tooptoop4 opened a new issue #1833: URL: https://github.com/apache/hudi/issues/1833
I have a single 700MB file containing 10mn rows (all unique keys, key is single column, single partition for all rows). 1. Create brand new table 2. Using spark datasource on the 700MB to write in COW insert mode, all rows to single partition takes 7.3mins (i thought could be faster but its acceptable). 88 parquet files end up on S3 table path after this succeeds (total size 288MB) 3. Repeat the exact same spark-submit (but with COW upsert mode) from point 2 above to single partition with exact same 700MB file (still running after more than 2hrs!) --total-executor-cores 16 --driver-memory 2G --executor-memory 16G --executor-cores 2 dynamic allocation of executors is on, shuffle service is on spark 2.4.6 hudi 0.5.3 "spark.sql.shuffle.partitions" is "16" "hoodie.insert.shuffle.parallelism" is "16" "hoodie.upsert.shuffle.parallelism" is "16" private static final String DEFAULT_INLINE_COMPACT = "true"; private static final String DEFAULT_CLEANER_FILE_VERSIONS_RETAINED = "1"; private static final String DEFAULT_CLEANER_COMMITS_RETAINED = "1"; private static final String DEFAULT_MAX_COMMITS_TO_KEEP = "3"; private static final String DEFAULT_MIN_COMMITS_TO_KEEP = "2"; private static final String DEFAULT_EMBEDDED_TIMELINE_SERVER_ENABLED = "false"; private static final String DEFAULT_FAIL_ON_TIMELINE_ARCHIVING_ENABLED = "false"; rest of configs are default 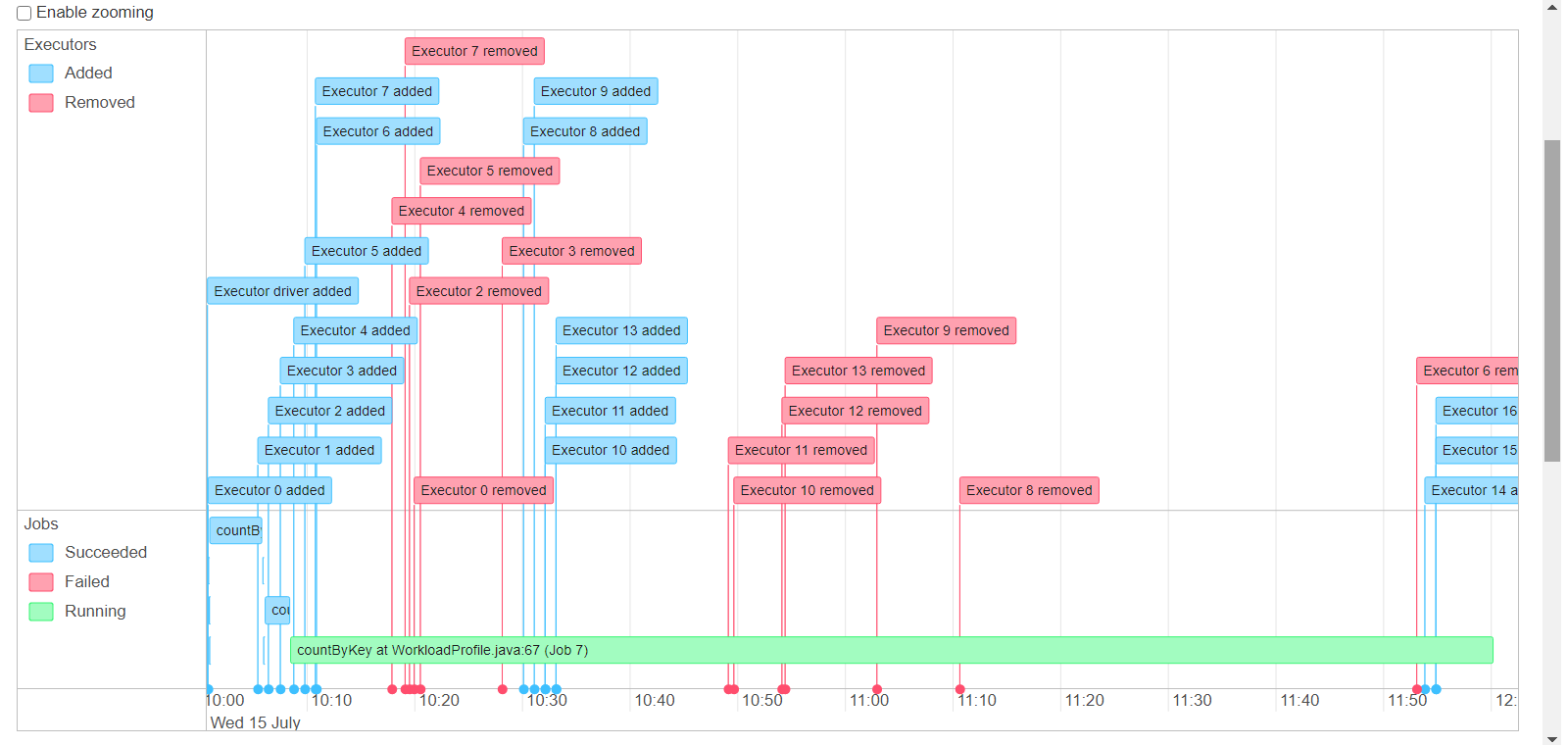 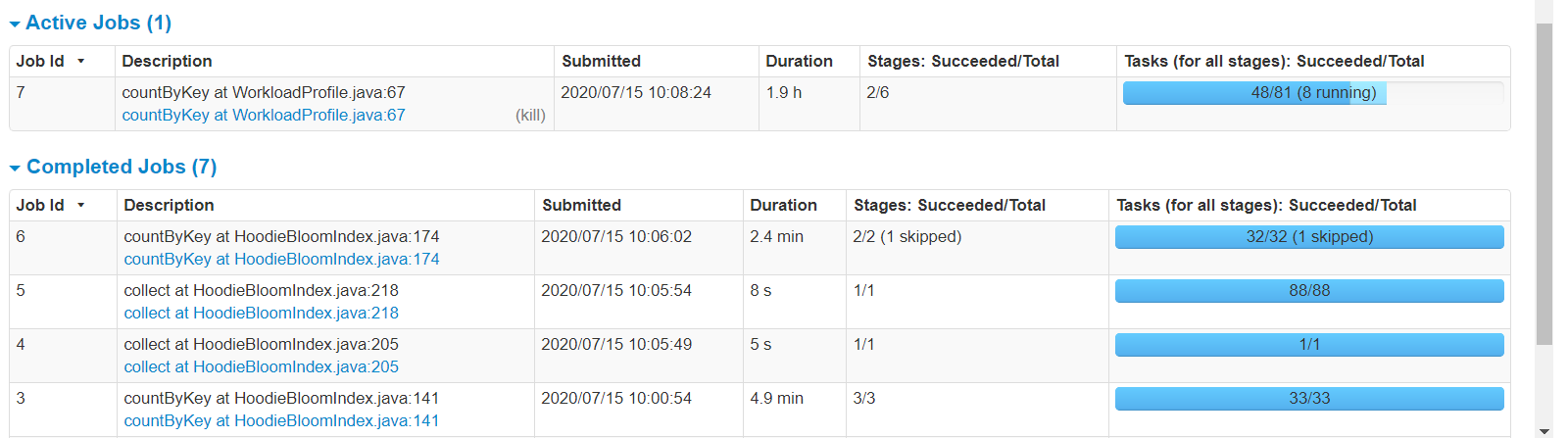 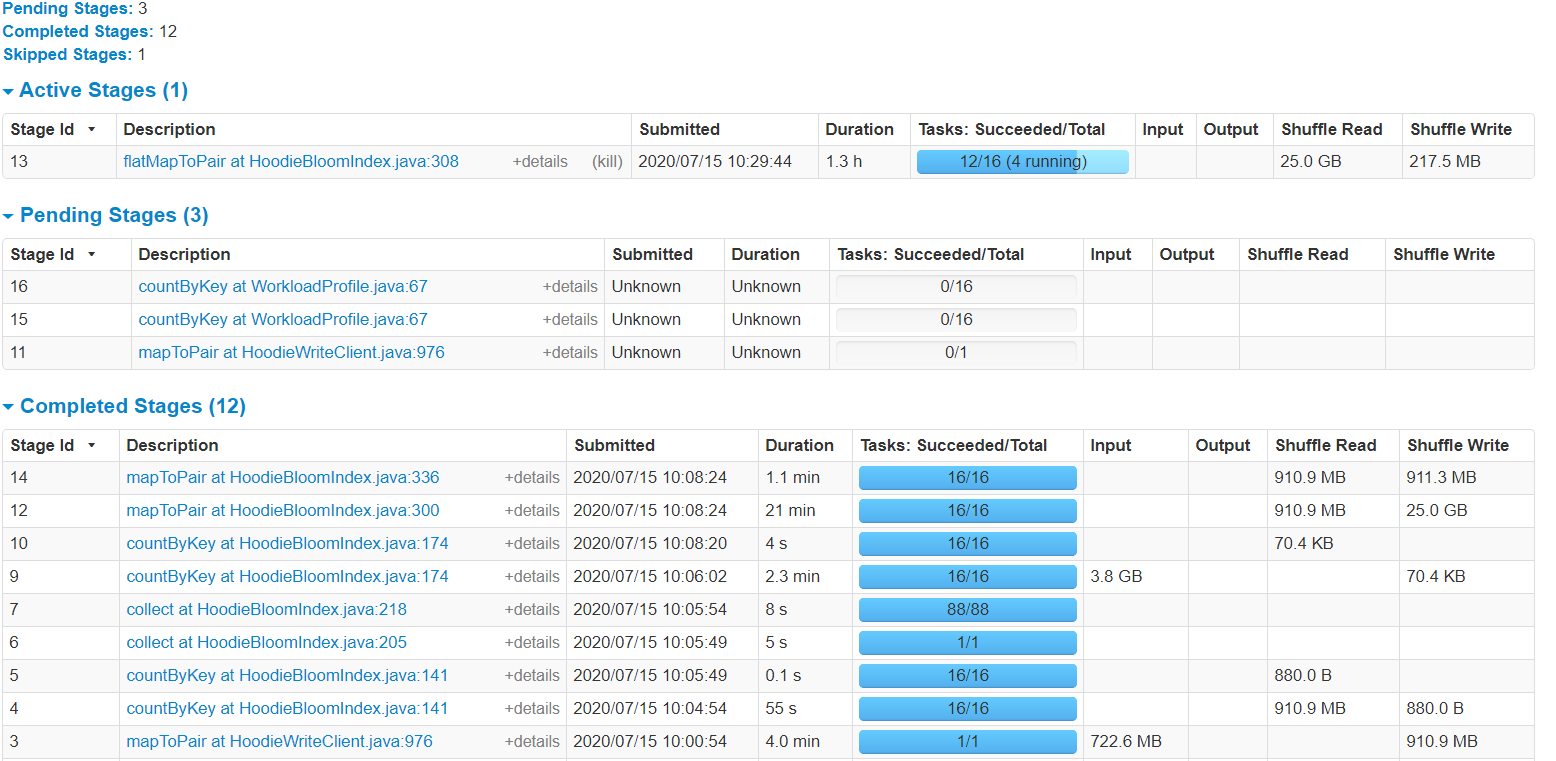 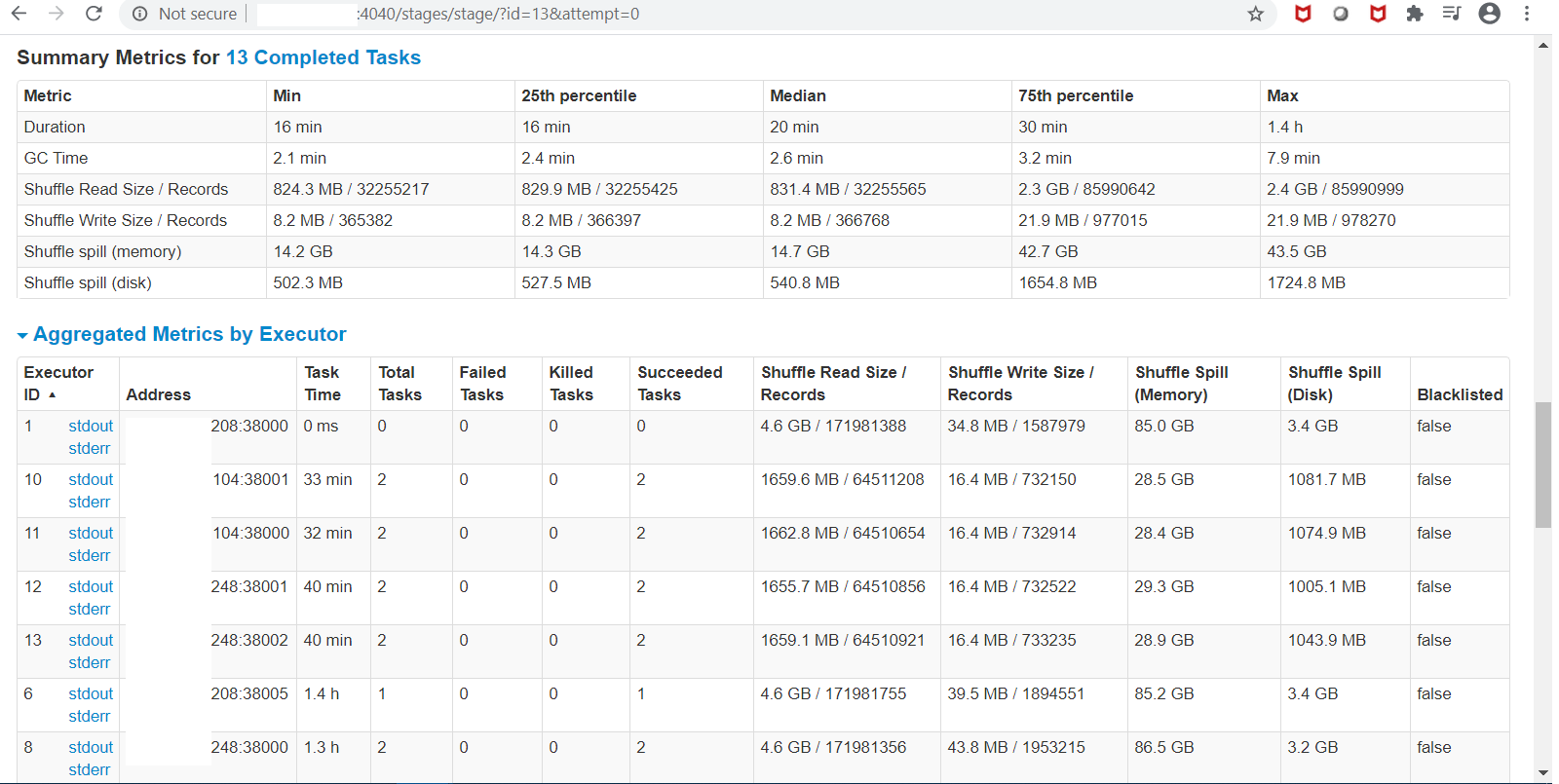 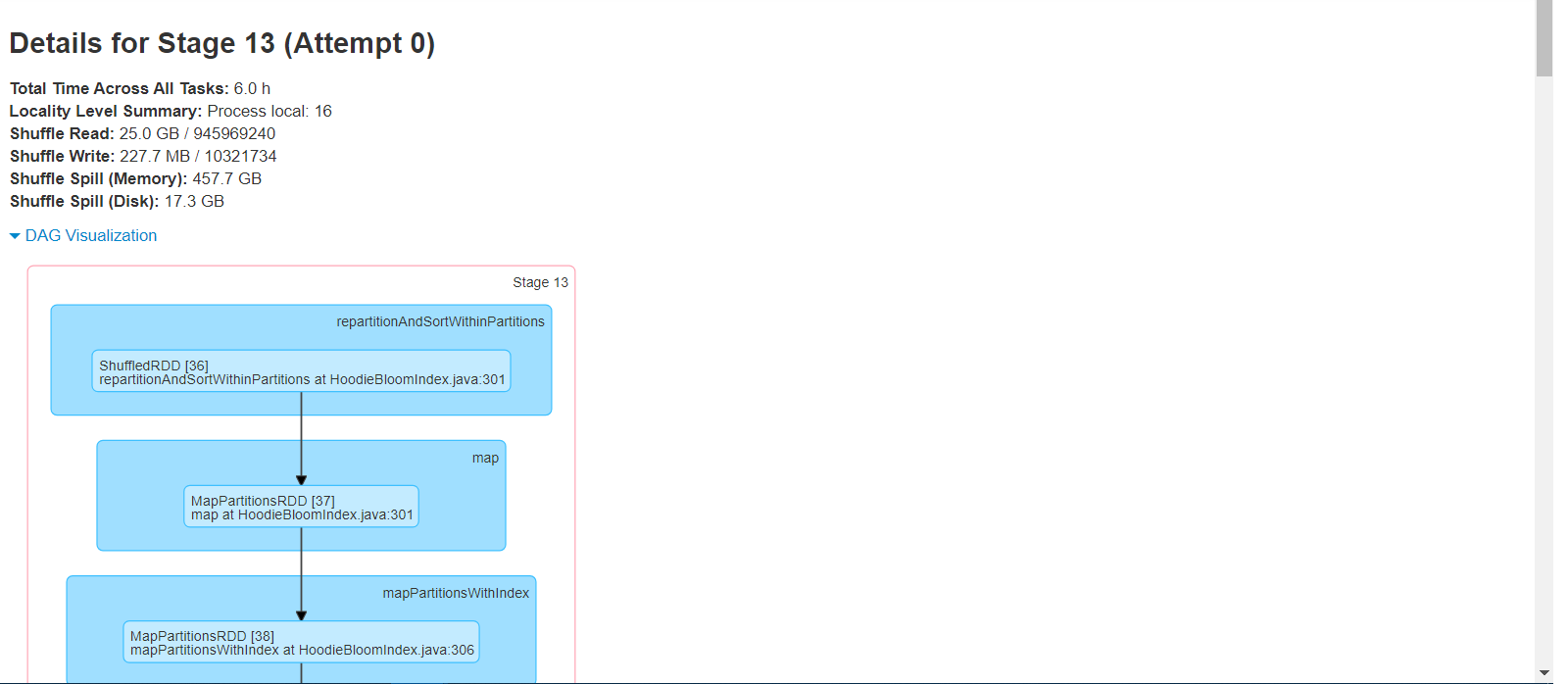 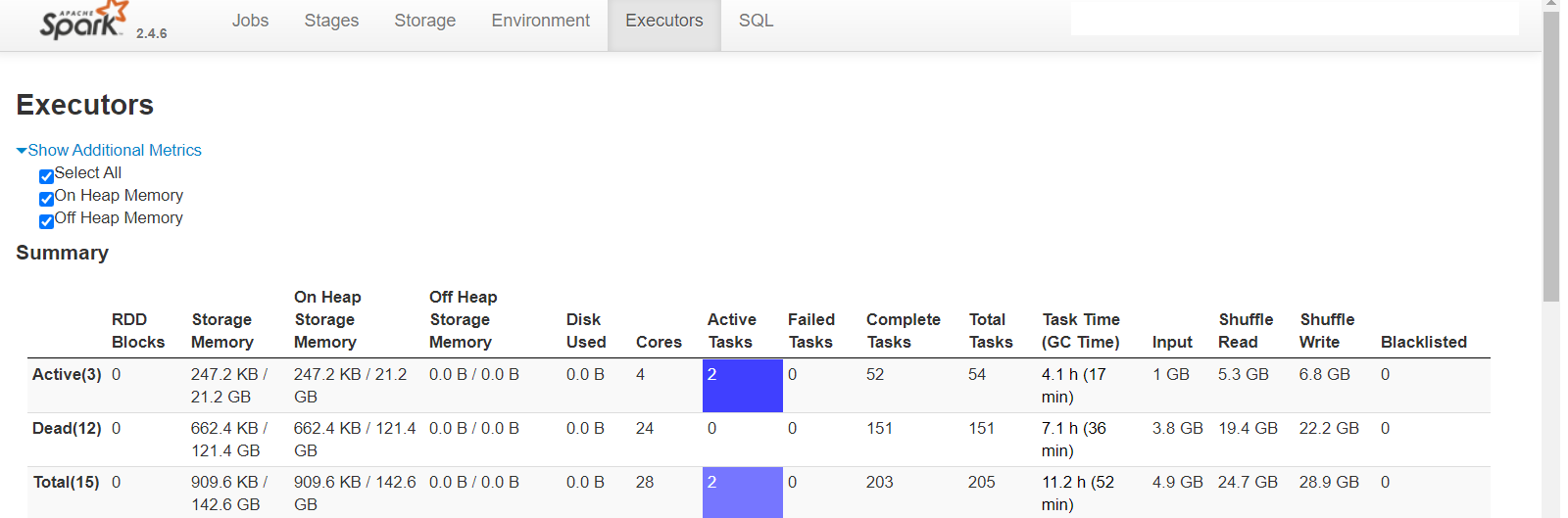 shuffle size seems to be extremely high! any idea how to speed this up? how long does it take you to do 100% update? ie run same 10mn/700MB file twice on new table ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}