[spark] branch master updated (9fd9830 -> 0fcb560)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9fd9830 [SPARK-38225][SQL] Adjust input `format` of function `to_binary` add 0fcb560 [SPARK-38138][SQL] Materialize QueryPlan subqueries No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/sql/catalyst/plans/QueryPlan.scala | 6 +++--- .../spark/sql/execution/adaptive/InsertAdaptiveSparkPlan.scala | 4 ++-- 2 files changed, 5 insertions(+), 5 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3a7eafd -> 9fd9830)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 3a7eafd [SPARK-38195][SQL] Add the `TIMESTAMPADD()` function add 9fd9830 [SPARK-38225][SQL] Adjust input `format` of function `to_binary` No new revisions were added by this update. Summary of changes: .../catalyst/expressions/stringExpressions.scala | 14 +- .../sql-tests/inputs/string-functions.sql | 3 ++- .../results/ansi/string-functions.sql.out | 30 ++ .../sql-tests/results/string-functions.sql.out | 30 ++ 4 files changed, 49 insertions(+), 28 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (837248a -> 3a7eafd)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 837248a [MINOR][DOC] Fix documentation for structured streaming - addListener add 3a7eafd [SPARK-38195][SQL] Add the `TIMESTAMPADD()` function No new revisions were added by this update. Summary of changes: docs/sql-ref-ansi-compliance.md| 1 + .../apache/spark/sql/catalyst/parser/SqlBase.g4| 4 ++ .../sql/catalyst/analysis/FunctionRegistry.scala | 1 + .../catalyst/expressions/datetimeExpressions.scala | 84 ++ .../spark/sql/catalyst/parser/AstBuilder.scala | 11 +++ .../spark/sql/catalyst/util/DateTimeUtils.scala| 36 ++ .../spark/sql/errors/QueryExecutionErrors.scala| 6 ++ .../expressions/DateExpressionsSuite.scala | 62 .../sql/catalyst/util/DateTimeUtilsSuite.scala | 36 +- .../sql-functions/sql-expression-schema.md | 3 +- .../test/resources/sql-tests/inputs/timestamp.sql | 6 ++ .../sql-tests/results/ansi/timestamp.sql.out | 34 - .../sql-tests/results/datetime-legacy.sql.out | 34 - .../resources/sql-tests/results/timestamp.sql.out | 34 - .../results/timestampNTZ/timestamp-ansi.sql.out| 34 - .../results/timestampNTZ/timestamp.sql.out | 34 - .../sql/errors/QueryExecutionErrorsSuite.scala | 12 +++- 17 files changed, 424 insertions(+), 8 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [MINOR][DOC] Fix documentation for structured streaming - addListener
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new bbbcb66 [MINOR][DOC] Fix documentation for structured streaming - addListener bbbcb66 is described below commit bbbcb663b88782c55bb9d3e5ec8b57336f468fa8 Author: Karthik Subramanian AuthorDate: Fri Feb 18 12:52:11 2022 +0900 [MINOR][DOC] Fix documentation for structured streaming - addListener ### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc. 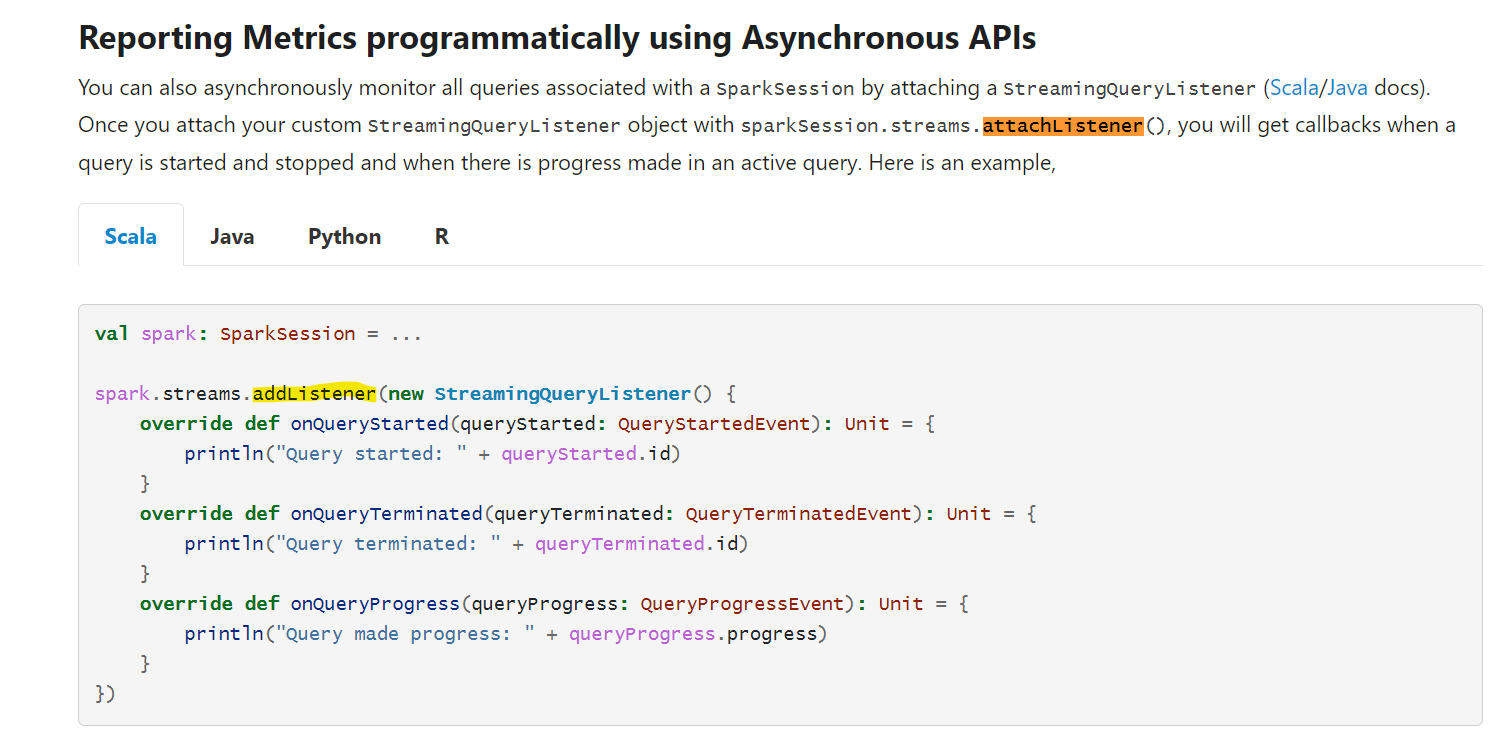 ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes #35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian Signed-off-by: Hyukjin Kwon (cherry picked from commit 837248a0c42d55ad48240647d503ad544e64f016) Signed-off-by: Hyukjin Kwon --- docs/structured-streaming-programming-guide.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/docs/structured-streaming-programming-guide.md b/docs/structured-streaming-programming-guide.md index ecb1294..1a4843a 100644 --- a/docs/structured-streaming-programming-guide.md +++ b/docs/structured-streaming-programming-guide.md @@ -2856,7 +2856,7 @@ You can also asynchronously monitor all queries associated with a `SparkSession` by attaching a `StreamingQueryListener` ([Scala](api/scala/org/apache/spark/sql/streaming/StreamingQueryListener.html)/[Java](api/java/org/apache/spark/sql/streaming/StreamingQueryListener.html) docs). Once you attach your custom `StreamingQueryListener` object with -`sparkSession.streams.attachListener()`, you will get callbacks when a query is started and +`sparkSession.streams.addListener()`, you will get callbacks when a query is started and stopped and when there is progress made in an active query. Here is an example, - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [MINOR][DOC] Fix documentation for structured streaming - addListener
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.1 by this push: new 5dd54f9 [MINOR][DOC] Fix documentation for structured streaming - addListener 5dd54f9 is described below commit 5dd54f9e341faee3653518e072c77077455cc84f Author: Karthik Subramanian AuthorDate: Fri Feb 18 12:52:11 2022 +0900 [MINOR][DOC] Fix documentation for structured streaming - addListener ### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc.  ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes #35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian Signed-off-by: Hyukjin Kwon (cherry picked from commit 837248a0c42d55ad48240647d503ad544e64f016) Signed-off-by: Hyukjin Kwon --- docs/structured-streaming-programming-guide.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/docs/structured-streaming-programming-guide.md b/docs/structured-streaming-programming-guide.md index 432ec7d..c0b65ac 100644 --- a/docs/structured-streaming-programming-guide.md +++ b/docs/structured-streaming-programming-guide.md @@ -3020,7 +3020,7 @@ You can also asynchronously monitor all queries associated with a `SparkSession` by attaching a `StreamingQueryListener` ([Scala](api/scala/org/apache/spark/sql/streaming/StreamingQueryListener.html)/[Java](api/java/org/apache/spark/sql/streaming/StreamingQueryListener.html) docs). Once you attach your custom `StreamingQueryListener` object with -`sparkSession.streams.attachListener()`, you will get callbacks when a query is started and +`sparkSession.streams.addListener()`, you will get callbacks when a query is started and stopped and when there is progress made in an active query. Here is an example, - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [MINOR][DOC] Fix documentation for structured streaming - addListener
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new a477f85 [MINOR][DOC] Fix documentation for structured streaming - addListener a477f85 is described below commit a477f85a41294d5ab10fe3d72ce21cdc00df304e Author: Karthik Subramanian AuthorDate: Fri Feb 18 12:52:11 2022 +0900 [MINOR][DOC] Fix documentation for structured streaming - addListener ### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc.  ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes #35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian Signed-off-by: Hyukjin Kwon (cherry picked from commit 837248a0c42d55ad48240647d503ad544e64f016) Signed-off-by: Hyukjin Kwon --- docs/structured-streaming-programming-guide.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/docs/structured-streaming-programming-guide.md b/docs/structured-streaming-programming-guide.md index 047340d..23c2e70 100644 --- a/docs/structured-streaming-programming-guide.md +++ b/docs/structured-streaming-programming-guide.md @@ -3264,7 +3264,7 @@ You can also asynchronously monitor all queries associated with a `SparkSession` by attaching a `StreamingQueryListener` ([Scala](api/scala/org/apache/spark/sql/streaming/StreamingQueryListener.html)/[Java](api/java/org/apache/spark/sql/streaming/StreamingQueryListener.html) docs). Once you attach your custom `StreamingQueryListener` object with -`sparkSession.streams.attachListener()`, you will get callbacks when a query is started and +`sparkSession.streams.addListener()`, you will get callbacks when a query is started and stopped and when there is progress made in an active query. Here is an example, - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3022fd4 -> 837248a)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 3022fd4 [SPARK-38197][CORE] Improve error message of BlockManager.fetchRemoteManagedBuffer add 837248a [MINOR][DOC] Fix documentation for structured streaming - addListener No new revisions were added by this update. Summary of changes: docs/structured-streaming-programming-guide.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38197][CORE] Improve error message of BlockManager.fetchRemoteManagedBuffer
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3022fd4 [SPARK-38197][CORE] Improve error message of
BlockManager.fetchRemoteManagedBuffer
3022fd4 is described below
commit 3022fd4ccfed676d4ba194afbfde2dd5ec1d348f
Author: Angerszh
AuthorDate: Thu Feb 17 19:52:16 2022 -0600
[SPARK-38197][CORE] Improve error message of
BlockManager.fetchRemoteManagedBuffer
### What changes were proposed in this pull request?
When locations's size is 1, and fetch failed, it only will print a error
message like
```
22/02/13 18:58:11 WARN BlockManager: Failed to fetch block after 1 fetch
failures. Most recent failure cause:
java.lang.IllegalStateException: Empty buffer received for non empty block
at
org.apache.spark.storage.BlockManager.fetchRemoteManagedBuffer(BlockManager.scala:1063)
at
org.apache.spark.storage.BlockManager.$anonfun$getRemoteBlock$8(BlockManager.scala:1005)
at scala.Option.orElse(Option.scala:447)
at
org.apache.spark.storage.BlockManager.getRemoteBlock(BlockManager.scala:1005)
at
org.apache.spark.storage.BlockManager.getRemoteValues(BlockManager.scala:951)
at org.apache.spark.storage.BlockManager.get(BlockManager.scala:1168)
at
org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:1230)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:384)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:335)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at
org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at
org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at
org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at
org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
We don't know the target nm ip and block id. This pr improve the error
message to show necessary information
### Why are the changes needed?
Improve error message
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes #35505 from AngersZh/SPARK-38197.
Authored-by: Angerszh
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/storage/BlockManager.scala | 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
b/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
index ec4dc77..7ae57f7 100644
--- a/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
+++ b/core/src/main/scala/org/apache/spark/storage/BlockManager.scala
@@ -1143,7 +1143,8 @@ private[spark] class BlockManager(
val buf = blockTransferService.fetchBlockSync(loc.host, loc.port,
loc.executorId,
blockId.toString, tempFileManager)
if (blockSize > 0 && buf.size() == 0) {
- throw new IllegalStateException("Empty buffer received for non empty
block")
+ throw new IllegalStateException("Empty buffer received for non empty
block " +
+s"when fetching remote block $blockId from $loc")
}
buf
} catch {
@@ -1155,7 +1156,8 @@
[spark] branch master updated (f82cf9e -> e86c8e2)
This is an automated email from the ASF dual-hosted git repository. kabhwan pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from f82cf9e [SPARK-34378][SQL][AVRO] Loosen AvroSerializer validation to allow extra nullable user-provided fields add e86c8e2 [SPARK-38214][SS] No need to filter windows when windowDuration is multiple of slideDuration No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/Analyzer.scala | 11 -- .../spark/sql/DataFrameTimeWindowingSuite.scala| 39 +- 2 files changed, 47 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3a179d7 -> f82cf9e)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 3a179d7 [MINOR][DOCS] Fixed closing tags in running-on-kubernetes.md add f82cf9e [SPARK-34378][SQL][AVRO] Loosen AvroSerializer validation to allow extra nullable user-provided fields No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/avro/AvroSerializer.scala | 2 +- .../org/apache/spark/sql/avro/AvroUtils.scala | 13 +-- .../spark/sql/avro/AvroSchemaHelperSuite.scala | 25 - .../org/apache/spark/sql/avro/AvroSerdeSuite.scala | 41 ++ .../org/apache/spark/sql/avro/AvroSuite.scala | 26 ++ 5 files changed, 87 insertions(+), 20 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4070ea8 -> 3a179d7)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4070ea8 [SPARK-38118][SQL] Func(wrong data type) in HAVING clause should throw data mismatch error add 3a179d7 [MINOR][DOCS] Fixed closing tags in running-on-kubernetes.md No new revisions were added by this update. Summary of changes: docs/running-on-kubernetes.md | 6 +++--- 1 file changed, 3 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (724bc31 -> 4070ea8)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 724bc31 [SPARK-38182][SQL] Fix NoSuchElementException if pushed filter does not contain any references add 4070ea8 [SPARK-38118][SQL] Func(wrong data type) in HAVING clause should throw data mismatch error No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/Analyzer.scala | 28 -- .../sql/catalyst/analysis/CheckAnalysis.scala | 2 +- .../spark/sql/catalyst/analysis/unresolved.scala | 1 + .../sql/catalyst/analysis/AnalysisSuite.scala | 24 +++ 4 files changed, 52 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (f33e371 -> 724bc31)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from f33e371 [SPARK-38244][K8S][BUILD] Upgrade kubernetes-client to 5.12.1 add 724bc31 [SPARK-38182][SQL] Fix NoSuchElementException if pushed filter does not contain any references No new revisions were added by this update. Summary of changes: .../execution/datasources/PartitioningAwareFileIndex.scala | 10 ++ .../spark/sql/execution/datasources/FileIndexSuite.scala | 12 2 files changed, 18 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch SPARK-38237 created (now ae1ebe0)
This is an automated email from the ASF dual-hosted git repository. kabhwan pushed a change to branch SPARK-38237 in repository https://gitbox.apache.org/repos/asf/spark.git. at ae1ebe0 [SPARK-38237][SQL] Rename back StatefulOpClusteredDistribution to HashClusteredDistribution No new revisions were added by this update. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (bd79378 -> 16b6686)
This is an automated email from the ASF dual-hosted git repository. zero323 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from bd79378 [SPARK-38216][SQL] Fail early if all the columns are partitioned columns when creating a Hive table add 16b6686 [SPARK-37410][PYTHON][ML] Inline hints for pyspark.ml.recommendation No new revisions were added by this update. Summary of changes: python/pyspark/ml/recommendation.py | 203 ++- python/pyspark/ml/recommendation.pyi | 149 - 2 files changed, 105 insertions(+), 247 deletions(-) delete mode 100644 python/pyspark/ml/recommendation.pyi - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0b17e87 -> bd79378)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0b17e87 [SPARK-38229][SQL] Should't check temp/external/ifNotExists with visitReplaceTable when parser add bd79378 [SPARK-38216][SQL] Fail early if all the columns are partitioned columns when creating a Hive table No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/execution/datasources/rules.scala | 10 +- .../org/apache/spark/sql/hive/execution/HiveDDLSuite.scala | 6 ++ 2 files changed, 7 insertions(+), 9 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (cfb048a -> 0b17e87)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from cfb048a [SPARK-37783][SQL][FOLLOWUP] Enable tail-recursion wherever possible add 0b17e87 [SPARK-38229][SQL] Should't check temp/external/ifNotExists with visitReplaceTable when parser No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/parser/AstBuilder.scala | 20 +++- 1 file changed, 3 insertions(+), 17 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (cfb048a -> 0b17e87)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from cfb048a [SPARK-37783][SQL][FOLLOWUP] Enable tail-recursion wherever possible add 0b17e87 [SPARK-38229][SQL] Should't check temp/external/ifNotExists with visitReplaceTable when parser No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/parser/AstBuilder.scala | 20 +++- 1 file changed, 3 insertions(+), 17 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org