[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16280702#comment-16280702
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm closed pull request #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/python/doc/source/index.rst b/python/doc/source/index.rst
index b933d2359..c35f20be8 100644
--- a/python/doc/source/index.rst
+++ b/python/doc/source/index.rst
@@ -18,10 +18,14 @@
Apache Arrow (Python)
=
-Arrow is a columnar in-memory analytics layer designed to accelerate big data.
-It houses a set of canonical in-memory representations of flat and hierarchical
-data along with multiple language-bindings for structure manipulation. It also
-provides IPC and common algorithm implementations.
+Apache Arrow is a cross-language development platform for in-memory data. It
+specifies a standardized language-independent columnar memory format for flat
+and hierarchical data, organized for efficient analytic operations on modern
+hardware. It also provides computational libraries and zero-copy streaming
+messaging and interprocess communication.
+
+The Arrow Python bindings have first-class integration with NumPy, pandas, and
+built-in Python objects.
This is the documentation of the Python API of Apache Arrow. For more details
on the format and other language bindings see
diff --git a/python/doc/source/ipc.rst b/python/doc/source/ipc.rst
index 17fe84e03..6842cb5be 100644
--- a/python/doc/source/ipc.rst
+++ b/python/doc/source/ipc.rst
@@ -256,6 +256,83 @@ Lastly, we use this context as an additioanl argument to
``pyarrow.serialize``:
buf = pa.serialize(val, context=context).to_buffer()
restored_val = pa.deserialize(buf, context=context)
+The ``SerializationContext`` also has convenience methods ``serialize`` and
+``deserialize``, so these are equivalent statements:
+
+.. code-block:: python
+
+ buf = context.serialize(val).to_buffer()
+ restored_val = context.deserialize(buf)
+
+Component-based Serialization
+~
+
+For serializing Python objects containing some number of NumPy arrays, Arrow
+buffers, or other data types, it may be desirable to transport their serialized
+representation without having to produce an intermediate copy using the
+``to_buffer`` method. To motivate this, support we have a list of NumPy arrays:
+
+.. ipython:: python
+
+ import numpy as np
+ data = [np.random.randn(10, 10) for i in range(5)]
+
+The call ``pa.serialize(data)`` does not copy the memory inside each of these
+NumPy arrays. This serialized representation can be then decomposed into a
+dictionary containing a sequence of ``pyarrow.Buffer`` objects containing
+metadata for each array and references to the memory inside the arrays. To do
+this, use the ``to_components`` method:
+
+.. ipython:: python
+
+ serialized = pa.serialize(data)
+ components = serialized.to_components()
+
+The particular details of the output of ``to_components`` are not too
+important. The objects in the ``'data'`` field are ``pyarrow.Buffer`` objects,
+which are zero-copy convertible to Python ``memoryview`` objects:
+
+.. ipython:: python
+
+ memoryview(components['data'][0])
+
+A memoryview can be converted back to a ``Buffer`` with ``pyarrow.frombuffer``:
+
+.. ipython:: python
+
+ mv = memoryview(components['data'][0])
+ buf = pa.frombuffer(mv)
+
+An object can be reconstructed from its component-based representation using
+``deserialize_components``:
+
+.. ipython:: python
+
+ restored_data = pa.deserialize_components(components)
+ restored_data[0]
+
+``deserialize_components`` is also available as a method on
+``SerializationContext`` objects.
+
+Serializing pandas Objects
+--
+
+We provide a serialization context that has optimized handling of pandas
+objects like ``DataFrame`` and ``Series``. This is the
+``pyarrow.pandas_serialization_context`` member. Combined with component-based
+serialization above, this enables zero-copy transport of pandas DataFrame
+objects not containing any Python objects:
+
+.. ipython:: python
+
+ import pandas as pd
+ df = pd.DataFrame({'a': [1, 2, 3, 4, 5]})
+ context = pa.pandas_serialization_context
+ serialized_df = context.serialize(df)
+ df_components = serialized_df.to_components()
+ original_df = context.deserialize_components(df_components)
+ original_df
+
Feather Format
--
diff --git a/python/manylinux1/README.md b/python/manylinux1/README.md
index
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16280572#comment-16280572
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349720241
@jreback seems there is some pickling issue with IntervalIndex in pandas
0.20.x, I was that something changed or fixed in 0.21? See
https://github.com/apache/arrow/pull/1390/commits/21adbe7d41db18a139f64c4939412142208946ae
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16280515#comment-16280515
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349706781
Seems there is some problem with the manylinux1 build, will dig in
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16279229#comment-16279229
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349451053
Done, and added docs. Will merge once the build passes
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16278429#comment-16278429
]
ASF GitHub Bot commented on ARROW-1784:
---
jreback commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349279650
@pitrou the internal conversion functions could / should be exposed in pandas
but should also live here until pyarrow drops support for < 0.22 (a while)
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16278410#comment-16278410
]
ASF GitHub Bot commented on ARROW-1784:
---
jreback commented on a change in pull request #1390: ARROW-1784: [Python]
Enable zero-copy serialization, deserialization of pandas.DataFrame via
components
URL: https://github.com/apache/arrow/pull/1390#discussion_r154838798
##
File path: python/pyarrow/pandas_compat.py
##
@@ -348,25 +349,85 @@ def get_datetimetz_type(values, dtype, type_):
return values, type_
+# --
+# Converting pandas.DataFrame to a dict containing only NumPy arrays or other
+# objects friendly to pyarrow.serialize
-def make_datetimetz(tz):
+
+def dataframe_to_serialized_dict(frame):
+block_manager = frame._data
+
+blocks = []
+axes = [ax for ax in block_manager.axes]
+
+for block in block_manager.blocks:
+values = block.values
+block_data = {}
+
+if isinstance(block, _int.DatetimeTZBlock):
+block_data['timezone'] = values.tz.zone
+values = values.values
+elif isinstance(block, _int.CategoricalBlock):
+block_data.update(dictionary=values.categories,
+ ordered=values.ordered)
+values = values.codes
+
+block_data.update(
+placement=block.mgr_locs.as_array,
+block=values
+)
+blocks.append(block_data)
+
+return {
+'blocks': blocks,
+'axes': axes
+}
+
+
+def serialized_dict_to_dataframe(data):
+reconstructed_blocks = [_reconstruct_block(block)
+for block in data['blocks']]
+
+block_mgr = _int.BlockManager(reconstructed_blocks, data['axes'])
+return pd.DataFrame(block_mgr)
+
+
+def _reconstruct_block(item):
+# Construct the individual blocks converting dictionary types to pandas
+# categorical types and Timestamps-with-timezones types to the proper
+# pandas Blocks
+
+block_arr = item['block']
+placement = item['placement']
+if 'dictionary' in item:
+cat = pd.Categorical(block_arr,
Review comment:
should be ``.from_codes`` as going to deprecate ``fastpath=`` soon
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16278394#comment-16278394
]
ASF GitHub Bot commented on ARROW-1784:
---
pitrou commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349268777
Shouldn't `dataframe_to_serialized_dict` and `serialized_dict_to_dataframe`
actually be exposed by Pandas? They seem generally useful (and touch internal
details of dataframes).
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277943#comment-16277943
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349181695
> I think I read that you all had set up nightly builds on the twosigma
channel?
yes, as soon as this is merged, it should show up in the next nightly
https://anaconda.org/twosigma/pyarrow/files. Though we are having a small
problem with the version numbers in the nightlies
(https://issues.apache.org/jira/browse/ARROW-1881) that needs to get fixed in
the next day or two (cc @xhochy)
> This is to be expected, right?
Yes, it's a nice confirmation that pandas definitely is not making any
unexpected memory copies (it can be quite zealous about copying stuff)
> That's surprisingly nice. Do you have a sense for what is going on here?
100ms in copying memory?
Yes, I think this is strictly from copying the internal numeric ndarrays.
The memory use vs. pickle will also be less by whatever the total pickled
footprint of those numeric arrays that are being copied
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277940#comment-16277940
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on a change in pull request #1390: ARROW-1784: [Python] Enable
zero-copy serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#discussion_r154836339
##
File path: python/pyarrow/pandas_compat.py
##
@@ -348,25 +349,85 @@ def get_datetimetz_type(values, dtype, type_):
return values, type_
+# --
+# Converting pandas.DataFrame to a dict containing only NumPy arrays or other
+# objects friendly to pyarrow.serialize
-def make_datetimetz(tz):
+
+def dataframe_to_serialized_dict(frame):
Review comment:
@jreback let me know if I missed anything on these functions
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277936#comment-16277936
]
ASF GitHub Bot commented on ARROW-1784:
---
mrocklin commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349180433
Thank you for putting this together. I look forward to trying this out with
Dask and seeing if it relieves the memory pressure we're seeing when sending
dataframes. What does the current dev-build process look like? I think I read
that you all had set up nightly builds on the twosigma channel?
> The impact of this is that when a DataFrame has no data that requires
pickling, the reconstruction is zero-copy. I will post some benchmarks to
illustrate the impact of this. The performance improvements are pretty
remarkable, nearly 1000x speedup on a large DataFrame.
This is to be expected, right?
> serialize with Arrow table as intermediary: 1.64s in, 1.44s out
> serialize using pickle: 623ms in, 489ms out
> serialize using component method: 554ms in, 408ms out
That's surprisingly nice. Do you have a sense for what is going on here?
100ms in copying memory?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277933#comment-16277933
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349179770
Most importantly for consumers like Dask, whenever there is an internal
block where a copy can be avoided, it is avoided. This will avoid excess memory
use on serialization (no additional copies) and extra memory use on receive (no
copies)
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277931#comment-16277931
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349179650
Here's the same thing with a bunch of strings.
* serialize with Arrow table as intermediary: 1.64s in, 1.44s out
* serialize using pickle: 623ms in, 489ms out
* serialize using component method: 554ms in, 408ms out
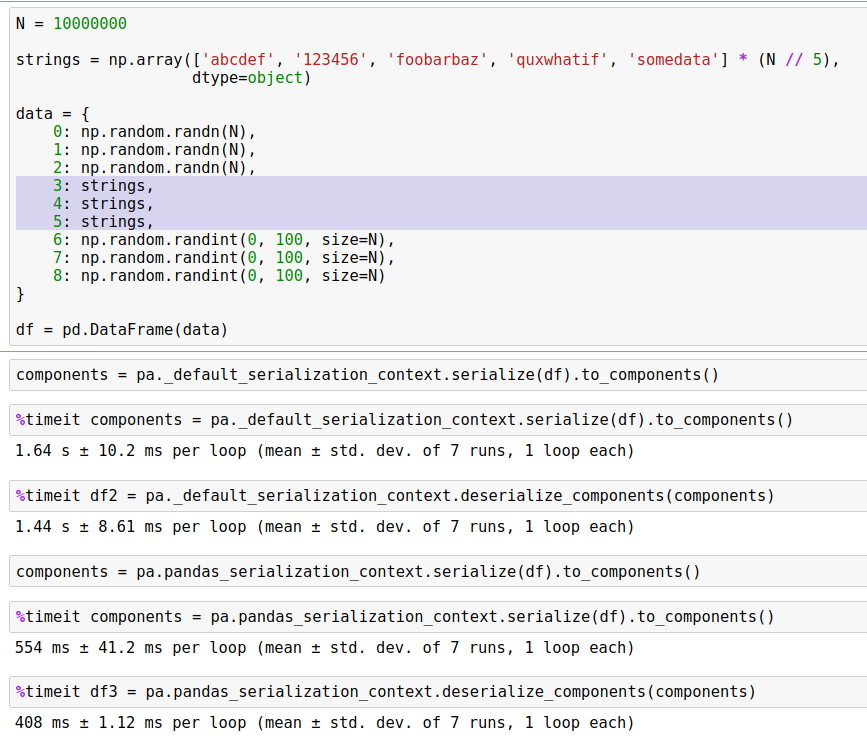
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277928#comment-16277928
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349179326
Here's an example of a DataFrame that zero-copies. Serialization time goes
from 200ms to 160 microseconds. Deserialization time from 56ms to about the
same. This serialization code path is going to Arrow representation as an
intermediary -- vanilla pickle is 126ms in, 60ms out.
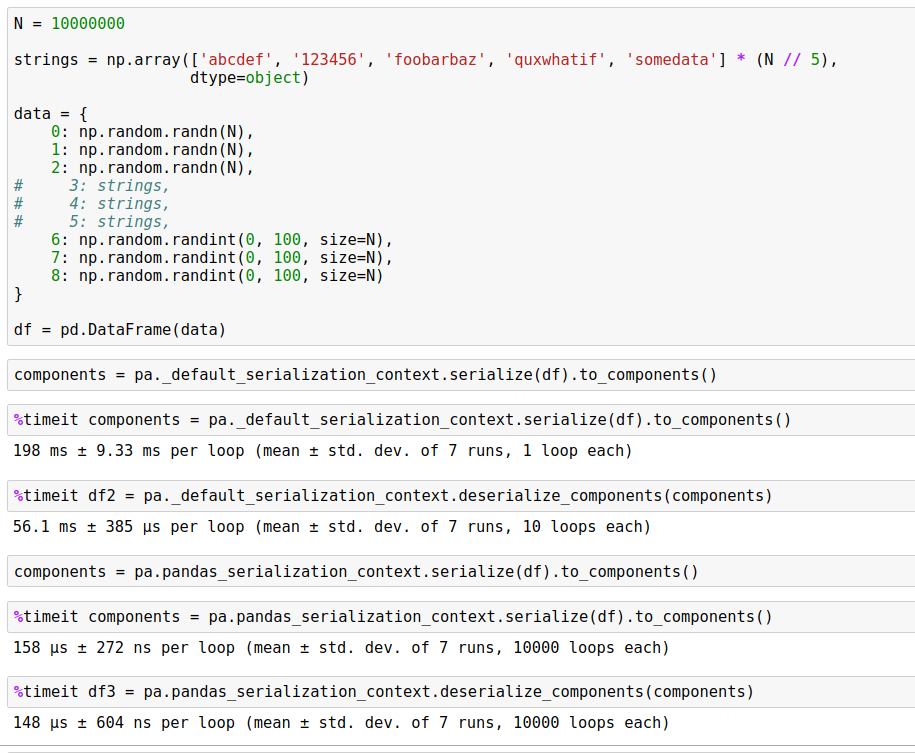
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16277927#comment-16277927
]
ASF GitHub Bot commented on ARROW-1784:
---
wesm commented on issue #1390: ARROW-1784: [Python] Enable zero-copy
serialization, deserialization of pandas.DataFrame via components
URL: https://github.com/apache/arrow/pull/1390#issuecomment-349179326
Here's an example of a DataFrame that zero-copies. Serialization time goes
from 200ms to 160 microseconds. Deserialization time from 56ms to about the
same. This serialization code path is going to Arrow representation as an
intermediary -- vanilla pickle is 126ms in (faster because I deliberately
created a large column with a lot of duplicated strings), 60ms out.

This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
>Assignee: Wes McKinney
> Labels: pull-request-available
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16246309#comment-16246309
]
Wes McKinney commented on ARROW-1784:
-
It's hard to prevent a memory doubling on receipt if you go column-wise (e.g.
{{pd.DataFrame(data)}} where data is a dict of columns will double memory). So
I think as long as we avoid memory doubling we are good
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (ARROW-1784) [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing the BlockManager rather than coercing to Arrow format
[
https://issues.apache.org/jira/browse/ARROW-1784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16246134#comment-16246134
]
Matthew Rocklin commented on ARROW-1784:
Note that matching the BlockManager itself is not important for us. I could
imagine doing things columnwise as well if that feels cleaner semantically or
more future-proof.
> [Python] Read and write pandas.DataFrame in pyarrow.serialize by decomposing
> the BlockManager rather than coercing to Arrow format
> --
>
> Key: ARROW-1784
> URL: https://issues.apache.org/jira/browse/ARROW-1784
> Project: Apache Arrow
> Issue Type: New Feature
> Components: Python
>Reporter: Wes McKinney
> Fix For: 0.8.0
>
>
> See discussion in https://github.com/dask/distributed/pull/931
> This will permit zero-copy reads for DataFrames not containing Python
> objects. In the event of an {{ObjectBlock}} these arrays will not be worse
> than pickle to reconstruct on the receiving side
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)