Re: [GitHub] [lucene-jira-archive] mocobeta opened a new issue, #1: Fix markup conversion error
The notifications are now sent to issues@ list. Still, it could be noisy to have them in there for many of you, we could not set a fake mail address to completely silence the notification. You might want to set a mail filter to screen out the notifications from the migration repository. Thanks. 2022年6月29日(水) 20:23 Tomoko Uchida : > I set https://github.com/apache/lucene-jira-archive/blob/main/.asf.yaml > to send all notifications to my ASF address, but this did not help... > > > > > 2022年6月29日(水) 19:24 Tomoko Uchida : > >> Sorry, it seems the all updates in >> https://github.com/apache/lucene-jira-archive are noticed in dev@ list. >> I don't see the configuration/setting for the repository. Could anyone >> mute this? >> >> Tomoko >> >> >> 2022年6月29日(水) 19:06 GitBox : >> >>> >>> mocobeta opened a new issue, #1: >>> URL: https://github.com/apache/lucene-jira-archive/issues/1 >>> >>>There are various errors in converting Jira markup to Markdown. >>> >>>For example: >>>- tables are broken >>>- bullet lists converted to bold blocks (?) >>>- bullet lists include unnecessary spaces between items >>>- indents are not preserved >>>- ... >>> >>>This issue tries to figure out the root cause of the errors and fix >>> those. >>> >>> >>> -- >>> This is an automated message from the Apache Git Service. >>> To respond to the message, please log on to GitHub and use the >>> URL above to go to the specific comment. >>> >>> To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org.apache.org >>> >>> For queries about this service, please contact Infrastructure at: >>> us...@infra.apache.org >>> >>> >>> - >>> To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org >>> For additional commands, e-mail: dev-h...@lucene.apache.org >>> >>>
Re: [GitHub] [lucene-jira-archive] mocobeta opened a new issue, #1: Fix markup conversion error
I set https://github.com/apache/lucene-jira-archive/blob/main/.asf.yaml to send all notifications to my ASF address, but this did not help... 2022年6月29日(水) 19:24 Tomoko Uchida : > Sorry, it seems the all updates in > https://github.com/apache/lucene-jira-archive are noticed in dev@ list. > I don't see the configuration/setting for the repository. Could anyone > mute this? > > Tomoko > > > 2022年6月29日(水) 19:06 GitBox : > >> >> mocobeta opened a new issue, #1: >> URL: https://github.com/apache/lucene-jira-archive/issues/1 >> >>There are various errors in converting Jira markup to Markdown. >> >>For example: >>- tables are broken >>- bullet lists converted to bold blocks (?) >>- bullet lists include unnecessary spaces between items >>- indents are not preserved >>- ... >> >>This issue tries to figure out the root cause of the errors and fix >> those. >> >> >> -- >> This is an automated message from the Apache Git Service. >> To respond to the message, please log on to GitHub and use the >> URL above to go to the specific comment. >> >> To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org.apache.org >> >> For queries about this service, please contact Infrastructure at: >> us...@infra.apache.org >> >> >> - >> To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org >> For additional commands, e-mail: dev-h...@lucene.apache.org >> >>
[GitHub] [lucene-jira-archive] mocobeta commented on issue #1: Fix markup conversion error
mocobeta commented on issue #1:
URL:
https://github.com/apache/lucene-jira-archive/issues/1#issuecomment-1169860211
Thanks for reporting.
I found Jira's number list (`#`) is not correctly converted and it is
interpreted as headers in Markdown.
Jira dump
```
"body": "I'm definitely not an expert on this but after some research I
found:\r\n # The real problem probably is we're assuming object alignment in 32
bit jvm is 4 bytes but they're actually default into 8 bytes in HotSpot JVM and
can't be anything less than 8 bytes
([https://stackoverflow.com/questions/44468639/memory-alignment-of-java-classes)]\r\n
# Object header may create offset for object alignment, like in your jol
analysis, the header is 12 bytes long and thus created a 12%8=4 bytes offset,
so that the target array size should cover those and that's why for {{byte[]}}
4,12,20... sizes are optimal, but I\u00a0*think* the header length can vary
depend on either jvm or system, since I've seen some post with 2 mark words in
the header which makes header 16 bytes\r\n\r\nSo there should be something we
could optimize here, but probably need to figure out a way to identify how many
bytes are in array header, ah
[RamUsageEstimator|https://github.com/apache/lucene/blob/main/lucene
/core/src/java/org/apache/lucene/util/RamUsageEstimator.java#L179,L187] listed
the details out, the 64 bit machine's header is already aligned so we don't
need to worry about the offset, and 32 bit machine's header is constant 12
bytes so with a 4 bytes offset.",
```
Converted markdown data
```
"body": "I'm definitely not an expert on this but after some research I
found:\r\n # The real problem probably is we're assuming object alignment in 32
bit jvm is 4 bytes but they're actually default into 8 bytes in HotSpot JVM and
can't be anything less than 8 bytes
(\r\n
# Object header may create offset for object alignment, like in your jol
analysis, the header is 12 bytes long and thus created a 12%8=4 bytes offset,
so that the target array size should cover those and that's why for `byte[]`
4,12,20... sizes are optimal, but I\u00a0**think** the header length can vary
depend on either jvm or system, since I've seen some post with 2 mark words in
the header which makes header 16 bytes\r\n\r\nSo there should be something we
could optimize here, but probably need to figure out a way to identify how many
bytes are in array header, ah
[RamUsageEstimator](https://github.com/apache/lucene/blob/main/lucen
e/core/src/java/org/apache/lucene/util/RamUsageEstimator.java#L179,L187)
listed the details out, the 64 bit machine's header is already aligned so we
don't need to worry about the offset, and 32 bit machine's header is constant
12 bytes so with a 4 bytes offset.\n\nAuthor: Patrick Zhai (`@zhaih`)\nCreated:
2022-06-09T07:07:05.021+\nUpdated: 2022-06-09T07:07:05.021+\n",
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org
For additional commands, e-mail: dev-h...@lucene.apache.org
Re: [GitHub] [lucene-jira-archive] mocobeta opened a new issue, #1: Fix markup conversion error
Sorry, it seems the all updates in https://github.com/apache/lucene-jira-archive are noticed in dev@ list. I don't see the configuration/setting for the repository. Could anyone mute this? Tomoko 2022年6月29日(水) 19:06 GitBox : > > mocobeta opened a new issue, #1: > URL: https://github.com/apache/lucene-jira-archive/issues/1 > >There are various errors in converting Jira markup to Markdown. > >For example: >- tables are broken >- bullet lists converted to bold blocks (?) >- bullet lists include unnecessary spaces between items >- indents are not preserved >- ... > >This issue tries to figure out the root cause of the errors and fix > those. > > > -- > This is an automated message from the Apache Git Service. > To respond to the message, please log on to GitHub and use the > URL above to go to the specific comment. > > To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org.apache.org > > For queries about this service, please contact Infrastructure at: > us...@infra.apache.org > > > - > To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org > For additional commands, e-mail: dev-h...@lucene.apache.org > >
[GitHub] [lucene-jira-archive] mocobeta opened a new issue, #3: Create mapping on Jira user id -> GitHub account
mocobeta opened a new issue, #3: URL: https://github.com/apache/lucene-jira-archive/issues/3 To correctly map Jira user ids in issues (reporter/assignee/author) to GitHub account, we need an account mapping file. This could be inferred from https://github.com/orgs/apache/people? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org For additional commands, e-mail: dev-h...@lucene.apache.org
[GitHub] [lucene-jira-archive] mocobeta opened a new issue, #2: Archive all Jira attachments
mocobeta opened a new issue, #2: URL: https://github.com/apache/lucene-jira-archive/issues/2 All attachments should be archived in `attachments/`. They will be referred from the migrated issues in https://github.com/apache/lucene. For files with the same names, we keep the latest versions only. (Jira shows links to the latest versions for attachments, so old versions are safely omitted.) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org For additional commands, e-mail: dev-h...@lucene.apache.org
[GitHub] [lucene-jira-archive] dweiss commented on issue #1: Fix markup conversion error
dweiss commented on issue #1: URL: https://github.com/apache/lucene-jira-archive/issues/1#issuecomment-1169793482 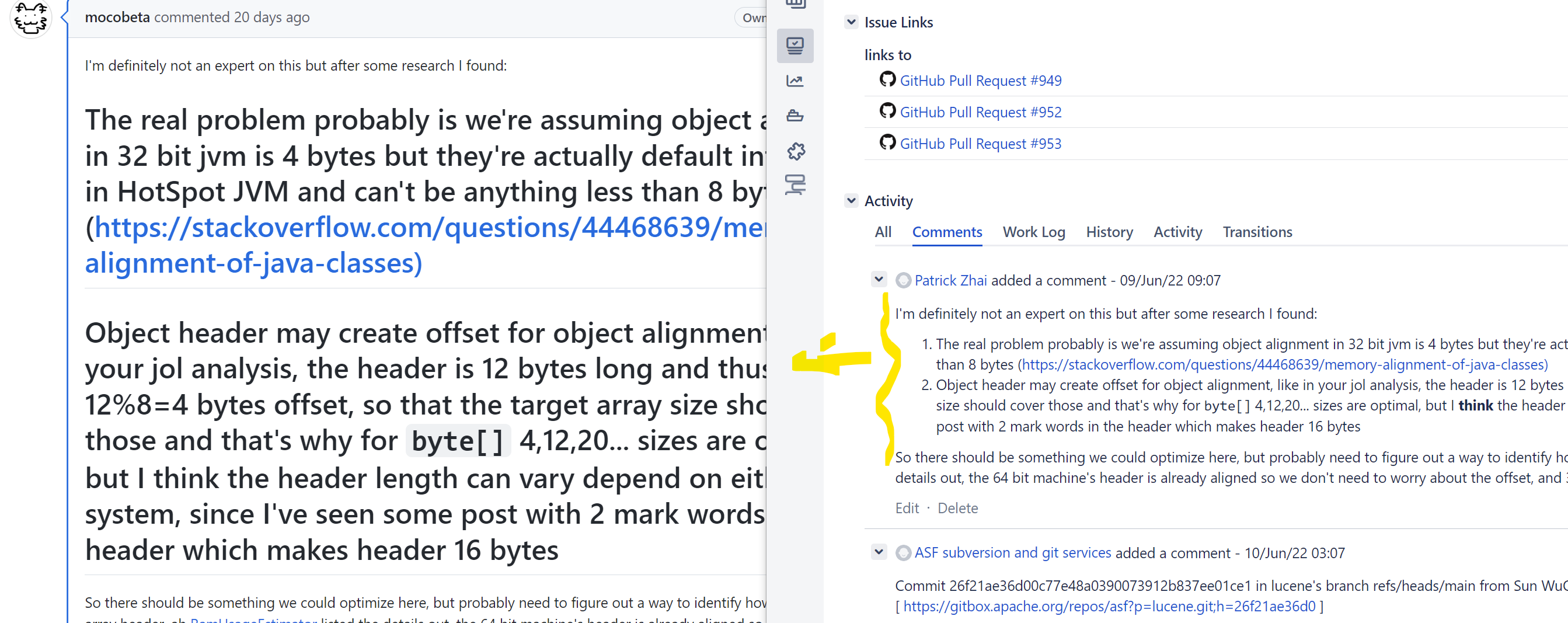 This is what the bold block-issue looks like. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org For additional commands, e-mail: dev-h...@lucene.apache.org
[GitHub] [lucene-jira-archive] mocobeta opened a new issue, #1: Fix markup conversion error
mocobeta opened a new issue, #1: URL: https://github.com/apache/lucene-jira-archive/issues/1 There are various errors in converting Jira markup to Markdown. For example: - tables are broken - bullet lists converted to bold blocks (?) - bullet lists include unnecessary spaces between items - indents are not preserved - ... This issue tries to figure out the root cause of the errors and fix those. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: dev-unsubscr...@lucene.apache.org For additional commands, e-mail: dev-h...@lucene.apache.org
Re: A prototype migration tool Jira to GitHub
I looked at the first random issue and noticed these (perhaps known) issues - https://github.com/mocobeta/sandbox-lucene-10557/issues/10838 1) lists are converted into bold blocks (without the list): https://github.com/mocobeta/sandbox-lucene-10557/issues/10838#issuecomment-1166777318 2) inline images in the description point at nothing. But it's already quite impressive. Dawid On Tue, Jun 28, 2022 at 6:49 PM Tomoko Uchida wrote: > > I finished the second prototype. With a few exceptions, almost all existing > issues were successfully migrated into the test repo. You can browse/search > them. > https://github.com/mocobeta/sandbox-lucene-10557/issues > > Some limitations in the first prototype have been addressed. For example, we > can preserve the original timestamp of the issues/comments. > I could list improvements and current limitations though, could you try it > out yourself; any issues should be found by Jira issue numbers. > Note that "attachments" are still not ported. We've found workarounds so it > will be addressed in the next iteration. > > I don't think we reached a conclusion, though, I fully recognize there are > strong requests on the atomic switch to GitHub and I haven't seen objections > on that so far - then I'll continue to work on improving the migration > quality. > I would finish playing around with prototyping and if there are next > iterations, these will be rehearsals for the actual migration. > > > Tomoko > > > 2022年6月27日(月) 10:27 Tomoko Uchida : >> >> > It looks like the GitHub Danger Zone can transfer a repository? >> >> "Transferring a repository" creates another repository different from >> apache/lucene. It'd make the migration process easy though, is it our >> intention to have an external repository for old issues? >> >> Tomoko >> >> >> 2022年6月27日(月) 8:24 Michael McCandless : >>> >>> It looks like the GitHub Danger Zone can transfer a repository? >>> >>> It's not clear if it can go from Personal -> Organization though. I see >>> Personal -> Personal and Organization -> Organization. >>> >>> https://docs.github.com/en/repositories/creating-and-managing-repositories/transferring-a-repository >>> >>> Mike McCandless >>> >>> http://blog.mikemccandless.com >>> >>> >>> On Sun, Jun 26, 2022 at 6:40 PM Tomoko Uchida >>> wrote: > > > 2022年6月27日(月) 5:16 Michael Sokolov : >> >> as for this access control/script monitoring problem, I wonder whether >> we could import all the issues into a new github repo owned by >> whomever is running the script, and then transfer from there to the >> lucene repo? It would be an extra step involving another script (or >> something), but maybe(?) that one could be much simpler since it is >> github->github?? If this works out, we could have full control of the >> first step and only hand off to infra the simpler copying job. >> > > I don't see the API or tool that transfers all issues from one repo to > another repo. To be exact, I don't see the API or tool that transfers all issues from one repo to another repo while keeping cross-issue links. If we want to preserve cross-issue links, there's no difference between "Jira to GitHub" and "GitHub to GitHub". > >> >> On Sat, Jun 25, 2022 at 7:53 AM Tomoko Uchida >> wrote: >> > >> > I may have to share another practical consideration on the migration >> > that I haven't mentioned yet. >> > >> > We are not allowed to have admin access to the lucene GitHub repo, so >> > can't run the import job(s) on ourselves. >> > We'll have to make a tool with clear instructions for the migration >> > and pass it to infra team, then support them via the jira (or slack?) >> > if there are any problems. >> > See https://issues.apache.org/jira/browse/INFRA-20118 >> > >> > We can do some preparation locally (e.g. dump Jira issues and convert >> > them to importable format to GitHub), but the actual first and second >> > pass import will be done by infra team. >> > I think I myself won't be able to have close contact with the infra >> > team if the migration operation is too complicated due to the time >> > difference and my communication ability - I'm not good at real-time >> > conversation in English. >> > So if we need a complex migration plan, I think I'll have to find >> > someone who is willing to take over the job. >> > >> > >> > >> > 2022年6月25日(土) 19:19 Tomoko Uchida : >> >> >> >> Hi Dawid, >> >> >> >> > Emm.. sorry for being slow - what is it that you want me to do? :) >> >> > Unwatch->Ignore? >> >> >> >> I'm sorry for being ambiguous. Could you set your notification >> >> setting on the repository as "Participating and @mentions"? >> >> In the testing of migration scripts, I will import many fake issues >> >> where
Re: Finding out which fields matched the query
I think it's a matter of tradeoff. For example when you do faceting then we
require complete evaluation, and since this field-matching is a kind of
aggregation I think it's OK if that's how it works. Users can choose which
technique they want to apply based on their usecase.
Anyway I don't think we must introduce this kind of collector in Lucene,
it's definitely something someone can write in his/her own project.
Shai
On Tue, Jun 28, 2022 at 4:09 PM Alan Woodward wrote:
> I think it depends on what information we actually want to get here. If
> it’s just finding which fields matched in which document, then running
> Matches over the top-k results is fine. If you want to get some kind of
> aggregate data, as in you want to get a list of fields that matched in
> *any* document (or conversely, a list of fields that *didn’t* match -
> useful if you want to prune your schema, for example), then Matches will be
> too slow. But at the same time, queries are designed to tell you which
> *documents* match efficiently, and they are allowed to advance their
> sub-queries lazily or indeed not at all if the result isn’t needed for
> scoring. So we don’t really have any way of finding this kind of
> information via a collector that is accurate and performs reasonably.
>
> It *might* be possible to rework Matches so that they act more like an
> iterator and maintain their state within a segment, but there hasn’t been a
> pressing need for that so far.
>
> On 27 Jun 2022, at 12:46, Shai Erera wrote:
>
> Thanks Alan, yeah I guess I was thinking about the usecase I described,
> which involves (usually) simple term queries, but you're definitely right
> about complex boolean clauses as well non-term queries.
>
> I think the case for highlighter is different though? I mean you usually
> generate highlights only for the top-K results and therefore are probably
> less affected by whether the matches() API is slower than a Collector. And
> if you invoke the API for every document in the index, it might be much
> slower (depending on the index size) than the Collector.
>
> Maybe a hybrid approach which runs the query and caches the docs in a
> DocIdSet (like FacetsCollector does) and then invokes the matches() API
> only on those hits, will let you enjoy the best of both worlds? Assuming
> though that the number of matching documents is not huge.
>
> So it seems there are several options and one should choose based on their
> usecase. Do you see an advantage for Lucene to offer a Collector for this
> usecase? Or should we tell users to use the matches API
>
> Shai
>
> On Mon, Jun 27, 2022 at 2:22 PM Dawid Weiss wrote:
>
>> A side note - I've been using a highlighter based on matches API for
>> quite some time now and it's been fantastic. Very precise and handles
>> non-trivial queries (interval queries) very well.
>>
>>
>> https://lucene.apache.org/core/9_2_0/highlighter/org/apache/lucene/search/matchhighlight/package-summary.html
>>
>> Dawid
>>
>> On Mon, Jun 27, 2022 at 1:10 PM Alan Woodward
>> wrote:
>> >
>> > Your approach is almost certainly more efficient, but it might give you
>> false matches in some cases - for example, if you have a complex query with
>> many nested MUST and SHOULD clauses, you can have a leaf TermScorer that is
>> positioned on the correct document, but which is part of a clause that
>> doesn’t actually match. It also only works for term queries, so it won’t
>> match phrases or span/interval groups. And Matches will work on points or
>> docvalues queries as well. The reason I added Matches in the first place
>> was precisely to handle these weird corner cases - I had written
>> highlighters which more or less did the same thing you describe with a
>> Collector and the Scorable tree, and I would occasionally get bad
>> highlights back.
>> >
>> > On 27 Jun 2022, at 10:51, Shai Erera wrote:
>> >
>> > Out of curiosity and for education purposes, is the Collector approach
>> I proposed wrong/inefficient? Or less efficient than the matches() API?
>> >
>> > I'm thinking, if you want to both match/rank documents and as a side
>> effect know which fields matched, the Collector will perform better than
>> Weight.matches(), but I could be wrong.
>> >
>> > Shai
>> >
>> > On Mon, Jun 27, 2022 at 11:57 AM Dawid Weiss
>> wrote:
>> >>
>> >> The matches API is awesome. Use it. You can also get a rough glimpse
>> >> into a superset of fields potentially matching the query via:
>> >>
>> >> query.visit(
>> >> new QueryVisitor() {
>> >> @Override
>> >> public boolean acceptField(String field) {
>> >> affectedFields.add(field);
>> >> return false;
>> >> }
>> >> });
>> >>
>> >>
>> https://lucene.apache.org/core/9_2_0/core/org/apache/lucene/search/Query.html#visit(org.apache.lucene.search.QueryVisitor)
>> >>
>> >> I'd go with the Matches API though.
>> >>
>> >> Dawid
>> >>
>> >> On Mon, Jun 27, 2022 at 10:48 AM Alan Woodward
>> wrote: