[spark] branch master updated: [SPARK-26659][SQL] Fix duplicate cmd.nodeName in the explain output of DataWritingCommandExec
This is an automated email from the ASF dual-hosted git repository.
lixiao pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e341864 [SPARK-26659][SQL] Fix duplicate cmd.nodeName in the explain
output of DataWritingCommandExec
e341864 is described below
commit e3418649dcb50f2a2fb977560d87a94c81516198
Author: Kris Mok
AuthorDate: Thu Jan 17 22:43:39 2019 -0800
[SPARK-26659][SQL] Fix duplicate cmd.nodeName in the explain output of
DataWritingCommandExec
## What changes were proposed in this pull request?
`DataWritingCommandExec` generates `cmd.nodeName` twice in its explain
output, e.g. when running this query `spark.sql("create table foo stored as
parquet as select id, id % 10 as cat1, id % 20 as cat2 from range(10)")`,
```
Execute OptimizedCreateHiveTableAsSelectCommand
OptimizedCreateHiveTableAsSelectCommand [Database:default, TableName: foo,
InsertIntoHiveTable]
+- *(1) Project [id#2L, (id#2L % 10) AS cat1#0L, (id#2L % 20) AS cat2#1L]
+- *(1) Range (0, 10, step=1, splits=8)
```
After the fix, it'll go back to normal:
```
Execute OptimizedCreateHiveTableAsSelectCommand [Database:default,
TableName: foo, InsertIntoHiveTable]
+- *(1) Project [id#2L, (id#2L % 10) AS cat1#0L, (id#2L % 20) AS cat2#1L]
+- *(1) Range (0, 10, step=1, splits=8)
```
This duplication is introduced when this specialized
`DataWritingCommandExec` was created in place of `ExecutedCommandExec`.
The former is a `UnaryExecNode` whose `children` include the physical plan
of the query, and the `cmd` is picked up via `TreeNode.stringArgs` into the
argument string. The duplication comes from: `DataWritingCommandExec.nodeName`
is `s"Execute ${cmd.nodeName}"` while the argument string is
`cmd.simpleString()` which also includes `cmd.nodeName`.
The latter didn't have that problem because it's a `LeafExecNode` with no
children, and it declares the `cmd` as being a part of the `innerChildren`
which is excluded from the argument string.
## How was this patch tested?
Manual testing of running the example above in a local Spark Shell.
Also added a new test case in `ExplainSuite`.
Closes #23579 from rednaxelafx/fix-explain.
Authored-by: Kris Mok
Signed-off-by: gatorsmile
---
.../spark/sql/execution/command/commands.scala | 3 +++
.../scala/org/apache/spark/sql/ExplainSuite.scala | 28 ++
2 files changed, 26 insertions(+), 5 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/command/commands.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/command/commands.scala
index 754a331..a1f2785 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/command/commands.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/command/commands.scala
@@ -110,6 +110,9 @@ case class DataWritingCommandExec(cmd: DataWritingCommand,
child: SparkPlan)
override def nodeName: String = "Execute " + cmd.nodeName
+ // override the default one, otherwise the `cmd.nodeName` will appear twice
from simpleString
+ override def argString(maxFields: Int): String = cmd.argString(maxFields)
+
override def executeCollect(): Array[InternalRow] = sideEffectResult.toArray
override def executeToIterator: Iterator[InternalRow] =
sideEffectResult.toIterator
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
index ce47592..ec68828 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
@@ -25,16 +25,25 @@ class ExplainSuite extends QueryTest with SharedSQLContext {
import testImplicits._
/**
- * Runs the plan and makes sure the plans contains all of the keywords.
+ * Get the explain from a DataFrame and run the specified action on it.
*/
- private def checkKeywordsExistsInExplain(df: DataFrame, keywords: String*):
Unit = {
+ private def withNormalizedExplain(df: DataFrame, extended: Boolean)(f:
String => Unit) = {
val output = new java.io.ByteArrayOutputStream()
Console.withOut(output) {
- df.explain(extended = true)
+ df.explain(extended = extended)
}
val normalizedOutput = output.toString.replaceAll("#\\d+", "#x")
-for (key <- keywords) {
- assert(normalizedOutput.contains(key))
+f(normalizedOutput)
+ }
+
+ /**
+ * Runs the plan and makes sure the plans contains all of the keywords.
+ */
+ private def checkKeywordsExistsInExplain(df: DataFrame, keywords: String*):
Unit = {
+withNormalizedExplain(df, extended = true) { normalizedOutput =>
+ for (key <- keywords) {
+assert(normalizedOutput.contains(key))
+ }
}
}
@@
svn commit: r32030 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_17_20_22-c2d0d70-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 18 04:34:25 2019 New Revision: 32030 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_17_20_22-c2d0d70 docs [This commit notification would consist of 1778 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26640][CORE][ML][SQL][STREAMING][PYSPARK] Code cleanup from lgtm.com analysis
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c2d0d70 [SPARK-26640][CORE][ML][SQL][STREAMING][PYSPARK] Code cleanup
from lgtm.com analysis
c2d0d70 is described below
commit c2d0d700b551e864bb7b2ae2a175ec8ade704488
Author: Sean Owen
AuthorDate: Thu Jan 17 19:40:39 2019 -0600
[SPARK-26640][CORE][ML][SQL][STREAMING][PYSPARK] Code cleanup from lgtm.com
analysis
## What changes were proposed in this pull request?
Misc code cleanup from lgtm.com analysis. See comments below for details.
## How was this patch tested?
Existing tests.
Closes #23571 from srowen/SPARK-26640.
Lead-authored-by: Sean Owen
Co-authored-by: Hyukjin Kwon
Co-authored-by: Sean Owen
Signed-off-by: Sean Owen
---
.../org/apache/spark/ui/static/executorspage.js| 3 +--
.../org/apache/spark/ui/static/historypage.js | 16 ++--
.../org/apache/spark/ui/static/spark-dag-viz.js| 8 +++---
.../org/apache/spark/ui/static/stagepage.js| 5 ++--
.../resources/org/apache/spark/ui/static/table.js | 2 +-
.../resources/org/apache/spark/ui/static/utils.js | 2 +-
.../resources/org/apache/spark/ui/static/webui.js | 2 +-
dev/pip-sanity-check.py| 1 -
dev/run-tests.py | 29 +-
.../JavaRandomForestClassificationExample.java | 2 +-
.../main/python/mllib/bisecting_k_means_example.py | 2 +-
.../python/mllib/isotonic_regression_example.py| 2 +-
.../python/mllib/multi_class_metrics_example.py| 6 ++---
.../main/python/mllib/ranking_metrics_example.py | 2 +-
.../main/python/mllib/standard_scaler_example.py | 2 +-
examples/src/main/python/sql/hive.py | 2 +-
.../spark/launcher/SparkSubmitCommandBuilder.java | 1 +
python/pyspark/broadcast.py| 1 -
python/pyspark/context.py | 1 -
python/pyspark/java_gateway.py | 4 +--
python/pyspark/ml/classification.py| 2 +-
python/pyspark/ml/fpm.py | 2 +-
python/pyspark/ml/regression.py| 1 -
python/pyspark/mllib/classification.py | 16 ++--
python/pyspark/mllib/clustering.py | 1 -
python/pyspark/mllib/evaluation.py | 3 +--
python/pyspark/mllib/feature.py| 2 --
python/pyspark/mllib/fpm.py| 4 +--
python/pyspark/mllib/regression.py | 24 +-
python/pyspark/mllib/tree.py | 2 +-
python/pyspark/mllib/util.py | 3 +--
python/pyspark/profiler.py | 4 +--
python/pyspark/rdd.py | 6 ++---
python/pyspark/sql/context.py | 6 ++---
python/pyspark/sql/types.py| 6 ++---
python/pyspark/streaming/context.py| 5 +---
python/pyspark/streaming/kinesis.py| 4 +--
python/pyspark/taskcontext.py | 1 -
python/pyspark/worker.py | 1 -
python/run-tests.py| 1 -
python/setup.py| 2 +-
.../spark/sql/execution/ui/static/spark-sql-viz.js | 2 +-
.../spark/streaming/ui/static/streaming-page.js| 8 +++---
43 files changed, 71 insertions(+), 128 deletions(-)
diff --git
a/core/src/main/resources/org/apache/spark/ui/static/executorspage.js
b/core/src/main/resources/org/apache/spark/ui/static/executorspage.js
index a48c02a..98d67c9 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/executorspage.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/executorspage.js
@@ -114,7 +114,6 @@ $(document).ready(function () {
var endPoint = createRESTEndPointForExecutorsPage(appId);
$.getJSON(endPoint, function (response, status, jqXHR) {
-var summary = [];
var allExecCnt = 0;
var allRDDBlocks = 0;
var allMemoryUsed = 0;
@@ -505,7 +504,7 @@ $(document).ready(function () {
{data: 'allTotalTasks'},
{
data: function (row, type) {
-return type === 'display' ?
(formatDuration(row.allTotalDuration, type) + ' (' +
formatDuration(row.allTotalGCTime, type) + ')') : row.allTotalDuration
+return type === 'display' ?
(formatDuration(row.allTotalDuration) + ' (' +
formatDuration(row.allTotalGCTime) + ')') : row.allTotalDuration
},
"fnCreatedCell": function (nTd, sData, oData,
iRow,
svn commit: r32027 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_17_15_36-0b3abef-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 17 23:48:28 2019 New Revision: 32027 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_17_15_36-0b3abef docs [This commit notification would consist of 1778 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32025 - in /dev/spark/2.4.1-SNAPSHOT-2019_01_17_13_12-5a2128c-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 17 21:29:15 2019 New Revision: 32025 Log: Apache Spark 2.4.1-SNAPSHOT-2019_01_17_13_12-5a2128c docs [This commit notification would consist of 1476 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32024 - in /dev/spark/2.3.4-SNAPSHOT-2019_01_17_13_12-8debdbd-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 17 21:27:34 2019 New Revision: 32024 Log: Apache Spark 2.3.4-SNAPSHOT-2019_01_17_13_12-8debdbd docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.3 updated: [SPARK-26638][PYSPARK][ML] Pyspark vector classes always return error for unary negation
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-2.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.3 by this push:
new 8debdbd [SPARK-26638][PYSPARK][ML] Pyspark vector classes always
return error for unary negation
8debdbd is described below
commit 8debdbdd8cd6032497353e604e61fa1215803881
Author: Sean Owen
AuthorDate: Thu Jan 17 14:24:21 2019 -0600
[SPARK-26638][PYSPARK][ML] Pyspark vector classes always return error for
unary negation
## What changes were proposed in this pull request?
Fix implementation of unary negation (`__neg__`) in Pyspark DenseVectors
## How was this patch tested?
Existing tests, plus new doctest
Closes #23570 from srowen/SPARK-26638.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 0b3abef1950f486001160ec578e4f628c199eeb4)
Signed-off-by: Sean Owen
---
python/pyspark/ml/linalg/__init__.py| 6 +-
python/pyspark/mllib/linalg/__init__.py | 6 +-
2 files changed, 10 insertions(+), 2 deletions(-)
diff --git a/python/pyspark/ml/linalg/__init__.py
b/python/pyspark/ml/linalg/__init__.py
index ad1b487..c2fc29d 100644
--- a/python/pyspark/ml/linalg/__init__.py
+++ b/python/pyspark/ml/linalg/__init__.py
@@ -270,6 +270,8 @@ class DenseVector(Vector):
DenseVector([3.0, 2.0])
>>> u % 2
DenseVector([1.0, 0.0])
+>>> -v
+DenseVector([-1.0, -2.0])
"""
def __init__(self, ar):
if isinstance(ar, bytes):
@@ -436,6 +438,9 @@ class DenseVector(Vector):
def __getattr__(self, item):
return getattr(self.array, item)
+def __neg__(self):
+return DenseVector(-self.array)
+
def _delegate(op):
def func(self, other):
if isinstance(other, DenseVector):
@@ -443,7 +448,6 @@ class DenseVector(Vector):
return DenseVector(getattr(self.array, op)(other))
return func
-__neg__ = _delegate("__neg__")
__add__ = _delegate("__add__")
__sub__ = _delegate("__sub__")
__mul__ = _delegate("__mul__")
diff --git a/python/pyspark/mllib/linalg/__init__.py
b/python/pyspark/mllib/linalg/__init__.py
index 7b24b3c..ced1eca 100644
--- a/python/pyspark/mllib/linalg/__init__.py
+++ b/python/pyspark/mllib/linalg/__init__.py
@@ -281,6 +281,8 @@ class DenseVector(Vector):
DenseVector([3.0, 2.0])
>>> u % 2
DenseVector([1.0, 0.0])
+>>> -v
+DenseVector([-1.0, -2.0])
"""
def __init__(self, ar):
if isinstance(ar, bytes):
@@ -480,6 +482,9 @@ class DenseVector(Vector):
def __getattr__(self, item):
return getattr(self.array, item)
+def __neg__(self):
+return DenseVector(-self.array)
+
def _delegate(op):
def func(self, other):
if isinstance(other, DenseVector):
@@ -487,7 +492,6 @@ class DenseVector(Vector):
return DenseVector(getattr(self.array, op)(other))
return func
-__neg__ = _delegate("__neg__")
__add__ = _delegate("__add__")
__sub__ = _delegate("__sub__")
__mul__ = _delegate("__mul__")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: [SPARK-26638][PYSPARK][ML] Pyspark vector classes always return error for unary negation
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-2.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.4 by this push:
new 5a2128c [SPARK-26638][PYSPARK][ML] Pyspark vector classes always
return error for unary negation
5a2128c is described below
commit 5a2128cdcfa63be36e751d328bc1bf5c60227752
Author: Sean Owen
AuthorDate: Thu Jan 17 14:24:21 2019 -0600
[SPARK-26638][PYSPARK][ML] Pyspark vector classes always return error for
unary negation
## What changes were proposed in this pull request?
Fix implementation of unary negation (`__neg__`) in Pyspark DenseVectors
## How was this patch tested?
Existing tests, plus new doctest
Closes #23570 from srowen/SPARK-26638.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 0b3abef1950f486001160ec578e4f628c199eeb4)
Signed-off-by: Sean Owen
---
python/pyspark/ml/linalg/__init__.py| 6 +-
python/pyspark/mllib/linalg/__init__.py | 6 +-
2 files changed, 10 insertions(+), 2 deletions(-)
diff --git a/python/pyspark/ml/linalg/__init__.py
b/python/pyspark/ml/linalg/__init__.py
index 2548fd0..9da9836 100644
--- a/python/pyspark/ml/linalg/__init__.py
+++ b/python/pyspark/ml/linalg/__init__.py
@@ -270,6 +270,8 @@ class DenseVector(Vector):
DenseVector([3.0, 2.0])
>>> u % 2
DenseVector([1.0, 0.0])
+>>> -v
+DenseVector([-1.0, -2.0])
"""
def __init__(self, ar):
if isinstance(ar, bytes):
@@ -436,6 +438,9 @@ class DenseVector(Vector):
def __getattr__(self, item):
return getattr(self.array, item)
+def __neg__(self):
+return DenseVector(-self.array)
+
def _delegate(op):
def func(self, other):
if isinstance(other, DenseVector):
@@ -443,7 +448,6 @@ class DenseVector(Vector):
return DenseVector(getattr(self.array, op)(other))
return func
-__neg__ = _delegate("__neg__")
__add__ = _delegate("__add__")
__sub__ = _delegate("__sub__")
__mul__ = _delegate("__mul__")
diff --git a/python/pyspark/mllib/linalg/__init__.py
b/python/pyspark/mllib/linalg/__init__.py
index 4afd666..94a3e2a 100644
--- a/python/pyspark/mllib/linalg/__init__.py
+++ b/python/pyspark/mllib/linalg/__init__.py
@@ -281,6 +281,8 @@ class DenseVector(Vector):
DenseVector([3.0, 2.0])
>>> u % 2
DenseVector([1.0, 0.0])
+>>> -v
+DenseVector([-1.0, -2.0])
"""
def __init__(self, ar):
if isinstance(ar, bytes):
@@ -480,6 +482,9 @@ class DenseVector(Vector):
def __getattr__(self, item):
return getattr(self.array, item)
+def __neg__(self):
+return DenseVector(-self.array)
+
def _delegate(op):
def func(self, other):
if isinstance(other, DenseVector):
@@ -487,7 +492,6 @@ class DenseVector(Vector):
return DenseVector(getattr(self.array, op)(other))
return func
-__neg__ = _delegate("__neg__")
__add__ = _delegate("__add__")
__sub__ = _delegate("__sub__")
__mul__ = _delegate("__mul__")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26638][PYSPARK][ML] Pyspark vector classes always return error for unary negation
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 0b3abef [SPARK-26638][PYSPARK][ML] Pyspark vector classes always
return error for unary negation
0b3abef is described below
commit 0b3abef1950f486001160ec578e4f628c199eeb4
Author: Sean Owen
AuthorDate: Thu Jan 17 14:24:21 2019 -0600
[SPARK-26638][PYSPARK][ML] Pyspark vector classes always return error for
unary negation
## What changes were proposed in this pull request?
Fix implementation of unary negation (`__neg__`) in Pyspark DenseVectors
## How was this patch tested?
Existing tests, plus new doctest
Closes #23570 from srowen/SPARK-26638.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
---
python/pyspark/ml/linalg/__init__.py| 6 +-
python/pyspark/mllib/linalg/__init__.py | 6 +-
2 files changed, 10 insertions(+), 2 deletions(-)
diff --git a/python/pyspark/ml/linalg/__init__.py
b/python/pyspark/ml/linalg/__init__.py
index 2548fd0..9da9836 100644
--- a/python/pyspark/ml/linalg/__init__.py
+++ b/python/pyspark/ml/linalg/__init__.py
@@ -270,6 +270,8 @@ class DenseVector(Vector):
DenseVector([3.0, 2.0])
>>> u % 2
DenseVector([1.0, 0.0])
+>>> -v
+DenseVector([-1.0, -2.0])
"""
def __init__(self, ar):
if isinstance(ar, bytes):
@@ -436,6 +438,9 @@ class DenseVector(Vector):
def __getattr__(self, item):
return getattr(self.array, item)
+def __neg__(self):
+return DenseVector(-self.array)
+
def _delegate(op):
def func(self, other):
if isinstance(other, DenseVector):
@@ -443,7 +448,6 @@ class DenseVector(Vector):
return DenseVector(getattr(self.array, op)(other))
return func
-__neg__ = _delegate("__neg__")
__add__ = _delegate("__add__")
__sub__ = _delegate("__sub__")
__mul__ = _delegate("__mul__")
diff --git a/python/pyspark/mllib/linalg/__init__.py
b/python/pyspark/mllib/linalg/__init__.py
index 4afd666..94a3e2a 100644
--- a/python/pyspark/mllib/linalg/__init__.py
+++ b/python/pyspark/mllib/linalg/__init__.py
@@ -281,6 +281,8 @@ class DenseVector(Vector):
DenseVector([3.0, 2.0])
>>> u % 2
DenseVector([1.0, 0.0])
+>>> -v
+DenseVector([-1.0, -2.0])
"""
def __init__(self, ar):
if isinstance(ar, bytes):
@@ -480,6 +482,9 @@ class DenseVector(Vector):
def __getattr__(self, item):
return getattr(self.array, item)
+def __neg__(self):
+return DenseVector(-self.array)
+
def _delegate(op):
def func(self, other):
if isinstance(other, DenseVector):
@@ -487,7 +492,6 @@ class DenseVector(Vector):
return DenseVector(getattr(self.array, op)(other))
return func
-__neg__ = _delegate("__neg__")
__add__ = _delegate("__add__")
__sub__ = _delegate("__sub__")
__mul__ = _delegate("__mul__")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32023 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_17_10_49-1b575ef-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 17 19:01:21 2019 New Revision: 32023 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_17_10_49-1b575ef docs [This commit notification would consist of 1778 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26622][SQL] Revise SQL Metrics labels
This is an automated email from the ASF dual-hosted git repository.
lixiao pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ede35c8 [SPARK-26622][SQL] Revise SQL Metrics labels
ede35c8 is described below
commit ede35c88e02323c69a5a6feb7e8ff4d29ffb0456
Author: Juliusz Sompolski
AuthorDate: Thu Jan 17 10:49:42 2019 -0800
[SPARK-26622][SQL] Revise SQL Metrics labels
## What changes were proposed in this pull request?
Try to make labels more obvious
"avg hash probe"avg hash probe bucket iterations
"partition pruning time (ms)" dynamic partition pruning time
"total number of files in the table"file count
"number of files that would be returned by partition pruning alone" file
count after partition pruning
"total size of files in the table" file size
"size of files that would be returned by partition pruning alone" file
size after partition pruning
"metadata time (ms)"metadata time
"aggregate time"time in aggregation build
"aggregate time"time in aggregation build
"time to construct rdd bc" time to build
"total time to remove rows" time to remove
"total time to update rows" time to update
Add proper metric type to some metrics:
"bytes of written output" written output - createSizeMetric
"metadata time" - createTimingMetric
"dataSize" - createSizeMetric
"collectTime" - createTimingMetric
"buildTime" - createTimingMetric
"broadcastTIme" - createTimingMetric
## How is this patch tested?
Existing tests.
Author: Stacy Kerkela
Signed-off-by: Juliusz Sompolski
Closes #23551 from juliuszsompolski/SPARK-26622.
Lead-authored-by: Juliusz Sompolski
Co-authored-by: Stacy Kerkela
Signed-off-by: gatorsmile
---
.../java/org/apache/spark/unsafe/map/BytesToBytesMap.java| 2 +-
.../spark/sql/execution/UnsafeFixedWidthAggregationMap.java | 6 +++---
.../org/apache/spark/sql/execution/DataSourceScanExec.scala | 4 ++--
.../spark/sql/execution/aggregate/HashAggregateExec.scala| 7 ---
.../sql/execution/aggregate/ObjectHashAggregateExec.scala| 2 +-
.../execution/aggregate/TungstenAggregationIterator.scala| 2 +-
.../apache/spark/sql/execution/basicPhysicalOperators.scala | 4 ++--
.../sql/execution/datasources/BasicWriteStatsTracker.scala | 2 +-
.../spark/sql/execution/exchange/BroadcastExchangeExec.scala | 8
.../spark/sql/execution/streaming/statefulOperators.scala| 4 ++--
.../apache/spark/sql/execution/metric/SQLMetricsSuite.scala | 12 ++--
.../spark/sql/execution/metric/SQLMetricsTestUtils.scala | 6 --
12 files changed, 31 insertions(+), 28 deletions(-)
diff --git
a/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
b/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
index 2ff98a6..13ca7fb 100644
--- a/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
+++ b/core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
@@ -854,7 +854,7 @@ public final class BytesToBytesMap extends MemoryConsumer {
/**
* Returns the average number of probes per key lookup.
*/
- public double getAverageProbesPerLookup() {
+ public double getAvgHashProbeBucketListIterations() {
return (1.0 * numProbes) / numKeyLookups;
}
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/UnsafeFixedWidthAggregationMap.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/UnsafeFixedWidthAggregationMap.java
index 7e76a65..117e98f 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/UnsafeFixedWidthAggregationMap.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/UnsafeFixedWidthAggregationMap.java
@@ -226,10 +226,10 @@ public final class UnsafeFixedWidthAggregationMap {
}
/**
- * Gets the average hash map probe per looking up for the underlying
`BytesToBytesMap`.
+ * Gets the average bucket list iterations per lookup in the underlying
`BytesToBytesMap`.
*/
- public double getAverageProbesPerLookup() {
-return map.getAverageProbesPerLookup();
+ public double getAvgHashProbeBucketListIterations() {
+return map.getAvgHashProbeBucketListIterations();
}
/**
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala
index f6f3fb1..f852a52 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala
@@ -319,8 +319,8 @@ case class FileSourceScanExec(
override lazy val metrics =
Map("numOutputRows" -> SQLMetrics.createMetric(sparkContext,
[spark] branch master updated: [SPARK-26621][CORE] Use ConfigEntry for hardcoded configs for shuffle categories.
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1b575ef5 [SPARK-26621][CORE] Use ConfigEntry for hardcoded configs for
shuffle categories.
1b575ef5 is described below
commit 1b575ef5d1b8e3e672b2fca5c354d6678bd78bd1
Author: liuxian
AuthorDate: Thu Jan 17 12:29:17 2019 -0600
[SPARK-26621][CORE] Use ConfigEntry for hardcoded configs for shuffle
categories.
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.shuffle` configs to use ConfigEntry and put
them in the config package.
## How was this patch tested?
Existing unit tests
Closes #23550 from 10110346/ConfigEntry_shuffle.
Authored-by: liuxian
Signed-off-by: Sean Owen
---
.../shuffle/sort/BypassMergeSortShuffleWriter.java | 3 +-
.../spark/shuffle/sort/ShuffleExternalSorter.java | 2 +-
.../spark/shuffle/sort/UnsafeShuffleWriter.java| 10 +--
.../scala/org/apache/spark/MapOutputTracker.scala | 13 ++--
.../src/main/scala/org/apache/spark/SparkEnv.scala | 4 +-
.../org/apache/spark/internal/config/package.scala | 90 ++
.../spark/serializer/SerializerManager.scala | 4 +-
.../spark/shuffle/BlockStoreShuffleReader.scala| 2 +-
.../spark/shuffle/sort/SortShuffleWriter.scala | 4 +-
.../org/apache/spark/storage/BlockManager.scala| 2 +-
.../main/scala/org/apache/spark/util/Utils.scala | 2 +-
.../util/collection/ExternalAppendOnlyMap.scala| 7 +-
.../spark/util/collection/ExternalSorter.scala | 6 +-
.../apache/spark/util/collection/Spillable.scala | 2 +-
.../shuffle/sort/UnsafeShuffleWriterSuite.java | 15 ++--
.../unsafe/map/AbstractBytesToBytesMapSuite.java | 7 +-
.../unsafe/sort/UnsafeExternalSorterSuite.java | 2 +-
.../org/apache/spark/ContextCleanerSuite.scala | 6 +-
.../apache/spark/ExternalShuffleServiceSuite.scala | 6 +-
.../org/apache/spark/MapOutputTrackerSuite.scala | 7 +-
.../test/scala/org/apache/spark/ShuffleSuite.scala | 14 ++--
.../scala/org/apache/spark/SortShuffleSuite.scala | 3 +-
.../spark/security/CryptoStreamUtilsSuite.scala| 4 +-
.../spark/serializer/KryoSerializerSuite.scala | 4 +-
.../shuffle/BlockStoreShuffleReaderSuite.scala | 5 +-
.../apache/spark/storage/BlockManagerSuite.scala | 6 +-
.../collection/ExternalAppendOnlyMapSuite.scala| 22 +++---
.../util/collection/ExternalSorterSuite.scala | 48 ++--
.../sql/execution/UnsafeExternalRowSorter.java | 4 +-
.../expressions/RowBasedKeyValueBatchSuite.java| 5 +-
.../sql/execution/UnsafeKVExternalSorter.java | 7 +-
.../execution/exchange/ShuffleExchangeExec.scala | 3 +-
.../sql/execution/UnsafeRowSerializerSuite.scala | 8 +-
33 files changed, 211 insertions(+), 116 deletions(-)
diff --git
a/core/src/main/java/org/apache/spark/shuffle/sort/BypassMergeSortShuffleWriter.java
b/core/src/main/java/org/apache/spark/shuffle/sort/BypassMergeSortShuffleWriter.java
index 997bc9e..32b4467 100644
---
a/core/src/main/java/org/apache/spark/shuffle/sort/BypassMergeSortShuffleWriter.java
+++
b/core/src/main/java/org/apache/spark/shuffle/sort/BypassMergeSortShuffleWriter.java
@@ -34,6 +34,7 @@ import com.google.common.io.Closeables;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
+import org.apache.spark.internal.config.package$;
import org.apache.spark.Partitioner;
import org.apache.spark.ShuffleDependency;
import org.apache.spark.SparkConf;
@@ -104,7 +105,7 @@ final class BypassMergeSortShuffleWriter extends
ShuffleWriter {
SparkConf conf,
ShuffleWriteMetricsReporter writeMetrics) {
// Use getSizeAsKb (not bytes) to maintain backwards compatibility if no
units are provided
-this.fileBufferSize = (int) conf.getSizeAsKb("spark.shuffle.file.buffer",
"32k") * 1024;
+this.fileBufferSize = (int) (long)
conf.get(package$.MODULE$.SHUFFLE_FILE_BUFFER_SIZE()) * 1024;
this.transferToEnabled = conf.getBoolean("spark.file.transferTo", true);
this.blockManager = blockManager;
final ShuffleDependency dep = handle.dependency();
diff --git
a/core/src/main/java/org/apache/spark/shuffle/sort/ShuffleExternalSorter.java
b/core/src/main/java/org/apache/spark/shuffle/sort/ShuffleExternalSorter.java
index dc43215..0247560 100644
---
a/core/src/main/java/org/apache/spark/shuffle/sort/ShuffleExternalSorter.java
+++
b/core/src/main/java/org/apache/spark/shuffle/sort/ShuffleExternalSorter.java
@@ -129,7 +129,7 @@ final class ShuffleExternalSorter extends MemoryConsumer {
(int)
conf.get(package$.MODULE$.SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD());
this.writeMetrics = writeMetrics;
this.inMemSorter = new ShuffleInMemorySorter(
- this, initialSize,
[spark] branch master updated: [SPARK-26593][SQL] Use Proleptic Gregorian calendar in casting UTF8String to Date/TimestampType
This is an automated email from the ASF dual-hosted git repository.
hvanhovell pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6f8c0e5 [SPARK-26593][SQL] Use Proleptic Gregorian calendar in
casting UTF8String to Date/TimestampType
6f8c0e5 is described below
commit 6f8c0e5255a30af6e0e0350b30247ea373861bed
Author: Maxim Gekk
AuthorDate: Thu Jan 17 17:53:00 2019 +0100
[SPARK-26593][SQL] Use Proleptic Gregorian calendar in casting UTF8String
to Date/TimestampType
## What changes were proposed in this pull request?
In the PR, I propose to use *java.time* classes in `stringToDate` and
`stringToTimestamp`. This switches the methods from the hybrid calendar
(Gregorian+Julian) to Proleptic Gregorian calendar. And it should make the
casting consistent to other Spark classes that converts textual representation
of dates/timestamps to `DateType`/`TimestampType`.
## How was this patch tested?
The changes were tested by existing suites - `HashExpressionsSuite`,
`CastSuite` and `DateTimeUtilsSuite`.
Closes #23512 from MaxGekk/utf8string-timestamp-parsing.
Lead-authored-by: Maxim Gekk
Co-authored-by: Maxim Gekk
Signed-off-by: Herman van Hovell
---
.../spark/sql/catalyst/util/DateFormatter.scala| 8 +-
.../spark/sql/catalyst/util/DateTimeUtils.scala| 311 +++--
.../sql/catalyst/util/TimestampFormatter.scala | 8 +-
.../expressions/DateExpressionsSuite.scala | 73 ++---
.../expressions/HashExpressionsSuite.scala | 4 +-
.../sql/catalyst/util/DateTimeTestUtils.scala | 2 -
.../sql/catalyst/util/DateTimeUtilsSuite.scala | 124 +++-
.../datasources/parquet/ParquetQuerySuite.scala| 53 ++--
8 files changed, 151 insertions(+), 432 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateFormatter.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateFormatter.scala
index adc69ab..9535a36 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateFormatter.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateFormatter.scala
@@ -20,6 +20,8 @@ package org.apache.spark.sql.catalyst.util
import java.time.{Instant, ZoneId}
import java.util.Locale
+import org.apache.spark.sql.catalyst.util.DateTimeUtils.instantToDays
+
sealed trait DateFormatter extends Serializable {
def parse(s: String): Int // returns days since epoch
def format(days: Int): String
@@ -38,11 +40,7 @@ class Iso8601DateFormatter(
toInstantWithZoneId(temporalAccessor, UTC)
}
- override def parse(s: String): Int = {
-val seconds = toInstant(s).getEpochSecond
-val days = Math.floorDiv(seconds, DateTimeUtils.SECONDS_PER_DAY)
-days.toInt
- }
+ override def parse(s: String): Int = instantToDays(toInstant(s))
override def format(days: Int): String = {
val instant = Instant.ofEpochSecond(days * DateTimeUtils.SECONDS_PER_DAY)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala
index da8899a..8676479 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala
@@ -18,13 +18,12 @@
package org.apache.spark.sql.catalyst.util
import java.sql.{Date, Timestamp}
-import java.text.{DateFormat, SimpleDateFormat}
+import java.time.{Instant, LocalDate, LocalDateTime, LocalTime, ZonedDateTime}
+import java.time.Year.isLeap
+import java.time.temporal.IsoFields
import java.util.{Calendar, Locale, TimeZone}
-import java.util.concurrent.ConcurrentHashMap
+import java.util.concurrent.{ConcurrentHashMap, TimeUnit}
import java.util.function.{Function => JFunction}
-import javax.xml.bind.DatatypeConverter
-
-import scala.annotation.tailrec
import org.apache.spark.unsafe.types.UTF8String
@@ -53,30 +52,12 @@ object DateTimeUtils {
final val NANOS_PER_MICROS = 1000L
final val MILLIS_PER_DAY = SECONDS_PER_DAY * 1000L
- // number of days in 400 years by Gregorian calendar
- final val daysIn400Years: Int = 146097
-
- // In the Julian calendar every year that is exactly divisible by 4 is a
leap year without any
- // exception. But in the Gregorian calendar every year that is exactly
divisible by four
- // is a leap year, except for years that are exactly divisible by 100, but
these centurial years
- // are leap years if they are exactly divisible by 400.
- // So there are 3 extra days in the Julian calendar within a 400 years cycle
compared to the
- // Gregorian calendar.
- final val extraLeapDaysIn400YearsJulian = 3
-
- // number of days in 400 years by Julian calendar
- final val
svn commit: r32017 - /dev/spark/v2.3.3-rc1-bin/
Author: yamamuro Date: Thu Jan 17 15:53:20 2019 New Revision: 32017 Log: Apache Spark v2.3.3-rc1 Added: dev/spark/v2.3.3-rc1-bin/ dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz (with props) dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.asc dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.sha512 dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz (with props) dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.asc dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.sha512 dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-hadoop2.6.tgz (with props) dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-hadoop2.6.tgz.asc dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-hadoop2.6.tgz.sha512 dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-hadoop2.7.tgz (with props) dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-hadoop2.7.tgz.asc dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-hadoop2.7.tgz.sha512 dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-without-hadoop.tgz (with props) dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-without-hadoop.tgz.asc dev/spark/v2.3.3-rc1-bin/spark-2.3.3-bin-without-hadoop.tgz.sha512 dev/spark/v2.3.3-rc1-bin/spark-2.3.3.tgz (with props) dev/spark/v2.3.3-rc1-bin/spark-2.3.3.tgz.asc dev/spark/v2.3.3-rc1-bin/spark-2.3.3.tgz.sha512 Added: dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz == Binary file - no diff available. Propchange: dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.asc == --- dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.asc (added) +++ dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.asc Thu Jan 17 15:53:20 2019 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- +Version: GnuPG v1 + +iQIcBAABAgAGBQJcQHopAAoJEG7F8QUt8I/0gHMQAJ8tWZUAYncu7n/FTuXfAFdv +2gr6Q9u9zQNeajFMBWNApTuYZdrEzYPz+ocyhUShESRzjNvhQa3JyfWtqkLlGqvq +gLC0phytV6WXOsdqUHjFs8OCToSpB6hSvqurQOxWGmA0uCmagjmD0eEDnsoHxd2j +/pEcXLBwrc9yGhZmIk0Sz+yU7PaTXxiYZgCsLY6qPPna0SnF4UWWw0ltnPMABPB8 +QtyT2iI5RzjRndyU2G+yv1cwAeXwD6jNbtQkOWprAUGhPCsS2BXkAeDY4aDGupa4 +IYxQ3lwDERx3cIZGdY3xoKAKKQR29UALCh+jUX2d1rSF+IRRyv7tl0Jc+IIhyU/3 +gtpMw+JqiqVOCP8Feb5B/oGD+gnUtqAVLggsJa7FYRzzDhY2EqohOLMeqqErrYAZ +Ockt+6u8No7Tfbz71pMBX9UBB9HKnYpiocxqBhphAa0c9OjVw5hSAsUyoelIYnJ6 +QIyWrGLqNiNaTkIUm0IKL4ni19MSpesM05gpCRcLgyeidNRf4u3WFFxJQRrE5/eh +AiQRTAhUfP6GkTYc+wFj4WOsTZHKPg8UCfJ5awkof0E61QZ+zv5McUCXTMgJr5B0 +dNL2KPbG62/+626EjuU90G7wtlp+c4Ywi43ayV1LLo3RUQyu+zdNiSMvn8ksWEAZ +jS5CROEO6lIBaJKJ8WuW +=tGPH +-END PGP SIGNATURE- Added: dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.sha512 == --- dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.sha512 (added) +++ dev/spark/v2.3.3-rc1-bin/SparkR_2.3.3.tar.gz.sha512 Thu Jan 17 15:53:20 2019 @@ -0,0 +1,3 @@ +SparkR_2.3.3.tar.gz: 836F3DF8 4A020797 4F8B81D7 65629B34 54FCB070 5DDDF7AF + 940A68AB 3056ADBB 2F76B08C E0046BCE 68B86E5E 56B1F92E + FC7AAE37 A44964E5 15E7DA24 A5146234 Added: dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz == Binary file - no diff available. Propchange: dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.asc == --- dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.asc (added) +++ dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.asc Thu Jan 17 15:53:20 2019 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- +Version: GnuPG v1 + +iQIcBAABAgAGBQJcQHouAAoJEG7F8QUt8I/0PLAP/2px9DN0ZDnE/Mpl4Yp/ltS1 +f/XEzdK7pxtGDgmOBRKWahKJAv7GUAlpLxAif8MBoq3V3GaWIQWcrXVuD2i8kVQl +E0hCZerwON+ns1HC/j7MEieSSxM/WBlDj5yMo23NZFlzi5lKdyOOtuIM4VeKbaaa +jbUjIGReM/zMmKsLtzPjh9p9OQ+BXcZ6xoKw/HO1FYDMn/CsqGqGIoEdzuND9KzD +6i3jVa3rzoZG4oH/e/N3tloCrwAeLUoL+4NKONzczWlYhRZW8gvBvoSSBLApi1nu +LQLvOlQKjybyxqPcfKWmtloKJyogYX1ZGdPzD5jc4yGYoKVX196Y1dndb6dzcUap +hf7JZ45Kx0WAsp/ZV5YY9bF+rS0EDZiHPQoyip3SqJizNaMXLxM2Wl+0zZGi0azf +06WjqvknC9YP85YBXsOthwy4+OipVbbggi7ihdiBiqat/N+PBa3+/UFkJhlrAPJD +I2/maEYfN1F3/NiBgwWosCRQw1yLCt1cF6NMPf3dto8JnBt4buu5W3VkIrnpstR6 +lqP5IBOYaBR1NuyvaXB50gbPWFDn3YRy7Ej0rPoXt31X0Nv3flinCwYnwyZa2bxC +7aTabfdWsx3vhWCcoWqid8wM/OawhwzqzGUbpGgeinqhWCXvAcgLcP+pDjnLpFOu +I9Ahvv3rYlwZNAWLovNc +=TUU/ +-END PGP SIGNATURE- Added: dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.sha512 == --- dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.sha512 (added) +++ dev/spark/v2.3.3-rc1-bin/pyspark-2.3.3.tar.gz.sha512
[spark] branch master updated: [SPARK-23817][SQL] Create file source V2 framework and migrate ORC read path
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c0632ce [SPARK-23817][SQL] Create file source V2 framework and
migrate ORC read path
c0632ce is described below
commit c0632cec04e5b0f3fb3c3f27c21a2d3f3fbb4f7e
Author: Gengliang Wang
AuthorDate: Thu Jan 17 23:33:29 2019 +0800
[SPARK-23817][SQL] Create file source V2 framework and migrate ORC read path
## What changes were proposed in this pull request?
Create a framework for file source V2 based on data source V2 API.
As a good example for demonstrating the framework, this PR also migrate ORC
source. This is because ORC file source supports both row scan and columnar
scan, and the implementation is simpler comparing with Parquet.
Note: Currently only read path of V2 API is done, this framework and
migration are only for the read path.
Supports the following scan:
- Scan ColumnarBatch
- Scan UnsafeRow
- Push down filters
- Push down required columns
Not supported( due to the limitation of data source V2 API):
- Stats metrics
- Catalog table
- Writes
## How was this patch tested?
Unit test
Closes #23383 from gengliangwang/latest_orcV2.
Authored-by: Gengliang Wang
Signed-off-by: Wenchen Fan
---
.../org/apache/spark/sql/internal/SQLConf.scala| 11 +-
.../spark/sql/sources/v2/DataSourceOptions.java| 10 ++
.../org/apache/spark/sql/DataFrameReader.scala | 18 ++-
.../org/apache/spark/sql/DataFrameWriter.scala | 3 +-
.../spark/sql/execution/DataSourceScanExec.scala | 107 +++--
.../spark/sql/execution/PartitionedFileUtil.scala | 94
.../spark/sql/execution/command/tables.scala | 5 +-
.../sql/execution/datasources/DataSource.scala | 97 +++-
.../datasources/FallbackOrcDataSourceV2.scala | 42 +
.../sql/execution/datasources/FilePartition.scala | 97
.../sql/execution/datasources/FileScanRDD.scala| 24 +--
.../execution/datasources/HadoopFsRelation.scala | 22 +--
.../execution/datasources/PartitioningUtils.scala | 36 -
.../sql/execution/datasources/orc/OrcFilters.scala | 20 +--
.../datasources/v2/EmptyPartitionReader.scala | 34 +
.../datasources/v2/FileDataSourceV2.scala | 54 +++
.../datasources/v2/FilePartitionReader.scala | 77 ++
.../v2/FilePartitionReaderFactory.scala| 61
.../sql/execution/datasources/v2/FileScan.scala| 61
.../execution/datasources/v2/FileScanBuilder.scala | 31
.../sql/execution/datasources/v2/FileTable.scala | 51 +++
.../datasources/v2/PartitionRecordReader.scala | 41 +
.../datasources/v2/orc/OrcDataSourceV2.scala | 46 ++
.../v2/orc/OrcPartitionReaderFactory.scala | 169 +
.../sql/execution/datasources/v2/orc/OrcScan.scala | 43 ++
.../datasources/v2/orc/OrcScanBuilder.scala| 62
.../execution/datasources/v2/orc/OrcTable.scala| 39 +
.../sql/internal/BaseSessionStateBuilder.scala | 1 +
.../scala/org/apache/spark/sql/QueryTest.scala | 5 +-
.../execution/datasources/orc/OrcFilterSuite.scala | 85 ++-
.../orc/OrcPartitionDiscoverySuite.scala | 7 +
.../execution/datasources/orc/OrcQuerySuite.scala | 9 +-
.../datasources/orc/OrcV1FilterSuite.scala | 104 +
.../sources/v2/FileDataSourceV2FallBackSuite.scala | 97
.../spark/sql/hive/HiveSessionStateBuilder.scala | 1 +
.../spark/sql/hive/MetastoreDataSourcesSuite.scala | 2 +-
36 files changed, 1436 insertions(+), 230 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
index c1b885a..ebc8c37 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
@@ -1419,8 +1419,15 @@ object SQLConf {
.timeConf(TimeUnit.MILLISECONDS)
.createWithDefault(100)
- val DISABLED_V2_STREAMING_WRITERS =
buildConf("spark.sql.streaming.disabledV2Writers")
+ val USE_V1_SOURCE_READER_LIST =
buildConf("spark.sql.sources.read.useV1SourceList")
.internal()
+.doc("A comma-separated list of data source short names or fully qualified
data source" +
+ " register class names for which data source V2 read paths are disabled.
Reads from these" +
+ " sources will fall back to the V1 sources.")
+.stringConf
+.createWithDefault("")
+
+ val DISABLED_V2_STREAMING_WRITERS =
buildConf("spark.sql.streaming.disabledV2Writers")
.doc("A comma-separated list of fully qualified data source
svn commit: r32013 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_17_05_53-650b879-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jan 17 14:05:24 2019 New Revision: 32013 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_17_05_53-650b879 docs [This commit notification would consist of 1778 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26457] Show hadoop configurations in HistoryServer environment tab
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 650b879 [SPARK-26457] Show hadoop configurations in HistoryServer
environment tab
650b879 is described below
commit 650b879de9e3b426fd38cdf1a8abf701a0c4a086
Author: xiaodeshan
AuthorDate: Thu Jan 17 05:51:43 2019 -0600
[SPARK-26457] Show hadoop configurations in HistoryServer environment tab
## What changes were proposed in this pull request?
I know that yarn provided all hadoop configurations. But I guess it may be
fine that the historyserver unify all configuration in it. It will be
convenient for us to debug some problems.
## How was this patch tested?
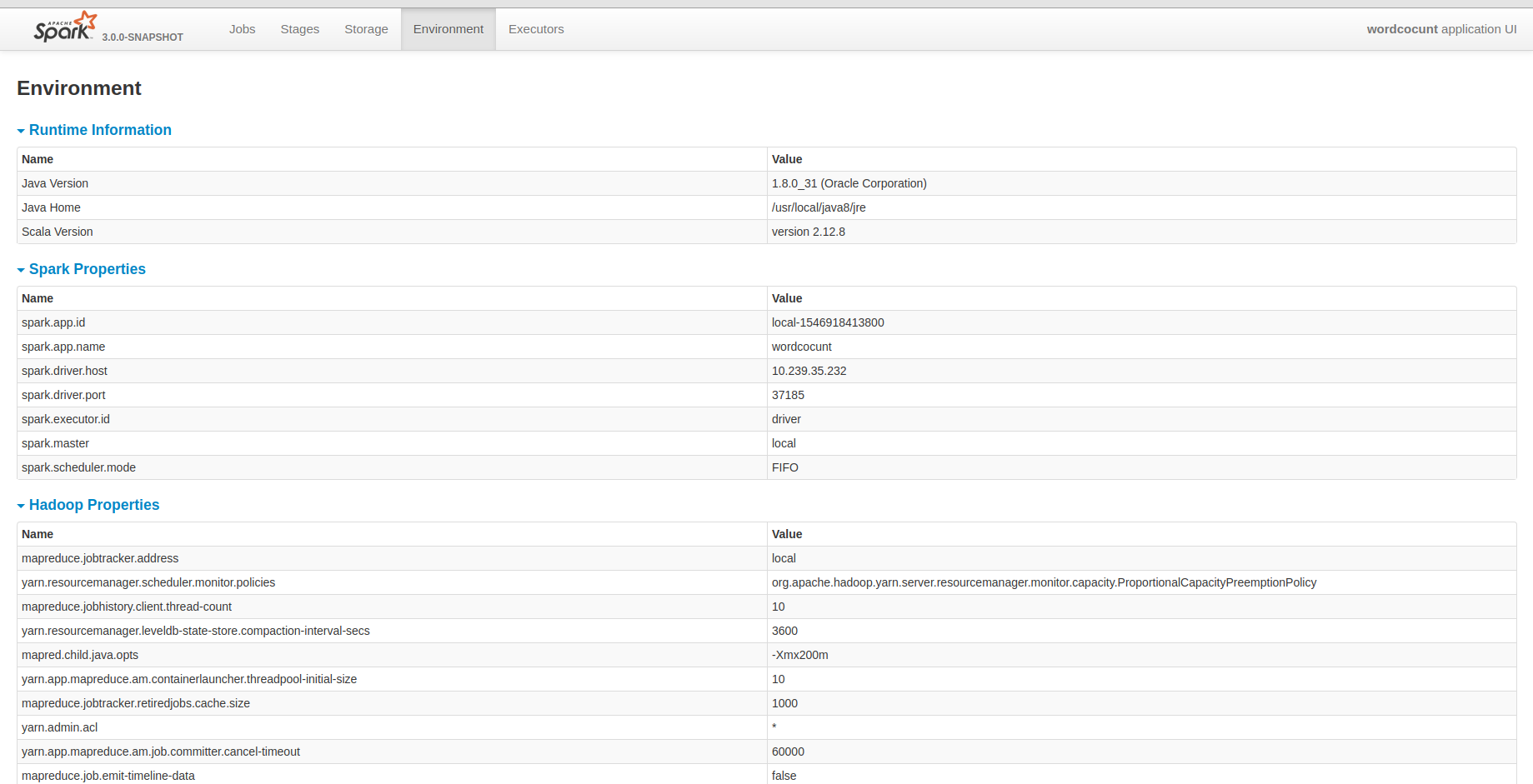
Closes #23486 from deshanxiao/spark-26457.
Lead-authored-by: xiaodeshan
Co-authored-by: deshanxiao <42019462+deshanx...@users.noreply.github.com>
Signed-off-by: Sean Owen
---
.../resources/org/apache/spark/ui/static/webui.js | 1 +
.../main/scala/org/apache/spark/SparkContext.scala | 4 ++--
core/src/main/scala/org/apache/spark/SparkEnv.scala | 7 +++
.../org/apache/spark/status/AppStatusListener.scala | 1 +
.../scala/org/apache/spark/status/api/v1/api.scala | 1 +
.../org/apache/spark/ui/env/EnvironmentPage.scala | 21 +
.../scala/org/apache/spark/util/JsonProtocol.scala | 6 ++
.../app_environment_expectation.json| 5 +
.../resources/spark-events/app-20161116163331- | 2 +-
.../deploy/history/FsHistoryProviderSuite.scala | 2 ++
.../spark/scheduler/EventLoggingListenerSuite.scala | 3 ++-
.../org/apache/spark/util/JsonProtocolSuite.scala | 4
project/MimaExcludes.scala | 3 +++
13 files changed, 52 insertions(+), 8 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/webui.js
b/core/src/main/resources/org/apache/spark/ui/static/webui.js
index b1254e0..9f5744a 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/webui.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/webui.js
@@ -63,6 +63,7 @@ $(function() {
collapseTablePageLoad('collapse-aggregated-finishedDrivers','aggregated-finishedDrivers');
collapseTablePageLoad('collapse-aggregated-runtimeInformation','aggregated-runtimeInformation');
collapseTablePageLoad('collapse-aggregated-sparkProperties','aggregated-sparkProperties');
+
collapseTablePageLoad('collapse-aggregated-hadoopProperties','aggregated-hadoopProperties');
collapseTablePageLoad('collapse-aggregated-systemProperties','aggregated-systemProperties');
collapseTablePageLoad('collapse-aggregated-classpathEntries','aggregated-classpathEntries');
collapseTablePageLoad('collapse-aggregated-activeJobs','aggregated-activeJobs');
diff --git a/core/src/main/scala/org/apache/spark/SparkContext.scala
b/core/src/main/scala/org/apache/spark/SparkContext.scala
index c9afc79..e0c0635 100644
--- a/core/src/main/scala/org/apache/spark/SparkContext.scala
+++ b/core/src/main/scala/org/apache/spark/SparkContext.scala
@@ -2370,8 +2370,8 @@ class SparkContext(config: SparkConf) extends Logging {
val schedulingMode = getSchedulingMode.toString
val addedJarPaths = addedJars.keys.toSeq
val addedFilePaths = addedFiles.keys.toSeq
- val environmentDetails = SparkEnv.environmentDetails(conf,
schedulingMode, addedJarPaths,
-addedFilePaths)
+ val environmentDetails = SparkEnv.environmentDetails(conf,
hadoopConfiguration,
+schedulingMode, addedJarPaths, addedFilePaths)
val environmentUpdate =
SparkListenerEnvironmentUpdate(environmentDetails)
listenerBus.post(environmentUpdate)
}
diff --git a/core/src/main/scala/org/apache/spark/SparkEnv.scala
b/core/src/main/scala/org/apache/spark/SparkEnv.scala
index 4d7542c..ff4a043 100644
--- a/core/src/main/scala/org/apache/spark/SparkEnv.scala
+++ b/core/src/main/scala/org/apache/spark/SparkEnv.scala
@@ -21,10 +21,12 @@ import java.io.File
import java.net.Socket
import java.util.Locale
+import scala.collection.JavaConverters._
import scala.collection.mutable
import scala.util.Properties
import com.google.common.collect.MapMaker
+import org.apache.hadoop.conf.Configuration
import org.apache.spark.annotation.DeveloperApi
import org.apache.spark.api.python.PythonWorkerFactory
@@ -400,6 +402,7 @@ object SparkEnv extends Logging {
private[spark]
def environmentDetails(
conf: SparkConf,
+ hadoopConf: Configuration,
schedulingMode: String,
addedJars: Seq[String],
addedFiles: Seq[String]): Map[String, Seq[(String, String)]] = {
@@ -435,9 +438,13 @@ object SparkEnv extends Logging {
val addedJarsAndFiles =