[GitHub] [kafka] satishd commented on a change in pull request #10173: KAFKA-9548 Added SPIs and public classes/interfaces introduced in KIP-405 for tiered storage feature in Kafka.
satishd commented on a change in pull request #10173:
URL: https://github.com/apache/kafka/pull/10173#discussion_r585333787
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogSegmentMetadata.java
##
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Serializable;
+import java.util.Collections;
+import java.util.Map;
+import java.util.NavigableMap;
+import java.util.Objects;
+import java.util.concurrent.ConcurrentSkipListMap;
+
+/**
+ * It describes the metadata about a topic partition's remote log segment in
the remote storage. This is uniquely
+ * represented with {@link RemoteLogSegmentId}.
+ *
+ * New instance is always created with the state as {@link
RemoteLogSegmentState#COPY_SEGMENT_STARTED}. This can be
+ * updated by applying {@link RemoteLogSegmentMetadataUpdate} for the
respective {@link RemoteLogSegmentId} of the
+ * {@code RemoteLogSegmentMetadata}.
+ */
+@InterfaceStability.Evolving
+public class RemoteLogSegmentMetadata implements Serializable {
Review comment:
No, this is not strictly needed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10173: KAFKA-9548 Added SPIs and public classes/interfaces introduced in KIP-405 for tiered storage feature in Kafka.
satishd commented on a change in pull request #10173:
URL: https://github.com/apache/kafka/pull/10173#discussion_r585282329
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogMetadataManager.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.Configurable;
+import org.apache.kafka.common.TopicIdPartition;
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Closeable;
+import java.util.Iterator;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+
+/**
+ * This interface provides storing and fetching remote log segment metadata
with strongly consistent semantics.
+ *
+ * This class can be plugged in to Kafka cluster by adding the implementation
class as
+ * remote.log.metadata.manager.class.name property value. There
is an inbuilt implementation backed by
+ * topic storage in the local cluster. This is used as the default
implementation if
+ * remote.log.metadata.manager.class.name is not configured.
+ *
+ *
+ * remote.log.metadata.manager.class.path property is about the
class path of the RemoteLogStorageManager
+ * implementation. If specified, the RemoteLogStorageManager implementation
and its dependent libraries will be loaded
+ * by a dedicated classloader which searches this class path before the Kafka
broker class path. The syntax of this
+ * parameter is same with the standard Java class path string.
+ *
+ *
+ * remote.log.metadata.manager.listener.name property is about
listener name of the local broker to which
+ * it should get connected if needed by RemoteLogMetadataManager
implementation. When this is configured all other
+ * required properties can be passed as properties with prefix of
'remote.log.metadata.manager.listener.
+ *
+ * "cluster.id", "broker.id" and all other properties prefixed with
"remote.log.metadata." are passed when
+ * {@link #configure(Map)} is invoked on this instance.
+ *
+ */
+@InterfaceStability.Evolving
+public interface RemoteLogMetadataManager extends Configurable, Closeable {
+
+/**
+ * Stores {@link }RemoteLogSegmentMetadata} with the containing {@link
}RemoteLogSegmentId} into {@link RemoteLogMetadataManager}.
+ *
+ * RemoteLogSegmentMetadata is identified by RemoteLogSegmentId.
+ *
+ * @param remoteLogSegmentMetadata metadata about the remote log segment.
+ * @throws RemoteStorageException if there are any storage related errors
occurred.
+ */
+void putRemoteLogSegmentMetadata(RemoteLogSegmentMetadata
remoteLogSegmentMetadata) throws RemoteStorageException;
+
+/**
+ * This method is used to update the {@link RemoteLogSegmentMetadata}.
Currently, it allows to update with the new
+ * state based on the life cycle of the segment. It can go through the
below state transitions.
+ *
+ *
+ * +-++--+
+ * |COPY_SEGMENT_STARTED |--->|COPY_SEGMENT_FINISHED |
+ * +---+-++--+---+
+ * | |
+ * | |
+ * v v
+ * +--+-+-+
+ * |DELETE_SEGMENT_STARTED|
+ * +---+--+
+ * |
+ * |
+ * v
+ * +---+---+
+ * |DELETE_SEGMENT_FINISHED|
+ * +---+
+ *
+ *
+ * {@link RemoteLogSegmentState#COPY_SEGMENT_STARTED} - This state
indicates that the segment copying to remote storage is started but not yet
finished.
+ * {@link RemoteLogSegmentState#COPY_SEGMENT_FINISHED} - This state
indicates that the segment copying to remote storage is finished.
+ *
+ * The leader broker copies the log segments to the remote storage and
puts the remote log segment metadata with the
+ * state as
[GitHub] [kafka] satishd commented on a change in pull request #10173: KAFKA-9548 Added SPIs and public classes/interfaces introduced in KIP-405 for tiered storage feature in Kafka.
satishd commented on a change in pull request #10173:
URL: https://github.com/apache/kafka/pull/10173#discussion_r585331289
##
File path: clients/src/main/java/org/apache/kafka/common/TopicIdPartition.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common;
+
+import java.io.Serializable;
+import java.util.Objects;
+import java.util.UUID;
+
+/**
+ * This represents universally unique identifier with topic id for a topic
partition. This makes sure that topics
+ * recreated with the same name will always have unique topic identifiers.
+ */
+public class TopicIdPartition implements Serializable {
Review comment:
sure, I will have a followup PR once this class is updated with Uuid.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-12393) Document multi-tenancy considerations
[ https://issues.apache.org/jira/browse/KAFKA-12393?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293471#comment-17293471 ] ASF GitHub Bot commented on KAFKA-12393: miguno commented on pull request #334: URL: https://github.com/apache/kafka-site/pull/334#issuecomment-788696584 @bbejeck wrote in https://github.com/apache/kafka-site/pull/334#pullrequestreview-600990037: > Also, @miguno, can you create an identical PR to go against docs in AK trunk? Yes, I will do this once the content review of this PR is completed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Document multi-tenancy considerations > - > > Key: KAFKA-12393 > URL: https://issues.apache.org/jira/browse/KAFKA-12393 > Project: Kafka > Issue Type: Bug > Components: documentation >Reporter: Michael G. Noll >Assignee: Michael G. Noll >Priority: Minor > > We should provide an overview of multi-tenancy consideration (e.g., user > spaces, security) as the current documentation lacks such information. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] satishd commented on a change in pull request #10173: KAFKA-9548 Added SPIs and public classes/interfaces introduced in KIP-405 for tiered storage feature in Kafka.
satishd commented on a change in pull request #10173:
URL: https://github.com/apache/kafka/pull/10173#discussion_r585283720
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogSegmentMetadata.java
##
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Serializable;
+import java.util.Collections;
+import java.util.Map;
+import java.util.NavigableMap;
+import java.util.Objects;
+import java.util.concurrent.ConcurrentSkipListMap;
+
+/**
+ * It describes the metadata about a topic partition's remote log segment in
the remote storage. This is uniquely
+ * represented with {@link RemoteLogSegmentId}.
+ *
+ * New instance is always created with the state as {@link
RemoteLogSegmentState#COPY_SEGMENT_STARTED}. This can be
+ * updated by applying {@link RemoteLogSegmentMetadataUpdate} for the
respective {@link RemoteLogSegmentId} of the
+ * {@code RemoteLogSegmentMetadata}.
+ */
+@InterfaceStability.Evolving
+public class RemoteLogSegmentMetadata implements Serializable {
Review comment:
It is strictly not required. I was using java serialization earlier(POC)
before I added Kafka protocol serdes for remote log segment or partition
metadata.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10173: KAFKA-9548 Added SPIs and public classes/interfaces introduced in KIP-405 for tiered storage feature in Kafka.
satishd commented on a change in pull request #10173:
URL: https://github.com/apache/kafka/pull/10173#discussion_r585269658
##
File path: clients/src/main/java/org/apache/kafka/common/TopicIdPartition.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common;
+
+import java.io.Serializable;
+import java.util.Objects;
+import java.util.UUID;
+
+/**
+ * This represents universally unique identifier with topic id for a topic
partition. This makes sure that topics
+ * recreated with the same name will always have unique topic identifiers.
+ */
+public class TopicIdPartition implements Serializable {
Review comment:
sure, I will have a followup PR once this class is updated with Uuid.
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogSegmentMetadata.java
##
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Serializable;
+import java.util.Collections;
+import java.util.Map;
+import java.util.NavigableMap;
+import java.util.Objects;
+import java.util.concurrent.ConcurrentSkipListMap;
+
+/**
+ * It describes the metadata about a topic partition's remote log segment in
the remote storage. This is uniquely
+ * represented with {@link RemoteLogSegmentId}.
+ *
+ * New instance is always created with the state as {@link
RemoteLogSegmentState#COPY_SEGMENT_STARTED}. This can be
+ * updated by applying {@link RemoteLogSegmentMetadataUpdate} for the
respective {@link RemoteLogSegmentId} of the
+ * {@code RemoteLogSegmentMetadata}.
+ */
+@InterfaceStability.Evolving
+public class RemoteLogSegmentMetadata implements Serializable {
Review comment:
It is strictly not required. I was using java serialization earlier
before I added Kafka protocol serdes for remote log segment or partition
metadata.
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogMetadataManager.java
##
@@ -0,0 +1,196 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.Configurable;
+import org.apache.kafka.common.TopicIdPartition;
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Closeable;
+import java.util.Iterator;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+
+/**
+ * This interface provides storing and fetching remote log segment metadata
with strongly consistent semantics.
+ *
+ * This class can be
[GitHub] [kafka] chia7712 commented on a change in pull request #10223: KAFKA-12394: Return `TOPIC_AUTHORIZATION_FAILED` in delete topic response if no describe permission
chia7712 commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585322244
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1884,20 +1884,26 @@ class KafkaApis(val requestChannel: RequestChannel,
val authorizedDeleteTopics =
authHelper.filterByAuthorized(request.context, DELETE, TOPIC,
results.asScala.filter(result => result.name() != null))(_.name)
results.forEach { topic =>
-val unresolvedTopicId = !(topic.topicId() == Uuid.ZERO_UUID) &&
topic.name() == null
- if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
- topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
- topic.setErrorMessage("Topic IDs are not supported on the server.")
- } else if (unresolvedTopicId)
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (!authorizedDeleteTopics.contains(topic.name))
- topic.setErrorCode(Errors.TOPIC_AUTHORIZATION_FAILED.code)
- else if (!metadataCache.contains(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_OR_PARTITION.code)
- else
- toDelete += topic.name
+val unresolvedTopicId = topic.topicId() != Uuid.ZERO_UUID &&
topic.name() == null
+if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
+ topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
+ topic.setErrorMessage("Topic IDs are not supported on the server.")
+} else if (unresolvedTopicId) {
+ topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
+} else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name)) {
+ // Because the client does not have Describe permission, the name
should
+ // not be returned in the response. Note, however, that we do not
consider
+ // the topicId itself to be sensitive, so there is no reason to
obscure
+ // this case with `UNKNOWN_TOPIC_ID`.
+ topic.setName(null)
+ topic.setErrorCode(Errors.TOPIC_AUTHORIZATION_FAILED.code)
+} else if (!authorizedDeleteTopics.contains(topic.name)) {
Review comment:
according to
https://github.com/apache/kafka/pull/10184#discussion_r585086425, should it
handle the case `name provided, topic missing, describable =>
UNKNOWN_TOPIC_OR_PARTITION`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on pull request #10244: KAFKA-12399: Add log4j2 Appender
dongjinleekr commented on pull request #10244: URL: https://github.com/apache/kafka/pull/10244#issuecomment-788692068 @omkreddy @huxihx Could you have a look? :smile: This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr opened a new pull request #10244: KAFKA-12399: Add log4j2 Appender
dongjinleekr opened a new pull request #10244: URL: https://github.com/apache/kafka/pull/10244 This PR implements `log4j2-appender`, a log4j2 equivalent of traditional `log4j-appender`. All `log4j-appender` configuration properties are supported, with some additions: 1. `brokerList` is deprecated for the consistency of the other CLI tools. `bootstrapServers` is added instead. 2. `requiredNumAcks` is deprecated for the consistency of `Producer`'s `Properties` instance. `acks` is added instead. 3. A new configuration option, `producerClass`, is added. Any `Producer` implementation with the `Properties` argument is supported. The unit test itself uses this feature with `MockProducer`. 4. In `log4j-appender`, the default values of `retries`, `requiredNumAcks`, `deliveryTimeoutMs`, `lingerMs`, and `batchSize` are redundantly defined in `Log4jAppender` implementation. Since their default values are already defined in `ProducerConfig`, `log4j2-appender` does not define their default values. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-8154) Buffer Overflow exceptions between brokers and with clients
[ https://issues.apache.org/jira/browse/KAFKA-8154?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293463#comment-17293463 ] Gordon commented on KAFKA-8154: --- Rushed, and grabbed the wrong file. Sorry about that. Added the kafka-clients jar, in case that saves you any effort. > Buffer Overflow exceptions between brokers and with clients > --- > > Key: KAFKA-8154 > URL: https://issues.apache.org/jira/browse/KAFKA-8154 > Project: Kafka > Issue Type: Bug > Components: clients >Affects Versions: 2.1.0 >Reporter: Rajesh Nataraja >Priority: Major > Attachments: server.properties.txt > > > https://github.com/apache/kafka/pull/6495 > https://github.com/apache/kafka/pull/5785 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12399) Add log4j2 Appender
Dongjin Lee created KAFKA-12399: --- Summary: Add log4j2 Appender Key: KAFKA-12399 URL: https://issues.apache.org/jira/browse/KAFKA-12399 Project: Kafka Issue Type: Improvement Components: logging Reporter: Dongjin Lee Assignee: Dongjin Lee As a following job of KAFKA-9366, we have to provide a log4j2 counterpart to log4j-appender. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-8206) A consumer can't discover new group coordinator when the cluster was partly restarted
[
https://issues.apache.org/jira/browse/KAFKA-8206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293424#comment-17293424
]
Ivan Yurchenko commented on KAFKA-8206:
---
Sorry, unfortunately, I didn't proceed to making a KIP. (BTW, I stopped seeing
this issue after some upgrade.)
> A consumer can't discover new group coordinator when the cluster was partly
> restarted
> -
>
> Key: KAFKA-8206
> URL: https://issues.apache.org/jira/browse/KAFKA-8206
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 1.0.0, 2.0.0, 2.2.0
>Reporter: alex gabriel
>Priority: Critical
> Labels: needs-kip
>
> *A consumer can't discover new group coordinator when the cluster was partly
> restarted*
> Preconditions:
> I use Kafka server and Java kafka-client lib 2.2 version
> I have 2 Kafka nodes running localy (localhost:9092, localhost:9093) and 1
> ZK(localhost:2181)
> I have replication factor 2 for the all my topics and
> '_unclean.leader.election.enable=true_' on both Kafka nodes.
> Steps to reproduce:
> 1) Start 2nodes (localhost:9092/localhost:9093)
> 2) Start consumer with 'bootstrap.servers=localhost:9092,localhost:9093'
> {noformat}
> // discovered group coordinator (0-node)
> 2019-04-09 16:23:18,963 INFO
> [org.apache.kafka.clients.consumer.internals.AbstractCoordinator$FindCoordinatorResponseHandler.onSuccess]
> - [Consumer clientId=events-consumer0, groupId=events-group-gabriel]
> Discovered group coordinator localhost:9092 (id: 2147483647 rack: null)>
> ...metadatacache is updated (2 nodes in the cluster list)
> 2019-04-09 16:23:18,928 DEBUG
> [org.apache.kafka.clients.NetworkClient$DefaultMetadataUpdater.maybeUpdate] -
> [Consumer clientId=events-consumer0, groupId=events-group-gabriel] Sending
> metadata request (type=MetadataRequest, topics=) to node localhost:9092
> (id: -1 rack: null)>
> 2019-04-09 16:23:18,940 DEBUG [org.apache.kafka.clients.Metadata.update] -
> Updated cluster metadata version 2 to MetadataCache{cluster=Cluster(id =
> P3pz1xU0SjK-Dhy6h2G5YA, nodes = [localhost:9092 (id: 0 rack: null),
> localhost:9093 (id: 1 rack: null)], partitions = [], controller =
> localhost:9092 (id: 0 rack: null))}>
> {noformat}
> 3) Shutdown 1-node (localhost:9093)
> {noformat}
> // metadata was updated to the 4 version (but for some reasons it still had 2
> alive nodes inside cluster)
> 2019-04-09 16:23:46,981 DEBUG [org.apache.kafka.clients.Metadata.update] -
> Updated cluster metadata version 4 to MetadataCache{cluster=Cluster(id =
> P3pz1xU0SjK-Dhy6h2G5YA, nodes = [localhost:9093 (id: 1 rack: null),
> localhost:9092 (id: 0 rack: null)], partitions = [Partition(topic =
> events-sorted, partition = 1, leader = 0, replicas = [0,1], isr = [0,1],
> offlineReplicas = []), Partition(topic = events-sorted, partition = 0, leader
> = 0, replicas = [0,1], isr = [0,1], offlineReplicas = [])], controller =
> localhost:9092 (id: 0 rack: null))}>
> //consumers thinks that node-1 is still alive and try to send coordinator
> lookup to it but failed
> 2019-04-09 16:23:46,981 INFO
> [org.apache.kafka.clients.consumer.internals.AbstractCoordinator$FindCoordinatorResponseHandler.onSuccess]
> - [Consumer clientId=events-consumer0, groupId=events-group-gabriel]
> Discovered group coordinator localhost:9093 (id: 2147483646 rack: null)>
> 2019-04-09 16:23:46,981 INFO
> [org.apache.kafka.clients.consumer.internals.AbstractCoordinator.markCoordinatorUnknown]
> - [Consumer clientId=events-consumer0, groupId=events-group-gabriel] Group
> coordinator localhost:9093 (id: 2147483646 rack: null) is unavailable or
> invalid, will attempt rediscovery>
> 2019-04-09 16:24:01,117 DEBUG
> [org.apache.kafka.clients.NetworkClient.handleDisconnections] - [Consumer
> clientId=events-consumer0, groupId=events-group-gabriel] Node 1 disconnected.>
> 2019-04-09 16:24:01,117 WARN
> [org.apache.kafka.clients.NetworkClient.processDisconnection] - [Consumer
> clientId=events-consumer0, groupId=events-group-gabriel] Connection to node 1
> (localhost:9093) could not be established. Broker may not be available.>
> // refreshing metadata again
> 2019-04-09 16:24:01,117 DEBUG
> [org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient$RequestFutureCompletionHandler.fireCompletion]
> - [Consumer clientId=events-consumer0, groupId=events-group-gabriel]
> Cancelled request with header RequestHeader(apiKey=FIND_COORDINATOR,
> apiVersion=2, clientId=events-consumer0, correlationId=112) due to node 1
> being disconnected>
> 2019-04-09 16:24:01,117 DEBUG
> [org.apache.kafka.clients.consumer.internals.AbstractCoordinator.ensureCoordinatorReady]
> - [Consumer clientId=events-consumer0, groupId=events-group-gabriel]
> Coordinator discovery failed, refreshing metadata>
> // metadata
[GitHub] [kafka] dengziming opened a new pull request #10243: KAFKA-12398: Fix flaky test `ConsumerBounceTest.testClose`
dengziming opened a new pull request #10243: URL: https://github.com/apache/kafka/pull/10243 *More detailed description of your change* The test fails some times as follow: 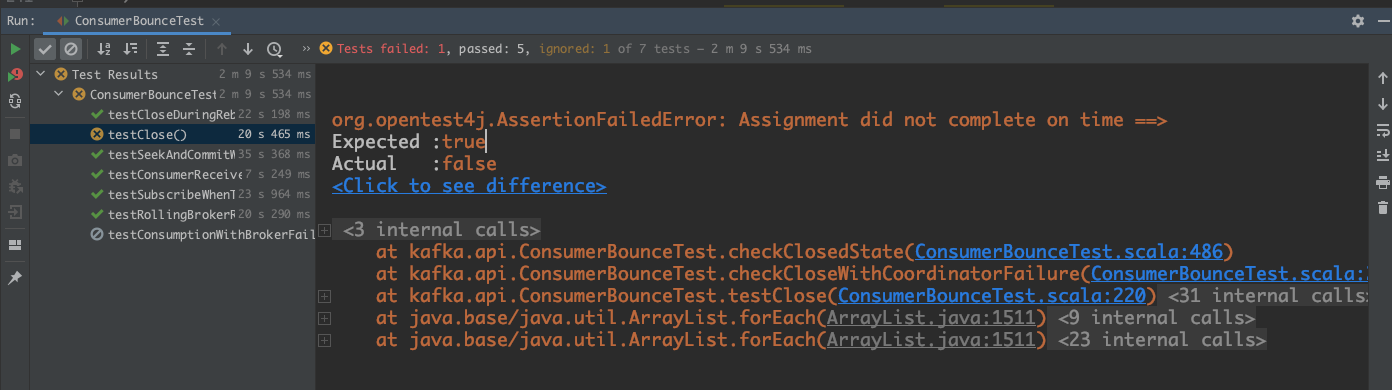 We'd better use `TestUtils.waitUntilTrue` instead of waiting for 1 second because sometimes 1 second is too long and sometimes is too short. *Summary of testing strategy (including rationale) for the feature or bug fix. Unit and/or integration tests are expected for any behaviour change and system tests should be considered for larger changes.* ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon opened a new pull request #10242: MINOR: format the revoking active log output
showuon opened a new pull request #10242: URL: https://github.com/apache/kafka/pull/10242 Missed one new line symbol. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-12398) Fix flaky test `ConsumerBounceTest.testClose`
dengziming created KAFKA-12398: -- Summary: Fix flaky test `ConsumerBounceTest.testClose` Key: KAFKA-12398 URL: https://issues.apache.org/jira/browse/KAFKA-12398 Project: Kafka Issue Type: Improvement Reporter: dengziming Assignee: dengziming Attachments: image-2021-03-02-14-22-34-367.png Sometimes it failed with the following error: !image-2021-03-02-14-22-34-367.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] lbradstreet opened a new pull request #10241: MINOR: time and log producer state recovery phases
lbradstreet opened a new pull request #10241: URL: https://github.com/apache/kafka/pull/10241 During a slow log recovery it's easy to think that loading `.snapshot` files is a multi-second process. Often it isn't the snapshot loading that takes most of the time, rather it's the time taken to further rebuild the producer state from segment files. This PR times both snapshot load and segment recovery phases to better indicate what is taking time. Example test output: ``` [2021-03-01 22:35:28,129] INFO [Log partition=foo-0, dir=/var/folders/cb/5my51vjd1js380qcr_v245bhgp/T/kafka-16876782135717603479] Reloading from producer snapshot and rebuilding producer state from offset 0 [2021-03-01 22:35:28,129] INFO [Log partition=foo-0, dir=/var/folders/cb/5my51vjd1js380qcr_v245bhgp/T/kafka-16876782135717603479] Producer state recovery took 0ms for snapshot load and 0ms for segment recovery from offset 0 [2021-03-01 22:35:28,131] INFO Completed load of Log(dir=/var/folders/cb/5my51vjd1js380qcr_v245bhgp/T/kafka- ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-8154) Buffer Overflow exceptions between brokers and with clients
[ https://issues.apache.org/jira/browse/KAFKA-8154?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293371#comment-17293371 ] Ori Popowski edited comment on KAFKA-8154 at 3/2/21, 5:48 AM: -- [~gordonmessmer] thank you very much for publishing this JAR. Edit: this JAR is empty. But I got the idea. Will try to build myself. Thanks was (Author: oripwk): [~gordonmessmer] thank you very much for publishing this JAR > Buffer Overflow exceptions between brokers and with clients > --- > > Key: KAFKA-8154 > URL: https://issues.apache.org/jira/browse/KAFKA-8154 > Project: Kafka > Issue Type: Bug > Components: clients >Affects Versions: 2.1.0 >Reporter: Rajesh Nataraja >Priority: Major > Attachments: server.properties.txt > > > https://github.com/apache/kafka/pull/6495 > https://github.com/apache/kafka/pull/5785 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-8154) Buffer Overflow exceptions between brokers and with clients
[ https://issues.apache.org/jira/browse/KAFKA-8154?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293371#comment-17293371 ] Ori Popowski commented on KAFKA-8154: - [~gordonmessmer] thank you very much for publishing this JAR > Buffer Overflow exceptions between brokers and with clients > --- > > Key: KAFKA-8154 > URL: https://issues.apache.org/jira/browse/KAFKA-8154 > Project: Kafka > Issue Type: Bug > Components: clients >Affects Versions: 2.1.0 >Reporter: Rajesh Nataraja >Priority: Major > Attachments: server.properties.txt > > > https://github.com/apache/kafka/pull/6495 > https://github.com/apache/kafka/pull/5785 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] chia7712 commented on a change in pull request #10206: KAFKA-12369; Implement `ListTransactions` API
chia7712 commented on a change in pull request #10206:
URL: https://github.com/apache/kafka/pull/10206#discussion_r585252099
##
File path:
clients/src/main/resources/common/message/ListTransactionsResponse.json
##
@@ -0,0 +1,35 @@
+// Licensed to the Apache Software Foundation (ASF) under one or more
+// contributor license agreements. See the NOTICE file distributed with
+// this work for additional information regarding copyright ownership.
+// The ASF licenses this file to You under the Apache License, Version 2.0
+// (the "License"); you may not use this file except in compliance with
+// the License. You may obtain a copy of the License at
+//
+//http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+{
+ "apiKey": 66,
+ "type": "response",
+ "name": "ListTransactionsResponse",
+ "validVersions": "0",
+ "flexibleVersions": "0+",
+ "fields": [
+ { "name": "ThrottleTimeMs", "type": "int32", "versions": "0+",
+"about": "The duration in milliseconds for which the request was
throttled due to a quota violation, or zero if the request did not violate any
quota." },
+ { "name": "ErrorCode", "type": "int16", "versions": "0+" },
+ { "name": "UnknownStateFilters", "type": "[]string", "default": "null",
"versions": "0+", "nullableVersions": "0+",
Review comment:
the name in request is called `StatesFilter`. Could you make consistent
naming?
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -3303,6 +3304,28 @@ class KafkaApis(val requestChannel: RequestChannel,
new
DescribeTransactionsResponse(response.setThrottleTimeMs(requestThrottleMs)))
}
+ def handleListTransactionsRequest(request: RequestChannel.Request): Unit = {
+val listTransactionsRequest = request.body[ListTransactionsRequest]
+val filteredProducerIds =
listTransactionsRequest.data.producerIdFilter.asScala.map(Long.unbox).toSet
+val filteredStates =
listTransactionsRequest.data.statesFilter.asScala.toSet
+val response = txnCoordinator.handleListTransactions(filteredProducerIds,
filteredStates)
+
+// The response should contain only transactionalIds that the principal
+// has `Describe` permission to access.
+if (response.transactionStates != null) {
Review comment:
Is this null check necessary? the filed is NOT nullable. There appears
to be a bug if we set null to it in production code.
##
File path:
clients/src/main/resources/common/message/ListTransactionsResponse.json
##
@@ -0,0 +1,35 @@
+// Licensed to the Apache Software Foundation (ASF) under one or more
+// contributor license agreements. See the NOTICE file distributed with
+// this work for additional information regarding copyright ownership.
+// The ASF licenses this file to You under the Apache License, Version 2.0
+// (the "License"); you may not use this file except in compliance with
+// the License. You may obtain a copy of the License at
+//
+//http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+{
+ "apiKey": 66,
+ "type": "response",
+ "name": "ListTransactionsResponse",
+ "validVersions": "0",
+ "flexibleVersions": "0+",
+ "fields": [
+ { "name": "ThrottleTimeMs", "type": "int32", "versions": "0+",
+"about": "The duration in milliseconds for which the request was
throttled due to a quota violation, or zero if the request did not violate any
quota." },
+ { "name": "ErrorCode", "type": "int16", "versions": "0+" },
+ { "name": "UnknownStateFilters", "type": "[]string", "default": "null",
"versions": "0+", "nullableVersions": "0+",
Review comment:
Why it requires `nullableVersions`?
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -3303,6 +3304,28 @@ class KafkaApis(val requestChannel: RequestChannel,
new
DescribeTransactionsResponse(response.setThrottleTimeMs(requestThrottleMs)))
}
+ def handleListTransactionsRequest(request: RequestChannel.Request): Unit = {
+val listTransactionsRequest = request.body[ListTransactionsRequest]
+val filteredProducerIds =
listTransactionsRequest.data.producerIdFilter.asScala.map(Long.unbox).toSet
+val filteredStates =
listTransactionsRequest.data.statesFilter.asScala.toSet
+val response =
[GitHub] [kafka] chia7712 commented on a change in pull request #10203: MINOR: Prepare for Gradle 7.0
chia7712 commented on a change in pull request #10203:
URL: https://github.com/apache/kafka/pull/10203#discussion_r585246882
##
File path: build.gradle
##
@@ -1586,15 +1605,17 @@ project(':streams:test-utils') {
archivesBaseName = "kafka-streams-test-utils"
dependencies {
-compile project(':streams')
-compile project(':clients')
+implementation project(':streams')
Review comment:
I guess this is similar to `connect-runtime` that it is easy to be used
in users' testing scope. Maybe we should keep exposing both modules.
##
File path: release.py
##
@@ -631,7 +631,7 @@ def select_gpg_key():
contents = f.read()
if not user_ok("Going to build and upload mvn artifacts based on these
settings:\n" + contents + '\nOK (y/n)?: '):
fail("Retry again later")
-cmd("Building and uploading archives", "./gradlewAll uploadArchives",
cwd=kafka_dir, env=jdk8_env, shell=True)
+cmd("Building and uploading archives", "./gradlewAll publish", cwd=kafka_dir,
env=jdk8_env, shell=True)
Review comment:
the root/`README.md` still use `./gradlewAll uploadArchives`. It would
be great to make them consistent.
##
File path: build.gradle
##
@@ -1468,7 +1461,7 @@ project(':streams') {
include('log4j*jar')
include('*hamcrest*')
}
-from (configurations.runtime) {
+from (configurations.runtimeClasspath) {
Review comment:
Is there a jira already?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #10193: MINOR: correct the error message of validating uint32
chia7712 commented on a change in pull request #10193:
URL: https://github.com/apache/kafka/pull/10193#discussion_r585237560
##
File path:
clients/src/main/java/org/apache/kafka/common/protocol/types/Type.java
##
@@ -320,7 +320,7 @@ public Long validate(Object item) {
if (item instanceof Long)
return (Long) item;
else
-throw new SchemaException(item + " is not a Long.");
+throw new SchemaException(item + " is not an unsigned
integer.");
Review comment:
make sense. will copy that.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on pull request #9758: URL: https://github.com/apache/kafka/pull/9758#issuecomment-788567775 @ijuma Thanks for all your great comments. I have updated this PR. Please take a look. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585235586
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/FetchResponse.java
##
@@ -365,17 +126,92 @@ public int sessionId() {
* @param partIterator The partition iterator.
* @return The response size in bytes.
*/
-public static int sizeOf(short version,
-
Iterator>> partIterator) {
+public static int sizeOf(short version,
+ Iterator> partIterator) {
// Since the throttleTimeMs and metadata field sizes are constant and
fixed, we can
// use arbitrary values here without affecting the result.
-FetchResponseData data = toMessage(0, Errors.NONE, partIterator,
INVALID_SESSION_ID);
+LinkedHashMap data =
new LinkedHashMap<>();
+partIterator.forEachRemaining(entry -> data.put(entry.getKey(),
entry.getValue()));
ObjectSerializationCache cache = new ObjectSerializationCache();
-return 4 + data.size(cache, version);
+return 4 + FetchResponse.of(Errors.NONE, 0, INVALID_SESSION_ID,
data).data.size(cache, version);
}
@Override
public boolean shouldClientThrottle(short version) {
return version >= 8;
}
-}
+
+public static Optional
divergingEpoch(FetchResponseData.PartitionData partitionResponse) {
+return partitionResponse.divergingEpoch().epoch() < 0 ?
Optional.empty()
+: Optional.of(partitionResponse.divergingEpoch());
+}
+
+public static boolean isDivergingEpoch(FetchResponseData.PartitionData
partitionResponse) {
+return partitionResponse.divergingEpoch().epoch() >= 0;
+}
+
+public static Optional
preferredReadReplica(FetchResponseData.PartitionData partitionResponse) {
+return partitionResponse.preferredReadReplica() ==
INVALID_PREFERRED_REPLICA_ID ? Optional.empty()
+: Optional.of(partitionResponse.preferredReadReplica());
+}
+
+public static boolean isPreferredReplica(FetchResponseData.PartitionData
partitionResponse) {
+return partitionResponse.preferredReadReplica() !=
INVALID_PREFERRED_REPLICA_ID;
+}
+
+public static FetchResponseData.PartitionData partitionResponse(int
partition, Errors error) {
+return new FetchResponseData.PartitionData()
+.setPartitionIndex(partition)
+.setErrorCode(error.code())
+.setHighWatermark(FetchResponse.INVALID_HIGH_WATERMARK);
+}
+
+/**
+ * cast the BaseRecords of PartitionData to Records. KRPC converts the
byte array to MemoryRecords so this method
+ * never fail if the data is from KRPC.
+ *
+ * @param partition partition data
+ * @return Records or empty record if the records in PartitionData is null.
+ */
+public static Records records(FetchResponseData.PartitionData partition) {
Review comment:
good point. will copy that
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10163: KAFKA-10357: Extract setup of changelog from Streams partition assignor
ableegoldman commented on a change in pull request #10163:
URL: https://github.com/apache/kafka/pull/10163#discussion_r583907570
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ChangelogTopics.java
##
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.processor.internals;
+
+import org.apache.kafka.common.TopicPartition;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.streams.processor.TaskId;
+import
org.apache.kafka.streams.processor.internals.InternalTopologyBuilder.TopicsInfo;
+import org.slf4j.Logger;
+
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+
+import static
org.apache.kafka.streams.processor.internals.assignment.StreamsAssignmentProtocolVersions.UNKNOWN;
+
+public class ChangelogTopics {
+
+private final InternalTopicManager internalTopicManager;
+private final Map topicGroups;
+private final Map> tasksForTopicGroup;
+private final Map> changelogPartitionsForTask
= new HashMap<>();
+private final Map>
preExistingChangelogPartitionsForTask = new HashMap<>();
+private final Set
preExistingNonSourceTopicBasedChangelogPartitions = new HashSet<>();
+private final Set sourceTopicBasedChangelogTopics = new
HashSet<>();
+private final Set sourceTopicBasedChangelogTopicPartitions
= new HashSet<>();
+private final Logger log;
+
+public ChangelogTopics(final InternalTopicManager internalTopicManager,
+ final Map topicGroups,
+ final Map> tasksForTopicGroup,
+ final String logPrefix) {
+this.internalTopicManager = internalTopicManager;
+this.topicGroups = topicGroups;
+this.tasksForTopicGroup = tasksForTopicGroup;
+final LogContext logContext = new LogContext(logPrefix);
+log = logContext.logger(getClass());
+}
+
+public void setup() {
Review comment:
Is there a specific reason we need to make an explicit call to `setup()`
rather than just doing this in the constructor? I'm always worried we'll end up
forgetting to call `setup` again after some refactoring and someone will waste
a day debugging their code because they tried to use a `Changelogs` object
before/without first calling `setup()`
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ChangelogTopics.java
##
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.processor.internals;
+
+import org.apache.kafka.common.TopicPartition;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.streams.processor.TaskId;
+import
org.apache.kafka.streams.processor.internals.InternalTopologyBuilder.TopicsInfo;
+import org.slf4j.Logger;
+
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+
+import static
org.apache.kafka.streams.processor.internals.assignment.StreamsAssignmentProtocolVersions.UNKNOWN;
+
+public class ChangelogTopics {
+
+private final InternalTopicManager internalTopicManager;
+private final Map topicGroups;
+private final Map> tasksForTopicGroup;
+private final Map>
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585229860
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/FetchResponse.java
##
@@ -365,17 +126,92 @@ public int sessionId() {
* @param partIterator The partition iterator.
* @return The response size in bytes.
*/
-public static int sizeOf(short version,
-
Iterator>> partIterator) {
+public static int sizeOf(short version,
+ Iterator> partIterator) {
// Since the throttleTimeMs and metadata field sizes are constant and
fixed, we can
// use arbitrary values here without affecting the result.
-FetchResponseData data = toMessage(0, Errors.NONE, partIterator,
INVALID_SESSION_ID);
+LinkedHashMap data =
new LinkedHashMap<>();
+partIterator.forEachRemaining(entry -> data.put(entry.getKey(),
entry.getValue()));
ObjectSerializationCache cache = new ObjectSerializationCache();
-return 4 + data.size(cache, version);
+return 4 + FetchResponse.of(Errors.NONE, 0, INVALID_SESSION_ID,
data).data.size(cache, version);
}
@Override
public boolean shouldClientThrottle(short version) {
return version >= 8;
}
-}
+
+public static Optional
divergingEpoch(FetchResponseData.PartitionData partitionResponse) {
+return partitionResponse.divergingEpoch().epoch() < 0 ?
Optional.empty()
+: Optional.of(partitionResponse.divergingEpoch());
+}
+
+public static boolean isDivergingEpoch(FetchResponseData.PartitionData
partitionResponse) {
+return partitionResponse.divergingEpoch().epoch() >= 0;
+}
+
+public static Optional
preferredReadReplica(FetchResponseData.PartitionData partitionResponse) {
+return partitionResponse.preferredReadReplica() ==
INVALID_PREFERRED_REPLICA_ID ? Optional.empty()
+: Optional.of(partitionResponse.preferredReadReplica());
+}
+
+public static boolean isPreferredReplica(FetchResponseData.PartitionData
partitionResponse) {
+return partitionResponse.preferredReadReplica() !=
INVALID_PREFERRED_REPLICA_ID;
+}
+
+public static FetchResponseData.PartitionData partitionResponse(int
partition, Errors error) {
+return new FetchResponseData.PartitionData()
+.setPartitionIndex(partition)
+.setErrorCode(error.code())
+.setHighWatermark(FetchResponse.INVALID_HIGH_WATERMARK);
+}
+
+/**
+ * cast the BaseRecords of PartitionData to Records. KRPC converts the
byte array to MemoryRecords so this method
+ * never fail if the data is from KRPC.
+ *
+ * @param partition partition data
+ * @return Records or empty record if the records in PartitionData is null.
+ */
+public static Records records(FetchResponseData.PartitionData partition) {
+return partition.records() == null ? MemoryRecords.EMPTY : (Records)
partition.records();
Review comment:
will copy that
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585226663
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/FetchResponse.java
##
@@ -365,17 +126,92 @@ public int sessionId() {
* @param partIterator The partition iterator.
* @return The response size in bytes.
*/
-public static int sizeOf(short version,
-
Iterator>> partIterator) {
+public static int sizeOf(short version,
+ Iterator> partIterator) {
// Since the throttleTimeMs and metadata field sizes are constant and
fixed, we can
// use arbitrary values here without affecting the result.
-FetchResponseData data = toMessage(0, Errors.NONE, partIterator,
INVALID_SESSION_ID);
+LinkedHashMap data =
new LinkedHashMap<>();
+partIterator.forEachRemaining(entry -> data.put(entry.getKey(),
entry.getValue()));
ObjectSerializationCache cache = new ObjectSerializationCache();
-return 4 + data.size(cache, version);
+return 4 + FetchResponse.of(Errors.NONE, 0, INVALID_SESSION_ID,
data).data.size(cache, version);
}
@Override
public boolean shouldClientThrottle(short version) {
return version >= 8;
}
-}
+
+public static Optional
divergingEpoch(FetchResponseData.PartitionData partitionResponse) {
+return partitionResponse.divergingEpoch().epoch() < 0 ?
Optional.empty()
+: Optional.of(partitionResponse.divergingEpoch());
+}
+
+public static boolean isDivergingEpoch(FetchResponseData.PartitionData
partitionResponse) {
+return partitionResponse.divergingEpoch().epoch() >= 0;
+}
+
+public static Optional
preferredReadReplica(FetchResponseData.PartitionData partitionResponse) {
+return partitionResponse.preferredReadReplica() ==
INVALID_PREFERRED_REPLICA_ID ? Optional.empty()
+: Optional.of(partitionResponse.preferredReadReplica());
+}
+
+public static boolean isPreferredReplica(FetchResponseData.PartitionData
partitionResponse) {
+return partitionResponse.preferredReadReplica() !=
INVALID_PREFERRED_REPLICA_ID;
+}
+
+public static FetchResponseData.PartitionData partitionResponse(int
partition, Errors error) {
+return new FetchResponseData.PartitionData()
+.setPartitionIndex(partition)
+.setErrorCode(error.code())
+.setHighWatermark(FetchResponse.INVALID_HIGH_WATERMARK);
+}
+
+/**
+ * cast the BaseRecords of PartitionData to Records. KRPC converts the
byte array to MemoryRecords so this method
+ * never fail if the data is from KRPC.
Review comment:
good one. will copy that
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on pull request #10215: URL: https://github.com/apache/kafka/pull/10215#issuecomment-788556426 This should be ready for a final review @cadonna @wcarlson5 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585225255
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -463,9 +464,8 @@ private void replaceStreamThread(final Throwable throwable)
{
closeToError();
}
final StreamThread deadThread = (StreamThread) Thread.currentThread();
-threads.remove(deadThread);
Review comment:
Yeah I think swapping the names would make the code unnecessarily
complicated, and it would definitely make reading the logs more difficult.
Just to note: in the current rebalance protocol, the thread name should not
impact the task assignment since within a client tasks are always just assigned
to their previous owner (we maximize stickiness & balance)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585224829
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -761,79 +754,84 @@ class KafkaApis(val requestChannel: RequestChannel,
// For fetch requests from clients, check if down-conversion is
disabled for the particular partition
if (!fetchRequest.isFromFollower &&
!logConfig.forall(_.messageDownConversionEnable)) {
trace(s"Conversion to message format ${downConvertMagic.get} is
disabled for partition $tp. Sending unsupported version response to $clientId.")
- errorResponse(Errors.UNSUPPORTED_VERSION)
+ FetchResponse.partitionResponse(tp.partition,
Errors.UNSUPPORTED_VERSION)
} else {
try {
trace(s"Down converting records from partition $tp to message
format version $magic for fetch request from $clientId")
// Because down-conversion is extremely memory intensive, we
want to try and delay the down-conversion as much
// as possible. With KIP-283, we have the ability to lazily
down-convert in a chunked manner. The lazy, chunked
// down-conversion always guarantees that at least one batch
of messages is down-converted and sent out to the
// client.
-val error = maybeDownConvertStorageError(partitionData.error)
-new FetchResponse.PartitionData[BaseRecords](error,
partitionData.highWatermark,
- partitionData.lastStableOffset, partitionData.logStartOffset,
- partitionData.preferredReadReplica,
partitionData.abortedTransactions,
- new LazyDownConversionRecords(tp, unconvertedRecords, magic,
fetchContext.getFetchOffset(tp).get, time))
+new FetchResponseData.PartitionData()
+ .setPartitionIndex(tp.partition)
+
.setErrorCode(maybeDownConvertStorageError(Errors.forCode(partitionData.errorCode)).code)
+ .setHighWatermark(partitionData.highWatermark)
+ .setLastStableOffset(partitionData.lastStableOffset)
+ .setLogStartOffset(partitionData.logStartOffset)
+ .setAbortedTransactions(partitionData.abortedTransactions)
+ .setRecords(new LazyDownConversionRecords(tp,
unconvertedRecords, magic, fetchContext.getFetchOffset(tp).get, time))
+
.setPreferredReadReplica(partitionData.preferredReadReplica())
} catch {
case e: UnsupportedCompressionTypeException =>
trace("Received unsupported compression type error during
down-conversion", e)
- errorResponse(Errors.UNSUPPORTED_COMPRESSION_TYPE)
+ FetchResponse.partitionResponse(tp.partition,
Errors.UNSUPPORTED_COMPRESSION_TYPE)
}
}
case None =>
-val error = maybeDownConvertStorageError(partitionData.error)
-new FetchResponse.PartitionData[BaseRecords](error,
- partitionData.highWatermark,
- partitionData.lastStableOffset,
- partitionData.logStartOffset,
- partitionData.preferredReadReplica,
- partitionData.abortedTransactions,
- partitionData.divergingEpoch,
- unconvertedRecords)
+new FetchResponseData.PartitionData()
+ .setPartitionIndex(tp.partition)
+
.setErrorCode(maybeDownConvertStorageError(Errors.forCode(partitionData.errorCode)).code)
+ .setHighWatermark(partitionData.highWatermark)
+ .setLastStableOffset(partitionData.lastStableOffset)
+ .setLogStartOffset(partitionData.logStartOffset)
+ .setAbortedTransactions(partitionData.abortedTransactions)
+ .setRecords(unconvertedRecords)
+ .setPreferredReadReplica(partitionData.preferredReadReplica)
+ .setDivergingEpoch(partitionData.divergingEpoch)
}
}
}
// the callback for process a fetch response, invoked before throttling
def processResponseCallback(responsePartitionData: Seq[(TopicPartition,
FetchPartitionData)]): Unit = {
- val partitions = new util.LinkedHashMap[TopicPartition,
FetchResponse.PartitionData[Records]]
+ val partitions = new util.LinkedHashMap[TopicPartition,
FetchResponseData.PartitionData]
val reassigningPartitions = mutable.Set[TopicPartition]()
responsePartitionData.foreach { case (tp, data) =>
val abortedTransactions = data.abortedTransactions.map(_.asJava).orNull
val lastStableOffset =
data.lastStableOffset.getOrElse(FetchResponse.INVALID_LAST_STABLE_OFFSET)
-if (data.isReassignmentFetch)
- reassigningPartitions.add(tp)
-val error =
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585224204
##
File path: core/src/test/scala/unit/kafka/server/FetchSessionTest.scala
##
@@ -534,15 +588,21 @@ class FetchSessionTest {
Optional.empty()))
val session2context = fetchManager.newContext(JFetchMetadata.INITIAL,
session1req, EMPTY_PART_LIST, false)
assertEquals(classOf[FullFetchContext], session2context.getClass)
-val session2RespData = new util.LinkedHashMap[TopicPartition,
FetchResponse.PartitionData[Records]]
-session2RespData.put(new TopicPartition("foo", 0), new
FetchResponse.PartitionData(
- Errors.NONE, 100, 100, 100, null, null))
-session2RespData.put(new TopicPartition("foo", 1), new
FetchResponse.PartitionData(
- Errors.NONE, 10, 10, 10, null, null))
+val session2RespData = new util.LinkedHashMap[TopicPartition,
FetchResponseData.PartitionData]
+session2RespData.put(new TopicPartition("foo", 0),
+ new FetchResponseData.PartitionData()
+.setHighWatermark(100)
+.setLastStableOffset(100)
+.setLogStartOffset(100))
+session2RespData.put(new TopicPartition("foo", 1),
+ new FetchResponseData.PartitionData()
+.setHighWatermark(10)
Review comment:
good catch. will fix all similar issues in next commit.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585223909
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1047,9 +1047,15 @@ private int getNumStreamThreads(final boolean
hasGlobalTopology) {
if
(!streamThread.waitOnThreadState(StreamThread.State.DEAD, timeoutMs - begin)) {
log.warn("Thread " + streamThread.getName() +
" did not shutdown in the allotted time");
timeout = true;
+// Don't remove from threads until shutdown is
complete. We will trim it from the
+// list once it reaches DEAD, and if for some
reason it's hanging indefinitely in the
+// shutdown then we should just consider this
thread.id to be burned
+} else {
+threads.remove(streamThread);
}
}
-threads.remove(streamThread);
+// Don't remove from threads until shutdown is
complete since this will let another thread
+// reuse its thread.id. We will trim any DEAD threads
from the list later
final long cacheSizePerThread =
getCacheSizePerThread(threads.size());
Review comment:
Good catch. I added a method `getNumLiveStreamThreads` to use instead of
just `threads.size()` which will trim the list of any DEAD threads and return
the actual number of living threads
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585221282
##
File path: core/src/test/scala/unit/kafka/server/AbstractFetcherThreadTest.scala
##
@@ -1144,8 +1143,14 @@ class AbstractFetcherThreadTest {
(Errors.NONE, records)
}
-(partition, new FetchData(error, leaderState.highWatermark,
leaderState.highWatermark, leaderState.logStartOffset,
- Optional.empty[Integer], List.empty.asJava, divergingEpoch.asJava,
records))
+(partition, new FetchResponseData.PartitionData()
+ .setErrorCode(error.code)
+ .setHighWatermark(leaderState.highWatermark)
+ .setLastStableOffset(leaderState.highWatermark)
+ .setLogStartOffset(leaderState.logStartOffset)
+ .setAbortedTransactions(Collections.emptyList())
+ .setRecords(records)
+ .setDivergingEpoch(divergingEpoch.getOrElse(new
FetchResponseData.EpochEndOffset)))
Review comment:
the type `FetchablePartitionResponse` is gone and the replacement
`FetchResponseData.PartitionData` (generated data) can't accept `Optional` type.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585220510
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1047,9 +1047,15 @@ private int getNumStreamThreads(final boolean
hasGlobalTopology) {
if
(!streamThread.waitOnThreadState(StreamThread.State.DEAD, timeoutMs - begin)) {
log.warn("Thread " + streamThread.getName() +
" did not shutdown in the allotted time");
timeout = true;
+// Don't remove from threads until shutdown is
complete. We will trim it from the
+// list once it reaches DEAD, and if for some
reason it's hanging indefinitely in the
Review comment:
We're trimming it in `getNextThreadIndex`. But if we're going to rely on
`threads.size()` elsewhere, which it seems we do, then yeah we should trim it
more aggressively
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758:
URL: https://github.com/apache/kafka/pull/9758#discussion_r585219789
##
File path: core/src/main/scala/kafka/server/AbstractFetcherThread.scala
##
@@ -416,9 +412,8 @@ abstract class AbstractFetcherThread(name: String,
"expected to persist.")
partitionsWithError += topicPartition
-case _ =>
- error(s"Error for partition $topicPartition at offset
${currentFetchState.fetchOffset}",
-partitionData.error.exception)
+case partitionError: Errors =>
Review comment:
you are right. fixed
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585219164
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1047,9 +1047,15 @@ private int getNumStreamThreads(final boolean
hasGlobalTopology) {
if
(!streamThread.waitOnThreadState(StreamThread.State.DEAD, timeoutMs - begin)) {
log.warn("Thread " + streamThread.getName() +
" did not shutdown in the allotted time");
timeout = true;
+// Don't remove from threads until shutdown is
complete. We will trim it from the
+// list once it reaches DEAD, and if for some
reason it's hanging indefinitely in the
+// shutdown then we should just consider this
thread.id to be burned
+} else {
+threads.remove(streamThread);
Review comment:
Yeah, I was mainly trying to keep things simple. There's definitely a
tradeoff in when we resize the cache: either we resize it right away and risk
an OOM or we resize it whenever we find newly DEAD threads but potentially have
to wait to "reclaim" the memory of a thread.
Both scenarios run into trouble when a thread is hanging in shutdown, but if
that occurs something has already gone wrong so I don't think we need to
guarantee Streams will continue running perfectly. But the downside to resizing
the cache only once a thread reaches DEAD is that a user could call
`removeStreamThread()` with a timeout of 0 and then never call add/remove
thread again, and they'll never get back the memory of the removed thread since
we only trim the `threads` inside these methods (or the exception handler). ie,
it seems ok to lazily remove DEAD threads if we only use the `threads` list to
find a unique `threadId`, but not to lazily resize the cache. WDYT?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] abbccdda commented on pull request #10240: KAFKA-12381: only return leader not available for internal topic creation
abbccdda commented on pull request #10240: URL: https://github.com/apache/kafka/pull/10240#issuecomment-788548109 Triggered system tests: trunk: https://jenkins.confluent.io/job/system-test-kafka-branch-builder/4408/ fix: https://jenkins.confluent.io/job/system-test-kafka-branch-builder/4409/ to see if we have the verifiable producer test fixed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] abbccdda opened a new pull request #10240: KAFKA-12381: only return leader not available for internal topic creation
abbccdda opened a new pull request #10240: URL: https://github.com/apache/kafka/pull/10240 We introduced a regression in https://github.com/apache/kafka/pull/9579 where originally we only return `INVALID_REPLICATION_FACTOR` for internal topic creation when there are not enough brokers. The mentioned PR expanded the scope and return this error to non-internal topic creation cases as well, which should be `LEADER_NOT_AVAILABLE` instead. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10223: KAFKA-12394: Return `TOPIC_AUTHORIZATION_FAILED` in delete topic response if no describe permission
hachikuji commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585212982
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1884,20 +1884,24 @@ class KafkaApis(val requestChannel: RequestChannel,
val authorizedDeleteTopics =
authHelper.filterByAuthorized(request.context, DELETE, TOPIC,
results.asScala.filter(result => result.name() != null))(_.name)
results.forEach { topic =>
-val unresolvedTopicId = !(topic.topicId() == Uuid.ZERO_UUID) &&
topic.name() == null
- if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
- topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
- topic.setErrorMessage("Topic IDs are not supported on the server.")
- } else if (unresolvedTopicId)
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (!authorizedDeleteTopics.contains(topic.name))
- topic.setErrorCode(Errors.TOPIC_AUTHORIZATION_FAILED.code)
- else if (!metadataCache.contains(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_OR_PARTITION.code)
- else
- toDelete += topic.name
+val unresolvedTopicId = topic.topicId() != Uuid.ZERO_UUID &&
topic.name() == null
+if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
+ topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
+ topic.setErrorMessage("Topic IDs are not supported on the server.")
+} else if (unresolvedTopicId) {
+ topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
+} else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name)) {
+ // Because the client does not have Describe permission, the name
should
+ // not be returned in the response.
+ topic.setName(null)
+ topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
Review comment:
@chia7712 @jolshan I ended up doing this here after all since it sounds
like there is consensus on not treating the topicId as sensitive based on the
JIRA discussion. Let me know if you have any concerns.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585107512
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1094,16 +1100,32 @@ private int getNumStreamThreads(final boolean
hasGlobalTopology) {
}
private int getNextThreadIndex() {
-final HashSet names = new HashSet<>();
-processStreamThread(thread -> names.add(thread.getName()));
-final String baseName = clientId + "-StreamThread-";
-for (int i = 1; i <= threads.size(); i++) {
-final String name = baseName + i;
-if (!names.contains(name)) {
-return i;
+final HashSet allLiveThreadNames = new HashSet<>();
+final AtomicInteger maxThreadId = new AtomicInteger(1);
Review comment:
It's because of the whole "variables used in a lambda must be final or
effectively final" thing
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10228: KAFKA-10251: increase timeout for consumeing records
showuon commented on pull request #10228: URL: https://github.com/apache/kafka/pull/10228#issuecomment-788534430 @ableegoldman , to investigate this flaky test, I have a drafted PR, to output some debug log on jenkins build. This is what I mentioned in the PR description: `failed at 1st try` https://ci-builds.apache.org/job/Kafka/job/kafka-pr/job/PR-9724/148/testReport/junit/kafka.api/TransactionsBounceTest/Build___JDK_15___testWithGroupMetadata__/ So, I cannot reproduce it on my local env, instead, I reproduce it on jenkins env. Thank you. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-12397) Error:KeeperErrorCode = BadVersion for /brokers/topics
Sachin created KAFKA-12397: -- Summary: Error:KeeperErrorCode = BadVersion for /brokers/topics Key: KAFKA-12397 URL: https://issues.apache.org/jira/browse/KAFKA-12397 Project: Kafka Issue Type: Bug Reporter: Sachin We are running Zookeeper and kafka on DCOS. Currently observing below errors in zookeeper logs: NFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@892] - Processing mntr command from /100.77.120.5:47676 2021-03-01 06:48:28,223 [myid:2] - INFO [Thread-7313:NIOServerCnxn@1040] - Closed socket connection for client /100.77.120.5:47676 (no session established for client) 2021-03-01 06:48:31,745 [myid:2] - INFO [ProcessThread(sid:2 cport:-1)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x208f3e3caa5 type:setData cxid:0x11772f zxid:0x571be5 txntype:-1 reqpath:n/a Error Path:/brokers/topics/connect-offsets/partitions/8/state Error:KeeperErrorCode = BadVersion for /brokers/topics/connect-offsets/partitions/8/state 2021-03-01 06:48:31,756 [myid:2] - INFO [ProcessThread(sid:2 cport:-1)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x208f3e3caa5 type:setData cxid:0x117731 zxid:0x571be6 txntype:-1 reqpath:n/a Error Path:/brokers/topics/connect-offsets/partitions/20/state Error:KeeperErrorCode = BadVersion for /brokers/topics/connect-offsets/partitions/20/state 2 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-12381) Incompatible change in verifiable_producer.log in 2.8
[
https://issues.apache.org/jira/browse/KAFKA-12381?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293286#comment-17293286
]
Boyang Chen commented on KAFKA-12381:
-
I checked 2.7 code, and we only return INVALID_REPLICATION_FACTOR for internal
topics:
{code:java}
if (isInternal(topic)) {
val topicMetadata = createInternalTopic(topic)
if (topicMetadata.errorCode == Errors.COORDINATOR_NOT_AVAILABLE.code)
metadataResponseTopic(Errors.INVALID_REPLICATION_FACTOR, topic, true,
util.Collections.emptyList())
else
topicMetadata
} else if (allowAutoTopicCreation && config.autoCreateTopicsEnable) {
createTopic(topic, config.numPartitions, config.defaultReplicationFactor)
} else {
metadataResponseTopic(Errors.UNKNOWN_TOPIC_OR_PARTITION, topic, false,
util.Collections.emptyList())
}
{code}
which seems to be lost in the new auto topic creation module. I will try to do
a fix there.
> Incompatible change in verifiable_producer.log in 2.8
> -
>
> Key: KAFKA-12381
> URL: https://issues.apache.org/jira/browse/KAFKA-12381
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 2.8.0
>Reporter: Colin McCabe
>Assignee: Boyang Chen
>Priority: Blocker
> Labels: kip-500
>
> In test_verifiable_producer.py , we used to see this error message in
> verifiable_producer.log when a topic couldn't be created:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=LEADER_NOT_AVAILABLE}
> (org.apache.kafka.clients.NetworkClient)
> The test does a grep LEADER_NOT_AVAILABLE on the log in this case, and it
> used to pass.
> Now we are instead seeing this in the log file:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=INVALID_REPLICATION_FACTOR}
> (org.apache.kafka.clients.NetworkClient)
> And of course now the test fails.
> The INVALID_REPLICATION_FACTOR is coming from the new auto topic creation
> manager.
> It is a simple matter to make the test pass -- I have confirmed that it
> passes if we grep for INVALID_REPLICATION_FACTOR in the log file instead of
> LEADER_NOT_AVAILABLE.
> I think we just need to decide if this change in behavior is acceptable or
> not.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] junrao commented on a change in pull request #10173: KAFKA-9548 Added SPIs and public classes/interfaces introduced in KIP-405 for tiered storage feature in Kafka.
junrao commented on a change in pull request #10173:
URL: https://github.com/apache/kafka/pull/10173#discussion_r585109788
##
File path: clients/src/main/java/org/apache/kafka/common/TopicIdPartition.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.common;
+
+import java.io.Serializable;
+import java.util.Objects;
+import java.util.UUID;
+
+/**
+ * This represents universally unique identifier with topic id for a topic
partition. This makes sure that topics
+ * recreated with the same name will always have unique topic identifiers.
+ */
+public class TopicIdPartition implements Serializable {
Review comment:
Could we consolidate this with the TopicIdPartition in BrokersToIsrs?
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogSegmentMetadata.java
##
@@ -0,0 +1,283 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Serializable;
+import java.util.Collections;
+import java.util.Map;
+import java.util.NavigableMap;
+import java.util.Objects;
+import java.util.concurrent.ConcurrentSkipListMap;
+
+/**
+ * It describes the metadata about a topic partition's remote log segment in
the remote storage. This is uniquely
+ * represented with {@link RemoteLogSegmentId}.
+ *
+ * New instance is always created with the state as {@link
RemoteLogSegmentState#COPY_SEGMENT_STARTED}. This can be
+ * updated by applying {@link RemoteLogSegmentMetadataUpdate} for the
respective {@link RemoteLogSegmentId} of the
+ * {@code RemoteLogSegmentMetadata}.
+ */
+@InterfaceStability.Evolving
+public class RemoteLogSegmentMetadata implements Serializable {
Review comment:
We typically don't use java serialization. Is Serializable needed? Ditto
in a few other classes.
##
File path:
clients/src/main/java/org/apache/kafka/server/log/remote/storage/RemoteLogSegmentId.java
##
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.common.TopicIdPartition;
+import org.apache.kafka.common.annotation.InterfaceStability;
+
+import java.io.Serializable;
+import java.util.Objects;
+import java.util.UUID;
+
+/**
+ * This class represents a universally unique identifier associated to a topic
partition's log segment. This will be
+ * regenerated for every attempt of copying a specific log segment in {@link
RemoteStorageManager#copyLogSegmentData(RemoteLogSegmentMetadata,
LogSegmentData)}.
+ * Once it is
[jira] [Commented] (KAFKA-12381) Incompatible change in verifiable_producer.log in 2.8
[
https://issues.apache.org/jira/browse/KAFKA-12381?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293264#comment-17293264
]
Jason Gustafson commented on KAFKA-12381:
-
[~bchen225242] I would not focus too much on the system test failure. The main
thing to verify is whether there is a behavior change here in the `Metadata`
response. If we are returning `INVALID_REPLICATION_FACTOR` in some case where
we were previously returning `LEADER_NOT_AVAILABLE`, then it is likely a
regression.
> Incompatible change in verifiable_producer.log in 2.8
> -
>
> Key: KAFKA-12381
> URL: https://issues.apache.org/jira/browse/KAFKA-12381
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 2.8.0
>Reporter: Colin McCabe
>Assignee: Boyang Chen
>Priority: Blocker
> Labels: kip-500
>
> In test_verifiable_producer.py , we used to see this error message in
> verifiable_producer.log when a topic couldn't be created:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=LEADER_NOT_AVAILABLE}
> (org.apache.kafka.clients.NetworkClient)
> The test does a grep LEADER_NOT_AVAILABLE on the log in this case, and it
> used to pass.
> Now we are instead seeing this in the log file:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=INVALID_REPLICATION_FACTOR}
> (org.apache.kafka.clients.NetworkClient)
> And of course now the test fails.
> The INVALID_REPLICATION_FACTOR is coming from the new auto topic creation
> manager.
> It is a simple matter to make the test pass -- I have confirmed that it
> passes if we grep for INVALID_REPLICATION_FACTOR in the log file instead of
> LEADER_NOT_AVAILABLE.
> I think we just need to decide if this change in behavior is acceptable or
> not.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-12359) Update Jetty to 11
[ https://issues.apache.org/jira/browse/KAFKA-12359?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293247#comment-17293247 ] John Stacy edited comment on KAFKA-12359 at 3/1/21, 11:49 PM: -- Due to this vulnerability (CVE-2020-27223), you might want to bump to 11.0.1: [https://github.com/eclipse/jetty.project/security/advisories/GHSA-m394-8rww-3jr7] was (Author: jrstacy): Due to this vulnerability, you might want to bump to 11.0.1: https://github.com/eclipse/jetty.project/security/advisories/GHSA-m394-8rww-3jr7 > Update Jetty to 11 > -- > > Key: KAFKA-12359 > URL: https://issues.apache.org/jira/browse/KAFKA-12359 > Project: Kafka > Issue Type: Improvement > Components: KafkaConnect, tools >Reporter: Dongjin Lee >Assignee: Dongjin Lee >Priority: Major > > I found this problem when I was working on > [KAFKA-12324|https://issues.apache.org/jira/browse/KAFKA-12324]. > As of present, Kafka Connect and Trogdor are using Jetty 9. Although Jetty's > stable release is 9.4, the Jetty community is now moving their focus to Jetty > 10 and 11, which requires Java 11 as a prerequisite. To minimize potential > security vulnerability, Kafka should migrate into Java 11 + Jetty 11 as soon > as Jetty 9.4 reaches the end of life. As a note, [Jetty 9.2 reached End of > Life in March > 2018|https://www.eclipse.org/lists/jetty-announce/msg00116.html], and 9.3 > also did in [February > 2020|https://www.eclipse.org/lists/jetty-announce/msg00140.html]. > In other words, the necessity of moving to Java 11 is heavily affected by > Jetty's maintenance plan. Jetty 9.4 seems like still be supported for a > certain period of time, but it is worth being aware of these relationships > and having a migration plan. > Updating Jetty to 11 is not resolved by simply changing the version. Along > with its API changes, we have to cope with additional dependencies, [Java EE > class name changes|https://webtide.com/renaming-from-javax-to-jakarta/], > Making Jackson to compatible with the changes, etc. > As a note: for the difference between Jetty 10 and 11, see > [here|https://webtide.com/jetty-10-and-11-have-arrived/] - in short, "Jetty > 11 is identical to Jetty 10 except that the javax.* packages now conform to > the new jakarta.* namespace.". -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-12359) Update Jetty to 11
[ https://issues.apache.org/jira/browse/KAFKA-12359?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293247#comment-17293247 ] John Stacy commented on KAFKA-12359: Due to this vulnerability, you might want to bump to 11.0.1: https://github.com/eclipse/jetty.project/security/advisories/GHSA-m394-8rww-3jr7 > Update Jetty to 11 > -- > > Key: KAFKA-12359 > URL: https://issues.apache.org/jira/browse/KAFKA-12359 > Project: Kafka > Issue Type: Improvement > Components: KafkaConnect, tools >Reporter: Dongjin Lee >Assignee: Dongjin Lee >Priority: Major > > I found this problem when I was working on > [KAFKA-12324|https://issues.apache.org/jira/browse/KAFKA-12324]. > As of present, Kafka Connect and Trogdor are using Jetty 9. Although Jetty's > stable release is 9.4, the Jetty community is now moving their focus to Jetty > 10 and 11, which requires Java 11 as a prerequisite. To minimize potential > security vulnerability, Kafka should migrate into Java 11 + Jetty 11 as soon > as Jetty 9.4 reaches the end of life. As a note, [Jetty 9.2 reached End of > Life in March > 2018|https://www.eclipse.org/lists/jetty-announce/msg00116.html], and 9.3 > also did in [February > 2020|https://www.eclipse.org/lists/jetty-announce/msg00140.html]. > In other words, the necessity of moving to Java 11 is heavily affected by > Jetty's maintenance plan. Jetty 9.4 seems like still be supported for a > certain period of time, but it is worth being aware of these relationships > and having a migration plan. > Updating Jetty to 11 is not resolved by simply changing the version. Along > with its API changes, we have to cope with additional dependencies, [Java EE > class name changes|https://webtide.com/renaming-from-javax-to-jakarta/], > Making Jackson to compatible with the changes, etc. > As a note: for the difference between Jetty 10 and 11, see > [here|https://webtide.com/jetty-10-and-11-have-arrived/] - in short, "Jetty > 11 is identical to Jetty 10 except that the javax.* packages now conform to > the new jakarta.* namespace.". -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-12394) Consider topic id existence and authorization errors
[ https://issues.apache.org/jira/browse/KAFKA-12394?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293235#comment-17293235 ] Jason Gustafson commented on KAFKA-12394: - The specific case where this came up was `DeleteTopic` handling. It sounds like there is basic agreement to use `TOPIC_AUTHORIZATION_FAILED`. Unless there are objections, I will go ahead and merge this into the minor PR here: https://github.com/apache/kafka/pull/10223. > Consider topic id existence and authorization errors > > > Key: KAFKA-12394 > URL: https://issues.apache.org/jira/browse/KAFKA-12394 > Project: Kafka > Issue Type: Improvement >Reporter: Jason Gustafson >Priority: Major > > We have historically had logic in the api layer to avoid leaking the > existence or non-existence of topics to clients which are not authorized to > describe them. The way we have done this is to always authorize the topic > name first before checking existence. > Topic ids make this more difficult because the resource (ie the topic name) > has to be derived. This means we have to check existence of the topic first. > If the topic does not exist, then our hands are tied and we have to return > UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the > client is authorized to describe it. The question comes then what we should > do if the client is not authorized? > The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this > is misleading and forces the client to retry even though they are doomed to > hit the same error. However, the client should generally handle this by > requesting Metadata using the topic name that they are interested in, which > would give them a chance to see the topic authorization error. Basically the > fact that you need describe permission in the first place to discover the > topic id makes this an unlikely scenario. > There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well. > Basically we could take the stance that we do not care about leaking the > existence of topic IDs since they do not reveal anything about the underlying > topic. Additionally, there is little likelihood of a user discovering a valid > UUID by accident or even through brute force. The benefit of this is that > users get a clear error for cases where a topic Id may have been discovered > through some external means. For example, an administrator finds a topic ID > in the logging and attempts to delete it using the new `deleteTopicsWithIds` > Admin API. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] hachikuji commented on pull request #10206: KAFKA-12369; Implement `ListTransactions` API
hachikuji commented on pull request #10206: URL: https://github.com/apache/kafka/pull/10206#issuecomment-788392877 @chia7712 I implemented your suggestion to include the unknown states in the response. Let me know how this looks to you. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10206: KAFKA-12369; Implement `ListTransactions` API
hachikuji commented on a change in pull request #10206:
URL: https://github.com/apache/kafka/pull/10206#discussion_r585128257
##
File path:
clients/src/main/resources/common/message/ListTransactionsResponse.json
##
@@ -0,0 +1,32 @@
+// Licensed to the Apache Software Foundation (ASF) under one or more
+// contributor license agreements. See the NOTICE file distributed with
+// this work for additional information regarding copyright ownership.
+// The ASF licenses this file to You under the Apache License, Version 2.0
+// (the "License"); you may not use this file except in compliance with
+// the License. You may obtain a copy of the License at
+//
+//http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+{
+ "apiKey": 66,
+ "type": "response",
+ "name": "ListTransactionsResponse",
+ "validVersions": "0",
+ "flexibleVersions": "0+",
+ "fields": [
+ { "name": "ThrottleTimeMs", "type": "int32", "versions": "0+",
+"about": "The duration in milliseconds for which the request was
throttled due to a quota violation, or zero if the request did not violate any
quota." },
+ { "name": "ErrorCode", "type": "int16", "versions": "0+" },
+ { "name": "TransactionStates", "type": "[]TransactionState", "versions":
"0+", "fields": [
+{ "name": "TransactionalId", "type": "string", "versions": "0+",
"entityType": "transactionalId" },
+{ "name": "ProducerId", "type": "int64", "versions": "0+",
"entityType": "producerId" },
+{ "name": "TransactionState", "type": "string", "versions": "0+" }
Review comment:
I added an `about` tag for `TransactionState`. I think the `entityType`
tag is enough for the other two fields.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10206: KAFKA-12369; Implement `ListTransactions` API
hachikuji commented on a change in pull request #10206:
URL: https://github.com/apache/kafka/pull/10206#discussion_r585123307
##
File path:
core/src/main/scala/kafka/coordinator/transaction/TransactionStateManager.scala
##
@@ -223,6 +224,46 @@ class TransactionStateManager(brokerId: Int,
throw new IllegalStateException(s"Unexpected empty transaction metadata
returned while putting $txnMetadata")))
}
+ def listTransactionStates(
+filterProducerIds: Set[Long],
+filterStateNames: Set[String]
+ ): Either[Errors, List[ListTransactionsResponseData.TransactionState]] = {
+inReadLock(stateLock) {
+ if (loadingPartitions.nonEmpty) {
+Left(Errors.COORDINATOR_LOAD_IN_PROGRESS)
+ } else {
+val filterStates = filterStateNames.flatMap(TransactionState.fromName)
Review comment:
You can see `listConsumerGroups` to see how this was handled in the
analogous case for consumer groups.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10232: KAFKA-12352: Make sure all rejoin group and reset state has a reason
ableegoldman commented on a change in pull request #10232:
URL: https://github.com/apache/kafka/pull/10232#discussion_r585070038
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -775,8 +776,6 @@ public void handle(SyncGroupResponse syncResponse,
}
}
} else {
-requestRejoin();
Review comment:
Just to clarify, you mean we don't need to rejoin here since we will
always raise an error, and always rejoin (if necessary) when checking that
error?
Or are you referring to the `requestRejoinOnResponseError` calls you added
to the two last cases in the below if/else?
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -961,29 +962,34 @@ protected synchronized String memberId() {
return generation.memberId;
}
-private synchronized void resetState() {
+private synchronized void resetState(final String reason) {
Review comment:
nit: rename to `resetStateAndGeneration`?
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -802,8 +801,10 @@ public void handle(SyncGroupResponse syncResponse,
log.info("SyncGroup failed: {} Marking coordinator
unknown. Sent generation was {}",
error.message(), sentGeneration);
markCoordinatorUnknown(error);
+requestRejoinOnResponseError(ApiKeys.SYNC_GROUP, error);
Review comment:
Why do we explicitly rejoin in this case, but not eg
`REBALANCE_IN_PROGRESS`? or `UNKNOWN_MEMBER_ID`/`ILLEGAL_GENERATION` ?
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -961,29 +962,34 @@ protected synchronized String memberId() {
return generation.memberId;
}
-private synchronized void resetState() {
+private synchronized void resetState(final String reason) {
+log.info("Resetting generation due to: {}", reason);
+
state = MemberState.UNJOINED;
generation = Generation.NO_GENERATION;
}
-private synchronized void resetStateAndRejoin() {
-resetState();
-rejoinNeeded = true;
+private synchronized void resetStateAndRejoin(final String reason) {
+resetState(reason);
+requestRejoin(reason);
}
synchronized void resetGenerationOnResponseError(ApiKeys api, Errors
error) {
-log.debug("Resetting generation after encountering {} from {} response
and requesting re-join", error, api);
Review comment:
SGTM. If we find it flooding the logs and not helpful we can reconsider
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585107512
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1094,16 +1100,32 @@ private int getNumStreamThreads(final boolean
hasGlobalTopology) {
}
private int getNextThreadIndex() {
-final HashSet names = new HashSet<>();
-processStreamThread(thread -> names.add(thread.getName()));
-final String baseName = clientId + "-StreamThread-";
-for (int i = 1; i <= threads.size(); i++) {
-final String name = baseName + i;
-if (!names.contains(name)) {
-return i;
+final HashSet allLiveThreadNames = new HashSet<>();
+final AtomicInteger maxThreadId = new AtomicInteger(1);
Review comment:
It's because variables used in a lamdba must "final or effectively
final" whatever that means
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10215: KAFKA-12375: don't reuse thread.id until a thread has fully shut down
ableegoldman commented on a change in pull request #10215:
URL: https://github.com/apache/kafka/pull/10215#discussion_r585107230
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -1094,16 +1100,32 @@ private int getNumStreamThreads(final boolean
hasGlobalTopology) {
}
private int getNextThreadIndex() {
-final HashSet names = new HashSet<>();
-processStreamThread(thread -> names.add(thread.getName()));
-final String baseName = clientId + "-StreamThread-";
-for (int i = 1; i <= threads.size(); i++) {
-final String name = baseName + i;
-if (!names.contains(name)) {
-return i;
+final HashSet allLiveThreadNames = new HashSet<>();
+final AtomicInteger maxThreadId = new AtomicInteger(1);
+synchronized (threads) {
+processStreamThread(thread -> {
+// trim any DEAD threads from the list so we can reuse the
thread.id
+// this is only safe to do once the thread has fully completed
shutdown
+if (thread.state() == StreamThread.State.DEAD) {
+threads.remove(thread);
+} else {
+allLiveThreadNames.add(thread.getName());
+final int threadId =
thread.getName().charAt(thread.getName().length() - 1);
Review comment:
Oh duh. That would have been an annoying bug to find in production
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585027051
##
File path: core/src/test/scala/unit/kafka/server/KafkaApisTest.scala
##
@@ -3479,6 +3481,161 @@ class KafkaApisTest {
assertEquals(List(mkTopicData(topic = "foo", Seq(1, 2))),
fooState.topics.asScala.toList)
}
+ @Test
+ def testDeleteTopicsByIdAuthorization(): Unit = {
+val authorizer: Authorizer = EasyMock.niceMock(classOf[Authorizer])
+val controllerContext: ControllerContext =
EasyMock.mock(classOf[ControllerContext])
+
+EasyMock.expect(clientControllerQuotaManager.newQuotaFor(
+ EasyMock.anyObject(classOf[RequestChannel.Request]),
+ EasyMock.anyShort()
+)).andReturn(UnboundedControllerMutationQuota)
+EasyMock.expect(controller.isActive).andReturn(true)
+
EasyMock.expect(controller.controllerContext).andStubReturn(controllerContext)
+
+// Try to delete three topics:
+// 1. One without describe permission
+// 2. One without delete permission
+// 3. One which is authorized, but doesn't exist
+
+expectTopicAuthorization(authorizer, AclOperation.DESCRIBE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.ALLOWED
+))
+
+expectTopicAuthorization(authorizer, AclOperation.DELETE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.DENIED
+))
+
+val topicIdsMap = Map(
+ Uuid.randomUuid() -> Some("foo"),
+ Uuid.randomUuid() -> Some("bar"),
+ Uuid.randomUuid() -> None
+)
+
+topicIdsMap.foreach { case (topicId, topicNameOpt) =>
+
EasyMock.expect(controllerContext.topicName(topicId)).andReturn(topicNameOpt)
+}
+
+val topicDatas = topicIdsMap.keys.map { topicId =>
+ new DeleteTopicsRequestData.DeleteTopicState().setTopicId(topicId)
+}.toList
+val deleteRequest = new DeleteTopicsRequest.Builder(new
DeleteTopicsRequestData()
+ .setTopics(topicDatas.asJava))
+ .build(ApiKeys.DELETE_TOPICS.latestVersion)
+
+val request = buildRequest(deleteRequest)
+val capturedResponse = expectNoThrottling(request)
+
+EasyMock.replay(replicaManager, clientRequestQuotaManager,
clientControllerQuotaManager,
+ requestChannel, txnCoordinator, controller, controllerContext,
authorizer)
+createKafkaApis(authorizer =
Some(authorizer)).handleDeleteTopicsRequest(request)
+
+val deleteResponse =
capturedResponse.getValue.asInstanceOf[DeleteTopicsResponse]
+
+topicIdsMap.foreach { case (topicId, nameOpt) =>
+ val response = deleteResponse.data.responses.asScala.find(_.topicId ==
topicId).get
+ nameOpt match {
+case Some("foo") =>
+ assertNull(response.name)
+ assertEquals(Errors.UNKNOWN_TOPIC_ID,
Errors.forCode(response.errorCode))
+case Some("bar") =>
+ assertEquals("bar", response.name)
+ assertEquals(Errors.TOPIC_AUTHORIZATION_FAILED,
Errors.forCode(response.errorCode))
+case None =>
+ assertNull(response.name)
+ assertEquals(Errors.UNKNOWN_TOPIC_ID,
Errors.forCode(response.errorCode))
+case _ =>
+ fail("Unexpected topic id/name mapping")
+ }
+}
+ }
+
+ @ParameterizedTest
+ @ValueSource(booleans = Array(true, false))
+ def testDeleteTopicsByNameAuthorization(usePrimitiveTopicNameArray:
Boolean): Unit = {
+val authorizer: Authorizer = EasyMock.niceMock(classOf[Authorizer])
+
+EasyMock.expect(clientControllerQuotaManager.newQuotaFor(
+ EasyMock.anyObject(classOf[RequestChannel.Request]),
+ EasyMock.anyShort()
+)).andReturn(UnboundedControllerMutationQuota)
+EasyMock.expect(controller.isActive).andReturn(true)
+
+// Try to delete three topics:
+// 1. One without describe permission
+// 2. One without delete permission
+// 3. One which is authorized, but doesn't exist
+
+expectTopicAuthorization(authorizer, AclOperation.DESCRIBE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.ALLOWED,
+ "baz" -> AuthorizationResult.ALLOWED
+))
+
+expectTopicAuthorization(authorizer, AclOperation.DELETE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.DENIED,
+ "baz" -> AuthorizationResult.ALLOWED
+))
+
+val deleteRequest = if (usePrimitiveTopicNameArray) {
+ new DeleteTopicsRequest.Builder(new DeleteTopicsRequestData()
+.setTopicNames(List("foo", "bar", "baz").asJava))
+.build(5.toShort)
+} else {
+ val topicDatas = List(
+new DeleteTopicsRequestData.DeleteTopicState().setName("foo"),
+new DeleteTopicsRequestData.DeleteTopicState().setName("bar"),
+new DeleteTopicsRequestData.DeleteTopicState().setName("baz")
+ )
+ new DeleteTopicsRequest.Builder(new DeleteTopicsRequestData()
+.setTopics(topicDatas.asJava))
+
[GitHub] [kafka] hachikuji commented on a change in pull request #10184: MINOR: enable topic deletion in the KIP-500 controller
hachikuji commented on a change in pull request #10184:
URL: https://github.com/apache/kafka/pull/10184#discussion_r585086425
##
File path: core/src/main/scala/kafka/server/ControllerApis.scala
##
@@ -154,17 +162,179 @@ class ControllerApis(val requestChannel: RequestChannel,
requestThrottleMs => createResponseCallback(requestThrottleMs))
}
+ def handleDeleteTopics(request: RequestChannel.Request): Unit = {
+val responses = deleteTopics(request.body[DeleteTopicsRequest].data,
+ request.context.apiVersion,
+ authHelper.authorize(request.context, DELETE, CLUSTER, CLUSTER_NAME),
+ names => authHelper.filterByAuthorized(request.context, DESCRIBE, TOPIC,
names)(n => n),
+ names => authHelper.filterByAuthorized(request.context, DELETE, TOPIC,
names)(n => n))
+requestHelper.sendResponseMaybeThrottle(request, throttleTimeMs => {
+ val responseData = new DeleteTopicsResponseData().
+setResponses(new DeletableTopicResultCollection(responses.iterator)).
+setThrottleTimeMs(throttleTimeMs)
+ new DeleteTopicsResponse(responseData)
+})
+ }
+
+ def deleteTopics(request: DeleteTopicsRequestData,
+ apiVersion: Int,
+ hasClusterAuth: Boolean,
+ getDescribableTopics: Iterable[String] => Set[String],
+ getDeletableTopics: Iterable[String] => Set[String]):
util.List[DeletableTopicResult] = {
+if (!config.deleteTopicEnable) {
+ if (apiVersion < 3) {
+throw new InvalidRequestException("Topic deletion is disabled.")
+ } else {
+throw new TopicDeletionDisabledException()
+ }
+}
+val responses = new util.ArrayList[DeletableTopicResult]
+val duplicatedTopicNames = new util.HashSet[String]
+val topicNamesToResolve = new util.HashSet[String]
+val topicIdsToResolve = new util.HashSet[Uuid]
+val duplicatedTopicIds = new util.HashSet[Uuid]
+
+def appendResponse(name: String, id: Uuid, error: ApiError): Unit = {
+ responses.add(new DeletableTopicResult().
+setName(name).
+setTopicId(id).
+setErrorCode(error.error.code).
+setErrorMessage(error.message))
+}
+
+def maybeAppendToTopicNamesToResolve(name: String): Unit = {
+ if (duplicatedTopicNames.contains(name) ||
!topicNamesToResolve.add(name)) {
+appendResponse(name, ZERO_UUID, new ApiError(INVALID_REQUEST,
"Duplicate topic name."))
+topicNamesToResolve.remove(name)
+duplicatedTopicNames.add(name)
+ }
+}
+
+def maybeAppendToIdsToResolve(id: Uuid): Unit = {
+ if (duplicatedTopicIds.contains(id) || !topicIdsToResolve.add(id)) {
+appendResponse(null, id, new ApiError(INVALID_REQUEST, "Duplicate
topic ID."))
+topicIdsToResolve.remove(id)
+duplicatedTopicIds.add(id)
+ }
+}
+
+request.topicNames.forEach(maybeAppendToTopicNamesToResolve)
+
+request.topics.forEach {
+ topic => if (topic.name == null) {
+if (topic.topicId.equals(ZERO_UUID)) {
+ appendResponse(null, ZERO_UUID, new ApiError(INVALID_REQUEST,
+"Neither topic name nor id were specified."))
+} else {
+ maybeAppendToIdsToResolve(topic.topicId)
+}
+ } else {
+if (topic.topicId.equals(ZERO_UUID)) {
+ maybeAppendToTopicNamesToResolve(topic.name)
+} else {
+ appendResponse(topic.name, topic.topicId, new
ApiError(INVALID_REQUEST,
+"You may not specify both topic name and topic id."))
+}
+ }
+}
+
+val idToName = new util.HashMap[Uuid, String]
+val unknownTopicNameErrors = new util.HashMap[String, ApiError]
+def maybeAppendToIdToName(id: Uuid, name: String): Unit = {
+ if (duplicatedTopicIds.contains(id) || idToName.put(id, name) != null) {
+ appendResponse(name, id, new ApiError(INVALID_REQUEST,
+ "The same topic was specified by name and by id."))
+ idToName.remove(id)
+ duplicatedTopicIds.add(id)
+ }
+}
+controller.findTopicIds(topicNamesToResolve).get().forEach { (name,
idOrError) =>
+ if (idOrError.isError)
+unknownTopicNameErrors.put(name, idOrError.error)
+ else
+maybeAppendToIdToName(idOrError.result, name)
+}
+
+/**
+ * There are 6 error cases to handle here if we don't have permission to
delete:
+ *
+ * 1. ID provided, topic missing => UNKNOWN_TOPIC_ID
+ * 2. ID provided, topic present, describeable =>
TOPIC_AUTHORIZATION_FAILED
+ * 3. ID provided, topic present, undescribeable => UNKNOWN_TOPIC_ID
+ * 4. name provided, topic missing, undescribable =>
UNKNOWN_TOPIC_OR_PARTITION
Review comment:
These cases seem wrong. It should be the following:
```
* 4. name provided, topic missing, undescribable =>
TOPIC_AUTHORIZATION_FAILED
* 5. name provided, topic missing, describable =>
[GitHub] [kafka] cmccabe commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
cmccabe commented on a change in pull request #10227: URL: https://github.com/apache/kafka/pull/10227#discussion_r585094036 ## File path: KIP-500.md ## @@ -0,0 +1,131 @@ +KIP-500 Early Access Release + + +# Introduction +It is now possible to run Apache Kafka without Apache ZooKeeper! We call this mode [self-managed mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum). It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it is available for testing in the Kafka 2.8 release. + +When the Kafka cluster is in self-managed mode, it does not store its metadata in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it stores its metadata in a Raft quorum of controller nodes. + +Self-managed mode has many benefits-- some obvious, and some not so obvious. Clearly, it is nice to manage and configure one service rather than two services. In addition, you can now run a single process Kafka cluster. Most important of all, self-managed mode is more scalable. We expect to be able to [support many more topics and partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/) in this mode. + +# Quickstart + +## Warning +Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released, it may not even be possible to upgrade your self-managed clusters from 2.8 to 3.0 without downtime. There may be bugs, including serious ones. You should *assume that your data could be lost at any time* if you try the early access release of KIP-500. + +## Generate a cluster ID +The first step is to generate an ID for your new cluster, using the kafka-storage tool: + + +$ ./bin/kafka-storage.sh random-uuid +xtzWWN4bTjitpL3kfd9s5g + + +## Format Storage Directories +The next step is to format your storage directories. If you are running in single-node mode, you can do this with one command: + + +$ ./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/raft-combined.properties +Formatting /tmp/raft-combined-logs + + +If you are using multiple nodes, then you should run the format command on each node. Be sure to use the same cluster ID for each one. + +## Start the Kafka Server +Finally, you are ready to start the Kafka server on each node. + + +$ ./bin/kafka-server-start.sh ./config/raft-combined.properties +[2021-02-26 15:37:11,071] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$) +[2021-02-26 15:37:11,294] INFO Setting -D jdk.tls.rejectClientInitiatedRenegotiation=true to disable client-initiated TLS renegotiation (org.apache.zookeeper.common.X509Util) +[2021-02-26 15:37:11,466] INFO [Log partition=@metadata-0, dir=/tmp/raft-combined-logs] Loading producer state till offset 0 with message format version 2 (kafka.log.Log) +[2021-02-26 15:37:11,509] INFO [raft-expiration-reaper]: Starting (kafka.raft.TimingWheelExpirationService$ExpiredOperationReaper) +[2021-02-26 15:37:11,640] INFO [RaftManager nodeId=1] Completed transition to Unattached(epoch=0, voters=[1], electionTimeoutMs=9037) (org.apache.kafka.raft.QuorumState) +... + + +Just like with a ZooKeeper based broker, you can connect to port 9092 (or whatever port you configured) to perform administrative operations or produce or consume data. + + +$ ./bin/kafka-topics.sh --create --topic foo --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 +Created topic foo. + + +# Deployment +Unlike in ZooKeeper-based mode, where any server can become the controller, in self-managed mode, only a small group of specially selected servers can act as controllers. The specially selected controller servers will participate in the metadata quorum. Each KIP-500 controller server is either active, or a hot standby for the current active controller server. + +Typically you will select either 3 or 5 servers for this role, depending on the size of your cluster. Just like with ZooKeeper, you must keep a majority of the controllers alive in order to maintain availability. So if you have 3 controllers, you can tolerate 1 failure; with 5 controllers, you can tolerate 2 failures. + +Each Kafka server now has a new configuration key called `process.roles` which can have the following values: + +* If `process.roles` is set to `broker`, the server acts as a self-managed broker. +* If `process.roles` is set to `controller`, the server acts as a self-managed controller. +* If `process.roles` is set to `broker,controller`, the server acts as both a self-managed broker and a self-managd controller. +* If `process.roles` is not set at all then we are assumed to be in ZooKeeper mode. As mentioned earlier, you can't yet transition
[GitHub] [kafka] rondagostino commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
rondagostino commented on a change in pull request #10227:
URL: https://github.com/apache/kafka/pull/10227#discussion_r585093860
##
File path: KIP-500.md
##
@@ -0,0 +1,131 @@
+KIP-500 Early Access Release
+
+
+# Introduction
+It is now possible to run Apache Kafka without Apache ZooKeeper! We call this
mode [self-managed
mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum).
It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it
is available for testing in the Kafka 2.8 release.
+
+When the Kafka cluster is in self-managed mode, it does not store its metadata
in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it
stores its metadata in a Raft quorum of controller nodes.
+
+Self-managed mode has many benefits-- some obvious, and some not so obvious.
Clearly, it is nice to manage and configure one service rather than two
services. In addition, you can now run a single process Kafka cluster. Most
important of all, self-managed mode is more scalable. We expect to be able to
[support many more topics and
partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/)
in this mode.
+
+# Quickstart
+
+## Warning
+Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for
production. We do not yet support upgrading existing ZooKeeper-based Kafka
clusters into this mode. In fact, when Kafka 3.0 is released, it may not even
be possible to upgrade your self-managed clusters from 2.8 to 3.0 without
downtime. There may be bugs, including serious ones. You should *assume that
your data could be lost at any time* if you try the early access release of
KIP-500.
+
+## Generate a cluster ID
+The first step is to generate an ID for your new cluster, using the
kafka-storage tool:
+
+
+$ ./bin/kafka-storage.sh random-uuid
+xtzWWN4bTjitpL3kfd9s5g
+
+
+## Format Storage Directories
+The next step is to format your storage directories. If you are running in
single-node mode, you can do this with one command:
+
+
+$ ./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c
./config/raft-combined.properties
Review comment:
How about `sm-{combined,broker,controller}.properties` where `sm` stands
for `self-managed`? I like that better than `nozk` becauae in a few years we
will still have "zk" in the name; I think a positive name -- it's a config file
for a self-managed case -- is better than a negative name (Look Mom, no
ZooKeeper!)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
cmccabe commented on a change in pull request #10227: URL: https://github.com/apache/kafka/pull/10227#discussion_r585091489 ## File path: KIP-500.md ## @@ -0,0 +1,131 @@ +KIP-500 Early Access Release + + +# Introduction +It is now possible to run Apache Kafka without Apache ZooKeeper! We call this mode [self-managed mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum). It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it is available for testing in the Kafka 2.8 release. + +When the Kafka cluster is in self-managed mode, it does not store its metadata in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it stores its metadata in a Raft quorum of controller nodes. + +Self-managed mode has many benefits-- some obvious, and some not so obvious. Clearly, it is nice to manage and configure one service rather than two services. In addition, you can now run a single process Kafka cluster. Most important of all, self-managed mode is more scalable. We expect to be able to [support many more topics and partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/) in this mode. + +# Quickstart + +## Warning +Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released, it may not even be possible to upgrade your self-managed clusters from 2.8 to 3.0 without downtime. There may be bugs, including serious ones. You should *assume that your data could be lost at any time* if you try the early access release of KIP-500. + +## Generate a cluster ID +The first step is to generate an ID for your new cluster, using the kafka-storage tool: + + +$ ./bin/kafka-storage.sh random-uuid +xtzWWN4bTjitpL3kfd9s5g + + +## Format Storage Directories +The next step is to format your storage directories. If you are running in single-node mode, you can do this with one command: + + +$ ./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/raft-combined.properties Review comment: Perhaps it could be "nozk-combined.properties", etc. just to keep it simple? I think that should be a separate PR, though (do you want to file it)? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
cmccabe commented on a change in pull request #10227: URL: https://github.com/apache/kafka/pull/10227#discussion_r585090820 ## File path: KIP-500.md ## @@ -0,0 +1,131 @@ +KIP-500 Early Access Release + + +# Introduction +It is now possible to run Apache Kafka without Apache ZooKeeper! We call this mode [self-managed mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum). It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it is available for testing in the Kafka 2.8 release. + +When the Kafka cluster is in self-managed mode, it does not store its metadata in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it stores its metadata in a Raft quorum of controller nodes. + +Self-managed mode has many benefits-- some obvious, and some not so obvious. Clearly, it is nice to manage and configure one service rather than two services. In addition, you can now run a single process Kafka cluster. Most important of all, self-managed mode is more scalable. We expect to be able to [support many more topics and partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/) in this mode. + +# Quickstart + +## Warning +Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released, it may not even be possible to upgrade your self-managed clusters from 2.8 to 3.0 without downtime. There may be bugs, including serious ones. You should *assume that your data could be lost at any time* if you try the early access release of KIP-500. + +## Generate a cluster ID +The first step is to generate an ID for your new cluster, using the kafka-storage tool: + + +$ ./bin/kafka-storage.sh random-uuid +xtzWWN4bTjitpL3kfd9s5g + + +## Format Storage Directories +The next step is to format your storage directories. If you are running in single-node mode, you can do this with one command: + + +$ ./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/raft-combined.properties +Formatting /tmp/raft-combined-logs + + +If you are using multiple nodes, then you should run the format command on each node. Be sure to use the same cluster ID for each one. + +## Start the Kafka Server +Finally, you are ready to start the Kafka server on each node. + + +$ ./bin/kafka-server-start.sh ./config/raft-combined.properties +[2021-02-26 15:37:11,071] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$) +[2021-02-26 15:37:11,294] INFO Setting -D jdk.tls.rejectClientInitiatedRenegotiation=true to disable client-initiated TLS renegotiation (org.apache.zookeeper.common.X509Util) +[2021-02-26 15:37:11,466] INFO [Log partition=@metadata-0, dir=/tmp/raft-combined-logs] Loading producer state till offset 0 with message format version 2 (kafka.log.Log) +[2021-02-26 15:37:11,509] INFO [raft-expiration-reaper]: Starting (kafka.raft.TimingWheelExpirationService$ExpiredOperationReaper) +[2021-02-26 15:37:11,640] INFO [RaftManager nodeId=1] Completed transition to Unattached(epoch=0, voters=[1], electionTimeoutMs=9037) (org.apache.kafka.raft.QuorumState) +... + + +Just like with a ZooKeeper based broker, you can connect to port 9092 (or whatever port you configured) to perform administrative operations or produce or consume data. + + +$ ./bin/kafka-topics.sh --create --topic foo --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 +Created topic foo. + + +# Deployment +Unlike in ZooKeeper-based mode, where any server can become the controller, in self-managed mode, only a small group of specially selected servers can act as controllers. The specially selected controller servers will participate in the metadata quorum. Each KIP-500 controller server is either active, or a hot standby for the current active controller server. + +Typically you will select either 3 or 5 servers for this role, depending on the size of your cluster. Just like with ZooKeeper, you must keep a majority of the controllers alive in order to maintain availability. So if you have 3 controllers, you can tolerate 1 failure; with 5 controllers, you can tolerate 2 failures. + +Each Kafka server now has a new configuration key called `process.roles` which can have the following values: + +* If `process.roles` is set to `broker`, the server acts as a self-managed broker. +* If `process.roles` is set to `controller`, the server acts as a self-managed controller. +* If `process.roles` is set to `broker,controller`, the server acts as both a self-managed broker and a self-managd controller. +* If `process.roles` is not set at all then we are assumed to be in ZooKeeper mode. As mentioned earlier, you can't yet transition
[GitHub] [kafka] cmccabe commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
cmccabe commented on a change in pull request #10227: URL: https://github.com/apache/kafka/pull/10227#discussion_r585089808 ## File path: KIP-500.md ## @@ -0,0 +1,131 @@ +KIP-500 Early Access Release + + +# Introduction +It is now possible to run Apache Kafka without Apache ZooKeeper! We call this mode [self-managed mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum). It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it is available for testing in the Kafka 2.8 release. + +When the Kafka cluster is in self-managed mode, it does not store its metadata in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it stores its metadata in a Raft quorum of controller nodes. + +Self-managed mode has many benefits-- some obvious, and some not so obvious. Clearly, it is nice to manage and configure one service rather than two services. In addition, you can now run a single process Kafka cluster. Most important of all, self-managed mode is more scalable. We expect to be able to [support many more topics and partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/) in this mode. + +# Quickstart + +## Warning +Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released, it may not even be possible to upgrade your self-managed clusters from 2.8 to 3.0 without downtime. There may be bugs, including serious ones. You should *assume that your data could be lost at any time* if you try the early access release of KIP-500. + +## Generate a cluster ID +The first step is to generate an ID for your new cluster, using the kafka-storage tool: + + +$ ./bin/kafka-storage.sh random-uuid +xtzWWN4bTjitpL3kfd9s5g + + +## Format Storage Directories +The next step is to format your storage directories. If you are running in single-node mode, you can do this with one command: + + +$ ./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/raft-combined.properties +Formatting /tmp/raft-combined-logs + + +If you are using multiple nodes, then you should run the format command on each node. Be sure to use the same cluster ID for each one. + +## Start the Kafka Server +Finally, you are ready to start the Kafka server on each node. Review comment: I'll just say "server" (singular) since it is singular in this example. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
cmccabe commented on a change in pull request #10227: URL: https://github.com/apache/kafka/pull/10227#discussion_r585089537 ## File path: KIP-500.md ## @@ -0,0 +1,131 @@ +KIP-500 Early Access Release + + +# Introduction +It is now possible to run Apache Kafka without Apache ZooKeeper! We call this mode [self-managed mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum). It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it is available for testing in the Kafka 2.8 release. + +When the Kafka cluster is in self-managed mode, it does not store its metadata in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it stores its metadata in a Raft quorum of controller nodes. + +Self-managed mode has many benefits-- some obvious, and some not so obvious. Clearly, it is nice to manage and configure one service rather than two services. In addition, you can now run a single process Kafka cluster. Most important of all, self-managed mode is more scalable. We expect to be able to [support many more topics and partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/) in this mode. + +# Quickstart + +## Warning +Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released, it may not even be possible to upgrade your self-managed clusters from 2.8 to 3.0 without downtime. There may be bugs, including serious ones. You should *assume that your data could be lost at any time* if you try the early access release of KIP-500. + +## Generate a cluster ID +The first step is to generate an ID for your new cluster, using the kafka-storage tool: + + +$ ./bin/kafka-storage.sh random-uuid +xtzWWN4bTjitpL3kfd9s5g + + +## Format Storage Directories +The next step is to format your storage directories. If you are running in single-node mode, you can do this with one command: + + +$ ./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/raft-combined.properties +Formatting /tmp/raft-combined-logs + + +If you are using multiple nodes, then you should run the format command on each node. Be sure to use the same cluster ID for each one. Review comment: It might be better to save that discussion for the "deployment section" since we haven't explained the different deployment models yet... or I guess we could move the deployment section to be first... not sure. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10227: KAFKA-12382: add a README for KIP-500
cmccabe commented on a change in pull request #10227: URL: https://github.com/apache/kafka/pull/10227#discussion_r585088151 ## File path: KIP-500.md ## @@ -0,0 +1,131 @@ +KIP-500 Early Access Release + + +# Introduction +It is now possible to run Apache Kafka without Apache ZooKeeper! We call this mode [self-managed mode](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum). It is currently *EARLY ACCESS AND SHOULD NOT BE USED IN PRODUCTION*, but it is available for testing in the Kafka 2.8 release. + +When the Kafka cluster is in self-managed mode, it does not store its metadata in ZooKeeper. In fact, you do not have to run ZooKeeper at all, because it stores its metadata in a Raft quorum of controller nodes. + +Self-managed mode has many benefits-- some obvious, and some not so obvious. Clearly, it is nice to manage and configure one service rather than two services. In addition, you can now run a single process Kafka cluster. Most important of all, self-managed mode is more scalable. We expect to be able to [support many more topics and partitions](https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper/) in this mode. + +# Quickstart + +## Warning +Self-managed mode in Kafka 2.8 is provided for testing only, *NOT* for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released, it may not even be possible to upgrade your self-managed clusters from 2.8 to 3.0 without downtime. There may be bugs, including serious ones. You should *assume that your data could be lost at any time* if you try the early access release of KIP-500. + +## Generate a cluster ID +The first step is to generate an ID for your new cluster, using the kafka-storage tool: + + +$ ./bin/kafka-storage.sh random-uuid +xtzWWN4bTjitpL3kfd9s5g + + +## Format Storage Directories +The next step is to format your storage directories. If you are running in single-node mode, you can do this with one command: Review comment: I wanted to avoid talking about combined mode before the section on Deployment. However, I will change this to "For a single-process test cluster..." to keep things simple. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12394) Consider topic id existence and authorization errors
[ https://issues.apache.org/jira/browse/KAFKA-12394?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293197#comment-17293197 ] Ismael Juma commented on KAFKA-12394: - Ah, yes. "topic IDs are not considered sensitive information" is what I was thinking about. > Consider topic id existence and authorization errors > > > Key: KAFKA-12394 > URL: https://issues.apache.org/jira/browse/KAFKA-12394 > Project: Kafka > Issue Type: Improvement >Reporter: Jason Gustafson >Priority: Major > > We have historically had logic in the api layer to avoid leaking the > existence or non-existence of topics to clients which are not authorized to > describe them. The way we have done this is to always authorize the topic > name first before checking existence. > Topic ids make this more difficult because the resource (ie the topic name) > has to be derived. This means we have to check existence of the topic first. > If the topic does not exist, then our hands are tied and we have to return > UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the > client is authorized to describe it. The question comes then what we should > do if the client is not authorized? > The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this > is misleading and forces the client to retry even though they are doomed to > hit the same error. However, the client should generally handle this by > requesting Metadata using the topic name that they are interested in, which > would give them a chance to see the topic authorization error. Basically the > fact that you need describe permission in the first place to discover the > topic id makes this an unlikely scenario. > There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well. > Basically we could take the stance that we do not care about leaking the > existence of topic IDs since they do not reveal anything about the underlying > topic. Additionally, there is little likelihood of a user discovering a valid > UUID by accident or even through brute force. The benefit of this is that > users get a clear error for cases where a topic Id may have been discovered > through some external means. For example, an administrator finds a topic ID > in the logging and attempts to delete it using the new `deleteTopicsWithIds` > Admin API. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] kkonstantine commented on a change in pull request #8259: KAFKA-7421: Ensure Connect's PluginClassLoader is truly parallel capable and resolve deadlock occurrences
kkonstantine commented on a change in pull request #8259:
URL: https://github.com/apache/kafka/pull/8259#discussion_r585078292
##
File path:
connect/runtime/src/test/java/org/apache/kafka/connect/runtime/isolation/SynchronizationTest.java
##
@@ -0,0 +1,468 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.connect.runtime.isolation;
+
+import static org.junit.Assert.fail;
+
+import java.lang.management.LockInfo;
+import java.lang.management.ManagementFactory;
+import java.lang.management.MonitorInfo;
+import java.lang.management.ThreadInfo;
+import java.net.URL;
+import java.security.AccessController;
+import java.security.PrivilegedAction;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map;
+import java.util.Objects;
+import java.util.concurrent.BrokenBarrierException;
+import java.util.concurrent.CyclicBarrier;
+import java.util.concurrent.LinkedBlockingDeque;
+import java.util.concurrent.ThreadFactory;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+import java.util.concurrent.TimeoutException;
+import java.util.concurrent.atomic.AtomicInteger;
+import java.util.function.Predicate;
+import java.util.stream.Collectors;
+import org.apache.kafka.common.config.AbstractConfig;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigDef.Importance;
+import org.apache.kafka.common.config.ConfigDef.Type;
+import org.apache.kafka.connect.runtime.WorkerConfig;
+import org.junit.After;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TestName;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SynchronizationTest {
+
+public static final Logger log =
LoggerFactory.getLogger(SynchronizationTest.class);
+
+@Rule
+public final TestName testName = new TestName();
+
+private String threadPrefix;
+private Plugins plugins;
+private ThreadPoolExecutor exec;
+private Breakpoint dclBreakpoint;
+private Breakpoint pclBreakpoint;
+
+@Before
+public void setup() {
+TestPlugins.assertAvailable();
+Map pluginProps = Collections.singletonMap(
+WorkerConfig.PLUGIN_PATH_CONFIG,
+String.join(",", TestPlugins.pluginPath())
+);
+threadPrefix = SynchronizationTest.class.getSimpleName()
++ "." + testName.getMethodName() + "-";
+dclBreakpoint = new Breakpoint<>();
+pclBreakpoint = new Breakpoint<>();
+plugins = new Plugins(pluginProps) {
+@Override
+protected DelegatingClassLoader
newDelegatingClassLoader(List paths) {
+return AccessController.doPrivileged(
+(PrivilegedAction) () ->
+new SynchronizedDelegatingClassLoader(paths)
+);
+}
+};
+exec = new ThreadPoolExecutor(
+2,
+2,
+1000L,
+TimeUnit.MILLISECONDS,
+new LinkedBlockingDeque<>(),
+threadFactoryWithNamedThreads(threadPrefix)
+);
+
+}
+
+@After
+public void tearDown() throws InterruptedException {
+dclBreakpoint.clear();
+pclBreakpoint.clear();
+exec.shutdown();
+exec.awaitTermination(1L, TimeUnit.SECONDS);
+}
+
+private static class Breakpoint {
+
+private Predicate predicate;
+private CyclicBarrier barrier;
+
+public synchronized void clear() {
+if (barrier != null) {
+barrier.reset();
+}
+predicate = null;
+barrier = null;
+}
+
+public synchronized void set(Predicate predicate) {
+clear();
+this.predicate = predicate;
+// As soon as the barrier is tripped, the barrier will be reset
for the next round.
+barrier = new CyclicBarrier(2);
+}
+
+/**
+ * From a thread under test, await for the test orchestrator to
continue execution
+ * @param obj Object to test with the breakpoint's current predicate
+
[jira] [Updated] (KAFKA-12396) Dedicated exception for kstreams when null key received
[
https://issues.apache.org/jira/browse/KAFKA-12396?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-12396:
Labels: beginner newbie (was: )
> Dedicated exception for kstreams when null key received
> ---
>
> Key: KAFKA-12396
> URL: https://issues.apache.org/jira/browse/KAFKA-12396
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Affects Versions: 2.6.0
>Reporter: Veniamin Kalegin
>Priority: Trivial
> Labels: beginner, newbie
>
> If kstreams application received null as a key (thanks to QA), kstream app
> gives long and confusing stack trace, it would be nice to have shorter and
> specific exception instead of
> {{org.apache.kafka.streams.errors.StreamsException: Exception caught in
> process. taskId=0_0, processor=KSTREAM-SOURCE-00, topic=(hidden),
> partition=0, offset=3722, stacktrace=java.lang.NullPointerException}}
> at
> org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:286)
> at
> org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:74)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:94)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:29)
> at
> org.apache.kafka.streams.state.internals.MeteredKeyValueStore.lambda$get$2(MeteredKeyValueStore.java:133)
> at
> org.apache.kafka.streams.state.internals.MeteredKeyValueStore$$Lambda$1048/0x60630fd0.get(Unknown
> Source)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:851)
> at
> org.apache.kafka.streams.state.internals.MeteredKeyValueStore.get(MeteredKeyValueStore.java:133)
> at
> org.apache.kafka.streams.processor.internals.AbstractReadWriteDecorator$KeyValueStoreReadWriteDecorator.get(AbstractReadWriteDecorator.java:78)
> at
> org.apache.kafka.streams.kstream.internals.KStreamTransformValues$KStreamTransformValuesProcessor.process(KStreamTransformValues.java:64)
> at
> org.apache.kafka.streams.processor.internals.ProcessorNode.lambda$process$2(ProcessorNode.java:142)
> at
> org.apache.kafka.streams.processor.internals.ProcessorNode$$Lambda$1047/0x60630b10.run(Unknown
> Source)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:836)
> at
> org.apache.kafka.streams.processor.internals.ProcessorNode.process(ProcessorNode.java:142)
> at
> org.apache.kafka.streams.processor.internals.ProcessorContextImpl.forward(ProcessorContextImpl.java:236)
> at
> org.apache.kafka.streams.processor.internals.ProcessorContextImpl.forward(ProcessorContextImpl.java:216)
> at
> org.apache.kafka.streams.processor.internals.ProcessorContextImpl.forward(ProcessorContextImpl.java:168)
> at
> org.apache.kafka.streams.processor.internals.SourceNode.process(SourceNode.java:96)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.lambda$process$1(StreamTask.java:679)
> at
> org.apache.kafka.streams.processor.internals.StreamTask$$Lambda$1046/0x605250f0.run(Unknown
> Source)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:836)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.process(StreamTask.java:679)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.process(TaskManager.java:1033)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:690)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:551)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:510)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.process(StreamTask.java:696)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.process(TaskManager.java:1033)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:690)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:551)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:510)
> Caused by: java.lang.NullPointerException
> at
> org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:286)
> at
> org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:74)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:94)
> at
>
[jira] [Commented] (KAFKA-12377) Flaky Test SaslAuthenticatorTest#testSslClientAuthRequiredForSaslSslListener
[
https://issues.apache.org/jira/browse/KAFKA-12377?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293191#comment-17293191
]
Matthias J. Sax commented on KAFKA-12377:
-
One more
> Flaky Test SaslAuthenticatorTest#testSslClientAuthRequiredForSaslSslListener
>
>
> Key: KAFKA-12377
> URL: https://issues.apache.org/jira/browse/KAFKA-12377
> Project: Kafka
> Issue Type: Test
> Components: core, security, unit tests
>Reporter: Matthias J. Sax
>Priority: Critical
> Labels: flaky-test
>
> {quote}org.opentest4j.AssertionFailedError: expected:
> but was: at
> org.junit.jupiter.api.AssertionUtils.fail(AssertionUtils.java:55) at
> org.junit.jupiter.api.AssertionUtils.failNotEqual(AssertionUtils.java:62) at
> org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:182) at
> org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:177) at
> org.junit.jupiter.api.Assertions.assertEquals(Assertions.java:1124) at
> org.apache.kafka.common.network.NetworkTestUtils.waitForChannelClose(NetworkTestUtils.java:111)
> at
> org.apache.kafka.common.security.authenticator.SaslAuthenticatorTest.createAndCheckClientConnectionFailure(SaslAuthenticatorTest.java:2187)
> at
> org.apache.kafka.common.security.authenticator.SaslAuthenticatorTest.createAndCheckSslAuthenticationFailure(SaslAuthenticatorTest.java:2210)
> at
> org.apache.kafka.common.security.authenticator.SaslAuthenticatorTest.verifySslClientAuthForSaslSslListener(SaslAuthenticatorTest.java:1846)
> at
> org.apache.kafka.common.security.authenticator.SaslAuthenticatorTest.testSslClientAuthRequiredForSaslSslListener(SaslAuthenticatorTest.java:1800){quote}
> STDOUT
> {quote}[2021-02-26 07:18:57,220] ERROR Extensions provided in login context
> without a token
> (org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule:318)
> java.io.IOException: Extensions provided in login context without a token at
> org.apache.kafka.common.security.oauthbearer.internals.unsecured.OAuthBearerUnsecuredLoginCallbackHandler.handle(OAuthBearerUnsecuredLoginCallbackHandler.java:165)
> at
> org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule.identifyToken(OAuthBearerLoginModule.java:316)
> at
> org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule.login(OAuthBearerLoginModule.java:301)
> [...]
> Caused by:
> org.apache.kafka.common.security.oauthbearer.internals.unsecured.OAuthBearerConfigException:
> Extensions provided in login context without a token at
> org.apache.kafka.common.security.oauthbearer.internals.unsecured.OAuthBearerUnsecuredLoginCallbackHandler.handleTokenCallback(OAuthBearerUnsecuredLoginCallbackHandler.java:192)
> at
> org.apache.kafka.common.security.oauthbearer.internals.unsecured.OAuthBearerUnsecuredLoginCallbackHandler.handle(OAuthBearerUnsecuredLoginCallbackHandler.java:163)
> ... 116 more{quote}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-10251) Flaky Test kafka.api.TransactionsBounceTest.testWithGroupMetadata
[
https://issues.apache.org/jira/browse/KAFKA-10251?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293187#comment-17293187
]
Matthias J. Sax commented on KAFKA-10251:
-
Failed again.
> Flaky Test kafka.api.TransactionsBounceTest.testWithGroupMetadata
> -
>
> Key: KAFKA-10251
> URL: https://issues.apache.org/jira/browse/KAFKA-10251
> Project: Kafka
> Issue Type: Bug
> Components: core
>Reporter: A. Sophie Blee-Goldman
>Assignee: Luke Chen
>Priority: Major
>
> h3. Stacktrace
> org.scalatest.exceptions.TestFailedException: Consumed 0 records before
> timeout instead of the expected 200 records at
> org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:530) at
> org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:529)
> at
> org.scalatest.Assertions$.newAssertionFailedException(Assertions.scala:1389)
> at org.scalatest.Assertions.fail(Assertions.scala:1091) at
> org.scalatest.Assertions.fail$(Assertions.scala:1087) at
> org.scalatest.Assertions$.fail(Assertions.scala:1389) at
> kafka.utils.TestUtils$.pollUntilAtLeastNumRecords(TestUtils.scala:842) at
> kafka.api.TransactionsBounceTest.testWithGroupMetadata(TransactionsBounceTest.scala:109)
>
>
> The logs are pretty much just this on repeat:
> {code:java}
> [2020-07-08 23:41:04,034] ERROR Error when sending message to topic
> output-topic with key: 9955, value: 9955 with error:
> (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback:52)
> org.apache.kafka.common.KafkaException: Failing batch since transaction was
> aborted at
> org.apache.kafka.clients.producer.internals.Sender.maybeSendAndPollTransactionalRequest(Sender.java:423)
> at
> org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:313)
> at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:240) at
> java.lang.Thread.run(Thread.java:748) [2020-07-08 23:41:04,034] ERROR Error
> when sending message to topic output-topic with key: 9959, value: 9959 with
> error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback:52)
> org.apache.kafka.common.KafkaException: Failing batch since transaction was
> aborted at
> org.apache.kafka.clients.producer.internals.Sender.maybeSendAndPollTransactionalRequest(Sender.java:423)
> at
> org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:313)
> at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:240) at
> java.lang.Thread.run(Thread.java:748)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10340) Source connectors should report error when trying to produce records to non-existent topics instead of hanging forever
[
https://issues.apache.org/jira/browse/KAFKA-10340?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293185#comment-17293185
]
Randall Hauch edited comment on KAFKA-10340 at 3/1/21, 9:34 PM:
Merged to `trunk` and backported to:
* `2.7` for inclusion in the upcoming 2.7.1
* `2.6` for inclusion in the upcoming 2.6.2
The `2.8` branch is currently blocked for the 2.8.0 release, so I've created
https://github.com/apache/kafka/pull/10238 for the 2.8 backport -- either if
this is approved as a 2.8.0 blocker or after 2.8.0 has been released.
Leaving this issue open until 2.8 is addressed.
was (Author: rhauch):
Merged to `trunk` and backported to:
* `2.7` for inclusion in the upcoming 2.7.1
* `2.6` for inclusion in the upcoming 2.6.2
The `2.8` branch is currently blocked for the 2.8.0 release, so I've created
https://github.com/apache/kafka/pull/10238 for the 2.8 backport -- either if
this is approved as a 2.8.0 blocker or after 2.8.0 has been released.
> Source connectors should report error when trying to produce records to
> non-existent topics instead of hanging forever
> --
>
> Key: KAFKA-10340
> URL: https://issues.apache.org/jira/browse/KAFKA-10340
> Project: Kafka
> Issue Type: Bug
> Components: KafkaConnect
>Affects Versions: 2.5.1, 2.7.0, 2.6.1, 2.8.0
>Reporter: Arjun Satish
>Assignee: Chris Egerton
>Priority: Major
> Fix For: 3.0.0, 2.7.1, 2.6.2
>
>
> Currently, a source connector will blindly attempt to write a record to a
> Kafka topic. When the topic does not exist, its creation is controlled by the
> {{auto.create.topics.enable}} config on the brokers. When auto.create is
> disabled, the producer.send() call on the Connect worker will hang
> indefinitely (due to the "infinite retries" configuration for said producer).
> In setups where this config is usually disabled, the source connector simply
> appears to hang and not produce any output.
> It is desirable to either log an info or an error message (or inform the user
> somehow) that the connector is simply stuck waiting for the destination topic
> to be created. When the worker has permissions to inspect the broker
> settings, it can use the {{listTopics}} and {{describeConfigs}} API in
> AdminClient to check if the topic exists, the broker can
> {{auto.create.topics.enable}} topics, and if these cases do not exist, either
> throw an error.
> With the recently merged
> [KIP-158|https://cwiki.apache.org/confluence/display/KAFKA/KIP-158%3A+Kafka+Connect+should+allow+source+connectors+to+set+topic-specific+settings+for+new+topics],
> this becomes even more specific a corner case: when topic creation settings
> are enabled, the worker should handle the corner case where topic creation is
> disabled, {{auto.create.topics.enable}} is set to false and topic does not
> exist.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-10340) Source connectors should report error when trying to produce records to non-existent topics instead of hanging forever
[
https://issues.apache.org/jira/browse/KAFKA-10340?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293185#comment-17293185
]
Randall Hauch commented on KAFKA-10340:
---
Merged to `trunk` and backported to:
* `2.7` for inclusion in the upcoming 2.7.1
* `2.6` for inclusion in the upcoming 2.6.2
The `2.8` branch is currently blocked for the 2.8.0 release, so I've created
https://github.com/apache/kafka/pull/10238 for the 2.8 backport -- either if
this is approved as a 2.8.0 blocker or after 2.8.0 has been released.
> Source connectors should report error when trying to produce records to
> non-existent topics instead of hanging forever
> --
>
> Key: KAFKA-10340
> URL: https://issues.apache.org/jira/browse/KAFKA-10340
> Project: Kafka
> Issue Type: Bug
> Components: KafkaConnect
>Affects Versions: 2.5.1, 2.7.0, 2.6.1, 2.8.0
>Reporter: Arjun Satish
>Assignee: Chris Egerton
>Priority: Major
> Fix For: 3.0.0, 2.7.1, 2.6.2
>
>
> Currently, a source connector will blindly attempt to write a record to a
> Kafka topic. When the topic does not exist, its creation is controlled by the
> {{auto.create.topics.enable}} config on the brokers. When auto.create is
> disabled, the producer.send() call on the Connect worker will hang
> indefinitely (due to the "infinite retries" configuration for said producer).
> In setups where this config is usually disabled, the source connector simply
> appears to hang and not produce any output.
> It is desirable to either log an info or an error message (or inform the user
> somehow) that the connector is simply stuck waiting for the destination topic
> to be created. When the worker has permissions to inspect the broker
> settings, it can use the {{listTopics}} and {{describeConfigs}} API in
> AdminClient to check if the topic exists, the broker can
> {{auto.create.topics.enable}} topics, and if these cases do not exist, either
> throw an error.
> With the recently merged
> [KIP-158|https://cwiki.apache.org/confluence/display/KAFKA/KIP-158%3A+Kafka+Connect+should+allow+source+connectors+to+set+topic-specific+settings+for+new+topics],
> this becomes even more specific a corner case: when topic creation settings
> are enabled, the worker should handle the corner case where topic creation is
> disabled, {{auto.create.topics.enable}} is set to false and topic does not
> exist.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-10340) Source connectors should report error when trying to produce records to non-existent topics instead of hanging forever
[
https://issues.apache.org/jira/browse/KAFKA-10340?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Randall Hauch updated KAFKA-10340:
--
Fix Version/s: 2.6.2
> Source connectors should report error when trying to produce records to
> non-existent topics instead of hanging forever
> --
>
> Key: KAFKA-10340
> URL: https://issues.apache.org/jira/browse/KAFKA-10340
> Project: Kafka
> Issue Type: Bug
> Components: KafkaConnect
>Affects Versions: 2.5.1, 2.7.0, 2.6.1, 2.8.0
>Reporter: Arjun Satish
>Assignee: Chris Egerton
>Priority: Major
> Fix For: 3.0.0, 2.7.1, 2.6.2
>
>
> Currently, a source connector will blindly attempt to write a record to a
> Kafka topic. When the topic does not exist, its creation is controlled by the
> {{auto.create.topics.enable}} config on the brokers. When auto.create is
> disabled, the producer.send() call on the Connect worker will hang
> indefinitely (due to the "infinite retries" configuration for said producer).
> In setups where this config is usually disabled, the source connector simply
> appears to hang and not produce any output.
> It is desirable to either log an info or an error message (or inform the user
> somehow) that the connector is simply stuck waiting for the destination topic
> to be created. When the worker has permissions to inspect the broker
> settings, it can use the {{listTopics}} and {{describeConfigs}} API in
> AdminClient to check if the topic exists, the broker can
> {{auto.create.topics.enable}} topics, and if these cases do not exist, either
> throw an error.
> With the recently merged
> [KIP-158|https://cwiki.apache.org/confluence/display/KAFKA/KIP-158%3A+Kafka+Connect+should+allow+source+connectors+to+set+topic-specific+settings+for+new+topics],
> this becomes even more specific a corner case: when topic creation settings
> are enabled, the worker should handle the corner case where topic creation is
> disabled, {{auto.create.topics.enable}} is set to false and topic does not
> exist.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-8154) Buffer Overflow exceptions between brokers and with clients
[ https://issues.apache.org/jira/browse/KAFKA-8154?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293184#comment-17293184 ] Gordon commented on KAFKA-8154: --- Yes, that's the right link. I've built kafka 2.6.1 with PR 9188 applied: https://github.com/gordonmessmer/kafkajar > Buffer Overflow exceptions between brokers and with clients > --- > > Key: KAFKA-8154 > URL: https://issues.apache.org/jira/browse/KAFKA-8154 > Project: Kafka > Issue Type: Bug > Components: clients >Affects Versions: 2.1.0 >Reporter: Rajesh Nataraja >Priority: Major > Attachments: server.properties.txt > > > https://github.com/apache/kafka/pull/6495 > https://github.com/apache/kafka/pull/5785 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10788) Streamlining Tests in CachingInMemoryKeyValueStoreTest
[
https://issues.apache.org/jira/browse/KAFKA-10788?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293179#comment-17293179
]
Bruno Cadonna commented on KAFKA-10788:
---
[~rohitdeshaws], Thank you for looking into this!
# I think you are better off if you start a new test class
{{CachingKeyValueStore}} that does not extend {{AbstractKeyValueStoreTest}}.
Keep in mind that you only want to test the code in {{CachingKeyValueStore}}
and not the code in the underlying store.
# You do not need a real underlying store for
{{shouldAvoidFlushingDeletionsWithoutDirtyKeys}}. You can specify the methods
that should be called on the mock for the underlying store with {{replay()}}
and you can verify the calls on the mock with {{verify()}}. See the EasyMock
docs for more details.
# Are you familiar with EasyMock? If not, I can imagine that some tests might
not seem comprehensive at first sight. See the EasyMock docs to understand them
better and let us know what you do not understand.
Hope that helps to unblock you.
> Streamlining Tests in CachingInMemoryKeyValueStoreTest
> --
>
> Key: KAFKA-10788
> URL: https://issues.apache.org/jira/browse/KAFKA-10788
> Project: Kafka
> Issue Type: Improvement
> Components: streams, unit tests
>Reporter: Sagar Rao
>Assignee: Rohit Deshpande
>Priority: Major
> Labels: newbie
>
> While reviewing, kIP-614, it was decided that tests for
> [CachingInMemoryKeyValueStoreTest.java|https://github.com/apache/kafka/pull/9508/files/899b79781d3412658293b918dce16709121accf1#diff-fdfe70d8fa0798642f0ed54785624aa9850d5d86afff2285acdf12f2775c3588]
> need to be streamlined to use mocked underlyingStore.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-5146) Kafka Streams: remove compile dependency on connect-json
[
https://issues.apache.org/jira/browse/KAFKA-5146?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293178#comment-17293178
]
Marco Lotz commented on KAFKA-5146:
---
[~ableegoldman] [~mjsax] whenever you have some spare time, can you please have
a quick look on the PR?
> Kafka Streams: remove compile dependency on connect-json
>
>
> Key: KAFKA-5146
> URL: https://issues.apache.org/jira/browse/KAFKA-5146
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 0.10.1.0, 0.10.2.0, 0.10.2.1
>Reporter: Michael G. Noll
>Assignee: Marco Lotz
>Priority: Minor
>
> We currently have a compile-dependency on `connect-json`:
> {code}
>
> org.apache.kafka
> connect-json
> 0.10.2.0
> compile
>
> {code}
> The snippet above is from the generated POM of Kafka Streams as of 0.10.2.0
> release.
> AFAICT the only reason for that is because the Kafka Streams *examples*
> showcase some JSON processing, but that’s it.
> First and foremost, we should remove the connect-json dependency, and also
> figure out a way to set up / structure the examples so we that we can
> continue showcasing JSON support. Alternatively, we could consider removing
> the JSON example (but I don't like that, personally).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-12396) Dedicated exception for kstreams when null key received
Veniamin Kalegin created KAFKA-12396:
Summary: Dedicated exception for kstreams when null key received
Key: KAFKA-12396
URL: https://issues.apache.org/jira/browse/KAFKA-12396
Project: Kafka
Issue Type: Improvement
Components: streams
Affects Versions: 2.6.0
Reporter: Veniamin Kalegin
If kstreams application received null as a key (thanks to QA), kstream app
gives long and confusing stack trace, it would be nice to have shorter and
specific exception instead of
{{org.apache.kafka.streams.errors.StreamsException: Exception caught in
process. taskId=0_0, processor=KSTREAM-SOURCE-00, topic=(hidden),
partition=0, offset=3722, stacktrace=java.lang.NullPointerException}}
at
org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:286)
at
org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:74)
at
org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:94)
at
org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:29)
at
org.apache.kafka.streams.state.internals.MeteredKeyValueStore.lambda$get$2(MeteredKeyValueStore.java:133)
at
org.apache.kafka.streams.state.internals.MeteredKeyValueStore$$Lambda$1048/0x60630fd0.get(Unknown
Source)
at
org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:851)
at
org.apache.kafka.streams.state.internals.MeteredKeyValueStore.get(MeteredKeyValueStore.java:133)
at
org.apache.kafka.streams.processor.internals.AbstractReadWriteDecorator$KeyValueStoreReadWriteDecorator.get(AbstractReadWriteDecorator.java:78)
at
org.apache.kafka.streams.kstream.internals.KStreamTransformValues$KStreamTransformValuesProcessor.process(KStreamTransformValues.java:64)
at
org.apache.kafka.streams.processor.internals.ProcessorNode.lambda$process$2(ProcessorNode.java:142)
at
org.apache.kafka.streams.processor.internals.ProcessorNode$$Lambda$1047/0x60630b10.run(Unknown
Source)
at
org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:836)
at
org.apache.kafka.streams.processor.internals.ProcessorNode.process(ProcessorNode.java:142)
at
org.apache.kafka.streams.processor.internals.ProcessorContextImpl.forward(ProcessorContextImpl.java:236)
at
org.apache.kafka.streams.processor.internals.ProcessorContextImpl.forward(ProcessorContextImpl.java:216)
at
org.apache.kafka.streams.processor.internals.ProcessorContextImpl.forward(ProcessorContextImpl.java:168)
at
org.apache.kafka.streams.processor.internals.SourceNode.process(SourceNode.java:96)
at
org.apache.kafka.streams.processor.internals.StreamTask.lambda$process$1(StreamTask.java:679)
at
org.apache.kafka.streams.processor.internals.StreamTask$$Lambda$1046/0x605250f0.run(Unknown
Source)
at
org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:836)
at
org.apache.kafka.streams.processor.internals.StreamTask.process(StreamTask.java:679)
at
org.apache.kafka.streams.processor.internals.TaskManager.process(TaskManager.java:1033)
at
org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:690)
at
org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:551)
at
org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:510)
at
org.apache.kafka.streams.processor.internals.StreamTask.process(StreamTask.java:696)
at
org.apache.kafka.streams.processor.internals.TaskManager.process(TaskManager.java:1033)
at
org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:690)
at
org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:551)
at
org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:510)
Caused by: java.lang.NullPointerException
at
org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:286)
at
org.apache.kafka.streams.state.internals.RocksDBStore.get(RocksDBStore.java:74)
at
org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:94)
at
org.apache.kafka.streams.state.internals.ChangeLoggingKeyValueBytesStore.get(ChangeLoggingKeyValueBytesStore.java:29)
at
org.apache.kafka.streams.state.internals.MeteredKeyValueStore.lambda$get$2(MeteredKeyValueStore.java:133)
at
org.apache.kafka.streams.state.internals.MeteredKeyValueStore$$Lambda$1048/0x60630fd0.get(Unknown
Source)
at
org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:851)
at
[jira] [Comment Edited] (KAFKA-12394) Consider topic id existence and authorization errors
[
https://issues.apache.org/jira/browse/KAFKA-12394?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293176#comment-17293176
]
Justine Olshan edited comment on KAFKA-12394 at 3/1/21, 9:20 PM:
-
The KIP states:
return {{UNKNOWN_TOPIC_ID}} error for the topic indicating the topic ID did not
exist. The check for the topic ID will occur before checking authorization on
the topic. Thus, topic IDs are not considered sensitive information.
So this would imply that {{TOPIC_AUTHORIZATION_FAILED}} would be acceptable by
the KIP. I think there was some discussion on a PR about revealing the
existence of topics.
One thing I'm a little confused about is how this is different from returning
{{UNKNOWN_TOPIC_OR_PARTITION}} on describe authorization failure. I guess the
administrator is not able to find a topic name in the logs, but besides that, I
think the scenarios are similar.
was (Author: jolshan):
The KIP states:
return {{UNKNOWN_TOPIC_ID }}error for the topic indicating the topic ID did not
exist. The check for the topic ID will occur before checking authorization on
the topic. Thus, topic IDs are not considered sensitive information.
So this would imply that {{TOPIC_AUTHORIZATION_FAILED}} would be acceptable by
the KIP. I think there was some discussion on a PR about revealing the
existence of topics.
One thing I'm a little confused about is how this is different from returning
{{ UNKNOWN_TOPIC_OR_PARTITION }} on describe authorization failure. I guess the
administrator is not able to find a topic name in the logs, but besides that, I
think the scenarios are similar.
> Consider topic id existence and authorization errors
>
>
> Key: KAFKA-12394
> URL: https://issues.apache.org/jira/browse/KAFKA-12394
> Project: Kafka
> Issue Type: Improvement
>Reporter: Jason Gustafson
>Priority: Major
>
> We have historically had logic in the api layer to avoid leaking the
> existence or non-existence of topics to clients which are not authorized to
> describe them. The way we have done this is to always authorize the topic
> name first before checking existence.
> Topic ids make this more difficult because the resource (ie the topic name)
> has to be derived. This means we have to check existence of the topic first.
> If the topic does not exist, then our hands are tied and we have to return
> UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the
> client is authorized to describe it. The question comes then what we should
> do if the client is not authorized?
> The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this
> is misleading and forces the client to retry even though they are doomed to
> hit the same error. However, the client should generally handle this by
> requesting Metadata using the topic name that they are interested in, which
> would give them a chance to see the topic authorization error. Basically the
> fact that you need describe permission in the first place to discover the
> topic id makes this an unlikely scenario.
> There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well.
> Basically we could take the stance that we do not care about leaking the
> existence of topic IDs since they do not reveal anything about the underlying
> topic. Additionally, there is little likelihood of a user discovering a valid
> UUID by accident or even through brute force. The benefit of this is that
> users get a clear error for cases where a topic Id may have been discovered
> through some external means. For example, an administrator finds a topic ID
> in the logging and attempts to delete it using the new `deleteTopicsWithIds`
> Admin API.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-12394) Consider topic id existence and authorization errors
[
https://issues.apache.org/jira/browse/KAFKA-12394?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293176#comment-17293176
]
Justine Olshan edited comment on KAFKA-12394 at 3/1/21, 9:20 PM:
-
The KIP states:
return {{UNKNOWN_TOPIC_ID}} error for the topic indicating the topic ID did not
exist. The check for the topic ID will occur before checking authorization on
the topic. Thus, topic IDs are not considered sensitive information.
So this would imply that {{TOPIC_AUTHORIZATION_FAILED}} would be acceptable by
the KIP. I think there was some discussion on a PR about revealing the
existence of topics, but the KIP does state this not being "sensitive".
One thing I'm a little confused about is how this is different from returning
{{UNKNOWN_TOPIC_OR_PARTITION}} on describe authorization failure. I guess the
administrator is not able to find a topic name in the logs, but besides that, I
think the scenarios are similar.
was (Author: jolshan):
The KIP states:
return {{UNKNOWN_TOPIC_ID}} error for the topic indicating the topic ID did not
exist. The check for the topic ID will occur before checking authorization on
the topic. Thus, topic IDs are not considered sensitive information.
So this would imply that {{TOPIC_AUTHORIZATION_FAILED}} would be acceptable by
the KIP. I think there was some discussion on a PR about revealing the
existence of topics.
One thing I'm a little confused about is how this is different from returning
{{UNKNOWN_TOPIC_OR_PARTITION}} on describe authorization failure. I guess the
administrator is not able to find a topic name in the logs, but besides that, I
think the scenarios are similar.
> Consider topic id existence and authorization errors
>
>
> Key: KAFKA-12394
> URL: https://issues.apache.org/jira/browse/KAFKA-12394
> Project: Kafka
> Issue Type: Improvement
>Reporter: Jason Gustafson
>Priority: Major
>
> We have historically had logic in the api layer to avoid leaking the
> existence or non-existence of topics to clients which are not authorized to
> describe them. The way we have done this is to always authorize the topic
> name first before checking existence.
> Topic ids make this more difficult because the resource (ie the topic name)
> has to be derived. This means we have to check existence of the topic first.
> If the topic does not exist, then our hands are tied and we have to return
> UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the
> client is authorized to describe it. The question comes then what we should
> do if the client is not authorized?
> The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this
> is misleading and forces the client to retry even though they are doomed to
> hit the same error. However, the client should generally handle this by
> requesting Metadata using the topic name that they are interested in, which
> would give them a chance to see the topic authorization error. Basically the
> fact that you need describe permission in the first place to discover the
> topic id makes this an unlikely scenario.
> There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well.
> Basically we could take the stance that we do not care about leaking the
> existence of topic IDs since they do not reveal anything about the underlying
> topic. Additionally, there is little likelihood of a user discovering a valid
> UUID by accident or even through brute force. The benefit of this is that
> users get a clear error for cases where a topic Id may have been discovered
> through some external means. For example, an administrator finds a topic ID
> in the logging and attempts to delete it using the new `deleteTopicsWithIds`
> Admin API.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-12394) Consider topic id existence and authorization errors
[
https://issues.apache.org/jira/browse/KAFKA-12394?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293176#comment-17293176
]
Justine Olshan commented on KAFKA-12394:
The KIP states:
return {{UNKNOWN_TOPIC_ID }}error for the topic indicating the topic ID did not
exist. The check for the topic ID will occur before checking authorization on
the topic. Thus, topic IDs are not considered sensitive information.
So this would imply that {{TOPIC_AUTHORIZATION_FAILED}} would be acceptable by
the KIP. I think there was some discussion on a PR about revealing the
existence of topics.
One thing I'm a little confused about is how this is different from returning
{{ UNKNOWN_TOPIC_OR_PARTITION }} on describe authorization failure. I guess the
administrator is not able to find a topic name in the logs, but besides that, I
think the scenarios are similar.
> Consider topic id existence and authorization errors
>
>
> Key: KAFKA-12394
> URL: https://issues.apache.org/jira/browse/KAFKA-12394
> Project: Kafka
> Issue Type: Improvement
>Reporter: Jason Gustafson
>Priority: Major
>
> We have historically had logic in the api layer to avoid leaking the
> existence or non-existence of topics to clients which are not authorized to
> describe them. The way we have done this is to always authorize the topic
> name first before checking existence.
> Topic ids make this more difficult because the resource (ie the topic name)
> has to be derived. This means we have to check existence of the topic first.
> If the topic does not exist, then our hands are tied and we have to return
> UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the
> client is authorized to describe it. The question comes then what we should
> do if the client is not authorized?
> The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this
> is misleading and forces the client to retry even though they are doomed to
> hit the same error. However, the client should generally handle this by
> requesting Metadata using the topic name that they are interested in, which
> would give them a chance to see the topic authorization error. Basically the
> fact that you need describe permission in the first place to discover the
> topic id makes this an unlikely scenario.
> There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well.
> Basically we could take the stance that we do not care about leaking the
> existence of topic IDs since they do not reveal anything about the underlying
> topic. Additionally, there is little likelihood of a user discovering a valid
> UUID by accident or even through brute force. The benefit of this is that
> users get a clear error for cases where a topic Id may have been discovered
> through some external means. For example, an administrator finds a topic ID
> in the logging and attempts to delete it using the new `deleteTopicsWithIds`
> Admin API.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] MarcoLotz commented on pull request #10042: KAFKA-9527: fix NPE when using time-based argument for Stream Resetter
MarcoLotz commented on pull request #10042: URL: https://github.com/apache/kafka/pull/10042#issuecomment-788295749 @mjsax can you please have a quick look on the updated tests? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vanhoale opened a new pull request #10239: KAFKA-12372 - Enhance TimestampCoverter to handle multiple timestamp or date fields
vanhoale opened a new pull request #10239: URL: https://github.com/apache/kafka/pull/10239 [JIRA](https://issues.apache.org/jira/browse/KAFKA-12372) Our team is having an issue of handling multiple timestamp fields in a kafka message, so for now if we use the converter then we have to add more fields in the config. We can implement it in a generic way to check if the field.schema().name() is timestamp or date then we can convert it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585036724
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1884,20 +1884,24 @@ class KafkaApis(val requestChannel: RequestChannel,
val authorizedDeleteTopics =
authHelper.filterByAuthorized(request.context, DELETE, TOPIC,
results.asScala.filter(result => result.name() != null))(_.name)
results.forEach { topic =>
-val unresolvedTopicId = !(topic.topicId() == Uuid.ZERO_UUID) &&
topic.name() == null
- if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
- topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
- topic.setErrorMessage("Topic IDs are not supported on the server.")
- } else if (unresolvedTopicId)
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (!authorizedDeleteTopics.contains(topic.name))
- topic.setErrorCode(Errors.TOPIC_AUTHORIZATION_FAILED.code)
- else if (!metadataCache.contains(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_OR_PARTITION.code)
- else
- toDelete += topic.name
+val unresolvedTopicId = topic.topicId() != Uuid.ZERO_UUID &&
topic.name() == null
+if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
+ topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
+ topic.setErrorMessage("Topic IDs are not supported on the server.")
+} else if (unresolvedTopicId) {
+ topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
+} else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name)) {
+ // Because the client does not have Describe permission, the name
should
+ // not be returned in the response.
+ topic.setName(null)
Review comment:
We have one dependence here which makes this a little more work than I
wanted to do here:
https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/server/KafkaApis.scala#L1909.
I filed a separate JIRA so that we don't forget about it:
https://issues.apache.org/jira/browse/KAFKA-12395.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (KAFKA-12395) Drop topic mapKey in DeleteTopics response
Jason Gustafson created KAFKA-12395: --- Summary: Drop topic mapKey in DeleteTopics response Key: KAFKA-12395 URL: https://issues.apache.org/jira/browse/KAFKA-12395 Project: Kafka Issue Type: Improvement Reporter: Jason Gustafson Now that DeleteTopic requests/responses may be keyed by topicId, the use of the the topic name as a map key in the response makes less sense. We should consider dropping it. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10383) KTable Join on Foreign key is opinionated
[ https://issues.apache.org/jira/browse/KAFKA-10383?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293166#comment-17293166 ] Marco Lotz commented on KAFKA-10383: [~mjsax] the KIP is available [here|https://cwiki.apache.org/confluence/display/KAFKA/KIP-718%3A+Make+KTable+Join+on+Foreign+key+unopinionated]. I will send the discuss email later today or tomorrow. > KTable Join on Foreign key is opinionated > -- > > Key: KAFKA-10383 > URL: https://issues.apache.org/jira/browse/KAFKA-10383 > Project: Kafka > Issue Type: Improvement > Components: streams >Affects Versions: 2.4.1 >Reporter: Marco Lotz >Assignee: Marco Lotz >Priority: Major > Labels: needs-kip > > *Status Quo:* > The current implementation of [KIP-213 > |[https://cwiki.apache.org/confluence/display/KAFKA/KIP-213+Support+non-key+joining+in+KTable]] > of Foreign Key Join between two KTables is _opinionated_ in terms of storage > layer. > Independently of the Materialization method provided in the method argument, > it generates an intermediary RocksDB state store. Thus, even when the > Materialization method provided is "in memory", it will use RocksDB > under-the-hood for this internal state-store. > > *Related problems:* > * IT Tests: Having an implicit materialization method for state-store > affects tests using foreign key state-stores. [On windows based systems > |[https://stackoverflow.com/questions/50602512/failed-to-delete-the-state-directory-in-ide-for-kafka-stream-application]], > that are affected by the RocksDB filesystem removal problem, an approach to > avoid the bug is to use in-memory state-stores (rather than exception > swallowing). Having the intermediate RocksDB storage being created > disregarding materialization method forces any IT test to necessarily use the > manual FS deletion with exception swallowing hack. > * Short lived Streams: Ktables can be short lived in a way that neither > persistent storage nor change-logs creation are desired. The current > implementation prevents this. > *Suggestion:* > One possible solution is to use a similar materialization method (to the one > provided in the argument) when creating the intermediary Foreign Key > state-store. If the Materialization is in memory and without changelog, the > same happens in the intermediate state-sore. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] jolshan commented on pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
jolshan commented on pull request #10223: URL: https://github.com/apache/kafka/pull/10223#issuecomment-788251941 @hachikuji Ah sorry. I was misreading the file name. Makes sense. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12381) Incompatible change in verifiable_producer.log in 2.8
[
https://issues.apache.org/jira/browse/KAFKA-12381?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293161#comment-17293161
]
Boyang Chen commented on KAFKA-12381:
-
[~cmccabe] Could you provide more specific details here, such like which test
case is failing and where you were fixing the log grep?
> Incompatible change in verifiable_producer.log in 2.8
> -
>
> Key: KAFKA-12381
> URL: https://issues.apache.org/jira/browse/KAFKA-12381
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 2.8.0
>Reporter: Colin McCabe
>Assignee: Boyang Chen
>Priority: Blocker
>
> In test_verifiable_producer.py , we used to see this error message in
> verifiable_producer.log when a topic couldn't be created:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=LEADER_NOT_AVAILABLE}
> (org.apache.kafka.clients.NetworkClient)
> The test does a grep LEADER_NOT_AVAILABLE on the log in this case, and it
> used to pass.
> Now we are instead seeing this in the log file:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=INVALID_REPLICATION_FACTOR}
> (org.apache.kafka.clients.NetworkClient)
> And of course now the test fails.
> The INVALID_REPLICATION_FACTOR is coming from the new auto topic creation
> manager.
> It is a simple matter to make the test pass -- I have confirmed that it
> passes if we grep for INVALID_REPLICATION_FACTOR in the log file instead of
> LEADER_NOT_AVAILABLE.
> I think we just need to decide if this change in behavior is acceptable or
> not.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-12381) Incompatible change in verifiable_producer.log in 2.8
[
https://issues.apache.org/jira/browse/KAFKA-12381?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Boyang Chen updated KAFKA-12381:
Component/s: core
> Incompatible change in verifiable_producer.log in 2.8
> -
>
> Key: KAFKA-12381
> URL: https://issues.apache.org/jira/browse/KAFKA-12381
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 2.8.0
>Reporter: Colin McCabe
>Assignee: Boyang Chen
>Priority: Blocker
>
> In test_verifiable_producer.py , we used to see this error message in
> verifiable_producer.log when a topic couldn't be created:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=LEADER_NOT_AVAILABLE}
> (org.apache.kafka.clients.NetworkClient)
> The test does a grep LEADER_NOT_AVAILABLE on the log in this case, and it
> used to pass.
> Now we are instead seeing this in the log file:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=INVALID_REPLICATION_FACTOR}
> (org.apache.kafka.clients.NetworkClient)
> And of course now the test fails.
> The INVALID_REPLICATION_FACTOR is coming from the new auto topic creation
> manager.
> It is a simple matter to make the test pass -- I have confirmed that it
> passes if we grep for INVALID_REPLICATION_FACTOR in the log file instead of
> LEADER_NOT_AVAILABLE.
> I think we just need to decide if this change in behavior is acceptable or
> not.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-12381) Incompatible change in verifiable_producer.log in 2.8
[
https://issues.apache.org/jira/browse/KAFKA-12381?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Boyang Chen updated KAFKA-12381:
Labels: kip-500 (was: )
> Incompatible change in verifiable_producer.log in 2.8
> -
>
> Key: KAFKA-12381
> URL: https://issues.apache.org/jira/browse/KAFKA-12381
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 2.8.0
>Reporter: Colin McCabe
>Assignee: Boyang Chen
>Priority: Blocker
> Labels: kip-500
>
> In test_verifiable_producer.py , we used to see this error message in
> verifiable_producer.log when a topic couldn't be created:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=LEADER_NOT_AVAILABLE}
> (org.apache.kafka.clients.NetworkClient)
> The test does a grep LEADER_NOT_AVAILABLE on the log in this case, and it
> used to pass.
> Now we are instead seeing this in the log file:
> WARN [Producer clientId=producer-1] Error while fetching metadata with
> correlation id 1 : {test_topic=INVALID_REPLICATION_FACTOR}
> (org.apache.kafka.clients.NetworkClient)
> And of course now the test fails.
> The INVALID_REPLICATION_FACTOR is coming from the new auto topic creation
> manager.
> It is a simple matter to make the test pass -- I have confirmed that it
> passes if we grep for INVALID_REPLICATION_FACTOR in the log file instead of
> LEADER_NOT_AVAILABLE.
> I think we just need to decide if this change in behavior is acceptable or
> not.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] hachikuji commented on a change in pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585027051
##
File path: core/src/test/scala/unit/kafka/server/KafkaApisTest.scala
##
@@ -3479,6 +3481,161 @@ class KafkaApisTest {
assertEquals(List(mkTopicData(topic = "foo", Seq(1, 2))),
fooState.topics.asScala.toList)
}
+ @Test
+ def testDeleteTopicsByIdAuthorization(): Unit = {
+val authorizer: Authorizer = EasyMock.niceMock(classOf[Authorizer])
+val controllerContext: ControllerContext =
EasyMock.mock(classOf[ControllerContext])
+
+EasyMock.expect(clientControllerQuotaManager.newQuotaFor(
+ EasyMock.anyObject(classOf[RequestChannel.Request]),
+ EasyMock.anyShort()
+)).andReturn(UnboundedControllerMutationQuota)
+EasyMock.expect(controller.isActive).andReturn(true)
+
EasyMock.expect(controller.controllerContext).andStubReturn(controllerContext)
+
+// Try to delete three topics:
+// 1. One without describe permission
+// 2. One without delete permission
+// 3. One which is authorized, but doesn't exist
+
+expectTopicAuthorization(authorizer, AclOperation.DESCRIBE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.ALLOWED
+))
+
+expectTopicAuthorization(authorizer, AclOperation.DELETE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.DENIED
+))
+
+val topicIdsMap = Map(
+ Uuid.randomUuid() -> Some("foo"),
+ Uuid.randomUuid() -> Some("bar"),
+ Uuid.randomUuid() -> None
+)
+
+topicIdsMap.foreach { case (topicId, topicNameOpt) =>
+
EasyMock.expect(controllerContext.topicName(topicId)).andReturn(topicNameOpt)
+}
+
+val topicDatas = topicIdsMap.keys.map { topicId =>
+ new DeleteTopicsRequestData.DeleteTopicState().setTopicId(topicId)
+}.toList
+val deleteRequest = new DeleteTopicsRequest.Builder(new
DeleteTopicsRequestData()
+ .setTopics(topicDatas.asJava))
+ .build(ApiKeys.DELETE_TOPICS.latestVersion)
+
+val request = buildRequest(deleteRequest)
+val capturedResponse = expectNoThrottling(request)
+
+EasyMock.replay(replicaManager, clientRequestQuotaManager,
clientControllerQuotaManager,
+ requestChannel, txnCoordinator, controller, controllerContext,
authorizer)
+createKafkaApis(authorizer =
Some(authorizer)).handleDeleteTopicsRequest(request)
+
+val deleteResponse =
capturedResponse.getValue.asInstanceOf[DeleteTopicsResponse]
+
+topicIdsMap.foreach { case (topicId, nameOpt) =>
+ val response = deleteResponse.data.responses.asScala.find(_.topicId ==
topicId).get
+ nameOpt match {
+case Some("foo") =>
+ assertNull(response.name)
+ assertEquals(Errors.UNKNOWN_TOPIC_ID,
Errors.forCode(response.errorCode))
+case Some("bar") =>
+ assertEquals("bar", response.name)
+ assertEquals(Errors.TOPIC_AUTHORIZATION_FAILED,
Errors.forCode(response.errorCode))
+case None =>
+ assertNull(response.name)
+ assertEquals(Errors.UNKNOWN_TOPIC_ID,
Errors.forCode(response.errorCode))
+case _ =>
+ fail("Unexpected topic id/name mapping")
+ }
+}
+ }
+
+ @ParameterizedTest
+ @ValueSource(booleans = Array(true, false))
+ def testDeleteTopicsByNameAuthorization(usePrimitiveTopicNameArray:
Boolean): Unit = {
+val authorizer: Authorizer = EasyMock.niceMock(classOf[Authorizer])
+
+EasyMock.expect(clientControllerQuotaManager.newQuotaFor(
+ EasyMock.anyObject(classOf[RequestChannel.Request]),
+ EasyMock.anyShort()
+)).andReturn(UnboundedControllerMutationQuota)
+EasyMock.expect(controller.isActive).andReturn(true)
+
+// Try to delete three topics:
+// 1. One without describe permission
+// 2. One without delete permission
+// 3. One which is authorized, but doesn't exist
+
+expectTopicAuthorization(authorizer, AclOperation.DESCRIBE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.ALLOWED,
+ "baz" -> AuthorizationResult.ALLOWED
+))
+
+expectTopicAuthorization(authorizer, AclOperation.DELETE, Map(
+ "foo" -> AuthorizationResult.DENIED,
+ "bar" -> AuthorizationResult.DENIED,
+ "baz" -> AuthorizationResult.ALLOWED
+))
+
+val deleteRequest = if (usePrimitiveTopicNameArray) {
+ new DeleteTopicsRequest.Builder(new DeleteTopicsRequestData()
+.setTopicNames(List("foo", "bar", "baz").asJava))
+.build(5.toShort)
+} else {
+ val topicDatas = List(
+new DeleteTopicsRequestData.DeleteTopicState().setName("foo"),
+new DeleteTopicsRequestData.DeleteTopicState().setName("bar"),
+new DeleteTopicsRequestData.DeleteTopicState().setName("baz")
+ )
+ new DeleteTopicsRequest.Builder(new DeleteTopicsRequestData()
+.setTopics(topicDatas.asJava))
+
[GitHub] [kafka] gharris1727 commented on pull request #8259: KAFKA-7421: Ensure Connect's PluginClassLoader is truly parallel capable and resolve deadlock occurrences
gharris1727 commented on pull request #8259: URL: https://github.com/apache/kafka/pull/8259#issuecomment-788250316 Now that the bug is fixed, some comments are explicitly incorrect. For example: ``` // 1. Lock the PluginClassLoader (via PluginClassLoader::loadClass) // This behavior is specific to the JVM, not the classloader implementation ``` And a lot have the wrong intent, or are misleading. Do you think we should fix some or all of these, or leave them as a detailed description of how the bug _did_ happen when it existed? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12394) Consider topic id existence and authorization errors
[
https://issues.apache.org/jira/browse/KAFKA-12394?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17293155#comment-17293155
]
Ismael Juma commented on KAFKA-12394:
-
{quote}There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well.
{quote}
I thought the KIP had specified ^. cc [~jolshan]
> Consider topic id existence and authorization errors
>
>
> Key: KAFKA-12394
> URL: https://issues.apache.org/jira/browse/KAFKA-12394
> Project: Kafka
> Issue Type: Improvement
>Reporter: Jason Gustafson
>Priority: Major
>
> We have historically had logic in the api layer to avoid leaking the
> existence or non-existence of topics to clients which are not authorized to
> describe them. The way we have done this is to always authorize the topic
> name first before checking existence.
> Topic ids make this more difficult because the resource (ie the topic name)
> has to be derived. This means we have to check existence of the topic first.
> If the topic does not exist, then our hands are tied and we have to return
> UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the
> client is authorized to describe it. The question comes then what we should
> do if the client is not authorized?
> The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this
> is misleading and forces the client to retry even though they are doomed to
> hit the same error. However, the client should generally handle this by
> requesting Metadata using the topic name that they are interested in, which
> would give them a chance to see the topic authorization error. Basically the
> fact that you need describe permission in the first place to discover the
> topic id makes this an unlikely scenario.
> There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well.
> Basically we could take the stance that we do not care about leaking the
> existence of topic IDs since they do not reveal anything about the underlying
> topic. Additionally, there is little likelihood of a user discovering a valid
> UUID by accident or even through brute force. The benefit of this is that
> users get a clear error for cases where a topic Id may have been discovered
> through some external means. For example, an administrator finds a topic ID
> in the logging and attempts to delete it using the new `deleteTopicsWithIds`
> Admin API.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] gharris1727 commented on a change in pull request #8259: KAFKA-7421: Ensure Connect's PluginClassLoader is truly parallel capable and resolve deadlock occurrences
gharris1727 commented on a change in pull request #8259:
URL: https://github.com/apache/kafka/pull/8259#discussion_r585020737
##
File path:
connect/runtime/src/test/java/org/apache/kafka/connect/runtime/isolation/SynchronizationTest.java
##
@@ -0,0 +1,468 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.connect.runtime.isolation;
+
+import static org.junit.Assert.fail;
+
+import java.lang.management.LockInfo;
+import java.lang.management.ManagementFactory;
+import java.lang.management.MonitorInfo;
+import java.lang.management.ThreadInfo;
+import java.net.URL;
+import java.security.AccessController;
+import java.security.PrivilegedAction;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map;
+import java.util.Objects;
+import java.util.concurrent.BrokenBarrierException;
+import java.util.concurrent.CyclicBarrier;
+import java.util.concurrent.LinkedBlockingDeque;
+import java.util.concurrent.ThreadFactory;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+import java.util.concurrent.TimeoutException;
+import java.util.concurrent.atomic.AtomicInteger;
+import java.util.function.Predicate;
+import java.util.stream.Collectors;
+import org.apache.kafka.common.config.AbstractConfig;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigDef.Importance;
+import org.apache.kafka.common.config.ConfigDef.Type;
+import org.apache.kafka.connect.runtime.WorkerConfig;
+import org.junit.After;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TestName;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SynchronizationTest {
+
+public static final Logger log =
LoggerFactory.getLogger(SynchronizationTest.class);
+
+@Rule
+public final TestName testName = new TestName();
+
+private String threadPrefix;
+private Plugins plugins;
+private ThreadPoolExecutor exec;
+private Breakpoint dclBreakpoint;
+private Breakpoint pclBreakpoint;
+
+@Before
+public void setup() {
+TestPlugins.assertAvailable();
+Map pluginProps = Collections.singletonMap(
+WorkerConfig.PLUGIN_PATH_CONFIG,
+String.join(",", TestPlugins.pluginPath())
+);
+threadPrefix = SynchronizationTest.class.getSimpleName()
++ "." + testName.getMethodName() + "-";
+dclBreakpoint = new Breakpoint<>();
+pclBreakpoint = new Breakpoint<>();
+plugins = new Plugins(pluginProps) {
+@Override
+protected DelegatingClassLoader
newDelegatingClassLoader(List paths) {
+return AccessController.doPrivileged(
+(PrivilegedAction) () ->
+new SynchronizedDelegatingClassLoader(paths)
+);
+}
+};
+exec = new ThreadPoolExecutor(
+2,
+2,
+1000L,
+TimeUnit.MILLISECONDS,
+new LinkedBlockingDeque<>(),
+threadFactoryWithNamedThreads(threadPrefix)
+);
+
+}
+
+@After
+public void tearDown() throws InterruptedException {
+dclBreakpoint.clear();
+pclBreakpoint.clear();
+exec.shutdown();
+exec.awaitTermination(1L, TimeUnit.SECONDS);
+}
+
+private static class Breakpoint {
+
+private Predicate predicate;
+private CyclicBarrier barrier;
+
+public synchronized void clear() {
+if (barrier != null) {
+barrier.reset();
+}
+predicate = null;
+barrier = null;
+}
+
+public synchronized void set(Predicate predicate) {
+clear();
+this.predicate = predicate;
+// As soon as the barrier is tripped, the barrier will be reset
for the next round.
+barrier = new CyclicBarrier(2);
+}
+
+/**
+ * From a thread under test, await for the test orchestrator to
continue execution
+ * @param obj Object to test with the breakpoint's current predicate
+ */
[GitHub] [kafka] hachikuji edited a comment on pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji edited a comment on pull request #10223: URL: https://github.com/apache/kafka/pull/10223#issuecomment-788239224 @jolshan @chia7712 I don't think `KafkaApis` has been rewritten yet. My suggestion is probably get this checked in as is so that we can definitely get it into 2.8. Then we should consider how to consolidate the handling logic in `ControllerApis` and `KafkaApis` after #10184 is merged. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji commented on pull request #10223: URL: https://github.com/apache/kafka/pull/10223#issuecomment-788239224 @jolshan @chia7712 I don't think `KafkaApis` has been rewritten yet. My suggestion is probably get this checked in as is so that we can definitely get it into 2.8. Then we should consider how to consolidate the handling logic in `ControllerApis` and `KafkaApis`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585017852
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1874,7 +1874,7 @@ class KafkaApis(val requestChannel: RequestChannel,
if (topic.name() != null && topic.topicId() != Uuid.ZERO_UUID)
throw new InvalidRequestException("Topic name and topic ID can not
both be specified.")
val name = if (topic.topicId() == Uuid.ZERO_UUID) topic.name()
-else
zkSupport.controller.controllerContext.topicNames.getOrElse(topic.topicId(),
null)
+else
zkSupport.controller.controllerContext.topicName(topic.topicId).orNull
Review comment:
I mainly did this for easier mocking. I would like to see reduced access
for `topicNames`, but that feels like something to address separately.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #10205: KAFKA-12323 Follow-up: Refactor the unit test a bit
guozhangwang commented on pull request #10205: URL: https://github.com/apache/kafka/pull/10205#issuecomment-788238202 Cherry-picked to 2.8 and 2.7, cc RM @vvcephei This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang merged pull request #10205: KAFKA-12323 Follow-up: Refactor the unit test a bit
guozhangwang merged pull request #10205: URL: https://github.com/apache/kafka/pull/10205 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10223: MINOR: Do not expose topic name in `DeleteTopic` response if no describe permission
hachikuji commented on a change in pull request #10223:
URL: https://github.com/apache/kafka/pull/10223#discussion_r585014029
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1884,20 +1884,24 @@ class KafkaApis(val requestChannel: RequestChannel,
val authorizedDeleteTopics =
authHelper.filterByAuthorized(request.context, DELETE, TOPIC,
results.asScala.filter(result => result.name() != null))(_.name)
results.forEach { topic =>
-val unresolvedTopicId = !(topic.topicId() == Uuid.ZERO_UUID) &&
topic.name() == null
- if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
- topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
- topic.setErrorMessage("Topic IDs are not supported on the server.")
- } else if (unresolvedTopicId)
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
- else if (!authorizedDeleteTopics.contains(topic.name))
- topic.setErrorCode(Errors.TOPIC_AUTHORIZATION_FAILED.code)
- else if (!metadataCache.contains(topic.name))
- topic.setErrorCode(Errors.UNKNOWN_TOPIC_OR_PARTITION.code)
- else
- toDelete += topic.name
+val unresolvedTopicId = topic.topicId() != Uuid.ZERO_UUID &&
topic.name() == null
+if (!config.usesTopicId &&
topicIdsFromRequest.contains(topic.topicId)) {
+ topic.setErrorCode(Errors.UNSUPPORTED_VERSION.code)
+ topic.setErrorMessage("Topic IDs are not supported on the server.")
+} else if (unresolvedTopicId) {
+ topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
+} else if (topicIdsFromRequest.contains(topic.topicId) &&
!authorizedDescribeTopics(topic.name)) {
+ // Because the client does not have Describe permission, the name
should
+ // not be returned in the response.
+ topic.setName(null)
+ topic.setErrorCode(Errors.UNKNOWN_TOPIC_ID.code)
Review comment:
I made the comment before fully realizing how topic IDs were
complicating the matter. I filed this JIRA to discuss further:
https://issues.apache.org/jira/browse/KAFKA-12394. I'd suggest that we keep the
current behavior in this PR and fix the small issue. It would be good to have
the tests in any case.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (KAFKA-12394) Consider topic id existence and authorization errors
Jason Gustafson created KAFKA-12394: --- Summary: Consider topic id existence and authorization errors Key: KAFKA-12394 URL: https://issues.apache.org/jira/browse/KAFKA-12394 Project: Kafka Issue Type: Improvement Reporter: Jason Gustafson We have historically had logic in the api layer to avoid leaking the existence or non-existence of topics to clients which are not authorized to describe them. The way we have done this is to always authorize the topic name first before checking existence. Topic ids make this more difficult because the resource (ie the topic name) has to be derived. This means we have to check existence of the topic first. If the topic does not exist, then our hands are tied and we have to return UNKNOWN_TOPIC_ID. If the topic does exist, then we need to check if the client is authorized to describe it. The question comes then what we should do if the client is not authorized? The current behavior is to return UNKNOWN_TOPIC_ID. The downside is that this is misleading and forces the client to retry even though they are doomed to hit the same error. However, the client should generally handle this by requesting Metadata using the topic name that they are interested in, which would give them a chance to see the topic authorization error. Basically the fact that you need describe permission in the first place to discover the topic id makes this an unlikely scenario. There is an argument to be made for TOPIC_AUTHORIZATION_FAILED as well. Basically we could take the stance that we do not care about leaking the existence of topic IDs since they do not reveal anything about the underlying topic. Additionally, there is little likelihood of a user discovering a valid UUID by accident or even through brute force. The benefit of this is that users get a clear error for cases where a topic Id may have been discovered through some external means. For example, an administrator finds a topic ID in the logging and attempts to delete it using the new `deleteTopicsWithIds` Admin API. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] rondagostino commented on pull request #10225: MINOR: fix security_test for ZK case due to error change
rondagostino commented on pull request #10225: URL: https://github.com/apache/kafka/pull/10225#issuecomment-788226851 This PR "fixes" the issue by changing the system test to check for the new error. We can close this PR in favor of another one if @abbccdda decides the behavior change is incorrect and can be corrected. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rondagostino commented on pull request #10225: MINOR: fix security_test for ZK case due to error change
rondagostino commented on pull request #10225: URL: https://github.com/apache/kafka/pull/10225#issuecomment-788225857 https://issues.apache.org/jira/browse/KAFKA-12381 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang merged pull request #10231: MINOR: Remove stack trace of the lock exception in a debug log4j
guozhangwang merged pull request #10231: URL: https://github.com/apache/kafka/pull/10231 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org