[spark] branch master updated: [SPARK-34087][SQL] Fix memory leak of ExecutionListenerBus
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4d90c5d [SPARK-34087][SQL] Fix memory leak of ExecutionListenerBus
4d90c5d is described below
commit 4d90c5dc0efcf77ef6735000ee7016428c57077b
Author: yi.wu
AuthorDate: Thu Mar 18 13:27:03 2021 +0900
[SPARK-34087][SQL] Fix memory leak of ExecutionListenerBus
### What changes were proposed in this pull request?
This PR proposes an alternative way to fix the memory leak of
`ExecutionListenerBus`, which would automatically clean them up.
Basically, the idea is to add `registerSparkListenerForCleanup` to
`ContextCleaner`, so we can remove the `ExecutionListenerBus` from
`LiveListenerBus` when the `SparkSession` is GC'ed.
On the other hand, to make the `SparkSession` GC-able, we need to get rid
of the reference of `SparkSession` in `ExecutionListenerBus`. Therefore, we
introduced the `sessionUUID`, which is a unique identifier for SparkSession, to
replace the `SparkSession` object.
Note that, the proposal wouldn't take effect when
`spark.cleaner.referenceTracking=false` since it depends on `ContextCleaner`.
### Why are the changes needed?
Fix the memory leak caused by `ExecutionListenerBus` mentioned in
SPARK-34087.
### Does this PR introduce _any_ user-facing change?
Yes, save memory for users.
### How was this patch tested?
Added unit test.
Closes #31839 from Ngone51/fix-mem-leak-of-ExecutionListenerBus.
Authored-by: yi.wu
Signed-off-by: HyukjinKwon
---
.../scala/org/apache/spark/ContextCleaner.scala| 21 +
.../scala/org/apache/spark/sql/SparkSession.scala | 3 ++
.../spark/sql/util/QueryExecutionListener.scala| 12
.../spark/sql/SparkSessionBuilderSuite.scala | 35 +-
4 files changed, 65 insertions(+), 6 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/ContextCleaner.scala
b/core/src/main/scala/org/apache/spark/ContextCleaner.scala
index cfa1139..34b3089 100644
--- a/core/src/main/scala/org/apache/spark/ContextCleaner.scala
+++ b/core/src/main/scala/org/apache/spark/ContextCleaner.scala
@@ -27,6 +27,7 @@ import org.apache.spark.broadcast.Broadcast
import org.apache.spark.internal.Logging
import org.apache.spark.internal.config._
import org.apache.spark.rdd.{RDD, ReliableRDDCheckpointData}
+import org.apache.spark.scheduler.SparkListener
import org.apache.spark.shuffle.api.ShuffleDriverComponents
import org.apache.spark.util.{AccumulatorContext, AccumulatorV2, ThreadUtils,
Utils}
@@ -39,6 +40,7 @@ private case class CleanShuffle(shuffleId: Int) extends
CleanupTask
private case class CleanBroadcast(broadcastId: Long) extends CleanupTask
private case class CleanAccum(accId: Long) extends CleanupTask
private case class CleanCheckpoint(rddId: Int) extends CleanupTask
+private case class CleanSparkListener(listener: SparkListener) extends
CleanupTask
/**
* A WeakReference associated with a CleanupTask.
@@ -175,6 +177,13 @@ private[spark] class ContextCleaner(
referenceBuffer.add(new CleanupTaskWeakReference(task, objectForCleanup,
referenceQueue))
}
+ /** Register a SparkListener to be cleaned up when its owner is garbage
collected. */
+ def registerSparkListenerForCleanup(
+ listenerOwner: AnyRef,
+ listener: SparkListener): Unit = {
+registerForCleanup(listenerOwner, CleanSparkListener(listener))
+ }
+
/** Keep cleaning RDD, shuffle, and broadcast state. */
private def keepCleaning(): Unit = Utils.tryOrStopSparkContext(sc) {
while (!stopped) {
@@ -197,6 +206,8 @@ private[spark] class ContextCleaner(
doCleanupAccum(accId, blocking = blockOnCleanupTasks)
case CleanCheckpoint(rddId) =>
doCleanCheckpoint(rddId)
+ case CleanSparkListener(listener) =>
+doCleanSparkListener(listener)
}
}
}
@@ -276,6 +287,16 @@ private[spark] class ContextCleaner(
}
}
+ def doCleanSparkListener(listener: SparkListener): Unit = {
+try {
+ logDebug(s"Cleaning Spark listener $listener")
+ sc.listenerBus.removeListener(listener)
+ logDebug(s"Cleaned Spark listener $listener")
+} catch {
+ case e: Exception => logError(s"Error cleaning Spark listener
$listener", e)
+}
+ }
+
private def broadcastManager = sc.env.broadcastManager
private def mapOutputTrackerMaster =
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster]
}
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
b/sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
index 678233d..5b33564 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
[spark] branch branch-3.1 updated: [SPARK-34762][BUILD] Fix the build failure with Scala 2.13 which is related to commons-cli
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 4bda955 [SPARK-34762][BUILD] Fix the build failure with Scala 2.13
which is related to commons-cli
4bda955 is described below
commit 4bda9558b80ae2cf28c62377c0633012f1189e72
Author: Kousuke Saruta
AuthorDate: Thu Mar 18 12:31:50 2021 +0900
[SPARK-34762][BUILD] Fix the build failure with Scala 2.13 which is related
to commons-cli
### What changes were proposed in this pull request?
This PR fixes the build failure with Scala 2.13 which is related to
`commons-cli`.
The last few days, build with Scala 2.13 on GA continues to fail and the
error message says like as follows.
```
[error]
/home/runner/work/spark/spark/sql/hive-thriftserver/src/main/java/org/apache/hive/service/server/HiveServer2.java:26:1:
error: package org.apache.commons.cli does not exist
1278[error] import org.apache.commons.cli.GnuParser;
```
The reason is that `mvn help` in `change-scala-version.sh` downloads the
POM file of `commons-cli` but doesn't download the JAR file, leading the build
failure.
This PR also adds `commons-cli` to the dependencies explicitly because
HiveThriftServer depends on it.
### Why are the changes needed?
Expect to fix the build failure with Scala 2.13.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that build successfully finishes with Scala 2.13 on my laptop.
```
find ~/.m2 -name commons-cli -exec rm -rf {} \;
find ~/.ivy2 -name commons-cli -exec rm -rf {} \;
find ~/.cache/ -name commons-cli -exec rm -rf {} \; // For Linux
find ~/Library/Caches -name commons-cli -exec rm -rf {} \; // For macOS
dev/change-scala-version 2.13
./build/sbt -Pyarn -Pmesos -Pkubernetes -Phive -Phive-thriftserver
-Phadoop-cloud -Pkinesis-asl -Pdocker-integration-tests
-Pkubernetes-integration-tests -Pspark-ganglia-lgpl -Pscala-2.13 clean compile
test:compile
```
Closes #31862 from sarutak/commons-cli.
Authored-by: Kousuke Saruta
Signed-off-by: HyukjinKwon
(cherry picked from commit c5cadfefdf9b4c6135355b49366fd9e9d1e3fcd0)
Signed-off-by: HyukjinKwon
---
dev/change-scala-version.sh | 5 +
pom.xml | 6 ++
sql/hive-thriftserver/pom.xml | 4
3 files changed, 15 insertions(+)
diff --git a/dev/change-scala-version.sh b/dev/change-scala-version.sh
index 9cdc7d9..6adfb23 100755
--- a/dev/change-scala-version.sh
+++ b/dev/change-scala-version.sh
@@ -60,6 +60,11 @@ BASEDIR=$(dirname $0)/..
find "$BASEDIR" -name 'pom.xml' -not -path '*target*' -print \
-exec bash -c "sed_i 's/\(artifactId.*\)_'$FROM_VERSION'/\1_'$TO_VERSION'/g'
{}" \;
+# dependency:get is workaround for SPARK-34762 to download the JAR file of
commons-cli.
+# Without this, build with Scala 2.13 using SBT will fail because the help
plugin used below downloads only the POM file.
+COMMONS_CLI_VERSION=`build/mvn help:evaluate -Dexpression=commons-cli.version
-q -DforceStdout`
+build/mvn dependency:get
-Dartifact=commons-cli:commons-cli:${COMMONS_CLI_VERSION} -q
+
# Update in parent POM
# First find the right full version from the profile's build
SCALA_VERSION=`build/mvn help:evaluate -Pscala-${TO_VERSION}
-Dexpression=scala.version -q -DforceStdout`
diff --git a/pom.xml b/pom.xml
index 6f2dfd1..77c4ea8 100644
--- a/pom.xml
+++ b/pom.xml
@@ -199,6 +199,7 @@
2.8
1.8
1.1.0
+1.2
[spark] branch master updated (569fb13 -> c5cadfe)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 569fb13 [SPARK-33602][SQL] Group exception messages in execution/datasources add c5cadfe [SPARK-34762][BUILD] Fix the build failure with Scala 2.13 which is related to commons-cli No new revisions were added by this update. Summary of changes: dev/change-scala-version.sh | 5 + pom.xml | 6 ++ sql/hive-thriftserver/pom.xml | 4 3 files changed, 15 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-34737][SQL][3.1] Cast input float to double in `TIMESTAMP_SECONDS`
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new c306de5 [SPARK-34737][SQL][3.1] Cast input float to double in
`TIMESTAMP_SECONDS`
c306de5 is described below
commit c306de52752351a40caa8a6926ba13cae56529c3
Author: Max Gekk
AuthorDate: Thu Mar 18 03:17:41 2021 +
[SPARK-34737][SQL][3.1] Cast input float to double in `TIMESTAMP_SECONDS`
### What changes were proposed in this pull request?
In the PR, I propose to cast the input float to double in the
`SecondsToTimestamp` expression in the same way as in the `Cast` expression.
### Why are the changes needed?
To have the same results from `CAST( AS TIMESTAMP)` and from
`TIMESTAMP_SECONDS`:
```sql
spark-sql> SELECT CAST(16777215.0f AS TIMESTAMP);
1970-07-14 07:20:15
spark-sql> SELECT TIMESTAMP_SECONDS(16777215.0f);
1970-07-14 07:20:14.951424
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes:
```sql
spark-sql> SELECT TIMESTAMP_SECONDS(16777215.0f);
1970-07-14 07:20:15
```
### How was this patch tested?
By running new test:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
```
Authored-by: Max Gekk
Signed-off-by: HyukjinKwon
(cherry picked from commit 7aaed76125c82aff8683fe319f8047c2cb87afdd)
Signed-off-by: Max Gekk
Closes #31872 from MaxGekk/adjust-SecondsToTimestamp-3.1.
Authored-by: Max Gekk
Signed-off-by: Wenchen Fan
---
.../apache/spark/sql/catalyst/expressions/datetimeExpressions.scala | 5 +++--
.../apache/spark/sql/catalyst/expressions/DateExpressionsSuite.scala | 1 +
2 files changed, 4 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
index c20dd61..4a27b2a 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
@@ -502,7 +502,7 @@ case class SecondsToTimestamp(child: Expression) extends
UnaryExpression
input.asInstanceOf[Decimal].toJavaBigDecimal.multiply(operand).longValueExact()
case _: FloatType => input =>
val f = input.asInstanceOf[Float]
- if (f.isNaN || f.isInfinite) null else (f * MICROS_PER_SECOND).toLong
+ if (f.isNaN || f.isInfinite) null else (f.toDouble *
MICROS_PER_SECOND).toLong
case _: DoubleType => input =>
val d = input.asInstanceOf[Double]
if (d.isNaN || d.isInfinite) null else (d * MICROS_PER_SECOND).toLong
@@ -517,13 +517,14 @@ case class SecondsToTimestamp(child: Expression) extends
UnaryExpression
val operand = s"new java.math.BigDecimal($MICROS_PER_SECOND)"
defineCodeGen(ctx, ev, c =>
s"$c.toJavaBigDecimal().multiply($operand).longValueExact()")
case other =>
+ val castToDouble = if (other.isInstanceOf[FloatType]) "(double)" else ""
nullSafeCodeGen(ctx, ev, c => {
val typeStr = CodeGenerator.boxedType(other)
s"""
|if ($typeStr.isNaN($c) || $typeStr.isInfinite($c)) {
| ${ev.isNull} = true;
|} else {
- | ${ev.value} = (long)($c * $MICROS_PER_SECOND);
+ | ${ev.value} = (long)($castToDouble$c * $MICROS_PER_SECOND);
|}
|""".stripMargin
})
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/DateExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/DateExpressionsSuite.scala
index 7977050..763ecba 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/DateExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/DateExpressionsSuite.scala
@@ -1365,6 +1365,7 @@ class DateExpressionsSuite extends SparkFunSuite with
ExpressionEvalHelper {
checkEvaluation(
SecondsToTimestamp(Literal(123.456789123)),
Instant.ofEpochSecond(123, 456789000))
+checkEvaluation(SecondsToTimestamp(Literal(16777215.0f)),
Instant.ofEpochSecond(16777215))
}
test("TIMESTAMP_MILLIS") {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-34749][SQL][3.1] Simplify ResolveCreateNamedStruct
This is an automated email from the ASF dual-hosted git repository.
yamamuro pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 448b8d0 [SPARK-34749][SQL][3.1] Simplify ResolveCreateNamedStruct
448b8d0 is described below
commit 448b8d07df41040058c21e6102406e1656727599
Author: Wenchen Fan
AuthorDate: Thu Mar 18 07:44:11 2021 +0900
[SPARK-34749][SQL][3.1] Simplify ResolveCreateNamedStruct
backports https://github.com/apache/spark/pull/31843
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31808 and
simplifies its fix to one line (excluding comments).
### Why are the changes needed?
code simplification
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes #31867 from cloud-fan/backport.
Authored-by: Wenchen Fan
Signed-off-by: Takeshi Yamamuro
---
.../org/apache/spark/sql/catalyst/analysis/Analyzer.scala | 2 --
.../spark/sql/catalyst/expressions/complexTypeCreator.scala | 10 +-
.../sql/catalyst/expressions/complexTypeExtractors.scala | 11 +--
.../spark/sql/catalyst/parser/ExpressionParserSuite.scala | 2 +-
4 files changed, 11 insertions(+), 14 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
index f98f33b..f4cdeab 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
@@ -3840,8 +3840,6 @@ object ResolveCreateNamedStruct extends Rule[LogicalPlan]
{
val children = e.children.grouped(2).flatMap {
case Seq(NamePlaceholder, e: NamedExpression) if e.resolved =>
Seq(Literal(e.name), e)
-case Seq(NamePlaceholder, e: ExtractValue) if e.resolved &&
e.name.isDefined =>
- Seq(Literal(e.name.get), e)
case kv =>
kv
}
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeCreator.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeCreator.scala
index cb59fbd..1779d41 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeCreator.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeCreator.scala
@@ -20,7 +20,7 @@ package org.apache.spark.sql.catalyst.expressions
import scala.collection.mutable.ArrayBuffer
import org.apache.spark.sql.catalyst.InternalRow
-import org.apache.spark.sql.catalyst.analysis.{Resolver, TypeCheckResult,
TypeCoercion, UnresolvedExtractValue}
+import org.apache.spark.sql.catalyst.analysis.{Resolver, TypeCheckResult,
TypeCoercion, UnresolvedAttribute, UnresolvedExtractValue}
import org.apache.spark.sql.catalyst.analysis.FunctionRegistry.{FUNC_ALIAS,
FunctionBuilder}
import org.apache.spark.sql.catalyst.expressions.codegen._
import org.apache.spark.sql.catalyst.expressions.codegen.Block._
@@ -336,6 +336,14 @@ object CreateStruct {
*/
def apply(children: Seq[Expression]): CreateNamedStruct = {
CreateNamedStruct(children.zipWithIndex.flatMap {
+ // For multi-part column name like `struct(a.b.c)`, it may be resolved
into:
+ // 1. Attribute if `a.b.c` is simply a qualified column name.
+ // 2. GetStructField if `a.b` refers to a struct-type column.
+ // 3. GetArrayStructFields if `a.b` refers to a array-of-struct-type
column.
+ // 4. GetMapValue if `a.b` refers to a map-type column.
+ // We should always use the last part of the column name (`c` in the
above example) as the
+ // alias name inside CreateNamedStruct.
+ case (u: UnresolvedAttribute, _) => Seq(Literal(u.nameParts.last), u)
case (e: NamedExpression, _) if e.resolved => Seq(Literal(e.name), e)
case (e: NamedExpression, _) => Seq(NamePlaceholder, e)
case (e, index) => Seq(Literal(s"col${index + 1}"), e)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
index 9b80140..ef247ef 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
@@ -94,10 +94,7 @@ object ExtractValue {
}
}
-trait ExtractValue extends Expression {
- // The name that is used to extract the value.
- def name: Option[String]
-}
+trait ExtractValue extends Expression
/**
*
[spark] branch master updated (9f7b0a0 -> 569fb13)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9f7b0a0 [SPARK-34758][SQL] Simplify Analyzer.resolveLiteralFunction add 569fb13 [SPARK-33602][SQL] Group exception messages in execution/datasources No new revisions were added by this update. Summary of changes: .../spark/sql/errors/QueryCompilationErrors.scala | 339 - .../spark/sql/errors/QueryExecutionErrors.scala| 242 ++- .../sql/execution/datasources/DataSource.scala | 105 +++ .../execution/datasources/DataSourceStrategy.scala | 39 +-- .../execution/datasources/DataSourceUtils.scala| 36 +-- .../sql/execution/datasources/FileFormat.scala | 3 +- .../execution/datasources/FileFormatWriter.scala | 5 +- .../sql/execution/datasources/FileScanRDD.scala| 8 +- .../InsertIntoHadoopFsRelationCommand.scala| 13 +- .../execution/datasources/PartitioningUtils.scala | 14 +- .../datasources/RecordReaderIterator.scala | 4 +- .../datasources/binaryfile/BinaryFileFormat.scala | 10 +- .../execution/datasources/jdbc/JDBCOptions.scala | 21 +- .../sql/execution/datasources/jdbc/JdbcUtils.scala | 36 +-- .../datasources/orc/OrcDeserializer.scala | 3 +- .../sql/execution/datasources/orc/OrcFilters.scala | 8 +- .../execution/datasources/orc/OrcSerializer.scala | 3 +- .../sql/execution/datasources/orc/OrcUtils.scala | 9 +- .../datasources/parquet/ParquetFileFormat.scala| 8 +- .../datasources/parquet/ParquetReadSupport.scala | 5 +- .../parquet/ParquetSchemaConverter.scala | 11 +- .../spark/sql/execution/datasources/rules.scala| 80 ++--- 22 files changed, 737 insertions(+), 265 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] Ngone51 commented on pull request #326: Add Yi Wu to committers' list
Ngone51 commented on pull request #326: URL: https://github.com/apache/spark-website/pull/326#issuecomment-801080558 @zero323 Thanks, Congrats you too :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Add Yi Wu to committers' list
This is an automated email from the ASF dual-hosted git repository. wuyi pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new a6a57a9 Add Yi Wu to committers' list a6a57a9 is described below commit a6a57a9f3d09bb6cce947653be5c1c2f55f67478 Author: yi.wu AuthorDate: Wed Mar 17 21:27:57 2021 +0800 Add Yi Wu to committers' list Author: yi.wu Closes #326 from Ngone51/add-myself-to-committer-list. --- committers.md| 1 + site/committers.html | 4 2 files changed, 5 insertions(+) diff --git a/committers.md b/committers.md index 7485509..ae84112 100644 --- a/committers.md +++ b/committers.md @@ -82,6 +82,7 @@ navigation: |Yuming Wang|eBay| |Zhenhua Wang|Huawei| |Patrick Wendell|Databricks| +|Yi Wu|Databricks| |Andrew Xia|Alibaba| |Reynold Xin|Databricks| |Weichen Xu|Databricks| diff --git a/site/committers.html b/site/committers.html index 7f248cb..5985718 100644 --- a/site/committers.html +++ b/site/committers.html @@ -499,6 +499,10 @@ Databricks + Yi Wu + Databricks + + Andrew Xia Alibaba - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] zero323 commented on pull request #326: Add Yi Wu to committers' list
zero323 commented on pull request #326: URL: https://github.com/apache/spark-website/pull/326#issuecomment-801052123 Congratulations @Ngone51 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] zero323 closed pull request #327: Add Maciej Szymkiewicz to committers
zero323 closed pull request #327: URL: https://github.com/apache/spark-website/pull/327 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Add Maciej Szymkiewicz to committers
This is an automated email from the ASF dual-hosted git repository. zero323 pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 08fec06 Add Maciej Szymkiewicz to committers 08fec06 is described below commit 08fec06cbc1a9dbff7ed390dde389679bc1847e1 Author: zero323 AuthorDate: Wed Mar 17 13:41:54 2021 +0100 Add Maciej Szymkiewicz to committers Author: zero323 Closes #327 from zero323/add-commiter-msz. --- committers.md| 1 + site/committers.html | 4 2 files changed, 5 insertions(+) diff --git a/committers.md b/committers.md index 714fa67..7485509 100644 --- a/committers.md +++ b/committers.md @@ -72,6 +72,7 @@ navigation: |Prashant Sharma|IBM| |Gabor Somogyi|Cloudera| |Ram Sriharsha|Databricks| +|Maciej Szymkiewicz|| |Jose Torres|Databricks| |DB Tsai|Apple| |Takuya Ueshin|Databricks| diff --git a/site/committers.html b/site/committers.html index 74e98ab..7f248cb 100644 --- a/site/committers.html +++ b/site/committers.html @@ -459,6 +459,10 @@ Databricks + Maciej Szymkiewicz + + + Jose Torres Databricks - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (bf4570b -> 9f7b0a0)
This is an automated email from the ASF dual-hosted git repository. yamamuro pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from bf4570b [SPARK-34749][SQL] Simplify ResolveCreateNamedStruct add 9f7b0a0 [SPARK-34758][SQL] Simplify Analyzer.resolveLiteralFunction No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/Analyzer.scala | 29 ++ 1 file changed, 7 insertions(+), 22 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (48637a9 -> bf4570b)
This is an automated email from the ASF dual-hosted git repository. yamamuro pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 48637a9 [SPARK-34766][SQL] Do not capture maven config for views add bf4570b [SPARK-34749][SQL] Simplify ResolveCreateNamedStruct No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/catalyst/analysis/Analyzer.scala | 2 -- .../sql/catalyst/expressions/complexTypeCreator.scala | 10 +- .../sql/catalyst/expressions/complexTypeExtractors.scala | 14 +- .../spark/sql/catalyst/parser/ExpressionParserSuite.scala | 2 +- 4 files changed, 11 insertions(+), 17 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (385f1e8 -> 48637a9)
This is an automated email from the ASF dual-hosted git repository. yao pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 385f1e8 [SPARK-34768][SQL] Respect the default input buffer size in Univocity add 48637a9 [SPARK-34766][SQL] Do not capture maven config for views No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/spark/sql/execution/command/views.scala | 3 ++- 1 file changed, 2 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] zero323 commented on pull request #327: Add Maciej Szymkiewicz to committers
zero323 commented on pull request #327: URL: https://github.com/apache/spark-website/pull/327#issuecomment-800995407 Thanks everyone! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-34768][SQL] Respect the default input buffer size in Univocity
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new fc30ec8 [SPARK-34768][SQL] Respect the default input buffer size in
Univocity
fc30ec8 is described below
commit fc30ec899b6191c99c6093b7849ec0df3af2214e
Author: HyukjinKwon
AuthorDate: Wed Mar 17 19:55:49 2021 +0900
[SPARK-34768][SQL] Respect the default input buffer size in Univocity
This PR proposes to follow Univocity's input buffer.
- Firstly, it's best to trust their judgement on the default values. Also
128 is too low.
- Default values arguably have more test coverage in Univocity.
- It will also fix https://github.com/uniVocity/univocity-parsers/issues/449
- ^ is a regression compared to Spark 2.4
No. In addition, It fixes a regression.
Manually tested, and added a unit test.
Closes #31858 from HyukjinKwon/SPARK-34768.
Authored-by: HyukjinKwon
Signed-off-by: HyukjinKwon
(cherry picked from commit 385f1e8f5de5dcad62554cd75446e98c9380b384)
Signed-off-by: HyukjinKwon
---
.../scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala | 3 ---
.../apache/spark/sql/execution/datasources/csv/CSVSuite.scala | 11 +++
2 files changed, 11 insertions(+), 3 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
index f2191fc..ee7fc1f 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
@@ -166,8 +166,6 @@ class CSVOptions(
val quoteAll = getBool("quoteAll", false)
- val inputBufferSize = 128
-
/**
* The max error content length in CSV parser/writer exception message.
*/
@@ -253,7 +251,6 @@ class CSVOptions(
settings.setIgnoreLeadingWhitespaces(ignoreLeadingWhiteSpaceInRead)
settings.setIgnoreTrailingWhitespaces(ignoreTrailingWhiteSpaceInRead)
settings.setReadInputOnSeparateThread(false)
-settings.setInputBufferSize(inputBufferSize)
settings.setMaxColumns(maxColumns)
settings.setNullValue(nullValue)
settings.setEmptyValue(emptyValueInRead)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index 4e93ea3..3b564b6 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
@@ -2378,6 +2378,17 @@ abstract class CSVSuite extends QueryTest with
SharedSparkSession with TestCsvDa
assert(readback.collect sameElements Array(Row("0"), Row("1"), Row("2")))
}
}
+
+ test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set
to true") {
+val bufSize = 128
+val line = "X" * (bufSize - 1) + "| |"
+withTempPath { path =>
+ Seq(line).toDF.write.text(path.getAbsolutePath)
+ assert(spark.read.format("csv")
+.option("delimiter", "|")
+.option("ignoreTrailingWhiteSpace",
"true").load(path.getAbsolutePath).count() == 1)
+}
+ }
}
class CSVv1Suite extends CSVSuite {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-34768][SQL] Respect the default input buffer size in Univocity
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 0922380 [SPARK-34768][SQL] Respect the default input buffer size in
Univocity
0922380 is described below
commit 0922380406f667ad11b0795ca63be2a8a21a7266
Author: HyukjinKwon
AuthorDate: Wed Mar 17 19:55:49 2021 +0900
[SPARK-34768][SQL] Respect the default input buffer size in Univocity
### What changes were proposed in this pull request?
This PR proposes to follow Univocity's input buffer.
### Why are the changes needed?
- Firstly, it's best to trust their judgement on the default values. Also
128 is too low.
- Default values arguably have more test coverage in Univocity.
- It will also fix https://github.com/uniVocity/univocity-parsers/issues/449
- ^ is a regression compared to Spark 2.4
### Does this PR introduce _any_ user-facing change?
No. In addition, It fixes a regression.
### How was this patch tested?
Manually tested, and added a unit test.
Closes #31858 from HyukjinKwon/SPARK-34768.
Authored-by: HyukjinKwon
Signed-off-by: HyukjinKwon
(cherry picked from commit 385f1e8f5de5dcad62554cd75446e98c9380b384)
Signed-off-by: HyukjinKwon
---
.../scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala | 3 ---
.../apache/spark/sql/execution/datasources/csv/CSVSuite.scala | 11 +++
2 files changed, 11 insertions(+), 3 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
index ec40599..c6a8061 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
@@ -166,8 +166,6 @@ class CSVOptions(
val quoteAll = getBool("quoteAll", false)
- val inputBufferSize = 128
-
/**
* The max error content length in CSV parser/writer exception message.
*/
@@ -259,7 +257,6 @@ class CSVOptions(
settings.setIgnoreLeadingWhitespaces(ignoreLeadingWhiteSpaceInRead)
settings.setIgnoreTrailingWhitespaces(ignoreTrailingWhiteSpaceInRead)
settings.setReadInputOnSeparateThread(false)
-settings.setInputBufferSize(inputBufferSize)
settings.setMaxColumns(maxColumns)
settings.setNullValue(nullValue)
settings.setEmptyValue(emptyValueInRead)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index 30f0e45..3fe6ce7 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
@@ -2452,6 +2452,17 @@ abstract class CSVSuite
assert(result.sameElements(exceptResults))
}
}
+
+ test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set
to true") {
+val bufSize = 128
+val line = "X" * (bufSize - 1) + "| |"
+withTempPath { path =>
+ Seq(line).toDF.write.text(path.getAbsolutePath)
+ assert(spark.read.format("csv")
+.option("delimiter", "|")
+.option("ignoreTrailingWhiteSpace",
"true").load(path.getAbsolutePath).count() == 1)
+}
+ }
}
class CSVv1Suite extends CSVSuite {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (1a4971d -> 385f1e8)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 1a4971d [SPARK-34770][SQL] InMemoryCatalog.tableExists should not fail if database doesn't exist add 385f1e8 [SPARK-34768][SQL] Respect the default input buffer size in Univocity No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala | 3 --- .../apache/spark/sql/execution/datasources/csv/CSVSuite.scala | 11 +++ 2 files changed, 11 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-34770][SQL] InMemoryCatalog.tableExists should not fail if database doesn't exist
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new b30e0a1 [SPARK-34770][SQL] InMemoryCatalog.tableExists should not
fail if database doesn't exist
b30e0a1 is described below
commit b30e0a1138146e5ef22c9a7b78a2543b434ed315
Author: Wenchen Fan
AuthorDate: Wed Mar 17 16:36:50 2021 +0800
[SPARK-34770][SQL] InMemoryCatalog.tableExists should not fail if database
doesn't exist
This PR updates `InMemoryCatalog.tableExists` to return false if database
doesn't exist, instead of failing. The new behavior is consistent with
`HiveExternalCatalog` which is used in production, so this bug mostly only
affects tests.
bug fix
no
a new test
Closes #31860 from cloud-fan/catalog.
Authored-by: Wenchen Fan
Signed-off-by: Wenchen Fan
(cherry picked from commit 1a4971d8a16b5bc624cef584271243bf64a51941)
Signed-off-by: Wenchen Fan
---
.../scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala | 3 +--
.../org/apache/spark/sql/catalyst/catalog/SessionCatalogSuite.scala| 3 +++
.../test/scala/org/apache/spark/sql/execution/SQLViewTestSuite.scala | 2 --
3 files changed, 4 insertions(+), 4 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala
index 90e6946..08b54fc 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala
@@ -342,8 +342,7 @@ class InMemoryCatalog(
}
override def tableExists(db: String, table: String): Boolean = synchronized {
-requireDbExists(db)
-catalog(db).tables.contains(table)
+catalog.contains(db) && catalog(db).tables.contains(table)
}
override def listTables(db: String): Seq[String] = synchronized {
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalogSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalogSuite.scala
index 98f9ce6..ad996db 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalogSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalogSuite.scala
@@ -691,6 +691,9 @@ abstract class SessionCatalogSuite extends AnalysisTest
with Eventually {
catalog.createTempView("tbl3", tempTable, overrideIfExists = false)
// tableExists should not check temp view.
assert(!catalog.tableExists(TableIdentifier("tbl3")))
+
+ // If database doesn't exist, return false instead of failing.
+ assert(!catalog.tableExists(TableIdentifier("tbl1", Some("non-exist"
}
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/SQLViewTestSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/SQLViewTestSuite.scala
index 52aa6d82..cf5ef63 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/SQLViewTestSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/SQLViewTestSuite.scala
@@ -295,8 +295,6 @@ abstract class SQLViewTestSuite extends QueryTest with
SQLTestUtils {
}
test("SPARK-34504: drop an invalid view") {
-// TODO: fix dropping non-existing global temp views.
-assume(viewTypeString != "GLOBAL TEMPORARY VIEW")
withTable("t") {
sql("CREATE TABLE t(s STRUCT) USING json")
val viewName = createView("v", "SELECT s.i FROM t")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (115f777 -> 1a4971d)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 115f777 [SPARK-21449][SQL][FOLLOWUP] Avoid log undesirable IllegalStateException when state close add 1a4971d [SPARK-34770][SQL] InMemoryCatalog.tableExists should not fail if database doesn't exist No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/sql/catalyst/catalog/InMemoryCatalog.scala | 3 +-- .../org/apache/spark/sql/catalyst/catalog/SessionCatalogSuite.scala| 3 +++ 2 files changed, 4 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-21449][SQL][FOLLOWUP] Avoid log undesirable IllegalStateException when state close
This is an automated email from the ASF dual-hosted git repository. yao pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 115f777 [SPARK-21449][SQL][FOLLOWUP] Avoid log undesirable IllegalStateException when state close 115f777 is described below commit 115f777cb0a9dff78497bad9b64daa5da1ee0e51 Author: Kent Yao AuthorDate: Wed Mar 17 15:21:23 2021 +0800 [SPARK-21449][SQL][FOLLOWUP] Avoid log undesirable IllegalStateException when state close ### What changes were proposed in this pull request? `TmpOutputFile` and `TmpErrOutputFile` are registered in `o.a.h.u.ShutdownHookManager `during creatation. The `state.close()` will delete them if they are not null and try remove them from the `o.a.h.u.ShutdownHookManager` which causes IllegalStateException when we call it in our ShutdownHookManager too. In this PR, we delete them ahead with a high priority hook in Spark and set them to null to bypass the deletion and canceling in `state.close()` ### Why are the changes needed? W/ or w/o this PR, the deletion of these files is not affected, we just mute an undesirable error log here. ### Does this PR introduce _any_ user-facing change? no, this is a follow-up ### How was this patch tested? the undesirable gone ```scala spark-sql> 21/03/16 18:41:31 ERROR Utils: Uncaught exception in thread shutdown-hook-0 java.lang.IllegalStateException: Shutdown in progress, cannot cancel a deleteOnExit at org.apache.hive.common.util.ShutdownHookManager.cancelDeleteOnExit(ShutdownHookManager.java:106) at org.apache.hadoop.hive.common.FileUtils.deleteTmpFile(FileUtils.java:861) at org.apache.hadoop.hive.ql.session.SessionState.deleteTmpErrOutputFile(SessionState.java:325) at org.apache.hadoop.hive.ql.session.SessionState.dropSessionPaths(SessionState.java:829) at org.apache.hadoop.hive.ql.session.SessionState.close(SessionState.java:1585) at org.apache.hadoop.hive.cli.CliSessionState.close(CliSessionState.java:66) at org.apache.spark.sql.hive.client.HiveClientImpl.closeState(HiveClientImpl.scala:172) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$new$1(HiveClientImpl.scala:175) at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:214) at org.apache.spark.util.SparkShutdownHookManager.$anonfun$runAll$2(ShutdownHookManager.scala:188) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1994) at org.apache.spark.util.SparkShutdownHookManager.$anonfun$runAll$1(ShutdownHookManager.scala:188) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.Try$.apply(Try.scala:213) at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:188) at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:178) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) (python) ✘ kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316 cd .. (python) kentyaohulk ~/Downloads/spark tar zxf spark-3.2.0-SNAPSHOT-bin-20210316.tgz (python) kentyaohulk ~/Downloads/spark cd - ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316 (python) kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316 bin/spark-sql --conf spark.local.dir=./local --conf spark.hive.exec.local.scratchdir=./local 21/03/16 18:42:15 WARN Utils: Your hostname, hulk.local resolves to a loopback address: 127.0.0.1; using 10.242.189.214 instead (on interface en0) 21/03/16 18:42:15 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 21/03/16 18:42:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/03/16 18:42:16 WARN SparkConf: Note that spark.local.dir will be overridden by the value set by the cluster manager (via SPARK_LOCAL_DIRS in mesos/standalone/kubernetes and LOCAL_DIRS in YARN). 21/03/16 18:42:18 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist 21/03/16 18:42:18
[spark] branch master updated: [SPARK-34575][SQL] Push down limit through window when partitionSpec is empty
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c234c5b [SPARK-34575][SQL] Push down limit through window when
partitionSpec is empty
c234c5b is described below
commit c234c5b5f1676fbb9a79dc865534fec566425326
Author: Yuming Wang
AuthorDate: Wed Mar 17 07:16:10 2021 +
[SPARK-34575][SQL] Push down limit through window when partitionSpec is
empty
### What changes were proposed in this pull request?
Push down limit through `Window` when the partitionSpec of all window
functions is empty and the same order is used. This is a real case from
production:

This pr support 2 cases:
1. All window functions have same orderSpec:
```sql
SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY a)
AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$()))
AS rn#4, rank(a#9L) windowspecdefinition(a#9L ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5],
[a#9L ASC NULLS FIRST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [a#9L ASC NULLS FIRST], true
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
2. There is a window function with a different orderSpec:
```sql
SELECT a, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY b
DESC) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Project [a#9L, rn#4, rk#5]
+- Window [rank(b#10L) windowspecdefinition(b#10L DESC NULLS LAST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5],
[b#10L DESC NULLS LAST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [b#10L DESC NULLS LAST], true
+- Window [row_number() windowspecdefinition(a#9L ASC NULLS
FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS
rn#4], [a#9L ASC NULLS FIRST]
+- Project [a#9L, b#10L]
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
### Why are the changes needed?
Improve query performance.
```scala
spark.range(5L).selectExpr("id AS a", "id AS
b").write.saveAsTable("t1")
spark.sql("SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rowId FROM t1 LIMIT
5").show
```
Before this pr | After this pr
-- | --
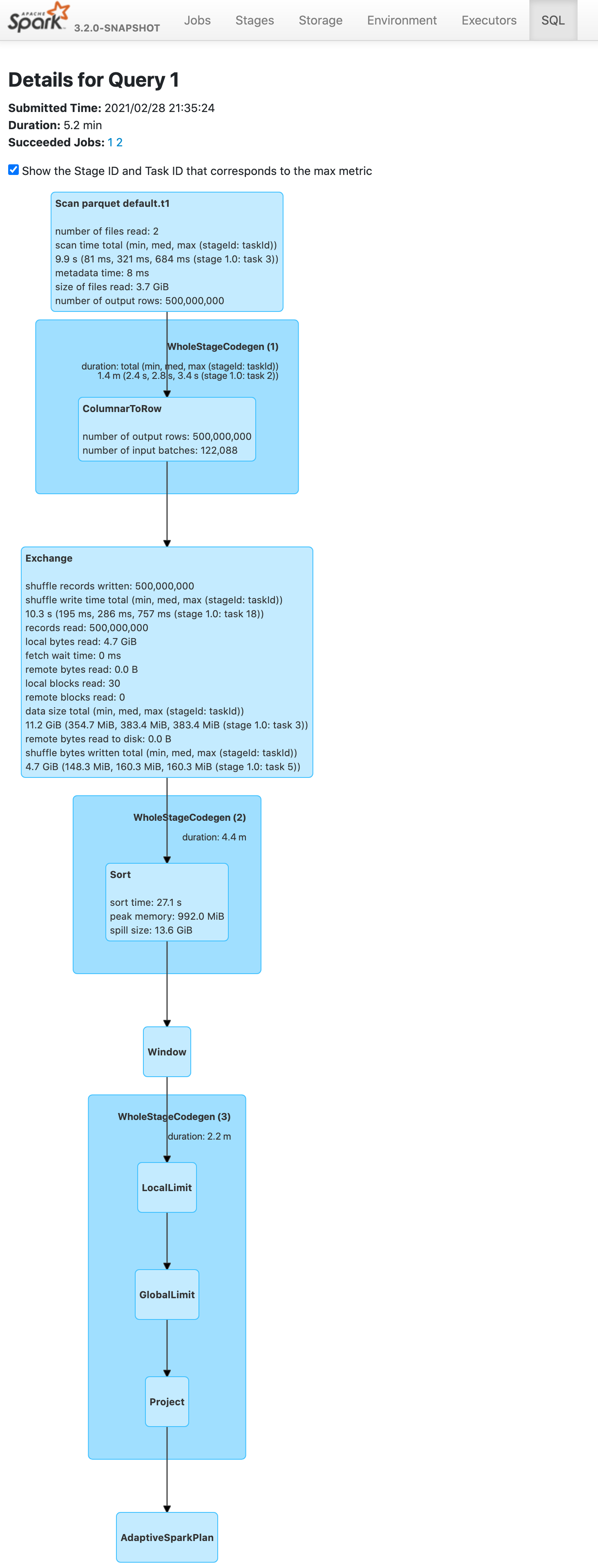
|
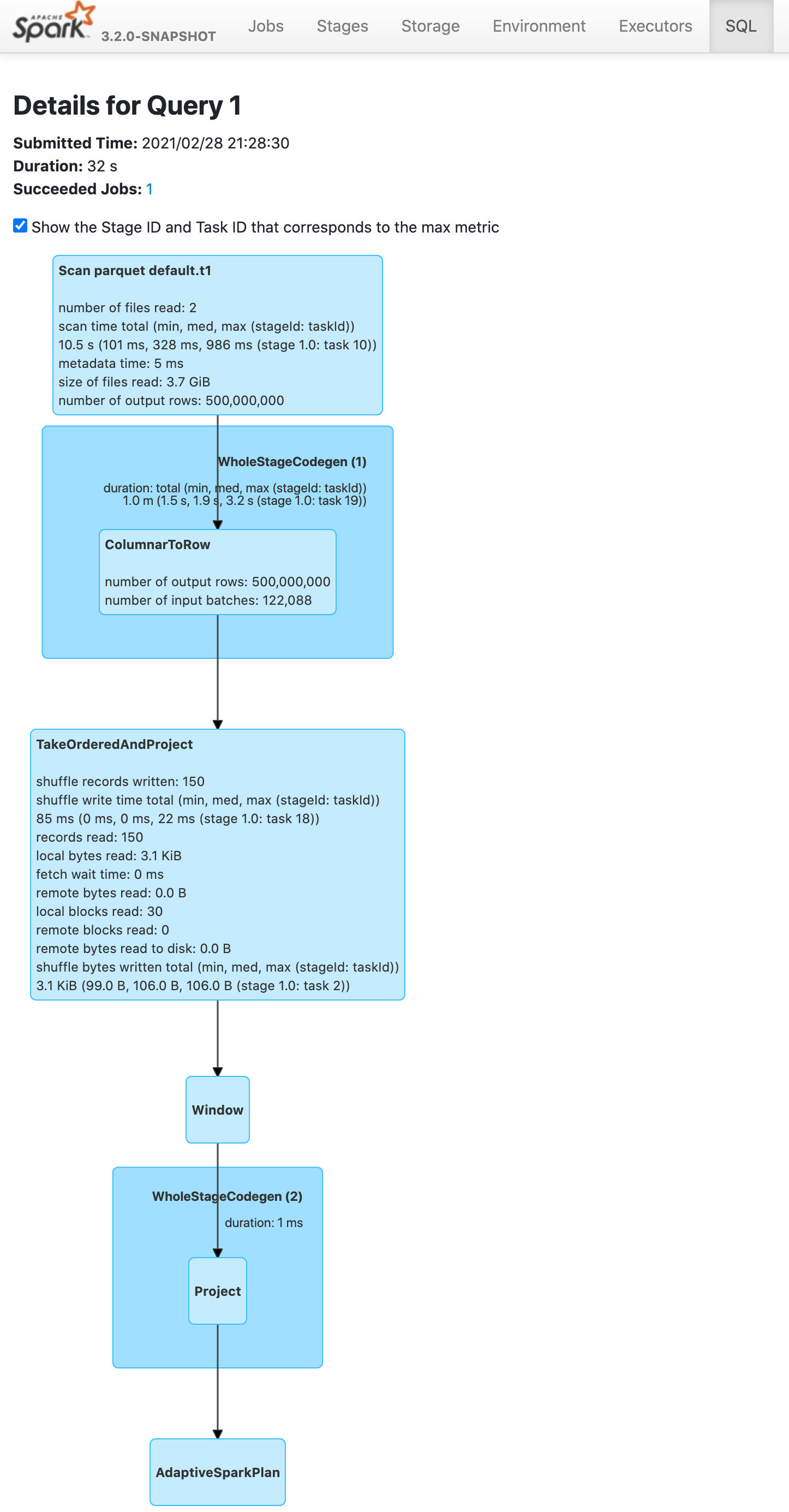
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes #31691 from wangyum/SPARK-34575.
Authored-by: Yuming Wang
Signed-off-by: Wenchen Fan
---
.../optimizer/LimitPushDownThroughWindow.scala | 56 ++
.../spark/sql/catalyst/optimizer/Optimizer.scala | 1 +
.../LimitPushdownThroughWindowSuite.scala | 190 +
.../scala/org/apache/spark/sql/SQLQuerySuite.scala | 34 +++-
4 files changed, 280 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushDownThroughWindow.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushDownThroughWindow.scala
new file mode 100644
index 000..0e89e4a
--- /dev/null
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushDownThroughWindow.scala
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, CurrentRow,
[spark] branch master updated (387d866 -> 1433031)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 387d866 [SPARK-34699][SQL] 'CREATE OR REPLACE TEMP VIEW USING' should uncache correctly add 1433031 [SPARK-34742][SQL] ANSI mode: Abs throws exception if input is out of range No new revisions were added by this update. Summary of changes: docs/sql-ref-ansi-compliance.md| 10 ++ .../sql/catalyst/analysis/AnsiTypeCoercion.scala | 2 +- .../spark/sql/catalyst/analysis/TypeCoercion.scala | 2 +- .../sql/catalyst/expressions/arithmetic.scala | 25 +++-- .../expressions/ArithmeticExpressionSuite.scala| 41 +- 5 files changed, 68 insertions(+), 12 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (af55373 -> 387d866)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from af55373 [SPARK-34504][SQL] Avoid unnecessary resolving of SQL temp views for DDL commands add 387d866 [SPARK-34699][SQL] 'CREATE OR REPLACE TEMP VIEW USING' should uncache correctly No new revisions were added by this update. Summary of changes: .../spark/sql/execution/datasources/ddl.scala | 23 ++- .../sql-tests/results/show-tables.sql.out | 1 + .../org/apache/spark/sql/CachedTableSuite.scala| 45 ++ 3 files changed, 67 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org