[GitHub] [incubator-hudi] yanghua commented on issue #991: Hudi Test Suite (Refactor)
yanghua commented on issue #991: Hudi Test Suite (Refactor) URL: https://github.com/apache/incubator-hudi/pull/991#issuecomment-559362785 There are so many conflicts. I have tried to rebase with the master branch, however, it's hard to do this for multiple branches. So I would like to firstly squash the commits and rebase to fix conflicts. FYI, cc @n3nash @vinothchandar This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] yanghua edited a comment on issue #991: Hudi Test Suite (Refactor)
yanghua edited a comment on issue #991: Hudi Test Suite (Refactor) URL: https://github.com/apache/incubator-hudi/pull/991#issuecomment-559362785 There are so many conflicts. I have tried to rebase with the master branch, however, it's hard to do this for multiple commits. So I would like to firstly squash the commits and rebase to fix conflicts. FYI, cc @n3nash @vinothchandar This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource
lamber-ken edited a comment on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource URL: https://github.com/apache/incubator-hudi/pull/1054#issuecomment-559321835 I am trying to figure out why ci build failed, waiting. 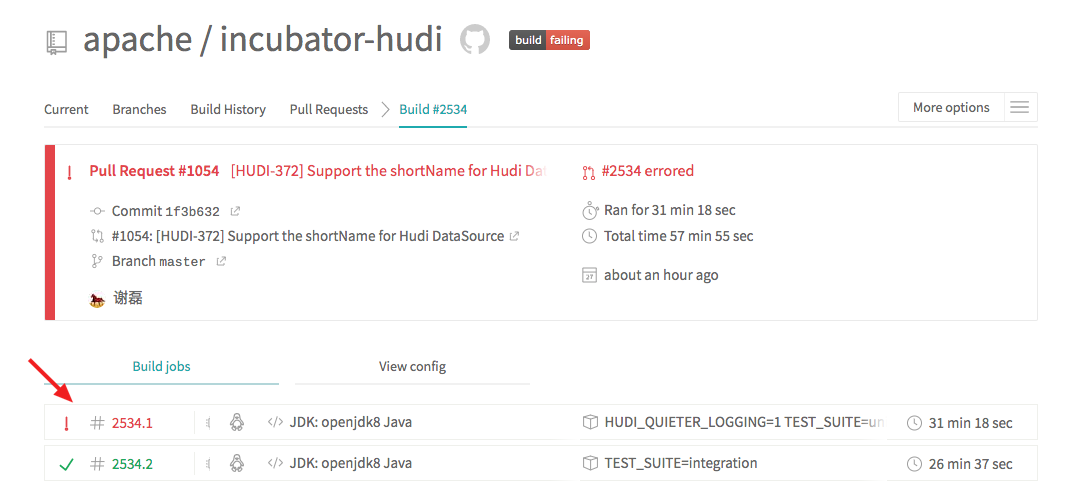 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource
lamber-ken commented on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource URL: https://github.com/apache/incubator-hudi/pull/1054#issuecomment-559332880 hi, @vinothchandar it seems that the ci may has some bug, because the building fail reasons are different, WTDY? https://travis-ci.org/apache/incubator-hudi/jobs/617982783?utm_medium=notification_source=github_status https://travis-ci.org/apache/incubator-hudi/jobs/617720826?utm_medium=notification_source=github_status This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource
lamber-ken edited a comment on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource URL: https://github.com/apache/incubator-hudi/pull/1054#issuecomment-559321835 I am trying to find out why ci build failed, waiting.  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource
lamber-ken commented on issue #1054: [HUDI-372] Support the shortName for Hudi DataSource URL: https://github.com/apache/incubator-hudi/pull/1054#issuecomment-559321835 I am trying to find out why ci build failed, waiting. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[incubator-hudi] branch master updated: [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule (#1056)
This is an automated email from the ASF dual-hosted git repository. leesf pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/incubator-hudi.git The following commit(s) were added to refs/heads/master by this push: new da8d133 [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule (#1056) da8d133 is described below commit da8d1334eecd65f2896613b1143d6ba31bae03b7 Author: lamber-ken AuthorDate: Thu Nov 28 09:25:56 2019 +0800 [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule (#1056) --- .../java/org/apache/hudi/AbstractHoodieClient.java | 8 ++-- .../org/apache/hudi/CompactionAdminClient.java | 28 +++-- .../java/org/apache/hudi/HoodieCleanClient.java| 12 +++--- .../java/org/apache/hudi/HoodieReadClient.java | 11 +++-- .../java/org/apache/hudi/HoodieWriteClient.java| 33 --- .../src/main/java/org/apache/hudi/WriteStatus.java | 9 ++-- .../client/embedded/EmbeddedTimelineService.java | 6 ++- .../org/apache/hudi/client/utils/ClientUtils.java | 1 + .../apache/hudi/config/HoodieCompactionConfig.java | 13 +++--- .../apache/hudi/config/HoodieHBaseIndexConfig.java | 3 +- .../org/apache/hudi/config/HoodieIndexConfig.java | 7 +++- .../org/apache/hudi/config/HoodieMemoryConfig.java | 8 ++-- .../apache/hudi/config/HoodieMetricsConfig.java| 6 ++- .../org/apache/hudi/config/HoodieWriteConfig.java | 19 + .../apache/hudi/func/BulkInsertMapFunction.java| 6 ++- .../hudi/func/CopyOnWriteLazyInsertIterable.java | 14 --- .../hudi/func/MergeOnReadLazyInsertIterable.java | 7 ++-- .../java/org/apache/hudi/func/OperationResult.java | 3 +- .../apache/hudi/func/ParquetReaderIterator.java| 6 ++- .../hudi/func/SparkBoundedInMemoryExecutor.java| 6 ++- .../java/org/apache/hudi/index/HoodieIndex.java| 4 +- .../org/apache/hudi/index/InMemoryHashIndex.java | 12 +++--- .../hudi/index/bloom/BloomIndexFileInfo.java | 1 + .../bloom/BucketizedBloomCheckPartitioner.java | 10 +++-- .../apache/hudi/index/bloom/HoodieBloomIndex.java | 23 ++- .../index/bloom/HoodieBloomIndexCheckFunction.java | 9 ++-- .../hudi/index/bloom/HoodieGlobalBloomIndex.java | 17 .../hbase/DefaultHBaseQPSResourceAllocator.java| 1 + .../org/apache/hudi/index/hbase/HBaseIndex.java| 41 +- .../org/apache/hudi/io/HoodieAppendHandle.java | 22 +- .../java/org/apache/hudi/io/HoodieCleanHelper.java | 16 .../org/apache/hudi/io/HoodieCommitArchiveLog.java | 30 +++--- .../org/apache/hudi/io/HoodieCreateHandle.java | 12 +++--- .../java/org/apache/hudi/io/HoodieIOHandle.java| 3 +- .../org/apache/hudi/io/HoodieKeyLookupHandle.java | 14 --- .../java/org/apache/hudi/io/HoodieMergeHandle.java | 20 + .../org/apache/hudi/io/HoodieRangeInfoHandle.java | 3 +- .../java/org/apache/hudi/io/HoodieReadHandle.java | 3 +- .../java/org/apache/hudi/io/HoodieWriteHandle.java | 14 --- .../apache/hudi/io/compact/HoodieCompactor.java| 8 ++-- .../io/compact/HoodieRealtimeTableCompactor.java | 32 --- .../strategy/BoundedIOCompactionStrategy.java | 6 ++- .../BoundedPartitionAwareCompactionStrategy.java | 8 ++-- .../io/compact/strategy/CompactionStrategy.java| 10 +++-- .../strategy/DayBasedCompactionStrategy.java | 10 +++-- .../LogFileSizeBasedCompactionStrategy.java| 9 ++-- .../strategy/UnBoundedCompactionStrategy.java | 3 +- .../UnBoundedPartitionAwareCompactionStrategy.java | 7 ++-- .../hudi/io/storage/HoodieParquetConfig.java | 3 +- .../hudi/io/storage/HoodieParquetWriter.java | 16 .../hudi/io/storage/HoodieStorageWriter.java | 6 ++- .../io/storage/HoodieStorageWriterFactory.java | 16 .../org/apache/hudi/metrics/HoodieMetrics.java | 5 ++- .../main/java/org/apache/hudi/metrics/Metrics.java | 8 ++-- .../hudi/metrics/MetricsGraphiteReporter.java | 8 ++-- .../hudi/metrics/MetricsReporterFactory.java | 3 +- .../apache/hudi/table/HoodieCopyOnWriteTable.java | 37 + .../apache/hudi/table/HoodieMergeOnReadTable.java | 26 ++-- .../java/org/apache/hudi/table/HoodieTable.java| 26 ++-- .../org/apache/hudi/table/RollbackExecutor.java| 27 ++-- .../table/UserDefinedBulkInsertPartitioner.java| 1 + .../org/apache/hudi/table/WorkloadProfile.java | 11 +++-- .../java/org/apache/hudi/table/WorkloadStat.java | 5 ++- hudi-client/src/test/java/HoodieClientExample.java | 14 --- .../org/apache/hudi/HoodieClientTestHarness.java | 24 ++- .../java/org/apache/hudi/TestAsyncCompaction.java | 28 +++-- .../src/test/java/org/apache/hudi/TestCleaner.java | 48 +++--- .../java/org/apache/hudi/TestClientRollback.java | 18
[GitHub] [incubator-hudi] leesf merged pull request #1056: [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule
leesf merged pull request #1056: [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1056 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (HUDI-372) Support the shortName for Hudi DataSource
[
https://issues.apache.org/jira/browse/HUDI-372?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
lamber-ken updated HUDI-372:
Summary: Support the shortName for Hudi DataSource (was: Support the
shortName for Hudi DataSouce)
> Support the shortName for Hudi DataSource
> -
>
> Key: HUDI-372
> URL: https://issues.apache.org/jira/browse/HUDI-372
> Project: Apache Hudi (incubating)
> Issue Type: Bug
>Reporter: lamber-ken
>Assignee: lamber-ken
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Fix the shortName of DataSouce, after this issue, we can use this command
> like this
> {code:java}
> spark.read.format("hudi")
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [incubator-hudi] lamber-ken commented on a change in pull request #1054: [HUDI-372] Support the shortName for Hudi DataSource
lamber-ken commented on a change in pull request #1054: [HUDI-372] Support the shortName for Hudi DataSource URL: https://github.com/apache/incubator-hudi/pull/1054#discussion_r351552235 ## File path: hudi-spark/src/main/resources/META-INF/services/org.apache.spark.sql.sources.DataSourceRegister ## @@ -0,0 +1,19 @@ + +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + + +org.apache.hudi.DefaultSource Review comment: done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on a change in pull request #1054: [HUDI-372] Support the shortName for Hudi DataSource
lamber-ken commented on a change in pull request #1054: [HUDI-372] Support the
shortName for Hudi DataSource
URL: https://github.com/apache/incubator-hudi/pull/1054#discussion_r351551514
##
File path: hudi-spark/src/test/scala/TestDataSource.scala
##
@@ -63,6 +63,19 @@ class TestDataSource extends AssertionsForJUnit {
fs = FSUtils.getFs(basePath, spark.sparkContext.hadoopConfiguration)
}
+ @Test def testShotNameStorage() {
Review comment:
good catch
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (HUDI-309) General Redesign of Archived Timeline for efficient scan and management
[ https://issues.apache.org/jira/browse/HUDI-309?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16984047#comment-16984047 ] Raymond Xu commented on HUDI-309: - [~nicholasjiang] I think the design in "Description" is meant for treating pair as an event (like a message consumed from Kafka) and then append it to some metadata log files, which will then be compacted into HFile for future query purpose. I think for the same active timeline, commitTime is the natural identifier for commit metadata. ([~vinoth] [~vbalaji] please correct me if I misunderstand it) So far my concern for this design is in the action type partition: as the action types are fixed to a small number, the files under each type partition will keep growing. Eventually if too many files accumulated under a particular partition (say "commit/"), would that cause issue on scanning? How about, as also [~nicholasjiang] points out, partitioning by "commitTime" (converted to "/MM/dd" or "/MM" or configurable) that would set certain upper bound to the number of files? > General Redesign of Archived Timeline for efficient scan and management > --- > > Key: HUDI-309 > URL: https://issues.apache.org/jira/browse/HUDI-309 > Project: Apache Hudi (incubating) > Issue Type: New Feature > Components: Common Core >Reporter: Balaji Varadarajan >Assignee: Vinoth Chandar >Priority: Major > Fix For: 0.5.1 > > Attachments: Archive TImeline Notes by Vinoth 1.jpg, Archived > Timeline Notes by Vinoth 2.jpg > > > As designed by Vinoth: > Goals > # Archived Metadata should be scannable in the same way as data > # Provides more safety by always serving committed data independent of > timeframe when the corresponding commit action was tried. Currently, we > implicitly assume a data file to be valid if its commit time is older than > the earliest time in the active timeline. While this works ok, any inherent > bugs in rollback could inadvertently expose a possibly duplicate file when > its commit timestamp becomes older than that of any commits in the timeline. > # We had to deal with lot of corner cases because of the way we treat a > "commit" as special after it gets archived. Examples also include Savepoint > handling logic by cleaner. > # Small Files : For Cloud stores, archiving simply moves fils from one > directory to another causing the archive folder to grow. We need a way to > efficiently compact these files and at the same time be friendly to scans > Design: > The basic file-group abstraction for managing file versions for data files > can be extended to managing archived commit metadata. The idea is to use an > optimal format (like HFile) for storing compacted version of Metadata> pairs. Every archiving run will read pairs > from active timeline and append to indexable log files. We will run periodic > minor compactions to merge multiple log files to a compacted HFile storing > metadata for a time-range. It should be also noted that we will partition by > the action types (commit/clean). This design would allow for the archived > timeline to be queryable for determining whether a timeline is valid or not. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [incubator-hudi] tooptoop4 commented on issue #750: Adding support for optional skipping single archiving failures
tooptoop4 commented on issue #750: Adding support for optional skipping single archiving failures URL: https://github.com/apache/incubator-hudi/pull/750#issuecomment-559253002 @RonBarabash does this fix issue with 0 byte .commit file? also how are u running hudi with spark 2.4? did u change spark version reference in hudi pom.xm!? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] pushpavanthar edited a comment on issue #969: [HUDI-251] JDBC incremental load to HUDI DeltaStreamer
pushpavanthar edited a comment on issue #969: [HUDI-251] JDBC incremental load to HUDI DeltaStreamer URL: https://github.com/apache/incubator-hudi/pull/969#issuecomment-559230742 Hi @vinothchandar and @taherk77 I would like to add 2 points to this feature to make this very generic - [ ] We might need support for combination of incrementing columns. Incrementing columns can be of below types 1. Timestamp columns 2. Auto Incrementing column 3. Timestamp + Auto Incrementing. Instead of code figuring out the incremental pull strategy, it'll be better if user provides it as config for each table. Considering Timestamp incrementing column, there can be more than once column contributing to this strategy. e.g. When a row is creation, only `created_at` column is set and `updated_at` is null by default. When the same row is updated, `updated_at` gets assigned to some timestamp. In such cases it is wise to consider both columns in the query formation. - [ ] We need to sort rows according to above mentioned incrementing columns to fetch rows in chunks (you can make use of `defaultFetchSize` in MySQL). I'm aware that sorting adds load on Database, but it helps in tracking the last pulled timestamp or auto incrementing id and help retry/resume from the point last recorded. This will be a saviour during failures. A sample MySQL query for incrementing timestamp columns as (`created_at` and `updated_at`) might look like `SELECT * FROM inventory.customers WHERE COALESCE(inventory.customers.updated_at, inventory.customers.created_at) > $last_recorder_time AND COALESCE(inventory.customers.updated_at,inventory.customers.created_at) < $current_time ORDER BY COALESCE(inventory.customers.updated_at,inventory.customers.created_at) ASC` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] pushpavanthar edited a comment on issue #969: [HUDI-251] JDBC incremental load to HUDI DeltaStreamer
pushpavanthar edited a comment on issue #969: [HUDI-251] JDBC incremental load to HUDI DeltaStreamer URL: https://github.com/apache/incubator-hudi/pull/969#issuecomment-559230742 I would like to add 2 points to this feature to make this very generic - [ ] We might need support for combination of incrementing columns. Incrementing columns can be of below types 1. Timestamp columns 2. Auto Incrementing column 3. Timestamp + Auto Incrementing. Instead of code figuring out the incremental pull strategy, it'll be better if user provides it as config for each table. Considering Timestamp incrementing column, there can be more than once column contributing to this strategy. e.g. When a row is creation, only `created_at` column is set and `updated_at` is null by default. When the same row is updated, `updated_at` gets assigned to some timestamp. In such cases it is wise to consider both columns in the query formation. - [ ] We need to sort rows according to above mentioned incrementing columns to fetch rows in chunks (you can make use of `defaultFetchSize` in MySQL). I'm aware that sorting adds load on Database, but it helps in tracking the last pulled timestamp or auto incrementing id and help retry/resume from the point last recorded. This will be a saviour during failures. A sample MySQL query for incrementing timestamp columns as (`created_at` and `updated_at`) might look like `SELECT * FROM inventory.customers WHERE COALESCE(inventory.customers.updated_at, inventory.customers.created_at) > $last_recorder_time AND COALESCE(inventory.customers.updated_at,inventory.customers.created_at) < $current_time ORDER BY COALESCE(inventory.customers.updated_at,inventory.customers.created_at) ASC` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] pushpavanthar commented on issue #969: [HUDI-251] JDBC incremental load to HUDI DeltaStreamer
pushpavanthar commented on issue #969: [HUDI-251] JDBC incremental load to HUDI DeltaStreamer URL: https://github.com/apache/incubator-hudi/pull/969#issuecomment-559230742 I would like to add 2 points to this feature to make this very generic - [ ] We might need support for combination of more than one incrementing columns. Incrementing columns can be of below types 1. Timestamp column 2. Auto Incrementing column 3. Timestamp + Auto Incrementing. Instead of code figuring out the incremental pull strategy, it'll be better if user provide it from config for each table. When accepting Timestamp incrementing column, there can be more than once columns contributing to this strategy. e.g. During a row is creation only `created_at` column is set and let's say `updated_at` is null by default. When the same row is updated, `updated_at` gets assigned to some timestamp. In such scenarios its wise to consider both columns in your query formation. - [ ] We need to sort rows according to above mentioned incrementing columns to fetch rows in chunks (you can make use of `defaultFetchSize` for MySQL). I understand this adds load on Database, but this tracks the last pulled timestamp or auto incrementing column and helps retry from that point for consecutive batches. This will be a saviour during failures. A sample MySQL query for incrementing timestamp columns as (`created_at` and `updated_at`) might look like `SELECT * FROM inventory.customers WHERE COALESCE(inventory.customers.updated_at, inventory.customers.created_at) > $last_recorder_time AND COALESCE(inventory.customers.updated_at,inventory.customers.created_at) < $current_time ORDER BY COALESCE(inventory.customers.updated_at,inventory.customers.created_at) ASC` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] nsivabalan commented on issue #1021: how can i deal this problem when partition's value changed with the same row_key?
nsivabalan commented on issue #1021: how can i deal this problem when
partition's value changed with the same row_key?
URL: https://github.com/apache/incubator-hudi/issues/1021#issuecomment-559224596
@vinothchandar : I found the root cause.
within HoodieGlobalIndex#explodeRecordRDDWithFileComparisons
```
JavaRDD> explodeRecordRDDWithFileComparisons(
final Map> partitionToFileIndexInfo,
JavaPairRDD partitionRecordKeyPairRDD) {
.
.
.
return partitionRecordKeyPairRDD.map(partitionRecordKeyPair -> {
String recordKey = partitionRecordKeyPair._2();
String partitionPath = partitionRecordKeyPair._1();
return indexFileFilter.getMatchingFiles(partitionPath,
recordKey).stream()
.map(file -> new Tuple2<>(file, new HoodieKey(recordKey,
indexToPartitionMap.get(file
.collect(Collectors.toList());
}).flatMap(List::iterator);
```
In this, indexFileFilter.getMatchingFiles(partitionPath, recordKey) returns
fileId from Partition1, where as incoming record is tagged with Partition2.
So, this is what I am thinking as the fix. as of now,
IndexFileFilter.getMatchingFiles(String partitionPath, String recordKey) is
returning Sets. Instead, IndexFileFilter.getMatchingFiles(String
partitionPath, String recordKey) should return Set>
and we should attach that as below.
```
return partitionRecordKeyPairRDD.map(partitionRecordKeyPair -> {
String recordKey = partitionRecordKeyPair._2();
String partitionPath = partitionRecordKeyPair._1();
return indexFileFilter.getMatchingFiles(partitionPath,
recordKey).stream()
.map( (origPartitionPath, matchingFile) -> new
Tuple2<>(matchingFile, new HoodieKey(recordKey, origPartitionPath)))
.collect(Collectors.toList());
}).flatMap(List::iterator);
```
But how do we intimate the user that these records are updated with
Partition1 and not Partition2 as per incoming records in upsert call?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] bschell commented on issue #1052: [HUDI-326] Add new index to suppport global update/delete
bschell commented on issue #1052: [HUDI-326] Add new index to suppport global update/delete URL: https://github.com/apache/incubator-hudi/pull/1052#issuecomment-559222366 I see, I think this feature could instead possibly be refactored into HoodieBloomIndex instead then as the logic is compatible. My thinking was that a user would use this Index only to scan extra partitions for global update/delete but could then use the normal HoodieBloomIndex by default for the improved performance. But that is more of a view than an index then. As it stands the current implementation of HoodieGlobalBloomIndex doesn't really guarantee globally unique keys either if an insert contains duplicates. This causes weird behaviors when records with duplicates are updated which is the reason why we created this Index. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] vinothchandar commented on issue #1052: [HUDI-326] Add new index to suppport global update/delete
vinothchandar commented on issue #1052: [HUDI-326] Add new index to suppport global update/delete URL: https://github.com/apache/incubator-hudi/pull/1052#issuecomment-559208611 > I have seen the JIRA that wants to set the HoodieIndex as part of the table properties. This conflicts with the usecase here. Can you help me understand the motivation of locking down the index type? The thinking was that if someone writes few commits using `HoodieBloomIndex` and then later switches to `HoodieGlobalBloomIndex` for e.g , then it won't guarantee globally unique keys as he/she might expect, since the first set of commits may have duplicates across partitions. If you take HBaseIndex, that's another clear example, user cannot just switch from HoodieBloomIndex to HBase without rebuilding the index first? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (HUDI-118) Hudi CLI : Provide options for passing properties to Compactor, Cleaner and ParquetImporter
[
https://issues.apache.org/jira/browse/HUDI-118?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16983739#comment-16983739
]
Balaji Varadarajan commented on HUDI-118:
-
[~Pratyaksh]
If you look at the referenced PR :
[https://github.com/apache/incubator-hudi/pull/691], there is a new command
line parameter "--hoodie-conf" that is added. The purpose of this option is to
override the properties that we get by reading the DFS properties file. Both
DFS properties file and the overridden properties are used to construct objects
like *HoodieWriteClient*.
There are some specific CLI commands in the files (CleansCommand,
CompactionCommand, HDFSParquetImporterCommand) which invoke the corresponding
utilities scripts touched in [https://github.com/apache/incubator-hudi/pull/691]
Along with "--hoodie-conf" argument, you might also have to add "–props"
argument as they both are missing in the hoodie-cli counterpart.
To your question on HDFSParquetImporterCommand, HDFSParquetImporter (in
hudi-utilities) has the following command line arguments
```
@Parameter(names = \{"--props"}, description = "path to properties file on
localfs or dfs, with configurations for "
+ "hoodie client for importing")
public String propsFilePath = null;
@Parameter(names = \{"--hoodie-conf"}, description = "Any configuration that
can be set in the properties file "
+ "(using the CLI parameter \"--propsFilePath\") can also be passed command
line using this parameter")
public List configs = new ArrayList<>();
```
These arguments are being used to construct HoodieWriteClient
```
HoodieWriteClient client =
UtilHelpers.createHoodieClient(jsc, cfg.targetPath, schemaStr,
cfg.parallelism, Option.empty(), props);
```
We would need both --props and --hoodie-conf to be passed from
HDFSParquetImportCommand.convert.
> Hudi CLI : Provide options for passing properties to Compactor, Cleaner and
> ParquetImporter
>
>
> Key: HUDI-118
> URL: https://issues.apache.org/jira/browse/HUDI-118
> Project: Apache Hudi (incubating)
> Issue Type: Improvement
> Components: CLI, newbie
>Reporter: Balaji Varadarajan
>Assignee: Pratyaksh Sharma
>Priority: Minor
>
> For non-trivial CLI operations, we have a standalone script in hudi-utilities
> that users can call directly using spark-submit (usually). We also have
> commands in hudi-cli to invoke the commands directly from hudi-cli shell.
> There was an earlier effort to allow users to pass properties directly to the
> scripts in hudi-utilities but we still need to give the same functionality to
> the corresponding commands in hudi-cli.
> In hudi-cli, Compaction (schedule/compact), Cleaner and HDFSParquetImporter
> command does not have option to pass DFS properties file. This is a followup
> to PR [https://github.com/apache/incubator-hudi/pull/691]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [incubator-hudi] vinothchandar commented on a change in pull request #1054: [HUDI-372] Support the shortName for Hudi DataSource
vinothchandar commented on a change in pull request #1054: [HUDI-372] Support the shortName for Hudi DataSource URL: https://github.com/apache/incubator-hudi/pull/1054#discussion_r351405009 ## File path: hudi-spark/src/main/resources/META-INF/services/org.apache.spark.sql.sources.DataSourceRegister ## @@ -0,0 +1,19 @@ + +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + + +org.apache.hudi.DefaultSource Review comment: nit: new line This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] vinothchandar commented on a change in pull request #1054: [HUDI-372] Support the shortName for Hudi DataSource
vinothchandar commented on a change in pull request #1054: [HUDI-372] Support
the shortName for Hudi DataSource
URL: https://github.com/apache/incubator-hudi/pull/1054#discussion_r351404770
##
File path: hudi-spark/src/test/scala/TestDataSource.scala
##
@@ -63,6 +63,19 @@ class TestDataSource extends AssertionsForJUnit {
fs = FSUtils.getFs(basePath, spark.sparkContext.hadoopConfiguration)
}
+ @Test def testShotNameStorage() {
Review comment:
typo: short
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (HUDI-373) Refactor hudi-client based on new ImportOrder code style rule
[ https://issues.apache.org/jira/browse/HUDI-373?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-373: Labels: pull-request-available (was: ) > Refactor hudi-client based on new ImportOrder code style rule > -- > > Key: HUDI-373 > URL: https://issues.apache.org/jira/browse/HUDI-373 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [incubator-hudi] lamber-ken opened a new pull request #1056: [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule
lamber-ken opened a new pull request #1056: [HUDI-373] Refactor hudi-client based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1056 ## What is the purpose of the pull request Refactor hudi-client based on new ImportOrder code style rule ## Brief change log - Refactor hudi-client based on new ImportOrder code style rule. ## Verify this pull request This pull request is a code cleanup without any test coverage. ## Committer checklist - [x] Has a corresponding JIRA in PR title & commit - [x] Commit message is descriptive of the change - [x] CI is green - [x] Necessary doc changes done or have another open PR - [x] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Resolved] (HUDI-366) Refactor some module codes based on new ImportOrder codestyle rule
[ https://issues.apache.org/jira/browse/HUDI-366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lamber-ken resolved HUDI-366. - Resolution: Resolved > Refactor some module codes based on new ImportOrder codestyle rule > -- > > Key: HUDI-366 > URL: https://issues.apache.org/jira/browse/HUDI-366 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Critical > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > Refactor some module codes based on new ImportOrder codestyle rule > > hudi-hadoop-mr > hudi-timeline-service > hudi-spark > hudi-integ-test > hudi- utilities > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[incubator-hudi] branch master updated: [HUDI-366] Refactor some module codes based on new ImportOrder code style rule (#1055)
This is an automated email from the ASF dual-hosted git repository. vinoyang pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/incubator-hudi.git The following commit(s) were added to refs/heads/master by this push: new f9139c0 [HUDI-366] Refactor some module codes based on new ImportOrder code style rule (#1055) f9139c0 is described below commit f9139c0f616775f4b3d0df95772f2621f0e7c9f1 Author: 谢磊 AuthorDate: Wed Nov 27 21:32:43 2019 +0800 [HUDI-366] Refactor some module codes based on new ImportOrder code style rule (#1055) [HUDI-366] Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / hudi-integ-test / hudi- utilities based on new ImportOrder code style rule --- .../hudi/hadoop/HoodieParquetInputFormat.java | 34 +++-- .../hudi/hadoop/HoodieROTablePathFilter.java | 20 .../hudi/hadoop/RecordReaderValueIterator.java | 10 ++-- .../hadoop/SafeParquetRecordReaderWrapper.java | 3 +- .../hadoop/hive/HoodieCombineHiveInputFormat.java | 38 +++--- .../realtime/AbstractRealtimeRecordReader.java | 34 +++-- .../realtime/HoodieParquetRealtimeInputFormat.java | 46 + .../hadoop/realtime/HoodieRealtimeFileSplit.java | 3 +- .../realtime/HoodieRealtimeRecordReader.java | 6 ++- .../realtime/RealtimeCompactedRecordReader.java| 18 --- .../realtime/RealtimeUnmergedRecordReader.java | 20 .../apache/hudi/hadoop/InputFormatTestUtil.java| 28 +- .../org/apache/hudi/hadoop/TestAnnotation.java | 5 +- .../apache/hudi/hadoop/TestHoodieInputFormat.java | 10 ++-- .../hudi/hadoop/TestHoodieROTablePathFilter.java | 16 +++--- .../hudi/hadoop/TestRecordReaderValueIterator.java | 12 +++-- .../realtime/TestHoodieRealtimeRecordReader.java | 59 -- .../java/org/apache/hudi/integ/ITTestBase.java | 18 --- .../org/apache/hudi/integ/ITTestHoodieDemo.java| 6 ++- .../org/apache/hudi/integ/ITTestHoodieSanity.java | 1 + .../main/java/org/apache/hudi/BaseAvroPayload.java | 8 +-- .../java/org/apache/hudi/ComplexKeyGenerator.java | 8 +-- .../main/java/org/apache/hudi/DataSourceUtils.java | 18 --- .../org/apache/hudi/HoodieDataSourceHelpers.java | 10 ++-- .../main/java/org/apache/hudi/KeyGenerator.java| 6 ++- .../apache/hudi/NonpartitionedKeyGenerator.java| 3 +- .../hudi/OverwriteWithLatestAvroPayload.java | 10 ++-- .../main/java/org/apache/hudi/QuickstartUtils.java | 18 --- .../java/org/apache/hudi/SimpleKeyGenerator.java | 3 +- hudi-spark/src/test/java/DataSourceTestUtils.java | 7 +-- hudi-spark/src/test/java/HoodieJavaApp.java| 12 +++-- .../src/test/java/HoodieJavaStreamingApp.java | 18 --- .../timeline/service/FileSystemViewHandler.java| 24 + .../hudi/timeline/service/TimelineService.java | 16 +++--- .../timeline/service/handlers/DataFileHandler.java | 8 +-- .../service/handlers/FileSliceHandler.java | 12 +++-- .../hudi/timeline/service/handlers/Handler.java| 6 ++- .../timeline/service/handlers/TimelineHandler.java | 10 ++-- .../view/TestRemoteHoodieTableFileSystemView.java | 1 + .../apache/hudi/utilities/HDFSParquetImporter.java | 43 .../hudi/utilities/HiveIncrementalPuller.java | 32 ++-- .../org/apache/hudi/utilities/HoodieCleaner.java | 18 --- .../hudi/utilities/HoodieCompactionAdminTool.java | 18 --- .../org/apache/hudi/utilities/HoodieCompactor.java | 16 +++--- .../hudi/utilities/HoodieSnapshotCopier.java | 25 + .../hudi/utilities/HoodieWithTimelineServer.java | 11 ++-- .../org/apache/hudi/utilities/UtilHelpers.java | 26 +- .../adhoc/UpgradePayloadFromUberToApache.java | 20 .../AbstractDeltaStreamerService.java | 8 +-- .../hudi/utilities/deltastreamer/Compactor.java| 6 ++- .../hudi/utilities/deltastreamer/DeltaSync.java| 42 --- .../deltastreamer/HoodieDeltaStreamer.java | 50 +- .../deltastreamer/HoodieDeltaStreamerMetrics.java | 3 +- .../deltastreamer/SchedulerConfGenerator.java | 12 +++-- .../deltastreamer/SourceFormatAdapter.java | 11 ++-- .../exception/HoodieIncrementalPullException.java | 3 +- .../keygen/TimestampBasedKeyGenerator.java | 18 --- .../hudi/utilities/perf/TimelineServerPerf.java| 36 ++--- .../utilities/schema/FilebasedSchemaProvider.java | 12 +++-- .../schema/NullTargetSchemaRegistryProvider.java | 3 +- .../utilities/schema/RowBasedSchemaProvider.java | 3 +- .../hudi/utilities/schema/SchemaProvider.java | 6 ++- .../utilities/schema/SchemaRegistryProvider.java | 12 +++-- .../hudi/utilities/sources/AvroDFSSource.java | 9 ++-- .../hudi/utilities/sources/AvroKafkaSource.java| 7 +-- .../apache/hudi/utilities/sources/AvroSource.java | 3 +-
[GitHub] [incubator-hudi] yanghua merged pull request #1055: [HUDI-366] Refactor some module codes based on new ImportOrder code style rule
yanghua merged pull request #1055: [HUDI-366] Refactor some module codes based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1055 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (HUDI-366) Refactor some module codes based on new ImportOrder codestyle rule
[ https://issues.apache.org/jira/browse/HUDI-366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lamber-ken updated HUDI-366: Summary: Refactor some module codes based on new ImportOrder codestyle rule (was: Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / hudi-integ-test based on new ImportOrder code style rule) > Refactor some module codes based on new ImportOrder codestyle rule > -- > > Key: HUDI-366 > URL: https://issues.apache.org/jira/browse/HUDI-366 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Critical > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Refactor some module codes based on new ImportOrder codestyle rule > > hudi-hadoop-mr > hudi-timeline-service > hudi-spark > hudi-integ-test > hudi- utilities > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-366) Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / hudi-integ-test based on new ImportOrder code style rule
[ https://issues.apache.org/jira/browse/HUDI-366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lamber-ken updated HUDI-366: Description: Refactor some module codes based on new ImportOrder codestyle rule hudi-hadoop-mr hudi-timeline-service hudi-spark hudi-integ-test hudi- utilities was:Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / hudi-integ-test based on new ImportOrder code style rule > Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / > hudi-integ-test based on new ImportOrder code style rule > > > Key: HUDI-366 > URL: https://issues.apache.org/jira/browse/HUDI-366 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Critical > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Refactor some module codes based on new ImportOrder codestyle rule > > hudi-hadoop-mr > hudi-timeline-service > hudi-spark > hudi-integ-test > hudi- utilities > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [incubator-hudi] lamber-ken commented on issue #1055: [HUDI-366] Refactor some mudule codes based on new ImportOrder code style rule
lamber-ken commented on issue #1055: [HUDI-366] Refactor some mudule codes based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1055#issuecomment-559064720 hi, @yanghua help to review, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (HUDI-118) Hudi CLI : Provide options for passing properties to Compactor, Cleaner and ParquetImporter
[ https://issues.apache.org/jira/browse/HUDI-118?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16983461#comment-16983461 ] Pratyaksh Sharma commented on HUDI-118: --- [~vbalaji] Yes the description is now clear. I am trying to understand the flow of the concerned commands (CleansCommand, CompactionCommand, HDFSParquetImporterCommand). IIUC, DFS properties file is needed to initiate HoodieTableMetaClient in CleansCommand and CompactionCommand since in these two, it is never getting initialised. However I am not able to understand the use case of adding the same in HDFSParquetImporterCommand. Would be great if you could help me here with your valuable inputs. > Hudi CLI : Provide options for passing properties to Compactor, Cleaner and > ParquetImporter > > > Key: HUDI-118 > URL: https://issues.apache.org/jira/browse/HUDI-118 > Project: Apache Hudi (incubating) > Issue Type: Improvement > Components: CLI, newbie >Reporter: Balaji Varadarajan >Assignee: Pratyaksh Sharma >Priority: Minor > > For non-trivial CLI operations, we have a standalone script in hudi-utilities > that users can call directly using spark-submit (usually). We also have > commands in hudi-cli to invoke the commands directly from hudi-cli shell. > There was an earlier effort to allow users to pass properties directly to the > scripts in hudi-utilities but we still need to give the same functionality to > the corresponding commands in hudi-cli. > In hudi-cli, Compaction (schedule/compact), Cleaner and HDFSParquetImporter > command does not have option to pass DFS properties file. This is a followup > to PR [https://github.com/apache/incubator-hudi/pull/691] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-373) Refactor hudi-client based on new ImportOrder code style rule
[ https://issues.apache.org/jira/browse/HUDI-373?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lamber-ken updated HUDI-373: Summary: Refactor hudi-client based on new ImportOrder code style rule (was: 1. Refactor hudi-client based on new ImportOrder code style rule) > Refactor hudi-client based on new ImportOrder code style rule > -- > > Key: HUDI-373 > URL: https://issues.apache.org/jira/browse/HUDI-373 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-373) 1. Refactor hudi-client based on new ImportOrder code style rule
lamber-ken created HUDI-373: --- Summary: 1. Refactor hudi-client based on new ImportOrder code style rule Key: HUDI-373 URL: https://issues.apache.org/jira/browse/HUDI-373 Project: Apache Hudi (incubating) Issue Type: Sub-task Reporter: lamber-ken -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (HUDI-369) Refactor hudi-utilities based on new ImportOrder code style rule
[ https://issues.apache.org/jira/browse/HUDI-369?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] lamber-ken closed HUDI-369. --- Resolution: Done > Refactor hudi-utilities based on new ImportOrder code style rule > > > Key: HUDI-369 > URL: https://issues.apache.org/jira/browse/HUDI-369 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-366) Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / hudi-integ-test based on new ImportOrder code style rule
[ https://issues.apache.org/jira/browse/HUDI-366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-366: Labels: pull-request-available (was: ) > Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / > hudi-integ-test based on new ImportOrder code style rule > > > Key: HUDI-366 > URL: https://issues.apache.org/jira/browse/HUDI-366 > Project: Apache Hudi (incubating) > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Critical > Labels: pull-request-available > > Refactor hudi-hadoop-mr / hudi-timeline-service / hudi-spark / > hudi-integ-test based on new ImportOrder code style rule -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [incubator-hudi] lamber-ken opened a new pull request #1055: [HUDI-366] Refactor some mudule codes based on new ImportOrder code style rule
lamber-ken opened a new pull request #1055: [HUDI-366] Refactor some mudule codes based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1055 ## What is the purpose of the pull request Refactor some mudule codes based on new ImportOrder code style rule. - hudi-hadoop-mr - hudi-timeline-service - hudi-spark - hudi-integ-test - hudi- utilities ## Brief change log - Modify some module codes ## Verify this pull request This pull request is a trivial rework code cleanup without any test coverage. ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (HUDI-372) Support the shortName for Hudi DataSouce
[
https://issues.apache.org/jira/browse/HUDI-372?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-372:
Labels: pull-request-available (was: )
> Support the shortName for Hudi DataSouce
>
>
> Key: HUDI-372
> URL: https://issues.apache.org/jira/browse/HUDI-372
> Project: Apache Hudi (incubating)
> Issue Type: Bug
>Reporter: lamber-ken
>Assignee: lamber-ken
>Priority: Major
> Labels: pull-request-available
>
> Fix the shortName of DataSouce, after this issue, we can use this command
> like this
> {code:java}
> spark.read.format("hudi")
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [incubator-hudi] lamber-ken opened a new pull request #1054: [HUDI-372] Support the shortName for Hudi DataSouce
lamber-ken opened a new pull request #1054: [HUDI-372] Support the shortName
for Hudi DataSouce
URL: https://github.com/apache/incubator-hudi/pull/1054
## What is the purpose of the pull request
Support the shortName for Hudi DataSouce, we can use shortName like
```
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath);
```
## Brief change log
- Add org.apache.spark.sql.sources.DataSourceRegister to META-INF/services
- Add test
## Verify this pull request
This pull request is already covered by existing tests, such as
`TestDataSource#testShotNameStorage`.
## Committer checklist
- [ ] Has a corresponding JIRA in PR title & commit
- [ ] Commit message is descriptive of the change
- [ ] CI is green
- [ ] Necessary doc changes done or have another open PR
- [ ] For large changes, please consider breaking it into sub-tasks under
an umbrella JIRA.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (HUDI-372) Support the shortName for Hudi DataSouce
[
https://issues.apache.org/jira/browse/HUDI-372?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
lamber-ken updated HUDI-372:
Summary: Support the shortName for Hudi DataSouce (was: Fix the shortName
of DataSouce)
> Support the shortName for Hudi DataSouce
>
>
> Key: HUDI-372
> URL: https://issues.apache.org/jira/browse/HUDI-372
> Project: Apache Hudi (incubating)
> Issue Type: Bug
>Reporter: lamber-ken
>Assignee: lamber-ken
>Priority: Major
>
> Fix the shortName of DataSouce, after this issue, we can use this command
> like this
> {code:java}
> spark.read.format("hudi")
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HUDI-184) Integrate Hudi with Apache Flink
[ https://issues.apache.org/jira/browse/HUDI-184?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16983313#comment-16983313 ] vinoyang commented on HUDI-184: --- [~vinoth] I wrote more thought in a Google doc, please see here: [https://docs.google.com/document/d/1wDTpzuehfcDYMTD3c-lJqIiP1rt095XBzdZoPYMTvlY/edit?usp=sharing] Please feel free to share your comments. > Integrate Hudi with Apache Flink > > > Key: HUDI-184 > URL: https://issues.apache.org/jira/browse/HUDI-184 > Project: Apache Hudi (incubating) > Issue Type: New Feature > Components: Write Client >Reporter: vinoyang >Assignee: vinoyang >Priority: Major > > Apache Flink is a popular streaming processing engine. > Integrating Hudi with Flink is a valuable work. > The discussion mailing thread is here: > [https://lists.apache.org/api/source.lua/1533de2d4cd4243fa9e8f8bf057ffd02f2ac0bec7c7539d8f72166ea@%3Cdev.hudi.apache.org%3E] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HUDI-288) Add support for ingesting multiple kafka streams in a single DeltaStreamer deployment
[
https://issues.apache.org/jira/browse/HUDI-288?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16983307#comment-16983307
]
Pratyaksh Sharma commented on HUDI-288:
---
[~xleesf] Here is what I have done -
Basically we want to have single instance running for multiple tables in one
go. But Hudi supports single topic and single target path with 1-1 mapping. To
overcome this, we wrote a wrapper to incorporate the following topic/table
overrides ->
1. Have separate topic for each table
2. Have separate record key and partition path for each table
3. Have separate schema-registry url for each table
4. Have separate hive_sync database and hive_sync table for every table
5. Support customised key generators for every table based on how the partition
path field is formatted and also specify the same format as a config
6. Target base path has a one to one mapping with topic. To achieve this,
target path was designed using the format -
// (this
customization was done in wrapper after reading the args passed with
spark-submit command)
7. Similar format is adopted for target_table_name as well, which is used at
the time of registering the metrics.
Custom POJO TableConfig is used to maintain all table/topic specific properties
and the corresponding JSON objects are written in the form of a list in a
separate file. The same needs to be passed to spark-submit command using
--files option. Wrapper reads this file and iterates over all the TableConfig
objects. It creates one HoodieDeltaStreamer instance for each such object and
hence does the ingestion for every topic running in a loop. This wrapper is
scheduled via oozie. Here is a sample TableConfig object -
{
"id":
"record_key_field": "",
"partition_key_field": "",
"kafka_topic": "",
"partition_input_format": "-MM-dd HH:mm:ss.S"
}
We can keep on adding more topic specific overrides as per our need and use
case. This design supports ingestion should run once for any table and not in
continuous mode. We can discuss further to see how we can support continuous
mode for all the tables using this wrapper.
Please let me know if this makes sense.
> Add support for ingesting multiple kafka streams in a single DeltaStreamer
> deployment
> -
>
> Key: HUDI-288
> URL: https://issues.apache.org/jira/browse/HUDI-288
> Project: Apache Hudi (incubating)
> Issue Type: Improvement
> Components: deltastreamer
>Reporter: Vinoth Chandar
>Assignee: leesf
>Priority: Major
>
> https://lists.apache.org/thread.html/3a69934657c48b1c0d85cba223d69cb18e18cd8aaa4817c9fd72cef6@
> has all the context
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (HUDI-372) Fix the shortName of DataSouce
[
https://issues.apache.org/jira/browse/HUDI-372?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
lamber-ken reassigned HUDI-372:
---
Assignee: lamber-ken
> Fix the shortName of DataSouce
> --
>
> Key: HUDI-372
> URL: https://issues.apache.org/jira/browse/HUDI-372
> Project: Apache Hudi (incubating)
> Issue Type: Bug
>Reporter: lamber-ken
>Assignee: lamber-ken
>Priority: Major
>
> Fix the shortName of DataSouce, after this issue, we can use this command
> like this
> {code:java}
> spark.read.format("hudi")
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (HUDI-372) Fix the shortName of DataSouce
lamber-ken created HUDI-372:
---
Summary: Fix the shortName of DataSouce
Key: HUDI-372
URL: https://issues.apache.org/jira/browse/HUDI-372
Project: Apache Hudi (incubating)
Issue Type: Bug
Reporter: lamber-ken
Fix the shortName of DataSouce, after this issue, we can use this command like
this
{code:java}
spark.read.format("hudi")
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (HUDI-364) Refactor hudi-hive based on new ImportOrder code style rule
[ https://issues.apache.org/jira/browse/HUDI-364?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang resolved HUDI-364. --- Resolution: Done Done via b77fad39b53049279bba1ba367f43cce73f48bfa > Refactor hudi-hive based on new ImportOrder code style rule > --- > > Key: HUDI-364 > URL: https://issues.apache.org/jira/browse/HUDI-364 > Project: Apache Hudi (incubating) > Issue Type: Sub-task > Components: Hive Integration >Reporter: lamber-ken >Assignee: lamber-ken >Priority: Critical > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > Refactor hudi-hive based on new ImportOrder code style rule -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [incubator-hudi] yanghua merged pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule
yanghua merged pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1048 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[incubator-hudi] branch master updated (d6e83e8 -> b77fad3)
This is an automated email from the ASF dual-hosted git repository. vinoyang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-hudi.git. from d6e83e8 [HUDI-325] Fix Hive partition error for updated HDFS Hudi table (#1001) add b77fad3 [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule (#1048) No new revisions were added by this update. Summary of changes: .../hudi/common/util/collection/DiskBasedMap.java | 3 +- .../java/org/apache/hudi/hive/HiveSyncConfig.java | 1 + .../java/org/apache/hudi/hive/HiveSyncTool.java| 21 +- .../org/apache/hudi/hive/HoodieHiveClient.java | 4 +- .../hudi/hive/MultiPartKeysValueExtractor.java | 1 + .../org/apache/hudi/hive/SchemaDifference.java | 3 +- .../SlashEncodedDayPartitionValueExtractor.java| 3 +- .../apache/hudi/hive/util/ColumnNameXLator.java| 1 + .../java/org/apache/hudi/hive/util/SchemaUtil.java | 22 +- .../org/apache/hudi/hive/TestHiveSyncTool.java | 24 ++- .../test/java/org/apache/hudi/hive/TestUtil.java | 48 +++--- .../org/apache/hudi/hive/util/HiveTestService.java | 20 + .../adhoc/UpgradePayloadFromUberToApache.java | 2 +- style/checkstyle.xml | 2 +- 14 files changed, 84 insertions(+), 71 deletions(-)
[GitHub] [incubator-hudi] yanghua commented on a change in pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule
yanghua commented on a change in pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1048#discussion_r351141351 ## File path: style/checkstyle.xml ## @@ -34,7 +34,7 @@ - + Review comment: OK This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on a change in pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule
lamber-ken commented on a change in pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1048#discussion_r351140686 ## File path: style/checkstyle.xml ## @@ -34,7 +34,7 @@ - + Review comment: No impact This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] yanghua commented on a change in pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule
yanghua commented on a change in pull request #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1048#discussion_r351139023 ## File path: style/checkstyle.xml ## @@ -34,7 +34,7 @@ - + Review comment: If we change this level, whether it would break the build progress for those modules which do not refactor the import orders currently? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule
lamber-ken commented on issue #1048: [HUDI-364] Refactor hudi-hive based on new ImportOrder code style rule URL: https://github.com/apache/incubator-hudi/pull/1048#issuecomment-558974640 @yanghua hi, build ok. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services