(cherry picked from commit 6121e91b7f5c9513d68674e4d5edbc3a4a5fd5fd)
Signed-off-by: Sean Owen
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/225b1afd
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/225b1afd
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/225b1afd
Branch: refs/heads/branch-2.3
Commit: 225b1afdd1582cd4087e7cb98834505eaf16743e
Parents: acf3b70
Author: brandonJY
Authored: Thu Jan 18 18:57:49 2018 -0600
Committer: Sean Owen
Committed: Thu Jan 18 18:57:56 2018 -0600
--
docs/structured-streaming-kafka-integration.md | 12 ++--
1 file changed, 6 insertions(+), 6 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/225b1afd/docs/structured-streaming-kafka-integration.md
--
diff --git a/docs/structured-streaming-kafka-integration.md
b/docs/structured-streaming-kafka-integration.md
index bab0be8..461c29c 100644
--- a/docs/structured-streaming-kafka-integration.md
+++ b/docs/structured-streaming-kafka-integration.md
@@ -61,7 +61,7 @@ df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
{% highlight java %}
// Subscribe to 1 topic
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -70,7 +70,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to multiple topics
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -79,7 +79,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to a pattern
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -171,7 +171,7 @@ df.selectExpr("CAST(key AS STRING)", "CAST(value AS
STRING)")
{% highlight java %}
// Subscribe to 1 topic defaults to the earliest and latest offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -180,7 +180,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to multiple topics, specifying explicit Kafka offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -191,7 +191,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to a pattern, at the earliest and latest offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [DOCS] change to dataset for java code in structured-streaming-kafka-integration document
Repository: spark
Updated Branches:
refs/heads/branch-2.2 d09eecccf -> 0e58fee9d
[DOCS] change to dataset for java code in
structured-streaming-kafka-integration document
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example
for Kafka integration is using `DataFrame`, shouldn't it be changed to
`DataSet`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark
2.2.1 with Kafka 1.0
Author: brandonJY
Closes #20312 from brandonJY/patch-2.
(cherry picked from commit 6121e91b7f5c9513d68674e4d5edbc3a4a5fd5fd)
Signed-off-by: Sean Owen
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/0e58fee9
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/0e58fee9
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/0e58fee9
Branch: refs/heads/branch-2.2
Commit: 0e58fee9dfbd82d54e1715533e4ceae9c916fb34
Parents: d09eecc
Author: brandonJY
Authored: Thu Jan 18 18:57:49 2018 -0600
Committer: Sean Owen
Committed: Thu Jan 18 18:58:06 2018 -0600
--
docs/structured-streaming-kafka-integration.md | 12 ++--
1 file changed, 6 insertions(+), 6 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/0e58fee9/docs/structured-streaming-kafka-integration.md
--
diff --git a/docs/structured-streaming-kafka-integration.md
b/docs/structured-streaming-kafka-integration.md
index 217c1a9..f516a72 100644
--- a/docs/structured-streaming-kafka-integration.md
+++ b/docs/structured-streaming-kafka-integration.md
@@ -59,7 +59,7 @@ df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
{% highlight java %}
// Subscribe to 1 topic
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -68,7 +68,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to multiple topics
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -77,7 +77,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to a pattern
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -169,7 +169,7 @@ df.selectExpr("CAST(key AS STRING)", "CAST(value AS
STRING)")
{% highlight java %}
// Subscribe to 1 topic defaults to the earliest and latest offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -178,7 +178,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to multiple topics, specifying explicit Kafka offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -189,7 +189,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to a pattern, at the earliest and latest offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [DOCS] change to dataset for java code in structured-streaming-kafka-integration document
Repository: spark
Updated Branches:
refs/heads/master 4cd2ecc0c -> 6121e91b7
[DOCS] change to dataset for java code in
structured-streaming-kafka-integration document
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example
for Kafka integration is using `DataFrame`, shouldn't it be changed to
`DataSet`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark
2.2.1 with Kafka 1.0
Author: brandonJY
Closes #20312 from brandonJY/patch-2.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/6121e91b
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/6121e91b
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/6121e91b
Branch: refs/heads/master
Commit: 6121e91b7f5c9513d68674e4d5edbc3a4a5fd5fd
Parents: 4cd2ecc
Author: brandonJY
Authored: Thu Jan 18 18:57:49 2018 -0600
Committer: Sean Owen
Committed: Thu Jan 18 18:57:49 2018 -0600
--
docs/structured-streaming-kafka-integration.md | 12 ++--
1 file changed, 6 insertions(+), 6 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/6121e91b/docs/structured-streaming-kafka-integration.md
--
diff --git a/docs/structured-streaming-kafka-integration.md
b/docs/structured-streaming-kafka-integration.md
index bab0be8..461c29c 100644
--- a/docs/structured-streaming-kafka-integration.md
+++ b/docs/structured-streaming-kafka-integration.md
@@ -61,7 +61,7 @@ df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
{% highlight java %}
// Subscribe to 1 topic
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -70,7 +70,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to multiple topics
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -79,7 +79,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to a pattern
-DataFrame df = spark
+Dataset df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -171,7 +171,7 @@ df.selectExpr("CAST(key AS STRING)", "CAST(value AS
STRING)")
{% highlight java %}
// Subscribe to 1 topic defaults to the earliest and latest offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -180,7 +180,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to multiple topics, specifying explicit Kafka offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
@@ -191,7 +191,7 @@ DataFrame df = spark
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to a pattern, at the earliest and latest offsets
-DataFrame df = spark
+Dataset df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23142][SS][DOCS] Added docs for continuous processing
Repository: spark Updated Branches: refs/heads/branch-2.3 7057e310a -> acf3b70d1 [SPARK-23142][SS][DOCS] Added docs for continuous processing ## What changes were proposed in this pull request? Added documentation for continuous processing. Modified two locations. - Modified the overview to have a mention of Continuous Processing. - Added a new section on Continuous Processing at the end.   ## How was this patch tested? N/A Author: Tathagata Das Closes #20308 from tdas/SPARK-23142. (cherry picked from commit 4cd2ecc0c7222fef1337e04f1948333296c3be86) Signed-off-by: Tathagata Das Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/acf3b70d Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/acf3b70d Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/acf3b70d Branch: refs/heads/branch-2.3 Commit: acf3b70d16cc4d2416b4ce3f42b3cf95836170ed Parents: 7057e31 Author: Tathagata Das Authored: Thu Jan 18 16:29:45 2018 -0800 Committer: Tathagata Das Committed: Thu Jan 18 16:29:56 2018 -0800 -- docs/structured-streaming-programming-guide.md | 98 - 1 file changed, 97 insertions(+), 1 deletion(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/acf3b70d/docs/structured-streaming-programming-guide.md -- diff --git a/docs/structured-streaming-programming-guide.md b/docs/structured-streaming-programming-guide.md index 1779a42..2ddba2f 100644 --- a/docs/structured-streaming-programming-guide.md +++ b/docs/structured-streaming-programming-guide.md @@ -10,7 +10,9 @@ title: Structured Streaming Programming Guide # Overview Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the [Dataset/DataFrame API](sql-programming-guide.html) in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The computation is executed on the same optimized Spark SQL engine. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write Ahead Logs. In short, *Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.* -In this guide, we are going to walk you through the programming model and the APIs. First, let's start with a simple example - a streaming word count. +Internally, by default, Structured Streaming queries are processed using a *micro-batch processing* engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees. However, since Spark 2.3, we have introduced a new low-latency processing mode called **Continuous Processing**, which can achieve end-to-end latencies as low as 1 millisecond with at-least-once guarantees. Without changing the Dataset/DataFrame operations in your queries, you will be able choose the mode based on your application requirements. + +In this guide, we are going to walk you through the programming model and the APIs. We are going to explain the concepts mostly using the default micro-batch processing model, and then [later](#continuous-processing-experimental) discuss Continuous Processing model. First, let's start with a simple example of a Structured Streaming query - a streaming word count. # Quick Example Letâs say you want to maintain a running word count of text data received from a data server listening on a TCP socket. Letâs see how you can express this using Structured Streaming. You can see the full code in @@ -2434,6 +2436,100 @@ write.stream(aggDF, "memory", outputMode = "complete", checkpointLocation = "pat +# Continuous Processing [Experimental] +**Continuous processing** is a new, experimental streaming execution mode introduced in Spark 2.3 that enables low (~1 ms) end-to-end latency with at-least-once fault-tolerance guarantees. Compare this with the default *micro-batch processing* engine which can achieve exactly-once guarantees but achieve latencies of ~100ms at best. For some types of queries (discussed below), you can choose which mode to execute them in without modifying the a
spark git commit: [SPARK-23142][SS][DOCS] Added docs for continuous processing
Repository: spark Updated Branches: refs/heads/master 5d7c4ba4d -> 4cd2ecc0c [SPARK-23142][SS][DOCS] Added docs for continuous processing ## What changes were proposed in this pull request? Added documentation for continuous processing. Modified two locations. - Modified the overview to have a mention of Continuous Processing. - Added a new section on Continuous Processing at the end.   ## How was this patch tested? N/A Author: Tathagata Das Closes #20308 from tdas/SPARK-23142. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/4cd2ecc0 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/4cd2ecc0 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/4cd2ecc0 Branch: refs/heads/master Commit: 4cd2ecc0c7222fef1337e04f1948333296c3be86 Parents: 5d7c4ba Author: Tathagata Das Authored: Thu Jan 18 16:29:45 2018 -0800 Committer: Tathagata Das Committed: Thu Jan 18 16:29:45 2018 -0800 -- docs/structured-streaming-programming-guide.md | 98 - 1 file changed, 97 insertions(+), 1 deletion(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/4cd2ecc0/docs/structured-streaming-programming-guide.md -- diff --git a/docs/structured-streaming-programming-guide.md b/docs/structured-streaming-programming-guide.md index 1779a42..2ddba2f 100644 --- a/docs/structured-streaming-programming-guide.md +++ b/docs/structured-streaming-programming-guide.md @@ -10,7 +10,9 @@ title: Structured Streaming Programming Guide # Overview Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the [Dataset/DataFrame API](sql-programming-guide.html) in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The computation is executed on the same optimized Spark SQL engine. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write Ahead Logs. In short, *Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.* -In this guide, we are going to walk you through the programming model and the APIs. First, let's start with a simple example - a streaming word count. +Internally, by default, Structured Streaming queries are processed using a *micro-batch processing* engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees. However, since Spark 2.3, we have introduced a new low-latency processing mode called **Continuous Processing**, which can achieve end-to-end latencies as low as 1 millisecond with at-least-once guarantees. Without changing the Dataset/DataFrame operations in your queries, you will be able choose the mode based on your application requirements. + +In this guide, we are going to walk you through the programming model and the APIs. We are going to explain the concepts mostly using the default micro-batch processing model, and then [later](#continuous-processing-experimental) discuss Continuous Processing model. First, let's start with a simple example of a Structured Streaming query - a streaming word count. # Quick Example Letâs say you want to maintain a running word count of text data received from a data server listening on a TCP socket. Letâs see how you can express this using Structured Streaming. You can see the full code in @@ -2434,6 +2436,100 @@ write.stream(aggDF, "memory", outputMode = "complete", checkpointLocation = "pat +# Continuous Processing [Experimental] +**Continuous processing** is a new, experimental streaming execution mode introduced in Spark 2.3 that enables low (~1 ms) end-to-end latency with at-least-once fault-tolerance guarantees. Compare this with the default *micro-batch processing* engine which can achieve exactly-once guarantees but achieve latencies of ~100ms at best. For some types of queries (discussed below), you can choose which mode to execute them in without modifying the application logic (i.e. without changing the DataFrame/Dataset operations). + +To run a supported query in c
svn commit: r24303 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_18_16_01-5d7c4ba-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 00:14:43 2018 New Revision: 24303 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_18_16_01-5d7c4ba docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-22962][K8S] Fail fast if submission client local files are used
Repository: spark
Updated Branches:
refs/heads/branch-2.3 a295034da -> 7057e310a
[SPARK-22962][K8S] Fail fast if submission client local files are used
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission
client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li
Closes #20320 from liyinan926/master.
(cherry picked from commit 5d7c4ba4d73a72f26d591108db3c20b4a6c84f3f)
Signed-off-by: Marcelo Vanzin
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/7057e310
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/7057e310
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/7057e310
Branch: refs/heads/branch-2.3
Commit: 7057e310ab3756c83c13586137e8390fe9ef7e9a
Parents: a295034
Author: Yinan Li
Authored: Thu Jan 18 14:44:22 2018 -0800
Committer: Marcelo Vanzin
Committed: Thu Jan 18 14:44:33 2018 -0800
--
docs/running-on-kubernetes.md | 5 +++-
.../k8s/submit/DriverConfigOrchestrator.scala | 14 -
.../submit/DriverConfigOrchestratorSuite.scala | 31 +++-
3 files changed, 47 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/7057e310/docs/running-on-kubernetes.md
--
diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md
index 08ec34c..d6b1735 100644
--- a/docs/running-on-kubernetes.md
+++ b/docs/running-on-kubernetes.md
@@ -117,7 +117,10 @@ This URI is the location of the example jar that is
already in the Docker image.
If your application's dependencies are all hosted in remote locations like
HDFS or HTTP servers, they may be referred to
by their appropriate remote URIs. Also, application dependencies can be
pre-mounted into custom-built Docker images.
Those dependencies can be added to the classpath by referencing them with
`local://` URIs and/or setting the
-`SPARK_EXTRA_CLASSPATH` environment variable in your Dockerfiles.
+`SPARK_EXTRA_CLASSPATH` environment variable in your Dockerfiles. The
`local://` scheme is also required when referring to
+dependencies in custom-built Docker images in `spark-submit`. Note that using
application dependencies from the submission
+client's local file system is currently not yet supported.
+
### Using Remote Dependencies
When there are application dependencies hosted in remote locations like HDFS
or HTTP servers, the driver and executor pods
http://git-wip-us.apache.org/repos/asf/spark/blob/7057e310/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
--
diff --git
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
index c9cc300..ae70904 100644
---
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
+++
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
@@ -20,7 +20,7 @@ import java.util.UUID
import com.google.common.primitives.Longs
-import org.apache.spark.SparkConf
+import org.apache.spark.{SparkConf, SparkException}
import org.apache.spark.deploy.k8s.{KubernetesUtils, MountSecretsBootstrap}
import org.apache.spark.deploy.k8s.Config._
import org.apache.spark.deploy.k8s.Constants._
@@ -117,6 +117,12 @@ private[spark] class DriverConfigOrchestrator(
.map(_.split(","))
.getOrElse(Array.empty[String])
+// TODO(SPARK-23153): remove once submission client local dependencies are
supported.
+if (existSubmissionLocalFiles(sparkJars) ||
existSubmissionLocalFiles(sparkFiles)) {
+ throw new SparkException("The Kubernetes mode does not yet support
referencing application " +
+"dependencies in the local file system.")
+}
+
val dependencyResolutionStep = if (sparkJars.nonEmpty ||
sparkFiles.nonEmpty) {
Seq(new DependencyResolutionStep(
sparkJars,
@@ -162,6 +168,12 @@ private[spark] class DriverConfigOrchestrator(
initContainerBootstrapStep
}
+ private def existSubmissionLocalFiles(files: Seq[String]): Boolean = {
+files.exists { uri =>
+ Utils.resolveURI(uri).getScheme == "file"
+}
+ }
+
private def existNonContainerLocalFiles(files: Seq[String]): Boolean = {
files.exists { uri =>
Utils.resolveURI(uri).getScheme != "local"
http
spark git commit: [SPARK-22962][K8S] Fail fast if submission client local files are used
Repository: spark
Updated Branches:
refs/heads/master e01919e83 -> 5d7c4ba4d
[SPARK-22962][K8S] Fail fast if submission client local files are used
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission
client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li
Closes #20320 from liyinan926/master.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/5d7c4ba4
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/5d7c4ba4
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/5d7c4ba4
Branch: refs/heads/master
Commit: 5d7c4ba4d73a72f26d591108db3c20b4a6c84f3f
Parents: e01919e
Author: Yinan Li
Authored: Thu Jan 18 14:44:22 2018 -0800
Committer: Marcelo Vanzin
Committed: Thu Jan 18 14:44:22 2018 -0800
--
docs/running-on-kubernetes.md | 5 +++-
.../k8s/submit/DriverConfigOrchestrator.scala | 14 -
.../submit/DriverConfigOrchestratorSuite.scala | 31 +++-
3 files changed, 47 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/5d7c4ba4/docs/running-on-kubernetes.md
--
diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md
index 08ec34c..d6b1735 100644
--- a/docs/running-on-kubernetes.md
+++ b/docs/running-on-kubernetes.md
@@ -117,7 +117,10 @@ This URI is the location of the example jar that is
already in the Docker image.
If your application's dependencies are all hosted in remote locations like
HDFS or HTTP servers, they may be referred to
by their appropriate remote URIs. Also, application dependencies can be
pre-mounted into custom-built Docker images.
Those dependencies can be added to the classpath by referencing them with
`local://` URIs and/or setting the
-`SPARK_EXTRA_CLASSPATH` environment variable in your Dockerfiles.
+`SPARK_EXTRA_CLASSPATH` environment variable in your Dockerfiles. The
`local://` scheme is also required when referring to
+dependencies in custom-built Docker images in `spark-submit`. Note that using
application dependencies from the submission
+client's local file system is currently not yet supported.
+
### Using Remote Dependencies
When there are application dependencies hosted in remote locations like HDFS
or HTTP servers, the driver and executor pods
http://git-wip-us.apache.org/repos/asf/spark/blob/5d7c4ba4/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
--
diff --git
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
index c9cc300..ae70904 100644
---
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
+++
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/DriverConfigOrchestrator.scala
@@ -20,7 +20,7 @@ import java.util.UUID
import com.google.common.primitives.Longs
-import org.apache.spark.SparkConf
+import org.apache.spark.{SparkConf, SparkException}
import org.apache.spark.deploy.k8s.{KubernetesUtils, MountSecretsBootstrap}
import org.apache.spark.deploy.k8s.Config._
import org.apache.spark.deploy.k8s.Constants._
@@ -117,6 +117,12 @@ private[spark] class DriverConfigOrchestrator(
.map(_.split(","))
.getOrElse(Array.empty[String])
+// TODO(SPARK-23153): remove once submission client local dependencies are
supported.
+if (existSubmissionLocalFiles(sparkJars) ||
existSubmissionLocalFiles(sparkFiles)) {
+ throw new SparkException("The Kubernetes mode does not yet support
referencing application " +
+"dependencies in the local file system.")
+}
+
val dependencyResolutionStep = if (sparkJars.nonEmpty ||
sparkFiles.nonEmpty) {
Seq(new DependencyResolutionStep(
sparkJars,
@@ -162,6 +168,12 @@ private[spark] class DriverConfigOrchestrator(
initContainerBootstrapStep
}
+ private def existSubmissionLocalFiles(files: Seq[String]): Boolean = {
+files.exists { uri =>
+ Utils.resolveURI(uri).getScheme == "file"
+}
+ }
+
private def existNonContainerLocalFiles(files: Seq[String]): Boolean = {
files.exists { uri =>
Utils.resolveURI(uri).getScheme != "local"
http://git-wip-us.apache.org/repos/asf/spark/blob/5d7c4ba4/resource-managers/kubernetes/core/src/test/scala/org/a
spark git commit: [SPARK-23094] Fix invalid character handling in JsonDataSource
Repository: spark
Updated Branches:
refs/heads/branch-2.3 b8c6d9303 -> a295034da
[SPARK-23094] Fix invalid character handling in JsonDataSource
## What changes were proposed in this pull request?
There were two related fixes regarding `from_json`, `get_json_object` and
`json_tuple` ([Fix
#1](https://github.com/apache/spark/commit/c8803c06854683c8761fdb3c0e4c55d5a9e22a95),
[Fix
#2](https://github.com/apache/spark/commit/86174ea89b39a300caaba6baffac70f3dc702788)),
but they weren't comprehensive it seems. I wanted to extend those fixes to all
the parsers, and add tests for each case.
## How was this patch tested?
Regression tests
Author: Burak Yavuz
Closes #20302 from brkyvz/json-invfix.
(cherry picked from commit e01919e834d301e13adc8919932796ebae900576)
Signed-off-by: hyukjinkwon
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/a295034d
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/a295034d
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/a295034d
Branch: refs/heads/branch-2.3
Commit: a295034da6178f8654c3977903435384b3765b5e
Parents: b8c6d93
Author: Burak Yavuz
Authored: Fri Jan 19 07:36:06 2018 +0900
Committer: hyukjinkwon
Committed: Fri Jan 19 07:36:21 2018 +0900
--
.../sql/catalyst/json/CreateJacksonParser.scala | 5 +--
.../sql/sources/JsonHadoopFsRelationSuite.scala | 34
2 files changed, 37 insertions(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/a295034d/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
index 025a388..b1672e7 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
@@ -40,10 +40,11 @@ private[sql] object CreateJacksonParser extends
Serializable {
}
def text(jsonFactory: JsonFactory, record: Text): JsonParser = {
-jsonFactory.createParser(record.getBytes, 0, record.getLength)
+val bain = new ByteArrayInputStream(record.getBytes, 0, record.getLength)
+jsonFactory.createParser(new InputStreamReader(bain, "UTF-8"))
}
def inputStream(jsonFactory: JsonFactory, record: InputStream): JsonParser =
{
-jsonFactory.createParser(record)
+jsonFactory.createParser(new InputStreamReader(record, "UTF-8"))
}
}
http://git-wip-us.apache.org/repos/asf/spark/blob/a295034d/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
index 49be304..27f398e 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
@@ -28,6 +28,8 @@ import org.apache.spark.sql.types._
class JsonHadoopFsRelationSuite extends HadoopFsRelationTest {
override val dataSourceName: String = "json"
+ private val badJson = "\u\u\uA\u0001AAA"
+
// JSON does not write data of NullType and does not play well with
BinaryType.
override protected def supportsDataType(dataType: DataType): Boolean =
dataType match {
case _: NullType => false
@@ -105,4 +107,36 @@ class JsonHadoopFsRelationSuite extends
HadoopFsRelationTest {
)
}
}
+
+ test("invalid json with leading nulls - from file (multiLine=true)") {
+import testImplicits._
+withTempDir { tempDir =>
+ val path = tempDir.getAbsolutePath
+ Seq(badJson, """{"a":1}""").toDS().write.mode("overwrite").text(path)
+ val expected = s"""$badJson\n{"a":1}\n"""
+ val schema = new StructType().add("a",
IntegerType).add("_corrupt_record", StringType)
+ val df =
+spark.read.format(dataSourceName).option("multiLine",
true).schema(schema).load(path)
+ checkAnswer(df, Row(null, expected))
+}
+ }
+
+ test("invalid json with leading nulls - from file (multiLine=false)") {
+import testImplicits._
+withTempDir { tempDir =>
+ val path = tempDir.getAbsolutePath
+ Seq(badJson, """{"a":1}""").toDS().write.mode("overwrite").text(path)
+ val schema = new StructType().add("a",
IntegerType).add("_corrupt_record", StringType)
+ val df =
+spark.read.format(dataSourceName).option("multiLine",
false).s
spark git commit: [SPARK-23094] Fix invalid character handling in JsonDataSource
Repository: spark
Updated Branches:
refs/heads/master f568e9cf7 -> e01919e83
[SPARK-23094] Fix invalid character handling in JsonDataSource
## What changes were proposed in this pull request?
There were two related fixes regarding `from_json`, `get_json_object` and
`json_tuple` ([Fix
#1](https://github.com/apache/spark/commit/c8803c06854683c8761fdb3c0e4c55d5a9e22a95),
[Fix
#2](https://github.com/apache/spark/commit/86174ea89b39a300caaba6baffac70f3dc702788)),
but they weren't comprehensive it seems. I wanted to extend those fixes to all
the parsers, and add tests for each case.
## How was this patch tested?
Regression tests
Author: Burak Yavuz
Closes #20302 from brkyvz/json-invfix.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e01919e8
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e01919e8
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e01919e8
Branch: refs/heads/master
Commit: e01919e834d301e13adc8919932796ebae900576
Parents: f568e9c
Author: Burak Yavuz
Authored: Fri Jan 19 07:36:06 2018 +0900
Committer: hyukjinkwon
Committed: Fri Jan 19 07:36:06 2018 +0900
--
.../sql/catalyst/json/CreateJacksonParser.scala | 5 +--
.../sql/sources/JsonHadoopFsRelationSuite.scala | 34
2 files changed, 37 insertions(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e01919e8/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
index 025a388..b1672e7 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
@@ -40,10 +40,11 @@ private[sql] object CreateJacksonParser extends
Serializable {
}
def text(jsonFactory: JsonFactory, record: Text): JsonParser = {
-jsonFactory.createParser(record.getBytes, 0, record.getLength)
+val bain = new ByteArrayInputStream(record.getBytes, 0, record.getLength)
+jsonFactory.createParser(new InputStreamReader(bain, "UTF-8"))
}
def inputStream(jsonFactory: JsonFactory, record: InputStream): JsonParser =
{
-jsonFactory.createParser(record)
+jsonFactory.createParser(new InputStreamReader(record, "UTF-8"))
}
}
http://git-wip-us.apache.org/repos/asf/spark/blob/e01919e8/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
index 49be304..27f398e 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/sources/JsonHadoopFsRelationSuite.scala
@@ -28,6 +28,8 @@ import org.apache.spark.sql.types._
class JsonHadoopFsRelationSuite extends HadoopFsRelationTest {
override val dataSourceName: String = "json"
+ private val badJson = "\u\u\uA\u0001AAA"
+
// JSON does not write data of NullType and does not play well with
BinaryType.
override protected def supportsDataType(dataType: DataType): Boolean =
dataType match {
case _: NullType => false
@@ -105,4 +107,36 @@ class JsonHadoopFsRelationSuite extends
HadoopFsRelationTest {
)
}
}
+
+ test("invalid json with leading nulls - from file (multiLine=true)") {
+import testImplicits._
+withTempDir { tempDir =>
+ val path = tempDir.getAbsolutePath
+ Seq(badJson, """{"a":1}""").toDS().write.mode("overwrite").text(path)
+ val expected = s"""$badJson\n{"a":1}\n"""
+ val schema = new StructType().add("a",
IntegerType).add("_corrupt_record", StringType)
+ val df =
+spark.read.format(dataSourceName).option("multiLine",
true).schema(schema).load(path)
+ checkAnswer(df, Row(null, expected))
+}
+ }
+
+ test("invalid json with leading nulls - from file (multiLine=false)") {
+import testImplicits._
+withTempDir { tempDir =>
+ val path = tempDir.getAbsolutePath
+ Seq(badJson, """{"a":1}""").toDS().write.mode("overwrite").text(path)
+ val schema = new StructType().add("a",
IntegerType).add("_corrupt_record", StringType)
+ val df =
+spark.read.format(dataSourceName).option("multiLine",
false).schema(schema).load(path)
+ checkAnswer(df, Seq(Row(1, null), Row(null, badJson)))
+}
+ }
+
+ te
svn commit: r24299 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_18_14_01-1f88fcd-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 18 22:14:50 2018 New Revision: 24299 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_18_14_01-1f88fcd docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23133][K8S] Fix passing java options to Executor
Repository: spark
Updated Branches:
refs/heads/branch-2.3 1f88fcd41 -> b8c6d9303
[SPARK-23133][K8S] Fix passing java options to Executor
Pass through spark java options to the executor in context of docker image.
Closes #20296
andrusha: Deployed two version of containers to local k8s, checked that java
options were present in the updated image on the running executor.
Manual test
Author: Andrew Korzhuev
Closes #20322 from foxish/patch-1.
(cherry picked from commit f568e9cf76f657d094f1d036ab5a95f2531f5761)
Signed-off-by: Marcelo Vanzin
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/b8c6d930
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/b8c6d930
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/b8c6d930
Branch: refs/heads/branch-2.3
Commit: b8c6d9303d029f6bf8ee43bae3f159112eb0fb79
Parents: 1f88fcd
Author: Andrew Korzhuev
Authored: Thu Jan 18 14:00:12 2018 -0800
Committer: Marcelo Vanzin
Committed: Thu Jan 18 14:01:19 2018 -0800
--
.../kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/b8c6d930/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
--
diff --git
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
index 0c28c75..b9090dc 100755
---
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
+++
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
@@ -42,7 +42,7 @@ shift 1
SPARK_CLASSPATH="$SPARK_CLASSPATH:${SPARK_HOME}/jars/*"
env | grep SPARK_JAVA_OPT_ | sed 's/[^=]*=\(.*\)/\1/g' > /tmp/java_opts.txt
-readarray -t SPARK_DRIVER_JAVA_OPTS < /tmp/java_opts.txt
+readarray -t SPARK_JAVA_OPTS < /tmp/java_opts.txt
if [ -n "$SPARK_MOUNTED_CLASSPATH" ]; then
SPARK_CLASSPATH="$SPARK_CLASSPATH:$SPARK_MOUNTED_CLASSPATH"
fi
@@ -54,7 +54,7 @@ case "$SPARK_K8S_CMD" in
driver)
CMD=(
${JAVA_HOME}/bin/java
- "${SPARK_DRIVER_JAVA_OPTS[@]}"
+ "${SPARK_JAVA_OPTS[@]}"
-cp "$SPARK_CLASSPATH"
-Xms$SPARK_DRIVER_MEMORY
-Xmx$SPARK_DRIVER_MEMORY
@@ -67,7 +67,7 @@ case "$SPARK_K8S_CMD" in
executor)
CMD=(
${JAVA_HOME}/bin/java
- "${SPARK_EXECUTOR_JAVA_OPTS[@]}"
+ "${SPARK_JAVA_OPTS[@]}"
-Xms$SPARK_EXECUTOR_MEMORY
-Xmx$SPARK_EXECUTOR_MEMORY
-cp "$SPARK_CLASSPATH"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23133][K8S] Fix passing java options to Executor
Repository: spark
Updated Branches:
refs/heads/master bf34d665b -> f568e9cf7
[SPARK-23133][K8S] Fix passing java options to Executor
Pass through spark java options to the executor in context of docker image.
Closes #20296
andrusha: Deployed two version of containers to local k8s, checked that java
options were present in the updated image on the running executor.
Manual test
Author: Andrew Korzhuev
Closes #20322 from foxish/patch-1.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/f568e9cf
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/f568e9cf
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/f568e9cf
Branch: refs/heads/master
Commit: f568e9cf76f657d094f1d036ab5a95f2531f5761
Parents: bf34d66
Author: Andrew Korzhuev
Authored: Thu Jan 18 14:00:12 2018 -0800
Committer: Marcelo Vanzin
Committed: Thu Jan 18 14:00:43 2018 -0800
--
.../kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/f568e9cf/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
--
diff --git
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
index 0c28c75..b9090dc 100755
---
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
+++
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
@@ -42,7 +42,7 @@ shift 1
SPARK_CLASSPATH="$SPARK_CLASSPATH:${SPARK_HOME}/jars/*"
env | grep SPARK_JAVA_OPT_ | sed 's/[^=]*=\(.*\)/\1/g' > /tmp/java_opts.txt
-readarray -t SPARK_DRIVER_JAVA_OPTS < /tmp/java_opts.txt
+readarray -t SPARK_JAVA_OPTS < /tmp/java_opts.txt
if [ -n "$SPARK_MOUNTED_CLASSPATH" ]; then
SPARK_CLASSPATH="$SPARK_CLASSPATH:$SPARK_MOUNTED_CLASSPATH"
fi
@@ -54,7 +54,7 @@ case "$SPARK_K8S_CMD" in
driver)
CMD=(
${JAVA_HOME}/bin/java
- "${SPARK_DRIVER_JAVA_OPTS[@]}"
+ "${SPARK_JAVA_OPTS[@]}"
-cp "$SPARK_CLASSPATH"
-Xms$SPARK_DRIVER_MEMORY
-Xmx$SPARK_DRIVER_MEMORY
@@ -67,7 +67,7 @@ case "$SPARK_K8S_CMD" in
executor)
CMD=(
${JAVA_HOME}/bin/java
- "${SPARK_EXECUTOR_JAVA_OPTS[@]}"
+ "${SPARK_JAVA_OPTS[@]}"
-Xms$SPARK_EXECUTOR_MEMORY
-Xmx$SPARK_EXECUTOR_MEMORY
-cp "$SPARK_CLASSPATH"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23144][SS] Added console sink for continuous processing
Repository: spark
Updated Branches:
refs/heads/branch-2.3 e6e8bbe84 -> 1f88fcd41
[SPARK-23144][SS] Added console sink for continuous processing
## What changes were proposed in this pull request?
Refactored ConsoleWriter into ConsoleMicrobatchWriter and
ConsoleContinuousWriter.
## How was this patch tested?
new unit test
Author: Tathagata Das
Closes #20311 from tdas/SPARK-23144.
(cherry picked from commit bf34d665b9c865e00fac7001500bf6d521c2dff9)
Signed-off-by: Tathagata Das
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/1f88fcd4
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/1f88fcd4
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/1f88fcd4
Branch: refs/heads/branch-2.3
Commit: 1f88fcd41c6c5521d732b25e83d6c9d150d7f24a
Parents: e6e8bbe
Author: Tathagata Das
Authored: Thu Jan 18 12:33:39 2018 -0800
Committer: Tathagata Das
Committed: Thu Jan 18 12:33:54 2018 -0800
--
.../spark/sql/execution/streaming/console.scala | 20 +++--
.../streaming/sources/ConsoleWriter.scala | 80 +++-
.../streaming/sources/ConsoleWriterSuite.scala | 26 ++-
3 files changed, 96 insertions(+), 30 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/1f88fcd4/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
index 9482037..f2aa325 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
@@ -19,13 +19,12 @@ package org.apache.spark.sql.execution.streaming
import java.util.Optional
-import scala.collection.JavaConverters._
-
import org.apache.spark.sql._
-import org.apache.spark.sql.execution.streaming.sources.ConsoleWriter
+import
org.apache.spark.sql.execution.streaming.sources.{ConsoleContinuousWriter,
ConsoleMicroBatchWriter, ConsoleWriter}
import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider,
DataSourceRegister}
import org.apache.spark.sql.sources.v2.{DataSourceV2, DataSourceV2Options}
-import org.apache.spark.sql.sources.v2.streaming.MicroBatchWriteSupport
+import org.apache.spark.sql.sources.v2.streaming.{ContinuousWriteSupport,
MicroBatchWriteSupport}
+import org.apache.spark.sql.sources.v2.streaming.writer.ContinuousWriter
import org.apache.spark.sql.sources.v2.writer.DataSourceV2Writer
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.StructType
@@ -37,16 +36,25 @@ case class ConsoleRelation(override val sqlContext:
SQLContext, data: DataFrame)
class ConsoleSinkProvider extends DataSourceV2
with MicroBatchWriteSupport
+ with ContinuousWriteSupport
with DataSourceRegister
with CreatableRelationProvider {
override def createMicroBatchWriter(
queryId: String,
- epochId: Long,
+ batchId: Long,
schema: StructType,
mode: OutputMode,
options: DataSourceV2Options): Optional[DataSourceV2Writer] = {
-Optional.of(new ConsoleWriter(epochId, schema, options))
+Optional.of(new ConsoleMicroBatchWriter(batchId, schema, options))
+ }
+
+ override def createContinuousWriter(
+ queryId: String,
+ schema: StructType,
+ mode: OutputMode,
+ options: DataSourceV2Options): Optional[ContinuousWriter] = {
+Optional.of(new ConsoleContinuousWriter(schema, options))
}
def createRelation(
http://git-wip-us.apache.org/repos/asf/spark/blob/1f88fcd4/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
index 3619799..6fb61df 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
@@ -20,45 +20,85 @@ package org.apache.spark.sql.execution.streaming.sources
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.sources.v2.DataSourceV2Options
+import org.apache.spark.sql.sources.v2.streaming.writer.ContinuousWriter
import org.apache.spark.sql.sources.v2.writer.{DataSourceV2Writer,
DataWriterFactory, WriterCommitMessage}
import org.apache.spark.sql.types.StructType
-/**
- * A [[DataSourceV2Writer]] t
spark git commit: [SPARK-23144][SS] Added console sink for continuous processing
Repository: spark
Updated Branches:
refs/heads/master 2d41f040a -> bf34d665b
[SPARK-23144][SS] Added console sink for continuous processing
## What changes were proposed in this pull request?
Refactored ConsoleWriter into ConsoleMicrobatchWriter and
ConsoleContinuousWriter.
## How was this patch tested?
new unit test
Author: Tathagata Das
Closes #20311 from tdas/SPARK-23144.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/bf34d665
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/bf34d665
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/bf34d665
Branch: refs/heads/master
Commit: bf34d665b9c865e00fac7001500bf6d521c2dff9
Parents: 2d41f04
Author: Tathagata Das
Authored: Thu Jan 18 12:33:39 2018 -0800
Committer: Tathagata Das
Committed: Thu Jan 18 12:33:39 2018 -0800
--
.../spark/sql/execution/streaming/console.scala | 20 +++--
.../streaming/sources/ConsoleWriter.scala | 80 +++-
.../streaming/sources/ConsoleWriterSuite.scala | 26 ++-
3 files changed, 96 insertions(+), 30 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/bf34d665/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
index 9482037..f2aa325 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/console.scala
@@ -19,13 +19,12 @@ package org.apache.spark.sql.execution.streaming
import java.util.Optional
-import scala.collection.JavaConverters._
-
import org.apache.spark.sql._
-import org.apache.spark.sql.execution.streaming.sources.ConsoleWriter
+import
org.apache.spark.sql.execution.streaming.sources.{ConsoleContinuousWriter,
ConsoleMicroBatchWriter, ConsoleWriter}
import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider,
DataSourceRegister}
import org.apache.spark.sql.sources.v2.{DataSourceV2, DataSourceV2Options}
-import org.apache.spark.sql.sources.v2.streaming.MicroBatchWriteSupport
+import org.apache.spark.sql.sources.v2.streaming.{ContinuousWriteSupport,
MicroBatchWriteSupport}
+import org.apache.spark.sql.sources.v2.streaming.writer.ContinuousWriter
import org.apache.spark.sql.sources.v2.writer.DataSourceV2Writer
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.StructType
@@ -37,16 +36,25 @@ case class ConsoleRelation(override val sqlContext:
SQLContext, data: DataFrame)
class ConsoleSinkProvider extends DataSourceV2
with MicroBatchWriteSupport
+ with ContinuousWriteSupport
with DataSourceRegister
with CreatableRelationProvider {
override def createMicroBatchWriter(
queryId: String,
- epochId: Long,
+ batchId: Long,
schema: StructType,
mode: OutputMode,
options: DataSourceV2Options): Optional[DataSourceV2Writer] = {
-Optional.of(new ConsoleWriter(epochId, schema, options))
+Optional.of(new ConsoleMicroBatchWriter(batchId, schema, options))
+ }
+
+ override def createContinuousWriter(
+ queryId: String,
+ schema: StructType,
+ mode: OutputMode,
+ options: DataSourceV2Options): Optional[ContinuousWriter] = {
+Optional.of(new ConsoleContinuousWriter(schema, options))
}
def createRelation(
http://git-wip-us.apache.org/repos/asf/spark/blob/bf34d665/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
index 3619799..6fb61df 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/ConsoleWriter.scala
@@ -20,45 +20,85 @@ package org.apache.spark.sql.execution.streaming.sources
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.sources.v2.DataSourceV2Options
+import org.apache.spark.sql.sources.v2.streaming.writer.ContinuousWriter
import org.apache.spark.sql.sources.v2.writer.{DataSourceV2Writer,
DataWriterFactory, WriterCommitMessage}
import org.apache.spark.sql.types.StructType
-/**
- * A [[DataSourceV2Writer]] that collects results to the driver and prints
them in the console.
- * Generated by
[[org.apache.spark.sql
spark git commit: [SPARK-23143][SS][PYTHON] Added python API for setting continuous trigger
Repository: spark
Updated Branches:
refs/heads/master 9678941f5 -> 2d41f040a
[SPARK-23143][SS][PYTHON] Added python API for setting continuous trigger
## What changes were proposed in this pull request?
Self-explanatory.
## How was this patch tested?
New python tests.
Author: Tathagata Das
Closes #20309 from tdas/SPARK-23143.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/2d41f040
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/2d41f040
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/2d41f040
Branch: refs/heads/master
Commit: 2d41f040a34d6483919fd5d491cf90eee5429290
Parents: 9678941
Author: Tathagata Das
Authored: Thu Jan 18 12:25:52 2018 -0800
Committer: Tathagata Das
Committed: Thu Jan 18 12:25:52 2018 -0800
--
python/pyspark/sql/streaming.py | 23 +++
python/pyspark/sql/tests.py | 6 ++
2 files changed, 25 insertions(+), 4 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/2d41f040/python/pyspark/sql/streaming.py
--
diff --git a/python/pyspark/sql/streaming.py b/python/pyspark/sql/streaming.py
index 24ae377..e2a97ac 100644
--- a/python/pyspark/sql/streaming.py
+++ b/python/pyspark/sql/streaming.py
@@ -786,7 +786,7 @@ class DataStreamWriter(object):
@keyword_only
@since(2.0)
-def trigger(self, processingTime=None, once=None):
+def trigger(self, processingTime=None, once=None, continuous=None):
"""Set the trigger for the stream query. If this is not set it will
run the query as fast
as possible, which is equivalent to setting the trigger to
``processingTime='0 seconds'``.
@@ -802,23 +802,38 @@ class DataStreamWriter(object):
>>> writer = sdf.writeStream.trigger(processingTime='5 seconds')
>>> # trigger the query for just once batch of data
>>> writer = sdf.writeStream.trigger(once=True)
+>>> # trigger the query for execution every 5 seconds
+>>> writer = sdf.writeStream.trigger(continuous='5 seconds')
"""
+params = [processingTime, once, continuous]
+
+if params.count(None) == 3:
+raise ValueError('No trigger provided')
+elif params.count(None) < 2:
+raise ValueError('Multiple triggers not allowed.')
+
jTrigger = None
if processingTime is not None:
-if once is not None:
-raise ValueError('Multiple triggers not allowed.')
if type(processingTime) != str or len(processingTime.strip()) == 0:
raise ValueError('Value for processingTime must be a non empty
string. Got: %s' %
processingTime)
interval = processingTime.strip()
jTrigger =
self._spark._sc._jvm.org.apache.spark.sql.streaming.Trigger.ProcessingTime(
interval)
+
elif once is not None:
if once is not True:
raise ValueError('Value for once must be True. Got: %s' % once)
jTrigger =
self._spark._sc._jvm.org.apache.spark.sql.streaming.Trigger.Once()
+
else:
-raise ValueError('No trigger provided')
+if type(continuous) != str or len(continuous.strip()) == 0:
+raise ValueError('Value for continuous must be a non empty
string. Got: %s' %
+ continuous)
+interval = continuous.strip()
+jTrigger =
self._spark._sc._jvm.org.apache.spark.sql.streaming.Trigger.Continuous(
+interval)
+
self._jwrite = self._jwrite.trigger(jTrigger)
return self
http://git-wip-us.apache.org/repos/asf/spark/blob/2d41f040/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index f84aa3d..2548359 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -1538,6 +1538,12 @@ class SQLTests(ReusedSQLTestCase):
except ValueError:
pass
+# Should not take multiple args
+try:
+df.writeStream.trigger(processingTime='5 seconds', continuous='1
second')
+except ValueError:
+pass
+
# Should take only keyword args
try:
df.writeStream.trigger('5 seconds')
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23143][SS][PYTHON] Added python API for setting continuous trigger
Repository: spark
Updated Branches:
refs/heads/branch-2.3 bfdbdd379 -> e6e8bbe84
[SPARK-23143][SS][PYTHON] Added python API for setting continuous trigger
## What changes were proposed in this pull request?
Self-explanatory.
## How was this patch tested?
New python tests.
Author: Tathagata Das
Closes #20309 from tdas/SPARK-23143.
(cherry picked from commit 2d41f040a34d6483919fd5d491cf90eee5429290)
Signed-off-by: Tathagata Das
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e6e8bbe8
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e6e8bbe8
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e6e8bbe8
Branch: refs/heads/branch-2.3
Commit: e6e8bbe84625861f3a4834a2d71cb2f0fe7f6b5a
Parents: bfdbdd3
Author: Tathagata Das
Authored: Thu Jan 18 12:25:52 2018 -0800
Committer: Tathagata Das
Committed: Thu Jan 18 12:26:07 2018 -0800
--
python/pyspark/sql/streaming.py | 23 +++
python/pyspark/sql/tests.py | 6 ++
2 files changed, 25 insertions(+), 4 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e6e8bbe8/python/pyspark/sql/streaming.py
--
diff --git a/python/pyspark/sql/streaming.py b/python/pyspark/sql/streaming.py
index 24ae377..e2a97ac 100644
--- a/python/pyspark/sql/streaming.py
+++ b/python/pyspark/sql/streaming.py
@@ -786,7 +786,7 @@ class DataStreamWriter(object):
@keyword_only
@since(2.0)
-def trigger(self, processingTime=None, once=None):
+def trigger(self, processingTime=None, once=None, continuous=None):
"""Set the trigger for the stream query. If this is not set it will
run the query as fast
as possible, which is equivalent to setting the trigger to
``processingTime='0 seconds'``.
@@ -802,23 +802,38 @@ class DataStreamWriter(object):
>>> writer = sdf.writeStream.trigger(processingTime='5 seconds')
>>> # trigger the query for just once batch of data
>>> writer = sdf.writeStream.trigger(once=True)
+>>> # trigger the query for execution every 5 seconds
+>>> writer = sdf.writeStream.trigger(continuous='5 seconds')
"""
+params = [processingTime, once, continuous]
+
+if params.count(None) == 3:
+raise ValueError('No trigger provided')
+elif params.count(None) < 2:
+raise ValueError('Multiple triggers not allowed.')
+
jTrigger = None
if processingTime is not None:
-if once is not None:
-raise ValueError('Multiple triggers not allowed.')
if type(processingTime) != str or len(processingTime.strip()) == 0:
raise ValueError('Value for processingTime must be a non empty
string. Got: %s' %
processingTime)
interval = processingTime.strip()
jTrigger =
self._spark._sc._jvm.org.apache.spark.sql.streaming.Trigger.ProcessingTime(
interval)
+
elif once is not None:
if once is not True:
raise ValueError('Value for once must be True. Got: %s' % once)
jTrigger =
self._spark._sc._jvm.org.apache.spark.sql.streaming.Trigger.Once()
+
else:
-raise ValueError('No trigger provided')
+if type(continuous) != str or len(continuous.strip()) == 0:
+raise ValueError('Value for continuous must be a non empty
string. Got: %s' %
+ continuous)
+interval = continuous.strip()
+jTrigger =
self._spark._sc._jvm.org.apache.spark.sql.streaming.Trigger.Continuous(
+interval)
+
self._jwrite = self._jwrite.trigger(jTrigger)
return self
http://git-wip-us.apache.org/repos/asf/spark/blob/e6e8bbe8/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index f84aa3d..2548359 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -1538,6 +1538,12 @@ class SQLTests(ReusedSQLTestCase):
except ValueError:
pass
+# Should not take multiple args
+try:
+df.writeStream.trigger(processingTime='5 seconds', continuous='1
second')
+except ValueError:
+pass
+
# Should take only keyword args
try:
df.writeStream.trigger('5 seconds')
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23029][DOCS] Specifying default units of configuration entries
Repository: spark
Updated Branches:
refs/heads/branch-2.3 bd0a1627b -> bfdbdd379
[SPARK-23029][DOCS] Specifying default units of configuration entries
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in
configuration entries of type size.
This is crucial since unit-less values are accepted and the user might assume
the base unit is bytes, which in most cases it is not, leading to hard-to-debug
problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira
Closes #20269 from ferdonline/docs_units.
(cherry picked from commit 9678941f54ebc5db935ed8d694e502086e2a31c0)
Signed-off-by: Sean Owen
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/bfdbdd37
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/bfdbdd37
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/bfdbdd37
Branch: refs/heads/branch-2.3
Commit: bfdbdd37951a872676a22b0524cbde12a1df418d
Parents: bd0a162
Author: Fernando Pereira
Authored: Thu Jan 18 13:02:03 2018 -0600
Committer: Sean Owen
Committed: Thu Jan 18 13:02:10 2018 -0600
--
.../main/scala/org/apache/spark/SparkConf.scala | 6 +-
.../apache/spark/internal/config/package.scala | 47 +
docs/configuration.md | 100 ++-
3 files changed, 85 insertions(+), 68 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/bfdbdd37/core/src/main/scala/org/apache/spark/SparkConf.scala
--
diff --git a/core/src/main/scala/org/apache/spark/SparkConf.scala
b/core/src/main/scala/org/apache/spark/SparkConf.scala
index d77303e..f53b2be 100644
--- a/core/src/main/scala/org/apache/spark/SparkConf.scala
+++ b/core/src/main/scala/org/apache/spark/SparkConf.scala
@@ -640,9 +640,9 @@ private[spark] object SparkConf extends Logging {
translation = s => s"${s.toLong * 10}s")),
"spark.reducer.maxSizeInFlight" -> Seq(
AlternateConfig("spark.reducer.maxMbInFlight", "1.4")),
-"spark.kryoserializer.buffer" ->
-Seq(AlternateConfig("spark.kryoserializer.buffer.mb", "1.4",
- translation = s => s"${(s.toDouble * 1000).toInt}k")),
+"spark.kryoserializer.buffer" -> Seq(
+ AlternateConfig("spark.kryoserializer.buffer.mb", "1.4",
+translation = s => s"${(s.toDouble * 1000).toInt}k")),
"spark.kryoserializer.buffer.max" -> Seq(
AlternateConfig("spark.kryoserializer.buffer.max.mb", "1.4")),
"spark.shuffle.file.buffer" -> Seq(
http://git-wip-us.apache.org/repos/asf/spark/blob/bfdbdd37/core/src/main/scala/org/apache/spark/internal/config/package.scala
--
diff --git a/core/src/main/scala/org/apache/spark/internal/config/package.scala
b/core/src/main/scala/org/apache/spark/internal/config/package.scala
index eb12ddf..bbfcfba 100644
--- a/core/src/main/scala/org/apache/spark/internal/config/package.scala
+++ b/core/src/main/scala/org/apache/spark/internal/config/package.scala
@@ -38,10 +38,13 @@ package object config {
ConfigBuilder("spark.driver.userClassPathFirst").booleanConf.createWithDefault(false)
private[spark] val DRIVER_MEMORY = ConfigBuilder("spark.driver.memory")
+.doc("Amount of memory to use for the driver process, in MiB unless
otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createWithDefaultString("1g")
private[spark] val DRIVER_MEMORY_OVERHEAD =
ConfigBuilder("spark.driver.memoryOverhead")
+.doc("The amount of off-heap memory to be allocated per driver in cluster
mode, " +
+ "in MiB unless otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createOptional
@@ -62,6 +65,7 @@ package object config {
.createWithDefault(false)
private[spark] val EVENT_LOG_OUTPUT_BUFFER_SIZE =
ConfigBuilder("spark.eventLog.buffer.kb")
+.doc("Buffer size to use when writing to output streams, in KiB unless
otherwise specified.")
.bytesConf(ByteUnit.KiB)
.createWithDefaultString("100k")
@@ -81,10 +85,13 @@ package object config {
ConfigBuilder("spark.executor.userClassPathFirst").booleanConf.createWithDefault(false)
private[spark] val EXECUTOR_MEMORY = ConfigBuilder("spark.executor.memory")
+.doc("Amount of memory to use per executor process, in MiB unless
otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createWithDefaultString("1g")
private[spark] val EXECUTOR_MEMORY_OVERHEAD =
ConfigBuilder("spark.executor.memoryOverhead")
+.doc("The amount of off-heap memory to be allocated per executor in
cluster mode, " +
+ "in MiB unless otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createOptional
@@ -353,7 +
spark git commit: [SPARK-23029][DOCS] Specifying default units of configuration entries
Repository: spark
Updated Branches:
refs/heads/master cf7ee1767 -> 9678941f5
[SPARK-23029][DOCS] Specifying default units of configuration entries
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in
configuration entries of type size.
This is crucial since unit-less values are accepted and the user might assume
the base unit is bytes, which in most cases it is not, leading to hard-to-debug
problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira
Closes #20269 from ferdonline/docs_units.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/9678941f
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/9678941f
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/9678941f
Branch: refs/heads/master
Commit: 9678941f54ebc5db935ed8d694e502086e2a31c0
Parents: cf7ee17
Author: Fernando Pereira
Authored: Thu Jan 18 13:02:03 2018 -0600
Committer: Sean Owen
Committed: Thu Jan 18 13:02:03 2018 -0600
--
.../main/scala/org/apache/spark/SparkConf.scala | 6 +-
.../apache/spark/internal/config/package.scala | 47 +
docs/configuration.md | 100 ++-
3 files changed, 85 insertions(+), 68 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/9678941f/core/src/main/scala/org/apache/spark/SparkConf.scala
--
diff --git a/core/src/main/scala/org/apache/spark/SparkConf.scala
b/core/src/main/scala/org/apache/spark/SparkConf.scala
index d77303e..f53b2be 100644
--- a/core/src/main/scala/org/apache/spark/SparkConf.scala
+++ b/core/src/main/scala/org/apache/spark/SparkConf.scala
@@ -640,9 +640,9 @@ private[spark] object SparkConf extends Logging {
translation = s => s"${s.toLong * 10}s")),
"spark.reducer.maxSizeInFlight" -> Seq(
AlternateConfig("spark.reducer.maxMbInFlight", "1.4")),
-"spark.kryoserializer.buffer" ->
-Seq(AlternateConfig("spark.kryoserializer.buffer.mb", "1.4",
- translation = s => s"${(s.toDouble * 1000).toInt}k")),
+"spark.kryoserializer.buffer" -> Seq(
+ AlternateConfig("spark.kryoserializer.buffer.mb", "1.4",
+translation = s => s"${(s.toDouble * 1000).toInt}k")),
"spark.kryoserializer.buffer.max" -> Seq(
AlternateConfig("spark.kryoserializer.buffer.max.mb", "1.4")),
"spark.shuffle.file.buffer" -> Seq(
http://git-wip-us.apache.org/repos/asf/spark/blob/9678941f/core/src/main/scala/org/apache/spark/internal/config/package.scala
--
diff --git a/core/src/main/scala/org/apache/spark/internal/config/package.scala
b/core/src/main/scala/org/apache/spark/internal/config/package.scala
index eb12ddf..bbfcfba 100644
--- a/core/src/main/scala/org/apache/spark/internal/config/package.scala
+++ b/core/src/main/scala/org/apache/spark/internal/config/package.scala
@@ -38,10 +38,13 @@ package object config {
ConfigBuilder("spark.driver.userClassPathFirst").booleanConf.createWithDefault(false)
private[spark] val DRIVER_MEMORY = ConfigBuilder("spark.driver.memory")
+.doc("Amount of memory to use for the driver process, in MiB unless
otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createWithDefaultString("1g")
private[spark] val DRIVER_MEMORY_OVERHEAD =
ConfigBuilder("spark.driver.memoryOverhead")
+.doc("The amount of off-heap memory to be allocated per driver in cluster
mode, " +
+ "in MiB unless otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createOptional
@@ -62,6 +65,7 @@ package object config {
.createWithDefault(false)
private[spark] val EVENT_LOG_OUTPUT_BUFFER_SIZE =
ConfigBuilder("spark.eventLog.buffer.kb")
+.doc("Buffer size to use when writing to output streams, in KiB unless
otherwise specified.")
.bytesConf(ByteUnit.KiB)
.createWithDefaultString("100k")
@@ -81,10 +85,13 @@ package object config {
ConfigBuilder("spark.executor.userClassPathFirst").booleanConf.createWithDefault(false)
private[spark] val EXECUTOR_MEMORY = ConfigBuilder("spark.executor.memory")
+.doc("Amount of memory to use per executor process, in MiB unless
otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createWithDefaultString("1g")
private[spark] val EXECUTOR_MEMORY_OVERHEAD =
ConfigBuilder("spark.executor.memoryOverhead")
+.doc("The amount of off-heap memory to be allocated per executor in
cluster mode, " +
+ "in MiB unless otherwise specified.")
.bytesConf(ByteUnit.MiB)
.createOptional
@@ -353,7 +360,7 @@ package object config {
private[spark] val BUFFER_WRITE_CHUNK_SIZE =
ConfigBuilder("spa
spark git commit: [SPARK-23147][UI] Fix task page table IndexOutOfBound Exception
Repository: spark
Updated Branches:
refs/heads/branch-2.3 e0421c650 -> bd0a1627b
[SPARK-23147][UI] Fix task page table IndexOutOfBound Exception
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks.
Furthermore, because the `dataSize` doesn't take running tasks into account, so
sometimes UI cannot show the running tasks. Besides table will only be
displayed when first task is finished according to the default
sortColumn("index").
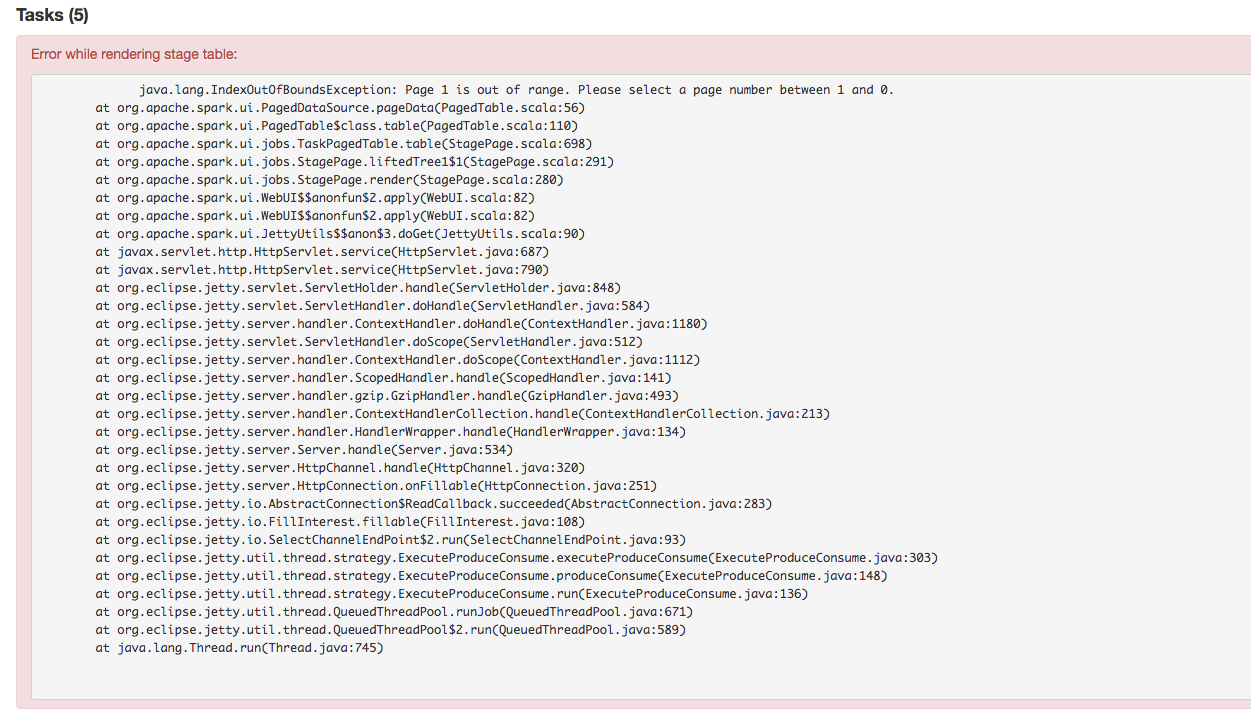
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i =>
Thread.sleep(1); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i =>
Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help
to review.
## How was this patch tested?
Manual test.
Author: jerryshao
Closes #20315 from jerryshao/SPARK-23147.
(cherry picked from commit cf7ee1767ddadce08dce050fc3b40c77cdd187da)
Signed-off-by: Marcelo Vanzin
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/bd0a1627
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/bd0a1627
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/bd0a1627
Branch: refs/heads/branch-2.3
Commit: bd0a1627b9396c69dbe3554e6ca6c700eeb08f74
Parents: e0421c6
Author: jerryshao
Authored: Thu Jan 18 10:19:36 2018 -0800
Committer: Marcelo Vanzin
Committed: Thu Jan 18 10:19:48 2018 -0800
--
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/bd0a1627/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
--
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 7c6e06c..af78373 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -676,7 +676,7 @@ private[ui] class TaskDataSource(
private var _tasksToShow: Seq[TaskData] = null
- override def dataSize: Int = stage.numCompleteTasks + stage.numFailedTasks +
stage.numKilledTasks
+ override def dataSize: Int = stage.numTasks
override def sliceData(from: Int, to: Int): Seq[TaskData] = {
if (_tasksToShow == null) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23147][UI] Fix task page table IndexOutOfBound Exception
Repository: spark
Updated Branches:
refs/heads/master 5063b7481 -> cf7ee1767
[SPARK-23147][UI] Fix task page table IndexOutOfBound Exception
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks.
Furthermore, because the `dataSize` doesn't take running tasks into account, so
sometimes UI cannot show the running tasks. Besides table will only be
displayed when first task is finished according to the default
sortColumn("index").

To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i =>
Thread.sleep(1); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i =>
Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help
to review.
## How was this patch tested?
Manual test.
Author: jerryshao
Closes #20315 from jerryshao/SPARK-23147.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/cf7ee176
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/cf7ee176
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/cf7ee176
Branch: refs/heads/master
Commit: cf7ee1767ddadce08dce050fc3b40c77cdd187da
Parents: 5063b74
Author: jerryshao
Authored: Thu Jan 18 10:19:36 2018 -0800
Committer: Marcelo Vanzin
Committed: Thu Jan 18 10:19:36 2018 -0800
--
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/cf7ee176/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
--
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 7c6e06c..af78373 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -676,7 +676,7 @@ private[ui] class TaskDataSource(
private var _tasksToShow: Seq[TaskData] = null
- override def dataSize: Int = stage.numCompleteTasks + stage.numFailedTasks +
stage.numKilledTasks
+ override def dataSize: Int = stage.numTasks
override def sliceData(from: Int, to: Int): Seq[TaskData] = {
if (_tasksToShow == null) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24290 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_18_08_01-5063b74-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 18 16:14:46 2018 New Revision: 24290 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_18_08_01-5063b74 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24288 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_18_06_01-e0421c6-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 18 14:14:38 2018 New Revision: 24288 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_18_06_01-e0421c6 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23141][SQL][PYSPARK] Support data type string as a returnType for registerJavaFunction.
Repository: spark
Updated Branches:
refs/heads/branch-2.3 8a9827482 -> e0421c650
[SPARK-23141][SQL][PYSPARK] Support data type string as a returnType for
registerJavaFunction.
## What changes were proposed in this pull request?
Currently `UDFRegistration.registerJavaFunction` doesn't support data type
string as a `returnType` whereas `UDFRegistration.register`, `udf`, or
`pandas_udf` does.
We can support it for `UDFRegistration.registerJavaFunction` as well.
## How was this patch tested?
Added a doctest and existing tests.
Author: Takuya UESHIN
Closes #20307 from ueshin/issues/SPARK-23141.
(cherry picked from commit 5063b7481173ad72bd0dc941b5cf3c9b26a591e4)
Signed-off-by: hyukjinkwon
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e0421c65
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e0421c65
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e0421c65
Branch: refs/heads/branch-2.3
Commit: e0421c65093f66b365539358dd9be38d2006fa47
Parents: 8a98274
Author: Takuya UESHIN
Authored: Thu Jan 18 22:33:04 2018 +0900
Committer: hyukjinkwon
Committed: Thu Jan 18 22:33:25 2018 +0900
--
python/pyspark/sql/functions.py | 6 --
python/pyspark/sql/udf.py | 14 --
2 files changed, 16 insertions(+), 4 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e0421c65/python/pyspark/sql/functions.py
--
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index 988c1d2..961b326 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2108,7 +2108,8 @@ def udf(f=None, returnType=StringType()):
can fail on special rows, the workaround is to incorporate the
condition into the functions.
:param f: python function if used as a standalone function
-:param returnType: a :class:`pyspark.sql.types.DataType` object
+:param returnType: the return type of the user-defined function. The value
can be either a
+:class:`pyspark.sql.types.DataType` object or a DDL-formatted type
string.
>>> from pyspark.sql.types import IntegerType
>>> slen = udf(lambda s: len(s), IntegerType())
@@ -2148,7 +2149,8 @@ def pandas_udf(f=None, returnType=None,
functionType=None):
Creates a vectorized user defined function (UDF).
:param f: user-defined function. A python function if used as a standalone
function
-:param returnType: a :class:`pyspark.sql.types.DataType` object
+:param returnType: the return type of the user-defined function. The value
can be either a
+:class:`pyspark.sql.types.DataType` object or a DDL-formatted type
string.
:param functionType: an enum value in
:class:`pyspark.sql.functions.PandasUDFType`.
Default: SCALAR.
http://git-wip-us.apache.org/repos/asf/spark/blob/e0421c65/python/pyspark/sql/udf.py
--
diff --git a/python/pyspark/sql/udf.py b/python/pyspark/sql/udf.py
index 1943bb7..c77f19f8 100644
--- a/python/pyspark/sql/udf.py
+++ b/python/pyspark/sql/udf.py
@@ -206,7 +206,8 @@ class UDFRegistration(object):
:param f: a Python function, or a user-defined function. The
user-defined function can
be either row-at-a-time or vectorized. See
:meth:`pyspark.sql.functions.udf` and
:meth:`pyspark.sql.functions.pandas_udf`.
-:param returnType: the return type of the registered user-defined
function.
+:param returnType: the return type of the registered user-defined
function. The value can
+be either a :class:`pyspark.sql.types.DataType` object or a
DDL-formatted type string.
:return: a user-defined function.
`returnType` can be optionally specified when `f` is a Python function
but not
@@ -303,21 +304,30 @@ class UDFRegistration(object):
:param name: name of the user-defined function
:param javaClassName: fully qualified name of java class
-:param returnType: a :class:`pyspark.sql.types.DataType` object
+:param returnType: the return type of the registered Java function.
The value can be either
+a :class:`pyspark.sql.types.DataType` object or a DDL-formatted
type string.
>>> from pyspark.sql.types import IntegerType
>>> spark.udf.registerJavaFunction(
... "javaStringLength",
"test.org.apache.spark.sql.JavaStringLength", IntegerType())
>>> spark.sql("SELECT javaStringLength('test')").collect()
[Row(UDF:javaStringLength(test)=4)]
+
>>> spark.udf.registerJavaFunction(
... "javaStringLength2",
"test.org.apache.spark.sql.JavaStringLength")
>>> spark.sql("SELEC
spark git commit: [SPARK-23141][SQL][PYSPARK] Support data type string as a returnType for registerJavaFunction.
Repository: spark
Updated Branches:
refs/heads/master e28eb4311 -> 5063b7481
[SPARK-23141][SQL][PYSPARK] Support data type string as a returnType for
registerJavaFunction.
## What changes were proposed in this pull request?
Currently `UDFRegistration.registerJavaFunction` doesn't support data type
string as a `returnType` whereas `UDFRegistration.register`, `udf`, or
`pandas_udf` does.
We can support it for `UDFRegistration.registerJavaFunction` as well.
## How was this patch tested?
Added a doctest and existing tests.
Author: Takuya UESHIN
Closes #20307 from ueshin/issues/SPARK-23141.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/5063b748
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/5063b748
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/5063b748
Branch: refs/heads/master
Commit: 5063b7481173ad72bd0dc941b5cf3c9b26a591e4
Parents: e28eb43
Author: Takuya UESHIN
Authored: Thu Jan 18 22:33:04 2018 +0900
Committer: hyukjinkwon
Committed: Thu Jan 18 22:33:04 2018 +0900
--
python/pyspark/sql/functions.py | 6 --
python/pyspark/sql/udf.py | 14 --
2 files changed, 16 insertions(+), 4 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/5063b748/python/pyspark/sql/functions.py
--
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index 988c1d2..961b326 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2108,7 +2108,8 @@ def udf(f=None, returnType=StringType()):
can fail on special rows, the workaround is to incorporate the
condition into the functions.
:param f: python function if used as a standalone function
-:param returnType: a :class:`pyspark.sql.types.DataType` object
+:param returnType: the return type of the user-defined function. The value
can be either a
+:class:`pyspark.sql.types.DataType` object or a DDL-formatted type
string.
>>> from pyspark.sql.types import IntegerType
>>> slen = udf(lambda s: len(s), IntegerType())
@@ -2148,7 +2149,8 @@ def pandas_udf(f=None, returnType=None,
functionType=None):
Creates a vectorized user defined function (UDF).
:param f: user-defined function. A python function if used as a standalone
function
-:param returnType: a :class:`pyspark.sql.types.DataType` object
+:param returnType: the return type of the user-defined function. The value
can be either a
+:class:`pyspark.sql.types.DataType` object or a DDL-formatted type
string.
:param functionType: an enum value in
:class:`pyspark.sql.functions.PandasUDFType`.
Default: SCALAR.
http://git-wip-us.apache.org/repos/asf/spark/blob/5063b748/python/pyspark/sql/udf.py
--
diff --git a/python/pyspark/sql/udf.py b/python/pyspark/sql/udf.py
index 1943bb7..c77f19f8 100644
--- a/python/pyspark/sql/udf.py
+++ b/python/pyspark/sql/udf.py
@@ -206,7 +206,8 @@ class UDFRegistration(object):
:param f: a Python function, or a user-defined function. The
user-defined function can
be either row-at-a-time or vectorized. See
:meth:`pyspark.sql.functions.udf` and
:meth:`pyspark.sql.functions.pandas_udf`.
-:param returnType: the return type of the registered user-defined
function.
+:param returnType: the return type of the registered user-defined
function. The value can
+be either a :class:`pyspark.sql.types.DataType` object or a
DDL-formatted type string.
:return: a user-defined function.
`returnType` can be optionally specified when `f` is a Python function
but not
@@ -303,21 +304,30 @@ class UDFRegistration(object):
:param name: name of the user-defined function
:param javaClassName: fully qualified name of java class
-:param returnType: a :class:`pyspark.sql.types.DataType` object
+:param returnType: the return type of the registered Java function.
The value can be either
+a :class:`pyspark.sql.types.DataType` object or a DDL-formatted
type string.
>>> from pyspark.sql.types import IntegerType
>>> spark.udf.registerJavaFunction(
... "javaStringLength",
"test.org.apache.spark.sql.JavaStringLength", IntegerType())
>>> spark.sql("SELECT javaStringLength('test')").collect()
[Row(UDF:javaStringLength(test)=4)]
+
>>> spark.udf.registerJavaFunction(
... "javaStringLength2",
"test.org.apache.spark.sql.JavaStringLength")
>>> spark.sql("SELECT javaStringLength2('test')").collect()
[Row(UDF:javaStringLength2(test)=4)]
+
+>>> spark
spark git commit: [SPARK-22036][SQL] Decimal multiplication with high precision/scale often returns NULL
Repository: spark Updated Branches: refs/heads/branch-2.3 f801ac417 -> 8a9827482 [SPARK-22036][SQL] Decimal multiplication with high precision/scale often returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido Closes #20023 from mgaido91/SPARK-22036. (cherry picked from commit e28eb431146bcdcaf02a6f6c406ca30920592a6a) Signed-off-by: Wenchen Fan Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/8a982748 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/8a982748 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/8a982748 Branch: refs/heads/branch-2.3 Commit: 8a98274823a4671cee85081dd19f40146e736325 Parents: f801ac4 Author: Marco Gaido Authored: Thu Jan 18 21:24:39 2018 +0800 Committer: Wenchen Fan Committed: Thu Jan 18 21:25:16 2018 +0800 -- docs/sql-programming-guide.md | 5 + .../catalyst/analysis/DecimalPrecision.scala| 114 ++--- .../sql/catalyst/expressions/literals.scala | 2 +- .../org/apache/spark/sql/internal/SQLConf.scala | 12 + .../apache/spark/sql/types/DecimalType.scala| 45 +++- .../sql/catalyst/analysis/AnalysisSuite.scala | 4 +- .../analysis/DecimalPrecisionSuite.scala| 20 +- .../native/decimalArithmeticOperations.sql | 47 .../native/decimalArithmeticOperations.sql.out | 245 +-- .../native/decimalPrecision.sql.out | 4 +- .../org/apache/spark/sql/SQLQuerySuite.scala| 18 -- 11 files changed, 434 insertions(+), 82 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/8a982748/docs/sql-programming-guide.md -- diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md index 258c769..3e2e48a 100644 --- a/docs/sql-programming-guide.md +++ b/docs/sql-programming-guide.md @@ -1793,6 +1793,11 @@ options. - Since Spark 2.3, when all inputs are binary, `functions.concat()` returns an output as binary. Otherwise, it returns as a string. Until Spark 2.3, it always returns as a string despite of input types. To keep the old behavior, set `spark.sql.function.concatBinaryAsString` to `true`. - Since Spark 2.3, when all inputs are binary, SQL `elt()` returns an output as binary. Otherwise, it returns as a string. Until Spark 2.3, it always returns as a string despite of input types. To keep the old behavior, set `spark.sql.function.eltOutputAsString` to `true`. + - Since Spark 2.3, by default arithmetic operations between decimals return a rounded value if an exact representation is not possible (instead of returning NULL). This is compliant to SQL ANSI 2011 specification and Hive's new behavior introduced in Hive 2.2 (HIVE-15331). This involves the following changes +- The rules to determine the result type of an arithmetic operation have been updated. In particular, if the precision / scale needed are out of the range of available values, the scale is reduced up to 6, in order to prevent the truncation of the integer part of the decimals. All the arithmetic operations are affected by the change, ie. addition (`+`), subtraction (`-`), multiplication (`*`), division (`/`), remainder (`%`) and p
spark git commit: [SPARK-22036][SQL] Decimal multiplication with high precision/scale often returns NULL
Repository: spark Updated Branches: refs/heads/master 7a2248341 -> e28eb4311 [SPARK-22036][SQL] Decimal multiplication with high precision/scale often returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido Closes #20023 from mgaido91/SPARK-22036. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e28eb431 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e28eb431 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e28eb431 Branch: refs/heads/master Commit: e28eb431146bcdcaf02a6f6c406ca30920592a6a Parents: 7a22483 Author: Marco Gaido Authored: Thu Jan 18 21:24:39 2018 +0800 Committer: Wenchen Fan Committed: Thu Jan 18 21:24:39 2018 +0800 -- docs/sql-programming-guide.md | 5 + .../catalyst/analysis/DecimalPrecision.scala| 114 ++--- .../sql/catalyst/expressions/literals.scala | 2 +- .../org/apache/spark/sql/internal/SQLConf.scala | 12 + .../apache/spark/sql/types/DecimalType.scala| 45 +++- .../sql/catalyst/analysis/AnalysisSuite.scala | 4 +- .../analysis/DecimalPrecisionSuite.scala| 20 +- .../native/decimalArithmeticOperations.sql | 47 .../native/decimalArithmeticOperations.sql.out | 245 +-- .../native/decimalPrecision.sql.out | 4 +- .../org/apache/spark/sql/SQLQuerySuite.scala| 18 -- 11 files changed, 434 insertions(+), 82 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/e28eb431/docs/sql-programming-guide.md -- diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md index 258c769..3e2e48a 100644 --- a/docs/sql-programming-guide.md +++ b/docs/sql-programming-guide.md @@ -1793,6 +1793,11 @@ options. - Since Spark 2.3, when all inputs are binary, `functions.concat()` returns an output as binary. Otherwise, it returns as a string. Until Spark 2.3, it always returns as a string despite of input types. To keep the old behavior, set `spark.sql.function.concatBinaryAsString` to `true`. - Since Spark 2.3, when all inputs are binary, SQL `elt()` returns an output as binary. Otherwise, it returns as a string. Until Spark 2.3, it always returns as a string despite of input types. To keep the old behavior, set `spark.sql.function.eltOutputAsString` to `true`. + - Since Spark 2.3, by default arithmetic operations between decimals return a rounded value if an exact representation is not possible (instead of returning NULL). This is compliant to SQL ANSI 2011 specification and Hive's new behavior introduced in Hive 2.2 (HIVE-15331). This involves the following changes +- The rules to determine the result type of an arithmetic operation have been updated. In particular, if the precision / scale needed are out of the range of available values, the scale is reduced up to 6, in order to prevent the truncation of the integer part of the decimals. All the arithmetic operations are affected by the change, ie. addition (`+`), subtraction (`-`), multiplication (`*`), division (`/`), remainder (`%`) and positive module (`pmod`). +- Literal values used in SQL operations are converted to DECIMAL with the
svn commit: r24286 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_18_04_01-7a22483-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 18 12:19:05 2018 New Revision: 24286 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_18_04_01-7a22483 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's planner
Repository: spark
Updated Branches:
refs/heads/branch-2.3 2a87c3a77 -> f801ac417
[SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's planner
## What changes were proposed in this pull request?
`DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which
will throw exception as described in
[SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140).
## How was this patch tested?
Manual test.
Author: jerryshao
Closes #20305 from jerryshao/SPARK-23140.
(cherry picked from commit 7a2248341396840628eef398aa512cac3e3bd55f)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/f801ac41
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/f801ac41
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/f801ac41
Branch: refs/heads/branch-2.3
Commit: f801ac417ba13a975887ba83904ee771bc3a003e
Parents: 2a87c3a
Author: jerryshao
Authored: Thu Jan 18 19:18:55 2018 +0800
Committer: Wenchen Fan
Committed: Thu Jan 18 19:20:16 2018 +0800
--
.../spark/sql/hive/HiveSessionStateBuilder.scala | 17 +
1 file changed, 1 insertion(+), 16 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/f801ac41/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
index dc92ad3..12c7436 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
@@ -96,22 +96,7 @@ class HiveSessionStateBuilder(session: SparkSession,
parentState: Option[Session
override val sparkSession: SparkSession = session
override def extraPlanningStrategies: Seq[Strategy] =
-super.extraPlanningStrategies ++ customPlanningStrategies
-
- override def strategies: Seq[Strategy] = {
-experimentalMethods.extraStrategies ++
- extraPlanningStrategies ++ Seq(
- FileSourceStrategy,
- DataSourceStrategy(conf),
- SpecialLimits,
- InMemoryScans,
- HiveTableScans,
- Scripts,
- Aggregation,
- JoinSelection,
- BasicOperators
-)
- }
+super.extraPlanningStrategies ++ customPlanningStrategies ++
Seq(HiveTableScans, Scripts)
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's planner
Repository: spark
Updated Branches:
refs/heads/master 1c76a91e5 -> 7a2248341
[SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's planner
## What changes were proposed in this pull request?
`DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which
will throw exception as described in
[SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140).
## How was this patch tested?
Manual test.
Author: jerryshao
Closes #20305 from jerryshao/SPARK-23140.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/7a224834
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/7a224834
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/7a224834
Branch: refs/heads/master
Commit: 7a2248341396840628eef398aa512cac3e3bd55f
Parents: 1c76a91
Author: jerryshao
Authored: Thu Jan 18 19:18:55 2018 +0800
Committer: Wenchen Fan
Committed: Thu Jan 18 19:18:55 2018 +0800
--
.../spark/sql/hive/HiveSessionStateBuilder.scala | 17 +
1 file changed, 1 insertion(+), 16 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/7a224834/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
index dc92ad3..12c7436 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionStateBuilder.scala
@@ -96,22 +96,7 @@ class HiveSessionStateBuilder(session: SparkSession,
parentState: Option[Session
override val sparkSession: SparkSession = session
override def extraPlanningStrategies: Seq[Strategy] =
-super.extraPlanningStrategies ++ customPlanningStrategies
-
- override def strategies: Seq[Strategy] = {
-experimentalMethods.extraStrategies ++
- extraPlanningStrategies ++ Seq(
- FileSourceStrategy,
- DataSourceStrategy(conf),
- SpecialLimits,
- InMemoryScans,
- HiveTableScans,
- Scripts,
- Aggregation,
- JoinSelection,
- BasicOperators
-)
- }
+super.extraPlanningStrategies ++ customPlanningStrategies ++
Seq(HiveTableScans, Scripts)
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24284 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_18_02_01-2a87c3a-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 18 10:14:47 2018 New Revision: 24284 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_18_02_01-2a87c3a docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24282 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_18_00_01-1c76a91-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 18 08:15:51 2018 New Revision: 24282 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_18_00_01-1c76a91 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org