[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first countByKey it have 22 and on the HoodieBloomIndex its 2 as observed from the Spark UI below.  The effect is clearly seen as we increase the size of the input data from 2 GB to 27 GB. For stage 2, 3, and 4, it was using the 90 executors as provided and decreases it accordingly. While for stage 5, only 2 executors were running from the start.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as a configuration? In general, are there specific ways to enhance the performance of bloom indexing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  The effect is clearly seen as we increase the size of the input data from 2 GB to 27 GB. For stage 2, 3, and 4, it was using the 90 executors as provided and decreases it accordingly. While for stage 5, only 2 executors were running from the start.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as a configuration? In general, are there specific ways to enhance the performance of bloom indexing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  The effect is clearly seen as we increase the size of the input data from 2 GB to 27 GB. For stage 2, 3, and 4, it was using the 90 executors as provided and decreases it accordingly. While for stage 5, only 2 executors were only running from the start.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as a configuration? In general, are there specific ways to enhance the performance of bloom indexing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  The effect is clearly seen as we increase the size of the input data from 2 GB to 27 GB. For stage 2, 3, and 4, it was using the 90 executors as provided and decreases it accordingly. While for stage 5, 2 executors were only running from the start.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as a configuration? In general, are there specific ways to enhance the performance of bloom indexing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  The effect is clearly seen as we increase the size of the input data from 2 GB to 27 GB.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as a configuration? In general, are there specific ways to enhance the performance of bloom indexing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  The effect is clearly seen as we increase the size of the input data from 2 GB to 27 GB.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as configuration? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This change seems to occur due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as configuration? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This seems of due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism for bloom index inside without the need to set it as configuration? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This seems of due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below.  How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism inside without the need to set it as configuration? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code to the countByKey for counting the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This seems of due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below. How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism inside without the need to set it as configuration?  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-516753477 After i used hoodie 0.4.6 version, the performance improved and now its taking 4 minutes.  I also added a similar code of the countByKey to count the records in the HoodieDeltaStreamer class and check why its taking long in the HoodieBloomIndex and it took about 9 seconds. While the countByKey of the HoodieBloomIndex is still taking 39 seconds. This seems of due to parallelism because on the first count it have 22 and on the HoodieBloom index its 2 as observed from the Spark UI below. How do we enhance the parallelism of the bloom index since hoodie is calculating the parallelism inside without the need to set it as configuration?  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-513581765 @vinothchandar, yes am on slack and next week sounds good. We can do it on Monday or Tuesday. The time zone here is Central European Summer Time (GMT + 2) and I think we have 9 hours time zone difference . So we can arrange a time which is convenient for both of us, like evening time here and morning time there or any other suggestion if you have. Does this work for you? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-511349113 I changed the driver memory and number of executors to be: spark.driver.memory = 7168m spark.executor.memory = 1024m spark.executor.instances =20 And in addition, i added the following settings: ``` spark.yarn.driver.memoryOverhead =1024 spark.yarn.executor.memoryOverhead=3072 spark.kryoserializer.buffer.max=512m spark.serializer=org.apache.spark.serializer.KryoSerializer spark.shuffle.memoryFraction=0.2 spark.shuffle.service.enabled=true spark.sql.hive.convertMetastoreParquet=false spark.storage.memoryFraction=0.6 spark.rdd.compress=true ``` Then the performance improved from 38 minutes to 19 minutes. But still this is not optimized as it should be because its taking to much time for 1888 MB of data. For further follow up am attaching the spark UI of job with the changed configurations.   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-511349113 I changed the driver memory and number of executors to be: spark.driver.memory = 7168m spark.executor.memory = 1024m spark.executor.instances =20 And in addition, i added the following settings: ``` spark.yarn.driver.memoryOverhead =1024 spark.yarn.executor.memoryOverhead=3072 spark.kryoserializer.buffer.max=512m spark.serializer=org.apache.spark.serializer.KryoSerializer spark.shuffle.memoryFraction=0.2 spark.shuffle.service.enabled=true spark.sql.hive.convertMetastoreParquet=false spark.storage.memoryFraction=0.6 spark.rdd.compress=true ``` Then the performance improved from 38 minutes to 19 minutes. But still this is not optimized as it should be because its taking to much time for 1888 MB of data. For further follow up am attaching the spark UI of job with the changed configurations.   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-511349113 I changed the driver memory and number of executors to be: spark.driver.memory = 7168m spark.executor.memory = 1024m spark.executor.instances =20 And in addition, i added the following settings: ``` spark.yarn.driver.memoryOverhead =1024 spark.yarn.executor.memoryOverhead=3072 spark.kryoserializer.buffer.max=512m spark.serializer=org.apache.spark.serializer.KryoSerializer spark.shuffle.memoryFraction=0.2 spark.shuffle.service.enabled=true spark.sql.hive.convertMetastoreParquet=false spark.storage.memoryFraction=0.6 spark.rdd.compress=true ``` Then the performance improved from 38 minutes to 19 minutes. But still this is not optimized as it should be because its taking to much time for 1888 MB of data. For further follow up am attaching the spark UI of job with the changed configurations.   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-511349113 I changed the driver memory and number of executors to be: spark.driver.memory = 7168m spark.executor.memory = 1024m spark.executor.instances =20 And in addition, i added the following settings: ``` spark.yarn.driver.memoryOverhead =1024 spark.yarn.executor.memoryOverhead=3072 spark.kryoserializer.buffer.max=512m spark.serializer=org.apache.spark.serializer.KryoSerializer spark.shuffle.memoryFraction=0.2 spark.shuffle.service.enabled=true spark.sql.hive.convertMetastoreParquet=false spark.storage.memoryFraction=0.6 spark.rdd.compress=true ``` Then the performance improved from 38 minutes to 19 minutes. But still this is not optimized as it should be because its taking to much time for 1888 MB of data. For further follow up am attaching the spark UI of job with the changed configurations.   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-510818215 The failures are: ``` org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 3 at org.apache.spark.MapOutputTracker$$anonfun$convertMapStatuses$2.apply(MapOutputTracker.scala:882) at org.apache.spark.MapOutputTracker$$anonfun$convertMapStatuses$2.apply(MapOutputTracker.scala:878) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at org.apache.spark.MapOutputTracker$.convertMapStatuses(MapOutputTracker.scala:878) at org.apache.spark.MapOutputTrackerWorker.getMapSizesByExecutorId(MapOutputTracker.scala:691) at org.apache.spark.shuffle.BlockStoreShuffleReader.read(BlockStoreShuffleReader.scala:49) at org.apache.spark.rdd.CoGroupedRDD$$anonfun$compute$2.apply(CoGroupedRDD.scala:148) at org.apache.spark.rdd.CoGroupedRDD$$anonfun$compute$2.apply(CoGroupedRDD.scala:137) at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:733) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:732) at org.apache.spark.rdd.CoGroupedRDD.compute(CoGroupedRDD.scala:137) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:337) at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:335) at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1182) at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1156) at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1091) at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1156) at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:882) at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:335) at org.apache.spark.rdd.RDD.iterator(RDD.scala:286) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) ``` In addition, stage 2 is showing that the input size is 1888.8 MB while stage 21 its showing 6.6 GB. Is this showing that a total of 6.6 GB is written as a hoodie modeled table? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [incubator-hudi] NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI
NetsanetGeb edited a comment on issue #714: Performance Comparison of HoodieDeltaStreamer and DataSourceAPI URL: https://github.com/apache/incubator-hudi/issues/714#issuecomment-510569606 **Benchmarking Hudi Upsert** I am trying to bench mark Hudi upsert operation and the latency of ingesting 6 GB of data is 38 minutes with the cluster i provided. How can i enhance this? For my specific use case, i used a spliced JSON data source with the schema having 20 columns. The settings i used for a cluster with (30 GB of RAM and 100 GB available disk) are: spark.driver.memory = 4096m spark.executor.memory = 6144m spark.executor.instances =3 spark.driver.cores =1 spark.executor.cores =1 hoodie.datasource.write.operation="upsert" hoodie.upsert.shuffle.parallellism="1500" You can see the details from the UI of the spark job provided below: 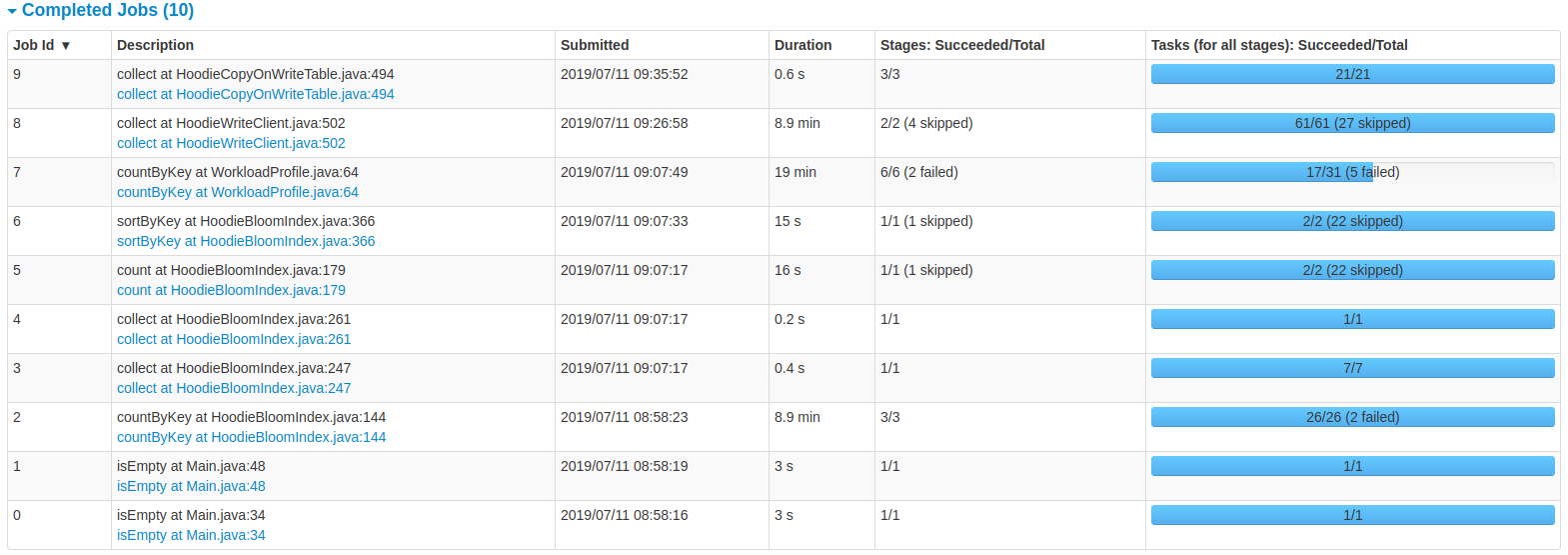 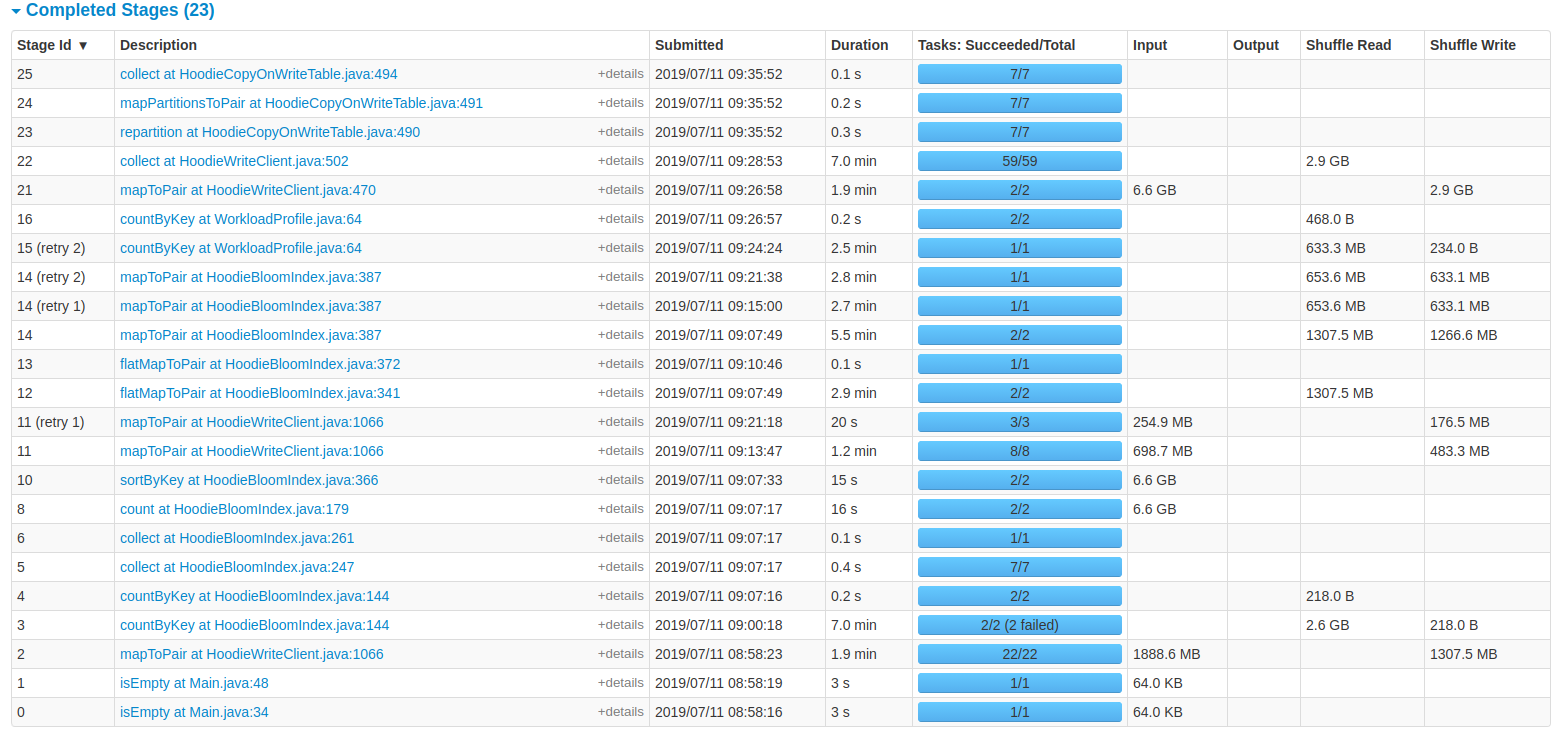 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services