LeoHsu0802 opened a new issue #2184:
URL: https://github.com/apache/hudi/issues/2184
Describe the problem you faced
partition value be duplicated after UPSERT
**Setting in Jupyter Notebook**
```
%%configure -f
{
"conf": {
"spark.jars": "hdfs:///user/hadoop/httpclient-4.5.9.jar,
hdfs:///user/hadoop/httpcore-4.4.11.jar,
hdfs:///user/hadoop/hudi-spark-bundle.jar, hdfs:///user/hadoop/spark-avro.jar",
"spark.sql.hive.convertMetastoreParquet":"false",
"spark.serializer":"org.apache.spark.serializer.KryoSerializer",
"spark.dynamicAllocation.executorIdleTimeout": 3600
}
}
```
**To Reproduce**
1. Load raw data to dataframe and write to S3 in Hudi dataset
```
(df.write.format("org.apache.hudi")
.option("hoodie.datasource.write.precombine.field", "tstamp")
.option("hoodie.datasource.write.recordkey.field", "id")
.option("hoodie.table.name", config['table_name'])
.option("hoodie.datasource.write.operation", "insert")
.option("hoodie.bulkinsert.shuffle.parallelism", 6)
.option("hoodie.consistency.check.enabled", "true")
.option("hoodie.datasource.write.keygenerator.class","org.apache.hudi.ComplexKeyGenerator")
.option("hoodie.datasource.write.partitionpath.field", 'country,
gateway, year, month, day')
.option("hoodie.datasource.hive_sync.table",config['table_name'])
.option("hoodie.datasource.hive_sync.enable","true")
.option("hoodie.datasource.hive_sync.partition_extractor_class","org.apache.hudi.hive.MultiPartKeysValueExtractor")
.option("hoodie.datasource.hive_sync.partition_fields", 'country,
gateway, year, month, day')
.option("hoodie.datasource.hive_sync.database", 'hudi_dev')
.mode("Overwrite")
.save(config['target']))
```
2. Write successfully and can be query in spark.sql
3. Change country value between id 101-105
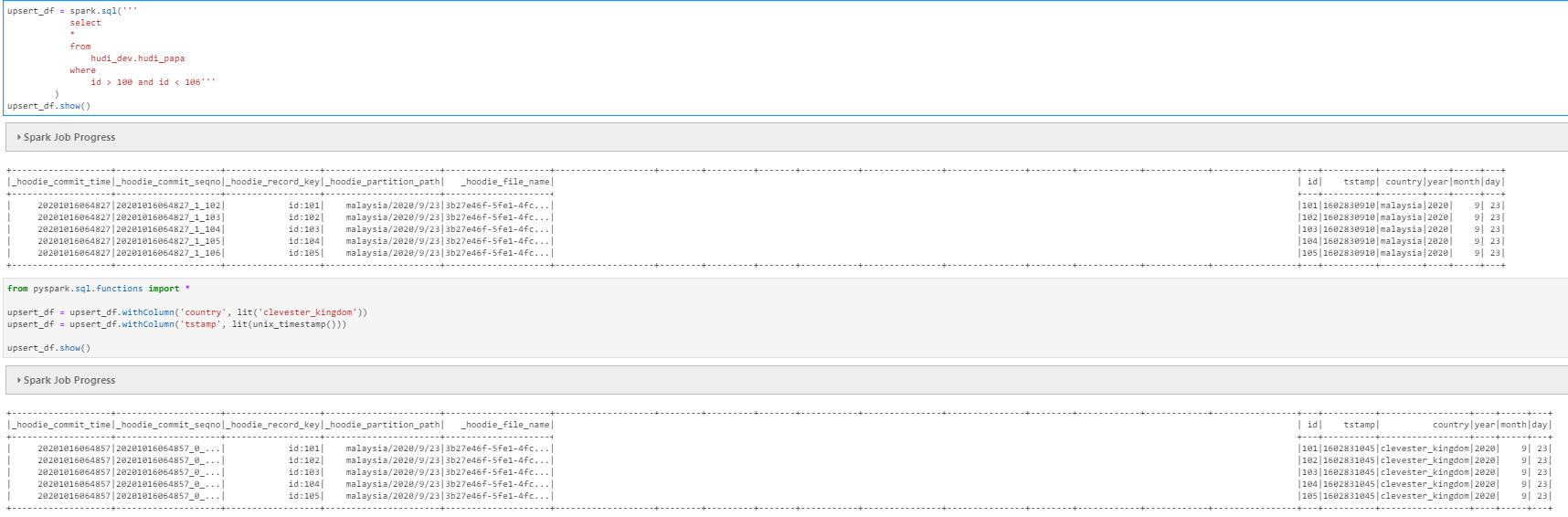
4. Upsert the dataframe
```
(upsert_df.write.format("org.apache.hudi")
.option("hoodie.datasource.write.precombine.field", "tstamp")
.option("hoodie.datasource.write.recordkey.field", "id")
.option("hoodie.table.name", config['table_name'])
.option("hoodie.datasource.write.operation", "upsert")
.option("hoodie.upsert.shuffle.parallelism", 20)
.option("hoodie.consistency.check.enabled", "true")
.option("hoodie.datasource.write.keygenerator.class","org.apache.hudi.keygen.ComplexKeyGenerator")
.option("hoodie.datasource.write.partitionpath.field", 'country, year,
month, day')
.option("hoodie.cleaner.policy", "KEEP_LATEST_COMMITS")
.option("hoodie.cleaner.commits.retained", "10")
.option("hoodie.datasource.hive_sync.table",config['table_name'])
.option("hoodie.datasource.hive_sync.enable","true")
.option("hoodie.datasource.hive_sync.partition_extractor_class","org.apache.hudi.hive.MultiPartKeysValueExtractor")
.option("hoodie.datasource.hive_sync.partition_fields", 'country,
year, month, day')
.option("hoodie.datasource.hive_sync.database", 'hudi_dev')
.mode("Append")
.save(config['target']))
```
5. Query the upsert result
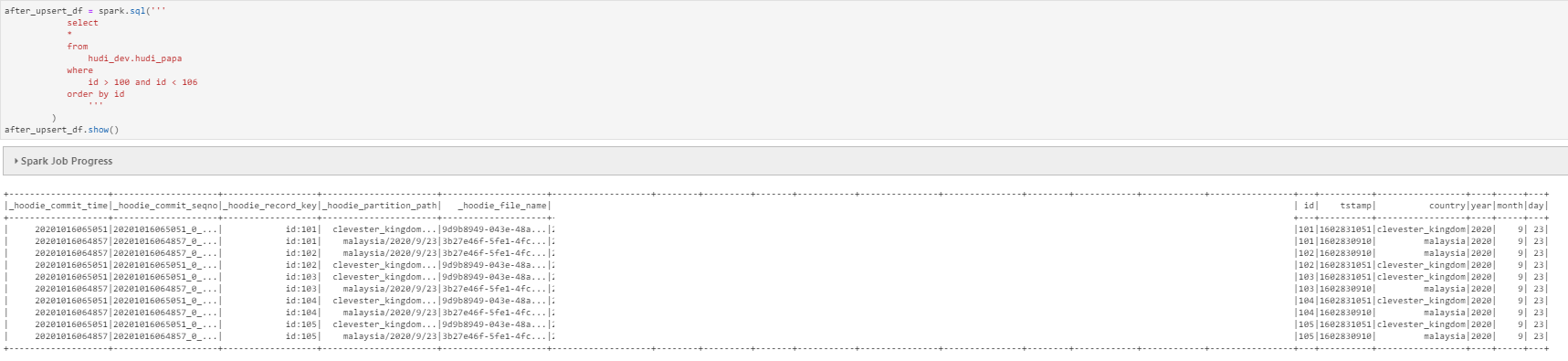
**Expected behavior**
I expected no duplicate data in query result
**Environment Description**
* EMR version : 5.31.0
* Hudi version : 0.6.0
* Spark version : 2.4.6
* Hive version : 2.3.7
* Hadoop version : Amazon 2.10.0
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
**Additional context**
httpclient-4.5.9.jar
httpcore-4.4.11.jar
hudi-spark-bundle.jar
spark-avro.jar"
**Stacktrace**
No
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}
{kind=link}