[spark] branch branch-3.1 updated: Revert "[SPARK-34674][CORE][K8S] Close SparkContext after the Main method has finished"
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 44ee132 Revert "[SPARK-34674][CORE][K8S] Close SparkContext after the
Main method has finished"
44ee132 is described below
commit 44ee13271cf8698df268c73a4fa7fd51c562949f
Author: Dongjoon Hyun
AuthorDate: Thu Apr 8 21:56:29 2021 -0700
Revert "[SPARK-34674][CORE][K8S] Close SparkContext after the Main method
has finished"
This reverts commit c625eb4f9f970108d93bf3342c7ccb7ec873dc27.
---
core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 6 --
1 file changed, 6 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
index 17950d6..bb3a20d 100644
--- a/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
@@ -952,12 +952,6 @@ private[spark] class SparkSubmit extends Logging {
} catch {
case t: Throwable =>
throw findCause(t)
-} finally {
- try {
-SparkContext.getActive.foreach(_.stop())
- } catch {
-case e: Throwable => logError(s"Failed to close SparkContext: $e")
- }
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ab97db7 -> ed3f103)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ab97db7 [SPARK-34674][CORE][K8S] Close SparkContext after the Main method has finished add ed3f103 Revert "[SPARK-34674][CORE][K8S] Close SparkContext after the Main method has finished" No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 6 -- 1 file changed, 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-34674][CORE][K8S] Close SparkContext after the Main method has finished
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new c625eb4 [SPARK-34674][CORE][K8S] Close SparkContext after the Main
method has finished
c625eb4 is described below
commit c625eb4f9f970108d93bf3342c7ccb7ec873dc27
Author: skotlov
AuthorDate: Thu Apr 8 16:51:38 2021 -0700
[SPARK-34674][CORE][K8S] Close SparkContext after the Main method has
finished
### What changes were proposed in this pull request?
Close SparkContext after the Main method has finished, to allow
SparkApplication on K8S to complete
### Why are the changes needed?
if I don't call the method sparkContext.stop() explicitly, then a Spark
driver process doesn't terminate even after its Main method has been completed.
This behaviour is different from spark on yarn, where the manual sparkContext
stopping is not required. It looks like, the problem is in using non-daemon
threads, which prevent the driver jvm process from terminating.
So I have inserted code that closes sparkContext automatically.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually on the production AWS EKS environment in my company.
Closes #32081 from kotlovs/close-spark-context-on-exit.
Authored-by: skotlov
Signed-off-by: Dongjoon Hyun
(cherry picked from commit ab97db75b2ab3ebb4d527610e2801df89cc23e2d)
Signed-off-by: Dongjoon Hyun
---
core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 6 ++
1 file changed, 6 insertions(+)
diff --git a/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
index bb3a20d..17950d6 100644
--- a/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
@@ -952,6 +952,12 @@ private[spark] class SparkSubmit extends Logging {
} catch {
case t: Throwable =>
throw findCause(t)
+} finally {
+ try {
+SparkContext.getActive.foreach(_.stop())
+ } catch {
+case e: Throwable => logError(s"Failed to close SparkContext: $e")
+ }
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (5013171 -> ab97db7)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 5013171 [SPARK-34973][SQL] Cleanup unused fields and methods in vectorized Parquet reader add ab97db7 [SPARK-34674][CORE][K8S] Close SparkContext after the Main method has finished No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala | 6 ++ 1 file changed, 6 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated (f7ac0db -> b4d9d4a)
This is an automated email from the ASF dual-hosted git repository. viirya pushed a change to branch branch-2.4 in repository https://gitbox.apache.org/repos/asf/spark.git. from f7ac0db [SPARK-34988][CORE][2.4] Upgrade Jetty for CVE-2021-28165 add b4d9d4a [SPARK-34994][BUILD][2.4] Fix git error when pushing the tag after release script succeeds No new revisions were added by this update. Summary of changes: dev/create-release/do-release.sh | 1 + 1 file changed, 1 insertion(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-34970][3.0][SQL] Redact map-type options in the output of explain()
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new ee264b1 [SPARK-34970][3.0][SQL] Redact map-type options in the output
of explain()
ee264b1 is described below
commit ee264b1ef1823cf90671c9565c7420da1ee7ba5d
Author: Gengliang Wang
AuthorDate: Thu Apr 8 13:35:30 2021 -0700
[SPARK-34970][3.0][SQL] Redact map-type options in the output of explain()
### What changes were proposed in this pull request?
The `explain()` method prints the arguments of tree nodes in
logical/physical plans. The arguments could contain a map-type option that
contains sensitive data.
We should map-type options in the output of `explain()`. Otherwise, we will
see sensitive data in explain output or Spark UI.
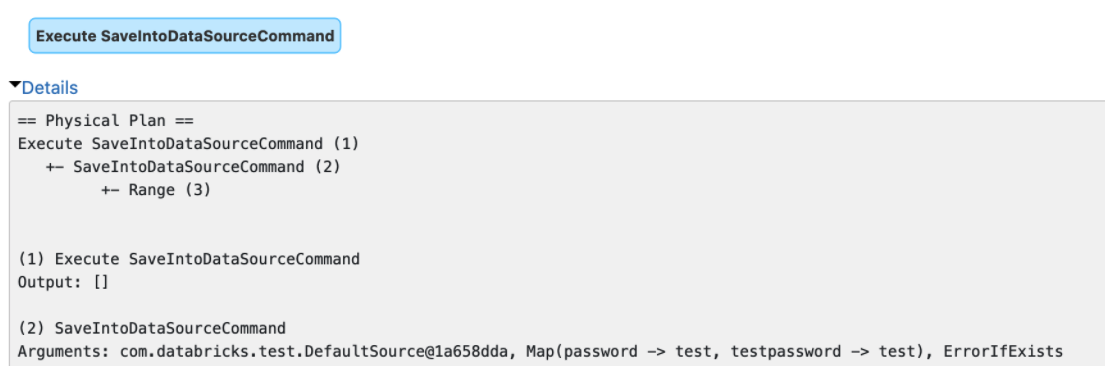
### Why are the changes needed?
Data security.
### Does this PR introduce _any_ user-facing change?
Yes, redact the map-type options in the output of `explain()`
### How was this patch tested?
Unit tests
Closes #32085 from gengliangwang/redact3.0.
Authored-by: Gengliang Wang
Signed-off-by: Dongjoon Hyun
---
.../apache/spark/sql/catalyst/trees/TreeNode.scala | 16 +++
.../resources/sql-tests/results/describe.sql.out | 2 +-
.../scala/org/apache/spark/sql/ExplainSuite.scala | 52 ++
3 files changed, 69 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
index 4dc3627..0ec2bbc 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
@@ -20,6 +20,7 @@ package org.apache.spark.sql.catalyst.trees
import java.util.UUID
import scala.collection.{mutable, Map}
+import scala.collection.JavaConverters._
import scala.reflect.ClassTag
import org.apache.commons.lang3.ClassUtils
@@ -39,6 +40,7 @@ import
org.apache.spark.sql.catalyst.util.StringUtils.PlanStringConcat
import org.apache.spark.sql.catalyst.util.truncatedString
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.types._
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
import org.apache.spark.storage.StorageLevel
import org.apache.spark.util.Utils
@@ -532,6 +534,16 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product {
private lazy val allChildren: Set[TreeNode[_]] = (children ++
innerChildren).toSet[TreeNode[_]]
+ private def redactMapString[K, V](map: Map[K, V], maxFields: Int):
List[String] = {
+// For security reason, redact the map value if the key is in centain
patterns
+val redactedMap = SQLConf.get.redactOptions(map.toMap)
+// construct the redacted map as strings of the format "key=value"
+val keyValuePairs = redactedMap.toSeq.map { item =>
+ item._1 + "=" + item._2
+}
+truncatedString(keyValuePairs, "[", ", ", "]", maxFields) :: Nil
+ }
+
/** Returns a string representing the arguments to this node, minus any
children */
def argString(maxFields: Int): String = stringArgs.flatMap {
case tn: TreeNode[_] if allChildren.contains(tn) => Nil
@@ -548,6 +560,10 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product {
case None => Nil
case Some(null) => Nil
case Some(any) => any :: Nil
+case map: CaseInsensitiveStringMap =>
+ redactMapString(map.asCaseSensitiveMap().asScala, maxFields)
+case map: Map[_, _] =>
+ redactMapString(map, maxFields)
case table: CatalogTable =>
table.storage.serde match {
case Some(serde) => table.identifier :: serde :: Nil
diff --git a/sql/core/src/test/resources/sql-tests/results/describe.sql.out
b/sql/core/src/test/resources/sql-tests/results/describe.sql.out
index a7de033..36118f8 100644
--- a/sql/core/src/test/resources/sql-tests/results/describe.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/describe.sql.out
@@ -571,7 +571,7 @@ struct
-- !query output
== Physical Plan ==
Execute DescribeTableCommand
- +- DescribeTableCommand `default`.`t`, Map(c -> Us, d -> 2), false
+ +- DescribeTableCommand `default`.`t`, [c=Us, d=2], false
-- !query
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
index 158d939..e8833b8 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
@@ -19,8 +19,10 @@ package org.apache.spark.sql
import
[spark] branch master updated (96a3533 -> 5013171)
This is an automated email from the ASF dual-hosted git repository. viirya pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 96a3533 [SPARK-34984][SQL] ANSI intervals formatting in hive results add 5013171 [SPARK-34973][SQL] Cleanup unused fields and methods in vectorized Parquet reader No new revisions were added by this update. Summary of changes: .../parquet/SpecificParquetRecordReaderBase.java | 61 -- .../parquet/VectorizedColumnReader.java| 51 +- 2 files changed, 14 insertions(+), 98 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (c1c9a31 -> 96a3533)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c1c9a31 [SPARK-34962][SQL] Explicit representation of * in UpdateAction and InsertAction in MergeIntoTable add 96a3533 [SPARK-34984][SQL] ANSI intervals formatting in hive results No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/execution/HiveResult.scala| 7 ++- .../apache/spark/sql/execution/HiveResultSuite.scala | 18 ++ 2 files changed, 24 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: [SPARK-34988][CORE][2.4] Upgrade Jetty for CVE-2021-28165
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-2.4 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-2.4 by this push: new f7ac0db [SPARK-34988][CORE][2.4] Upgrade Jetty for CVE-2021-28165 f7ac0db is described below commit f7ac0dbe63cda76fa1882574234780f1d5e14858 Author: Kousuke Saruta AuthorDate: Thu Apr 8 10:42:12 2021 -0500 [SPARK-34988][CORE][2.4] Upgrade Jetty for CVE-2021-28165 ### What changes were proposed in this pull request? This PR backports #32091. This PR upgrades the version of Jetty to 9.4.39. ### Why are the changes needed? CVE-2021-28165 affects the version of Jetty that Spark uses and it seems to be a little bit serious. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-28165 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32093 from sarutak/backport-SPARK-34988. Authored-by: Kousuke Saruta Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-3.1 | 4 ++-- pom.xml| 2 +- 2 files changed, 3 insertions(+), 3 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-3.1 b/dev/deps/spark-deps-hadoop-3.1 index 90775e1..7e0871b 100644 --- a/dev/deps/spark-deps-hadoop-3.1 +++ b/dev/deps/spark-deps-hadoop-3.1 @@ -116,8 +116,8 @@ jersey-container-servlet/2.22.2//jersey-container-servlet-2.22.2.jar jersey-guava/2.22.2//jersey-guava-2.22.2.jar jersey-media-jaxb/2.22.2//jersey-media-jaxb-2.22.2.jar jersey-server/2.22.2//jersey-server-2.22.2.jar -jetty-webapp/9.4.36.v20210114//jetty-webapp-9.4.36.v20210114.jar -jetty-xml/9.4.36.v20210114//jetty-xml-9.4.36.v20210114.jar +jetty-webapp/9.4.39.v20210325//jetty-webapp-9.4.39.v20210325.jar +jetty-xml/9.4.39.v20210325//jetty-xml-9.4.39.v20210325.jar jline/2.14.6//jline-2.14.6.jar joda-time/2.9.3//joda-time-2.9.3.jar jodd-core/3.5.2//jodd-core-3.5.2.jar diff --git a/pom.xml b/pom.xml index 2b51d4d..972c359 100644 --- a/pom.xml +++ b/pom.xml @@ -134,7 +134,7 @@ 1.5.5 nohive 1.6.0 -9.4.36.v20210114 +9.4.39.v20210325 3.1.0 0.9.3 2.4.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-34988][CORE][3.0] Upgrade Jetty for CVE-2021-28165
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new bd972fe [SPARK-34988][CORE][3.0] Upgrade Jetty for CVE-2021-28165 bd972fe is described below commit bd972fed00d5e5413f008b8168aeb381da91938b Author: Kousuke Saruta AuthorDate: Thu Apr 8 10:41:43 2021 -0500 [SPARK-34988][CORE][3.0] Upgrade Jetty for CVE-2021-28165 ### What changes were proposed in this pull request? This PR backports #32091. This PR upgrades the version of Jetty to 9.4.39. ### Why are the changes needed? CVE-2021-28165 affects the version of Jetty that Spark uses and it seems to be a little bit serious. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-28165 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32094 from sarutak/SPARK-34988-branch-3.0. Authored-by: Kousuke Saruta Signed-off-by: Sean Owen --- pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/pom.xml b/pom.xml index 1a42165..e501a2b 100644 --- a/pom.xml +++ b/pom.xml @@ -140,7 +140,7 @@ com.twitter 1.6.0 -9.4.36.v20210114 +9.4.39.v20210325 3.1.0 0.9.5 2.4.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (90613df -> c1c9a31)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 90613df [SPARK-33233][SQL] CUBE/ROLLUP/GROUPING SETS support GROUP BY ordinal add c1c9a31 [SPARK-34962][SQL] Explicit representation of * in UpdateAction and InsertAction in MergeIntoTable No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/Analyzer.scala | 20 .../ReplaceNullWithFalseInPredicate.scala | 4 +++- .../spark/sql/catalyst/parser/AstBuilder.scala | 4 ++-- .../sql/catalyst/plans/logical/v2Commands.scala| 10 .../ReplaceNullWithFalseInPredicateSuite.scala | 18 ++- .../spark/sql/catalyst/parser/DDLParserSuite.scala | 5 ++-- .../execution/command/PlanResolutionSuite.scala| 27 -- 7 files changed, 75 insertions(+), 13 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ac01070 -> 90613df)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ac01070 [SPARK-34946][SQL] Block unsupported correlated scalar subquery in Aggregate add 90613df [SPARK-33233][SQL] CUBE/ROLLUP/GROUPING SETS support GROUP BY ordinal No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/Analyzer.scala | 30 +++- .../analysis/SubstituteUnresolvedOrdinals.scala| 17 +- .../sql-tests/inputs/group-by-ordinal.sql | 35 .../sql-tests/results/group-by-ordinal.sql.out | 200 - 4 files changed, 269 insertions(+), 13 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated (84d96e8 -> 4a6b13b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git. from 84d96e8 [SPARK-34922][SQL][3.1] Use a relative cost comparison function in the CBO add 4a6b13b [SPARK-34988][CORE][3.1] Upgrade Jetty for CVE-2021-28165 No new revisions were added by this update. Summary of changes: pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (59c8131 -> ac01070)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 59c8131 [SPARK-34988][CORE] Upgrade Jetty for CVE-2021-28165 add ac01070 [SPARK-34946][SQL] Block unsupported correlated scalar subquery in Aggregate No new revisions were added by this update. Summary of changes: .../sql/catalyst/analysis/CheckAnalysis.scala | 23 ++-- .../spark/sql/catalyst/optimizer/subquery.scala| 15 ++ .../sql/catalyst/analysis/AnalysisErrorSuite.scala | 32 ++ 3 files changed, 68 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (e5d972e -> 59c8131)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from e5d972e [SPARK-34955][SQL] ADD JAR command cannot add jar files which contains whitespaces in the path add 59c8131 [SPARK-34988][CORE] Upgrade Jetty for CVE-2021-28165 No new revisions were added by this update. Summary of changes: pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org