[jira] [Commented] (DRILL-6872) Add support for Join with small build side table between Lateral & Unnest subquery.
[
https://issues.apache.org/jira/browse/DRILL-6872?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702514#comment-16702514
]
Sorabh Hamirwasia commented on DRILL-6872:
--
That and the special case will be more easy to handle compared to full EMIT
support in Hash Join. In small table case the build side will be read only once
and will not see EMIT outcome from right side. The same hash table will be used
for all the left side batches with EMIT outcome.
The special case is also an useful scenario which is known where UNNESTed data
can be joined with data in IN clause or another smaller table. Unnest can
produce county code whereas other build side table can have country name for
country codes. Other than that it's not known if Hash Join will be useful in
Lateral/Unnest subquery or not which requires full EMIT protocol support.
> Add support for Join with small build side table between Lateral & Unnest
> subquery.
> ---
>
> Key: DRILL-6872
> URL: https://issues.apache.org/jira/browse/DRILL-6872
> Project: Apache Drill
> Issue Type: Improvement
> Components: Execution - Flow
>Reporter: Sorabh Hamirwasia
>Priority: Major
>
> We want to support Hash Join in Lateral & Unnest subquery for special case of
> small table on build side of the Hash Join. In this case basically build side
> is a small table which is scanned once by Hash Join and then for each left
> side batch with EMIT outcome, same build side information is used. The
> example plan will look like below:
> {code:java}
> LJ
> / \
> Scan HashJoin
> / \
> Unnest Scan (Build)
> {code}
>
> Here we should also think about sniffing logic in Hash Join operator which
> can cause deadlock for this scenario.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Khatua updated DRILL-6867: Labels: ready-to-commit (was: ) > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Labels: ready-to-commit > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702401#comment-16702401 ] ASF GitHub Bot commented on DRILL-6867: --- kkhatua removed a comment on issue #1551: DRILL-6867: WebUI Query editor cursor position URL: https://github.com/apache/drill/pull/1551#issuecomment-442611104 Thanks for making the change to `monospace'` A default monospace font on the Linux platform should address the issue of the missing `courier` font and we need not include any other special font. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Labels: ready-to-commit > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702398#comment-16702398 ] ASF GitHub Bot commented on DRILL-6867: --- kkhatua commented on issue #1551: DRILL-6867: WebUI Query editor cursor position URL: https://github.com/apache/drill/pull/1551#issuecomment-442611104 Thanks for making the change to `monospace'` A default monospace font on the Linux platform should address the issue of the missing `courier` font and we need not include any other special font. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6792) Find the right probe side fragment to any storage plugin
[ https://issues.apache.org/jira/browse/DRILL-6792?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702309#comment-16702309 ] ASF GitHub Bot commented on DRILL-6792: --- kkhatua removed a comment on issue #1504: DRILL-6792: Find the right probe side fragment wrapper & fix DrillBuf… URL: https://github.com/apache/drill/pull/1504#issuecomment-442570977 @weijietong I noticed there are changes between the last unsquashed commit and the latest commit that you force-pushed. I'm assuming nothing changed code-wise, but I see you've introduced a new dependency: `antlr-runtime` and that the Guava imports (Google Common) is not shaded. For example, ``` import com.google.common.collect.Lists; import com.google.common.collect.Sets; `` should be changed to ``` import org.apache.drill.shaded.guava.com.google.common.collect.Lists; import org.apache.drill.shaded.guava.com.google.common.collect.Sets; ``` This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Find the right probe side fragment to any storage plugin > > > Key: DRILL-6792 > URL: https://issues.apache.org/jira/browse/DRILL-6792 > Project: Apache Drill > Issue Type: Improvement > Components: Execution - Flow >Reporter: weijie.tong >Assignee: weijie.tong >Priority: Major > Labels: ready-to-commit > Fix For: 1.15.0 > > > The current implementation of JPPD to find the probe side wrapper depends on > the GroupScan's digest. But there's no promise the GroupScan's digest will > not be changed since it is attached to the RuntimeFilterDef by different > storage plugin implementation logic.So here we assign a unique identifier to > the RuntimeFilter operator, and find the right probe side fragment wrapper by > the runtime filter identifier at the RuntimeFilterRouter class. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6792) Find the right probe side fragment to any storage plugin
[ https://issues.apache.org/jira/browse/DRILL-6792?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702310#comment-16702310 ] ASF GitHub Bot commented on DRILL-6792: --- kkhatua commented on issue #1504: DRILL-6792: Find the right probe side fragment wrapper & fix DrillBuf… URL: https://github.com/apache/drill/pull/1504#issuecomment-442573143 Ignore my comment a few minutes ago. Got a wrong diff done. Thanks, @weijietong This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Find the right probe side fragment to any storage plugin > > > Key: DRILL-6792 > URL: https://issues.apache.org/jira/browse/DRILL-6792 > Project: Apache Drill > Issue Type: Improvement > Components: Execution - Flow >Reporter: weijie.tong >Assignee: weijie.tong >Priority: Major > Labels: ready-to-commit > Fix For: 1.15.0 > > > The current implementation of JPPD to find the probe side wrapper depends on > the GroupScan's digest. But there's no promise the GroupScan's digest will > not be changed since it is attached to the RuntimeFilterDef by different > storage plugin implementation logic.So here we assign a unique identifier to > the RuntimeFilter operator, and find the right probe side fragment wrapper by > the runtime filter identifier at the RuntimeFilterRouter class. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6792) Find the right probe side fragment to any storage plugin
[ https://issues.apache.org/jira/browse/DRILL-6792?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702301#comment-16702301 ] ASF GitHub Bot commented on DRILL-6792: --- kkhatua commented on issue #1504: DRILL-6792: Find the right probe side fragment wrapper & fix DrillBuf… URL: https://github.com/apache/drill/pull/1504#issuecomment-442570977 @weijietong I noticed there are changes between the last unsquashed commit and the latest commit that you force-pushed. I'm assuming nothing changed code-wise, but I see you've introduced a new dependency: `antlr-runtime` and that the Guava imports (Google Common) is not shaded. For example, ``` import com.google.common.collect.Lists; import com.google.common.collect.Sets; `` should be changed to ``` import org.apache.drill.shaded.guava.com.google.common.collect.Lists; import org.apache.drill.shaded.guava.com.google.common.collect.Sets; ``` This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Find the right probe side fragment to any storage plugin > > > Key: DRILL-6792 > URL: https://issues.apache.org/jira/browse/DRILL-6792 > Project: Apache Drill > Issue Type: Improvement > Components: Execution - Flow >Reporter: weijie.tong >Assignee: weijie.tong >Priority: Major > Labels: ready-to-commit > Fix For: 1.15.0 > > > The current implementation of JPPD to find the probe side wrapper depends on > the GroupScan's digest. But there's no promise the GroupScan's digest will > not be changed since it is attached to the RuntimeFilterDef by different > storage plugin implementation logic.So here we assign a unique identifier to > the RuntimeFilter operator, and find the right probe side fragment wrapper by > the runtime filter identifier at the RuntimeFilterRouter class. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702192#comment-16702192
]
ASF GitHub Bot commented on DRILL-6863:
---
vdiravka commented on a change in pull request #1557: DRILL-6863: Drop table is
not working if path within workspace starts…
URL: https://github.com/apache/drill/pull/1557#discussion_r237181857
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/sql/TestCTTAS.java
##
@@ -446,6 +446,23 @@ public void testJoinTemporaryWithPersistentTable() throws
Exception {
.go();
}
+ @Test
+ public void testCreateTemporaryTableWithAndWithoutLeadingSlashAreTheSame()
throws Exception{
+String tablename = "tmp_table";
+
+try {
+ test("CREATE TEMPORARY TABLE %s.%s AS SELECT * from cp.`region.json`",
DFS_TMP_SCHEMA, tablename);
Review comment:
lead all identifiers to the same upper or below case.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702191#comment-16702191
]
ASF GitHub Bot commented on DRILL-6863:
---
vdiravka commented on a change in pull request #1557: DRILL-6863: Drop table is
not working if path within workspace starts…
URL: https://github.com/apache/drill/pull/1557#discussion_r237189306
##
File path: exec/java-exec/src/test/java/org/apache/drill/TestDropTable.java
##
@@ -21,23 +21,28 @@
import org.apache.drill.categories.UnlikelyTest;
import org.apache.drill.common.exceptions.UserException;
import org.apache.hadoop.fs.Path;
+import org.junit.BeforeClass;
import org.junit.Test;
import org.junit.Assert;
import org.junit.experimental.categories.Category;
@Category(SqlTest.class)
public class TestDropTable extends PlanTestBase {
- private static final String CREATE_SIMPLE_TABLE = "create table %s as select
1 from cp.`employee.json`";
- private static final String CREATE_SIMPLE_VIEW = "create view %s as select 1
from cp.`employee.json`";
- private static final String DROP_TABLE = "drop table %s";
- private static final String DROP_TABLE_IF_EXISTS = "drop table if exists %s";
- private static final String DROP_VIEW_IF_EXISTS = "drop view if exists %s";
- private static final String BACK_TICK = "`";
+ private static final String CREATE_SIMPLE_TABLE = "create table `%s` as
select 1 from cp.`employee.json`";
Review comment:
What is changed in these rows except the row with `BACK_TICK`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702190#comment-16702190
]
ASF GitHub Bot commented on DRILL-6863:
---
vdiravka commented on a change in pull request #1557: DRILL-6863: Drop table is
not working if path within workspace starts…
URL: https://github.com/apache/drill/pull/1557#discussion_r237191015
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/sql/TestViewSupport.java
##
@@ -751,4 +751,53 @@ public void selectFromViewCreatedOnCalcite1_4() throws
Exception {
.baselineValues("HeadQuarters")
.go();
}
+
+ @Test
+ public void testDropViewNameStartsWithSlash() throws Exception {
+String viewName = "views/tmp_view";
+try {
+ test("CREATE VIEW `%s`.`%s` AS SELECT * FROM cp.`region.json`",
DFS_TMP_SCHEMA, viewName);
+ testBuilder()
+ .sqlQuery("DROP VIEW `%s`.`%s`", DFS_TMP_SCHEMA, "/" + viewName)
+ .unOrdered()
+ .baselineColumns("ok", "summary")
+ .baselineValues(true,
+ String.format("View [%s] deleted successfully from schema
[%s].", viewName, DFS_TMP_SCHEMA))
+ .go();
+} finally {
+ test("DROP VIEW IF EXISTS `%s`.`%s`", DFS_TMP_SCHEMA, viewName);
+}
+ }
+
+ @Test
+ public void testViewIsCreatedWithinWorkspace() throws Exception {
Review comment:
Do we need similar test cases for tables?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702193#comment-16702193
]
ASF GitHub Bot commented on DRILL-6863:
---
vdiravka commented on a change in pull request #1557: DRILL-6863: Drop table is
not working if path within workspace starts…
URL: https://github.com/apache/drill/pull/1557#discussion_r237187041
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/sql/TestViewSupport.java
##
@@ -751,4 +751,53 @@ public void selectFromViewCreatedOnCalcite1_4() throws
Exception {
.baselineValues("HeadQuarters")
.go();
}
+
+ @Test
+ public void testDropViewNameStartsWithSlash() throws Exception {
+String viewName = "views/tmp_view";
+try {
+ test("CREATE VIEW `%s`.`%s` AS SELECT * FROM cp.`region.json`",
DFS_TMP_SCHEMA, viewName);
+ testBuilder()
+ .sqlQuery("DROP VIEW `%s`.`%s`", DFS_TMP_SCHEMA, "/" + viewName)
+ .unOrdered()
+ .baselineColumns("ok", "summary")
+ .baselineValues(true,
+ String.format("View [%s] deleted successfully from schema
[%s].", viewName, DFS_TMP_SCHEMA))
+ .go();
+} finally {
+ test("DROP VIEW IF EXISTS `%s`.`%s`", DFS_TMP_SCHEMA, viewName);
+}
+ }
+
+ @Test
+ public void testViewIsCreatedWithinWorkspace() throws Exception {
+String viewName = "views/tmp_view";
+try {
+ test("CREATE VIEW `%s`.`%s` AS SELECT * FROM cp.`region.json`",
DFS_TMP_SCHEMA, "/" + viewName);
+ testBuilder()
+ .sqlQuery("SELECT region_id FROM `%s`.`%s` LIMIT 1", DFS_TMP_SCHEMA,
viewName)
+ .unOrdered()
+ .baselineColumns("region_id")
+ .baselineValues(0L)
+ .go();
+} finally {
+ test("DROP VIEW IF EXISTS `%s`.`%s`", DFS_TMP_SCHEMA, viewName);
+}
+ }
+
+ @Test
+ public void testViewIsFoundWithinWorkspaceWhenNameStartsWithSlash() throws
Exception {
Review comment:
I think `WithinWorkspace` can be ommited, since there is always some
workspace used for tables. Even for default workspace it is still valid. Right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702189#comment-16702189
]
ASF GitHub Bot commented on DRILL-6863:
---
vdiravka commented on a change in pull request #1557: DRILL-6863: Drop table is
not working if path within workspace starts…
URL: https://github.com/apache/drill/pull/1557#discussion_r237182591
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/sql/TestCTTAS.java
##
@@ -446,6 +446,23 @@ public void testJoinTemporaryWithPersistentTable() throws
Exception {
.go();
}
+ @Test
+ public void testCreateTemporaryTableWithAndWithoutLeadingSlashAreTheSame()
throws Exception{
Review comment:
`Create` can be omitted possibly
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (DRILL-6874) CTAS from json to parquet is not working on S3 storage
[
https://issues.apache.org/jira/browse/DRILL-6874?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva reassigned DRILL-6874:
---
Assignee: Bohdan Kazydub
> CTAS from json to parquet is not working on S3 storage
> --
>
> Key: DRILL-6874
> URL: https://issues.apache.org/jira/browse/DRILL-6874
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
> Attachments: ctasjsontoparquet.zip, drillbit.log,
> drillbit_queries.json, s3src.json, sqlline.log
>
>
> Json file "s3src.json" was uploaded to the s3 storage.
> Query from Json works fine:
> select * from s3.tmp.`s3src.json`;
> | id | first_name | last_name |
> | 1 | first_name1 | last_name1 |
> | 2 | first_name2 | last_name2 |
> | 3 | first_name3 | last_name3 |
> | 4 | first_name4 | last_name4 |
> | 5 | first_name5 | last_name5 |
> 5 rows selected (2.803 seconds)
> CTAS from this json file returns successfully result:
> create table s3.tmp.`ctasjsontoparquet` as select * from s3.tmp.`s3src.json`;
> | Fragment | Number of records written |
> | 0_0 | 5 |
> 1 row selected (9.264 seconds)
> *Query from the created parquet table {color:#d04437}throws an error:{color}*
> select * from s3.tmp.`ctasjsontoparquet`;
> {code:java}
> Error: INTERNAL_ERROR ERROR: Error in parquet record reader.
> Message: Failure in setting up reader
> Parquet Metadata: ParquetMetaData{FileMetaData{schema: message root {
> optional int64 id;
> optional binary first_name (UTF8);
> optional binary last_name (UTF8);
> }
> , metadata: {drill-writer.version=2, drill.version=1.15.0-SNAPSHOT}}, blocks:
> [BlockMetaData{5, 360 [ColumnMetaData{UNCOMPRESSED [id] optional int64 id
> [BIT_PACKED, RLE, PLAIN], 4}, ColumnMetaData{UNCOMPRESSED [first_name]
> optional binary first_name (UTF8) [BIT_PACKED, RLE, PLAIN], 111},
> ColumnMetaData{UNCOMPRESSED [last_name] optional binary last_name (UTF8)
> [BIT_PACKED, RLE, PLAIN], 241}]}]}
> Fragment 0:0
> Please, refer to logs for more information.
> [Error Id: 885723e4-8385-4fb0-87dd-c08b0570db95 on maprhost:31010]
> (state=,code=0)
> {code}
> The same CTAS query works fine on MapRFS and FileSystem storages.
> Log files, json file and created parquet file from S3 are in the attachments.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6869) Drill allows to create views outside workspace
[
https://issues.apache.org/jira/browse/DRILL-6869?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6869:
Reviewer: Vitalii Diravka
> Drill allows to create views outside workspace
> --
>
> Key: DRILL-6869
> URL: https://issues.apache.org/jira/browse/DRILL-6869
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Minor
> Fix For: 1.16.0
>
> Attachments: Amazon_S3_FS_stor_plugin.json,
> FileSystem_stor_plugin.json, MapR_FS_stor_plugin.json
>
>
> Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
> On MaprFS and S3 storages Drill allows to create views outside workspace.
> *Example on MapRFS:*
> create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
> cp.`employee.json` LIMIT 20;
> |ok|summary|
> |true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
> 1 row selected (0.93 seconds)
> The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,*
> but not in used workspace "/tmp" folder.
> Select query works with root "/" folder {color:#d04437}*outside*{color} the
> dfs.tmp workspace:
> select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
> |EXPR$0|
> |20|
> 1 row selected (1.813 seconds)
>
> *Example on S3*:
> create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
> cp.`employee.json` LIMIT 20;
> |ok|summary|
> |true|View '/testbugons3' *created successfully in 's3.tmp' schema*|
> 1 row selected (3.455 seconds)
>
> The file "testbugons3.view.drill" was *created* in the *root "/" bucket
> folder*, but not in used workspace "/tmp" folder.
> Select query also works with root "/" bucket folder
> {color:#d04437}*outside*{color} the s3.tmp workspace:
> select count * from s3.tmp.`/testbugons3`;
> |EXPR$0|
> |20|
> 1 row selected (3.209 seconds)
>
> *Expected result:*
> View should be created within workspace
> On FileSystem storage plugin Drill doesn't allow to create views outside
> workspace.
> Query "create view dfs.tmp.`/testbugonfs` as SELECT * FROM
> cp.`employee.json` LIMIT 20;"
> Returns an error: "{color:#d04437}Error: SYSTEM ERROR:
> FileNotFoundException: /testbugonfs.view.drill (Permission denied){color}".
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6863:
Reviewer: Vitalii Diravka
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6863) Drop table is not working if path within workspace starts with '/'
[
https://issues.apache.org/jira/browse/DRILL-6863?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702136#comment-16702136
]
ASF GitHub Bot commented on DRILL-6863:
---
KazydubB opened a new pull request #1557: DRILL-6863: Drop table is not working
if path within workspace starts…
URL: https://github.com/apache/drill/pull/1557
… with "/"
- Made workspace to be honored when table/view name starts with "/" for DROP
TABLE, DROP VIEW, CREATE VIEW and SELECT from view queries;
- Made "/{name}" and "{name}" to be equivalent names (the leading "/" is
removed) when creating temporary tables so that `SELECT ... FROM "/{name}" ...`
and `SELECT ... FROM "{name}" ...` produce the same results and behave as
regular tables in the context.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Drop table is not working if path within workspace starts with '/'
> --
>
> Key: DRILL-6863
> URL: https://issues.apache.org/jira/browse/DRILL-6863
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Major
> Fix For: 1.16.0
>
>
> Drill works incorrectly if path to the table within workspace starts with '/'
> Request "drop table s3.tmp.`drill/transitive_closure/tab1`" works fine,
> but if I add '/' in the begining of the tables path "drop table
> s3.tmp.`{color:#d04437}/{color}drill/transitive_closure/tab1`", Drill is
> trying to find table in the root directory but not in workspace path.
> *Actual result:*
> Drill returns successfully response
> "Table [/drill/transitive_closure/tab1] dropped"
> but table was not dropped.
>
> *Expected result:*
> Table was droped.
> Bug can be reproduced on S3 and DFS storages. On FileSystem storage Drill
> successfully returns error message if "drop table" query starts with '/' in
> table path.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6869) Drill allows to create views outside workspace
[
https://issues.apache.org/jira/browse/DRILL-6869?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bohdan Kazydub updated DRILL-6869:
--
Description:
Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
On MaprFS and S3 storages Drill allows to create views outside workspace.
*Example on MapRFS:*
create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
1 row selected (0.93 seconds)
The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,* but
not in used workspace "/tmp" folder.
Select query works with root "/" folder {color:#d04437}*outside*{color} the
dfs.tmp workspace:
select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
|EXPR$0|
|20|
1 row selected (1.813 seconds)
*Example on S3*:
create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugons3' *created successfully in 's3.tmp' schema*|
1 row selected (3.455 seconds)
The file "testbugons3.view.drill" was *created* in the *root "/" bucket
folder*, but not in used workspace "/tmp" folder.
Select query also works with root "/" bucket folder
{color:#d04437}*outside*{color} the s3.tmp workspace:
select count * from s3.tmp.`/testbugons3`;
|EXPR$0|
|20|
1 row selected (3.209 seconds)
*Expected result:*
View should be created within workspace
On FileSystem storage plugin Drill doesn't allow to create views outside
workspace.
Query "create view dfs.tmp.`/testbugonfs` as SELECT * FROM cp.`employee.json`
LIMIT 20;"
Returns an error: "{color:#d04437}Error: SYSTEM ERROR: FileNotFoundException:
/testbugonfs.view.drill (Permission denied){color}".
was:
Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
On MaprFS and S3 storages Drill allows to create views outside workspace.
*Example on MapRFS:*
create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
1 row selected (0.93 seconds)
The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,* but
not in used workspace "/tmp" folder.
Select query works with root "/" folder {color:#d04437}*outside*{color} the
dfs.tmp workspace:
select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
|EXPR$0|
|20|
1 row selected (1.813 seconds)
*Example on S3*:
create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugons3' *created successfully in 's3.tmp' schema*|
1 row selected (3.455 seconds)
The file "testbugons3.view.drill" was *created* in the *root "/" bucket
folder*, but not in used workspace "/tmp" folder.
Select query also works with root "/" bucket folder
{color:#d04437}*outside*{color} the s3.tmp workspace:
select count * from s3.tmp.`/testbugons3`;
|EXPR$0|
|20|
1 row selected (3.209 seconds)
*Expected result:* should be like on FileSystem storage:
On FileSystem storage plugin Drill doesn't allow to create views outside
workspace.
Query "create view dfs.tmp.`/testbugonfs` as SELECT * FROM cp.`employee.json`
LIMIT 20;"
Returns an error: "{color:#d04437}Error: SYSTEM ERROR: FileNotFoundException:
/testbugonfs.view.drill (Permission denied){color}".
> Drill allows to create views outside workspace
> --
>
> Key: DRILL-6869
> URL: https://issues.apache.org/jira/browse/DRILL-6869
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Minor
> Fix For: 1.16.0
>
> Attachments: Amazon_S3_FS_stor_plugin.json,
> FileSystem_stor_plugin.json, MapR_FS_stor_plugin.json
>
>
> Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
> On MaprFS and S3 storages Drill allows to create views outside workspace.
> *Example on MapRFS:*
> create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
> cp.`employee.json` LIMIT 20;
> |ok|summary|
> |true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
> 1 row selected (0.93 seconds)
> The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,*
> but not in used workspace "/tmp" folder.
> Select query works with root "/" folder {color:#d04437}*outside*{color} the
> dfs.tmp workspace:
> select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
> |EXPR$0|
> |20|
> 1 row selected (1.813 seconds)
>
> *Example on S3*:
> create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
> cp.`employee.json` LIMIT 20;
> |ok|summary|
[jira] [Updated] (DRILL-6874) CTAS from json to parquet is not working on S3 storage
[
https://issues.apache.org/jira/browse/DRILL-6874?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6874:
Fix Version/s: 1.16.0
> CTAS from json to parquet is not working on S3 storage
> --
>
> Key: DRILL-6874
> URL: https://issues.apache.org/jira/browse/DRILL-6874
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Priority: Major
> Fix For: 1.16.0
>
> Attachments: ctasjsontoparquet.zip, drillbit.log,
> drillbit_queries.json, s3src.json, sqlline.log
>
>
> Json file "s3src.json" was uploaded to the s3 storage.
> Query from Json works fine:
> select * from s3.tmp.`s3src.json`;
> | id | first_name | last_name |
> | 1 | first_name1 | last_name1 |
> | 2 | first_name2 | last_name2 |
> | 3 | first_name3 | last_name3 |
> | 4 | first_name4 | last_name4 |
> | 5 | first_name5 | last_name5 |
> 5 rows selected (2.803 seconds)
> CTAS from this json file returns successfully result:
> create table s3.tmp.`ctasjsontoparquet` as select * from s3.tmp.`s3src.json`;
> | Fragment | Number of records written |
> | 0_0 | 5 |
> 1 row selected (9.264 seconds)
> *Query from the created parquet table {color:#d04437}throws an error:{color}*
> select * from s3.tmp.`ctasjsontoparquet`;
> {code:java}
> Error: INTERNAL_ERROR ERROR: Error in parquet record reader.
> Message: Failure in setting up reader
> Parquet Metadata: ParquetMetaData{FileMetaData{schema: message root {
> optional int64 id;
> optional binary first_name (UTF8);
> optional binary last_name (UTF8);
> }
> , metadata: {drill-writer.version=2, drill.version=1.15.0-SNAPSHOT}}, blocks:
> [BlockMetaData{5, 360 [ColumnMetaData{UNCOMPRESSED [id] optional int64 id
> [BIT_PACKED, RLE, PLAIN], 4}, ColumnMetaData{UNCOMPRESSED [first_name]
> optional binary first_name (UTF8) [BIT_PACKED, RLE, PLAIN], 111},
> ColumnMetaData{UNCOMPRESSED [last_name] optional binary last_name (UTF8)
> [BIT_PACKED, RLE, PLAIN], 241}]}]}
> Fragment 0:0
> Please, refer to logs for more information.
> [Error Id: 885723e4-8385-4fb0-87dd-c08b0570db95 on maprhost:31010]
> (state=,code=0)
> {code}
> The same CTAS query works fine on MapRFS and FileSystem storages.
> Log files, json file and created parquet file from S3 are in the attachments.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6869) Drill allows to create views outside workspace
[
https://issues.apache.org/jira/browse/DRILL-6869?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bohdan Kazydub updated DRILL-6869:
--
Description:
Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
On MaprFS and S3 storages Drill allows to create views outside workspace.
*Example on MapRFS:*
create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
1 row selected (0.93 seconds)
The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,* but
not in used workspace "/tmp" folder.
Select query works with root "/" folder {color:#d04437}*outside*{color} the
dfs.tmp workspace:
select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
|EXPR$0|
|20|
1 row selected (1.813 seconds)
*Example on S3*:
create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugons3' *created successfully in 's3.tmp' schema*|
1 row selected (3.455 seconds)
The file "testbugons3.view.drill" was *created* in the *root "/" bucket
folder*, but not in used workspace "/tmp" folder.
Select query also works with root "/" bucket folder
{color:#d04437}*outside*{color} the s3.tmp workspace:
select count * from s3.tmp.`/testbugons3`;
|EXPR$0|
|20|
1 row selected (3.209 seconds)
*Expected result:* should be like on FileSystem storage:
On FileSystem storage plugin Drill doesn't allow to create views outside
workspace.
Query "create view dfs.tmp.`/testbugonfs` as SELECT * FROM cp.`employee.json`
LIMIT 20;"
Returns an error: "{color:#d04437}Error: SYSTEM ERROR: FileNotFoundException:
/testbugonfs.view.drill (Permission denied){color}".
was:
Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
On MaprFS and S3 storages Drill allows to create views outside workspace.
*Example on MapRFS:*
create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
1 row selected (0.93 seconds)
The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,* but
not in used workspace "/tmp" folder.
Select query works with root "/" folder {color:#d04437}*outside*{color} the
dfs.tmp workspace:
select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
|EXPR$0|
|20|
1 row selected (1.813 seconds)
*Example on S3*:
create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
cp.`employee.json` LIMIT 20;
|ok|summary|
|true|View '/testbugons3' *created successfully in 's3.tmp' schema*|
1 row selected (3.455 seconds)
The file "testbugons3.view.drill" was *created* in the *root "/" bucket
folder*, but not in used workspace "/tmp" folder.
Select query also works with root "/" bucket folder
{color:#d04437}*outside*{color} the s3.tmp workspace:
select count * from s3.tmp.`/testbugons3`;
|EXPR$0|
|20|
1 row selected (3.209 seconds)
*Expected result* should be like on FileSystem storage:
On FileSystem storage plugin Drill doesn't allow to create views outside
workspace.
Query "create view dfs.tmp.`/testbugonfs` as SELECT * FROM cp.`employee.json`
LIMIT 20;"
Returns an error: "{color:#d04437}Error: SYSTEM ERROR: FileNotFoundException:
/testbugonfs.view.drill (Permission denied){color}".
> Drill allows to create views outside workspace
> --
>
> Key: DRILL-6869
> URL: https://issues.apache.org/jira/browse/DRILL-6869
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Bohdan Kazydub
>Priority: Minor
> Fix For: 1.16.0
>
> Attachments: Amazon_S3_FS_stor_plugin.json,
> FileSystem_stor_plugin.json, MapR_FS_stor_plugin.json
>
>
> Parameter 'allowAccessOutsideWorkspace' is false for tested workspaces.
> On MaprFS and S3 storages Drill allows to create views outside workspace.
> *Example on MapRFS:*
> create view dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs` as SELECT * FROM
> cp.`employee.json` LIMIT 20;
> |ok|summary|
> |true|View '/testbugonmfs' *created successfully in 'dfs.tmp' schema*|
> 1 row selected (0.93 seconds)
> The file "testbugonmfs.view.drill" was *created* in the *root "/" folder,*
> but not in used workspace "/tmp" folder.
> Select query works with root "/" folder {color:#d04437}*outside*{color} the
> dfs.tmp workspace:
> select count * from dfs.tmp.`{color:#d04437}*/*{color}testbugonmfs`;
> |EXPR$0|
> |20|
> 1 row selected (1.813 seconds)
>
> *Example on S3*:
> create view s3.tmp.`{color:#d04437}*/*{color}testbugons3` as SELECT * FROM
> cp.`employee.json` LIMIT 20;
> |ok|summary|
>
[jira] [Created] (DRILL-6874) CTAS from json to parquet is not working on S3 storage
Denys Ordynskiy created DRILL-6874:
--
Summary: CTAS from json to parquet is not working on S3 storage
Key: DRILL-6874
URL: https://issues.apache.org/jira/browse/DRILL-6874
Project: Apache Drill
Issue Type: Bug
Affects Versions: 1.15.0
Reporter: Denys Ordynskiy
Attachments: ctasjsontoparquet.zip, drillbit.log,
drillbit_queries.json, s3src.json, sqlline.log
Json file "s3src.json" was uploaded to the s3 storage.
Query from Json works fine:
select * from s3.tmp.`s3src.json`;
| id | first_name | last_name |
| 1 | first_name1 | last_name1 |
| 2 | first_name2 | last_name2 |
| 3 | first_name3 | last_name3 |
| 4 | first_name4 | last_name4 |
| 5 | first_name5 | last_name5 |
5 rows selected (2.803 seconds)
CTAS from this json file returns successfully result:
create table s3.tmp.`ctasjsontoparquet` as select * from s3.tmp.`s3src.json`;
| Fragment | Number of records written |
| 0_0 | 5 |
1 row selected (9.264 seconds)
*Query from the created parquet table {color:#d04437}throws an error:{color}*
select * from s3.tmp.`ctasjsontoparquet`;
{code:java}
Error: INTERNAL_ERROR ERROR: Error in parquet record reader.
Message: Failure in setting up reader
Parquet Metadata: ParquetMetaData{FileMetaData{schema: message root {
optional int64 id;
optional binary first_name (UTF8);
optional binary last_name (UTF8);
}
, metadata: {drill-writer.version=2, drill.version=1.15.0-SNAPSHOT}}, blocks:
[BlockMetaData{5, 360 [ColumnMetaData{UNCOMPRESSED [id] optional int64 id
[BIT_PACKED, RLE, PLAIN], 4}, ColumnMetaData{UNCOMPRESSED [first_name] optional
binary first_name (UTF8) [BIT_PACKED, RLE, PLAIN], 111},
ColumnMetaData{UNCOMPRESSED [last_name] optional binary last_name (UTF8)
[BIT_PACKED, RLE, PLAIN], 241}]}]}
Fragment 0:0
Please, refer to logs for more information.
[Error Id: 885723e4-8385-4fb0-87dd-c08b0570db95 on maprhost:31010]
(state=,code=0)
{code}
The same CTAS query works fine on MapRFS and FileSystem storages.
Log files, json file and created parquet file from S3 are in the attachments.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702108#comment-16702108 ] ASF GitHub Bot commented on DRILL-6867: --- oleg-zinovev edited a comment on issue #1551: DRILL-6867: WebUI Query editor cursor position URL: https://github.com/apache/drill/pull/1551#issuecomment-442509671 @vdiravka , @kkhatua 1) Ace editor requires monospace font. Here (http://web.mit.edu/jmorzins/www/fonts.html) I can find only two `common monospace fonts`: `courier` and `courier new`. Both of them missing in Ubuntu 18.10. 2) Firefox on Ubuntu with monospace font: 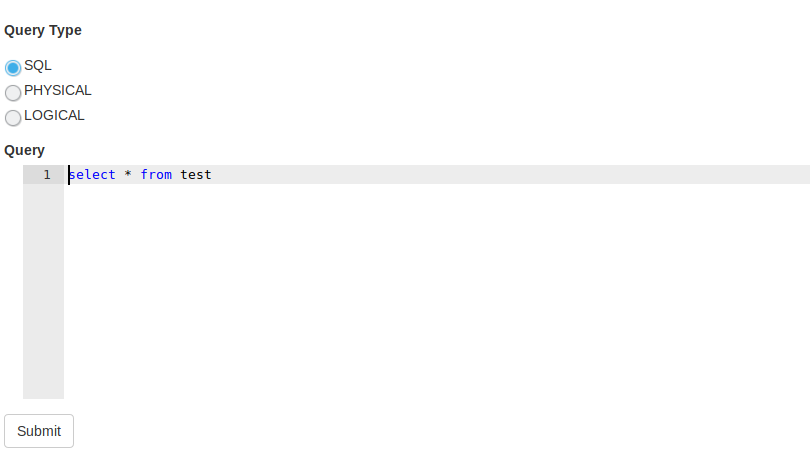 P.S. I remove Ubuntu Mono (too small) and Consolas (missing in Ubuntu as well). This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702104#comment-16702104 ] ASF GitHub Bot commented on DRILL-6867: --- oleg-zinovev edited a comment on issue #1551: DRILL-6867: WebUI Query editor cursor position URL: https://github.com/apache/drill/pull/1551#issuecomment-442509671 @vdiravka , @kkhatua 1) Ace editor requires monospace font. Both 'courier' and 'courier new' missing in Ubuntu 18.10. 2) Firefox on Ubuntu with monospace font:  P.S. I remove Ubuntu Mono (too small) and Consolas (missing in Ubuntu as well). This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702102#comment-16702102 ] ASF GitHub Bot commented on DRILL-6867: --- oleg-zinovev edited a comment on issue #1551: DRILL-6867: WebUI Query editor cursor position URL: https://github.com/apache/drill/pull/1551#issuecomment-442509671 @vdiravka , @kkhatua 1) Ace editor requires monospace font. Both 'courier' and 'courier new' missing in Ubuntu 18.10. 2) Firefox on Ubuntu with monospace font:  P.S. I remove Ubuntu Mono (was too small) and Consolas (missing in Ubuntu as well). This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6867) WebUI Query editor cursor position
[ https://issues.apache.org/jira/browse/DRILL-6867?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16702100#comment-16702100 ] ASF GitHub Bot commented on DRILL-6867: --- oleg-zinovev commented on issue #1551: DRILL-6867: WebUI Query editor cursor position URL: https://github.com/apache/drill/pull/1551#issuecomment-442509671 @vdiravka , @kkhatua 1) Ace editor requires monospace font. Both 'courier' and 'courier new' missing in Ubuntu 18.10. 2) Firefox on Ubuntu with monospace font:  This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > WebUI Query editor cursor position > -- > > Key: DRILL-6867 > URL: https://issues.apache.org/jira/browse/DRILL-6867 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.14.0 >Reporter: Oleg Zinoviev >Assignee: Oleg Zinoviev >Priority: Minor > Fix For: 1.15.0 > > Attachments: query.png > > > In Firefox (at least on Ununtu 18.10), the position of the cursor does not > match the text when editing the SQL-query > !query.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-6866) Upgrade to SqlLine 1.6.0
[
https://issues.apache.org/jira/browse/DRILL-6866?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Volodymyr Vysotskyi updated DRILL-6866:
---
Labels: doc-impacting ready-to-commit (was: doc-impacting)
> Upgrade to SqlLine 1.6.0
>
>
> Key: DRILL-6866
> URL: https://issues.apache.org/jira/browse/DRILL-6866
> Project: Apache Drill
> Issue Type: Task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting, ready-to-commit
> Fix For: 1.15.0
>
>
> Upgrade to SqlLine 1.6.0 once the release is out.
> *For documentation*
> *Known issue*
> Old history file should be deleted prior to using Drill with SqlLine 1.6:
> {noformat}
> ./drill-embedded
> Exception in thread "main" java.lang.IllegalArgumentException: Bad history
> file syntax! The history file `/Users/arina/.sqlline/history` may be an older
> history: please remove it or use a different history file.
> at
> org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
> at
> org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
> at java.util.Iterator.forEachRemaining(Iterator.java:116)
> at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
> at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
> at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
> at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
> at sqlline.SqlLine.begin(SqlLine.java:510)
> at sqlline.SqlLine.start(SqlLine.java:264)
> at sqlline.SqlLine.main(SqlLine.java:195)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6866) Upgrade to SqlLine 1.6.0
[
https://issues.apache.org/jira/browse/DRILL-6866?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6866:
Description:
Upgrade to SqlLine 1.6.0 once the release is out.
*For documentation*
*Known issue*
Old history file should be deleted prior to using Drill with SqlLine 1.6:
{noformat}
./drill-embedded
Exception in thread "main" java.lang.IllegalArgumentException: Bad history file
syntax! The history file `/Users/arina/.sqlline/history` may be an older
history: please remove it or use a different history file.
at
org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
at
org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
at
java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
at sqlline.SqlLine.begin(SqlLine.java:510)
at sqlline.SqlLine.start(SqlLine.java:264)
at sqlline.SqlLine.main(SqlLine.java:195)
{noformat}
was:
Upgrade to SqlLine 1.6.0 once the release is out.
*Known issue*
Old history file should be deleted prior to using Drill with SqlLine 1.6:
{noformat}
./drill-embedded
Exception in thread "main" java.lang.IllegalArgumentException: Bad history file
syntax! The history file `/Users/arina/.sqlline/history` may be an older
history: please remove it or use a different history file.
at
org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
at
org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
at
java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
at sqlline.SqlLine.begin(SqlLine.java:510)
at sqlline.SqlLine.start(SqlLine.java:264)
at sqlline.SqlLine.main(SqlLine.java:195)
{noformat}
> Upgrade to SqlLine 1.6.0
>
>
> Key: DRILL-6866
> URL: https://issues.apache.org/jira/browse/DRILL-6866
> Project: Apache Drill
> Issue Type: Task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.15.0
>
>
> Upgrade to SqlLine 1.6.0 once the release is out.
> *For documentation*
> *Known issue*
> Old history file should be deleted prior to using Drill with SqlLine 1.6:
> {noformat}
> ./drill-embedded
> Exception in thread "main" java.lang.IllegalArgumentException: Bad history
> file syntax! The history file `/Users/arina/.sqlline/history` may be an older
> history: please remove it or use a different history file.
> at
> org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
> at
> org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
> at java.util.Iterator.forEachRemaining(Iterator.java:116)
> at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
> at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
> at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
> at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
> at sqlline.SqlLine.begin(SqlLine.java:510)
> at sqlline.SqlLine.start(SqlLine.java:264)
> at sqlline.SqlLine.main(SqlLine.java:195)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6866) Upgrade to SqlLine 1.6.0
[
https://issues.apache.org/jira/browse/DRILL-6866?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6866:
Labels: doc-impacting (was: )
> Upgrade to SqlLine 1.6.0
>
>
> Key: DRILL-6866
> URL: https://issues.apache.org/jira/browse/DRILL-6866
> Project: Apache Drill
> Issue Type: Task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.15.0
>
>
> Upgrade to SqlLine 1.6.0 once the release is out.
> *Known issue*
> Old history file should be deleted prior to using Drill with SqlLine 1.6:
> {noformat}
> ./drill-embedded
> Exception in thread "main" java.lang.IllegalArgumentException: Bad history
> file syntax! The history file `/Users/arina/.sqlline/history` may be an older
> history: please remove it or use a different history file.
> at
> org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
> at
> org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
> at java.util.Iterator.forEachRemaining(Iterator.java:116)
> at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
> at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
> at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
> at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
> at sqlline.SqlLine.begin(SqlLine.java:510)
> at sqlline.SqlLine.start(SqlLine.java:264)
> at sqlline.SqlLine.main(SqlLine.java:195)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6866) Upgrade to SqlLine 1.6.0
[
https://issues.apache.org/jira/browse/DRILL-6866?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6866:
Reviewer: Volodymyr Vysotskyi
> Upgrade to SqlLine 1.6.0
>
>
> Key: DRILL-6866
> URL: https://issues.apache.org/jira/browse/DRILL-6866
> Project: Apache Drill
> Issue Type: Task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.15.0
>
>
> Upgrade to SqlLine 1.6.0 once the release is out.
> *Known issue*
> Old history file should be deleted prior to using Drill with SqlLine 1.6:
> {noformat}
> ./drill-embedded
> Exception in thread "main" java.lang.IllegalArgumentException: Bad history
> file syntax! The history file `/Users/arina/.sqlline/history` may be an older
> history: please remove it or use a different history file.
> at
> org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
> at
> org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
> at java.util.Iterator.forEachRemaining(Iterator.java:116)
> at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
> at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
> at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
> at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
> at sqlline.SqlLine.begin(SqlLine.java:510)
> at sqlline.SqlLine.start(SqlLine.java:264)
> at sqlline.SqlLine.main(SqlLine.java:195)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6866) Upgrade to SqlLine 1.6.0
[
https://issues.apache.org/jira/browse/DRILL-6866?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16701847#comment-16701847
]
ASF GitHub Bot commented on DRILL-6866:
---
arina-ielchiieva opened a new pull request #1556: DRILL-6866: Upgrade to
SqlLine 1.6.0
URL: https://github.com/apache/drill/pull/1556
1. Changed SqlLine version to 1.6.0.
2. Overridden new getVersion method in DrillSqlLineApplication.
3. Set maxColumnWidth to 100 to avoid issue described in
[DRILL-6769](https://issues.apache.org/jira/browse/DRILL-6769).
4. Changed access modifier from package default to public for JDBC classes
that implement external interfaces to avoid issues when calling methods from
these classes using reflection.
Jira - [DRILL-6866](https://issues.apache.org/jira/browse/DRILL-6866).
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade to SqlLine 1.6.0
>
>
> Key: DRILL-6866
> URL: https://issues.apache.org/jira/browse/DRILL-6866
> Project: Apache Drill
> Issue Type: Task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Fix For: 1.15.0
>
>
> Upgrade to SqlLine 1.6.0 once the release is out.
> *Known issue*
> Old history file should be deleted prior to using Drill with SqlLine 1.6:
> {noformat}
> ./drill-embedded
> Exception in thread "main" java.lang.IllegalArgumentException: Bad history
> file syntax! The history file `/Users/arina/.sqlline/history` may be an older
> history: please remove it or use a different history file.
> at
> org.jline.reader.impl.history.DefaultHistory.addHistoryLine(DefaultHistory.java:104)
> at
> org.jline.reader.impl.history.DefaultHistory.lambda$load$0(DefaultHistory.java:86)
> at java.util.Iterator.forEachRemaining(Iterator.java:116)
> at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
> at org.jline.reader.impl.history.DefaultHistory.load(DefaultHistory.java:86)
> at org.jline.reader.impl.history.DefaultHistory.attach(DefaultHistory.java:69)
> at sqlline.SqlLine.getConsoleReader(SqlLine.java:614)
> at sqlline.SqlLine.begin(SqlLine.java:510)
> at sqlline.SqlLine.start(SqlLine.java:264)
> at sqlline.SqlLine.main(SqlLine.java:195)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6562) Plugin Management improvements
[ https://issues.apache.org/jira/browse/DRILL-6562?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Vitalii Diravka updated DRILL-6562: --- Component/s: Web Server Client - HTTP > Plugin Management improvements > -- > > Key: DRILL-6562 > URL: https://issues.apache.org/jira/browse/DRILL-6562 > Project: Apache Drill > Issue Type: Improvement > Components: Client - HTTP, Web Server >Affects Versions: 1.14.0 >Reporter: Abhishek Girish >Assignee: Vitalii Diravka >Priority: Major > Labels: doc-impacting > Fix For: 1.15.0 > > Attachments: image-2018-07-23-02-55-02-024.png, > image-2018-10-22-20-20-24-658.png, image-2018-10-22-20-20-59-105.png > > > Follow-up to DRILL-4580. > Provide ability to export all storage plugin configurations at once, with a > new "Export All" option on the Storage page of the Drill web UI -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-6792) Find the right probe side fragment to any storage plugin
[ https://issues.apache.org/jira/browse/DRILL-6792?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Vitalii Diravka updated DRILL-6792: --- Labels: ready-to-commit (was: ) > Find the right probe side fragment to any storage plugin > > > Key: DRILL-6792 > URL: https://issues.apache.org/jira/browse/DRILL-6792 > Project: Apache Drill > Issue Type: Improvement > Components: Execution - Flow >Reporter: weijie.tong >Assignee: weijie.tong >Priority: Major > Labels: ready-to-commit > Fix For: 1.15.0 > > > The current implementation of JPPD to find the probe side wrapper depends on > the GroupScan's digest. But there's no promise the GroupScan's digest will > not be changed since it is attached to the RuntimeFilterDef by different > storage plugin implementation logic.So here we assign a unique identifier to > the RuntimeFilter operator, and find the right probe side fragment wrapper by > the runtime filter identifier at the RuntimeFilterRouter class. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-6806) Start moving code for handling a partition in HashAgg into a separate class
[ https://issues.apache.org/jira/browse/DRILL-6806?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Vitalii Diravka updated DRILL-6806: --- Fix Version/s: (was: 1.15.0) 1.16.0 > Start moving code for handling a partition in HashAgg into a separate class > --- > > Key: DRILL-6806 > URL: https://issues.apache.org/jira/browse/DRILL-6806 > Project: Apache Drill > Issue Type: Sub-task >Reporter: Timothy Farkas >Assignee: Timothy Farkas >Priority: Major > Fix For: 1.16.0 > > > Since this involves a lot of refactoring this will be a multiple PR effort. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6769) Sqlline doesn't see line endings when it prints first row fo the explain plan results table
[ https://issues.apache.org/jira/browse/DRILL-6769?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16701751#comment-16701751 ] Arina Ielchiieva commented on DRILL-6769: - maxColumndWidth will be set to 100. > Sqlline doesn't see line endings when it prints first row fo the explain plan > results table > --- > > Key: DRILL-6769 > URL: https://issues.apache.org/jira/browse/DRILL-6769 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.15.0 >Reporter: Denys Ordynskiy >Assignee: Arina Ielchiieva >Priority: Major > Fix For: 1.15.0 > > Attachments: Sqlline.png > > > After Sqlline was upgraded in DRILL-3853, in the query "EXPLAIN PLAN FOR .." > results table has a very long first row with titles. > After I run the query "EXPLAIN PLAN FOR SELECT 1;", width of the table column > is calculated by the number of symbols in the biggest cell of columns. > If there are new lines in the data, Sqlline should set width of this column > by the longest line of the cells data instead of number of all symbols of > that cell. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-6769) Sqlline doesn't see line endings when it prints first row fo the explain plan results table
[ https://issues.apache.org/jira/browse/DRILL-6769?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Arina Ielchiieva updated DRILL-6769: Fix Version/s: 1.15.0 > Sqlline doesn't see line endings when it prints first row fo the explain plan > results table > --- > > Key: DRILL-6769 > URL: https://issues.apache.org/jira/browse/DRILL-6769 > Project: Apache Drill > Issue Type: Bug >Affects Versions: 1.15.0 >Reporter: Denys Ordynskiy >Assignee: Arina Ielchiieva >Priority: Major > Fix For: 1.15.0 > > Attachments: Sqlline.png > > > After Sqlline was upgraded in DRILL-3853, in the query "EXPLAIN PLAN FOR .." > results table has a very long first row with titles. > After I run the query "EXPLAIN PLAN FOR SELECT 1;", width of the table column > is calculated by the number of symbols in the biggest cell of columns. > If there are new lines in the data, Sqlline should set width of this column > by the longest line of the cells data instead of number of all symbols of > that cell. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (DRILL-6857) Limit is not being pushed into scan when selecting from a parquet file with multiple row groups.
[
https://issues.apache.org/jira/browse/DRILL-6857?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Anton Gozhiy closed DRILL-6857.
---
> Limit is not being pushed into scan when selecting from a parquet file with
> multiple row groups.
>
>
> Key: DRILL-6857
> URL: https://issues.apache.org/jira/browse/DRILL-6857
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Anton Gozhiy
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.15.0
>
> Attachments: DRILL_5796_test_data.parquet
>
>
> *Data:*
> A parquet file that contains more than one row group. Example is attached.
> *Query:*
> {code:sql}
> explain plan for select * from dfs.tmp.`DRILL_5796_test_data.parquet` limit 1
> {code}
> *Expected result:*
> numFiles=1, numRowGroups=1
> *Actual result:*
> numFiles=1, numRowGroups=3
> {noformat}
> 00-00Screen : rowType = RecordType(DYNAMIC_STAR **): rowcount = 1.0,
> cumulative cost = {274.1 rows, 280.1 cpu, 270.0 io, 0.0 network, 0.0 memory},
> id = 13671
> 00-01 Project(**=[$0]) : rowType = RecordType(DYNAMIC_STAR **): rowcount
> = 1.0, cumulative cost = {274.0 rows, 280.0 cpu, 270.0 io, 0.0 network, 0.0
> memory}, id = 13670
> 00-02SelectionVectorRemover : rowType = RecordType(DYNAMIC_STAR **):
> rowcount = 1.0, cumulative cost = {273.0 rows, 279.0 cpu, 270.0 io, 0.0
> network, 0.0 memory}, id = 13669
> 00-03 Limit(fetch=[1]) : rowType = RecordType(DYNAMIC_STAR **):
> rowcount = 1.0, cumulative cost = {272.0 rows, 278.0 cpu, 270.0 io, 0.0
> network, 0.0 memory}, id = 13668
> 00-04Limit(fetch=[1]) : rowType = RecordType(DYNAMIC_STAR **):
> rowcount = 1.0, cumulative cost = {271.0 rows, 274.0 cpu, 270.0 io, 0.0
> network, 0.0 memory}, id = 13667
> 00-05 Scan(table=[[dfs, tmp, DRILL_5796_test_data.parquet]],
> groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath
> [path=maprfs:///tmp/DRILL_5796_test_data.parquet]],
> selectionRoot=maprfs:/tmp/DRILL_5796_test_data.parquet, numFiles=1,
> numRowGroups=3, usedMetadataFile=false, columns=[`**`]]]) : rowType =
> RecordType(DYNAMIC_STAR **): rowcount = 270.0, cumulative cost = {270.0 rows,
> 270.0 cpu, 270.0 io, 0.0 network, 0.0 memory}, id = 13666
> {noformat}
> *Note:*
> The limit pushdown works with the same data partitioned by files (1 row group
> for a file )
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6857) Limit is not being pushed into scan when selecting from a parquet file with multiple row groups.
[
https://issues.apache.org/jira/browse/DRILL-6857?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16701730#comment-16701730
]
Anton Gozhiy commented on DRILL-6857:
-
Verified with Drill 1.15.0-SNAPSHOT (commit id
cd4d68b4c23e7c4cff9769d02bb462cc0707a4ac)
Cases checked:
* Query from the bug
* Limit 0
* Limit for boundary values (around row group row count)
* Query with item star operator
* Complex fields
* Negative cases for agg functions, filters, order by, joins etc
> Limit is not being pushed into scan when selecting from a parquet file with
> multiple row groups.
>
>
> Key: DRILL-6857
> URL: https://issues.apache.org/jira/browse/DRILL-6857
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Anton Gozhiy
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.15.0
>
> Attachments: DRILL_5796_test_data.parquet
>
>
> *Data:*
> A parquet file that contains more than one row group. Example is attached.
> *Query:*
> {code:sql}
> explain plan for select * from dfs.tmp.`DRILL_5796_test_data.parquet` limit 1
> {code}
> *Expected result:*
> numFiles=1, numRowGroups=1
> *Actual result:*
> numFiles=1, numRowGroups=3
> {noformat}
> 00-00Screen : rowType = RecordType(DYNAMIC_STAR **): rowcount = 1.0,
> cumulative cost = {274.1 rows, 280.1 cpu, 270.0 io, 0.0 network, 0.0 memory},
> id = 13671
> 00-01 Project(**=[$0]) : rowType = RecordType(DYNAMIC_STAR **): rowcount
> = 1.0, cumulative cost = {274.0 rows, 280.0 cpu, 270.0 io, 0.0 network, 0.0
> memory}, id = 13670
> 00-02SelectionVectorRemover : rowType = RecordType(DYNAMIC_STAR **):
> rowcount = 1.0, cumulative cost = {273.0 rows, 279.0 cpu, 270.0 io, 0.0
> network, 0.0 memory}, id = 13669
> 00-03 Limit(fetch=[1]) : rowType = RecordType(DYNAMIC_STAR **):
> rowcount = 1.0, cumulative cost = {272.0 rows, 278.0 cpu, 270.0 io, 0.0
> network, 0.0 memory}, id = 13668
> 00-04Limit(fetch=[1]) : rowType = RecordType(DYNAMIC_STAR **):
> rowcount = 1.0, cumulative cost = {271.0 rows, 274.0 cpu, 270.0 io, 0.0
> network, 0.0 memory}, id = 13667
> 00-05 Scan(table=[[dfs, tmp, DRILL_5796_test_data.parquet]],
> groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath
> [path=maprfs:///tmp/DRILL_5796_test_data.parquet]],
> selectionRoot=maprfs:/tmp/DRILL_5796_test_data.parquet, numFiles=1,
> numRowGroups=3, usedMetadataFile=false, columns=[`**`]]]) : rowType =
> RecordType(DYNAMIC_STAR **): rowcount = 270.0, cumulative cost = {270.0 rows,
> 270.0 cpu, 270.0 io, 0.0 network, 0.0 memory}, id = 13666
> {noformat}
> *Note:*
> The limit pushdown works with the same data partitioned by files (1 row group
> for a file )
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Closed] (DRILL-6858) INFORMATION_SCHEMA.`FILES` table not show any files if storage contains "write only" folder
[
https://issues.apache.org/jira/browse/DRILL-6858?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Denys Ordynskiy closed DRILL-6858.
--
Successfully tested on S3, FileSystem and MapRFS.
> INFORMATION_SCHEMA.`FILES` table not show any files if storage contains
> "write only" folder
> ---
>
> Key: DRILL-6858
> URL: https://issues.apache.org/jira/browse/DRILL-6858
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.15.0
>Reporter: Denys Ordynskiy
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.15.0
>
>
> *Steps to reproduce bug:*
> * storage contains folder with "write only" permission;
> * Drill option "storage.list_files_recursively" is false;
> * query result for "SELECT * FROM INFORMATION_SCHEMA.`FILES`;" shows the
> list of the files and folders for every workspace for each storage plugin;
> * set Drill option "storage.list_files_recursively" to true;
> * run query "SELECT * FROM INFORMATION_SCHEMA.`FILES`;"
> *Actual result:*
> Drill returns empty results table if workspace has a folder with "write only"
> permission. Even if this workspace contains files and folders, that have
> "read" access right.
> *Expected result:*
> Drill returns list of files for each folder with "read" permission and hide
> files list for "write only" folders. Showing only folders name when
> permission is "write only".
>
> This bug can be reproduced on "Amazon S3" and "File System" Drill storage
> plugins.
>
> In "drillbit.log" for "*File System*" Drill storage plugin:
> {code:java}
> 2018-11-15 20:20:19,760 [2412471b-a4f5-d247-0db6-5d50cdcef634:frag:0:0] WARN
> o.a.d.e.s.i.InfoSchemaRecordGenerator - Failure while trying to list files
> java.io.FileNotFoundException: file:///home/mapr/test/writeonly: null file
> list{code}
>
> In "drillbit.log" for "*Amazon S3*" Drill storage plugin:
> {code:java}
> 2018-11-15 16:50:04,735 [24127862-a0e3-02ad-6b66-d649a62e8b8a:frag:0:0] WARN
> o.a.d.e.s.i.InfoSchemaRecordGenerator - Failure while trying to list files
> java.io.FileNotFoundException: No such file or directory:
> s3a://bucket/writeonly{code}
>
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)