[spark] branch master updated (37453ad5c85 -> e27fe82b450)
This is an automated email from the ASF dual-hosted git repository. ruifengz pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 37453ad5c85 [SPARK-41369][CONNECT][BUILD][FOLLOW-UP] Update connect server module name add e27fe82b450 [SPARK-41381][CONNECT][PYTHON] Implement `count_distinct` and `sum_distinct` functions No new revisions were added by this update. Summary of changes: .../main/protobuf/spark/connect/expressions.proto | 5 +- .../sql/connect/planner/SparkConnectPlanner.scala | 4 +- python/pyspark/sql/connect/column.py | 10 +- python/pyspark/sql/connect/functions.py| 140 ++--- .../pyspark/sql/connect/proto/expressions_pb2.py | 18 +-- .../pyspark/sql/connect/proto/expressions_pb2.pyi | 6 + .../sql/tests/connect/test_connect_function.py | 19 ++- 7 files changed, 116 insertions(+), 86 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d9c7908f348 -> 37453ad5c85)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from d9c7908f348 [SPARK-41397][CONNECT][PYTHON] Implement part of string/binary functions add 37453ad5c85 [SPARK-41369][CONNECT][BUILD][FOLLOW-UP] Update connect server module name No new revisions were added by this update. Summary of changes: connector/connect/server/pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41397][CONNECT][PYTHON] Implement part of string/binary functions
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d9c7908f348 [SPARK-41397][CONNECT][PYTHON] Implement part of
string/binary functions
d9c7908f348 is described below
commit d9c7908f348fa7771182dca49fa032f6d1b689be
Author: Xinrong Meng
AuthorDate: Wed Dec 7 12:06:57 2022 +0800
[SPARK-41397][CONNECT][PYTHON] Implement part of string/binary functions
### What changes were proposed in this pull request?
Implement the first half of string/binary functions. The rest of the
string/binary functions will be implemented in a separate PR for easier review.
### Why are the changes needed?
For API coverage on Spark Connect.
### Does this PR introduce _any_ user-facing change?
Yes. New functions are available on Spark Connect.
### How was this patch tested?
Unit tests.
Closes #38921 from xinrong-meng/connect_func_string.
Authored-by: Xinrong Meng
Signed-off-by: Ruifeng Zheng
---
python/pyspark/sql/connect/functions.py| 346 +
.../sql/tests/connect/test_connect_function.py | 61
2 files changed, 407 insertions(+)
diff --git a/python/pyspark/sql/connect/functions.py
b/python/pyspark/sql/connect/functions.py
index b576a092f99..e57ffd10462 100644
--- a/python/pyspark/sql/connect/functions.py
+++ b/python/pyspark/sql/connect/functions.py
@@ -3208,3 +3208,349 @@ def variance(col: "ColumnOrName") -> Column:
++
"""
return var_samp(col)
+
+
+# String/Binary functions
+
+
+def upper(col: "ColumnOrName") -> Column:
+"""
+Converts a string expression to upper case.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+col : :class:`~pyspark.sql.Column` or str
+target column to work on.
+
+Returns
+---
+:class:`~pyspark.sql.Column`
+upper case values.
+
+Examples
+
+>>> df = spark.createDataFrame(["Spark", "PySpark", "Pandas API"],
"STRING")
+>>> df.select(upper("value")).show()
+++
+|upper(value)|
+++
+| SPARK|
+| PYSPARK|
+| PANDAS API|
+++
+"""
+return _invoke_function_over_columns("upper", col)
+
+
+def lower(col: "ColumnOrName") -> Column:
+"""
+Converts a string expression to lower case.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+col : :class:`~pyspark.sql.Column` or str
+target column to work on.
+
+Returns
+---
+:class:`~pyspark.sql.Column`
+lower case values.
+
+Examples
+
+>>> df = spark.createDataFrame(["Spark", "PySpark", "Pandas API"],
"STRING")
+>>> df.select(lower("value")).show()
+++
+|lower(value)|
+++
+| spark|
+| pyspark|
+| pandas api|
+++
+"""
+return _invoke_function_over_columns("lower", col)
+
+
+def ascii(col: "ColumnOrName") -> Column:
+"""
+Computes the numeric value of the first character of the string column.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+col : :class:`~pyspark.sql.Column` or str
+target column to work on.
+
+Returns
+---
+:class:`~pyspark.sql.Column`
+numeric value.
+
+Examples
+
+>>> df = spark.createDataFrame(["Spark", "PySpark", "Pandas API"],
"STRING")
+>>> df.select(ascii("value")).show()
+++
+|ascii(value)|
+++
+| 83|
+| 80|
+| 80|
+++
+"""
+return _invoke_function_over_columns("ascii", col)
+
+
+def base64(col: "ColumnOrName") -> Column:
+"""
+Computes the BASE64 encoding of a binary column and returns it as a string
column.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+col : :class:`~pyspark.sql.Column` or str
+target column to work on.
+
+Returns
+---
+:class:`~pyspark.sql.Column`
+BASE64 encoding of string value.
+
+Examples
+
+>>> df = spark.createDataFrame(["Spark", "PySpark", "Pandas API"],
"STRING")
+>>> df.select(base64("value")).show()
+++
+| base64(value)|
+++
+|U3Bhcms=|
+|UHlTcGFyaw==|
+|UGFuZGFzIEFQSQ==|
+++
+"""
+return _invoke_function_over_columns("base64", col)
+
+
+def unbase64(col: "ColumnOrName") -> Column:
+"""
+Decodes a BASE64 encoded string column and returns it as a binary column.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+col : :class:`~pyspark.sql.Column` or str
+target column to work on.
+
+Returns
+---
+:class:`~pyspark.sql.Column`
+
[spark] branch master updated (65d46f7e400 -> 47ef8fc831c)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 65d46f7e400 [SPARK-41382][CONNECT][PYTHON] Implement `product` function add 47ef8fc831c [SPARK-41410][K8S][FOLLOWUP] Remove PVC_COUNTER decrement No new revisions were added by this update. Summary of changes: .../cluster/k8s/ExecutorPodsAllocator.scala| 1 - .../cluster/k8s/ExecutorPodsAllocatorSuite.scala | 41 ++ 2 files changed, 41 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41382][CONNECT][PYTHON] Implement `product` function
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 65d46f7e400 [SPARK-41382][CONNECT][PYTHON] Implement `product` function
65d46f7e400 is described below
commit 65d46f7e4000fba514878287f5218dc93961c999
Author: Ruifeng Zheng
AuthorDate: Wed Dec 7 11:41:46 2022 +0800
[SPARK-41382][CONNECT][PYTHON] Implement `product` function
### What changes were proposed in this pull request?
Implement `product` function
### Why are the changes needed?
for API coverage
### Does this PR introduce _any_ user-facing change?
new API
### How was this patch tested?
added test
Closes #38915 from zhengruifeng/connect_function_product.
Authored-by: Ruifeng Zheng
Signed-off-by: Ruifeng Zheng
---
.../sql/connect/planner/SparkConnectPlanner.scala | 27 +-
python/pyspark/sql/connect/functions.py| 61 +++---
.../sql/tests/connect/test_connect_function.py | 1 +
3 files changed, 56 insertions(+), 33 deletions(-)
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index 2a9f4260ff2..20cf68c3c08 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -406,7 +406,8 @@ class SparkConnectPlanner(session: SparkSession) {
case proto.Expression.ExprTypeCase.UNRESOLVED_ATTRIBUTE =>
transformUnresolvedExpression(exp)
case proto.Expression.ExprTypeCase.UNRESOLVED_FUNCTION =>
-transformScalarFunction(exp.getUnresolvedFunction)
+transformUnregisteredFunction(exp.getUnresolvedFunction)
+ .getOrElse(transformUnresolvedFunction(exp.getUnresolvedFunction))
case proto.Expression.ExprTypeCase.ALIAS => transformAlias(exp.getAlias)
case proto.Expression.ExprTypeCase.EXPRESSION_STRING =>
transformExpressionString(exp.getExpressionString)
@@ -538,7 +539,8 @@ class SparkConnectPlanner(session: SparkSession) {
* Proto representation of the function call.
* @return
*/
- private def transformScalarFunction(fun:
proto.Expression.UnresolvedFunction): Expression = {
+ private def transformUnresolvedFunction(
+ fun: proto.Expression.UnresolvedFunction): Expression = {
if (fun.getIsUserDefinedFunction) {
UnresolvedFunction(
session.sessionState.sqlParser.parseFunctionIdentifier(fun.getFunctionName),
@@ -552,6 +554,27 @@ class SparkConnectPlanner(session: SparkSession) {
}
}
+ /**
+ * For some reason, not all functions are registered in 'FunctionRegistry'.
For a unregistered
+ * function, we can still wrap it under the proto 'UnresolvedFunction', and
then resolve it in
+ * this method.
+ */
+ private def transformUnregisteredFunction(
+ fun: proto.Expression.UnresolvedFunction): Option[Expression] = {
+fun.getFunctionName match {
+ case "product" =>
+if (fun.getArgumentsCount != 1) {
+ throw InvalidPlanInput("Product requires single child expression")
+}
+Some(
+ aggregate
+.Product(transformExpression(fun.getArgumentsList.asScala.head))
+.toAggregateExpression())
+
+ case _ => None
+}
+ }
+
private def transformAlias(alias: proto.Expression.Alias): NamedExpression =
{
if (alias.getNameCount == 1) {
val md = if (alias.hasMetadata()) {
diff --git a/python/pyspark/sql/connect/functions.py
b/python/pyspark/sql/connect/functions.py
index a52fc58fd0a..b576a092f99 100644
--- a/python/pyspark/sql/connect/functions.py
+++ b/python/pyspark/sql/connect/functions.py
@@ -2920,37 +2920,36 @@ def percentile_approx(
return _invoke_function("percentile_approx", _to_col(col), percentage_col,
lit(accuracy))
-# TODO(SPARK-41382): add product in FunctionRegistry?
-# def product(col: "ColumnOrName") -> Column:
-# """
-# Aggregate function: returns the product of the values in a group.
-#
-# .. versionadded:: 3.4.0
-#
-# Parameters
-# --
-# col : str, :class:`Column`
-# column containing values to be multiplied together
-#
-# Returns
-# ---
-# :class:`~pyspark.sql.Column`
-# the column for computed results.
-#
-# Examples
-#
-# >>> df = spark.range(1, 10).toDF('x').withColumn('mod3', col('x') % 3)
-# >>> prods = df.groupBy('mod3').agg(product('x').alias('product'))
-# >>> prods.orderBy('mod3').show()
-# ++---+
-# |mod3|product|
-# ++---+
-# | 0| 162.0|
-#
[spark] branch master updated (30957a992ed -> ec8952747d3)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 30957a992ed [SPARK-41366][CONNECT] DF.groupby.agg() should be compatible add ec8952747d3 [SPARK-41369][CONNECT] Add connect common to servers' shaded jar No new revisions were added by this update. Summary of changes: connector/connect/server/pom.xml | 1 + 1 file changed, 1 insertion(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (e58f12d1843 -> 30957a992ed)
This is an automated email from the ASF dual-hosted git repository. hvanhovell pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from e58f12d1843 [SPARK-41411][SS] Multi-Stateful Operator watermark support bug fix add 30957a992ed [SPARK-41366][CONNECT] DF.groupby.agg() should be compatible No new revisions were added by this update. Summary of changes: .../sql/connect/planner/SparkConnectPlanner.scala | 2 +- python/pyspark/sql/connect/column.py | 4 + python/pyspark/sql/connect/dataframe.py| 109 +++-- .../sql/tests/connect/test_connect_basic.py| 22 + .../sql/tests/connect/test_connect_function.py | 8 +- 5 files changed, 130 insertions(+), 15 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41411][SS] Multi-Stateful Operator watermark support bug fix
This is an automated email from the ASF dual-hosted git repository. kabhwan pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new e58f12d1843 [SPARK-41411][SS] Multi-Stateful Operator watermark support bug fix e58f12d1843 is described below commit e58f12d1843af39ed4ac0c2ff108490ae303e7e4 Author: Wei Liu AuthorDate: Wed Dec 7 08:35:21 2022 +0900 [SPARK-41411][SS] Multi-Stateful Operator watermark support bug fix ### What changes were proposed in this pull request? Fix a typo in passing event time watermark to`StreamingSymmetricHashJoinExec` that causes logic errors. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing unit tests. Closes #38945 from WweiL/multi-stateful-ops-fix. Authored-by: Wei Liu Signed-off-by: Jungtaek Lim --- .../org/apache/spark/sql/execution/streaming/IncrementalExecution.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/IncrementalExecution.scala b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/IncrementalExecution.scala index 574709d05b0..e5e4dc7d0dc 100644 --- a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/IncrementalExecution.scala +++ b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/IncrementalExecution.scala @@ -242,7 +242,7 @@ class IncrementalExecution( j.copy( stateInfo = Some(nextStatefulOperationStateInfo), eventTimeWatermarkForLateEvents = Some(eventTimeWatermarkForLateEvents), - eventTimeWatermarkForEviction = Some(eventTimeWatermarkForLateEvents), + eventTimeWatermarkForEviction = Some(eventTimeWatermarkForEviction), stateWatermarkPredicates = StreamingSymmetricHashJoinHelper.getStateWatermarkPredicates( j.left.output, j.right.output, j.leftKeys, j.rightKeys, j.condition.full, - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ad503ca70ac -> cc55de33420)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from ad503ca70ac [SPARK-41369][CONNECT][BUILD] Split connect project into common and server projects add cc55de33420 [SPARK-41410][K8S] Support PVC-oriented executor pod allocation No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/deploy/k8s/Config.scala | 14 +++- .../cluster/k8s/ExecutorPodsAllocator.scala| 20 +- .../cluster/k8s/ExecutorPodsAllocatorSuite.scala | 75 +- 3 files changed, 105 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41369][CONNECT][BUILD] Split connect project into common and server projects
This is an automated email from the ASF dual-hosted git repository.
hvanhovell pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ad503ca70ac [SPARK-41369][CONNECT][BUILD] Split connect project into
common and server projects
ad503ca70ac is described below
commit ad503ca70acd3d5e3d815efac6f675b14797ded1
Author: vicennial
AuthorDate: Tue Dec 6 17:06:31 2022 -0400
[SPARK-41369][CONNECT][BUILD] Split connect project into common and server
projects
### What changes were proposed in this pull request?
We split the current `connector/connect` project into two projects:
- `connector/connect/common`: this contains the proto definitions, and
build targets for proto buf related code generation. In the future this can
also contain utilities that are shared between the server and the client.
- `connector/connect/server`: this contains the code for the connect server
and plugin (all the current scala code). This includes the dsl because it is
used for server related tests. In the future we might replace the DSL by the
scala client.
### Why are the changes needed?
In preparation for the Spark Connect Scala Client we need to split the
server and the proto files. This, together with another refactoring in
Catalyst, will allow us to create a client with a minimal set of dependencies.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes #38944 from hvanhovell/refactorConnect-finalShade.
Lead-authored-by: vicennial
Co-authored-by: Herman van Hovell
Signed-off-by: Herman van Hovell
---
connector/connect/common/pom.xml | 225 +
.../connect/{ => common}/src/main/buf.gen.yaml | 0
.../connect/{ => common}/src/main/buf.work.yaml| 0
.../{ => common}/src/main/protobuf/buf.yaml| 0
.../src/main/protobuf/spark/connect/base.proto | 0
.../src/main/protobuf/spark/connect/commands.proto | 0
.../main/protobuf/spark/connect/expressions.proto | 0
.../main/protobuf/spark/connect/relations.proto| 0
.../src/main/protobuf/spark/connect/types.proto| 0
connector/connect/dev/generate_protos.sh | 2 +-
connector/connect/{ => server}/pom.xml | 85 ++--
.../spark/sql/connect/SparkConnectPlugin.scala | 0
.../apache/spark/sql/connect/config/Connect.scala | 0
.../org/apache/spark/sql/connect/dsl/package.scala | 0
.../connect/planner/DataTypeProtoConverter.scala | 0
.../sql/connect/planner/SparkConnectPlanner.scala | 0
.../service/SparkConnectInterceptorRegistry.scala | 0
.../sql/connect/service/SparkConnectService.scala | 0
.../service/SparkConnectStreamHandler.scala| 0
.../src/test/resources/log4j2.properties | 0
.../messages/ConnectProtoMessagesSuite.scala | 0
.../connect/planner/SparkConnectPlannerSuite.scala | 0
.../connect/planner/SparkConnectProtoSuite.scala | 0
.../connect/planner/SparkConnectServiceSuite.scala | 0
.../connect/service/InterceptorRegistrySuite.scala | 0
pom.xml| 3 +-
project/SparkBuild.scala | 114 ---
python/pyspark/testing/connectutils.py | 2 +-
28 files changed, 332 insertions(+), 99 deletions(-)
diff --git a/connector/connect/common/pom.xml b/connector/connect/common/pom.xml
new file mode 100644
index 000..555afd5bc44
--- /dev/null
+++ b/connector/connect/common/pom.xml
@@ -0,0 +1,225 @@
+
+
+
+http://maven.apache.org/POM/4.0.0;
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance;
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd;>
+4.0.0
+
+org.apache.spark
+spark-parent_2.12
+3.4.0-SNAPSHOT
+../../../pom.xml
+
+
+spark-connect-common_2.12
+jar
+Spark Project Connect Common
+https://spark.apache.org/
+
+connect-common
+31.0.1-jre
+1.0.1
+1.47.0
+6.0.53
+
+
+
+org.scala-lang
+scala-library
+
+
+com.google.guava
+guava
+${guava.version}
+compile
+
+
+com.google.guava
+failureaccess
+${guava.failureaccess.version}
+
+
+com.google.protobuf
+protobuf-java
+${protobuf.version}
+compile
+
+
+io.grpc
+grpc-netty
+${io.grpc.version}
+
+
+io.grpc
+grpc-protobuf
+${io.grpc.version}
+
+
+io.grpc
+grpc-services
+${io.grpc.version}
[GitHub] [spark-website] dongjoon-hyun commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
dongjoon-hyun commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339756003 Thank you, @bjornjorgensen and @srowen ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339751699 Merged to asf-site -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 402123288 Change download text for spark 3.2.3. from Apache Hadoop 3.3
to Apache Hadoop 3.2
402123288 is described below
commit 402123288523e823ad080188fd906dfcbe1b8bc4
Author: Bjørn Jørgensen
AuthorDate: Tue Dec 6 11:50:20 2022 -0600
Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache
Hadoop 3.2
This is only for Apache Spark 3.2.3
Change Apache Hadoop 3.3 to Apache Hadoop 3.2
I have not
Make sure that you generate site HTML with `bundle exec jekyll build`, and
include the changes to the HTML in your pull request. See README.md for more
information.
Author: Bjørn Jørgensen
Author: Bjørn
Closes #429 from bjornjorgensen/patch-1.
---
js/downloads.js | 4 ++--
site/js/downloads.js | 4 ++--
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/js/downloads.js b/js/downloads.js
index 6b6c0e570..4b1ed14ef 100644
--- a/js/downloads.js
+++ b/js/downloads.js
@@ -14,8 +14,8 @@ function addRelease(version, releaseDate, packages, mirrored)
{
var sources = {pretty: "Source Code", tag: "sources"};
var hadoopFree = {pretty: "Pre-built with user-provided Apache Hadoop", tag:
"without-hadoop"};
var hadoop2p7 = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2.7"};
-var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3.2"};
-var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3.2-scala2.13"};
+var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.2 and later", tag:
"hadoop3.2"};
+var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.2 and later
(Scala 2.13)", tag: "hadoop3.2-scala2.13"};
var hadoop2p = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2"};
var hadoop3p = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3"};
var hadoop3pscala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3-scala2.13"};
diff --git a/site/js/downloads.js b/site/js/downloads.js
index 6b6c0e570..4b1ed14ef 100644
--- a/site/js/downloads.js
+++ b/site/js/downloads.js
@@ -14,8 +14,8 @@ function addRelease(version, releaseDate, packages, mirrored)
{
var sources = {pretty: "Source Code", tag: "sources"};
var hadoopFree = {pretty: "Pre-built with user-provided Apache Hadoop", tag:
"without-hadoop"};
var hadoop2p7 = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2.7"};
-var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3.2"};
-var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3.2-scala2.13"};
+var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.2 and later", tag:
"hadoop3.2"};
+var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.2 and later
(Scala 2.13)", tag: "hadoop3.2-scala2.13"};
var hadoop2p = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2"};
var hadoop3p = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3"};
var hadoop3pscala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3-scala2.13"};
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen closed pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen closed pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2 URL: https://github.com/apache/spark-website/pull/429 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] bjornjorgensen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339726712 Now it looks like this 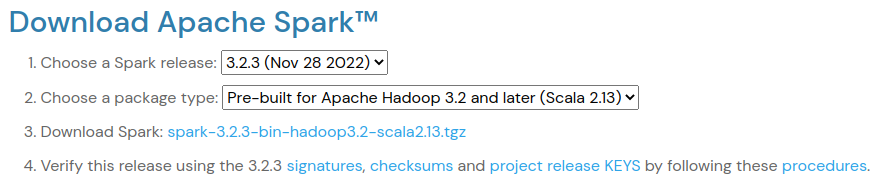 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41393][BUILD] Upgrade slf4j to 2.0.5
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 89b2ee27d25 [SPARK-41393][BUILD] Upgrade slf4j to 2.0.5 89b2ee27d25 is described below commit 89b2ee27d258dec8fe265fa862846e800a374d8e Author: yangjie01 AuthorDate: Tue Dec 6 07:57:39 2022 -0800 [SPARK-41393][BUILD] Upgrade slf4j to 2.0.5 ### What changes were proposed in this pull request? This pr aims upgrade slf4j related dependencies from 2.0.4 to 2.0.5. ### Why are the changes needed? A version add SecurityManager support: - [add SecurityManager support ](https://github.com/qos-ch/slf4j/commit/3bc58f3e81cfbe5ef9011c5124c0bd13dceee3a9) The release notes as follows: - https://www.slf4j.org/news.html#2.0.5 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA Closes #38918 from LuciferYang/SPARK-41393. Authored-by: yangjie01 Signed-off-by: Dongjoon Hyun --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 6 +++--- dev/deps/spark-deps-hadoop-3-hive-2.3 | 6 +++--- pom.xml | 2 +- 3 files changed, 7 insertions(+), 7 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index c65b32ffecb..ad7a8a1a4c6 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -134,7 +134,7 @@ javax.jdo/3.2.0-m3//javax.jdo-3.2.0-m3.jar javolution/5.5.1//javolution-5.5.1.jar jaxb-api/2.2.11//jaxb-api-2.2.11.jar jaxb-runtime/2.3.2//jaxb-runtime-2.3.2.jar -jcl-over-slf4j/2.0.4//jcl-over-slf4j-2.0.4.jar +jcl-over-slf4j/2.0.5//jcl-over-slf4j-2.0.5.jar jdo-api/3.0.1//jdo-api-3.0.1.jar jersey-client/2.36//jersey-client-2.36.jar jersey-common/2.36//jersey-common-2.36.jar @@ -158,7 +158,7 @@ json4s-scalap_2.12/3.7.0-M11//json4s-scalap_2.12-3.7.0-M11.jar jsp-api/2.1//jsp-api-2.1.jar jsr305/3.0.0//jsr305-3.0.0.jar jta/1.1//jta-1.1.jar -jul-to-slf4j/2.0.4//jul-to-slf4j-2.0.4.jar +jul-to-slf4j/2.0.5//jul-to-slf4j-2.0.5.jar kryo-shaded/4.0.2//kryo-shaded-4.0.2.jar kubernetes-client-api/6.2.0//kubernetes-client-api-6.2.0.jar kubernetes-client/6.2.0//kubernetes-client-6.2.0.jar @@ -247,7 +247,7 @@ scala-parser-combinators_2.12/2.1.1//scala-parser-combinators_2.12-2.1.1.jar scala-reflect/2.12.17//scala-reflect-2.12.17.jar scala-xml_2.12/2.1.0//scala-xml_2.12-2.1.0.jar shims/0.9.35//shims-0.9.35.jar -slf4j-api/2.0.4//slf4j-api-2.0.4.jar +slf4j-api/2.0.5//slf4j-api-2.0.5.jar snakeyaml/1.33//snakeyaml-1.33.jar snappy-java/1.1.8.4//snappy-java-1.1.8.4.jar spire-macros_2.12/0.17.0//spire-macros_2.12-0.17.0.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index 7958d623c2b..cac2e9f3056 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -119,7 +119,7 @@ javax.jdo/3.2.0-m3//javax.jdo-3.2.0-m3.jar javolution/5.5.1//javolution-5.5.1.jar jaxb-api/2.2.11//jaxb-api-2.2.11.jar jaxb-runtime/2.3.2//jaxb-runtime-2.3.2.jar -jcl-over-slf4j/2.0.4//jcl-over-slf4j-2.0.4.jar +jcl-over-slf4j/2.0.5//jcl-over-slf4j-2.0.5.jar jdo-api/3.0.1//jdo-api-3.0.1.jar jdom2/2.0.6//jdom2-2.0.6.jar jersey-client/2.36//jersey-client-2.36.jar @@ -142,7 +142,7 @@ json4s-jackson_2.12/3.7.0-M11//json4s-jackson_2.12-3.7.0-M11.jar json4s-scalap_2.12/3.7.0-M11//json4s-scalap_2.12-3.7.0-M11.jar jsr305/3.0.0//jsr305-3.0.0.jar jta/1.1//jta-1.1.jar -jul-to-slf4j/2.0.4//jul-to-slf4j-2.0.4.jar +jul-to-slf4j/2.0.5//jul-to-slf4j-2.0.5.jar kryo-shaded/4.0.2//kryo-shaded-4.0.2.jar kubernetes-client-api/6.2.0//kubernetes-client-api-6.2.0.jar kubernetes-client/6.2.0//kubernetes-client-6.2.0.jar @@ -234,7 +234,7 @@ scala-parser-combinators_2.12/2.1.1//scala-parser-combinators_2.12-2.1.1.jar scala-reflect/2.12.17//scala-reflect-2.12.17.jar scala-xml_2.12/2.1.0//scala-xml_2.12-2.1.0.jar shims/0.9.35//shims-0.9.35.jar -slf4j-api/2.0.4//slf4j-api-2.0.4.jar +slf4j-api/2.0.5//slf4j-api-2.0.5.jar snakeyaml/1.33//snakeyaml-1.33.jar snappy-java/1.1.8.4//snappy-java-1.1.8.4.jar spire-macros_2.12/0.17.0//spire-macros_2.12-0.17.0.jar diff --git a/pom.xml b/pom.xml index f878d8bb36b..9e56560cd74 100644 --- a/pom.xml +++ b/pom.xml @@ -114,7 +114,7 @@ 3.8.6 1.6.0 spark -2.0.4 +2.0.5 2.19.0 3.3.4 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41398][SQL] Relax constraints on Storage-Partitioned Join when partition keys after runtime filtering do not match
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 92fea74fda1 [SPARK-41398][SQL] Relax constraints on
Storage-Partitioned Join when partition keys after runtime filtering do not
match
92fea74fda1 is described below
commit 92fea74fda1f2f764f6fc38c82eb2dff7972ad87
Author: Chao Sun
AuthorDate: Tue Dec 6 07:48:34 2022 -0800
[SPARK-41398][SQL] Relax constraints on Storage-Partitioned Join when
partition keys after runtime filtering do not match
### What changes were proposed in this pull request?
This PR relaxes the current constraint of Storage-Partitioned Join which
requires that the partition keys after runtime filtering to be exact the same
as the partition keys before the filtering.
### Why are the changes needed?
At the moment, Spark requires that when Storage-Partitioned Join is used
together with runtime filtering, the partition keys before and after the
filtering shall exact match. If not, a `SparkException` is thrown.
However, this is not strictly necessary in the case where the partition
keys after the filtering is a subset of the original keys. In this scenario, we
can use empty partitions for those missing keys in the latter.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Modified an existing test case to match the change.
Closes #38924 from sunchao/SPARK-41398.
Authored-by: Chao Sun
Signed-off-by: Dongjoon Hyun
---
.../execution/datasources/v2/BatchScanExec.scala | 36 --
.../connector/KeyGroupedPartitioningSuite.scala| 6 ++--
2 files changed, 29 insertions(+), 13 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/BatchScanExec.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/BatchScanExec.scala
index 48569ddc07d..0f7bdd9e1fb 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/BatchScanExec.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/BatchScanExec.scala
@@ -81,18 +81,21 @@ case class BatchScanExec(
val newRows = new InternalRowSet(p.expressions.map(_.dataType))
newRows ++=
newPartitions.map(_.asInstanceOf[HasPartitionKey].partitionKey())
- val oldRows = p.partitionValuesOpt.get
- if (oldRows.size != newRows.size) {
-throw new SparkException("Data source must have preserved the
original partitioning " +
-"during runtime filtering: the number of unique partition
values obtained " +
-s"through HasPartitionKey changed: before ${oldRows.size},
after ${newRows.size}")
+ val oldRows = p.partitionValuesOpt.get.toSet
+ // We require the new number of partition keys to be equal or less
than the old number
+ // of partition keys here. In the case of less than, empty
partitions will be added for
+ // those missing keys that are not present in the new input
partitions.
+ if (oldRows.size < newRows.size) {
+throw new SparkException("During runtime filtering, data source
must either report " +
+"the same number of partition keys, or a subset of partition
keys from the " +
+s"original. Before: ${oldRows.size} partition keys. After:
${newRows.size} " +
+"partition keys")
}
- if (!oldRows.forall(newRows.contains)) {
-throw new SparkException("Data source must have preserved the
original partitioning " +
-"during runtime filtering: the number of unique partition
values obtained " +
-s"through HasPartitionKey remain the same but do not exactly
match")
+ if (!newRows.forall(oldRows.contains)) {
+throw new SparkException("During runtime filtering, data source
must not report new " +
+"partition keys that are not present in the original
partitioning.")
}
groupPartitions(newPartitions).get.map(_._2)
@@ -114,8 +117,21 @@ case class BatchScanExec(
// return an empty RDD with 1 partition if dynamic filtering removed the
only split
sparkContext.parallelize(Array.empty[InternalRow], 1)
} else {
+ var finalPartitions = filteredPartitions
+
+ outputPartitioning match {
+case p: KeyGroupedPartitioning =>
+ val partitionMapping = finalPartitions.map(s =>
+s.head.asInstanceOf[HasPartitionKey].partitionKey() -> s).toMap
+ finalPartitions = p.partitionValuesOpt.get.map { partKey =>
+// Use empty partition for those partition keys that are not
present
+
[GitHub] [spark-website] srowen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339528551 Or frankly just make the same edit to both copies of the .js file and it should be fine -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339398036 Just revert the sitemap changes -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] bjornjorgensen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339390522 I'm trying to fix the errors This is what I have don so far. bundle install bundle exec jekyll bundle exec jekyll build but now there are   This dosent look rigth.. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339321984 Oh I misread where `hadoop3pscala213` is used. Yeah this is OK -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41317][CONNECT][TESTS][FOLLOWUP] Import `WriteOperation` only when `pandas` is available
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new b6656afa4e5 [SPARK-41317][CONNECT][TESTS][FOLLOWUP] Import `WriteOperation` only when `pandas` is available b6656afa4e5 is described below commit b6656afa4e54e489c4642522ec74d850f53d3a83 Author: Dongjoon Hyun AuthorDate: Tue Dec 6 03:03:17 2022 -0800 [SPARK-41317][CONNECT][TESTS][FOLLOWUP] Import `WriteOperation` only when `pandas` is available ### What changes were proposed in this pull request? This is the last piece to recover `pyspark-connect` tests on a system where pandas is unavailable. ### Why are the changes needed? **BEFORE** ``` $ python/run-tests.py --modules pyspark-connect ... ModuleNotFoundError: No module named 'pandas' ``` **AFTER** ``` $ python/run-tests.py --modules pyspark-connect Running PySpark tests. Output is in /Users/dongjoon/APACHE/spark-merge/python/unit-tests.log Will test against the following Python executables: ['python3.9'] Will test the following Python modules: ['pyspark-connect'] python3.9 python_implementation is CPython python3.9 version is: Python 3.9.14 Starting test(python3.9): pyspark.sql.tests.connect.test_connect_column_expressions (temp output: /Users/dongjoon/APACHE/spark-merge/python/target/fc8f073e-edbe-470f-a3cc-f35b3f4b5262/python3.9__pyspark.sql.tests.connect.test_connect_column_expressions___lzz5fky.log) Starting test(python3.9): pyspark.sql.tests.connect.test_connect_basic (temp output: /Users/dongjoon/APACHE/spark-merge/python/target/c14dfac4-14df-45b4-b54e-6dbc3c58f128/python3.9__pyspark.sql.tests.connect.test_connect_basic__x8rz2dz1.log) Starting test(python3.9): pyspark.sql.tests.connect.test_connect_column (temp output: /Users/dongjoon/APACHE/spark-merge/python/target/5810e639-75c1-4e6c-91b3-2a1894dab319/python3.9__pyspark.sql.tests.connect.test_connect_column__3e_qmue7.log) Starting test(python3.9): pyspark.sql.tests.connect.test_connect_function (temp output: /Users/dongjoon/APACHE/spark-merge/python/target/8bebb3be-c146-4030-96b3-82ff7a873d49/python3.9__pyspark.sql.tests.connect.test_connect_function__hwe9aca8.log) Finished test(python3.9): pyspark.sql.tests.connect.test_connect_column_expressions (1s) ... 9 tests were skipped Starting test(python3.9): pyspark.sql.tests.connect.test_connect_plan_only (temp output: /Users/dongjoon/APACHE/spark-merge/python/target/97cbccca-1e9a-44d9-958f-e2368266b437/python3.9__pyspark.sql.tests.connect.test_connect_plan_only__dffs5ux1.log) Finished test(python3.9): pyspark.sql.tests.connect.test_connect_column (1s) ... 2 tests were skipped Starting test(python3.9): pyspark.sql.tests.connect.test_connect_select_ops (temp output: /Users/dongjoon/APACHE/spark-merge/python/target/297a054f-c577-4aee-b1ff-48d48beb423c/python3.9__pyspark.sql.tests.connect.test_connect_select_ops__4e__w6gh.log) Finished test(python3.9): pyspark.sql.tests.connect.test_connect_function (1s) ... 5 tests were skipped Finished test(python3.9): pyspark.sql.tests.connect.test_connect_basic (1s) ... 48 tests were skipped Finished test(python3.9): pyspark.sql.tests.connect.test_connect_select_ops (0s) ... 2 tests were skipped Finished test(python3.9): pyspark.sql.tests.connect.test_connect_plan_only (1s) ... 28 tests were skipped Tests passed in 2 seconds Skipped tests in pyspark.sql.tests.connect.test_connect_basic with python3.9: test_channel_properties (pyspark.sql.tests.connect.test_connect_basic.ChannelBuilderTests) ... skip (0.002s) test_invalid_connection_strings (pyspark.sql.tests.connect.test_connect_basic.ChannelBuilderTests) ... skip (0.000s) test_metadata (pyspark.sql.tests.connect.test_connect_basic.ChannelBuilderTests) ... skip (0.000s) test_sensible_defaults (pyspark.sql.tests.connect.test_connect_basic.ChannelBuilderTests) ... skip (0.000s) test_valid_channel_creation (pyspark.sql.tests.connect.test_connect_basic.ChannelBuilderTests) ... skip (0.000s) test_agg_with_avg (pyspark.sql.tests.connect.test_connect_basic.SparkConnectTests) ... skip (0.000s) test_agg_with_two_agg_exprs (pyspark.sql.tests.connect.test_connect_basic.SparkConnectTests) ... skip (0.000s) test_collect (pyspark.sql.tests.connect.test_connect_basic.SparkConnectTests) ... skip (0.000s) test_count (pyspark.sql.tests.connect.test_connect_basic.SparkConnectTests) ... skip (0.000s) test_create_global_temp_view (pyspark.sql.tests.connect.test_connect_basic.SparkConnectTests) ... skip (0.000s) test_create_session_local_temp_view (pyspark.sql.tests.connect.test_connect_basic.SparkConnectTests) ... skip (0.000s)
[GitHub] [spark-website] dongjoon-hyun commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
dongjoon-hyun commented on PR #429:
URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339049452
I was also confused about that, but this PR looks correct because Apache
Spark 3.3.1 uses `packagesV13` (hadoop3p, hadoop3pscala213, ...) which is
unchanged by this PR.
```scala
- var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3.2"};
- var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and
later (Scala 2.13)", tag: "hadoop3.2-scala2.13"};
+ var hadoop3p3 = {pretty: "Pre-built for Apache Hadoop 3.2 and later", tag:
"hadoop3.2"};
+ var hadoop3p3scala213 = {pretty: "Pre-built for Apache Hadoop 3.2 and
later (Scala 2.13)", tag: "hadoop3.2-scala2.13"};
var hadoop2p = {pretty: "Pre-built for Apache Hadoop 2.7", tag: "hadoop2"};
var hadoop3p = {pretty: "Pre-built for Apache Hadoop 3.3 and later", tag:
"hadoop3"};
var hadoop3pscala213 = {pretty: "Pre-built for Apache Hadoop 3.3 and later
(Scala 2.13)", tag: "hadoop3-scala2.13"};
// 3.2.0+
var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7, hadoopFree,
sources];
// 3.3.0+
var packagesV13 = [hadoop3p, hadoop3pscala213, hadoop2p, hadoopFree,
sources];
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] dongjoon-hyun commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
dongjoon-hyun commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1339043018 +1 for @srowen 's comment. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41121][BUILD] Upgrade `sbt-assembly` to 2.0.0
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new fb40e07800b [SPARK-41121][BUILD] Upgrade `sbt-assembly` to 2.0.0
fb40e07800b is described below
commit fb40e07800bb5523eef5b87e5bb13e6d05176ea7
Author: panbingkun
AuthorDate: Tue Dec 6 01:32:03 2022 -0800
[SPARK-41121][BUILD] Upgrade `sbt-assembly` to 2.0.0
### What changes were proposed in this pull request?
This pr aims upgrade sbt-assembly plugin from 1.2.0 to 2.0.0
### Why are the changes needed?
Release notes as follows:
https://github.com/sbt/sbt-assembly/releases/tag/v2.0.0
https://user-images.githubusercontent.com/15246973/201500241-f40341b6-bbd2-4224-b18e-f2a696cae23b.png;>
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #38637 from panbingkun/upgrade_sbt-assembly.
Authored-by: panbingkun
Signed-off-by: Dongjoon Hyun
---
project/plugins.sbt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/project/plugins.sbt b/project/plugins.sbt
index c0c418bd521..b0ed3fc569e 100644
--- a/project/plugins.sbt
+++ b/project/plugins.sbt
@@ -25,7 +25,7 @@ libraryDependencies += "com.puppycrawl.tools" % "checkstyle"
% "9.3"
// checkstyle uses guava 31.0.1-jre.
libraryDependencies += "com.google.guava" % "guava" % "31.0.1-jre"
-addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "1.2.0")
+addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "2.0.0")
addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "5.2.4")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (198d11b9b6a -> 62d553297af)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 198d11b9b6a [SPARK-41001][CONNECT][TESTS][FOLLOWUP] ChannelBuilderTests` should be skipped by `should_test_connect` flag add 62d553297af [SPARK-41247][BUILD][FOLLOWUP] Make sbt and maven use the same Protobuf version No new revisions were added by this update. Summary of changes: pom.xml | 1 + project/SparkBuild.scala | 3 ++- 2 files changed, 3 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (b6ec1ce41d8 -> 198d11b9b6a)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from b6ec1ce41d8 [SPARK-41346][CONNECT][TESTS][FOLLOWUP] Fix `test_connect_function` to import `PandasOnSparkTestCase` properly add 198d11b9b6a [SPARK-41001][CONNECT][TESTS][FOLLOWUP] ChannelBuilderTests` should be skipped by `should_test_connect` flag No new revisions were added by this update. Summary of changes: python/pyspark/sql/tests/connect/test_connect_basic.py| 7 +-- python/pyspark/sql/tests/connect/test_connect_function.py | 2 +- python/pyspark/testing/connectutils.py| 1 + 3 files changed, 7 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org