This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4d51bfa725c [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should
provide FAIR scheduler
4d51bfa725c is described below
commit 4d51bfa725c26996641f566e42ae392195d639c5
Author: Dongjoon Hyun <dongj...@apache.org>
AuthorDate: Mon Jan 23 23:47:26 2023 -0800
[SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR
scheduler
### What changes were proposed in this pull request?
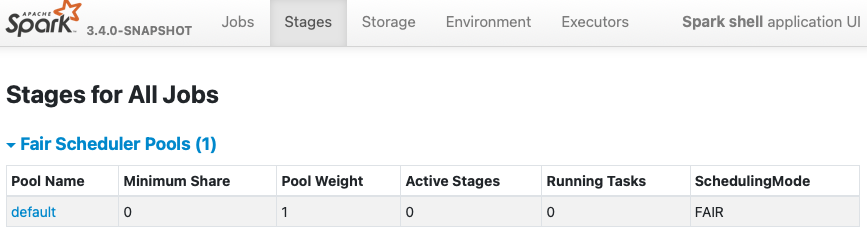
Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR
Scheduling Within an Application`.
https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application

This bug is hidden in our CI because we have `fairscheduler.xml` always as
one of test resources.
-
https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml
### Why are the changes needed?
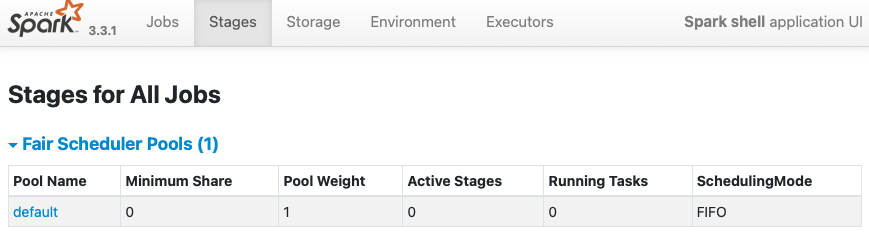
Currently, when `spark.scheduler.mode=FAIR` is given without scheduler
allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler
which is wrong. We need to switch the mode to `FAIR` from `FIFO`.
**BEFORE**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration
file not found so jobs will be scheduled in FIFO order. To use fair scheduling,
configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to
a file that contains the configuration.
Spark context Web UI available at http://localhost:4040
```
**AFTER**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://localhost:4040
```
### Does this PR introduce _any_ user-facing change?
Yes, but this is a bug fix to match with Apache Spark official
documentation.
### How was this patch tested?
Pass the CIs.
Closes #39703 from dongjoon-hyun/SPARK-42157.
Authored-by: Dongjoon Hyun <dongj...@apache.org>
Signed-off-by: Dongjoon Hyun <dongj...@apache.org>
---
.../scala/org/apache/spark/scheduler/SchedulableBuilder.scala | 11 +++++++----
1 file changed, 7 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
index e7c45a9faa1..a30744da9ee 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
@@ -27,7 +27,7 @@ import org.apache.hadoop.fs.Path
import org.apache.spark.SparkContext
import org.apache.spark.internal.Logging
-import org.apache.spark.internal.config.SCHEDULER_ALLOCATION_FILE
+import org.apache.spark.internal.config.{SCHEDULER_ALLOCATION_FILE,
SCHEDULER_MODE}
import org.apache.spark.scheduler.SchedulingMode.SchedulingMode
import org.apache.spark.util.Utils
@@ -86,9 +86,12 @@ private[spark] class FairSchedulableBuilder(val rootPool:
Pool, sc: SparkContext
logInfo(s"Creating Fair Scheduler pools from default file:
$DEFAULT_SCHEDULER_FILE")
Some((is, DEFAULT_SCHEDULER_FILE))
} else {
- logWarning("Fair Scheduler configuration file not found so jobs will
be scheduled in " +
- s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE or " +
- s"set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the
configuration.")
+ val schedulingMode =
SchedulingMode.withName(sc.conf.get(SCHEDULER_MODE))
+ rootPool.addSchedulable(new Pool(
+ DEFAULT_POOL_NAME, schedulingMode, DEFAULT_MINIMUM_SHARE,
DEFAULT_WEIGHT))
+ logInfo("Fair scheduler configuration not found, created default
pool: " +
+ "%s, schedulingMode: %s, minShare: %d, weight: %d".format(
+ DEFAULT_POOL_NAME, schedulingMode, DEFAULT_MINIMUM_SHARE,
DEFAULT_WEIGHT))
None
}
}
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}