[jira] [Commented] (FLINK-13925) ClassLoader in BlobLibraryCacheManager is not using context class loader
[ https://issues.apache.org/jira/browse/FLINK-13925?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921963#comment-16921963 ] Jark Wu commented on FLINK-13925: - I changed the fix version to 1.8.3 because of releasing 1.8.2. > ClassLoader in BlobLibraryCacheManager is not using context class loader > > > Key: FLINK-13925 > URL: https://issues.apache.org/jira/browse/FLINK-13925 > Project: Flink > Issue Type: Bug >Affects Versions: 1.8.1, 1.9.0 >Reporter: Jan Lukavský >Priority: Major > Labels: pull-request-available > Fix For: 1.9.1, 1.8.3 > > Time Spent: 10m > Remaining Estimate: 0h > > Use thread's current context classloader as parent class loader of flink user > code class loaders. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Updated] (FLINK-13925) ClassLoader in BlobLibraryCacheManager is not using context class loader
[ https://issues.apache.org/jira/browse/FLINK-13925?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-13925: Fix Version/s: (was: 1.8.2) 1.8.3 > ClassLoader in BlobLibraryCacheManager is not using context class loader > > > Key: FLINK-13925 > URL: https://issues.apache.org/jira/browse/FLINK-13925 > Project: Flink > Issue Type: Bug >Affects Versions: 1.8.1, 1.9.0 >Reporter: Jan Lukavský >Priority: Major > Labels: pull-request-available > Fix For: 1.9.1, 1.8.3 > > Time Spent: 10m > Remaining Estimate: 0h > > Use thread's current context classloader as parent class loader of flink user > code class loaders. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Updated] (FLINK-13689) Rest High Level Client for Elasticsearch6.x connector leaks threads if no connection could be established
[
https://issues.apache.org/jira/browse/FLINK-13689?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-13689:
Fix Version/s: (was: 1.8.2)
1.8.3
> Rest High Level Client for Elasticsearch6.x connector leaks threads if no
> connection could be established
> -
>
> Key: FLINK-13689
> URL: https://issues.apache.org/jira/browse/FLINK-13689
> Project: Flink
> Issue Type: Bug
> Components: Connectors / ElasticSearch
>Affects Versions: 1.8.1
>Reporter: Rishindra Kumar
>Assignee: Rishindra Kumar
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.8.3
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> If the created Elastic Search Rest High Level Client(rhlClient) is
> unreachable, Current code throws RuntimeException. But, it doesn't close the
> client which causes thread leak.
>
> *Current Code*
> *if (!rhlClient.ping()) {*
> *throw new RuntimeException("There are no reachable Elasticsearch
> nodes!");*
> *}*
>
> *Change Needed*
> rhlClient needs to be closed.
>
> *Steps to Reproduce*
> 1. Add the ElasticSearch Sink to the stream. Start the Flink program without
> starting the ElasticSearch.
> 2. Program will give error: "*Too many open files*" and it doesn't write even
> though you start the Elastic Search later.
>
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (FLINK-13689) Rest High Level Client for Elasticsearch6.x connector leaks threads if no connection could be established
[
https://issues.apache.org/jira/browse/FLINK-13689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921962#comment-16921962
]
Jark Wu commented on FLINK-13689:
-
I changed the fix version to 1.8.3 because of releasing 1.8.2. Please let me
know if you want it in 1.8.2.
> Rest High Level Client for Elasticsearch6.x connector leaks threads if no
> connection could be established
> -
>
> Key: FLINK-13689
> URL: https://issues.apache.org/jira/browse/FLINK-13689
> Project: Flink
> Issue Type: Bug
> Components: Connectors / ElasticSearch
>Affects Versions: 1.8.1
>Reporter: Rishindra Kumar
>Assignee: Rishindra Kumar
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.8.3
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> If the created Elastic Search Rest High Level Client(rhlClient) is
> unreachable, Current code throws RuntimeException. But, it doesn't close the
> client which causes thread leak.
>
> *Current Code*
> *if (!rhlClient.ping()) {*
> *throw new RuntimeException("There are no reachable Elasticsearch
> nodes!");*
> *}*
>
> *Change Needed*
> rhlClient needs to be closed.
>
> *Steps to Reproduce*
> 1. Add the ElasticSearch Sink to the stream. Start the Flink program without
> starting the ElasticSearch.
> 2. Program will give error: "*Too many open files*" and it doesn't write even
> though you start the Elastic Search later.
>
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (FLINK-11958) flink on windows yarn deploy failed
[ https://issues.apache.org/jira/browse/FLINK-11958?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921961#comment-16921961 ] Jark Wu commented on FLINK-11958: - I changed the fix version to 1.8.3 because of releasing 1.8.2. > flink on windows yarn deploy failed > --- > > Key: FLINK-11958 > URL: https://issues.apache.org/jira/browse/FLINK-11958 > Project: Flink > Issue Type: Bug > Components: Deployment / YARN >Affects Versions: 1.7.2 >Reporter: Matrix42 >Assignee: Matrix42 >Priority: Major > Labels: pull-request-available > Fix For: 1.7.3, 1.8.3 > > Time Spent: 20m > Remaining Estimate: 0h > > Flink Version : 1.7.2 > Hadoop Version:2.7.5 > Yarn log: > Application application_1551710861615_0002 failed 1 times due to AM Container > for appattempt_1551710861615_0002_01 exited with exitCode: 1 > For more detailed output, check application tracking > page:http://DESKTOP-919H80J:8088/cluster/app/application_1551710861615_0002Then, > click on links to logs of each attempt. > Diagnostics: Exception from container-launch. > Container id: container_1551710861615_0002_01_01 > Exit code: 1 > Stack trace: ExitCodeException exitCode=1: > at org.apache.hadoop.util.Shell.runCommand(Shell.java:585) > at org.apache.hadoop.util.Shell.run(Shell.java:482) > at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:776) > at > org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212) > at > org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) > at > org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) > at java.util.concurrent.FutureTask.run(FutureTask.java:266) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) > Shell output: 移动了 1 个文件。 > Container exited with a non-zero exit code 1 > Failing this attempt. Failing the application. > > jobmanager.err: > '$JAVA_HOME' 不是内部或外部命令,也不是可运行的程序或批处理文件。 > english: (Not internal or external commands, nor runnable programs or batch > files) > > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] wuchong commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
wuchong commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320577723
##
File path: docs/dev/table/hive/index.md
##
@@ -79,7 +79,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
flink-shaded-hadoop-2-uber
- 2.7.5-{{site.version}}
+ 2.7.5-7.0
Review comment:
Yes. That looks good to me. Please add a note after that.
"Please update the shaded_version once new flink-shaded is released."
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
wuchong commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320577723
##
File path: docs/dev/table/hive/index.md
##
@@ -79,7 +79,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
flink-shaded-hadoop-2-uber
- 2.7.5-{{site.version}}
+ 2.7.5-7.0
Review comment:
Yes. That looks good to me. Please add a note after that.
"Please update the version once new flink-shaded is released."
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput
flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput URL: https://github.com/apache/flink/pull/9483#issuecomment-522602263 ## CI report: * 5d079442de5815edf896b85fa7aa3ca599975bb0 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123734022) * 725be7c2226608382c67d5b3d372886be737fff6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124870650) * eeb6f54f2316e5a6ef8f1cbed4f002c3ae37107e : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/12569) * e8d22a8c88d9c4a3d10fe989761c54e2d56ba3bf : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/125557289) * 9b8109a8586bcf8095eba8d24c6cd0dbb21d7810 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125559250) * ac519615c6a2e28bb6544d2dce2dee43a03f3928 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125831290) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-13838) Support -yta(--yarnshipArchives) arguments in flink run command line
[ https://issues.apache.org/jira/browse/FLINK-13838?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921956#comment-16921956 ] Yang Wang commented on FLINK-13838: --- Hi [~Zentol] It is just a command-line argument and forwarding the unzip and rename to yarn. > Support -yta(--yarnshipArchives) arguments in flink run command line > > > Key: FLINK-13838 > URL: https://issues.apache.org/jira/browse/FLINK-13838 > Project: Flink > Issue Type: New Feature > Components: Command Line Client >Reporter: Yang Wang >Priority: Major > > Currently we could use --yarnship to transfer jars, files and directory for > cluster and add them to classpath. However, compressed package could not be > supported. If we have a compressed package including some config files, so > files and jars, the --yarnshipArchives will be very useful. > > What’s the difference between -yt and -yta? > -yt [file:///tmp/a.tar.gz] The file will be transferred by Yarn and keep the > original compressed file(not be unpacked) in the workdir of > jobmanager/taskmanager container. > -yta [file:///tmp/a.tar.gz#dict1] The file will be transferred by Yarn and > unpacked to a new directory with name dict1 in the workdir. > > -yta,--yarnshipArchives Ship archives for cluster (t for > transfer), Use ',' to separate > multiple files. The archives could > be > in local file system or distributed > file system. Use URI schema to > specify > which file system the file belongs. > If > schema is missing, would try to get > the archives in local file system. > Use > '#' after the file path to specify a > new name in workdir. (eg: -yta > > file:///tmp/a.tar.gz#dict1,hdfs:///$na > menode_address/tmp/b.tar.gz) -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese
flinkbot edited a comment on issue #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese URL: https://github.com/apache/flink/pull/9606#issuecomment-527740326 ## CI report: * 17b141e4c01648d012fa722cc927803785e4204b : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125834960) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot commented on issue #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese
flinkbot commented on issue #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese URL: https://github.com/apache/flink/pull/9606#issuecomment-527740326 ## CI report: * 17b141e4c01648d012fa722cc927803785e4204b : UNKNOWN This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320571826
##
File path: docs/dev/table/hive/index.md
##
@@ -79,7 +79,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
flink-shaded-hadoop-2-uber
- 2.7.5-{{site.version}}
+ 2.7.5-7.0
Review comment:
I want to add comment in `docs/_config.yml` as follows
`# Plain flink-shaded version is needed for e.g. the hive connector.
`
`shaded_version: "7.0"`
Do you think that is ok? Thank you! @wuchong @bowenli86 @zentol
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot commented on issue #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese
flinkbot commented on issue #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese URL: https://github.com/apache/flink/pull/9606#issuecomment-527738237 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 17b141e4c01648d012fa722cc927803785e4204b (Wed Sep 04 04:48:16 UTC 2019) ✅no warnings Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-13946) Remove deactivated JobSession-related code.
[ https://issues.apache.org/jira/browse/FLINK-13946?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921951#comment-16921951 ] TisonKun commented on FLINK-13946: -- Good to hear. I'm volunteer to review your patch :-) > Remove deactivated JobSession-related code. > --- > > Key: FLINK-13946 > URL: https://issues.apache.org/jira/browse/FLINK-13946 > Project: Flink > Issue Type: Improvement > Components: Client / Job Submission >Affects Versions: 1.9.0 >Reporter: Kostas Kloudas >Assignee: Kostas Kloudas >Priority: Major > > This issue refers to removing the code related to job session as described in > [FLINK-2097|https://issues.apache.org/jira/browse/FLINK-2097]. The feature > is deactivated, as pointed by the comment > [here|https://github.com/apache/flink/blob/master/flink-java/src/main/java/org/apache/flink/api/java/ExecutionEnvironment.java#L285] > and it complicates the code paths related to job submission, namely the > lifecycle of the Remote and LocalExecutors. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Updated] (FLINK-13677) Translate "Monitoring Back Pressure" page into Chinese
[ https://issues.apache.org/jira/browse/FLINK-13677?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-13677: --- Labels: pull-request-available (was: ) > Translate "Monitoring Back Pressure" page into Chinese > -- > > Key: FLINK-13677 > URL: https://issues.apache.org/jira/browse/FLINK-13677 > Project: Flink > Issue Type: Sub-task > Components: chinese-translation, Documentation >Affects Versions: 1.10.0 >Reporter: fanrui >Assignee: fanrui >Priority: Major > Labels: pull-request-available > Fix For: 1.10.0 > > > The page url is > [https://ci.apache.org/projects/flink/flink-docs-master/zh/monitoring/back_pressure.html] > The markdown file is located in "docs/monitoring/back_pressure.zh.md" -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] 1996fanrui opened a new pull request #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese
1996fanrui opened a new pull request #9606: [FLINK-13677][docs-zh] Translate "Monitoring Back Pressure" page into Chinese URL: https://github.com/apache/flink/pull/9606 ## What is the purpose of the change Translate "Monitoring Back Pressure" page into Chinese ## Brief change log Translate "Monitoring Back Pressure" page into Chinese ## Verifying this change This change is to add a new translated document. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320569863
##
File path: docs/dev/table/hive/index.md
##
@@ -69,7 +69,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
- flink-hadoop-compatibility_{{site.version}}
+
flink-hadoop-compatibility{{site.scala_version_suffix}}
Review comment:
Thank you very much, I will revert it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320569834
##
File path: docs/dev/table/hive/index.md
##
@@ -60,7 +60,7 @@ To integrate with Hive, users need the following
dependencies in their project.
{% highlight xml %}
org.apache.flink
- flink-connector-hive{{ site.scala_version_suffix }}
+ flink-connector-hive{{site.scala_version_suffix}}
Review comment:
Thank you very much, I will revert it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (FLINK-11958) flink on windows yarn deploy failed
[ https://issues.apache.org/jira/browse/FLINK-11958?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-11958: Fix Version/s: (was: 1.8.2) 1.8.3 > flink on windows yarn deploy failed > --- > > Key: FLINK-11958 > URL: https://issues.apache.org/jira/browse/FLINK-11958 > Project: Flink > Issue Type: Bug > Components: Deployment / YARN >Affects Versions: 1.7.2 >Reporter: Matrix42 >Assignee: Matrix42 >Priority: Major > Labels: pull-request-available > Fix For: 1.7.3, 1.8.3 > > Time Spent: 20m > Remaining Estimate: 0h > > Flink Version : 1.7.2 > Hadoop Version:2.7.5 > Yarn log: > Application application_1551710861615_0002 failed 1 times due to AM Container > for appattempt_1551710861615_0002_01 exited with exitCode: 1 > For more detailed output, check application tracking > page:http://DESKTOP-919H80J:8088/cluster/app/application_1551710861615_0002Then, > click on links to logs of each attempt. > Diagnostics: Exception from container-launch. > Container id: container_1551710861615_0002_01_01 > Exit code: 1 > Stack trace: ExitCodeException exitCode=1: > at org.apache.hadoop.util.Shell.runCommand(Shell.java:585) > at org.apache.hadoop.util.Shell.run(Shell.java:482) > at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:776) > at > org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212) > at > org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) > at > org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) > at java.util.concurrent.FutureTask.run(FutureTask.java:266) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) > Shell output: 移动了 1 个文件。 > Container exited with a non-zero exit code 1 > Failing this attempt. Failing the application. > > jobmanager.err: > '$JAVA_HOME' 不是内部或外部命令,也不是可运行的程序或批处理文件。 > english: (Not internal or external commands, nor runnable programs or batch > files) > > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput
flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput URL: https://github.com/apache/flink/pull/9483#issuecomment-522602263 ## CI report: * 5d079442de5815edf896b85fa7aa3ca599975bb0 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123734022) * 725be7c2226608382c67d5b3d372886be737fff6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124870650) * eeb6f54f2316e5a6ef8f1cbed4f002c3ae37107e : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/12569) * e8d22a8c88d9c4a3d10fe989761c54e2d56ba3bf : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/125557289) * 9b8109a8586bcf8095eba8d24c6cd0dbb21d7810 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125559250) * ac519615c6a2e28bb6544d2dce2dee43a03f3928 : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125831290) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] bowenli86 commented on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x
bowenli86 commented on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x URL: https://github.com/apache/flink/pull/9580#issuecomment-527728995 The python test failed in CI, but master has been green. Can you double check what's going on with python? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput
zhijiangW commented on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput URL: https://github.com/apache/flink/pull/9483#issuecomment-527728751 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] bowenli86 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
bowenli86 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320562043
##
File path: docs/dev/table/hive/index.md
##
@@ -60,7 +60,7 @@ To integrate with Hive, users need the following
dependencies in their project.
{% highlight xml %}
org.apache.flink
- flink-connector-hive{{ site.scala_version_suffix }}
+ flink-connector-hive{{site.scala_version_suffix}}
Review comment:
please revert this. It's standard to use `{{ site.scala_version_suffix }}`
in Flink doc.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] bowenli86 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
bowenli86 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320562335
##
File path: docs/dev/table/hive/index.md
##
@@ -69,7 +69,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
- flink-hadoop-compatibility_{{site.version}}
+
flink-hadoop-compatibility{{site.scala_version_suffix}}
Review comment:
please use `{{ site.scala_version_suffix }}`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput
flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput URL: https://github.com/apache/flink/pull/9483#issuecomment-522602263 ## CI report: * 5d079442de5815edf896b85fa7aa3ca599975bb0 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123734022) * 725be7c2226608382c67d5b3d372886be737fff6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124870650) * eeb6f54f2316e5a6ef8f1cbed4f002c3ae37107e : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/12569) * e8d22a8c88d9c4a3d10fe989761c54e2d56ba3bf : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/125557289) * 9b8109a8586bcf8095eba8d24c6cd0dbb21d7810 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125559250) * ac519615c6a2e28bb6544d2dce2dee43a03f3928 : UNKNOWN This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Assigned] (FLINK-13677) Translate "Monitoring Back Pressure" page into Chinese
[ https://issues.apache.org/jira/browse/FLINK-13677?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu reassigned FLINK-13677: --- Assignee: fanrui > Translate "Monitoring Back Pressure" page into Chinese > -- > > Key: FLINK-13677 > URL: https://issues.apache.org/jira/browse/FLINK-13677 > Project: Flink > Issue Type: Sub-task > Components: chinese-translation, Documentation >Affects Versions: 1.10.0 >Reporter: fanrui >Assignee: fanrui >Priority: Major > Fix For: 1.10.0 > > > The page url is > [https://ci.apache.org/projects/flink/flink-docs-master/zh/monitoring/back_pressure.html] > The markdown file is located in "docs/monitoring/back_pressure.zh.md" -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] wangyang0918 commented on a change in pull request #9587: [FLINK-13685][yarn] Validate YARN deployment against YARN scheduler maximum vcore size
wangyang0918 commented on a change in pull request #9587: [FLINK-13685][yarn] Validate YARN deployment against YARN scheduler maximum vcore size URL: https://github.com/apache/flink/pull/9587#discussion_r320558203 ## File path: flink-yarn/src/main/java/org/apache/flink/yarn/AbstractYarnClusterDescriptor.java ## @@ -483,12 +483,14 @@ private void validateClusterSpecification(ClusterSpecification clusterSpecificat } final int yarnMinAllocationMB = yarnConfiguration.getInt(YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB, 0); + final int yarnSchedulerMaxVcores = yarnConfiguration.getInt(YarnConfiguration.RM_SCHEDULER_MAXIMUM_ALLOCATION_VCORES, 0); Review comment: @gyfora I think you misunderstood my point. The `maximumResourceCapability` what i mean is `GetNewApplicationResponse.getMaximumResourceCapability()`. I have checked the yarn code and write a unit test to confirm. The `maximumResourceCapability.getVirtualCores()` returns the correct max allocation vcores of yarn scheduler. It is equals to the min one of `yarn.scheduler.maximum-allocation-vcores` and `yarn.nodemanager.resource.vcores`. Get the max allocation vcores from yarn configuration in flink client in not very good. We should better get it from the yarn RM side. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] wangyang0918 commented on a change in pull request #9587: [FLINK-13685][yarn] Validate YARN deployment against YARN scheduler maximum vcore size
wangyang0918 commented on a change in pull request #9587: [FLINK-13685][yarn] Validate YARN deployment against YARN scheduler maximum vcore size URL: https://github.com/apache/flink/pull/9587#discussion_r320558203 ## File path: flink-yarn/src/main/java/org/apache/flink/yarn/AbstractYarnClusterDescriptor.java ## @@ -483,12 +483,14 @@ private void validateClusterSpecification(ClusterSpecification clusterSpecificat } final int yarnMinAllocationMB = yarnConfiguration.getInt(YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB, 0); + final int yarnSchedulerMaxVcores = yarnConfiguration.getInt(YarnConfiguration.RM_SCHEDULER_MAXIMUM_ALLOCATION_VCORES, 0); Review comment: @gyfora I think you misunderstood my point. The `maximumResourceCapability` what i mean is `GetNewApplicationResponse.getMaximumResourceCapability()`. I have checked the yarn code and write a unit test to confirm. The `maximumResourceCapability.getVirtualCores()` returns the value of the configuration `yarn.scheduler.maximum-allocation-vcores` of yarn scheduler. Get the max allocation vcores from yarn configuration in flink client in not very good. We should better get it from the yarn RM side. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-4399) Add support for oversized messages
[
https://issues.apache.org/jira/browse/FLINK-4399?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921901#comment-16921901
]
Biao Liu commented on FLINK-4399:
-
Hi [~till.rohrmann], I agree it's a critical issue.
I understand there are tons of work in this release cycle. I really appreciate
that you could squeeze time for reviewing & discussing the design.
I don't think this improvement must be included in 1.10. We could give it a low
priority. Maybe get back to this issue after finishing the main work of 1.10? I
could pin you then.
> Add support for oversized messages
> --
>
> Key: FLINK-4399
> URL: https://issues.apache.org/jira/browse/FLINK-4399
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Coordination
> Environment: FLIP-6 feature branch
>Reporter: Stephan Ewen
>Assignee: Biao Liu
>Priority: Major
> Labels: flip-6
>
> Currently, messages larger than the maximum Akka Framesize cause an error
> when being transported. We should add a way to pass messages that are larger
> than the Framesize, as may happen for:
> - {{collect()}} calls that collect large data sets (via accumulators)
> - Job submissions and operator deployments where the functions closures are
> large (for example because it contains large pre-loaded data)
> - Function restore in cases where restored state is larger than
> checkpointed state (union state)
> I suggest to use the {{BlobManager}} to transfer large payload.
> - On the sender side, oversized messages are stored under a transient blob
> (which is deleted after first retrieval, or after a certain number of minutes)
> - The sender sends a "pointer to blob message" instead.
> - The receiver grabs the message from the blob upon receiving the pointer
> message
> The RPC Service should be optionally initializable with a "large message
> handler" which is internally the {{BlobManager}}.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Created] (FLINK-13951) Unable to call limit without sort for batch mode
Jeff Zhang created FLINK-13951:
--
Summary: Unable to call limit without sort for batch mode
Key: FLINK-13951
URL: https://issues.apache.org/jira/browse/FLINK-13951
Project: Flink
Issue Type: Improvement
Components: Table SQL / API
Affects Versions: 1.9.0
Reporter: Jeff Zhang
Here's the sample code: tenv.sql(select * from a).fetch(n)
{code:java}
Fail to run sql command: select * from a
org.apache.flink.table.api.ValidationException: A limit operation must be
preceded by a sort operation.
at
org.apache.flink.table.operations.utils.factories.SortOperationFactory.validateAndGetChildSort(SortOperationFactory.java:117)
at
org.apache.flink.table.operations.utils.factories.SortOperationFactory.createLimitWithFetch(SortOperationFactory.java:102)
at
org.apache.flink.table.operations.utils.OperationTreeBuilder.limitWithFetch(OperationTreeBuilder.java:388)
at org.apache.flink.table.api.internal.TableImpl.fetch(TableImpl.java:406)
{code}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (FLINK-13481) allow user launch job on yarn from SQL Client command line
[ https://issues.apache.org/jira/browse/FLINK-13481?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921897#comment-16921897 ] Hongtao Zhang commented on FLINK-13481: --- [~zjffdu] do we have any updates about this issue ? > allow user launch job on yarn from SQL Client command line > -- > > Key: FLINK-13481 > URL: https://issues.apache.org/jira/browse/FLINK-13481 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Client >Affects Versions: 1.10.0 > Environment: Flink 1.10 > CDH 5.13.3 > > >Reporter: Hongtao Zhang >Priority: Critical > Fix For: 1.10.0 > > > Flink SQL Client active command line doesn't load the FlinkYarnSessionCli > general options > the general options contains "addressOption" which user can specify > --jobmanager="yarn-cluster" or -m to run the SQL on YARN Cluster > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (FLINK-13950) should report an error if hive table partition keys are not in the last schema fields
[ https://issues.apache.org/jira/browse/FLINK-13950?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921896#comment-16921896 ] Hongtao Zhang commented on FLINK-13950: --- cc [~lirui] . by talking with LiRui, the team will launch Flink-Hive partition table design FLIP to the community, and the final fix solution should be pending for the discussion result > should report an error if hive table partition keys are not in the last > schema fields > - > > Key: FLINK-13950 > URL: https://issues.apache.org/jira/browse/FLINK-13950 > Project: Flink > Issue Type: Improvement > Components: Connectors / Hive >Affects Versions: 1.9.0, 1.10.0 >Reporter: Hongtao Zhang >Priority: Critical > > when creating a hive table via hive catalog API, we will build the table > schema first and then optionally we can choose one or more fields as the > partition keys when user want to create partition table. > > according to hive partition rule, the partition keys should be last fields > of the table. but now hive catalog create table API didn't report an error > when user specify the first / middle fields of the table schema. > > we should report an error for this scenario -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (FLINK-13025) Elasticsearch 7.x support
[ https://issues.apache.org/jira/browse/FLINK-13025?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921894#comment-16921894 ] limbo commented on FLINK-13025: --- [~yanghua] as Leonid llyevsky mentioned, I just test the elasticsearch6 connector and not include the 7.x client. And [~yanghua] is right, elasticsearch7 connector would be needed if the elasticsearch not confirm the compatibility of the public API. > Elasticsearch 7.x support > - > > Key: FLINK-13025 > URL: https://issues.apache.org/jira/browse/FLINK-13025 > Project: Flink > Issue Type: New Feature > Components: Connectors / ElasticSearch >Affects Versions: 1.8.0 >Reporter: Keegan Standifer >Priority: Major > > Elasticsearch 7.0.0 was released in April of 2019: > [https://www.elastic.co/blog/elasticsearch-7-0-0-released] > The latest elasticsearch connector is > [flink-connector-elasticsearch6|https://github.com/apache/flink/tree/master/flink-connectors/flink-connector-elasticsearch6] -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Created] (FLINK-13950) should report an error if hive table partition keys are not in the last schema fields
Hongtao Zhang created FLINK-13950: - Summary: should report an error if hive table partition keys are not in the last schema fields Key: FLINK-13950 URL: https://issues.apache.org/jira/browse/FLINK-13950 Project: Flink Issue Type: Improvement Components: Connectors / Hive Affects Versions: 1.9.0, 1.10.0 Reporter: Hongtao Zhang when creating a hive table via hive catalog API, we will build the table schema first and then optionally we can choose one or more fields as the partition keys when user want to create partition table. according to hive partition rule, the partition keys should be last fields of the table. but now hive catalog create table API didn't report an error when user specify the first / middle fields of the table schema. we should report an error for this scenario -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Issue Comment Deleted] (FLINK-13677) Translate "Monitoring Back Pressure" page into Chinese
[ https://issues.apache.org/jira/browse/FLINK-13677?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] fanrui updated FLINK-13677: --- Comment: was deleted (was: [https://flink.apache.org/2019/06/05/flink-network-stack.html] [https://flink.apache.org/2019/07/23/flink-network-stack-2.html] 这两个页面显示 flink1.9之后,反压改变比较大,是不是这个 “Monitoring Back Pressure” 页面将有大改动,如果有,以后再翻译吧) > Translate "Monitoring Back Pressure" page into Chinese > -- > > Key: FLINK-13677 > URL: https://issues.apache.org/jira/browse/FLINK-13677 > Project: Flink > Issue Type: Sub-task > Components: chinese-translation, Documentation >Affects Versions: 1.10.0 >Reporter: fanrui >Priority: Major > Fix For: 1.10.0 > > > The page url is > [https://ci.apache.org/projects/flink/flink-docs-master/zh/monitoring/back_pressure.html] > The markdown file is located in "docs/monitoring/back_pressure.zh.md" -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (FLINK-13677) Translate "Monitoring Back Pressure" page into Chinese
[ https://issues.apache.org/jira/browse/FLINK-13677?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921887#comment-16921887 ] fanrui commented on FLINK-13677: Hi,[~jark], Can you assigned to me? I will completed in today. Thanks. > Translate "Monitoring Back Pressure" page into Chinese > -- > > Key: FLINK-13677 > URL: https://issues.apache.org/jira/browse/FLINK-13677 > Project: Flink > Issue Type: Sub-task > Components: chinese-translation, Documentation >Affects Versions: 1.10.0 >Reporter: fanrui >Priority: Major > Fix For: 1.10.0 > > > The page url is > [https://ci.apache.org/projects/flink/flink-docs-master/zh/monitoring/back_pressure.html] > The markdown file is located in "docs/monitoring/back_pressure.zh.md" -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] jinglining edited a comment on issue #9601: [FLINK-13894][web]Web Ui add log url for subtask of vertex
jinglining edited a comment on issue #9601: [FLINK-13894][web]Web Ui add log url for subtask of vertex URL: https://github.com/apache/flink/pull/9601#issuecomment-527712818 > As usual, please include a screenshot of the changes. 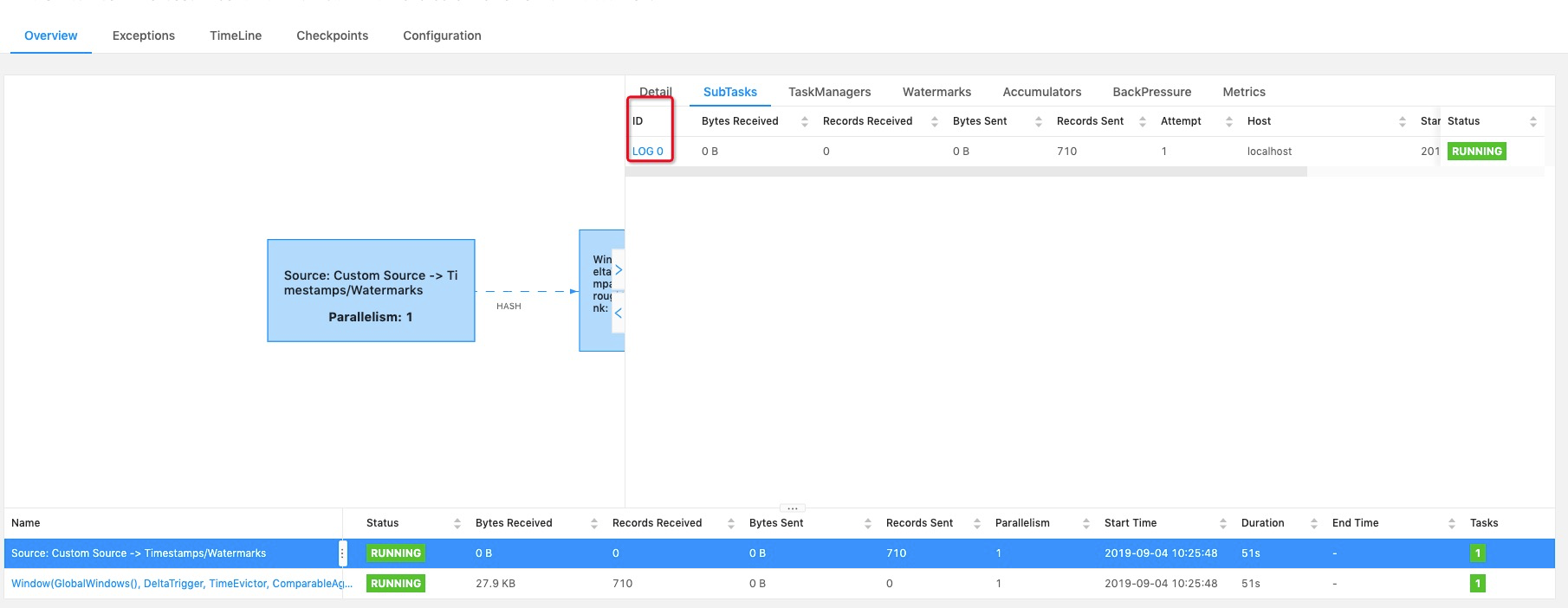 This is the screenshot of the changes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-13938) Use yarn public distributed cache to speed up containers launch
[
https://issues.apache.org/jira/browse/FLINK-13938?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921883#comment-16921883
]
Yang Wang commented on FLINK-13938:
---
[~yanghua], thanks for your comments. I think we could benefit from it a lot in
large scale deployment. Some users have came across the same problems in user
email list.
[https://lists.apache.org/thread.html/9fb117fd2347fe8d48d103691a0bdd8132dcde61a4e2b4fb98bfbfbe@%3Cdev.flink.apache.org%3E]
[~till.rohrmann], i have some bandwidth to work on this. Do you mind to assign
this ticket to me?
> Use yarn public distributed cache to speed up containers launch
> ---
>
> Key: FLINK-13938
> URL: https://issues.apache.org/jira/browse/FLINK-13938
> Project: Flink
> Issue Type: New Feature
>Reporter: Yang Wang
>Priority: Major
>
> By default, the LocalResourceVisibility is APPLICATION, so they will be
> downloaded only once and shared for all taskmanager containers of a same
> application in the same node. However, different applications will have to
> download all jars every time, including the flink-dist.jar. I think we could
> use the yarn public cache to eliminate the unnecessary jars downloading and
> make launching container faster.
>
> How to use the shared lib feature?
> # Upload a copy of flink release binary to hdfs.
> # Use the -ysl argument to specify the shared lib
> {code:java}
> ./bin/flink run -d -m yarn-cluster -p 20 -ysl
> hdfs:///flink/release/flink-1.9.0/lib examples/streaming/WindowJoin.jar{code}
>
> -ysl, --yarnsharedLib Upload a copy of flink lib beforehand
> and specify the
> path to use public
> visibility feature
> of YARN NodeManager
> localizing
> resources.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[GitHub] [flink] jinglining commented on issue #9601: [FLINK-13894][web]Web Ui add log url for subtask of vertex
jinglining commented on issue #9601: [FLINK-13894][web]Web Ui add log url for subtask of vertex URL: https://github.com/apache/flink/pull/9601#issuecomment-527712818 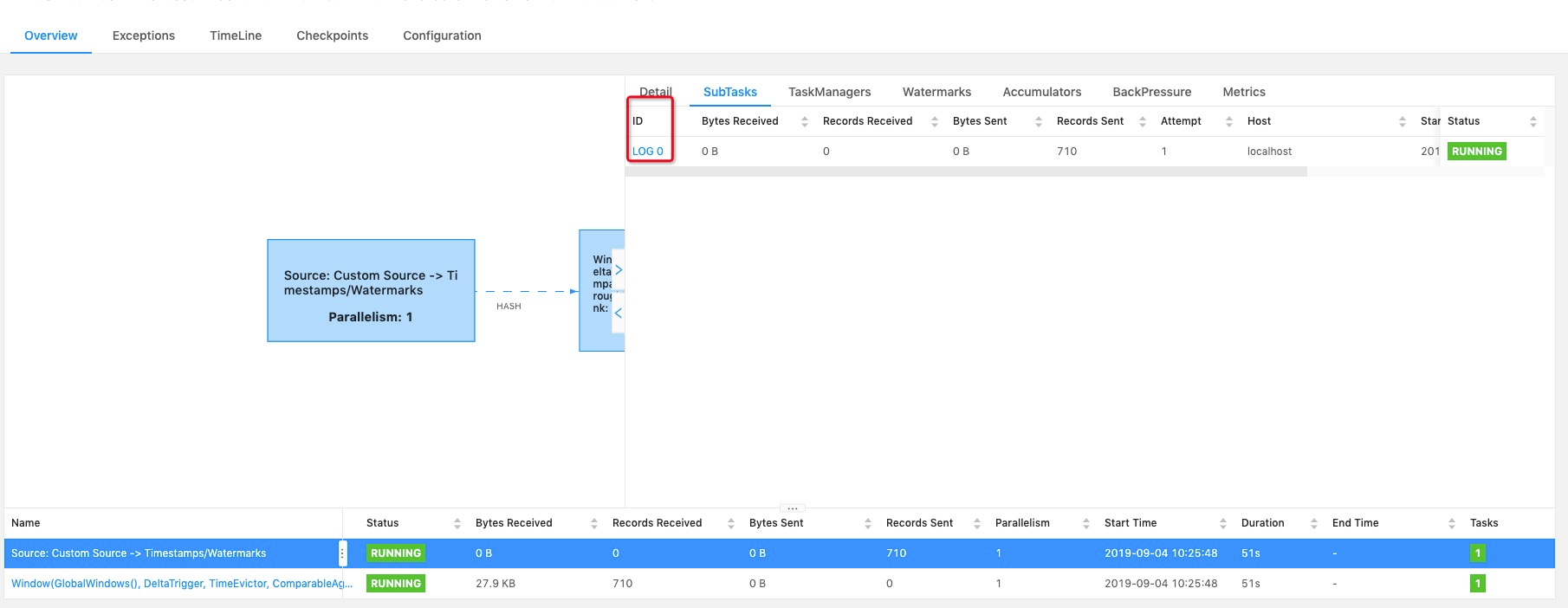 > As usual, please include a screenshot of the changes.  This is the screenshot of the changes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput
flinkbot edited a comment on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput URL: https://github.com/apache/flink/pull/9483#issuecomment-522602263 ## CI report: * 5d079442de5815edf896b85fa7aa3ca599975bb0 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123734022) * 725be7c2226608382c67d5b3d372886be737fff6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124870650) * eeb6f54f2316e5a6ef8f1cbed4f002c3ae37107e : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/12569) * e8d22a8c88d9c4a3d10fe989761c54e2d56ba3bf : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/125557289) * 9b8109a8586bcf8095eba8d24c6cd0dbb21d7810 : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125559250) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (FLINK-13926) `ProcessingTimeSessionWindows` and `EventTimeSessionWindows` should be generic
[
https://issues.apache.org/jira/browse/FLINK-13926?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921878#comment-16921878
]
zhihao zhang edited comment on FLINK-13926 at 9/4/19 2:13 AM:
--
The api usage between `EventTimeSessionWindows` and
`DynamicEventTimeSessionWindows` are Incomprehensible, for example:
{code:java}
DynamicEventTimeSessionWindows assigner =
DynamicEventTimeSessionWindows.withDynamicGap(extractor);
{code}
and
{code:java}
EventTimeSessionWindows assigner =
EventTimeSessionWindows.withDynamicGap(extractor);
{code}
one of them have a type parameter, but another one does not. it really makes me
confused for the first time.
was (Author: izhangzhihao):
The api usage between `EventTimeSessionWindows` and
`EventProcessingTimeSessionWindows` are Incomprehensible, for example:
{code:java}
DynamicEventTimeSessionWindows assigner =
DynamicEventTimeSessionWindows.withDynamicGap(extractor);
{code}
and
{code:java}
EventTimeSessionWindows assigner =
EventTimeSessionWindows.withDynamicGap(extractor);
{code}
one of them have a type parameter, but another one does not. it really makes me
confused for the first time.
> `ProcessingTimeSessionWindows` and `EventTimeSessionWindows` should be
> generic
> ---
>
> Key: FLINK-13926
> URL: https://issues.apache.org/jira/browse/FLINK-13926
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Affects Versions: 1.9.0
>Reporter: zhihao zhang
>Priority: Major
> Labels: pull-request-available, windows
> Fix For: 2.0.0
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> `ProcessingTimeSessionWindows` and `EventTimeSessionWindows` should be
> generic just like `DynamicEventTimeSessionWindows` and
> `DynamicProcessingTimeSessionWindows`.
> now:
>
> {code:java}
> public class ProcessingTimeSessionWindows extends
> MergingWindowAssigner {}
> {code}
> proposal:
>
> {code:java}
> public class ProcessingTimeSessionWindows extends MergingWindowAssigner TimeWindow> {}
> {code}
> If this ticket is ok to go, I would like to take it.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Updated] (FLINK-13938) Use yarn public distributed cache to speed up containers launch
[
https://issues.apache.org/jira/browse/FLINK-13938?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yang Wang updated FLINK-13938:
--
Description:
By default, the LocalResourceVisibility is APPLICATION, so they will be
downloaded only once and shared for all taskmanager containers of a same
application in the same node. However, different applications will have to
download all jars every time, including the flink-dist.jar. I think we could
use the yarn public cache to eliminate the unnecessary jars downloading and
make launching container faster.
How to use the shared lib feature?
# Upload a copy of flink release binary to hdfs.
# Use the -ysl argument to specify the shared lib
{code:java}
./bin/flink run -d -m yarn-cluster -p 20 -ysl
hdfs:///flink/release/flink-1.9.0/lib examples/streaming/WindowJoin.jar{code}
-ysl, --yarnsharedLib Upload a copy of flink lib beforehand
and specify the path
to use public
visibility feature of
YARN NodeManager
localizing resources.
was:
By default, the LocalResourceVisibility is APPLICATION, so they will be
downloaded only once and shared for all taskmanager containers of a same
application in the same node. However, different applications will have to
download all jars every time, including the flink-dist.jar. I think we could
use the yarn public cache to eliminate the unnecessary jars downloading and
make launching container faster.
How to use the shared lib feature?
# Upload a copy of flink release binary to hdfs.
# Use the -ysl argument to specify the shared lib
{code:java}
./bin/flink run -d -m yarn-cluster -p 20 -ysl
hdfs:///flink/release/flink-1.9.0/lib examples/streaming/WindowJoin.jar{code}
-ysl,--yarnsharedLib Upload a copy of flink lib beforehand
and specify the path
to use public
visibility feature of
YARN NodeManager
localizing resources.
> Use yarn public distributed cache to speed up containers launch
> ---
>
> Key: FLINK-13938
> URL: https://issues.apache.org/jira/browse/FLINK-13938
> Project: Flink
> Issue Type: New Feature
>Reporter: Yang Wang
>Priority: Major
>
> By default, the LocalResourceVisibility is APPLICATION, so they will be
> downloaded only once and shared for all taskmanager containers of a same
> application in the same node. However, different applications will have to
> download all jars every time, including the flink-dist.jar. I think we could
> use the yarn public cache to eliminate the unnecessary jars downloading and
> make launching container faster.
>
> How to use the shared lib feature?
> # Upload a copy of flink release binary to hdfs.
> # Use the -ysl argument to specify the shared lib
> {code:java}
> ./bin/flink run -d -m yarn-cluster -p 20 -ysl
> hdfs:///flink/release/flink-1.9.0/lib examples/streaming/WindowJoin.jar{code}
>
> -ysl, --yarnsharedLib Upload a copy of flink lib beforehand
> and specify the
> path to use public
> visibility feature
> of YARN NodeManager
> localizing
> resources.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (FLINK-13926) `ProcessingTimeSessionWindows` and `EventTimeSessionWindows` should be generic
[
https://issues.apache.org/jira/browse/FLINK-13926?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921878#comment-16921878
]
zhihao zhang commented on FLINK-13926:
--
The api usage between `EventTimeSessionWindows` and
`EventProcessingTimeSessionWindows` are Incomprehensible, for example:
{code:java}
DynamicEventTimeSessionWindows assigner =
DynamicEventTimeSessionWindows.withDynamicGap(extractor);
{code}
and
{code:java}
EventTimeSessionWindows assigner =
EventTimeSessionWindows.withDynamicGap(extractor);
{code}
one of them have a type parameter, but another one does not. it really makes me
confused for the first time.
> `ProcessingTimeSessionWindows` and `EventTimeSessionWindows` should be
> generic
> ---
>
> Key: FLINK-13926
> URL: https://issues.apache.org/jira/browse/FLINK-13926
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Affects Versions: 1.9.0
>Reporter: zhihao zhang
>Priority: Major
> Labels: pull-request-available, windows
> Fix For: 2.0.0
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> `ProcessingTimeSessionWindows` and `EventTimeSessionWindows` should be
> generic just like `DynamicEventTimeSessionWindows` and
> `DynamicProcessingTimeSessionWindows`.
> now:
>
> {code:java}
> public class ProcessingTimeSessionWindows extends
> MergingWindowAssigner {}
> {code}
> proposal:
>
> {code:java}
> public class ProcessingTimeSessionWindows extends MergingWindowAssigner TimeWindow> {}
> {code}
> If this ticket is ok to go, I would like to take it.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[GitHub] [flink] zhijiangW commented on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput
zhijiangW commented on issue #9483: [FLINK-13767][task] Migrate isFinished method from AvailabilityListener to AsyncDataInput URL: https://github.com/apache/flink/pull/9483#issuecomment-527708284 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-13925) ClassLoader in BlobLibraryCacheManager is not using context class loader
[ https://issues.apache.org/jira/browse/FLINK-13925?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921817#comment-16921817 ] Jark Wu commented on FLINK-13925: - Hi [~janl], because this is not a critical or blocker issue, the ongoing 1.8.2 release may not wait for this fix. Is that fine with you? Anyway, we can have the fix in the next minor release. > ClassLoader in BlobLibraryCacheManager is not using context class loader > > > Key: FLINK-13925 > URL: https://issues.apache.org/jira/browse/FLINK-13925 > Project: Flink > Issue Type: Bug >Affects Versions: 1.8.1, 1.9.0 >Reporter: Jan Lukavský >Priority: Major > Labels: pull-request-available > Fix For: 1.8.2, 1.9.1 > > Time Spent: 10m > Remaining Estimate: 0h > > Use thread's current context classloader as parent class loader of flink user > code class loaders. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Created] (FLINK-13949) Delete deduplicating JobVertexDetailsInfo.VertexTaskDetail
lining created FLINK-13949: -- Summary: Delete deduplicating JobVertexDetailsInfo.VertexTaskDetail Key: FLINK-13949 URL: https://issues.apache.org/jira/browse/FLINK-13949 Project: Flink Issue Type: Improvement Components: Runtime / REST Reporter: lining As there is SubtaskExecutionAttemptDetailsInfo for subtask, so we can use it replace JobVertexDetailsInfo.VertexTaskDetail. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink
flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink URL: https://github.com/apache/flink/pull/9581#issuecomment-526715445 ## CI report: * dc9cdc1364b9050c3d2f3cba062310ff68d83b8e : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125277359) * 5893967f343a3d2e3b4c92122303e00b01b0f8ff : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125282063) * ca8f65756da270da937077a2553a9506066b36bc : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125303705) * fc346331b4e7460c75c2e4eb0eefd5f1d1bd7dc9 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125561291) * 3156f2214291b0b18807c50675f7ac6b15e42ba4 : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/125817723) * 66ba043a392e7be15c7aed2f7e2edcaef1472c15 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125818539) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-12399) FilterableTableSource does not use filters on job run
[
https://issues.apache.org/jira/browse/FLINK-12399?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921808#comment-16921808
]
Kurt Young commented on FLINK-12399:
Hi [~walterddr], sorry for the delay, I will take a look at your solution.
> FilterableTableSource does not use filters on job run
> -
>
> Key: FLINK-12399
> URL: https://issues.apache.org/jira/browse/FLINK-12399
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API
>Affects Versions: 1.8.0
>Reporter: Josh Bradt
>Assignee: Rong Rong
>Priority: Major
> Labels: pull-request-available
> Attachments: flink-filter-bug.tar.gz
>
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> As discussed [on the mailing
> list|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Filter-push-down-not-working-for-a-custom-BatchTableSource-tp27654.html],
> there appears to be a bug where a job that uses a custom
> FilterableTableSource does not keep the filters that were pushed down into
> the table source. More specifically, the table source does receive filters
> via applyPredicates, and a new table source with those filters is returned,
> but the final job graph appears to use the original table source, which does
> not contain any filters.
> I attached a minimal example program to this ticket. The custom table source
> is as follows:
> {code:java}
> public class CustomTableSource implements BatchTableSource,
> FilterableTableSource {
> private static final Logger LOG =
> LoggerFactory.getLogger(CustomTableSource.class);
> private final Filter[] filters;
> private final FilterConverter converter = new FilterConverter();
> public CustomTableSource() {
> this(null);
> }
> private CustomTableSource(Filter[] filters) {
> this.filters = filters;
> }
> @Override
> public DataSet getDataSet(ExecutionEnvironment execEnv) {
> if (filters == null) {
>LOG.info(" No filters defined ");
> } else {
> LOG.info(" Found filters ");
> for (Filter filter : filters) {
> LOG.info("FILTER: {}", filter);
> }
> }
> return execEnv.fromCollection(allModels());
> }
> @Override
> public TableSource applyPredicate(List predicates) {
> LOG.info("Applying predicates");
> List acceptedFilters = new ArrayList<>();
> for (final Expression predicate : predicates) {
> converter.convert(predicate).ifPresent(acceptedFilters::add);
> }
> return new CustomTableSource(acceptedFilters.toArray(new Filter[0]));
> }
> @Override
> public boolean isFilterPushedDown() {
> return filters != null;
> }
> @Override
> public TypeInformation getReturnType() {
> return TypeInformation.of(Model.class);
> }
> @Override
> public TableSchema getTableSchema() {
> return TableSchema.fromTypeInfo(getReturnType());
> }
> private List allModels() {
> List models = new ArrayList<>();
> models.add(new Model(1, 2, 3, 4));
> models.add(new Model(10, 11, 12, 13));
> models.add(new Model(20, 21, 22, 23));
> return models;
> }
> }
> {code}
>
> When run, it logs
> {noformat}
> 15:24:54,888 INFO com.klaviyo.filterbug.CustomTableSource
>- Applying predicates
> 15:24:54,901 INFO com.klaviyo.filterbug.CustomTableSource
>- Applying predicates
> 15:24:54,910 INFO com.klaviyo.filterbug.CustomTableSource
>- Applying predicates
> 15:24:54,977 INFO com.klaviyo.filterbug.CustomTableSource
>- No filters defined {noformat}
> which appears to indicate that although filters are getting pushed down, the
> final job does not use them.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (FLINK-11202) Split log file per job
[ https://issues.apache.org/jira/browse/FLINK-11202?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921807#comment-16921807 ] vinoyang commented on FLINK-11202: -- [~jungggle] Can you give more detailed information about your scenarios(Flink deployment mode) and why do you need this feature? > Split log file per job > -- > > Key: FLINK-11202 > URL: https://issues.apache.org/jira/browse/FLINK-11202 > Project: Flink > Issue Type: New Feature > Components: Runtime / Coordination >Reporter: chauncy >Assignee: vinoyang >Priority: Major > > Debugging issues is difficult since Task-/JobManagers create a single log > file in standalone cluster environments. I think having a log file for each > job would be preferable. > The design documentation : > https://docs.google.com/document/d/1TTYAtFoTWaGCveKDZH394FYdRyNyQFnVoW5AYFvnr5I/edit?usp=sharing -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (FLINK-11202) Split log file per job
[ https://issues.apache.org/jira/browse/FLINK-11202?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921801#comment-16921801 ] Jiang Jungle commented on FLINK-11202: -- How is the work going? It hasn't been updated for months. I think this is a very necessary feature. > Split log file per job > -- > > Key: FLINK-11202 > URL: https://issues.apache.org/jira/browse/FLINK-11202 > Project: Flink > Issue Type: New Feature > Components: Runtime / Coordination >Reporter: chauncy >Assignee: vinoyang >Priority: Major > > Debugging issues is difficult since Task-/JobManagers create a single log > file in standalone cluster environments. I think having a log file for each > job would be preferable. > The design documentation : > https://docs.google.com/document/d/1TTYAtFoTWaGCveKDZH394FYdRyNyQFnVoW5AYFvnr5I/edit?usp=sharing -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (FLINK-13906) ExecutionConfigTests.test_equals_and_hash failed on Travis
[
https://issues.apache.org/jira/browse/FLINK-13906?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921800#comment-16921800
]
Hequn Cheng commented on FLINK-13906:
-
[~jark] Thanks for the advice, good idea.
> ExecutionConfigTests.test_equals_and_hash failed on Travis
> --
>
> Key: FLINK-13906
> URL: https://issues.apache.org/jira/browse/FLINK-13906
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.10.0
>Reporter: Till Rohrmann
>Assignee: Wei Zhong
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.10.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> The {{ExecutionConfigTests.test_equals_and_hash}} Python test failed on
> Travis with
> {code}
> === FAILURES
> ===
> __ ExecutionConfigTests.test_equals_and_hash
> ___
> self = testMethod=test_equals_and_hash>
> def test_equals_and_hash(self):
>
> config1 =
> ExecutionEnvironment.get_execution_environment().get_config()
>
> config2 =
> ExecutionEnvironment.get_execution_environment().get_config()
>
> self.assertEqual(config1, config2)
>
> > self.assertEqual(hash(config1), hash(config2))
> E AssertionError: 1609772339 != -295934785
> pyflink/common/tests/test_execution_config.py:277: AssertionError
> 1 failed, 373 passed in 50.62 seconds
> =
> ERROR: InvocationError for command
> /home/travis/build/flink-ci/flink/flink-python/.tox/py27/bin/pytest (exited
> with code 1)
> {code}
> https://api.travis-ci.com/v3/job/229361674/log.txt
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink
flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink URL: https://github.com/apache/flink/pull/9581#issuecomment-526715445 ## CI report: * dc9cdc1364b9050c3d2f3cba062310ff68d83b8e : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125277359) * 5893967f343a3d2e3b4c92122303e00b01b0f8ff : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125282063) * ca8f65756da270da937077a2553a9506066b36bc : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125303705) * fc346331b4e7460c75c2e4eb0eefd5f1d1bd7dc9 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125561291) * 3156f2214291b0b18807c50675f7ac6b15e42ba4 : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/125817723) * 66ba043a392e7be15c7aed2f7e2edcaef1472c15 : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125818539) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320526221
##
File path: docs/dev/table/hive/index.md
##
@@ -79,7 +79,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
flink-shaded-hadoop-2-uber
- 2.7.5-{{site.version}}
+ 2.7.5-7.0
Review comment:
And ,how can we add comments to be easy to understand? @wuchong @bowenli86
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink
flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink URL: https://github.com/apache/flink/pull/9581#issuecomment-526715445 ## CI report: * dc9cdc1364b9050c3d2f3cba062310ff68d83b8e : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125277359) * 5893967f343a3d2e3b4c92122303e00b01b0f8ff : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125282063) * ca8f65756da270da937077a2553a9506066b36bc : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125303705) * fc346331b4e7460c75c2e4eb0eefd5f1d1bd7dc9 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125561291) * 3156f2214291b0b18807c50675f7ac6b15e42ba4 : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125817723) * 66ba043a392e7be15c7aed2f7e2edcaef1472c15 : UNKNOWN This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix the error of the hive connector dependency ve…
yangjf2019 commented on a change in pull request #9591: [FLINK-13937][docs] Fix
the error of the hive connector dependency ve…
URL: https://github.com/apache/flink/pull/9591#discussion_r320525253
##
File path: docs/dev/table/hive/index.md
##
@@ -79,7 +79,7 @@ To integrate with Hive, users need the following
dependencies in their project.
org.apache.flink
flink-shaded-hadoop-2-uber
- 2.7.5-{{site.version}}
+ 2.7.5-7.0
Review comment:
Hi, @wuchong , Thank you ,I will add a `shaded-version` in
`docs/_config.yml`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink
flinkbot edited a comment on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink URL: https://github.com/apache/flink/pull/9581#issuecomment-526715445 ## CI report: * dc9cdc1364b9050c3d2f3cba062310ff68d83b8e : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125277359) * 5893967f343a3d2e3b4c92122303e00b01b0f8ff : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125282063) * ca8f65756da270da937077a2553a9506066b36bc : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125303705) * fc346331b4e7460c75c2e4eb0eefd5f1d1bd7dc9 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125561291) * 3156f2214291b0b18807c50675f7ac6b15e42ba4 : UNKNOWN This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yxu-valleytider commented on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink
yxu-valleytider commented on issue #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileSink URL: https://github.com/apache/flink/pull/9581#issuecomment-527681585 PTAL @kl0u This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yxu-valleytider commented on a change in pull request #9581: [FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to allow for easier subclassing of StreamingFileS
yxu-valleytider commented on a change in pull request #9581:
[FLINK-13864][streaming]: Modify the StreamingFileSink Builder interface to
allow for easier subclassing of StreamingFileSink
URL: https://github.com/apache/flink/pull/9581#discussion_r320514871
##
File path:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/functions/sink/filesystem/StreamingFileSink.java
##
@@ -314,25 +332,30 @@ private BulkFormatBuilder(
this.partFileSuffix =
Preconditions.checkNotNull(partFileSuffix);
}
- public StreamingFileSink.BulkFormatBuilder
withBucketCheckInterval(long interval) {
- return new BulkFormatBuilder<>(basePath, writerFactory,
bucketAssigner, interval, bucketFactory, partFilePrefix, partFileSuffix);
+ public T withBucketCheckInterval(long interval) {
+ this.bucketCheckInterval = interval;
+ return self();
}
- public StreamingFileSink.BulkFormatBuilder
withBucketAssigner(BucketAssigner assigner) {
- return new BulkFormatBuilder<>(basePath, writerFactory,
Preconditions.checkNotNull(assigner), bucketCheckInterval, new
DefaultBucketFactoryImpl<>(), partFilePrefix, partFileSuffix);
+ public T withBucketAssigner(BucketAssigner
assigner) {
Review comment:
@kl0u Did a small experiment with a non-string BucketID assigner :
```
class NonStringBucketIdAssigner implements BucketAssigner {
...
}
```
and
```
CustomizedStreamingFileSink.forBulkFormat(...)
.withBucketAssigner(new NonStringBucketIdAssigner())
.build();
```
The casting appears to be successful as long as the `assigner` parameter can
be casted to `BucketAssigner`. It makes sense considering the effect of
unbounded type erasure.
Also updating the PR to reflect this in the casting statement. If the
casting is truly a concern we could keep the original method with different
method names, e.g., `newBuilderWithBucketAssigner`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-12847) Update Kinesis Connectors to latest Apache licensed libraries
[ https://issues.apache.org/jira/browse/FLINK-12847?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921762#comment-16921762 ] Praveen Gattu commented on FLINK-12847: --- Thanks [~phoenixjiangnan] for merging this change. > Update Kinesis Connectors to latest Apache licensed libraries > - > > Key: FLINK-12847 > URL: https://issues.apache.org/jira/browse/FLINK-12847 > Project: Flink > Issue Type: Improvement > Components: Connectors / Kinesis >Reporter: Dyana Rose >Assignee: Dyana Rose >Priority: Major > Labels: pull-request-available > Fix For: 1.10.0 > > Time Spent: 20m > Remaining Estimate: 0h > > Currently the referenced Kinesis Client Library and Kinesis Producer Library > code in the flink-connector-kinesis is licensed under the Amazon Software > License which is not compatible with the Apache License. This then requires a > fair amount of work in the CI pipeline and for users who want to use the > flink-connector-kinesis. > The Kinesis Client Library v2.x and the AWS Java SDK v2.x both are now on the > Apache 2.0 license. > [https://github.com/awslabs/amazon-kinesis-client/blob/master/LICENSE.txt] > [https://github.com/aws/aws-sdk-java-v2/blob/master/LICENSE.txt] > There is a PR for the Kinesis Producer Library to update it to the Apache 2.0 > license ([https://github.com/awslabs/amazon-kinesis-producer/pull/256]) > The task should include, but not limited to, upgrading KCL/KPL to new > versions of Apache 2.0 license, changing licenses and NOTICE files in > flink-connector-kinesis, and adding flink-connector-kinesis to build, CI and > artifact publishing pipeline, updating the build profiles, updating > documentation that references the license incompatibility > The expected outcome of this issue is that the flink-connector-kinesis will > be included with the standard build artifacts and will no longer need to be > built separately by users. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9517: [FLINK-13779][metrics] PrometheusPushGatewayReporter support push metrics with groupingKey
flinkbot edited a comment on issue #9517: [FLINK-13779][metrics] PrometheusPushGatewayReporter support push metrics with groupingKey URL: https://github.com/apache/flink/pull/9517#issuecomment-524187390 ## CI report: * cdbd732fd99f2d2b5ad3cac2d119ef201079aafa : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/124323759) * 19d2487dac6bcdd9308ab9948d610b3b3edf5b8f : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124325244) * 63209029449bc869bfe957850809564f6682ed56 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124347410) * 6f7573b875238677c7eab4e1f4d67075f5ad7888 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/124522987) * 4ae793b9648b8913b76d775452e13dbccbd746c5 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124841676) * 1b4278c8baabf82e6e1338e69eace2adb9ba1a93 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/124851649) * 5c8542c3050121606c176a430d5871f4b087576b : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125380066) * 8e8c5b21bd37e8b581ee1d1432f2ce692cb3263e : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125750180) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-13948) Fix loss of state for Identical Windows merging after initial merge
Scott Waller created FLINK-13948: Summary: Fix loss of state for Identical Windows merging after initial merge Key: FLINK-13948 URL: https://issues.apache.org/jira/browse/FLINK-13948 Project: Flink Issue Type: Bug Components: API / DataStream Affects Versions: 1.8.0 Reporter: Scott Waller In the situation where there is a merging window, if we've performed a merge into a new window, and another window comes into the set that is exactly identical to the window created by the merge, the state window is replaced by the incoming window, and we lose the previous state. Example: Window (1,2) comes in to an empty set. The mapping is (1,2) -> (1,2) Window (1,3) comes into the set, we merge. The mapping is (1,3) -> (1,2) Window (1,3) comes into the set, we don't merge. The new mapping is (1,3) -> (1,3). This mapping will cause us to lose the previous state when its persisted. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x
flinkbot edited a comment on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x URL: https://github.com/apache/flink/pull/9580#issuecomment-526707203 ## CI report: * 9fcdfdece0af746c7d88a42cb512b2c44c75039c : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125274599) * 334ade297027c3ed1d7ad7666e4b957206ea0c33 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125306507) * b8dc475b7766026ebda4f778209616357a42c98f : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125307444) * 4cee29f4fd9335303f38e8b7e33fe98f75076c5c : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125792172) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zentol commented on a change in pull request #9555: [FLINK-13868][REST] Job vertex add taskmanager id in rest api
zentol commented on a change in pull request #9555: [FLINK-13868][REST] Job
vertex add taskmanager id in rest api
URL: https://github.com/apache/flink/pull/9555#discussion_r320473933
##
File path: flink-runtime-web/src/test/resources/rest_api_v1.snapshot
##
@@ -1628,7 +1628,7 @@
"type" : "array",
"items" : {
"type" : "object",
-"id" :
"urn:jsonschema:org:apache:flink:runtime:rest:messages:JobVertexDetailsInfo:VertexTaskDetail",
+"id" :
"urn:jsonschema:org:apache:flink:runtime:rest:messages:job:SubtaskExecutionAttemptDetailsInfo",
Review comment:
yes, this is fine.´; it's just schema meta-data, which isn't relevant for
backwards-compatibility.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Closed] (FLINK-13885) Remove HighAvailabilityOptions#HA_JOB_DELAY which is no longer used
[
https://issues.apache.org/jira/browse/FLINK-13885?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Till Rohrmann closed FLINK-13885.
-
Release Note: The configuration option `high-availability.job.delay` has
been deprecated since it is no longer used.
Resolution: Done
Done via 536ccd78c667c284f235e4bdee648fe28688453c
> Remove HighAvailabilityOptions#HA_JOB_DELAY which is no longer used
> ---
>
> Key: FLINK-13885
> URL: https://issues.apache.org/jira/browse/FLINK-13885
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.8.1, 1.9.0, 1.10.0
>Reporter: Till Rohrmann
>Assignee: Till Rohrmann
>Priority: Minor
> Fix For: 1.10.0
>
>
> The {{HighAvailabilityOptions.HA_JOB_DELAY}} is no longer used and can be
> removed.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[GitHub] [flink] tillrohrmann closed pull request #9554: [FLNK-13885] Remove HighAvailabilityOptions#HA_JOB_DELAY
tillrohrmann closed pull request #9554: [FLNK-13885] Remove HighAvailabilityOptions#HA_JOB_DELAY URL: https://github.com/apache/flink/pull/9554 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x
flinkbot edited a comment on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x URL: https://github.com/apache/flink/pull/9580#issuecomment-526707203 ## CI report: * 9fcdfdece0af746c7d88a42cb512b2c44c75039c : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125274599) * 334ade297027c3ed1d7ad7666e4b957206ea0c33 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125306507) * b8dc475b7766026ebda4f778209616357a42c98f : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125307444) * 4cee29f4fd9335303f38e8b7e33fe98f75076c5c : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125792172) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9517: [FLINK-13779][metrics] PrometheusPushGatewayReporter support push metrics with groupingKey
flinkbot edited a comment on issue #9517: [FLINK-13779][metrics] PrometheusPushGatewayReporter support push metrics with groupingKey URL: https://github.com/apache/flink/pull/9517#issuecomment-524187390 ## CI report: * cdbd732fd99f2d2b5ad3cac2d119ef201079aafa : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/124323759) * 19d2487dac6bcdd9308ab9948d610b3b3edf5b8f : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124325244) * 63209029449bc869bfe957850809564f6682ed56 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124347410) * 6f7573b875238677c7eab4e1f4d67075f5ad7888 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/124522987) * 4ae793b9648b8913b76d775452e13dbccbd746c5 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124841676) * 1b4278c8baabf82e6e1338e69eace2adb9ba1a93 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/124851649) * 5c8542c3050121606c176a430d5871f4b087576b : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125380066) * 8e8c5b21bd37e8b581ee1d1432f2ce692cb3263e : PENDING [Build](https://travis-ci.com/flink-ci/flink/builds/125750180) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zentol commented on issue #9517: [FLINK-13779][metrics] PrometheusPushGatewayReporter support push metrics with groupingKey
zentol commented on issue #9517: [FLINK-13779][metrics] PrometheusPushGatewayReporter support push metrics with groupingKey URL: https://github.com/apache/flink/pull/9517#issuecomment-527611373 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x
flinkbot edited a comment on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x URL: https://github.com/apache/flink/pull/9580#issuecomment-526707203 ## CI report: * 9fcdfdece0af746c7d88a42cb512b2c44c75039c : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125274599) * 334ade297027c3ed1d7ad7666e4b957206ea0c33 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125306507) * b8dc475b7766026ebda4f778209616357a42c98f : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125307444) * 4cee29f4fd9335303f38e8b7e33fe98f75076c5c : UNKNOWN This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] xuefuz commented on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x
xuefuz commented on issue #9580: [FLINK-13930][hive] Support Hive version 3.1.x URL: https://github.com/apache/flink/pull/9580#issuecomment-527607765 PR updated based on review feedback. @lirui-apache @bowenli86 Could you please take another look? Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] xuefuz commented on a change in pull request #9580: [FLINK-13930][hive] Support Hive version 3.1.x
xuefuz commented on a change in pull request #9580: [FLINK-13930][hive] Support Hive version 3.1.x URL: https://github.com/apache/flink/pull/9580#discussion_r320443658 ## File path: flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/table/functions/hive/HiveGenericUDF.java ## @@ -40,10 +41,11 @@ private static final Logger LOG = LoggerFactory.getLogger(HiveGenericUDF.class); private transient GenericUDF.DeferredObject[] deferredObjects; + private transient HiveShim hiveShim; Review comment: I created https://issues.apache.org/jira/browse/FLINK-13947 to investigate this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-13947) Check Hive shim serialization in Hive UDF wrapper classes and test coverage
[ https://issues.apache.org/jira/browse/FLINK-13947?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xuefu Zhang updated FLINK-13947: Description: Check 1. if HiveShim needs to be serializable and serialized in a few Hive UDF wrapper classes such as HiveGenericUDF. 2. Make sure we have end-to-end test coverage for Hive UDF usage. (was: Including 3.1.0, 3.1.1, and 3.1.2.) > Check Hive shim serialization in Hive UDF wrapper classes and test coverage > --- > > Key: FLINK-13947 > URL: https://issues.apache.org/jira/browse/FLINK-13947 > Project: Flink > Issue Type: Improvement > Components: Connectors / Hive >Reporter: Xuefu Zhang >Assignee: Xuefu Zhang >Priority: Major > Labels: pull-request-available > Fix For: 1.10.0 > > > Check 1. if HiveShim needs to be serializable and serialized in a few Hive > UDF wrapper classes such as HiveGenericUDF. 2. Make sure we have end-to-end > test coverage for Hive UDF usage. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Created] (FLINK-13947) Check Hive shim serialization in Hive UDF wrapper classes and test coverage
Xuefu Zhang created FLINK-13947: --- Summary: Check Hive shim serialization in Hive UDF wrapper classes and test coverage Key: FLINK-13947 URL: https://issues.apache.org/jira/browse/FLINK-13947 Project: Flink Issue Type: Improvement Components: Connectors / Hive Reporter: Xuefu Zhang Assignee: Xuefu Zhang Fix For: 1.10.0 Including 3.1.0, 3.1.1, and 3.1.2. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (FLINK-13609) StreamingFileSink - reset part counter on bucket change
[
https://issues.apache.org/jira/browse/FLINK-13609?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921675#comment-16921675
]
Joao Boto commented on FLINK-13609:
---
[~kkl0u] I think this could be closed as we agree that the counter will not
reset and this should be documented ([~gyfora])
And if you want that we discuss alternatives to counter we could create another
Jira with that focus, putting alternatives as timestamp, or other
configuration, or allow that user could configure that with same class or
anything like that.
> StreamingFileSink - reset part counter on bucket change
> ---
>
> Key: FLINK-13609
> URL: https://issues.apache.org/jira/browse/FLINK-13609
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / FileSystem
>Reporter: Joao Boto
>Priority: Major
>
> When writing to files using StreamingFileSink on bucket change we expect that
> partcounter will reset its counter to 0
> as a example
> * using DateTimeBucketAssigner using ({color:#6a8759}/MM/dd/HH{color})
> * and ten files hour (for simplicity)
> this will create the:
> * bucket 2019/08/07/00 with files partfile-0-0 to partfile-0-9
> * bucket 2019/08/07/01 with files partfile-0-10 to partfile-0-19
> * bucket 2019/08/07/02 with files partfile-0-20 to partfile-0-29
> and we expect this:
> * bucket 2019/08/07/00 with files partfile-0-0 to partfile-0-9
> * bucket 2019/08/07/01 with files partfile-0-0 to partfile-0-9
> * bucket 2019/08/07/02 with files partfile-0-0 to partfile-0-9
>
> [~kkl0u] i don't know if it's the expected behavior (or this can be
> configured)
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[GitHub] [flink] flinkbot edited a comment on issue #9603: [FLINK-13942][docs] Add "Getting Started" overview page.
flinkbot edited a comment on issue #9603: [FLINK-13942][docs] Add "Getting Started" overview page. URL: https://github.com/apache/flink/pull/9603#issuecomment-527425650 ## CI report: * 7a34d1ebced7aa1793ec090942fb0bc566fbbd47 : UNKNOWN * 791ed20b3a4dfa6c525e6a781fb0fc16446dd5ce : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125770978) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #9210: [FLINK-12746][docs] Getting Started - DataStream Example Walkthrough
flinkbot edited a comment on issue #9210: [FLINK-12746][docs] Getting Started - DataStream Example Walkthrough URL: https://github.com/apache/flink/pull/9210#issuecomment-514437706 ## CI report: * 5eb979da047c442c0205464c92b5bd9ee3a740dc : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120299964) * d7bf53a30514664925357bd5817305a02553d0a3 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120506936) * 02cca7fb6283b84a20ee019159ccb023ccffbd82 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120769129) * 5009b10d38eef92f25bfe4ff4608f2dd121ea9c6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120915709) * e3b272586d8f41d3800e86134730c4dc427952a6 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120916220) * f1aee543a7aef88e3cf052f4d686ab0a8e5938e5 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120996260) * c66060dba290844085f90f554d447c6d7033779d : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/121131224) * 700e5c19a3d49197ef2b18a646f0b6e1bf783ba8 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/121174288) * 6f3fccea82189ef95d46f12212f6f7386fc11668 : CANCELED [Build](https://travis-ci.com/flink-ci/flink/builds/123540519) * 829c9c0505b6f08bb68e20a34e0613d83ae21758 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123545553) * 6f4f9ad2b9840347bda3474fe18f4b6b0b870c01 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123789816) * 8df2872cf6f575acbacbc8aff510c67dccfa2931 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123979061) * 910d77ed9e3bba1309110ffc51a985fd623c90bf : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/124126522) * 23ad7779caa7e30a6380d76ddeeae76baa7b8b35 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125765073) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #8303: [FLINK-12343] [flink-yarn] add file replication config for yarn configuration
flinkbot edited a comment on issue #8303: [FLINK-12343] [flink-yarn] add file replication config for yarn configuration URL: https://github.com/apache/flink/pull/8303#issuecomment-511684151 ## CI report: * 6a7ca58b4a04f6dce250045e021702e67e82b893 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119421914) * 4d38a8df0d59734c4b2386689a2f17b9f2b44b12 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119441376) * 9c14836f8639e98d58cf7bb32e38b938b3843994 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/119577044) * 76186776c5620598a19234245bbd05dfdfb1c62c : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/120113740) * 628ca7b316ad3968c90192a47a84dd01f26e2578 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/122381349) * d204a725ff3c8a046cbd1b84e34d9e3ae8aafeac : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123620485) * 143efadbdb6c4681569d5b412a175edfb1633b85 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123637809) * b78b64a82ed2a9a92886095ec42f06d5082ad830 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/123671219) * 5145a0b9d6b320456bb971d96b9cc47707c8fd28 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125476639) * 0d4d944c28c59ca1caa6c453c347ec786b40d245 : FAILURE [Build](https://travis-ci.com/flink-ci/flink/builds/125762588) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320400652
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320397067
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] flinkbot edited a comment on issue #9530: [FLINK-13842][docs] Improve Documentation of the StreamingFileSink
flinkbot edited a comment on issue #9530: [FLINK-13842][docs] Improve Documentation of the StreamingFileSink URL: https://github.com/apache/flink/pull/9530#issuecomment-524624121 ## CI report: * f0ac794544411b47703a225715fb50f44d1472e0 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/124492706) * cf4df2f502dd5ec2aed06fc1625969f7f13a5e99 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/124501819) * 45cbcafc4eb17f5db641584ba4aebe1206ad9744 : SUCCESS [Build](https://travis-ci.com/flink-ci/flink/builds/125765037) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320387915
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320383675
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320345449
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1505 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are still used by
unreleased snapshots.
+*/
+ private final TreeSet snapshotVersions;
+
+ /**
+* The size of skip
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320364798
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320378689
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320397067
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320381660
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320400878
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320365537
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320348900
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1505 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are still used by
unreleased snapshots.
+*/
+ private final TreeSet snapshotVersions;
+
+ /**
+* The size of skip
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320386447
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320360192
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320322422
##
File path:
flink-core/src/test/java/org/apache/flink/core/memory/ByteBufferUtilsTest.java
##
@@ -0,0 +1,195 @@
+/*
+ *
+ * * Licensed to the Apache Software Foundation (ASF) under one
+ * * or more contributor license agreements. See the NOTICE file
+ * * distributed with this work for additional information
+ * * regarding copyright ownership. The ASF licenses this file
+ * * to you under the Apache License, Version 2.0 (the
+ * * "License"); you may not use this file except in compliance
+ * * with the License. You may obtain a copy of the License at
+ * *
+ * * http://www.apache.org/licenses/LICENSE-2.0
+ * *
+ * * Unless required by applicable law or agreed to in writing, software
+ * * distributed under the License is distributed on an "AS IS" BASIS,
+ * * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * * See the License for the specific language governing permissions and
+ * * limitations under the License.
+ *
+ */
+
+package org.apache.flink.core.memory;
+
+import org.apache.flink.util.TestLogger;
+
+import org.junit.Assert;
+import org.junit.Test;
+
+import java.nio.ByteBuffer;
+
+import static org.hamcrest.Matchers.greaterThan;
+import static org.hamcrest.Matchers.is;
+import static org.hamcrest.Matchers.lessThan;
+
+/**
+ * Tests for {@link ByteBufferUtils}.
+ */
+public class ByteBufferUtilsTest extends TestLogger {
+
+ @Test
+ public void testDirectBBWriteAndRead() {
+ testWithDifferentOffset(true);
+ }
+
+ @Test
+ public void testHeapBBWriteAndRead() {
+ testWithDifferentOffset(false);
+ }
+
+ @Test
+ public void testCompareDirectBBToArray() {
+ testCompareTo(true, false, false);
+ }
+
+ @Test
+ public void testCompareDirectBBToDirectBB() {
+ testCompareTo(true, true, true);
+ }
+
+ @Test
+ public void testCompareDirectBBToHeapBB() {
+ testCompareTo(true, true, false);
+ }
+
+ @Test
+ public void testCompareHeapBBToArray() {
+ testCompareTo(false, false, false);
+ }
+
+ @Test
+ public void testCompareHeapBBToDirectBB() {
+ testCompareTo(false, true, true);
+ }
+
+ @Test
+ public void testCompareHeapBBToHeapBB() {
+ testCompareTo(false, true, false);
+ }
+
+ private void testCompareTo(boolean isLeftBBDirect, boolean
isRightBuffer, boolean isRightDirect) {
+ testEquals(isLeftBBDirect, isRightBuffer, isRightDirect);
+ testLessThan(isLeftBBDirect, isRightBuffer, isRightDirect);
+ testGreaterThan(isLeftBBDirect, isRightBuffer, isRightDirect);
+ }
+
+ private void testEquals(boolean isLeftBBDirect, boolean isRightBuffer,
boolean isRightDirect) {
+ byte[] leftBufferBytes = new byte[]{'a', 'b', 'c', 'd', 'e'};
+ byte[] rightBufferBytes = new byte[]{'b', 'c', 'd', 'e', 'f'};
+ ByteBuffer left = isLeftBBDirect
+ ?
ByteBuffer.allocateDirect(leftBufferBytes.length).put(leftBufferBytes)
+ : ByteBuffer.wrap(leftBufferBytes);
Review comment:
nit: this could be factored out and then shared for generating the `left`
and `right` `ByteBuffer` instances.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320388346
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320357938
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320343879
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320347175
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320387263
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320320123
##
File path:
flink-core/src/main/java/org/apache/flink/core/memory/ByteBufferUtils.java
##
@@ -0,0 +1,389 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.core.memory;
+
+import javax.annotation.Nonnull;
+import javax.annotation.Nullable;
+
+import java.lang.reflect.Field;
+import java.nio.ByteBuffer;
+
+/**
+ * Utilities to get/put data to {@link ByteBuffer}. All methods don't change
+ * byte buffer's position.
+ *
+ * This class partially refers to
org.apache.hadoop.hbase.util.ByteBufferUtils.
Review comment:
We could also add a link to Github:
https://github.com/apache/hbase/blob/master/hbase-common/src/main/java/org/apache/hadoop/hbase/util/ByteBufferUtils.java
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State Backends] Support on-disk state storage for spill-able heap backend
tillrohrmann commented on a change in pull request #9501: [FLINK-12697] [State
Backends] Support on-disk state storage for spill-able heap backend
URL: https://github.com/apache/flink/pull/9501#discussion_r320400652
##
File path:
flink-state-backends/flink-statebackend-heap-spillable/src/main/java/org/apache/flink/runtime/state/heap/CopyOnWriteSkipListStateMap.java
##
@@ -0,0 +1,1527 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.state.heap;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.core.memory.ByteBufferUtils;
+import org.apache.flink.runtime.state.StateEntry;
+import org.apache.flink.runtime.state.StateTransformationFunction;
+import org.apache.flink.runtime.state.heap.space.Allocator;
+import org.apache.flink.runtime.state.heap.space.Chunk;
+import org.apache.flink.runtime.state.heap.space.SpaceUtils;
+import org.apache.flink.runtime.state.internal.InternalKvState;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.ResourceGuard;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nonnull;
+
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.NoSuchElementException;
+import java.util.Set;
+import java.util.Spliterators;
+import java.util.TreeSet;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.concurrent.atomic.AtomicBoolean;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+import static org.apache.flink.runtime.state.heap.SkipListUtils.HEAD_NODE;
+import static org.apache.flink.runtime.state.heap.SkipListUtils.NIL_NODE;
+import static
org.apache.flink.runtime.state.heap.SkipListUtils.NIL_VALUE_POINTER;
+
+/**
+ * Implementation of state map which is based on skip list with copy-on-write
support. states will
+ * be serialized to bytes and stored in the space allocated with the given
allocator.
+ *
+ * @param type of key
+ * @param type of namespace
+ * @param type of state
+ */
+public class CopyOnWriteSkipListStateMap extends StateMap
implements AutoCloseable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CopyOnWriteSkipListStateMap.class);
+
+ /**
+* Default max number of logically-removed keys to delete one time.
+*/
+ private static final int DEFAULT_MAX_KEYS_TO_DELETE_ONE_TIME = 3;
+
+ /**
+* Default ratio of the logically-removed keys to trigger deletion when
snapshot.
+*/
+ private static final float DEFAULT_LOGICAL_REMOVED_KEYS_RATIO = 0.2f;
+
+ /**
+* The serializer used to serialize the key and namespace to bytes
stored in skip list.
+*/
+ private final SkipListKeySerializer skipListKeySerializer;
+
+ /**
+* The serializer used to serialize the state to bytes stored in skip
list.
+*/
+ private final SkipListValueSerializer skipListValueSerializer;
+
+ /**
+* Space allocator.
+*/
+ private final Allocator spaceAllocator;
+
+ /**
+* The level index header.
+*/
+ private final LevelIndexHeader levelIndexHeader;
+
+ /**
+* Seed to generate random index level.
+*/
+ private int randomSeed;
+
+ /**
+* The current version of this map. Used for copy-on-write mechanics.
+*/
+ private int stateMapVersion;
+
+ /**
+* The highest version of this map that is still required by any
unreleased snapshot.
+*/
+ private int highestRequiredSnapshotVersion;
+
+ /**
+* Snapshots no more than this version must have been finished, but
there may be some
+* snapshots more than this version are still running.
+*/
+ private volatile int highestFinishedSnapshotVersion;
+
+ /**
+* Maintains an ordered set of version ids that are