[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9777/ ---
[GitHub] carbondata issue #2945: [CARBONDATA-3123] Fixed JVM crash issue with CarbonR...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2945 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1520/ ---
[GitHub] carbondata issue #2945: [CARBONDATA-3123] Fixed JVM crash issue with CarbonR...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/2945 retest this please ---
[GitHub] carbondata issue #2945: [CARBONDATA-3123] Fixed JVM crash issue with CarbonR...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2945 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1728/ ---
[GitHub] carbondata issue #2945: [CARBONDATA-3123] Fixed JVM crash issue with CarbonR...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2945 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9776/ ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1519/ ---
[GitHub] carbondata issue #2945: [CARBONDATA-3123] Fixed JVM crash issue with CarbonR...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2945 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1518/ ---
[GitHub] carbondata pull request #2945: [CARBONDATA-3123] Fixed JVM crash issue with ...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/2945 [CARBONDATA-3123] Fixed JVM crash issue with CarbonRecordReader(SDK Reader). **Problem:** As CarbonReaderBuilder is executed on the main thread therefore while Reader creation we are setting TaskId to threadlocal. When multiple readers are created using the split API then the TaskID for the last initialized reader would be overridden and all the readers will use the same TaskID. Due to this when one reader is reading and the other reader is freeing memory after its task completion the same memory block would be cleared and read at the same time causing SIGSEGV error. **Solution:** Do not set TaskID to thread local while Reader Initialization. ThreadLocalTaskInfo.getCarbonTaskInfo will take care of assigning new TaskID if not already present. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata bug/CARBONDATA-3123 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2945.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2945 commit cce1811fa518545b6b31246efd5668048e7d24ea Author: kunal642 Date: 2018-11-23T05:41:44Z [CARBONDATA-3123] Fixed JVM crash issue with CarbonRecordReader(SDK Reader). **Problem:** As CarbonReaderBuilder is executed on the main thread therefore while Reader creation we are setting TaskId to threadlocal. When multiple readers are created using the split API then the TaskID for the last initialized reader would be overridden and all the readers will use the same TaskID. Due to this when one reader is reading and the other reader is freeing memory after its task completion the same memory block would be cleared and read at the same time causing SIGSEGV error. **Solution:** Do not set TaskID to thread local while Reader Initialization. ThreadLocalTaskInfo.getCarbonTaskInfo will take care of assigning new TaskID if not already present. ---
[jira] [Created] (CARBONDATA-3123) JVM crash when reading through CarbonReader
Kunal Kapoor created CARBONDATA-3123:
Summary: JVM crash when reading through CarbonReader
Key: CARBONDATA-3123
URL: https://issues.apache.org/jira/browse/CARBONDATA-3123
Project: CarbonData
Issue Type: Bug
Environment: Java - 1.8.0_40
CPU(s): 8
Cores(s): 8
Reporter: Kunal Kapoor
Assignee: Kunal Kapoor
Fix For: 1.5.1
How to Reproduce:
{code:java}
// ExecutorService executorService = Executors.newFixedThreadPool(8);
try {
CarbonReader reader2 =
CarbonReader.builder(dataDir).withRowRecordReader().build();
List multipleReaders = reader2.split(8);
try {
List tasks = new ArrayList<>();
List results = new ArrayList<>();
count = 0;
long start = System.currentTimeMillis();
for (CarbonReader reader_i : multipleReaders) {
results.add(executorService.submit(new ReadLogic(reader_i)));
}
for (Future result_i : results) {
count += (long) result_i.get();
}
long end = System.currentTimeMillis();
System.out.println("[Parallel read] Time: " + (end - start) + " ms");
Assert.assertEquals(numFiles * numRowsPerFile, count);
} catch (Exception e) {
e.printStackTrace();
Assert.fail(e.getMessage());
}
} catch (Exception e) {
e.printStackTrace();
Assert.fail(e.getMessage());
} finally {
executorService.shutdown();
executorService.awaitTermination(10, TimeUnit.MINUTES);
CarbonProperties.getInstance()
.addProperty(CarbonCommonConstants.ENABLE_UNSAFE_IN_QUERY_EXECUTION,
"false");
}{code}
When the above code is executed the JVM crashes with a SIGSEGV fault error.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9775/ ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1727/ ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1517/ ---
[GitHub] carbondata pull request #2936: [CARBONDATA-3118] Parallelize block pruning o...
Github user ajantha-bhat commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2936#discussion_r235846200
--- Diff:
core/src/main/java/org/apache/carbondata/core/datamap/TableDataMap.java ---
@@ -120,37 +132,166 @@ public BlockletDetailsFetcher
getBlockletDetailsFetcher() {
* @param filterExp
* @return
*/
- public List prune(List segments,
FilterResolverIntf filterExp,
- List partitions) throws IOException {
-List blocklets = new ArrayList<>();
-SegmentProperties segmentProperties;
-Map> dataMaps =
dataMapFactory.getDataMaps(segments);
+ public List prune(List segments, final
FilterResolverIntf filterExp,
+ final List partitions) throws IOException {
+final List blocklets = new ArrayList<>();
+final Map> dataMaps =
dataMapFactory.getDataMaps(segments);
+// for non-filter queries
+if (filterExp == null) {
+ // if filter is not passed, then return all the blocklets.
+ return pruneWithoutFilter(segments, partitions, blocklets);
+}
+// for filter queries
+int totalFiles = 0;
+boolean isBlockDataMapType = true;
+for (Segment segment : segments) {
+ for (DataMap dataMap : dataMaps.get(segment)) {
+if (!(dataMap instanceof BlockDataMap)) {
--- End diff --
This one, I have to figure out, number of entries in all kinds of datamap
and need to test those scenario. I will handle in next PR
---
[GitHub] carbondata pull request #2936: [CARBONDATA-3118] Parallelize block pruning o...
Github user ajantha-bhat commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2936#discussion_r235842114
--- Diff:
core/src/main/java/org/apache/carbondata/core/datamap/TableDataMap.java ---
@@ -120,37 +132,166 @@ public BlockletDetailsFetcher
getBlockletDetailsFetcher() {
* @param filterExp
* @return
*/
- public List prune(List segments,
FilterResolverIntf filterExp,
- List partitions) throws IOException {
-List blocklets = new ArrayList<>();
-SegmentProperties segmentProperties;
-Map> dataMaps =
dataMapFactory.getDataMaps(segments);
+ public List prune(List segments, final
FilterResolverIntf filterExp,
+ final List partitions) throws IOException {
+final List blocklets = new ArrayList<>();
+final Map> dataMaps =
dataMapFactory.getDataMaps(segments);
+// for non-filter queries
+if (filterExp == null) {
+ // if filter is not passed, then return all the blocklets.
+ return pruneWithoutFilter(segments, partitions, blocklets);
+}
+// for filter queries
+int totalFiles = 0;
+boolean isBlockDataMapType = true;
+for (Segment segment : segments) {
+ for (DataMap dataMap : dataMaps.get(segment)) {
+if (!(dataMap instanceof BlockDataMap)) {
+ isBlockDataMapType = false;
+ break;
+}
+totalFiles += ((BlockDataMap) dataMap).getTotalBlocks();
+ }
+ if (!isBlockDataMapType) {
+// totalFiles fill be 0 for non-BlockDataMap Type. ex: lucene,
bloom datamap. use old flow.
+break;
+ }
+}
+int numOfThreadsForPruning = getNumOfThreadsForPruning();
+int filesPerEachThread = totalFiles / numOfThreadsForPruning;
+if (numOfThreadsForPruning == 1 || filesPerEachThread == 1
+|| segments.size() < numOfThreadsForPruning || totalFiles
+<
CarbonCommonConstants.CARBON_DRIVER_PRUNING_MULTI_THREAD_ENABLE_FILES_COUNT) {
+ // use multi-thread, only if the files are more than 0.1 million.
+ // As 0.1 million files block pruning can take only 1 second.
+ // Doing multi-thread for smaller values is not recommended as
+ // driver should have minimum threads opened to support multiple
concurrent queries.
+ return pruneWithFilter(segments, filterExp, partitions, blocklets,
dataMaps);
+}
+// handle by multi-thread
+return pruneWithFilterMultiThread(segments, filterExp, partitions,
blocklets, dataMaps,
+totalFiles);
+ }
+
+ private List pruneWithoutFilter(List segments,
+ List partitions, List blocklets)
throws IOException {
+for (Segment segment : segments) {
+ List allBlocklets =
blockletDetailsFetcher.getAllBlocklets(segment, partitions);
+ blocklets.addAll(
+
addSegmentId(blockletDetailsFetcher.getExtendedBlocklets(allBlocklets, segment),
+ segment.toString()));
+}
+return blocklets;
+ }
+
+ private List pruneWithFilter(List segments,
+ FilterResolverIntf filterExp, List partitions,
+ List blocklets, Map>
dataMaps) throws IOException {
for (Segment segment : segments) {
List pruneBlocklets = new ArrayList<>();
- // if filter is not passed then return all the blocklets
- if (filterExp == null) {
-pruneBlocklets = blockletDetailsFetcher.getAllBlocklets(segment,
partitions);
- } else {
-segmentProperties =
segmentPropertiesFetcher.getSegmentProperties(segment);
-for (DataMap dataMap : dataMaps.get(segment)) {
- pruneBlocklets.addAll(dataMap.prune(filterExp,
segmentProperties, partitions));
+ SegmentProperties segmentProperties =
segmentPropertiesFetcher.getSegmentProperties(segment);
+ for (DataMap dataMap : dataMaps.get(segment)) {
+pruneBlocklets.addAll(dataMap.prune(filterExp, segmentProperties,
partitions));
+ }
+ blocklets.addAll(
+
addSegmentId(blockletDetailsFetcher.getExtendedBlocklets(pruneBlocklets,
segment),
+ segment.toString()));
+}
+return blocklets;
+ }
+
+ private List pruneWithFilterMultiThread(List
segments,
+ final FilterResolverIntf filterExp, final List
partitions,
+ List blocklets, final Map>
dataMaps,
+ int totalFiles) {
+int numOfThreadsForPruning = getNumOfThreadsForPruning();
+int filesPerEachThread = (int) Math.ceil((double)totalFiles /
numOfThreadsForPruning);
+int prev = 0;
+int filesCount = 0;
+int processedFileCount = 0;
+List> segmentList = new ArrayList<>();
--- End diff --
done
---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed the parent version error in M...
Github user xubo245 commented on the issue: https://github.com/apache/carbondata/pull/2943 retest this please ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed the parent version error in M...
Github user xubo245 commented on the issue: https://github.com/apache/carbondata/pull/2943 please change the contentï¼Update version 1.5.0 to 1.5.1 =ãUpdate version 1.5.0 to 1.5.2-SNAPSHOT ---
[GitHub] carbondata pull request #2942: [CARBONDATA-3121] Improvement of CarbonReader...
Github user xubo245 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2942#discussion_r235835735
--- Diff:
core/src/main/java/org/apache/carbondata/core/scan/result/iterator/ChunkRowIterator.java
---
@@ -52,17 +49,11 @@ public ChunkRowIterator(CarbonIterator
iterator) {
* @return {@code true} if the iteration has more elements
*/
@Override public boolean hasNext() {
-if (null != currentChunk) {
- if ((currentChunk.hasNext())) {
-return true;
- } else if (!currentChunk.hasNext()) {
-while (iterator.hasNext()) {
- currentChunk = iterator.next();
- if (currentChunk != null && currentChunk.hasNext()) {
-return true;
- }
-}
- }
+if (currentChunk != null && currentChunk.hasNext()) {
--- End diff --
Have you tested/compare the performance before/after this change?
---
[GitHub] carbondata pull request #2944: [CARBONDATA-3122]CarbonReader memory leak
Github user xubo245 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2944#discussion_r235835645
--- Diff:
core/src/main/java/org/apache/carbondata/core/scan/processor/DataBlockIterator.java
---
@@ -262,6 +262,7 @@ public void close() {
if (blockletScannedResult != null) {
blockletScannedResult.freeMemory();
}
+future=null;
--- End diff --
please add white space before/after =
---
[GitHub] carbondata pull request #2943: [CARBONDATA-3120]Fixed the parent version err...
Github user xubo245 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2943#discussion_r235835392 --- Diff: datamap/mv/core/pom.xml --- @@ -22,7 +22,7 @@ org.apache.carbondata carbondata-parent -1.5.0-SNAPSHOT +1.5.1 --- End diff -- @ravipesala @sraghunandan Have you tested MV module before/when we release 1.5.1-rc1? Why didn't change it? ---
[GitHub] carbondata pull request #2915: [CARBONDATA-3095] Optimize the documentation ...
Github user xubo245 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2915#discussion_r235834831 --- Diff: docs/sdk-guide.md --- @@ -674,6 +693,16 @@ Find example code at [CarbonReaderExample](https://github.com/apache/carbondata/ public CarbonReaderBuilder filter(Expression filterExpression); ``` +``` + /** + * set read batch size before build --- End diff -- ok, done ---
[GitHub] carbondata issue #2915: [CARBONDATA-3095] Optimize the documentation of SDK/...
Github user xubo245 commented on the issue: https://github.com/apache/carbondata/pull/2915 @KanakaKumar @kunal642 @ajantha-bhat CI pass, please check it. ---
[GitHub] carbondata issue #2944: [CARBONDATA-3122]CarbonReader memory leak
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2944 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9774/ ---
[GitHub] carbondata issue #2944: [CARBONDATA-3122]CarbonReader memory leak
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2944 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1726/ ---
[GitHub] carbondata issue #2944: [CARBONDATA-3122]CarbonReader memory leak
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2944 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1516/ ---
[GitHub] carbondata pull request #2944: [CARBONDATA-3122]CarbonReader memory leak
GitHub user BJangir opened a pull request: https://github.com/apache/carbondata/pull/2944 [CARBONDATA-3122]CarbonReader memory leak **Issue Detail** CarbonReader has List of initialized RecordReader for each Split and each split holds page data till the reference of RecordReader is present in the List . Same is applicable for GC once user comes out from his/her calling method ( not cleaned even in `close()` ) but till then from each split , last page will be in memory which is not correct. For ex. if 1K carbon files then last page ( ~32K * 100 ,size if 100 String columns in memory ) of each file will be in memory till last split so total ~3GB memory will be occupied ( 1K * 32K * 100 . Check heap dump of 3 split after `reader.close()` is called ,It is be seen that currentreader+all list reader are still holding memory. 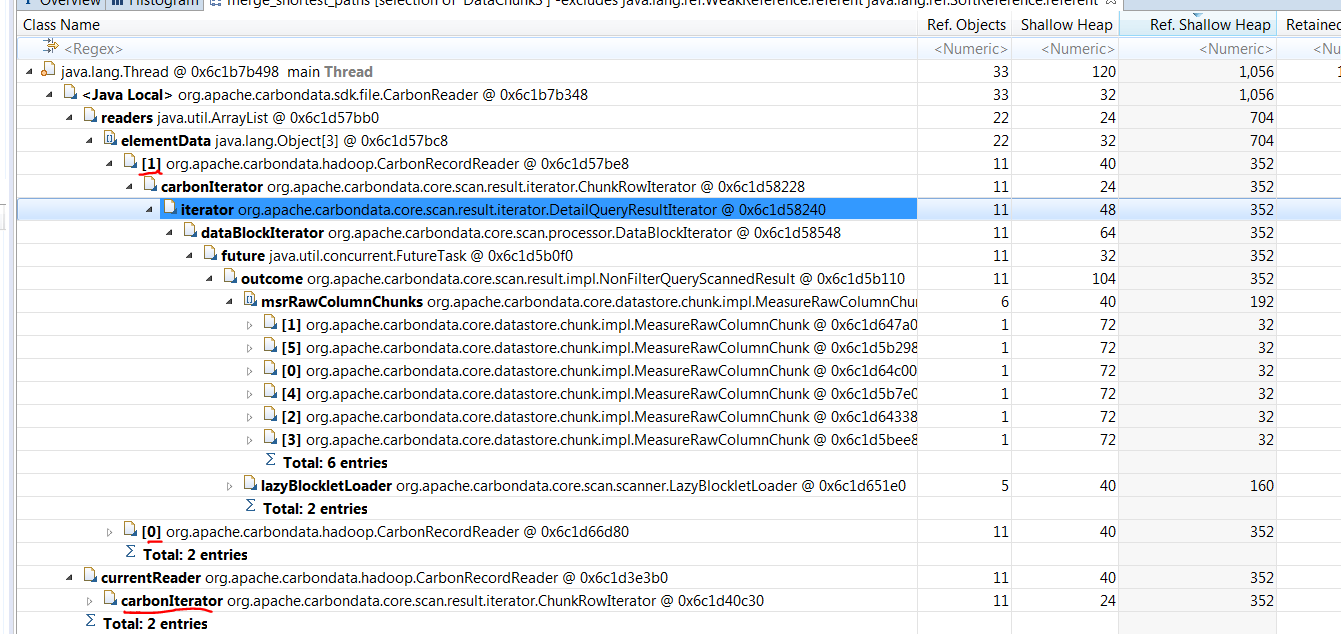 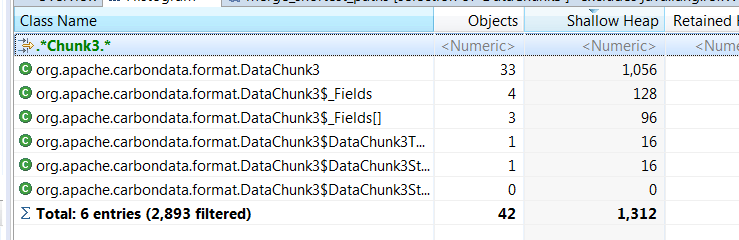 **Solution** 1. Once reader is finished assign `currentReader` to `null` in RecordReader List. OR 2. Assign future object as `null` in org.apache.carbondata.core.scan.processor.DataBlockIterator#close() Solution 2 is adopted so that it will give benefit to other than CarbonReader Flow. **After Fix**  Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? NA - [ ] Any backward compatibility impacted? NA - [ ] Document update required? NA - [ ] Testing done Manual Test - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/BJangir/incubator-carbondata reader_mem_leak Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2944.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2944 commit 198c042251f1269a75de51d36d42e5bcd23fe651 Author: BJangir Date: 2018-11-22T17:04:32Z [CARBONDATA-3122]CarbonReader memory leak ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9773/ ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1725/ ---
[jira] [Created] (CARBONDATA-3122) CarbonReader memory leak
Babulal created CARBONDATA-3122: --- Summary: CarbonReader memory leak Key: CARBONDATA-3122 URL: https://issues.apache.org/jira/browse/CARBONDATA-3122 Project: CarbonData Issue Type: Bug Reporter: Babulal CarbonReader For All split one last page will be always in memory until CarbonReader object is not out of scope. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1515/ ---
[GitHub] carbondata pull request #2936: [CARBONDATA-3118] Parallelize block pruning o...
Github user ajantha-bhat commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2936#discussion_r235774840
--- Diff:
core/src/main/java/org/apache/carbondata/core/datamap/TableDataMap.java ---
@@ -120,37 +132,166 @@ public BlockletDetailsFetcher
getBlockletDetailsFetcher() {
* @param filterExp
* @return
*/
- public List prune(List segments,
FilterResolverIntf filterExp,
- List partitions) throws IOException {
-List blocklets = new ArrayList<>();
-SegmentProperties segmentProperties;
-Map> dataMaps =
dataMapFactory.getDataMaps(segments);
+ public List prune(List segments, final
FilterResolverIntf filterExp,
+ final List partitions) throws IOException {
+final List blocklets = new ArrayList<>();
+final Map> dataMaps =
dataMapFactory.getDataMaps(segments);
+// for non-filter queries
+if (filterExp == null) {
+ // if filter is not passed, then return all the blocklets.
+ return pruneWithoutFilter(segments, partitions, blocklets);
+}
+// for filter queries
+int totalFiles = 0;
+boolean isBlockDataMapType = true;
+for (Segment segment : segments) {
+ for (DataMap dataMap : dataMaps.get(segment)) {
+if (!(dataMap instanceof BlockDataMap)) {
--- End diff --
Two reasons:
1. number of datamaps will be very less if it is not a block or blocklet
datamap. Hence multi-threading is not required (as it is overhead for driver in
concurrent scenarios)
2. Other datamaps doesn't have number entries count in them.
I will check
---
[GitHub] carbondata pull request #2943: [CARBONDATA-3120]Fixed the parent version err...
Github user zzcclp commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2943#discussion_r235773522 --- Diff: datamap/mv/core/pom.xml --- @@ -22,7 +22,7 @@ org.apache.carbondata carbondata-parent -1.5.0-SNAPSHOT +1.5.1 --- End diff -- The package version you downloaded is from a tag, not from branch-1.5. the version of all modules on branch-1.5 is 1.5.2-SNAPSHOT, when to be released, version manager will change version to 1.5.1 to tag a version package. ---
[GitHub] carbondata pull request #2943: [CARBONDATA-3120]Fixed the parent version err...
Github user Jonathan-Wei commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2943#discussion_r235768878 --- Diff: datamap/mv/core/pom.xml --- @@ -22,7 +22,7 @@ org.apache.carbondata carbondata-parent -1.5.0-SNAPSHOT +1.5.1 --- End diff -- The package version I downloaded was 1.5.1. apache-carbondata-1.5.1-rc1.tar.gz ---
[GitHub] carbondata pull request #2943: [CARBONDATA-3120]Fixed the parent version err...
Github user zzcclp commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2943#discussion_r235763601 --- Diff: datamap/mv/plan/pom.xml --- @@ -22,7 +22,7 @@ org.apache.carbondata carbondata-parent -1.5.0-SNAPSHOT +1.5.1 --- End diff -- please use 1.5.2-SNAPSHOT, not 1.5.1, the same as other module. ---
[GitHub] carbondata pull request #2943: [CARBONDATA-3120]Fixed the parent version err...
Github user zzcclp commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2943#discussion_r235763576 --- Diff: datamap/mv/core/pom.xml --- @@ -22,7 +22,7 @@ org.apache.carbondata carbondata-parent -1.5.0-SNAPSHOT +1.5.1 --- End diff -- please use 1.5.2-SNAPSHOT, not 1.5.1, the same as other module. ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed the parent version error in M...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2943 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1514/ ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed the parent version error in M...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2943 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9772/ ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed the parent version error in M...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2943 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1724/ ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed the parent version error in M...
Github user brijoobopanna commented on the issue: https://github.com/apache/carbondata/pull/2943 retest this please ---
[GitHub] carbondata issue #2805: [Documentation] Local dictionary Data which are not ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2805 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1722/ ---
[GitHub] carbondata issue #2915: [CARBONDATA-3095] Optimize the documentation of SDK/...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2915 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9771/ ---
[GitHub] carbondata issue #2915: [CARBONDATA-3095] Optimize the documentation of SDK/...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2915 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1723/ ---
[GitHub] carbondata issue #2805: [Documentation] Local dictionary Data which are not ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2805 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9770/ ---
[GitHub] carbondata pull request #2923: [CARBONDATA-3101] Fixed dataload failure when...
Github user asfgit closed the pull request at: https://github.com/apache/carbondata/pull/2923 ---
[GitHub] carbondata issue #2923: [CARBONDATA-3101] Fixed dataload failure when a colu...
Github user manishgupta88 commented on the issue: https://github.com/apache/carbondata/pull/2923 LGTM ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]Fixed mv pom.xml version mismatch p...
Github user Jonathan-Wei commented on the issue: https://github.com/apache/carbondata/pull/2943 I download the apache-carbondata-1.5.1-rc1.tar.gz package. After decompression, the datamap mv/core mv/plan project was added to the main pom for compilationã I check the pom file, parent.version is 1.5.0-snapshot. But apache-carbondata-1.5.1-rc1.tar.gz is 1.5.1. ---
[GitHub] carbondata issue #2923: [CARBONDATA-3101] Fixed dataload failure when a colu...
Github user ravipesala commented on the issue: https://github.com/apache/carbondata/pull/2923 LGTM ---
[jira] [Resolved] (CARBONDATA-3117) Rearrange the projection list in the Scan
[ https://issues.apache.org/jira/browse/CARBONDATA-3117?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ravindra Pesala resolved CARBONDATA-3117. - Resolution: Fixed Fix Version/s: 1.5.1 > Rearrange the projection list in the Scan > - > > Key: CARBONDATA-3117 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3117 > Project: CarbonData > Issue Type: Bug >Reporter: dhatchayani >Assignee: dhatchayani >Priority: Minor > Fix For: 1.5.1 > > Time Spent: 50m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] carbondata pull request #2933: [CARBONDATA-3117] Rearrange the projection li...
Github user asfgit closed the pull request at: https://github.com/apache/carbondata/pull/2933 ---
[GitHub] carbondata issue #2915: [CARBONDATA-3095] Optimize the documentation of SDK/...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2915 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1513/ ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]apache-carbondata-1.5.1-rc1.tar.gz ...
Github user xubo245 commented on the issue: https://github.com/apache/carbondata/pull/2943 Can you optimize the title? simplify . and describe details in content. What's more, please finish the checklist. ---
[GitHub] carbondata issue #2943: [CARBONDATA-3120]apache-carbondata-1.5.1-rc1.tar.gz ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2943 Can one of the admins verify this patch? ---
[GitHub] carbondata pull request #2943: [CARBONDATA-3120]apache-carbondata-1.5.1-rc1....
GitHub user Jonathan-Wei opened a pull request: https://github.com/apache/carbondata/pull/2943 [CARBONDATA-3120]apache-carbondata-1.5.1-rc1.tar.gz Datamap's core and plan project, pom.xml, is version 1.5.0, which results in an inability to compile properly fix carbondata 1.5.1 Datamap's core and plan project, pom.xml version mismatch problem. Update version 1.5.0 to 1.5.1 Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/Jonathan-Wei/carbondata local-1.5 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2943.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2943 commit 2fe4e0d0beebafd778e70d3b8780e27c22cd07b9 Author: Jonathan.Wei <252637867@...> Date: 2018-11-22T12:18:50Z fix CARBONDATA-3120 fix carbondata 1.5.1 Datamap's core and plan project, pom.xml version mismatch problem. Update version 1.5.0 to 1.5.1 ---
[GitHub] carbondata issue #2805: [Documentation] Local dictionary Data which are not ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2805 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1512/ ---
[GitHub] carbondata issue #2915: [CARBONDATA-3095] Optimize the documentation of SDK/...
Github user xubo245 commented on the issue: https://github.com/apache/carbondata/pull/2915 @KanakaKumar Updated ---
[GitHub] carbondata issue #2942: [CARBONDATA-3121] Improvement of CarbonReader build ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2942 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9769/ ---
[GitHub] carbondata issue #2942: [CARBONDATA-3121] Improvement of CarbonReader build ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2942 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1721/ ---
[GitHub] carbondata pull request #2915: [CARBONDATA-3095] Optimize the documentation ...
Github user xubo245 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2915#discussion_r235703636 --- Diff: docs/sdk-guide.md --- @@ -684,6 +713,17 @@ Find example code at [CarbonReaderExample](https://github.com/apache/carbondata/ public CarbonReaderBuilder withHadoopConf(Configuration conf); ``` +``` + /** + * configure hadoop configuration with key value --- End diff -- ok, done ---
[GitHub] carbondata issue #2942: [CARBONDATA-3121] Improvement of CarbonReader build ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2942 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1511/ ---
[GitHub] carbondata pull request #2849: [CARBONDATA-2896] Added TestCases for Adaptiv...
Github user asfgit closed the pull request at: https://github.com/apache/carbondata/pull/2849 ---
[GitHub] carbondata issue #2849: [CARBONDATA-2896] Added TestCases for Adaptive encod...
Github user kumarvishal09 commented on the issue: https://github.com/apache/carbondata/pull/2849 LGTM ---
[jira] [Resolved] (CARBONDATA-3114) Remove Null Values for a Dictionary_Include Timestamp column for Range Filters
[ https://issues.apache.org/jira/browse/CARBONDATA-3114?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kumar vishal resolved CARBONDATA-3114. -- Resolution: Fixed > Remove Null Values for a Dictionary_Include Timestamp column for Range Filters > -- > > Key: CARBONDATA-3114 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3114 > Project: CarbonData > Issue Type: Bug >Reporter: Indhumathi Muthumurugesh >Assignee: Indhumathi Muthumurugesh >Priority: Minor > Time Spent: 2h 40m > Remaining Estimate: 0h > > Issue: > Null Values are not removed in case of RangeFilters, if column is a > dictionary and no_inverted_index column -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] carbondata pull request #2937: [CARBONDATA-3114]Remove Null Values for a Dic...
Github user asfgit closed the pull request at: https://github.com/apache/carbondata/pull/2937 ---
[GitHub] carbondata issue #2937: [CARBONDATA-3114]Remove Null Values for a Dictionary...
Github user kumarvishal09 commented on the issue: https://github.com/apache/carbondata/pull/2937 LGTM ---
[GitHub] carbondata pull request #2923: [CARBONDATA-3101] Fixed dataload failure when...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2923#discussion_r235681603
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/standardpartition/StandardPartitionTableQueryTestCase.scala
---
@@ -437,6 +437,20 @@ test("Creation of partition table should fail if the
colname in table schema and
sql("drop datamap if exists preaggTable on table partitionTable")
}
+ test("validate data in partition table after dropping and adding a
column") {
+sql("drop table if exists par")
+sql("create table par(name string) partitioned by (age double) stored
by " +
+ "'carbondata'")
+sql(s"load data local inpath '$resourcesPath/uniqwithoutheader.csv'
into table par options" +
+s"('header'='false')")
+sql("alter table par drop columns(name)")
+sql("alter table par add columns(name string)")
+sql(s"load data local inpath '$resourcesPath/uniqwithoutheader.csv'
into table par options" +
+s"('header'='false')")
--- End diff --
@ravipesala Spark-2.1 and 2.2 both put partition column at the last even if
a new column is added.
---
[GitHub] carbondata pull request #2942: [CARBONDATA-3121] Improvement of CarbonReader...
GitHub user NamanRastogi opened a pull request: https://github.com/apache/carbondata/pull/2942 [CARBONDATA-3121] Improvement of CarbonReader build time CarbonReader builder is taking huge time. **Reason** Initialization of ChunkRowIterator is triggring actual I/O operation, and thus huge build time. **Solution** remove CarbonIterator.hasNext() from build. - [x] Any interfaces changed? No - [x] Any backward compatibility impacted? No - [x] Document update required? No - [x] Testing done Yes - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/NamanRastogi/carbondata build_improv Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2942.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2942 commit 721b9bb6a4d408ba6658ba55ff1fe431f4e2523a Author: Naman Rastogi Date: 2018-11-22T08:27:50Z Improvement of CarbonRecord build time ---
[jira] [Created] (CARBONDATA-3121) CarbonReader build time is huge
Naman Rastogi created CARBONDATA-3121: - Summary: CarbonReader build time is huge Key: CARBONDATA-3121 URL: https://issues.apache.org/jira/browse/CARBONDATA-3121 Project: CarbonData Issue Type: Improvement Components: core Reporter: Naman Rastogi Assignee: Naman Rastogi CarbonReader build is fetching data and triggering I/O operation instead of only initializing the iterator, thus large build time. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] carbondata issue #2917: [WIP]Show load/insert/update/delete row number
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2917 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1720/ ---
[GitHub] carbondata issue #2917: [WIP]Show load/insert/update/delete row number
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2917 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9768/ ---
[GitHub] carbondata issue #2917: [WIP]Show load/insert/update/delete row number
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2917 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1510/ ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1719/ ---
[jira] [Resolved] (CARBONDATA-3115) Fix CodeGen error in preaggregate table and codegen display issue in oldstores
[ https://issues.apache.org/jira/browse/CARBONDATA-3115?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kumar vishal resolved CARBONDATA-3115. -- Resolution: Fixed > Fix CodeGen error in preaggregate table and codegen display issue in oldstores > -- > > Key: CARBONDATA-3115 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3115 > Project: CarbonData > Issue Type: Bug >Reporter: Indhumathi Muthumurugesh >Assignee: Indhumathi Muthumurugesh >Priority: Major > Attachments: image-2018-11-21-20-28-38-226.png > > Time Spent: 1h 10m > Remaining Estimate: 0h > > Issues: > * While querying a preaggregate table, codegen error is displayed > * In old stores, code is getting displayed while executing queries. > !image-2018-11-21-20-28-38-226.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] carbondata pull request #2939: [CARBONDATA-3115] Fix CodeGen error in preagg...
Github user asfgit closed the pull request at: https://github.com/apache/carbondata/pull/2939 ---
[GitHub] carbondata issue #2939: [CARBONDATA-3115] Fix CodeGen error in preaggregate ...
Github user kumarvishal09 commented on the issue: https://github.com/apache/carbondata/pull/2939 LGTM ---
[jira] [Created] (CARBONDATA-3120) apache-carbondata-1.5.1-rc1.tar.gz Datamap's core and plan project, pom.xml, is version 1.5.0, which results in an inability to compile properly
Jonathan.Wei created CARBONDATA-3120:
Summary: apache-carbondata-1.5.1-rc1.tar.gz Datamap's core and
plan project, pom.xml, is version 1.5.0, which results in an inability to
compile properly
Key: CARBONDATA-3120
URL: https://issues.apache.org/jira/browse/CARBONDATA-3120
Project: CarbonData
Issue Type: Bug
Components: build
Affects Versions: 1.5.1
Environment: MacOS
apache-carbondata-1.5.1-rc1
Reporter: Jonathan.Wei
Fix For: 1.5.1
Hi,guy!
I download the apache-carbondata-1.5.1-rc1.tar.gz。
After decompression, the datamap mv/core mv/plan project was added to
the main pom for compilation。
But the But the compilation failed。
LOG:
{code:java}
[ERROR] [ERROR] Some problems were encountered while processing the POMs:
[FATAL] Non-resolvable parent POM for
org.apache.carbondata:carbondata-mv-core:[unknown-version]: Could not find
artifact org.apache.carbondata:carbondata-parent:pom:1.5.0-SNAPSHOT and
'parent.relativePath' points at wrong local POM @ line 22, column 11
[FATAL] Non-resolvable parent POM for
org.apache.carbondata:carbondata-mv-plan:[unknown-version]: Could not find
artifact org.apache.carbondata:carbondata-parent:pom:1.5.0-SNAPSHOT and
'parent.relativePath' points at wrong local POM @ line 22, column 11
[WARNING] 'build.plugins.plugin.version' for
com.ning.maven.plugins:maven-duplicate-finder-plugin is missing. @
org.apache.carbondata:carbondata-presto:[unknown-version],
/Users/jonathanwei/summary/carbondata/carbondata-apache-carbondata-1.5.1-rc1/integration/presto/pom.xml,
line 620, column 15
[WARNING] 'build.plugins.plugin.version' for
pl.project13.maven:git-commit-id-plugin is missing. @
org.apache.carbondata:carbondata-presto:[unknown-version],
/Users/jonathanwei/summary/carbondata/carbondata-apache-carbondata-1.5.1-rc1/integration/presto/pom.xml,
line 633, column 15
[WARNING] 'build.plugins.plugin.version' for
com.ning.maven.plugins:maven-duplicate-finder-plugin is missing. @
org.apache.carbondata:carbondata-examples-spark2:[unknown-version],
/Users/jonathanwei/summary/carbondata/carbondata-apache-carbondata-1.5.1-rc1/examples/spark2/pom.xml,
line 184, column 15
@
[ERROR] The build could not read 2 projects -> [Help 1]
[ERROR]
[ERROR] The project
org.apache.carbondata:carbondata-mv-core:[unknown-version]
(/Users/jonathanwei/summary/carbondata/carbondata-apache-carbondata-1.5.1-rc1/datamap/mv/core/pom.xml)
has 1 error
[ERROR] Non-resolvable parent POM for
org.apache.carbondata:carbondata-mv-core:[unknown-version]: Could not find
artifact org.apache.carbondata:carbondata-parent:pom:1.5.0-SNAPSHOT and
'parent.relativePath' points at wrong local POM @ line 22, column 11 -> [Help 2]
[ERROR]
[ERROR] The project
org.apache.carbondata:carbondata-mv-plan:[unknown-version]
(/Users/jonathanwei/summary/carbondata/carbondata-apache-carbondata-1.5.1-rc1/datamap/mv/plan/pom.xml)
has 1 error
[ERROR] Non-resolvable parent POM for
org.apache.carbondata:carbondata-mv-plan:[unknown-version]: Could not find
artifact org.apache.carbondata:carbondata-parent:pom:1.5.0-SNAPSHOT and
'parent.relativePath' points at wrong local POM @ line 22, column 11 -> [Help 2]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e
switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please
read the following articles:
[ERROR] [Help 1]
http://cwiki.apache.org/confluence/display/MAVEN/ProjectBuildingException
[ERROR] [Help 2]
http://cwiki.apache.org/confluence/display/MAVEN/UnresolvableModelException
{code}
I check the pom file, parent.version is 1.5.0-snapshot. But
apache-carbondata-1.5.1-rc1.tar.gz is 1.5.1.
mv/core pom.xml
{code:java}
org.apache.carbondata
carbondata-parent
1.5.0-SNAPSHOT
../../../pom.xml
carbondata-mv-core
Apache CarbonData :: Materialized View Core
{code}
mv/plan pom.xml
{code:java}
org.apache.carbondata
carbondata-parent
1.5.0-SNAPSHOT
../../../pom.xml
carbondata-mv-plan
Apache CarbonData :: Materialized View Plan
{code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] carbondata pull request #2917: [WIP]Show load/insert/update/delete row numbe...
Github user kevinjmh commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2917#discussion_r235654816
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/iud/TestShowIUDRowCount.scala
---
@@ -0,0 +1,60 @@
+package org.apache.carbondata.spark.testsuite.iud
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.test.util.QueryTest
+import org.scalatest.{BeforeAndAfterAll, BeforeAndAfterEach}
+
+class TestShowIUDRowCount extends QueryTest with BeforeAndAfterEach with
BeforeAndAfterAll {
+
+ override protected def beforeAll(): Unit = {
+dropTable("iud_rows")
+ }
+
+ override protected def beforeEach(): Unit = {
+dropTable("iud_rows")
+ }
+
+ override protected def afterEach(): Unit = {
+dropTable("iud_rows")
+ }
+
+ test("Test show load row count") {
+sql("""create table iud_rows (c1 string,c2 int,c3 string,c5 string)
+|STORED BY 'org.apache.carbondata.format'""".stripMargin)
+checkAnswer(
+ sql(s"""LOAD DATA LOCAL INPATH '$resourcesPath/IUD/dest.csv' INTO
table iud_rows"""),
--- End diff --
why `sql()` function in QueryTest get different plan to self made spark
context or beeline
---
[jira] [Updated] (CARBONDATA-3114) Remove Null Values for a Dictionary_Include Timestamp column for Range Filters
[ https://issues.apache.org/jira/browse/CARBONDATA-3114?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Indhumathi Muthumurugesh updated CARBONDATA-3114: - Summary: Remove Null Values for a Dictionary_Include Timestamp column for Range Filters (was: Remove Null Values in all types of columns for RangeFilters) > Remove Null Values for a Dictionary_Include Timestamp column for Range Filters > -- > > Key: CARBONDATA-3114 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3114 > Project: CarbonData > Issue Type: Bug >Reporter: Indhumathi Muthumurugesh >Assignee: Indhumathi Muthumurugesh >Priority: Minor > Time Spent: 2.5h > Remaining Estimate: 0h > > Issue: > Null Values are not removed in case of RangeFilters, if column is a > dictionary and no_inverted_index column -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9767/ ---
[GitHub] carbondata pull request #2915: [CARBONDATA-3095] Optimize the documentation ...
Github user KanakaKumar commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2915#discussion_r235648435 --- Diff: docs/sdk-guide.md --- @@ -674,6 +693,16 @@ Find example code at [CarbonReaderExample](https://github.com/apache/carbondata/ public CarbonReaderBuilder filter(Expression filterExpression); ``` +``` + /** + * set read batch size before build --- End diff -- Sets the batch size of records ---
[GitHub] carbondata issue #2937: [CARBONDATA-3114]Remove Null Values for a Dictionary...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2937 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1718/ ---
[GitHub] carbondata issue #2937: [CARBONDATA-3114]Remove Null Values for a Dictionary...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2937 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9766/ ---
[GitHub] carbondata pull request #2915: [CARBONDATA-3095] Optimize the documentation ...
Github user KanakaKumar commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2915#discussion_r235645252 --- Diff: docs/sdk-guide.md --- @@ -684,6 +713,17 @@ Find example code at [CarbonReaderExample](https://github.com/apache/carbondata/ public CarbonReaderBuilder withHadoopConf(Configuration conf); ``` +``` + /** + * configure hadoop configuration with key value --- End diff -- Change to "Updates the hadoop configuration with the given key value" ---
[GitHub] carbondata issue #2936: [CARBONDATA-3118] Parallelize block pruning of defau...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2936 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1509/ ---
[GitHub] carbondata issue #2937: [CARBONDATA-3114]Remove Null Values for a Dictionary...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2937 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1508/ ---