[GitHub] [kafka] dajac commented on pull request #7265: Don't merge this, just testing something in the build
dajac commented on pull request #7265: URL: https://github.com/apache/kafka/pull/7265#issuecomment-715752369 @mumrah I guess that we could close this one, isn't it? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac closed pull request #7336: KAFKA-8107:Flaky Test kafka.api.ClientIdQuotaTest.testQuotaOverrideDe…
dajac closed pull request #7336: URL: https://github.com/apache/kafka/pull/7336 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac commented on pull request #7336: KAFKA-8107:Flaky Test kafka.api.ClientIdQuotaTest.testQuotaOverrideDe…
dajac commented on pull request #7336: URL: https://github.com/apache/kafka/pull/7336#issuecomment-715749977 Closing as this has been fixed by https://github.com/apache/kafka/pull/8394. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10639) There should be an EnvironmentConfigProvider that will do variable substitution using environment variable.
[ https://issues.apache.org/jira/browse/KAFKA-10639?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17220011#comment-17220011 ] Brad Davis commented on KAFKA-10639: I've actually already locally implemented this, but want to contribute it back upstream. The limiting factor is primarily making sure that there are appropriate tests around it and ensuring conformance to existing coding standards. > There should be an EnvironmentConfigProvider that will do variable > substitution using environment variable. > --- > > Key: KAFKA-10639 > URL: https://issues.apache.org/jira/browse/KAFKA-10639 > Project: Kafka > Issue Type: Improvement > Components: config >Affects Versions: 2.5.1 >Reporter: Brad Davis >Priority: Major > > Running Kafka Connect in the same docker container in multiple stages (like > dev vs production) means that a file based approach to secret hiding using > the file config provider isn't viable. However, docker container instances > can have their environment variables customized on a per-container basis, and > our existing tech stack typically exposes per-stage secrets (like the dev DB > password vs the prod DB password) through env vars within the containers. > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-10639) There should be an EnvironmentConfigProvider that will do variable substitution using environment variable.
Brad Davis created KAFKA-10639: -- Summary: There should be an EnvironmentConfigProvider that will do variable substitution using environment variable. Key: KAFKA-10639 URL: https://issues.apache.org/jira/browse/KAFKA-10639 Project: Kafka Issue Type: Improvement Components: config Affects Versions: 2.5.1 Reporter: Brad Davis Running Kafka Connect in the same docker container in multiple stages (like dev vs production) means that a file based approach to secret hiding using the file config provider isn't viable. However, docker container instances can have their environment variables customized on a per-container basis, and our existing tech stack typically exposes per-stage secrets (like the dev DB password vs the prod DB password) through env vars within the containers. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] RamanVerma commented on a change in pull request #9364: KAFKA-10471 Mark broker crash during log loading as unclean shutdown
RamanVerma commented on a change in pull request #9364:
URL: https://github.com/apache/kafka/pull/9364#discussion_r511277713
##
File path: core/src/main/scala/kafka/log/LogManager.scala
##
@@ -298,26 +300,38 @@ class LogManager(logDirs: Seq[File],
/**
* Recover and load all logs in the given data directories
*/
- private def loadLogs(): Unit = {
+ private[log] def loadLogs(): Unit = {
info(s"Loading logs from log dirs $liveLogDirs")
val startMs = time.hiResClockMs()
val threadPools = ArrayBuffer.empty[ExecutorService]
val offlineDirs = mutable.Set.empty[(String, IOException)]
-val jobs = mutable.Map.empty[File, Seq[Future[_]]]
+val jobs = ArrayBuffer.empty[Seq[Future[_]]]
var numTotalLogs = 0
for (dir <- liveLogDirs) {
val logDirAbsolutePath = dir.getAbsolutePath
+ var hadCleanShutdown: Boolean = false
try {
val pool = Executors.newFixedThreadPool(numRecoveryThreadsPerDataDir)
threadPools.append(pool)
val cleanShutdownFile = new File(dir, Log.CleanShutdownFile)
if (cleanShutdownFile.exists) {
info(s"Skipping recovery for all logs in $logDirAbsolutePath since
clean shutdown file was found")
+ // Cache the clean shutdown status and use that for rest of log
loading workflow. Delete the CleanShutdownFile
+ // so that if broker crashes while loading the log, it is considered
hard shutdown during the next boot up. KAFKA-10471
+ try {
+cleanShutdownFile.delete()
+ } catch {
+case e: IOException =>
Review comment:
`java.nio.file.Files` API throws `IOException` but not the one used here
`java.io.File`. Will remove this exception
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] stan-confluent commented on pull request #9488: Pin ducktape to version 0.7.10
stan-confluent commented on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715656921 https://github.com/apache/kafka/pull/9490 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent commented on pull request #9490: Pin ducktape to version 0.7.10
stan-confluent commented on pull request #9490: URL: https://github.com/apache/kafka/pull/9490#issuecomment-715656906 cc @omkreddy @edenhill @sdanduConf @andrewegel This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent opened a new pull request #9490: Pin ducktape to version 0.7.10
stan-confluent opened a new pull request #9490: URL: https://github.com/apache/kafka/pull/9490 Ducktape version 0.7.10 pinned paramiko to version 2.3.2 to deal with random SSHExceptions confluent had been seeing since ducktape was updated to a later version of paramiko. The idea is that we can backport ducktape 0.7.10 change as far back as possible, while 2.7 and trunk can update to 0.8.0 and python3 separately. Tested: In progress, but unlikely to affect anything, since the only difference between ducktape 0.7.9 and 0.7.10 is paramiko version downgrade. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] warrenzhu25 opened a new pull request #9491: KAFKA-10623: Refactor code to avoid discovery conflicts for admin.VersionRange
warrenzhu25 opened a new pull request #9491: URL: https://github.com/apache/kafka/pull/9491 Rename admin.VersionRange into admin.Versions to avoid discovery conflicts ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent commented on pull request #9488: Pin ducktape to version 0.7.10
stan-confluent commented on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715656527 @omkreddy sounds good, let me also re-run the tests on 2.6, just to be sure. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent closed pull request #9488: Pin ducktape to version 0.7.10
stan-confluent closed pull request #9488: URL: https://github.com/apache/kafka/pull/9488 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy edited a comment on pull request #9488: Pin ducktape to version 0.7.10
omkreddy edited a comment on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715651991 @stan-confluent Yes, Please update the PR and base against 2.6. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy edited a comment on pull request #9488: Pin ducktape to version 0.7.10
omkreddy edited a comment on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715651991 @stan-confluent Yes, Please update the PR and re-point to 2.6. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy commented on pull request #9488: Pin ducktape to version 0.7.10
omkreddy commented on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715651991 @stan-confluent Yes, Pls update the PR and re-point to 2.6. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent commented on pull request #9488: Pin ducktape to version 0.7.10
stan-confluent commented on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715651165 > We have PR #9480 to update the version in setup.py. I plan to commit #9480 to trunk and 2,.7 branches. > > I think, we can update ducktape 0.7.10 to 2.6 and below. Awesome, thanks Manikumar. Do you want me to re-point this PR to 2.6 branch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent commented on a change in pull request #9480: KAFKA-10592: Fix vagrant for a system tests with python3
stan-confluent commented on a change in pull request #9480: URL: https://github.com/apache/kafka/pull/9480#discussion_r511233150 ## File path: tests/setup.py ## @@ -51,7 +51,7 @@ def run_tests(self): license="apache2.0", packages=find_packages(), include_package_data=True, - install_requires=["ducktape==0.7.9", "requests==2.22.0"], + install_requires=["ducktape==0.8.0", "requests==2.24.0"], Review comment: Why do we need to pin `requests` explicitly? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy edited a comment on pull request #9488: Pin ducktape to version 0.7.10
omkreddy edited a comment on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715649754 We have PR https://github.com/apache/kafka/pull/9480 to update the version in setup.py. I plan to commit #9480 to trunk and 2,.7 branches. I think, we can update ducktape 0.7.10 to 2.6 and below. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy edited a comment on pull request #9488: Pin ducktape to version 0.7.10
omkreddy edited a comment on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715649754 We have a PR https://github.com/apache/kafka/pull/9480 to update the version in setup.py. I plan to commit #9480 to trunk and 2,.7 branches. I think, we can update ducktape 0.7.10 to 2.6 and below. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy commented on pull request #9488: Pin ducktape to version 0.7.10
omkreddy commented on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715649754 We have a PR https://github.com/apache/kafka/pull/9480 to update the version in setup.py. I plan to commit #9480 to trunk and 2,.7 branches. I think, we can update duktape 0.7.10 to 2.6 and below. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #9489: MINOR: demote "Committing task offsets" log to DEBUG
ableegoldman commented on pull request #9489: URL: https://github.com/apache/kafka/pull/9489#issuecomment-715639072 @guozhangwang @vvcephei WDYT? I'm generally all for more logs but this is pretty extreme This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman opened a new pull request #9489: MINOR: demote "Committing task offsets" log to DEBUG
ableegoldman opened a new pull request #9489: URL: https://github.com/apache/kafka/pull/9489 This message absolutely floods the logs, especially in an eos application where the commit interval is just 100ms. It's definitely a useful message but I don't think there's any justification for it being at the INFO level when it's logged 10 times a second. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10545) Create topic IDs and propagate to brokers
[ https://issues.apache.org/jira/browse/KAFKA-10545?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Justine Olshan updated KAFKA-10545: --- Description: First step for KIP-516 The goals are: * Create and store topic IDs in a ZK Node and controller memory. * Propagate topic ID to brokers with updated LeaderAndIsrRequest, UpdateMetadata * Store topic ID in memory on broker, persistent file in log was: First step for KIP-516 The goals are: * Create and store topic IDs in a ZK Node and controller memory. * Propagate topic ID to brokers with updated LeaderAndIsrRequest * Store topic ID in memory on broker, persistent file in log > Create topic IDs and propagate to brokers > - > > Key: KAFKA-10545 > URL: https://issues.apache.org/jira/browse/KAFKA-10545 > Project: Kafka > Issue Type: Sub-task >Reporter: Justine Olshan >Assignee: Justine Olshan >Priority: Major > > First step for KIP-516 > The goals are: > * Create and store topic IDs in a ZK Node and controller memory. > * Propagate topic ID to brokers with updated LeaderAndIsrRequest, > UpdateMetadata > * Store topic ID in memory on broker, persistent file in log -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10547) Add topic IDs to MetadataResponse
[ https://issues.apache.org/jira/browse/KAFKA-10547?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Justine Olshan updated KAFKA-10547: --- Summary: Add topic IDs to MetadataResponse (was: Add topic IDs to MetadataResponse, UpdateMetadata) > Add topic IDs to MetadataResponse > - > > Key: KAFKA-10547 > URL: https://issues.apache.org/jira/browse/KAFKA-10547 > Project: Kafka > Issue Type: Sub-task >Reporter: Justine Olshan >Priority: Major > > Prevent reads from deleted topics > Will be able to use TopicDescription to identify the topic ID -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] stan-confluent commented on pull request #9488: Pin ducktape to version 0.7.10
stan-confluent commented on pull request #9488: URL: https://github.com/apache/kafka/pull/9488#issuecomment-715636766 cc @omkreddy @edenhill - folks, I think you've been working on updating kafkatest to python 3, so adding you as reviewers. also cc @andrewegel and @sdanduConf This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] stan-confluent opened a new pull request #9488: Pin ducktape to version 0.7.10
stan-confluent opened a new pull request #9488: URL: https://github.com/apache/kafka/pull/9488 Ducktape version 0.7.10 pinned paramiko to version 2.3.2 to deal with random `SSHException`s confluent had been seeing since ducktape was updated to a later version of paramiko. This PR pins both the version in `setup.py` and in `ducker-ak`'s `Dockerfile` to the same version. Previously ducker version was pinned to 0.8.0. I'll send a separate PR that pins both versions to 0.8.0 (unless someone is already working on that separately) - the idea is that we can backport ducktape 0.7.10 change as far back as possible, while keep the ducktape 0.8.0 change in trunk only (unless we plan to backport python3 changes). Tested: http://confluent-kafka-branch-builder-system-test-results.s3-us-west-2.amazonaws.com/2020-10-23--001.1603440055--stan-confluent--ducktape-710--3c51234d0/report.html There are 10 failing tests, 9 of which have been failing before this change, and 1 (streams_upgrade_test) I've seen failing on different branches recently as well, though it was passing on trunk as of couple of days ago. Since ducktape version only changed the paramiko dependencies, I don't think it could've affected it. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9418: KAFKA-10601; Add support for append linger to Raft implementation
hachikuji commented on a change in pull request #9418:
URL: https://github.com/apache/kafka/pull/9418#discussion_r511200238
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -0,0 +1,294 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.internals;
+
+import org.apache.kafka.common.memory.MemoryPool;
+import org.apache.kafka.common.record.CompressionType;
+import org.apache.kafka.common.record.MemoryRecords;
+import org.apache.kafka.common.record.RecordBatch;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Timer;
+import org.apache.kafka.raft.RecordSerde;
+
+import java.io.Closeable;
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.concurrent.locks.ReentrantLock;
+
+/**
+ * TODO: Also flush after minimum size limit is reached?
+ */
+public class BatchAccumulator implements Closeable {
+private final int epoch;
+private final Time time;
+private final Timer lingerTimer;
+private final int lingerMs;
+private final int maxBatchSize;
+private final CompressionType compressionType;
+private final MemoryPool memoryPool;
+private final ReentrantLock lock;
+private final RecordSerde serde;
+
+private long nextOffset;
+private BatchBuilder currentBatch;
+private List> completed;
+
+public BatchAccumulator(
+int epoch,
+long baseOffset,
+int lingerMs,
+int maxBatchSize,
+MemoryPool memoryPool,
+Time time,
+CompressionType compressionType,
+RecordSerde serde
+) {
+this.epoch = epoch;
+this.lingerMs = lingerMs;
+this.maxBatchSize = maxBatchSize;
+this.memoryPool = memoryPool;
+this.time = time;
+this.lingerTimer = time.timer(lingerMs);
+this.compressionType = compressionType;
+this.serde = serde;
+this.nextOffset = baseOffset;
+this.completed = new ArrayList<>();
+this.lock = new ReentrantLock();
+}
+
+/**
+ * Append a list of records into an atomic batch. We guarantee all records
+ * are included in the same underlying record batch so that either all of
+ * the records become committed or none of them do.
+ *
+ * @param epoch the expected leader epoch
+ * @param records the list of records to include in a batch
+ * @return the offset of the last message or {@link Long#MAX_VALUE} if the
epoch
+ * does not match
+ */
+public Long append(int epoch, List records) {
+if (epoch != this.epoch) {
+// If the epoch does not match, then the state machine probably
+// has not gotten the notification about the latest epoch change.
+// In this case, ignore the append and return a large offset value
+// which will never be committed.
Review comment:
Right. It is important to ensure that the state machine has observed the
latest leader epoch. Otherwise there may be committed data inflight which the
state machine has yet to see.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10633) Constant probing rebalances in Streams 2.6
[ https://issues.apache.org/jira/browse/KAFKA-10633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219963#comment-17219963 ] A. Sophie Blee-Goldman commented on KAFKA-10633: The issue with directory contents being deleted but not the directories themselves sounds like KAFKA-10564 (also fixed in 2.7.0/2.6.1). I don't believe that particular bug has any real implications, other than being annoying/misleading in the logs – it should still delete everything in the task directory, including the checkpoint file which is how the assignor determines which persistent state is/isn't on an instance. I'm kind of surprised that you would still get a rebalance after redeploying like that when using static membership. Unless it takes longer than the static group membership timeout I guess. To be honest, I'm not that familiar with the specifics of static membership in general – maybe [~bchen225242] can chime in here. But I suppose I would start by checking out the logs on the Streams side after it comes back up, and see if it's logged any reason for triggering a rebalance explicitly. (There are a few reasons to trigger a rebalance after a static member is bounced, for example if it's hostname changed for IQ. If anything like that happened it should be logged clearly) > Constant probing rebalances in Streams 2.6 > -- > > Key: KAFKA-10633 > URL: https://issues.apache.org/jira/browse/KAFKA-10633 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Bradley Peterson >Priority: Major > Attachments: Discover 2020-10-21T23 34 03.867Z - 2020-10-21T23 44 > 46.409Z.csv > > > We are seeing a few issues with the new rebalancing behavior in Streams 2.6. > This ticket is for constant probing rebalances on one StreamThread, but I'll > mention the other issues, as they may be related. > First, when we redeploy the application we see tasks being moved, even though > the task assignment was stable before redeploying. We would expect to see > tasks assigned back to the same instances and no movement. The application is > in EC2, with persistent EBS volumes, and we use static group membership to > avoid rebalancing. To redeploy the app we terminate all EC2 instances. The > new instances will reattach the EBS volumes and use the same group member id. > After redeploying, we sometimes see the group leader go into a tight probing > rebalance loop. This doesn't happen immediately, it could be several hours > later. Because the redeploy caused task movement, we see expected probing > rebalances every 10 minutes. But, then one thread will go into a tight loop > logging messages like "Triggering the followup rebalance scheduled for > 1603323868771 ms.", handling the partition assignment (which doesn't change), > then "Requested to schedule probing rebalance for 1603323868771 ms." This > repeats several times a second until the app is restarted again. I'll attach > a log export from one such incident. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] bbejeck edited a comment on pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
bbejeck edited a comment on pull request #9486: URL: https://github.com/apache/kafka/pull/9486#issuecomment-715620710 Need to test locally that the `uploadArchives` task triggers `archive` blocks in the build.gradle file. If correct then the `kafka-streams-scala-scaladoc.jar` should get created properly, and with scaladoc disabled for core, we won't publish non-public scaladoc This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] bbejeck commented on pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
bbejeck commented on pull request #9486: URL: https://github.com/apache/kafka/pull/9486#issuecomment-715620710 Need to test locally that the `uploadArchives` task triggers `archive` blocks in the build.gradle file. If correct then the `kafka-streams-scala-scaladoc.jar` should get created properly This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10633) Constant probing rebalances in Streams 2.6
[ https://issues.apache.org/jira/browse/KAFKA-10633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219958#comment-17219958 ] Bradley Peterson commented on KAFKA-10633: -- Sophie (et al.), do you have any thoughts about what would cause rebalances (and task movements) after redeploying? If we could fix that, then this would be less of a problem, because we would rarely have probing rebalances. We do have another problem where state directories are not deleted, but their contents are (almost like KAFKA-6647, but not quite the same). Is it possible that is confusing the task assignor? > Constant probing rebalances in Streams 2.6 > -- > > Key: KAFKA-10633 > URL: https://issues.apache.org/jira/browse/KAFKA-10633 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Bradley Peterson >Priority: Major > Attachments: Discover 2020-10-21T23 34 03.867Z - 2020-10-21T23 44 > 46.409Z.csv > > > We are seeing a few issues with the new rebalancing behavior in Streams 2.6. > This ticket is for constant probing rebalances on one StreamThread, but I'll > mention the other issues, as they may be related. > First, when we redeploy the application we see tasks being moved, even though > the task assignment was stable before redeploying. We would expect to see > tasks assigned back to the same instances and no movement. The application is > in EC2, with persistent EBS volumes, and we use static group membership to > avoid rebalancing. To redeploy the app we terminate all EC2 instances. The > new instances will reattach the EBS volumes and use the same group member id. > After redeploying, we sometimes see the group leader go into a tight probing > rebalance loop. This doesn't happen immediately, it could be several hours > later. Because the redeploy caused task movement, we see expected probing > rebalances every 10 minutes. But, then one thread will go into a tight loop > logging messages like "Triggering the followup rebalance scheduled for > 1603323868771 ms.", handling the partition assignment (which doesn't change), > then "Requested to schedule probing rebalance for 1603323868771 ms." This > repeats several times a second until the app is restarted again. I'll attach > a log export from one such incident. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] rajinisivaram commented on a change in pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on a change in pull request #9382: URL: https://github.com/apache/kafka/pull/9382#discussion_r511174838 ## File path: core/src/main/scala/kafka/server/ReplicaManager.scala ## @@ -770,7 +770,7 @@ class ReplicaManager(val config: KafkaConfig, logManager.abortAndPauseCleaning(topicPartition) val initialFetchState = InitialFetchState(BrokerEndPoint(config.brokerId, "localhost", -1), - partition.getLeaderEpoch, futureLog.highWatermark) + partition.getLeaderEpoch, futureLog.highWatermark, lastFetchedEpoch = None) Review comment: Looking at this again, I think a bit more work is required to set the offsets and epoch correctly for AlterLogDirsThread in order to use `lastFetchedEpoch`. So I have reverted the changes for ReplicaAlterLogDirsThread. Will do that in a follow-on PR instead. In this PR, we will use the old truncation path in this case. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331 add a streams handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r511149017
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -346,26 +351,92 @@ public void setStateListener(final
KafkaStreams.StateListener listener) {
* Set the handler invoked when a {@link
StreamsConfig#NUM_STREAM_THREADS_CONFIG internal thread} abruptly
* terminates due to an uncaught exception.
*
- * @param eh the uncaught exception handler for all internal threads;
{@code null} deletes the current handler
+ * @param uncaughtExceptionHandler the uncaught exception handler for all
internal threads; {@code null} deletes the current handler
* @throws IllegalStateException if this {@code KafkaStreams} instance is
not in state {@link State#CREATED CREATED}.
+ *
+ * @Deprecated Since 2.7.0. Use {@link
KafkaStreams#setUncaughtExceptionHandler(StreamsUncaughtExceptionHandler)}
instead.
+ *
*/
-public void setUncaughtExceptionHandler(final
Thread.UncaughtExceptionHandler eh) {
+public void setUncaughtExceptionHandler(final
Thread.UncaughtExceptionHandler uncaughtExceptionHandler) {
synchronized (stateLock) {
if (state == State.CREATED) {
for (final StreamThread thread : threads) {
-thread.setUncaughtExceptionHandler(eh);
+
thread.setUncaughtExceptionHandler(uncaughtExceptionHandler);
}
if (globalStreamThread != null) {
-globalStreamThread.setUncaughtExceptionHandler(eh);
+
globalStreamThread.setUncaughtExceptionHandler(uncaughtExceptionHandler);
}
} else {
throw new IllegalStateException("Can only set
UncaughtExceptionHandler in CREATED state. " +
-"Current state is: " + state);
+"Current state is: " + state);
+}
+}
+}
+
+/**
+ * Set the handler invoked when a {@link
StreamsConfig#NUM_STREAM_THREADS_CONFIG internal thread}
+ * throws an unexpected exception.
+ * These might be exceptions indicating rare bugs in Kafka Streams, or they
+ * might be exceptions thrown by your code, for example a
NullPointerException thrown from your processor
+ * logic.
+ *
+ * Note, this handler must be threadsafe, since it will be shared among
all threads, and invoked from any
+ * thread that encounters such an exception.
+ *
+ * @param streamsUncaughtExceptionHandler the uncaught exception handler
of type {@link StreamsUncaughtExceptionHandler} for all internal threads;
{@code null} deletes the current handler
+ * @throws IllegalStateException if this {@code KafkaStreams} instance is
not in state {@link State#CREATED CREATED}.
+ * @throws NullPointerException @NotNull if
streamsUncaughtExceptionHandler is null.
+ */
+public void setUncaughtExceptionHandler(final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final StreamsUncaughtExceptionHandler handler = exception ->
handleStreamsUncaughtException(exception, streamsUncaughtExceptionHandler);
+synchronized (stateLock) {
+if (state == State.CREATED) {
+Objects.requireNonNull(streamsUncaughtExceptionHandler);
+for (final StreamThread thread : threads) {
+thread.setStreamsUncaughtExceptionHandler(handler);
+}
+if (globalStreamThread != null) {
+globalStreamThread.setUncaughtExceptionHandler(handler);
+}
+} else {
+throw new IllegalStateException("Can only set
UncaughtExceptionHandler in CREATED state. " +
+"Current state is: " + state);
}
}
}
+private StreamsUncaughtExceptionHandler.StreamThreadExceptionResponse
handleStreamsUncaughtException(final Throwable e,
+
final StreamsUncaughtExceptionHandler
streamsUncaughtExceptionHandler) {
+final StreamsUncaughtExceptionHandler.StreamThreadExceptionResponse
action = streamsUncaughtExceptionHandler.handle(e);
+switch (action) {
+//case REPLACE_STREAM_THREAD:
+//log.error("Encountered the following exception during
processing " +
+//"and the the stream thread will be replaced: ", e);
+//this.addStreamsThread();
+//break;
+case SHUTDOWN_CLIENT:
+log.error("Encountered the following exception during
processing " +
+"and the client is going to shut down: ", e);
+close(Duration.ZERO);
+break;
+case SHUTDOWN_APPLICATION:
+
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331 add a streams handler
wcarlson5 commented on a change in pull request #9487: URL: https://github.com/apache/kafka/pull/9487#discussion_r511148601 ## File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java ## @@ -782,7 +849,12 @@ private KafkaStreams(final InternalTopologyBuilder internalTopologyBuilder, cacheSizePerThread, stateDirectory, delegatingStateRestoreListener, -i + 1); +i + 1, +KafkaStreams.this::close, Review comment: This will call closeToError but I am testing if that has a problem. So far it does not This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wcarlson5 commented on pull request #9273: KAFKA-9331: changes for Streams uncaught exception handler
wcarlson5 commented on pull request #9273: URL: https://github.com/apache/kafka/pull/9273#issuecomment-715581699 Moved to https://github.com/apache/kafka/pull/9487 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wcarlson5 closed pull request #9273: KAFKA-9331: changes for Streams uncaught exception handler
wcarlson5 closed pull request #9273: URL: https://github.com/apache/kafka/pull/9273 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wcarlson5 opened a new pull request #9487: KAFKA-9331 add a streams handler
wcarlson5 opened a new pull request #9487: URL: https://github.com/apache/kafka/pull/9487 *More detailed description of your change, if necessary. The PR title and PR message become the squashed commit message, so use a separate comment to ping reviewers.* *Summary of testing strategy (including rationale) for the feature or bug fix. Unit and/or integration tests are expected for any behaviour change and system tests should be considered for larger changes.* ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on a change in pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
mjsax commented on a change in pull request #9486:
URL: https://github.com/apache/kafka/pull/9486#discussion_r511135914
##
File path: build.gradle
##
@@ -942,6 +942,7 @@ project(':core') {
from(project(':streams').jar) { into("libs/") }
from(project(':streams').configurations.runtime) { into("libs/") }
from(project(':streams:streams-scala').jar) { into("libs/") }
+
from(project(':streams:streams-scala').configurations.archives.artifacts.files.filter
{ file -> file.name.matches(".*scaladoc.*")}) { into("libs/") }
Review comment:
Do we actually need to do this? I don't see any other line here that
would copy JavaDocs-jar into the `lib` directory?
\cc @ijuma
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #9418: KAFKA-10601; Add support for append linger to Raft implementation
jsancio commented on a change in pull request #9418:
URL: https://github.com/apache/kafka/pull/9418#discussion_r52281
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -0,0 +1,294 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.raft.internals;
+
+import org.apache.kafka.common.memory.MemoryPool;
+import org.apache.kafka.common.record.CompressionType;
+import org.apache.kafka.common.record.MemoryRecords;
+import org.apache.kafka.common.record.RecordBatch;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Timer;
+import org.apache.kafka.raft.RecordSerde;
+
+import java.io.Closeable;
+import java.nio.ByteBuffer;
+import java.util.ArrayList;
+import java.util.List;
+import java.util.concurrent.locks.ReentrantLock;
+
+/**
+ * TODO: Also flush after minimum size limit is reached?
+ */
+public class BatchAccumulator implements Closeable {
+private final int epoch;
+private final Time time;
+private final Timer lingerTimer;
+private final int lingerMs;
+private final int maxBatchSize;
+private final CompressionType compressionType;
+private final MemoryPool memoryPool;
+private final ReentrantLock lock;
+private final RecordSerde serde;
+
+private long nextOffset;
+private BatchBuilder currentBatch;
+private List> completed;
+
+public BatchAccumulator(
+int epoch,
+long baseOffset,
+int lingerMs,
+int maxBatchSize,
+MemoryPool memoryPool,
+Time time,
+CompressionType compressionType,
+RecordSerde serde
+) {
+this.epoch = epoch;
+this.lingerMs = lingerMs;
+this.maxBatchSize = maxBatchSize;
+this.memoryPool = memoryPool;
+this.time = time;
+this.lingerTimer = time.timer(lingerMs);
+this.compressionType = compressionType;
+this.serde = serde;
+this.nextOffset = baseOffset;
+this.completed = new ArrayList<>();
+this.lock = new ReentrantLock();
+}
+
+/**
+ * Append a list of records into an atomic batch. We guarantee all records
+ * are included in the same underlying record batch so that either all of
+ * the records become committed or none of them do.
+ *
+ * @param epoch the expected leader epoch
+ * @param records the list of records to include in a batch
+ * @return the offset of the last message or {@link Long#MAX_VALUE} if the
epoch
+ * does not match
+ */
+public Long append(int epoch, List records) {
+if (epoch != this.epoch) {
+// If the epoch does not match, then the state machine probably
+// has not gotten the notification about the latest epoch change.
+// In this case, ignore the append and return a large offset value
+// which will never be committed.
+return Long.MAX_VALUE;
+}
+
+Object serdeContext = serde.newWriteContext();
+int batchSize = 0;
+for (T record : records) {
+batchSize += serde.recordSize(record, serdeContext);
+}
+
+if (batchSize > maxBatchSize) {
+throw new IllegalArgumentException("The total size of " + records
+ " is " + batchSize +
+", which exceeds the maximum allowed batch size of " +
maxBatchSize);
+}
+
+lock.lock();
+try {
+BatchBuilder batch = maybeAllocateBatch(batchSize);
+if (batch == null) {
+return null;
+}
+
+if (isEmpty()) {
+lingerTimer.update();
+lingerTimer.reset(lingerMs);
+}
+
+for (T record : records) {
+batch.appendRecord(record, serdeContext);
+nextOffset += 1;
+}
+
+return nextOffset - 1;
+} finally {
+lock.unlock();
+}
+}
+
+private BatchBuilder maybeAllocateBatch(int batchSize) {
+if (currentBatch == null) {
+startNewBatch();
+} else if (!currentBatch.hasRoomFor(batchSize)) {
+
[GitHub] [kafka] bbejeck commented on pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
bbejeck commented on pull request #9486: URL: https://github.com/apache/kafka/pull/9486#issuecomment-715558972 >We probably only want to publish scaladoc for kafka streams since it's the only module that has a public Scala API. ack, working on that now This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
mjsax commented on pull request #9486: URL: https://github.com/apache/kafka/pull/9486#issuecomment-715556674 @ijuma Correct! That is what KAFKA-9381 actually is all about. LGTM. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
ijuma commented on pull request #9486: URL: https://github.com/apache/kafka/pull/9486#issuecomment-715554159 We probably only want to publish scaladoc for kafka streams since it's the only module that has a public Scala API. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10638) QueryableStateIntegrationTest fails due to stricter store checking
[
https://issues.apache.org/jira/browse/KAFKA-10638?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bill Bejeck updated KAFKA-10638:
Fix Version/s: 2.7.0
> QueryableStateIntegrationTest fails due to stricter store checking
> --
>
> Key: KAFKA-10638
> URL: https://issues.apache.org/jira/browse/KAFKA-10638
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.7.0
>Reporter: John Roesler
>Assignee: John Roesler
>Priority: Blocker
> Fix For: 2.7.0
>
>
> Observed:
> {code:java}
> org.apache.kafka.streams.errors.InvalidStateStoreException: Cannot get state
> store source-table because the stream thread is PARTITIONS_ASSIGNED, not
> RUNNING
> at
> org.apache.kafka.streams.state.internals.StreamThreadStateStoreProvider.stores(StreamThreadStateStoreProvider.java:81)
> at
> org.apache.kafka.streams.state.internals.WrappingStoreProvider.stores(WrappingStoreProvider.java:50)
> at
> org.apache.kafka.streams.state.internals.CompositeReadOnlyKeyValueStore.get(CompositeReadOnlyKeyValueStore.java:52)
> at
> org.apache.kafka.streams.integration.StoreQueryIntegrationTest.shouldQuerySpecificActivePartitionStores(StoreQueryIntegrationTest.java:200)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> at org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:61)
> at org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> at
> org.junit.runners.BlockJUnit4ClassRunner$1.evaluate(BlockJUnit4ClassRunner.java:100)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:366)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:103)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:63)
> at org.junit.runners.ParentRunner$4.run(ParentRunner.java:331)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:79)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:329)
> at org.junit.runners.ParentRunner.access$100(ParentRunner.java:66)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:293)
> at org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:413)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.runTestClass(JUnitTestClassExecutor.java:110)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.execute(JUnitTestClassExecutor.java:58)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.execute(JUnitTestClassExecutor.java:38)
> at
> org.gradle.api.internal.tasks.testing.junit.AbstractJUnitTestClassProcessor.processTestClass(AbstractJUnitTestClassProcessor.java:62)
> at
> org.gradle.api.internal.tasks.testing.SuiteTestClassProcessor.processTestClass(SuiteTestClassProcessor.java:51)
> at sun.reflect.GeneratedMethodAccessor23.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:36)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
> at
> org.gradle.internal.dispatch.ContextClassLoaderDispatch.dispatch(ContextClassLoaderDispatch.java:33)
> at
> org.gradle.internal.dispatch.ProxyDispatchAdapter$DispatchingInvocationHandler.invoke(ProxyDispatchAdapter.java:94)
> at com.sun.proxy.$Proxy2.processTestClass(Unknown Source)
> at
> org.gradle.api.internal.tasks.testing.worker.TestWorker.processTestClass(TestWorker.java:119)
> at
[GitHub] [kafka] bbejeck commented on pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
bbejeck commented on pull request #9486: URL: https://github.com/apache/kafka/pull/9486#issuecomment-715526717 Results of rendering contents of scaladoc jar 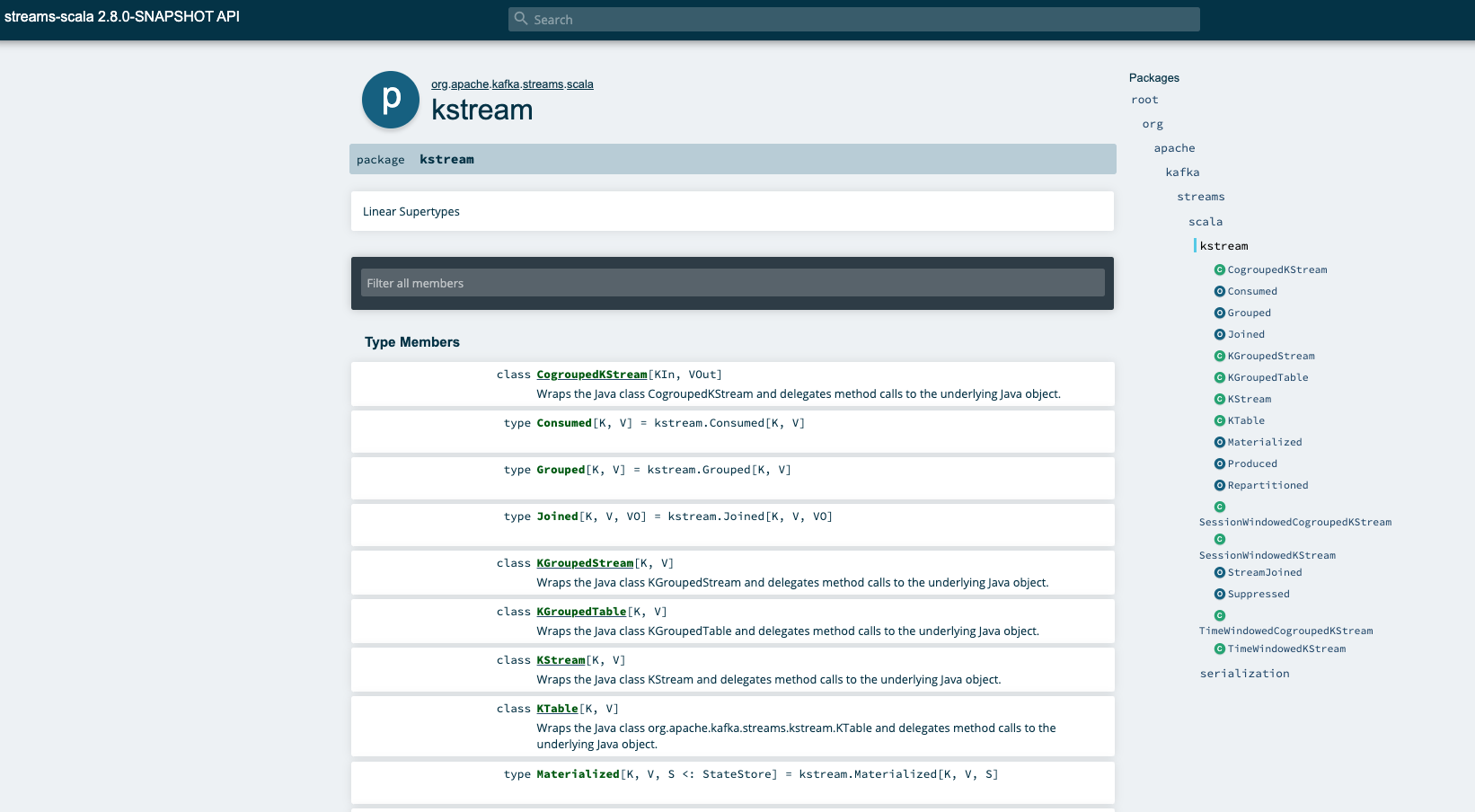 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] bbejeck commented on a change in pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
bbejeck commented on a change in pull request #9486:
URL: https://github.com/apache/kafka/pull/9486#discussion_r511082358
##
File path: build.gradle
##
@@ -1439,7 +1440,7 @@ project(':streams:streams-scala') {
}
jar {
-dependsOn 'copyDependantLibs'
+dependsOn 'copyDependantLibs' , 'scaladocJar'
Review comment:
@ijuma good point, I've removed it and still get the required doc jars
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10638) QueryableStateIntegrationTest fails due to stricter store checking
[
https://issues.apache.org/jira/browse/KAFKA-10638?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219873#comment-17219873
]
John Roesler commented on KAFKA-10638:
--
Hey [~bbejeck] , I've marked this as a 2.7.0 blocker. It's a regression (due to
KAFKA-10598), but fortunately, only a regression in the store query test.
Still, we should get the fix in.
> QueryableStateIntegrationTest fails due to stricter store checking
> --
>
> Key: KAFKA-10638
> URL: https://issues.apache.org/jira/browse/KAFKA-10638
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.7.0
>Reporter: John Roesler
>Assignee: John Roesler
>Priority: Blocker
>
> Observed:
> {code:java}
> org.apache.kafka.streams.errors.InvalidStateStoreException: Cannot get state
> store source-table because the stream thread is PARTITIONS_ASSIGNED, not
> RUNNING
> at
> org.apache.kafka.streams.state.internals.StreamThreadStateStoreProvider.stores(StreamThreadStateStoreProvider.java:81)
> at
> org.apache.kafka.streams.state.internals.WrappingStoreProvider.stores(WrappingStoreProvider.java:50)
> at
> org.apache.kafka.streams.state.internals.CompositeReadOnlyKeyValueStore.get(CompositeReadOnlyKeyValueStore.java:52)
> at
> org.apache.kafka.streams.integration.StoreQueryIntegrationTest.shouldQuerySpecificActivePartitionStores(StoreQueryIntegrationTest.java:200)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> at org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:61)
> at org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> at
> org.junit.runners.BlockJUnit4ClassRunner$1.evaluate(BlockJUnit4ClassRunner.java:100)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:366)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:103)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:63)
> at org.junit.runners.ParentRunner$4.run(ParentRunner.java:331)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:79)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:329)
> at org.junit.runners.ParentRunner.access$100(ParentRunner.java:66)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:293)
> at org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:413)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.runTestClass(JUnitTestClassExecutor.java:110)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.execute(JUnitTestClassExecutor.java:58)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.execute(JUnitTestClassExecutor.java:38)
> at
> org.gradle.api.internal.tasks.testing.junit.AbstractJUnitTestClassProcessor.processTestClass(AbstractJUnitTestClassProcessor.java:62)
> at
> org.gradle.api.internal.tasks.testing.SuiteTestClassProcessor.processTestClass(SuiteTestClassProcessor.java:51)
> at sun.reflect.GeneratedMethodAccessor23.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:36)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
> at
> org.gradle.internal.dispatch.ContextClassLoaderDispatch.dispatch(ContextClassLoaderDispatch.java:33)
> at
> org.gradle.internal.dispatch.ProxyDispatchAdapter$DispatchingInvocationHandler.invoke(ProxyDispatchAdapter.java:94)
> at
[jira] [Created] (KAFKA-10638) QueryableStateIntegrationTest fails due to stricter store checking
John Roesler created KAFKA-10638:
Summary: QueryableStateIntegrationTest fails due to stricter store
checking
Key: KAFKA-10638
URL: https://issues.apache.org/jira/browse/KAFKA-10638
Project: Kafka
Issue Type: Bug
Components: streams
Affects Versions: 2.7.0
Reporter: John Roesler
Assignee: John Roesler
Observed:
{code:java}
org.apache.kafka.streams.errors.InvalidStateStoreException: Cannot get state
store source-table because the stream thread is PARTITIONS_ASSIGNED, not RUNNING
at
org.apache.kafka.streams.state.internals.StreamThreadStateStoreProvider.stores(StreamThreadStateStoreProvider.java:81)
at
org.apache.kafka.streams.state.internals.WrappingStoreProvider.stores(WrappingStoreProvider.java:50)
at
org.apache.kafka.streams.state.internals.CompositeReadOnlyKeyValueStore.get(CompositeReadOnlyKeyValueStore.java:52)
at
org.apache.kafka.streams.integration.StoreQueryIntegrationTest.shouldQuerySpecificActivePartitionStores(StoreQueryIntegrationTest.java:200)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
at
org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at
org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
at
org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at
org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
at
org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
at org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:61)
at org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
at
org.junit.runners.BlockJUnit4ClassRunner$1.evaluate(BlockJUnit4ClassRunner.java:100)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:366)
at
org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:103)
at
org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:63)
at org.junit.runners.ParentRunner$4.run(ParentRunner.java:331)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:79)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:329)
at org.junit.runners.ParentRunner.access$100(ParentRunner.java:66)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:293)
at org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
at org.junit.runners.ParentRunner.run(ParentRunner.java:413)
at
org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.runTestClass(JUnitTestClassExecutor.java:110)
at
org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.execute(JUnitTestClassExecutor.java:58)
at
org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecutor.execute(JUnitTestClassExecutor.java:38)
at
org.gradle.api.internal.tasks.testing.junit.AbstractJUnitTestClassProcessor.processTestClass(AbstractJUnitTestClassProcessor.java:62)
at
org.gradle.api.internal.tasks.testing.SuiteTestClassProcessor.processTestClass(SuiteTestClassProcessor.java:51)
at sun.reflect.GeneratedMethodAccessor23.invoke(Unknown Source)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:36)
at
org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
at
org.gradle.internal.dispatch.ContextClassLoaderDispatch.dispatch(ContextClassLoaderDispatch.java:33)
at
org.gradle.internal.dispatch.ProxyDispatchAdapter$DispatchingInvocationHandler.invoke(ProxyDispatchAdapter.java:94)
at com.sun.proxy.$Proxy2.processTestClass(Unknown Source)
at
org.gradle.api.internal.tasks.testing.worker.TestWorker.processTestClass(TestWorker.java:119)
at sun.reflect.GeneratedMethodAccessor22.invoke(Unknown Source)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:36)
at
[GitHub] [kafka] ijuma commented on a change in pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
ijuma commented on a change in pull request #9486:
URL: https://github.com/apache/kafka/pull/9486#discussion_r511073744
##
File path: build.gradle
##
@@ -1439,7 +1440,7 @@ project(':streams:streams-scala') {
}
jar {
-dependsOn 'copyDependantLibs'
+dependsOn 'copyDependantLibs' , 'scaladocJar'
Review comment:
Hmm, seems weird to require scaladoc when building jars.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10633) Constant probing rebalances in Streams 2.6
[ https://issues.apache.org/jira/browse/KAFKA-10633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219866#comment-17219866 ] Bradley Peterson commented on KAFKA-10633: -- Thank you, Sophie! I'll do a build with the PR for KAFKA-10455 and confirm that it fixes this issue. > Constant probing rebalances in Streams 2.6 > -- > > Key: KAFKA-10633 > URL: https://issues.apache.org/jira/browse/KAFKA-10633 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Bradley Peterson >Priority: Major > Attachments: Discover 2020-10-21T23 34 03.867Z - 2020-10-21T23 44 > 46.409Z.csv > > > We are seeing a few issues with the new rebalancing behavior in Streams 2.6. > This ticket is for constant probing rebalances on one StreamThread, but I'll > mention the other issues, as they may be related. > First, when we redeploy the application we see tasks being moved, even though > the task assignment was stable before redeploying. We would expect to see > tasks assigned back to the same instances and no movement. The application is > in EC2, with persistent EBS volumes, and we use static group membership to > avoid rebalancing. To redeploy the app we terminate all EC2 instances. The > new instances will reattach the EBS volumes and use the same group member id. > After redeploying, we sometimes see the group leader go into a tight probing > rebalance loop. This doesn't happen immediately, it could be several hours > later. Because the redeploy caused task movement, we see expected probing > rebalances every 10 minutes. But, then one thread will go into a tight loop > logging messages like "Triggering the followup rebalance scheduled for > 1603323868771 ms.", handling the partition assignment (which doesn't change), > then "Requested to schedule probing rebalance for 1603323868771 ms." This > repeats several times a second until the app is restarted again. I'll attach > a log export from one such incident. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10284) Group membership update due to static member rejoin should be persisted
[ https://issues.apache.org/jira/browse/KAFKA-10284?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] John Roesler updated KAFKA-10284: - Fix Version/s: 2.5.2 > Group membership update due to static member rejoin should be persisted > --- > > Key: KAFKA-10284 > URL: https://issues.apache.org/jira/browse/KAFKA-10284 > Project: Kafka > Issue Type: Bug > Components: consumer >Affects Versions: 2.3.0, 2.4.0, 2.5.0, 2.6.0 >Reporter: Boyang Chen >Assignee: feyman >Priority: Critical > Labels: help-wanted > Fix For: 2.7.0, 2.5.2, 2.6.1 > > Attachments: How to reproduce the issue in KAFKA-10284.md > > > For known static members rejoin, we would update its corresponding member.id > without triggering a new rebalance. This serves the purpose for avoiding > unnecessary rebalance for static membership, as well as fencing purpose if > some still uses the old member.id. > The bug is that we don't actually persist the membership update, so if no > upcoming rebalance gets triggered, this new member.id information will get > lost during group coordinator immigration, thus bringing up the zombie member > identity. > The bug find credit goes to [~hachikuji] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] vvcephei commented on pull request #9414: KAFKA-10585: Kafka Streams should clean up the state store directory from cleanup
vvcephei commented on pull request #9414: URL: https://github.com/apache/kafka/pull/9414#issuecomment-715502309 Thanks for that fix, @dongjinleekr ! Unfortunately, there are still 61 test failures: https://ci-builds.apache.org/job/Kafka/job/kafka-pr/job/PR-9414/6/?cloudbees-analytics-link=scm-reporting%2Fstage%2Ffailure#showFailuresLink Do you mind taking another look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10633) Constant probing rebalances in Streams 2.6
[ https://issues.apache.org/jira/browse/KAFKA-10633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219861#comment-17219861 ] A. Sophie Blee-Goldman commented on KAFKA-10633: A thread should always reset its scheduled rebalance after triggering one, and it will only set the rebalance schedule when it receives its assignment after a rebalance. And the probing rebalance is always scheduled for 10min past the current time, so the fact that you see the same time printed in the "Triggering the follow rebalance" and "Requested to schedule probing rebalance" messages indicates that the member did not actually go through a rebalance, it just received its previous assignment directly from the broker. Also, a rebalance will never be completed in under a second, so seeing `Triggering the followup rebalance scheduled for 1603323868771 ms` followed immediately by `Requested to schedule probing rebalance for 1603323868771 ms` seems to verify that it did not in fact go through a rebalance. [~thebearmayor] this issue is fixed in 2.7.0 and 2.6.1 – not sure when 2.6.1 will be released but the 2.7.0 release is currently in progress so it should hopefully be available soon. Apologies for our oversight in designing KIP-441 > Constant probing rebalances in Streams 2.6 > -- > > Key: KAFKA-10633 > URL: https://issues.apache.org/jira/browse/KAFKA-10633 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Bradley Peterson >Priority: Major > Attachments: Discover 2020-10-21T23 34 03.867Z - 2020-10-21T23 44 > 46.409Z.csv > > > We are seeing a few issues with the new rebalancing behavior in Streams 2.6. > This ticket is for constant probing rebalances on one StreamThread, but I'll > mention the other issues, as they may be related. > First, when we redeploy the application we see tasks being moved, even though > the task assignment was stable before redeploying. We would expect to see > tasks assigned back to the same instances and no movement. The application is > in EC2, with persistent EBS volumes, and we use static group membership to > avoid rebalancing. To redeploy the app we terminate all EC2 instances. The > new instances will reattach the EBS volumes and use the same group member id. > After redeploying, we sometimes see the group leader go into a tight probing > rebalance loop. This doesn't happen immediately, it could be several hours > later. Because the redeploy caused task movement, we see expected probing > rebalances every 10 minutes. But, then one thread will go into a tight loop > logging messages like "Triggering the followup rebalance scheduled for > 1603323868771 ms.", handling the partition assignment (which doesn't change), > then "Requested to schedule probing rebalance for 1603323868771 ms." This > repeats several times a second until the app is restarted again. I'll attach > a log export from one such incident. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10633) Constant probing rebalances in Streams 2.6
[ https://issues.apache.org/jira/browse/KAFKA-10633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219859#comment-17219859 ] A. Sophie Blee-Goldman commented on KAFKA-10633: I'm like 99% sure this will turn out to be KAFKA-10455 > Constant probing rebalances in Streams 2.6 > -- > > Key: KAFKA-10633 > URL: https://issues.apache.org/jira/browse/KAFKA-10633 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.6.0 >Reporter: Bradley Peterson >Priority: Major > Attachments: Discover 2020-10-21T23 34 03.867Z - 2020-10-21T23 44 > 46.409Z.csv > > > We are seeing a few issues with the new rebalancing behavior in Streams 2.6. > This ticket is for constant probing rebalances on one StreamThread, but I'll > mention the other issues, as they may be related. > First, when we redeploy the application we see tasks being moved, even though > the task assignment was stable before redeploying. We would expect to see > tasks assigned back to the same instances and no movement. The application is > in EC2, with persistent EBS volumes, and we use static group membership to > avoid rebalancing. To redeploy the app we terminate all EC2 instances. The > new instances will reattach the EBS volumes and use the same group member id. > After redeploying, we sometimes see the group leader go into a tight probing > rebalance loop. This doesn't happen immediately, it could be several hours > later. Because the redeploy caused task movement, we see expected probing > rebalances every 10 minutes. But, then one thread will go into a tight loop > logging messages like "Triggering the followup rebalance scheduled for > 1603323868771 ms.", handling the partition assignment (which doesn't change), > then "Requested to schedule probing rebalance for 1603323868771 ms." This > repeats several times a second until the app is restarted again. I'll attach > a log export from one such incident. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] vvcephei merged pull request #9481: KAFKA-10284: Disable static membership test in 2.4
vvcephei merged pull request #9481: URL: https://github.com/apache/kafka/pull/9481 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on pull request #9481: KAFKA-10284: Disable static membership test in 2.4
vvcephei commented on pull request #9481: URL: https://github.com/apache/kafka/pull/9481#issuecomment-715499343 Thanks @abbccdda ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #9481: KAFKA-10284: Disable static membership test in 2.4
vvcephei commented on a change in pull request #9481: URL: https://github.com/apache/kafka/pull/9481#discussion_r511058225 ## File path: tests/kafkatest/tests/streams/streams_static_membership_test.py ## @@ -48,6 +49,7 @@ def __init__(self, test_context): throughput=1000, acks=1) +@ignore Review comment: ```suggestion # This test fails due to a bug that is fixed in 2.5+ (KAFKA-10284). We opted not to backport # the fix to 2.4 and instead marked this test as ignored. If desired, the fix can be backported, # but it is non-trivial to do so. @ignore ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on pull request #9382: URL: https://github.com/apache/kafka/pull/9382#issuecomment-715493391 @hachikuji Thanks for the review, have addressed the comments. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on a change in pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on a change in pull request #9382: URL: https://github.com/apache/kafka/pull/9382#discussion_r511051808 ## File path: core/src/main/scala/kafka/server/ReplicaManager.scala ## @@ -770,7 +770,7 @@ class ReplicaManager(val config: KafkaConfig, logManager.abortAndPauseCleaning(topicPartition) val initialFetchState = InitialFetchState(BrokerEndPoint(config.brokerId, "localhost", -1), - partition.getLeaderEpoch, futureLog.highWatermark) + partition.getLeaderEpoch, futureLog.highWatermark, lastFetchedEpoch = None) Review comment: I had reset this because `ReassignPartitionsIntegrationTest.testAlterLogDirReassignmentThrottle` was failing consistently when the offset was test. Having spent a whole day looking at what I had broken, I think it is an existing issue. The test itself looks new and I can recreate it on trunk. Looks like https://issues.apache.org/jira/browse/KAFKA-9087. Will look into that separately. For now, I have updated this path. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on a change in pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on a change in pull request #9382: URL: https://github.com/apache/kafka/pull/9382#discussion_r511047510 ## File path: core/src/main/scala/kafka/server/AbstractFetcherThread.scala ## @@ -629,7 +680,9 @@ abstract class AbstractFetcherThread(name: String, val initialLag = leaderEndOffset - offsetToFetch fetcherLagStats.getAndMaybePut(topicPartition).lag = initialLag - PartitionFetchState(offsetToFetch, Some(initialLag), currentLeaderEpoch, state = Fetching) + // We don't expect diverging epochs from the next fetch request, so resetting `lastFetchedEpoch` Review comment: Updated This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on a change in pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on a change in pull request #9382:
URL: https://github.com/apache/kafka/pull/9382#discussion_r511047757
##
File path: core/src/main/scala/kafka/server/AbstractFetcherThread.scala
##
@@ -341,11 +352,18 @@ abstract class AbstractFetcherThread(name: String,
// ReplicaDirAlterThread may have removed topicPartition
from the partitionStates after processing the partition data
if (validBytes > 0 &&
partitionStates.contains(topicPartition)) {
// Update partitionStates only if there is no
exception during processPartitionData
-val newFetchState = PartitionFetchState(nextOffset,
Some(lag), currentFetchState.currentLeaderEpoch, state = Fetching)
+val newFetchState = PartitionFetchState(nextOffset,
Some(lag),
+ currentFetchState.currentLeaderEpoch, state =
Fetching,
+ Some(currentFetchState.currentLeaderEpoch))
Review comment:
Oops, fixed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on a change in pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on a change in pull request #9382:
URL: https://github.com/apache/kafka/pull/9382#discussion_r511046915
##
File path: core/src/main/scala/kafka/server/AbstractFetcherThread.scala
##
@@ -426,21 +454,42 @@ abstract class AbstractFetcherThread(name: String,
warn(s"Partition $topicPartition marked as failed")
}
- def addPartitions(initialFetchStates: Map[TopicPartition, OffsetAndEpoch]):
Set[TopicPartition] = {
+ /**
+ * Returns initial partition fetch state based on current state and the
provided `initialFetchState`.
+ * From IBP 2.7 onwards, we can rely on truncation based on diverging data
returned in fetch responses.
+ * For older versions, we can skip the truncation step iff the leader epoch
matches the existing epoch.
+ */
+ private def partitionFetchState(tp: TopicPartition, initialFetchState:
InitialFetchState, currentState: PartitionFetchState): PartitionFetchState = {
+if (isTruncationOnFetchSupported && initialFetchState.initOffset >= 0 &&
initialFetchState.lastFetchedEpoch.nonEmpty) {
+ if (currentState == null) {
+return PartitionFetchState(initialFetchState.initOffset, None,
initialFetchState.currentLeaderEpoch,
+ state = Fetching, initialFetchState.lastFetchedEpoch)
+ }
+ // If we are in `Fetching` state can continue to fetch regardless of
current leader epoch and truncate
+ // if necessary based on diverging epochs returned by the leader. If we
are currently in Truncating state,
+ // fall through and handle based on current epoch.
+ if (currentState.state == Fetching) {
+return currentState
Review comment:
Updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on a change in pull request #9382: KAFKA-10554; Perform follower truncation based on diverging epochs in Fetch response
rajinisivaram commented on a change in pull request #9382:
URL: https://github.com/apache/kafka/pull/9382#discussion_r511047109
##
File path: core/src/main/scala/kafka/server/AbstractFetcherThread.scala
##
@@ -461,8 +510,9 @@ abstract class AbstractFetcherThread(name: String,
val maybeTruncationComplete = fetchOffsets.get(topicPartition) match {
case Some(offsetTruncationState) =>
val state = if (offsetTruncationState.truncationCompleted)
Fetching else Truncating
+// Resetting `lastFetchedEpoch` since we are truncating and don't
expect diverging epoch in the next fetch
Review comment:
Updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] bbejeck opened a new pull request #9486: KAFKA-9381: Fix releaseTarGz to publish valid scaladoc files
bbejeck opened a new pull request #9486: URL: https://github.com/apache/kafka/pull/9486 Fixes the release target to produce valid scaladoc and javadoc jar files To test: 1. `./gradlew clean && ./gradlewAll releaseTarGz 2. cd into `core/build/distributions` 3. run `tar xvzf kafka_2.13-2.8.0-SNAPSHOT.tgz` 4. run `ls -la kafka_2.13-2.8.0-SNAPSHOT/libs | grep doc` 5. This should produce the following ``` -rw-r--r--1 bill staff 1326180 Oct 23 12:58 kafka-streams-scala_2.13-2.8.0-SNAPSHOT-scaladoc.jar -rw-r--r--1 bill staff413518 Oct 23 12:56 kafka_2.13-2.8.0-SNAPSHOT-javadoc.jar -rw-r--r--1 bill staff 6554029 Oct 23 12:57 kafka_2.13-2.8.0-SNAPSHOT-scaladoc.jar ``` Note the size of the docs jars 6. Repeat steps for `kafka_2.12-2.8.0-SNAPSHOT.tgz ` ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-9381) Javadocs + Scaladocs not published on maven central
[ https://issues.apache.org/jira/browse/KAFKA-9381?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bill Bejeck updated KAFKA-9381: --- Priority: Blocker (was: Critical) > Javadocs + Scaladocs not published on maven central > --- > > Key: KAFKA-9381 > URL: https://issues.apache.org/jira/browse/KAFKA-9381 > Project: Kafka > Issue Type: Bug > Components: documentation, streams >Affects Versions: 1.0.0, 1.0.1, 1.0.2, 1.1.0, 1.1.1, 2.0.0, 2.0.1, 2.1.0, > 2.2.0, 2.1.1, 2.3.0, 2.2.1, 2.2.2, 2.4.0, 2.3.1, 2.5.0, 2.4.1 >Reporter: Julien Jean Paul Sirocchi >Assignee: Bill Bejeck >Priority: Blocker > Fix For: 2.8.0 > > > As per title, empty (aside for MANIFEST, LICENCE and NOTICE) > javadocs/scaladocs jars on central for any version (kafka nor scala), e.g. > [http://repo1.maven.org/maven2/org/apache/kafka/kafka-streams-scala_2.12/2.3.1/] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-9381) Javadocs + Scaladocs not published on maven central
[ https://issues.apache.org/jira/browse/KAFKA-9381?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bill Bejeck updated KAFKA-9381: --- Fix Version/s: (was: 2.8.0) 2.7.0 > Javadocs + Scaladocs not published on maven central > --- > > Key: KAFKA-9381 > URL: https://issues.apache.org/jira/browse/KAFKA-9381 > Project: Kafka > Issue Type: Bug > Components: documentation, streams >Affects Versions: 1.0.0, 1.0.1, 1.0.2, 1.1.0, 1.1.1, 2.0.0, 2.0.1, 2.1.0, > 2.2.0, 2.1.1, 2.3.0, 2.2.1, 2.2.2, 2.4.0, 2.3.1, 2.5.0, 2.4.1 >Reporter: Julien Jean Paul Sirocchi >Assignee: Bill Bejeck >Priority: Blocker > Fix For: 2.7.0 > > > As per title, empty (aside for MANIFEST, LICENCE and NOTICE) > javadocs/scaladocs jars on central for any version (kafka nor scala), e.g. > [http://repo1.maven.org/maven2/org/apache/kafka/kafka-streams-scala_2.12/2.3.1/] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] cadonna edited a comment on pull request #9479: KAFKA-10631: Handle ProducerFencedException on offset commit
cadonna edited a comment on pull request #9479: URL: https://github.com/apache/kafka/pull/9479#issuecomment-715463242 Yeah, that was also my conclusion! Additionally, I trust @abbccdda's approval since -- according to the git history -- he is familiar with the code. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on pull request #9479: KAFKA-10631: Handle ProducerFencedException on offset commit
cadonna commented on pull request #9479: URL: https://github.com/apache/kafka/pull/9479#issuecomment-715463242 Yeah, that was also my conclusion! Additionally, I trust @abbccdda approval since -- according to the git history -- he is familiar with the code. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] abbccdda commented on a change in pull request #9103: KAFKA-10181: Use Envelope RPC to do redirection for (Incremental)AlterConfig, AlterClientQuota and CreateTopics
abbccdda commented on a change in pull request #9103:
URL: https://github.com/apache/kafka/pull/9103#discussion_r511012913
##
File path: core/src/main/scala/kafka/network/SocketServer.scala
##
@@ -1005,6 +1013,36 @@ private[kafka] class Processor(val id: Int,
selector.clearCompletedReceives()
}
+ private def parseEnvelopeRequest(receive: NetworkReceive,
+ nowNanos: Long,
+ connectionId: String,
+ context: RequestContext,
+ principalSerde:
Option[KafkaPrincipalSerde]) = {
+val envelopeRequest =
context.parseRequest(receive.payload).request.asInstanceOf[EnvelopeRequest]
+
+val originalHeader = RequestHeader.parse(envelopeRequest.requestData)
+// Leave the principal null here is ok since we will fail the request
during Kafka API handling.
+val originalPrincipal = if (principalSerde.isDefined)
+ principalSerde.get.deserialize(envelopeRequest.principalData)
+else
+ null
+
+// The forwarding broker and the active controller should have the same
DNS resolution, and we need
+// to have the original client address for authentication purpose.
+val originalClientAddress =
InetAddress.getByName(envelopeRequest.clientHostName)
Review comment:
So the proposal is simply for saving the unnecessary dns translation?
Not sure if representing as bytes would also serve the security purpose as well.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] junrao commented on a change in pull request #9364: KAFKA-10471 Mark broker crash during log loading as unclean shutdown
junrao commented on a change in pull request #9364:
URL: https://github.com/apache/kafka/pull/9364#discussion_r510527544
##
File path: core/src/main/scala/kafka/log/LogManager.scala
##
@@ -298,26 +300,38 @@ class LogManager(logDirs: Seq[File],
/**
* Recover and load all logs in the given data directories
*/
- private def loadLogs(): Unit = {
+ private[log] def loadLogs(): Unit = {
info(s"Loading logs from log dirs $liveLogDirs")
val startMs = time.hiResClockMs()
val threadPools = ArrayBuffer.empty[ExecutorService]
val offlineDirs = mutable.Set.empty[(String, IOException)]
-val jobs = mutable.Map.empty[File, Seq[Future[_]]]
+val jobs = ArrayBuffer.empty[Seq[Future[_]]]
var numTotalLogs = 0
for (dir <- liveLogDirs) {
val logDirAbsolutePath = dir.getAbsolutePath
+ var hadCleanShutdown: Boolean = false
try {
val pool = Executors.newFixedThreadPool(numRecoveryThreadsPerDataDir)
threadPools.append(pool)
val cleanShutdownFile = new File(dir, Log.CleanShutdownFile)
if (cleanShutdownFile.exists) {
info(s"Skipping recovery for all logs in $logDirAbsolutePath since
clean shutdown file was found")
+ // Cache the clean shutdown status and use that for rest of log
loading workflow. Delete the CleanShutdownFile
+ // so that if broker crashes while loading the log, it is considered
hard shutdown during the next boot up. KAFKA-10471
+ try {
+cleanShutdownFile.delete()
+ } catch {
+case e: IOException =>
Review comment:
This is an existing issue, but cleanShutdownFile.delete() doesn't seem
to throw IOException.
##
File path: core/src/test/scala/unit/kafka/log/LogTest.scala
##
@@ -1257,7 +1328,7 @@ class LogTest {
log.close()
// After reloading log, producer state should not be regenerated
-val reloadedLog = createLog(logDir, logConfig, logStartOffset = 1L)
+val reloadedLog = createLog(logDir, logConfig, logStartOffset = 1L,
lastShutdownClean = false)
Review comment:
Hmm, it seems that this tests expects a clean shutdown.
##
File path: core/src/test/scala/unit/kafka/log/LogTest.scala
##
@@ -2131,12 +2202,12 @@ class LogTest {
assertEquals("Should have same number of time index entries as before.",
numTimeIndexEntries, log.activeSegment.timeIndex.entries)
}
-log = createLog(logDir, logConfig, recoveryPoint = lastOffset)
+log = createLog(logDir, logConfig, recoveryPoint = lastOffset,
lastShutdownClean = false)
Review comment:
It seems that this expects a clean shutdown.
##
File path: core/src/test/scala/unit/kafka/log/LogTest.scala
##
@@ -4445,11 +4504,9 @@ class LogTest {
(log, segmentWithOverflow)
}
- private def recoverAndCheck(config: LogConfig,
- expectedKeys: Iterable[Long],
- expectDeletedFiles: Boolean = true): Log = {
-LogTest.recoverAndCheck(logDir, config, expectedKeys, brokerTopicStats,
mockTime, mockTime.scheduler,
- expectDeletedFiles)
+ private def recoverAndCheck(config: LogConfig, expectedKeys: Iterable[Long],
expectDeletedFiles: Boolean = true) = {
Review comment:
This is an existing problem. Since no callers are explicitly setting
expectDeletedFiles, could we just remove this param?
##
File path: core/src/test/scala/unit/kafka/log/LogTest.scala
##
@@ -3623,7 +3690,7 @@ class LogTest {
log.close()
// reopen the log and recover from the beginning
-val recoveredLog = createLog(logDir, LogConfig())
+val recoveredLog = createLog(logDir, LogConfig(), lastShutdownClean =
false)
Review comment:
It seem the createLog() call on line 3976 inside
testRecoverOnlyLastSegment() needs to have lastShutdownClean = false.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] abbccdda commented on a change in pull request #9103: KAFKA-10181: Use Envelope RPC to do redirection for (Incremental)AlterConfig, AlterClientQuota and CreateTopics
abbccdda commented on a change in pull request #9103:
URL: https://github.com/apache/kafka/pull/9103#discussion_r511007228
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -126,11 +125,44 @@ class KafkaApis(val requestChannel: RequestChannel,
info("Shutdown complete.")
}
+ private def checkForwarding(request: RequestChannel.Request): Unit = {
+if (!request.header.apiKey.forwardable &&
request.envelopeContext.isDefined) {
Review comment:
For pt2, if the forwarding is not enabled on the active controller, but
it has the capability, should we just serve the request?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10627) Connect TimestampConverter transform does not support multiple formats for the same field and only allows one field to be transformed at a time
[
https://issues.apache.org/jira/browse/KAFKA-10627?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219788#comment-17219788
]
Joshua Grisham commented on KAFKA-10627:
I have actually made the changes that I think will work for all of this. Will
try to put together a PR maybe on Monday.
> Connect TimestampConverter transform does not support multiple formats for
> the same field and only allows one field to be transformed at a time
> ---
>
> Key: KAFKA-10627
> URL: https://issues.apache.org/jira/browse/KAFKA-10627
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Joshua Grisham
>Priority: Minor
>
> Some of the limitations of the *TimestampConverter* transform are causing
> issues for us since we have a lot of different producers from different
> systems producing events to some of our topics. We try our best to have
> governance on the data formats including strict usage of Avro schemas but
> there are still variations in timestamp data types that are allowed by the
> schema.
> In the end there will be multiple formats coming into the same timestamp
> fields (for example, with and without milliseconds, with and without a
> timezone specifier, etc).
> And then you get failed events in Connect with messages like this:
> {noformat}
> org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error
> handler
> at
> org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperatorror(RetryWithToleranceOperator.java:178)
> at
> org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execute(RetryWithToleranceOperator.java:104)
> at
> org.apache.ntime.TransformationChain.apply(TransformationChain.java:50)
> at
> org.apache.kafka.connect.runtime.WorkerSinkTask.convertAndTransformRecord(WorkerSinkTask.java:514)
> at
> org.aect.runtime.WorkerSinkTask.convertMessages(WorkerSinkTask.java:469)
> at
> org.apache.kafka.connect.runtime.WorkerSinkTask.poll(WorkerSinkTask.java:325)
> at org.apache.kafka.corkerSinkTask.iteration(WorkerSinkTask.java:228)
> at
> org.apache.kafka.connect.runtime.WorkerSinkTask.execute(WorkerSinkTask.java:196)
> at org.apache.kafka.connect.runtime.WorrkerTask.java:184)
> at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:234)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> atrrent.FutureTask.run(FutureTask.java:266)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at java.util.concurrent.ThreadPoolExecutor$WorolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: org.apache.kafka.connect.errors.DataException: Could not parse
> timestamp: value (2020-10-06T12:12:27h pattern (-MM-dd'T'HH:mm:ss.SSSX)
> at
> org.apache.kafka.connect.transforms.TimestampConverter$1.toRaw(TimestampConverter.java:120)
> at
> org.apache.kafka.connect.transformrter.convertTimestamp(TimestampConverter.java:450)
> at
> org.apache.kafka.connect.transforms.TimestampConverter.applyValueWithSchema(TimestampConverter.java:375)
> at
> org.apachtransforms.TimestampConverter.applyWithSchema(TimestampConverter.java:362)
> at
> org.apache.kafka.connect.transforms.TimestampConverter.apply(TimestampConverter.java:279)
> at
> .connect.runtime.TransformationChain.lambda$apply$0(TransformationChain.java:50)
> at
> org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execAndRetry(RetryWithT.java:128)
> at
> org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execAndHandleError(RetryWithToleranceOperator.java:162)
> ... 14 more
> Caused by: java.text.Unparseable date: \"2020-10-06T12:12:27Z\"
> at java.text.DateFormat.parse(DateFormat.java:366)
> at
> org.apache.kafka.connect.transforms.TimestampConverter$1.toRaw(TimestampCo)
> ... 21 more
> {noformat}
>
> My thinking is that maybe a good solution is to switch from using
> *java.util.Date* to instead using *java.util.Time*, then instead of
> *SimpleDateFormatter* switch to *DateTimeFormatter* which will allow usage of
> more sophisticated patterns in the config to match multiple different
> allowable formats.
> For example instead of effectively doing this:
> {code:java}
> SimpleDateFormat format = new
> SimpleDateFormat("-MM-dd'T'HH:mm:ss.SSSX");{code}
> It can be something like this:
> {code:java}
> DateTimeFormatter format = DateTimeFormatter.ofPattern("[-MM-dd[['T'][
> ]HH:mm:ss[.SSSz][.SSS[XXX][X");{code}
> Also if there are multiple timestamp fields in the schema/events, then
[GitHub] [kafka] justpolidor commented on pull request #8500: Make Kafka Connect Source idempotent
justpolidor commented on pull request #8500: URL: https://github.com/apache/kafka/pull/8500#issuecomment-715446450 Why this pull request isn't merged? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] justpolidor edited a comment on pull request #8500: Make Kafka Connect Source idempotent
justpolidor edited a comment on pull request #8500: URL: https://github.com/apache/kafka/pull/8500#issuecomment-715446450 Why isn't this pull request merged? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #9479: KAFKA-10631: Handle ProducerFencedException on offset commit
ableegoldman commented on pull request #9479: URL: https://github.com/apache/kafka/pull/9479#issuecomment-715443836 Ah nevermind, I see that this was introduced when we swapped INVALID_PRODUCER_EPOCH for PRODUCER_FENCED so it makes sense that we should handle PRODUCER_FENCED in the same way as the old error code This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jsancio commented on pull request #9476: MINOR: Refactor RaftClientTest to be used by other tests
jsancio commented on pull request #9476: URL: https://github.com/apache/kafka/pull/9476#issuecomment-715440476 Thanks @hachikuji for reviewing and merging the PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #9479: KAFKA-10631: Handle ProducerFencedException on offset commit
ableegoldman commented on pull request #9479: URL: https://github.com/apache/kafka/pull/9479#issuecomment-715429024 @cadonna did we double-check with the core/clients people to make sure this is right? It's not immediately obvious to me that this is a problem in the TransactionManager and not just in the way we handle it within Streams. But maybe it is obvious to someone who looked into the code more than I have (And I agree with Apurva, how did this not come up sooner? 樂 ) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac commented on pull request #168: KAFKA-1811 Ensuring registered broker host:port is unique
dajac commented on pull request #168: URL: https://github.com/apache/kafka/pull/168#issuecomment-715424065 This has been somewhat addressed by https://github.com/apache/kafka/pull/4897. The JIRA has been closed so I will close this PR. Please, reopen it if it is still relevant. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac closed pull request #168: KAFKA-1811 Ensuring registered broker host:port is unique
dajac closed pull request #168: URL: https://github.com/apache/kafka/pull/168 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10024) Add dynamic configuration and enforce quota for per-IP connection rate limits (KIP-612, part 2)
[ https://issues.apache.org/jira/browse/KAFKA-10024?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David Jacot updated KAFKA-10024: Summary: Add dynamic configuration and enforce quota for per-IP connection rate limits (KIP-612, part 2) (was: Add dynamic configuration and enforce quota for per-IP connection rate limits) > Add dynamic configuration and enforce quota for per-IP connection rate limits > (KIP-612, part 2) > --- > > Key: KAFKA-10024 > URL: https://issues.apache.org/jira/browse/KAFKA-10024 > Project: Kafka > Issue Type: Improvement > Components: core >Reporter: Anna Povzner >Assignee: David Mao >Priority: Major > Labels: features > > This JIRA is for the second part of KIP-612 – Add per-IP connection creation > rate limits. > As described here: > [https://cwiki.apache.org/confluence/display/KAFKA/KIP-612%3A+Ability+to+Limit+Connection+Creation+Rate+on+Brokers] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dajac commented on a change in pull request #9386: KAFKA-10024: Add dynamic configuration and enforce quota for per-IP connection rate limits
dajac commented on a change in pull request #9386:
URL: https://github.com/apache/kafka/pull/9386#discussion_r510873494
##
File path: core/src/main/scala/kafka/network/SocketServer.scala
##
@@ -1246,7 +1337,57 @@ class ConnectionQuotas(config: KafkaConfig, time: Time,
metrics: Metrics) extend
private[network] def updateBrokerMaxConnectionRate(maxConnectionRate: Int):
Unit = {
// if there is a connection waiting on the rate throttle delay, we will
let it wait the original delay even if
// the rate limit increases, because it is just one connection per
listener and the code is simpler that way
-updateConnectionRateQuota(maxConnectionRate)
+updateConnectionRateQuota(maxConnectionRate, BrokerQuotaEntity)
+ }
+
+ /**
+ * Update the connection rate quota for a given IP and updates quota configs
for updated IPs.
+ * If an IP is given, metric config will be updated only for the given IP,
otherwise
+ * all metric configs will be checked and updated if required
+ *
+ * @param ip ip to update or default if None
+ * @param maxConnectionRate new connection rate, or resets entity to default
if None
+ */
+ def updateIpConnectionRate(ip: Option[String], maxConnectionRate:
Option[Int]): Unit = {
+def isIpConnectionRateMetric(metricName: MetricName) = {
+ metricName.name == ConnectionRateMetricName &&
+ metricName.group == MetricsGroup &&
+ metricName.tags.containsKey(IpMetricTag)
+}
+
+def shouldUpdateQuota(metric: KafkaMetric, quotaLimit: Int) = {
+ quotaLimit != metric.config.quota.bound
+}
+
+ip match {
+ case Some(addr) =>
+val address = InetAddress.getByName(addr)
+maxConnectionRate match {
+ case Some(rate) =>
+info(s"Updating max connection rate override for $address to
$rate")
+connectionRatePerIp.put(address, rate)
+ case None =>
+info(s"Removing max connection rate override for $address")
+connectionRatePerIp.remove(address)
+}
+updateConnectionRateQuota(connectionRateForIp(address),
IpQuotaEntity(address))
+ case None =>
+val newQuota =
maxConnectionRate.getOrElse(DynamicConfig.Ip.DefaultConnectionCreationRate)
+info(s"Updating default max IP connection rate to $newQuota")
+defaultConnectionRatePerIp = newQuota
+val allMetrics = metrics.metrics
+allMetrics.forEach { (metricName, metric) =>
+ if (isIpConnectionRateMetric(metricName) &&
shouldUpdateQuota(metric, newQuota)) {
+info(s"Updating existing connection rate sensor for
${metricName.tags} to $newQuota")
+metric.config(rateQuotaMetricConfig(newQuota))
+ }
Review comment:
I wonder if using `newQuota` is correct here. My understanding is that
`ip == None` means that we update the default quota which is used if there is
not per ip quota defined. So, we should also check if there is a per ip quota
defined before overriding it with the new default, isn't it?
I would be great if we could add more unit tests to cover this logic with
multiple IPs and/or default.
##
File path: core/src/main/scala/kafka/network/SocketServer.scala
##
@@ -526,10 +527,14 @@ private[kafka] abstract class
AbstractServerThread(connectionQuotas: ConnectionQ
if (channel != null) {
debug(s"Closing connection from
${channel.socket.getRemoteSocketAddress()}")
connectionQuotas.dec(listenerName, channel.socket.getInetAddress)
- CoreUtils.swallow(channel.socket().close(), this, Level.ERROR)
- CoreUtils.swallow(channel.close(), this, Level.ERROR)
+ closeSocket(channel)
}
}
+
+ protected def closeSocket(channel: SocketChannel): Unit = {
Review comment:
nit: Could we make this one private?
##
File path: core/src/main/scala/kafka/network/SocketServer.scala
##
@@ -1375,6 +1516,45 @@ class ConnectionQuotas(config: KafkaConfig, time: Time,
metrics: Metrics) extend
}
}
+ /**
+ * To avoid over-recording listener/broker connection rate, we unrecord a
listener or broker connection
+ * if the IP gets throttled later.
+ *
+ * @param listenerName listener to unrecord connection
+ * @param timeMs current time in milliseconds
+ */
+ private def unrecordListenerConnection(listenerName: ListenerName, timeMs:
Long): Unit = {
+if (!protectedListener(listenerName)) {
+ brokerConnectionRateSensor.record(-1.0, timeMs, false)
+}
+maxConnectionsPerListener
+ .get(listenerName)
+ .foreach(_.connectionRateSensor.record(-1.0, timeMs, false))
+ }
+
+ /**
+ * Calculates the delay needed to bring the observed connection creation
rate to the IP limit.
+ * If the connection would cause an IP quota violation, un-record the
connection
+ *
+ * @param address
+ * @param timeMs
+ * @return
Review comment:
nit: To be completed.
##
File path:
[jira] [Created] (KAFKA-10637) KafkaProducer: IllegalMonitorStateException
Lefteris Katiforis created KAFKA-10637:
--
Summary: KafkaProducer: IllegalMonitorStateException
Key: KAFKA-10637
URL: https://issues.apache.org/jira/browse/KAFKA-10637
Project: Kafka
Issue Type: Bug
Components: producer
Affects Versions: 2.5.1
Reporter: Lefteris Katiforis
Kafka producer throws the following exception:
{code:java}
{\"log\":\"java.lang.IllegalMonitorStateException: current thread is not
owner\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415014714Z\"}"}
java.base/java.lang.Object.wait(Native
Method)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.41502027Z\"}"}
org.apache.kafka.common.utils.SystemTime.waitObject(SystemTime.java:55)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415024923Z\"}"}
at
org.apache.kafka.clients.producer.internals.ProducerMetadata.awaitUpdate(ProducerMetadata.java:119)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415029863Z\"}"}
org.apache.kafka.clients.producer.KafkaProducer.waitOnMetadata(KafkaProducer.java:1029)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415034336Z\"}"}
org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:883)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415038722Z\"}"}
org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:862)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415042939Z\"}"}
org.springframework.kafka.core.DefaultKafkaProducerFactory$CloseSafeProducer.send(DefaultKafkaProducerFactory.java:781)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415047238Z\"}"}
org.springframework.kafka.core.KafkaTemplate.doSend(KafkaTemplate.java:562)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415051555Z\"}"}
org.springframework.kafka.core.KafkaTemplate.send(KafkaTemplate.java:369)\\n\",\"stream\":\"stdout\",\"time\":\"2020-10-23T12:48:50.415055882Z\"}"}{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-8733) Offline partitions occur when leader's disk is slow in reads while responding to follower fetch requests.
[
https://issues.apache.org/jira/browse/KAFKA-8733?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219704#comment-17219704
]
Flavien Raynaud commented on KAFKA-8733:
Good point, we've not tried this in production. We haven't had enough
occurrences of this issue (thankfully :p) to know how long it takes between
"leader has disk issues and slow reads" and "leader dies because of disk
failure, revoking leadership", and what would be a good compromise with the "a
follower is genuinely falling behind" case.
We can try this for some of our clusters with lower consistency requirements,
but it may be weeks/months before we hit this issue happen again.
> Offline partitions occur when leader's disk is slow in reads while responding
> to follower fetch requests.
> -
>
> Key: KAFKA-8733
> URL: https://issues.apache.org/jira/browse/KAFKA-8733
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 1.1.2, 2.4.0
>Reporter: Satish Duggana
>Assignee: Satish Duggana
>Priority: Critical
> Attachments: weighted-io-time-2.png, wio-time.png
>
>
> We found offline partitions issue multiple times on some of the hosts in our
> clusters. After going through the broker logs and hosts’s disk stats, it
> looks like this issue occurs whenever the read/write operations take more
> time on that disk. In a particular case where read time is more than the
> replica.lag.time.max.ms, follower replicas will be out of sync as their
> earlier fetch requests are stuck while reading the local log and their fetch
> status is not yet updated as mentioned in the below code of `ReplicaManager`.
> If there is an issue in reading the data from the log for a duration more
> than replica.lag.time.max.ms then all the replicas will be out of sync and
> partition becomes offline if min.isr.replicas > 1 and unclean.leader.election
> is false.
>
> {code:java}
> def readFromLog(): Seq[(TopicPartition, LogReadResult)] = {
> val result = readFromLocalLog( // this call took more than
> `replica.lag.time.max.ms`
> replicaId = replicaId,
> fetchOnlyFromLeader = fetchOnlyFromLeader,
> readOnlyCommitted = fetchOnlyCommitted,
> fetchMaxBytes = fetchMaxBytes,
> hardMaxBytesLimit = hardMaxBytesLimit,
> readPartitionInfo = fetchInfos,
> quota = quota,
> isolationLevel = isolationLevel)
> if (isFromFollower) updateFollowerLogReadResults(replicaId, result). //
> fetch time gets updated here, but mayBeShrinkIsr should have been already
> called and the replica is removed from isr
> else result
> }
> val logReadResults = readFromLog()
> {code}
> Attached the graphs of disk weighted io time stats when this issue occurred.
> I will raise [KIP-501|https://s.apache.org/jhbpn] describing options on how
> to handle this scenario.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10466) Add Regex option for replacement on MaskField SMT
[ https://issues.apache.org/jira/browse/KAFKA-10466?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219606#comment-17219606 ] Shadi edited comment on KAFKA-10466 at 10/23/20, 10:09 AM: --- [~daehokimm] Hi, send and email to [d...@kafka.apache.org|mailto:to%c2%a0...@kafka.apache.org] to ask for contributor permission, add your Jira id: daehokimm to the email. was (Author: kajevand): [~daehokimm] Hi, send and email to [d...@kafka.apache.org|mailto:to%c2%a0...@kafka.apache.org] to get contributor permission, add your Jira id: daehokimm to the email. > Add Regex option for replacement on MaskField SMT > -- > > Key: KAFKA-10466 > URL: https://issues.apache.org/jira/browse/KAFKA-10466 > Project: Kafka > Issue Type: Improvement > Components: KafkaConnect >Affects Versions: 2.6.0 >Reporter: Daeho Kim >Priority: Major > Labels: Needs-kip, newbie > > The _org.apache.kafka.connect.transforms.MaskField_ SMT can use replacement > for numeric and string type fields. it would be nice to optionally be able to > masking with regular expression for string fields only. then it can mask the > data partially. > > Use cases : mask out the IP address just the last two parts. (ex. > 123.45.67.89 -> 123.45.***.***) > > Since this changes the API, and thus will require a KIP. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10466) Add Regex option for replacement on MaskField SMT
[ https://issues.apache.org/jira/browse/KAFKA-10466?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219606#comment-17219606 ] Shadi commented on KAFKA-10466: --- [~daehokimm] Hi, send and email to [d...@kafka.apache.org|mailto:to%c2%a0...@kafka.apache.org] to get contributor permission, add your Jira id: daehokimm to the email. > Add Regex option for replacement on MaskField SMT > -- > > Key: KAFKA-10466 > URL: https://issues.apache.org/jira/browse/KAFKA-10466 > Project: Kafka > Issue Type: Improvement > Components: KafkaConnect >Affects Versions: 2.6.0 >Reporter: Daeho Kim >Priority: Major > Labels: Needs-kip, newbie > > The _org.apache.kafka.connect.transforms.MaskField_ SMT can use replacement > for numeric and string type fields. it would be nice to optionally be able to > masking with regular expression for string fields only. then it can mask the > data partially. > > Use cases : mask out the IP address just the last two parts. (ex. > 123.45.67.89 -> 123.45.***.***) > > Since this changes the API, and thus will require a KIP. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] soarez commented on pull request #9000: KAFKA-10036 Improve handling and documentation of Suppliers
soarez commented on pull request #9000: URL: https://github.com/apache/kafka/pull/9000#issuecomment-715213289 Yes, sorry for that @mjsax . I thought I had already pushed the fix. Not enough ☕ Fixed it but seems one test still failed for JDK 8 - `org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta` - but it seems unrelated to this patch and [known to be flaky](https://github.com/apache/kafka/pull/9466#issuecomment-713246622). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-9755) Implement versioning scheme for features
[ https://issues.apache.org/jira/browse/KAFKA-9755?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219553#comment-17219553 ] feyman commented on KAFKA-9755: --- Hi, [~kprakasam], can I take sub-task 7/8 as start-up tasks to get familiar with the feature versioning schemes? Thanks! > Implement versioning scheme for features > > > Key: KAFKA-9755 > URL: https://issues.apache.org/jira/browse/KAFKA-9755 > Project: Kafka > Issue Type: Improvement > Components: controller, core, protocol, streams >Reporter: Kowshik Prakasam >Priority: Major > > Details are in this wiki: > [https://cwiki.apache.org/confluence/display/KAFKA/KIP-584%3A+Versioning+scheme+for+features] > . > This is the master Jira for tracking the implementation of versioning scheme > for features to facilitate client discovery and feature gating (as explained > in the above wiki). -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10323) NullPointerException during rebalance
[ https://issues.apache.org/jira/browse/KAFKA-10323?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chia-Ping Tsai updated KAFKA-10323: --- Labels: (was: newbie) > NullPointerException during rebalance > - > > Key: KAFKA-10323 > URL: https://issues.apache.org/jira/browse/KAFKA-10323 > Project: Kafka > Issue Type: Bug > Components: KafkaConnect >Affects Versions: 2.5.0 >Reporter: yazgoo >Assignee: Luke Chen >Priority: Major > > *confluent platform version: 5.5.0-ccs* > connector used: s3 > Connector stops after rebalancing: > ERROR [Worker clientId=connect-1, groupId=connect] Couldn't instantiate task > because it has an invalid task configuration. This task will not > execute until reconfigured. > java.lang.NullPointerException > at org.apache.kafka.connect.runtime.Worker.startTask(Worker.java:427) > at > org.apache.kafka.connect.runtime.distributed.DistributedHerder.startTask(DistributedHerder.java:1147) > at > org.apache.kafka.connect.runtime.distributed.DistributedHerder.access$1600(DistributedHerder.java:126) > at > org.apache.kafka.connect.runtime.distributed.DistributedHerder$12.call(DistributedHerder.java:1162) > at > org.apache.kafka.connect.runtime.distributed.DistributedHerder$12.call(DistributedHerder.java:1158) > at java.util.concurrent.FutureTask.run(FutureTask.java:266) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-5676) MockStreamsMetrics should be in o.a.k.test
[
https://issues.apache.org/jira/browse/KAFKA-5676?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219548#comment-17219548
]
Chia-Ping Tsai commented on KAFKA-5676:
---
Go through streams code base, it seems most internals directly use
StreamsMetricsImpl rather than StreamsMetrics. not sure whether it is
worthwhile to do "true" mock of StreamsMetrics.
> MockStreamsMetrics should be in o.a.k.test
> --
>
> Key: KAFKA-5676
> URL: https://issues.apache.org/jira/browse/KAFKA-5676
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Reporter: Guozhang Wang
>Priority: Major
> Labels: newbie
> Time Spent: 96h
> Remaining Estimate: 0h
>
> {{MockStreamsMetrics}}'s package should be `o.a.k.test` not
> `o.a.k.streams.processor.internals`.
> In addition, it should not require a {{Metrics}} parameter in its constructor
> as it is only needed for its extended base class; the right way of mocking
> should be implementing {{StreamsMetrics}} with mock behavior than extended a
> real implementaion of {{StreamsMetricsImpl}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] ning2008wisc edited a comment on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc edited a comment on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case: (2a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If we believe the topic config validation is trivial, I am more than happy to remove it (2b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (2c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (2d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) which can not reveal the insight that consumers consume the same records more than once when broker failure happens. (2e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right way to structure tests with more than one scenarios (SSL v.s. non-SSL) If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ning2008wisc edited a comment on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc edited a comment on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case: (2a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If we believe the topic config validation is trivial, I am more than happy to remove it (2b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (2c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (2d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) which can not reveal the insight that consumers consume the same records more than once when broker failure happens. (2e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right way tp structure tests with more than one scenarios (SSL v.s. non-SSL) If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ning2008wisc edited a comment on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc edited a comment on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case (a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If we believe the topic config validation is trivial, I am more than happy to remove it (b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) which can not reveal the insight that consumers consume the same records more than once when broker failure happens. (e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right way tp structure tests with more than one scenarios (SSL v.s. non-SSL) If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ning2008wisc edited a comment on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc edited a comment on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case (a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If we believe the topic config validation is trivial, I am more than happy to remove it (b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) which can not reveal the insight that consumers consume the same records more than once when broker failure happens. (e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right way tp structure tests with more than one scenarios (SSL v.s. non-SSL) If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ning2008wisc edited a comment on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc edited a comment on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case (a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If we believe the topic config validation is trivial, I am more than happy to remove it (b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) which can not reveal the insight that consumers consume the same records more than once when broker failure happens. (e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right way tp structure tests with more than one scenarios (SSL v.s. non-SSL) If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ning2008wisc edited a comment on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc edited a comment on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case (a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If we believe the topic config validation is trivial, I am more than happy to remove it (b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) which can not reveal the insight that consumers consume the same records more than once when broker failure happens. (e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right way tp structure tests with more than one scenarios (SSL v.s. non-SSL) If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ning2008wisc commented on pull request #9224: KAFKA-10304: refactor MM2 integration tests
ning2008wisc commented on pull request #9224: URL: https://github.com/apache/kafka/pull/9224#issuecomment-714955565 Thanks @mimaison for your high-level advice and detailed review. (1) I responded to your every comments. A "thumb-up" means I made the suggested change (2) regarding the increased complexity, here is my analysis for each test case (a) `testReplication`: This is an existing test and no new stuff are added, except checking if topic config are also mirrored. If the topic config validation is trivial, I am happy to remove it (b) `testReplicationWithEmptyPartition`: This is an existing test and no new stuff are added (c) `testOneWayReplicationWithAutoOffsetSync`: This is an existing test and no new stuff are added (d) `testWithBrokerRestart`: This is a **new** test, which introduced background producer and consumer, called `ThreadedProducer` and `ThreadedConsumer`. The purpose of background producer and consumer is to better test the failure case to avoid serialization (produce -> broker restart -> consumer) by decoupling the producer thread, embedded kafka and consumer thread. (e) `MirrorConnectorsIntegrationSSLTest`: This is a **new** test and it should be pretty lean and neat. In addition, the **new** base test class `MirrorConnectorsIntegrationBaseTest` follows the existing practice of K-stream integration test structure https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/ResetIntegrationWithSslTest.java#L37 so I assume it is likely the right structure to extend from a base class. If we have to control the complexity, I would prefer to drop `testWithBrokerRestart` and keep `MirrorConnectorsIntegrationSSLTest`, as it makes sense to run simple validation in SSL setup. Thanks and would like to hear more thoughts and feedback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-8733) Offline partitions occur when leader's disk is slow in reads while responding to follower fetch requests.
[
https://issues.apache.org/jira/browse/KAFKA-8733?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219491#comment-17219491
]
Cheng Tan edited comment on KAFKA-8733 at 10/23/20, 6:22 AM:
-
[~flavr]
What would happen if you increase the lag timeout to a fairly large value so
that the leaders do not remove replicas from the ISR so aggressively? I know
this may seem like a simple fix but we are trying to evaluate.
was (Author: d8tltanc):
[~flavr] increasing the lag timeout to a fairly large value so that the
leaders do not remove replicas from the ISR so aggressively
> Offline partitions occur when leader's disk is slow in reads while responding
> to follower fetch requests.
> -
>
> Key: KAFKA-8733
> URL: https://issues.apache.org/jira/browse/KAFKA-8733
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 1.1.2, 2.4.0
>Reporter: Satish Duggana
>Assignee: Satish Duggana
>Priority: Critical
> Attachments: weighted-io-time-2.png, wio-time.png
>
>
> We found offline partitions issue multiple times on some of the hosts in our
> clusters. After going through the broker logs and hosts’s disk stats, it
> looks like this issue occurs whenever the read/write operations take more
> time on that disk. In a particular case where read time is more than the
> replica.lag.time.max.ms, follower replicas will be out of sync as their
> earlier fetch requests are stuck while reading the local log and their fetch
> status is not yet updated as mentioned in the below code of `ReplicaManager`.
> If there is an issue in reading the data from the log for a duration more
> than replica.lag.time.max.ms then all the replicas will be out of sync and
> partition becomes offline if min.isr.replicas > 1 and unclean.leader.election
> is false.
>
> {code:java}
> def readFromLog(): Seq[(TopicPartition, LogReadResult)] = {
> val result = readFromLocalLog( // this call took more than
> `replica.lag.time.max.ms`
> replicaId = replicaId,
> fetchOnlyFromLeader = fetchOnlyFromLeader,
> readOnlyCommitted = fetchOnlyCommitted,
> fetchMaxBytes = fetchMaxBytes,
> hardMaxBytesLimit = hardMaxBytesLimit,
> readPartitionInfo = fetchInfos,
> quota = quota,
> isolationLevel = isolationLevel)
> if (isFromFollower) updateFollowerLogReadResults(replicaId, result). //
> fetch time gets updated here, but mayBeShrinkIsr should have been already
> called and the replica is removed from isr
> else result
> }
> val logReadResults = readFromLog()
> {code}
> Attached the graphs of disk weighted io time stats when this issue occurred.
> I will raise [KIP-501|https://s.apache.org/jhbpn] describing options on how
> to handle this scenario.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-8733) Offline partitions occur when leader's disk is slow in reads while responding to follower fetch requests.
[
https://issues.apache.org/jira/browse/KAFKA-8733?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17219491#comment-17219491
]
Cheng Tan commented on KAFKA-8733:
--
[~flavr] increasing the lag timeout to a fairly large value so that the
leaders do not remove replicas from the ISR so aggressively
> Offline partitions occur when leader's disk is slow in reads while responding
> to follower fetch requests.
> -
>
> Key: KAFKA-8733
> URL: https://issues.apache.org/jira/browse/KAFKA-8733
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 1.1.2, 2.4.0
>Reporter: Satish Duggana
>Assignee: Satish Duggana
>Priority: Critical
> Attachments: weighted-io-time-2.png, wio-time.png
>
>
> We found offline partitions issue multiple times on some of the hosts in our
> clusters. After going through the broker logs and hosts’s disk stats, it
> looks like this issue occurs whenever the read/write operations take more
> time on that disk. In a particular case where read time is more than the
> replica.lag.time.max.ms, follower replicas will be out of sync as their
> earlier fetch requests are stuck while reading the local log and their fetch
> status is not yet updated as mentioned in the below code of `ReplicaManager`.
> If there is an issue in reading the data from the log for a duration more
> than replica.lag.time.max.ms then all the replicas will be out of sync and
> partition becomes offline if min.isr.replicas > 1 and unclean.leader.election
> is false.
>
> {code:java}
> def readFromLog(): Seq[(TopicPartition, LogReadResult)] = {
> val result = readFromLocalLog( // this call took more than
> `replica.lag.time.max.ms`
> replicaId = replicaId,
> fetchOnlyFromLeader = fetchOnlyFromLeader,
> readOnlyCommitted = fetchOnlyCommitted,
> fetchMaxBytes = fetchMaxBytes,
> hardMaxBytesLimit = hardMaxBytesLimit,
> readPartitionInfo = fetchInfos,
> quota = quota,
> isolationLevel = isolationLevel)
> if (isFromFollower) updateFollowerLogReadResults(replicaId, result). //
> fetch time gets updated here, but mayBeShrinkIsr should have been already
> called and the replica is removed from isr
> else result
> }
> val logReadResults = readFromLog()
> {code}
> Attached the graphs of disk weighted io time stats when this issue occurred.
> I will raise [KIP-501|https://s.apache.org/jhbpn] describing options on how
> to handle this scenario.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)