(spark) branch master updated: [SPARK-46663][PYTHON] Disable memory profiler for pandas UDFs with iterators
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 48152b1779a5 [SPARK-46663][PYTHON] Disable memory profiler for pandas
UDFs with iterators
48152b1779a5 is described below
commit 48152b1779a5b8191dd0e09424fdb552cac55d49
Author: Xinrong Meng
AuthorDate: Tue Jan 16 11:20:40 2024 -0800
[SPARK-46663][PYTHON] Disable memory profiler for pandas UDFs with iterators
### What changes were proposed in this pull request?
When using pandas UDFs with iterators, if users enable the profiling spark
conf, a warning indicating non-support should be raised, and profiling should
be disabled.
However, currently, after raising the not-supported warning, the memory
profiler is still being enabled.
The PR proposed to fix that.
### Why are the changes needed?
A bug fix to eliminate misleading behavior.
### Does this PR introduce _any_ user-facing change?
The noticeable changes will affect only those using the PySpark shell. This
is because, in the PySpark shell, the memory profiler will raise an error,
which in turn blocks the execution of the UDF.
### How was this patch tested?
Manual test.
### Was this patch authored or co-authored using generative AI tooling?
Setup:
```py
$ ./bin/pyspark --conf spark.python.profile=true
>>> from typing import Iterator
>>> from pyspark.sql.functions import *
>>> import pandas as pd
>>> pandas_udf("long")
... def plus_one(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
... for s in iterator:
... yield s + 1
...
>>> df = spark.createDataFrame(pd.DataFrame([1, 2, 3], columns=["v"]))
```
Before:
```
>>> df.select(plus_one(df.v)).show()
UserWarning: Profiling UDFs with iterators input/output is not supported.
Traceback (most recent call last):
...
OSError: could not get source code
```
After:
```
>>> df.select(plus_one(df.v)).show()
/Users/xinrong.meng/spark/python/pyspark/sql/udf.py:417: UserWarning:
Profiling UDFs with iterators input/output is not supported.
+---+
|plus_one(v)|
+---+
| 2|
| 3|
| 4|
+---+
```
Closes #44668 from xinrong-meng/fix_mp.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/tests/test_udf_profiler.py | 45 ++-
python/pyspark/sql/udf.py | 33 ++--
2 files changed, 60 insertions(+), 18 deletions(-)
diff --git a/python/pyspark/sql/tests/test_udf_profiler.py
b/python/pyspark/sql/tests/test_udf_profiler.py
index 136f423d0a35..776d5da88bb2 100644
--- a/python/pyspark/sql/tests/test_udf_profiler.py
+++ b/python/pyspark/sql/tests/test_udf_profiler.py
@@ -19,11 +19,13 @@ import tempfile
import unittest
import os
import sys
+import warnings
from io import StringIO
+from typing import Iterator
from pyspark import SparkConf
from pyspark.sql import SparkSession
-from pyspark.sql.functions import udf
+from pyspark.sql.functions import udf, pandas_udf
from pyspark.profiler import UDFBasicProfiler
@@ -101,6 +103,47 @@ class UDFProfilerTests(unittest.TestCase):
df = self.spark.range(10)
df.select(add1("id"), add2("id"), add1("id")).collect()
+# Unsupported
+def exec_pandas_udf_iter_to_iter(self):
+import pandas as pd
+
+@pandas_udf("int")
+def iter_to_iter(batch_ser: Iterator[pd.Series]) ->
Iterator[pd.Series]:
+for ser in batch_ser:
+yield ser + 1
+
+self.spark.range(10).select(iter_to_iter("id")).collect()
+
+# Unsupported
+def exec_map(self):
+import pandas as pd
+
+def map(pdfs: Iterator[pd.DataFrame]) -> Iterator[pd.DataFrame]:
+for pdf in pdfs:
+yield pdf[pdf.id == 1]
+
+df = self.spark.createDataFrame([(1, 1.0), (1, 2.0), (2, 3.0), (2,
5.0)], ("id", "v"))
+df.mapInPandas(map, schema=df.schema).collect()
+
+def test_unsupported(self):
+with warnings.catch_warnings(record=True) as warns:
+warnings.simplefilter("always")
+self.exec_pandas_udf_iter_to_iter()
+user_warns = [warn.message for warn in warns if
isinstance(warn.message, UserWarning)]
+self.assertTrue(len(user_warns) > 0)
+self.assertTrue(
+"Profiling UDFs with iterators input/output is not supported"
in str(user_warns[0])
+)
+
+with warnings.catch_warnin
(spark) branch master updated: [SPARK-46867][PYTHON][CONNECT][TESTS] Remove unnecessary dependency from test_mixed_udf_and_sql.py
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 79918028b142 [SPARK-46867][PYTHON][CONNECT][TESTS] Remove unnecessary
dependency from test_mixed_udf_and_sql.py
79918028b142 is described below
commit 79918028b142685fe1c3871a3593e91100ab6bbf
Author: Xinrong Meng
AuthorDate: Thu Jan 25 14:16:12 2024 -0800
[SPARK-46867][PYTHON][CONNECT][TESTS] Remove unnecessary dependency from
test_mixed_udf_and_sql.py
### What changes were proposed in this pull request?
Remove unnecessary dependency from test_mixed_udf_and_sql.py.
### Why are the changes needed?
Otherwise, test_mixed_udf_and_sql.py depends on Spark Connect's dependency
"grpc", possibly leading to conflicts or compatibility issues.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Test change only.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes #44886 from xinrong-meng/fix_dep.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/tests/connect/test_parity_pandas_udf_scalar.py | 4
python/pyspark/sql/tests/pandas/test_pandas_udf_scalar.py | 5 +++--
2 files changed, 7 insertions(+), 2 deletions(-)
diff --git a/python/pyspark/sql/tests/connect/test_parity_pandas_udf_scalar.py
b/python/pyspark/sql/tests/connect/test_parity_pandas_udf_scalar.py
index c950ca2e17c3..6a3d03246549 100644
--- a/python/pyspark/sql/tests/connect/test_parity_pandas_udf_scalar.py
+++ b/python/pyspark/sql/tests/connect/test_parity_pandas_udf_scalar.py
@@ -15,6 +15,7 @@
# limitations under the License.
#
import unittest
+from pyspark.sql.connect.column import Column
from pyspark.sql.tests.pandas.test_pandas_udf_scalar import
ScalarPandasUDFTestsMixin
from pyspark.testing.connectutils import ReusedConnectTestCase
@@ -51,6 +52,9 @@ class PandasUDFScalarParityTests(ScalarPandasUDFTestsMixin,
ReusedConnectTestCas
def test_vectorized_udf_invalid_length(self):
self.check_vectorized_udf_invalid_length()
+def test_mixed_udf_and_sql(self):
+self._test_mixed_udf_and_sql(Column)
+
if __name__ == "__main__":
from pyspark.sql.tests.connect.test_parity_pandas_udf_scalar import * #
noqa: F401
diff --git a/python/pyspark/sql/tests/pandas/test_pandas_udf_scalar.py
b/python/pyspark/sql/tests/pandas/test_pandas_udf_scalar.py
index dfbab5c8b3cd..9f6bdb83caf7 100644
--- a/python/pyspark/sql/tests/pandas/test_pandas_udf_scalar.py
+++ b/python/pyspark/sql/tests/pandas/test_pandas_udf_scalar.py
@@ -1321,8 +1321,9 @@ class ScalarPandasUDFTestsMixin:
self.assertEqual(expected_multi, df_multi_2.collect())
def test_mixed_udf_and_sql(self):
-from pyspark.sql.connect.column import Column as ConnectColumn
+self._test_mixed_udf_and_sql(Column)
+def _test_mixed_udf_and_sql(self, col_type):
df = self.spark.range(0, 1).toDF("v")
# Test mixture of UDFs, Pandas UDFs and SQL expression.
@@ -1333,7 +1334,7 @@ class ScalarPandasUDFTestsMixin:
return x + 1
def f2(x):
-assert type(x) in (Column, ConnectColumn)
+assert type(x) == col_type
return x + 10
@pandas_udf("int")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
(spark) branch master updated: [SPARK-46689][SPARK-46690][PYTHON][CONNECT] Support v2 profiling in group/cogroup applyInPandas/applyInArrow
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1a66c8c78a46 [SPARK-46689][SPARK-46690][PYTHON][CONNECT] Support v2
profiling in group/cogroup applyInPandas/applyInArrow
1a66c8c78a46 is described below
commit 1a66c8c78a468a5bdc6c033e8c7a26693e4bf62e
Author: Xinrong Meng
AuthorDate: Thu Feb 8 10:56:28 2024 -0800
[SPARK-46689][SPARK-46690][PYTHON][CONNECT] Support v2 profiling in
group/cogroup applyInPandas/applyInArrow
### What changes were proposed in this pull request?
Support v2 (perf, memory) profiling in group/cogroup
applyInPandas/applyInArrow, which rely on physical plan nodes
FlatMapGroupsInBatchExec and FlatMapCoGroupsInBatchExec.
### Why are the changes needed?
Complete v2 profiling support.
### Does this PR introduce _any_ user-facing change?
Yes. V2 profiling in group/cogroup applyInPandas/applyInArrow is supported.
### How was this patch tested?
Unit tests.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes #45050 from xinrong-meng/other_p2.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/tests/test_udf_profiler.py | 123 +
python/pyspark/tests/test_memory_profiler.py | 123 +
.../python/FlatMapCoGroupsInBatchExec.scala| 2 +-
.../python/FlatMapGroupsInBatchExec.scala | 2 +-
4 files changed, 248 insertions(+), 2 deletions(-)
diff --git a/python/pyspark/sql/tests/test_udf_profiler.py
b/python/pyspark/sql/tests/test_udf_profiler.py
index 99719b5475c1..4f767d274414 100644
--- a/python/pyspark/sql/tests/test_udf_profiler.py
+++ b/python/pyspark/sql/tests/test_udf_profiler.py
@@ -394,6 +394,129 @@ class UDFProfiler2TestsMixin:
io.getvalue(),
f"2.*{os.path.basename(inspect.getfile(_do_computation))}"
)
+@unittest.skipIf(
+not have_pandas or not have_pyarrow,
+cast(str, pandas_requirement_message or pyarrow_requirement_message),
+)
+def test_perf_profiler_group_apply_in_pandas(self):
+# FlatMapGroupsInBatchExec
+df = self.spark.createDataFrame(
+[(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)], ("id", "v")
+)
+
+def normalize(pdf):
+v = pdf.v
+return pdf.assign(v=(v - v.mean()) / v.std())
+
+with self.sql_conf({"spark.sql.pyspark.udf.profiler": "perf"}):
+df.groupby("id").applyInPandas(normalize, schema="id long, v
double").show()
+
+self.assertEqual(1, len(self.profile_results),
str(self.profile_results.keys()))
+
+for id in self.profile_results:
+with self.trap_stdout() as io:
+self.spark.showPerfProfiles(id)
+
+self.assertIn(f"Profile of UDF", io.getvalue())
+self.assertRegex(
+io.getvalue(),
f"2.*{os.path.basename(inspect.getfile(_do_computation))}"
+)
+
+@unittest.skipIf(
+not have_pandas or not have_pyarrow,
+cast(str, pandas_requirement_message or pyarrow_requirement_message),
+)
+def test_perf_profiler_cogroup_apply_in_pandas(self):
+# FlatMapCoGroupsInBatchExec
+import pandas as pd
+
+df1 = self.spark.createDataFrame(
+[(2101, 1, 1.0), (2101, 2, 2.0), (2102, 1, 3.0),
(2102, 2, 4.0)],
+("time", "id", "v1"),
+)
+df2 = self.spark.createDataFrame(
+[(2101, 1, "x"), (2101, 2, "y")], ("time", "id", "v2")
+)
+
+def asof_join(left, right):
+return pd.merge_asof(left, right, on="time", by="id")
+
+with self.sql_conf({"spark.sql.pyspark.udf.profiler": "perf"}):
+df1.groupby("id").cogroup(df2.groupby("id")).applyInPandas(
+asof_join, schema="time int, id int, v1 double, v2 string"
+).show()
+
+self.assertEqual(1, len(self.profile_results),
str(self.profile_results.keys()))
+
+for id in self.profile_results:
+with self.trap_stdout() as io:
+self.spark.showPerfProfiles(id)
+
+self.assertIn(f"Profile of UDF", io.getvalue())
+self.assertRegex(
+io.getvalue(),
f"2.*{os.path.basename(inspect.getfile(_do_computation))}"
+)
+
+@unittest.skipIf(
+not have_pandas or not have_pyarrow,
+cast(str, pandas_requirement_message or pyarrow_requirement_messag
(spark) branch master updated: [SPARK-47014][PYTHON][CONNECT] Implement methods dumpPerfProfiles and dumpMemoryProfiles of SparkSession
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4b9e9d7a9b7c [SPARK-47014][PYTHON][CONNECT] Implement methods
dumpPerfProfiles and dumpMemoryProfiles of SparkSession
4b9e9d7a9b7c is described below
commit 4b9e9d7a9b7c1b21c7d04cdf0095cc069a35b757
Author: Xinrong Meng
AuthorDate: Wed Feb 14 10:37:33 2024 -0800
[SPARK-47014][PYTHON][CONNECT] Implement methods dumpPerfProfiles and
dumpMemoryProfiles of SparkSession
### What changes were proposed in this pull request?
Implement methods dumpPerfProfiles and dumpMemoryProfiles of SparkSession
### Why are the changes needed?
Complete support of (v2) SparkSession-based profiling.
### Does this PR introduce _any_ user-facing change?
Yes. dumpPerfProfiles and dumpMemoryProfiles of SparkSession are supported.
An example of dumpPerfProfiles is shown below.
```py
>>> udf("long")
... def add(x):
... return x + 1
...
>>> spark.conf.set("spark.sql.pyspark.udf.profiler", "perf")
>>> spark.range(10).select(add("id")).collect()
...
>>> spark.dumpPerfProfiles("dummy_dir")
>>> os.listdir("dummy_dir")
['udf_2.pstats']
```
### How was this patch tested?
Unit tests.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes #45073 from xinrong-meng/dump_profile.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/connect/session.py | 10 +
python/pyspark/sql/profiler.py| 65 +++
python/pyspark/sql/session.py | 10 +
python/pyspark/sql/tests/test_udf_profiler.py | 20 +
python/pyspark/tests/test_memory_profiler.py | 22 +
5 files changed, 110 insertions(+), 17 deletions(-)
diff --git a/python/pyspark/sql/connect/session.py
b/python/pyspark/sql/connect/session.py
index 9a678c28a6cc..764f71ccc415 100644
--- a/python/pyspark/sql/connect/session.py
+++ b/python/pyspark/sql/connect/session.py
@@ -958,6 +958,16 @@ class SparkSession:
showMemoryProfiles.__doc__ = PySparkSession.showMemoryProfiles.__doc__
+def dumpPerfProfiles(self, path: str, id: Optional[int] = None) -> None:
+self._profiler_collector.dump_perf_profiles(path, id)
+
+dumpPerfProfiles.__doc__ = PySparkSession.dumpPerfProfiles.__doc__
+
+def dumpMemoryProfiles(self, path: str, id: Optional[int] = None) -> None:
+self._profiler_collector.dump_memory_profiles(path, id)
+
+dumpMemoryProfiles.__doc__ = PySparkSession.dumpMemoryProfiles.__doc__
+
SparkSession.__doc__ = PySparkSession.__doc__
diff --git a/python/pyspark/sql/profiler.py b/python/pyspark/sql/profiler.py
index 565752197238..0db9d9b8b9b4 100644
--- a/python/pyspark/sql/profiler.py
+++ b/python/pyspark/sql/profiler.py
@@ -15,6 +15,7 @@
# limitations under the License.
#
from abc import ABC, abstractmethod
+import os
import pstats
from threading import RLock
from typing import Dict, Optional, TYPE_CHECKING
@@ -158,6 +159,70 @@ class ProfilerCollector(ABC):
"""
...
+def dump_perf_profiles(self, path: str, id: Optional[int] = None) -> None:
+"""
+Dump the perf profile results into directory `path`.
+
+.. versionadded:: 4.0.0
+
+Parameters
+--
+path: str
+A directory in which to dump the perf profile.
+id : int, optional
+A UDF ID to be shown. If not specified, all the results will be
shown.
+"""
+with self._lock:
+stats = self._perf_profile_results
+
+def dump(id: int) -> None:
+s = stats.get(id)
+
+if s is not None:
+if not os.path.exists(path):
+os.makedirs(path)
+p = os.path.join(path, f"udf_{id}_perf.pstats")
+s.dump_stats(p)
+
+if id is not None:
+dump(id)
+else:
+for id in sorted(stats.keys()):
+dump(id)
+
+def dump_memory_profiles(self, path: str, id: Optional[int] = None) ->
None:
+"""
+Dump the memory profile results into directory `path`.
+
+.. versionadded:: 4.0.0
+
+Parameters
+--
+path: str
+A directory in which to dump the memory profile.
+id : int, optional
+A UDF ID to be shown. If not specified, all the results will be
shown.
+"""
+with self._lock:
+code_map = self._memory_profile_res
(spark) branch master updated (6de527e9ee94 -> 6185e5cad7be)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 6de527e9ee94 [SPARK-43259][SQL] Assign a name to the error class _LEGACY_ERROR_TEMP_2024 add 6185e5cad7be [SPARK-47132][DOCS][PYTHON] Correct docstring for pyspark's dataframe.head No new revisions were added by this update. Summary of changes: python/pyspark/sql/dataframe.py | 7 +-- 1 file changed, 5 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
(spark) branch master updated (06c741a0061b -> d20650bc8cf2)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 06c741a0061b [SPARK-47129][CONNECT][SQL] Make `ResolveRelations` cache connect plan properly add d20650bc8cf2 [SPARK-46975][PS] Support dedicated fallback methods No new revisions were added by this update. Summary of changes: python/pyspark/pandas/frame.py | 49 +++--- 1 file changed, 36 insertions(+), 13 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
(spark) branch master updated: [SPARK-47276][PYTHON][CONNECT] Introduce `spark.profile.clear` for SparkSession-based profiling
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 501999a834ea [SPARK-47276][PYTHON][CONNECT] Introduce
`spark.profile.clear` for SparkSession-based profiling
501999a834ea is described below
commit 501999a834ea7761a792b823c543e40fba84231d
Author: Xinrong Meng
AuthorDate: Thu Mar 7 13:20:39 2024 -0800
[SPARK-47276][PYTHON][CONNECT] Introduce `spark.profile.clear` for
SparkSession-based profiling
### What changes were proposed in this pull request?
Introduce `spark.profile.clear` for SparkSession-based profiling.
### Why are the changes needed?
A straightforward and unified interface for managing and resetting
profiling results for SparkSession-based profilers.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.profile.clear` is supported as shown below.
Preparation:
```py
>>> from pyspark.sql.functions import pandas_udf
>>> df = spark.range(3)
>>> pandas_udf("long")
... def add1(x):
... return x + 1
...
>>> added = df.select(add1("id"))
>>> spark.conf.set("spark.sql.pyspark.udf.profiler", "perf")
>>> added.show()
++
|add1(id)|
++
...
++
>>> spark.profile.show()
Profile of UDF
1410 function calls (1374 primitive calls) in 0.004 seconds
...
```
Example usage:
```py
>>> spark.profile.profiler_collector._profile_results
{2: (, None)}
>>> spark.profile.clear(1) # id mismatch
>>> spark.profile.profiler_collector._profile_results
{2: (, None)}
>>> spark.profile.clear(type="memory") # type mismatch
>>> spark.profile.profiler_collector._profile_results
{2: (, None)}
>>> spark.profile.clear() # clear all
>>> spark.profile.profiler_collector._profile_results
{}
>>> spark.profile.show()
>>>
```
### How was this patch tested?
Unit tests.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes #45378 from xinrong-meng/profile_clear.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/profiler.py| 79 +++
python/pyspark/sql/tests/test_session.py | 27 +
python/pyspark/sql/tests/test_udf_profiler.py | 26 +
python/pyspark/tests/test_memory_profiler.py | 59
4 files changed, 191 insertions(+)
diff --git a/python/pyspark/sql/profiler.py b/python/pyspark/sql/profiler.py
index 5ab27bce2582..711e39de4723 100644
--- a/python/pyspark/sql/profiler.py
+++ b/python/pyspark/sql/profiler.py
@@ -224,6 +224,56 @@ class ProfilerCollector(ABC):
for id in sorted(code_map.keys()):
dump(id)
+def clear_perf_profiles(self, id: Optional[int] = None) -> None:
+"""
+Clear the perf profile results.
+
+.. versionadded:: 4.0.0
+
+Parameters
+--
+id : int, optional
+The UDF ID whose profiling results should be cleared.
+If not specified, all the results will be cleared.
+"""
+with self._lock:
+if id is not None:
+if id in self._profile_results:
+perf, mem, *_ = self._profile_results[id]
+self._profile_results[id] = (None, mem, *_)
+if mem is None:
+self._profile_results.pop(id, None)
+else:
+for id, (perf, mem, *_) in list(self._profile_results.items()):
+self._profile_results[id] = (None, mem, *_)
+if mem is None:
+self._profile_results.pop(id, None)
+
+def clear_memory_profiles(self, id: Optional[int] = None) -> None:
+"""
+Clear the memory profile results.
+
+.. versionadded:: 4.0.0
+
+Parameters
+--
+id : int, optional
+The UDF ID whose profiling results should be cleared.
+If not specified, all the results will be cleared.
+"""
+with self._lock:
+if id is not None:
+if id in self._profile_results:
+perf, mem, *_ = self._profile_results[id]
+self._profile_results[id] = (perf, None, *_)
+if perf is N
(spark) branch master updated (f9ebe1b3d24b -> 6c827c10dc15)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from f9ebe1b3d24b [SPARK-46375][DOCS] Add user guide for Python data source API add 6c827c10dc15 [SPARK-47876][PYTHON][DOCS] Improve docstring of mapInArrow No new revisions were added by this update. Summary of changes: python/pyspark/sql/pandas/map_ops.py | 19 +-- 1 file changed, 9 insertions(+), 10 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
(spark) branch master updated: [SPARK-47864][FOLLOWUP][PYTHON][DOCS] Fix minor typo: "MLLib" -> "MLlib"
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e50737be366a [SPARK-47864][FOLLOWUP][PYTHON][DOCS] Fix minor typo:
"MLLib" -> "MLlib"
e50737be366a is described below
commit e50737be366ac0e8d5466b714f7d41991d0b05a8
Author: Haejoon Lee
AuthorDate: Tue Apr 23 10:10:20 2024 -0700
[SPARK-47864][FOLLOWUP][PYTHON][DOCS] Fix minor typo: "MLLib" -> "MLlib"
### What changes were proposed in this pull request?
This PR followups for https://github.com/apache/spark/pull/46096 to fix
minor typo.
### Why are the changes needed?
To use official naming from documentation for `MLlib` instead of `MLLib`.
See https://spark.apache.org/mllib/.
### Does this PR introduce _any_ user-facing change?
No API change, but the user-facing documentation will be updated.
### How was this patch tested?
Manually built the doc from local test envs.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes #46174 from itholic/minor_typo_installation.
Authored-by: Haejoon Lee
Signed-off-by: Xinrong Meng
---
python/docs/source/getting_started/install.rst | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/python/docs/source/getting_started/install.rst
b/python/docs/source/getting_started/install.rst
index 33a0560764df..ee894981387a 100644
--- a/python/docs/source/getting_started/install.rst
+++ b/python/docs/source/getting_started/install.rst
@@ -244,7 +244,7 @@ Additional libraries that enhance functionality but are not
included in the inst
- **matplotlib**: Provide plotting for visualization. The default is
**plotly**.
-MLLib DataFrame-based API
+MLlib DataFrame-based API
^
Installable with ``pip install "pyspark[ml]"``.
@@ -252,7 +252,7 @@ Installable with ``pip install "pyspark[ml]"``.
=== = ==
Package Supported version Note
=== = ==
-`numpy` >=1.21Required for MLLib DataFrame-based API
+`numpy` >=1.21Required for MLlib DataFrame-based API
=== = ==
Additional libraries that enhance functionality but are not included in the
installation packages:
@@ -272,5 +272,5 @@ Installable with ``pip install "pyspark[mllib]"``.
=== = ==
Package Supported version Note
=== = ==
-`numpy` >=1.21Required for MLLib
+`numpy` >=1.21Required for MLlib
=== = ==
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
(spark) branch master updated: [SPARK-46277][PYTHON] Validate startup urls with the config being set
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 027aeb1764a8 [SPARK-46277][PYTHON] Validate startup urls with the
config being set
027aeb1764a8 is described below
commit 027aeb1764a816858b7ea071cd2b620f02a6a525
Author: Xinrong Meng
AuthorDate: Thu Dec 7 13:45:31 2023 -0800
[SPARK-46277][PYTHON] Validate startup urls with the config being set
### What changes were proposed in this pull request?
Validate startup urls with the config being set, see example in the "Does
this PR introduce _any_ user-facing change".
### Why are the changes needed?
Clear and user-friendly error messages.
### Does this PR introduce _any_ user-facing change?
Yes.
FROM
```py
>>> SparkSession.builder.config(map={"spark.master": "x", "spark.remote":
"y"})
>> SparkSession.builder.config(map={"spark.master": "x", "spark.remote":
"y"}).config("x", "z") # Only raises the error when adding new configs
Traceback (most recent call last):
...
RuntimeError: Spark master cannot be configured with Spark Connect server;
however, found URL for Spark Connect [y]
```
TO
```py
>>> SparkSession.builder.config(map={"spark.master": "x", "spark.remote":
"y"})
Traceback (most recent call last):
...
RuntimeError: Spark master cannot be configured with Spark Connect server;
however, found URL for Spark Connect [y]
```
### How was this patch tested?
Unit tests.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes #44194 from xinrong-meng/fix_session.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/errors/error_classes.py | 6 +++---
python/pyspark/sql/session.py| 28 +++-
python/pyspark/sql/tests/test_session.py | 30 --
3 files changed, 42 insertions(+), 22 deletions(-)
diff --git a/python/pyspark/errors/error_classes.py
b/python/pyspark/errors/error_classes.py
index 965fd04a9135..cc8400270967 100644
--- a/python/pyspark/errors/error_classes.py
+++ b/python/pyspark/errors/error_classes.py
@@ -86,12 +86,12 @@ ERROR_CLASSES_JSON = """
},
"CANNOT_CONFIGURE_SPARK_CONNECT": {
"message": [
- "Spark Connect server cannot be configured with Spark master; however,
found URL for Spark master []."
+ "Spark Connect server cannot be configured: Existing [],
New []."
]
},
- "CANNOT_CONFIGURE_SPARK_MASTER": {
+ "CANNOT_CONFIGURE_SPARK_CONNECT_MASTER": {
"message": [
- "Spark master cannot be configured with Spark Connect server; however,
found URL for Spark Connect []."
+ "Spark Connect server and Spark master cannot be configured together:
Spark master [], Spark Connect []."
]
},
"CANNOT_CONVERT_COLUMN_INTO_BOOL": {
diff --git a/python/pyspark/sql/session.py b/python/pyspark/sql/session.py
index 7f4589557cd2..86aacfa54c6e 100644
--- a/python/pyspark/sql/session.py
+++ b/python/pyspark/sql/session.py
@@ -286,17 +286,17 @@ class SparkSession(SparkConversionMixin):
with self._lock:
if conf is not None:
for k, v in conf.getAll():
-self._validate_startup_urls()
self._options[k] = v
+self._validate_startup_urls()
elif map is not None:
for k, v in map.items(): # type: ignore[assignment]
v = to_str(v) # type: ignore[assignment]
-self._validate_startup_urls()
self._options[k] = v
+self._validate_startup_urls()
else:
value = to_str(value)
-self._validate_startup_urls()
self._options[cast(str, key)] = value
+self._validate_startup_urls()
return self
def _validate_startup_urls(
@@ -306,22 +306,16 @@ class SparkSession(SparkConversionMixin):
Helper function that validates the combination of startup URLs and
raises an exception
if incompatible options are selected.
"""
-if "spark.master" in self._options and (
+if ("spark.master" in self._options or "MASTER" in os.environ) and
(
"spark.remote" in self._options or "SP
[spark] branch master updated: [SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d2d1b50bfac [SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView
d2d1b50bfac is described below
commit d2d1b50bfacf1c5bdcf56f150ae44d1b7e5cb5a6
Author: Rui Wang
AuthorDate: Mon Dec 5 09:20:10 2022 -0800
[SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView
### What changes were proposed in this pull request?
Implement DataFrame TempView (which is createTemView and
createOrReplaceTempView). This is a session local temp view which is different
from the global temp view.
### Why are the changes needed?
API coverage.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
UT
Closes #38891 from amaliujia/createTempView.
Authored-by: Rui Wang
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/connect/dataframe.py| 38 ++
.../sql/tests/connect/test_connect_basic.py| 14 +++-
2 files changed, 51 insertions(+), 1 deletion(-)
diff --git a/python/pyspark/sql/connect/dataframe.py
b/python/pyspark/sql/connect/dataframe.py
index 8e8a5f4d318..026b7e6099f 100644
--- a/python/pyspark/sql/connect/dataframe.py
+++ b/python/pyspark/sql/connect/dataframe.py
@@ -1554,6 +1554,44 @@ class DataFrame(object):
"""
print(self._explain_string(extended=extended, mode=mode))
+def createTempView(self, name: str) -> None:
+"""Creates a local temporary view with this :class:`DataFrame`.
+
+The lifetime of this temporary table is tied to the
:class:`SparkSession`
+that was used to create this :class:`DataFrame`.
+throws :class:`TempTableAlreadyExistsException`, if the view name
already exists in the
+catalog.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+name : str
+Name of the view.
+"""
+command = plan.CreateView(
+child=self._plan, name=name, is_global=False, replace=False
+).command(session=self._session.client)
+self._session.client.execute_command(command)
+
+def createOrReplaceTempView(self, name: str) -> None:
+"""Creates or replaces a local temporary view with this
:class:`DataFrame`.
+
+The lifetime of this temporary table is tied to the
:class:`SparkSession`
+that was used to create this :class:`DataFrame`.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+name : str
+Name of the view.
+"""
+command = plan.CreateView(
+child=self._plan, name=name, is_global=False, replace=True
+).command(session=self._session.client)
+self._session.client.execute_command(command)
+
def createGlobalTempView(self, name: str) -> None:
"""Creates a global temporary view with this :class:`DataFrame`.
diff --git a/python/pyspark/sql/tests/connect/test_connect_basic.py
b/python/pyspark/sql/tests/connect/test_connect_basic.py
index abab47b36bf..22ee98558de 100644
--- a/python/pyspark/sql/tests/connect/test_connect_basic.py
+++ b/python/pyspark/sql/tests/connect/test_connect_basic.py
@@ -530,11 +530,23 @@ class SparkConnectTests(SparkConnectSQLTestCase):
self.connect.sql("SELECT 2 AS X LIMIT
1").createOrReplaceGlobalTempView("view_1")
self.assertTrue(self.spark.catalog.tableExists("global_temp.view_1"))
-# Test when creating a view which is alreayd exists but
+# Test when creating a view which is already exists but
self.assertTrue(self.spark.catalog.tableExists("global_temp.view_1"))
with self.assertRaises(grpc.RpcError):
self.connect.sql("SELECT 1 AS X LIMIT
0").createGlobalTempView("view_1")
+def test_create_session_local_temp_view(self):
+# SPARK-41372: test session local temp view creation.
+with self.tempView("view_local_temp"):
+self.connect.sql("SELECT 1 AS X").createTempView("view_local_temp")
+self.assertEqual(self.connect.sql("SELECT * FROM
view_local_temp").count(), 1)
+self.connect.sql("SELECT 1 AS X LIMIT
0").createOrReplaceTempView("view_local_temp")
+self.assertEqual(self.connect.sql("SELECT * FROM
view_local_temp").count(), 0)
+
+# Test when creating a view which is already exists but
+with self.assertRaises(grpc.RpcError):
+self.connect.sql("SELECT 1 AS X LIMIT
0").
[spark] branch master updated: [SPARK-41225][CONNECT][PYTHON][FOLLOW-UP] Disable unsupported functions
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 29a70117b27 [SPARK-41225][CONNECT][PYTHON][FOLLOW-UP] Disable
unsupported functions
29a70117b27 is described below
commit 29a70117b272582d11e7b7b8951dff1be91d3de7
Author: Martin Grund
AuthorDate: Fri Dec 9 14:55:50 2022 -0800
[SPARK-41225][CONNECT][PYTHON][FOLLOW-UP] Disable unsupported functions
### What changes were proposed in this pull request?
This patch adds method stubs for unsupported functions in the Python client
for Spark Connect in the `Column` class that will throw a
`NoteImplementedError` when called. This is to give a clear indication to the
users that these methods will be implemented in the future.
### Why are the changes needed?
UX
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
UT
Closes #39009 from grundprinzip/SPARK-41225-v2.
Authored-by: Martin Grund
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/connect/column.py | 36 ++
.../sql/tests/connect/test_connect_column.py | 25 +++
2 files changed, 61 insertions(+)
diff --git a/python/pyspark/sql/connect/column.py
b/python/pyspark/sql/connect/column.py
index 63e95c851db..f1a909b89fc 100644
--- a/python/pyspark/sql/connect/column.py
+++ b/python/pyspark/sql/connect/column.py
@@ -786,3 +786,39 @@ class Column:
def __repr__(self) -> str:
return "Column<'%s'>" % self._expr.__repr__()
+
+def otherwise(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("otherwise() is not yet implemented.")
+
+def over(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("over() is not yet implemented.")
+
+def isin(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("isin() is not yet implemented.")
+
+def when(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("when() is not yet implemented.")
+
+def getItem(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("getItem() is not yet implemented.")
+
+def astype(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("astype() is not yet implemented.")
+
+def between(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("between() is not yet implemented.")
+
+def getField(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("getField() is not yet implemented.")
+
+def withField(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("withField() is not yet implemented.")
+
+def dropFields(self, *args: Any, **kwargs: Any) -> None:
+raise NotImplementedError("dropFields() is not yet implemented.")
+
+def __getitem__(self, k: Any) -> None:
+raise NotImplementedError("apply() - __getitem__ is not yet
implemented.")
+
+def __iter__(self) -> None:
+raise TypeError("Column is not iterable")
diff --git a/python/pyspark/sql/tests/connect/test_connect_column.py
b/python/pyspark/sql/tests/connect/test_connect_column.py
index c73f1b5b0c7..734b0bbf226 100644
--- a/python/pyspark/sql/tests/connect/test_connect_column.py
+++ b/python/pyspark/sql/tests/connect/test_connect_column.py
@@ -119,6 +119,31 @@ class SparkConnectTests(SparkConnectSQLTestCase):
df.select(df.id.cast(x)).toPandas(),
df2.select(df2.id.cast(x)).toPandas()
)
+def test_unsupported_functions(self):
+# SPARK-41225: Disable unsupported functions.
+c = self.connect.range(1).id
+for f in (
+"otherwise",
+"over",
+"isin",
+"when",
+"getItem",
+"astype",
+"between",
+"getField",
+"withField",
+"dropFields",
+):
+with self.assertRaises(NotImplementedError):
+getattr(c, f)()
+
+with self.assertRaises(NotImplementedError):
+c["a"]
+
+with self.assertRaises(TypeError):
+for x in c:
+pass
+
if __name__ == "__main__":
import unittest
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40307][PYTHON] Introduce Arrow-optimized Python UDFs
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1d3ec69dfdf [SPARK-40307][PYTHON] Introduce Arrow-optimized Python UDFs
1d3ec69dfdf is described below
commit 1d3ec69dfdf3edb0d688fb5294f8a17cc8f5e7e9
Author: Xinrong Meng
AuthorDate: Thu Jan 12 20:23:20 2023 +0800
[SPARK-40307][PYTHON] Introduce Arrow-optimized Python UDFs
### What changes were proposed in this pull request?
Introduce Arrow-optimized Python UDFs. Please refer to
[design](https://docs.google.com/document/d/e/2PACX-1vQxFyrMqFM3zhDhKlczrl9ONixk56cVXUwDXK0MMx4Vv2kH3oo-tWYoujhrGbCXTF78CSD2kZtnhnrQ/pub)
for design details and micro benchmarks.
There are two ways to enable/disable the Arrow optimization for Python UDFs:
- the Spark configuration `spark.sql.execution.pythonUDF.arrow.enabled`,
disabled by default.
- the `useArrow` parameter of the `udf` function, None by default.
The Spark configuration takes effect only when `useArrow` is None.
Otherwise, `useArrow` decides whether a specific user-defined function is
optimized by Arrow or not.
The reason why we introduce these two ways is to provide both a convenient,
per-Spark-session control and a finer-grained, per-UDF control of the Arrow
optimization for Python UDFs.
### Why are the changes needed?
Python user-defined function (UDF) enables users to run arbitrary code
against PySpark columns. It uses Pickle for (de)serialization and executes row
by row.
One major performance bottleneck of Python UDFs is (de)serialization, that
is, the data interchanging between the worker JVM and the spawned Python
subprocess which actually executes the UDF.
The PR proposes a better alternative to handle the (de)serialization:
Arrow, which is used in the (de)serialization of Pandas UDF already.
Benchmark
The micro benchmarks are conducted in a cluster with 1 driver (i3.2xlarge),
2 workers (i3.2xlarge). An i3.2xlarge machine has 61 GB Memory, 8 Cores. The
datasets used in the benchmarks are generated and sized 5 GB, 10 GB, 20 GB and
40 GB.
As shown below, Arrow-optimized Python UDFs are **~1.4x** faster than
non-Arrow-optimized Python UDFs.
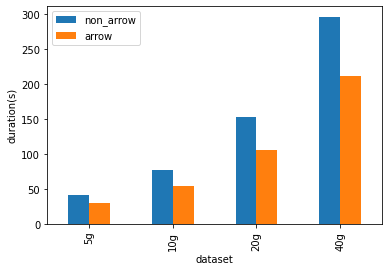
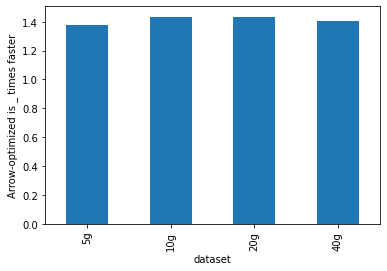
Please refer to
[design](https://docs.google.com/document/d/e/2PACX-1vQxFyrMqFM3zhDhKlczrl9ONixk56cVXUwDXK0MMx4Vv2kH3oo-tWYoujhrGbCXTF78CSD2kZtnhnrQ/pub)
for details.
### Does this PR introduce _any_ user-facing change?
No, since the Arrow optimization for Python UDFs is disabled by default.
### How was this patch tested?
Unit tests.
Below is the script to generate the result table when the Arrow's type
coercion is needed, as in the
[docstring](https://github.com/apache/spark/pull/39384/files#diff-2df611ab00519d2d67e5fc20960bd5a6bd76ecd6f7d56cd50d8befd6ce30081bR96-R111)
of `_create_py_udf` .
```
import sys
import array
import datetime
from decimal import Decimal
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql.functions import udf
data = [
None,
True,
1,
"a",
datetime.date(1970, 1, 1),
datetime.datetime(1970, 1, 1, 0, 0),
1.0,
array.array("i", [1]),
[1],
(1,),
bytearray([65, 66, 67]),
Decimal(1),
{"a": 1},
]
types = [
BooleanType(),
ByteType(),
ShortType(),
IntegerType(),
LongType(),
StringType(),
DateType(),
TimestampType(),
FloatType(),
DoubleType(),
BinaryType(),
DecimalType(10, 0),
]
df = spark.range(1)
results = []
count = 0
total = len(types) * len(data)
spark.sparkContext.setLogLevel("FATAL")
for t in types:
result = []
for v in data:
try:
row = df.select(udf(lambda _: v, t)("id")).first()
ret_str = repr(row[0])
except Exception:
ret_str = "X"
result.append(ret_str)
progress = "SQL Type: [%s]\n Python Value: [%s(%s)]\n Result
Python Value: [%s]" % (
t.simpleString(), str(v), type(v).__name__, ret_str)
count += 1
print("%s/%s:\n %s" % (count, total, progress))
results.append([t.simpleString()] + list(map(str, result)))
schema = ["SQL Type \\ Python Val
[spark] branch branch-3.4 created (now c43be4eeeea)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git at c43be4a [SPARK-42119][SQL] Add built-in table-valued functions inline and inline_outer No new revisions were added by this update. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42126][PYTHON][CONNECT] Accept return type in DDL strings for Python Scalar UDFs in Spark Connect
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new dbd667e7bc5 [SPARK-42126][PYTHON][CONNECT] Accept return type in DDL
strings for Python Scalar UDFs in Spark Connect
dbd667e7bc5 is described below
commit dbd667e7bc5fee443b8a39ca56d4cf3dd1bb2bae
Author: Xinrong Meng
AuthorDate: Thu Jan 26 19:15:13 2023 +0800
[SPARK-42126][PYTHON][CONNECT] Accept return type in DDL strings for Python
Scalar UDFs in Spark Connect
### What changes were proposed in this pull request?
Accept return type in DDL strings for Python Scalar UDFs in Spark Connect.
The approach proposed in this PR is a workaround to parse DataType from DDL
strings. We should think of a more elegant alternative to replace that later.
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. Return type in DDL strings are accepted now.
### How was this patch tested?
Unit tests.
Closes #39739 from xinrong-meng/datatype_ddl.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/connect/udf.py| 20 +++-
.../sql/tests/connect/test_connect_function.py | 8
2 files changed, 27 insertions(+), 1 deletion(-)
diff --git a/python/pyspark/sql/connect/udf.py
b/python/pyspark/sql/connect/udf.py
index 4a465084838..d0eb2fdfe6c 100644
--- a/python/pyspark/sql/connect/udf.py
+++ b/python/pyspark/sql/connect/udf.py
@@ -28,6 +28,7 @@ from pyspark.sql.connect.expressions import (
)
from pyspark.sql.connect.column import Column
from pyspark.sql.types import DataType, StringType
+from pyspark.sql.utils import is_remote
if TYPE_CHECKING:
@@ -90,7 +91,24 @@ class UserDefinedFunction:
)
self.func = func
-self._returnType = returnType
+
+if isinstance(returnType, str):
+# Currently we don't have a way to have a current Spark session in
Spark Connect, and
+# pyspark.sql.SparkSession has a centralized logic to control the
session creation.
+# So uses pyspark.sql.SparkSession for now. Should replace this to
using the current
+# Spark session for Spark Connect in the future.
+from pyspark.sql import SparkSession as PySparkSession
+
+assert is_remote()
+return_type_schema = ( # a workaround to parse the DataType from
DDL strings
+PySparkSession.builder.getOrCreate()
+.createDataFrame(data=[], schema=returnType)
+.schema
+)
+assert len(return_type_schema.fields) == 1, "returnType should be
singular"
+self._returnType = return_type_schema.fields[0].dataType
+else:
+self._returnType = returnType
self._name = name or (
func.__name__ if hasattr(func, "__name__") else
func.__class__.__name__
)
diff --git a/python/pyspark/sql/tests/connect/test_connect_function.py
b/python/pyspark/sql/tests/connect/test_connect_function.py
index 7042a7e8e6f..50fadb49ed4 100644
--- a/python/pyspark/sql/tests/connect/test_connect_function.py
+++ b/python/pyspark/sql/tests/connect/test_connect_function.py
@@ -2299,6 +2299,14 @@ class SparkConnectFunctionTests(ReusedConnectTestCase,
PandasOnSparkTestUtils, S
cdf.withColumn("A", CF.udf(lambda x: x + 1)(cdf.a)).toPandas(),
sdf.withColumn("A", SF.udf(lambda x: x + 1)(sdf.a)).toPandas(),
)
+self.assert_eq( # returnType as DDL strings
+cdf.withColumn("C", CF.udf(lambda x: len(x),
"int")(cdf.c)).toPandas(),
+sdf.withColumn("C", SF.udf(lambda x: len(x),
"int")(sdf.c)).toPandas(),
+)
+self.assert_eq( # returnType as DataType
+cdf.withColumn("C", CF.udf(lambda x: len(x),
IntegerType())(cdf.c)).toPandas(),
+sdf.withColumn("C", SF.udf(lambda x: len(x),
IntegerType())(sdf.c)).toPandas(),
+)
# as a decorator
@CF.udf(StringType())
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42126][PYTHON][CONNECT] Accept return type in DDL strings for Python Scalar UDFs in Spark Connect
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 79e8df84309 [SPARK-42126][PYTHON][CONNECT] Accept return type in DDL
strings for Python Scalar UDFs in Spark Connect
79e8df84309 is described below
commit 79e8df84309ed54d0c3fc7face414e6c440daa81
Author: Xinrong Meng
AuthorDate: Thu Jan 26 19:15:13 2023 +0800
[SPARK-42126][PYTHON][CONNECT] Accept return type in DDL strings for Python
Scalar UDFs in Spark Connect
### What changes were proposed in this pull request?
Accept return type in DDL strings for Python Scalar UDFs in Spark Connect.
The approach proposed in this PR is a workaround to parse DataType from DDL
strings. We should think of a more elegant alternative to replace that later.
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. Return type in DDL strings are accepted now.
### How was this patch tested?
Unit tests.
Closes #39739 from xinrong-meng/datatype_ddl.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit dbd667e7bc5fee443b8a39ca56d4cf3dd1bb2bae)
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/connect/udf.py| 20 +++-
.../sql/tests/connect/test_connect_function.py | 8
2 files changed, 27 insertions(+), 1 deletion(-)
diff --git a/python/pyspark/sql/connect/udf.py
b/python/pyspark/sql/connect/udf.py
index 4a465084838..d0eb2fdfe6c 100644
--- a/python/pyspark/sql/connect/udf.py
+++ b/python/pyspark/sql/connect/udf.py
@@ -28,6 +28,7 @@ from pyspark.sql.connect.expressions import (
)
from pyspark.sql.connect.column import Column
from pyspark.sql.types import DataType, StringType
+from pyspark.sql.utils import is_remote
if TYPE_CHECKING:
@@ -90,7 +91,24 @@ class UserDefinedFunction:
)
self.func = func
-self._returnType = returnType
+
+if isinstance(returnType, str):
+# Currently we don't have a way to have a current Spark session in
Spark Connect, and
+# pyspark.sql.SparkSession has a centralized logic to control the
session creation.
+# So uses pyspark.sql.SparkSession for now. Should replace this to
using the current
+# Spark session for Spark Connect in the future.
+from pyspark.sql import SparkSession as PySparkSession
+
+assert is_remote()
+return_type_schema = ( # a workaround to parse the DataType from
DDL strings
+PySparkSession.builder.getOrCreate()
+.createDataFrame(data=[], schema=returnType)
+.schema
+)
+assert len(return_type_schema.fields) == 1, "returnType should be
singular"
+self._returnType = return_type_schema.fields[0].dataType
+else:
+self._returnType = returnType
self._name = name or (
func.__name__ if hasattr(func, "__name__") else
func.__class__.__name__
)
diff --git a/python/pyspark/sql/tests/connect/test_connect_function.py
b/python/pyspark/sql/tests/connect/test_connect_function.py
index 7042a7e8e6f..50fadb49ed4 100644
--- a/python/pyspark/sql/tests/connect/test_connect_function.py
+++ b/python/pyspark/sql/tests/connect/test_connect_function.py
@@ -2299,6 +2299,14 @@ class SparkConnectFunctionTests(ReusedConnectTestCase,
PandasOnSparkTestUtils, S
cdf.withColumn("A", CF.udf(lambda x: x + 1)(cdf.a)).toPandas(),
sdf.withColumn("A", SF.udf(lambda x: x + 1)(sdf.a)).toPandas(),
)
+self.assert_eq( # returnType as DDL strings
+cdf.withColumn("C", CF.udf(lambda x: len(x),
"int")(cdf.c)).toPandas(),
+sdf.withColumn("C", SF.udf(lambda x: len(x),
"int")(sdf.c)).toPandas(),
+)
+self.assert_eq( # returnType as DataType
+cdf.withColumn("C", CF.udf(lambda x: len(x),
IntegerType())(cdf.c)).toPandas(),
+sdf.withColumn("C", SF.udf(lambda x: len(x),
IntegerType())(sdf.c)).toPandas(),
+)
# as a decorator
@CF.udf(StringType())
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42125][CONNECT][PYTHON] Pandas UDF in Spark Connect
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 0db63df2b28 [SPARK-42125][CONNECT][PYTHON] Pandas UDF in Spark Connect
0db63df2b28 is described below
commit 0db63df2b2829f1358fb711cd657a22b7838ece2
Author: Xinrong Meng
AuthorDate: Tue Jan 31 09:12:20 2023 +0800
[SPARK-42125][CONNECT][PYTHON] Pandas UDF in Spark Connect
### What changes were proposed in this pull request?
Support Pandas UDF in Spark Connect.
Since Pandas UDF and scalar inline Python UDF share the same proto message,
`ScalarInlineUserDefinedFunction` is renamed to `CommonUserDefinedFunction`.
### Why are the changes needed?
To reach parity with the vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. Pandas UDF is supported in Spark Connect, as shown below.
```py
>>> from pyspark.sql.functions import pandas_udf
>>> import pandas as pd
>>> pandas_udf("double")
... def mean_udf(v: pd.Series) -> float:
... return v.mean()
...
>>> df = spark.createDataFrame([(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2,
10.0)], ("id", "v"))
>>> type(df)
>>> df.groupby("id").agg(mean_udf("v")).show()
+---+---+
| id|mean_udf(v)|
+---+---+
| 1|1.5|
| 2|6.0|
+---+---+
>>>
```
### How was this patch tested?
Existing tests.
Closes #39753 from xinrong-meng/connect_pd_udf.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
.../main/protobuf/spark/connect/expressions.proto| 4 ++--
.../sql/connect/planner/SparkConnectPlanner.scala| 12 ++--
.../connect/messages/ConnectProtoMessagesSuite.scala | 10 +-
python/pyspark/sql/connect/expressions.py| 13 +++--
python/pyspark/sql/connect/proto/expressions_pb2.py | 20 ++--
python/pyspark/sql/connect/proto/expressions_pb2.pyi | 20 ++--
python/pyspark/sql/connect/udf.py| 4 ++--
python/pyspark/sql/pandas/functions.py | 11 ++-
8 files changed, 52 insertions(+), 42 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
index 7ae0a6c5008..5b27d4593db 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
@@ -44,7 +44,7 @@ message Expression {
UnresolvedExtractValue unresolved_extract_value = 12;
UpdateFields update_fields = 13;
UnresolvedNamedLambdaVariable unresolved_named_lambda_variable = 14;
-ScalarInlineUserDefinedFunction scalar_inline_user_defined_function = 15;
+CommonInlineUserDefinedFunction common_inline_user_defined_function = 15;
// This field is used to mark extensions to the protocol. When plugins
generate arbitrary
// relations they can add them here. During the planning the correct
resolution is done.
@@ -297,7 +297,7 @@ message Expression {
}
}
-message ScalarInlineUserDefinedFunction {
+message CommonInlineUserDefinedFunction {
// (Required) Name of the user-defined function.
string function_name = 1;
// (Required) Indicate if the user-defined function is deterministic.
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index dc921cee282..9b5c4b93f62 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -742,8 +742,8 @@ class SparkConnectPlanner(val session: SparkSession) {
transformWindowExpression(exp.getWindow)
case proto.Expression.ExprTypeCase.EXTENSION =>
transformExpressionPlugin(exp.getExtension)
- case proto.Expression.ExprTypeCase.SCALAR_INLINE_USER_DEFINED_FUNCTION =>
-
transformScalarInlineUserDefinedFunction(exp.getScalarInlineUserDefinedFunction)
+ case proto.Expression.ExprTypeCase.COMMON_INLINE_USER_DEFINED_FUNCTION =>
+
transformCommonInlineUserDefinedFunction(exp.getCommonInlineUserDefinedFunction)
case _ =>
throw InvalidPlanInput(
s"Expression with ID: ${exp.getExprTypeCase.getNumber} is not
supported")
@@ -826,10 +826,10 @@ class SparkConnectPlanner(val session: SparkSession) {
* @re
[spark] branch branch-3.4 updated: [SPARK-42125][CONNECT][PYTHON] Pandas UDF in Spark Connect
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new f599c9daeb0 [SPARK-42125][CONNECT][PYTHON] Pandas UDF in Spark Connect
f599c9daeb0 is described below
commit f599c9daeb06c81c9986d73a94abdf2592ac6f75
Author: Xinrong Meng
AuthorDate: Tue Jan 31 09:12:20 2023 +0800
[SPARK-42125][CONNECT][PYTHON] Pandas UDF in Spark Connect
### What changes were proposed in this pull request?
Support Pandas UDF in Spark Connect.
Since Pandas UDF and scalar inline Python UDF share the same proto message,
`ScalarInlineUserDefinedFunction` is renamed to `CommonUserDefinedFunction`.
### Why are the changes needed?
To reach parity with the vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. Pandas UDF is supported in Spark Connect, as shown below.
```py
>>> from pyspark.sql.functions import pandas_udf
>>> import pandas as pd
>>> pandas_udf("double")
... def mean_udf(v: pd.Series) -> float:
... return v.mean()
...
>>> df = spark.createDataFrame([(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2,
10.0)], ("id", "v"))
>>> type(df)
>>> df.groupby("id").agg(mean_udf("v")).show()
+---+---+
| id|mean_udf(v)|
+---+---+
| 1|1.5|
| 2|6.0|
+---+---+
>>>
```
### How was this patch tested?
Existing tests.
Closes #39753 from xinrong-meng/connect_pd_udf.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit 0db63df2b2829f1358fb711cd657a22b7838ece2)
Signed-off-by: Xinrong Meng
---
.../main/protobuf/spark/connect/expressions.proto| 4 ++--
.../sql/connect/planner/SparkConnectPlanner.scala| 12 ++--
.../connect/messages/ConnectProtoMessagesSuite.scala | 10 +-
python/pyspark/sql/connect/expressions.py| 13 +++--
python/pyspark/sql/connect/proto/expressions_pb2.py | 20 ++--
python/pyspark/sql/connect/proto/expressions_pb2.pyi | 20 ++--
python/pyspark/sql/connect/udf.py| 4 ++--
python/pyspark/sql/pandas/functions.py | 11 ++-
8 files changed, 52 insertions(+), 42 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
index 7ae0a6c5008..5b27d4593db 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
@@ -44,7 +44,7 @@ message Expression {
UnresolvedExtractValue unresolved_extract_value = 12;
UpdateFields update_fields = 13;
UnresolvedNamedLambdaVariable unresolved_named_lambda_variable = 14;
-ScalarInlineUserDefinedFunction scalar_inline_user_defined_function = 15;
+CommonInlineUserDefinedFunction common_inline_user_defined_function = 15;
// This field is used to mark extensions to the protocol. When plugins
generate arbitrary
// relations they can add them here. During the planning the correct
resolution is done.
@@ -297,7 +297,7 @@ message Expression {
}
}
-message ScalarInlineUserDefinedFunction {
+message CommonInlineUserDefinedFunction {
// (Required) Name of the user-defined function.
string function_name = 1;
// (Required) Indicate if the user-defined function is deterministic.
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index dc921cee282..9b5c4b93f62 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -742,8 +742,8 @@ class SparkConnectPlanner(val session: SparkSession) {
transformWindowExpression(exp.getWindow)
case proto.Expression.ExprTypeCase.EXTENSION =>
transformExpressionPlugin(exp.getExtension)
- case proto.Expression.ExprTypeCase.SCALAR_INLINE_USER_DEFINED_FUNCTION =>
-
transformScalarInlineUserDefinedFunction(exp.getScalarInlineUserDefinedFunction)
+ case proto.Expression.ExprTypeCase.COMMON_INLINE_USER_DEFINED_FUNCTION =>
+
transformCommonInlineUserDefinedFunction(exp.getCommonInlineUserDefinedFunction)
case _ =>
throw InvalidPlanInput(
s"Expression with ID: ${exp.getExprTypeCase.getNumb
[spark] branch master updated: [SPARK-42210][CONNECT][PYTHON] Standardize registered pickled Python UDFs
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e7eb836376b [SPARK-42210][CONNECT][PYTHON] Standardize registered
pickled Python UDFs
e7eb836376b is described below
commit e7eb836376b72ae58b741e87d40f2d42c9914537
Author: Xinrong Meng
AuthorDate: Thu Feb 9 18:18:08 2023 +0800
[SPARK-42210][CONNECT][PYTHON] Standardize registered pickled Python UDFs
### What changes were proposed in this pull request?
Standardize registered pickled Python UDFs, specifically, implement
`spark.udf.register()`.
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.udf.register()` is added as shown below:
```py
>>> spark.udf
>>> f = spark.udf.register("f", lambda x: x+1, "int")
>>> f
at 0x7fbc905e5e50>
>>> spark.sql("SELECT f(id) FROM range(2)").collect()
[Row(f(id)=1), Row(f(id)=2)]
```
### How was this patch tested?
Unit tests.
Closes #39860 from xinrong-meng/connect_registered_udf.
Lead-authored-by: Xinrong Meng
Co-authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
.../src/main/protobuf/spark/connect/commands.proto | 1 +
.../sql/connect/planner/SparkConnectPlanner.scala | 33
python/pyspark/sql/connect/client.py | 59 ++
python/pyspark/sql/connect/expressions.py | 7 +++
python/pyspark/sql/connect/proto/commands_pb2.py | 40 +++
python/pyspark/sql/connect/proto/commands_pb2.pyi | 17 ++-
python/pyspark/sql/connect/session.py | 9 +++-
python/pyspark/sql/connect/udf.py | 58 -
python/pyspark/sql/session.py | 6 +--
.../sql/tests/connect/test_connect_basic.py| 1 -
.../pyspark/sql/tests/connect/test_parity_udf.py | 17 ---
python/pyspark/sql/udf.py | 3 ++
12 files changed, 216 insertions(+), 35 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
b/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
index 05c91d2c992..73218697577 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
@@ -31,6 +31,7 @@ option java_package = "org.apache.spark.connect.proto";
// produce a relational result.
message Command {
oneof command_type {
+CommonInlineUserDefinedFunction register_function = 1;
WriteOperation write_operation = 2;
CreateDataFrameViewCommand create_dataframe_view = 3;
WriteOperationV2 write_operation_v2 = 4;
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index c8a0860b871..3bf5d2b1d30 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -44,6 +44,7 @@ import org.apache.spark.sql.errors.QueryCompilationErrors
import org.apache.spark.sql.execution.QueryExecution
import org.apache.spark.sql.execution.arrow.ArrowConverters
import org.apache.spark.sql.execution.command.CreateViewCommand
+import org.apache.spark.sql.execution.python.UserDefinedPythonFunction
import org.apache.spark.sql.functions.{col, expr}
import org.apache.spark.sql.internal.CatalogImpl
import org.apache.spark.sql.types._
@@ -1399,6 +1400,8 @@ class SparkConnectPlanner(val session: SparkSession) {
def process(command: proto.Command): Unit = {
command.getCommandTypeCase match {
+ case proto.Command.CommandTypeCase.REGISTER_FUNCTION =>
+handleRegisterUserDefinedFunction(command.getRegisterFunction)
case proto.Command.CommandTypeCase.WRITE_OPERATION =>
handleWriteOperation(command.getWriteOperation)
case proto.Command.CommandTypeCase.CREATE_DATAFRAME_VIEW =>
@@ -1411,6 +1414,36 @@ class SparkConnectPlanner(val session: SparkSession) {
}
}
+ private def handleRegisterUserDefinedFunction(
+ fun: proto.CommonInlineUserDefinedFunction): Unit = {
+fun.getFunctionCase match {
+ case proto.CommonInlineUserDefinedFunction.FunctionCase.PYTHON_UDF =>
+handleRegisterPythonUDF(fun)
+ case _ =>
+throw InvalidPlanInput(
+ s"Function with ID: ${fun.getFunctionCase.getNumber} is not
supported")
+}
+ }
+
+
[spark] branch branch-3.4 updated: [SPARK-42210][CONNECT][PYTHON] Standardize registered pickled Python UDFs
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 9e2fc6448e7 [SPARK-42210][CONNECT][PYTHON] Standardize registered
pickled Python UDFs
9e2fc6448e7 is described below
commit 9e2fc6448e71c00b831d34e289278e6418d6d59f
Author: Xinrong Meng
AuthorDate: Thu Feb 9 18:18:08 2023 +0800
[SPARK-42210][CONNECT][PYTHON] Standardize registered pickled Python UDFs
### What changes were proposed in this pull request?
Standardize registered pickled Python UDFs, specifically, implement
`spark.udf.register()`.
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.udf.register()` is added as shown below:
```py
>>> spark.udf
>>> f = spark.udf.register("f", lambda x: x+1, "int")
>>> f
at 0x7fbc905e5e50>
>>> spark.sql("SELECT f(id) FROM range(2)").collect()
[Row(f(id)=1), Row(f(id)=2)]
```
### How was this patch tested?
Unit tests.
Closes #39860 from xinrong-meng/connect_registered_udf.
Lead-authored-by: Xinrong Meng
Co-authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit e7eb836376b72ae58b741e87d40f2d42c9914537)
Signed-off-by: Xinrong Meng
---
.../src/main/protobuf/spark/connect/commands.proto | 1 +
.../sql/connect/planner/SparkConnectPlanner.scala | 33
python/pyspark/sql/connect/client.py | 59 ++
python/pyspark/sql/connect/expressions.py | 7 +++
python/pyspark/sql/connect/proto/commands_pb2.py | 40 +++
python/pyspark/sql/connect/proto/commands_pb2.pyi | 17 ++-
python/pyspark/sql/connect/session.py | 9 +++-
python/pyspark/sql/connect/udf.py | 58 -
python/pyspark/sql/session.py | 6 +--
.../sql/tests/connect/test_connect_basic.py| 1 -
.../pyspark/sql/tests/connect/test_parity_udf.py | 17 ---
python/pyspark/sql/udf.py | 3 ++
12 files changed, 216 insertions(+), 35 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
b/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
index 05c91d2c992..73218697577 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/commands.proto
@@ -31,6 +31,7 @@ option java_package = "org.apache.spark.connect.proto";
// produce a relational result.
message Command {
oneof command_type {
+CommonInlineUserDefinedFunction register_function = 1;
WriteOperation write_operation = 2;
CreateDataFrameViewCommand create_dataframe_view = 3;
WriteOperationV2 write_operation_v2 = 4;
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index c8a0860b871..3bf5d2b1d30 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -44,6 +44,7 @@ import org.apache.spark.sql.errors.QueryCompilationErrors
import org.apache.spark.sql.execution.QueryExecution
import org.apache.spark.sql.execution.arrow.ArrowConverters
import org.apache.spark.sql.execution.command.CreateViewCommand
+import org.apache.spark.sql.execution.python.UserDefinedPythonFunction
import org.apache.spark.sql.functions.{col, expr}
import org.apache.spark.sql.internal.CatalogImpl
import org.apache.spark.sql.types._
@@ -1399,6 +1400,8 @@ class SparkConnectPlanner(val session: SparkSession) {
def process(command: proto.Command): Unit = {
command.getCommandTypeCase match {
+ case proto.Command.CommandTypeCase.REGISTER_FUNCTION =>
+handleRegisterUserDefinedFunction(command.getRegisterFunction)
case proto.Command.CommandTypeCase.WRITE_OPERATION =>
handleWriteOperation(command.getWriteOperation)
case proto.Command.CommandTypeCase.CREATE_DATAFRAME_VIEW =>
@@ -1411,6 +1414,36 @@ class SparkConnectPlanner(val session: SparkSession) {
}
}
+ private def handleRegisterUserDefinedFunction(
+ fun: proto.CommonInlineUserDefinedFunction): Unit = {
+fun.getFunctionCase match {
+ case proto.CommonInlineUserDefinedFunction.FunctionCase.PYTHON_UDF =>
+handleRegisterPythonUDF(fun)
+ case _ =>
+throw Inval
[spark] branch master updated: [SPARK-42263][CONNECT][PYTHON] Implement `spark.catalog.registerFunction`
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c619a402451 [SPARK-42263][CONNECT][PYTHON] Implement
`spark.catalog.registerFunction`
c619a402451 is described below
commit c619a402451df9ae5b305e5a48eb244c9ffd2eb6
Author: Xinrong Meng
AuthorDate: Tue Feb 14 13:56:12 2023 +0800
[SPARK-42263][CONNECT][PYTHON] Implement `spark.catalog.registerFunction`
### What changes were proposed in this pull request?
Implement `spark.catalog.registerFunction`.
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.catalog.registerFunction` is supported, as shown below.
```py
>>> udf
... def f():
... return 'hi'
...
>>> spark.catalog.registerFunction('HI', f)
>>> spark.sql("SELECT HI()").collect()
[Row(HI()='hi')]
```
### How was this patch tested?
Unit tests.
Closes #39984 from xinrong-meng/catalog_register.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/catalog.py | 3 ++
python/pyspark/sql/connect/catalog.py | 13 --
python/pyspark/sql/connect/udf.py | 2 +-
.../sql/tests/connect/test_connect_basic.py| 7
.../pyspark/sql/tests/connect/test_parity_udf.py | 49 +++---
python/pyspark/sql/tests/test_udf.py | 4 +-
6 files changed, 21 insertions(+), 57 deletions(-)
diff --git a/python/pyspark/sql/catalog.py b/python/pyspark/sql/catalog.py
index a7f3e761f3f..c83d02d4cb3 100644
--- a/python/pyspark/sql/catalog.py
+++ b/python/pyspark/sql/catalog.py
@@ -924,6 +924,9 @@ class Catalog:
.. deprecated:: 2.3.0
Use :func:`spark.udf.register` instead.
+
+.. versionchanged:: 3.4.0
+Support Spark Connect.
"""
warnings.warn("Deprecated in 2.3.0. Use spark.udf.register instead.",
FutureWarning)
return self._sparkSession.udf.register(name, f, returnType)
diff --git a/python/pyspark/sql/connect/catalog.py
b/python/pyspark/sql/connect/catalog.py
index b7ea44e831e..233fb904529 100644
--- a/python/pyspark/sql/connect/catalog.py
+++ b/python/pyspark/sql/connect/catalog.py
@@ -18,8 +18,9 @@ from pyspark.sql.connect import check_dependencies
check_dependencies(__name__, __file__)
-from typing import Any, List, Optional, TYPE_CHECKING
+from typing import Any, Callable, List, Optional, TYPE_CHECKING
+import warnings
import pandas as pd
from pyspark.sql.types import StructType
@@ -36,6 +37,7 @@ from pyspark.sql.connect import plan
if TYPE_CHECKING:
from pyspark.sql.connect.session import SparkSession
+from pyspark.sql.connect._typing import DataTypeOrString,
UserDefinedFunctionLike
class Catalog:
@@ -306,8 +308,13 @@ class Catalog:
refreshByPath.__doc__ = PySparkCatalog.refreshByPath.__doc__
-def registerFunction(self, *args: Any, **kwargs: Any) -> None:
-raise NotImplementedError("registerFunction() is not implemented.")
+def registerFunction(
+self, name: str, f: Callable[..., Any], returnType:
Optional["DataTypeOrString"] = None
+) -> "UserDefinedFunctionLike":
+warnings.warn("Deprecated in 2.3.0. Use spark.udf.register instead.",
FutureWarning)
+return self._sparkSession.udf.register(name, f, returnType)
+
+registerFunction.__doc__ = PySparkCatalog.registerFunction.__doc__
Catalog.__doc__ = PySparkCatalog.__doc__
diff --git a/python/pyspark/sql/connect/udf.py
b/python/pyspark/sql/connect/udf.py
index 39c31e85992..bef5a99a65b 100644
--- a/python/pyspark/sql/connect/udf.py
+++ b/python/pyspark/sql/connect/udf.py
@@ -212,7 +212,7 @@ class UDFRegistration:
)
return_udf = f
self.sparkSession._client.register_udf(
-f, f.returnType, name, f.evalType, f.deterministic
+f.func, f.returnType, name, f.evalType, f.deterministic
)
else:
if returnType is None:
diff --git a/python/pyspark/sql/tests/connect/test_connect_basic.py
b/python/pyspark/sql/tests/connect/test_connect_basic.py
index 9e9341c9a2a..8bfffee1ac1 100644
--- a/python/pyspark/sql/tests/connect/test_connect_basic.py
+++ b/python/pyspark/sql/tests/connect/test_connect_basic.py
@@ -2805,13 +2805,6 @@ class SparkConnectBasicTests(SparkConnectSQLTestCase):
with self.assertRaises(NotImplementedError):
getattr(self.connect, f)()
-def test_unsupported_catalog_functions(self):
-# SPAR
[spark] branch branch-3.4 updated: [SPARK-42263][CONNECT][PYTHON] Implement `spark.catalog.registerFunction`
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new ea0f50b18d6 [SPARK-42263][CONNECT][PYTHON] Implement
`spark.catalog.registerFunction`
ea0f50b18d6 is described below
commit ea0f50b18d6230fd5c5362b84f3dabc045635883
Author: Xinrong Meng
AuthorDate: Tue Feb 14 13:56:12 2023 +0800
[SPARK-42263][CONNECT][PYTHON] Implement `spark.catalog.registerFunction`
### What changes were proposed in this pull request?
Implement `spark.catalog.registerFunction`.
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.catalog.registerFunction` is supported, as shown below.
```py
>>> udf
... def f():
... return 'hi'
...
>>> spark.catalog.registerFunction('HI', f)
>>> spark.sql("SELECT HI()").collect()
[Row(HI()='hi')]
```
### How was this patch tested?
Unit tests.
Closes #39984 from xinrong-meng/catalog_register.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit c619a402451df9ae5b305e5a48eb244c9ffd2eb6)
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/catalog.py | 3 ++
python/pyspark/sql/connect/catalog.py | 13 --
python/pyspark/sql/connect/udf.py | 2 +-
.../sql/tests/connect/test_connect_basic.py| 7
.../pyspark/sql/tests/connect/test_parity_udf.py | 49 +++---
python/pyspark/sql/tests/test_udf.py | 4 +-
6 files changed, 21 insertions(+), 57 deletions(-)
diff --git a/python/pyspark/sql/catalog.py b/python/pyspark/sql/catalog.py
index a7f3e761f3f..c83d02d4cb3 100644
--- a/python/pyspark/sql/catalog.py
+++ b/python/pyspark/sql/catalog.py
@@ -924,6 +924,9 @@ class Catalog:
.. deprecated:: 2.3.0
Use :func:`spark.udf.register` instead.
+
+.. versionchanged:: 3.4.0
+Support Spark Connect.
"""
warnings.warn("Deprecated in 2.3.0. Use spark.udf.register instead.",
FutureWarning)
return self._sparkSession.udf.register(name, f, returnType)
diff --git a/python/pyspark/sql/connect/catalog.py
b/python/pyspark/sql/connect/catalog.py
index b7ea44e831e..233fb904529 100644
--- a/python/pyspark/sql/connect/catalog.py
+++ b/python/pyspark/sql/connect/catalog.py
@@ -18,8 +18,9 @@ from pyspark.sql.connect import check_dependencies
check_dependencies(__name__, __file__)
-from typing import Any, List, Optional, TYPE_CHECKING
+from typing import Any, Callable, List, Optional, TYPE_CHECKING
+import warnings
import pandas as pd
from pyspark.sql.types import StructType
@@ -36,6 +37,7 @@ from pyspark.sql.connect import plan
if TYPE_CHECKING:
from pyspark.sql.connect.session import SparkSession
+from pyspark.sql.connect._typing import DataTypeOrString,
UserDefinedFunctionLike
class Catalog:
@@ -306,8 +308,13 @@ class Catalog:
refreshByPath.__doc__ = PySparkCatalog.refreshByPath.__doc__
-def registerFunction(self, *args: Any, **kwargs: Any) -> None:
-raise NotImplementedError("registerFunction() is not implemented.")
+def registerFunction(
+self, name: str, f: Callable[..., Any], returnType:
Optional["DataTypeOrString"] = None
+) -> "UserDefinedFunctionLike":
+warnings.warn("Deprecated in 2.3.0. Use spark.udf.register instead.",
FutureWarning)
+return self._sparkSession.udf.register(name, f, returnType)
+
+registerFunction.__doc__ = PySparkCatalog.registerFunction.__doc__
Catalog.__doc__ = PySparkCatalog.__doc__
diff --git a/python/pyspark/sql/connect/udf.py
b/python/pyspark/sql/connect/udf.py
index 39c31e85992..bef5a99a65b 100644
--- a/python/pyspark/sql/connect/udf.py
+++ b/python/pyspark/sql/connect/udf.py
@@ -212,7 +212,7 @@ class UDFRegistration:
)
return_udf = f
self.sparkSession._client.register_udf(
-f, f.returnType, name, f.evalType, f.deterministic
+f.func, f.returnType, name, f.evalType, f.deterministic
)
else:
if returnType is None:
diff --git a/python/pyspark/sql/tests/connect/test_connect_basic.py
b/python/pyspark/sql/tests/connect/test_connect_basic.py
index 9e9341c9a2a..8bfffee1ac1 100644
--- a/python/pyspark/sql/tests/connect/test_connect_basic.py
+++ b/python/pyspark/sql/tests/connect/test_connect_basic.py
@@ -2805,13 +2805,6 @@ class SparkConnectBasicTests(SparkConnectSQLTestCase):
with self.assertRaises(NotImplementedError):
[spark] 01/01: Preparing Spark release v3.4.0-rc1
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git commit 1845fa200cbf4283e8be5fdd240821b7a13b00b7 Author: Xinrong Meng AuthorDate: Thu Feb 16 23:07:56 2023 + Preparing Spark release v3.4.0-rc1 --- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 4 ++-- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 42 files changed, 43 insertions(+), 43 deletions(-) diff --git a/assembly/pom.xml b/assembly/pom.xml index f37edcd7e49..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index d19883549d0..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index ff2cc71c2c9..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index de4730c5b71..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index a77732bb8b8..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml index f4e442b3ba7..2ee25ebfffc 100644 --- a/common/sketch/pom.xml +++ b/common/sketch/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/tags/pom.xml b/common/tags/pom.xml index 216812152ad..5c31e6eb365 100644 --- a/common/tags/pom.xml +++ b/common/tags/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT
[spark] tag v3.4.0-rc1 created (now 1845fa200cb)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git at 1845fa200cb (commit) This tag includes the following new commits: new 1845fa200cb Preparing Spark release v3.4.0-rc1 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc1
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git commit d89d6abd83a51fcab75e0aea0a3d5ba943bd2280 Author: Xinrong Meng AuthorDate: Fri Feb 17 03:54:15 2023 + Preparing Spark release v3.4.0-rc1 --- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 4 ++-- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 42 files changed, 43 insertions(+), 43 deletions(-) diff --git a/assembly/pom.xml b/assembly/pom.xml index f37edcd7e49..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index d19883549d0..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index ff2cc71c2c9..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index de4730c5b71..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index a77732bb8b8..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml index f4e442b3ba7..2ee25ebfffc 100644 --- a/common/sketch/pom.xml +++ b/common/sketch/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/tags/pom.xml b/common/tags/pom.xml index 216812152ad..5c31e6eb365 100644 --- a/common/tags/pom.xml +++ b/common/tags/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0-SNAPSHOT
[spark] tag v3.4.0-rc1 created (now d89d6abd83a)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git at d89d6abd83a (commit) This tag includes the following new commits: new d89d6abd83a Preparing Spark release v3.4.0-rc1 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit 9f22acdc32055d5437f43fa0f77644433ec32822 Author: Xinrong Meng AuthorDate: Fri Feb 17 03:54:24 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index 58dd9ef46e0..a4111eb64d9 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
[spark] branch branch-3.4 updated (7c1c8be960e -> 9f22acdc320)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from 7c1c8be960e [SPARK-42468][CONNECT] Implement agg by (String, String)* add d89d6abd83a Preparing Spark release v3.4.0-rc1 new 9f22acdc320 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] tag v3.4.0-rc1 created (now 09c2a32a9f3)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git at 09c2a32a9f3 (commit) This tag includes the following new commits: new 09c2a32a9f3 Preparing Spark release v3.4.0-rc1 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc1
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git commit 09c2a32a9f3982bb54da8d1246ac28fedd6f4b35 Author: Xinrong Meng AuthorDate: Fri Feb 17 21:33:33 2023 + Preparing Spark release v3.4.0-rc1 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index a4111eb64d9..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml inde
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit e4a6e5809c054d65b31f22d21d4f4f9251531300 Author: Xinrong Meng AuthorDate: Fri Feb 17 21:33:40 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index 58dd9ef46e0..a4111eb64d9 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
[spark] branch branch-3.4 updated (b38c2e18d62 -> e4a6e5809c0)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from b38c2e18d62 [SPARK-42461][CONNECT] Scala Client implement first batch of functions add 09c2a32a9f3 Preparing Spark release v3.4.0-rc1 new e4a6e5809c0 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60185 - /dev/spark/v3.4.0-rc1-bin/
Author: xinrong Date: Sat Feb 18 01:19:55 2023 New Revision: 60185 Log: Apache Spark v3.4.0-rc1 Added: dev/spark/v3.4.0-rc1-bin/ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc Sat Feb 18 01:19:55 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEDDPTXhqSlrMs8xAFrNhPIJMLR+gFAmPwIpYTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCs2E8gkwtH6MJNEAC0W8XElAhDay5i0fZ3jNAKSGUy6UHj +VRk4QgPRCdOHABL1sp3TxtvGR2Pv8MaXF6SnRIQA5T8SVJjklmkZTcgxs2KY+kpQ +ZKBT2iXzVYSjx+VFL4Ppw4llpnFg1hWoW/5VBq2tS7/iop3o53gLPxd/cx+Qh3tb ++ZO/6Fv0ZF9ANZKlx/N6MUx+7hZKsopnWh42Gso8yNSMspMWMr3DFHIKAcAm7EIO +nqHkNYMRcNvOzXa7YHzgAvos1lC+nbyEdY9wYh6HXEY3QMf6LFlREFebfb0Eexrw +onudAgbv+8/7lchjV26WLXQXsnt4wnm+Nl00Q+9cdOoBBKvM7tCSMpu16RUbKOF6 +5Ts6yQei/IIjw4o7zVGMnviQZPTGeqkYlTd+ndYL/fNK6U1OE8emD9adtMDNEeDZ +dSR24nzk2jVQWcLPQ2W2IQ23cXdlE6YMr36/7Td337ANyoE8qEj7Rwz5deKGKo5X +r3NMSbBNqDN9ooKTf6W5c69b+SX0e+dIU+5GFm6MFimeBTMiWgFF9CP/J+HYuQxy +CCQUP6hPWUtIUF6i9YZHkk9KbSY3+kAOmmb3Yk4rFDkVZl1VAHInVNVvh1zXS878 +RMrv4Uq2yHJ3snXYD9LjoHUUoqbCswPTtmtxwPk96x0PkPEJPtvTjg2JQTKvPzNo +lmyo9WbB/roHZQ== +=BGmb +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 Sat Feb 18 01:19:55 2023 @@ -0,0 +1 @@ +a66e13fa49db6f0bbd7c6a8c07677d4dec0873d28cbc1165f9b1db66d3f4bf847eafb9afd38b2c66f58aacc4172beded0ab0ec5314bcdfc9adcfa3e5d97e3689 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc Sat Feb 18 01:19:55 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEDDPTXhqSlrMs8xAFrNhPIJMLR+gFAmPwIpoTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCs2E8gkwtH6G7QD/9eIZ5yAVJiuiudt8aFlTj/E00rVMEV +bXf8Q/Yf5KjVL+NLsMAJKOB6mGfvsuafI9HaNWnK/xQ+Vzqip53jKbpOc/X5LEPM +sZuX7SM79ztNll/8DBzlapHVUzUHI7VKVw3MwEDX3yahBnBn17x9h4fPnQE577ok +2AbPND1G+7OcJjcLJuVQG17EeMWe9t0JnwZNXGhVfAR4xjZQzO8C9g+kMmKs6i0p +PeLrJS2j4xyRRZnr2CYSM/3VFzLuOzbLM0aGOj9KrNpbkE5aZ/1wdIim0k4T28e9 +amIkRNoVpU/TrR2f45TevNFMZJI8FBdyYus2hIIqQTm4THjFm4ImTnXBIbXv07Vh +IpsHPWLZ3FXgg4wSnYGZQNw47xkgk0JwupnWObpT9lubzhsh11n7fF3wKObBmIUE +v5SNaArZuq785u7YTosiz/71rIp0WLDBhCEyShR0Yjii8oqdfjGumce2bxiR0E21 +TyOJFJBLFXadh9BVYWJKBJk++gMx9EFatBq+EEpEfwJ29T+lJWBlonSZLAG14nnu +T94dDmtL1kPxyDY98BWPykEPliXEe+ahIHZk6T4qL81+Xqx8QE9bh8eqn2iC5rgt +URnsWCcet6p4vDmDpYe1udLxgYEv2Tj80uuIHK0WDmUZQxFFWwrQsqDzUPtC8F4u +B11HNp711dGrZQ== +=6c/U +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
[spark] tag v3.4.0-rc1 created (now 96cff939031)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git at 96cff939031 (commit) This tag includes the following new commits: new 96cff939031 Preparing Spark release v3.4.0-rc1 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc1
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git commit 96cff93903153a3bcdca02d346daa9d65614d00a Author: Xinrong Meng AuthorDate: Sat Feb 18 12:11:25 2023 + Preparing Spark release v3.4.0-rc1 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index a4111eb64d9..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml inde
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit fdbc57aaf431745ced4a1bea4057553e0c939d32 Author: Xinrong Meng AuthorDate: Sat Feb 18 12:12:49 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index 58dd9ef46e0..a4111eb64d9 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
[spark] branch branch-3.4 updated (2b54f076794 -> fdbc57aaf43)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from 2b54f076794 [SPARK-42430][DOC][FOLLOW-UP] Revise the java doc for TimestampNTZ & ANSI interval types add 96cff939031 Preparing Spark release v3.4.0-rc1 new fdbc57aaf43 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60202 - /dev/spark/v3.4.0-rc1-bin/
Author: xinrong Date: Mon Feb 20 00:49:21 2023 New Revision: 60202 Log: Removing RC artifacts. Removed: dev/spark/v3.4.0-rc1-bin/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60203 - /dev/spark/v3.4.0-rc1-bin/
Author: xinrong Date: Mon Feb 20 01:01:42 2023 New Revision: 60203 Log: Apache Spark v3.4.0-rc1 Added: dev/spark/v3.4.0-rc1-bin/ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc Mon Feb 20 01:01:42 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEDDPTXhqSlrMs8xAFrNhPIJMLR+gFAmPxf5cTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCs2E8gkwtH6I6gEACmdKxXlIrG6Nzi7Hv8Xie11LIRzVUP +59kSQ/bOYEdloW5gx5nLg+Cpcwh+yvgEvT0clvTNznXD4NEDRuS9XyPsRoXos+Ct +YL/xJo23+3zX1/OGE4P/fi7NXrgC3GmX3KKzpn3RkKuC6QRh6U1R1jlkl896LcHK +fOcLDuLCAKA6fy+EmlkX6H4sZGGLM5b2gYJcukvbA8bH5kdyWF2mPgprYwVUtryE +UfciZ9O5BSaawA5fo2MTmaI/9JAN9j1Vnxg+CQVnDN9arnQMp/0PegblyEa7ZRjt +ww8r/Ylq5F9Yi1wFLLhkgyF7KzLQtO8Bl/ar1UoDhWnTnNaAEUbEtVCN2Wy1E1y/ +BK2nKYzNM3cqXnLXMyXxSVVl6Cx4NXVpDxt94VlvO5S+ijFmyd2DyN2G/MCF9yJg +IQcad+vVtt6BdXbmFW+lD4eVFtXbX+eKrDPVKLMYCaWyTZkw3aCachSprjJabX0l +ph4ogML8iOVQiODobKzI+S4EXRMe5KDD9VXAVbN+1jOyTdnU7WYqSWI3rh7BGBwO +ihwBOHOjI+dkr0awBTmDKMXWaLeUYiDfXqeoVxNtXJ7SptPJcfkd47XpR9Tgw6yU +oxYMHLMrYYAC6qFMxjWbJz029FJxBvRJCmynQPCd7p0tmPL0qteqGymckjGUv8ko +TdJcHjdc2+UyeQ== +=TUhq +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 Mon Feb 20 01:01:42 2023 @@ -0,0 +1 @@ +38b2b86698d182620785b8f34d6f9a35e0a7f2ae2208e999cece2928ff66d50e75c621ce35189610d830f2475c2c134c3be5d4460050da65da23523d88707ceb SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc Mon Feb 20 01:01:42 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEDDPTXhqSlrMs8xAFrNhPIJMLR+gFAmPxf5wTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCs2E8gkwtH6F2ZEACP0qBBbAv0z3lbq2Hvn3jeWyZVWbBy +BVWvfadOOKqKeC9VAgdfY6t6WT8yti0g5Ax+WqmgWHHLgjOKRECTWdlaSqD5m9bh +ALNphiKafoQjneqkwegNuN4uWNikGQzmCGqJLQG7bGy+9NoO2ib/pN6an4bmIxtb +uqdglfB7bC+MXB4YKdqyW5LfE1gi3diSXngBdU0p0nBqsDiUcC+gCZPIt8z5AN8i +c9rNoFrEEZ3jb14335AtkIufP6ebK2YT/1NF/FdirNB1hgtAfIRREi7jzptAuHYt +jDvuNxo6O2+G80ExbK0z7Ab3Qv3seSzLJYaIalRSAIn+NqH60g9PRv1/80FYLVUv +VYKKf4Y+KqGn4/rwaxWiUL1ggkbcbay1cpbJWxMc1ARKO1uUaTwjgEPoNEIXg0uU +VYsQwfS61Tp+wkRLFQ/2yXp5S4kOgI+gyOpe2QVXioJvtgUc3CWCWBOsRvPUOLQt +wv91pnqu+m7YcUfOmosJvtQudBCT/STz1fnMCug0YygWMj6u5QhTXpbj+UycOVkq +Q0TvFe+kDsptQWKX2uHlYOvBA8CfzVDeauoDTvEOwx4lxPB1C6GZ1LrD/RTk5SEh +5r8Wotul5JdbCxHpynqcDruGXBZv2SOa7ChF8q8S6CdrSxLdWWPekt0Q0zzg63cJ +n4x/dQdcXBDaXA== +=O8hd +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r60229 - /dev/spark/v3.4.0-rc1-bin/
Author: xinrong Date: Tue Feb 21 00:44:12 2023 New Revision: 60229 Log: Removing RC artifacts. Removed: dev/spark/v3.4.0-rc1-bin/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc1
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git commit 81d39dcf742ed7114d6e01ecc2487825651e30cb Author: Xinrong Meng AuthorDate: Tue Feb 21 02:43:05 2023 + Preparing Spark release v3.4.0-rc1 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index a4111eb64d9..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml inde
[spark] tag v3.4.0-rc1 created (now 81d39dcf742)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git at 81d39dcf742 (commit) This tag includes the following new commits: new 81d39dcf742 Preparing Spark release v3.4.0-rc1 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated (4560d4c4f75 -> 1dfa58d78eb)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from 4560d4c4f75 [SPARK-41952][SQL] Fix Parquet zstd off-heap memory leak as a workaround for PARQUET-2160 add 81d39dcf742 Preparing Spark release v3.4.0-rc1 new 1dfa58d78eb Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit 1dfa58d78eba7080a244945c23f7b35b62dde12b Author: Xinrong Meng AuthorDate: Tue Feb 21 02:43:10 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index 58dd9ef46e0..a4111eb64d9 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
[spark] branch master updated (0e8a20e6da1 -> 0c20263dcd0)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 0e8a20e6da1 [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation add 0c20263dcd0 [SPARK-42507][SQL][TESTS] Simplify ORC schema merging conflict error check No new revisions were added by this update. Summary of changes: .../spark/sql/execution/datasources/orc/OrcSourceSuite.scala | 7 ++- 1 file changed, 2 insertions(+), 5 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42507][SQL][TESTS] Simplify ORC schema merging conflict error check
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new f394322be3b [SPARK-42507][SQL][TESTS] Simplify ORC schema merging
conflict error check
f394322be3b is described below
commit f394322be3b9a0451e0dff158129b607549b9160
Author: Dongjoon Hyun
AuthorDate: Tue Feb 21 17:48:09 2023 +0800
[SPARK-42507][SQL][TESTS] Simplify ORC schema merging conflict error check
### What changes were proposed in this pull request?
This PR aims to simplify ORC schema merging conflict error check.
### Why are the changes needed?
Currently, `branch-3.4` CI is broken because the order of partitions.
- https://github.com/apache/spark/runs/11463120795
- https://github.com/apache/spark/runs/11463886897
- https://github.com/apache/spark/runs/11467827738
- https://github.com/apache/spark/runs/11471484144
- https://github.com/apache/spark/runs/11471507531
- https://github.com/apache/spark/runs/11474764316

### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the CIs.
Closes #40101 from dongjoon-hyun/SPARK-42507.
Authored-by: Dongjoon Hyun
Signed-off-by: Xinrong Meng
(cherry picked from commit 0c20263dcd0c394f8bfd6fa2bfc62031135de06a)
Signed-off-by: Xinrong Meng
---
.../spark/sql/execution/datasources/orc/OrcSourceSuite.scala | 7 ++-
1 file changed, 2 insertions(+), 5 deletions(-)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcSourceSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcSourceSuite.scala
index c821276431e..024f5f6b67e 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcSourceSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcSourceSuite.scala
@@ -455,11 +455,8 @@ abstract class OrcSuite
throw new UnsupportedOperationException(s"Unknown ORC
implementation: $impl")
}
-checkError(
- exception = innerException.asInstanceOf[SparkException],
- errorClass = "CANNOT_MERGE_INCOMPATIBLE_DATA_TYPE",
- parameters = Map("left" -> "\"BIGINT\"", "right" -> "\"STRING\"")
-)
+assert(innerException.asInstanceOf[SparkException].getErrorClass ===
+ "CANNOT_MERGE_INCOMPATIBLE_DATA_TYPE")
}
// it is ok if no schema merging
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc1
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git commit e2484f626bb338274665a49078b528365ea18c3b Author: Xinrong Meng AuthorDate: Tue Feb 21 10:39:21 2023 + Preparing Spark release v3.4.0-rc1 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index a4111eb64d9..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml inde
[spark] tag v3.4.0-rc1 created (now e2484f626bb)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc1 in repository https://gitbox.apache.org/repos/asf/spark.git at e2484f626bb (commit) This tag includes the following new commits: new e2484f626bb Preparing Spark release v3.4.0-rc1 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated (f394322be3b -> 63be7fd7334)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from f394322be3b [SPARK-42507][SQL][TESTS] Simplify ORC schema merging conflict error check add e2484f626bb Preparing Spark release v3.4.0-rc1 new 63be7fd7334 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit 63be7fd7334111474e79d88c687d376ede30e37f Author: Xinrong Meng AuthorDate: Tue Feb 21 10:39:26 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index 58dd9ef46e0..a4111eb64d9 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
svn commit: r60238 - /dev/spark/v3.4.0-rc1-bin/
Author: xinrong Date: Tue Feb 21 11:57:55 2023 New Revision: 60238 Log: Apache Spark v3.4.0-rc1 Added: dev/spark/v3.4.0-rc1-bin/ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc1-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.asc Tue Feb 21 11:57:55 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmP0sVMTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6Thsbk1D/4wKDoCUBbr0bOOPpGKbMyWggJQDdvl +xCDXR5nFFkLdY6vZFerIp32jX1JFQA2Enr24iCBy00ERszFT9LMRP66nOG3OseU1 +6eI4Y4l5ACAD35qdUjFsuPNPy71Q2HqWrY52isMZWfj8TYY9X3T3w9Wox6KgTOon +rGoOtj+N6tAF5ACvJIX43li8JPesJQNl1epbu2LtrZa+tFyfgQBowuHmhiQ5PQ/v +EufANZytLWllzX81EfNbiJ9hN9geqIHgXew6b1rtd8IS05PdDimA/uwtP+LqBBqq +MKfUA6Tf8T9SpN36ZN6/lfOKVKu0OFXc9qfJIj9cdBfhTcoP1vUGVMqNtWEQQFqo +DZVRnBrnnx5lQOYry3gm4UgdLtHpwqvOZtqpmbvSHV503+JCqBnFnw8jvGzaVfWZ +OIPa4AuhjAxqMcnCdLHmpg/QcX07/tPXPO0kpEWz7a1QjF6C+gidtbgIghY/HIzs +lNfI3TdWop3Wwnpa0kHHlwi15jfeaxnPQDtIw/YRWojbztE0wG8rXycoWl2h0o05 +XQ55Rl9qEviW3GPOW52SGAD47+2j3eU6lFEs+xz85E/jxIneYkuweMJ5Vk1iTdEH +7yfjQqVozR3QeyaYll9W1ax50LUtrMx5vTMdy82L0yzg0NQctqEa+I3HRQjgxVFB +7gqTLxqG8bpyPA== +=+Kud +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc1-bin/SparkR_3.4.0.tar.gz.sha512 Tue Feb 21 11:57:55 2023 @@ -0,0 +1 @@ +21574f5fb95f397640c896678002559a10b6e264b3887115128bde380682065e8a3883dd94136c318c78f3047a7cd4a2763b617863686329b47532983f171240 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.asc Tue Feb 21 11:57:55 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmP0sVUTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsWbPD/9dWcxjrRR54QccE8zwX5oaiboVFXuI +0BLahV54IQi4HZjVgRHzbEWD/qaemW5Brcos003nsaGnXT0m0oi656X2967ZuJTk +zYanrIafACwplVo7uxcq2VBp6IKcDkWEUL42fAcV5GN1/1NpNHqzZqZMGe5ufKLB +05Np0ac8L6XXMpIG0to6H1LEmAW7/4PBARpzt6/TgZjoEI7a7YHMUlL0OjmHmP/m +3Ck8slg+Osk2opYJL4AXycFh36Ns43OG3TnhfLYyDG0jtiXpWBZ4Yt2bin55j0f/ +yrDe1lDlRJ14pXay2f/s5eFrz16qHfRluWZzxcEyJjZva1AD5V1XMh/zsRGDfvUZ +BkEM2GHYn3gZH9uuGfYbqL+pcZgrmVjZMgcZfhjyxLrRW8WBFr9g5lCIQF+4lpU8 +JwM4W3eOLyaC3wpVTfPU8rJfGExeBLhJ7zAyw65+yUx27KMUWatzGuQSA63iE1bg +FIruQABSDsenFARnLybB8l41t0PTGlWU9+g5E4BlU/+GbnxaQEuOTSnZOenhPOGe +n2g4Yfr81aYqVX8VKL0wzYXeB39SaXrtGhUaWVjFookNb42SNB1IPG2xQ+qQtcMw +jv1m+1BIMWXDLZcLlrIViEzoyNhIy83CipDujJpoh4tlXb3OHOJqYuIZjMPhgVcB +vtJFP8xIOdwRIg== +=058e +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc1-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r60241 - in /dev/spark/v3.4.0-rc1-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Tue Feb 21 13:34:14 2023 New Revision: 60241 Log: Apache Spark v3.4.0-rc1 docs [This commit notification would consist of 2806 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60249 - /dev/spark/KEYS
Author: xinrong Date: Wed Feb 22 03:51:47 2023 New Revision: 60249 Log: Update KEYS Modified: dev/spark/KEYS Modified: dev/spark/KEYS == --- dev/spark/KEYS (original) +++ dev/spark/KEYS Wed Feb 22 03:51:47 2023 @@ -1848,4 +1848,61 @@ P+3d/bY7eHLaFnkIuQR2dzaJti/nf2b/7VQHLm6H Y2wH1LgDJJsoBLPFNxhgTLjMlErwsZlacmXyogrmOS+ZvgQz/LZ1mIryTAkd1Gym JznYPjY83fSKkeCh =3Ggj --END PGP PUBLIC KEY BLOCK- \ No newline at end of file +-END PGP PUBLIC KEY BLOCK- + +pub rsa4096 2022-08-16 [SC] + 0C33D35E1A9296B32CF31005ACD84F20930B47E8 +uid [ultimate] Xinrong Meng (CODE SIGNING KEY) +sub rsa4096 2022-08-16 [E] +-BEGIN PGP PUBLIC KEY BLOCK- + +mQINBGL64s8BEADCeefEm9XB63o/xIGpnwurEL24h5LsZdA7k7juZ5C1Fu6m5amT +0A1n49YncYv6jDQD8xh+eiZ11+mYEAzkmGD+aVEMQA0/Zrp0rMe22Ymq5fQHfRCO +88sQl4PvmqaElcAswFz7RP+55GWSIfEbZIJhZQdukaVCZuC+Xpb68TAj2OSXZ+Mt +m8RdJXIJpmD0P6R7bvY4LPZL8tY7wtnxUj1I9wRnXc0AnbPfI6gGyF+b0x54b4Ey +2+sZ6tNH501I9hgdEOWj+nqQFZTTzZQPI1r3nPIA28T9VDOKi5dmoI6iXFjCWZ2N +dmsw8GN+45V1udOgylE2Mop7URzOQYlqaFnJvXzO/nZhAqbetrMmZ6jmlbqLEq/D +C8cgYFuMwER3oAC0OwpSz2HLCya95xHDdPqX+Iag0h0bbFBxSNpgzQiUk1mvSYXa ++7HGQ3rIfy7+87hA1BIHaN0L1oOw37UWk2IGDvS29JlGJ3SJDX5Ir5uBvW6k9So6 +xG9vT+l+R878rLcjJLJT4Me4pk4z8O4Uo+IY0uptiTYnvYRXBOw9wk9KpSckbr+s +I2keVwa+0fui4c1ESwNHR8HviALho9skvwaCAP3TUZ43SHeDU840M9LwDWc6VNc1 +x30YbgYeKtyU1deh7pcBhykUJPrZ457OllG8SbnhAncwmf8TaJjUkQARAQAB +tDRYaW5yb25nIE1lbmcgKENPREUgU0lHTklORyBLRVkpIDx4aW5yb25nQGFwYWNo +ZS5vcmc+iQJOBBMBCAA4FiEEDDPTXhqSlrMs8xAFrNhPIJMLR+gFAmL64s8CGwMF +CwkIBwIGFQoJCAsCBBYCAwECHgECF4AACgkQrNhPIJMLR+gNSRAAkhNM7vAFRwaX +MachhS97+L2ZklerzeZuCP0zeYZ9gZloGUx+eM3MWOglUcKH0f6DjPitMMCr1Qbo +OsENANTS5ZOp4r4rhbbNhYbA8Wbx8H+ZABmCuUNJMjmeVh3qL1WmHclApegqxiSH +uc9xXB1RZOJH2pS2v7UXW2c/Y745oT/YxWX9hBeJUPWmg6M6jn1/osnqmUngXSvB +HNzxzHT1gJJNEcRU3r5bKAJlLWBZzLO4pIgtFqIfpS79ieG54OwedrW3oqOheFKa +LTYInFAdscmZwIo8jHakqf+UMu3H5dzABBRATDvcci7nBPi+J8F7qLvklzb1zd0L +Ir/QnAy3zFUYUbwwRXDy0Gi0HsU5xP9QYT3pmtW3I+Xlwpso417XoE+1DYtizjbx +FuJaSNs7K7VPaELezdvtFL0SGYNkpxz7EiVcW6TxmLsLBoNAeaKhHYtwhblQKznv +6mEbjmiAo3oB68ghI+3xW2mZ+T+t3sgl5aNWiZ6RQx5v4liYc4vShmewcKGWvN7T +RC5Ert0GxMJGsx7fIRAgWDOI1aMj5bx9H23d3RKxJWrRCXhSlg1lyzVj+GCrhYAy +16/JH5ph0m+FCVwAP0GhHsZCQV1AT+YL7lgEZvmGq0ucDShc69lLh7qsxMg7zckk +l66F14Imuz0EasVCdI3IwkuTFch9Quu5Ag0EYvrizwEQANpINEPd+Vio1D0opPBO +Sa4keWk5IvvGETt6jUBemQten1gOB89Zba3E8ZgJpPobaThFrpsQJ9wNM8+KBHGm +U+DTP+JC+65J9Eq6KA8qcH2jn3xKBWipWUACKUCvpFSNq63f3+RVbAyTYdykRhEU +Ih+7eFtl3X0Q6v92TMZL26euXqt73UoOsoulKEmfSyhiQBQX7WNCtq3JR/mZ4+OA +/N3J7qw+emvKG3t8h3/5CtpZWEMaJwaGyyENScsw5KEOYjl9o11mMeYRYfZ0n0h7 +DA8BmBl/k71+UvdopdzuwjRib02uZfdCC15tltLpoVeL/pa0GRmTRuCJARwjDD95 +xbrrYYqw2wD6l3Mtv/EooIBdzGpP15VnD4DFC5W9vxnxuEfSnX0DxCObsd6MCzZw +GOiF4HudfFzB2SiE/OXNaAxdpSD9C8n0Y3ac74dk6uamzCkSnCjzzAOytFZY18fi +N5ihDA9+2TeEOL0RVrQw0Mdc4X80A1dlCJ6Gh1Py4WOtDxB5UmSY2olvV6p5pRRD +1HEnM9bivPdEErYpUI72K4L5feXFxt/obQ0rZMmmnYMldAcPcqsTMVgPWZICK/z0 +X/SrOR0YEa28XA+V69o4TwPR77oUK6t3SiFzAi3VmQtAP6NkqL+FNMa0V1ZiEPse +lZhKVziNh5Jb8bnkQA6+9Md3ABEBAAGJAjYEGAEIACAWIQQMM9NeGpKWsyzzEAWs +2E8gkwtH6AUCYvrizwIbDAAKCRCs2E8gkwtH6OYIEACtPjMCg+x+vxVU8KhqwxpA +UyDOuNbzB2TSMmETgGqHDqk/F4eSlMvZTukGlo5yPDYXhd7vUT45mrlRq8ljzBLr +NkX2mkGgocdjAjSF2rgugMb+APpKNFxZtUPKosyyOPS9z4+4tjxfCpj2u2hZy8PD +C3/6dz9Yga0kgWu2GWFZFFZiGxPyUCkjnUBWz53dT/1JwWt3W81bihVfhLX9CVgO +KPEoZ96BaEucAHY0r/yq0zAq/+DCTYRrDLkeuZaDTB1RThWOrW+GCoPcIxbLi4/j +/YkIGQCaYvpVsuacklwqhSxhucqctRklGHLrjLdxrqcS1pIfraCsRJazUoO1Uu7n +DQ/aF9fczzX9nKv7t341lGn+Ujv5EEuaA/y38XSffsHxCmpEcvjGAH0NZsjHbYd/ +abeFTAnMV1r2r9/UcyuosEsaRyjW4Ljd51wWyGVv4Ky40HJYRmtefJX+1QDAntPJ +lVPHQCa2B/YIDrFeokXFxDqONkA+fFm+lDb83lhAAhjxCwfbytZqJFTvYh7TQTLx +3+ZA1BoFhxIHnR2mrFK+yqny9w6YAeZ8YMG5edH1EKoNVfic7OwwId1eQL6FCKCv +F3sNZiCC3i7P6THg9hZSF1eNbfiuZuMxUbw3OZgYhyXLB023vEZ1mUQCAcbfsQxU +sw6Rs2zVSxvPcg5CN8APig== +=fujW +-END PGP PUBLIC KEY BLOCK- - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60251 - /dev/spark/KEYS
Author: xinrong Date: Wed Feb 22 07:01:27 2023 New Revision: 60251 Log: Update KEYS Modified: dev/spark/KEYS Modified: dev/spark/KEYS == --- dev/spark/KEYS (original) +++ dev/spark/KEYS Wed Feb 22 07:01:27 2023 @@ -1850,59 +1850,59 @@ JznYPjY83fSKkeCh =3Ggj -END PGP PUBLIC KEY BLOCK- -pub rsa4096 2022-08-16 [SC] - 0C33D35E1A9296B32CF31005ACD84F20930B47E8 -uid [ultimate] Xinrong Meng (CODE SIGNING KEY) -sub rsa4096 2022-08-16 [E] +pub rsa4096 2023-02-21 [SC] + CC68B3D16FE33A766705160BA7E57908C7A4E1B1 +uid [ultimate] Xinrong Meng (RELEASE SIGNING KEY) +sub rsa4096 2023-02-21 [E] -BEGIN PGP PUBLIC KEY BLOCK- -mQINBGL64s8BEADCeefEm9XB63o/xIGpnwurEL24h5LsZdA7k7juZ5C1Fu6m5amT -0A1n49YncYv6jDQD8xh+eiZ11+mYEAzkmGD+aVEMQA0/Zrp0rMe22Ymq5fQHfRCO -88sQl4PvmqaElcAswFz7RP+55GWSIfEbZIJhZQdukaVCZuC+Xpb68TAj2OSXZ+Mt -m8RdJXIJpmD0P6R7bvY4LPZL8tY7wtnxUj1I9wRnXc0AnbPfI6gGyF+b0x54b4Ey -2+sZ6tNH501I9hgdEOWj+nqQFZTTzZQPI1r3nPIA28T9VDOKi5dmoI6iXFjCWZ2N -dmsw8GN+45V1udOgylE2Mop7URzOQYlqaFnJvXzO/nZhAqbetrMmZ6jmlbqLEq/D -C8cgYFuMwER3oAC0OwpSz2HLCya95xHDdPqX+Iag0h0bbFBxSNpgzQiUk1mvSYXa -+7HGQ3rIfy7+87hA1BIHaN0L1oOw37UWk2IGDvS29JlGJ3SJDX5Ir5uBvW6k9So6 -xG9vT+l+R878rLcjJLJT4Me4pk4z8O4Uo+IY0uptiTYnvYRXBOw9wk9KpSckbr+s -I2keVwa+0fui4c1ESwNHR8HviALho9skvwaCAP3TUZ43SHeDU840M9LwDWc6VNc1 -x30YbgYeKtyU1deh7pcBhykUJPrZ457OllG8SbnhAncwmf8TaJjUkQARAQAB -tDRYaW5yb25nIE1lbmcgKENPREUgU0lHTklORyBLRVkpIDx4aW5yb25nQGFwYWNo -ZS5vcmc+iQJOBBMBCAA4FiEEDDPTXhqSlrMs8xAFrNhPIJMLR+gFAmL64s8CGwMF -CwkIBwIGFQoJCAsCBBYCAwECHgECF4AACgkQrNhPIJMLR+gNSRAAkhNM7vAFRwaX -MachhS97+L2ZklerzeZuCP0zeYZ9gZloGUx+eM3MWOglUcKH0f6DjPitMMCr1Qbo -OsENANTS5ZOp4r4rhbbNhYbA8Wbx8H+ZABmCuUNJMjmeVh3qL1WmHclApegqxiSH -uc9xXB1RZOJH2pS2v7UXW2c/Y745oT/YxWX9hBeJUPWmg6M6jn1/osnqmUngXSvB -HNzxzHT1gJJNEcRU3r5bKAJlLWBZzLO4pIgtFqIfpS79ieG54OwedrW3oqOheFKa -LTYInFAdscmZwIo8jHakqf+UMu3H5dzABBRATDvcci7nBPi+J8F7qLvklzb1zd0L -Ir/QnAy3zFUYUbwwRXDy0Gi0HsU5xP9QYT3pmtW3I+Xlwpso417XoE+1DYtizjbx -FuJaSNs7K7VPaELezdvtFL0SGYNkpxz7EiVcW6TxmLsLBoNAeaKhHYtwhblQKznv -6mEbjmiAo3oB68ghI+3xW2mZ+T+t3sgl5aNWiZ6RQx5v4liYc4vShmewcKGWvN7T -RC5Ert0GxMJGsx7fIRAgWDOI1aMj5bx9H23d3RKxJWrRCXhSlg1lyzVj+GCrhYAy -16/JH5ph0m+FCVwAP0GhHsZCQV1AT+YL7lgEZvmGq0ucDShc69lLh7qsxMg7zckk -l66F14Imuz0EasVCdI3IwkuTFch9Quu5Ag0EYvrizwEQANpINEPd+Vio1D0opPBO -Sa4keWk5IvvGETt6jUBemQten1gOB89Zba3E8ZgJpPobaThFrpsQJ9wNM8+KBHGm -U+DTP+JC+65J9Eq6KA8qcH2jn3xKBWipWUACKUCvpFSNq63f3+RVbAyTYdykRhEU -Ih+7eFtl3X0Q6v92TMZL26euXqt73UoOsoulKEmfSyhiQBQX7WNCtq3JR/mZ4+OA -/N3J7qw+emvKG3t8h3/5CtpZWEMaJwaGyyENScsw5KEOYjl9o11mMeYRYfZ0n0h7 -DA8BmBl/k71+UvdopdzuwjRib02uZfdCC15tltLpoVeL/pa0GRmTRuCJARwjDD95 -xbrrYYqw2wD6l3Mtv/EooIBdzGpP15VnD4DFC5W9vxnxuEfSnX0DxCObsd6MCzZw -GOiF4HudfFzB2SiE/OXNaAxdpSD9C8n0Y3ac74dk6uamzCkSnCjzzAOytFZY18fi -N5ihDA9+2TeEOL0RVrQw0Mdc4X80A1dlCJ6Gh1Py4WOtDxB5UmSY2olvV6p5pRRD -1HEnM9bivPdEErYpUI72K4L5feXFxt/obQ0rZMmmnYMldAcPcqsTMVgPWZICK/z0 -X/SrOR0YEa28XA+V69o4TwPR77oUK6t3SiFzAi3VmQtAP6NkqL+FNMa0V1ZiEPse -lZhKVziNh5Jb8bnkQA6+9Md3ABEBAAGJAjYEGAEIACAWIQQMM9NeGpKWsyzzEAWs -2E8gkwtH6AUCYvrizwIbDAAKCRCs2E8gkwtH6OYIEACtPjMCg+x+vxVU8KhqwxpA -UyDOuNbzB2TSMmETgGqHDqk/F4eSlMvZTukGlo5yPDYXhd7vUT45mrlRq8ljzBLr -NkX2mkGgocdjAjSF2rgugMb+APpKNFxZtUPKosyyOPS9z4+4tjxfCpj2u2hZy8PD -C3/6dz9Yga0kgWu2GWFZFFZiGxPyUCkjnUBWz53dT/1JwWt3W81bihVfhLX9CVgO -KPEoZ96BaEucAHY0r/yq0zAq/+DCTYRrDLkeuZaDTB1RThWOrW+GCoPcIxbLi4/j -/YkIGQCaYvpVsuacklwqhSxhucqctRklGHLrjLdxrqcS1pIfraCsRJazUoO1Uu7n -DQ/aF9fczzX9nKv7t341lGn+Ujv5EEuaA/y38XSffsHxCmpEcvjGAH0NZsjHbYd/ -abeFTAnMV1r2r9/UcyuosEsaRyjW4Ljd51wWyGVv4Ky40HJYRmtefJX+1QDAntPJ -lVPHQCa2B/YIDrFeokXFxDqONkA+fFm+lDb83lhAAhjxCwfbytZqJFTvYh7TQTLx -3+ZA1BoFhxIHnR2mrFK+yqny9w6YAeZ8YMG5edH1EKoNVfic7OwwId1eQL6FCKCv -F3sNZiCC3i7P6THg9hZSF1eNbfiuZuMxUbw3OZgYhyXLB023vEZ1mUQCAcbfsQxU -sw6Rs2zVSxvPcg5CN8APig== -=fujW +mQINBGP0Hf0BEACyHWHb/DyfpkIC64sJQKR7GGLBicFOxsVNYrxxcZJvdnfjFnHC +ajib6m6dIQ5g+YgH23U/jIpHhZbXLWrQkyuYW4JbaG8uobK5S7crAqpYjtwRJHRe +R4f8DO6nWUNxZGHYFU46zvt7GuBjN005u+X2Oxq9xau+CVgkS1r/vbykxDwGOcYM +/vmgITo+Zk2zs2Krea+ul0aVZRvhGB8ZHHSdz83NTDm0DwlzALFodLWIRvSblqtZ +SPVKntzmN6OYjVjPMK6HgLlVlH2WqOIexuZnbadioM6+Hg/eihXQVLU7wpBBliFA +KTUnCNRRxEF8M7zPKEpyQbV2KJqMLdGLpE+ZEfzOKUxbCBmzF1MQ5Pxm4mm8RlvA +DDoOI/I3IstoizsxI6hV7U3w22R4c++qmFtX/lzgDnCKfISBTQaofiVlvMg7fx+f +7bA1oJxlMJMpjNO9s3qudMAxtrSzHUnIt2ThsxcsL+wfu/HxvR1+PfX6eCCXaVjN +/ii0EkWbHBq6Jb1IDzKuU02oX0TWQisDqn+IHq8/Q46PH3H2nF6hfg8zJXMkTusc +T8AmCoQCeVEPMbnVTWW9sVJC2gQPrCQJHEUbu5OHb9REtJ3GqtRw+mogTrpO5ads +PO61a94fJQcTDgR59hShrXiXxUK07C/rXqexcVnXEZyfn/5ZnqmgdVNt2wARAQAB +tDdYaW5yb25nIE1lbmcgKFJFTEVBU0UgU0lHTklORyBLRVkpIDx4aW5yb25nQGFw +YWNoZS5vcmc+iQJOBBMBCgA4FiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmP0Hf0C +GwMFCwkIBwIGFQoJCAsCBBYCAwECHgECF4AACgkQp+V5CMek4bFlWg//YIN9HNQ2 +yj3gW9lXVTWtSzJvlnwZr5V9JBGevpWMNF3U38Dk0nlQUiSvHdpfQjIyITOYR9Iv +GxuZCp5szVaRc00pfQWFy684zLvwqrjKekLzCpkqTOGXHO2RxeJH2ZBqcI9OSpR5 +B2J94dlQItM/bKsXhMNOwmVtS6kSW36aN/0Nd9ZQF
[spark] branch master updated: [SPARK-42510][CONNECT][PYTHON] Implement `DataFrame.mapInPandas`
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 9abccad1d93 [SPARK-42510][CONNECT][PYTHON] Implement
`DataFrame.mapInPandas`
9abccad1d93 is described below
commit 9abccad1d93a243d7e47e53dcbc85568a460c529
Author: Xinrong Meng
AuthorDate: Sat Feb 25 07:39:54 2023 +0800
[SPARK-42510][CONNECT][PYTHON] Implement `DataFrame.mapInPandas`
### What changes were proposed in this pull request?
Implement `DataFrame.mapInPandas` and enable parity tests to vanilla
PySpark.
A proto message `FrameMap` is intorudced for `mapInPandas` and
`mapInArrow`(to implement next).
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `DataFrame.mapInPandas` is supported. An example is as shown below.
```py
>>> df = spark.range(2)
>>> def filter_func(iterator):
... for pdf in iterator:
... yield pdf[pdf.id == 1]
...
>>> df.mapInPandas(filter_func, df.schema)
DataFrame[id: bigint]
>>> df.mapInPandas(filter_func, df.schema).show()
+---+
| id|
+---+
| 1|
+---+
```
### How was this patch tested?
Unit tests.
Closes #40104 from xinrong-meng/mapInPandas.
Lead-authored-by: Xinrong Meng ]
Co-authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
.../main/protobuf/spark/connect/relations.proto| 10 +
.../sql/connect/planner/SparkConnectPlanner.scala | 18 +-
dev/sparktestsupport/modules.py| 1 +
python/pyspark/sql/connect/_typing.py | 8 +-
python/pyspark/sql/connect/client.py | 2 +-
python/pyspark/sql/connect/dataframe.py| 22 +-
python/pyspark/sql/connect/expressions.py | 6 +-
python/pyspark/sql/connect/plan.py | 25 ++-
python/pyspark/sql/connect/proto/relations_pb2.py | 222 +++--
python/pyspark/sql/connect/proto/relations_pb2.pyi | 36
python/pyspark/sql/connect/types.py| 4 +-
python/pyspark/sql/connect/udf.py | 20 +-
python/pyspark/sql/pandas/map_ops.py | 3 +
.../sql/tests/connect/test_parity_pandas_map.py| 50 +
python/pyspark/sql/tests/pandas/test_pandas_map.py | 46 +++--
15 files changed, 331 insertions(+), 142 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
b/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
index 29fffd65c75..4d96b6b0c7e 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
@@ -60,6 +60,7 @@ message Relation {
Unpivot unpivot = 25;
ToSchema to_schema = 26;
RepartitionByExpression repartition_by_expression = 27;
+FrameMap frame_map = 28;
// NA functions
NAFill fill_na = 90;
@@ -768,3 +769,12 @@ message RepartitionByExpression {
// (Optional) number of partitions, must be positive.
optional int32 num_partitions = 3;
}
+
+message FrameMap {
+ // (Required) Input relation for a Frame Map API: mapInPandas, mapInArrow.
+ Relation input = 1;
+
+ // (Required) Input user-defined function of a Frame Map API.
+ CommonInlineUserDefinedFunction func = 2;
+}
+
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index 268bf02fad9..cc43c1cace3 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -24,7 +24,7 @@ import com.google.common.collect.{Lists, Maps}
import com.google.protobuf.{Any => ProtoAny}
import org.apache.spark.TaskContext
-import org.apache.spark.api.python.SimplePythonFunction
+import org.apache.spark.api.python.{PythonEvalType, SimplePythonFunction}
import org.apache.spark.connect.proto
import org.apache.spark.sql.{Column, Dataset, Encoders, SparkSession}
import org.apache.spark.sql.catalyst.{expressions, AliasIdentifier,
FunctionIdentifier}
@@ -106,6 +106,8 @@ class SparkConnectPlanner(val session: SparkSession) {
case proto.Relation.RelTypeCase.UNPIVOT =>
transformUnpivot(rel.getUnpivot)
case proto.Relation.RelTypeCase.REPARTITION_BY_EXPRESSION =>
transformRepartitionByExpression(rel.getRepartitionByExpression)
+ case proto.Relation.RelTypeCase.FRAME_MAP =>
+transformFrameMap(rel.getFrameMap)
case proto.Relation.R
[spark] branch branch-3.4 updated: [SPARK-42510][CONNECT][PYTHON] Implement `DataFrame.mapInPandas`
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 000895da3f6 [SPARK-42510][CONNECT][PYTHON] Implement
`DataFrame.mapInPandas`
000895da3f6 is described below
commit 000895da3f6c0d17ccfdfe79c0ca34dfb9fb6e7b
Author: Xinrong Meng
AuthorDate: Sat Feb 25 07:39:54 2023 +0800
[SPARK-42510][CONNECT][PYTHON] Implement `DataFrame.mapInPandas`
### What changes were proposed in this pull request?
Implement `DataFrame.mapInPandas` and enable parity tests to vanilla
PySpark.
A proto message `FrameMap` is intorudced for `mapInPandas` and
`mapInArrow`(to implement next).
### Why are the changes needed?
To reach parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `DataFrame.mapInPandas` is supported. An example is as shown below.
```py
>>> df = spark.range(2)
>>> def filter_func(iterator):
... for pdf in iterator:
... yield pdf[pdf.id == 1]
...
>>> df.mapInPandas(filter_func, df.schema)
DataFrame[id: bigint]
>>> df.mapInPandas(filter_func, df.schema).show()
+---+
| id|
+---+
| 1|
+---+
```
### How was this patch tested?
Unit tests.
Closes #40104 from xinrong-meng/mapInPandas.
Lead-authored-by: Xinrong Meng ]
Co-authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit 9abccad1d93a243d7e47e53dcbc85568a460c529)
Signed-off-by: Xinrong Meng
---
.../main/protobuf/spark/connect/relations.proto| 10 +
.../sql/connect/planner/SparkConnectPlanner.scala | 18 +-
dev/sparktestsupport/modules.py| 1 +
python/pyspark/sql/connect/_typing.py | 8 +-
python/pyspark/sql/connect/client.py | 2 +-
python/pyspark/sql/connect/dataframe.py| 22 +-
python/pyspark/sql/connect/expressions.py | 6 +-
python/pyspark/sql/connect/plan.py | 25 ++-
python/pyspark/sql/connect/proto/relations_pb2.py | 222 +++--
python/pyspark/sql/connect/proto/relations_pb2.pyi | 36
python/pyspark/sql/connect/types.py| 4 +-
python/pyspark/sql/connect/udf.py | 20 +-
python/pyspark/sql/pandas/map_ops.py | 3 +
.../sql/tests/connect/test_parity_pandas_map.py| 50 +
python/pyspark/sql/tests/pandas/test_pandas_map.py | 46 +++--
15 files changed, 331 insertions(+), 142 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
b/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
index 29fffd65c75..4d96b6b0c7e 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/relations.proto
@@ -60,6 +60,7 @@ message Relation {
Unpivot unpivot = 25;
ToSchema to_schema = 26;
RepartitionByExpression repartition_by_expression = 27;
+FrameMap frame_map = 28;
// NA functions
NAFill fill_na = 90;
@@ -768,3 +769,12 @@ message RepartitionByExpression {
// (Optional) number of partitions, must be positive.
optional int32 num_partitions = 3;
}
+
+message FrameMap {
+ // (Required) Input relation for a Frame Map API: mapInPandas, mapInArrow.
+ Relation input = 1;
+
+ // (Required) Input user-defined function of a Frame Map API.
+ CommonInlineUserDefinedFunction func = 2;
+}
+
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index 268bf02fad9..cc43c1cace3 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -24,7 +24,7 @@ import com.google.common.collect.{Lists, Maps}
import com.google.protobuf.{Any => ProtoAny}
import org.apache.spark.TaskContext
-import org.apache.spark.api.python.SimplePythonFunction
+import org.apache.spark.api.python.{PythonEvalType, SimplePythonFunction}
import org.apache.spark.connect.proto
import org.apache.spark.sql.{Column, Dataset, Encoders, SparkSession}
import org.apache.spark.sql.catalyst.{expressions, AliasIdentifier,
FunctionIdentifier}
@@ -106,6 +106,8 @@ class SparkConnectPlanner(val session: SparkSession) {
case proto.Relation.RelTypeCase.UNPIVOT =>
transformUnpivot(rel.getUnpivot)
case proto.Relation.RelTypeCase.REPARTITION_BY_EXPRESSION =>
transformRepartitionByExpression(rel.getRepartitionByExpression)
+
[spark] 01/01: Preparing Spark release v3.4.0-rc2
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc2 in repository https://gitbox.apache.org/repos/asf/spark.git commit 759511bb59b206ac5ff18f377c239a2f38bf5db6 Author: Xinrong Meng AuthorDate: Thu Mar 2 06:25:32 2023 + Preparing Spark release v3.4.0-rc2 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index a4111eb64d9..58dd9ef46e0 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml index 22ce7
[spark] tag v3.4.0-rc2 created (now 759511bb59b)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc2 in repository https://gitbox.apache.org/repos/asf/spark.git at 759511bb59b (commit) This tag includes the following new commits: new 759511bb59b Preparing Spark release v3.4.0-rc2 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit aeacf0d0f24ec509b7bbf318bb71edb1cba8bc36 Author: Xinrong Meng AuthorDate: Thu Mar 2 06:25:37 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index 58dd9ef46e0..a4111eb64d9 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
[spark] branch branch-3.4 updated (4fa4d2fd54c -> aeacf0d0f24)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from 4fa4d2fd54c [SPARK-41823][CONNECT][FOLLOW-UP][TESTS] Disable ANSI mode in ProtoToParsedPlanTestSuite add 759511bb59b Preparing Spark release v3.4.0-rc2 new aeacf0d0f24 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60406 - /dev/spark/v3.4.0-rc2-bin/
Author: xinrong Date: Thu Mar 2 07:42:27 2023 New Revision: 60406 Log: Apache Spark v3.4.0-rc2 Added: dev/spark/v3.4.0-rc2-bin/ dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc2-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc2-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc2-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc2-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.asc Thu Mar 2 07:42:27 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQAUvITHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsRPdEACTNy0qOWmOXidbPjyZzJCdr8zkAIZX +UGhVWPrlF0sQR1FzTtPPwwI4sywSC+DNAetcYVXEzOVfNf3I/UgE02183xCQJVfx +EaE+lpCmIwFjY+AcPGwz7fZ+aTxFa2f9wu04G+q9Uaw40Ys/WMmvck/Wg4Ih0nj3 +PbBuftQIy5K1YHJOx6PvkzCpZsmP4njNGrJ+IJU8vpYh35zp8E3jkfbECCvKkTWE +ABWGxpAKjN5npkarbNpZp8Emd6EtrRYaJzDPApjW6GFSQAmZwE0WJj2nKJu4Aszu +fstx27dZ4bvx3bgbfSEmRgTc5VD7glzvWKIWqt0PdkDq1AQdwdFodZfJFqXUccuk +G3yL+RTrggtvDBEjcMh+ym6kOrHmUBgy7SqPfOI5UPO8PQ+KdhE94tqXfhHAl5QS +Okw1XWc2EQzDyeu/j+Kp4yc0tbZRnuqkAzS5yLJVix0z4GBOyRyvTsDLykwEM9h+ +jniFAkWfu+su9JRMfIdaXqak1DgyVZ9bxZOfLIo7lA5U4vYxCZM5TU8ToNDnnOWd +O0pbweQ/W4UdXP6AYEJt2J8wItDiv+xry4jI9JqTEPV5IbrAZjZmJ/RoMzjeh+eA +WwqSEXuWXrUStb9bPfhFnryYmbKGYGG7dRP6HnnaFlevBc6qrNlMPL3xedZsk12b +opcLL5skNQoHuA== +=6ENL +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc2-bin/SparkR_3.4.0.tar.gz.sha512 Thu Mar 2 07:42:27 2023 @@ -0,0 +1 @@ +9f719616f1547d449488957cc74d6dd9080e32096e1178deb0c339be47bb06e158d8b0c7a80f1e53595b34467d5b5b7f23d66643cca1fa9f5e8c7b9687893b59 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.asc Thu Mar 2 07:42:27 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQAUvQTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsSCWD/9LhMRWQlceBu5wuEwGdwCTSEvQvpCl +zDn1HKCwqXQvzj5YPOllSBolHCQgy1U3S08CeGF8kB+hT/MSozif/+qzMNTFWfz8 +EEyB02XxWjOXO38muJ51/r3WXseoB0L/yMqdipgZAQRT5A5i9xBZqH718a7k6pow +m+/8qD4oMYmnWE9X2TwW47uSCMpKOgZRSALBwx5HAQ6HADHfW3q6Rwdm6yL6vv0J +n/FTMjeKAKwetSYhwDwPCXaTTKaw8h90IWHOykZdv8IoynUO4egKfoeHeOKQ8Dyl +8mlqIWsQi0wdcrfAlKp2HjD001j0iUV8ZfDkZsmReTRNf8Y7yKdFF6BBAW+zPwAw +ILsb0HeP50s36WiON7Ywjy8pXJdOBN+6QiM9CIP7c5D45RNAbPe8ARhDZwuHZTMy +7jzAYnrjDIXlrFGmpFS2I+xk0/ZoI2H6BC8V7t5ZvhJ8Qm7SifAgfOt5G9rlUwu0 +BnCE3INQghRq5mv9aH40aHZPhVUN8woTxUussNXeqds4cAVXdvj7BQJMqZtplj1N +k4bFKvjjtO/GbrbTcNTClqk7CtII4GRQCJWmV7ksvDejavRfDMJn6Bt/ZhHYfDPw +rOXXuMX/HdVgH1E+RhntqnejilGuKNsWf08dZPgQ1kwMd2fnygDMoaUbG769nJqW +JLAkWKLvu+YXFA== +=R11G +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc2-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r60407 - in /dev/spark/v3.4.0-rc2-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Thu Mar 2 09:35:10 2023 New Revision: 60407 Log: Apache Spark v3.4.0-rc2 docs [This commit notification would consist of 2806 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42643][CONNECT][PYTHON] Register Java (aggregate) user-defined functions
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 92aa08786fe [SPARK-42643][CONNECT][PYTHON] Register Java (aggregate)
user-defined functions
92aa08786fe is described below
commit 92aa08786feaf473330a863d19b0c902b721789e
Author: Xinrong Meng
AuthorDate: Wed Mar 8 14:23:18 2023 +0800
[SPARK-42643][CONNECT][PYTHON] Register Java (aggregate) user-defined
functions
### What changes were proposed in this pull request?
Implement `spark.udf.registerJavaFunction` and `spark.udf.registerJavaUDAF`.
A new proto `JavaUDF` is introduced.
### Why are the changes needed?
Parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.udf.registerJavaFunction` and `spark.udf.registerJavaUDAF` are
supported now.
### How was this patch tested?
Parity unit tests.
Closes #40244 from xinrong-meng/registerJava.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
.../main/protobuf/spark/connect/expressions.proto | 13 -
.../sql/connect/planner/SparkConnectPlanner.scala | 21
python/pyspark/sql/connect/client.py | 39 ++-
python/pyspark/sql/connect/expressions.py | 44 +++--
.../pyspark/sql/connect/proto/expressions_pb2.py | 26 +++---
.../pyspark/sql/connect/proto/expressions_pb2.pyi | 56 +-
python/pyspark/sql/connect/udf.py | 17 ++-
.../pyspark/sql/tests/connect/test_parity_udf.py | 30 +++-
python/pyspark/sql/udf.py | 6 +++
9 files changed, 212 insertions(+), 40 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
index 6eb769ad27e..0aee3ca13b9 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
@@ -312,7 +312,7 @@ message Expression {
message CommonInlineUserDefinedFunction {
// (Required) Name of the user-defined function.
string function_name = 1;
- // (Required) Indicate if the user-defined function is deterministic.
+ // (Optional) Indicate if the user-defined function is deterministic.
bool deterministic = 2;
// (Optional) Function arguments. Empty arguments are allowed.
repeated Expression arguments = 3;
@@ -320,6 +320,7 @@ message CommonInlineUserDefinedFunction {
oneof function {
PythonUDF python_udf = 4;
ScalarScalaUDF scalar_scala_udf = 5;
+JavaUDF java_udf = 6;
}
}
@@ -345,3 +346,13 @@ message ScalarScalaUDF {
bool nullable = 4;
}
+message JavaUDF {
+ // (Required) Fully qualified name of Java class
+ string class_name = 1;
+
+ // (Optional) Output type of the Java UDF
+ optional string output_type = 2;
+
+ // (Required) Indicate if the Java user-defined function is an aggregate
function
+ bool aggregate = 3;
+}
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index d7b3c057d92..3b9443f4e3c 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -1552,6 +1552,8 @@ class SparkConnectPlanner(val session: SparkSession) {
fun.getFunctionCase match {
case proto.CommonInlineUserDefinedFunction.FunctionCase.PYTHON_UDF =>
handleRegisterPythonUDF(fun)
+ case proto.CommonInlineUserDefinedFunction.FunctionCase.JAVA_UDF =>
+handleRegisterJavaUDF(fun)
case _ =>
throw InvalidPlanInput(
s"Function with ID: ${fun.getFunctionCase.getNumber} is not
supported")
@@ -1577,6 +1579,25 @@ class SparkConnectPlanner(val session: SparkSession) {
session.udf.registerPython(fun.getFunctionName, udpf)
}
+ private def handleRegisterJavaUDF(fun:
proto.CommonInlineUserDefinedFunction): Unit = {
+val udf = fun.getJavaUdf
+val dataType =
+ if (udf.hasOutputType) {
+DataType.parseTypeWithFallback(
+ schema = udf.getOutputType,
+ parser = DataType.fromDDL,
+ fallbackParser = DataType.fromJson) match {
+ case s: DataType => s
+ case other => throw InvalidPlanInput(s"Invalid return type $other")
+}
+ } else null
+if (udf.getAggregate) {
+ session.udf.registerJavaUDAF(fun.getFunctionName, udf.getClassName)
+} else {
+ session.udf.registerJava(fu
[spark] branch branch-3.4 updated: [SPARK-42643][CONNECT][PYTHON] Register Java (aggregate) user-defined functions
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 0e959a53908 [SPARK-42643][CONNECT][PYTHON] Register Java (aggregate)
user-defined functions
0e959a53908 is described below
commit 0e959a539086cda5dd911477ee5568ab540a2249
Author: Xinrong Meng
AuthorDate: Wed Mar 8 14:23:18 2023 +0800
[SPARK-42643][CONNECT][PYTHON] Register Java (aggregate) user-defined
functions
### What changes were proposed in this pull request?
Implement `spark.udf.registerJavaFunction` and `spark.udf.registerJavaUDAF`.
A new proto `JavaUDF` is introduced.
### Why are the changes needed?
Parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `spark.udf.registerJavaFunction` and `spark.udf.registerJavaUDAF` are
supported now.
### How was this patch tested?
Parity unit tests.
Closes #40244 from xinrong-meng/registerJava.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit 92aa08786feaf473330a863d19b0c902b721789e)
Signed-off-by: Xinrong Meng
---
.../main/protobuf/spark/connect/expressions.proto | 13 -
.../sql/connect/planner/SparkConnectPlanner.scala | 21
python/pyspark/sql/connect/client.py | 39 ++-
python/pyspark/sql/connect/expressions.py | 44 +++--
.../pyspark/sql/connect/proto/expressions_pb2.py | 26 +++---
.../pyspark/sql/connect/proto/expressions_pb2.pyi | 56 +-
python/pyspark/sql/connect/udf.py | 17 ++-
.../pyspark/sql/tests/connect/test_parity_udf.py | 30 +++-
python/pyspark/sql/udf.py | 6 +++
9 files changed, 212 insertions(+), 40 deletions(-)
diff --git
a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
index 6eb769ad27e..0aee3ca13b9 100644
--- a/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
+++ b/connector/connect/common/src/main/protobuf/spark/connect/expressions.proto
@@ -312,7 +312,7 @@ message Expression {
message CommonInlineUserDefinedFunction {
// (Required) Name of the user-defined function.
string function_name = 1;
- // (Required) Indicate if the user-defined function is deterministic.
+ // (Optional) Indicate if the user-defined function is deterministic.
bool deterministic = 2;
// (Optional) Function arguments. Empty arguments are allowed.
repeated Expression arguments = 3;
@@ -320,6 +320,7 @@ message CommonInlineUserDefinedFunction {
oneof function {
PythonUDF python_udf = 4;
ScalarScalaUDF scalar_scala_udf = 5;
+JavaUDF java_udf = 6;
}
}
@@ -345,3 +346,13 @@ message ScalarScalaUDF {
bool nullable = 4;
}
+message JavaUDF {
+ // (Required) Fully qualified name of Java class
+ string class_name = 1;
+
+ // (Optional) Output type of the Java UDF
+ optional string output_type = 2;
+
+ // (Required) Indicate if the Java user-defined function is an aggregate
function
+ bool aggregate = 3;
+}
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index d7b3c057d92..3b9443f4e3c 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -1552,6 +1552,8 @@ class SparkConnectPlanner(val session: SparkSession) {
fun.getFunctionCase match {
case proto.CommonInlineUserDefinedFunction.FunctionCase.PYTHON_UDF =>
handleRegisterPythonUDF(fun)
+ case proto.CommonInlineUserDefinedFunction.FunctionCase.JAVA_UDF =>
+handleRegisterJavaUDF(fun)
case _ =>
throw InvalidPlanInput(
s"Function with ID: ${fun.getFunctionCase.getNumber} is not
supported")
@@ -1577,6 +1579,25 @@ class SparkConnectPlanner(val session: SparkSession) {
session.udf.registerPython(fun.getFunctionName, udpf)
}
+ private def handleRegisterJavaUDF(fun:
proto.CommonInlineUserDefinedFunction): Unit = {
+val udf = fun.getJavaUdf
+val dataType =
+ if (udf.hasOutputType) {
+DataType.parseTypeWithFallback(
+ schema = udf.getOutputType,
+ parser = DataType.fromDDL,
+ fallbackParser = DataType.fromJson) match {
+ case s: DataType => s
+ case other => throw InvalidPlanInput(s"Invalid return type $other")
+}
+ } else null
+if (udf.getAggregate) {
[spark] tag v3.4.0-rc3 created (now b9be9ce15a8)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc3 in repository https://gitbox.apache.org/repos/asf/spark.git at b9be9ce15a8 (commit) This tag includes the following new commits: new b9be9ce15a8 Preparing Spark release v3.4.0-rc3 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc3
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc3 in repository https://gitbox.apache.org/repos/asf/spark.git commit b9be9ce15a82b18cca080ee365d308c0820a29a9 Author: Xinrong Meng AuthorDate: Thu Mar 9 05:34:00 2023 + Preparing Spark release v3.4.0-rc3 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index b86fee4bceb..c58da7aa112 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml index 22ce7
svn commit: r60498 - /dev/spark/v3.4.0-rc3-bin/
Author: xinrong Date: Thu Mar 9 07:11:38 2023 New Revision: 60498 Log: Apache Spark v3.4.0-rc3 Added: dev/spark/v3.4.0-rc3-bin/ dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc3-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc3-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc3-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc3-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.asc Thu Mar 9 07:11:38 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQJhjwTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsRdDEACd98Pk0bSFtKVHER3hjis2R2cg1pgG +gWiqBZArn1GiB6ck0KHglMklJTFFsw2q9/mro42uVhj0b0hJYcTb2hBO+7vyEYeU +a+YGhik6FXaQQBL1+oB5aTn2FcnNi7no1Qa+x4opkG7d1giapzQe/oZK1D7RNiYZ +FAdoDhsUTYCeWDVXbRAcEMca49ltsZDPe45XRHwSgXT45hi6s9oRd78G6v2srbMb ++g7ce4KzAhupZrb5wCnP1MmiWWG1gnfcG0n11LDsiAhYPzzDgW/S4urcqIhWu0+4 +uUSrL6es4mprt1SMybBbmyGrHLuXjdmbBy5XHWy576GoCANdJRffImtmbXFFqp5q +uau5MDCMFcQwp8pOGjTIDYL4q0p9Kpx3mQ2ykQxWiWg/TgVBQ2leadya8yUV9zZ9 +Y6vuRf9R3iYcXTp3B5XlOWtzjYBICa2XQlizOV3U35xybhSFQHLdUSdBBPMLFsDS +YxYw1+dm8SjGfHhtsTOsk0ZhgSNgpDC8PBP6UUlz/8qRy4UdjQRrVgkqFmIFcLZs +CPdX5XlH32PQYtN55qGc6AZECoUpbpigGZetvKqdD5SWyf8maRZZsD+XdR7BT9rk +LLQTJKak3VQRAn80ONx+JxgzH3B5uV1ldN22vr5nLECpJZDbGjC6etystZDujEYh +szr47LujCxLTNw== +=l4pQ +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc3-bin/SparkR_3.4.0.tar.gz.sha512 Thu Mar 9 07:11:38 2023 @@ -0,0 +1 @@ +4703ffdbf82aaf5b30b6afe680a2b21ca15c957863c3648e7e5f120663506fc9e633727a6b7809f7cff7763a9f6227902f6d83fac7c87d3791234afef147cfc3 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.asc Thu Mar 9 07:11:38 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQJhj4THHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsaMFD/0VbikHk10VpDiRp7RVhquRXR/qHkiK +ioI02DrZJsZiRElV69Bfxvb1HQSKJhE9xXC+GkS7N+s0neNMXBpYsSxigRICG+Vi +nPJifZVCNzpckkD5t8t+07X5eTRR7VoRPsHkaYSNKxXiMfXYbOpBOLcP/cvrdPSi +nXsOnLm3dhxU7kMS+Qy4jbCzQN1fb4XPagxdvPji/aKo6LBw/YiqWHPhHcHlW89h +cGRAQpN1VjfNkO1zfGxV/h5kD8L/my0zsVMOxtF/r6Qc7FZGBilfMuw8d+8WSVAr +kRx+s2kB8vuH/undWoRSwpItqv0/gcyFCCvMmLQlbEA0Ku/ldE88XESIuI25uTcC +tVJFC01Gauh7KlkI4hzsuwlhcDH/geLE1DS59fKC5UMqEYvaKQyQZFzyX0/eFIIS +8KRZo3B5NUfEXE3fMDOGE8FgJ76QPQ3HO2tB9f+ICeu1/1RioqgucZ7jcKfFIx/J +FzZ7FkNuLSl3CEnH5BlqdoaCCdmOsZVqcPgaZaGUncgK6ygBWEIEK/I6pE9Sye+Y +ncBM76ZJf3NsE4Kzdw/v0NCrLaTdIMIK3W3fvVY94IPdk2EY6MuEnGDqG1bn88u4 +zYfP118WS4KtN6fSkczHGf+7+LQIiWrovIb+cQP+TXKeCinRbK1/I6pBWnn4/0u1 +DApXYisgegSYPg== +=ykwM +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc3-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r60500 - in /dev/spark/v3.4.0-rc3-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Thu Mar 9 07:54:14 2023 New Revision: 60500 Log: Apache Spark v3.4.0-rc3 docs [This commit notification would consist of 2807 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42739][BUILD] Ensure release tag to be pushed to release branch
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 785188dd8b5 [SPARK-42739][BUILD] Ensure release tag to be pushed to
release branch
785188dd8b5 is described below
commit 785188dd8b5e74510c29edbff5b9991d88855e43
Author: Xinrong Meng
AuthorDate: Fri Mar 10 11:04:34 2023 +0800
[SPARK-42739][BUILD] Ensure release tag to be pushed to release branch
### What changes were proposed in this pull request?
In the release script, add a check to ensure release tag to be pushed to
release branch.
### Why are the changes needed?
To ensure the success of a RC cut. Otherwise, release conductors have to
manually check that.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
```
~/spark [_d_branch] $ git commit -am '_d_commmit'
...
~/spark [_d_branch] $ git tag '_d_tag'
~/spark [_d_branch] $ git push origin _d_tag
~/spark [_d_branch] $ git branch -r --contains tags/_d_tag | grep origin
~/spark [_d_branch] $ echo $?
1
~/spark [_d_branch] $ git push origin HEAD:_d_branch
...
~/spark [_d_branch] $ git branch -r --contains tags/_d_tag | grep origin
origin/_d_branch
~/spark [_d_branch] $ echo $?
0
```
Closes #40357 from xinrong-meng/chk_release.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
---
dev/create-release/release-tag.sh | 6 ++
1 file changed, 6 insertions(+)
diff --git a/dev/create-release/release-tag.sh
b/dev/create-release/release-tag.sh
index 255bda37ad8..fa701dd74b2 100755
--- a/dev/create-release/release-tag.sh
+++ b/dev/create-release/release-tag.sh
@@ -122,6 +122,12 @@ if ! is_dry_run; then
git push origin $RELEASE_TAG
if [[ $RELEASE_VERSION != *"preview"* ]]; then
git push origin HEAD:$GIT_BRANCH
+if git branch -r --contains tags/$RELEASE_TAG | grep origin; then
+ echo "Pushed $RELEASE_TAG to $GIT_BRANCH."
+else
+ echo "Failed to push $RELEASE_TAG to $GIT_BRANCH. Please start over."
+ exit 1
+fi
else
echo "It's preview release. We only push $RELEASE_TAG to remote."
fi
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42739][BUILD] Ensure release tag to be pushed to release branch
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 49cf58e30c7 [SPARK-42739][BUILD] Ensure release tag to be pushed to
release branch
49cf58e30c7 is described below
commit 49cf58e30c79734af4a30787a0220aeba69839c5
Author: Xinrong Meng
AuthorDate: Fri Mar 10 11:04:34 2023 +0800
[SPARK-42739][BUILD] Ensure release tag to be pushed to release branch
### What changes were proposed in this pull request?
In the release script, add a check to ensure release tag to be pushed to
release branch.
### Why are the changes needed?
To ensure the success of a RC cut. Otherwise, release conductors have to
manually check that.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
```
~/spark [_d_branch] $ git commit -am '_d_commmit'
...
~/spark [_d_branch] $ git tag '_d_tag'
~/spark [_d_branch] $ git push origin _d_tag
~/spark [_d_branch] $ git branch -r --contains tags/_d_tag | grep origin
~/spark [_d_branch] $ echo $?
1
~/spark [_d_branch] $ git push origin HEAD:_d_branch
...
~/spark [_d_branch] $ git branch -r --contains tags/_d_tag | grep origin
origin/_d_branch
~/spark [_d_branch] $ echo $?
0
```
Closes #40357 from xinrong-meng/chk_release.
Authored-by: Xinrong Meng
Signed-off-by: Xinrong Meng
(cherry picked from commit 785188dd8b5e74510c29edbff5b9991d88855e43)
Signed-off-by: Xinrong Meng
---
dev/create-release/release-tag.sh | 6 ++
1 file changed, 6 insertions(+)
diff --git a/dev/create-release/release-tag.sh
b/dev/create-release/release-tag.sh
index 255bda37ad8..fa701dd74b2 100755
--- a/dev/create-release/release-tag.sh
+++ b/dev/create-release/release-tag.sh
@@ -122,6 +122,12 @@ if ! is_dry_run; then
git push origin $RELEASE_TAG
if [[ $RELEASE_VERSION != *"preview"* ]]; then
git push origin HEAD:$GIT_BRANCH
+if git branch -r --contains tags/$RELEASE_TAG | grep origin; then
+ echo "Pushed $RELEASE_TAG to $GIT_BRANCH."
+else
+ echo "Failed to push $RELEASE_TAG to $GIT_BRANCH. Please start over."
+ exit 1
+fi
else
echo "It's preview release. We only push $RELEASE_TAG to remote."
fi
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] tag v3.4.0-rc4 created (now 4000d6884ce)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc4 in repository https://gitbox.apache.org/repos/asf/spark.git at 4000d6884ce (commit) This tag includes the following new commits: new 4000d6884ce Preparing Spark release v3.4.0-rc4 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc4
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc4 in repository https://gitbox.apache.org/repos/asf/spark.git commit 4000d6884ce973eb420e871c8d333431490be763 Author: Xinrong Meng AuthorDate: Fri Mar 10 03:26:48 2023 + Preparing Spark release v3.4.0-rc4 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index b86fee4bceb..c58da7aa112 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml inde
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit bc1671023c3360380bbb67ae8fec959efb072996 Author: Xinrong Meng AuthorDate: Fri Mar 10 03:26:54 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index c58da7aa112..b86fee4bceb 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
[spark] branch branch-3.4 updated (49cf58e30c7 -> bc1671023c3)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from 49cf58e30c7 [SPARK-42739][BUILD] Ensure release tag to be pushed to release branch add 4000d6884ce Preparing Spark release v3.4.0-rc4 new bc1671023c3 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r60507 - /dev/spark/v3.4.0-rc4-bin/
Author: xinrong Date: Fri Mar 10 04:47:20 2023 New Revision: 60507 Log: Apache Spark v3.4.0-rc4 Added: dev/spark/v3.4.0-rc4-bin/ dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc4-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc4-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc4-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc4-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.asc Fri Mar 10 04:47:20 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQKtesTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6Thsed/D/9ECWrN2Ra7rPZt1lvSh9H/DON0HzZ0 +UXLPKZpCXkdFM7TXMksVF0qE/iqPwfgfxv9uY0Ura71+to/+6L1l9U+svKwNl7ze +0vby8tZMLwiqpVlIihLObrLXLSfUF9hBOo1Xuh60DZjiNaACZ/5Pi0vIhIQiiLJb +TOG5bFejim9/8pbK9l54M2eP9e1fxYDLAwZCGCvtzN0Ddf1hhZQomG4QJeCJV9YZ +/rSF6cmyale+0U/UIE/ci9Jj7gzzxAxa5CBFVYyjsNLRksM9LzbYGck2VuC6UZT4 +TdcF1Ia834BnSCOEgesyPrM7FD6ljNr7ks7UMI3PG4yVtAdeNzDCyZhX6OXU+zCY +olbqHl1RzAgrvA+rUoQH6vRaKVKTFQTSkohrQSg3tmSqPYfxNxac75K7I3F9A5qM +DXHkXrSAdCOV+T88yw75zjr2xLiLLGIuBrYc/5lk3JxS9Rw6aDrfxLgZMpfdnsuL +PxAMai2xnZhvQrAAIPUKRN+TR72fpVFIAJB9nEReDF6m9cmhdhQt+xKR6xCDs9fb +Cx+G8ZBPvJeheGFiKmjeAT4zh+C3B7BxhlvvCP5Q6GOtWv+8CBardAVV2OSP2T/t +SxFEjBZwqNrwtBFY0txYnDTGnv6vK3dG86FnaE6R57p2W5vAKrmSmp3ZL+YhUKe7 +HGk4OdoEG93bww== +=FJdV +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc4-bin/SparkR_3.4.0.tar.gz.sha512 Fri Mar 10 04:47:20 2023 @@ -0,0 +1 @@ +6e7bc60a43243e9026e92af81386fc9d57a6231c1a59a6fb4e39cf16cd150a3b5e1e9237b377d3e5a74d16f804f9a5d13a897e8455f640eacec1c79ef3d10407 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.asc Fri Mar 10 04:47:20 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQKte0THHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsWYaD/9zcUOMr+07jy7Ok2xKkEq4hlsSH1xu +4Y61P1CTFhtOc9DG/O2jfX8Tsnp/b6gY3nJHGhrtdY0LCMPiMG+5uHO3/wO53pE0 +6DEtZH1I38rbILpb9kDCftCQS6keZR79Zl8N0G5D+P56grNdI4aqDo1Ntxvs366r +0rAWGIpVbvr5w5MBqvyn96Sk2ac/SbZVeE5NHCVwPWCQz6povLTDDESWETQIW5TZ +VTQsErI4joWplWWlI8D8x8XABVaD0BaKFwuJpPploKVkhSyOECUDM5W0xhuGNArn +h5GofcXXvCBKqoI3ngXg72G6fVamDJ0b/DCsmpLflwEaInhlDYj9BVbTUAgvYHwa +eDgLEbvZ4at/5OVf+A/VxnXLfL1DJLiGgfk7J4QqNMTdqfCtyEs4yxQ4t6OZ93mN +g6VcNYzayKEZffmC29QDtce5wpl530C543cSW7QFMgIg0ly0pfDF1J63hsQ86TZV +D/Nu41KiQXFq4CMD08mxu1gSTllTIED+5VUcbJpmep2Pa28tIvleVCxXQBXpx5Bw +pz3AJIU/Og4y8xZfspeUON9qvSHAwLGO6T9QAslaciJA/mK2vNzHLgaTSZtXRSzv +MIsmpfEHoE8HsgUk/YLCheSNTZRkKgCWySMBnNaY0HFF86R/HvA+rL97CoFTKX9C +Gpsg/vHReYkRFw== +=4f38 +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc4-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r60509 - in /dev/spark/v3.4.0-rc4-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Fri Mar 10 06:12:05 2023 New Revision: 60509 Log: Apache Spark v3.4.0-rc4 docs [This commit notification would consist of 2807 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42864][ML][3.4] Make `IsotonicRegression.PointsAccumulator` private
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 5222cfd58a7 [SPARK-42864][ML][3.4] Make
`IsotonicRegression.PointsAccumulator` private
5222cfd58a7 is described below
commit 5222cfd58a717fec7a025fdf4dfcde0bb4daf80c
Author: Ruifeng Zheng
AuthorDate: Tue Mar 21 12:55:44 2023 +0800
[SPARK-42864][ML][3.4] Make `IsotonicRegression.PointsAccumulator` private
### What changes were proposed in this pull request?
Make `IsotonicRegression.PointsAccumulator` private, which was introduced
in
https://github.com/apache/spark/commit/3d05c7e037eff79de8ef9f6231aca8340bcc65ef
### Why are the changes needed?
`PointsAccumulator` is implementation details, should not be exposed
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing UT
Closes #40500 from zhengruifeng/isotonicRegression_private.
Authored-by: Ruifeng Zheng
Signed-off-by: Xinrong Meng
---
.../org/apache/spark/mllib/regression/IsotonicRegression.scala | 6 ++
1 file changed, 2 insertions(+), 4 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/mllib/regression/IsotonicRegression.scala
b/mllib/src/main/scala/org/apache/spark/mllib/regression/IsotonicRegression.scala
index fbf0dc9c357..12a78ef4ec1 100644
---
a/mllib/src/main/scala/org/apache/spark/mllib/regression/IsotonicRegression.scala
+++
b/mllib/src/main/scala/org/apache/spark/mllib/regression/IsotonicRegression.scala
@@ -331,7 +331,7 @@ class IsotonicRegression private (private var isotonic:
Boolean) extends Seriali
if (cleanInput.length <= 1) {
cleanInput
} else {
- val pointsAccumulator = new IsotonicRegression.PointsAccumulator
+ val pointsAccumulator = new PointsAccumulator
// Go through input points, merging all points with equal feature values
into a single point.
// Equality of features is defined by shouldAccumulate method. The label
of the accumulated
@@ -490,15 +490,13 @@ class IsotonicRegression private (private var isotonic:
Boolean) extends Seriali
.sortBy(_._2)
poolAdjacentViolators(parallelStepResult)
}
-}
-object IsotonicRegression {
/**
* Utility class, holds a buffer of all points with unique features so far,
and performs
* weighted sum accumulation of points. Hides these details for better
readability of the
* main algorithm.
*/
- class PointsAccumulator {
+ private class PointsAccumulator {
private val output = ArrayBuffer[(Double, Double, Double)]()
private var (currentLabel: Double, currentFeature: Double, currentWeight:
Double) =
(0d, 0d, 0d)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated (b74f7922577 -> 3122d4f4c76)
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a change to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
from b74f7922577 [SPARK-42861][SQL] Use private[sql] instead of
protected[sql] to avoid generating API doc
add 3122d4f4c76 [SPARK-42891][CONNECT][PYTHON][3.4] Implement CoGrouped
Map API
No new revisions were added by this update.
Summary of changes:
.../main/protobuf/spark/connect/relations.proto| 18 ++
.../sql/connect/planner/SparkConnectPlanner.scala | 22 ++
dev/sparktestsupport/modules.py| 1 +
python/pyspark/sql/connect/_typing.py | 2 +
python/pyspark/sql/connect/group.py| 49 +++-
python/pyspark/sql/connect/plan.py | 40
python/pyspark/sql/connect/proto/relations_pb2.py | 250 +++--
python/pyspark/sql/connect/proto/relations_pb2.pyi | 80 +++
python/pyspark/sql/pandas/group_ops.py | 9 +
.../sql/tests/connect/test_connect_basic.py| 5 +-
..._map.py => test_parity_pandas_cogrouped_map.py} | 54 ++---
.../sql/tests/pandas/test_pandas_cogrouped_map.py | 6 +-
12 files changed, 374 insertions(+), 162 deletions(-)
copy python/pyspark/sql/tests/connect/{test_parity_pandas_grouped_map.py =>
test_parity_pandas_cogrouped_map.py} (61%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc5
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc5 in repository https://gitbox.apache.org/repos/asf/spark.git commit f39ad617d32a671e120464e4a75986241d72c487 Author: Xinrong Meng AuthorDate: Thu Mar 30 02:18:27 2023 + Preparing Spark release v3.4.0-rc5 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index b86fee4bceb..c58da7aa112 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml inde
[spark] tag v3.4.0-rc5 created (now f39ad617d32)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc5 in repository https://gitbox.apache.org/repos/asf/spark.git at f39ad617d32 (commit) This tag includes the following new commits: new f39ad617d32 Preparing Spark release v3.4.0-rc5 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated (ce36692eeee -> 6a6f50444d4)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from ce36692 [SPARK-42631][CONNECT][FOLLOW-UP] Expose Column.expr to extensions add f39ad617d32 Preparing Spark release v3.4.0-rc5 new 6a6f50444d4 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit 6a6f50444d43af24773ecc158aa127027f088288 Author: Xinrong Meng AuthorDate: Thu Mar 30 02:18:32 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index c58da7aa112..b86fee4bceb 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
svn commit: r60925 - /dev/spark/v3.4.0-rc5-bin/
Author: xinrong Date: Thu Mar 30 03:39:03 2023 New Revision: 60925 Log: Apache Spark v3.4.0-rc5 Added: dev/spark/v3.4.0-rc5-bin/ dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc5-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc5-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc5-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc5-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.asc Thu Mar 30 03:39:03 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQlA+wTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6Thsdo/D/9CLT5v+RVNTX0mmZq501F205cDUan+ +tiC/G2ddtGfSLcRAWeWqoDFWOkeupwEqtKMoqQGnElXM7qVF2miBfcohBxm3151l +UBJD6paLgSrI2omxxqBNTB265BbojbmQcZx5UjHzO/opVahllET/7RXI6I8k/gsC +hpoSJe77SHPXsLQpSFPaxct7Qy6IwwLq8yvVZIFlrYgjqvWBa3zsnqb4T6W859lb +uiAAWJTJ0xQPF/u9TmXM8a9vFRfo3rXuttW8W7wKlHQjZgDJpNSJyQCaVmWYUssM +2nzrfiwy7/E5wGzFsdxzO8lOlyeA6Cdmhwo8G5xcZnjNt9032DrAYFdo5rIoim9v +irsqWyOJ5XclUOWpxKpXdYPcQGpEW74vUBymAW5P6jt0Yi2/3qvZSiwh1qceJ8Fo +nut0HUWIFkohDoattkCjoA1yconcJd4+FuoDxrCX+QWAlchgR4eijMWfYCyH/7LX +SucOJOK80psdGnZGuecuRjCzhvnbPjjNjS3dYMrudLlgxHyb2ahjeHXpVyDjI/O6 +AwUmJtUEGHk0Ypa8OHlgzB8UUaZRQDIiwL8j8tlIHYMt+VdQLUtvyK+hqe45It6F +OAlocOnign7Ej/9EGyJfKXX0gZr6NmkuANWggPRIrIs1NSnqz4bDWQRGwVOkpb7x +NOdLdMoi6QMC0A== +=H+Kf +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc5-bin/SparkR_3.4.0.tar.gz.sha512 Thu Mar 30 03:39:03 2023 @@ -0,0 +1 @@ +c3086edefab6656535e234fd11d0a2a4d4c6ede97b85f94801d06064bd89c6f58196714e335e92ffd2ac83c82714ad8a9a51165621ecff194af290c1eb537ef2 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.asc Thu Mar 30 03:39:03 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQlA+4THHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6Thsb0pEACXvrvU/8Xh7ns7J8RtV/Wmf4oMu9Mk +i6G8JwBUTS1kqRe9Xb1g3GJxNil8HTta1yNKgjvkTDc6EXIYrtQD4PpL6cuumckW +0+itx9dih22OcvfN6sJNizAtRoTcpXx7UHq00dAjzHHbOv0dwGqnjKRU3UUQ/XnY +RjT3kM4isf95TzAmEFwsXNSzkUY0+EzDgfhnDAwb60nzTzZ2bEiZnLP1JC2iScDI +jSXMoWtZTaJz51bssKzzXpVmrwBxLDgSPlDM5KVmeD+WQMqS7Hk51bSikSEW1X39 +CO7hEXw+SYLQB5yKaqu03diErTOWmP6aJ8tbHCPWNrs3JMJkm4/Cj6Sc2JOktixO +Ns8Pc82kpnvG0eWCMXwihZa7pxnq59ByZsxYAfmcIdf4q02VJNetFjplgXAs2jjy +n9UZ6l8ZrCjUW2/AB3TSSibXLXMvuI6PLSYnKY9IP0t0dqxnBIKkACTx8qBA/o+I +0n02LBJCD8ZPJvHpI2MGlaFGftbQx4LUXX4CFlAz+RI9iizCbpjrDYFzvXBEY7ri +46i5uL+sHkP6Uj/8fNJ3QRhggb19i0NajzofSs5vNsVk2qHjHokIjG/kOkpCfBzC +6rM5zd/OyQNZmbHThlOjAdEvTSgasXb/5uHpwWDHbTlPGJYMZOWzuBdDSfBlHW/t +56VKCDfYO11shA== +=a3bs +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc5-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r60926 - in /dev/spark/v3.4.0-rc5-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Thu Mar 30 04:53:57 2023 New Revision: 60926 Log: Apache Spark v3.4.0-rc5 docs [This commit notification would consist of 2789 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc6
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc6 in repository https://gitbox.apache.org/repos/asf/spark.git commit 28d0723beb3579c17df84bb22c98a487d7a72023 Author: Xinrong Meng AuthorDate: Thu Apr 6 16:38:28 2023 + Preparing Spark release v3.4.0-rc6 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index b86fee4bceb..c58da7aa112 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml index 22ce7
[spark] tag v3.4.0-rc6 created (now 28d0723beb3)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc6 in repository https://gitbox.apache.org/repos/asf/spark.git at 28d0723beb3 (commit) This tag includes the following new commits: new 28d0723beb3 Preparing Spark release v3.4.0-rc6 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated (90376424779 -> 1d974a7a78f)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from 90376424779 [SPARK-43041][SQL] Restore constructors of exceptions for compatibility in connector API add 28d0723beb3 Preparing Spark release v3.4.0-rc6 new 1d974a7a78f Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit 1d974a7a78fa2a4d688d5e8606dcd084ab08b220 Author: Xinrong Meng AuthorDate: Thu Apr 6 16:38:33 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index c58da7aa112..b86fee4bceb 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
svn commit: r61108 - /dev/spark/v3.4.0-rc6-bin/
Author: xinrong Date: Thu Apr 6 17:58:16 2023 New Revision: 61108 Log: Apache Spark v3.4.0-rc6 Added: dev/spark/v3.4.0-rc6-bin/ dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc6-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc6-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc6-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc6-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.asc Thu Apr 6 17:58:16 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQvB8kTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsToQEACqdYF76eiLZgfskKs8ZpVroBu6FV0l +kT6CPB72l1l1vrfSDa9BbYW/Ty0QB0/t2ZV74p1avk5w/qyM6Otg7Gtkx3qFBMZw +YIcMUFdeeXYc8hiOLFqoTHfdQVzvJNaoXofbfZAOcEOR4cRhofXPsgRYGQK8ZJwQ +2Ek9a6KKUzn8bWfS2v+Z/bjLfArZ0QP2/qs9qdghsJqfhS6vGvFz9H45vfzpJyGw +WdRQIRdmGvsxX9cyOG6QJv9Aq7MuT+hDBM0H/yip3wppEKSjIByj0MqapnuUrkML +06SeK3fVx/sy9UzEHKWZKGDDiqlx5TCCaGC44N/+yiytmtrB3RxKhSiFy4G2s41+ +fqkMVgA3tbR2zIea/FJHYo7iO4YZMKN9YmXYFFZzARcwZgUVbyDvoLg07Rsww921 +FcoPYiUsFmA7Eb1vyp0HWmXYqwqSkuRujLkf4LkpX1JiRh0I2EEThPQ042nN+trN +2iW35q9WCOJVbcdLcMv6KVP3Ipa6A9BGc4bvd+cmi7P9Fv8zgboDbIV8XiC45dRb +v1C8NZ9Zca8V3XAdy+nds8fJW1Bvc6O12ch8MtMauV4TH22rTfmWBuVABsglQQlG +c8sCLSOdRo1k80pBFZFg4ZFMFs/NjNa0PDtD8hZIhJEk24AaxCLQT/YlyUu9flqp +37JM51CLEIL+xA== +=2jm9 +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc6-bin/SparkR_3.4.0.tar.gz.sha512 Thu Apr 6 17:58:16 2023 @@ -0,0 +1 @@ +2101b54ecaf72f6175a7e83651bee5cd2ca292ecb54f59461d7edb535d03130c9019eaa502912562d5aa1d5cec54f0eed3f862b51b6467b5beb6fcf09945b7b4 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.asc Thu Apr 6 17:58:16 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQvB8sTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsQb0D/4072E3g9OGkQjzd1KuzEoY3bk79eRC +l6qohjnUlhP4j1l/sqNdtiS1hz1g5PgDpJlxlj20st3A9P7A0bOZN3r4BsMd38nA ++D0xIjdgqhax3XZVHhETudPwKWyboWM+Id32cuiJifGYPz9MnJBkTFQMxlZWz7Ny +hbwNC2H435anO1BGiuyiUaFztfoOJ5aMZZaQHfXTAszwm7KJhkpZP1NC0YVdklhI +71id0OYNziIIkYLJpSAlzQk2RLvR8Ok9NyELSOc6AzQ5tmLIVLWFVb9tfH69cYo8 +DHOEQqD4KdwDsb030lvXbQ4n6blns1b+i7gOdWzr6a/sQd1TwGq2SDkYlcQ++8/W +HU7+9C9Oula/RpzYcvPiWnneoAjN7zZgJfYm8aCEP62mCH/eQVJePDBnRLQUTtWD +gbBIId/qFXDYi1DOmFzz6Awh/EGA04TrnBbKqVSPC9g6p3VQCoUTNKwVKLCyvQx5 +QxbtpP7FjSxdB4TQAiDyo0U/o6b6AEx+wz43G14sv9gD3wNK8wtIBbh2PMrQuL0M +7QSgFwVkp6vLmRjsrSslrxW8zqbfc0HkrTSNnV2odtRcv0ZsAEikWMki68cnkjbC +GPFiUxjlNz1yMRrG/3dnmfHOvnlt84HtzUzxObxVO2xXgjSV5mEG94hywTEHeTA1 +dceim2kd4JjGSg== +=0nLo +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc6-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r61110 - in /dev/spark/v3.4.0-rc6-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Thu Apr 6 19:21:26 2023 New Revision: 61110 Log: Apache Spark v3.4.0-rc6 docs [This commit notification would consist of 2789 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] tag v3.4.0-rc7 created (now 87a5442f7ed)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to tag v3.4.0-rc7 in repository https://gitbox.apache.org/repos/asf/spark.git at 87a5442f7ed (commit) This tag includes the following new commits: new 87a5442f7ed Preparing Spark release v3.4.0-rc7 The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing Spark release v3.4.0-rc7
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to tag v3.4.0-rc7 in repository https://gitbox.apache.org/repos/asf/spark.git commit 87a5442f7ed96b11051d8a9333476d080054e5a0 Author: Xinrong Meng AuthorDate: Fri Apr 7 01:28:44 2023 + Preparing Spark release v3.4.0-rc7 --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index fa7028630a8..4a32762b34c 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.1 +Version: 3.4.0 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index b86fee4bceb..c58da7aa112 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index f9ecfb3d692..95ea15552da 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index 22ee65b7d25..e4d98471bf9 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 2c67da81ca4..7a6d5aedf65 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 219682e047d..1c421754083 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.1-SNAPSHOT +3.4.0 ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch/pom.xml index 22ce7
[spark] branch branch-3.4 updated (b2ff4c4f7ec -> e4eea55d0a2)
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a change to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git from b2ff4c4f7ec [SPARK-39696][CORE] Fix data race in access to TaskMetrics.externalAccums add 87a5442f7ed Preparing Spark release v3.4.0-rc7 new e4eea55d0a2 Preparing development version 3.4.1-SNAPSHOT The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] 01/01: Preparing development version 3.4.1-SNAPSHOT
This is an automated email from the ASF dual-hosted git repository. xinrong pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git commit e4eea55d0a2ef7a8b8a44994750fdfd383517944 Author: Xinrong Meng AuthorDate: Fri Apr 7 01:28:49 2023 + Preparing development version 3.4.1-SNAPSHOT --- R/pkg/DESCRIPTION | 2 +- assembly/pom.xml | 2 +- common/kvstore/pom.xml | 2 +- common/network-common/pom.xml | 2 +- common/network-shuffle/pom.xml | 2 +- common/network-yarn/pom.xml| 2 +- common/sketch/pom.xml | 2 +- common/tags/pom.xml| 2 +- common/unsafe/pom.xml | 2 +- connector/avro/pom.xml | 2 +- connector/connect/client/jvm/pom.xml | 2 +- connector/connect/common/pom.xml | 2 +- connector/connect/server/pom.xml | 2 +- connector/docker-integration-tests/pom.xml | 2 +- connector/kafka-0-10-assembly/pom.xml | 2 +- connector/kafka-0-10-sql/pom.xml | 2 +- connector/kafka-0-10-token-provider/pom.xml| 2 +- connector/kafka-0-10/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 2 +- connector/kinesis-asl/pom.xml | 2 +- connector/protobuf/pom.xml | 2 +- connector/spark-ganglia-lgpl/pom.xml | 2 +- core/pom.xml | 2 +- docs/_config.yml | 6 +++--- examples/pom.xml | 2 +- graphx/pom.xml | 2 +- hadoop-cloud/pom.xml | 2 +- launcher/pom.xml | 2 +- mllib-local/pom.xml| 2 +- mllib/pom.xml | 2 +- pom.xml| 2 +- python/pyspark/version.py | 2 +- repl/pom.xml | 2 +- resource-managers/kubernetes/core/pom.xml | 2 +- resource-managers/kubernetes/integration-tests/pom.xml | 2 +- resource-managers/mesos/pom.xml| 2 +- resource-managers/yarn/pom.xml | 2 +- sql/catalyst/pom.xml | 2 +- sql/core/pom.xml | 2 +- sql/hive-thriftserver/pom.xml | 2 +- sql/hive/pom.xml | 2 +- streaming/pom.xml | 2 +- tools/pom.xml | 2 +- 43 files changed, 45 insertions(+), 45 deletions(-) diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION index 4a32762b34c..fa7028630a8 100644 --- a/R/pkg/DESCRIPTION +++ b/R/pkg/DESCRIPTION @@ -1,6 +1,6 @@ Package: SparkR Type: Package -Version: 3.4.0 +Version: 3.4.1 Title: R Front End for 'Apache Spark' Description: Provides an R Front end for 'Apache Spark' <https://spark.apache.org>. Authors@R: diff --git a/assembly/pom.xml b/assembly/pom.xml index c58da7aa112..b86fee4bceb 100644 --- a/assembly/pom.xml +++ b/assembly/pom.xml @@ -21,7 +21,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../pom.xml diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml index 95ea15552da..f9ecfb3d692 100644 --- a/common/kvstore/pom.xml +++ b/common/kvstore/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml index e4d98471bf9..22ee65b7d25 100644 --- a/common/network-common/pom.xml +++ b/common/network-common/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml index 7a6d5aedf65..2c67da81ca4 100644 --- a/common/network-shuffle/pom.xml +++ b/common/network-shuffle/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/network-yarn/pom.xml b/common/network-yarn/pom.xml index 1c421754083..219682e047d 100644 --- a/common/network-yarn/pom.xml +++ b/common/network-yarn/pom.xml @@ -22,7 +22,7 @@ org.apache.spark spark-parent_2.12 -3.4.0 +3.4.1-SNAPSHOT ../../pom.xml diff --git a/common/sketch/pom.xml b/common/sketch
svn commit: r61114 - /dev/spark/v3.4.0-rc7-bin/
Author: xinrong Date: Fri Apr 7 02:45:25 2023 New Revision: 61114 Log: Apache Spark v3.4.0-rc7 Added: dev/spark/v3.4.0-rc7-bin/ dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.asc dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz (with props) dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.asc dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.sha512 dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz (with props) dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.asc dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-hadoop3-scala2.13.tgz.sha512 dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-hadoop3.tgz (with props) dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-hadoop3.tgz.asc dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-hadoop3.tgz.sha512 dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-without-hadoop.tgz (with props) dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-without-hadoop.tgz.asc dev/spark/v3.4.0-rc7-bin/spark-3.4.0-bin-without-hadoop.tgz.sha512 dev/spark/v3.4.0-rc7-bin/spark-3.4.0.tgz (with props) dev/spark/v3.4.0-rc7-bin/spark-3.4.0.tgz.asc dev/spark/v3.4.0-rc7-bin/spark-3.4.0.tgz.sha512 Added: dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.asc Fri Apr 7 02:45:25 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQvg1kTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsXF3D/9DJKcP/8+T/T2cddS049hOxspKDbm2 +Q1oIy04RZ1KllpeZtZVxpUCy7vE7F2srNjFrZ3OMY76/DeyBdwUBLGbrpA51FBRy +RmVM2x9Z9zj2rhfWK02IqC9a7RueMif15UwIGQSCEsS3H5ep3eHR2O4Vqof42rpj +Qf8hTqRC3y6OPxKS/kyhwof3CtzSe5TzmGeQ8GLlsr1cOQ1K8V6tRv4L4xtqYKlx +NA0ekUWKMylVzNj7AxdoWUpRCJyy+GbzT8PKp53imwaUjVp3FU8F3yZTd3kj9rxY +aNY5pWVTj2930gqDKHnJcGs3jq39GfjKu1hKMN+XAwmJEi//I2W96xvbEjoBxEh3 +SES5oyPLGCUHhWPFB+wsw3hD3JelJKI7X7KLdOl5KTccECbTIxm141zv/tB3RNRE +07DmCYiVrvsi5+CTngbXCcJVG0PZJ59vlSE58bYLe0cafKjRXMHWX1YT+YeeES4m +jWhU9PClnAnS4Z7uCrmcI9/nXFiavNkSdp2yRLfS4Eew1Mtavd49exk68NrVhKBs +VY1h3Sl1NY7UfcaWtUrCng8bCyHbWNIwoZ8yNJaDXKbvKyxTX88T+x4ulysyB6Xo +7bAnx1KlrZBaVRG/iE6dnLglokW7dbBoE09QcBDslPjbfTSX8ldaPSGKK1Bwe/D3 +1nb+LTsY6sZNQg== +=s5Gu +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.sha512 (added) +++ dev/spark/v3.4.0-rc7-bin/SparkR_3.4.0.tar.gz.sha512 Fri Apr 7 02:45:25 2023 @@ -0,0 +1 @@ +4c7c4fa6018cb000dca30a34b5d963b30334be7230161a4f01b5c3192a3f87b0a54030b08f9bbfd58a3a796fb4bb7c607c1ba757f303f4da21e0f50dbce77b94 SparkR_3.4.0.tar.gz Added: dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.asc == --- dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.asc (added) +++ dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.asc Fri Apr 7 02:45:25 2023 @@ -0,0 +1,17 @@ +-BEGIN PGP SIGNATURE- + +iQJHBAABCgAxFiEEzGiz0W/jOnZnBRYLp+V5CMek4bEFAmQvg1sTHHhpbnJvbmdA +YXBhY2hlLm9yZwAKCRCn5XkIx6ThsWuEEACDllGUxRb6YQEI2/pjfmRjtRo3WFMy +SZzNTkBaGmJii8wB9I9OuUtJ5k1MCHSjWW6cwMZ4JJb8BDZ2ZVDy/66tZoKAIK7u +aUvbjcF8IpudwqTTn0VBfQVsLzE9G4clEoGFJpeCvg61+CqY1sxkhtg6FFMTgyhb +aMZOlz9uvEnYoYXoM0ZU4aLNAxclnhmE42+5j1MF3aiSR3Q/WaZEx/ECcEF4XhE1 +Q+53AmvnPm6yFFcqRQd023xWMnP6Y1zBBLnp2GZ2/SzCUkJrfvdueCDiOaiFrdnO +Jrf45ZBMaOcloy/tGSKl/ykjjYKEUVk980Y6guC63Nym+sf19Da8eD2AqQSxxLiQ +4tLH8owFHP4tr4C4MmfVD3R1HyNFk97scRDjCrCA0wMGLy9B3oSbE0yoRDRxZyei +dT7y2OsGYQ7bSV1+sV6uQB59QarxBINOrl5nH/L8qz+H7tWA/UMCHCmlSyuYc/m4 +D0IMj4cDrpbahVN1dQelDOwO+pmMrlXMXkA4HAwJPQd5V0wcGWJWYlEz4FeoGr+0 +BkuNdngw21NnwH8ebbW2KbdNe235yfNfXK+pVQq5NerUKBuBpzM73AqI3idjFzTd +pgeYrmbUMQxgPKZgZ/Fm025fwxW6e1z9aJdPJOa1baXT1gaiUtalzok7/En2t/Wj +48RFugofvd1TGA== +=s7ET +-END PGP SIGNATURE- Added: dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.sha512 == --- dev/spark/v3.4.0-rc7-bin/pyspark-3.4.0.tar.gz.sha512 (added) +++ dev/spark
svn commit: r61125 - in /dev/spark/v3.4.0-rc7-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Fri Apr 7 19:11:49 2023 New Revision: 61125 Log: Apache Spark v3.4.0-rc7 docs [This commit notification would consist of 2789 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r61236 - in /dev/spark: v3.4.0-rc1-bin/ v3.4.0-rc1-docs/ v3.4.0-rc2-bin/ v3.4.0-rc2-docs/ v3.4.0-rc3-bin/ v3.4.0-rc3-docs/ v3.4.0-rc4-bin/ v3.4.0-rc4-docs/ v3.4.0-rc5-bin/ v3.4.0-rc5-docs/
Author: xinrong Date: Thu Apr 13 19:33:23 2023 New Revision: 61236 Log: Removing RC artifacts. Removed: dev/spark/v3.4.0-rc1-bin/ dev/spark/v3.4.0-rc1-docs/ dev/spark/v3.4.0-rc2-bin/ dev/spark/v3.4.0-rc2-docs/ dev/spark/v3.4.0-rc3-bin/ dev/spark/v3.4.0-rc3-docs/ dev/spark/v3.4.0-rc4-bin/ dev/spark/v3.4.0-rc4-docs/ dev/spark/v3.4.0-rc5-bin/ dev/spark/v3.4.0-rc5-docs/ dev/spark/v3.4.0-rc6-bin/ dev/spark/v3.4.0-rc6-docs/ dev/spark/v3.4.0-rc7-docs/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r61281 - in /dev/spark/v3.4.0-rc7-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/R/articles/ _site/api/R/deps/ _site/api/R/deps/bootstrap-5.2.2/ _site/api/R/deps/jquery-3.6.0/ _site/api
Author: xinrong Date: Fri Apr 14 18:58:10 2023 New Revision: 61281 Log: Apache Spark v3.4.0-rc7 docs [This commit notification would consist of 2789 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Fix the download page of Spark 3.4.0
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 624de69568 Fix the download page of Spark 3.4.0
624de69568 is described below
commit 624de69568e5c743206a63cfc49d8647e41e1167
Author: Gengliang Wang
AuthorDate: Fri Apr 14 13:03:59 2023 -0700
Fix the download page of Spark 3.4.0
Currently it shows 3.3.2 on top
https://user-images.githubusercontent.com/1097932/232143660-9d97a7c0-5eb0-44af-9f06-41cb6386a2dd.png";>
After fix:
https://user-images.githubusercontent.com/1097932/232143685-ee5b06e6-3af9-43ea-8690-209f4d8cd25f.png";>
Author: Gengliang Wang
Closes #451 from gengliangwang/fixDownload.
---
js/downloads.js | 2 +-
site/js/downloads.js | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/js/downloads.js b/js/downloads.js
index 915b9c8809..9781273310 100644
--- a/js/downloads.js
+++ b/js/downloads.js
@@ -25,9 +25,9 @@ var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7,
hadoopFree, sources]
// 3.3.0+
var packagesV13 = [hadoop3p, hadoop3pscala213, hadoop2p, hadoopFree, sources];
+addRelease("3.4.0", new Date("04/13/2023"), packagesV13, true);
addRelease("3.3.2", new Date("02/17/2023"), packagesV13, true);
addRelease("3.2.4", new Date("04/13/2023"), packagesV12, true);
-addRelease("3.4.0", new Date("04/13/2023"), packagesV13, true);
function append(el, contents) {
el.innerHTML += contents;
diff --git a/site/js/downloads.js b/site/js/downloads.js
index 915b9c8809..9781273310 100644
--- a/site/js/downloads.js
+++ b/site/js/downloads.js
@@ -25,9 +25,9 @@ var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7,
hadoopFree, sources]
// 3.3.0+
var packagesV13 = [hadoop3p, hadoop3pscala213, hadoop2p, hadoopFree, sources];
+addRelease("3.4.0", new Date("04/13/2023"), packagesV13, true);
addRelease("3.3.2", new Date("02/17/2023"), packagesV13, true);
addRelease("3.2.4", new Date("04/13/2023"), packagesV12, true);
-addRelease("3.4.0", new Date("04/13/2023"), packagesV13, true);
function append(el, contents) {
el.innerHTML += contents;
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r61288 - in /dev/spark: v3.2.4-rc1-docs/ v3.4.0-rc7-docs/
Author: xinrong Date: Fri Apr 14 20:31:17 2023 New Revision: 61288 Log: Removing RC artifacts. Removed: dev/spark/v3.2.4-rc1-docs/ dev/spark/v3.4.0-rc7-docs/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org