[spark] branch master updated: [SPARK-39616][BUILD][ML][FOLLOWUP] Fix flaky doctests
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6f37986cc15 [SPARK-39616][BUILD][ML][FOLLOWUP] Fix flaky doctests
6f37986cc15 is described below
commit 6f37986cc155cae71957c314a7e2c7c848d94ff2
Author: Ruifeng Zheng
AuthorDate: Tue Jul 5 22:42:35 2022 -0700
[SPARK-39616][BUILD][ML][FOLLOWUP] Fix flaky doctests
### What changes were proposed in this pull request?
Skip flaky doctests
### Why are the changes needed?
```
File "/__w/spark/spark/python/pyspark/mllib/linalg/distributed.py", line
859, in __main__.IndexedRowMatrix.computeSVD
Failed example:
svd_model.V # doctest: +ELLIPSIS
Expected:
DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0)
Got:
DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, -0.0], 0)
**
File "/__w/spark/spark/python/pyspark/mllib/linalg/distributed.py", line
426, in __main__.RowMatrix.computeSVD
Failed example:
svd_model.V # doctest: +ELLIPSIS
Expected:
DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0)
Got:
DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, -0.0], 0)
**
1 of 6 in __main__.IndexedRowMatrix.computeSVD
1 of 6 in __main__.RowMatrix.computeSVD
***Test Failed*** 2 failures.
Had test failures in pyspark.mllib.linalg.distributed with python3.9; see
logs.
```
https://github.com/apache/spark/pull/37002 occasionally cause above tests
output `-0.0` instead of `0.0`, I think they are both acceptable.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
updated doctests
Closes #37097 from zhengruifeng/build_breeze_followup.
Authored-by: Ruifeng Zheng
Signed-off-by: Dongjoon Hyun
---
python/pyspark/mllib/linalg/distributed.py | 8
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/python/pyspark/mllib/linalg/distributed.py
b/python/pyspark/mllib/linalg/distributed.py
index 40a247da1e6..1a2e38f81e7 100644
--- a/python/pyspark/mllib/linalg/distributed.py
+++ b/python/pyspark/mllib/linalg/distributed.py
@@ -423,8 +423,8 @@ class RowMatrix(DistributedMatrix):
[DenseVector([-0.7071, 0.7071]), DenseVector([-0.7071, -0.7071])]
>>> svd_model.s
DenseVector([3.4641, 3.1623])
->>> svd_model.V # doctest: +ELLIPSIS
-DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0)
+>>> svd_model.V
+DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472,
...0.0], 0)
"""
j_model = self._java_matrix_wrapper.call("computeSVD", int(k),
bool(computeU), float(rCond))
return SingularValueDecomposition(j_model)
@@ -857,8 +857,8 @@ class IndexedRowMatrix(DistributedMatrix):
IndexedRow(1, [-0.707106781187,-0.707106781187])]
>>> svd_model.s
DenseVector([3.4641, 3.1623])
->>> svd_model.V # doctest: +ELLIPSIS
-DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0)
+>>> svd_model.V
+DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472,
...0.0], 0)
"""
j_model = self._java_matrix_wrapper.call("computeSVD", int(k),
bool(computeU), float(rCond))
return SingularValueDecomposition(j_model)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8adc8dd84b4 -> c1d1ec5f3bd)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 8adc8dd84b4 [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference add c1d1ec5f3bd [SPARK-39522][INFRA] Add Apache Spark infra GA image cache No new revisions were added by this update. Summary of changes: .github/workflows/build_infra_images_cache.yml | 63 ++ dev/infra/Dockerfile | 54 ++ 2 files changed, 117 insertions(+) create mode 100644 .github/workflows/build_infra_images_cache.yml create mode 100644 dev/infra/Dockerfile - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 8adc8dd84b4 [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference 8adc8dd84b4 is described below commit 8adc8dd84b4d3567efa71ad0b924bab580af8999 Author: Ruifeng Zheng AuthorDate: Wed Jul 6 08:25:38 2022 +0900 [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference ### What changes were proposed in this pull request? 1, add new methods to `catalog.rst`; 2, follow sphinx synctax `AnalysisException` -> ``:class:`AnalysisException`` ### Why are the changes needed? Make sure new catalog methods listed in API reference ### Does this PR introduce _any_ user-facing change? No, docs only ### How was this patch tested? manually doc build and check, such as 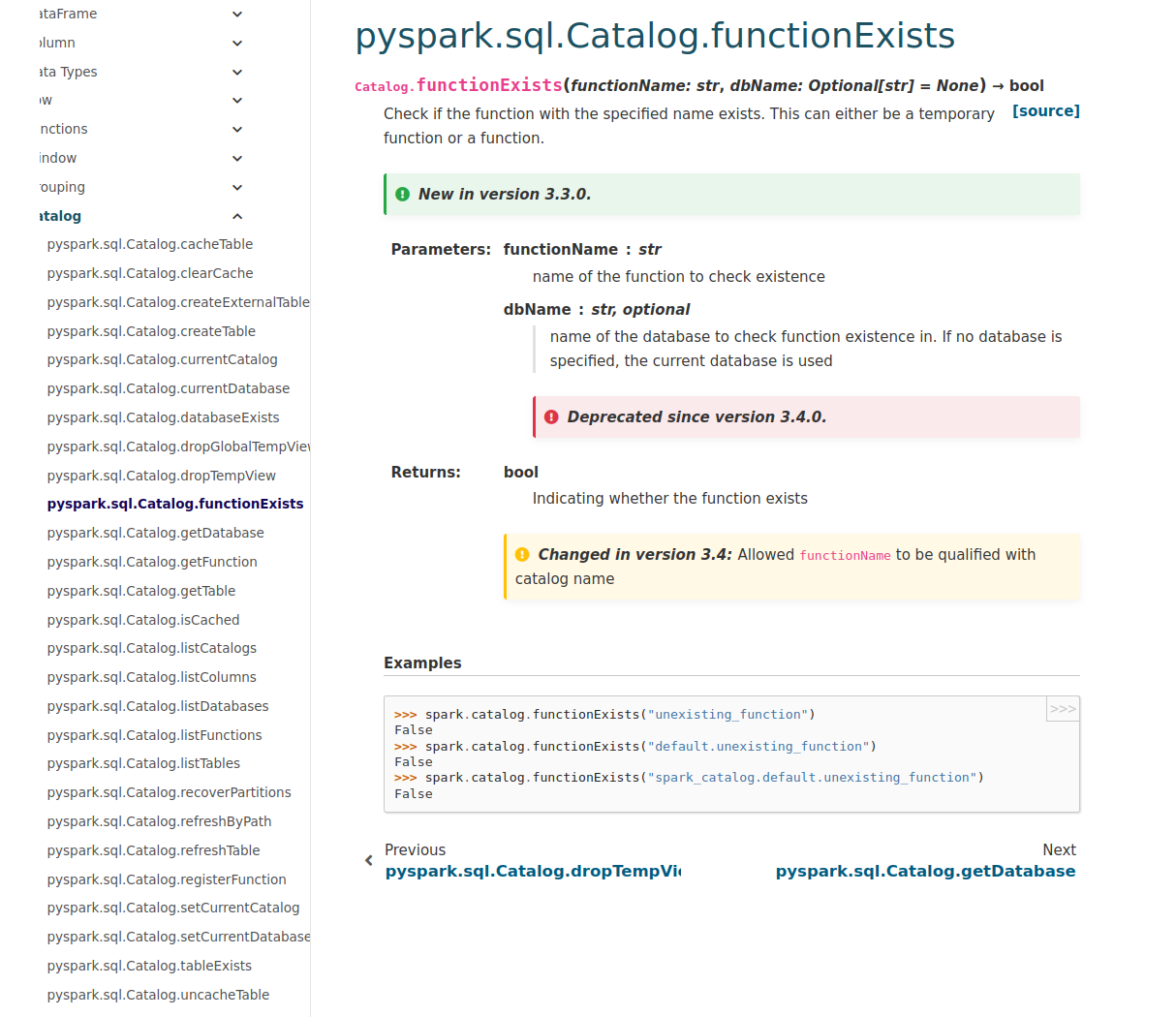 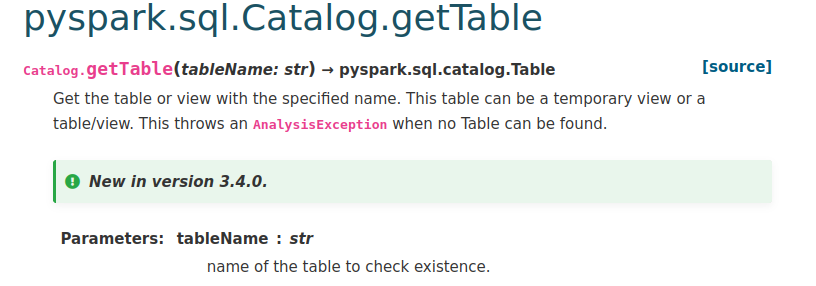 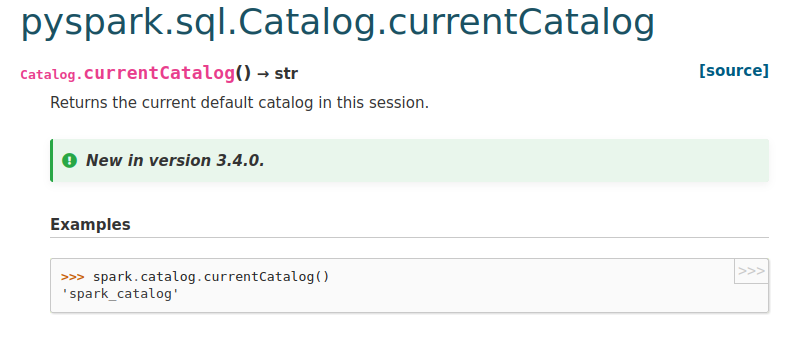 Closes #37092 from zhengruifeng/py_fix_catalog_doc. Authored-by: Ruifeng Zheng Signed-off-by: Hyukjin Kwon --- python/docs/source/reference/pyspark.sql/catalog.rst | 6 ++ python/pyspark/sql/catalog.py| 6 +++--- 2 files changed, 9 insertions(+), 3 deletions(-) diff --git a/python/docs/source/reference/pyspark.sql/catalog.rst b/python/docs/source/reference/pyspark.sql/catalog.rst index 8267e06410e..742af104dfb 100644 --- a/python/docs/source/reference/pyspark.sql/catalog.rst +++ b/python/docs/source/reference/pyspark.sql/catalog.rst @@ -29,12 +29,17 @@ Catalog Catalog.clearCache Catalog.createExternalTable Catalog.createTable +Catalog.currentCatalog Catalog.currentDatabase Catalog.databaseExists Catalog.dropGlobalTempView Catalog.dropTempView Catalog.functionExists +Catalog.getDatabase +Catalog.getFunction +Catalog.getTable Catalog.isCached +Catalog.listCatalogs Catalog.listColumns Catalog.listDatabases Catalog.listFunctions @@ -43,6 +48,7 @@ Catalog Catalog.refreshByPath Catalog.refreshTable Catalog.registerFunction +Catalog.setCurrentCatalog Catalog.setCurrentDatabase Catalog.tableExists Catalog.uncacheTable diff --git a/python/pyspark/sql/catalog.py b/python/pyspark/sql/catalog.py index 7efaf14eb82..548750d7120 100644 --- a/python/pyspark/sql/catalog.py +++ b/python/pyspark/sql/catalog.py @@ -152,7 +152,7 @@ class Catalog: def getDatabase(self, dbName: str) -> Database: """Get the database with the specified name. -This throws an AnalysisException when the database cannot be found. +This throws an :class:`AnalysisException` when the database cannot be found. .. versionadded:: 3.4.0 @@ -244,7 +244,7 @@ class Catalog: def getTable(self, tableName: str) -> Table: """Get the table or view with the specified name. This table can be a temporary view or a -table/view. This throws an AnalysisException when no Table can be found. +table/view. This throws an :class:`AnalysisException` when no Table can be found. .. versionadded:: 3.4.0 @@ -363,7 +363,7 @@ class Catalog: def getFunction(self, functionName: str) -> Function: """Get the function with the specified name. This function can be a temporary function or a -function. This throws an AnalysisException when the function cannot be found. +function. This throws an :class:`AnalysisException` when the function cannot be found. .. versionadded:: 3.4.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (79f133b7bbc -> 5cccefaf3a9)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 79f133b7bbc [SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC permission add 5cccefaf3a9 [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once No new revisions were added by this update. Summary of changes: .github/workflows/build_branch32.yml | 8 .github/workflows/build_hadoop2.yml | 4 ++-- 2 files changed, 6 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC permission
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 79f133b7bbc [SPARK-39688][K8S] `getReusablePVCs` should handle
accounts with no PVC permission
79f133b7bbc is described below
commit 79f133b7bbc1d9aa6a20dd8a34ec120902f96155
Author: Dongjoon Hyun
AuthorDate: Tue Jul 5 13:26:43 2022 -0700
[SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC
permission
### What changes were proposed in this pull request?
This PR aims to handle `KubernetesClientException` in `getReusablePVCs`
method to handle gracefully the cases where accounts has no PVC permission
including `listing`.
### Why are the changes needed?
To prevent a regression in Apache Spark 3.4.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs with the newly added test case.
Closes #37095 from dongjoon-hyun/SPARK-39688.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
---
.../cluster/k8s/ExecutorPodsAllocator.scala| 28 +-
.../cluster/k8s/ExecutorPodsAllocatorSuite.scala | 10 +++-
2 files changed, 26 insertions(+), 12 deletions(-)
diff --git
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
index 3519efd3fcb..9bdc30e4466 100644
---
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
+++
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
@@ -25,7 +25,7 @@ import scala.collection.mutable
import scala.util.control.NonFatal
import io.fabric8.kubernetes.api.model.{HasMetadata, PersistentVolumeClaim,
Pod, PodBuilder}
-import io.fabric8.kubernetes.client.KubernetesClient
+import io.fabric8.kubernetes.client.{KubernetesClient,
KubernetesClientException}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
import org.apache.spark.deploy.k8s.Config._
@@ -360,16 +360,22 @@ class ExecutorPodsAllocator(
private def getReusablePVCs(applicationId: String, pvcsInUse: Seq[String]) =
{
if (conf.get(KUBERNETES_DRIVER_OWN_PVC) &&
conf.get(KUBERNETES_DRIVER_REUSE_PVC) &&
driverPod.nonEmpty) {
- val createdPVCs = kubernetesClient
-.persistentVolumeClaims
-.withLabel("spark-app-selector", applicationId)
-.list()
-.getItems
-.asScala
-
- val reusablePVCs = createdPVCs.filterNot(pvc =>
pvcsInUse.contains(pvc.getMetadata.getName))
- logInfo(s"Found ${reusablePVCs.size} reusable PVCs from
${createdPVCs.size} PVCs")
- reusablePVCs
+ try {
+val createdPVCs = kubernetesClient
+ .persistentVolumeClaims
+ .withLabel("spark-app-selector", applicationId)
+ .list()
+ .getItems
+ .asScala
+
+val reusablePVCs = createdPVCs.filterNot(pvc =>
pvcsInUse.contains(pvc.getMetadata.getName))
+logInfo(s"Found ${reusablePVCs.size} reusable PVCs from
${createdPVCs.size} PVCs")
+reusablePVCs
+ } catch {
+case _: KubernetesClientException =>
+ logInfo("Cannot list PVC resources. Please check account
permissions.")
+ mutable.Buffer.empty[PersistentVolumeClaim]
+ }
} else {
mutable.Buffer.empty[PersistentVolumeClaim]
}
diff --git
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
index 87bd8ef3d9d..7ce0b57d1e9 100644
---
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
+++
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
@@ -20,9 +20,10 @@ import java.time.Instant
import java.util.concurrent.atomic.AtomicInteger
import scala.collection.JavaConverters._
+import scala.collection.mutable
import io.fabric8.kubernetes.api.model._
-import io.fabric8.kubernetes.client.KubernetesClient
+import io.fabric8.kubernetes.client.{KubernetesClient,
KubernetesClientException}
import io.fabric8.kubernetes.client.dsl.PodResource
import org.mockito.{Mock, MockitoAnnotations}
import org.mockito.ArgumentMatchers.{any, eq => meq}
@@ -762,6 +763,13 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
" namespace default"))
}
+ test("SPARK-39688: getReusablePVCs should
[spark] branch branch-3.3 updated (2edd344392a -> f9e3668dbb1)
This is an automated email from the ASF dual-hosted git repository. huaxingao pushed a change to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git from 2edd344392a [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ add f9e3668dbb1 [SPARK-39656][SQL][3.3] Fix wrong namespace in DescribeNamespaceExec No new revisions were added by this update. Summary of changes: .../spark/sql/execution/datasources/v2/DescribeNamespaceExec.scala | 3 ++- .../apache/spark/sql/execution/command/v2/DescribeNamespaceSuite.scala | 2 +- 2 files changed, 3 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated (3d084fe3217 -> 1c0bd4c15a2)
This is an automated email from the ASF dual-hosted git repository. huaxingao pushed a change to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git from 3d084fe3217 [SPARK-39677][SQL][DOCS][3.2] Fix args formatting of the regexp and like functions add 1c0bd4c15a2 [SPARK-39656][SQL][3.2] Fix wrong namespace in DescribeNamespaceExec No new revisions were added by this update. Summary of changes: .../spark/sql/execution/datasources/v2/DescribeNamespaceExec.scala | 3 ++- .../scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala | 6 +++--- 2 files changed, 5 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ecbfff0efe2 -> 40e00b883f8)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from ecbfff0efe2 [SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust safe.directory for container based job add 40e00b883f8 [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0 No new revisions were added by this update. Summary of changes: R/run-tests.sh | 4 ++-- dev/deps/spark-deps-hadoop-2-hive-2.3 | 8 +++- dev/deps/spark-deps-hadoop-3-hive-2.3 | 8 +++- .../regression/GeneralizedLinearRegression.scala | 1 + .../spark/ml/regression/LinearRegression.scala | 1 + .../mllib/classification/NaiveBayesSuite.scala | 1 + pom.xml| 22 +- python/pyspark/mllib/linalg/distributed.py | 4 ++-- python/run-tests.py| 3 ++- 9 files changed, 16 insertions(+), 36 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated (6ae97e26bda -> 3d084fe3217)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git from 6ae97e26bda [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ add 3d084fe3217 [SPARK-39677][SQL][DOCS][3.2] Fix args formatting of the regexp and like functions No new revisions were added by this update. Summary of changes: .../catalyst/expressions/regexpExpressions.scala | 36 -- 1 file changed, 12 insertions(+), 24 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated (cc8ab362798 -> 07f5926a6c3)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch branch-3.1 in repository https://gitbox.apache.org/repos/asf/spark.git from cc8ab362798 [SPARK-39656][SQL][3.1] Fix wrong namespace in DescribeNamespaceExec add 07f5926a6c3 [SPARK-39677][SQL][DOCS][3.1] Fix args formatting of the regexp and like functions No new revisions were added by this update. Summary of changes: .../catalyst/expressions/regexpExpressions.scala | 36 -- 1 file changed, 12 insertions(+), 24 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust safe.directory for container based job
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ecbfff0efe2 [SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust
safe.directory for container based job
ecbfff0efe2 is described below
commit ecbfff0efe2ba92068554e1434d90ec6dbec8248
Author: Yikun Jiang
AuthorDate: Tue Jul 5 20:54:07 2022 +0900
[SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust safe.directory for
container based job
### What changes were proposed in this pull request?
This patch add GITHUB_WORKSPACE to git trust safe.directory for container
based job.
There are 3 container based job in Spark Infra:
- sparkr
- lint
- pyspark
### Why are the changes needed?
When upgrade `git >= 2.35.2` (such as latest dev docker image in my case),
fix a
[CVE-2022-24765](https://github.blog/2022-04-12-git-security-vulnerability-announced/#cve-2022-24765)
, and it has been backported [latest ubuntu
git](https://github.com/actions/checkout/issues/760#issuecomment-1099355820)
The `GITHUB_WORKSPACE` is belong to action user (in host), but the
container user is `root` (in container) (root is required in our spark job), so
cause the error like:
```
fatal: unsafe repository ('/__w/spark/spark' is owned by someone else)
To add an exception for this directory, call:
git config --global --add safe.directory /__w/spark/spark
fatal: unsafe repository ('/__w/spark/spark' is owned by someone else)
To add an exception for this directory, call:
git config --global --add safe.directory /__w/spark/spark
```
The solution is from `action/checkout`
https://github.com/actions/checkout/issues/760 , just add `GITHUB_WORKSPACE` to
git trust safe.directory to make container user can checkout successfully.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
CI passed.
CI passed with latest ubuntu hosted runner, here is a simple e2e test for
pyspark job https://github.com/apache/spark/pull/37005
Closes #37079 from Yikun/SPARK-39610.
Authored-by: Yikun Jiang
Signed-off-by: Hyukjin Kwon
---
.github/workflows/build_and_test.yml | 9 +
1 file changed, 9 insertions(+)
diff --git a/.github/workflows/build_and_test.yml
b/.github/workflows/build_and_test.yml
index ef2235c3749..ca375be2777 100644
--- a/.github/workflows/build_and_test.yml
+++ b/.github/workflows/build_and_test.yml
@@ -289,6 +289,9 @@ jobs:
fetch-depth: 0
repository: apache/spark
ref: ${{ inputs.branch }}
+- name: Add GITHUB_WORKSPACE to git trust safe.directory
+ run: |
+git config --global --add safe.directory ${GITHUB_WORKSPACE}
- name: Sync the current branch with the latest in Apache Spark
if: github.repository != 'apache/spark'
run: |
@@ -374,6 +377,9 @@ jobs:
fetch-depth: 0
repository: apache/spark
ref: ${{ inputs.branch }}
+- name: Add GITHUB_WORKSPACE to git trust safe.directory
+ run: |
+git config --global --add safe.directory ${GITHUB_WORKSPACE}
- name: Sync the current branch with the latest in Apache Spark
if: github.repository != 'apache/spark'
run: |
@@ -439,6 +445,9 @@ jobs:
fetch-depth: 0
repository: apache/spark
ref: ${{ inputs.branch }}
+- name: Add GITHUB_WORKSPACE to git trust safe.directory
+ run: |
+git config --global --add safe.directory ${GITHUB_WORKSPACE}
- name: Sync the current branch with the latest in Apache Spark
if: github.repository != 'apache/spark'
run: |
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39579][PYTHON][FOLLOWUP] fix functionExists(functionName, dbName) when dbName is not None
This is an automated email from the ASF dual-hosted git repository. ruifengz pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 1100d75f53c [SPARK-39579][PYTHON][FOLLOWUP] fix functionExists(functionName, dbName) when dbName is not None 1100d75f53c is described below commit 1100d75f53c16f44dd414b8a0be477760420507d Author: Ruifeng Zheng AuthorDate: Tue Jul 5 19:53:13 2022 +0800 [SPARK-39579][PYTHON][FOLLOWUP] fix functionExists(functionName, dbName) when dbName is not None ### What changes were proposed in this pull request? fix functionExists(functionName, dbName) ### Why are the changes needed? https://github.com/apache/spark/pull/36977 introduce a bug in `functionExists(functionName, dbName)`, when dbName is not None, should call `self._jcatalog.functionExists(dbName, functionName)` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing testsuite Closes #37088 from zhengruifeng/py_3l_fix_functionExists. Authored-by: Ruifeng Zheng Signed-off-by: Ruifeng Zheng --- python/pyspark/sql/catalog.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/sql/catalog.py b/python/pyspark/sql/catalog.py index 42c040c284b..7efaf14eb82 100644 --- a/python/pyspark/sql/catalog.py +++ b/python/pyspark/sql/catalog.py @@ -359,7 +359,7 @@ class Catalog: "a future version. Use functionExists(`dbName.tableName`) instead.", FutureWarning, ) -return self._jcatalog.functionExists(self.currentDatabase(), functionName) +return self._jcatalog.functionExists(dbName, functionName) def getFunction(self, functionName: str) -> Function: """Get the function with the specified name. This function can be a temporary function or a - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new 6ae97e26bda [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ 6ae97e26bda is described below commit 6ae97e26bdaaed1c243441170d70e04cc9aa2e89 Author: Yikun Jiang AuthorDate: Tue Jul 5 20:52:36 2022 +0900 [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ ### What changes were proposed in this pull request? This PR fix the wrong aliases in `__array_ufunc__` ### Why are the changes needed? When running test with numpy 1.23.0 (current latest), hit a bug: `NotImplementedError: pandas-on-Spark objects currently do not support .` In `__array_ufunc__` we first call `maybe_dispatch_ufunc_to_dunder_op` to try dunder methods first, and then we try pyspark API. `maybe_dispatch_ufunc_to_dunder_op` is from pandas code. pandas fix a bug https://github.com/pandas-dev/pandas/pull/44822#issuecomment-991166419 https://github.com/pandas-dev/pandas/pull/44822/commits/206b2496bc6f6aa025cb26cb42f52abeec227741 when upgrade to numpy 1.23.0, we need to also sync this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Current CI passed - The exsiting UT `test_series_datetime` already cover this, I also test it in my local env with 1.23.0 ```shell pip install "numpy==1.23.0" python/run-tests --testnames 'pyspark.pandas.tests.test_series_datetime SeriesDateTimeTest.test_arithmetic_op_exceptions' ``` Closes #37078 from Yikun/SPARK-39611. Authored-by: Yikun Jiang Signed-off-by: Hyukjin Kwon (cherry picked from commit fb48a14a67940b9270390b8ce74c19ae58e2880e) Signed-off-by: Hyukjin Kwon --- python/pyspark/pandas/numpy_compat.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/numpy_compat.py b/python/pyspark/pandas/numpy_compat.py index d487a1bebf6..e6e7a681aa9 100644 --- a/python/pyspark/pandas/numpy_compat.py +++ b/python/pyspark/pandas/numpy_compat.py @@ -157,7 +157,7 @@ def maybe_dispatch_ufunc_to_dunder_op( "true_divide": "truediv", "power": "pow", "remainder": "mod", -"divide": "div", +"divide": "truediv", "equal": "eq", "not_equal": "ne", "less": "lt", - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new 2edd344392a [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ 2edd344392a is described below commit 2edd344392a5ddb44f97449b8ad3c6292eb334e3 Author: Yikun Jiang AuthorDate: Tue Jul 5 20:52:36 2022 +0900 [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ ### What changes were proposed in this pull request? This PR fix the wrong aliases in `__array_ufunc__` ### Why are the changes needed? When running test with numpy 1.23.0 (current latest), hit a bug: `NotImplementedError: pandas-on-Spark objects currently do not support .` In `__array_ufunc__` we first call `maybe_dispatch_ufunc_to_dunder_op` to try dunder methods first, and then we try pyspark API. `maybe_dispatch_ufunc_to_dunder_op` is from pandas code. pandas fix a bug https://github.com/pandas-dev/pandas/pull/44822#issuecomment-991166419 https://github.com/pandas-dev/pandas/pull/44822/commits/206b2496bc6f6aa025cb26cb42f52abeec227741 when upgrade to numpy 1.23.0, we need to also sync this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Current CI passed - The exsiting UT `test_series_datetime` already cover this, I also test it in my local env with 1.23.0 ```shell pip install "numpy==1.23.0" python/run-tests --testnames 'pyspark.pandas.tests.test_series_datetime SeriesDateTimeTest.test_arithmetic_op_exceptions' ``` Closes #37078 from Yikun/SPARK-39611. Authored-by: Yikun Jiang Signed-off-by: Hyukjin Kwon (cherry picked from commit fb48a14a67940b9270390b8ce74c19ae58e2880e) Signed-off-by: Hyukjin Kwon --- python/pyspark/pandas/numpy_compat.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/numpy_compat.py b/python/pyspark/pandas/numpy_compat.py index ea72fa658e4..f9b7bd67a9b 100644 --- a/python/pyspark/pandas/numpy_compat.py +++ b/python/pyspark/pandas/numpy_compat.py @@ -166,7 +166,7 @@ def maybe_dispatch_ufunc_to_dunder_op( "true_divide": "truediv", "power": "pow", "remainder": "mod", -"divide": "div", +"divide": "truediv", "equal": "eq", "not_equal": "ne", "less": "lt", - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new fb48a14a679 [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ fb48a14a679 is described below commit fb48a14a67940b9270390b8ce74c19ae58e2880e Author: Yikun Jiang AuthorDate: Tue Jul 5 20:52:36 2022 +0900 [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ ### What changes were proposed in this pull request? This PR fix the wrong aliases in `__array_ufunc__` ### Why are the changes needed? When running test with numpy 1.23.0 (current latest), hit a bug: `NotImplementedError: pandas-on-Spark objects currently do not support .` In `__array_ufunc__` we first call `maybe_dispatch_ufunc_to_dunder_op` to try dunder methods first, and then we try pyspark API. `maybe_dispatch_ufunc_to_dunder_op` is from pandas code. pandas fix a bug https://github.com/pandas-dev/pandas/pull/44822#issuecomment-991166419 https://github.com/pandas-dev/pandas/pull/44822/commits/206b2496bc6f6aa025cb26cb42f52abeec227741 when upgrade to numpy 1.23.0, we need to also sync this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Current CI passed - The exsiting UT `test_series_datetime` already cover this, I also test it in my local env with 1.23.0 ```shell pip install "numpy==1.23.0" python/run-tests --testnames 'pyspark.pandas.tests.test_series_datetime SeriesDateTimeTest.test_arithmetic_op_exceptions' ``` Closes #37078 from Yikun/SPARK-39611. Authored-by: Yikun Jiang Signed-off-by: Hyukjin Kwon --- python/pyspark/pandas/numpy_compat.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/numpy_compat.py b/python/pyspark/pandas/numpy_compat.py index ea72fa658e4..f9b7bd67a9b 100644 --- a/python/pyspark/pandas/numpy_compat.py +++ b/python/pyspark/pandas/numpy_compat.py @@ -166,7 +166,7 @@ def maybe_dispatch_ufunc_to_dunder_op( "true_divide": "truediv", "power": "pow", "remainder": "mod", -"divide": "div", +"divide": "truediv", "equal": "eq", "not_equal": "ne", "less": "lt", - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-39612][SQL][TESTS] DataFrame.exceptAll followed by count should work
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 364a4f52610 [SPARK-39612][SQL][TESTS] DataFrame.exceptAll followed by
count should work
364a4f52610 is described below
commit 364a4f52610fdacdefc2d16af984900c55f8e31b
Author: Hyukjin Kwon
AuthorDate: Tue Jul 5 20:44:43 2022 +0900
[SPARK-39612][SQL][TESTS] DataFrame.exceptAll followed by count should work
### What changes were proposed in this pull request?
This PR adds a test case broken by
https://github.com/apache/spark/commit/4b9343593eca780ca30ffda45244a71413577884
which was reverted in
https://github.com/apache/spark/commit/161c596cafea9c235b5c918d8999c085401d73a9.
### Why are the changes needed?
To prevent a regression in the future. This was a regression in Apache
Spark 3.3 that used to work in Apache Spark 3.2.
### Does this PR introduce _any_ user-facing change?
Yes, it makes `DataFrame.exceptAll` followed by `count` working.
### How was this patch tested?
The unit test was added.
Closes #37084 from HyukjinKwon/SPARK-39612.
Authored-by: Hyukjin Kwon
Signed-off-by: Hyukjin Kwon
(cherry picked from commit 947e271402f749f6f58b79fecd59279eaf86db57)
Signed-off-by: Hyukjin Kwon
---
sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala | 5 +
1 file changed, 5 insertions(+)
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
index 728ba3d6456..a4651c913c6 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
@@ -3215,6 +3215,11 @@ class DataFrameSuite extends QueryTest
}
}
}
+
+ test("SPARK-39612: exceptAll with following count should work") {
+val d1 = Seq("a").toDF
+assert(d1.exceptAll(d1).count() === 0)
+ }
}
case class GroupByKey(a: Int, b: Int)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39612][SQL][TESTS] DataFrame.exceptAll followed by count should work
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 947e271402f [SPARK-39612][SQL][TESTS] DataFrame.exceptAll followed by
count should work
947e271402f is described below
commit 947e271402f749f6f58b79fecd59279eaf86db57
Author: Hyukjin Kwon
AuthorDate: Tue Jul 5 20:44:43 2022 +0900
[SPARK-39612][SQL][TESTS] DataFrame.exceptAll followed by count should work
### What changes were proposed in this pull request?
This PR adds a test case broken by
https://github.com/apache/spark/commit/4b9343593eca780ca30ffda45244a71413577884
which was reverted in
https://github.com/apache/spark/commit/161c596cafea9c235b5c918d8999c085401d73a9.
### Why are the changes needed?
To prevent a regression in the future. This was a regression in Apache
Spark 3.3 that used to work in Apache Spark 3.2.
### Does this PR introduce _any_ user-facing change?
Yes, it makes `DataFrame.exceptAll` followed by `count` working.
### How was this patch tested?
The unit test was added.
Closes #37084 from HyukjinKwon/SPARK-39612.
Authored-by: Hyukjin Kwon
Signed-off-by: Hyukjin Kwon
---
sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala | 5 +
1 file changed, 5 insertions(+)
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
index 4daa0a1b3b6..41593c701a7 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala
@@ -3239,6 +3239,11 @@ class DataFrameSuite extends QueryTest
}
}
}
+
+ test("SPARK-39612: exceptAll with following count should work") {
+val d1 = Seq("a").toDF
+assert(d1.exceptAll(d1).count() === 0)
+ }
}
case class GroupByKey(a: Int, b: Int)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4e42f8b12e8 -> 12698625b7e)
This is an automated email from the ASF dual-hosted git repository. yumwang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 4e42f8b12e8 [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions add 12698625b7e [SPARK-39606][SQL] Use child stats to estimate order operator No new revisions were added by this update. Summary of changes: .../plans/logical/statsEstimation/BasicStatsPlanVisitor.scala | 4 +--- .../logical/statsEstimation/SizeInBytesOnlyStatsPlanVisitor.scala | 2 +- .../sql/catalyst/statsEstimation/BasicStatsEstimationSuite.scala | 2 +- 3 files changed, 3 insertions(+), 5 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new 2069fd03fd3 [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions 2069fd03fd3 is described below commit 2069fd03fd30faaabd1d73ca0416a76ab5908937 Author: Max Gekk AuthorDate: Tue Jul 5 13:37:41 2022 +0300 [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions ### What changes were proposed in this pull request? In the PR, I propose to fix args formatting of some regexp functions by adding explicit new lines. That fixes the following items in arg lists. Before: https://user-images.githubusercontent.com/1580697/177274234-04209d43-a542-4c71-b5ca-6f3239208015.png;> After: https://user-images.githubusercontent.com/1580697/177280718-cb05184c-8559-4461-b94d-dfaaafda7dd2.png;> ### Why are the changes needed? To improve readability of Spark SQL docs. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By building docs and checking manually: ``` $ SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 bundle exec jekyll build ``` Closes #37082 from MaxGekk/fix-regexp-docs. Authored-by: Max Gekk Signed-off-by: Max Gekk (cherry picked from commit 4e42f8b12e8dc57a15998f22d508a19cf3c856aa) Signed-off-by: Max Gekk --- .../catalyst/expressions/regexpExpressions.scala | 46 -- 1 file changed, 16 insertions(+), 30 deletions(-) diff --git a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala index 01763f082d6..e3eea6f46e2 100644 --- a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala +++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala @@ -84,16 +84,12 @@ abstract class StringRegexExpression extends BinaryExpression Arguments: * str - a string expression * pattern - a string expression. The pattern is a string which is matched literally, with - exception to the following special symbols: - - _ matches any one character in the input (similar to . in posix regular expressions) - + exception to the following special symbols: + _ matches any one character in the input (similar to . in posix regular expressions)\ % matches zero or more characters in the input (similar to .* in posix regular - expressions) - + expressions) Since Spark 2.0, string literals are unescaped in our SQL parser. For example, in order - to match "\abc", the pattern should be "\\abc". - + to match "\abc", the pattern should be "\\abc". When SQL config 'spark.sql.parser.escapedStringLiterals' is enabled, it falls back to Spark 1.6 behavior regarding string literal parsing. For example, if the config is enabled, the pattern to match "\abc" should be "\abc". @@ -189,7 +185,7 @@ case class Like(left: Expression, right: Expression, escapeChar: Char) copy(left = newLeft, right = newRight) } -// scalastyle:off line.contains.tab +// scalastyle:off line.contains.tab line.size.limit /** * Simple RegEx case-insensitive pattern matching function */ @@ -200,16 +196,12 @@ case class Like(left: Expression, right: Expression, escapeChar: Char) Arguments: * str - a string expression * pattern - a string expression. The pattern is a string which is matched literally and - case-insensitively, with exception to the following special symbols: - - _ matches any one character in the input (similar to . in posix regular expressions) - + case-insensitively, with exception to the following special symbols: + _ matches any one character in the input (similar to . in posix regular expressions) % matches zero or more characters in the input (similar to .* in posix regular - expressions) - + expressions) Since Spark 2.0, string literals are unescaped in our SQL parser. For example, in order - to match "\abc", the pattern should be "\\abc". - + to match "\abc", the pattern should be "\\abc". When SQL config 'spark.sql.parser.escapedStringLiterals' is enabled, it falls back to Spark 1.6 behavior regarding string literal parsing. For example, if the config is enabled, the pattern to match "\abc" should be "\abc". @@ -237,7 +229,7 @@ case class Like(left: Expression, right: Expression, escapeChar: Char) """, since = "3.3.0", group =
[spark] branch master updated (161c596cafe -> 4e42f8b12e8)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 161c596cafe Revert "[SPARK-38531][SQL] Fix the condition of "Prune unrequired child index" branch of ColumnPruning" add 4e42f8b12e8 [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions No new revisions were added by this update. Summary of changes: .../catalyst/expressions/regexpExpressions.scala | 46 -- 1 file changed, 16 insertions(+), 30 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: Revert "[SPARK-38531][SQL] Fix the condition of "Prune unrequired child index" branch of ColumnPruning"
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 4512e094303 Revert "[SPARK-38531][SQL] Fix the condition of "Prune
unrequired child index" branch of ColumnPruning"
4512e094303 is described below
commit 4512e0943036d30587ab19a95efb0e66b47dd746
Author: Hyukjin Kwon
AuthorDate: Tue Jul 5 18:02:37 2022 +0900
Revert "[SPARK-38531][SQL] Fix the condition of "Prune unrequired child
index" branch of ColumnPruning"
This reverts commit 17c56fc03b8e7269b293d6957c542eab9d723d52.
---
.../catalyst/optimizer/NestedColumnAliasing.scala | 19 -
.../spark/sql/catalyst/optimizer/Optimizer.scala | 15 +-
.../catalyst/optimizer/ColumnPruningSuite.scala| 32 --
3 files changed, 8 insertions(+), 58 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
index 6ba7907fdab..977e9b1ab13 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
@@ -314,25 +314,6 @@ object NestedColumnAliasing {
}
}
-object GeneratorUnrequiredChildrenPruning {
- def unapply(plan: LogicalPlan): Option[LogicalPlan] = plan match {
-case p @ Project(_, g: Generate) =>
- val requiredAttrs = p.references ++ g.generator.references
- val newChild = ColumnPruning.prunedChild(g.child, requiredAttrs)
- val unrequired = g.generator.references -- p.references
- val unrequiredIndices = newChild.output.zipWithIndex.filter(t =>
unrequired.contains(t._1))
-.map(_._2)
- if (!newChild.fastEquals(g.child) ||
-unrequiredIndices.toSet != g.unrequiredChildIndex.toSet) {
-Some(p.copy(child = g.copy(child = newChild, unrequiredChildIndex =
unrequiredIndices)))
- } else {
-None
- }
-case _ => None
- }
-}
-
-
/**
* This prunes unnecessary nested columns from [[Generate]], or [[Project]] ->
[[Generate]]
*/
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
index 02f9a9eb01c..21903976656 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
@@ -842,12 +842,13 @@ object ColumnPruning extends Rule[LogicalPlan] {
e.copy(child = prunedChild(child, e.references))
// prune unrequired references
-// There are 2 types of pruning here:
-// 1. For attributes in g.child.outputSet that is not used by the
generator nor the project,
-//we directly remove it from the output list of g.child.
-// 2. For attributes that is not used by the project but it is used by the
generator, we put
-//it in g.unrequiredChildIndex to save memory usage.
-case GeneratorUnrequiredChildrenPruning(rewrittenPlan) => rewrittenPlan
+case p @ Project(_, g: Generate) if p.references != g.outputSet =>
+ val requiredAttrs = p.references -- g.producedAttributes ++
g.generator.references
+ val newChild = prunedChild(g.child, requiredAttrs)
+ val unrequired = g.generator.references -- p.references
+ val unrequiredIndices = newChild.output.zipWithIndex.filter(t =>
unrequired.contains(t._1))
+.map(_._2)
+ p.copy(child = g.copy(child = newChild, unrequiredChildIndex =
unrequiredIndices))
// prune unrequired nested fields from `Generate`.
case GeneratorNestedColumnAliasing(rewrittenPlan) => rewrittenPlan
@@ -907,7 +908,7 @@ object ColumnPruning extends Rule[LogicalPlan] {
})
/** Applies a projection only when the child is producing unnecessary
attributes */
- def prunedChild(c: LogicalPlan, allReferences: AttributeSet): LogicalPlan =
+ private def prunedChild(c: LogicalPlan, allReferences: AttributeSet) =
if (!c.outputSet.subsetOf(allReferences)) {
Project(c.output.filter(allReferences.contains), c)
} else {
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/ColumnPruningSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/ColumnPruningSuite.scala
index 0101c855152..0655acbcb1b 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/ColumnPruningSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/ColumnPruningSuite.scala
@@ -24,7 +24,6 @@ import org.apache.spark.sql.catalyst.dsl.expressions._
import org.apache.spark.sql.catalyst.dsl.plans._
[spark] branch master updated (b37defef418 -> 161c596cafe)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from b37defef418 [SPARK-39564][SQL][FOLLOWUP] Consider the case of serde available in CatalogTable on explain string for LogicalRelation add 161c596cafe Revert "[SPARK-38531][SQL] Fix the condition of "Prune unrequired child index" branch of ColumnPruning" No new revisions were added by this update. Summary of changes: .../catalyst/optimizer/NestedColumnAliasing.scala | 19 - .../spark/sql/catalyst/optimizer/Optimizer.scala | 15 +- .../catalyst/optimizer/ColumnPruningSuite.scala| 32 -- 3 files changed, 8 insertions(+), 58 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-39564][SQL][FOLLOWUP] Consider the case of serde available in CatalogTable on explain string for LogicalRelation
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b37defef418 [SPARK-39564][SQL][FOLLOWUP] Consider the case of serde
available in CatalogTable on explain string for LogicalRelation
b37defef418 is described below
commit b37defef4183c51e64fd9629d26ca6aecd320a1b
Author: Jungtaek Lim
AuthorDate: Tue Jul 5 16:47:34 2022 +0800
[SPARK-39564][SQL][FOLLOWUP] Consider the case of serde available in
CatalogTable on explain string for LogicalRelation
### What changes were proposed in this pull request?
This PR is a follow-up of #36963.
With the change of #36963, LogicalRelation prints out the catalog table
differently in explain on logical plan. It only prints out the qualified table
name, and optionally also prints the class of serde if the information is
available.
#36963 does not account the part which can be optionally written (serde
class). While this does not break "current" tests, it would be ideal to address
the issue in prior.
This PR proposes to introduce a new internal config to exclude serde on
output of CatalogTable in SQL explain, which is intended to use only for test
e.g. SQLQueryTestSuite.
### Why are the changes needed?
It could probably be a possible bug in future, though it would be just a
test side.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UTs. The internal test failed because of this (it exposed the
serde class), and we fixed the test with this patch.
Closes #37042 from HeartSaVioR/SPARK-39564-followup.
Authored-by: Jungtaek Lim
Signed-off-by: Wenchen Fan
---
.../main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala | 6 +-
.../src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala | 3 +++
2 files changed, 8 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
index 8081a3edc81..71d8a0740bc 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
@@ -886,7 +886,11 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product with Tre
private def stringArgsForCatalogTable(table: CatalogTable): Seq[Any] = {
table.storage.serde match {
- case Some(serde) => table.identifier :: serde :: Nil
+ case Some(serde)
+// SPARK-39564: don't print out serde to avoid introducing complicated
and error-prone
+// regex magic.
+if !SQLConf.get.getConfString("spark.test.noSerdeInExplain",
"false").toBoolean =>
+table.identifier :: serde :: Nil
case _ => table.identifier :: Nil
}
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala
index 0601dce1d4b..bd48d173039 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/SQLQueryTestSuite.scala
@@ -147,6 +147,9 @@ class SQLQueryTestSuite extends QueryTest with
SharedSparkSession with SQLHelper
.set(SQLConf.SHUFFLE_PARTITIONS, 4)
// use Java 8 time API to handle negative years properly
.set(SQLConf.DATETIME_JAVA8API_ENABLED, true)
+// SPARK-39564: don't print out serde to avoid introducing complicated and
error-prone
+// regex magic.
+.set("spark.test.noSerdeInExplain", "true")
// SPARK-32106 Since we add SQL test 'transform.sql' will use `cat` command,
// here we need to ignore it.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-39676][CORE][TESTS] Add task partition id for TaskInfo assertEquals method in JsonProtocolSuite
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 3f969ada5fe [SPARK-39676][CORE][TESTS] Add task partition id for
TaskInfo assertEquals method in JsonProtocolSuite
3f969ada5fe is described below
commit 3f969ada5fecddab272f2abbc849d2591f30f44c
Author: Qian.Sun
AuthorDate: Tue Jul 5 15:40:44 2022 +0900
[SPARK-39676][CORE][TESTS] Add task partition id for TaskInfo assertEquals
method in JsonProtocolSuite
### What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/35185 , task partition id was added
in taskInfo. And, JsonProtocolSuite#assertEquals about TaskInfo doesn't have
partitionId.
### Why are the changes needed?
Should assert partitionId equals or not.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
No need to add unit test.
Closes #37081 from dcoliversun/SPARK-39676.
Authored-by: Qian.Sun
Signed-off-by: Hyukjin Kwon
---
core/src/test/scala/org/apache/spark/util/JsonProtocolSuite.scala | 2 ++
1 file changed, 2 insertions(+)
diff --git a/core/src/test/scala/org/apache/spark/util/JsonProtocolSuite.scala
b/core/src/test/scala/org/apache/spark/util/JsonProtocolSuite.scala
index 36b61f67e3b..3b7929b278e 100644
--- a/core/src/test/scala/org/apache/spark/util/JsonProtocolSuite.scala
+++ b/core/src/test/scala/org/apache/spark/util/JsonProtocolSuite.scala
@@ -790,6 +790,8 @@ private[spark] object JsonProtocolSuite extends Assertions {
assert(info1.taskId === info2.taskId)
assert(info1.index === info2.index)
assert(info1.attemptNumber === info2.attemptNumber)
+// The "Partition ID" field was added in Spark 3.3.0
+assert(info1.partitionId === info2.partitionId)
assert(info1.launchTime === info2.launchTime)
assert(info1.executorId === info2.executorId)
assert(info1.host === info2.host)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3c9b296928a -> 863c945b707)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 3c9b296928a [SPARK-39453][SQL][TESTS][FOLLOWUP] Let `RAND` in filter is more meaningful add 863c945b707 [SPARK-39676][CORE][TESTS] Add task partition id for TaskInfo assertEquals method in JsonProtocolSuite No new revisions were added by this update. Summary of changes: core/src/test/scala/org/apache/spark/util/JsonProtocolSuite.scala | 2 ++ 1 file changed, 2 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org