[GitHub] [hbase] taklwu commented on pull request #4414: HBASE-27013 Introduce read all bytes when using pread for prefetch
taklwu commented on PR #4414: URL: https://github.com/apache/hbase/pull/4414#issuecomment-1121943249 spotless check is saying something unrelated to my change..should I fix all of them ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4414: HBASE-27013 Introduce read all bytes when using pread for prefetch
Apache-HBase commented on PR #4414: URL: https://github.com/apache/hbase/pull/4414#issuecomment-1121936269 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 0m 46s | Docker mode activated. | ||| _ Prechecks _ | | +1 :green_heart: | dupname | 0m 0s | No case conflicting files found. | | +1 :green_heart: | hbaseanti | 0m 0s | Patch does not have any anti-patterns. | | +1 :green_heart: | @author | 0m 0s | The patch does not contain any @author tags. | ||| _ master Compile Tests _ | | +0 :ok: | mvndep | 0m 50s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 3m 30s | master passed | | +1 :green_heart: | compile | 2m 46s | master passed | | +1 :green_heart: | checkstyle | 0m 38s | master passed | | -1 :x: | spotless | 0m 40s | branch has 66 errors when running spotless:check, run spotless:apply to fix. | | +1 :green_heart: | spotbugs | 1m 38s | master passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 10s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 2m 10s | the patch passed | | +1 :green_heart: | compile | 2m 39s | the patch passed | | +1 :green_heart: | javac | 2m 39s | the patch passed | | +1 :green_heart: | checkstyle | 0m 37s | the patch passed | | +1 :green_heart: | whitespace | 0m 0s | The patch has no whitespace issues. | | +1 :green_heart: | hadoopcheck | 11m 49s | Patch does not cause any errors with Hadoop 3.1.2 3.2.2 3.3.1. | | -1 :x: | spotless | 0m 32s | patch has 66 errors when running spotless:check, run spotless:apply to fix. | | +1 :green_heart: | spotbugs | 1m 48s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | asflicense | 0m 15s | The patch does not generate ASF License warnings. | | | | 35m 57s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4414/2/artifact/yetus-general-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4414 | | Optional Tests | dupname asflicense javac spotbugs hadoopcheck hbaseanti spotless checkstyle compile | | uname | Linux 5659d2664266 5.4.0-1043-aws #45~18.04.1-Ubuntu SMP Fri Apr 9 23:32:25 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | master / f6e9d3e1dd | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | spotless | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4414/2/artifact/yetus-general-check/output/branch-spotless.txt | | spotless | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4414/2/artifact/yetus-general-check/output/patch-spotless.txt | | Max. process+thread count | 64 (vs. ulimit of 3) | | modules | C: hbase-common hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4414/2/console | | versions | git=2.17.1 maven=3.6.3 spotbugs=4.2.2 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HBASE-26994) MasterFileSystem create directory without permission check
[
https://issues.apache.org/jira/browse/HBASE-26994?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534135#comment-17534135
]
Hudson commented on HBASE-26994:
Results for branch branch-2.4
[build #349 on
builds.a.o|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.4/349/]:
(x) *{color:red}-1 overall{color}*
details (if available):
(/) {color:green}+1 general checks{color}
-- For more information [see general
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.4/349/General_20Nightly_20Build_20Report/]
(/) {color:green}+1 jdk8 hadoop2 checks{color}
-- For more information [see jdk8 (hadoop2)
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.4/349/JDK8_20Nightly_20Build_20Report_20_28Hadoop2_29/]
(/) {color:green}+1 jdk8 hadoop3 checks{color}
-- For more information [see jdk8 (hadoop3)
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.4/349/JDK8_20Nightly_20Build_20Report_20_28Hadoop3_29/]
(/) {color:green}+1 jdk11 hadoop3 checks{color}
-- For more information [see jdk11
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.4/349/JDK11_20Nightly_20Build_20Report_20_28Hadoop3_29/]
(/) {color:green}+1 source release artifact{color}
-- See build output for details.
(x) {color:red}-1 client integration test{color}
--Failed when running client tests on top of Hadoop 2. [see log for
details|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.4/349//artifact/output-integration/hadoop-2.log].
(note that this means we didn't run on Hadoop 3)
> MasterFileSystem create directory without permission check
> --
>
> Key: HBASE-26994
> URL: https://issues.apache.org/jira/browse/HBASE-26994
> Project: HBase
> Issue Type: Bug
> Components: master
>Affects Versions: 2.4.12
>Reporter: Zhang Dongsheng
>Assignee: Zhang Dongsheng
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3, 2.4.13
>
> Attachments: HBASE-26994.patch
>
>
> Method checkStagingDir and checkSubDir first check if directory is exist ,if
> not , create it with special permission. If exist then setPermission for this
> directory. BUT if not exist ,we still need set special permission for this
> directory
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [hbase] Apache-HBase commented on pull request #4382: HBASE-26925 Create WAL event tracker table to track all the WAL events.
Apache-HBase commented on PR #4382: URL: https://github.com/apache/hbase/pull/4382#issuecomment-1121916394 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 1m 1s | Docker mode activated. | | -0 :warning: | yetus | 0m 2s | Unprocessed flag(s): --brief-report-file --spotbugs-strict-precheck --whitespace-eol-ignore-list --whitespace-tabs-ignore-list --quick-hadoopcheck | ||| _ Prechecks _ | ||| _ HBASE-26913-replication-observability-framework Compile Tests _ | | +0 :ok: | mvndep | 0m 36s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 3m 25s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | compile | 1m 44s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | shadedjars | 4m 28s | branch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 19s | HBASE-26913-replication-observability-framework passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 11s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 3m 9s | the patch passed | | +1 :green_heart: | compile | 1m 48s | the patch passed | | +1 :green_heart: | javac | 1m 48s | the patch passed | | +1 :green_heart: | shadedjars | 4m 20s | patch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 17s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | unit | 1m 53s | hbase-common in the patch passed. | | +1 :green_heart: | unit | 0m 39s | hbase-hadoop-compat in the patch passed. | | +1 :green_heart: | unit | 1m 38s | hbase-client in the patch passed. | | -1 :x: | unit | 237m 40s | hbase-server in the patch failed. | | | | 268m 16s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/artifact/yetus-jdk11-hadoop3-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4382 | | Optional Tests | javac javadoc unit shadedjars compile | | uname | Linux 1082917d34e4 5.4.0-1025-aws #25~18.04.1-Ubuntu SMP Fri Sep 11 12:03:04 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | HBASE-26913-replication-observability-framework / 64a6ba3647 | | Default Java | AdoptOpenJDK-11.0.10+9 | | unit | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/artifact/yetus-jdk11-hadoop3-check/output/patch-unit-hbase-server.txt | | Test Results | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/testReport/ | | Max. process+thread count | 2666 (vs. ulimit of 3) | | modules | C: hbase-common hbase-hadoop-compat hbase-client hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/console | | versions | git=2.17.1 maven=3.6.3 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4382: HBASE-26925 Create WAL event tracker table to track all the WAL events.
Apache-HBase commented on PR #4382: URL: https://github.com/apache/hbase/pull/4382#issuecomment-1121885763 :confetti_ball: **+1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 0m 24s | Docker mode activated. | | -0 :warning: | yetus | 0m 2s | Unprocessed flag(s): --brief-report-file --spotbugs-strict-precheck --whitespace-eol-ignore-list --whitespace-tabs-ignore-list --quick-hadoopcheck | ||| _ Prechecks _ | ||| _ HBASE-26913-replication-observability-framework Compile Tests _ | | +0 :ok: | mvndep | 0m 12s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 2m 12s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | compile | 1m 20s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | shadedjars | 3m 38s | branch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 5s | HBASE-26913-replication-observability-framework passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 13s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 2m 9s | the patch passed | | +1 :green_heart: | compile | 1m 26s | the patch passed | | +1 :green_heart: | javac | 1m 26s | the patch passed | | +1 :green_heart: | shadedjars | 3m 38s | patch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 5s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | unit | 1m 25s | hbase-common in the patch passed. | | +1 :green_heart: | unit | 0m 35s | hbase-hadoop-compat in the patch passed. | | +1 :green_heart: | unit | 1m 8s | hbase-client in the patch passed. | | +1 :green_heart: | unit | 214m 30s | hbase-server in the patch passed. | | | | 237m 2s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/artifact/yetus-jdk8-hadoop3-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4382 | | Optional Tests | javac javadoc unit shadedjars compile | | uname | Linux 32ac203e45cb 5.4.0-96-generic #109-Ubuntu SMP Wed Jan 12 16:49:16 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | HBASE-26913-replication-observability-framework / 64a6ba3647 | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | Test Results | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/testReport/ | | Max. process+thread count | 3360 (vs. ulimit of 3) | | modules | C: hbase-common hbase-hadoop-compat hbase-client hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/console | | versions | git=2.17.1 maven=3.6.3 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] taklwu commented on a diff in pull request #4414: HBASE-27013 Introduce read all bytes when using pread for prefetch
taklwu commented on code in PR #4414:
URL: https://github.com/apache/hbase/pull/4414#discussion_r868786596
##
hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java:
##
@@ -284,6 +311,10 @@ private static boolean preadWithExtraDirectly(ByteBuff
buff, FSDataInputStream d
throw e;
}
if (ret < 0) {
+if (remain <= extraLen) {
+ // break for the "extra data" when hitting end of stream and
remaining is necessary
+ break;
Review Comment:
you got it right. e.g. if there is a case that we read a HFile does not have
the trailer, and just end with the last data block, we're hitting here.
I added that because I found this logic exists already as part of
BlockIOUtils#readWithExtraOnHeap (see below).
https://github.com/apache/hbase/blob/f6e9d3e1dd6546663319c436286ab58dd0e731ed/hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java#L154-L156
I thought this is good for handling some case that we don't expect
automatically, but we can remove it to let the premature EOF throws back to the
client.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (HBASE-27013) Introduce read all bytes when using pread for prefetch
[
https://issues.apache.org/jira/browse/HBASE-27013?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534042#comment-17534042
]
Tak-Lon (Stephen) Wu edited comment on HBASE-27013 at 5/10/22 3:40 AM:
---
bq. we can not reuse the stream to send multiple pread requests with random
offset
the concept of reuse the same stream is about how much it read a head
(readahead range) from a single/current HTTP call to the object store, e.g. S3.
If seek/pread ask the the range that has been already read ahead from the HTTP
response, we don't need to reopen a new HTTP to maintain the streaming data. in
other words, it's a different type of streaming implementation that based on a
HTTP connection to the blob storage. the problem of this prefetch is that, if
we're using {{fs.s3a.experimental.input.fadvise=sequential}} as that we have
read a lot of data from the remote data into a local buffer, we don't want to
completely drain and abort the connection. (meanwhile, we knew that
{{fs.s3a.experimental.input.fadvise=random}}) can read small data into buffer
one at a time but it's slower a lot)
bq. Seems not like a good enough pread implementation
I would say we're using the HDFS semantic with blob storage like S3A, such that
we're doing interesting thing for any supported blob storage. HDFS, as Josh
also pointed out, is just faster a lot than any file system implementation
written for blob storage
bq. FSDataInputStream may be used by different read requests so even if you
fixed this problem, it could still introduce a lot of aborts as different read
request may read from different offsets...
So, it won't introduce other aborts when reading other offsets because the
problem we're facing in this JIRA only for Prefetch, and I should have proved
that in my prototype. To view it in the technical way, it's the other way
around that, we're closing and aborting as of today without my change.
Where the improvement of this JIRA is only about a Store open or prefetch when
Store Open, the actual usage is to customize the prefetch (via Store File
Manager) with the proposed configuration ({{hfile.pread.all.bytes.enabled}})
during the store is opening and use this optional read all bytes feature. (but
don't provide this store file manager because this option is disabled by
default)
To sum, if we're introducing a lot of aborts, then I think our implementation
isn't right but I still don't find a case that we have introduced new aborts if
we're reading the extra header that is part of the data block of the HFile.
was (Author: taklwu):
bq. we can not reuse the stream to send multiple pread requests with random
offset
the concept of reuse the same stream is about how much it read a head
(readahead range) from a single/current HTTP call to the object store, e.g. S3.
If seek/pread ask the the range that has been already read ahead from the HTTP
response, we don't need to reopen a new HTTP to maintain the streaming data. in
other words, it's a different type of streaming implementation that based on a
HTTP connection to the blob storage. the problem of this prefetch is that, if
we're using {{fs.s3a.experimental.input.fadvise=sequential}} as that we have
read a lot of data from the remote data into a local buffer, we don't want to
completely drain and abort the connection. (meanwhile, we knew that
{{fs.s3a.experimental.input.fadvise=random}}) can read small data into buffer
one at a time but it's slower a lot)
bq. Seems not like a good enough pread implementation
I would say we're using the HDFS semantic with blob storage like S3A, such that
we're doing interesting thing for any supported blob storage. HDFS, as Josh
also pointed out, is just faster a lot than any file system implementation
written for blob storage
bq. FSDataInputStream may be used by different read requests so even if you
fixed this problem, it could still introduce a lot of aborts as different read
request may read from different offsets...
So, it won't introduce other aborts when reading other offsets because the
problem we're facing in this JIRA only for Prefetch, and I should have proved
that in my prototype. To view it in the technical way, it's the other way
around that, we're closing and aborting as of today without my change.
Where the improvement of this JIRA is only about a Store open or prefetch when
Store Open, the actual usage is to customize the prefetch (via Store File
Manager) with the proposed configuration ({{hfile.pread.all.bytes.enabled}})
during the store is opening and use this optional read all bytes feature. (but
don't provide this store file manager because this option is disabled by
default)
To sum, if we're introducing a lot of aborts, then I think our implementation
isn't right but I still don't find a case that we can introduce abort if we're
reading the extra head
[jira] [Updated] (HBASE-27019) Remove TRACE level logging in hbase-compression modules
[
https://issues.apache.org/jira/browse/HBASE-27019?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andrew Kyle Purtell updated HBASE-27019:
Fix Version/s: 2.5.0
3.0.0-alpha-3
> Remove TRACE level logging in hbase-compression modules
> ---
>
> Key: HBASE-27019
> URL: https://issues.apache.org/jira/browse/HBASE-27019
> Project: HBase
> Issue Type: Bug
>Reporter: Andrew Kyle Purtell
>Assignee: Andrew Kyle Purtell
>Priority: Trivial
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> TRACE level logging is expensive enough to warrant removal. They were useful
> during development but now are just overhead.
> {noformat}
> 12700390224.07% 127 jbyte_disjoint_arraycopy
> {noformat}
> {noformat}
> [ 0] jbyte_disjoint_arraycopy
> [ 1] org.slf4j.impl.Reload4jLoggerAdapter.isTraceEnabled
> [ 2] org.slf4j.impl.Reload4jLoggerAdapter.trace
> [ 3]
> org.apache.hadoop.hbase.io.compress.aircompressor.HadoopCompressor.setInput
> [ 4] org.apache.hadoop.io.compress.BlockCompressorStream.write
> [ 5] java.io.OutputStream.write
> [ 6] com.salesforce.hbase.util.TestUtils.outputStreamTest
> [ 7] com.salesforce.hbase.util.TestUtils.outputStreamTest
> [ 8] com.salesforce.hbase.BenchmarkAircompressorLz4.test
> [ 9]
> com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_avgt_jmhStub
> [10]
> com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_AverageTime
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (HBASE-27019) Remove TRACE level logging in hbase-compression modules
[
https://issues.apache.org/jira/browse/HBASE-27019?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andrew Kyle Purtell updated HBASE-27019:
Description:
TRACE level logging is expensive enough to warrant removal. They were useful
during development but now are just overhead.
{noformat}
12700390224.07% 127 jbyte_disjoint_arraycopy
{noformat}
e.g.
{noformat}
[ 0] jbyte_disjoint_arraycopy
[ 1] org.slf4j.impl.Reload4jLoggerAdapter.isTraceEnabled
[ 2] org.slf4j.impl.Reload4jLoggerAdapter.trace
[ 3]
org.apache.hadoop.hbase.io.compress.aircompressor.HadoopCompressor.setInput
[ 4] org.apache.hadoop.io.compress.BlockCompressorStream.write
[ 5] java.io.OutputStream.write
[ 6] com.salesforce.hbase.util.TestUtils.outputStreamTest
[ 7] com.salesforce.hbase.util.TestUtils.outputStreamTest
[ 8] com.salesforce.hbase.BenchmarkAircompressorLz4.test
[ 9]
com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_avgt_jmhStub
[10]
com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_AverageTime
{noformat}
was:
TRACE level logging is expensive enough to warrant removal. They were useful
during development but now are just overhead.
{noformat}
12700390224.07% 127 jbyte_disjoint_arraycopy
{noformat}
{noformat}
[ 0] jbyte_disjoint_arraycopy
[ 1] org.slf4j.impl.Reload4jLoggerAdapter.isTraceEnabled
[ 2] org.slf4j.impl.Reload4jLoggerAdapter.trace
[ 3]
org.apache.hadoop.hbase.io.compress.aircompressor.HadoopCompressor.setInput
[ 4] org.apache.hadoop.io.compress.BlockCompressorStream.write
[ 5] java.io.OutputStream.write
[ 6] com.salesforce.hbase.util.TestUtils.outputStreamTest
[ 7] com.salesforce.hbase.util.TestUtils.outputStreamTest
[ 8] com.salesforce.hbase.BenchmarkAircompressorLz4.test
[ 9]
com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_avgt_jmhStub
[10]
com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_AverageTime
{noformat}
> Remove TRACE level logging in hbase-compression modules
> ---
>
> Key: HBASE-27019
> URL: https://issues.apache.org/jira/browse/HBASE-27019
> Project: HBase
> Issue Type: Bug
>Reporter: Andrew Kyle Purtell
>Assignee: Andrew Kyle Purtell
>Priority: Trivial
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> TRACE level logging is expensive enough to warrant removal. They were useful
> during development but now are just overhead.
> {noformat}
> 12700390224.07% 127 jbyte_disjoint_arraycopy
> {noformat}
> e.g.
> {noformat}
> [ 0] jbyte_disjoint_arraycopy
> [ 1] org.slf4j.impl.Reload4jLoggerAdapter.isTraceEnabled
> [ 2] org.slf4j.impl.Reload4jLoggerAdapter.trace
> [ 3]
> org.apache.hadoop.hbase.io.compress.aircompressor.HadoopCompressor.setInput
> [ 4] org.apache.hadoop.io.compress.BlockCompressorStream.write
> [ 5] java.io.OutputStream.write
> [ 6] com.salesforce.hbase.util.TestUtils.outputStreamTest
> [ 7] com.salesforce.hbase.util.TestUtils.outputStreamTest
> [ 8] com.salesforce.hbase.BenchmarkAircompressorLz4.test
> [ 9]
> com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_avgt_jmhStub
> [10]
> com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_AverageTime
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Created] (HBASE-27019) Remove TRACE level logging in hbase-compression modules
Andrew Kyle Purtell created HBASE-27019:
---
Summary: Remove TRACE level logging in hbase-compression modules
Key: HBASE-27019
URL: https://issues.apache.org/jira/browse/HBASE-27019
Project: HBase
Issue Type: Bug
Reporter: Andrew Kyle Purtell
TRACE level logging is expensive enough to warrant removal. They were useful
during development but now are just overhead.
{noformat}
12700390224.07% 127 jbyte_disjoint_arraycopy
{noformat}
{noformat}
[ 0] jbyte_disjoint_arraycopy
[ 1] org.slf4j.impl.Reload4jLoggerAdapter.isTraceEnabled
[ 2] org.slf4j.impl.Reload4jLoggerAdapter.trace
[ 3]
org.apache.hadoop.hbase.io.compress.aircompressor.HadoopCompressor.setInput
[ 4] org.apache.hadoop.io.compress.BlockCompressorStream.write
[ 5] java.io.OutputStream.write
[ 6] com.salesforce.hbase.util.TestUtils.outputStreamTest
[ 7] com.salesforce.hbase.util.TestUtils.outputStreamTest
[ 8] com.salesforce.hbase.BenchmarkAircompressorLz4.test
[ 9]
com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_avgt_jmhStub
[10]
com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_AverageTime
{noformat}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Assigned] (HBASE-27019) Remove TRACE level logging in hbase-compression modules
[
https://issues.apache.org/jira/browse/HBASE-27019?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andrew Kyle Purtell reassigned HBASE-27019:
---
Assignee: Andrew Kyle Purtell
> Remove TRACE level logging in hbase-compression modules
> ---
>
> Key: HBASE-27019
> URL: https://issues.apache.org/jira/browse/HBASE-27019
> Project: HBase
> Issue Type: Bug
>Reporter: Andrew Kyle Purtell
>Assignee: Andrew Kyle Purtell
>Priority: Trivial
>
> TRACE level logging is expensive enough to warrant removal. They were useful
> during development but now are just overhead.
> {noformat}
> 12700390224.07% 127 jbyte_disjoint_arraycopy
> {noformat}
> {noformat}
> [ 0] jbyte_disjoint_arraycopy
> [ 1] org.slf4j.impl.Reload4jLoggerAdapter.isTraceEnabled
> [ 2] org.slf4j.impl.Reload4jLoggerAdapter.trace
> [ 3]
> org.apache.hadoop.hbase.io.compress.aircompressor.HadoopCompressor.setInput
> [ 4] org.apache.hadoop.io.compress.BlockCompressorStream.write
> [ 5] java.io.OutputStream.write
> [ 6] com.salesforce.hbase.util.TestUtils.outputStreamTest
> [ 7] com.salesforce.hbase.util.TestUtils.outputStreamTest
> [ 8] com.salesforce.hbase.BenchmarkAircompressorLz4.test
> [ 9]
> com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_avgt_jmhStub
> [10]
> com.salesforce.hbase.jmh_generated.BenchmarkAircompressorLz4_test_jmhTest.test_AverageTime
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [hbase] tomscut commented on pull request #4411: HBASE-27003 Optimize log format for PerformanceEvaluation
tomscut commented on PR #4411: URL: https://github.com/apache/hbase/pull/4411#issuecomment-1121750311 Thanks @virajjasani for your review. I found some spotless report in https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4411/1/artifact/yetus-general-check/output/patch-spotless.txt. This has nothing to do with the change, right? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4416: HBASE-27018 Add a tool command list_liveservers
Apache-HBase commented on PR #4416: URL: https://github.com/apache/hbase/pull/4416#issuecomment-1121746870 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 0m 37s | Docker mode activated. | | -0 :warning: | yetus | 0m 2s | Unprocessed flag(s): --brief-report-file --spotbugs-strict-precheck --whitespace-eol-ignore-list --whitespace-tabs-ignore-list --quick-hadoopcheck | ||| _ Prechecks _ | ||| _ master Compile Tests _ | | +1 :green_heart: | mvninstall | 4m 13s | master passed | | +1 :green_heart: | javadoc | 0m 18s | master passed | ||| _ Patch Compile Tests _ | | +1 :green_heart: | mvninstall | 3m 33s | the patch passed | | +1 :green_heart: | javadoc | 0m 11s | the patch passed | ||| _ Other Tests _ | | -1 :x: | unit | 10m 6s | hbase-shell in the patch failed. | | | | 20m 6s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-jdk11-hadoop3-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4416 | | Optional Tests | javac javadoc unit | | uname | Linux 5b9af2cf1609 5.4.0-96-generic #109-Ubuntu SMP Wed Jan 12 16:49:16 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | master / f6e9d3e1dd | | Default Java | AdoptOpenJDK-11.0.10+9 | | unit | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-jdk11-hadoop3-check/output/patch-unit-hbase-shell.txt | | Test Results | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/testReport/ | | Max. process+thread count | 1416 (vs. ulimit of 3) | | modules | C: hbase-shell U: hbase-shell | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/console | | versions | git=2.17.1 maven=3.6.3 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4416: HBASE-27018 Add a tool command list_liveservers
Apache-HBase commented on PR #4416: URL: https://github.com/apache/hbase/pull/4416#issuecomment-1121741071 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 0m 37s | Docker mode activated. | | -0 :warning: | yetus | 0m 3s | Unprocessed flag(s): --brief-report-file --spotbugs-strict-precheck --whitespace-eol-ignore-list --whitespace-tabs-ignore-list --quick-hadoopcheck | ||| _ Prechecks _ | ||| _ master Compile Tests _ | | +1 :green_heart: | mvninstall | 3m 38s | master passed | | +1 :green_heart: | javadoc | 0m 9s | master passed | ||| _ Patch Compile Tests _ | | +1 :green_heart: | mvninstall | 2m 9s | the patch passed | | +1 :green_heart: | javadoc | 0m 8s | the patch passed | ||| _ Other Tests _ | | -1 :x: | unit | 7m 37s | hbase-shell in the patch failed. | | | | 15m 21s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-jdk8-hadoop3-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4416 | | Optional Tests | javac javadoc unit | | uname | Linux 137c82539d9e 5.4.0-1043-aws #45~18.04.1-Ubuntu SMP Fri Apr 9 23:32:25 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | master / f6e9d3e1dd | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | unit | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-jdk8-hadoop3-check/output/patch-unit-hbase-shell.txt | | Test Results | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/testReport/ | | Max. process+thread count | 1499 (vs. ulimit of 3) | | modules | C: hbase-shell U: hbase-shell | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/console | | versions | git=2.17.1 maven=3.6.3 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4382: HBASE-26925 Create WAL event tracker table to track all the WAL events.
Apache-HBase commented on PR #4382: URL: https://github.com/apache/hbase/pull/4382#issuecomment-1121738810 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 1m 16s | Docker mode activated. | ||| _ Prechecks _ | | +1 :green_heart: | dupname | 0m 1s | No case conflicting files found. | | +1 :green_heart: | hbaseanti | 0m 0s | Patch does not have any anti-patterns. | | +1 :green_heart: | @author | 0m 0s | The patch does not contain any @author tags. | ||| _ HBASE-26913-replication-observability-framework Compile Tests _ | | +0 :ok: | mvndep | 0m 12s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 2m 10s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | compile | 3m 45s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | checkstyle | 1m 8s | HBASE-26913-replication-observability-framework passed | | +0 :ok: | refguide | 1m 51s | branch has no errors when building the reference guide. See footer for rendered docs, which you should manually inspect. | | +1 :green_heart: | spotless | 0m 41s | branch has no errors when running spotless:check. | | +1 :green_heart: | spotbugs | 2m 45s | HBASE-26913-replication-observability-framework passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 11s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 2m 15s | the patch passed | | +1 :green_heart: | compile | 3m 40s | the patch passed | | +1 :green_heart: | javac | 3m 40s | the patch passed | | -0 :warning: | checkstyle | 0m 31s | hbase-server: The patch generated 1 new + 13 unchanged - 0 fixed = 14 total (was 13) | | +1 :green_heart: | whitespace | 0m 0s | The patch has no whitespace issues. | | +1 :green_heart: | xml | 0m 1s | The patch has no ill-formed XML file. | | +0 :ok: | refguide | 1m 51s | patch has no errors when building the reference guide. See footer for rendered docs, which you should manually inspect. | | +1 :green_heart: | hadoopcheck | 11m 43s | Patch does not cause any errors with Hadoop 3.1.2 3.2.2 3.3.1. | | -1 :x: | spotless | 0m 36s | patch has 34 errors when running spotless:check, run spotless:apply to fix. | | +1 :green_heart: | spotbugs | 3m 9s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | asflicense | 0m 37s | The patch does not generate ASF License warnings. | | | | 44m 38s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/artifact/yetus-general-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4382 | | Optional Tests | dupname asflicense javac spotbugs hadoopcheck hbaseanti spotless checkstyle compile refguide xml | | uname | Linux c8d4937bd6ae 5.4.0-90-generic #101-Ubuntu SMP Fri Oct 15 20:00:55 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | HBASE-26913-replication-observability-framework / 64a6ba3647 | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | refguide | https://nightlies.apache.org/hbase/HBase-PreCommit-GitHub-PR/PR-4382/6/yetus-general-check/output/branch-site/book.html | | checkstyle | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/artifact/yetus-general-check/output/diff-checkstyle-hbase-server.txt | | refguide | https://nightlies.apache.org/hbase/HBase-PreCommit-GitHub-PR/PR-4382/6/yetus-general-check/output/patch-site/book.html | | spotless | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/artifact/yetus-general-check/output/patch-spotless.txt | | Max. process+thread count | 64 (vs. ulimit of 3) | | modules | C: hbase-common hbase-hadoop-compat hbase-client hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/6/console | | versions | git=2.17.1 maven=3.6.3 spotbugs=4.2.2 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4416: HBASE-27018 Add a tool command list_liveservers
Apache-HBase commented on PR #4416: URL: https://github.com/apache/hbase/pull/4416#issuecomment-1121737371 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 1m 4s | Docker mode activated. | ||| _ Prechecks _ | | +1 :green_heart: | dupname | 0m 0s | No case conflicting files found. | | +1 :green_heart: | @author | 0m 0s | The patch does not contain any @author tags. | ||| _ master Compile Tests _ | | +1 :green_heart: | mvninstall | 2m 27s | master passed | | -1 :x: | spotless | 0m 39s | branch has 68 errors when running spotless:check, run spotless:apply to fix. | ||| _ Patch Compile Tests _ | | +1 :green_heart: | mvninstall | 2m 9s | the patch passed | | -0 :warning: | rubocop | 0m 3s | The patch generated 3 new + 23 unchanged - 0 fixed = 26 total (was 23) | | +1 :green_heart: | whitespace | 0m 0s | The patch has no whitespace issues. | | -1 :x: | spotless | 0m 36s | patch has 68 errors when running spotless:check, run spotless:apply to fix. | ||| _ Other Tests _ | | +1 :green_heart: | asflicense | 0m 10s | The patch does not generate ASF License warnings. | | | | 8m 19s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-general-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4416 | | Optional Tests | dupname asflicense javac spotless rubocop | | uname | Linux ffc0b595e5b7 5.4.0-90-generic #101-Ubuntu SMP Fri Oct 15 20:00:55 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | master / f6e9d3e1dd | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | spotless | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-general-check/output/branch-spotless.txt | | rubocop | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-general-check/output/diff-patch-rubocop.txt | | spotless | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/artifact/yetus-general-check/output/patch-spotless.txt | | Max. process+thread count | 66 (vs. ulimit of 3) | | modules | C: hbase-shell U: hbase-shell | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4416/1/console | | versions | git=2.17.1 maven=3.6.3 rubocop=0.80.0 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] tomscut opened a new pull request, #4416: HBASE-27018 Add a tool command list_liveservers
tomscut opened a new pull request, #4416: URL: https://github.com/apache/hbase/pull/4416 To make it easier for us to query the living region Servers. We can add a command `list_liveservers`. There are already `list_deadServers` and `list_Decommissioned_regionServers`. 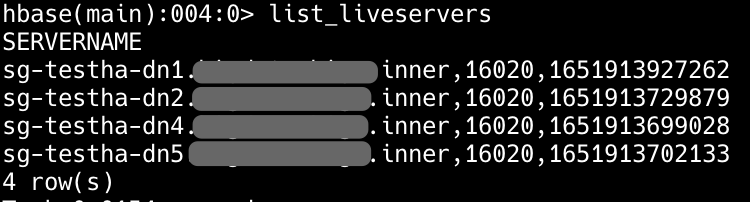 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HBASE-27018) Add a tool command list_liveservers
[ https://issues.apache.org/jira/browse/HBASE-27018?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Tao Li updated HBASE-27018: --- Attachment: image-2022-05-10-08-34-33-711.png > Add a tool command list_liveservers > --- > > Key: HBASE-27018 > URL: https://issues.apache.org/jira/browse/HBASE-27018 > Project: HBase > Issue Type: New Feature >Reporter: Tao Li >Assignee: Tao Li >Priority: Major > Attachments: image-2022-05-10-08-34-33-711.png > > > To make it easier for us to query the living region Servers. We can add a > command `list_liveservers`. There are already `list_deadServers` and > `list_Decommissioned_regionServers`. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (HBASE-27018) Add a tool command list_liveservers
[ https://issues.apache.org/jira/browse/HBASE-27018?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Tao Li updated HBASE-27018: --- Description: To make it easier for us to query the living region Servers. We can add a command `list_liveservers`. There are already `list_deadServers` and `list_Decommissioned_regionServers`. !image-2022-05-10-08-34-33-711.png|width=457,height=123! was:To make it easier for us to query the living region Servers. We can add a command `list_liveservers`. There are already `list_deadServers` and `list_Decommissioned_regionServers`. > Add a tool command list_liveservers > --- > > Key: HBASE-27018 > URL: https://issues.apache.org/jira/browse/HBASE-27018 > Project: HBase > Issue Type: New Feature >Reporter: Tao Li >Assignee: Tao Li >Priority: Major > Attachments: image-2022-05-10-08-34-33-711.png > > > To make it easier for us to query the living region Servers. We can add a > command `list_liveservers`. There are already `list_deadServers` and > `list_Decommissioned_regionServers`. > !image-2022-05-10-08-34-33-711.png|width=457,height=123! > -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (HBASE-27018) Add a tool command list_liveservers
Tao Li created HBASE-27018: -- Summary: Add a tool command list_liveservers Key: HBASE-27018 URL: https://issues.apache.org/jira/browse/HBASE-27018 Project: HBase Issue Type: New Feature Reporter: Tao Li Assignee: Tao Li To make it easier for us to query the living region Servers. We can add a command `list_liveservers`. There are already `list_deadServers` and `list_Decommissioned_regionServers`. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [hbase] Apache-HBase commented on pull request #4382: HBASE-26925 Create WAL event tracker table to track all the WAL events.
Apache-HBase commented on PR #4382: URL: https://github.com/apache/hbase/pull/4382#issuecomment-1121699013 :confetti_ball: **+1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 4m 32s | Docker mode activated. | | -0 :warning: | yetus | 0m 3s | Unprocessed flag(s): --brief-report-file --spotbugs-strict-precheck --whitespace-eol-ignore-list --whitespace-tabs-ignore-list --quick-hadoopcheck | ||| _ Prechecks _ | ||| _ HBASE-26913-replication-observability-framework Compile Tests _ | | +0 :ok: | mvndep | 0m 48s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 3m 36s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | compile | 1m 27s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | shadedjars | 3m 55s | branch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 10s | HBASE-26913-replication-observability-framework passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 11s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 2m 46s | the patch passed | | +1 :green_heart: | compile | 1m 29s | the patch passed | | +1 :green_heart: | javac | 1m 29s | the patch passed | | +1 :green_heart: | shadedjars | 3m 56s | patch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 4s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | unit | 1m 44s | hbase-common in the patch passed. | | +1 :green_heart: | unit | 0m 34s | hbase-hadoop-compat in the patch passed. | | +1 :green_heart: | unit | 1m 27s | hbase-client in the patch passed. | | +1 :green_heart: | unit | 236m 38s | hbase-server in the patch passed. | | | | 268m 13s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/artifact/yetus-jdk11-hadoop3-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4382 | | Optional Tests | javac javadoc unit shadedjars compile | | uname | Linux 516a994741c8 5.4.0-1025-aws #25~18.04.1-Ubuntu SMP Fri Sep 11 12:03:04 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | HBASE-26913-replication-observability-framework / 64a6ba3647 | | Default Java | AdoptOpenJDK-11.0.10+9 | | Test Results | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/testReport/ | | Max. process+thread count | 2697 (vs. ulimit of 3) | | modules | C: hbase-common hbase-hadoop-compat hbase-client hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/console | | versions | git=2.17.1 maven=3.6.3 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hbase] Apache-HBase commented on pull request #4382: HBASE-26925 Create WAL event tracker table to track all the WAL events.
Apache-HBase commented on PR #4382: URL: https://github.com/apache/hbase/pull/4382#issuecomment-1121684236 :broken_heart: **-1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 0m 26s | Docker mode activated. | | -0 :warning: | yetus | 0m 2s | Unprocessed flag(s): --brief-report-file --spotbugs-strict-precheck --whitespace-eol-ignore-list --whitespace-tabs-ignore-list --quick-hadoopcheck | ||| _ Prechecks _ | ||| _ HBASE-26913-replication-observability-framework Compile Tests _ | | +0 :ok: | mvndep | 0m 13s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 2m 22s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | compile | 1m 30s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | shadedjars | 3m 39s | branch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 6s | HBASE-26913-replication-observability-framework passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 13s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 2m 13s | the patch passed | | +1 :green_heart: | compile | 1m 26s | the patch passed | | +1 :green_heart: | javac | 1m 26s | the patch passed | | +1 :green_heart: | shadedjars | 3m 37s | patch has no errors when building our shaded downstream artifacts. | | +1 :green_heart: | javadoc | 1m 6s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | unit | 1m 28s | hbase-common in the patch passed. | | +1 :green_heart: | unit | 0m 34s | hbase-hadoop-compat in the patch passed. | | +1 :green_heart: | unit | 1m 9s | hbase-client in the patch passed. | | -1 :x: | unit | 210m 37s | hbase-server in the patch failed. | | | | 233m 45s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/artifact/yetus-jdk8-hadoop3-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4382 | | Optional Tests | javac javadoc unit shadedjars compile | | uname | Linux f69c571e89f0 5.4.0-96-generic #109-Ubuntu SMP Wed Jan 12 16:49:16 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | HBASE-26913-replication-observability-framework / 64a6ba3647 | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | unit | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/artifact/yetus-jdk8-hadoop3-check/output/patch-unit-hbase-server.txt | | Test Results | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/testReport/ | | Max. process+thread count | 2483 (vs. ulimit of 3) | | modules | C: hbase-common hbase-hadoop-compat hbase-client hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/console | | versions | git=2.17.1 maven=3.6.3 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (HBASE-27013) Introduce read all bytes when using pread for prefetch
[
https://issues.apache.org/jira/browse/HBASE-27013?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534042#comment-17534042
]
Tak-Lon (Stephen) Wu edited comment on HBASE-27013 at 5/9/22 10:24 PM:
---
bq. we can not reuse the stream to send multiple pread requests with random
offset
the concept of reuse the same stream is about how much it read a head
(readahead range) from a single/current HTTP call to the object store, e.g. S3.
If seek/pread ask the the range that has been already read ahead from the HTTP
response, we don't need to reopen a new HTTP to maintain the streaming data. in
other words, it's a different type of streaming implementation that based on a
HTTP connection to the blob storage. the problem of this prefetch is that, if
we're using {{fs.s3a.experimental.input.fadvise=sequential}} as that we have
read a lot of data from the remote data into a local buffer, we don't want to
completely drain and abort the connection. (meanwhile, we knew that
{{fs.s3a.experimental.input.fadvise=random}}) can read small data into buffer
one at a time but it's slower a lot)
bq. Seems not like a good enough pread implementation
I would say we're using the HDFS semantic with blob storage like S3A, such that
we're doing interesting thing for any supported blob storage. HDFS, as Josh
also pointed out, is just faster a lot than any file system implementation
written for blob storage
bq. FSDataInputStream may be used by different read requests so even if you
fixed this problem, it could still introduce a lot of aborts as different read
request may read from different offsets...
So, it won't introduce other aborts when reading other offsets because the
problem we're facing in this JIRA only for Prefetch, and I should have proved
that in my prototype. To view it in the technical way, it's the other way
around that, we're closing and aborting as of today without my change.
Where the improvement of this JIRA is only about a Store open or prefetch when
Store Open, the actual usage is to customize the prefetch (via Store File
Manager) with the proposed configuration ({{hfile.pread.all.bytes.enabled}})
during the store is opening and use this optional read all bytes feature. (but
don't provide this store file manager because this option is disabled by
default)
To sum, if we're introducing a lot of aborts, then I think our implementation
isn't right but I still don't find a case that we can introduce abort if we're
reading the extra header that is part of the data block of the HFile
was (Author: taklwu):
bq. we can not reuse the stream to send multiple pread requests with random
offset
the concept of reuse the same stream is about how much it read a head
(readahead range) from a single/current HTTP call to the object store, e.g. S3.
If seek/pread ask the the range that has been already read ahead from the HTTP
response, we don't need to reopen a new HTTP to maintain the streaming data. in
other words, it's a different type of streaming implementation that based on a
HTTP connection to the blob storage. the problem of this prefetch is that, if
we're using {{fs.s3a.experimental.input.fadvise=sequential}} as that we have
read a lot of data from the remote data into a local buffer, we don't want to
completely drain and abort the connection. (meanwhile, we knew that
{{fs.s3a.experimental.input.fadvise=random}}) can read small data into buffer
one at a time but it's slower a lot)
bq. Seems not like a good enough pread implementation
I would say we're using the HDFS semantic with blob storage like S3A, such that
we're doing interesting thing for any supported blob storage. HDFS, as Josh
also pointed out, is just faster a lot than any file system implementation
written for blob storage
> FSDataInputStream may be used by different read requests so even if you fixed
> this problem, it could still introduce a lot of aborts as different read
> request may read from different offsets...
So, it won't introduce other aborts when reading other offsets because the
problem we're facing in this JIRA only for Prefetch, and I should have proved
that in my prototype. To view it in the technical way, it's the other way
around that, we're closing and aborting as of today without my change.
Where the improvement of this JIRA is only about a Store open or prefetch when
Store Open, the actual usage is to customize the prefetch (via Store File
Manager) with the proposed configuration ({{hfile.pread.all.bytes.enabled}})
during the store is opening and use this optional read all bytes feature. (but
don't provide this store file manager because this option is disabled by
default)
To sum, if we're introducing a lot of aborts, then I think our implementation
isn't right but I still don't find a case that we can introduce abort if we're
reading the extra header that
[jira] [Commented] (HBASE-27013) Introduce read all bytes when using pread for prefetch
[
https://issues.apache.org/jira/browse/HBASE-27013?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534042#comment-17534042
]
Tak-Lon (Stephen) Wu commented on HBASE-27013:
--
bq. we can not reuse the stream to send multiple pread requests with random
offset
the concept of reuse the same stream is about how much it read a head
(readahead range) from a single/current HTTP call to the object store, e.g. S3.
If seek/pread ask the the range that has been already read ahead from the HTTP
response, we don't need to reopen a new HTTP to maintain the streaming data. in
other words, it's a different type of streaming implementation that based on a
HTTP connection to the blob storage. the problem of this prefetch is that, if
we're using {{fs.s3a.experimental.input.fadvise=sequential}} as that we have
read a lot of data from the remote data into a local buffer, we don't want to
completely drain and abort the connection. (meanwhile, we knew that
{{fs.s3a.experimental.input.fadvise=random}}) can read small data into buffer
one at a time but it's slower a lot)
bq. Seems not like a good enough pread implementation
I would say we're using the HDFS semantic with blob storage like S3A, such that
we're doing interesting thing for any supported blob storage. HDFS, as Josh
also pointed out, is just faster a lot than any file system implementation
written for blob storage
> FSDataInputStream may be used by different read requests so even if you fixed
> this problem, it could still introduce a lot of aborts as different read
> request may read from different offsets...
So, it won't introduce other aborts when reading other offsets because the
problem we're facing in this JIRA only for Prefetch, and I should have proved
that in my prototype. To view it in the technical way, it's the other way
around that, we're closing and aborting as of today without my change.
Where the improvement of this JIRA is only about a Store open or prefetch when
Store Open, the actual usage is to customize the prefetch (via Store File
Manager) with the proposed configuration ({{hfile.pread.all.bytes.enabled}})
during the store is opening and use this optional read all bytes feature. (but
don't provide this store file manager because this option is disabled by
default)
To sum, if we're introducing a lot of aborts, then I think our implementation
isn't right but I still don't find a case that we can introduce abort if we're
reading the extra header that is part of the data block of the HFile
> Introduce read all bytes when using pread for prefetch
> --
>
> Key: HBASE-27013
> URL: https://issues.apache.org/jira/browse/HBASE-27013
> Project: HBase
> Issue Type: Improvement
> Components: HFile, Performance
>Affects Versions: 2.5.0, 2.6.0, 3.0.0-alpha-3, 2.4.13
>Reporter: Tak-Lon (Stephen) Wu
>Assignee: Tak-Lon (Stephen) Wu
>Priority: Major
>
> h2. Problem statement
> When prefetching HFiles from blob storage like S3 and use it with the storage
> implementation like S3A, we found there is a logical issue in HBase pread
> that causes the reading of the remote HFile aborts the input stream multiple
> times. This aborted stream and reopen slow down the reads and trigger many
> aborted bytes and waste time in recreating the connection especially when SSL
> is enabled.
> h2. ROOT CAUSE
> The root cause of above issue was due to
> [BlockIOUtils#preadWithExtra|https://github.com/apache/hbase/blob/9c8c9e7fbf8005ea89fa9b13d6d063b9f0240443/hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java#L214-L257]
> is reading an input stream that does not guarrentee to return the data block
> and the next block header as an option data to be cached.
> In the case of the input stream read short and when the input stream read
> passed the length of the necessary data block with few more bytes within the
> size of next block header, the
> [BlockIOUtils#preadWithExtra|https://github.com/apache/hbase/blob/9c8c9e7fbf8005ea89fa9b13d6d063b9f0240443/hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java#L214-L257]
> returns to the caller without a cached the next block header. As a result,
> before HBase tries to read the next block,
> [HFileBlock#readBlockDataInternal|https://github.com/apache/hbase/blob/9c8c9e7fbf8005ea89fa9b13d6d063b9f0240443/hbase-server/src/main/java/org/apache/hadoop/hbase/io/hfile/HFileBlock.java#L1648-L1664]
> in hbase tries to re-read the next block header from the input stream. Here,
> the reusable input stream has move the current position pointer ahead from
> the offset of the last read data block, when using with the [S3A
> implementation|https://github.com/apache/hadoop/blob/29401c820377d02a992eecde51083cf87f8e57
[GitHub] [hbase] joshelser commented on a diff in pull request #4414: HBASE-27013 Introduce read all bytes when using pread for prefetch
joshelser commented on code in PR #4414:
URL: https://github.com/apache/hbase/pull/4414#discussion_r868474782
##
hbase-server/src/test/java/org/apache/hadoop/hbase/io/hfile/TestBlockIOUtils.java:
##
@@ -92,6 +107,102 @@ public void testReadFully() throws IOException {
assertArrayEquals(Bytes.toBytes(s), heapBuf);
}
+ @Test
+ public void testPreadWithReadFullBytes() throws IOException {
+testPreadReadFullBytesInternal(true);
+ }
+
+ @Test
+ public void testPreadWithoutReadFullBytes() throws IOException {
+testPreadReadFullBytesInternal(false);
+ }
+
+ private void testPreadReadFullBytesInternal(boolean readAllBytes) throws
IOException {
+Configuration conf = TEST_UTIL.getConfiguration();
+conf.setBoolean(HConstants.HFILE_PREAD_ALL_BYTES_ENABLED_KEY,
readAllBytes);
+FileSystem fs = TEST_UTIL.getTestFileSystem();
+Path path = new Path(TEST_UTIL.getDataTestDirOnTestFS(),
testName.getMethodName());
+Random rand = new Random();
Review Comment:
There may be value in being able to specify a specific seed here, such that
if you do see a test failure in a specific case, we can actually try to
reproduce that failure.
##
hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java:
##
@@ -284,6 +311,10 @@ private static boolean preadWithExtraDirectly(ByteBuff
buff, FSDataInputStream d
throw e;
}
if (ret < 0) {
+if (remain <= extraLen) {
+ // break for the "extra data" when hitting end of stream and
remaining is necessary
+ break;
Review Comment:
If I rephrase your comment: the client is asking for data which cannot
possibly exist because the `extraLen` would read off the end of the file. The
client told us to try to read an extra header after the current datablock but
there is no "next header" to read because we're at the end of the file.
I worry that this may mask a problem where a file is corrupt but we would
miss the "premature EOF" IOException which should be thrown.
##
hbase-server/src/test/java/org/apache/hadoop/hbase/io/hfile/TestBlockIOUtils.java:
##
@@ -92,6 +107,102 @@ public void testReadFully() throws IOException {
assertArrayEquals(Bytes.toBytes(s), heapBuf);
}
+ @Test
+ public void testPreadWithReadFullBytes() throws IOException {
+testPreadReadFullBytesInternal(true);
+ }
+
+ @Test
+ public void testPreadWithoutReadFullBytes() throws IOException {
+testPreadReadFullBytesInternal(false);
+ }
+
+ private void testPreadReadFullBytesInternal(boolean readAllBytes) throws
IOException {
+Configuration conf = TEST_UTIL.getConfiguration();
+conf.setBoolean(HConstants.HFILE_PREAD_ALL_BYTES_ENABLED_KEY,
readAllBytes);
+FileSystem fs = TEST_UTIL.getTestFileSystem();
+Path path = new Path(TEST_UTIL.getDataTestDirOnTestFS(),
testName.getMethodName());
+Random rand = new Random();
+long totalDataBlockBytes = writeBlocks(TEST_UTIL.getConfiguration(), rand,
+ Compression.Algorithm.GZ, path);
+readDataBlocksAndVerify(fs, path, totalDataBlockBytes);
+ }
+
+ private long writeBlocks(Configuration conf, Random rand,
Compression.Algorithm compressAlgo,
+Path path) throws IOException {
+FileSystem fs = HFileSystem.get(conf);
+FSDataOutputStream os = fs.create(path);
+HFileContext meta = new HFileContextBuilder().withHBaseCheckSum(true)
+
.withCompression(compressAlgo).withBytesPerCheckSum(HFile.DEFAULT_BYTES_PER_CHECKSUM).build();
Review Comment:
`.withBytesPerCheckSum(HFile.DEFAULT_BYTES_PER_CHECKSUM)` is unnecessary. As
is `withHBaseCheckSum(true)`
##
hbase-server/src/test/java/org/apache/hadoop/hbase/io/hfile/TestBlockIOUtils.java:
##
@@ -92,6 +107,102 @@ public void testReadFully() throws IOException {
assertArrayEquals(Bytes.toBytes(s), heapBuf);
}
+ @Test
+ public void testPreadWithReadFullBytes() throws IOException {
+testPreadReadFullBytesInternal(true);
+ }
+
+ @Test
+ public void testPreadWithoutReadFullBytes() throws IOException {
+testPreadReadFullBytesInternal(false);
+ }
+
+ private void testPreadReadFullBytesInternal(boolean readAllBytes) throws
IOException {
+Configuration conf = TEST_UTIL.getConfiguration();
+conf.setBoolean(HConstants.HFILE_PREAD_ALL_BYTES_ENABLED_KEY,
readAllBytes);
+FileSystem fs = TEST_UTIL.getTestFileSystem();
+Path path = new Path(TEST_UTIL.getDataTestDirOnTestFS(),
testName.getMethodName());
+Random rand = new Random();
+long totalDataBlockBytes = writeBlocks(TEST_UTIL.getConfiguration(), rand,
+ Compression.Algorithm.GZ, path);
+readDataBlocksAndVerify(fs, path, totalDataBlockBytes);
+ }
+
+ private long writeBlocks(Configuration conf, Random rand,
Compression.Algorithm compressAlgo,
+Path path) throws IOException {
+FileSystem fs = HFileSystem.get(conf);
+FSDataOutputStream os = fs.create(path);
+HFileConte
[jira] [Updated] (HBASE-26953) CallDroppedException message says "server 0.0.0.0 is overloaded"
[ https://issues.apache.org/jira/browse/HBASE-26953?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Rushabh Shah updated HBASE-26953: - Labels: newbie (was: ) > CallDroppedException message says "server 0.0.0.0 is overloaded" > > > Key: HBASE-26953 > URL: https://issues.apache.org/jira/browse/HBASE-26953 > Project: HBase > Issue Type: Bug >Reporter: Bryan Beaudreault >Assignee: Ayesha Mosaddeque >Priority: Trivial > Labels: newbie > > This is not a super useful error when seen on the client side. Maybe we can > have it pull in the ServerName instead, or at the very least resolve to the > hostname. > > https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/hadoop/hbase/ipc/CallRunner.java#L213 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Assigned] (HBASE-26218) Better logging in CanaryTool
[ https://issues.apache.org/jira/browse/HBASE-26218?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Viraj Jasani reassigned HBASE-26218: Assignee: Ishika Soni (was: Kiran Kumar Maturi) > Better logging in CanaryTool > > > Key: HBASE-26218 > URL: https://issues.apache.org/jira/browse/HBASE-26218 > Project: HBase > Issue Type: Improvement >Reporter: Caroline Zhou >Assignee: Ishika Soni >Priority: Minor > > CanaryTool logs currently don't indicate which mode they pertain to – they > should at least make note of that. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Assigned] (HBASE-26511) hbase shell config override option does not work
[
https://issues.apache.org/jira/browse/HBASE-26511?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Viraj Jasani reassigned HBASE-26511:
Assignee: Tushar Raina (was: Kiran Kumar Maturi)
> hbase shell config override option does not work
>
>
> Key: HBASE-26511
> URL: https://issues.apache.org/jira/browse/HBASE-26511
> Project: HBase
> Issue Type: Bug
> Components: shell
>Affects Versions: 3.0.0-alpha-2
>Reporter: Istvan Toth
>Assignee: Tushar Raina
>Priority: Major
>
> According to the docs, we should be able to specify properties on the command
> line with the -D switch.
> https://hbase.apache.org/book.html#_overriding_configuration_starting_the_hbase_shell
> However:
> {noformat}
> ./bin/hbase shell
> -Dhbase.zookeeper.quorum=ZK0.remote.cluster.example.org,ZK1.remote.cluster.example.org,ZK2.remote.cluster.example.org
> -Draining=false
> Usage: shell [OPTIONS] [SCRIPTFILE [ARGUMENTS]]
> -d | --debugSet DEBUG log levels.
> -h | --help This help.
> -n | --noninteractive Do not run within an IRB session and exit with
> non-zero
> status on first error.
> --top-level-defsCompatibility flag to export HBase shell commands
> onto
> Ruby's main object
> -Dkey=value Pass hbase-*.xml Configuration overrides. For
> example, to
> use an alternate zookeeper ensemble, pass:
>-Dhbase.zookeeper.quorum=zookeeper.example.org
> For faster fail, pass the below and vary the values:
>-Dhbase.client.retries.number=7
>-Dhbase.ipc.client.connect.max.retries=3
> classpath:/jar-bootstrap.rb: invalid option -- b
> GetoptLong::InvalidOption: invalid option -- b
> set_error at
> uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/getoptlong.rb:395
> get at
> uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/getoptlong.rb:572
>each at
> uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/getoptlong.rb:603
>loop at org/jruby/RubyKernel.java:1442
>each at
> uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/getoptlong.rb:602
> at classpath:/jar-bootstrap.rb:98
> {noformat}
> Something is broken in the command line parsing.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Assigned] (HBASE-26953) CallDroppedException message says "server 0.0.0.0 is overloaded"
[ https://issues.apache.org/jira/browse/HBASE-26953?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Viraj Jasani reassigned HBASE-26953: Assignee: Ayesha Mosaddeque (was: Kiran Kumar Maturi) > CallDroppedException message says "server 0.0.0.0 is overloaded" > > > Key: HBASE-26953 > URL: https://issues.apache.org/jira/browse/HBASE-26953 > Project: HBase > Issue Type: Bug >Reporter: Bryan Beaudreault >Assignee: Ayesha Mosaddeque >Priority: Trivial > > This is not a super useful error when seen on the client side. Maybe we can > have it pull in the ServerName instead, or at the very least resolve to the > hostname. > > https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/hadoop/hbase/ipc/CallRunner.java#L213 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [hbase] Apache-HBase commented on pull request #4382: HBASE-26925 Create WAL event tracker table to track all the WAL events.
Apache-HBase commented on PR #4382: URL: https://github.com/apache/hbase/pull/4382#issuecomment-1121545001 :confetti_ball: **+1 overall** | Vote | Subsystem | Runtime | Comment | |::|--:|:|:| | +0 :ok: | reexec | 7m 1s | Docker mode activated. | ||| _ Prechecks _ | | +1 :green_heart: | dupname | 0m 1s | No case conflicting files found. | | +1 :green_heart: | hbaseanti | 0m 0s | Patch does not have any anti-patterns. | | +1 :green_heart: | @author | 0m 0s | The patch does not contain any @author tags. | ||| _ HBASE-26913-replication-observability-framework Compile Tests _ | | +0 :ok: | mvndep | 0m 15s | Maven dependency ordering for branch | | +1 :green_heart: | mvninstall | 2m 26s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | compile | 3m 46s | HBASE-26913-replication-observability-framework passed | | +1 :green_heart: | checkstyle | 1m 12s | HBASE-26913-replication-observability-framework passed | | +0 :ok: | refguide | 2m 27s | branch has no errors when building the reference guide. See footer for rendered docs, which you should manually inspect. | | +1 :green_heart: | spotless | 0m 45s | branch has no errors when running spotless:check. | | +1 :green_heart: | spotbugs | 2m 46s | HBASE-26913-replication-observability-framework passed | ||| _ Patch Compile Tests _ | | +0 :ok: | mvndep | 0m 11s | Maven dependency ordering for patch | | +1 :green_heart: | mvninstall | 2m 10s | the patch passed | | +1 :green_heart: | compile | 3m 43s | the patch passed | | +1 :green_heart: | javac | 3m 43s | the patch passed | | -0 :warning: | checkstyle | 0m 30s | hbase-server: The patch generated 1 new + 13 unchanged - 0 fixed = 14 total (was 13) | | +1 :green_heart: | whitespace | 0m 0s | The patch has no whitespace issues. | | +1 :green_heart: | xml | 0m 1s | The patch has no ill-formed XML file. | | +0 :ok: | refguide | 1m 53s | patch has no errors when building the reference guide. See footer for rendered docs, which you should manually inspect. | | +1 :green_heart: | hadoopcheck | 11m 55s | Patch does not cause any errors with Hadoop 3.1.2 3.2.2 3.3.1. | | +1 :green_heart: | spotless | 0m 42s | patch has no errors when running spotless:check. | | +1 :green_heart: | spotbugs | 3m 10s | the patch passed | ||| _ Other Tests _ | | +1 :green_heart: | asflicense | 0m 37s | The patch does not generate ASF License warnings. | | | | 51m 37s | | | Subsystem | Report/Notes | |--:|:-| | Docker | ClientAPI=1.41 ServerAPI=1.41 base: https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/artifact/yetus-general-check/output/Dockerfile | | GITHUB PR | https://github.com/apache/hbase/pull/4382 | | Optional Tests | dupname asflicense javac spotbugs hadoopcheck hbaseanti spotless checkstyle compile refguide xml | | uname | Linux 3d5dc1f4e5b0 5.4.0-90-generic #101-Ubuntu SMP Fri Oct 15 20:00:55 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux | | Build tool | maven | | Personality | dev-support/hbase-personality.sh | | git revision | HBASE-26913-replication-observability-framework / 64a6ba3647 | | Default Java | AdoptOpenJDK-1.8.0_282-b08 | | refguide | https://nightlies.apache.org/hbase/HBase-PreCommit-GitHub-PR/PR-4382/5/yetus-general-check/output/branch-site/book.html | | checkstyle | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/artifact/yetus-general-check/output/diff-checkstyle-hbase-server.txt | | refguide | https://nightlies.apache.org/hbase/HBase-PreCommit-GitHub-PR/PR-4382/5/yetus-general-check/output/patch-site/book.html | | Max. process+thread count | 64 (vs. ulimit of 3) | | modules | C: hbase-common hbase-hadoop-compat hbase-client hbase-server U: . | | Console output | https://ci-hbase.apache.org/job/HBase-PreCommit-GitHub-PR/job/PR-4382/5/console | | versions | git=2.17.1 maven=3.6.3 spotbugs=4.2.2 | | Powered by | Apache Yetus 0.12.0 https://yetus.apache.org | This message was automatically generated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HBASE-27013) Introduce read all bytes when using pread for prefetch
[
https://issues.apache.org/jira/browse/HBASE-27013?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533995#comment-17533995
]
Josh Elser commented on HBASE-27013:
{quote}So the problem here is, the implementation of S3A is not HDFS, we can
not reuse the stream to send multiple pread requests with random offset. Seems
not like a good enough pread implementation...
{quote}
Yeah, s3a != hdfs is definitely a major pain point. IIUC, HBase nor HDFS are
doing anything wrong, per se. HDFS just happens to handle this super fast and
s3a... doesn't.
{quote}In general, in pread mode, a FSDataInputStream may be used by different
read requests so even if you fixed this problem, it could still introduce a lot
of aborts as different read request may read from different offsets...
{quote}
Right again – focus being put on prefetching as we know that once hfiles are
cached, things are super fast. Thus, this is the first problem to chase.
However, any operations over a table which isn't fully cache would end up
over-reading from s3. I had thought about whether we just write a custom Reader
for the prefetch case, but then we wouldn't address the rest of the access
paths (e.g. scans).
Stephen's worst case numbers are still ~130MB/s to pull down HFiles from S3 to
cache which is good on the surface, but not so good when you compare to the
closer to 1GB/s that you can get through awscli (and whatever their
parallelized downloader was called). One optimization at a time :)
> Introduce read all bytes when using pread for prefetch
> --
>
> Key: HBASE-27013
> URL: https://issues.apache.org/jira/browse/HBASE-27013
> Project: HBase
> Issue Type: Improvement
> Components: HFile, Performance
>Affects Versions: 2.5.0, 2.6.0, 3.0.0-alpha-3, 2.4.13
>Reporter: Tak-Lon (Stephen) Wu
>Assignee: Tak-Lon (Stephen) Wu
>Priority: Major
>
> h2. Problem statement
> When prefetching HFiles from blob storage like S3 and use it with the storage
> implementation like S3A, we found there is a logical issue in HBase pread
> that causes the reading of the remote HFile aborts the input stream multiple
> times. This aborted stream and reopen slow down the reads and trigger many
> aborted bytes and waste time in recreating the connection especially when SSL
> is enabled.
> h2. ROOT CAUSE
> The root cause of above issue was due to
> [BlockIOUtils#preadWithExtra|https://github.com/apache/hbase/blob/9c8c9e7fbf8005ea89fa9b13d6d063b9f0240443/hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java#L214-L257]
> is reading an input stream that does not guarrentee to return the data block
> and the next block header as an option data to be cached.
> In the case of the input stream read short and when the input stream read
> passed the length of the necessary data block with few more bytes within the
> size of next block header, the
> [BlockIOUtils#preadWithExtra|https://github.com/apache/hbase/blob/9c8c9e7fbf8005ea89fa9b13d6d063b9f0240443/hbase-common/src/main/java/org/apache/hadoop/hbase/io/util/BlockIOUtils.java#L214-L257]
> returns to the caller without a cached the next block header. As a result,
> before HBase tries to read the next block,
> [HFileBlock#readBlockDataInternal|https://github.com/apache/hbase/blob/9c8c9e7fbf8005ea89fa9b13d6d063b9f0240443/hbase-server/src/main/java/org/apache/hadoop/hbase/io/hfile/HFileBlock.java#L1648-L1664]
> in hbase tries to re-read the next block header from the input stream. Here,
> the reusable input stream has move the current position pointer ahead from
> the offset of the last read data block, when using with the [S3A
> implementation|https://github.com/apache/hadoop/blob/29401c820377d02a992eecde51083cf87f8e57af/hadoop-tools/hadoop-aws/src/main/java/org/apache/hadoop/fs/s3a/S3AInputStream.java#L339-L361],
> the input stream is then closed, aborted all the remaining bytes and reopen
> a new input stream at the offset of the last read data block .
> h2. How do we fix it?
> S3A is doing the right job that HBase is telling to move the offset from
> position A back to A - N, so there is not much thing we can do on how S3A
> handle the inputstream. meanwhile in the case of HDFS, this operation is fast.
> Such that, we should fix in HBase level, and try always to read datablock +
> next block header when we're using blob storage to avoid expensive draining
> the bytes in a stream and reopen the socket with the remote storage.
> h2. Draw back and discussion
> * A known drawback is, when we're at the last block, we will read extra
> length that should not be a header, and we still read that into the byte
> buffer array. the size should be always 33 bytes, and it should not a big
> issue in data correctness because the trailer will t
[jira] [Commented] (HBASE-26994) MasterFileSystem create directory without permission check
[
https://issues.apache.org/jira/browse/HBASE-26994?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533988#comment-17533988
]
Hudson commented on HBASE-26994:
Results for branch branch-2.5
[build #114 on
builds.a.o|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.5/114/]:
(/) *{color:green}+1 overall{color}*
details (if available):
(/) {color:green}+1 general checks{color}
-- For more information [see general
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.5/114/General_20Nightly_20Build_20Report/]
(/) {color:green}+1 jdk8 hadoop2 checks{color}
-- For more information [see jdk8 (hadoop2)
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.5/114/JDK8_20Nightly_20Build_20Report_20_28Hadoop2_29/]
(/) {color:green}+1 jdk8 hadoop3 checks{color}
-- For more information [see jdk8 (hadoop3)
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.5/114/JDK8_20Nightly_20Build_20Report_20_28Hadoop3_29/]
(/) {color:green}+1 jdk11 hadoop3 checks{color}
-- For more information [see jdk11
report|https://ci-hbase.apache.org/job/HBase%20Nightly/job/branch-2.5/114/JDK11_20Nightly_20Build_20Report_20_28Hadoop3_29/]
(/) {color:green}+1 source release artifact{color}
-- See build output for details.
(/) {color:green}+1 client integration test{color}
> MasterFileSystem create directory without permission check
> --
>
> Key: HBASE-26994
> URL: https://issues.apache.org/jira/browse/HBASE-26994
> Project: HBase
> Issue Type: Bug
> Components: master
>Affects Versions: 2.4.12
>Reporter: Zhang Dongsheng
>Assignee: Zhang Dongsheng
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3, 2.4.13
>
> Attachments: HBASE-26994.patch
>
>
> Method checkStagingDir and checkSubDir first check if directory is exist ,if
> not , create it with special permission. If exist then setPermission for this
> directory. BUT if not exist ,we still need set special permission for this
> directory
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533885#comment-17533885
]
Andrew Kyle Purtell commented on HBASE-26999:
-
Thank you for the commit to branch-2.5
Yeah I realize I will need to come back here with the complete sequence of
events. TBD...
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Affects Versions: 2.5.0, 3.0.0-alpha-2, 2.6.0
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 2.6.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, file2 and file3;
> 2) Compaction started on RS1;
> 3) RS1 entered a long GC pause, lost ZK lock. Compaction is still running,
> though.
> 4) RS2 opens R. The related File SFT instance for this store then creates a
> new meta file with file1, file2 and file3.
> 5) Compaction on RS1 successfully completes the
> *storeEngine.replaceStoreFiles* call. This updates the in memory cache of
> valid files (StoreFileManager) and the SFT metafile for the store engine on
> RS1 with the compaction resulting file, say file4, removing file1, file2 and
> file3. Note that the SFT meta file
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533860#comment-17533860
]
Wellington Chevreuil commented on HBASE-26999:
--
{quote}In the test scenario where we observe these log lines, flushes and
compactions do complete successfully, because we are not injecting chaos of any
kind, _except_ for the case where compactions are cancelled/interrupted when a
region is being closed (for load balancing), so that is where I would look
first.
{quote}
My understanding from reading *HStore.doCompaction* code is that we only update
SFT and SFM once the compaction result files got successfully committed, so
cancelling compactions _shouldn't_ cause this. Could you confirm these 0 sized
hfiles were results of compactions (HStore would log a _"Completed compaction
of"_ info level message mentioned the name of the resulting file)?
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Affects Versions: 2.5.0, 3.0.0-alpha-2, 2.6.0
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 2.6.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, f
[jira] [Commented] (HBASE-26969) Eliminate MOB renames when SFT is enabled
[
https://issues.apache.org/jira/browse/HBASE-26969?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533854#comment-17533854
]
Szabolcs Bukros commented on HBASE-26969:
-
Thanks [~apurtell] !
> Eliminate MOB renames when SFT is enabled
> -
>
> Key: HBASE-26969
> URL: https://issues.apache.org/jira/browse/HBASE-26969
> Project: HBase
> Issue Type: Task
> Components: mob
>Affects Versions: 2.5.0, 3.0.0-alpha-3
>Reporter: Szabolcs Bukros
>Assignee: Szabolcs Bukros
>Priority: Major
> Fix For: 2.6.0, 3.0.0-alpha-3
>
>
> MOB file compaction and flush still relies on renames even when SFT is
> enabled.
> My proposed changes are:
> * when requireWritingToTmpDirFirst is false during mob flush/compact instead
> of using the temp writer we should create a different writer using a
> {color:#00}StoreFileWriterCreationTracker that writes directly to the mob
> store folder{color}
> * {color:#00}these StoreFileWriterCreationTracker should be stored in
> the MobStore. This would requires us to extend MobStore with a createWriter
> and a finalizeWriter method to handle this{color}
> * {color:#00}refactor {color}MobFileCleanerChore to run on the RS
> instead on Master to allow access to the
> {color:#00}StoreFileWriterCreationTracker{color}s to make sure the
> currently written files are not cleaned up
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533845#comment-17533845
]
Wellington Chevreuil commented on HBASE-26999:
--
{quote}
Please commit to branch-2.5
{quote}
Done.
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Affects Versions: 2.5.0, 3.0.0-alpha-2, 2.6.0
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 2.6.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, file2 and file3;
> 2) Compaction started on RS1;
> 3) RS1 entered a long GC pause, lost ZK lock. Compaction is still running,
> though.
> 4) RS2 opens R. The related File SFT instance for this store then creates a
> new meta file with file1, file2 and file3.
> 5) Compaction on RS1 successfully completes the
> *storeEngine.replaceStoreFiles* call. This updates the in memory cache of
> valid files (StoreFileManager) and the SFT metafile for the store engine on
> RS1 with the compaction resulting file, say file4, removing file1, file2 and
> file3. Note that the SFT meta file used by RS1 here is different (older) than
> the one used by RS2.
> 6) C
[jira] [Updated] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Wellington Chevreuil updated HBASE-26999:
-
Fix Version/s: 2.6.0
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Affects Versions: 2.5.0, 3.0.0-alpha-2, 2.6.0
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 2.6.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, file2 and file3;
> 2) Compaction started on RS1;
> 3) RS1 entered a long GC pause, lost ZK lock. Compaction is still running,
> though.
> 4) RS2 opens R. The related File SFT instance for this store then creates a
> new meta file with file1, file2 and file3.
> 5) Compaction on RS1 successfully completes the
> *storeEngine.replaceStoreFiles* call. This updates the in memory cache of
> valid files (StoreFileManager) and the SFT metafile for the store engine on
> RS1 with the compaction resulting file, say file4, removing file1, file2 and
> file3. Note that the SFT meta file used by RS1 here is different (older) than
> the one used by RS2.
> 6) Compaction on RS1 tries to update WAL marker, but fails to do so, as the
> WAL already go
[jira] [Updated] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Wellington Chevreuil updated HBASE-26999:
-
Affects Version/s: 3.0.0-alpha-2
2.5.0
2.6.0
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Affects Versions: 2.5.0, 3.0.0-alpha-2, 2.6.0
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, file2 and file3;
> 2) Compaction started on RS1;
> 3) RS1 entered a long GC pause, lost ZK lock. Compaction is still running,
> though.
> 4) RS2 opens R. The related File SFT instance for this store then creates a
> new meta file with file1, file2 and file3.
> 5) Compaction on RS1 successfully completes the
> *storeEngine.replaceStoreFiles* call. This updates the in memory cache of
> valid files (StoreFileManager) and the SFT metafile for the store engine on
> RS1 with the compaction resulting file, say file4, removing file1, file2 and
> file3. Note that the SFT meta file used by RS1 here is different (older) than
> the one used by RS2.
> 6) Compaction on RS1 tries to
[jira] [Comment Edited] (HBASE-26969) Eliminate MOB renames when SFT is enabled
[
https://issues.apache.org/jira/browse/HBASE-26969?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533837#comment-17533837
]
Andrew Kyle Purtell edited comment on HBASE-26969 at 5/9/22 2:34 PM:
-
[~bszabolcs] I added
bq. The file based StoreFileTracker, FileBasedStoreFileTracker, is currently
incompatible with the Medium Objects (MOB) feature. Do not enable them
together.
to the release notes of HBASE-26826, so they will appear in the release notes
for 2.5.0. (I did not update HBASE-26067 notes in expectation issues will be
addressed before a release incorporating the original commit is released.) If
you would prefer an alternative, please provide it here and I will update the
text again.
was (Author: apurtell):
[~bszabolcs] I added
bq. The file based StoreFileTracker, FileBasedStoreFileTracker, is currently
incompatible with the Medium Objects (MOB) feature. Do not enable them
together.
to the release notes of HBASE-26067 and HBASE-26826, so they will appear in all
relevant release notes. If you would prefer an alternative, please provide it
here and I will update the text again.
> Eliminate MOB renames when SFT is enabled
> -
>
> Key: HBASE-26969
> URL: https://issues.apache.org/jira/browse/HBASE-26969
> Project: HBase
> Issue Type: Task
> Components: mob
>Affects Versions: 2.5.0, 3.0.0-alpha-3
>Reporter: Szabolcs Bukros
>Assignee: Szabolcs Bukros
>Priority: Major
> Fix For: 2.6.0, 3.0.0-alpha-3
>
>
> MOB file compaction and flush still relies on renames even when SFT is
> enabled.
> My proposed changes are:
> * when requireWritingToTmpDirFirst is false during mob flush/compact instead
> of using the temp writer we should create a different writer using a
> {color:#00}StoreFileWriterCreationTracker that writes directly to the mob
> store folder{color}
> * {color:#00}these StoreFileWriterCreationTracker should be stored in
> the MobStore. This would requires us to extend MobStore with a createWriter
> and a finalizeWriter method to handle this{color}
> * {color:#00}refactor {color}MobFileCleanerChore to run on the RS
> instead on Master to allow access to the
> {color:#00}StoreFileWriterCreationTracker{color}s to make sure the
> currently written files are not cleaned up
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (HBASE-26067) Change the way on how we track store file list
[ https://issues.apache.org/jira/browse/HBASE-26067?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Andrew Kyle Purtell updated HBASE-26067: Release Note: Introduces the StoreFileTracker interface to HBase. This is a server-side interface which abstracts how a Store (column family) knows what files should be included in that Store. Previously, HBase relied on a listing the directory a Store used for storage to determine the files which should make up that Store. After this feature, there are two implementations of StoreFileTrackers. The first (and default) implementation is listing the Store directory. The second is a new implementation which records files which belong to a Store within each Store. Whenever the list of files that make up a Store change, this metadata file will be updated. This feature is notable in that it better enables HBase to function on storage systems which do not provide the typical posix filesystem semantics, most importantly, those which do not implement a file rename operation which is atomic. Storage systems which do not implement atomic renames often implement a rename as a copy and delete operation which amplifies the I/O costs by 2x. At scale, this feature should have a 2x reduction in I/O costs when using storage systems that do not provide atomic renames, most importantly in HBase compactions and memstore flushes. See the corresponding section, "Store File Tracking", in the HBase book for more information on how to use this feature. was: Introduces the StoreFileTracker interface to HBase. This is a server-side interface which abstracts how a Store (column family) knows what files should be included in that Store. Previously, HBase relied on a listing the directory a Store used for storage to determine the files which should make up that Store. After this feature, there are two implementations of StoreFileTrackers. The first (and default) implementation is listing the Store directory. The second is a new implementation which records files which belong to a Store within each Store. Whenever the list of files that make up a Store change, this metadata file will be updated. This feature is notable in that it better enables HBase to function on storage systems which do not provide the typical posix filesystem semantics, most importantly, those which do not implement a file rename operation which is atomic. Storage systems which do not implement atomic renames often implement a rename as a copy and delete operation which amplifies the I/O costs by 2x. At scale, this feature should have a 2x reduction in I/O costs when using storage systems that do not provide atomic renames, most importantly in HBase compactions and memstore flushes. See the corresponding section, "Store File Tracking", in the HBase book for more information on how to use this feature. The file based StoreFileTracker, FileBasedStoreFileTracker, is currently incompatible with the Medium Objects (MOB) feature. Do not enable them together. > Change the way on how we track store file list > -- > > Key: HBASE-26067 > URL: https://issues.apache.org/jira/browse/HBASE-26067 > Project: HBase > Issue Type: Umbrella > Components: HFile >Reporter: Duo Zhang >Assignee: Duo Zhang >Priority: Major > Fix For: 2.6.0, 3.0.0-alpha-3 > > > Open a separated jira to track the work since it can not be fully included in > HBASE-24749. > I think this could be a landed prior to HBASE-24749, as if this works, we > could have different implementations for tracking store file list. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (HBASE-26969) Eliminate MOB renames when SFT is enabled
[
https://issues.apache.org/jira/browse/HBASE-26969?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533837#comment-17533837
]
Andrew Kyle Purtell commented on HBASE-26969:
-
[~bszabolcs] I added
bq. The file based StoreFileTracker, FileBasedStoreFileTracker, is currently
incompatible with the Medium Objects (MOB) feature. Do not enable them
together.
to the release notes of HBASE-26067 and HBASE-26826, so they will appear in all
relevant release notes. If you would prefer an alternative, please provide it
here and I will update the text again.
> Eliminate MOB renames when SFT is enabled
> -
>
> Key: HBASE-26969
> URL: https://issues.apache.org/jira/browse/HBASE-26969
> Project: HBase
> Issue Type: Task
> Components: mob
>Affects Versions: 2.5.0, 3.0.0-alpha-3
>Reporter: Szabolcs Bukros
>Assignee: Szabolcs Bukros
>Priority: Major
> Fix For: 2.6.0, 3.0.0-alpha-3
>
>
> MOB file compaction and flush still relies on renames even when SFT is
> enabled.
> My proposed changes are:
> * when requireWritingToTmpDirFirst is false during mob flush/compact instead
> of using the temp writer we should create a different writer using a
> {color:#00}StoreFileWriterCreationTracker that writes directly to the mob
> store folder{color}
> * {color:#00}these StoreFileWriterCreationTracker should be stored in
> the MobStore. This would requires us to extend MobStore with a createWriter
> and a finalizeWriter method to handle this{color}
> * {color:#00}refactor {color}MobFileCleanerChore to run on the RS
> instead on Master to allow access to the
> {color:#00}StoreFileWriterCreationTracker{color}s to make sure the
> currently written files are not cleaned up
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (HBASE-26826) Backport StoreFileTracker (HBASE-26067, HBASE-26584, and others) to branch-2.5
[ https://issues.apache.org/jira/browse/HBASE-26826?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Andrew Kyle Purtell updated HBASE-26826: Release Note: Introduces the StoreFileTracker interface to HBase. This is a server-side interface which abstracts how a Store (column family) knows what files should be included in that Store. Previously, HBase relied on a listing the directory a Store used for storage to determine the files which should make up that Store. After this feature, there are two implementations of StoreFileTrackers. The first (and default) implementation is listing the Store directory. The second is a new implementation which records files which belong to a Store within each Store. Whenever the list of files that make up a Store change, this metadata file will be updated. This feature is notable in that it better enables HBase to function on storage systems which do not provide the typical posix filesystem semantics, most importantly, those which do not implement a file rename operation which is atomic. Storage systems which do not implement atomic renames often implement a rename as a copy and delete operation which amplifies the I/O costs by 2x. At scale, this feature should have a 2x reduction in I/O costs when using storage systems that do not provide atomic renames, most importantly in HBase compactions and memstore flushes. See the corresponding section, "Store File Tracking", in the HBase book for more information on how to use this feature. The file based StoreFileTracker, FileBasedStoreFileTracker, is currently incompatible with the Medium Objects (MOB) feature. Do not enable them together. was: Introduces the StoreFileTracker interface to HBase. This is a server-side interface which abstracts how a Store (column family) knows what files should be included in that Store. Previously, HBase relied on a listing the directory a Store used for storage to determine the files which should make up that Store. After this feature, there are two implementations of StoreFileTrackers. The first (and default) implementation is listing the Store directory. The second is a new implementation which records files which belong to a Store within each Store. Whenever the list of files that make up a Store change, this metadata file will be updated. This feature is notable in that it better enables HBase to function on storage systems which do not provide the typical posix filesystem semantics, most importantly, those which do not implement a file rename operation which is atomic. Storage systems which do not implement atomic renames often implement a rename as a copy and delete operation which amplifies the I/O costs by 2x. At scale, this feature should have a 2x reduction in I/O costs when using storage systems that do not provide atomic renames, most importantly in HBase compactions and memstore flushes. See the corresponding section, "Store File Tracking", in the HBase book for more information on how to use this feature. > Backport StoreFileTracker (HBASE-26067, HBASE-26584, and others) to branch-2.5 > -- > > Key: HBASE-26826 > URL: https://issues.apache.org/jira/browse/HBASE-26826 > Project: HBase > Issue Type: Task > Components: Operability, regionserver >Reporter: Andrew Kyle Purtell >Assignee: Andrew Kyle Purtell >Priority: Major > Fix For: 2.5.0 > > > In a discussion on dev@ the idea was floated that StoreFileTracker could be > backported into branch-2.5 to be released as part of 2.5.0 as an experimental > feature. This issue considers the backport. > There are sixteen subtasks on HBASE-26067 and several other tangential > commits. Cherry pick the list in sequence, fixing up as necessary. These > appear to be the core commits: > - commit 6aaef8978 HBASE-26064 Introduce a StoreFileTracker to abstract the > store file tracking logic > - commit 43b40e937 HBASE-25988 Store the store file list by a file (#3578) > - commit 6e053765e HBASE-26079 Use StoreFileTracker when splitting and > merging (#3617) > - commit 090b2fecf HBASE-26224 Introduce a MigrationStoreFileTracker to > support migrating from different store file tracker implementations (#3656) > - commit 0ee168933 HBASE-26246 Persist the StoreFileTracker configurations to > TableDescriptor when creating table (#3666) > - commit 2052e80e5 HBASE-26248 Should find a suitable way to let users > specify the store file tracker implementation (#3665) > - commit 5ff0f98a5 HBASE-26264 Add more checks to prevent misconfiguration on > store file tracker (#3681) > - commit fc4f6d10e HBASE-26280 Use store file tracker when snapshoting (#3685) > - commit 06db852aa HBASE-26326 CreateTableProcedure fails when > FileBasedStoreFileTracker… (#3721
[jira] [Updated] (HBASE-26067) Change the way on how we track store file list
[ https://issues.apache.org/jira/browse/HBASE-26067?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Andrew Kyle Purtell updated HBASE-26067: Release Note: Introduces the StoreFileTracker interface to HBase. This is a server-side interface which abstracts how a Store (column family) knows what files should be included in that Store. Previously, HBase relied on a listing the directory a Store used for storage to determine the files which should make up that Store. After this feature, there are two implementations of StoreFileTrackers. The first (and default) implementation is listing the Store directory. The second is a new implementation which records files which belong to a Store within each Store. Whenever the list of files that make up a Store change, this metadata file will be updated. This feature is notable in that it better enables HBase to function on storage systems which do not provide the typical posix filesystem semantics, most importantly, those which do not implement a file rename operation which is atomic. Storage systems which do not implement atomic renames often implement a rename as a copy and delete operation which amplifies the I/O costs by 2x. At scale, this feature should have a 2x reduction in I/O costs when using storage systems that do not provide atomic renames, most importantly in HBase compactions and memstore flushes. See the corresponding section, "Store File Tracking", in the HBase book for more information on how to use this feature. The file based StoreFileTracker, FileBasedStoreFileTracker, is currently incompatible with the Medium Objects (MOB) feature. Do not enable them together. was: Introduces the StoreFileTracker interface to HBase. This is a server-side interface which abstracts how a Store (column family) knows what files should be included in that Store. Previously, HBase relied on a listing the directory a Store used for storage to determine the files which should make up that Store. After this feature, there are two implementations of StoreFileTrackers. The first (and default) implementation is listing the Store directory. The second is a new implementation which records files which belong to a Store within each Store. Whenever the list of files that make up a Store change, this metadata file will be updated. This feature is notable in that it better enables HBase to function on storage systems which do not provide the typical posix filesystem semantics, most importantly, those which do not implement a file rename operation which is atomic. Storage systems which do not implement atomic renames often implement a rename as a copy and delete operation which amplifies the I/O costs by 2x. At scale, this feature should have a 2x reduction in I/O costs when using storage systems that do not provide atomic renames, most importantly in HBase compactions and memstore flushes. See the corresponding section, "Store File Tracking", in the HBase book for more information on how to use this feature. > Change the way on how we track store file list > -- > > Key: HBASE-26067 > URL: https://issues.apache.org/jira/browse/HBASE-26067 > Project: HBase > Issue Type: Umbrella > Components: HFile >Reporter: Duo Zhang >Assignee: Duo Zhang >Priority: Major > Fix For: 2.6.0, 3.0.0-alpha-3 > > > Open a separated jira to track the work since it can not be fully included in > HBASE-24749. > I think this could be a landed prior to HBASE-24749, as if this works, we > could have different implementations for tracking store file list. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Comment Edited] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533834#comment-17533834
]
Andrew Kyle Purtell edited comment on HBASE-26999 at 5/9/22 2:19 PM:
-
[~zhangduo] Makes sense, HFiles must exist (and be zero length) for that log
line to be printed, so it isn't incorrect removal of files from the SFT, it is
incorrect addition. In the test scenario where we observe these log lines,
flushes and compactions do complete successfully, because we are not injecting
chaos of any kind, _except_ for the case where compactions are
cancelled/interrupted when a region is being closed (for load balancing), so
that is where I would look first.
[~wchevreuil]
bq. Another interesting behaviour noticed is that in the case of two
StoreEngine instances of the same store, say, when we have the region re-opened
in a new RS and the old RS still thinks it's active and the region is open,
there will be two SFT meta files being updated.
This reminds me we are going to use HBASE-26726, so let me enable that in the
test scenario. Not expecting the results to change, though, but it would
simplify things a bit.
was (Author: apurtell):
[~zhangduo] Makes sense, HFiles must be zero length for that log line to be
printed, so it isn't incorrect removal of files from the SFT, it is incorrect
addition. In the test scenario where we observe these log lines, flushes and
compactions do complete successfully, because we are not injecting chaos of any
kind, _except_ for the case where compactions are cancelled/interrupted when a
region is being closed (for load balancing), so that is where I would look
first.
[~wchevreuil]
bq. Another interesting behaviour noticed is that in the case of two
StoreEngine instances of the same store, say, when we have the region re-opened
in a new RS and the old RS still thinks it's active and the region is open,
there will be two SFT meta files being updated.
This reminds me we are going to use HBASE-26726, so let me enable that in the
test scenario. Not expecting the results to change, though, but it would
simplify things a bit.
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compact
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533834#comment-17533834
]
Andrew Kyle Purtell commented on HBASE-26999:
-
[~zhangduo] Makes sense, HFiles must be zero length for that log line to be
printed, so it isn't incorrect removal of files from the SFT, it is incorrect
addition. In the test scenario where we observe these log lines, flushes and
compactions do complete successfully, because we are not injecting chaos of any
kind, _except_ for the case where compactions are cancelled/interrupted when a
region is being closed (for load balancing), so that is where I would look
first.
[~wchevreuil]
bq. Another interesting behaviour noticed is that in the case of two
StoreEngine instances of the same store, say, when we have the region re-opened
in a new RS and the old RS still thinks it's active and the region is open,
there will be two SFT meta files being updated.
This reminds me we are going to use HBASE-26726, so let me enable that in the
test scenario. Not expecting the results to change, though, but it would
simplify things a bit.
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the origin
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533829#comment-17533829
]
Andrew Kyle Purtell commented on HBASE-26999:
-
[~wchevreuil] Please commit to branch-2.5
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, file2 and file3;
> 2) Compaction started on RS1;
> 3) RS1 entered a long GC pause, lost ZK lock. Compaction is still running,
> though.
> 4) RS2 opens R. The related File SFT instance for this store then creates a
> new meta file with file1, file2 and file3.
> 5) Compaction on RS1 successfully completes the
> *storeEngine.replaceStoreFiles* call. This updates the in memory cache of
> valid files (StoreFileManager) and the SFT metafile for the store engine on
> RS1 with the compaction resulting file, say file4, removing file1, file2 and
> file3. Note that the SFT meta file used by RS1 here is different (older) than
> the one used by RS2.
> 6) Compaction on RS1 tries to update WAL marker, but fails to do so, as the
>
[jira] [Commented] (HBASE-26969) Eliminate MOB renames when SFT is enabled
[
https://issues.apache.org/jira/browse/HBASE-26969?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533817#comment-17533817
]
Szabolcs Bukros commented on HBASE-26969:
-
[~apurtell] It looks like the MOB feature is currently incompatible with
FileBased SFT. Without this issue fixed the currently
written/temporary/outdated/trash files in the store dir can break the
MobFileCleanerChore and the related issue shows that snapshotting a MOB enabled
table while FileBased SFT is used results in dataloss. Since 2.5.0 being so
close to release this fact should be documented somewhere.
I'm planning to add a more detailed description of the issues I have
encountered while trying to make these features work together as soon as I can
publish a PR for reference.
> Eliminate MOB renames when SFT is enabled
> -
>
> Key: HBASE-26969
> URL: https://issues.apache.org/jira/browse/HBASE-26969
> Project: HBase
> Issue Type: Task
> Components: mob
>Affects Versions: 2.5.0, 3.0.0-alpha-3
>Reporter: Szabolcs Bukros
>Assignee: Szabolcs Bukros
>Priority: Major
> Fix For: 2.6.0, 3.0.0-alpha-3
>
>
> MOB file compaction and flush still relies on renames even when SFT is
> enabled.
> My proposed changes are:
> * when requireWritingToTmpDirFirst is false during mob flush/compact instead
> of using the temp writer we should create a different writer using a
> {color:#00}StoreFileWriterCreationTracker that writes directly to the mob
> store folder{color}
> * {color:#00}these StoreFileWriterCreationTracker should be stored in
> the MobStore. This would requires us to extend MobStore with a createWriter
> and a finalizeWriter method to handle this{color}
> * {color:#00}refactor {color}MobFileCleanerChore to run on the RS
> instead on Master to allow access to the
> {color:#00}StoreFileWriterCreationTracker{color}s to make sure the
> currently written files are not cleaned up
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (HBASE-27017) MOB snapshot is broken when FileBased SFT is used
[ https://issues.apache.org/jira/browse/HBASE-27017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533807#comment-17533807 ] Szabolcs Bukros commented on HBASE-27017: - This issue was found while working on HBASE-26969. TestMobCompactionWithDefaults uses cloneSnapshot. > MOB snapshot is broken when FileBased SFT is used > - > > Key: HBASE-27017 > URL: https://issues.apache.org/jira/browse/HBASE-27017 > Project: HBase > Issue Type: Bug > Components: mob >Affects Versions: 2.5.0, 3.0.0-alpha-2 >Reporter: Szabolcs Bukros >Priority: Major > > During snapshot MOB regions are treated like any other region. When a > snapshot is taken and hfile references are collected a StoreFileTracker is > created to get the current active hfile list. But the MOB region stores are > not tracked so an empty list is returned, resulting in a broken snapshot. > When this snapshot is cloned the resulting table will have no MOB files or > references. > The problematic code can be found here: > [https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/hadoop/hbase/snapshot/SnapshotManifest.java#L313] -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (HBASE-27017) MOB snapshot is broken when FileBased SFT is used
Szabolcs Bukros created HBASE-27017: --- Summary: MOB snapshot is broken when FileBased SFT is used Key: HBASE-27017 URL: https://issues.apache.org/jira/browse/HBASE-27017 Project: HBase Issue Type: Bug Components: mob Affects Versions: 3.0.0-alpha-2, 2.5.0 Reporter: Szabolcs Bukros During snapshot MOB regions are treated like any other region. When a snapshot is taken and hfile references are collected a StoreFileTracker is created to get the current active hfile list. But the MOB region stores are not tracked so an empty list is returned, resulting in a broken snapshot. When this snapshot is cloned the resulting table will have no MOB files or references. The problematic code can be found here: [https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/hadoop/hbase/snapshot/SnapshotManifest.java#L313] -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533786#comment-17533786
]
Duo Zhang commented on HBASE-26999:
---
{code}
// Check for empty hfile. Should never be the case but can happen
// after data loss in hdfs for whatever reason (upgrade, etc.): HBASE-646
// NOTE: that the HFileLink is just a name, so it's an empty file.
if (!HFileLink.isHFileLink(p) && fileStatus.getLen() <= 0) {
LOG.warn("Skipping {} because it is empty. HBASE-646 DATA LOSS?", p);
return false;
}
{code}
This is the piece of code which generates the warn log. I do not think it is
related to race when updating SFT, it is more like we fail to write a store
file but then we still add it to the SFT file.
I suggest you check the related compation logs which generates the file(or
maybe it is generated by flush?) [~apurtell]
Thanks.
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
> + }
> + synchronized (filesCompacting) {
> + filesCompacting.removeAll(compactedFiles);
> + }
> + // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> + // sizes later so it's not super-critical if we miss these.
> + RegionServerServices rsServices = region.getRegionServerServices();
> + if (rsServices != null && rsServices.getRegionServerSpaceQuotaManager()
> != null) {
> + updateSpaceQuotaAfterFileReplacement(
> + rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> + compactedFiles, result); {noformat}
> While running some large scale load test, we run into File SFT metafiles
> inconsistency that we believe could have been avoided if the original order
> was in place. Here the scenario we had:
> 1) Region R with one CF f was open on RS1. At this time, the given store had
> some files, let's say these were file1, file2 and file3;
> 2) Compaction started on RS1;
> 3) RS1 ent
[jira] [Commented] (HBASE-26999) HStore should try write WAL compaction marker before replacing compacted files in StoreEngine
[
https://issues.apache.org/jira/browse/HBASE-26999?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533742#comment-17533742
]
Wellington Chevreuil commented on HBASE-26999:
--
Thanks for reviewing this, [~apurtell] [~zhangduo] ! I had now merged this into
master and branch-2.
Since this is a bug fix, I believe it should go into branch-2.5 as well, but
want to confirm if this is fine and is not going sink your works related to the
2.5.0 RC0 [~apurtell] ?
As for the reported issue above:
{quote}eventually all files in a small subset of stores were (erroneously)
compacted away.
{quote}
And it didn't produce any valid, compaction result file?
{quote}
I'm going to retest with this change applied before debugging further because
it seems to be a race/timing issue related to compaction. Notably this was a
test performed without active chaos. There were no server failures.
{quote}
Right, I'm not optimistic this fix would work for your case, [~apurtell]. I
believe it only prevents the SFM "in-memory" cache from being updated in case
RS is already aborting. One thing that I had noticed whilst troubleshooting
this is that SFT has it's own in-memory cache of "active" files, and it gets
updated on its own locking context, separately from the SFM "in-memory" cache.
I didn't think it could create further problems by the way the updates of SFT
and SFM are being called, but I might had missed something.
Another interesting behaviour noticed is that in the case of two StoreEngine
instances of the same store, say, when we have the region re-opened in a new RS
and the old RS still thinks it's active and the region is open, there will be
two SFT meta files being updated. This current patch would prevent that
situation from progressing to a point the rogue RS could cause problems, but
could we have other scenarios where two StoreEngine instances of the same store
are up?
> HStore should try write WAL compaction marker before replacing compacted
> files in StoreEngine
> -
>
> Key: HBASE-26999
> URL: https://issues.apache.org/jira/browse/HBASE-26999
> Project: HBase
> Issue Type: Sub-task
>Reporter: Wellington Chevreuil
>Assignee: Wellington Chevreuil
>Priority: Major
> Fix For: 2.5.0, 3.0.0-alpha-3
>
>
> On HBASE-26064, it seems we altered the order we update different places with
> the results of a compaction:
> {noformat}
> @@ -1510,14 +1149,13 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> List newFiles) throws IOException {
> // Do the steps necessary to complete the compaction.
> setStoragePolicyFromFileName(newFiles);
> - List sfs = commitStoreFiles(newFiles, true);
> + List sfs = storeEngine.commitStoreFiles(newFiles, true);
> if (this.getCoprocessorHost() != null) {
> for (HStoreFile sf : sfs) {
> getCoprocessorHost().postCompact(this, sf, cr.getTracker(), cr,
> user);
> }
> }
> - writeCompactionWalRecord(filesToCompact, sfs);
> - replaceStoreFiles(filesToCompact, sfs);
> + replaceStoreFiles(filesToCompact, sfs, true);
> ...
> @@ -1581,25 +1219,24 @@ public class HStore implements Store, HeapSize,
> StoreConfigInformation,
> this.region.getRegionInfo(), compactionDescriptor,
> this.region.getMVCC());
> }
>
> - void replaceStoreFiles(Collection compactedFiles,
> Collection result)
> - throws IOException {
> - this.lock.writeLock().lock();
> - try {
> -
> this.storeEngine.getStoreFileManager().addCompactionResults(compactedFiles,
> result);
> - synchronized (filesCompacting) {
> - filesCompacting.removeAll(compactedFiles);
> - }
> -
> - // These may be null when the RS is shutting down. The space quota
> Chores will fix the Region
> - // sizes later so it's not super-critical if we miss these.
> - RegionServerServices rsServices = region.getRegionServerServices();
> - if (rsServices != null &&
> rsServices.getRegionServerSpaceQuotaManager() != null) {
> - updateSpaceQuotaAfterFileReplacement(
> -
> rsServices.getRegionServerSpaceQuotaManager().getRegionSizeStore(),
> getRegionInfo(),
> - compactedFiles, result);
> - }
> - } finally {
> - this.lock.writeLock().unlock();
> + @RestrictedApi(explanation = "Should only be called in TestHStore", link =
> "",
> + allowedOnPath = ".*/(HStore|TestHStore).java")
> + void replaceStoreFiles(Collection compactedFiles,
> Collection result,
> + boolean writeCompactionMarker) throws IOException {
> + storeEngine.replaceStoreFiles(compactedFiles, result);
> + if (writeCompactionMarker) {
> + writeCompactionWalRecord(compactedFiles, result);
>
[GitHub] [hbase] wchevreuil merged pull request #4407: HBASE-26999 HStore should try write WAL compaction marker before repl…
wchevreuil merged PR #4407: URL: https://github.com/apache/hbase/pull/4407 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@hbase.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HBASE-27016) when “zookeeper.session.timeout” is set to a negative number, HMaster cannot stop normally
[
https://issues.apache.org/jira/browse/HBASE-27016?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingxuan Fu updated HBASE-27016:
Description:
In hbase- default.xml
{code:java}
zookeeper.session.timeout
9
ZooKeeper session timeout in milliseconds. It is used in two
different ways.
First, this value is used in the ZK client that HBase uses to connect to
the ensemble.
It is also used by HBase when it starts a ZK server and it is passed as
the 'maxSessionTimeout'.
See
https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_zkSessions.
For example, if an HBase region server connects to a ZK ensemble that's
also managed
by HBase, then the session timeout will be the one specified by this
configuration.
But, a region server that connects to an ensemble managed with a
different configuration
will be subjected that ensemble's maxSessionTimeout. So, even though
HBase might propose
using 90 seconds, the ensemble can have a max timeout lower than this and
it will take
precedence. The current default maxSessionTimeout that ZK ships with is
40 seconds, which is lower than
HBase's.
{code}
The impact caused by setting zookeeper.session.timeout to negative number is
different in local mode and pseudo-distributed mode.
After starting hbase in local mode, hmaster will replace the sessiontimeout
configured in this start master() with the default value of 1 when it is
judged as local mode, so setting zookeeper.session.timeout to a negative number
in hbase-site.xml will have no effect on the hbase startup process.
{code:java}
private int startMaster() {
Configuration conf = getConf();
TraceUtil.initTracer(conf);
try {
// If 'local', defer to LocalHBaseCluster instance. Starts master
// and regionserver both in the one JVM.
if (LocalHBaseCluster.isLocal(conf)) {
...
int localZKClusterSessionTimeout;
localZKClusterSessionTimeout = conf.getInt(HConstants.ZK_SESSION_TIMEOUT
+ ".localHBaseCluster", 10*1000);
conf.setInt(HConstants.ZK_SESSION_TIMEOUT, localZKClusterSessionTimeout);
LOG.info("Starting a zookeeper cluster");
...
}
{code}
Take the example of setting zookeeper.session.timeout to -1 in hbase-site.xml
to start hbase in local mode normally.
{code:java}
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./start-hbase.sh
running master, logging to
/home/hadoop/hbase-2.2.2-ori/bin/../logs/hbase-hadoop-master-ljq1.out
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ jps
25667 HMaster
21859 Jps{code}
{code:java}
2022-05-09 11:16:57,571 INFO [master/ljq1:16000:becomeActiveMaster]
master.HMaster: Master has completed initialization 8.179sec{code}
However, next, when the hbase shell as a client initiates a request for basic
database operations to the started HBase, the zookeeper.session.timeout is
negative causing a ConnectionLoss error and any requested operation is invalid
as it recreates the conf to load the configuration.
{code:java}
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./hbase shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.2, re6513a76c91cceda95dad7af246ac81d46fa2589, Sat Oct 19 10:10:12
UTC 2019
Took 0.0212 seconds
hbase(main):001:0> status
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "status"'
Took 34.2850 seconds
hbase(main):002:0> create 'a','a1','a22'
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "create"'
Took 33.2029 seconds{code}
The log shows that a socket connection was received, but consistently throws a
warning that no additional data could be read from the client session and that
the client may have closed the socket.
Next, use the official termination method . /stop-hbase.sh to shut down hbase,
it will also recreate the conf and load the configuration when shutting down.
zookeeper.session.timeout will be negative and the terminal will be stuck in an
infinite wait, and eventually the process will have to be terminated by kill
-9, which is the official termination method . /stop-hbase.sh to shut down
hbase is not effective.
{code:java}
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./stop-hbase.sh
stopping
hbase..
[jira] [Updated] (HBASE-27016) when “zookeeper.session.timeout” is set to a negative number, HMaster cannot stop normally
[
https://issues.apache.org/jira/browse/HBASE-27016?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingxuan Fu updated HBASE-27016:
Description:
{{In hbase- default.xml}}
{code:java}
zookeeper.session.timeout
9
ZooKeeper session timeout in milliseconds. It is used in two
different ways.
First, this value is used in the ZK client that HBase uses to connect to
the ensemble.
It is also used by HBase when it starts a ZK server and it is passed as
the 'maxSessionTimeout'.
See
https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_zkSessions.
For example, if an HBase region server connects to a ZK ensemble that's
also managed
by HBase, then the session timeout will be the one specified by this
configuration.
But, a region server that connects to an ensemble managed with a
different configuration
will be subjected that ensemble's maxSessionTimeout. So, even though
HBase might propose
using 90 seconds, the ensemble can have a max timeout lower than this and
it will take
precedence. The current default maxSessionTimeout that ZK ships with is
40 seconds, which is lower than
HBase's.
{code}
The impact caused by setting zookeeper.session.timeout to negative number is
different in local mode and pseudo-distributed mode.
After starting hbase in local mode, hmaster will replace the sessiontimeout
configured in this start master() with the default value of 1 when it is
judged as local mode, so setting zookeeper.session.timeout to a negative number
in hbase-site.xml will have no effect on the hbase startup process.
{code:java}
private int startMaster() {
Configuration conf = getConf();
TraceUtil.initTracer(conf);
try {
// If 'local', defer to LocalHBaseCluster instance. Starts master
// and regionserver both in the one JVM.
if (LocalHBaseCluster.isLocal(conf)) {
...
int localZKClusterSessionTimeout;
localZKClusterSessionTimeout = conf.getInt(HConstants.ZK_SESSION_TIMEOUT
+ ".localHBaseCluster", 10*1000);
conf.setInt(HConstants.ZK_SESSION_TIMEOUT, localZKClusterSessionTimeout);
LOG.info("Starting a zookeeper cluster");
...
}
{code}
Take the example of setting zookeeper.session.timeout to -1 in hbase-site.xml
to start hbase in local mode normally.
{code:java}
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./start-hbase.sh
running master, logging to
/home/hadoop/hbase-2.2.2-ori/bin/../logs/hbase-hadoop-master-ljq1.out
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ jps
25667 HMaster
21859 Jps{code}
{code:java}
2022-05-09 11:16:57,571 INFO [master/ljq1:16000:becomeActiveMaster]
master.HMaster: Master has completed initialization 8.179sec{code}
However, next, when the hbase shell as a client initiates a request for basic
database operations to the started HBase, the zookeeper.session.timeout is
negative causing a ConnectionLoss error and any requested operation is invalid
as it recreates the conf to load the configuration.
{code:java}
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./hbase shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.2, re6513a76c91cceda95dad7af246ac81d46fa2589, Sat Oct 19 10:10:12
UTC 2019
Took 0.0212 seconds
hbase(main):001:0> status
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "status"'
Took 34.2850 seconds
hbase(main):002:0> create 'a','a1','a22'
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "create"'
Took 33.2029 seconds{code}
The log shows that a socket connection was received, but consistently throws a
warning that no additional data could be read from the client session and that
the client may have closed the socket.
Next, use the official termination method . /stop-hbase.sh to shut down hbase,
it will also recreate the conf and load the configuration when shutting down.
zookeeper.session.timeout will be negative and the terminal will be stuck in an
infinite wait, and eventually the process will have to be terminated by kill
-9, which is the official termination method . /stop-hbase.sh to shut down
hbase is not effective.
{code:java}
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./stop-hbase.sh
stopping
hbase.
[jira] [Updated] (HBASE-27016) when “zookeeper.session.timeout” is set to a negative number, HMaster cannot stop normally
[
https://issues.apache.org/jira/browse/HBASE-27016?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingxuan Fu updated HBASE-27016:
Description:
{{In hbase- default.xml}}
zookeeper.session.timeout
9
ZooKeeper session timeout in milliseconds. It is used in two
different ways.
First, this value is used in the ZK client that HBase uses to connect
to the ensemble.
It is also used by HBase when it starts a ZK server and it is passed as
the 'maxSessionTimeout'.
See
https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_zkSessions.
For example, if an HBase region server connects to a ZK ensemble that's
also managed
by HBase, then the session timeout will be the one specified by this
configuration.
But, a region server that connects to an ensemble managed with a
different configuration
will be subjected that ensemble's maxSessionTimeout. So, even though
HBase might propose
using 90 seconds, the ensemble can have a max timeout lower than this
and it will take
precedence. The current default maxSessionTimeout that ZK ships with is
40 seconds, which is lower than
HBase's.
The impact caused by setting zookeeper.session.timeout to negative number is
different in local mode and pseudo-distributed mode.
After starting hbase in local mode, hmaster will replace the sessiontimeout
configured in this start master() with the default value of 1 when it is
judged as local mode, so setting zookeeper.session.timeout to a negative number
in hbase-site.xml will have no effect on the hbase startup process.
private int startMaster() {
Configuration conf = getConf();
TraceUtil.initTracer(conf);
try {
// If 'local', defer to LocalHBaseCluster instance. Starts master
// and regionserver both in the one JVM.
if (LocalHBaseCluster.isLocal(conf))
{ ... int localZKClusterSessionTimeout;
localZKClusterSessionTimeout = conf.getInt(HConstants.ZK_SESSION_TIMEOUT +
".localHBaseCluster", 10*1000); conf.setInt(HConstants.ZK_SESSION_TIMEOUT,
localZKClusterSessionTimeout); LOG.info("Starting a zookeeper cluster");
... }
Take the example of setting zookeeper.session.timeout to -1 in hbase-site.xml
to start hbase in local mode normally.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./start-hbase.sh
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in
version 9.0 and will likely be removed in a future release.
running master, logging to
/home/hadoop/hbase-2.2.2-ori/bin/../logs/hbase-hadoop-master-ljq1.out
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in
version 9.0 and will likely be removed in a future release.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ jps
25667 HMaster
21859 Jps
2022-05-09 11:16:57,571 INFO [master/ljq1:16000:becomeActiveMaster]
master.HMaster: Master has completed initialization 8.179sec
However, next, when the hbase shell as a client initiates a request for basic
database operations to the started HBase, the zookeeper.session.timeout is
negative causing a ConnectionLoss error and any requested operation is invalid
as it recreates the conf to load the configuration.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./hbase shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: [http://hbase.apache.org/2.0/book.html#shell]
Version 2.2.2, re6513a76c91cceda95dad7af246ac81d46fa2589, Sat Oct 19 10:10:12
UTC 2019
Took 0.0212 seconds
hbase(main):001:0> status
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "status"'
Took 34.2850 seconds
hbase(main):002:0> create 'a','a1','a22'
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "create"'
Took 33.2029 seconds
The log shows that a socket connection was received, but consistently throws a
warning that no additional data could be read from the client session and that
the client may have closed the socket.
Next, use the official termination method . /stop-hbase.sh to shut down hbase,
it will also recreate the conf and load the configuration when shutting down.
zookeeper.session.timeout will be negative and the terminal will be stuck in an
infinite wait, and eventually the process will have to be terminated by kill
-9, which is the official termination method . /stop-hbase.sh to shut down
hbase is not effective.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./stop-hbas
[jira] [Updated] (HBASE-27016) when “zookeeper.session.timeout” is set to a negative number, HMaster cannot stop normally
[
https://issues.apache.org/jira/browse/HBASE-27016?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingxuan Fu updated HBASE-27016:
Description:
{{In hbase- default.xml}}
{{}}
{{ zookeeper.session.timeout}}
{{ 9}}
{{ ZooKeeper session timeout in milliseconds. It is used in two
different ways.}}
{{ First, this value is used in the ZK client that HBase uses to connect
to the ensemble.}}
{{ It is also used by HBase when it starts a ZK server and it is passed as
the 'maxSessionTimeout'.}}
{{ See
[https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_zkSessions].}}
{{ For example, if an HBase region server connects to a ZK ensemble that's
also managed}}
{{ by HBase, then the session timeout will be the one specified by this
configuration.}}
{{ But, a region server that connects to an ensemble managed with a
different configuration}}
{{ will be subjected that ensemble's maxSessionTimeout. So, even though
HBase might propose}}
{{ using 90 seconds, the ensemble can have a max timeout lower than this
and it will take}}
{{ precedence. The current default maxSessionTimeout that ZK ships with is
40 seconds, which is lower than}}
{{ HBase's.}}
{{ }}
{{}}
The impact caused by setting zookeeper.session.timeout to negative number is
different in local mode and pseudo-distributed mode.
After starting hbase in local mode, hmaster will replace the sessiontimeout
configured in this start master() with the default value of 1 when it is
judged as local mode, so setting zookeeper.session.timeout to a negative number
in hbase-site.xml will have no effect on the hbase startup process.
private int startMaster() {
Configuration conf = getConf();
TraceUtil.initTracer(conf);
try {
// If 'local', defer to LocalHBaseCluster instance. Starts master
// and regionserver both in the one JVM.
if (LocalHBaseCluster.isLocal(conf))
{ ... int localZKClusterSessionTimeout;
localZKClusterSessionTimeout = conf.getInt(HConstants.ZK_SESSION_TIMEOUT +
".localHBaseCluster", 10*1000); conf.setInt(HConstants.ZK_SESSION_TIMEOUT,
localZKClusterSessionTimeout); LOG.info("Starting a zookeeper cluster");
... }
Take the example of setting zookeeper.session.timeout to -1 in hbase-site.xml
to start hbase in local mode normally.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./start-hbase.sh
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in
version 9.0 and will likely be removed in a future release.
running master, logging to
/home/hadoop/hbase-2.2.2-ori/bin/../logs/hbase-hadoop-master-ljq1.out
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in
version 9.0 and will likely be removed in a future release.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ jps
25667 HMaster
21859 Jps
2022-05-09 11:16:57,571 INFO [master/ljq1:16000:becomeActiveMaster]
master.HMaster: Master has completed initialization 8.179sec
However, next, when the hbase shell as a client initiates a request for basic
database operations to the started HBase, the zookeeper.session.timeout is
negative causing a ConnectionLoss error and any requested operation is invalid
as it recreates the conf to load the configuration.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./hbase shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: [http://hbase.apache.org/2.0/book.html#shell]
Version 2.2.2, re6513a76c91cceda95dad7af246ac81d46fa2589, Sat Oct 19 10:10:12
UTC 2019
Took 0.0212 seconds
hbase(main):001:0> status
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "status"'
Took 34.2850 seconds
hbase(main):002:0> create 'a','a1','a22'
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "create"'
Took 33.2029 seconds
The log shows that a socket connection was received, but consistently throws a
warning that no additional data could be read from the client session and that
the client may have closed the socket.
Next, use the official termination method . /stop-hbase.sh to shut down hbase,
it will also recreate the conf and load the configuration when shutting down.
zookeeper.session.timeout will be negative and the terminal will be stuck in an
infinite wait, and eventually the process will have to be terminated by kill
-9, which is the official termination method . /stop-hbase.sh to shut down
hbase is not effective.
hadoop
[jira] [Created] (HBASE-27016) when “zookeeper.session.timeout” is set to a negative number, HMaster cannot stop normally
Jingxuan Fu created HBASE-27016:
---
Summary: when “zookeeper.session.timeout” is set to a negative
number, HMaster cannot stop normally
Key: HBASE-27016
URL: https://issues.apache.org/jira/browse/HBASE-27016
Project: HBase
Issue Type: Bug
Affects Versions: 2.2.2
Environment: HBase 2.2.2
os.name=Linux
os.arch=amd64
os.version=5.4.0-72-generic
java.version=1.8.0_211
java.vendor=Oracle Corporation
Reporter: Jingxuan Fu
Assignee: Jingxuan Fu
In hbase- default.xml
zookeeper.session.timeout
9
ZooKeeper session timeout in milliseconds. It is used in two
different ways.
First, this value is used in the ZK client that HBase uses to connect
to the ensemble.
It is also used by HBase when it starts a ZK server and it is passed as
the 'maxSessionTimeout'.
See
https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_zkSessions.
For example, if an HBase region server connects to a ZK ensemble that's
also managed
by HBase, then the session timeout will be the one specified by this
configuration.
But, a region server that connects to an ensemble managed with a
different configuration
will be subjected that ensemble's maxSessionTimeout. So, even though
HBase might propose
using 90 seconds, the ensemble can have a max timeout lower than this
and it will take
precedence. The current default maxSessionTimeout that ZK ships with is
40 seconds, which is lower than
HBase's.
The impact caused by setting zookeeper.session.timeout to negative number is
different in local mode and pseudo-distributed mode.
After starting hbase in local mode, hmaster will replace the sessiontimeout
configured in this start master() with the default value of 1 when it is
judged as local mode, so setting zookeeper.session.timeout to a negative number
in hbase-site.xml will have no effect on the hbase startup process.
private int startMaster() {
Configuration conf = getConf();
TraceUtil.initTracer(conf);
try {
// If 'local', defer to LocalHBaseCluster instance. Starts master
// and regionserver both in the one JVM.
if (LocalHBaseCluster.isLocal(conf)) {
...
int localZKClusterSessionTimeout;
localZKClusterSessionTimeout = conf.getInt(HConstants.ZK_SESSION_TIMEOUT
+ ".localHBaseCluster", 10*1000);
conf.setInt(HConstants.ZK_SESSION_TIMEOUT, localZKClusterSessionTimeout);
LOG.info("Starting a zookeeper cluster");
...
}
Take the example of setting zookeeper.session.timeout to -1 in hbase-site.xml
to start hbase in local mode normally.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./start-hbase.sh
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in
version 9.0 and will likely be removed in a future release.
running master, logging to
/home/hadoop/hbase-2.2.2-ori/bin/../logs/hbase-hadoop-master-ljq1.out
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in
version 9.0 and will likely be removed in a future release.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ jps
25667 HMaster
21859 Jps
2022-05-09 11:16:57,571 INFO [master/ljq1:16000:becomeActiveMaster]
master.HMaster: Master has completed initialization 8.179sec
However, next, when the hbase shell as a client initiates a request for basic
database operations to the started HBase, the zookeeper.session.timeout is
negative causing a ConnectionLoss error and any requested operation is invalid
as it recreates the conf to load the configuration.
hadoop@ljq1:~/hbase-2.2.2-ori/bin$ ./hbase shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.2, re6513a76c91cceda95dad7af246ac81d46fa2589, Sat Oct 19 10:10:12
UTC 2019
Took 0.0212 seconds
hbase(main):001:0> status
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "status"'
Took 34.2850 seconds
hbase(main):002:0> create 'a','a1','a22'
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help "create"'
Took 33.2029 seconds
The log shows that a socket connection was received, but consistently throws a
warning that no additional data could be read from the client session and that
the client may have closed the socket.
Next, use the official termination method . /stop-hbase.sh to shut down hbas
[jira] [Commented] (HBASE-26218) Better logging in CanaryTool
[ https://issues.apache.org/jira/browse/HBASE-26218?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533660#comment-17533660 ] Ishika Soni commented on HBASE-26218: - [~kiran.maturi] Can you assign this Jira to me > Better logging in CanaryTool > > > Key: HBASE-26218 > URL: https://issues.apache.org/jira/browse/HBASE-26218 > Project: HBase > Issue Type: Improvement >Reporter: Caroline Zhou >Assignee: Kiran Kumar Maturi >Priority: Minor > > CanaryTool logs currently don't indicate which mode they pertain to – they > should at least make note of that. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (HBASE-15529) Override needBalance in StochasticLoadBalancer
[ https://issues.apache.org/jira/browse/HBASE-15529?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] selina.yan updated HBASE-15529: --- Description: StochasticLoadBalancer includes cost functions to compute the cost of region rount, r/w qps, table load, region locality, memstore size, and storefile size. Every cost function returns a number between 0 and 1 inclusive and the computed costs are scaled by their respective multipliers. The bigger multiplier means that the respective cost function have tMore formatting optionshe bigger weight. But needBalance decide whether to balance only by region count and doesn't consider r/w qps, locality even you config these cost function with bigger multiplier. StochasticLoadBalancer should override needBalance and decide whether to balance by it's configs of cost functions. Add one new config hbase.master.balancer.stochastic.minCostNeedBalance, cluster need balance when (total cost / sum multiplier) > minCostNeedBalance. was: StochasticLoadBalancer includes cost functions to compute the cost of region rount, r/w qps, table load, region locality, memstore size, and storefile size. Every cost function returns a number between 0 and 1 inclusive and the computed costs are scaled by their respective multipliers. The bigger multiplier means that the respective cost function have the bigger weight. But needBalance decide whether to balance only by region count and doesn't consider r/w qps, locality even you config these cost function with bigger multiplier. StochasticLoadBalancer should override needBalance and decide whether to balance by it's configs of cost functions. Add one new config hbase.master.balancer.stochastic.minCostNeedBalance, cluster need balance when (total cost / sum multiplier) > minCostNeedBalance. > Override needBalance in StochasticLoadBalancer > -- > > Key: HBASE-15529 > URL: https://issues.apache.org/jira/browse/HBASE-15529 > Project: HBase > Issue Type: Improvement >Reporter: Guanghao Zhang >Assignee: Guanghao Zhang >Priority: Minor > Fix For: 1.4.0, 1.3.3, 2.0.0 > > Attachments: 15529-v1.patch, HBASE-15529-v1.patch, > HBASE-15529-v2.patch, HBASE-15529-v3.patch, HBASE-15529.patch > > > StochasticLoadBalancer includes cost functions to compute the cost of region > rount, r/w qps, table load, region locality, memstore size, and storefile > size. Every cost function returns a number between 0 and 1 inclusive and the > computed costs are scaled by their respective multipliers. The bigger > multiplier means that the respective cost function have tMore formatting > optionshe bigger weight. But needBalance decide whether to balance only by > region count and doesn't consider r/w qps, locality even you config these > cost function with bigger multiplier. StochasticLoadBalancer should override > needBalance and decide whether to balance by it's configs of cost functions. > Add one new config hbase.master.balancer.stochastic.minCostNeedBalance, > cluster need balance when (total cost / sum multiplier) > minCostNeedBalance. -- This message was sent by Atlassian Jira (v8.20.7#820007)