[GitHub] [flink] flinkbot edited a comment on issue #11871: [FLINK-17333][doc] add doc for 'create catalog' ddl
flinkbot edited a comment on issue #11871: URL: https://github.com/apache/flink/pull/11871#issuecomment-618188399 ## CI report: * ac40522a46f3f22f747e1196d45d91543cc6a87a Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161564583) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=102) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11872: [FLINK-17227][metrics]Remove Datadog shade-plugin relocations
flinkbot edited a comment on issue #11872: URL: https://github.com/apache/flink/pull/11872#issuecomment-618188449 ## CI report: * 6ee34138baa74abb4b7c1f71ea98e360340a2b8c Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161564598) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=103) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11749: [FLINK-16669][python][table] Support Python UDF in SQL function DDL.
flinkbot edited a comment on issue #11749: URL: https://github.com/apache/flink/pull/11749#issuecomment-613901508 ## CI report: * e3255e2c9750fa3c457bc853849c5c02ad463c2d Travis: [FAILURE](https://travis-ci.com/github/flink-ci/flink/builds/161384844) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=43) * af2712838656f4c716a40d0248d2d9b0129b29cd UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #10059: [FLINK-14543][FLINK-15901][table] Support partition for temporary table and HiveCatalog
flinkbot edited a comment on issue #10059: URL: https://github.com/apache/flink/pull/10059#issuecomment-548289939 ## CI report: * 5f91592c6f010dbb52511c54568c5d3c82082433 UNKNOWN * 13dab75e74ed139bb8802dcf2de0ef87464f046b Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161549021) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=93) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-17335) JDBCUpsertTableSink Upsert mysql exception No value specified for parameter 1
[
https://issues.apache.org/jira/browse/FLINK-17335?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yutao updated FLINK-17335:
--
Description:
JDBCUpsertTableSink build = JDBCUpsertTableSink.builder()
.setTableSchema(results.getSchema())
.setOptions(JDBCOptions.builder()
.setDBUrl("MultiQueries=true=true=UTF-8")
.setDriverName("com.mysql.jdbc.Driver")
.setUsername("***")
.setPassword("***")
.setTableName("xkf_join_result")
.build())
.setFlushIntervalMills(1000)
.setFlushMaxSize(100)
.setMaxRetryTimes(3)
.build();
DataStream> retract = bsTableEnv.toRetractStream(results,
Row.class);
retract.print();
build.emitDataStream(retract);
java.sql.SQLException: No value specified for parameter 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:965)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:898)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:887)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:861)
at
com.mysql.jdbc.PreparedStatement.checkAllParametersSet(PreparedStatement.java:2211)
at com.mysql.jdbc.PreparedStatement.fillSendPacket(PreparedStatement.java:2191)
at com.mysql.jdbc.PreparedStatement.fillSendPacket(PreparedStatement.java:2121)
at com.mysql.jdbc.PreparedStatement.execute(PreparedStatement.java:1162)
at
org.apache.flink.api.java.io.jdbc.writer.UpsertWriter.executeBatch(UpsertWriter.java:118)
at
org.apache.flink.api.java.io.jdbc.JDBCUpsertOutputFormat.flush(JDBCUpsertOutputFormat.java:159)
at
org.apache.flink.api.java.io.jdbc.JDBCUpsertSinkFunction.snapshotState(JDBCUpsertSinkFunction.java:56)
at
org.apache.flink.streaming.util.functions.StreamingFunctionUtils.trySnapshotFunctionState(StreamingFunctionUtils.java:118)
at
org.apache.flink.streaming.util.functions.StreamingFunctionUtils.snapshotFunctionState(StreamingFunctionUtils.java:99)
at
org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.snapshotState(AbstractUdfStreamOperator.java:90)
at
org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:402)
at
org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.checkpointStreamOperator(StreamTask.java:1420)
at
org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.executeCheckpointing(StreamTask.java:1354)
in code UpsertWriter you can see executeBatch() method ;when only one record
and tuple2’s first element is true then end for round
;deleteStatement.executeBatch(); get error
@Override
public void executeBatch() throws SQLException {
if (keyToRows.size() > 0) {
for (Map.Entry> entry : keyToRows.entrySet()) {
Row pk = entry.getKey();
Tuple2 tuple = entry.getValue();
if (tuple.f0) {
processOneRowInBatch(pk, tuple.f1);
} else {
setRecordToStatement(deleteStatement, pkTypes, pk);
deleteStatement.addBatch();
}
}
internalExecuteBatch();
deleteStatement.executeBatch();
keyToRows.clear();
}
> JDBCUpsertTableSink Upsert mysql exception No value specified for parameter 1
> -
>
> Key: FLINK-17335
> URL: https://issues.apache.org/jira/browse/FLINK-17335
> Project: Flink
> Issue Type: Bug
> Components: Connectors / JDBC
>Affects Versions: 1.10.0
>Reporter: yutao
>Priority: Major
>
> JDBCUpsertTableSink build = JDBCUpsertTableSink.builder()
> .setTableSchema(results.getSchema())
> .setOptions(JDBCOptions.builder()
> .setDBUrl("MultiQueries=true=true=UTF-8")
> .setDriverName("com.mysql.jdbc.Driver")
> .setUsername("***")
> .setPassword("***")
> .setTableName("xkf_join_result")
> .build())
> .setFlushIntervalMills(1000)
> .setFlushMaxSize(100)
> .setMaxRetryTimes(3)
> .build();
> DataStream> retract =
> bsTableEnv.toRetractStream(results, Row.class);
> retract.print();
> build.emitDataStream(retract);
> java.sql.SQLException: No value specified for parameter 1
> at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:965)
> at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:898)
> at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:887)
> at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:861)
> at
> com.mysql.jdbc.PreparedStatement.checkAllParametersSet(PreparedStatement.java:2211)
> at
> com.mysql.jdbc.PreparedStatement.fillSendPacket(PreparedStatement.java:2191)
> at
> com.mysql.jdbc.PreparedStatement.fillSendPacket(PreparedStatement.java:2121)
> at com.mysql.jdbc.PreparedStatement.execute(PreparedStatement.java:1162)
> at
> org.apache.flink.api.java.io.jdbc.writer.UpsertWriter.executeBatch(UpsertWriter.java:118)
> at
> org.apache.flink.api.java.io.jdbc.JDBCUpsertOutputFormat.flush(JDBCUpsertOutputFormat.java:159)
> at
> org.apache.flink.api.java.io.jdbc.JDBCUpsertSinkFunction.snapshotState(JDBCUpsertSinkFunction.java:56)
> at
>
[jira] [Created] (FLINK-17335) JDBCUpsertTableSink Upsert mysql exception No value specified for parameter 1
yutao created FLINK-17335: - Summary: JDBCUpsertTableSink Upsert mysql exception No value specified for parameter 1 Key: FLINK-17335 URL: https://issues.apache.org/jira/browse/FLINK-17335 Project: Flink Issue Type: Bug Components: Connectors / JDBC Affects Versions: 1.10.0 Reporter: yutao -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on issue #11872: [FLINK-17227][metrics]Remove Datadog shade-plugin relocations
flinkbot commented on issue #11872: URL: https://github.com/apache/flink/pull/11872#issuecomment-618188449 ## CI report: * 6ee34138baa74abb4b7c1f71ea98e360340a2b8c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11870: [FLINK-17117][SQL-Blink]Remove useless cast class code for processElement method in SourceCon…
flinkbot edited a comment on issue #11870: URL: https://github.com/apache/flink/pull/11870#issuecomment-618183162 ## CI report: * c4c6356dfbd46e26171b6128482eecab13fe7d96 Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161563127) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=101) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11797: [FLINK-17169][table-blink] Refactor BaseRow to use RowKind instead of byte header
flinkbot edited a comment on issue #11797: URL: https://github.com/apache/flink/pull/11797#issuecomment-615294694 ## CI report: * 85f40e3041783b1dbda1eb3b812f23e77936f7b3 UNKNOWN * b0730cb05f9d77f9d34ab7221020931ef5d2532d Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161547746) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=91) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11869: [FLINK-17111][table] Support SHOW VIEWS in Flink SQL
flinkbot edited a comment on issue #11869: URL: https://github.com/apache/flink/pull/11869#issuecomment-618183108 ## CI report: * 28223e277ee06677a7c973300e3e1c85902874fd Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161563117) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=100) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11766: [FLINK-16812][jdbc] support array types in PostgresRowConverter
flinkbot edited a comment on issue #11766: URL: https://github.com/apache/flink/pull/11766#issuecomment-614431072 ## CI report: * 3d58ff0f0f2f4caac54b5bc38dac153ae4f4ecf2 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/160495187) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=7558) * 8f39828265ace10973087d314a1efe93c08c1ea0 Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161563026) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=98) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on issue #11871: [FLINK-17333][doc] add doc for 'create catalog' ddl
flinkbot commented on issue #11871: URL: https://github.com/apache/flink/pull/11871#issuecomment-618188399 ## CI report: * ac40522a46f3f22f747e1196d45d91543cc6a87a UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11859: [FLINK-16485][python] Support vectorized Python UDF in batch mode of old planner
flinkbot edited a comment on issue #11859: URL: https://github.com/apache/flink/pull/11859#issuecomment-617655293 ## CI report: * d7d37b26b6dc41871ee56900f8e9b6ed16b3fcf6 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161549162) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=94) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11867: [FLINK-17309][e2e tests][WIP]TPC-DS fail to run data generator
flinkbot edited a comment on issue #11867: URL: https://github.com/apache/flink/pull/11867#issuecomment-617863974 ## CI report: * 9c3d9347f989a84184f598190271f5e0b4703ba0 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161547778) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=92) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11804: [FLINK-16473][doc][jdbc] add documentation for JDBCCatalog and PostgresCatalog
flinkbot edited a comment on issue #11804: URL: https://github.com/apache/flink/pull/11804#issuecomment-615960634 ## CI report: * d467bd31393f9dc171b6625f9053360b73bfd64d Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161487842) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=86) * b87a6c85fdcb0e63257ae3ee917837bff41c68ed Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161563068) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=99) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on issue #11870: [FLINK-17117][SQL-Blink]Remove useless cast class code for processElement method in SourceCon…
flinkbot commented on issue #11870: URL: https://github.com/apache/flink/pull/11870#issuecomment-618183162 ## CI report: * c4c6356dfbd46e26171b6128482eecab13fe7d96 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11804: [FLINK-16473][doc][jdbc] add documentation for JDBCCatalog and PostgresCatalog
flinkbot edited a comment on issue #11804: URL: https://github.com/apache/flink/pull/11804#issuecomment-615960634 ## CI report: * d467bd31393f9dc171b6625f9053360b73bfd64d Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161487842) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=86) * b87a6c85fdcb0e63257ae3ee917837bff41c68ed UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on issue #11869: [FLINK-17111][table] Support SHOW VIEWS in Flink SQL
flinkbot commented on issue #11869: URL: https://github.com/apache/flink/pull/11869#issuecomment-618183108 ## CI report: * 28223e277ee06677a7c973300e3e1c85902874fd UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11859: [FLINK-16485][python] Support vectorized Python UDF in batch mode of old planner
flinkbot edited a comment on issue #11859: URL: https://github.com/apache/flink/pull/11859#issuecomment-617655293 ## CI report: * d7d37b26b6dc41871ee56900f8e9b6ed16b3fcf6 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161549162) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=94) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11766: [FLINK-16812][jdbc] support array types in PostgresRowConverter
flinkbot edited a comment on issue #11766: URL: https://github.com/apache/flink/pull/11766#issuecomment-614431072 ## CI report: * 3d58ff0f0f2f4caac54b5bc38dac153ae4f4ecf2 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/160495187) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=7558) * 8f39828265ace10973087d314a1efe93c08c1ea0 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on issue #11871: [FLINK-17333][doc] add doc for 'create catalog' ddl
flinkbot commented on issue #11871: URL: https://github.com/apache/flink/pull/11871#issuecomment-618182406 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit ac40522a46f3f22f747e1196d45d91543cc6a87a (Thu Apr 23 05:14:31 UTC 2020) ✅no warnings Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-17289) Translate tutorials/etl.md to chinese
[ https://issues.apache.org/jira/browse/FLINK-17289?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee reassigned FLINK-17289: Assignee: Li Ying > Translate tutorials/etl.md to chinese > - > > Key: FLINK-17289 > URL: https://issues.apache.org/jira/browse/FLINK-17289 > Project: Flink > Issue Type: Improvement > Components: chinese-translation, Documentation / Training >Reporter: David Anderson >Assignee: Li Ying >Priority: Major > > This is one of the new tutorials, and it needs translation. > docs/tutorials/etl.zh.md does not exist yet. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on issue #11872: [FLINK-17227][metrics]Remove Datadog shade-plugin relocations
flinkbot commented on issue #11872: URL: https://github.com/apache/flink/pull/11872#issuecomment-618182391 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 6ee34138baa74abb4b7c1f71ea98e360340a2b8c (Thu Apr 23 05:14:29 UTC 2020) **Warnings:** * **1 pom.xml files were touched**: Check for build and licensing issues. * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-17289) Translate tutorials/etl.md to chinese
[ https://issues.apache.org/jira/browse/FLINK-17289?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090254#comment-17090254 ] Jingsong Lee commented on FLINK-17289: -- [~lyee] Assigned. > Translate tutorials/etl.md to chinese > - > > Key: FLINK-17289 > URL: https://issues.apache.org/jira/browse/FLINK-17289 > Project: Flink > Issue Type: Improvement > Components: chinese-translation, Documentation / Training >Reporter: David Anderson >Assignee: Li Ying >Priority: Major > > This is one of the new tutorials, and it needs translation. > docs/tutorials/etl.zh.md does not exist yet. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (FLINK-17289) Translate tutorials/etl.md to chinese
[ https://issues.apache.org/jira/browse/FLINK-17289?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090188#comment-17090188 ] Li Ying edited comment on FLINK-17289 at 4/23/20, 5:11 AM: --- Hi David, I'd like to do the translation. Could you please assign this job to me :) was (Author: lyee): Hi David, I'd like to do the translation. Could you please assigh this job to me :) > Translate tutorials/etl.md to chinese > - > > Key: FLINK-17289 > URL: https://issues.apache.org/jira/browse/FLINK-17289 > Project: Flink > Issue Type: Improvement > Components: chinese-translation, Documentation / Training >Reporter: David Anderson >Priority: Major > > This is one of the new tutorials, and it needs translation. > docs/tutorials/etl.zh.md does not exist yet. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-17334) Flink does not support HIVE UDFs with primitive return types
[ https://issues.apache.org/jira/browse/FLINK-17334?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090249#comment-17090249 ] Jingsong Lee commented on FLINK-17334: -- Hi [~royruan] thanks for reporting. Can you provide more information? Like what hive UDF? Maybe you can show the code. > Flink does not support HIVE UDFs with primitive return types > - > > Key: FLINK-17334 > URL: https://issues.apache.org/jira/browse/FLINK-17334 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Affects Versions: 1.10.0 >Reporter: xin.ruan >Priority: Major > Fix For: 1.10.1 > > Original Estimate: 72h > Remaining Estimate: 72h > > We are currently migrating Hive UDF to Flink. While testing compatibility, we > found that Flink cannot support primitive types like boolean, int, etc. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-17333) add doc for "create ddl"
[ https://issues.apache.org/jira/browse/FLINK-17333?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-17333: --- Labels: pull-request-available (was: ) > add doc for "create ddl" > > > Key: FLINK-17333 > URL: https://issues.apache.org/jira/browse/FLINK-17333 > Project: Flink > Issue Type: Improvement > Components: Documentation, Table SQL / API >Reporter: Bowen Li >Assignee: Bowen Li >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-17333) add doc for 'create catalog' ddl
[ https://issues.apache.org/jira/browse/FLINK-17333?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bowen Li updated FLINK-17333: - Summary: add doc for 'create catalog' ddl (was: add doc for "create ddl") > add doc for 'create catalog' ddl > > > Key: FLINK-17333 > URL: https://issues.apache.org/jira/browse/FLINK-17333 > Project: Flink > Issue Type: Improvement > Components: Documentation, Table SQL / API >Reporter: Bowen Li >Assignee: Bowen Li >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (FLINK-17209) Allow users to specify dialect in sql-client yaml
[ https://issues.apache.org/jira/browse/FLINK-17209?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee closed FLINK-17209. Resolution: Fixed master: aa489269a1429f25136765af94b05d10ef5b7fd3 > Allow users to specify dialect in sql-client yaml > - > > Key: FLINK-17209 > URL: https://issues.apache.org/jira/browse/FLINK-17209 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Client >Reporter: Rui Li >Assignee: Rui Li >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > Time Spent: 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (FLINK-17198) DDL and DML compatibility for Hive connector
[ https://issues.apache.org/jira/browse/FLINK-17198?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee reassigned FLINK-17198: Assignee: Rui Li > DDL and DML compatibility for Hive connector > > > Key: FLINK-17198 > URL: https://issues.apache.org/jira/browse/FLINK-17198 > Project: Flink > Issue Type: New Feature > Components: Connectors / Hive, Table SQL / Client >Reporter: Rui Li >Assignee: Rui Li >Priority: Major > Fix For: 1.11.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-17227) Remove Datadog relocations
[ https://issues.apache.org/jira/browse/FLINK-17227?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-17227: --- Labels: pull-request-available (was: ) > Remove Datadog relocations > -- > > Key: FLINK-17227 > URL: https://issues.apache.org/jira/browse/FLINK-17227 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics >Reporter: Chesnay Schepler >Assignee: molsion mo >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > > Now that we load the Datadog reporter as a plugin we should remove the > shade-plugin configuration/relocations. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-17209) Allow users to specify dialect in sql-client yaml
[ https://issues.apache.org/jira/browse/FLINK-17209?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee updated FLINK-17209: - Fix Version/s: 1.11.0 > Allow users to specify dialect in sql-client yaml > - > > Key: FLINK-17209 > URL: https://issues.apache.org/jira/browse/FLINK-17209 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Client >Reporter: Rui Li >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > Time Spent: 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] molsionmo opened a new pull request #11872: [FLINK-17227][metrics]Remove Datadog shade-plugin relocations
molsionmo opened a new pull request #11872: URL: https://github.com/apache/flink/pull/11872 ## What is the purpose of the change *Now that we load the Datadog reporters as plugins we should remove the shade-plugin configuration/relocations.* ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-17209) Allow users to specify dialect in sql-client yaml
[ https://issues.apache.org/jira/browse/FLINK-17209?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee reassigned FLINK-17209: Assignee: Rui Li > Allow users to specify dialect in sql-client yaml > - > > Key: FLINK-17209 > URL: https://issues.apache.org/jira/browse/FLINK-17209 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Client >Reporter: Rui Li >Assignee: Rui Li >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > Time Spent: 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] bowenli86 opened a new pull request #11871: [FLINK-17333][doc] add doc for 'create catalog' ddl
bowenli86 opened a new pull request #11871: URL: https://github.com/apache/flink/pull/11871 ## What is the purpose of the change add doc for "create catalog" ddl ## Brief change log ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: n/a ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (docs) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] bowenli86 commented on issue #11766: [FLINK-16812][jdbc] support array types in PostgresRowConverter
bowenli86 commented on issue #11766: URL: https://github.com/apache/flink/pull/11766#issuecomment-618180474 @wuchong addressed comments. pls take another look This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] bowenli86 commented on issue #11804: [FLINK-16473][doc][jdbc] add documentation for JDBCCatalog and PostgresCatalog
bowenli86 commented on issue #11804: URL: https://github.com/apache/flink/pull/11804#issuecomment-618180336 @wuchong can you take another look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-17334) Flink does not support HIVE UDFs with primitive return types
[ https://issues.apache.org/jira/browse/FLINK-17334?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] xin.ruan updated FLINK-17334: - Summary: Flink does not support HIVE UDFs with primitive return types (was: Flink does not support UDFs with primitive return types) > Flink does not support HIVE UDFs with primitive return types > - > > Key: FLINK-17334 > URL: https://issues.apache.org/jira/browse/FLINK-17334 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Affects Versions: 1.10.0 >Reporter: xin.ruan >Priority: Major > Fix For: 1.10.1 > > Original Estimate: 72h > Remaining Estimate: 72h > > We are currently migrating Hive UDF to Flink. While testing compatibility, we > found that Flink cannot support primitive types like boolean, int, etc. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-17334) Flink does not support UDFs with primitive return types
xin.ruan created FLINK-17334: Summary: Flink does not support UDFs with primitive return types Key: FLINK-17334 URL: https://issues.apache.org/jira/browse/FLINK-17334 Project: Flink Issue Type: Bug Components: Connectors / Hive Affects Versions: 1.10.0 Reporter: xin.ruan Fix For: 1.10.1 We are currently migrating Hive UDF to Flink. While testing compatibility, we found that Flink cannot support primitive types like boolean, int, etc. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (FLINK-17138) LocalExecutorITCase.testParameterizedTypes failed on travis
[
https://issues.apache.org/jira/browse/FLINK-17138?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee resolved FLINK-17138.
--
Resolution: Fixed
master: 27d1a48cc5c1ef7baf506d7c0db4d01ebdca6b70
Feel free to re-open if it is reproduced.
> LocalExecutorITCase.testParameterizedTypes failed on travis
> ---
>
> Key: FLINK-17138
> URL: https://issues.apache.org/jira/browse/FLINK-17138
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.10.0
>Reporter: Piotr Nowojski
>Assignee: Rui Li
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.11.0
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> https://api.travis-ci.org/v3/job/674770944/log.txt
> release-1.10 branch build failed with
> {code}
> 11:49:51.608 [INFO] Running
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 11:52:40.202 [ERROR] Tests run: 64, Failures: 0, Errors: 1, Skipped: 5, Time
> elapsed: 168.589 s <<< FAILURE! - in
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 11:52:40.209 [ERROR] testParameterizedTypes[Planner:
> blink](org.apache.flink.table.client.gateway.local.LocalExecutorITCase) Time
> elapsed: 5.609 s <<< ERROR!
> org.apache.flink.table.client.gateway.SqlExecutionException: Invalid SQL
> statement.
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:903)
> Caused by: org.apache.flink.table.api.ValidationException: SQL validation
> failed. Failed to get PrimaryKey constraints
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:903)
> Caused by: org.apache.flink.table.catalog.exceptions.CatalogException: Failed
> to get PrimaryKey constraints
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:903)
> Caused by: java.lang.reflect.InvocationTargetException
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:903)
> Caused by: org.apache.hadoop.hive.metastore.api.MetaException: No current
> connection.
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:903)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot commented on issue #11870: [FLINK-17117][SQL-Blink]Remove useless cast class code for processElement method in SourceCon…
flinkbot commented on issue #11870: URL: https://github.com/apache/flink/pull/11870#issuecomment-618179221 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit c4c6356dfbd46e26171b6128482eecab13fe7d96 (Thu Apr 23 05:02:05 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-17333) add doc for "create ddl"
Bowen Li created FLINK-17333: Summary: add doc for "create ddl" Key: FLINK-17333 URL: https://issues.apache.org/jira/browse/FLINK-17333 Project: Flink Issue Type: Improvement Components: Documentation, Table SQL / API Reporter: Bowen Li Assignee: Bowen Li Fix For: 1.11.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] hehuiyuan opened a new pull request #11870: [FLINK-17117][SQL-Blink]Remove useless cast class code for processElement method in SourceCon…
hehuiyuan opened a new pull request #11870:
URL: https://github.com/apache/flink/pull/11870
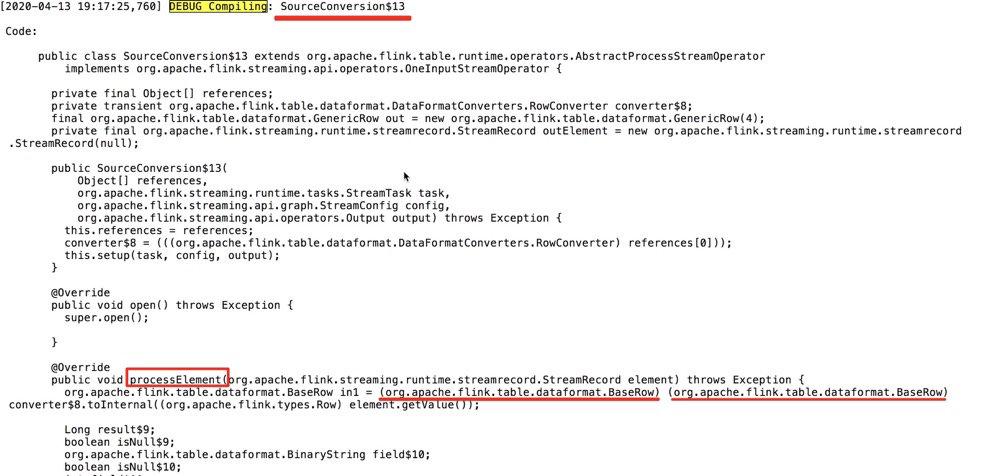
This method `generateOneInputStreamOperator` when OperatorCodeGenerator
generates SourceConversion:
```
@Override
public void processElement($STREAM_RECORD $ELEMENT) throws Exception {
$inputTypeTerm $inputTerm = ($inputTypeTerm)
${converter(s"$ELEMENT.getValue()")};
${ctx.reusePerRecordCode()}
${ctx.reuseLocalVariableCode()}
${if (lazyInputUnboxingCode) "" else ctx.reuseInputUnboxingCode()}
$processCode
}
$inputTypeTerm $inputTerm = ($inputTypeTerm)
${converter(s"$ELEMENT.getValue()")};
ScanUtil calls generateOneInputStreamOperator
val generatedOperator =
OperatorCodeGenerator.generateOneInputStreamOperator[Any, BaseRow](
ctx,
convertName,
processCode,
outputRowType,
converter = inputTermConverter)
//inputTermConverter
val (inputTermConverter, inputRowType) = {
val convertFunc = CodeGenUtils.genToInternal(ctx, inputType)
internalInType match {
case rt: RowType => (convertFunc, rt)
case _ => ((record: String) =>
s"$GENERIC_ROW.of(${convertFunc(record)})",
RowType.of(internalInType))
}
}
```
There is an useless cast class code:
```
$inputTypeTerm $inputTerm = ($inputTypeTerm)
${converter(s"$ELEMENT.getValue()")};
```
CodeGenUtils.scala : genToInternal
```
def genToInternal(ctx: CodeGeneratorContext, t: DataType): String => String
= {
val iTerm = boxedTypeTermForType(fromDataTypeToLogicalType(t))
if (isConverterIdentity(t)) {
term => s"($iTerm) $term"
} else {
val eTerm = boxedTypeTermForExternalType(t)
val converter = ctx.addReusableObject(
DataFormatConverters.getConverterForDataType(t),
"converter")
term => s"($iTerm) $converter.toInternal(($eTerm) $term)"
}
}
```
The code `($iTerm) ` and `($inputTypeTerm)` are same.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-17117) There are an useless cast operation for sql on blink when generate code
[
https://issues.apache.org/jira/browse/FLINK-17117?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-17117:
---
Labels: pull-request-available (was: )
> There are an useless cast operation for sql on blink when generate code
>
>
> Key: FLINK-17117
> URL: https://issues.apache.org/jira/browse/FLINK-17117
> Project: Flink
> Issue Type: Wish
> Components: Table SQL / Planner
>Reporter: hehuiyuan
>Assignee: hehuiyuan
>Priority: Minor
> Labels: pull-request-available
> Attachments: image-2020-04-13-19-44-19-174.png
>
>
> !image-2020-04-13-19-44-19-174.png|width=641,height=305!
>
> This mehthod `generateOneInputStreamOperator` when OperatorCodeGenerator
> generates SourceConversion:
> {code:java}
> @Override
> public void processElement($STREAM_RECORD $ELEMENT) throws Exception {
> $inputTypeTerm $inputTerm = ($inputTypeTerm)
> ${converter(s"$ELEMENT.getValue()")};
> ${ctx.reusePerRecordCode()}
> ${ctx.reuseLocalVariableCode()}
> ${if (lazyInputUnboxingCode) "" else ctx.reuseInputUnboxingCode()}
> $processCode
> }
> {code}
>
> {code:java}
> $inputTypeTerm $inputTerm = ($inputTypeTerm)
> ${converter(s"$ELEMENT.getValue()")};
> {code}
> ScanUtil calls generateOneInputStreamOperator
> {code:java}
> val generatedOperator =
> OperatorCodeGenerator.generateOneInputStreamOperator[Any, BaseRow](
> ctx,
> convertName,
> processCode,
> outputRowType,
> converter = inputTermConverter)
> //inputTermConverter
> val (inputTermConverter, inputRowType) = {
> val convertFunc = CodeGenUtils.genToInternal(ctx, inputType)
> internalInType match {
> case rt: RowType => (convertFunc, rt)
> case _ => ((record: String) => s"$GENERIC_ROW.of(${convertFunc(record)})",
> RowType.of(internalInType))
> }
> }
> {code}
> CodeGenUtils.scala : genToInternal
> {code:java}
> def genToInternal(ctx: CodeGeneratorContext, t: DataType): String => String =
> {
> val iTerm = boxedTypeTermForType(fromDataTypeToLogicalType(t))
> if (isConverterIdentity(t)) {
> term => s"($iTerm) $term"
> } else {
> val eTerm = boxedTypeTermForExternalType(t)
> val converter = ctx.addReusableObject(
> DataFormatConverters.getConverterForDataType(t),
> "converter")
> term => s"($iTerm) $converter.toInternal(($eTerm) $term)"
> }
> }
> {code}
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10059: [FLINK-14543][FLINK-15901][table] Support partition for temporary table and HiveCatalog
flinkbot edited a comment on issue #10059: URL: https://github.com/apache/flink/pull/10059#issuecomment-548289939 ## CI report: * 5f91592c6f010dbb52511c54568c5d3c82082433 UNKNOWN * 13dab75e74ed139bb8802dcf2de0ef87464f046b Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161549021) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=93) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on issue #11869: [FLINK-17111][table] Support SHOW VIEWS in Flink SQL
flinkbot commented on issue #11869: URL: https://github.com/apache/flink/pull/11869#issuecomment-618175194 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 28223e277ee06677a7c973300e3e1c85902874fd (Thu Apr 23 04:47:15 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-17111).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-17111) Support SHOW VIEWS in Flink SQL
[ https://issues.apache.org/jira/browse/FLINK-17111?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-17111: --- Labels: pull-request-available (was: ) > Support SHOW VIEWS in Flink SQL > > > Key: FLINK-17111 > URL: https://issues.apache.org/jira/browse/FLINK-17111 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Zhenghua Gao >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > > SHOW TABLES and SHOW VIEWS are not SQL standard-compliant commands. > MySQL supports SHOW TABLES which lists the non-TEMPORARY tables(and views) in > a given database, and doesn't support SHOW VIEWS. > Oracle/SQL Server/PostgreSQL don't support SHOW TABLES and SHOW VIEWS. A > workaround is to query a system table which stores metadata of tables and > views. > Hive supports both SHOW TABLES and SHOW VIEWS. > We follows the Hive style which lists all tables and views with SHOW TABLES > and lists only views with SHOW VIEWS. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] docete opened a new pull request #11869: [FLINK-17111][table] Support SHOW VIEWS in Flink SQL
docete opened a new pull request #11869: URL: https://github.com/apache/flink/pull/11869 ## What is the purpose of the change FLINK-17106 introduces create/drop view in Flink SQL. But we can't list views from TableEnvironment or SQL. This PR supports SHOW VIEWS in Flink SQL. BTW: We follows the Hive style which lists all tables and views with SHOW TABLES and lists only views with SHOW VIEWS. ## Brief change log - 546d367 Add show views syntax in sql parser - fe6f4d9 Add listViews interface in TableEnvironment - 39fb3f9 hotfix create/drop view in batch mode for legacy planner - 05288fe Support SHOW VIEWS in blink planner - 28223e2 Support SHOW VIEWS in legacy planner ## Verifying this change This change added tests ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (**yes** / no) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (**yes** / no) - If yes, how is the feature documented? (not applicable / docs / **JavaDocs** / not documented) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11867: [FLINK-17309][e2e tests][WIP]TPC-DS fail to run data generator
flinkbot edited a comment on issue #11867: URL: https://github.com/apache/flink/pull/11867#issuecomment-617863974 ## CI report: * 9c3d9347f989a84184f598190271f5e0b4703ba0 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161547778) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=92) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-17332) Fix restart policy not equals to Never for native task manager pods
Canbin Zheng created FLINK-17332:
Summary: Fix restart policy not equals to Never for native task
manager pods
Key: FLINK-17332
URL: https://issues.apache.org/jira/browse/FLINK-17332
Project: Flink
Issue Type: Bug
Components: Deployment / Kubernetes
Affects Versions: 1.10.0, 1.10.1
Reporter: Canbin Zheng
Fix For: 1.11.0
Currently, we do not explicitly set the {{RestartPolicy}} for the TaskManager
Pod in native K8s setups so that it is {{Always}} by default. The task manager
pod itself should not restart the failed Container, the decision should always
made by the job manager.
Therefore, this ticket proposes to set the {{RestartPolicy}} to {{Never}} for
the task manager pods.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-17332) Fix restart policy not equals to Never for native task manager pods
[
https://issues.apache.org/jira/browse/FLINK-17332?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Canbin Zheng updated FLINK-17332:
-
Description:
Currently, we do not explicitly set the {{RestartPolicy}} for the task manager
pods in the native K8s setups so that it is {{Always}} by default. The task
manager pod itself should not restart the failed Container, the decision should
always be made by the job manager.
Therefore, this ticket proposes to set the {{RestartPolicy}} to {{Never}} for
the task manager pods.
was:
Currently, we do not explicitly set the {{RestartPolicy}} for the TaskManager
Pod in native K8s setups so that it is {{Always}} by default. The task manager
pod itself should not restart the failed Container, the decision should always
made by the job manager.
Therefore, this ticket proposes to set the {{RestartPolicy}} to {{Never}} for
the task manager pods.
> Fix restart policy not equals to Never for native task manager pods
> ---
>
> Key: FLINK-17332
> URL: https://issues.apache.org/jira/browse/FLINK-17332
> Project: Flink
> Issue Type: Bug
> Components: Deployment / Kubernetes
>Affects Versions: 1.10.0, 1.10.1
>Reporter: Canbin Zheng
>Priority: Major
> Fix For: 1.11.0
>
>
> Currently, we do not explicitly set the {{RestartPolicy}} for the task
> manager pods in the native K8s setups so that it is {{Always}} by default.
> The task manager pod itself should not restart the failed Container, the
> decision should always be made by the job manager.
> Therefore, this ticket proposes to set the {{RestartPolicy}} to {{Never}} for
> the task manager pods.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #11797: [FLINK-17169][table-blink] Refactor BaseRow to use RowKind instead of byte header
flinkbot edited a comment on issue #11797: URL: https://github.com/apache/flink/pull/11797#issuecomment-615294694 ## CI report: * 85f40e3041783b1dbda1eb3b812f23e77936f7b3 UNKNOWN * b0730cb05f9d77f9d34ab7221020931ef5d2532d Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161547746) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=91) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-17331) Add NettyMessageContent interface for all the class which could be write to NettyMessage
Yangze Guo created FLINK-17331:
--
Summary: Add NettyMessageContent interface for all the class which
could be write to NettyMessage
Key: FLINK-17331
URL: https://issues.apache.org/jira/browse/FLINK-17331
Project: Flink
Issue Type: Improvement
Reporter: Yangze Guo
Currently, there are some classes, e.g. {{JobVertexID}}, {{ExecutionAttemptID}}
need to write to {{NettyMessage}}. However, the size of these classes in
{{ByteBuf}} are directly written in {{NettyMessage}} class, which is
error-prone. If someone edits those classes, there would be no warning or error
during the compile phase. I think it would be better to add a
{{NettyMessageContent}}(the name could be discussed) interface:
{code:java}
public interface NettyMessageContent {
void writeTo(ByteBuf bug)
int getContentLen();
}
{code}
Regarding the {{fromByteBuf}}, since it is a static method, we could not add it
to the interface. We might explain it in the javaDoc of {{NettyMessageContent}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-17330) Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking edges
[
https://issues.apache.org/jira/browse/FLINK-17330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Zhu Zhu updated FLINK-17330:
Description:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1 = {A1, B1, C1, D1}
R2 = {A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). This is
because R1 can be scheduled only if R2 finishes, while R2 can be scheduled only
if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
was:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1 = {A1, B1, C1, D1}
R2 = {A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
> Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking
> edges
> ---
>
> Key: FLINK-17330
> URL: https://issues.apache.org/jira/browse/FLINK-17330
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.11.0
>Reporter: Zhu Zhu
>Priority: Major
> Fix For: 1.11.0
>
>
> Imagine a job like this:
> A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
> A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
> parallelism=2 for all vertices.
> We will have 2 execution pipelined regions:
> R1 = {A1, B1, C1, D1}
> R2 = {A2, B2, C2, D2}
> R1 has a cross-region input edge (B2->D1).
> R2 has a cross-region input edge (B1->D2).
> Scheduling deadlock will happen since we schedule a region only when all its
> inputs are consumable (i.e. blocking partitions to be finished). This is
> because R1 can be scheduled only if R2 finishes, while R2 can be scheduled
> only if R1 finishes.
> To avoid this, one solution is to force a logical pipelined region with
> intra-region ALL-to-ALL blocking edges to form one only execution pipelined
> region, so that there would not be cyclic input dependency between regions.
> Besides that, we should also pay attention to avoid cyclic cross-region
> POINTWISE blocking edges.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-17330) Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking edges
[
https://issues.apache.org/jira/browse/FLINK-17330?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090210#comment-17090210
]
Zhu Zhu commented on FLINK-17330:
-
cc [~gjy] [~trohrmann]
Sorry this case was neglected.
What do you think of the proposal to "make logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region" to avoid cyclic input dependencies between regions?
> Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking
> edges
> ---
>
> Key: FLINK-17330
> URL: https://issues.apache.org/jira/browse/FLINK-17330
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.11.0
>Reporter: Zhu Zhu
>Priority: Major
> Fix For: 1.11.0
>
>
> Imagine a job like this:
> A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
> A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
> parallelism=2 for all vertices.
> We will have 2 execution pipelined regions:
> R1 = {A1, B1, C1, D1}
> R2 = {A2, B2, C2, D2}
> R1 has a cross-region input edge (B2->D1).
> R2 has a cross-region input edge (B1->D2).
> Scheduling deadlock will happen since we schedule a region only when all its
> inputs are consumable (i.e. blocking partitions to be finished). Because R1
> can be scheduled only if R2 finishes, while R2 can be scheduled only if R1
> finishes.
> To avoid this, one solution is to force a logical pipelined region with
> intra-region ALL-to-ALL blocking edges to form one only execution pipelined
> region, so that there would not be cyclic input dependency between regions.
> Besides that, we should also pay attention to avoid cyclic cross-region
> POINTWISE blocking edges.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-17330) Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking edges
[
https://issues.apache.org/jira/browse/FLINK-17330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Zhu Zhu updated FLINK-17330:
Description:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1={A1, B1, C1, D1}
R2={A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
was:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1={A1, B1, C1, D1}, R2={A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
> Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking
> edges
> ---
>
> Key: FLINK-17330
> URL: https://issues.apache.org/jira/browse/FLINK-17330
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.11.0
>Reporter: Zhu Zhu
>Priority: Major
> Fix For: 1.11.0
>
>
> Imagine a job like this:
> A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
> A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
> parallelism=2 for all vertices.
> We will have 2 execution pipelined regions:
> R1={A1, B1, C1, D1}
> R2={A2, B2, C2, D2}
> R1 has a cross-region input edge (B2->D1).
> R2 has a cross-region input edge (B1->D2).
> Scheduling deadlock will happen since we schedule a region only when all its
> inputs are consumable (i.e. blocking partitions to be finished). Because R1
> can be scheduled only if R2 finishes, while R2 can be scheduled only if R1
> finishes.
> To avoid this, one solution is to force a logical pipelined region with
> intra-region ALL-to-ALL blocking edges to form one only execution pipelined
> region, so that there would not be cyclic input dependency between regions.
> Besides that, we should also pay attention to avoid cyclic cross-region
> POINTWISE blocking edges.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-17330) Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking edges
[
https://issues.apache.org/jira/browse/FLINK-17330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Zhu Zhu updated FLINK-17330:
Description:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1 = {A1, B1, C1, D1}
R2 = {A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
was:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1={A1, B1, C1, D1}
R2={A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
> Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking
> edges
> ---
>
> Key: FLINK-17330
> URL: https://issues.apache.org/jira/browse/FLINK-17330
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.11.0
>Reporter: Zhu Zhu
>Priority: Major
> Fix For: 1.11.0
>
>
> Imagine a job like this:
> A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
> A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
> parallelism=2 for all vertices.
> We will have 2 execution pipelined regions:
> R1 = {A1, B1, C1, D1}
> R2 = {A2, B2, C2, D2}
> R1 has a cross-region input edge (B2->D1).
> R2 has a cross-region input edge (B1->D2).
> Scheduling deadlock will happen since we schedule a region only when all its
> inputs are consumable (i.e. blocking partitions to be finished). Because R1
> can be scheduled only if R2 finishes, while R2 can be scheduled only if R1
> finishes.
> To avoid this, one solution is to force a logical pipelined region with
> intra-region ALL-to-ALL blocking edges to form one only execution pipelined
> region, so that there would not be cyclic input dependency between regions.
> Besides that, we should also pay attention to avoid cyclic cross-region
> POINTWISE blocking edges.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-17330) Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking edges
[
https://issues.apache.org/jira/browse/FLINK-17330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Zhu Zhu updated FLINK-17330:
Description:
Imagine a job like this:
A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1={A1, B1, C1, D1}, R2={A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
was:
Imagine a job like this:
A --(pipelined FORWARD)--> B --(blocking ALL-to-ALL)--> D
A --(pipelined FORWARD)--> C --(pipelined FORWARD)--> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1={A1, B1, C1, D1}, R2={A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
> Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking
> edges
> ---
>
> Key: FLINK-17330
> URL: https://issues.apache.org/jira/browse/FLINK-17330
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Affects Versions: 1.11.0
>Reporter: Zhu Zhu
>Priority: Major
> Fix For: 1.11.0
>
>
> Imagine a job like this:
> A -- (pipelined FORWARD) --> B -- (blocking ALL-to-ALL) --> D
> A -- (pipelined FORWARD) --> C -- (pipelined FORWARD) --> D
> parallelism=2 for all vertices.
> We will have 2 execution pipelined regions:
> R1={A1, B1, C1, D1}, R2={A2, B2, C2, D2}
> R1 has a cross-region input edge (B2->D1).
> R2 has a cross-region input edge (B1->D2).
> Scheduling deadlock will happen since we schedule a region only when all its
> inputs are consumable (i.e. blocking partitions to be finished). Because R1
> can be scheduled only if R2 finishes, while R2 can be scheduled only if R1
> finishes.
> To avoid this, one solution is to force a logical pipelined region with
> intra-region ALL-to-ALL blocking edges to form one only execution pipelined
> region, so that there would not be cyclic input dependency between regions.
> Besides that, we should also pay attention to avoid cyclic cross-region
> POINTWISE blocking edges.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-17330) Avoid scheduling deadlocks caused by intra-logical-region ALL-to-ALL blocking edges
Zhu Zhu created FLINK-17330:
---
Summary: Avoid scheduling deadlocks caused by intra-logical-region
ALL-to-ALL blocking edges
Key: FLINK-17330
URL: https://issues.apache.org/jira/browse/FLINK-17330
Project: Flink
Issue Type: Sub-task
Components: Runtime / Coordination
Affects Versions: 1.11.0
Reporter: Zhu Zhu
Fix For: 1.11.0
Imagine a job like this:
A --(pipelined FORWARD)--> B --(blocking ALL-to-ALL)--> D
A --(pipelined FORWARD)--> C --(pipelined FORWARD)--> D
parallelism=2 for all vertices.
We will have 2 execution pipelined regions:
R1={A1, B1, C1, D1}, R2={A2, B2, C2, D2}
R1 has a cross-region input edge (B2->D1).
R2 has a cross-region input edge (B1->D2).
Scheduling deadlock will happen since we schedule a region only when all its
inputs are consumable (i.e. blocking partitions to be finished). Because R1 can
be scheduled only if R2 finishes, while R2 can be scheduled only if R1 finishes.
To avoid this, one solution is to force a logical pipelined region with
intra-region ALL-to-ALL blocking edges to form one only execution pipelined
region, so that there would not be cyclic input dependency between regions.
Besides that, we should also pay attention to avoid cyclic cross-region
POINTWISE blocking edges.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #11855: [FLINK-13639] Refactor the IntermediateResultPartitionID to consist o…
flinkbot edited a comment on issue #11855: URL: https://github.com/apache/flink/pull/11855#issuecomment-617596227 ## CI report: * 77720a95c9fb8163487dbec5bc82681f1e7f9fde Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161400024) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=54) * 32d5ffa4730232c0ae2d978c4a9537604e5510db UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-17328) Expose network metric for job vertex in rest api
[ https://issues.apache.org/jira/browse/FLINK-17328?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090203#comment-17090203 ] lining edited comment on FLINK-17328 at 4/23/20, 3:40 AM: -- [Gary Yao|https://issues.apache.org/jira/secure/ViewProfile.jspa?name=gjy] could you assign it to me? was (Author: lining): [~gary] could you assign it to me? > Expose network metric for job vertex in rest api > > > Key: FLINK-17328 > URL: https://issues.apache.org/jira/browse/FLINK-17328 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics, Runtime / REST >Reporter: lining >Priority: Major > > JobVertexDetailsHandler > * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, > inputFloatingBuffersUsageAvg > * back-pressured for show whether it is back pressured(merge all iths > subtasks) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-17328) Expose network metric for job vertex in rest api
[ https://issues.apache.org/jira/browse/FLINK-17328?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090203#comment-17090203 ] lining commented on FLINK-17328: [~gary] could you assign it to me? > Expose network metric for job vertex in rest api > > > Key: FLINK-17328 > URL: https://issues.apache.org/jira/browse/FLINK-17328 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics, Runtime / REST >Reporter: lining >Priority: Major > > JobVertexDetailsHandler > * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, > inputFloatingBuffersUsageAvg > * back-pressured for show whether it is back pressured(merge all iths > subtasks) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-14815) Expose network metric for sub task in rest api
[ https://issues.apache.org/jira/browse/FLINK-14815?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lining updated FLINK-14815: --- Description: * SubTask ** pool usage: outPoolUsage, inputExclusiveBuffersUsage, inputFloatingBuffersUsage. *** If the subtask is not back pressured, but it is causing backpressure (full input, empty output) *** By comparing exclusive/floating buffers usage, whether all channels are back-pressure or only some of them ** back-pressured for show whether it is back pressured. was: * SubTask ** pool usage: outPoolUsage, inputExclusiveBuffersUsage, inputFloatingBuffersUsage. *** If the subtask is not back pressured, but it is causing backpressure (full input, empty output) *** By comparing exclusive/floating buffers usage, whether all channels are back-pressure or only some of them ** back-pressured for show whether it is back pressured. * Vertex ** pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, inputFloatingBuffersUsageAvg ** back-pressured for show whether it is back pressured(merge all iths subtasks) > Expose network metric for sub task in rest api > -- > > Key: FLINK-14815 > URL: https://issues.apache.org/jira/browse/FLINK-14815 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics, Runtime / Network, Runtime / REST >Reporter: lining >Assignee: lining >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > * SubTask > ** pool usage: outPoolUsage, inputExclusiveBuffersUsage, > inputFloatingBuffersUsage. > *** If the subtask is not back pressured, but it is causing backpressure > (full input, empty output) > *** By comparing exclusive/floating buffers usage, whether all channels are > back-pressure or only some of them > ** back-pressured for show whether it is back pressured. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-17173) Supports query hint to config "IdleStateRetentionTime" per operator in SQL
[
https://issues.apache.org/jira/browse/FLINK-17173?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090202#comment-17090202
]
Jiahui Jiang commented on FLINK-17173:
--
[~danny0405] I just saw your [design
doc|[https://docs.google.com/document/d/1mykz-w2t1Yw7CH6NjUWpWqCAf_6YNKxSc59gXafrNCs/edit]]
for pluggable hints, I didn't realized that's supported already before. Then
it totally makes sense to have the hints to be per operator.
> Supports query hint to config "IdleStateRetentionTime" per operator in SQL
> --
>
> Key: FLINK-17173
> URL: https://issues.apache.org/jira/browse/FLINK-17173
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / API
>Affects Versions: 1.11.0
>Reporter: Danny Chen
>Priority: Major
>
> The motivation why we need this (copy from user mailing list [~qzhzm173227])
> In some of the use cases our users have, they have a couple of complex join
> queries where the key domains key evolving - we definitely want some sort of
> state retention for those queries; but there are other where the key domain
> doesn't evolve overtime, but there isn't really a guarantee on what's the
> maximum gap between 2 records of the same key to appear in the stream, we
> don't want to accidentally invalidate the state for those keys in these
> streams.
> Because of queries with different requirements can both exist in the
> pipeline, I think we have to config `IDLE_STATE_RETENTION_TIME` per operator.
> Just wondering, has similar requirement not come up much for SQL users
> before? (being able to set table / query configuration inside SQL queries)
> We are also a little bit concerned because right now since
> 'toRetractStream(Table, Class, QueryConfig)' is deprecated, relying on the
> fact that TableConfig is read during toDataStream feels like relying on an
> implementation details that just happens to work, and there is no guarantee
> that it will keep working in the future versions...
> Demo syntax:
> {code:sql}
> CREATE TABLE `/output` AS
> SELECT /*+ IDLE_STATE_RETENTION_TIME(minTime ='5m', maxTime ='11m') */ *
> FROM `/input1` a
> INNER JOIN `/input2` b
> ON a.column_name = b.column_name;
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-17329) Quickstarts Scala nightly e2e test failed on travis
Yu Li created FLINK-17329:
-
Summary: Quickstarts Scala nightly e2e test failed on travis
Key: FLINK-17329
URL: https://issues.apache.org/jira/browse/FLINK-17329
Project: Flink
Issue Type: Bug
Components: Quickstarts
Affects Versions: 1.10.0, 1.11.0
Reporter: Yu Li
Fix For: 1.11.0, 1.10.2
The `Quickstarts Scala nightly end-to-end test` case failed on travis due to
failed to download elastic search package:
{noformat}
Downloading Elasticsearch from
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.1.2.tar.gz
...
% Total% Received % Xferd Average Speed TimeTime Time Current
Dload Upload Total SpentLeft Speed
0 00 00 0 0 0 --:--:-- --:--:-- --:--:-- 0
33 31.7M 33 10.6M0 0 31.1M 0 0:00:01 --:--:-- 0:00:01 31.0M
curl: (56) GnuTLS recv error (-54): Error in the pull function.
gzip: stdin: unexpected end of file
tar: Unexpected EOF in archive
tar: Unexpected EOF in archive
tar: Error is not recoverable: exiting now
{noformat}
https://api.travis-ci.org/v3/job/677803024/log.txt
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-17328) Expose network metric for job vertex in rest api
[ https://issues.apache.org/jira/browse/FLINK-17328?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lining updated FLINK-17328: --- Description: JobVertexDetailsHandler * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, inputFloatingBuffersUsageAvg * back-pressured for show whether it is back pressured(merge all iths subtasks) was: JobDetailsHandler * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, inputFloatingBuffersUsageAvg * back-pressured for show whether it is back pressured(merge all iths subtasks) > Expose network metric for job vertex in rest api > > > Key: FLINK-17328 > URL: https://issues.apache.org/jira/browse/FLINK-17328 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics, Runtime / REST >Reporter: lining >Priority: Major > > JobVertexDetailsHandler > * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, > inputFloatingBuffersUsageAvg > * back-pressured for show whether it is back pressured(merge all iths > subtasks) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] wuchong commented on a change in pull request #11804: [FLINK-16473][doc][jdbc] add documentation for JDBCCatalog and PostgresCatalog
wuchong commented on a change in pull request #11804:
URL: https://github.com/apache/flink/pull/11804#discussion_r413482942
##
File path: docs/dev/table/catalogs.md
##
@@ -37,6 +41,97 @@ Or permanent metadata, like that in a Hive Metastore.
Catalogs provide a unified
The `GenericInMemoryCatalog` is an in-memory implementation of a catalog. All
objects will be available only for the lifetime of the session.
+### JDBCCatalog
+
+The `JDBCCatalog` enables users to connect Flink to relational databases over
JDBC protocol.
+
+ PostgresCatalog
+
+`PostgresCatalog` is the only implementation of JDBC Catalog at the moment.
+
+ Usage of JDBCCatalog
+
+Set a `JDBCatalog` with the following parameters:
+
+- name: required, name of the catalog
+- default database: required, default database to connect to
+- username: required, username of Postgres account
+- password: required, password of the account
+- base url: required, should be of format "jdbc:postgresql://:", and
should not contain database name here
+
+
+
+{% highlight java %}
+
+EnvironmentSettings settings =
EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+String name= "mypg";
+String defaultDatabase = "mydb";
+String username= "...";
+String password= "...";
+String baseUrl = "..."
+
+JDBCCatalog catalog = new JDBCCatalog(name, defaultDatabase, username,
password, baseUrl);
+tableEnv.registerCatalog("mypg", catalog);
+
+// set the JDBCCatalog as the current catalog of the session
+tableEnv.useCatalog("mypg");
+{% endhighlight %}
+
+
+{% highlight scala %}
+
+val settings =
EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
+val tableEnv = TableEnvironment.create(settings)
+
+val name= "mypg"
+val defaultDatabase = "mydb"
+val username= "..."
+val password= "..."
+val baseUrl = "..."
+
+val catalog = new JDBCCatalog(name, defaultDatabase, username, password,
baseUrl)
+tableEnv.registerCatalog("mypg", catalog)
+
+// set the JDBCCatalog as the current catalog of the session
+tableEnv.useCatalog("mypg")
+{% endhighlight %}
+
+
+{% highlight yaml %}
+
+execution:
+planner: blink
+...
+current-catalog: mypg # set the JDBCCatalog as the current catalog of the
session
+current-database: mydb
+
+catalogs:
+ - name: mypg
+ type: jdbc
+ default-database: mydb
+ username: ...
+ password: ...
+ base-url: ...
+{% endhighlight %}
+
+
Review comment:
Could you name this `SQL` to align with other tabs in this page?
And please also move it before `YAML`, we should recommend users to use
`SQL` instead of `YAML`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-14815) Expose network metric for sub task in rest api
[ https://issues.apache.org/jira/browse/FLINK-14815?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lining updated FLINK-14815: --- Summary: Expose network metric for sub task in rest api (was: Expose network metric in rest api) > Expose network metric for sub task in rest api > -- > > Key: FLINK-14815 > URL: https://issues.apache.org/jira/browse/FLINK-14815 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics, Runtime / Network, Runtime / REST >Reporter: lining >Assignee: lining >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > * SubTask > ** pool usage: outPoolUsage, inputExclusiveBuffersUsage, > inputFloatingBuffersUsage. > *** If the subtask is not back pressured, but it is causing backpressure > (full input, empty output) > *** By comparing exclusive/floating buffers usage, whether all channels are > back-pressure or only some of them > ** back-pressured for show whether it is back pressured. > * Vertex > ** pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, > inputFloatingBuffersUsageAvg > ** back-pressured for show whether it is back pressured(merge all iths > subtasks) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-17328) Expose network metric for job vertex in rest api
[ https://issues.apache.org/jira/browse/FLINK-17328?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lining updated FLINK-17328: --- Parent: FLINK-14712 Issue Type: Sub-task (was: Improvement) > Expose network metric for job vertex in rest api > > > Key: FLINK-17328 > URL: https://issues.apache.org/jira/browse/FLINK-17328 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Metrics, Runtime / REST >Reporter: lining >Priority: Major > > JobDetailsHandler > * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, > inputFloatingBuffersUsageAvg > * back-pressured for show whether it is back pressured(merge all iths > subtasks) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-17328) Expose network metric for job vertex in rest api
lining created FLINK-17328: -- Summary: Expose network metric for job vertex in rest api Key: FLINK-17328 URL: https://issues.apache.org/jira/browse/FLINK-17328 Project: Flink Issue Type: Improvement Components: Runtime / Metrics, Runtime / REST Reporter: lining JobDetailsHandler * pool usage: outPoolUsageAvg, inputExclusiveBuffersUsageAvg, inputFloatingBuffersUsageAvg * back-pressured for show whether it is back pressured(merge all iths subtasks) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] wuchong commented on a change in pull request #11837: [FLINK-16160][table-planner-blink] Fix proctime()/rowtime() doesn't w…
wuchong commented on a change in pull request #11837:
URL: https://github.com/apache/flink/pull/11837#discussion_r413470860
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/planner/catalog/CatalogSchemaTable.java
##
@@ -153,6 +166,27 @@ private static RelDataType getRowType(RelDataTypeFactory
typeFactory,
}
}
}
+
+ // The following block is a workaround to support tables
defined by TableEnvironment.connect() and
+ // the actual table sources implement
DefinedProctimeAttribute/DefinedRowtimeAttributes.
+ // It should be removed after we remove
DefinedProctimeAttribute/DefinedRowtimeAttributes.
+ Optional sourceOpt = findAndCreateTableSource(new
TableConfig().getConfiguration());
+ if
(tableSchema.getTableColumns().stream().noneMatch(TableColumn::isGenerated)
+ && tableSchema.getWatermarkSpecs().isEmpty()
+ && sourceOpt.isPresent()) {
+ TableSource source = sourceOpt.get();
+ if ((source instanceof DefinedProctimeAttribute
+ && ((DefinedProctimeAttribute)
source).getProctimeAttribute() != null)
+ ||
+ (source instanceof
DefinedRowtimeAttributes
+ &&
((DefinedRowtimeAttributes) source).getRowtimeAttributeDescriptors() != null
+ &&
!((DefinedRowtimeAttributes)
source).getRowtimeAttributeDescriptors().isEmpty())) {
Review comment:
Add a `hasProctimeAttribute` to `TableSourceValidation` and the
condition can be simplified into
```java
if (hasRowtimeAttribute(source) && hasProctimeAttribute(source))
```
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/planner/catalog/CatalogSchemaTable.java
##
@@ -153,6 +166,27 @@ private static RelDataType getRowType(RelDataTypeFactory
typeFactory,
}
}
}
+
+ // The following block is a workaround to support tables
defined by TableEnvironment.connect() and
+ // the actual table sources implement
DefinedProctimeAttribute/DefinedRowtimeAttributes.
+ // It should be removed after we remove
DefinedProctimeAttribute/DefinedRowtimeAttributes.
+ Optional sourceOpt = findAndCreateTableSource(new
TableConfig().getConfiguration());
Review comment:
```suggestion
Optional> sourceOpt =
findAndCreateTableSource(new TableConfig().getConfiguration());
```
Add `` to TableSource to avoid IDEA warning.
##
File path:
flink-table/flink-table-planner-blink/src/test/scala/org/apache/flink/table/planner/plan/stream/sql/TableSourceTest.scala
##
@@ -130,6 +131,60 @@ class TableSourceTest extends TableTestBase {
util.verifyPlan(sqlQuery)
}
+
+ @Test
+ def testLegacyRowTimeTableGroupWindow(): Unit = {
+util.tableEnv.connect(new ConnectorDescriptor("TestTableSourceWithTime",
1, false) {
+ override protected def toConnectorProperties: JMap[String, String] = {
+Collections.emptyMap()
+ }
Review comment:
Can we have a dedicated descriptor for `TestTableSourceWithTime`? This
code looks confusing.
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/planner/catalog/CatalogSchemaTable.java
##
@@ -153,6 +166,27 @@ private static RelDataType getRowType(RelDataTypeFactory
typeFactory,
}
}
}
+
+ // The following block is a workaround to support tables
defined by TableEnvironment.connect() and
+ // the actual table sources implement
DefinedProctimeAttribute/DefinedRowtimeAttributes.
+ // It should be removed after we remove
DefinedProctimeAttribute/DefinedRowtimeAttributes.
+ Optional sourceOpt = findAndCreateTableSource(new
TableConfig().getConfiguration());
+ if
(tableSchema.getTableColumns().stream().noneMatch(TableColumn::isGenerated)
+ && tableSchema.getWatermarkSpecs().isEmpty()
Review comment:
Add `isStreamingMode` into this condition, and
`findAndCreateTableSource` when the condition is satisfied.
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/planner/catalog/CatalogSchemaTable.java
##
@@ -153,6 +166,27 @@ private static RelDataType getRowType(RelDataTypeFactory
typeFactory,
}
}
}
+
+ // The following block is a
[jira] [Commented] (FLINK-17289) Translate tutorials/etl.md to chinese
[ https://issues.apache.org/jira/browse/FLINK-17289?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090188#comment-17090188 ] Li Ying commented on FLINK-17289: - Hi David, I'd like to do the translation. Could you please assigh this job to me :) > Translate tutorials/etl.md to chinese > - > > Key: FLINK-17289 > URL: https://issues.apache.org/jira/browse/FLINK-17289 > Project: Flink > Issue Type: Improvement > Components: chinese-translation, Documentation / Training >Reporter: David Anderson >Priority: Major > > This is one of the new tutorials, and it needs translation. > docs/tutorials/etl.zh.md does not exist yet. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #11859: [FLINK-16485][python] Support vectorized Python UDF in batch mode of old planner
flinkbot edited a comment on issue #11859: URL: https://github.com/apache/flink/pull/11859#issuecomment-617655293 ## CI report: * 6bfb3f29fa88ad7314ccd9bd3a9eb0568d63c9c9 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161400110) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=56) * d7d37b26b6dc41871ee56900f8e9b6ed16b3fcf6 Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161549162) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=94) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #10059: [FLINK-14543][FLINK-15901][table] Support partition for temporary table and HiveCatalog
flinkbot edited a comment on issue #10059: URL: https://github.com/apache/flink/pull/10059#issuecomment-548289939 ## CI report: * 91c3f6c3986386cd4f5c914029b807ecd979e50c Travis: [CANCELED](https://travis-ci.com/github/flink-ci/flink/builds/161448300) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=76) * 5f91592c6f010dbb52511c54568c5d3c82082433 UNKNOWN * 13dab75e74ed139bb8802dcf2de0ef87464f046b Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161549021) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=93) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-17323) ChannelStateReader rejects requests about unkown channels (Unaligned checkpoints)
[ https://issues.apache.org/jira/browse/FLINK-17323?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zhijiang closed FLINK-17323. Resolution: Fixed Merged in master: 07667d29181be2cd4281d36c8cdfbd9a6c4e704a > ChannelStateReader rejects requests about unkown channels (Unaligned > checkpoints) > - > > Key: FLINK-17323 > URL: https://issues.apache.org/jira/browse/FLINK-17323 > Project: Flink > Issue Type: Bug > Components: Runtime / Task >Affects Versions: 1.11.0 >Reporter: Roman Khachatryan >Assignee: Roman Khachatryan >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > > ChannelStateReader expects requests only for channels or subpartitions that > have state. > In case of upscaling or starting from scratch this behavior is incorrect. It > should return NO_MORE_DATA. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #11855: [FLINK-13639] Refactor the IntermediateResultPartitionID to consist o…
flinkbot edited a comment on issue #11855: URL: https://github.com/apache/flink/pull/11855#issuecomment-617596227 ## CI report: * 77720a95c9fb8163487dbec5bc82681f1e7f9fde Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161400024) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=54) * 32d5ffa4730232c0ae2d978c4a9537604e5510db UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11797: [FLINK-17169][table-blink] Refactor BaseRow to use RowKind instead of byte header
flinkbot edited a comment on issue #11797: URL: https://github.com/apache/flink/pull/11797#issuecomment-615294694 ## CI report: * 85f40e3041783b1dbda1eb3b812f23e77936f7b3 UNKNOWN * f4560ce97f1b94b5d3ffa9c280879f227fc4211a Travis: [FAILURE](https://travis-ci.com/github/flink-ci/flink/builds/161484823) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=85) * b0730cb05f9d77f9d34ab7221020931ef5d2532d Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161547746) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=91) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11867: [FLINK-17309][e2e tests][WIP]TPC-DS fail to run data generator
flinkbot edited a comment on issue #11867: URL: https://github.com/apache/flink/pull/11867#issuecomment-617863974 ## CI report: * 51571402e16bb71237a68a153191ba3a7d97bbf8 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161468937) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=83) * 9c3d9347f989a84184f598190271f5e0b4703ba0 Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161547778) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=92) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11859: [FLINK-16485][python] Support vectorized Python UDF in batch mode of old planner
flinkbot edited a comment on issue #11859: URL: https://github.com/apache/flink/pull/11859#issuecomment-617655293 ## CI report: * 6bfb3f29fa88ad7314ccd9bd3a9eb0568d63c9c9 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161400110) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=56) * d7d37b26b6dc41871ee56900f8e9b6ed16b3fcf6 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #10059: [FLINK-14543][FLINK-15901][table] Support partition for temporary table and HiveCatalog
flinkbot edited a comment on issue #10059: URL: https://github.com/apache/flink/pull/10059#issuecomment-548289939 ## CI report: * 91c3f6c3986386cd4f5c914029b807ecd979e50c Travis: [CANCELED](https://travis-ci.com/github/flink-ci/flink/builds/161448300) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=76) * 5f91592c6f010dbb52511c54568c5d3c82082433 UNKNOWN * 13dab75e74ed139bb8802dcf2de0ef87464f046b UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on issue #11794: [FLINK-17126] [table-planner] Correct the execution behavior of BatchTableEnvironment
wuchong commented on issue #11794: URL: https://github.com/apache/flink/pull/11794#issuecomment-618137477 Hi @kl0u , we refactored `BatchTableEnviroment` to use `executor` to submit the Pipline. That's why we need an executor for `CollectionEnvironment` because tests are using `CollectionEnvironment`. Sorry for didn't ping you to review this part. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11867: [FLINK-17309][e2e tests][WIP]TPC-DS fail to run data generator
flinkbot edited a comment on issue #11867: URL: https://github.com/apache/flink/pull/11867#issuecomment-617863974 ## CI report: * 51571402e16bb71237a68a153191ba3a7d97bbf8 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161468937) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=83) * 9c3d9347f989a84184f598190271f5e0b4703ba0 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11797: [FLINK-17169][table-blink] Refactor BaseRow to use RowKind instead of byte header
flinkbot edited a comment on issue #11797: URL: https://github.com/apache/flink/pull/11797#issuecomment-615294694 ## CI report: * 85f40e3041783b1dbda1eb3b812f23e77936f7b3 UNKNOWN * f4560ce97f1b94b5d3ffa9c280879f227fc4211a Travis: [FAILURE](https://travis-ci.com/github/flink-ci/flink/builds/161484823) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=85) * b0730cb05f9d77f9d34ab7221020931ef5d2532d UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11855: [FLINK-13639] Refactor the IntermediateResultPartitionID to consist o…
flinkbot edited a comment on issue #11855: URL: https://github.com/apache/flink/pull/11855#issuecomment-617596227 ## CI report: * 77720a95c9fb8163487dbec5bc82681f1e7f9fde Travis: [PENDING](https://travis-ci.com/github/flink-ci/flink/builds/161400024) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=54) * 32d5ffa4730232c0ae2d978c4a9537604e5510db UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] godfreyhe commented on issue #11794: [FLINK-17126] [table-planner] Correct the execution behavior of BatchTableEnvironment
godfreyhe commented on issue #11794: URL: https://github.com/apache/flink/pull/11794#issuecomment-618133036 hi @kl0u `CollectionEnvironment` is used in flink-table-planner for testing, e.g. `org.apache.flink.table.runtime.batch.sql.TableEnvironmentITCase#testInsertIntoMemoryTable` and `org.apache.flink.table.runtime.batch.table.TableSinkITCase#testOutputFormatTableSink`. User could also use a collection as source for demo. After we use executor to submit a job, an executor for `CollectionEnvironment` is also needed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on issue #11855: [FLINK-13639] Refactor the IntermediateResultPartitionID to consist o…
KarmaGYZ commented on issue #11855: URL: https://github.com/apache/flink/pull/11855#issuecomment-618130733 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on issue #11855: [FLINK-13639] Refactor the IntermediateResultPartitionID to consist o…
KarmaGYZ commented on issue #11855: URL: https://github.com/apache/flink/pull/11855#issuecomment-618130670 @flinkbot run azure This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] leonardBang commented on issue #11867: [FLINK-17309][e2e tests][WIP]TPC-DS fail to run data generator
leonardBang commented on issue #11867: URL: https://github.com/apache/flink/pull/11867#issuecomment-618130592 @flinkbot run azure This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on a change in pull request #11838: [FLINK-16965] Convert Graphite reporter to plugin
KarmaGYZ commented on a change in pull request #11838:
URL: https://github.com/apache/flink/pull/11838#discussion_r413450999
##
File path: flink-metrics/flink-metrics-graphite/pom.xml
##
@@ -65,31 +65,4 @@ under the License.
${dropwizard.version}
-
-
-
-
- org.apache.maven.plugins
- maven-shade-plugin
-
-
- shade-flink
- package
-
- shade
-
-
-
-
-
org.apache.flink:flink-metrics-dropwizard
-
io.dropwizard.metrics:metrics-core
Review comment:
You mean we still need to shade "io.dropwizard.metrics:metrics-core" and
"io.dropwizard.metrics:metrics-graphite", right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (FLINK-16766) Support create StreamTableEnvironment without passing StreamExecutionEnvironment
[ https://issues.apache.org/jira/browse/FLINK-16766?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Hequn Cheng closed FLINK-16766. --- Resolution: Resolved > Support create StreamTableEnvironment without passing > StreamExecutionEnvironment > > > Key: FLINK-16766 > URL: https://issues.apache.org/jira/browse/FLINK-16766 > Project: Flink > Issue Type: Improvement > Components: API / Python >Reporter: Hequn Cheng >Assignee: Nicholas Jiang >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > Time Spent: 10m > Remaining Estimate: 0h > > Currently, when we create a BatchTableEnvironment, the ExecutionEnvironment > is an optional parameter, while for the StreamTableEnvironment, the > ExecutionEnvironment is not optional. We should make them consistent -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-16766) Support create StreamTableEnvironment without passing StreamExecutionEnvironment
[ https://issues.apache.org/jira/browse/FLINK-16766?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Hequn Cheng updated FLINK-16766: Fix Version/s: (was: 1.9.4) (was: 1.10.1) > Support create StreamTableEnvironment without passing > StreamExecutionEnvironment > > > Key: FLINK-16766 > URL: https://issues.apache.org/jira/browse/FLINK-16766 > Project: Flink > Issue Type: Improvement > Components: API / Python >Reporter: Hequn Cheng >Assignee: Nicholas Jiang >Priority: Major > Labels: pull-request-available > Fix For: 1.11.0 > > Time Spent: 10m > Remaining Estimate: 0h > > Currently, when we create a BatchTableEnvironment, the ExecutionEnvironment > is an optional parameter, while for the StreamTableEnvironment, the > ExecutionEnvironment is not optional. We should make them consistent -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-16766) Support create StreamTableEnvironment without passing StreamExecutionEnvironment
[ https://issues.apache.org/jira/browse/FLINK-16766?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17090151#comment-17090151 ] Hequn Cheng commented on FLINK-16766: - Resolved in 1.11.0 via c6949540c6c639695e1a0fb2684b467c6219024f > Support create StreamTableEnvironment without passing > StreamExecutionEnvironment > > > Key: FLINK-16766 > URL: https://issues.apache.org/jira/browse/FLINK-16766 > Project: Flink > Issue Type: Improvement > Components: API / Python >Reporter: Hequn Cheng >Assignee: Nicholas Jiang >Priority: Major > Labels: pull-request-available > Fix For: 1.10.1, 1.11.0, 1.9.4 > > Time Spent: 10m > Remaining Estimate: 0h > > Currently, when we create a BatchTableEnvironment, the ExecutionEnvironment > is an optional parameter, while for the StreamTableEnvironment, the > ExecutionEnvironment is not optional. We should make them consistent -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #11804: [FLINK-16473][doc][jdbc] add documentation for JDBCCatalog and PostgresCatalog
flinkbot edited a comment on issue #11804: URL: https://github.com/apache/flink/pull/11804#issuecomment-615960634 ## CI report: * d467bd31393f9dc171b6625f9053360b73bfd64d Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161487842) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=86) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] docete commented on issue #11837: [FLINK-16160][table-planner-blink] Fix proctime()/rowtime() doesn't w…
docete commented on issue #11837: URL: https://github.com/apache/flink/pull/11837#issuecomment-618122640 @wuchong pls have a look This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11867: [FLINK-17309][e2e tests][WIP]TPC-DS fail to run data generator
flinkbot edited a comment on issue #11867: URL: https://github.com/apache/flink/pull/11867#issuecomment-617863974 ## CI report: * 51571402e16bb71237a68a153191ba3a7d97bbf8 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161468937) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=83) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11865: Revert "[FLINK-14499][metric] MetricRegistry#getMetricQueryServiceGatewayRpcAddress is Nonnull"
flinkbot edited a comment on issue #11865: URL: https://github.com/apache/flink/pull/11865#issuecomment-617839769 ## CI report: * 7a81c3644e88e09b2a88c1737c495a83f8fbde6c Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161461284) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=82) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11853: [FLINK-15006][table-planner] Add option to shuffle-by-partition when dynamic inserting
flinkbot edited a comment on issue #11853: URL: https://github.com/apache/flink/pull/11853#issuecomment-617586421 ## CI report: * 99b58fba1e22bdbba0896f0aba181eafc6a28e7f Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161461206) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=81) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11863: [FLINK-17048][mesos] Add memory related JVM args to Mesos JM startup scripts
flinkbot edited a comment on issue #11863: URL: https://github.com/apache/flink/pull/11863#issuecomment-617687609 ## CI report: * d559c7119084b47c163dd4e1523b3f9487d88e82 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161452814) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=79) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11864: [FLINK-17301] Set BIND_HOST to localhost in TaskManagerRunnerStartupTest
flinkbot edited a comment on issue #11864: URL: https://github.com/apache/flink/pull/11864#issuecomment-617827070 ## CI report: * e0907be73cf672f719d282a4e80a99a1e4cb7e13 Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161456797) Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=80) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on issue #11804: [FLINK-16473][doc][jdbc] add documentation for JDBCCatalog and PostgresCatalog
flinkbot edited a comment on issue #11804: URL: https://github.com/apache/flink/pull/11804#issuecomment-615960634 ## CI report: * d467bd31393f9dc171b6625f9053360b73bfd64d Travis: [SUCCESS](https://travis-ci.com/github/flink-ci/flink/builds/161487842) Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=86) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org