This is an automated email from the ASF dual-hosted git repository.
lixiao pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 870f972 [SPARK-28104][SQL] Implement Spark's own GetColumnsOperation
870f972 is described below
commit 870f972dcc7b2b0e5bea2ae64f2c9598c681eddf
Author: Yuming Wang <yumw...@ebay.com>
AuthorDate: Sat Jun 22 09:15:07 2019 -0700
[SPARK-28104][SQL] Implement Spark's own GetColumnsOperation
## What changes were proposed in this pull request?
[SPARK-24196](https://issues.apache.org/jira/browse/SPARK-24196) and
[SPARK-24570](https://issues.apache.org/jira/browse/SPARK-24570) implemented
Spark's own `GetSchemasOperation` and `GetTablesOperation`. This pr implements
Spark's own `GetColumnsOperation`.
## How was this patch tested?
unit tests and manual tests:
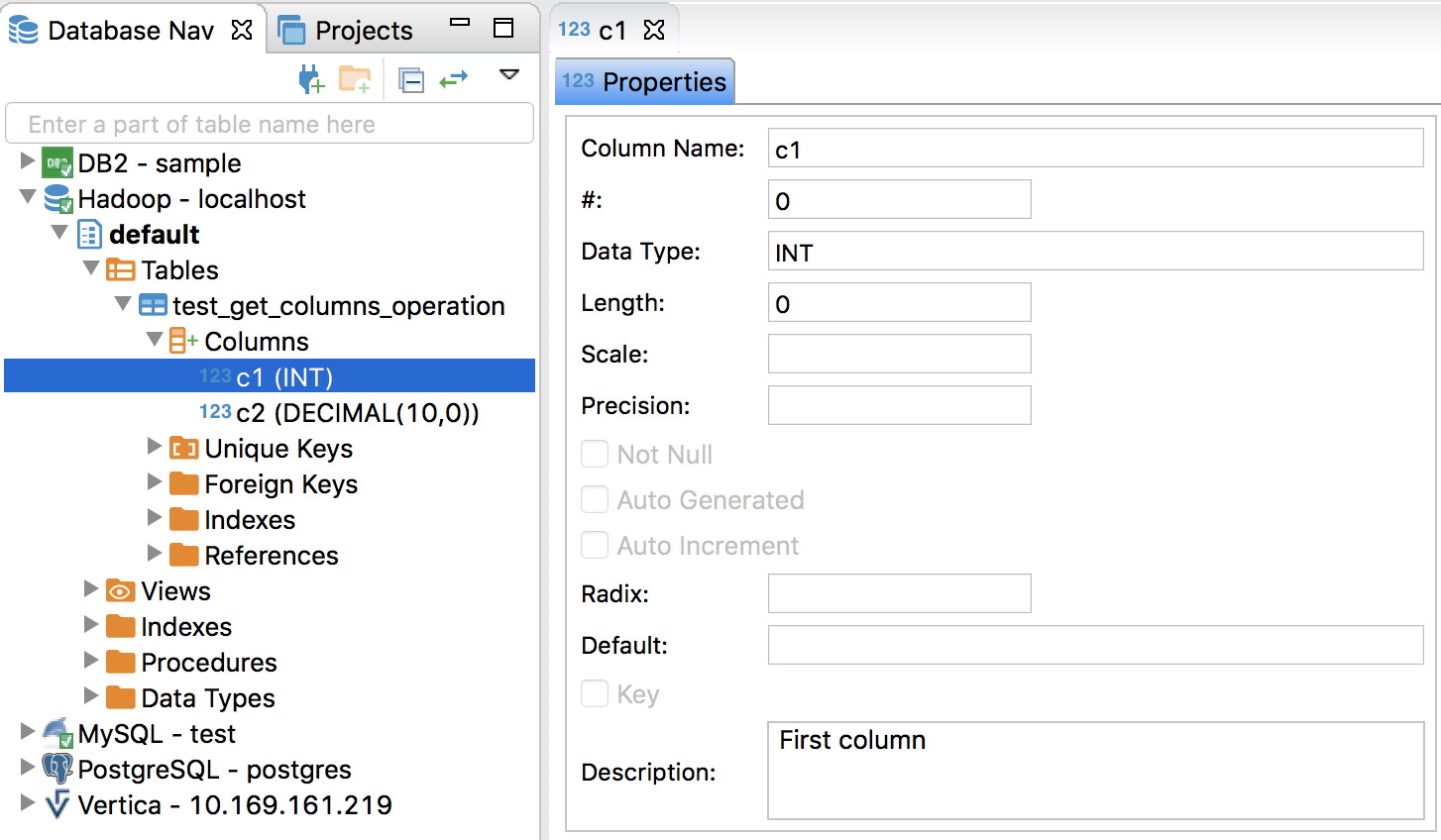
Closes #24906 from wangyum/SPARK-28104.
Authored-by: Yuming Wang <yumw...@ebay.com>
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
---
.../thriftserver/SparkGetColumnsOperation.scala | 142 +++++++++++++++++++++
.../server/SparkSQLOperationManager.scala | 20 ++-
.../thriftserver/HiveThriftServer2Suites.scala | 9 +-
.../thriftserver/SparkMetadataOperationSuite.scala | 92 ++++++++++++-
.../service/cli/operation/GetColumnsOperation.java | 4 +-
.../hive/thriftserver/ThriftserverShimUtils.scala | 5 +-
.../service/cli/operation/GetColumnsOperation.java | 4 +-
.../hive/thriftserver/ThriftserverShimUtils.scala | 4 +
8 files changed, 270 insertions(+), 10 deletions(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala
new file mode 100644
index 0000000..4b78e2f
--- /dev/null
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.thriftserver
+
+import java.util.UUID
+import java.util.regex.Pattern
+
+import scala.collection.JavaConverters.seqAsJavaListConverter
+
+import
org.apache.hadoop.hive.ql.security.authorization.plugin.{HiveOperationType,
HivePrivilegeObject}
+import
org.apache.hadoop.hive.ql.security.authorization.plugin.HivePrivilegeObject.HivePrivilegeObjectType
+import org.apache.hive.service.cli._
+import org.apache.hive.service.cli.operation.GetColumnsOperation
+import org.apache.hive.service.cli.session.HiveSession
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.SQLContext
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.SessionCatalog
+import
org.apache.spark.sql.hive.thriftserver.ThriftserverShimUtils.toJavaSQLType
+
+/**
+ * Spark's own SparkGetColumnsOperation
+ *
+ * @param sqlContext SQLContext to use
+ * @param parentSession a HiveSession from SessionManager
+ * @param catalogName catalog name. NULL if not applicable.
+ * @param schemaName database name, NULL or a concrete database name
+ * @param tableName table name
+ * @param columnName column name
+ */
+private[hive] class SparkGetColumnsOperation(
+ sqlContext: SQLContext,
+ parentSession: HiveSession,
+ catalogName: String,
+ schemaName: String,
+ tableName: String,
+ columnName: String)
+ extends GetColumnsOperation(parentSession, catalogName, schemaName,
tableName, columnName)
+ with Logging {
+
+ val catalog: SessionCatalog = sqlContext.sessionState.catalog
+
+ private var statementId: String = _
+
+ override def runInternal(): Unit = {
+ val cmdStr = s"catalog : $catalogName, schemaPattern : $schemaName,
tablePattern : $tableName" +
+ s", columnName : $columnName"
+ logInfo(s"GetColumnsOperation: $cmdStr")
+
+ setState(OperationState.RUNNING)
+ // Always use the latest class loader provided by executionHive's state.
+ val executionHiveClassLoader = sqlContext.sharedState.jarClassLoader
+ Thread.currentThread().setContextClassLoader(executionHiveClassLoader)
+
+ val schemaPattern = convertSchemaPattern(schemaName)
+ val tablePattern = convertIdentifierPattern(tableName, true)
+
+ var columnPattern: Pattern = null
+ if (columnName != null) {
+ columnPattern = Pattern.compile(convertIdentifierPattern(columnName,
false))
+ }
+
+ val db2Tabs = catalog.listDatabases(schemaPattern).map { dbName =>
+ (dbName, catalog.listTables(dbName, tablePattern))
+ }.toMap
+
+ if (isAuthV2Enabled) {
+ val privObjs = seqAsJavaListConverter(getPrivObjs(db2Tabs)).asJava
+ val cmdStr =
+ s"catalog : $catalogName, schemaPattern : $schemaName, tablePattern :
$tableName"
+ authorizeMetaGets(HiveOperationType.GET_COLUMNS, privObjs, cmdStr)
+ }
+
+ try {
+ db2Tabs.foreach {
+ case (dbName, tables) =>
+ catalog.getTablesByName(tables).foreach { catalogTable =>
+ catalogTable.schema.foreach { column =>
+ if (columnPattern != null &&
!columnPattern.matcher(column.name).matches()) {
+ } else {
+ val rowData = Array[AnyRef](
+ null, // TABLE_CAT
+ dbName, // TABLE_SCHEM
+ catalogTable.identifier.table, // TABLE_NAME
+ column.name, // COLUMN_NAME
+ toJavaSQLType(column.dataType.sql).asInstanceOf[AnyRef], //
DATA_TYPE
+ column.dataType.sql, // TYPE_NAME
+ null, // COLUMN_SIZE
+ null, // BUFFER_LENGTH, unused
+ null, // DECIMAL_DIGITS
+ null, // NUM_PREC_RADIX
+ (if (column.nullable) 1 else 0).asInstanceOf[AnyRef], //
NULLABLE
+ column.getComment().getOrElse(""), // REMARKS
+ null, // COLUMN_DEF
+ null, // SQL_DATA_TYPE
+ null, // SQL_DATETIME_SUB
+ null, // CHAR_OCTET_LENGTH
+ null, // ORDINAL_POSITION
+ "YES", // IS_NULLABLE
+ null, // SCOPE_CATALOG
+ null, // SCOPE_SCHEMA
+ null, // SCOPE_TABLE
+ null, // SOURCE_DATA_TYPE
+ "NO" // IS_AUTO_INCREMENT
+ )
+ rowSet.addRow(rowData)
+ }
+ }
+ }
+ }
+ setState(OperationState.FINISHED)
+ } catch {
+ case e: HiveSQLException =>
+ setState(OperationState.ERROR)
+ throw e
+ }
+ }
+
+ private def getPrivObjs(db2Tabs: Map[String, Seq[TableIdentifier]]):
Seq[HivePrivilegeObject] = {
+ db2Tabs.foldLeft(Seq.empty[HivePrivilegeObject])({
+ case (i, (dbName, tables)) => i ++ tables.map { tableId =>
+ new HivePrivilegeObject(HivePrivilegeObjectType.TABLE_OR_VIEW, dbName,
tableId.table)
+ }
+ })
+ }
+}
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/server/SparkSQLOperationManager.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/server/SparkSQLOperationManager.scala
index 7947d17..44b0908 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/server/SparkSQLOperationManager.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/server/SparkSQLOperationManager.scala
@@ -21,13 +21,13 @@ import java.util.{List => JList, Map => JMap}
import java.util.concurrent.ConcurrentHashMap
import org.apache.hive.service.cli._
-import org.apache.hive.service.cli.operation.{ExecuteStatementOperation,
GetSchemasOperation, MetadataOperation, Operation, OperationManager}
+import org.apache.hive.service.cli.operation.{ExecuteStatementOperation,
GetColumnsOperation, GetSchemasOperation, MetadataOperation, Operation,
OperationManager}
import org.apache.hive.service.cli.session.HiveSession
import org.apache.spark.internal.Logging
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.hive.HiveUtils
-import org.apache.spark.sql.hive.thriftserver.{ReflectionUtils,
SparkExecuteStatementOperation, SparkGetSchemasOperation,
SparkGetTablesOperation}
+import org.apache.spark.sql.hive.thriftserver.{ReflectionUtils,
SparkExecuteStatementOperation, SparkGetColumnsOperation,
SparkGetSchemasOperation, SparkGetTablesOperation}
import org.apache.spark.sql.internal.SQLConf
/**
@@ -92,6 +92,22 @@ private[thriftserver] class SparkSQLOperationManager()
operation
}
+ override def newGetColumnsOperation(
+ parentSession: HiveSession,
+ catalogName: String,
+ schemaName: String,
+ tableName: String,
+ columnName: String): GetColumnsOperation = synchronized {
+ val sqlContext = sessionToContexts.get(parentSession.getSessionHandle)
+ require(sqlContext != null, s"Session handle:
${parentSession.getSessionHandle} has not been" +
+ s" initialized or had already closed.")
+ val operation = new SparkGetColumnsOperation(sqlContext, parentSession,
+ catalogName, schemaName, tableName, columnName)
+ handleToOperation.put(operation.getHandle, operation)
+ logDebug(s"Created GetColumnsOperation with session=$parentSession.")
+ operation
+ }
+
def setConfMap(conf: SQLConf, confMap: java.util.Map[String, String]): Unit
= {
val iterator = confMap.entrySet().iterator()
while (iterator.hasNext) {
diff --git
a/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
b/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
index d4abf68..b06856b 100644
---
a/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
+++
b/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
@@ -21,7 +21,7 @@ import java.io.{File, FilenameFilter}
import java.net.URL
import java.nio.charset.StandardCharsets
import java.sql.{Date, DriverManager, SQLException, Statement}
-import java.util.UUID
+import java.util.{Locale, UUID}
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
@@ -820,7 +820,12 @@ abstract class HiveThriftJdbcTest extends
HiveThriftServer2Test {
statements.zip(fs).foreach { case (s, f) => f(s) }
} finally {
tableNames.foreach { name =>
- statements(0).execute(s"DROP TABLE IF EXISTS $name")
+ // TODO: Need a better way to drop the view.
+ if (name.toUpperCase(Locale.ROOT).startsWith("VIEW")) {
+ statements(0).execute(s"DROP VIEW IF EXISTS $name")
+ } else {
+ statements(0).execute(s"DROP TABLE IF EXISTS $name")
+ }
}
statements.foreach(_.close())
connections.foreach(_.close())
diff --git
a/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
b/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
index 6f0e2e3..4a9993b 100644
---
a/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
+++
b/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
@@ -146,7 +146,7 @@ class SparkMetadataOperationSuite extends
HiveThriftJdbcTest {
}
}
- withJdbcStatement("table1", "table2") { statement =>
+ withJdbcStatement("table1", "table2", "view1") { statement =>
Seq(
"CREATE TABLE table1(key INT, val STRING)",
"CREATE TABLE table2(key INT, val STRING)",
@@ -177,4 +177,94 @@ class SparkMetadataOperationSuite extends
HiveThriftJdbcTest {
}
}
}
+
+ test("Spark's own GetColumnsOperation(SparkGetColumnsOperation)") {
+ def testGetColumnsOperation(
+ schema: String,
+ tableNamePattern: String,
+ columnNamePattern: String)(f: HiveQueryResultSet => Unit): Unit = {
+ val rawTransport = new TSocket("localhost", serverPort)
+ val connection = new
HiveConnection(s"jdbc:hive2://localhost:$serverPort", new Properties)
+ val user = System.getProperty("user.name")
+ val transport = PlainSaslHelper.getPlainTransport(user, "anonymous",
rawTransport)
+ val client = new ThriftserverShimUtils.Client(new
TBinaryProtocol(transport))
+ transport.open()
+
+ var rs: HiveQueryResultSet = null
+
+ try {
+ val openResp = client.OpenSession(new
ThriftserverShimUtils.TOpenSessionReq)
+ val sessHandle = openResp.getSessionHandle
+
+ val getColumnsReq = new
ThriftserverShimUtils.TGetColumnsReq(sessHandle)
+ getColumnsReq.setSchemaName(schema)
+ getColumnsReq.setTableName(tableNamePattern)
+ getColumnsReq.setColumnName(columnNamePattern)
+
+ rs = new HiveQueryResultSet.Builder(connection)
+ .setClient(client)
+ .setSessionHandle(sessHandle)
+ .setStmtHandle(client.GetColumns(getColumnsReq).getOperationHandle)
+ .build()
+
+ f(rs)
+ } finally {
+ rs.close()
+ connection.close()
+ transport.close()
+ rawTransport.close()
+ }
+ }
+
+ def checkResult(
+ columns: Seq[(String, String, String, String, String)],
+ rs: HiveQueryResultSet) : Unit = {
+ if (columns.nonEmpty) {
+ for (i <- columns.indices) {
+ assert(rs.next())
+ val col = columns(i)
+ assert(rs.getString("TABLE_NAME") === col._1)
+ assert(rs.getString("COLUMN_NAME") === col._2)
+ assert(rs.getString("DATA_TYPE") === col._3)
+ assert(rs.getString("TYPE_NAME") === col._4)
+ assert(rs.getString("REMARKS") === col._5)
+ }
+ } else {
+ assert(!rs.next())
+ }
+ }
+
+ withJdbcStatement("table1", "table2", "view1") { statement =>
+ Seq(
+ "CREATE TABLE table1(key INT comment 'Int column', val STRING comment
'String column')",
+ "CREATE TABLE table2(key INT, val DECIMAL comment 'Decimal column')",
+ "CREATE VIEW view1 AS SELECT key FROM table1"
+ ).foreach(statement.execute)
+
+ testGetColumnsOperation("%", "%", null) { rs =>
+ checkResult(
+ Seq(
+ ("table1", "key", "4", "INT", "Int column"),
+ ("table1", "val", "12", "STRING", "String column"),
+ ("table2", "key", "4", "INT", ""),
+ ("table2", "val", "3", "DECIMAL(10,0)", "Decimal column"),
+ ("view1", "key", "4", "INT", "Int column")), rs)
+ }
+
+ testGetColumnsOperation("%", "table1", null) { rs =>
+ checkResult(
+ Seq(
+ ("table1", "key", "4", "INT", "Int column"),
+ ("table1", "val", "12", "STRING", "String column")), rs)
+ }
+
+ testGetColumnsOperation("%", "table1", "key") { rs =>
+ checkResult(Seq(("table1", "key", "4", "INT", "Int column")), rs)
+ }
+
+ testGetColumnsOperation("%", "table_not_exist", null) { rs =>
+ checkResult(Seq.empty, rs)
+ }
+ }
+ }
}
diff --git
a/sql/hive-thriftserver/v1.2.1/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
b/sql/hive-thriftserver/v1.2.1/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
index 5efb075..96ba489 100644
---
a/sql/hive-thriftserver/v1.2.1/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
+++
b/sql/hive-thriftserver/v1.2.1/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
@@ -49,7 +49,7 @@ import org.apache.hive.service.cli.session.HiveSession;
*/
public class GetColumnsOperation extends MetadataOperation {
- private static final TableSchema RESULT_SET_SCHEMA = new TableSchema()
+ protected static final TableSchema RESULT_SET_SCHEMA = new TableSchema()
.addPrimitiveColumn("TABLE_CAT", Type.STRING_TYPE,
"Catalog name. NULL if not applicable")
.addPrimitiveColumn("TABLE_SCHEM", Type.STRING_TYPE,
@@ -109,7 +109,7 @@ public class GetColumnsOperation extends MetadataOperation {
private final String tableName;
private final String columnName;
- private final RowSet rowSet;
+ protected final RowSet rowSet;
protected GetColumnsOperation(HiveSession parentSession, String catalogName,
String schemaName,
String tableName, String columnName) {
diff --git
a/sql/hive-thriftserver/v1.2.1/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
b/sql/hive-thriftserver/v1.2.1/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
index bb50496..b0702ad 100644
---
a/sql/hive-thriftserver/v1.2.1/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
+++
b/sql/hive-thriftserver/v1.2.1/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
@@ -19,7 +19,7 @@ package org.apache.spark.sql.hive.thriftserver
import org.apache.commons.logging.LogFactory
import org.apache.hadoop.hive.ql.session.SessionState
-import org.apache.hive.service.cli.{RowSet, RowSetFactory, TableSchema}
+import org.apache.hive.service.cli.{RowSet, RowSetFactory, TableSchema, Type}
/**
* Various utilities for hive-thriftserver used to upgrade the built-in Hive.
@@ -31,6 +31,7 @@ private[thriftserver] object ThriftserverShimUtils {
private[thriftserver] type TOpenSessionReq =
org.apache.hive.service.cli.thrift.TOpenSessionReq
private[thriftserver] type TGetSchemasReq =
org.apache.hive.service.cli.thrift.TGetSchemasReq
private[thriftserver] type TGetTablesReq =
org.apache.hive.service.cli.thrift.TGetTablesReq
+ private[thriftserver] type TGetColumnsReq =
org.apache.hive.service.cli.thrift.TGetColumnsReq
private[thriftserver] def getConsole: SessionState.LogHelper = {
val LOG = LogFactory.getLog(classOf[SparkSQLCLIDriver])
@@ -43,4 +44,6 @@ private[thriftserver] object ThriftserverShimUtils {
RowSetFactory.create(getResultSetSchema, getProtocolVersion)
}
+ private[thriftserver] def toJavaSQLType(s: String): Int =
Type.getType(s).toJavaSQLType
+
}
diff --git
a/sql/hive-thriftserver/v2.3.5/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
b/sql/hive-thriftserver/v2.3.5/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
index 7dcaf02..c25c742 100644
---
a/sql/hive-thriftserver/v2.3.5/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
+++
b/sql/hive-thriftserver/v2.3.5/src/main/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java
@@ -56,7 +56,7 @@ import org.apache.hive.service.cli.session.HiveSession;
*/
public class GetColumnsOperation extends MetadataOperation {
- private static final TableSchema RESULT_SET_SCHEMA = new TableSchema()
+ protected static final TableSchema RESULT_SET_SCHEMA = new TableSchema()
.addPrimitiveColumn("TABLE_CAT", Type.STRING_TYPE,
"Catalog name. NULL if not applicable")
.addPrimitiveColumn("TABLE_SCHEM", Type.STRING_TYPE,
@@ -116,7 +116,7 @@ public class GetColumnsOperation extends MetadataOperation {
private final String tableName;
private final String columnName;
- private final RowSet rowSet;
+ protected final RowSet rowSet;
protected GetColumnsOperation(HiveSession parentSession, String catalogName,
String schemaName,
String tableName, String columnName) {
diff --git
a/sql/hive-thriftserver/v2.3.5/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
b/sql/hive-thriftserver/v2.3.5/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
index 9aca30c..75637a8 100644
---
a/sql/hive-thriftserver/v2.3.5/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
+++
b/sql/hive-thriftserver/v2.3.5/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
@@ -18,6 +18,7 @@
package org.apache.spark.sql.hive.thriftserver
import org.apache.hadoop.hive.ql.session.SessionState
+import org.apache.hadoop.hive.serde2.thrift.Type
import org.apache.hive.service.cli.{RowSet, RowSetFactory, TableSchema}
import org.slf4j.LoggerFactory
@@ -31,6 +32,7 @@ private[thriftserver] object ThriftserverShimUtils {
private[thriftserver] type TOpenSessionReq =
org.apache.hive.service.rpc.thrift.TOpenSessionReq
private[thriftserver] type TGetSchemasReq =
org.apache.hive.service.rpc.thrift.TGetSchemasReq
private[thriftserver] type TGetTablesReq =
org.apache.hive.service.rpc.thrift.TGetTablesReq
+ private[thriftserver] type TGetColumnsReq =
org.apache.hive.service.rpc.thrift.TGetColumnsReq
private[thriftserver] def getConsole: SessionState.LogHelper = {
val LOG = LoggerFactory.getLogger(classOf[SparkSQLCLIDriver])
@@ -43,4 +45,6 @@ private[thriftserver] object ThriftserverShimUtils {
RowSetFactory.create(getResultSetSchema, getProtocolVersion, false)
}
+ private[thriftserver] def toJavaSQLType(s: String): Int =
Type.getType(s).toJavaSQLType
+
}
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
{kind=link}