[GitHub] [tvm] jwfromm commented on issue #7203: [Bug] [Relay] Error when compiling a simple ONNX model with Abs and PRelu
jwfromm commented on issue #7203: URL: https://github.com/apache/tvm/issues/7203#issuecomment-754380843 This bug is also fixed in #7208 and was caused by the same issue as #7202. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] insop commented on issue #7186: [Frontend][MXNet] Importer Missing Operators
insop commented on issue #7186: URL: https://github.com/apache/tvm/issues/7186#issuecomment-754387174 For `_npi_stack ` : https://github.com/apache/tvm/pull/7209 is submitted. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] luyaor edited a comment on pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
luyaor edited a comment on pull request #7208: URL: https://github.com/apache/tvm/pull/7208#issuecomment-754398110 Hi @jwfromm @mbrookhart , thanks for the response and effort on this case. The PR looks good to me. I am currently working on a research project related to TVM, would like to make more contributions to TVM and also looking forward to the feedback from community. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] luyaor commented on pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
luyaor commented on pull request #7208: URL: https://github.com/apache/tvm/pull/7208#issuecomment-754398110 Hi @jwfromm @mbrookhart , thanks for the response and effort on this case. The PR looks good to me. I am currently working on the research project related to TVM, would like to make more contributions to TVM and also looking forward to the feedback from community. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (d052752 -> 23bd825)
This is an automated email from the ASF dual-hosted git repository. zhaowu pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from d052752 [ConvertLayout] slice_like support (#7184) add 23bd825 [AutoScheduler] Add custom build function (#7185) No new revisions were added by this update. Summary of changes: python/tvm/auto_scheduler/measure.py | 44 1 file changed, 35 insertions(+), 9 deletions(-)
[GitHub] [tvm] FrozenGene commented on pull request #7185: [AutoScheduler] Add custom build function
FrozenGene commented on pull request #7185: URL: https://github.com/apache/tvm/pull/7185#issuecomment-754430231 Thanks for the great work @leowang1225 and thanks for the reviewing @jcf94 , it is merged now. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] insop commented on a change in pull request #7164: [µTVM] Add documentation
insop commented on a change in pull request #7164: URL: https://github.com/apache/tvm/pull/7164#discussion_r551695870 ## File path: docs/dev/index.rst ## @@ -396,3 +396,11 @@ Security :maxdepth: 1 security + + +microTVM +- +.. toctree:: Review comment: Looks great and LGTM. Thank you @areusch . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] merrymercy commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
merrymercy commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551763767
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -116,12 +117,17 @@ def __init__(self, verbose_eval=25,
num_warmup_sample=100, seed=None):
self.plan_size = 32
self.num_warmup_sample = num_warmup_sample
self.verbose_eval = verbose_eval
+self.model_file = model_file
+if model_file:
+logger.info("XGBModel: Load pretrained model from %s...",
model_file)
+self.load(model_file)
Review comment:
Remove this. No python/sklearn model has api or behavior like this.
Calling `model.load(model_file)` explicitly is cleaner than adding
`model_file` to the constructor.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jwfromm commented on issue #7202: [Bug] [Relay] Error when compiling a simple ONNX model
jwfromm commented on issue #7202: URL: https://github.com/apache/tvm/issues/7202#issuecomment-754372403 Thanks for finding this bug, it's due to a bad assumption made in Prelu conversion about the input layout. The issue is fixed in https://github.com/apache/tvm/pull/7208 and I've confirmed the test script works with that change. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] fantasyRqg opened a new pull request #7211: Build multi models into one system-lib
fantasyRqg opened a new pull request #7211:
URL: https://github.com/apache/tvm/pull/7211
Deploy models on Android & iOS platform must use system-lib. Avoid usage of
`dlopen`.
[bundle_deploy](https://github.com/apache/tvm/tree/main/apps/bundle_deploy)
demonstrated how to deploy a model which build a model which target system-lib
BUT we need more than one models
Related Discussions:
- [How to deploy two different tvm compiled model in c++
statically?](https://discuss.tvm.apache.org/t/how-to-deploy-two-different-tvm-compiled-model-in-c-statically/2492)
- [Combine multi SYSTEM-LIB module libs to
one](https://discuss.tvm.apache.org/t/discuss-combine-multi-system-lib-module-libs-to-one/8724).
The implementation steps are different from what I thought at the beginning
cc @wweic @zhiics
Please forgive me for my poor English
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] insop opened a new pull request #7209: [Frontend][MXNet] add _npi_stack, issue #7186
insop opened a new pull request #7209: URL: https://github.com/apache/tvm/pull/7209 - https://github.com/apache/tvm/issues/7186 - add MxNet stack, `_npi_stack` - https://mxnet.apache.org/versions/master/api/python/docs/api/np/generated/mxnet.np.stack.html?highlight=stack @junrushao1994 , @sxjscience This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jwfromm commented on pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
jwfromm commented on pull request #7208: URL: https://github.com/apache/tvm/pull/7208#issuecomment-754372193 @luyaor @mbrookhart @masahi can you guys take a look at this tiny PR? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jwfromm opened a new pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
jwfromm opened a new pull request #7208: URL: https://github.com/apache/tvm/pull/7208 Our current prelu converter assumes that incoming data is in NCHW format and that the slope will have C total elements. Neither of these are actual requirements for ONNX PreLu. As pointed out in https://github.com/apache/tvm/issues/7202, our converter fails in other cases. This PR makes our importer prelu compliant with the onnx spec. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi opened a new pull request #7210: [VM] Per-input, data dependence speficiation for shape func
masahi opened a new pull request #7210: URL: https://github.com/apache/tvm/pull/7210 Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from [Reviewers](https://github.com/apache/incubator-tvm/blob/master/CONTRIBUTORS.md#reviewers) by @ them in the pull request thread. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi edited a comment on pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
masahi edited a comment on pull request #7208: URL: https://github.com/apache/tvm/pull/7208#issuecomment-754410295 Hi @luyaor you are welcome to poke at pytorch frontend too, I hope it is more robust than onnx frontend :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
masahi commented on pull request #7208: URL: https://github.com/apache/tvm/pull/7208#issuecomment-754410295 Hi @luyaor you are welcome to poke at pytorch frontend too, I hope it is more robust then onnx frontend :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] fantasyRqg commented on pull request #7211: Build multi models into one system-lib
fantasyRqg commented on pull request #7211: URL: https://github.com/apache/tvm/pull/7211#issuecomment-754468357 ```log enabled targets: llvm -device=arm_cpu; llvm pytest marker: == test session starts == platform linux -- Python 3.8.0, pytest-6.1.1, py-1.9.0, pluggy-0.13.1 -- /usr/local/bin/python3 cachedir: .pytest_cache rootdir: /root/tvm, configfile: pytest.ini collected 14 items tests/python/unittest/test_runtime_rpc.py::test_bigendian_rpc PASSED [ 7%] tests/python/unittest/test_runtime_rpc.py::test_rpc_simple PASSED [ 14%] tests/python/unittest/test_runtime_rpc.py::test_rpc_runtime_string PASSED [ 21%] tests/python/unittest/test_runtime_rpc.py::test_rpc_array PASSED [ 28%] tests/python/unittest/test_runtime_rpc.py::test_rpc_large_array PASSED [ 35%] tests/python/unittest/test_runtime_rpc.py::test_rpc_echo PASSED [ 42%] tests/python/unittest/test_runtime_rpc.py::test_rpc_file_exchange PASSED [ 50%] tests/python/unittest/test_runtime_rpc.py::test_rpc_remote_module PASSED [ 57%] tests/python/unittest/test_runtime_rpc.py::test_rpc_return_func PASSED [ 64%] tests/python/unittest/test_runtime_rpc.py::test_rpc_session_constructor_args PASSED [ 71%] tests/python/unittest/test_runtime_rpc.py::test_rpc_return_ndarray PASSED [ 78%] tests/python/unittest/test_runtime_rpc.py::test_local_func PASSED [ 85%] tests/python/unittest/test_runtime_rpc.py::test_rpc_tracker_register PASSED [ 92%] tests/python/unittest/test_runtime_rpc.py::test_rpc_tracker_request PASSED [100%] == 14 passed in 7.20s === ``` `test_rpc_echo` passed on my ubuntu. trigger ci again This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jwfromm commented on pull request #7208: [Relay][Frontend][Onnx] Fix mismatch between Onnx Prelu definition and importer.
jwfromm commented on pull request #7208: URL: https://github.com/apache/tvm/pull/7208#issuecomment-754406762 These two errors that you generated were excellent real bugs with the importer and were very easy to understand and replicate with your post. If they're being auto-generated they look excellent! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] FrozenGene merged pull request #7185: [AutoScheduler] Add custom build function
FrozenGene merged pull request #7185: URL: https://github.com/apache/tvm/pull/7185 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] merrymercy commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
merrymercy commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551763123
##
File path: python/tvm/auto_scheduler/task_scheduler.py
##
@@ -82,11 +82,12 @@ def make_search_policies(
if isinstance(search_policy, str):
policy_type, model_type = search_policy.split(".")
if model_type == "xgb":
-cost_model = XGBModel(num_warmup_sample=len(tasks) *
num_measures_per_round)
-if load_model_file:
-logger.info("TaskScheduler: Load pretrained model...")
-cost_model.load(load_model_file)
-elif load_log_file:
+cost_model = XGBModel(
+num_warmup_sample=len(tasks) * num_measures_per_round,
+model_file=load_model_file,
+)
+if load_log_file:
+logger.info("TaskScheduler: Reload measured states and train
the model...")
Review comment:
`load_model_file` and `load_log_file` are mutually exclusive, because
`update_from_file` will retrain a model and overwrite the loaded model.
I think the old code is better.
I don't know why the old code cannot satisfy your need.
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -141,6 +147,12 @@ def update(self, inputs, results):
self.inputs.extend(inputs)
self.results.extend(results)
+if len(self.inputs) - self.last_train_length < self.last_train_length
/ 5:
Review comment:
Add a new bool argument `adapative_training` as the switch of this
feature.
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -116,12 +117,17 @@ def __init__(self, verbose_eval=25,
num_warmup_sample=100, seed=None):
self.plan_size = 32
self.num_warmup_sample = num_warmup_sample
self.verbose_eval = verbose_eval
+self.model_file = model_file
+if model_file:
+logger.info("XGBModel: Load pretrained model from %s...",
model_file)
+self.load(model_file)
Review comment:
Remove this. No python/sklearn model has api or behavior like this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[tvm-site] branch asf-site updated: Build at Mon Jan 4 16:23:05 EST 2021
This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/tvm-site.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 5581d5b Build at Mon Jan 4 16:23:05 EST 2021
5581d5b is described below
commit 5581d5befbe474fe7dad4bd97e90ee53cabba921
Author: tqchen
AuthorDate: Mon Jan 4 16:23:05 2021 -0500
Build at Mon Jan 4 16:23:05 EST 2021
---
atom.xml | 2 +-
feed.xml | 2 +-
rss.xml | 4 ++--
3 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/atom.xml b/atom.xml
index 9c061c8..84cd5f0 100644
--- a/atom.xml
+++ b/atom.xml
@@ -4,7 +4,7 @@
TVM
https://tvm.apache.org; rel="self"/>
https://tvm.apache.org"/>
- 2020-12-07T10:45:44-05:00
+ 2021-01-04T16:22:52-05:00
https://tvm.apache.org
diff --git a/feed.xml b/feed.xml
index 64f5387..a3d90e2 100644
--- a/feed.xml
+++ b/feed.xml
@@ -1,4 +1,4 @@
-http://www.w3.org/2005/Atom; >https://jekyllrb.com/;
version="4.1.1">Jekyll2020-12-07T10:45:44-05:00/feed.xmlTVM{name=nil}Bring Your Own Datatypes: Enabling Custom Datatype [...]
+http://www.w3.org/2005/Atom; >https://jekyllrb.com/;
version="4.1.1">Jekyll2021-01-04T16:22:52-05:00/feed.xmlTVM{name=nil}Bring Your Own Datatypes: Enabling Custom Datatype [...]
h2 id=introductionIntroduction/h2
diff --git a/rss.xml b/rss.xml
index f3dee7f..f2dfac7 100644
--- a/rss.xml
+++ b/rss.xml
@@ -5,8 +5,8 @@
TVM -
https://tvm.apache.org
https://tvm.apache.org; rel="self"
type="application/rss+xml" />
-Mon, 07 Dec 2020 10:45:44 -0500
-Mon, 07 Dec 2020 10:45:44 -0500
+Mon, 04 Jan 2021 16:22:52 -0500
+Mon, 04 Jan 2021 16:22:52 -0500
60
[GitHub] [tvm] mbrookhart commented on pull request #7172: [TOPI] Parallelize GPU NMS inner loop
mbrookhart commented on pull request #7172: URL: https://github.com/apache/tvm/pull/7172#issuecomment-754276271 Kudos! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac merged pull request #7205: [BYOC][TRT] Fix TRT conversion for reshape op - ReshapeAttrs no longer has reverse
comaniac merged pull request #7205: URL: https://github.com/apache/tvm/pull/7205 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: ReshapeAttrs no longer has reverse (#7205)
This is an automated email from the ASF dual-hosted git repository.
comaniac pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new 7163b5c ReshapeAttrs no longer has reverse (#7205)
7163b5c is described below
commit 7163b5c02fd25326e7c68ccc3b41d30f4a912952
Author: Trevor Morris
AuthorDate: Mon Jan 4 14:01:53 2021 -0800
ReshapeAttrs no longer has reverse (#7205)
---
src/runtime/contrib/tensorrt/tensorrt_ops.cc | 1 -
1 file changed, 1 deletion(-)
diff --git a/src/runtime/contrib/tensorrt/tensorrt_ops.cc
b/src/runtime/contrib/tensorrt/tensorrt_ops.cc
index 1e6867b..69bb1dc 100644
--- a/src/runtime/contrib/tensorrt/tensorrt_ops.cc
+++ b/src/runtime/contrib/tensorrt/tensorrt_ops.cc
@@ -921,7 +921,6 @@ class ReshapeOpConverter : public TensorRTOpConverter {
void Convert(TensorRTOpConverterParams* params) const {
auto input = params->inputs.at(0).tensor;
-
ICHECK_EQ(std::stoi(params->node.GetAttr>("reverse")[0]),
false);
auto str_newshape =
params->node.GetAttr>("newshape");
std::vector new_shape;
const int start_index = TRT_HAS_IMPLICIT_BATCH(params) ? 1 : 0;
[GitHub] [tvm] comaniac commented on pull request #7205: [BYOC][TRT] Fix TRT conversion for reshape op - ReshapeAttrs no longer has reverse
comaniac commented on pull request #7205: URL: https://github.com/apache/tvm/pull/7205#issuecomment-754249830 Thanks @trevor-m @junrushao1994 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] lhutton1 commented on a change in pull request #7206: [BYOC][ACL] Depthwise convolution support
lhutton1 commented on a change in pull request #7206:
URL: https://github.com/apache/tvm/pull/7206#discussion_r551595603
##
File path: python/tvm/relay/op/contrib/arm_compute_lib.py
##
@@ -19,12 +19,15 @@
import numpy as np
import tvm
+import tvm._ffi
Review comment:
Better to use more specific import
```suggestion
from tvm._ffi import register_func
```
##
File path: python/tvm/relay/op/contrib/arm_compute_lib.py
##
@@ -71,6 +74,61 @@ def partition_for_arm_compute_lib(mod, params=None):
return seq(mod)
+@tvm._ffi.register_func("relay.ext.arm_compute_lib.optimize")
Review comment:
With above change
```suggestion
@register_func("relay.ext.arm_compute_lib.optimize")
```
##
File path: python/tvm/relay/op/contrib/arm_compute_lib.py
##
@@ -71,6 +74,61 @@ def partition_for_arm_compute_lib(mod, params=None):
return seq(mod)
+@tvm._ffi.register_func("relay.ext.arm_compute_lib.optimize")
+def preprocess_module(mod):
+"""
+Pre-process a module containing functions ready for ACL codegen. For
now we enforce OHWI
+kernel layout and fold the transforms away.
+
+` Parameters
Review comment:
Remove `
##
File path: src/relay/backend/contrib/arm_compute_lib/codegen.cc
##
@@ -126,7 +127,7 @@ class ACLJSONSerializer : public
backend::contrib::JSONSerializer {
nodes.activation = current_call;
current_call = current_call->args[0].as();
}
-if (backend::IsOp(current_call, "nn.bias_add")) {
+if (backend::IsOp(current_call, "add")) {
Review comment:
I remember needing to change this but I didn't get to the bottom of why.
Is there an explanation?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197: URL: https://github.com/apache/tvm/pull/7197#discussion_r551211822 ## File path: python/tvm/auto_scheduler/cost_model/xgb_model.py ## @@ -141,6 +146,12 @@ def update(self, inputs, results): self.inputs.extend(inputs) self.results.extend(results) +if len(self.inputs) - self.last_train_length < self.last_train_length / 5: Review comment: When there're too many logs, auto scheduler will spent much time on cost model training than program measuring in each search round. This modification is just used to reduce the times of cost model training. At the beginning, we train the cost model in each search round, and when many logs are accumulated, we train the cost model after several search rounds. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197: URL: https://github.com/apache/tvm/pull/7197#discussion_r551211822 ## File path: python/tvm/auto_scheduler/cost_model/xgb_model.py ## @@ -141,6 +146,12 @@ def update(self, inputs, results): self.inputs.extend(inputs) self.results.extend(results) +if len(self.inputs) - self.last_train_length < self.last_train_length / 5: Review comment: When there're too many logs, auto scheduler will spent much time on cost model training than program measuring in each search round. This modification is just used to reduce the times of cost model training. At the beginning, we train the cost model in each search round, and when many logs are accumulated, we train the cost model after several search rounds. `len(self.inputs) - self.last_train_length` is the increased measure pairs since last training, we should not just use `len(inputs)`. And the number 5 is just a magic number I pick, I'm not sure how to choose a better threshold. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] kalman5 opened a new pull request #7199: Fixed temporary lock_guard instances.
kalman5 opened a new pull request #7199: URL: https://github.com/apache/tvm/pull/7199 This diff fixes the temporary lock_guard instances giving those a name. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] aaltonenzhang opened a new issue #7198: some confusions when import official tensorflow models
aaltonenzhang opened a new issue #7198: URL: https://github.com/apache/tvm/issues/7198 When testing tensorflow models from tfhub at [https://tfhub.dev/](url), I found issues when import tensorflow IRs. 1. When I import saved model using TFParser.parse() and from_tensorflow(), I found that for some models, it's seems that the tags are not consistent with the real saved model. 2. I found that import model from checkpoint is not supported yet, but will tvm support it in the future? And what if there are no meta data exported from the checkpoint? Is it mandatory to modify python code of each cases without meta data? 3. Why does only constant values are supported for dims parameter of Fill operator? Will you support it later? For efficientnet, I convert saved model to be tflite format and found this problem. 4. Function not found - __inference_signature_wrapper_4615. issues are listed below: > model name | import result -- | -- efficientnet | For dims parameter of Fill operator, only constant values are supported retinanet | StatefulPartitionedCall:6 is not in graph albert | StatefulPartitionedCall:6 is not in graph bert | StatefulPartitionedCall:6 is not in graph ncf | Function not found - __inference_signature_wrapper_4615 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
comaniac commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551199732
##
File path: python/tvm/auto_scheduler/task_scheduler.py
##
@@ -82,11 +82,12 @@ def make_search_policies(
if isinstance(search_policy, str):
policy_type, model_type = search_policy.split(".")
if model_type == "xgb":
-cost_model = XGBModel(num_warmup_sample=len(tasks) *
num_measures_per_round)
-if load_model_file:
-logger.info("TaskScheduler: Load pretrained model...")
-cost_model.load(load_model_file)
-elif load_log_file:
+cost_model = XGBModel(
+num_warmup_sample=len(tasks) * num_measures_per_round,
+model_file=load_model_file,
+)
+if load_log_file:
+logger.info("TaskScheduler: Reload measured states and
pretrain model...")
Review comment:
```suggestion
logger.info("TaskScheduler: Reload measured states and
pretrained model...")
```
##
File path: src/auto_scheduler/feature.cc
##
@@ -1462,12 +1462,18 @@ void GetPerStoreFeaturesFromMeasurePairs(const
Array& inputs,
if (find_res == task_cache.end()) {
if (inputs[i]->task->compute_dag.defined()) { // the measure input is
complete
task = inputs[i]->task;
- } else { // the measure input is incomplete
-// rebuild task for incomplete measure pairs read from file
-Array tensors = (*workload_key_to_tensors)(workload_key);
-task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
- inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
- inputs[i]->task->layout_rewrite_option);
+ } else {
+// The measure input is incomplete, rebuild task for incomplete
measure pairs read from file
+try {
+ Array tensors = (*workload_key_to_tensors)(workload_key);
+ task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
+inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
+inputs[i]->task->layout_rewrite_option);
+} catch (std::exception& e) {
+ // Cannot build ComputeDAG from workload key, the task may have not
been registered in
+ // this search round
+ continue;
Review comment:
Should we have a warning here? Otherwise it may be confusing.
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -141,6 +146,12 @@ def update(self, inputs, results):
self.inputs.extend(inputs)
self.results.extend(results)
+if len(self.inputs) - self.last_train_length < self.last_train_length
/ 5:
Review comment:
```suggestion
if len(inputs) < self.last_train_length / 5:
```
Could you explain a bit more on this logic or make it more straightforward?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] luyaor opened a new issue #7203: [Bug] [Relay] Error when compiling a simple ONNX model
luyaor opened a new issue #7203:
URL: https://github.com/apache/tvm/issues/7203
## Description
When compiling following model with TVM, it will error.
The model(with ONNX as frontend) with error is as follows, check bug.onnx in
[bug3.zip](https://github.com/apache/tvm/files/5764602/bug3.zip)
## Error Log
```
Traceback (most recent call last):
File "check.py", line 11, in
mod, params = relay.frontend.from_onnx(onnx_model, {})
File "/Users/luyaor/Documents/tvm/python/tvm/relay/frontend/onnx.py", line
2806, in from_onnx
mod, params = g.from_onnx(graph, opset, freeze_params)
File "/Users/luyaor/Documents/tvm/python/tvm/relay/frontend/onnx.py", line
2613, in from_onnx
op = self._convert_operator(op_name, inputs, attr, opset)
File "/Users/luyaor/Documents/tvm/python/tvm/relay/frontend/onnx.py", line
2721, in _convert_operator
sym = convert_map[op_name](inputs, attrs, self._params)
File "/Users/luyaor/Documents/tvm/python/tvm/relay/frontend/onnx.py", line
820, in _impl_v1
input_channels = infer_shape(inputs[0])[1]
IndexError: tuple index out of range
```
## How to reproduce
### Environment
Python3, with tvm, onnx
tvm version:
[`c31e338`](https://github.com/apache/tvm/commit/c31e338d5f98a8e8c97286c5b93b20caee8be602)
Wed Dec 9 14:52:58 2020 +0900
1. Download [bug3.zip](https://github.com/apache/tvm/files/5764602/bug3.zip)
2. Run `python check.py`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551195931
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
yes
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[tvm] branch main updated: Fix ICHECK_NOTNULL in logging.g (#7193)
This is an automated email from the ASF dual-hosted git repository. comaniac pushed a commit to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git The following commit(s) were added to refs/heads/main by this push: new eb64e25 Fix ICHECK_NOTNULL in logging.g (#7193) eb64e25 is described below commit eb64e259546574372c8bb88eee3a4b83130b8b7d Author: Ritwik Das AuthorDate: Mon Jan 4 01:22:43 2021 -0800 Fix ICHECK_NOTNULL in logging.g (#7193) --- include/tvm/support/logging.h | 8 1 file changed, 4 insertions(+), 4 deletions(-) diff --git a/include/tvm/support/logging.h b/include/tvm/support/logging.h index d98363e..ced1902 100644 --- a/include/tvm/support/logging.h +++ b/include/tvm/support/logging.h @@ -139,10 +139,10 @@ constexpr const char* kTVM_INTERNAL_ERROR_MESSAGE = #define ICHECK_GE(x, y) ICHECK_BINARY_OP(_GE, >=, x, y) #define ICHECK_EQ(x, y) ICHECK_BINARY_OP(_EQ, ==, x, y) #define ICHECK_NE(x, y) ICHECK_BINARY_OP(_NE, !=, x, y) -#define ICHECK_NOTNULL(x) \ - ((x) == nullptr ? dmlc::LogMessageFatal(__FILE__, __LINE__).stream() \ -<< tvm::kTVM_INTERNAL_ERROR_MESSAGE << __INDENT << "Check not null: " #x \ -<< ' ', \ +#define ICHECK_NOTNULL(x)\ + ((x) == nullptr ? dmlc::LogMessageFatal(__FILE__, __LINE__).stream() \ +<< tvm::kTVM_INTERNAL_ERROR_MESSAGE << ICHECK_INDENT \ +<< "Check not null: " #x << ' ', \ (x) : (x)) // NOLINT(*) /*! \brief The diagnostic level, controls the printing of the message. */
[GitHub] [tvm] comaniac commented on pull request #7193: Fix ICHECK_NOTNULL in logging.h
comaniac commented on pull request #7193: URL: https://github.com/apache/tvm/pull/7193#issuecomment-753861130 Thanks @codeislife99 @junrushao1994 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac merged pull request #7193: Fix ICHECK_NOTNULL in logging.h
comaniac merged pull request #7193: URL: https://github.com/apache/tvm/pull/7193 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] insop commented on issue #7196: unsupported operators from tensorflow model garden models
insop commented on issue #7196: URL: https://github.com/apache/tvm/issues/7196#issuecomment-753866375 @aaltonenzhang Nit, it seems the embedded url (https://github.com/tensorflow/models/tree/master/community) in the above post is not the actual url shown, i.e. if you click the link you will go to different site. And I see the similar in https://github.com/apache/tvm/issues/7198 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551206249
##
File path: src/auto_scheduler/feature.cc
##
@@ -1462,12 +1462,18 @@ void GetPerStoreFeaturesFromMeasurePairs(const
Array& inputs,
if (find_res == task_cache.end()) {
if (inputs[i]->task->compute_dag.defined()) { // the measure input is
complete
task = inputs[i]->task;
- } else { // the measure input is incomplete
-// rebuild task for incomplete measure pairs read from file
-Array tensors = (*workload_key_to_tensors)(workload_key);
-task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
- inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
- inputs[i]->task->layout_rewrite_option);
+ } else {
+// The measure input is incomplete, rebuild task for incomplete
measure pairs read from file
+try {
+ Array tensors = (*workload_key_to_tensors)(workload_key);
+ task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
+inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
+inputs[i]->task->layout_rewrite_option);
+} catch (std::exception& e) {
+ // Cannot build ComputeDAG from workload key, the task may have not
been registered in
+ // this search round
+ continue;
Review comment:
Emm ... I think this should be fine here.
For example, I have a `log.json` which contains 100 tasks, and I would like
to only tune the last 10 tasks next time(in another `python _tune.py`
call). Without this `try ... catch`, we'll get error in reading the first 90
tasks because they have not been registered.
And this modification just makes it works by skip loading the log of the
first 90 tasks.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] luyaor opened a new issue #7200: [Bug] Error when compiling a simple ONNX model with MatMul operator for opt_level=2
luyaor opened a new issue #7200: URL: https://github.com/apache/tvm/issues/7200 ## Description When compiling following model with opt_level=2, TVM will crash. While if turn opt_level to 3, it will run normally. The model(with ONNX as frontend) with error is as follows, check bug.onnx in bug0.zip. 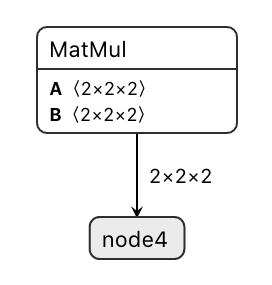 ## Error Log ``` Traceback (most recent call last): File "check.py", line 19, in tvm_graph, tvm_lib, tvm_params = relay.build_module.build(mod, target, params=params) File "/Users/luyaor/Documents/tvm/python/tvm/relay/build_module.py", line 275, in build graph_json, mod, params = bld_mod.build(mod, target, target_host, params) File "/Users/luyaor/Documents/tvm/python/tvm/relay/build_module.py", line 138, in build self._build(mod, target, target_host) File "/Users/luyaor/Documents/tvm/python/tvm/_ffi/_ctypes/packed_func.py", line 237, in __call__ raise get_last_ffi_error() tvm._ffi.base.TVMError: Traceback (most recent call last): [bt] (8) 9 libtvm.dylib0x0001112c2a02 tvm::relay::StorageAllocator::Plan(tvm::relay::Function const&) + 354 [bt] (7) 8 libtvm.dylib0x0001112c68ca tvm::relay::StorageAllocaBaseVisitor::Run(tvm::relay::Function const&) + 154 [bt] (6) 7 libtvm.dylib0x0001112c44c7 tvm::relay::StorageAllocaBaseVisitor::GetToken(tvm::RelayExpr const&) + 23 [bt] (5) 6 libtvm.dylib0x000111359b58 tvm::relay::ExprVisitor::VisitExpr(tvm::RelayExpr const&) + 344 [bt] (4) 5 libtvm.dylib0x0001110f1fad tvm::relay::ExprFunctor::VisitExpr(tvm::RelayExpr const&) + 173 [bt] (3) 4 libtvm.dylib0x0001110f22a0 tvm::NodeFunctor*)>::operator()(tvm::runtime::ObjectRef const&, tvm::relay::ExprFunctor*) const + 288 [bt] (2) 3 libtvm.dylib0x0001112c425b tvm::relay::StorageAllocator::CreateToken(tvm::RelayExprNode const*, bool) + 1179 [bt] (1) 2 libtvm.dylib0x0001112c6093 tvm::relay::StorageAllocator::GetMemorySize(tvm::relay::StorageToken*) + 451 [bt] (0) 1 libtvm.dylib0x0001105dac6f dmlc::LogMessageFatal::~LogMessageFatal() + 111 File "/Users/luyaor/Documents/tvm/src/relay/backend/graph_plan_memory.cc", line 292 TVMError: --- An internal invariant was violated during the execution of TVM. Please read TVM's error reporting guidelines. More details can be found here: https://discuss.tvm.ai/t/error-reporting/7793. --- Check failed: pval != nullptr == false: Cannot allocate memory symbolic tensor shape [?, ?, ?] ``` ## How to reproduce ### Environment Python3, with tvm, onnx tvm version: c31e338d5f98a8e8c97286c5b93b20caee8be602 Wed Dec 9 14:52:58 2020 +0900 Conda environment reference: see environment.yml 1. Download [bug0.zip](https://github.com/apache/tvm/files/5764374/bug0.zip) 2. Run `python check.py`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 opened a new pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 opened a new pull request #7197: URL: https://github.com/apache/tvm/pull/7197 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551207425
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
`
def cross_compiler(
compile_func, options=None, output_format=None, get_target_triple=None,
add_files=None
):
...
def _fcompile(outputs, objects, options=None):
all_options = base_options
if options is not None:
all_options += options
compile_func(outputs, objects + add_files, options=all_options,
**kwargs)
if not output_format and hasattr(compile_func, "output_format"):
output_format = compile_func.output_format
output_format = output_format if output_format else "so"
if not get_target_triple and hasattr(compile_func, "get_target_triple"):
get_target_triple = compile_func.get_target_triple
_fcompile.output_format = output_format
_fcompile.get_target_triple = get_target_triple
return _fcompile
`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197: URL: https://github.com/apache/tvm/pull/7197#discussion_r551211822 ## File path: python/tvm/auto_scheduler/cost_model/xgb_model.py ## @@ -141,6 +146,12 @@ def update(self, inputs, results): self.inputs.extend(inputs) self.results.extend(results) +if len(self.inputs) - self.last_train_length < self.last_train_length / 5: Review comment: When there're too many logs, auto scheduler will spent much time on cost model training than program measuring in each search round. This modification is just used to reduce the times of cost model training. At the beginning, we train the cost model in each search round, and when many logs are accumulated, we train the cost model after several search rounds. `len(self.inputs) - self.last_train_length` is the increased measure pairs since last training, we should not just use len(inputs). And the number 5 is just a magic number I pick, I'm not sure how to choose the threshold better. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197: URL: https://github.com/apache/tvm/pull/7197#discussion_r551211822 ## File path: python/tvm/auto_scheduler/cost_model/xgb_model.py ## @@ -141,6 +146,12 @@ def update(self, inputs, results): self.inputs.extend(inputs) self.results.extend(results) +if len(self.inputs) - self.last_train_length < self.last_train_length / 5: Review comment: When there're too many logs, auto scheduler will spent much time on cost model training than program measuring in each search round. This modification is just used to reduce the times of cost model training. At the beginning, we train the cost model in each search round, and when many logs are accumulated, we train the cost model after several search rounds. `len(self.inputs) - self.last_train_length` is the increased measure pairs since last training, we should not just use `len(inputs)`. And the number 5 is just a magic number I pick, I'm not sure how to choose the threshold better. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197: URL: https://github.com/apache/tvm/pull/7197#discussion_r551211822 ## File path: python/tvm/auto_scheduler/cost_model/xgb_model.py ## @@ -141,6 +146,12 @@ def update(self, inputs, results): self.inputs.extend(inputs) self.results.extend(results) +if len(self.inputs) - self.last_train_length < self.last_train_length / 5: Review comment: When there're too many logs, auto scheduler will spend much time on cost model training than program measuring in each search round. This modification is just used to reduce the times of cost model training. At the beginning, we train the cost model in each search round, and when many logs are accumulated, we train the cost model after several search rounds. `len(self.inputs) - self.last_train_length` is the increased measure pairs since last training, we should not just use `len(inputs)`. The `inputs` and `results` will be extened to `self.inputs` and `self.results`. And the number 5 is just a magic number I pick, I'm not sure how to choose a better threshold. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] rhzhang1995 opened a new issue #7204: mesg: ttyname failed: Inappropriate ioctl for device
rhzhang1995 opened a new issue #7204: URL: https://github.com/apache/tvm/issues/7204 When I was using Alveo U50 to configure TVM, I entered command “./tvm/docker/build.sh demo_vitis_ai bash”, and finally 2“mesg: ttyname failed: Inappropriate ioctl for device” appeared. Is TVM incompatible with Alveo U50?Thank you! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
jcf94 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551179115
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
Ok, then I dont have other better opinions, I'm going to do some test on
arm cpus these days, maybe I'll encounter similar problem like you.
Is it possible to:
```python
use_ndk = True
@tvm._ffi.register_func("special_wrapper")
def _wrapper():
return cc.cross_compiler(ndk.create_shared, options=ndk_options)
build_func = "special_wrapper"
tuner = auto_scheduler.TaskScheduler(tasks, task_weights)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=200, # change this to 2 to achieve the best
performance
builder=auto_scheduler.LocalBuilder(build_func=build_func if use_ndk
else "default"),
runner=auto_scheduler.RPCRunner(
device_key, host=tracker_ip, port=tracker_port, repeat=3, timeout=50
),
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
```
?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on pull request #7197: URL: https://github.com/apache/tvm/pull/7197#issuecomment-753862836 Thanks! @junrushao1994 Also cc @merrymercy @comaniac This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551206249
##
File path: src/auto_scheduler/feature.cc
##
@@ -1462,12 +1462,18 @@ void GetPerStoreFeaturesFromMeasurePairs(const
Array& inputs,
if (find_res == task_cache.end()) {
if (inputs[i]->task->compute_dag.defined()) { // the measure input is
complete
task = inputs[i]->task;
- } else { // the measure input is incomplete
-// rebuild task for incomplete measure pairs read from file
-Array tensors = (*workload_key_to_tensors)(workload_key);
-task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
- inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
- inputs[i]->task->layout_rewrite_option);
+ } else {
+// The measure input is incomplete, rebuild task for incomplete
measure pairs read from file
+try {
+ Array tensors = (*workload_key_to_tensors)(workload_key);
+ task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
+inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
+inputs[i]->task->layout_rewrite_option);
+} catch (std::exception& e) {
+ // Cannot build ComputeDAG from workload key, the task may have not
been registered in
+ // this search round
+ continue;
Review comment:
Emm ... I think this should be fine here.
For example, I have a `log.json` which contains 100 tasks, and I would like
to only tune the last 10 tasks next time. Without this `try ... catch`, we'll
get error in reading the first 90 tasks because they have not been registered.
And this modification just makes it works without loading the log of the
first 90 tasks.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551207425
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
`
def cross_compiler(
compile_func, options=None, output_format=None, get_target_triple=None,
add_files=None
):
def _fcompile(outputs, objects, options=None):
all_options = base_options
if options is not None:
all_options += options
compile_func(outputs, objects + add_files, options=all_options,
**kwargs)
if not output_format and hasattr(compile_func, "output_format"):
output_format = compile_func.output_format
output_format = output_format if output_format else "so"
if not get_target_triple and hasattr(compile_func, "get_target_triple"):
get_target_triple = compile_func.get_target_triple
_fcompile.output_format = output_format
_fcompile.get_target_triple = get_target_triple
return _fcompile
`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551207425
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
`
def cross_compiler(
compile_func, options=None, output_format=None, get_target_triple=None,
add_files=None
):
def _fcompile(outputs, objects, options=None):
all_options = base_options
if options is not None:
all_options += options
compile_func(outputs, objects + add_files, options=all_options,
**kwargs)
if not output_format and hasattr(compile_func, "output_format"):
output_format = compile_func.output_format
output_format = output_format if output_format else "so"
if not get_target_triple and hasattr(compile_func, "get_target_triple"):
get_target_triple = compile_func.get_target_triple
_fcompile.output_format = output_format
_fcompile.get_target_triple = get_target_triple
return _fcompile
`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] FrozenGene commented on a change in pull request #7185: [AutoScheduler] Add custom build function
FrozenGene commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551215468
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
i think just pass the custom function name doesn't have much benefit. We
could just pass
```python
use_ndk = True
build_func = cc.cross_compiler(ndk.create_shared, options=ndk_options)
tuner = auto_scheduler.TaskScheduler(tasks, task_weights)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=200, # change this to 2 to achieve the best
performance
builder=auto_scheduler.LocalBuilder(build_func=build_func if use_ndk
else "default"),
runner=auto_scheduler.RPCRunner(
device_key, host=tracker_ip, port=tracker_port, repeat=3, timeout=50
),
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197: URL: https://github.com/apache/tvm/pull/7197#discussion_r551211822 ## File path: python/tvm/auto_scheduler/cost_model/xgb_model.py ## @@ -141,6 +146,12 @@ def update(self, inputs, results): self.inputs.extend(inputs) self.results.extend(results) +if len(self.inputs) - self.last_train_length < self.last_train_length / 5: Review comment: When there're too many logs, auto scheduler will spend much time on cost model training than program measuring in each search round. This modification is just used to reduce the times of cost model training. At the beginning, we train the cost model in each search round, and when many logs are accumulated, we train the cost model after several search rounds. `len(self.inputs) - self.last_train_length` is the increased measure pairs since last training, we should not just use `len(inputs)`. And the number 5 is just a magic number I pick, I'm not sure how to choose a better threshold. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] kalman5 commented on pull request #7199: Fixed temporary lock_guard instances.
kalman5 commented on pull request #7199: URL: https://github.com/apache/tvm/pull/7199#issuecomment-753911981 @jcf94 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] luyaor opened a new issue #7201: [Bug] Error when compiling a simple ONNX model for opt_level=3
luyaor opened a new issue #7201: URL: https://github.com/apache/tvm/issues/7201 ## Description When compiling following model with opt_level=3, TVM will crash. While if turn opt_level to 2, it will run normally. The model(with ONNX as frontend) with error is as follows, check bug.onnx in bug1.zip.  ## Error Log ``` Traceback (most recent call last): File "check.py", line 19, in tvm_graph, tvm_lib, tvm_params = relay.build_module.build(mod, target, params=params) File "/Users/luyaor/Documents/tvm/python/tvm/relay/build_module.py", line 275, in build graph_json, mod, params = bld_mod.build(mod, target, target_host, params) File "/Users/luyaor/Documents/tvm/python/tvm/relay/build_module.py", line 138, in build self._build(mod, target, target_host) File "/Users/luyaor/Documents/tvm/python/tvm/_ffi/_ctypes/packed_func.py", line 237, in __call__ raise get_last_ffi_error() tvm._ffi.base.TVMError: Traceback (most recent call last): [bt] (8) 9 libtvm.dylib0x000111b9b2a0 tvm::NodeFunctor*)>::operator()(tvm::runtime::ObjectRef const&, tvm::relay::ExprFunctor*) const + 288 [bt] (7) 8 libtvm.dylib0x000111c8c289 tvm::relay::IndexedForwardGraph::Creator::VisitExpr_(tvm::relay::FunctionNode const*) + 297 [bt] (6) 7 libtvm.dylib0x000111e03015 tvm::relay::ExprVisitor::VisitExpr_(tvm::relay::FunctionNode const*) + 149 [bt] (5) 6 libtvm.dylib0x000111e02b58 tvm::relay::ExprVisitor::VisitExpr(tvm::RelayExpr const&) + 344 [bt] (4) 5 libtvm.dylib0x000111b9afad tvm::relay::ExprFunctor::VisitExpr(tvm::RelayExpr const&) + 173 [bt] (3) 4 libtvm.dylib0x000111b9b2a0 tvm::NodeFunctor*)>::operator()(tvm::runtime::ObjectRef const&, tvm::relay::ExprFunctor*) const + 288 [bt] (2) 3 libtvm.dylib0x000111c8c5c3 tvm::relay::IndexedForwardGraph::Creator::VisitExpr_(tvm::relay::CallNode const*) + 659 [bt] (1) 2 libtvm.dylib0x000f36d8 tvm::AttrRegistryMapContainerMap::operator[](tvm::Op const&) const + 408 [bt] (0) 1 libtvm.dylib0x000111083c6f dmlc::LogMessageFatal::~LogMessageFatal() + 111 File "/Users/luyaor/Documents/tvm/include/tvm/node/attr_registry_map.h", line 61 TVMError: --- An internal invariant was violated during the execution of TVM. Please read TVM's error reporting guidelines. More details can be found here: https://discuss.tvm.ai/t/error-reporting/7793. --- Check failed: idx < data_.size() && data_[idx].second != 0 == false: Attribute TOpPattern has not been registered for nn.dropout ``` ## How to reproduce ### Environment Python3, with tvm, onnx tvm version: c31e338d5f98a8e8c97286c5b93b20caee8be602 Wed Dec 9 14:52:58 2020 +0900 1. Download [bug1.zip](https://github.com/apache/tvm/files/5764418/bug1.zip) 2. Run `python check.py`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] kalman5 edited a comment on pull request #7199: Fixed temporary lock_guard instances.
kalman5 edited a comment on pull request #7199: URL: https://github.com/apache/tvm/pull/7199#issuecomment-753911981 For reviewers @jcf94 @ZihengJiang This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] luyaor opened a new issue #7202: [Bug] [Relay] Error when compiling a simple ONNX model
luyaor opened a new issue #7202: URL: https://github.com/apache/tvm/issues/7202 ## Description When compiling following model with TVM, it will error. The model(with ONNX as frontend) with error is as follows, check bug.onnx in bug2.zip.  Error Log ``` The Relay type checker is unable to show the following types match. In particular dimension 0 conflicts: 3 does not match 1. The Relay type checker is unable to show the following types match. In particular `Tensor[(3), float32]` does not match `Tensor[(1), float32]` note: run with `TVM_BACKTRACE=1` environment variable to display a backtrace. ``` ## How to reproduce ### Environment Python3, with tvm, onnx, you could also use Conda as `conda env create -f environment.yml` tvm version: [`c31e338`](https://github.com/apache/tvm/commit/c31e338d5f98a8e8c97286c5b93b20caee8be602) Wed Dec 9 14:52:58 2020 +0900 1. Download [bug2.zip](https://github.com/apache/tvm/files/5764543/bug2.zip) 2. Run `python check.py`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] FrozenGene commented on a change in pull request #7185: [AutoScheduler] Add custom build function
FrozenGene commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551167353
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
I query this piece of code git history , it is related with this pr:
https://github.com/apache/tvm/pull/6671. seems it is about spawn problem
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551170406
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
@jcf94
I try use @tvm._ffi.register_func, but the custom build func is a python
callable, it is not just function name. we need the whole python callable
context, and the callable also have attribute. like cross_compiler, it has
output_format and get_target_triple attributes.
use_ndk = True
build_func = cc.cross_compiler(ndk.create_shared, options=ndk_options)
tuner = auto_scheduler.TaskScheduler(tasks, task_weights)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=200, # change this to 2 to achieve the best
performance
builder=auto_scheduler.LocalBuilder(build_func=build_func if use_ndk
else "default"),
runner=auto_scheduler.RPCRunner(
device_key, host=tracker_ip, port=tracker_port, repeat=3,
timeout=50
),
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551170406
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
@jcf94
I try use @tvm._ffi.register_func, but the custom build func is a python
callable, it is not just function name. we need the whole python callable
context, and the callable also have attribute. like cross_compiler, it has
output_format and get_target_triple attributes.
_
use_ndk = True
build_func = cc.cross_compiler(ndk.create_shared, options=ndk_options)
tuner = auto_scheduler.TaskScheduler(tasks, task_weights)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=200, # change this to 2 to achieve the best
performance
builder=auto_scheduler.LocalBuilder(build_func=build_func if use_ndk
else "default"),
runner=auto_scheduler.RPCRunner(
device_key, host=tracker_ip, port=tracker_port, repeat=3,
timeout=50
),
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
_
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on pull request #7185: [AutoScheduler] Add custom build function
jcf94 commented on pull request #7185: URL: https://github.com/apache/tvm/pull/7185#issuecomment-753822379 > @jcf94 could you have another one round of review? Sorry for I'm a little busy this afternoon. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551170406
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
@jcf94
I try use @tvm._ffi.register_func, but the custom build func is a python
callable, it is not just function. we need the whole python callable context,
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551170406
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
@jcf94
I try use @tvm._ffi.register_func, but the custom build func is a python
callable, it is not just function. we need the whole python callable context,
build_func = cc.cross_compiler(ndk.create_shared, options=ndk_options)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[tvm] branch main updated (86a8504 -> 25f0252)
This is an automated email from the ASF dual-hosted git repository. liangfu pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 86a8504 [Frontend][MXNet] add _npi_subtract_scalar (#7191) add 25f0252 Makes sure g_last_error is null terminated. (#7190) No new revisions were added by this update. Summary of changes: src/runtime/crt/common/crt_runtime_api.c | 5 - 1 file changed, 4 insertions(+), 1 deletion(-)
[GitHub] [tvm] liangfu merged pull request #7190: Makes sure g_last_error is null terminated.
liangfu merged pull request #7190: URL: https://github.com/apache/tvm/pull/7190 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] liangfu commented on pull request #7190: Makes sure g_last_error is null terminated.
liangfu commented on pull request #7190: URL: https://github.com/apache/tvm/pull/7190#issuecomment-753837813 Thanks @cxcxcxcx for the proposed change. This is now merged. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
jcf94 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551163552
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
@FrozenGene @leowang1225
I remember that we have used the global variable here at first. But it was
modified to use serialized args later because of some special reason(which I
have forgetten)
So this way may cause some other problem. I'm thinking that just pass the
registered function name here as a string and this can be serialized easily.
Also cc @merrymercy @comaniac if you can figure out the reason of not using
global variable here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
jcf94 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551163552
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
@FrozenGene @leowang1225
I remember that we have used the global variable at first. But it was
modified to use serialized args later because of some special reason(which I
have forgetten)
So this way may cause some other problem. I'm thinking that just pass the
registered function name here as a string and this can be serialized easily.
Also cc @merrymercy @comaniac if you can figure out the reason of not using
global variable here.
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -303,12 +312,26 @@ class LocalBuilder(ProgramBuilder):
This is used in a wrapper of the multiprocessing.Process.join().
n_parallel : int = multiprocessing.cpu_count()
Number of threads used to build in parallel.
-build_func : str = 'default'
-The name of registered build function.
+build_func: callable or str = "default"
+If is 'default', use default build function
+If is 'ndk', use function for android ndk
+If is callable, use it as custom build function, expect lib_format
field.
"""
def __init__(self, timeout=15, n_parallel=multiprocessing.cpu_count(),
build_func="default"):
-self.__init_handle_by_constructor__(_ffi_api.LocalBuilder, timeout,
n_parallel, build_func)
+if build_func == "default":
Review comment:
@FrozenGene @leowang1225
Since we pass the `BuildFunc.name` to the constructor, how about just
register the custom build function by `@tvm._ffi.register_func` and pass the
fuction name to it?
In this way, it can be serialized in args in the `local_build_worker` below.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] liangfu commented on a change in pull request #7190: Makes sure g_last_error is null terminated.
liangfu commented on a change in pull request #7190:
URL: https://github.com/apache/tvm/pull/7190#discussion_r551175687
##
File path: src/runtime/crt/common/crt_runtime_api.c
##
@@ -38,7 +38,10 @@
static char g_last_error[1024];
-void TVMAPISetLastError(const char* msg) { strncpy(g_last_error, msg,
sizeof(g_last_error)); }
+void TVMAPISetLastError(const char* msg) {
+ strncpy(g_last_error, msg, sizeof(g_last_error) - 1);
+ g_last_error[sizeof(g_last_error) - 1] = 0;
Review comment:
Good point. On a second thought, the proposed change is good enough to
put msg to g_last_error.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
jcf94 commented on a change in pull request #7185:
URL: https://github.com/apache/tvm/pull/7185#discussion_r551179115
##
File path: python/tvm/auto_scheduler/measure.py
##
@@ -624,12 +652,10 @@ def local_build_worker(args):
The build result of this Builder thread.
"""
inp, build_func, timeout, verbose = args
-if build_func == "default":
-build_func = tar.tar
-elif build_func == "ndk":
-build_func = ndk.create_shared
-else:
-raise ValueError("Invalid build_func" + build_func)
+assert build_func == BuildFunc.name, (
+"BuildFunc.name: " + BuildFunc.name + ", but args is: " + build_func
+)
+build_func = BuildFunc.build_func
Review comment:
Ok, then I dont have other better opinions, I'm going to do some test on
arm cpus these days, maybe I'll encounter similar problem like you.
Is it possible to:
```python
use_ndk = True
@tvm._ffi.register_func("special_wrapper")
def _wrapper():
return cc.cross_compiler(ndk.create_shared, options=ndk_options)
build_func = "special_wrapper"
tuner = auto_scheduler.TaskScheduler(tasks, task_weights)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=200, # change this to 2 to achieve the best
performance
builder=auto_scheduler.LocalBuilder(build_func=build_func if use_ndk
else "default"),
runner=auto_scheduler.RPCRunner(
device_key, host=tracker_ip, port=tracker_port, repeat=3, timeout=50
),
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] aaltonenzhang opened a new issue #7196: unsupported operators from tensorflow model garden models
aaltonenzhang opened a new issue #7196:
URL: https://github.com/apache/tvm/issues/7196
I'm checking tensorflow models from tensorflow models garden at
[https://github.com/tensorflow/models/tree/master/community](url).
For community models, there are types and operators which tvm doesn't
supported. Most of them are quantize related, and some are not. I really hope
these operators could be supported officially and I can check if these models
work well.
The details are listed below.
>
model name | result
-- | --
inceptionv3_int8 | Op type not registered 'QuantizedConcatV2'
inceptionv4_int8 | Op type not registered 'QuantizedConcatV2'
mobilenetv1_int8 | The following operators are not implemented:
{'QuantizeV2', 'Dequantize', 'QuantizedAvgPool',
'QuantizedDepthwiseConv2DWithBiasAndReluAndRequantize',
'QuantizedConv2DWithBiasAndReluAndRequantize',
'QuantizedConv2DWithBiasAndRequantize'}
resnet101_int8 | The following operators are not implemented:
{'Dequantize', 'QuantizedConv2DWithBiasAndRequantize', 'QuantizeV2',
'QuantizedConv2DWithBiasAndReluAndRequantize', 'QuantizedMaxPool',
'QuantizedConv2DWithBiasSignedSumAndReluAndRequantize',
'QuantizedConv2DWithBiasSumAndReluAndRequantize'}
resnet50_int8 | The following operators are not implemented: {'Dequantize',
'QuantizeV2', 'QuantizedConv2DWithBiasSumAndReluAndRequantize',
'QuantizedConv2DWithBiasAndReluAndRequantize',
'QuantizedConv2DWithBiasSignedSumAndReluAndRequantize',
'QuantizedConv2DWithBiasAndRequantize'}
resnet50_v1_5_bfloat16 | data type 'bfloat16' not understood
resnet50v1_5_int8 | The following operators are not implemented:
{'QuantizedConv2DWithBiasAndReluAndRequantize',
'QuantizedConv2DWithBiasSumAndReluAndRequantize', 'QuantizedMaxPool',
'QuantizedConv2DWithBiasSignedSumAndReluAndRequantize', 'Dequantize',
'QuantizeV2', 'QuantizedConv2DWithBiasAndRequantize'}
ssdmobilenet_fp32 | The following operators are not implemented:
{'CombinedNonMaxSuppression'}
ssdmobilenet_int8 | The following operators are not implemented:
{'QuantizedDepthwiseConv2DWithBiasAndReluAndRequantize',
'CombinedNonMaxSuppression', 'Dequantize',
'QuantizedConv2DWithBiasAndRequantize', 'QuantizeV2',
'QuantizedConv2DWithBiasAndReluAndRequantize'}
ssd_resnet34_fp32_1200x1200 | The following operators are not implemented:
{'CombinedNonMaxSuppression'}
ssd_resnet34_int8_bs1 | The following operators are not implemented:
{'QuantizedConv2DWithBiasSignedSumAndReluAndRequantize',
'QuantizedConv2DWithBiasAndRequantize', 'QuantizedMaxPool', 'QuantizeV2',
'QuantizedConv2DWithBiasAndReluAndRequantize',
'QuantizedConv2DWithBiasSumAndReluAndRequantize', 'Dequantize'}
ssd_resnet34_int8_1200x1200 | The following operators are not implemented:
{'QuantizeV2', 'QuantizedConv2DWithBiasSignedSumAndReluAndRequantize',
'QuantizedConv2DWithBiasSumAndReluAndRequantize', 'CombinedNonMaxSuppression',
'QuantizedConv2DWithBiasAndReluAndRequantize',
'QuantizedConv2DWithBiasAndRequantize', 'Dequantize', 'QuantizedMaxPool'}
wide_deep_fp32 | RuntimeError: Unsupported dtype: int64
wide_deep_int8 | The following operators are not implemented:
{'QuantizedMatMulWithBias', 'Requantize',
'QuantizedMatMulWithBiasAndReluAndRequantize', 'Dequantize', 'QuantizeV2'}
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] tqchen merged pull request #7199: Fixed temporary lock_guard instances.
tqchen merged pull request #7199: URL: https://github.com/apache/tvm/pull/7199 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: Fixed temporary lock_guard instances. (#7199)
This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new 7053235 Fixed temporary lock_guard instances. (#7199)
7053235 is described below
commit 705323592b49e8971c70e46d604e85635438f16d
Author: Gaetano
AuthorDate: Mon Jan 4 15:39:54 2021 +0100
Fixed temporary lock_guard instances. (#7199)
---
src/target/generic_func.cc | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/src/target/generic_func.cc b/src/target/generic_func.cc
index 16e5a5f..5dbceec 100644
--- a/src/target/generic_func.cc
+++ b/src/target/generic_func.cc
@@ -51,7 +51,7 @@ struct GenericFunc::Manager {
GenericFunc GenericFunc::Get(const std::string& name) {
Manager* m = Manager::Global();
- std::lock_guard(m->mutex);
+ std::lock_guard lock(m->mutex);
auto it = m->fmap.find(name);
if (it == m->fmap.end()) {
auto f = make_object();
@@ -66,7 +66,7 @@ GenericFunc GenericFunc::Get(const std::string& name) {
void GenericFunc::RegisterGenericFunc(GenericFunc func, const std::string&
name) {
Manager* m = Manager::Global();
- std::lock_guard(m->mutex);
+ std::lock_guard lock(m->mutex);
auto it = m->fmap.find(name);
ICHECK(it == m->fmap.end()) << "GenericFunc already registered " << name;
func->name_ = name;
[GitHub] [tvm] junrushao1994 commented on issue #7204: mesg: ttyname failed: Inappropriate ioctl for device
junrushao1994 commented on issue #7204: URL: https://github.com/apache/tvm/issues/7204#issuecomment-754021201 It is not an error actually. In our CI pipeline, we can see this message on the beginning of every stage... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mbrookhart commented on a change in pull request #7125: Sparse reshape op
mbrookhart commented on a change in pull request #7125:
URL: https://github.com/apache/tvm/pull/7125#discussion_r551422829
##
File path: include/tvm/topi/transform.h
##
@@ -1386,6 +1386,88 @@ inline Array meshgrid(const Array&
inputs, const std::string& in
return result;
}
+/*!
+ * \brief Compute new sparse indices and return them after the sparse_reshape
operation
+ *
+ * \param sparse_indices Indices where values of the dense tensor exist
+ * \param prev_shape Old Shape of the sparse tensor corresponding to
sparse_indices
+ * \param new_shape Desired Shape of the sparse tensor which will correspond
to output
+ * \param name The name of the operation
+ * \param tag The tag to mark the operation
+ *
+ * \return A Tensor whose op member is the sparse_reshape operation
+ */
+inline Array SparseReshape(const Tensor& sparse_indices, const Tensor&
prev_shape,
+ const Tensor& new_shape,
+ const std::string name = "T_sparse_reshape",
+ std::string tag = kInjective) {
+ Array result;
+ Array new_sparse_indices_shape{sparse_indices->shape[0],
new_shape->shape[0]};
+
+ int new_shape_size = GetConstInt(new_shape->shape[0]);
+ int prev_shape_size = GetConstInt(prev_shape->shape[0]);
Review comment:
My main complaint is that this will fail with dynamic input shapes. From
what I understand, you expect multiple chained dynamically-shaped sparse ops in
the model you're trying to target, so I'm hesitant to merge this because I'm
under the impression that this will not solve the larger problem you're trying
to solve.
I'd really like to see you either test the model in a branch containing all
three of your PRs, or write a unit test with a representative subgraph.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] mbrookhart commented on pull request #7195: [THRUST] Faster multi dimensional argsort by segmented sort
mbrookhart commented on pull request #7195: URL: https://github.com/apache/tvm/pull/7195#issuecomment-754095011 This looks great. My only concern would possibly be that some object detection models (I'm thinking gluon SSD) have a very large number of boxes they sort before NMS. Could you add shapes (1, 1e5) and (1, 1e6) to your test? I expect my mergesort will fail badly, but I wonder what the difference between your implementation and the current thrust implementation will be. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mbrookhart commented on pull request #7195: [THRUST] Faster multi dimensional argsort by segmented sort
mbrookhart commented on pull request #7195: URL: https://github.com/apache/tvm/pull/7195#issuecomment-754096681 Also, I think you and I are using different versions of CUDA for the same GPU, that might explain the difference in the numbers I posted in #7099 and you posted here. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] trevor-m opened a new pull request #7205: [BYOC][TRT] Fix TRT conversion for reshape op - ReshapeAttrs no longer has reverse
trevor-m opened a new pull request #7205: URL: https://github.com/apache/tvm/pull/7205 Updates TRT converter for Reshape op after https://github.com/apache/tvm/pull/7086 removed `reverse` attr. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
areusch commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551452806
##
File path: src/runtime/graph/debug/graph_runtime_debug.cc
##
@@ -153,9 +153,10 @@ class GraphRuntimeDebug : public GraphRuntime {
const TVMContext& ctx = data_entry_[entry_id(index, 0)]->ctx;
TVMSynchronize(ctx.device_type, ctx.device_id, nullptr);
auto op_tend = std::chrono::high_resolution_clock::now();
-double op_duration =
-std::chrono::duration_cast >(op_tend -
op_tbegin).count();
-return op_duration;
+double op_duration_us =
+std::chrono::duration_cast >(op_tend -
op_tbegin).count() *
Review comment:
ah...I think this was an incomplete migration in I forgot to fix when
forward-porting. I think we should also either adjust
[src/runtime/crt/common/crt_runtime_api.c](https://github.com/apache/tvm/blob/0230ddf3436f82a57719a8761fcccf39626ee2be/src/runtime/crt/common/crt_runtime_api.c#L487)
or update the layers above this to respect seconds. I personally think seconds
makes more sense as a unit for time expressed in double, but we should make
that change in a separate PR.
is this change needed to make your PR pass CI? if not, perhaps we should
split into another or at least adjust both locations?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] comaniac commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
comaniac commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551479201
##
File path: src/auto_scheduler/feature.cc
##
@@ -1462,12 +1462,18 @@ void GetPerStoreFeaturesFromMeasurePairs(const
Array& inputs,
if (find_res == task_cache.end()) {
if (inputs[i]->task->compute_dag.defined()) { // the measure input is
complete
task = inputs[i]->task;
- } else { // the measure input is incomplete
-// rebuild task for incomplete measure pairs read from file
-Array tensors = (*workload_key_to_tensors)(workload_key);
-task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
- inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
- inputs[i]->task->layout_rewrite_option);
+ } else {
+// The measure input is incomplete, rebuild task for incomplete
measure pairs read from file
+try {
+ Array tensors = (*workload_key_to_tensors)(workload_key);
+ task = SearchTask(ComputeDAG(tensors), workload_key,
inputs[i]->task->target,
+inputs[i]->task->target_host,
inputs[i]->task->hardware_params,
+inputs[i]->task->layout_rewrite_option);
+} catch (std::exception& e) {
+ // Cannot build ComputeDAG from workload key, the task may have not
been registered in
+ // this search round
+ continue;
Review comment:
Yeah I know. I was thinking a case that you have a `log.json` which has
no records for the task you are going to tune, so all of them are ignored when
loading. I was thinking to have a message by the end of feature extraction like
we previously did ("encountered XXX errors which are safely ignored"), but
since that message has been removed, maybe we're good for now.
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -141,6 +146,12 @@ def update(self, inputs, results):
self.inputs.extend(inputs)
self.results.extend(results)
+if len(self.inputs) - self.last_train_length < self.last_train_length
/ 5:
Review comment:
Now I got your point, but I'm not sure if reduces training frequency
could solve the problem in general. At the first glance, we could stop to train
the cost model if 1) the accuracy of the current one is sufficient, 2) or we
already have sufficient number of records. Your solution is similar to 2, so
I'm curious if we already have sufficient number of records, then how much
accuracy could be further improved if we train the model again next time with
>20% more data?
On the other hand, I'm wondering if we could leverage the first solution.
For example, we calculate the test accuracy of the measured records after every
round. If the accuracy is higher than the threshold, then we skip the training
in the next round.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] d-smirnov commented on pull request #6998: [TFLite] Strided slice handling of shrink_axis_mask improved
d-smirnov commented on pull request #6998: URL: https://github.com/apache/tvm/pull/6998#issuecomment-754128584 bump cc @siju-samuel @FrozenGene Please, also advise on extra check to _assert_allclose_ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac merged pull request #7194: [CUBLAS, CUDNN] Support dynamic batch size
comaniac merged pull request #7194: URL: https://github.com/apache/tvm/pull/7194 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (7053235 -> 361f508)
This is an automated email from the ASF dual-hosted git repository. comaniac pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 7053235 Fixed temporary lock_guard instances. (#7199) add 361f508 [CUBLAS, CUDNN] Support dynamic batch size (#7194) No new revisions were added by this update. Summary of changes: python/tvm/contrib/cudnn.py| 81 ++ python/tvm/topi/cuda/conv2d.py | 24 +++-- python/tvm/topi/cuda/conv3d.py | 26 +++--- python/tvm/topi/cuda/dense.py | 3 +- tests/python/relay/test_any.py | 50 +- 5 files changed, 121 insertions(+), 63 deletions(-)
[GitHub] [tvm] comaniac commented on pull request #7194: [CUBLAS, CUDNN] Support dynamic batch size
comaniac commented on pull request #7194: URL: https://github.com/apache/tvm/pull/7194#issuecomment-754218139 Thanks @masahi @kevinthesun This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] d-smirnov opened a new pull request #7206: [BYOC][ACL] Depthwise convolution support
d-smirnov opened a new pull request #7206: URL: https://github.com/apache/tvm/pull/7206 Added support for depthwise convolution. ACL only supports depth-wise convolution when kernel size is 3x3 and 5x5 and strides are (1, 1) or (2, 2), if this is not the case then fallback to TVM. Also rework tests to remove non-deterministic trials. - ACL is Compute Library for the Arm Architecture - All credits to Luke Hutton @lhutton1 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi edited a comment on pull request #7195: [THRUST] Faster multi dimensional argsort by segmented sort
masahi edited a comment on pull request #7195: URL: https://github.com/apache/tvm/pull/7195#issuecomment-754199021 @mbrookhart I have a fast-path for one segment case, so the perf is the same between current / new. I'll update the condition to work for dimension other than two. https://github.com/apache/tvm/blob/26254f522de531569441eac4fecb45885fcdc30a/src/runtime/contrib/thrust/thrust.cu#L57 @trevor-m Yes I briefly looked at cub's segmented sort. My impression is that it launches one thread block per segment. This sounds great when there are many segments to sort and each of segment is not so big. I'm not sure if that is a good fit for our use case - I think we are more likely to sort a few, but large segments, and most likely we only have one segment. I'm actually surprised to hear that TRT uses cub's segmented sort. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #7195: [THRUST] Faster multi dimensional argsort by segmented sort
masahi commented on pull request #7195: URL: https://github.com/apache/tvm/pull/7195#issuecomment-754199021 @mbrookhart I have a fast-path for one segment case, so the perf is the same between current / new. I'll update the condition to work for dimension other then two. https://github.com/apache/tvm/blob/26254f522de531569441eac4fecb45885fcdc30a/src/runtime/contrib/thrust/thrust.cu#L57 @trevor-m Yes I briefly looked at cub's segmented sort. My impression is that it launches one thread block per segment. This sounds great when there are many segments to sort and each of segment is not so big. I'm not sure if that is a good fit for our use case - I think we are more likely to sort a few, but large segments, and most likely we only have one segment. I'm actually surprised to hear that TRT uses cub's segmented sort. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] trevor-m commented on pull request #7195: [THRUST] Faster multi dimensional argsort by segmented sort
trevor-m commented on pull request #7195: URL: https://github.com/apache/tvm/pull/7195#issuecomment-754151980 Nice! Have you also looked at CUB's [DeviceSegmentedRadixSort::SortPairsDescending](https://nvlabs.github.io/cub/structcub_1_1_device_segmented_radix_sort.html#abbba6639f928bebd19435f185ea10618) ? It sounds like it is exactly what you need with no tricks required. It's used by some fast NMS implementations such as [TensorRT](https://github.com/NVIDIA/TensorRT/tree/master/plugin/batchedNMSPlugin). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] icemelon9 commented on a change in pull request #7120: [PatternLang] Add Syntatic Sugar to the C++ pattern API and support DataType Attribute Matching
icemelon9 commented on a change in pull request #7120:
URL: https://github.com/apache/tvm/pull/7120#discussion_r551668826
##
File path: include/tvm/relay/dataflow_pattern.h
##
@@ -46,6 +48,29 @@ class DFPatternNode : public Object {
*/
class DFPattern : public ObjectRef {
public:
+ /*! \brief Syntatic Sugar for creating a CallPattern */
+ DFPattern operator()(const std::vector& args);
+ /*! \brief Syntatic Sugar for creating a CallPattern with an "add" op */
Review comment:
I see. sure.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] jcf94 opened a new issue #7207: [BUG] Get wrong measure time in graph debug runtime
jcf94 opened a new issue #7207: URL: https://github.com/apache/tvm/issues/7207 This bug was introduced in #6964 . Currently, use graph debug runtime will get wrong time result. Cause: https://github.com/apache/tvm/blob/d05275298d9e630af6d8ff958753fd010759935c/src/runtime/graph/debug/graph_runtime_debug.cc#L150-L159 This function returns a time with second, but is expected to return microsecond. cc @areusch This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jcf94 commented on a change in pull request #7197: [Fix][Autoscheduler] Costmodel enhancement & bug fix for graph debug runtime
jcf94 commented on a change in pull request #7197:
URL: https://github.com/apache/tvm/pull/7197#discussion_r551675372
##
File path: src/runtime/graph/debug/graph_runtime_debug.cc
##
@@ -153,9 +153,10 @@ class GraphRuntimeDebug : public GraphRuntime {
const TVMContext& ctx = data_entry_[entry_id(index, 0)]->ctx;
TVMSynchronize(ctx.device_type, ctx.device_id, nullptr);
auto op_tend = std::chrono::high_resolution_clock::now();
-double op_duration =
-std::chrono::duration_cast >(op_tend -
op_tbegin).count();
-return op_duration;
+double op_duration_us =
+std::chrono::duration_cast >(op_tend -
op_tbegin).count() *
Review comment:
Thanks! This does not block my PR, and I would remove this part from
here.
I've opened a new issue #7207 to track this bug.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] FrozenGene commented on a change in pull request #7185: [AutoScheduler] Add custom build function
FrozenGene commented on a change in pull request #7185: URL: https://github.com/apache/tvm/pull/7185#discussion_r551678095 ## File path: python/tvm/auto_scheduler/measure.py ## @@ -303,12 +315,28 @@ class LocalBuilder(ProgramBuilder): This is used in a wrapper of the multiprocessing.Process.join(). n_parallel : int = multiprocessing.cpu_count() Number of threads used to build in parallel. -build_func : str = 'default' -The name of registered build function. +build_func: callable or str = "default" +If is 'default', use default build function +If is 'ndk', use function for android ndk +If is callable, use it as custom build function, expect lib_format field. """ def __init__(self, timeout=15, n_parallel=multiprocessing.cpu_count(), build_func="default"): -self.__init_handle_by_constructor__(_ffi_api.LocalBuilder, timeout, n_parallel, build_func) +if build_func == "default": +BuildFunc.name = "default" +BuildFunc.build_func = tar.tar +elif build_func == "ndk": +BuildFunc.name = "ndk" +BuildFunc.build_func = ndk.create_shared +elif not isinstance(build_func, str): +BuildFunc.name = "custom" +BuildFunc.build_func = build_func Review comment: Sorry, could we modify a little logic here? because we will not enter into the `else` branch if we use this condition. For example, we should use `elif callable(build_func):`... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on a change in pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on a change in pull request #7185: URL: https://github.com/apache/tvm/pull/7185#discussion_r551682259 ## File path: python/tvm/auto_scheduler/measure.py ## @@ -303,12 +315,28 @@ class LocalBuilder(ProgramBuilder): This is used in a wrapper of the multiprocessing.Process.join(). n_parallel : int = multiprocessing.cpu_count() Number of threads used to build in parallel. -build_func : str = 'default' -The name of registered build function. +build_func: callable or str = "default" +If is 'default', use default build function +If is 'ndk', use function for android ndk +If is callable, use it as custom build function, expect lib_format field. """ def __init__(self, timeout=15, n_parallel=multiprocessing.cpu_count(), build_func="default"): -self.__init_handle_by_constructor__(_ffi_api.LocalBuilder, timeout, n_parallel, build_func) +if build_func == "default": +BuildFunc.name = "default" +BuildFunc.build_func = tar.tar +elif build_func == "ndk": +BuildFunc.name = "ndk" +BuildFunc.build_func = ndk.create_shared +elif not isinstance(build_func, str): +BuildFunc.name = "custom" +BuildFunc.build_func = build_func Review comment: OK, I have already modified This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] aaltonenzhang removed a comment on issue #7196: unsupported operators from tensorflow model garden models
aaltonenzhang removed a comment on issue #7196: URL: https://github.com/apache/tvm/issues/7196#issuecomment-754320776 @insop It seems that there are something wrong when you click the url, but you can copy and paste it to your browser. And for the issue #7198, it's also created by me, but they are different problems. Please help me to check them, thank you! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] aaltonenzhang commented on issue #7196: unsupported operators from tensorflow model garden models
aaltonenzhang commented on issue #7196: URL: https://github.com/apache/tvm/issues/7196#issuecomment-754362026 @insop reedited the url link for both of the two issues. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] aaltonenzhang edited a comment on issue #7196: unsupported operators from tensorflow model garden models
aaltonenzhang edited a comment on issue #7196: URL: https://github.com/apache/tvm/issues/7196#issuecomment-754362026 @insop reedited the url links for both of the two issues. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac commented on pull request #7184: [ConvertLayout] slice_like support
comaniac commented on pull request #7184: URL: https://github.com/apache/tvm/pull/7184#issuecomment-754279843 Kindly remind @anijain2305 @yzhliu for reviewing this PR :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on a change in pull request #7164: [µTVM] Add documentation
areusch commented on a change in pull request #7164: URL: https://github.com/apache/tvm/pull/7164#discussion_r551656029 ## File path: docs/dev/microtvm_design.rst ## @@ -0,0 +1,340 @@ +.. Licensed to the Apache Software Foundation (ASF) under one +or more contributor license agreements. See the NOTICE file +distributed with this work for additional information +regarding copyright ownership. The ASF licenses this file +to you under the Apache License, Version 2.0 (the +"License"); you may not use this file except in compliance +with the License. You may obtain a copy of the License at +..http://www.apache.org/licenses/LICENSE-2.0 +.. Unless required by applicable law or agreed to in writing, +software distributed under the License is distributed on an +"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +KIND, either express or implied. See the License for the +specific language governing permissions and limitations +under the License. + +** +microTVM Design Document +** + +.. contents:: Table of Contents +:depth: 3 + +Background +=== + +TVM is a model deployment framework that has demonstrated good performance across a wide range of +models on traditional operating systems. Given TVM's layered approach to compilation, it is a +natural extension to target bare metal devices. While most of the compilation flow does not need to +change for a proof-of-concept implementation on such devices, the runtime cannot depend on: + +* **Virtual Memory**, and by extension any system-provided ``malloc``. Additionally, bare metal + devices typically have very limited memory (measured in KB). Because of this, libraries designed + for such platforms typically need to be more judicious in using memory, and need to release + memory when it is not in use. +* Traditional OS abstractions, such as **files**, **libraries**, and **kernel functions**. Some + projects implement support for these, but they are by no means standard. +* Support for programming languages other than **C**. + +Such changes require a different appraoch from the TVM C++ runtime typically used on traditional +Operating Systems. + +Typical Use +=== + +This section discusses our vision of the "typical" microTVM use case. Each component used to achieve +this typical use case is intended to be designed for flexibility, but this unifying vision serves to +motivate the inclusion of each part of the design. + +.. image:: microtvm_workflow.svg + +The parts of this process are described below: + +#. **Model Import**. The user imports an existing model or describes a new model to TVM, producing a + *Relay module*. + +#. **Model Transformations**. The user can apply transformations, such as quantization, to the + model. After each transformation, the user should still have a Relay module. + +#. **Compilation** (Scheduling and Code Generation). TVM implements each operator into Tensor IR by + assigning a schedule and schedule configuration to each Relay operator. Then, code (C source or + compiled object) is generated for each operator. + +#. **Integration**. The generated code is integrated along with the TVM C Runtime library into a + user-supplied binary project. In some cases (such as when the project is standardized across + multiple SoC/development boards), this process is handled automatically. + +#. **Deployment**. The project is built and the residual firmware binary is flashed onto the device. + Model inference is driven either by TVM using an on-device RPC server, or on the device using the + on-device Graph Runtime. + +Design Goals + + +microTVM aims to achieve these design goals: + +1. **Portable Code**. microTVM can translate any Relay model into C code that can compile with only + a C standard library. +2. **Minimal Overhead**. microTVM generates target-specific, highly optimized code. As much overhead + from the runtime should be removed. +3. **Accessible Code**. microTVM considers C source code as a first-class output mechanism so that + it is easier for a firmware engineer to understand and tweak. microTVM + +Overview + + +microTVM requires changes at all levels of the TVM compiler stack. The following sub-sections enumerate +these changes at a high level, and follow-on sections discuss the specifics in more detail. + +Modeling Target Platforms +- + +TVM's search-based optimization approach allows it to largely avoid system-level modeling of targets +in favor of experimental results. However, some modelling is necessary in order to ensure TVM is +comparing apples-to-apples search results, and to avoid wasting time during the search by attempting +to compile invalid code for a target. + +microTVM models these parts of the target: + +* The CPU used, through the ``-mcpu`` and ``-march`` target flags. +* The presence
[GitHub] [tvm] areusch commented on a change in pull request #7164: [µTVM] Add documentation
areusch commented on a change in pull request #7164: URL: https://github.com/apache/tvm/pull/7164#discussion_r551658680 ## File path: docs/dev/microtvm_design.rst ## @@ -0,0 +1,340 @@ +.. Licensed to the Apache Software Foundation (ASF) under one +or more contributor license agreements. See the NOTICE file +distributed with this work for additional information +regarding copyright ownership. The ASF licenses this file +to you under the Apache License, Version 2.0 (the +"License"); you may not use this file except in compliance +with the License. You may obtain a copy of the License at +..http://www.apache.org/licenses/LICENSE-2.0 +.. Unless required by applicable law or agreed to in writing, +software distributed under the License is distributed on an +"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +KIND, either express or implied. See the License for the +specific language governing permissions and limitations +under the License. + +** +microTVM Design Document +** + +.. contents:: Table of Contents +:depth: 3 + +Background +=== + +TVM is a model deployment framework that has demonstrated good performance across a wide range of +models on traditional operating systems. Given TVM's layered approach to compilation, it is a +natural extension to target bare metal devices. While most of the compilation flow does not need to +change for a proof-of-concept implementation on such devices, the runtime cannot depend on: + +* **Virtual Memory**, and by extension any system-provided ``malloc``. Additionally, bare metal + devices typically have very limited memory (measured in KB). Because of this, libraries designed + for such platforms typically need to be more judicious in using memory, and need to release + memory when it is not in use. +* Traditional OS abstractions, such as **files**, **libraries**, and **kernel functions**. Some + projects implement support for these, but they are by no means standard. +* Support for programming languages other than **C**. + +Such changes require a different appraoch from the TVM C++ runtime typically used on traditional +Operating Systems. + +Typical Use +=== + +This section discusses our vision of the "typical" microTVM use case. Each component used to achieve +this typical use case is intended to be designed for flexibility, but this unifying vision serves to +motivate the inclusion of each part of the design. + +.. image:: microtvm_workflow.svg + +The parts of this process are described below: + +#. **Model Import**. The user imports an existing model or describes a new model to TVM, producing a + *Relay module*. + +#. **Model Transformations**. The user can apply transformations, such as quantization, to the + model. After each transformation, the user should still have a Relay module. + +#. **Compilation** (Scheduling and Code Generation). TVM implements each operator into Tensor IR by + assigning a schedule and schedule configuration to each Relay operator. Then, code (C source or + compiled object) is generated for each operator. + +#. **Integration**. The generated code is integrated along with the TVM C Runtime library into a + user-supplied binary project. In some cases (such as when the project is standardized across + multiple SoC/development boards), this process is handled automatically. + +#. **Deployment**. The project is built and the residual firmware binary is flashed onto the device. + Model inference is driven either by TVM using an on-device RPC server, or on the device using the + on-device Graph Runtime. + +Design Goals + + +microTVM aims to achieve these design goals: + +1. **Portable Code**. microTVM can translate any Relay model into C code that can compile with only + a C standard library. +2. **Minimal Overhead**. microTVM generates target-specific, highly optimized code. As much overhead + from the runtime should be removed. +3. **Accessible Code**. microTVM considers C source code as a first-class output mechanism so that + it is easier for a firmware engineer to understand and tweak. microTVM + +Overview + + +microTVM requires changes at all levels of the TVM compiler stack. The following sub-sections enumerate +these changes at a high level, and follow-on sections discuss the specifics in more detail. + +Modeling Target Platforms +- + +TVM's search-based optimization approach allows it to largely avoid system-level modeling of targets +in favor of experimental results. However, some modelling is necessary in order to ensure TVM is +comparing apples-to-apples search results, and to avoid wasting time during the search by attempting +to compile invalid code for a target. + +microTVM models these parts of the target: + +* The CPU used, through the ``-mcpu`` and ``-march`` target flags. +* The presence
[GitHub] [tvm] comaniac merged pull request #7184: [ConvertLayout] slice_like support
comaniac merged pull request #7184: URL: https://github.com/apache/tvm/pull/7184 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: [ConvertLayout] slice_like support (#7184)
This is an automated email from the ASF dual-hosted git repository.
comaniac pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new d052752 [ConvertLayout] slice_like support (#7184)
d052752 is described below
commit d05275298d9e630af6d8ff958753fd010759935c
Author: Cody Yu
AuthorDate: Mon Jan 4 17:17:53 2021 -0800
[ConvertLayout] slice_like support (#7184)
---
src/relay/op/tensor/transform.cc | 41 +
tests/python/relay/test_pass_convert_op_layout.py | 70 +++
2 files changed, 111 insertions(+)
diff --git a/src/relay/op/tensor/transform.cc b/src/relay/op/tensor/transform.cc
index 19ca612..1ff428c 100644
--- a/src/relay/op/tensor/transform.cc
+++ b/src/relay/op/tensor/transform.cc
@@ -2752,6 +2752,46 @@ Expr MakeSliceLike(Expr data, Expr shape_like,
Array axes) {
return Call(op, {data, shape_like}, Attrs(attrs), {});
}
+Array> SliceLikeInferCorrectLayout(const Attrs& attrs,
+ const Array&
new_in_layouts,
+ const Array&
old_in_layouts,
+ const
Array& old_in_types) {
+ Array new_axes;
+ if (old_in_layouts.defined() && new_in_layouts.defined()) {
+ICHECK_EQ(new_in_layouts.size(), 2);
+ICHECK_EQ(new_in_layouts[0]->name, new_in_layouts[1]->name);
+ICHECK_EQ(old_in_layouts.size(), 2);
+ICHECK_EQ(old_in_layouts[0]->name, old_in_layouts[1]->name);
+
+auto old_layout = old_in_layouts[0];
+auto new_layout = new_in_layouts[0];
+
+// Discard "const" qualifier.
+auto* params = const_cast(attrs.as());
+ICHECK(params != nullptr);
+
+for (auto axis : params->axes) {
+ auto new_axis = new_layout.IndexOf(old_layout[axis->value]);
+ // Cannot find the target axis in the new layout.
+ if (new_axis == -1) {
+new_axes.clear();
+break;
+ }
+ new_axes.push_back(new_axis);
+}
+if (!new_axes.empty()) {
+ params->axes = std::move(new_axes);
+ return Array>({{new_layout, new_layout}, {new_layout}});
+}
+ }
+
+ if (old_in_layouts.defined()) {
+ICHECK_EQ(old_in_layouts.size(), 2);
+return {{old_in_layouts[0], old_in_layouts[1]}, {old_in_layouts[1]}};
+ }
+ return Array>({{Layout::Undef(), Layout::Undef()},
{Layout::Undef()}});
+}
+
Array SliceLikeCompute(const Attrs& attrs, const
Array& inputs,
const Type& out_type) {
const auto* param = attrs.as();
@@ -2801,6 +2841,7 @@ RELAY_REGISTER_OP("slice_like")
.set_support_level(10)
.add_type_rel("SliceLike", SliceLikeRel)
.set_attr("FTVMCompute", SliceLikeCompute)
+.set_attr("FInferCorrectLayout",
SliceLikeInferCorrectLayout)
.set_attr("TOpPattern", kInjective);
// relay.layout_transform
diff --git a/tests/python/relay/test_pass_convert_op_layout.py
b/tests/python/relay/test_pass_convert_op_layout.py
index 6765d1f..4c4bb9d 100644
--- a/tests/python/relay/test_pass_convert_op_layout.py
+++ b/tests/python/relay/test_pass_convert_op_layout.py
@@ -499,6 +499,75 @@ def test_bn_convert_layout():
assert len(has_lt) == 1
+def test_slice_like_convert_layout():
+def verify_slice_like(after, expected_axes):
+# Verify if the slice_like after the convert layout has the expected
axes.
+has_expected = list()
+checker = lambda x: has_expected.append(
+isinstance(x, tvm.relay.expr.Call)
+and x.op.name == "slice_like"
+and str(x.attrs.axes) == str(expected_axes)
+)
+relay.analysis.post_order_visit(after, checker)
+assert any(has_expected)
+
+def func_nhwc():
+x = relay.var("x", shape=(1, 56, 56, 64))
+weight1 = relay.var("weight1", shape=(3, 3, 64, 32))
+y = relay.nn.conv2d(
+x,
+weight1,
+channels=32,
+kernel_size=(3, 3),
+padding=(1, 1),
+data_layout="NHWC",
+kernel_layout="HWIO",
+)
+out = relay.slice_like(y, y, axes=[1, 2])
+return relay.Function(analysis.free_vars(out), out)
+
+after = run_opt_pass(func_nhwc(), transform.ConvertLayout({"nn.conv2d":
["NCHW", "default"]}))
+verify_slice_like(after, [2, 3])
+
+def func_nchw():
+x = relay.var("x", shape=(1, 64, 56, 56))
+weight1 = relay.var("weight1", shape=(32, 64, 3, 3))
+y = relay.nn.conv2d(
+x,
+weight1,
+channels=32,
+kernel_size=(3, 3),
+padding=(1, 1),
+data_layout="NCHW",
+kernel_layout="OIHW",
+)
+out = relay.slice_like(y, y, axes=[2, 3])
+return relay.Function(analysis.free_vars(out), out)
+
+after = run_opt_pass(func_nchw(), transform.ConvertLayout({"nn.conv2d":