[GitHub] [spark-website] HeartSaVioR commented on pull request #389: Promote Structured Streaming over Spark Streaming (DStream)
HeartSaVioR commented on PR #389: URL: https://github.com/apache/spark-website/pull/389#issuecomment-1129550667 cc. @gengliangwang -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] HeartSaVioR opened a new pull request, #389: Promote Structured Streaming over Spark Streaming (DStream)
HeartSaVioR opened a new pull request, #389: URL: https://github.com/apache/spark-website/pull/389 This PR proposes to promote Structured Streaming over Spark Streaming, as we see efforts of community are more focused on Structured Streaming (based on Spark SQL) than Spark Streaming (DStream). We would like to encourage end users to use Structured Streaming than Spark Streaming whenever possible for their workloads. Here are screenshots of pages this PR changes. 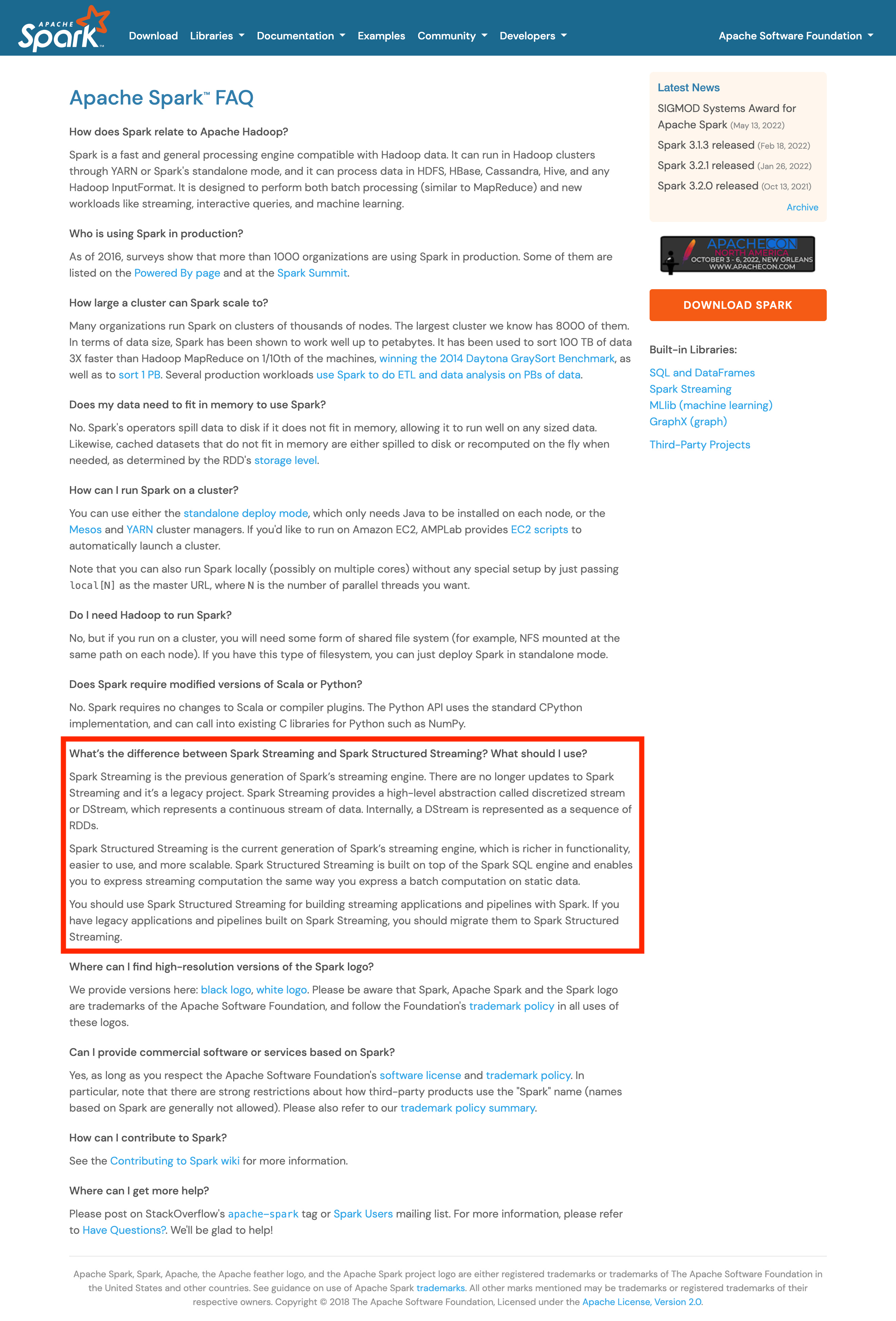  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39193][SQL] Fasten Timestamp type inference of JSON/CSV data sources
This is an automated email from the ASF dual-hosted git repository.
gengliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 888bf1b2ef4 [SPARK-39193][SQL] Fasten Timestamp type inference of
JSON/CSV data sources
888bf1b2ef4 is described below
commit 888bf1b2ef44a27c3d4be716a72175bbaa8c6453
Author: Gengliang Wang
AuthorDate: Wed May 18 10:59:52 2022 +0800
[SPARK-39193][SQL] Fasten Timestamp type inference of JSON/CSV data sources
### What changes were proposed in this pull request?
When reading JSON/CSV files with inferring timestamp types
(`.option("inferTimestamp", true)`), the Timestamp conversion will throw and
catch exceptions.
As we are putting decent error messages in the exception:
```
def cannotCastToDateTimeError(
value: Any, from: DataType, to: DataType, errorContext: String):
Throwable = {
val valueString = toSQLValue(value, from)
new SparkDateTimeException("INVALID_SYNTAX_FOR_CAST",
Array(toSQLType(to), valueString, SQLConf.ANSI_ENABLED.key,
errorContext))
}
```
Throwing and catching the timestamp parsing exceptions is actually not
cheap. It consumes more than 90% of the type inference time.
This PR improves the default timestamp parsing by returning optional
results instead of throwing/catching the exceptions. With this PR, the schema
inference time is reduced by 90% in a local benchmark.
Note this PR is for the default timestamp parser. It doesn't cover the
scenarios of
* users provide a customized timestamp format via option
* users enable legacy timestamp formatter
We can have follow-ups for it.
### Why are the changes needed?
Performance improvement
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UT
Also manual test the runtime to inferring a JSON file of 624MB with
inferring timestamp enabled:
```
spark.read.option("inferTimestamp", true).json(file)
```
Before the change, it takes 166 seconds
After the change, it only 16 seconds.
Closes #36562 from gengliangwang/improveInferTS.
Lead-authored-by: Gengliang Wang
Co-authored-by: Gengliang Wang
Signed-off-by: Gengliang Wang
---
.../spark/sql/catalyst/csv/CSVInferSchema.scala| 4 +-
.../spark/sql/catalyst/json/JsonInferSchema.scala | 4 +-
.../sql/catalyst/util/TimestampFormatter.scala | 51 ++
.../catalyst/util/TimestampFormatterSuite.scala| 15 +++
4 files changed, 70 insertions(+), 4 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
index f30fa8a0b5f..8b0c6c49b85 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
@@ -178,7 +178,7 @@ class CSVInferSchema(val options: CSVOptions) extends
Serializable {
// We can only parse the value as TimestampNTZType if it does not have
zone-offset or
// time-zone component and can be parsed with the timestamp formatter.
// Otherwise, it is likely to be a timestamp with timezone.
-if ((allCatch opt timestampNTZFormatter.parseWithoutTimeZone(field,
false)).isDefined) {
+if (timestampNTZFormatter.parseWithoutTimeZoneOptional(field,
false).isDefined) {
SQLConf.get.timestampType
} else {
tryParseTimestamp(field)
@@ -187,7 +187,7 @@ class CSVInferSchema(val options: CSVOptions) extends
Serializable {
private def tryParseTimestamp(field: String): DataType = {
// This case infers a custom `dataFormat` is set.
-if ((allCatch opt timestampParser.parse(field)).isDefined) {
+if (timestampParser.parseOptional(field).isDefined) {
TimestampType
} else {
tryParseBoolean(field)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
index d08773d8469..f6064bd7195 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
@@ -151,10 +151,10 @@ private[sql] class JsonInferSchema(options: JSONOptions)
extends Serializable {
if (options.prefersDecimal && decimalTry.isDefined) {
decimalTry.get
} else if (options.inferTimestamp &&
-(allCatch opt timestampNTZFormatter.parseWithoutTimeZone(field,
false)).isDefined) {
+timestampNTZFormatter.parseWithoutTimeZoneOptional(field,
false).isDefined) {
[spark] branch branch-3.3 updated: [SPARK-39193][SQL] Fasten Timestamp type inference of JSON/CSV data sources
This is an automated email from the ASF dual-hosted git repository.
gengliang pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 0e998d31234 [SPARK-39193][SQL] Fasten Timestamp type inference of
JSON/CSV data sources
0e998d31234 is described below
commit 0e998d31234f08be956c5bd2dec0b086952c2e18
Author: Gengliang Wang
AuthorDate: Wed May 18 10:59:52 2022 +0800
[SPARK-39193][SQL] Fasten Timestamp type inference of JSON/CSV data sources
### What changes were proposed in this pull request?
When reading JSON/CSV files with inferring timestamp types
(`.option("inferTimestamp", true)`), the Timestamp conversion will throw and
catch exceptions.
As we are putting decent error messages in the exception:
```
def cannotCastToDateTimeError(
value: Any, from: DataType, to: DataType, errorContext: String):
Throwable = {
val valueString = toSQLValue(value, from)
new SparkDateTimeException("INVALID_SYNTAX_FOR_CAST",
Array(toSQLType(to), valueString, SQLConf.ANSI_ENABLED.key,
errorContext))
}
```
Throwing and catching the timestamp parsing exceptions is actually not
cheap. It consumes more than 90% of the type inference time.
This PR improves the default timestamp parsing by returning optional
results instead of throwing/catching the exceptions. With this PR, the schema
inference time is reduced by 90% in a local benchmark.
Note this PR is for the default timestamp parser. It doesn't cover the
scenarios of
* users provide a customized timestamp format via option
* users enable legacy timestamp formatter
We can have follow-ups for it.
### Why are the changes needed?
Performance improvement
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UT
Also manual test the runtime to inferring a JSON file of 624MB with
inferring timestamp enabled:
```
spark.read.option("inferTimestamp", true).json(file)
```
Before the change, it takes 166 seconds
After the change, it only 16 seconds.
Closes #36562 from gengliangwang/improveInferTS.
Lead-authored-by: Gengliang Wang
Co-authored-by: Gengliang Wang
Signed-off-by: Gengliang Wang
(cherry picked from commit 888bf1b2ef44a27c3d4be716a72175bbaa8c6453)
Signed-off-by: Gengliang Wang
---
.../spark/sql/catalyst/csv/CSVInferSchema.scala| 4 +-
.../spark/sql/catalyst/json/JsonInferSchema.scala | 4 +-
.../sql/catalyst/util/TimestampFormatter.scala | 51 ++
.../catalyst/util/TimestampFormatterSuite.scala| 15 +++
4 files changed, 70 insertions(+), 4 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
index f30fa8a0b5f..8b0c6c49b85 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVInferSchema.scala
@@ -178,7 +178,7 @@ class CSVInferSchema(val options: CSVOptions) extends
Serializable {
// We can only parse the value as TimestampNTZType if it does not have
zone-offset or
// time-zone component and can be parsed with the timestamp formatter.
// Otherwise, it is likely to be a timestamp with timezone.
-if ((allCatch opt timestampNTZFormatter.parseWithoutTimeZone(field,
false)).isDefined) {
+if (timestampNTZFormatter.parseWithoutTimeZoneOptional(field,
false).isDefined) {
SQLConf.get.timestampType
} else {
tryParseTimestamp(field)
@@ -187,7 +187,7 @@ class CSVInferSchema(val options: CSVOptions) extends
Serializable {
private def tryParseTimestamp(field: String): DataType = {
// This case infers a custom `dataFormat` is set.
-if ((allCatch opt timestampParser.parse(field)).isDefined) {
+if (timestampParser.parseOptional(field).isDefined) {
TimestampType
} else {
tryParseBoolean(field)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
index d08773d8469..f6064bd7195 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JsonInferSchema.scala
@@ -151,10 +151,10 @@ private[sql] class JsonInferSchema(options: JSONOptions)
extends Serializable {
if (options.prefersDecimal && decimalTry.isDefined) {
decimalTry.get
} else if (options.inferTimestamp &&
-(allCatch opt timestampNTZFormatter.parseWithoutTimeZone(field,
[spark] branch master updated (69b8655d529 -> a4902c08f8c)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 69b8655d529 [SPARK-39192][PS][SQL] Make pandas-on-spark's kurt consistent with pandas add a4902c08f8c [SPARK-39054][PYTHON][PS] Ensure infer schema accuracy in GroupBy.apply No new revisions were added by this update. Summary of changes: python/pyspark/pandas/groupby.py| 5 - python/pyspark/pandas/tests/test_groupby.py | 16 2 files changed, 20 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39192][PS][SQL] Make pandas-on-spark's kurt consistent with pandas
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 69b8655d529 [SPARK-39192][PS][SQL] Make pandas-on-spark's kurt
consistent with pandas
69b8655d529 is described below
commit 69b8655d529a36d9b041a9e03d3349f5f2c4cdfc
Author: Ruifeng Zheng
AuthorDate: Wed May 18 08:39:16 2022 +0900
[SPARK-39192][PS][SQL] Make pandas-on-spark's kurt consistent with pandas
### What changes were proposed in this pull request?
make pandas-on-spark's kurt consistent with pandas
### Why are the changes needed?
1, the formulas of Kurtosis were different between spark sql and pandas;
2, pandas zeros out small `numerator` and `denominator` for better
numerical stability;
### Does this PR introduce _any_ user-facing change?
yes, the logic of kurt changed
### How was this patch tested?
added UT
Closes #36560 from zhengruifeng/impl_pandas_kurt.
Authored-by: Ruifeng Zheng
Signed-off-by: Hyukjin Kwon
---
python/pyspark/pandas/generic.py | 12
.../pyspark/pandas/tests/test_generic_functions.py | 4 +--
python/pyspark/pandas/tests/test_stats.py | 9 +-
.../expressions/aggregate/CentralMomentAgg.scala | 33 ++
.../spark/sql/api/python/PythonSQLUtils.scala | 6 +++-
5 files changed, 55 insertions(+), 9 deletions(-)
diff --git a/python/pyspark/pandas/generic.py b/python/pyspark/pandas/generic.py
index f5073315164..ec38935ced8 100644
--- a/python/pyspark/pandas/generic.py
+++ b/python/pyspark/pandas/generic.py
@@ -1556,20 +1556,20 @@ class Frame(object, metaclass=ABCMeta):
Examples
->>> df = ps.DataFrame({'a': [1, 2, 3, np.nan], 'b': [0.1, 0.2, 0.3,
np.nan]},
+>>> df = ps.DataFrame({'a': [1, 2, 3, np.nan, 6], 'b': [0.1, 0.2, 0.3,
np.nan, 0.8]},
... columns=['a', 'b'])
On a DataFrame:
>>> df.kurtosis()
-a -1.5
-b -1.5
+a1.50
+b2.703924
dtype: float64
On a Series:
>>> df['a'].kurtosis()
--1.5
+1.5
"""
axis = validate_axis(axis)
@@ -1587,7 +1587,9 @@ class Frame(object, metaclass=ABCMeta):
spark_type_to_pandas_dtype(spark_type),
spark_type.simpleString()
)
)
-return F.kurtosis(spark_column)
+
+sql_utils = SparkContext._active_spark_context._jvm.PythonSQLUtils
+return Column(sql_utils.pandasKurtosis(spark_column._jc))
return self._reduce_for_stat_function(
kurtosis,
diff --git a/python/pyspark/pandas/tests/test_generic_functions.py
b/python/pyspark/pandas/tests/test_generic_functions.py
index 5062daa77e2..2a83a038713 100644
--- a/python/pyspark/pandas/tests/test_generic_functions.py
+++ b/python/pyspark/pandas/tests/test_generic_functions.py
@@ -150,8 +150,8 @@ class GenericFunctionsTest(PandasOnSparkTestCase,
TestUtils):
self.assert_eq(pdf.a.kurtosis(skipna=False),
psdf.a.kurtosis(skipna=False))
self.assert_eq(pdf.a.kurtosis(), psdf.a.kurtosis())
self.assert_eq(pdf.b.kurtosis(skipna=False),
psdf.b.kurtosis(skipna=False))
-# self.assert_eq(pdf.b.kurtosis(), psdf.b.kurtosis()) AssertionError:
nan != -2.0
-self.assert_eq(-1.5, psdf.c.kurtosis())
+self.assert_eq(pdf.b.kurtosis(), psdf.b.kurtosis())
+self.assert_eq(pdf.c.kurtosis(), psdf.c.kurtosis())
if __name__ == "__main__":
diff --git a/python/pyspark/pandas/tests/test_stats.py
b/python/pyspark/pandas/tests/test_stats.py
index ccce140a4ac..e8f5048033b 100644
--- a/python/pyspark/pandas/tests/test_stats.py
+++ b/python/pyspark/pandas/tests/test_stats.py
@@ -180,6 +180,7 @@ class StatsTest(PandasOnSparkTestCase, SQLTestUtils):
self.assert_eq(psdf.min(axis=1), pdf.min(axis=1))
self.assert_eq(psdf.sum(axis=1), pdf.sum(axis=1))
self.assert_eq(psdf.product(axis=1), pdf.product(axis=1))
+self.assert_eq(psdf.kurtosis(axis=0), pdf.kurtosis(axis=0),
almost=True)
self.assert_eq(psdf.kurtosis(axis=1), pdf.kurtosis(axis=1))
self.assert_eq(psdf.skew(axis=0), pdf.skew(axis=0), almost=True)
self.assert_eq(psdf.skew(axis=1), pdf.skew(axis=1))
@@ -216,6 +217,11 @@ class StatsTest(PandasOnSparkTestCase, SQLTestUtils):
psdf.product(axis=1, numeric_only=True),
pdf.product(axis=1, numeric_only=True).astype(float),
)
+self.assert_eq(
+psdf.kurtosis(axis=0, numeric_only=True),
+pdf.kurtosis(axis=0, numeric_only=True),
+almost=True,
+)
[spark] branch master updated: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f5f67b851e2 [SPARK-39143][SQL] Support CSV scans with DEFAULT values
f5f67b851e2 is described below
commit f5f67b851e28afd898a2e3844c088c3041a199fe
Author: Daniel Tenedorio
AuthorDate: Wed May 18 08:38:43 2022 +0900
[SPARK-39143][SQL] Support CSV scans with DEFAULT values
### What changes were proposed in this pull request?
Support CSV scans when the table schema has associated DEFAULT column
values.
Example:
```
create table t(i int) using csv;
insert into t values(42);
alter table t add column s string default concat('abc', def');
select * from t;
> 42, 'abcdef'
```
### Why are the changes needed?
This change makes it easier to build, query, and maintain tables backed by
CSV data.
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
This PR includes new test coverage.
Closes #36501 from dtenedor/default-csv.
Authored-by: Daniel Tenedorio
Signed-off-by: Hyukjin Kwon
---
.../spark/sql/catalyst/csv/UnivocityParser.scala | 17 +++--
.../spark/sql/errors/QueryCompilationErrors.scala | 6 ++
.../org/apache/spark/sql/types/StructField.scala | 11
.../org/apache/spark/sql/types/StructType.scala| 28 -
.../apache/spark/sql/types/StructTypeSuite.scala | 63 +++
.../org/apache/spark/sql/sources/InsertSuite.scala | 73 ++
6 files changed, 192 insertions(+), 6 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala
index 56166950e67..ff46672e67f 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala
@@ -29,6 +29,7 @@ import org.apache.spark.sql.catalyst.{InternalRow,
NoopFilters, OrderedFilters}
import org.apache.spark.sql.catalyst.expressions.{Cast, EmptyRow, ExprUtils,
GenericInternalRow, Literal}
import org.apache.spark.sql.catalyst.util._
import org.apache.spark.sql.catalyst.util.LegacyDateFormats.FAST_DATE_FORMAT
+import org.apache.spark.sql.catalyst.util.ResolveDefaultColumns._
import org.apache.spark.sql.errors.QueryExecutionErrors
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.sources.Filter
@@ -67,9 +68,16 @@ class UnivocityParser(
private val tokenIndexArr =
requiredSchema.map(f =>
java.lang.Integer.valueOf(dataSchema.indexOf(f))).toArray
+ // True if we should inform the Univocity CSV parser to select which fields
to read by their
+ // positions. Generally assigned by input configuration options, except when
input column(s) have
+ // default values, in which case we omit the explicit indexes in order to
know how many tokens
+ // were present in each line instead.
+ private def columnPruning: Boolean = options.columnPruning &&
+
!requiredSchema.exists(_.metadata.contains(EXISTS_DEFAULT_COLUMN_METADATA_KEY))
+
// When column pruning is enabled, the parser only parses the required
columns based on
// their positions in the data schema.
- private val parsedSchema = if (options.columnPruning) requiredSchema else
dataSchema
+ private val parsedSchema = if (columnPruning) requiredSchema else dataSchema
val tokenizer: CsvParser = {
val parserSetting = options.asParserSettings
@@ -266,7 +274,7 @@ class UnivocityParser(
*/
val parse: String => Option[InternalRow] = {
// This is intentionally a val to create a function once and reuse.
-if (options.columnPruning && requiredSchema.isEmpty) {
+if (columnPruning && requiredSchema.isEmpty) {
// If `columnPruning` enabled and partition attributes scanned only,
// `schema` gets empty.
(_: String) => Some(InternalRow.empty)
@@ -276,7 +284,7 @@ class UnivocityParser(
}
}
- private val getToken = if (options.columnPruning) {
+ private val getToken = if (columnPruning) {
(tokens: Array[String], index: Int) => tokens(index)
} else {
(tokens: Array[String], index: Int) => tokens(tokenIndexArr(index))
@@ -318,7 +326,8 @@ class UnivocityParser(
case e: SparkUpgradeException => throw e
case NonFatal(e) =>
badRecordException = badRecordException.orElse(Some(e))
- row.setNullAt(i)
+ // Use the corresponding DEFAULT value associated with the column,
if any.
+ row.update(i, requiredSchema.defaultValues(i))
}
i += 1
}
diff --git
[spark] branch branch-3.2 updated: [SPARK-39104][SQL] InMemoryRelation#isCachedColumnBuffersLoaded should be thread-safe
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new cb85686a4b4 [SPARK-39104][SQL]
InMemoryRelation#isCachedColumnBuffersLoaded should be thread-safe
cb85686a4b4 is described below
commit cb85686a4b493fa3ef4233ecd54b7360f1ddc102
Author: Cheng Pan
AuthorDate: Tue May 17 18:26:55 2022 -0500
[SPARK-39104][SQL] InMemoryRelation#isCachedColumnBuffersLoaded should be
thread-safe
### What changes were proposed in this pull request?
Add `synchronized` on method `isCachedColumnBuffersLoaded`
### Why are the changes needed?
`isCachedColumnBuffersLoaded` should has `synchronized` wrapped, otherwise
may cause NPE when modify `_cachedColumnBuffers` concurrently.
```
def isCachedColumnBuffersLoaded: Boolean = {
_cachedColumnBuffers != null && isCachedRDDLoaded
}
def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
bmMaster.getBlockStatus(RDDBlockId(_cachedColumnBuffers.id,
partition.index), false)
.exists { case(_, blockStatus) => blockStatus.isCached }
}
if (rddLoaded) {
_cachedColumnBuffersAreLoaded = rddLoaded
}
rddLoaded
}
}
```
```
java.lang.NullPointerException
at
org.apache.spark.sql.execution.columnar.CachedRDDBuilder.isCachedRDDLoaded(InMemoryRelation.scala:247)
at
org.apache.spark.sql.execution.columnar.CachedRDDBuilder.isCachedColumnBuffersLoaded(InMemoryRelation.scala:241)
at
org.apache.spark.sql.execution.CacheManager.$anonfun$uncacheQuery$8(CacheManager.scala:189)
at
org.apache.spark.sql.execution.CacheManager.$anonfun$uncacheQuery$8$adapted(CacheManager.scala:176)
at
scala.collection.TraversableLike.$anonfun$filterImpl$1(TraversableLike.scala:304)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at
scala.collection.TraversableLike.filterImpl(TraversableLike.scala:303)
at
scala.collection.TraversableLike.filterImpl$(TraversableLike.scala:297)
at
scala.collection.AbstractTraversable.filterImpl(Traversable.scala:108)
at scala.collection.TraversableLike.filter(TraversableLike.scala:395)
at scala.collection.TraversableLike.filter$(TraversableLike.scala:395)
at scala.collection.AbstractTraversable.filter(Traversable.scala:108)
at
org.apache.spark.sql.execution.CacheManager.recacheByCondition(CacheManager.scala:219)
at
org.apache.spark.sql.execution.CacheManager.uncacheQuery(CacheManager.scala:176)
at org.apache.spark.sql.Dataset.unpersist(Dataset.scala:3220)
at org.apache.spark.sql.Dataset.unpersist(Dataset.scala:3231)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes #36496 from pan3793/SPARK-39104.
Authored-by: Cheng Pan
Signed-off-by: Sean Owen
(cherry picked from commit 3c8d8d7a864281fbe080316ad8de9b8eac80fa71)
Signed-off-by: Sean Owen
---
.../sql/execution/columnar/InMemoryRelation.scala | 9 +++-
.../columnar/InMemoryColumnarQuerySuite.scala | 53 ++
2 files changed, 60 insertions(+), 2 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
index 525653c3cfc..f6444ca5b9b 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
@@ -238,10 +238,15 @@ case class CachedRDDBuilder(
}
def isCachedColumnBuffersLoaded: Boolean = {
-_cachedColumnBuffers != null && isCachedRDDLoaded
+if (_cachedColumnBuffers != null) {
+ synchronized {
+return _cachedColumnBuffers != null && isCachedRDDLoaded
+ }
+}
+false
}
- def isCachedRDDLoaded: Boolean = {
+ private def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
diff --git
[spark] branch branch-3.3 updated: [SPARK-39104][SQL] InMemoryRelation#isCachedColumnBuffersLoaded should be thread-safe
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new e52b0487583 [SPARK-39104][SQL]
InMemoryRelation#isCachedColumnBuffersLoaded should be thread-safe
e52b0487583 is described below
commit e52b0487583314ae159dab3496be3c28df3e56b7
Author: Cheng Pan
AuthorDate: Tue May 17 18:26:55 2022 -0500
[SPARK-39104][SQL] InMemoryRelation#isCachedColumnBuffersLoaded should be
thread-safe
### What changes were proposed in this pull request?
Add `synchronized` on method `isCachedColumnBuffersLoaded`
### Why are the changes needed?
`isCachedColumnBuffersLoaded` should has `synchronized` wrapped, otherwise
may cause NPE when modify `_cachedColumnBuffers` concurrently.
```
def isCachedColumnBuffersLoaded: Boolean = {
_cachedColumnBuffers != null && isCachedRDDLoaded
}
def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
bmMaster.getBlockStatus(RDDBlockId(_cachedColumnBuffers.id,
partition.index), false)
.exists { case(_, blockStatus) => blockStatus.isCached }
}
if (rddLoaded) {
_cachedColumnBuffersAreLoaded = rddLoaded
}
rddLoaded
}
}
```
```
java.lang.NullPointerException
at
org.apache.spark.sql.execution.columnar.CachedRDDBuilder.isCachedRDDLoaded(InMemoryRelation.scala:247)
at
org.apache.spark.sql.execution.columnar.CachedRDDBuilder.isCachedColumnBuffersLoaded(InMemoryRelation.scala:241)
at
org.apache.spark.sql.execution.CacheManager.$anonfun$uncacheQuery$8(CacheManager.scala:189)
at
org.apache.spark.sql.execution.CacheManager.$anonfun$uncacheQuery$8$adapted(CacheManager.scala:176)
at
scala.collection.TraversableLike.$anonfun$filterImpl$1(TraversableLike.scala:304)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at
scala.collection.TraversableLike.filterImpl(TraversableLike.scala:303)
at
scala.collection.TraversableLike.filterImpl$(TraversableLike.scala:297)
at
scala.collection.AbstractTraversable.filterImpl(Traversable.scala:108)
at scala.collection.TraversableLike.filter(TraversableLike.scala:395)
at scala.collection.TraversableLike.filter$(TraversableLike.scala:395)
at scala.collection.AbstractTraversable.filter(Traversable.scala:108)
at
org.apache.spark.sql.execution.CacheManager.recacheByCondition(CacheManager.scala:219)
at
org.apache.spark.sql.execution.CacheManager.uncacheQuery(CacheManager.scala:176)
at org.apache.spark.sql.Dataset.unpersist(Dataset.scala:3220)
at org.apache.spark.sql.Dataset.unpersist(Dataset.scala:3231)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes #36496 from pan3793/SPARK-39104.
Authored-by: Cheng Pan
Signed-off-by: Sean Owen
(cherry picked from commit 3c8d8d7a864281fbe080316ad8de9b8eac80fa71)
Signed-off-by: Sean Owen
---
.../sql/execution/columnar/InMemoryRelation.scala | 9 +++-
.../columnar/InMemoryColumnarQuerySuite.scala | 53 ++
2 files changed, 60 insertions(+), 2 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
index 89323e7d1a4..0ace24777b7 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
@@ -238,10 +238,15 @@ case class CachedRDDBuilder(
}
def isCachedColumnBuffersLoaded: Boolean = {
-_cachedColumnBuffers != null && isCachedRDDLoaded
+if (_cachedColumnBuffers != null) {
+ synchronized {
+return _cachedColumnBuffers != null && isCachedRDDLoaded
+ }
+}
+false
}
- def isCachedRDDLoaded: Boolean = {
+ private def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
diff --git
[spark] branch master updated: [SPARK-39104][SQL] InMemoryRelation#isCachedColumnBuffersLoaded should be thread-safe
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3c8d8d7a864 [SPARK-39104][SQL]
InMemoryRelation#isCachedColumnBuffersLoaded should be thread-safe
3c8d8d7a864 is described below
commit 3c8d8d7a864281fbe080316ad8de9b8eac80fa71
Author: Cheng Pan
AuthorDate: Tue May 17 18:26:55 2022 -0500
[SPARK-39104][SQL] InMemoryRelation#isCachedColumnBuffersLoaded should be
thread-safe
### What changes were proposed in this pull request?
Add `synchronized` on method `isCachedColumnBuffersLoaded`
### Why are the changes needed?
`isCachedColumnBuffersLoaded` should has `synchronized` wrapped, otherwise
may cause NPE when modify `_cachedColumnBuffers` concurrently.
```
def isCachedColumnBuffersLoaded: Boolean = {
_cachedColumnBuffers != null && isCachedRDDLoaded
}
def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
bmMaster.getBlockStatus(RDDBlockId(_cachedColumnBuffers.id,
partition.index), false)
.exists { case(_, blockStatus) => blockStatus.isCached }
}
if (rddLoaded) {
_cachedColumnBuffersAreLoaded = rddLoaded
}
rddLoaded
}
}
```
```
java.lang.NullPointerException
at
org.apache.spark.sql.execution.columnar.CachedRDDBuilder.isCachedRDDLoaded(InMemoryRelation.scala:247)
at
org.apache.spark.sql.execution.columnar.CachedRDDBuilder.isCachedColumnBuffersLoaded(InMemoryRelation.scala:241)
at
org.apache.spark.sql.execution.CacheManager.$anonfun$uncacheQuery$8(CacheManager.scala:189)
at
org.apache.spark.sql.execution.CacheManager.$anonfun$uncacheQuery$8$adapted(CacheManager.scala:176)
at
scala.collection.TraversableLike.$anonfun$filterImpl$1(TraversableLike.scala:304)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at
scala.collection.TraversableLike.filterImpl(TraversableLike.scala:303)
at
scala.collection.TraversableLike.filterImpl$(TraversableLike.scala:297)
at
scala.collection.AbstractTraversable.filterImpl(Traversable.scala:108)
at scala.collection.TraversableLike.filter(TraversableLike.scala:395)
at scala.collection.TraversableLike.filter$(TraversableLike.scala:395)
at scala.collection.AbstractTraversable.filter(Traversable.scala:108)
at
org.apache.spark.sql.execution.CacheManager.recacheByCondition(CacheManager.scala:219)
at
org.apache.spark.sql.execution.CacheManager.uncacheQuery(CacheManager.scala:176)
at org.apache.spark.sql.Dataset.unpersist(Dataset.scala:3220)
at org.apache.spark.sql.Dataset.unpersist(Dataset.scala:3231)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes #36496 from pan3793/SPARK-39104.
Authored-by: Cheng Pan
Signed-off-by: Sean Owen
---
.../sql/execution/columnar/InMemoryRelation.scala | 9 +++-
.../columnar/InMemoryColumnarQuerySuite.scala | 53 ++
2 files changed, 60 insertions(+), 2 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
index 89323e7d1a4..0ace24777b7 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala
@@ -238,10 +238,15 @@ case class CachedRDDBuilder(
}
def isCachedColumnBuffersLoaded: Boolean = {
-_cachedColumnBuffers != null && isCachedRDDLoaded
+if (_cachedColumnBuffers != null) {
+ synchronized {
+return _cachedColumnBuffers != null && isCachedRDDLoaded
+ }
+}
+false
}
- def isCachedRDDLoaded: Boolean = {
+ private def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/columnar/InMemoryColumnarQuerySuite.scala
[spark] branch branch-3.3 updated: [SPARK-39208][SQL] Fix query context bugs in decimal overflow under codegen mode
This is an automated email from the ASF dual-hosted git repository.
gengliang pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 4fb7fe2a406 [SPARK-39208][SQL] Fix query context bugs in decimal
overflow under codegen mode
4fb7fe2a406 is described below
commit 4fb7fe2a40623526ed22311eac16c937450031e5
Author: Gengliang Wang
AuthorDate: Tue May 17 22:31:30 2022 +0800
[SPARK-39208][SQL] Fix query context bugs in decimal overflow under codegen
mode
### What changes were proposed in this pull request?
1. Fix logical bugs in adding query contexts as references under codegen
mode.
https://github.com/apache/spark/pull/36040/files#diff-4a70d2f3a4b99f58796b87192143f9838f4c4cf469f3313eb30af79c4e07153aR145
The code
```
val errorContextCode = if (nullOnOverflow) {
ctx.addReferenceObj("errCtx", queryContext)
} else {
"\"\""
}
```
should be
```
val errorContextCode = if (nullOnOverflow) {
"\"\""
} else {
ctx.addReferenceObj("errCtx", queryContext)
}
```
2. Similar to https://github.com/apache/spark/pull/36557, make
`CheckOverflowInSum` support query context when WSCG is not available.
### Why are the changes needed?
Bugfix and enhancement in the query context of decimal expressions.
### Does this PR introduce _any_ user-facing change?
No, the query context is not released yet.
### How was this patch tested?
New UT
Closes #36577 from gengliangwang/fixDecimalSumOverflow.
Authored-by: Gengliang Wang
Signed-off-by: Gengliang Wang
(cherry picked from commit 191e535b975e5813719d3143797c9fcf86321368)
Signed-off-by: Gengliang Wang
---
.../sql/catalyst/expressions/aggregate/Sum.scala| 21 ++---
.../catalyst/expressions/decimalExpressions.scala | 15 ---
.../expressions/DecimalExpressionSuite.scala| 19 +++
.../scala/org/apache/spark/sql/SQLQuerySuite.scala | 19 +++
4 files changed, 52 insertions(+), 22 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/Sum.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/Sum.scala
index f2c6925b837..fa43565d807 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/Sum.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/Sum.scala
@@ -143,10 +143,11 @@ abstract class SumBase(child: Expression) extends
DeclarativeAggregate
* So now, if ansi is enabled, then throw exception, if not then return null.
* If sum is not null, then return the sum.
*/
- protected def getEvaluateExpression: Expression = resultType match {
+ protected def getEvaluateExpression(queryContext: String): Expression =
resultType match {
case d: DecimalType =>
- If(isEmpty, Literal.create(null, resultType),
-CheckOverflowInSum(sum, d, !useAnsiAdd))
+ val checkOverflowInSum =
+CheckOverflowInSum(sum, d, !useAnsiAdd, queryContext)
+ If(isEmpty, Literal.create(null, resultType), checkOverflowInSum)
case _ if shouldTrackIsEmpty =>
If(isEmpty, Literal.create(null, resultType), sum)
case _ => sum
@@ -172,7 +173,7 @@ abstract class SumBase(child: Expression) extends
DeclarativeAggregate
case class Sum(
child: Expression,
useAnsiAdd: Boolean = SQLConf.get.ansiEnabled)
- extends SumBase(child) {
+ extends SumBase(child) with SupportQueryContext {
def this(child: Expression) = this(child, useAnsiAdd =
SQLConf.get.ansiEnabled)
override def shouldTrackIsEmpty: Boolean = resultType match {
@@ -186,7 +187,13 @@ case class Sum(
override lazy val mergeExpressions: Seq[Expression] = getMergeExpressions
- override lazy val evaluateExpression: Expression = getEvaluateExpression
+ override lazy val evaluateExpression: Expression =
getEvaluateExpression(queryContext)
+
+ override def initQueryContext(): String = if (useAnsiAdd) {
+origin.context
+ } else {
+""
+ }
}
// scalastyle:off line.size.limit
@@ -243,9 +250,9 @@ case class TrySum(child: Expression) extends SumBase(child)
{
override lazy val evaluateExpression: Expression =
if (useAnsiAdd) {
- TryEval(getEvaluateExpression)
+ TryEval(getEvaluateExpression(""))
} else {
- getEvaluateExpression
+ getEvaluateExpression("")
}
override protected def withNewChildInternal(newChild: Expression):
Expression =
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/decimalExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/decimalExpressions.scala
index
[spark] branch master updated (c5351f85dec -> 191e535b975)
This is an automated email from the ASF dual-hosted git repository. gengliang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from c5351f85dec [SPARK-32268][SQL][TESTS][FOLLOW-UP] Use function registry in the SparkSession add 191e535b975 [SPARK-39208][SQL] Fix query context bugs in decimal overflow under codegen mode No new revisions were added by this update. Summary of changes: .../sql/catalyst/expressions/aggregate/Sum.scala| 21 ++--- .../catalyst/expressions/decimalExpressions.scala | 15 --- .../expressions/DecimalExpressionSuite.scala| 19 +++ .../scala/org/apache/spark/sql/SQLQuerySuite.scala | 19 +++ 4 files changed, 52 insertions(+), 22 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-32268][SQL][TESTS][FOLLOW-UP] Use function registry in the SparkSession
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new c07f65c5168 [SPARK-32268][SQL][TESTS][FOLLOW-UP] Use function registry
in the SparkSession
c07f65c5168 is described below
commit c07f65c51681107e869d2ebb46aa546ac3871e3a
Author: Hyukjin Kwon
AuthorDate: Tue May 17 23:05:48 2022 +0900
[SPARK-32268][SQL][TESTS][FOLLOW-UP] Use function registry in the
SparkSession
### What changes were proposed in this pull request?
This PR proposes:
1. Use the function registry in the Spark Session being used
2. Move function registration into `beforeAll`
### Why are the changes needed?
Registration of the function without `beforeAll` at `builtin` can affect
other tests. See also
https://lists.apache.org/thread/jp0ccqv10ht716g9xldm2ohdv3mpmmz1.
### Does this PR introduce _any_ user-facing change?
No, test-only.
### How was this patch tested?
Unittests fixed.
Closes #36576 from HyukjinKwon/SPARK-32268-followup.
Authored-by: Hyukjin Kwon
Signed-off-by: Hyukjin Kwon
(cherry picked from commit c5351f85dec628a5c806893aa66777cbd77a4d65)
Signed-off-by: Hyukjin Kwon
---
.../spark/sql/BloomFilterAggregateQuerySuite.scala | 34 --
1 file changed, 18 insertions(+), 16 deletions(-)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/BloomFilterAggregateQuerySuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/BloomFilterAggregateQuerySuite.scala
index 7fc89ecc88b..05513cddccb 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/BloomFilterAggregateQuerySuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/BloomFilterAggregateQuerySuite.scala
@@ -18,7 +18,6 @@
package org.apache.spark.sql
import org.apache.spark.sql.catalyst.FunctionIdentifier
-import org.apache.spark.sql.catalyst.analysis.FunctionRegistry
import org.apache.spark.sql.catalyst.expressions._
import org.apache.spark.sql.catalyst.expressions.aggregate.BloomFilterAggregate
import org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec
@@ -35,23 +34,26 @@ class BloomFilterAggregateQuerySuite extends QueryTest with
SharedSparkSession {
val funcId_bloom_filter_agg = new FunctionIdentifier("bloom_filter_agg")
val funcId_might_contain = new FunctionIdentifier("might_contain")
- // Register 'bloom_filter_agg' to builtin.
- FunctionRegistry.builtin.registerFunction(funcId_bloom_filter_agg,
-new ExpressionInfo(classOf[BloomFilterAggregate].getName,
"bloom_filter_agg"),
-(children: Seq[Expression]) => children.size match {
- case 1 => new BloomFilterAggregate(children.head)
- case 2 => new BloomFilterAggregate(children.head, children(1))
- case 3 => new BloomFilterAggregate(children.head, children(1),
children(2))
-})
-
- // Register 'might_contain' to builtin.
- FunctionRegistry.builtin.registerFunction(funcId_might_contain,
-new ExpressionInfo(classOf[BloomFilterMightContain].getName,
"might_contain"),
-(children: Seq[Expression]) => BloomFilterMightContain(children.head,
children(1)))
+ override def beforeAll(): Unit = {
+super.beforeAll()
+// Register 'bloom_filter_agg' to builtin.
+
spark.sessionState.functionRegistry.registerFunction(funcId_bloom_filter_agg,
+ new ExpressionInfo(classOf[BloomFilterAggregate].getName,
"bloom_filter_agg"),
+ (children: Seq[Expression]) => children.size match {
+case 1 => new BloomFilterAggregate(children.head)
+case 2 => new BloomFilterAggregate(children.head, children(1))
+case 3 => new BloomFilterAggregate(children.head, children(1),
children(2))
+ })
+
+// Register 'might_contain' to builtin.
+spark.sessionState.functionRegistry.registerFunction(funcId_might_contain,
+ new ExpressionInfo(classOf[BloomFilterMightContain].getName,
"might_contain"),
+ (children: Seq[Expression]) => BloomFilterMightContain(children.head,
children(1)))
+ }
override def afterAll(): Unit = {
-FunctionRegistry.builtin.dropFunction(funcId_bloom_filter_agg)
-FunctionRegistry.builtin.dropFunction(funcId_might_contain)
+spark.sessionState.functionRegistry.dropFunction(funcId_bloom_filter_agg)
+spark.sessionState.functionRegistry.dropFunction(funcId_might_contain)
super.afterAll()
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (6d74557c385 -> c5351f85dec)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 6d74557c385 [SPARK-39102][CORE][SQL][DSTREAM] Add checkstyle rules to disabled use of Guava's `Files.createTempDir()` add c5351f85dec [SPARK-32268][SQL][TESTS][FOLLOW-UP] Use function registry in the SparkSession No new revisions were added by this update. Summary of changes: .../spark/sql/BloomFilterAggregateQuerySuite.scala | 34 -- 1 file changed, 18 insertions(+), 16 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39102][CORE][SQL][DSTREAM] Add checkstyle rules to disabled use of Guava's `Files.createTempDir()`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6d74557c385 [SPARK-39102][CORE][SQL][DSTREAM] Add checkstyle rules to
disabled use of Guava's `Files.createTempDir()`
6d74557c385 is described below
commit 6d74557c385d487fb50b5603d9c322d0ae9d9b74
Author: yangjie01
AuthorDate: Tue May 17 08:44:29 2022 -0500
[SPARK-39102][CORE][SQL][DSTREAM] Add checkstyle rules to disabled use of
Guava's `Files.createTempDir()`
### What changes were proposed in this pull request?
The main change of this pr as follows:
- Add a checkstyle to `scalastyle-config.xml` to disabled use of Guava's
`Files.createTempDir()` for Scala
- Add a checkstyle to `dev/checkstyle.xml` to disabled use of Guava's
`Files.createTempDir()` for Java
- Introduce `JavaUtils.createTempDir()` method to replace the use of
Guava's `Files.createTempDir()` in Java code
- Use `Utils.createTempDir()` to replace the use of Guava's
`Files.createTempDir()` in Scala code
### Why are the changes needed?
Avoid the use of Guava's `Files.createTempDir()` in Spark code due to
[CVE-2020-8908](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8908)
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes #36529 from LuciferYang/SPARK-39102.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../org/apache/spark/network/util/JavaUtils.java | 56 +
.../org/apache/spark/network/StreamTestHelper.java | 4 +-
.../apache/spark/network/util/JavaUtilsSuite.java | 58 ++
.../network/shuffle/ExternalBlockHandlerSuite.java | 4 +-
.../network/shuffle/TestShuffleDataContext.java| 5 +-
.../test/org/apache/spark/Java8RDDAPISuite.java| 7 +--
.../java/test/org/apache/spark/JavaAPISuite.java | 5 +-
.../org/apache/spark/deploy/IvyTestUtils.scala | 3 +-
.../apache/spark/deploy/RPackageUtilsSuite.scala | 3 +-
dev/checkstyle.xml | 6 +++
scalastyle-config.xml | 7 +++
.../org/apache/spark/streaming/JavaAPISuite.java | 9 ++--
12 files changed, 147 insertions(+), 20 deletions(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
b/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
index b5497087634..f699bdd95c3 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
@@ -21,7 +21,9 @@ import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.ReadableByteChannel;
import java.nio.charset.StandardCharsets;
+import java.nio.file.Files;
import java.util.Locale;
+import java.util.UUID;
import java.util.concurrent.TimeUnit;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@@ -362,6 +364,60 @@ public class JavaUtils {
}
}
+ /**
+ * Create a temporary directory inside `java.io.tmpdir` with default
namePrefix "spark".
+ * The directory will be automatically deleted when the VM shuts down.
+ */
+ public static File createTempDir() throws IOException {
+return createTempDir(System.getProperty("java.io.tmpdir"), "spark");
+ }
+
+ /**
+ * Create a temporary directory inside the given parent directory. The
directory will be
+ * automatically deleted when the VM shuts down.
+ */
+ public static File createTempDir(String root, String namePrefix) throws
IOException {
+if (root == null) root = System.getProperty("java.io.tmpdir");
+if (namePrefix == null) namePrefix = "spark";
+File dir = createDirectory(root, namePrefix);
+dir.deleteOnExit();
+return dir;
+ }
+
+ /**
+ * Create a directory inside the given parent directory with default
namePrefix "spark".
+ * The directory is guaranteed to be newly created, and is not marked for
automatic deletion.
+ */
+ public static File createDirectory(String root) throws IOException {
+return createDirectory(root, "spark");
+ }
+
+ /**
+ * Create a directory inside the given parent directory. The directory is
guaranteed to be
+ * newly created, and is not marked for automatic deletion.
+ */
+ public static File createDirectory(String root, String namePrefix) throws
IOException {
+if (namePrefix == null) namePrefix = "spark";
+int attempts = 0;
+int maxAttempts = 10;
+File dir = null;
+while (dir == null) {
+ attempts += 1;
+ if (attempts > maxAttempts) {
+throw new IOException("Failed to create a temp directory (under " +
root + ") after " +
+ maxAttempts + " attempts!");
+ }
+ try {
+dir = new
[spark] branch master updated: [SPARK-39196][CORE][SQL][K8S] replace `getOrElse(null)` with `orNull`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b4c019627b6 [SPARK-39196][CORE][SQL][K8S] replace `getOrElse(null)`
with `orNull`
b4c019627b6 is described below
commit b4c019627b676edf850c00bb070377896b66fad2
Author: Qian.Sun
AuthorDate: Tue May 17 08:43:02 2022 -0500
[SPARK-39196][CORE][SQL][K8S] replace `getOrElse(null)` with `orNull`
### What changes were proposed in this pull request?
This PR aims to replace `getOrElse(null)` with `orNull`.
### Why are the changes needed?
Code simplification.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the GA.
Closes #36567 from dcoliversun/SPARK-39196.
Authored-by: Qian.Sun
Signed-off-by: Sean Owen
---
.../src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala| 2 +-
core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala| 2 +-
core/src/main/scala/org/apache/spark/rdd/RDD.scala| 2 +-
core/src/main/scala/org/apache/spark/util/JsonProtocol.scala | 2 +-
graphx/src/main/scala/org/apache/spark/graphx/lib/TriangleCount.scala | 2 +-
.../org/apache/spark/deploy/k8s/SparkKubernetesClientFactory.scala| 2 +-
.../org/apache/spark/deploy/k8s/integrationtest/KubernetesSuite.scala | 4 ++--
.../deploy/k8s/integrationtest/backend/cloud/KubeConfigBackend.scala | 3 +--
.../apache/spark/sql/catalyst/expressions/higherOrderFunctions.scala | 4 ++--
.../main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala | 2 +-
.../apache/spark/sql/catalyst/analysis/AnsiTypeCoercionSuite.scala| 2 +-
.../org/apache/spark/sql/catalyst/analysis/TypeCoercionSuite.scala| 4 ++--
.../spark/sql/hive/thriftserver/ui/ThriftServerSessionPage.scala | 2 +-
.../org/apache/spark/streaming/receiver/ReceiverSupervisor.scala | 2 +-
14 files changed, 17 insertions(+), 18 deletions(-)
diff --git
a/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala
b/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala
index c82fda85eb4..a7840ef1055 100644
---
a/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala
+++
b/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala
@@ -162,7 +162,7 @@ private[kafka010] class KafkaSource(
}
override def reportLatestOffset(): streaming.Offset = {
-latestPartitionOffsets.map(KafkaSourceOffset(_)).getOrElse(null)
+latestPartitionOffsets.map(KafkaSourceOffset(_)).orNull
}
override def latestOffset(startOffset: streaming.Offset, limit: ReadLimit):
streaming.Offset = {
diff --git a/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala
b/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala
index 15707ab9157..efe31be897b 100644
--- a/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala
+++ b/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala
@@ -556,7 +556,7 @@ private[spark] abstract class BasePythonRunner[IN, OUT](
val obj = new Array[Byte](exLength)
stream.readFully(obj)
new PythonException(new String(obj, StandardCharsets.UTF_8),
-writerThread.exception.getOrElse(null))
+writerThread.exception.orNull)
}
protected def handleEndOfDataSection(): Unit = {
diff --git a/core/src/main/scala/org/apache/spark/rdd/RDD.scala
b/core/src/main/scala/org/apache/spark/rdd/RDD.scala
index c76b0d95d10..89397b8aa69 100644
--- a/core/src/main/scala/org/apache/spark/rdd/RDD.scala
+++ b/core/src/main/scala/org/apache/spark/rdd/RDD.scala
@@ -1816,7 +1816,7 @@ abstract class RDD[T: ClassTag](
*/
@Experimental
@Since("3.1.0")
- def getResourceProfile(): ResourceProfile = resourceProfile.getOrElse(null)
+ def getResourceProfile(): ResourceProfile = resourceProfile.orNull
// ===
// Other internal methods and fields
diff --git a/core/src/main/scala/org/apache/spark/util/JsonProtocol.scala
b/core/src/main/scala/org/apache/spark/util/JsonProtocol.scala
index ef5a812e4b6..0c15b13d5a1 100644
--- a/core/src/main/scala/org/apache/spark/util/JsonProtocol.scala
+++ b/core/src/main/scala/org/apache/spark/util/JsonProtocol.scala
@@ -1272,7 +1272,7 @@ private[spark] object JsonProtocol {
val properties = new Properties
mapFromJson(json).foreach { case (k, v) => properties.setProperty(k, v) }
properties
-}.getOrElse(null)
+}.orNull
}
def UUIDFromJson(json: JValue): UUID = {
diff --git
a/graphx/src/main/scala/org/apache/spark/graphx/lib/TriangleCount.scala
[spark] branch master updated: [SPARK-36718][SQL][FOLLOWUP] Improve the extract-only check in CollapseProject
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 98fad57221d [SPARK-36718][SQL][FOLLOWUP] Improve the extract-only
check in CollapseProject
98fad57221d is described below
commit 98fad57221d4dffc6f1fe28d9aca1093172ecf72
Author: Wenchen Fan
AuthorDate: Tue May 17 15:56:47 2022 +0800
[SPARK-36718][SQL][FOLLOWUP] Improve the extract-only check in
CollapseProject
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/36510 , to fix a
corner case: if the `CreateStruct` is only referenced once in non-extract
expressions, we should still allow collapsing the projects.
### Why are the changes needed?
completely fix the perf regression
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
a new test
Closes #36572 from cloud-fan/regression.
Authored-by: Wenchen Fan
Signed-off-by: Wenchen Fan
---
.../apache/spark/sql/catalyst/optimizer/Optimizer.scala | 16 +---
.../sql/catalyst/optimizer/CollapseProjectSuite.scala| 11 +++
2 files changed, 20 insertions(+), 7 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
index 9215609f154..2f93cf2d8c3 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
@@ -1008,20 +1008,22 @@ object CollapseProject extends Rule[LogicalPlan] with
AliasHelper {
val producer = producerMap.getOrElse(reference, reference)
producer.deterministic && (count == 1 || alwaysInline || {
val relatedConsumers =
consumers.filter(_.references.contains(reference))
-val extractOnly = relatedConsumers.forall(isExtractOnly(_,
reference))
+// It's still exactly-only if there is only one reference in
non-extract expressions,
+// as we won't duplicate the expensive CreateStruct-like
expressions.
+val extractOnly = relatedConsumers.map(refCountInNonExtract(_,
reference)).sum <= 1
shouldInline(producer, extractOnly)
})
}
}
- private def isExtractOnly(expr: Expression, ref: Attribute): Boolean = {
-def hasRefInNonExtractValue(e: Expression): Boolean = e match {
- case a: Attribute => a.semanticEquals(ref)
+ private def refCountInNonExtract(expr: Expression, ref: Attribute): Int = {
+def refCount(e: Expression): Int = e match {
+ case a: Attribute if a.semanticEquals(ref) => 1
// The first child of `ExtractValue` is the complex type to be extracted.
- case e: ExtractValue if e.children.head.semanticEquals(ref) => false
- case _ => e.children.exists(hasRefInNonExtractValue)
+ case e: ExtractValue if e.children.head.semanticEquals(ref) => 0
+ case _ => e.children.map(refCount).sum
}
-!hasRefInNonExtractValue(expr)
+refCount(expr)
}
/**
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
index dd075837d51..baa7c94069a 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
@@ -143,6 +143,17 @@ class CollapseProjectSuite extends PlanTest {
.select(($"a" + ($"a" + 1)).as("add"))
.analyze
comparePlans(optimized2, expected2)
+
+// referencing `CreateStruct` only once in non-extract expression is OK.
+val query3 = testRelation
+ .select(namedStruct("a", $"a", "a_plus_1", $"a" + 1).as("struct"))
+ .select($"struct", $"struct".getField("a"))
+ .analyze
+val optimized3 = Optimize.execute(query3)
+val expected3 = testRelation
+ .select(namedStruct("a", $"a", "a_plus_1", $"a" + 1).as("struct"),
$"a".as("struct.a"))
+ .analyze
+comparePlans(optimized3, expected3)
}
test("preserve top-level alias metadata while collapsing projects") {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-36718][SQL][FOLLOWUP] Improve the extract-only check in CollapseProject
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new c25624b4d0c [SPARK-36718][SQL][FOLLOWUP] Improve the extract-only
check in CollapseProject
c25624b4d0c is described below
commit c25624b4d0c2d77f0a6db7e70ecf750e9a1143f2
Author: Wenchen Fan
AuthorDate: Tue May 17 15:56:47 2022 +0800
[SPARK-36718][SQL][FOLLOWUP] Improve the extract-only check in
CollapseProject
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/36510 , to fix a
corner case: if the `CreateStruct` is only referenced once in non-extract
expressions, we should still allow collapsing the projects.
### Why are the changes needed?
completely fix the perf regression
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
a new test
Closes #36572 from cloud-fan/regression.
Authored-by: Wenchen Fan
Signed-off-by: Wenchen Fan
(cherry picked from commit 98fad57221d4dffc6f1fe28d9aca1093172ecf72)
Signed-off-by: Wenchen Fan
---
.../apache/spark/sql/catalyst/optimizer/Optimizer.scala | 16 +---
.../sql/catalyst/optimizer/CollapseProjectSuite.scala| 11 +++
2 files changed, 20 insertions(+), 7 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
index 759a7044f15..94e9d3cdd14 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
@@ -991,20 +991,22 @@ object CollapseProject extends Rule[LogicalPlan] with
AliasHelper {
val producer = producerMap.getOrElse(reference, reference)
producer.deterministic && (count == 1 || alwaysInline || {
val relatedConsumers =
consumers.filter(_.references.contains(reference))
-val extractOnly = relatedConsumers.forall(isExtractOnly(_,
reference))
+// It's still exactly-only if there is only one reference in
non-extract expressions,
+// as we won't duplicate the expensive CreateStruct-like
expressions.
+val extractOnly = relatedConsumers.map(refCountInNonExtract(_,
reference)).sum <= 1
shouldInline(producer, extractOnly)
})
}
}
- private def isExtractOnly(expr: Expression, ref: Attribute): Boolean = {
-def hasRefInNonExtractValue(e: Expression): Boolean = e match {
- case a: Attribute => a.semanticEquals(ref)
+ private def refCountInNonExtract(expr: Expression, ref: Attribute): Int = {
+def refCount(e: Expression): Int = e match {
+ case a: Attribute if a.semanticEquals(ref) => 1
// The first child of `ExtractValue` is the complex type to be extracted.
- case e: ExtractValue if e.children.head.semanticEquals(ref) => false
- case _ => e.children.exists(hasRefInNonExtractValue)
+ case e: ExtractValue if e.children.head.semanticEquals(ref) => 0
+ case _ => e.children.map(refCount).sum
}
-!hasRefInNonExtractValue(expr)
+refCount(expr)
}
/**
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
index f6c3209726b..ba5c5572e24 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/CollapseProjectSuite.scala
@@ -141,6 +141,17 @@ class CollapseProjectSuite extends PlanTest {
.select(($"a" + ($"a" + 1)).as("add"))
.analyze
comparePlans(optimized2, expected2)
+
+// referencing `CreateStruct` only once in non-extract expression is OK.
+val query3 = testRelation
+ .select(namedStruct("a", $"a", "a_plus_1", $"a" + 1).as("struct"))
+ .select($"struct", $"struct".getField("a"))
+ .analyze
+val optimized3 = Optimize.execute(query3)
+val expected3 = testRelation
+ .select(namedStruct("a", $"a", "a_plus_1", $"a" + 1).as("struct"),
$"a".as("struct.a"))
+ .analyze
+comparePlans(optimized3, expected3)
}
test("preserve top-level alias metadata while collapsing projects") {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org