spark git commit: add one supported type missing from the javadoc
Repository: spark
Updated Branches:
refs/heads/master e4fee395e -> c7c0b086a
add one supported type missing from the javadoc
## What changes were proposed in this pull request?
The supported java.math.BigInteger type is not mentioned in the javadoc of
Encoders.bean()
## How was this patch tested?
only Javadoc fix
Please review http://spark.apache.org/contributing.html before opening a pull
request.
Author: James Yu
Closes #21544 from yuj/master.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/c7c0b086
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/c7c0b086
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/c7c0b086
Branch: refs/heads/master
Commit: c7c0b086a0b18424725433ade840d5121ac2b86e
Parents: e4fee39
Author: James Yu
Authored: Fri Jun 15 21:04:04 2018 -0700
Committer: Reynold Xin
Committed: Fri Jun 15 21:04:04 2018 -0700
--
sql/catalyst/src/main/scala/org/apache/spark/sql/Encoders.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/c7c0b086/sql/catalyst/src/main/scala/org/apache/spark/sql/Encoders.scala
--
diff --git a/sql/catalyst/src/main/scala/org/apache/spark/sql/Encoders.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/Encoders.scala
index 0b95a88..b47ec0b 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/Encoders.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/Encoders.scala
@@ -132,7 +132,7 @@ object Encoders {
* - primitive types: boolean, int, double, etc.
* - boxed types: Boolean, Integer, Double, etc.
* - String
- * - java.math.BigDecimal
+ * - java.math.BigDecimal, java.math.BigInteger
* - time related: java.sql.Date, java.sql.Timestamp
* - collection types: only array and java.util.List currently, map support
is in progress
* - nested java bean.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-24216][SQL] Spark TypedAggregateExpression uses getSimpleName that is not safe in scala
Repository: spark
Updated Branches:
refs/heads/branch-2.3 d42610440 -> 9d63e540e
[SPARK-24216][SQL] Spark TypedAggregateExpression uses getSimpleName that is
not safe in scala
When user create a aggregator object in scala and pass the aggregator to Spark
Dataset's agg() method, Spark's will initialize TypedAggregateExpression with
the nodeName field as aggregator.getClass.getSimpleName. However, getSimpleName
is not safe in scala environment, depending on how user creates the aggregator
object. For example, if the aggregator class full qualified name is
"com.my.company.MyUtils$myAgg$2$", the getSimpleName will throw
java.lang.InternalError "Malformed class name". This has been reported in
scalatest https://github.com/scalatest/scalatest/pull/1044 and discussed in
many scala upstream jiras such as SI-8110, SI-5425.
To fix this issue, we follow the solution in
https://github.com/scalatest/scalatest/pull/1044 to add safer version of
getSimpleName as a util method, and TypedAggregateExpression will invoke this
util method rather than getClass.getSimpleName.
added unit test
Author: Fangshi Li
Closes #21276 from fangshil/SPARK-24216.
(cherry picked from commit cc88d7fad16e8b5cbf7b6b9bfe412908782b4a45)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/9d63e540
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/9d63e540
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/9d63e540
Branch: refs/heads/branch-2.3
Commit: 9d63e540e00bc655faf6d8fe1d0035bc0b9a9192
Parents: d426104
Author: Fangshi Li
Authored: Tue Jun 12 12:10:08 2018 -0700
Committer: Wenchen Fan
Committed: Fri Jun 15 20:23:05 2018 -0700
--
.../org/apache/spark/util/AccumulatorV2.scala | 6 +-
.../scala/org/apache/spark/util/Utils.scala | 59 +++-
.../org/apache/spark/util/UtilsSuite.scala | 16 ++
.../apache/spark/ml/util/Instrumentation.scala | 5 +-
.../aggregate/TypedAggregateExpression.scala| 5 +-
5 files changed, 86 insertions(+), 5 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/9d63e540/core/src/main/scala/org/apache/spark/util/AccumulatorV2.scala
--
diff --git a/core/src/main/scala/org/apache/spark/util/AccumulatorV2.scala
b/core/src/main/scala/org/apache/spark/util/AccumulatorV2.scala
index 3b469a6..bf618b4 100644
--- a/core/src/main/scala/org/apache/spark/util/AccumulatorV2.scala
+++ b/core/src/main/scala/org/apache/spark/util/AccumulatorV2.scala
@@ -200,10 +200,12 @@ abstract class AccumulatorV2[IN, OUT] extends
Serializable {
}
override def toString: String = {
+// getClass.getSimpleName can cause Malformed class name error,
+// call safer `Utils.getSimpleName` instead
if (metadata == null) {
- "Un-registered Accumulator: " + getClass.getSimpleName
+ "Un-registered Accumulator: " + Utils.getSimpleName(getClass)
} else {
- getClass.getSimpleName + s"(id: $id, name: $name, value: $value)"
+ Utils.getSimpleName(getClass) + s"(id: $id, name: $name, value: $value)"
}
}
}
http://git-wip-us.apache.org/repos/asf/spark/blob/9d63e540/core/src/main/scala/org/apache/spark/util/Utils.scala
--
diff --git a/core/src/main/scala/org/apache/spark/util/Utils.scala
b/core/src/main/scala/org/apache/spark/util/Utils.scala
index 12d0934..d4b72e8 100644
--- a/core/src/main/scala/org/apache/spark/util/Utils.scala
+++ b/core/src/main/scala/org/apache/spark/util/Utils.scala
@@ -19,6 +19,7 @@ package org.apache.spark.util
import java.io._
import java.lang.{Byte => JByte}
+import java.lang.InternalError
import java.lang.management.{LockInfo, ManagementFactory, MonitorInfo,
ThreadInfo}
import java.lang.reflect.InvocationTargetException
import java.math.{MathContext, RoundingMode}
@@ -1875,7 +1876,7 @@ private[spark] object Utils extends Logging {
/** Return the class name of the given object, removing all dollar signs */
def getFormattedClassName(obj: AnyRef): String = {
-obj.getClass.getSimpleName.replace("$", "")
+getSimpleName(obj.getClass).replace("$", "")
}
/** Return an option that translates JNothing to None */
@@ -2817,6 +2818,62 @@ private[spark] object Utils extends Logging {
HashCodes.fromBytes(secretBytes).toString()
}
+ /**
+ * Safer than Class obj's getSimpleName which may throw Malformed class name
error in scala.
+ * This method mimicks scalatest's getSimpleNameOfAnObjectsClass.
+ */
+ def getSimpleName(cls: Class[_]): String = {
+try {
+ return cls.getSimpleName
+} catch {
+ case err: InternalError => return
stripDollars(stripPackages(cls.getName))
+}
+ }
+
+ /**
svn commit: r27499 - in /dev/spark/2.3.2-SNAPSHOT-2018_06_15_18_01-d426104-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Sat Jun 16 01:15:16 2018 New Revision: 27499 Log: Apache Spark 2.3.2-SNAPSHOT-2018_06_15_18_01-d426104 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r27494 - in /dev/spark/2.4.0-SNAPSHOT-2018_06_15_16_01-e4fee39-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 23:16:01 2018 New Revision: 27494 Log: Apache Spark 2.4.0-SNAPSHOT-2018_06_15_16_01-e4fee39 docs [This commit notification would consist of 1468 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-24452][SQL][CORE] Avoid possible overflow in int add or multiple
Repository: spark
Updated Branches:
refs/heads/branch-2.3 a7d378e78 -> d42610440
[SPARK-24452][SQL][CORE] Avoid possible overflow in int add or multiple
This PR fixes possible overflow in int add or multiply. In particular, their
overflows in multiply are detected by [Spotbugs](https://spotbugs.github.io/)
The following assignments may cause overflow in right hand side. As a result,
the result may be negative.
```
long = int * int
long = int + int
```
To avoid this problem, this PR performs cast from int to long in right hand
side.
Existing UTs.
Author: Kazuaki Ishizaki
Closes #21481 from kiszk/SPARK-24452.
(cherry picked from commit 90da7dc241f8eec2348c0434312c97c116330bc4)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/d4261044
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/d4261044
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/d4261044
Branch: refs/heads/branch-2.3
Commit: d42610440ac2e58ef77fcf42ad81ee4fdf5691ba
Parents: a7d378e
Author: Kazuaki Ishizaki
Authored: Fri Jun 15 13:47:48 2018 -0700
Committer: Wenchen Fan
Committed: Fri Jun 15 13:49:04 2018 -0700
--
.../spark/unsafe/map/BytesToBytesMap.java | 2 +-
.../spark/deploy/worker/DriverRunner.scala | 2 +-
.../org/apache/spark/rdd/AsyncRDDActions.scala | 2 +-
.../org/apache/spark/storage/BlockManager.scala | 2 +-
.../catalyst/expressions/UnsafeArrayData.java | 14 +--
.../VariableLengthRowBasedKeyValueBatch.java| 2 +-
.../vectorized/OffHeapColumnVector.java | 106 +--
.../vectorized/OnHeapColumnVector.java | 10 +-
.../apache/spark/sql/hive/client/HiveShim.scala | 2 +-
.../streaming/util/FileBasedWriteAheadLog.scala | 2 +-
10 files changed, 72 insertions(+), 72 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/d4261044/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
--
diff --git
a/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
b/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
index 5f00455..9a767dd 100644
--- a/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
+++ b/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
@@ -703,7 +703,7 @@ public final class BytesToBytesMap extends MemoryConsumer {
// must be stored in the same memory page.
// (8 byte key length) (key) (value) (8 byte pointer to next value)
int uaoSize = UnsafeAlignedOffset.getUaoSize();
- final long recordLength = (2 * uaoSize) + klen + vlen + 8;
+ final long recordLength = (2L * uaoSize) + klen + vlen + 8;
if (currentPage == null || currentPage.size() - pageCursor <
recordLength) {
if (!acquireNewPage(recordLength + uaoSize)) {
return false;
http://git-wip-us.apache.org/repos/asf/spark/blob/d4261044/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
b/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
index 58a1811..a6d13d1 100644
--- a/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
@@ -225,7 +225,7 @@ private[deploy] class DriverRunner(
// check if attempting another run
keepTrying = supervise && exitCode != 0 && !killed
if (keepTrying) {
-if (clock.getTimeMillis() - processStart > successfulRunDuration *
1000) {
+if (clock.getTimeMillis() - processStart > successfulRunDuration *
1000L) {
waitSeconds = 1
}
logInfo(s"Command exited with status $exitCode, re-launching after
$waitSeconds s.")
http://git-wip-us.apache.org/repos/asf/spark/blob/d4261044/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
--
diff --git a/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
b/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
index c9ed12f..47669a0 100644
--- a/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
+++ b/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
@@ -95,7 +95,7 @@ class AsyncRDDActions[T: ClassTag](self: RDD[T]) extends
Serializable with Loggi
// the left side of max is >=1 whenever partsScanned >= 2
numPartsToTry = Math.max(1,
(1.5 * num * partsScanned / results.size).toInt - partsScanned)
-numPartsToTry = Math.min(numPartsToTry, partsScanned * 4)
+
spark git commit: [SPARK-24525][SS] Provide an option to limit number of rows in a MemorySink
Repository: spark
Updated Branches:
refs/heads/master 90da7dc24 -> e4fee395e
[SPARK-24525][SS] Provide an option to limit number of rows in a MemorySink
## What changes were proposed in this pull request?
Provide an option to limit number of rows in a MemorySink. Currently,
MemorySink and MemorySinkV2 have unbounded size, meaning that if they're used
on big data, they can OOM the stream. This change adds a maxMemorySinkRows
option to limit how many rows MemorySink and MemorySinkV2 can hold. By default,
they are still unbounded.
## How was this patch tested?
Added new unit tests.
Author: Mukul Murthy
Closes #21559 from mukulmurthy/SPARK-24525.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e4fee395
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e4fee395
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e4fee395
Branch: refs/heads/master
Commit: e4fee395ecd93ad4579d9afbf0861f82a303e563
Parents: 90da7dc
Author: Mukul Murthy
Authored: Fri Jun 15 13:56:48 2018 -0700
Committer: Burak Yavuz
Committed: Fri Jun 15 13:56:48 2018 -0700
--
.../spark/sql/execution/streaming/memory.scala | 70 +++--
.../execution/streaming/sources/memoryV2.scala | 44 ---
.../spark/sql/streaming/DataStreamWriter.scala | 4 +-
.../execution/streaming/MemorySinkSuite.scala | 62 ++-
.../execution/streaming/MemorySinkV2Suite.scala | 80 +++-
.../apache/spark/sql/streaming/StreamTest.scala | 4 +-
6 files changed, 239 insertions(+), 25 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e4fee395/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
index b137f98..7fa13c4 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
@@ -33,6 +33,7 @@ import org.apache.spark.sql.catalyst.expressions.{Attribute,
UnsafeRow}
import org.apache.spark.sql.catalyst.plans.logical.{LeafNode, LogicalPlan,
Statistics}
import
org.apache.spark.sql.catalyst.plans.logical.statsEstimation.EstimationUtils
import org.apache.spark.sql.catalyst.streaming.InternalOutputModes._
+import org.apache.spark.sql.sources.v2.DataSourceOptions
import org.apache.spark.sql.sources.v2.reader.{InputPartition,
InputPartitionReader, SupportsScanUnsafeRow}
import org.apache.spark.sql.sources.v2.reader.streaming.{MicroBatchReader,
Offset => OffsetV2}
import org.apache.spark.sql.streaming.OutputMode
@@ -221,19 +222,60 @@ class MemoryStreamInputPartition(records:
Array[UnsafeRow])
}
/** A common trait for MemorySinks with methods used for testing */
-trait MemorySinkBase extends BaseStreamingSink {
+trait MemorySinkBase extends BaseStreamingSink with Logging {
def allData: Seq[Row]
def latestBatchData: Seq[Row]
def dataSinceBatch(sinceBatchId: Long): Seq[Row]
def latestBatchId: Option[Long]
+
+ /**
+ * Truncates the given rows to return at most maxRows rows.
+ * @param rows The data that may need to be truncated.
+ * @param batchLimit Number of rows to keep in this batch; the rest will be
truncated
+ * @param sinkLimit Total number of rows kept in this sink, for logging
purposes.
+ * @param batchId The ID of the batch that sent these rows, for logging
purposes.
+ * @return Truncated rows.
+ */
+ protected def truncateRowsIfNeeded(
+ rows: Array[Row],
+ batchLimit: Int,
+ sinkLimit: Int,
+ batchId: Long): Array[Row] = {
+if (rows.length > batchLimit && batchLimit >= 0) {
+ logWarning(s"Truncating batch $batchId to $batchLimit rows because of
sink limit $sinkLimit")
+ rows.take(batchLimit)
+} else {
+ rows
+}
+ }
+}
+
+/**
+ * Companion object to MemorySinkBase.
+ */
+object MemorySinkBase {
+ val MAX_MEMORY_SINK_ROWS = "maxRows"
+ val MAX_MEMORY_SINK_ROWS_DEFAULT = -1
+
+ /**
+ * Gets the max number of rows a MemorySink should store. This number is
based on the memory
+ * sink row limit option if it is set. If not, we use a large value so that
data truncates
+ * rather than causing out of memory errors.
+ * @param options Options for writing from which we get the max rows option
+ * @return The maximum number of rows a memorySink should store.
+ */
+ def getMemorySinkCapacity(options: DataSourceOptions): Int = {
+val maxRows = options.getInt(MAX_MEMORY_SINK_ROWS,
MAX_MEMORY_SINK_ROWS_DEFAULT)
+if (maxRows >= 0) maxRows else Int.MaxValue - 10
+ }
}
/**
* A sink that store
spark git commit: [SPARK-24452][SQL][CORE] Avoid possible overflow in int add or multiple
Repository: spark
Updated Branches:
refs/heads/master b5ccf0d39 -> 90da7dc24
[SPARK-24452][SQL][CORE] Avoid possible overflow in int add or multiple
## What changes were proposed in this pull request?
This PR fixes possible overflow in int add or multiply. In particular, their
overflows in multiply are detected by [Spotbugs](https://spotbugs.github.io/)
The following assignments may cause overflow in right hand side. As a result,
the result may be negative.
```
long = int * int
long = int + int
```
To avoid this problem, this PR performs cast from int to long in right hand
side.
## How was this patch tested?
Existing UTs.
Author: Kazuaki Ishizaki
Closes #21481 from kiszk/SPARK-24452.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/90da7dc2
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/90da7dc2
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/90da7dc2
Branch: refs/heads/master
Commit: 90da7dc241f8eec2348c0434312c97c116330bc4
Parents: b5ccf0d
Author: Kazuaki Ishizaki
Authored: Fri Jun 15 13:47:48 2018 -0700
Committer: Wenchen Fan
Committed: Fri Jun 15 13:47:48 2018 -0700
--
.../spark/unsafe/map/BytesToBytesMap.java | 2 +-
.../spark/deploy/worker/DriverRunner.scala | 2 +-
.../org/apache/spark/rdd/AsyncRDDActions.scala | 2 +-
.../org/apache/spark/storage/BlockManager.scala | 2 +-
.../catalyst/expressions/UnsafeArrayData.java | 14 +--
.../VariableLengthRowBasedKeyValueBatch.java| 2 +-
.../vectorized/OffHeapColumnVector.java | 106 +--
.../vectorized/OnHeapColumnVector.java | 10 +-
.../sources/RateStreamMicroBatchReader.scala| 2 +-
.../apache/spark/sql/hive/client/HiveShim.scala | 2 +-
.../streaming/util/FileBasedWriteAheadLog.scala | 2 +-
11 files changed, 73 insertions(+), 73 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/90da7dc2/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
--
diff --git
a/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
b/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
index 5f00455..9a767dd 100644
--- a/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
+++ b/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
@@ -703,7 +703,7 @@ public final class BytesToBytesMap extends MemoryConsumer {
// must be stored in the same memory page.
// (8 byte key length) (key) (value) (8 byte pointer to next value)
int uaoSize = UnsafeAlignedOffset.getUaoSize();
- final long recordLength = (2 * uaoSize) + klen + vlen + 8;
+ final long recordLength = (2L * uaoSize) + klen + vlen + 8;
if (currentPage == null || currentPage.size() - pageCursor <
recordLength) {
if (!acquireNewPage(recordLength + uaoSize)) {
return false;
http://git-wip-us.apache.org/repos/asf/spark/blob/90da7dc2/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
b/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
index 58a1811..a6d13d1 100644
--- a/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/worker/DriverRunner.scala
@@ -225,7 +225,7 @@ private[deploy] class DriverRunner(
// check if attempting another run
keepTrying = supervise && exitCode != 0 && !killed
if (keepTrying) {
-if (clock.getTimeMillis() - processStart > successfulRunDuration *
1000) {
+if (clock.getTimeMillis() - processStart > successfulRunDuration *
1000L) {
waitSeconds = 1
}
logInfo(s"Command exited with status $exitCode, re-launching after
$waitSeconds s.")
http://git-wip-us.apache.org/repos/asf/spark/blob/90da7dc2/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
--
diff --git a/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
b/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
index 13db498..ba9dae4 100644
--- a/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
+++ b/core/src/main/scala/org/apache/spark/rdd/AsyncRDDActions.scala
@@ -95,7 +95,7 @@ class AsyncRDDActions[T: ClassTag](self: RDD[T]) extends
Serializable with Loggi
// the left side of max is >=1 whenever partsScanned >= 2
numPartsToTry = Math.max(1,
(1.5 * num * partsScanned / results.size).toInt - partsScanned)
-numPartsToTry = Math.min(numP
spark git commit: [SPARK-24396][SS][PYSPARK] Add Structured Streaming ForeachWriter for python
Repository: spark Updated Branches: refs/heads/master 495d8cf09 -> b5ccf0d39 [SPARK-24396][SS][PYSPARK] Add Structured Streaming ForeachWriter for python ## What changes were proposed in this pull request? This PR adds `foreach` for streaming queries in Python. Users will be able to specify their processing logic in two different ways. - As a function that takes a row as input. - As an object that has methods `open`, `process`, and `close` methods. See the python docs in this PR for more details. ## How was this patch tested? Added java and python unit tests Author: Tathagata Das Closes #21477 from tdas/SPARK-24396. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/b5ccf0d3 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/b5ccf0d3 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/b5ccf0d3 Branch: refs/heads/master Commit: b5ccf0d3957a444db93893c0ce4417bfbbb11822 Parents: 495d8cf Author: Tathagata Das Authored: Fri Jun 15 12:56:39 2018 -0700 Committer: Tathagata Das Committed: Fri Jun 15 12:56:39 2018 -0700 -- python/pyspark/sql/streaming.py | 162 python/pyspark/sql/tests.py | 257 +++ python/pyspark/tests.py | 4 +- .../org/apache/spark/sql/ForeachWriter.scala| 62 - .../execution/python/PythonForeachWriter.scala | 161 .../sources/ForeachWriterProvider.scala | 52 +++- .../spark/sql/streaming/DataStreamWriter.scala | 48 +--- .../python/PythonForeachWriterSuite.scala | 137 ++ 8 files changed, 811 insertions(+), 72 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/b5ccf0d3/python/pyspark/sql/streaming.py -- diff --git a/python/pyspark/sql/streaming.py b/python/pyspark/sql/streaming.py index fae50b3..4984593 100644 --- a/python/pyspark/sql/streaming.py +++ b/python/pyspark/sql/streaming.py @@ -854,6 +854,168 @@ class DataStreamWriter(object): self._jwrite = self._jwrite.trigger(jTrigger) return self +@since(2.4) +def foreach(self, f): +""" +Sets the output of the streaming query to be processed using the provided writer ``f``. +This is often used to write the output of a streaming query to arbitrary storage systems. +The processing logic can be specified in two ways. + +#. A **function** that takes a row as input. +This is a simple way to express your processing logic. Note that this does +not allow you to deduplicate generated data when failures cause reprocessing of +some input data. That would require you to specify the processing logic in the next +way. + +#. An **object** with a ``process`` method and optional ``open`` and ``close`` methods. +The object can have the following methods. + +* ``open(partition_id, epoch_id)``: *Optional* method that initializes the processing +(for example, open a connection, start a transaction, etc). Additionally, you can +use the `partition_id` and `epoch_id` to deduplicate regenerated data +(discussed later). + +* ``process(row)``: *Non-optional* method that processes each :class:`Row`. + +* ``close(error)``: *Optional* method that finalizes and cleans up (for example, +close connection, commit transaction, etc.) after all rows have been processed. + +The object will be used by Spark in the following way. + +* A single copy of this object is responsible of all the data generated by a +single task in a query. In other words, one instance is responsible for +processing one partition of the data generated in a distributed manner. + +* This object must be serializable because each task will get a fresh +serialized-deserialized copy of the provided object. Hence, it is strongly +recommended that any initialization for writing data (e.g. opening a +connection or starting a transaction) is done after the `open(...)` +method has been called, which signifies that the task is ready to generate data. + +* The lifecycle of the methods are as follows. + +For each partition with ``partition_id``: + +... For each batch/epoch of streaming data with ``epoch_id``: + +... Method ``open(partitionId, epochId)`` is called. + +... If ``open(...)`` returns true, for each row in the partition and +batch/epoch, method ``process(row)`` is called. + +
svn commit: r27492 - in /dev/spark/2.4.0-SNAPSHOT-2018_06_15_12_01-495d8cf-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 19:15:50 2018 New Revision: 27492 Log: Apache Spark 2.4.0-SNAPSHOT-2018_06_15_12_01-495d8cf docs [This commit notification would consist of 1468 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r27490 - in /dev/spark/2.3.2-SNAPSHOT-2018_06_15_10_01-a7d378e-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 17:15:38 2018 New Revision: 27490 Log: Apache Spark 2.3.2-SNAPSHOT-2018_06_15_10_01-a7d378e docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-24490][WEBUI] Use WebUI.addStaticHandler in web UIs
Repository: spark
Updated Branches:
refs/heads/master 6567fc43a -> 495d8cf09
[SPARK-24490][WEBUI] Use WebUI.addStaticHandler in web UIs
`WebUI` defines `addStaticHandler` that web UIs don't use (and simply introduce
duplication). Let's clean them up and remove duplications.
Local build and waiting for Jenkins
Author: Jacek Laskowski
Closes #21510 from jaceklaskowski/SPARK-24490-Use-WebUI.addStaticHandler.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/495d8cf0
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/495d8cf0
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/495d8cf0
Branch: refs/heads/master
Commit: 495d8cf09ae7134aa6d2feb058612980e02955fa
Parents: 6567fc4
Author: Jacek Laskowski
Authored: Fri Jun 15 09:59:02 2018 -0700
Committer: Marcelo Vanzin
Committed: Fri Jun 15 09:59:02 2018 -0700
--
.../spark/deploy/history/HistoryServer.scala| 2 +-
.../spark/deploy/master/ui/MasterWebUI.scala| 2 +-
.../spark/deploy/worker/ui/WorkerWebUI.scala| 2 +-
.../scala/org/apache/spark/ui/SparkUI.scala | 2 +-
.../main/scala/org/apache/spark/ui/WebUI.scala | 52 ++--
.../spark/deploy/mesos/ui/MesosClusterUI.scala | 2 +-
.../spark/streaming/ui/StreamingTab.scala | 2 +-
7 files changed, 33 insertions(+), 31 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/495d8cf0/core/src/main/scala/org/apache/spark/deploy/history/HistoryServer.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/history/HistoryServer.scala
b/core/src/main/scala/org/apache/spark/deploy/history/HistoryServer.scala
index 066275e..56f3f59 100644
--- a/core/src/main/scala/org/apache/spark/deploy/history/HistoryServer.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/history/HistoryServer.scala
@@ -124,7 +124,7 @@ class HistoryServer(
attachHandler(ApiRootResource.getServletHandler(this))
-attachHandler(createStaticHandler(SparkUI.STATIC_RESOURCE_DIR, "/static"))
+addStaticHandler(SparkUI.STATIC_RESOURCE_DIR)
val contextHandler = new ServletContextHandler
contextHandler.setContextPath(HistoryServer.UI_PATH_PREFIX)
http://git-wip-us.apache.org/repos/asf/spark/blob/495d8cf0/core/src/main/scala/org/apache/spark/deploy/master/ui/MasterWebUI.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/master/ui/MasterWebUI.scala
b/core/src/main/scala/org/apache/spark/deploy/master/ui/MasterWebUI.scala
index 35b7ddd..e87b224 100644
--- a/core/src/main/scala/org/apache/spark/deploy/master/ui/MasterWebUI.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/master/ui/MasterWebUI.scala
@@ -43,7 +43,7 @@ class MasterWebUI(
val masterPage = new MasterPage(this)
attachPage(new ApplicationPage(this))
attachPage(masterPage)
-attachHandler(createStaticHandler(MasterWebUI.STATIC_RESOURCE_DIR,
"/static"))
+addStaticHandler(MasterWebUI.STATIC_RESOURCE_DIR)
attachHandler(createRedirectHandler(
"/app/kill", "/", masterPage.handleAppKillRequest, httpMethods =
Set("POST")))
attachHandler(createRedirectHandler(
http://git-wip-us.apache.org/repos/asf/spark/blob/495d8cf0/core/src/main/scala/org/apache/spark/deploy/worker/ui/WorkerWebUI.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/worker/ui/WorkerWebUI.scala
b/core/src/main/scala/org/apache/spark/deploy/worker/ui/WorkerWebUI.scala
index db696b0..ea67b74 100644
--- a/core/src/main/scala/org/apache/spark/deploy/worker/ui/WorkerWebUI.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/worker/ui/WorkerWebUI.scala
@@ -47,7 +47,7 @@ class WorkerWebUI(
val logPage = new LogPage(this)
attachPage(logPage)
attachPage(new WorkerPage(this))
-attachHandler(createStaticHandler(WorkerWebUI.STATIC_RESOURCE_BASE,
"/static"))
+addStaticHandler(WorkerWebUI.STATIC_RESOURCE_BASE)
attachHandler(createServletHandler("/log",
(request: HttpServletRequest) => logPage.renderLog(request),
worker.securityMgr,
http://git-wip-us.apache.org/repos/asf/spark/blob/495d8cf0/core/src/main/scala/org/apache/spark/ui/SparkUI.scala
--
diff --git a/core/src/main/scala/org/apache/spark/ui/SparkUI.scala
b/core/src/main/scala/org/apache/spark/ui/SparkUI.scala
index b44ac0e..d315ef6 100644
--- a/core/src/main/scala/org/apache/spark/ui/SparkUI.scala
+++ b/core/src/main/scala/org/apache/spark/ui/SparkUI.scala
@@ -65,7 +65,7 @@ private[spark] class SparkUI private (
attachTab(new StorageTab(this, store))
attachTab(new Environment
spark git commit: [SPARK-24531][TESTS] Replace 2.3.0 version with 2.3.1
Repository: spark
Updated Branches:
refs/heads/branch-2.3 d3255a571 -> a7d378e78
[SPARK-24531][TESTS] Replace 2.3.0 version with 2.3.1
The PR updates the 2.3 version tested to the new release 2.3.1.
existing UTs
Author: Marco Gaido
Closes #21543 from mgaido91/patch-1.
(cherry picked from commit 3bf76918fb67fb3ee9aed254d4fb3b87a7e66117)
Signed-off-by: Marcelo Vanzin
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/a7d378e7
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/a7d378e7
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/a7d378e7
Branch: refs/heads/branch-2.3
Commit: a7d378e78d73503d4d1ad37d94641200a9ea1b2d
Parents: d3255a5
Author: Marco Gaido
Authored: Wed Jun 13 15:18:19 2018 -0700
Committer: Marcelo Vanzin
Committed: Fri Jun 15 09:42:24 2018 -0700
--
.../apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/a7d378e7/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
index 6f904c9..5149218 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
@@ -195,7 +195,7 @@ class HiveExternalCatalogVersionsSuite extends
SparkSubmitTestUtils {
object PROCESS_TABLES extends QueryTest with SQLTestUtils {
// Tests the latest version of every release line.
- val testingVersions = Seq("2.0.2", "2.1.2", "2.2.1", "2.3.0")
+ val testingVersions = Seq("2.0.2", "2.1.2", "2.2.1", "2.3.1")
protected var spark: SparkSession = _
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r27484 - in /dev/spark/2.3.2-SNAPSHOT-2018_06_15_06_01-d3255a5-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 13:15:24 2018 New Revision: 27484 Log: Apache Spark 2.3.2-SNAPSHOT-2018_06_15_06_01-d3255a5 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: revert [SPARK-21743][SQL] top-most limit should not cause memory leak
Repository: spark
Updated Branches:
refs/heads/branch-2.3 7f1708a44 -> d3255a571
revert [SPARK-21743][SQL] top-most limit should not cause memory leak
## What changes were proposed in this pull request?
There is a performance regression in Spark 2.3. When we read a big compressed
text file which is un-splittable(e.g. gz), and then take the first record,
Spark will scan all the data in the text file which is very slow. For example,
`spark.read.text("/tmp/test.csv.gz").head(1)`, we can check out the SQL UI and
see that the file is fully scanned.
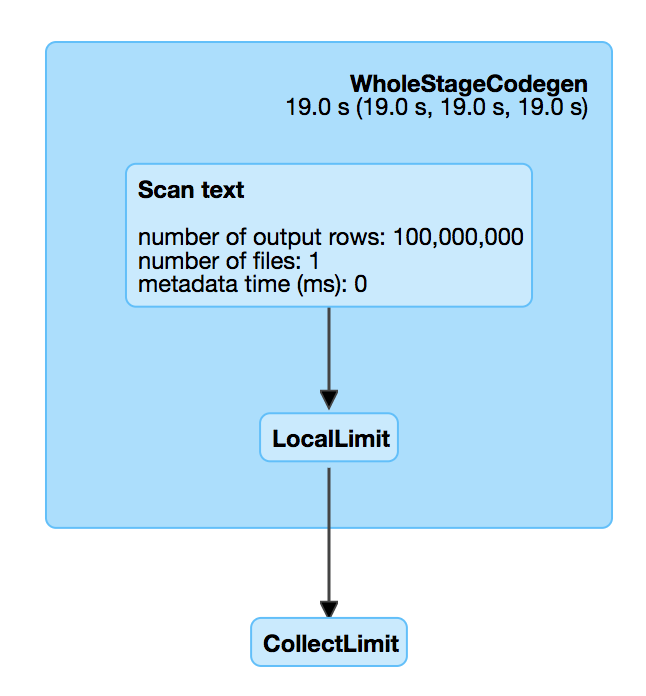
This is introduced by #18955 , which adds a LocalLimit to the query when
executing `Dataset.head`. The foundamental problem is, `Limit` is not well
whole-stage-codegened. It keeps consuming the input even if we have already hit
the limitation.
However, if we just fix LIMIT whole-stage-codegen, the memory leak test will
fail, as we don't fully consume the inputs to trigger the resource cleanup.
To fix it completely, we should do the following
1. fix LIMIT whole-stage-codegen, stop consuming inputs after hitting the
limitation.
2. in whole-stage-codegen, provide a way to release resource of the parant
operator, and apply it in LIMIT
3. automatically release resource when task ends.
Howere this is a non-trivial change, and is risky to backport to Spark 2.3.
This PR proposes to revert #18955 in Spark 2.3. The memory leak is not a big
issue. When task ends, Spark will release all the pages allocated by this task,
which is kind of releasing most of the resources.
I'll submit a exhaustive fix to master later.
## How was this patch tested?
N/A
Author: Wenchen Fan
Closes #21573 from cloud-fan/limit.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/d3255a57
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/d3255a57
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/d3255a57
Branch: refs/heads/branch-2.3
Commit: d3255a57109a5cea79948aa4192008b988961aa3
Parents: 7f1708a
Author: Wenchen Fan
Authored: Fri Jun 15 14:33:17 2018 +0200
Committer: Herman van Hovell
Committed: Fri Jun 15 14:33:17 2018 +0200
--
.../org/apache/spark/sql/execution/SparkStrategies.scala | 7 +--
.../src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala | 5 -
2 files changed, 1 insertion(+), 11 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/d3255a57/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala
index c6565fc..a0a641b 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala
@@ -70,12 +70,7 @@ abstract class SparkStrategies extends
QueryPlanner[SparkPlan] {
case Limit(IntegerLiteral(limit), Project(projectList, Sort(order,
true, child))) =>
TakeOrderedAndProjectExec(limit, order, projectList,
planLater(child)) :: Nil
case Limit(IntegerLiteral(limit), child) =>
- // With whole stage codegen, Spark releases resources only when all
the output data of the
- // query plan are consumed. It's possible that `CollectLimitExec`
only consumes a little
- // data from child plan and finishes the query without releasing
resources. Here we wrap
- // the child plan with `LocalLimitExec`, to stop the processing of
whole stage codegen and
- // trigger the resource releasing work, after we consume `limit`
rows.
- CollectLimitExec(limit, LocalLimitExec(limit, planLater(child))) ::
Nil
+ CollectLimitExec(limit, planLater(child)) :: Nil
case other => planLater(other) :: Nil
}
case Limit(IntegerLiteral(limit), Sort(order, true, child)) =>
http://git-wip-us.apache.org/repos/asf/spark/blob/d3255a57/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
--
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
index ebebf62..bc57efe 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
@@ -2720,11 +2720,6 @@ class SQLQuerySuite extends QueryTest with
SharedSQLContext {
}
}
- test("SPARK-21743: top-most limit should not cause memory leak") {
-// In unit test, S
svn commit: r27481 - in /dev/spark/2.4.0-SNAPSHOT-2018_06_15_04_02-6567fc4-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 11:20:31 2018 New Revision: 27481 Log: Apache Spark 2.4.0-SNAPSHOT-2018_06_15_04_02-6567fc4 docs [This commit notification would consist of 1468 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r27480 - in /dev/spark/2.3.2-SNAPSHOT-2018_06_15_02_01-7f1708a-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 09:15:40 2018 New Revision: 27480 Log: Apache Spark 2.3.2-SNAPSHOT-2018_06_15_02_01-7f1708a docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [PYTHON] Fix typo in serializer exception
Repository: spark
Updated Branches:
refs/heads/master 22daeba59 -> 6567fc43a
[PYTHON] Fix typo in serializer exception
## What changes were proposed in this pull request?
Fix typo in exception raised in Python serializer
## How was this patch tested?
No code changes
Please review http://spark.apache.org/contributing.html before opening a pull
request.
Author: Ruben Berenguel Montoro
Closes #21566 from rberenguel/fix_typo_pyspark_serializers.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/6567fc43
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/6567fc43
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/6567fc43
Branch: refs/heads/master
Commit: 6567fc43aca75b41900cde976594e21c8b0ca98a
Parents: 22daeba
Author: Ruben Berenguel Montoro
Authored: Fri Jun 15 16:59:00 2018 +0800
Committer: hyukjinkwon
Committed: Fri Jun 15 16:59:00 2018 +0800
--
python/pyspark/serializers.py | 17 +
1 file changed, 9 insertions(+), 8 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/6567fc43/python/pyspark/serializers.py
--
diff --git a/python/pyspark/serializers.py b/python/pyspark/serializers.py
index 15753f7..4c16b5f 100644
--- a/python/pyspark/serializers.py
+++ b/python/pyspark/serializers.py
@@ -33,8 +33,9 @@ The serializer is chosen when creating L{SparkContext}:
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>> sc.stop()
-PySpark serialize objects in batches; By default, the batch size is chosen
based
-on the size of objects, also configurable by SparkContext's C{batchSize}
parameter:
+PySpark serializes objects in batches; by default, the batch size is chosen
based
+on the size of objects and is also configurable by SparkContext's C{batchSize}
+parameter:
>>> sc = SparkContext('local', 'test', batchSize=2)
>>> rdd = sc.parallelize(range(16), 4).map(lambda x: x)
@@ -100,7 +101,7 @@ class Serializer(object):
def _load_stream_without_unbatching(self, stream):
"""
Return an iterator of deserialized batches (iterable) of objects from
the input stream.
-if the serializer does not operate on batches the default
implementation returns an
+If the serializer does not operate on batches the default
implementation returns an
iterator of single element lists.
"""
return map(lambda x: [x], self.load_stream(stream))
@@ -461,7 +462,7 @@ class NoOpSerializer(FramedSerializer):
return obj
-# Hook namedtuple, make it picklable
+# Hack namedtuple, make it picklable
__cls = {}
@@ -525,15 +526,15 @@ def _hijack_namedtuple():
cls = _old_namedtuple(*args, **kwargs)
return _hack_namedtuple(cls)
-# replace namedtuple with new one
+# replace namedtuple with the new one
collections.namedtuple.__globals__["_old_namedtuple_kwdefaults"] =
_old_namedtuple_kwdefaults
collections.namedtuple.__globals__["_old_namedtuple"] = _old_namedtuple
collections.namedtuple.__globals__["_hack_namedtuple"] = _hack_namedtuple
collections.namedtuple.__code__ = namedtuple.__code__
collections.namedtuple.__hijack = 1
-# hack the cls already generated by namedtuple
-# those created in other module can be pickled as normal,
+# hack the cls already generated by namedtuple.
+# Those created in other modules can be pickled as normal,
# so only hack those in __main__ module
for n, o in sys.modules["__main__"].__dict__.items():
if (type(o) is type and o.__base__ is tuple
@@ -627,7 +628,7 @@ class AutoSerializer(FramedSerializer):
elif _type == b'P':
return pickle.loads(obj[1:])
else:
-raise ValueError("invalid sevialization type: %s" % _type)
+raise ValueError("invalid serialization type: %s" % _type)
class CompressedSerializer(FramedSerializer):
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [PYTHON] Fix typo in serializer exception
Repository: spark
Updated Branches:
refs/heads/branch-2.3 e6bf325de -> 7f1708a44
[PYTHON] Fix typo in serializer exception
## What changes were proposed in this pull request?
Fix typo in exception raised in Python serializer
## How was this patch tested?
No code changes
Please review http://spark.apache.org/contributing.html before opening a pull
request.
Author: Ruben Berenguel Montoro
Closes #21566 from rberenguel/fix_typo_pyspark_serializers.
(cherry picked from commit 6567fc43aca75b41900cde976594e21c8b0ca98a)
Signed-off-by: hyukjinkwon
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/7f1708a4
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/7f1708a4
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/7f1708a4
Branch: refs/heads/branch-2.3
Commit: 7f1708a44759724b116742683e2d4290362a3b59
Parents: e6bf325
Author: Ruben Berenguel Montoro
Authored: Fri Jun 15 16:59:00 2018 +0800
Committer: hyukjinkwon
Committed: Fri Jun 15 16:59:21 2018 +0800
--
python/pyspark/serializers.py | 17 +
1 file changed, 9 insertions(+), 8 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/7f1708a4/python/pyspark/serializers.py
--
diff --git a/python/pyspark/serializers.py b/python/pyspark/serializers.py
index 91a7f09..6d107f3 100644
--- a/python/pyspark/serializers.py
+++ b/python/pyspark/serializers.py
@@ -33,8 +33,9 @@ The serializer is chosen when creating L{SparkContext}:
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>> sc.stop()
-PySpark serialize objects in batches; By default, the batch size is chosen
based
-on the size of objects, also configurable by SparkContext's C{batchSize}
parameter:
+PySpark serializes objects in batches; by default, the batch size is chosen
based
+on the size of objects and is also configurable by SparkContext's C{batchSize}
+parameter:
>>> sc = SparkContext('local', 'test', batchSize=2)
>>> rdd = sc.parallelize(range(16), 4).map(lambda x: x)
@@ -99,7 +100,7 @@ class Serializer(object):
def _load_stream_without_unbatching(self, stream):
"""
Return an iterator of deserialized batches (iterable) of objects from
the input stream.
-if the serializer does not operate on batches the default
implementation returns an
+If the serializer does not operate on batches the default
implementation returns an
iterator of single element lists.
"""
return map(lambda x: [x], self.load_stream(stream))
@@ -456,7 +457,7 @@ class NoOpSerializer(FramedSerializer):
return obj
-# Hook namedtuple, make it picklable
+# Hack namedtuple, make it picklable
__cls = {}
@@ -520,15 +521,15 @@ def _hijack_namedtuple():
cls = _old_namedtuple(*args, **kwargs)
return _hack_namedtuple(cls)
-# replace namedtuple with new one
+# replace namedtuple with the new one
collections.namedtuple.__globals__["_old_namedtuple_kwdefaults"] =
_old_namedtuple_kwdefaults
collections.namedtuple.__globals__["_old_namedtuple"] = _old_namedtuple
collections.namedtuple.__globals__["_hack_namedtuple"] = _hack_namedtuple
collections.namedtuple.__code__ = namedtuple.__code__
collections.namedtuple.__hijack = 1
-# hack the cls already generated by namedtuple
-# those created in other module can be pickled as normal,
+# hack the cls already generated by namedtuple.
+# Those created in other modules can be pickled as normal,
# so only hack those in __main__ module
for n, o in sys.modules["__main__"].__dict__.items():
if (type(o) is type and o.__base__ is tuple
@@ -611,7 +612,7 @@ class AutoSerializer(FramedSerializer):
elif _type == b'P':
return pickle.loads(obj[1:])
else:
-raise ValueError("invalid sevialization type: %s" % _type)
+raise ValueError("invalid serialization type: %s" % _type)
class CompressedSerializer(FramedSerializer):
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r27475 - in /dev/spark/2.4.0-SNAPSHOT-2018_06_15_00_01-22daeba-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jun 15 07:17:08 2018 New Revision: 27475 Log: Apache Spark 2.4.0-SNAPSHOT-2018_06_15_00_01-22daeba docs [This commit notification would consist of 1468 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org