spark git commit: [SPARK-20090][FOLLOW-UP] Revert the deprecation of `names` in PySpark
Repository: spark
Updated Branches:
refs/heads/branch-2.3 43f5e4067 -> 3737c3d32
[SPARK-20090][FOLLOW-UP] Revert the deprecation of `names` in PySpark
## What changes were proposed in this pull request?
Deprecating the field `name` in PySpark is not expected. This PR is to revert
the change.
## How was this patch tested?
N/A
Author: gatorsmile
Closes #20595 from gatorsmile/removeDeprecate.
(cherry picked from commit 407f67249639709c40c46917700ed6dd736daa7d)
Signed-off-by: hyukjinkwon
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/3737c3d3
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/3737c3d3
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/3737c3d3
Branch: refs/heads/branch-2.3
Commit: 3737c3d32bb92e73cadaf3b1b9759d9be00b288d
Parents: 43f5e40
Author: gatorsmile
Authored: Tue Feb 13 15:05:13 2018 +0900
Committer: hyukjinkwon
Committed: Tue Feb 13 15:05:33 2018 +0900
--
python/pyspark/sql/types.py | 3 ---
1 file changed, 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/3737c3d3/python/pyspark/sql/types.py
--
diff --git a/python/pyspark/sql/types.py b/python/pyspark/sql/types.py
index e25941c..cd85740 100644
--- a/python/pyspark/sql/types.py
+++ b/python/pyspark/sql/types.py
@@ -455,9 +455,6 @@ class StructType(DataType):
Iterating a :class:`StructType` will iterate its :class:`StructField`\\s.
A contained :class:`StructField` can be accessed by name or position.
-.. note:: `names` attribute is deprecated in 2.3. Use `fieldNames` method
instead
-to get a list of field names.
-
>>> struct1 = StructType([StructField("f1", StringType(), True)])
>>> struct1["f1"]
StructField(f1,StringType,true)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-20090][FOLLOW-UP] Revert the deprecation of `names` in PySpark
Repository: spark
Updated Branches:
refs/heads/master f17b936f0 -> 407f67249
[SPARK-20090][FOLLOW-UP] Revert the deprecation of `names` in PySpark
## What changes were proposed in this pull request?
Deprecating the field `name` in PySpark is not expected. This PR is to revert
the change.
## How was this patch tested?
N/A
Author: gatorsmile
Closes #20595 from gatorsmile/removeDeprecate.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/407f6724
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/407f6724
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/407f6724
Branch: refs/heads/master
Commit: 407f67249639709c40c46917700ed6dd736daa7d
Parents: f17b936
Author: gatorsmile
Authored: Tue Feb 13 15:05:13 2018 +0900
Committer: hyukjinkwon
Committed: Tue Feb 13 15:05:13 2018 +0900
--
python/pyspark/sql/types.py | 3 ---
1 file changed, 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/407f6724/python/pyspark/sql/types.py
--
diff --git a/python/pyspark/sql/types.py b/python/pyspark/sql/types.py
index e25941c..cd85740 100644
--- a/python/pyspark/sql/types.py
+++ b/python/pyspark/sql/types.py
@@ -455,9 +455,6 @@ class StructType(DataType):
Iterating a :class:`StructType` will iterate its :class:`StructField`\\s.
A contained :class:`StructField` can be accessed by name or position.
-.. note:: `names` attribute is deprecated in 2.3. Use `fieldNames` method
instead
-to get a list of field names.
-
>>> struct1 = StructType([StructField("f1", StringType(), True)])
>>> struct1["f1"]
StructField(f1,StringType,true)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24996 - in /dev/spark/v2.3.0-rc3-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _site/api/java/org/apache/spark
Author: sameerag Date: Tue Feb 13 05:31:05 2018 New Revision: 24996 Log: Apache Spark v2.3.0-rc3 docs [This commit notification would consist of 1446 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23303][SQL] improve the explain result for data source v2 relations
Repository: spark
Updated Branches:
refs/heads/master ed4e78bd6 -> f17b936f0
[SPARK-23303][SQL] improve the explain result for data source v2 relations
## What changes were proposed in this pull request?
The current explain result for data source v2 relation is unreadable:
```
== Parsed Logical Plan ==
'Filter ('i > 6)
+- AnalysisBarrier
+- Project [j#1]
+- DataSourceV2Relation [i#0, j#1],
org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- Filter (i#0 > 6)
+- Project [j#1, i#0]
+- DataSourceV2Relation [i#0, j#1],
org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Optimized Logical Plan ==
Project [j#1]
+- Filter isnotnull(i#0)
+- DataSourceV2Relation [i#0, j#1],
org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Physical Plan ==
*(1) Project [j#1]
+- *(1) Filter isnotnull(i#0)
+- *(1) DataSourceV2Scan [i#0, j#1],
org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
```
after this PR
```
== Parsed Logical Plan ==
'Project [unresolvedalias('j, None)]
+- AnalysisBarrier
+- Relation AdvancedDataSourceV2[i#0, j#1]
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- Relation AdvancedDataSourceV2[i#0, j#1]
== Optimized Logical Plan ==
Relation AdvancedDataSourceV2[j#1]
== Physical Plan ==
*(1) Scan AdvancedDataSourceV2[j#1]
```
---
```
== Analyzed Logical Plan ==
i: int, j: int
Filter (i#88 > 3)
+- Relation JavaAdvancedDataSourceV2[i#88, j#89]
== Optimized Logical Plan ==
Filter isnotnull(i#88)
+- Relation JavaAdvancedDataSourceV2[i#88, j#89] (PushedFilter:
[GreaterThan(i,3)])
== Physical Plan ==
*(1) Filter isnotnull(i#88)
+- *(1) Scan JavaAdvancedDataSourceV2[i#88, j#89] (PushedFilter:
[GreaterThan(i,3)])
```
an example for streaming query
```
== Parsed Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class
org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0,
java.lang.String, true], true, false) AS value#6]
+- MapElements , class java.lang.String,
[StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4:
java.lang.String
+- Streaming Relation FakeDataSourceV2$[value#25]
== Analyzed Logical Plan ==
value: string, count(1): bigint
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class
org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0,
java.lang.String, true], true, false) AS value#6]
+- MapElements , class java.lang.String,
[StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4:
java.lang.String
+- Streaming Relation FakeDataSourceV2$[value#25]
== Optimized Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class
org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0,
java.lang.String, true], true, false) AS value#6]
+- MapElements , class java.lang.String,
[StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject value#25.toString, obj#4: java.lang.String
+- Streaming Relation FakeDataSourceV2$[value#25]
== Physical Plan ==
*(4) HashAggregate(keys=[value#6], functions=[count(1)], output=[value#6,
count(1)#11L])
+- StateStoreSave [value#6], state info [ checkpoint =
*(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state,
runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions
= 5], Complete, 0
+- *(3) HashAggregate(keys=[value#6], functions=[merge_count(1)],
output=[value#6, count#16L])
+- StateStoreRestore [value#6], state info [ checkpoint =
*(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state,
runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions
= 5]
+- *(2) HashAggregate(keys=[value#6], functions=[merge_count(1)],
output=[value#6, count#16L])
+- Exchange hashpartitioning(value#6, 5)
+- *(1) HashAggregate(keys=[value#6],
functions=[partial_count(1)], output=[value#6, count#16L])
+- *(1) SerializeFromObject [staticinvoke(class
org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0,
java.lang.String, true], true, false) AS value#6]
+- *(1) MapElements , obj#5: java.lang.String
+- *(1) DeserializeToObject value#25.toString, obj#4:
java.lang.String
+- *(1) Scan FakeDataSourceV2$[value#25]
```
## How was this patch tested?
N/A
Author: Wenchen Fan
Closes #20477 from cloud-fan/explain.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.
spark git commit: [SPARK-23379][SQL] skip when setting the same current database in HiveClientImpl
Repository: spark
Updated Branches:
refs/heads/master c1bcef876 -> ed4e78bd6
[SPARK-23379][SQL] skip when setting the same current database in HiveClientImpl
## What changes were proposed in this pull request?
If the target database name is as same as the current database, we should be
able to skip one metastore access.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests,
manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a pull
request.
Author: Feng Liu
Closes #20565 from liufengdb/remove-redundant.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/ed4e78bd
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/ed4e78bd
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/ed4e78bd
Branch: refs/heads/master
Commit: ed4e78bd606e7defc2cd01a5c2e9b47954baa424
Parents: c1bcef8
Author: Feng Liu
Authored: Mon Feb 12 20:57:26 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 20:57:26 2018 -0800
--
.../org/apache/spark/sql/hive/client/HiveClientImpl.scala | 10 ++
1 file changed, 6 insertions(+), 4 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/ed4e78bd/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
index c223f51..146fa54 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
@@ -292,10 +292,12 @@ private[hive] class HiveClientImpl(
}
private def setCurrentDatabaseRaw(db: String): Unit = {
-if (databaseExists(db)) {
- state.setCurrentDatabase(db)
-} else {
- throw new NoSuchDatabaseException(db)
+if (state.getCurrentDatabase != db) {
+ if (databaseExists(db)) {
+state.setCurrentDatabase(db)
+ } else {
+throw new NoSuchDatabaseException(db)
+ }
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24992 - in /dev/spark/2.4.0-SNAPSHOT-2018_02_12_20_01-c1bcef8-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Tue Feb 13 04:15:30 2018 New Revision: 24992 Log: Apache Spark 2.4.0-SNAPSHOT-2018_02_12_20_01-c1bcef8 docs [This commit notification would consist of 1444 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23323][SQL] Support commit coordinator for DataSourceV2 writes
Repository: spark
Updated Branches:
refs/heads/master 4104b68e9 -> c1bcef876
[SPARK-23323][SQL] Support commit coordinator for DataSourceV2 writes
## What changes were proposed in this pull request?
DataSourceV2 batch writes should use the output commit coordinator if it is
required by the data source. This adds a new method,
`DataWriterFactory#useCommitCoordinator`, that determines whether the
coordinator will be used. If the write factory returns true,
`WriteToDataSourceV2` will use the coordinator for batch writes.
## How was this patch tested?
This relies on existing write tests, which now use the commit coordinator.
Author: Ryan Blue
Closes #20490 from rdblue/SPARK-23323-add-commit-coordinator.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/c1bcef87
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/c1bcef87
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/c1bcef87
Branch: refs/heads/master
Commit: c1bcef876c1415e39e624cfbca9c9bdeae24cbb9
Parents: 4104b68
Author: Ryan Blue
Authored: Tue Feb 13 11:40:34 2018 +0800
Committer: Wenchen Fan
Committed: Tue Feb 13 11:40:34 2018 +0800
--
.../sql/sources/v2/writer/DataSourceWriter.java | 19 +++--
.../datasources/v2/WriteToDataSourceV2.scala| 41
2 files changed, 48 insertions(+), 12 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/c1bcef87/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceWriter.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceWriter.java
b/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceWriter.java
index e3f682b..0a0fd8d 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceWriter.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceWriter.java
@@ -64,6 +64,16 @@ public interface DataSourceWriter {
DataWriterFactory createWriterFactory();
/**
+ * Returns whether Spark should use the commit coordinator to ensure that at
most one attempt for
+ * each task commits.
+ *
+ * @return true if commit coordinator should be used, false otherwise.
+ */
+ default boolean useCommitCoordinator() {
+return true;
+ }
+
+ /**
* Handles a commit message on receiving from a successful data writer.
*
* If this method fails (by throwing an exception), this writing job is
considered to to have been
@@ -79,10 +89,11 @@ public interface DataSourceWriter {
* failed, and {@link #abort(WriterCommitMessage[])} would be called. The
state of the destination
* is undefined and @{@link #abort(WriterCommitMessage[])} may not be able
to deal with it.
*
- * Note that, one partition may have multiple committed data writers because
of speculative tasks.
- * Spark will pick the first successful one and get its commit message.
Implementations should be
- * aware of this and handle it correctly, e.g., have a coordinator to make
sure only one data
- * writer can commit, or have a way to clean up the data of
already-committed writers.
+ * Note that speculative execution may cause multiple tasks to run for a
partition. By default,
+ * Spark uses the commit coordinator to allow at most one attempt to commit.
Implementations can
+ * disable this behavior by overriding {@link #useCommitCoordinator()}. If
disabled, multiple
+ * attempts may have committed successfully and one successful commit
message per task will be
+ * passed to this commit method. The remaining commit messages are ignored
by Spark.
*/
void commit(WriterCommitMessage[] messages);
http://git-wip-us.apache.org/repos/asf/spark/blob/c1bcef87/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2.scala
index eefbcf4..535e796 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2.scala
@@ -18,6 +18,7 @@
package org.apache.spark.sql.execution.datasources.v2
import org.apache.spark.{SparkEnv, SparkException, TaskContext}
+import org.apache.spark.executor.CommitDeniedException
import org.apache.spark.internal.Logging
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
@@ -53,6 +54,7 @@ case class WriteToDataSourceV2Exec(writer: DataSourceWriter,
query: Spa
svn commit: r24988 - in /dev/spark/2.3.1-SNAPSHOT-2018_02_12_18_01-43f5e40-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Tue Feb 13 02:15:16 2018 New Revision: 24988 Log: Apache Spark 2.3.1-SNAPSHOT-2018_02_12_18_01-43f5e40 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24987 - /dev/spark/v2.3.0-rc3-bin/
Author: sameerag Date: Tue Feb 13 00:54:47 2018 New Revision: 24987 Log: Apache Spark v2.3.0-rc3 Added: dev/spark/v2.3.0-rc3-bin/ dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz (with props) dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.asc dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.md5 dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.sha512 dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz (with props) dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz.asc dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz.md5 dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz.sha512 dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.6.tgz (with props) dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.6.tgz.asc dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.6.tgz.md5 dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.6.tgz.sha512 dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.7.tgz (with props) dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.7.tgz.asc dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.7.tgz.md5 dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-hadoop2.7.tgz.sha512 dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-without-hadoop.tgz (with props) dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-without-hadoop.tgz.asc dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-without-hadoop.tgz.md5 dev/spark/v2.3.0-rc3-bin/spark-2.3.0-bin-without-hadoop.tgz.sha512 dev/spark/v2.3.0-rc3-bin/spark-2.3.0.tgz (with props) dev/spark/v2.3.0-rc3-bin/spark-2.3.0.tgz.asc dev/spark/v2.3.0-rc3-bin/spark-2.3.0.tgz.md5 dev/spark/v2.3.0-rc3-bin/spark-2.3.0.tgz.sha512 dev/spark/v2.3.0-rc3-bin/spark-parent_2.11.iml Added: dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.asc == --- dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.asc (added) +++ dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.asc Tue Feb 13 00:54:47 2018 @@ -0,0 +1,16 @@ +-BEGIN PGP SIGNATURE- + +iQIzBAABCAAdFiEE8sZCQuwb7Gnqj7413OS/2AdGHpYFAlqCNqQACgkQ3OS/2AdG +Hpa5dA/+LUIl5WF/ks8FLYWM+YTtnzYy9NJsxL0Zk01zr/9UrcFciiuvkaiNFYsE +fPFD0N+UjHydUnrTz7ysna02+AWuRbq/mlBkrJK+sfOFoT0fl0DMNLOZiPLlvq5S +tvmv1iNjtZNCe5kFUB5XQ1aFI/9zlp9BgJAm/x7oCUe8uwEKpYfUVvQ+o6y01RvE +XInst4XgS1ObKKRF1jE9QB+TxMysmvk7c0HFIgvfAi1bd9g2ilyGcyi77iFrjmk7 +riXqDFIF39Zm3sZpQnDn2lqMlfmzW2ymrHy4UrV76FWb6f/ExKHNw3kV7a62pudv +/ao2TQkxLLnodRuptru+gEk4mLJoc4XkSftg5RL94s2wxCroPx3c05iu0wfsp+DL +pzxGacJa3tKNKSxyTcrhY8pyq1OefpSrrVPhpsXGwUqpR4X2/6Aql0Cojuu29C4J +1ZZFtzjq7S82uiv88Stb55XOjCJRL91rTlGYok53c8+FsAK7ofcO0opUGbtJaYMy +gpLnIddrUisiZoxzdpPmf8R4IGM7Okg+VEz/0LowN9XoL/ck65p+ASW593Wzk0W7 +TrvpZcfAO3M5ELg1CTP9PMcKWTkFJ19DjEeBt0CirIJzP5GJuJX/opItAfaD/opz +CPMsAcjPpq9x332x0JIgUnTpC3G0WPI575EPhH1DVRHl2EfzCRc= +=QwEF +-END PGP SIGNATURE- Added: dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.md5 == --- dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.md5 (added) +++ dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.md5 Tue Feb 13 00:54:47 2018 @@ -0,0 +1 @@ +SparkR_2.3.0.tar.gz: 30 5B 98 63 D3 86 C0 18 A7 32 7C 79 80 FE 19 17 Added: dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.sha512 == --- dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.sha512 (added) +++ dev/spark/v2.3.0-rc3-bin/SparkR_2.3.0.tar.gz.sha512 Tue Feb 13 00:54:47 2018 @@ -0,0 +1,3 @@ +SparkR_2.3.0.tar.gz: 69AEFA33 5D355D4C 264D38E2 24F08BE0 7B99CA07 4E2BF424 + 4F6F0F8A 7BE0ADF1 E279C512 E447C29B E1C697DB 24ADF0BF + 92936EF2 8DC1803B 6DC25C0A 1FB3ED71 Added: dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz == Binary file - no diff available. Propchange: dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz -- svn:mime-type = application/octet-stream Added: dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz.asc == --- dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz.asc (added) +++ dev/spark/v2.3.0-rc3-bin/pyspark-2.3.0.tar.gz.asc Tue Feb 13 00:54:47 2018 @@ -0,0 +1,16 @@ +-BEGIN PGP SIGNATURE- + +iQIzBAABCAAdFiEE8sZCQuwb7Gnqj7413OS/2AdGHpYFAlqCNbUACgkQ3OS/2AdG +Hpb6rhAAvlEn/1aWZBuVqIaunIYTLy+jJqYFw4GrYc/cpJZISuiBC9cCXudUjn4x +04Rh5/EqlL/hQe7OBjHR0OFFZXVnHYAG+vzRngWO6oi6kzR5Qyo0Ls9mVrj8JDYh +w4nXJjt6pfYg76hnHViKiwkvCAHQlIHYhgkDByD6AUr+IUuWP/bifJIbXsMKWSBG +MXm+sZ7EZJiw+b8xDbVSFtX5m/F8
spark git commit: [SPARK-23352][PYTHON][BRANCH-2.3] Explicitly specify supported types in Pandas UDFs
Repository: spark
Updated Branches:
refs/heads/branch-2.3 befb22de8 -> 43f5e4067
[SPARK-23352][PYTHON][BRANCH-2.3] Explicitly specify supported types in Pandas
UDFs
## What changes were proposed in this pull request?
This PR backports https://github.com/apache/spark/pull/20531:
It explicitly specifies supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in
`returnType` ahead with documenting this; however, it happened to fix multiple
things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Since we can check the return type ahead, we can fail fast before actual
execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon
Closes #20588 from HyukjinKwon/PR_TOOL_PICK_PR_20531_BRANCH-2.3.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/43f5e406
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/43f5e406
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/43f5e406
Branch: refs/heads/branch-2.3
Commit: 43f5e40679f771326b2ee72f14cf1ab0ed2ad692
Parents: befb22d
Author: hyukjinkwon
Authored: Mon Feb 12 16:47:28 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 16:47:28 2018 -0800
--
docs/sql-programming-guide.md | 4 +-
python/pyspark/sql/tests.py | 86
python/pyspark/sql/types.py | 4 +
python/pyspark/sql/udf.py | 25 --
.../org/apache/spark/sql/internal/SQLConf.scala | 2 +-
5 files changed, 77 insertions(+), 44 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/43f5e406/docs/sql-programming-guide.md
--
diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md
index dcef6e5..0f9f01e 100644
--- a/docs/sql-programming-guide.md
+++ b/docs/sql-programming-guide.md
@@ -1676,7 +1676,7 @@ Using the above optimizations with Arrow will produce the
same results as when A
enabled. Note that even with Arrow, `toPandas()` results in the collection of
all records in the
DataFrame to the driver program and should be done on a small subset of the
data. Not all Spark
data types are currently supported and an error can be raised if a column has
an unsupported type,
-see [Supported Types](#supported-sql-arrow-types). If an error occurs during
`createDataFrame()`,
+see [Supported SQL Types](#supported-sql-arrow-types). If an error occurs
during `createDataFrame()`,
Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
@@ -1734,7 +1734,7 @@ For detailed usage, please see
[`pyspark.sql.functions.pandas_udf`](api/python/p
### Supported SQL Types
-Currently, all Spark SQL data types are supported by Arrow-based conversion
except `MapType`,
+Currently, all Spark SQL data types are supported by Arrow-based conversion
except `BinaryType`, `MapType`,
`ArrayType` of `TimestampType`, and nested `StructType`.
### Setting Arrow Batch Size
http://git-wip-us.apache.org/repos/asf/spark/blob/43f5e406/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index 5480144..904fa7a 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -3736,10 +3736,10 @@ class PandasUDFTests(ReusedSQLTestCase):
self.assertEqual(foo.returnType, schema)
self.assertEqual(foo.evalType,
PythonEvalType.SQL_GROUPED_MAP_PANDAS_UDF)
-@pandas_udf(returnType='v double', functionType=PandasUDFType.SCALAR)
+@pandas_udf(returnType='double', functionType=PandasUDFType.SCALAR)
def foo(x):
return x
-self.assertEqual(foo.returnType, schema)
+self.assertEqual(foo.returnType, DoubleType())
self.assertEqual(foo.evalType, PythonEvalType.SQL_SCALAR_PANDAS_UDF)
@pandas_udf(returnType=schema, functionType=PandasUDFType.GROUPED_MAP)
@@ -3776,7 +3776,7 @@ class PandasUDFTests(ReusedSQLTestCase):
@pandas_udf(returnType=PandasUDFType.GROUPED_MAP)
def foo(df):
return d
spark git commit: [SPARK-23230][SQL] When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error
Repository: spark
Updated Branches:
refs/heads/branch-2.3 2b80571e2 -> befb22de8
[SPARK-23230][SQL] When hive.default.fileformat is other kinds of file types,
create textfile table cause a serde error
When hive.default.fileformat is other kinds of file types, create textfile
table cause a serde error.
We should take the default type of textfile and sequencefile both as
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.
```
set hive.default.fileformat=orc;
create table tbl( i string ) stored as textfile;
desc formatted tbl;
Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
```
Author: sychen
Closes #20406 from cxzl25/default_serde.
(cherry picked from commit 4104b68e958cd13975567a96541dac7cccd8195c)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/befb22de
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/befb22de
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/befb22de
Branch: refs/heads/branch-2.3
Commit: befb22de81aad41673eec9dba7585b80c6cb2564
Parents: 2b80571
Author: sychen
Authored: Mon Feb 12 16:00:47 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 16:01:16 2018 -0800
--
.../apache/spark/sql/internal/HiveSerDe.scala| 6 --
.../sql/hive/execution/HiveSerDeSuite.scala | 19 +++
2 files changed, 23 insertions(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/befb22de/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
b/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
index dac4636..eca612f 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
@@ -31,7 +31,8 @@ object HiveSerDe {
"sequencefile" ->
HiveSerDe(
inputFormat =
Option("org.apache.hadoop.mapred.SequenceFileInputFormat"),
-outputFormat =
Option("org.apache.hadoop.mapred.SequenceFileOutputFormat")),
+outputFormat =
Option("org.apache.hadoop.mapred.SequenceFileOutputFormat"),
+serde = Option("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe")),
"rcfile" ->
HiveSerDe(
@@ -54,7 +55,8 @@ object HiveSerDe {
"textfile" ->
HiveSerDe(
inputFormat = Option("org.apache.hadoop.mapred.TextInputFormat"),
-outputFormat =
Option("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat")),
+outputFormat =
Option("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"),
+serde = Option("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe")),
"avro" ->
HiveSerDe(
http://git-wip-us.apache.org/repos/asf/spark/blob/befb22de/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
index 1c9f001..d7752e9 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
@@ -100,6 +100,25 @@ class HiveSerDeSuite extends HiveComparisonTest with
PlanTest with BeforeAndAfte
assert(output ==
Some("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"))
assert(serde ==
Some("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"))
}
+
+withSQLConf("hive.default.fileformat" -> "orc") {
+ val (desc, exists) = extractTableDesc(
+"CREATE TABLE IF NOT EXISTS fileformat_test (id int) STORED AS
textfile")
+ assert(exists)
+ assert(desc.storage.inputFormat ==
Some("org.apache.hadoop.mapred.TextInputFormat"))
+ assert(desc.storage.outputFormat ==
+Some("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"))
+ assert(desc.storage.serde ==
Some("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"))
+}
+
+withSQLConf("hive.default.fileformat" -> "orc") {
+ val (desc, exists) = extractTableDesc(
+"CREATE TABLE IF NOT EXISTS fileformat_test (id int) STORED AS
sequencefile")
+ assert(exists)
+ assert(desc.storage.inputFormat ==
Some("org.apache.hadoop.mapred.SequenceFileInputFormat"))
+ assert(desc.storage.outputFormat ==
Some("org.apache.hadoop.mapred.SequenceFileOutputFormat"))
+ assert(des
spark git commit: [SPARK-23230][SQL] When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error
Repository: spark
Updated Branches:
refs/heads/master 6cb59708c -> 4104b68e9
[SPARK-23230][SQL] When hive.default.fileformat is other kinds of file types,
create textfile table cause a serde error
When hive.default.fileformat is other kinds of file types, create textfile
table cause a serde error.
We should take the default type of textfile and sequencefile both as
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.
```
set hive.default.fileformat=orc;
create table tbl( i string ) stored as textfile;
desc formatted tbl;
Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
```
Author: sychen
Closes #20406 from cxzl25/default_serde.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/4104b68e
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/4104b68e
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/4104b68e
Branch: refs/heads/master
Commit: 4104b68e958cd13975567a96541dac7cccd8195c
Parents: 6cb5970
Author: sychen
Authored: Mon Feb 12 16:00:47 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 16:00:47 2018 -0800
--
.../apache/spark/sql/internal/HiveSerDe.scala| 6 --
.../sql/hive/execution/HiveSerDeSuite.scala | 19 +++
2 files changed, 23 insertions(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/4104b68e/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
b/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
index dac4636..eca612f 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/internal/HiveSerDe.scala
@@ -31,7 +31,8 @@ object HiveSerDe {
"sequencefile" ->
HiveSerDe(
inputFormat =
Option("org.apache.hadoop.mapred.SequenceFileInputFormat"),
-outputFormat =
Option("org.apache.hadoop.mapred.SequenceFileOutputFormat")),
+outputFormat =
Option("org.apache.hadoop.mapred.SequenceFileOutputFormat"),
+serde = Option("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe")),
"rcfile" ->
HiveSerDe(
@@ -54,7 +55,8 @@ object HiveSerDe {
"textfile" ->
HiveSerDe(
inputFormat = Option("org.apache.hadoop.mapred.TextInputFormat"),
-outputFormat =
Option("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat")),
+outputFormat =
Option("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"),
+serde = Option("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe")),
"avro" ->
HiveSerDe(
http://git-wip-us.apache.org/repos/asf/spark/blob/4104b68e/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
index 1c9f001..d7752e9 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveSerDeSuite.scala
@@ -100,6 +100,25 @@ class HiveSerDeSuite extends HiveComparisonTest with
PlanTest with BeforeAndAfte
assert(output ==
Some("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"))
assert(serde ==
Some("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"))
}
+
+withSQLConf("hive.default.fileformat" -> "orc") {
+ val (desc, exists) = extractTableDesc(
+"CREATE TABLE IF NOT EXISTS fileformat_test (id int) STORED AS
textfile")
+ assert(exists)
+ assert(desc.storage.inputFormat ==
Some("org.apache.hadoop.mapred.TextInputFormat"))
+ assert(desc.storage.outputFormat ==
+Some("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"))
+ assert(desc.storage.serde ==
Some("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"))
+}
+
+withSQLConf("hive.default.fileformat" -> "orc") {
+ val (desc, exists) = extractTableDesc(
+"CREATE TABLE IF NOT EXISTS fileformat_test (id int) STORED AS
sequencefile")
+ assert(exists)
+ assert(desc.storage.inputFormat ==
Some("org.apache.hadoop.mapred.SequenceFileInputFormat"))
+ assert(desc.storage.outputFormat ==
Some("org.apache.hadoop.mapred.SequenceFileOutputFormat"))
+ assert(desc.storage.serde ==
Some("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"))
+}
}
test("cr
spark git commit: [SPARK-23313][DOC] Add a migration guide for ORC
Repository: spark
Updated Branches:
refs/heads/branch-2.3 9632c461e -> 2b80571e2
[SPARK-23313][DOC] Add a migration guide for ORC
## What changes were proposed in this pull request?
This PR adds a migration guide documentation for ORC.
## How was this patch tested?
N/A.
Author: Dongjoon Hyun
Closes #20484 from dongjoon-hyun/SPARK-23313.
(cherry picked from commit 6cb59708c70c03696c772fbb5d158eed57fe67d4)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/2b80571e
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/2b80571e
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/2b80571e
Branch: refs/heads/branch-2.3
Commit: 2b80571e215d56d15c59f0fc5db053569a79efae
Parents: 9632c46
Author: Dongjoon Hyun
Authored: Mon Feb 12 15:26:37 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 15:27:00 2018 -0800
--
docs/sql-programming-guide.md | 29 +
1 file changed, 29 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/2b80571e/docs/sql-programming-guide.md
--
diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md
index eab4030..dcef6e5 100644
--- a/docs/sql-programming-guide.md
+++ b/docs/sql-programming-guide.md
@@ -1776,6 +1776,35 @@ working with timestamps in `pandas_udf`s to get the best
performance, see
## Upgrading From Spark SQL 2.2 to 2.3
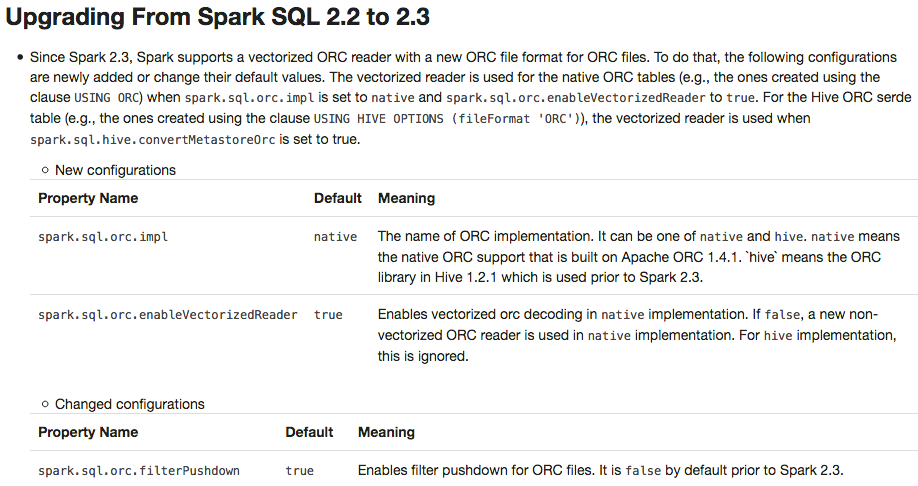
+ - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC
file format for ORC files. To do that, the following configurations are newly
added or change their default values. The vectorized reader is used for the
native ORC tables (e.g., the ones created using the clause `USING ORC`) when
`spark.sql.orc.impl` is set to `native` and
`spark.sql.orc.enableVectorizedReader` is set to `true`. For the Hive ORC serde
table (e.g., the ones created using the clause `USING HIVE OPTIONS (fileFormat
'ORC')`), the vectorized reader is used when
`spark.sql.hive.convertMetastoreOrc` is set to `true`.
+
+- New configurations
+
+
+ Property
NameDefaultMeaning
+
+spark.sql.orc.impl
+native
+The name of ORC implementation. It can be one of
native and hive. native means the native
ORC support that is built on Apache ORC 1.4.1. `hive` means the ORC library in
Hive 1.2.1 which is used prior to Spark 2.3.
+
+
+spark.sql.orc.enableVectorizedReader
+true
+Enables vectorized orc decoding in native
implementation. If false, a new non-vectorized ORC reader is used
in native implementation. For hive implementation,
this is ignored.
+
+
+
+- Changed configurations
+
+
+ Property
NameDefaultMeaning
+
+spark.sql.orc.filterPushdown
+true
+Enables filter pushdown for ORC files. It is false by
default prior to Spark 2.3.
+
+
+
- Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when
the referenced columns only include the internal corrupt record column (named
`_corrupt_record` by default). For example,
`spark.read.schema(schema).json(file).filter($"_corrupt_record".isNotNull).count()`
and `spark.read.schema(schema).json(file).select("_corrupt_record").show()`.
Instead, you can cache or save the parsed results and then send the same query.
For example, `val df = spark.read.schema(schema).json(file).cache()` and then
`df.filter($"_corrupt_record".isNotNull).count()`.
- The `percentile_approx` function previously accepted numeric type input
and output double type results. Now it supports date type, timestamp type and
numeric types as input types. The result type is also changed to be the same as
the input type, which is more reasonable for percentiles.
- Since Spark 2.3, the Join/Filter's deterministic predicates that are after
the first non-deterministic predicates are also pushed down/through the child
operators, if possible. In prior Spark versions, these filters are not eligible
for predicate pushdown.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23313][DOC] Add a migration guide for ORC
Repository: spark
Updated Branches:
refs/heads/master fba01b9a6 -> 6cb59708c
[SPARK-23313][DOC] Add a migration guide for ORC
## What changes were proposed in this pull request?
This PR adds a migration guide documentation for ORC.

## How was this patch tested?
N/A.
Author: Dongjoon Hyun
Closes #20484 from dongjoon-hyun/SPARK-23313.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/6cb59708
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/6cb59708
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/6cb59708
Branch: refs/heads/master
Commit: 6cb59708c70c03696c772fbb5d158eed57fe67d4
Parents: fba01b9
Author: Dongjoon Hyun
Authored: Mon Feb 12 15:26:37 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 15:26:37 2018 -0800
--
docs/sql-programming-guide.md | 29 +
1 file changed, 29 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/6cb59708/docs/sql-programming-guide.md
--
diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md
index 6174a93..0f9f01e 100644
--- a/docs/sql-programming-guide.md
+++ b/docs/sql-programming-guide.md
@@ -1776,6 +1776,35 @@ working with timestamps in `pandas_udf`s to get the best
performance, see
## Upgrading From Spark SQL 2.2 to 2.3
+ - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC
file format for ORC files. To do that, the following configurations are newly
added or change their default values. The vectorized reader is used for the
native ORC tables (e.g., the ones created using the clause `USING ORC`) when
`spark.sql.orc.impl` is set to `native` and
`spark.sql.orc.enableVectorizedReader` is set to `true`. For the Hive ORC serde
table (e.g., the ones created using the clause `USING HIVE OPTIONS (fileFormat
'ORC')`), the vectorized reader is used when
`spark.sql.hive.convertMetastoreOrc` is set to `true`.
+
+- New configurations
+
+
+ Property
NameDefaultMeaning
+
+spark.sql.orc.impl
+native
+The name of ORC implementation. It can be one of
native and hive. native means the native
ORC support that is built on Apache ORC 1.4.1. `hive` means the ORC library in
Hive 1.2.1 which is used prior to Spark 2.3.
+
+
+spark.sql.orc.enableVectorizedReader
+true
+Enables vectorized orc decoding in native
implementation. If false, a new non-vectorized ORC reader is used
in native implementation. For hive implementation,
this is ignored.
+
+
+
+- Changed configurations
+
+
+ Property
NameDefaultMeaning
+
+spark.sql.orc.filterPushdown
+true
+Enables filter pushdown for ORC files. It is false by
default prior to Spark 2.3.
+
+
+
- Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when
the referenced columns only include the internal corrupt record column (named
`_corrupt_record` by default). For example,
`spark.read.schema(schema).json(file).filter($"_corrupt_record".isNotNull).count()`
and `spark.read.schema(schema).json(file).select("_corrupt_record").show()`.
Instead, you can cache or save the parsed results and then send the same query.
For example, `val df = spark.read.schema(schema).json(file).cache()` and then
`df.filter($"_corrupt_record".isNotNull).count()`.
- The `percentile_approx` function previously accepted numeric type input
and output double type results. Now it supports date type, timestamp type and
numeric types as input types. The result type is also changed to be the same as
the input type, which is more reasonable for percentiles.
- Since Spark 2.3, the Join/Filter's deterministic predicates that are after
the first non-deterministic predicates are also pushed down/through the child
operators, if possible. In prior Spark versions, these filters are not eligible
for predicate pushdown.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23378][SQL] move setCurrentDatabase from HiveExternalCatalog to HiveClientImpl
Repository: spark
Updated Branches:
refs/heads/master 0c66fe4f2 -> fba01b9a6
[SPARK-23378][SQL] move setCurrentDatabase from HiveExternalCatalog to
HiveClientImpl
## What changes were proposed in this pull request?
This removes the special case that `alterPartitions` call from
`HiveExternalCatalog` can reset the current database in the hive client as a
side effect.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests,
manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a pull
request.
Author: Feng Liu
Closes #20564 from liufengdb/move.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/fba01b9a
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/fba01b9a
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/fba01b9a
Branch: refs/heads/master
Commit: fba01b9a65e5d9438d35da0bd807c179ba741911
Parents: 0c66fe4
Author: Feng Liu
Authored: Mon Feb 12 14:58:31 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 14:58:31 2018 -0800
--
.../spark/sql/hive/HiveExternalCatalog.scala| 5
.../spark/sql/hive/client/HiveClientImpl.scala | 26 +++-
2 files changed, 20 insertions(+), 11 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/fba01b9a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
index 3b8a8ca..1ee1d57 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
@@ -1107,11 +1107,6 @@ private[spark] class HiveExternalCatalog(conf:
SparkConf, hadoopConf: Configurat
}
}
-// Note: Before altering table partitions in Hive, you *must* set the
current database
-// to the one that contains the table of interest. Otherwise you will end
up with the
-// most helpful error message ever: "Unable to alter partition. alter is
not possible."
-// See HIVE-2742 for more detail.
-client.setCurrentDatabase(db)
client.alterPartitions(db, table, withStatsProps)
}
http://git-wip-us.apache.org/repos/asf/spark/blob/fba01b9a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
index 6c0f414..c223f51 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
@@ -291,14 +291,18 @@ private[hive] class HiveClientImpl(
state.err = stream
}
- override def setCurrentDatabase(databaseName: String): Unit = withHiveState {
-if (databaseExists(databaseName)) {
- state.setCurrentDatabase(databaseName)
+ private def setCurrentDatabaseRaw(db: String): Unit = {
+if (databaseExists(db)) {
+ state.setCurrentDatabase(db)
} else {
- throw new NoSuchDatabaseException(databaseName)
+ throw new NoSuchDatabaseException(db)
}
}
+ override def setCurrentDatabase(databaseName: String): Unit = withHiveState {
+setCurrentDatabaseRaw(databaseName)
+ }
+
override def createDatabase(
database: CatalogDatabase,
ignoreIfExists: Boolean): Unit = withHiveState {
@@ -598,8 +602,18 @@ private[hive] class HiveClientImpl(
db: String,
table: String,
newParts: Seq[CatalogTablePartition]): Unit = withHiveState {
-val hiveTable = toHiveTable(getTable(db, table), Some(userName))
-shim.alterPartitions(client, table, newParts.map { p => toHivePartition(p,
hiveTable) }.asJava)
+// Note: Before altering table partitions in Hive, you *must* set the
current database
+// to the one that contains the table of interest. Otherwise you will end
up with the
+// most helpful error message ever: "Unable to alter partition. alter is
not possible."
+// See HIVE-2742 for more detail.
+val original = state.getCurrentDatabase
+try {
+ setCurrentDatabaseRaw(db)
+ val hiveTable = toHiveTable(getTable(db, table), Some(userName))
+ shim.alterPartitions(client, table, newParts.map { toHivePartition(_,
hiveTable) }.asJava)
+} finally {
+ state.setCurrentDatabase(original)
+}
}
/**
---
svn commit: r24978 - in /dev/spark/2.3.1-SNAPSHOT-2018_02_12_14_01-9632c46-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 22:15:13 2018 New Revision: 24978 Log: Apache Spark 2.3.1-SNAPSHOT-2018_02_12_14_01-9632c46 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-22002][SQL][FOLLOWUP][TEST] Add a test to check if the original schema doesn't have metadata.
Repository: spark
Updated Branches:
refs/heads/branch-2.3 4e138207e -> 9632c461e
[SPARK-22002][SQL][FOLLOWUP][TEST] Add a test to check if the original schema
doesn't have metadata.
## What changes were proposed in this pull request?
This is a follow-up pr of #19231 which modified the behavior to remove metadata
from JDBC table schema.
This pr adds a test to check if the schema doesn't have metadata.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN
Closes #20585 from ueshin/issues/SPARK-22002/fup1.
(cherry picked from commit 0c66fe4f22f8af4932893134bb0fd56f00fabeae)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/9632c461
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/9632c461
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/9632c461
Branch: refs/heads/branch-2.3
Commit: 9632c461e6931a1a4d05684d0f62ee36f9e90b77
Parents: 4e13820
Author: Takuya UESHIN
Authored: Mon Feb 12 12:20:29 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 12:21:04 2018 -0800
--
.../org/apache/spark/sql/jdbc/JDBCSuite.scala | 22
1 file changed, 22 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/9632c461/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
--
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
index cb2df0a..5238adc 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
@@ -1168,4 +1168,26 @@ class JDBCSuite extends SparkFunSuite
val df3 = sql("SELECT * FROM test_sessionInitStatement")
assert(df3.collect() === Array(Row(21519, 1234)))
}
+
+ test("jdbc data source shouldn't have unnecessary metadata in its schema") {
+val schema = StructType(Seq(
+ StructField("NAME", StringType, true), StructField("THEID", IntegerType,
true)))
+
+val df = spark.read.format("jdbc")
+ .option("Url", urlWithUserAndPass)
+ .option("DbTaBle", "TEST.PEOPLE")
+ .load()
+assert(df.schema === schema)
+
+withTempView("people_view") {
+ sql(
+s"""
+ |CREATE TEMPORARY VIEW people_view
+ |USING org.apache.spark.sql.jdbc
+ |OPTIONS (uRl '$url', DbTaBlE 'TEST.PEOPLE', User 'testUser',
PassWord 'testPass')
+""".stripMargin.replaceAll("\n", " "))
+
+ assert(sql("select * from people_view").schema === schema)
+}
+ }
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-22002][SQL][FOLLOWUP][TEST] Add a test to check if the original schema doesn't have metadata.
Repository: spark
Updated Branches:
refs/heads/master 5bb11411a -> 0c66fe4f2
[SPARK-22002][SQL][FOLLOWUP][TEST] Add a test to check if the original schema
doesn't have metadata.
## What changes were proposed in this pull request?
This is a follow-up pr of #19231 which modified the behavior to remove metadata
from JDBC table schema.
This pr adds a test to check if the schema doesn't have metadata.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN
Closes #20585 from ueshin/issues/SPARK-22002/fup1.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/0c66fe4f
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/0c66fe4f
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/0c66fe4f
Branch: refs/heads/master
Commit: 0c66fe4f22f8af4932893134bb0fd56f00fabeae
Parents: 5bb1141
Author: Takuya UESHIN
Authored: Mon Feb 12 12:20:29 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 12:20:29 2018 -0800
--
.../org/apache/spark/sql/jdbc/JDBCSuite.scala | 22
1 file changed, 22 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/0c66fe4f/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
--
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
index cb2df0a..5238adc 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
@@ -1168,4 +1168,26 @@ class JDBCSuite extends SparkFunSuite
val df3 = sql("SELECT * FROM test_sessionInitStatement")
assert(df3.collect() === Array(Row(21519, 1234)))
}
+
+ test("jdbc data source shouldn't have unnecessary metadata in its schema") {
+val schema = StructType(Seq(
+ StructField("NAME", StringType, true), StructField("THEID", IntegerType,
true)))
+
+val df = spark.read.format("jdbc")
+ .option("Url", urlWithUserAndPass)
+ .option("DbTaBle", "TEST.PEOPLE")
+ .load()
+assert(df.schema === schema)
+
+withTempView("people_view") {
+ sql(
+s"""
+ |CREATE TEMPORARY VIEW people_view
+ |USING org.apache.spark.sql.jdbc
+ |OPTIONS (uRl '$url', DbTaBlE 'TEST.PEOPLE', User 'testUser',
PassWord 'testPass')
+""".stripMargin.replaceAll("\n", " "))
+
+ assert(sql("select * from people_view").schema === schema)
+}
+ }
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24968 - in /dev/spark/2.4.0-SNAPSHOT-2018_02_12_12_01-5bb1141-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 20:15:07 2018 New Revision: 24968 Log: Apache Spark 2.4.0-SNAPSHOT-2018_02_12_12_01-5bb1141 docs [This commit notification would consist of 1444 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23388][SQL] Support for Parquet Binary DecimalType in VectorizedColumnReader
Repository: spark
Updated Branches:
refs/heads/branch-2.3 70be6038d -> 4e138207e
[SPARK-23388][SQL] Support for Parquet Binary DecimalType in
VectorizedColumnReader
## What changes were proposed in this pull request?
Re-add support for parquet binary DecimalType in VectorizedColumnReader
## How was this patch tested?
Existing test suite
Author: James Thompson
Closes #20580 from jamesthomp/jt/add-back-binary-decimal.
(cherry picked from commit 5bb11411aec18b8d623e54caba5397d7cb8e89f0)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/4e138207
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/4e138207
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/4e138207
Branch: refs/heads/branch-2.3
Commit: 4e138207ebb11a08393c15e5e39f46a5dc1e7c66
Parents: 70be603
Author: James Thompson
Authored: Mon Feb 12 11:34:56 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 11:35:06 2018 -0800
--
.../sql/execution/datasources/parquet/VectorizedColumnReader.java | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/4e138207/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
index c120863..47dd625 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
@@ -444,7 +444,8 @@ public class VectorizedColumnReader {
// This is where we implement support for the valid type conversions.
// TODO: implement remaining type conversions
VectorizedValuesReader data = (VectorizedValuesReader) dataColumn;
-if (column.dataType() == DataTypes.StringType || column.dataType() ==
DataTypes.BinaryType) {
+if (column.dataType() == DataTypes.StringType || column.dataType() ==
DataTypes.BinaryType
+|| DecimalType.isByteArrayDecimalType(column.dataType())) {
defColumn.readBinarys(num, column, rowId, maxDefLevel, data);
} else if (column.dataType() == DataTypes.TimestampType) {
if (!shouldConvertTimestamps()) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23388][SQL] Support for Parquet Binary DecimalType in VectorizedColumnReader
Repository: spark
Updated Branches:
refs/heads/master 4a4dd4f36 -> 5bb11411a
[SPARK-23388][SQL] Support for Parquet Binary DecimalType in
VectorizedColumnReader
## What changes were proposed in this pull request?
Re-add support for parquet binary DecimalType in VectorizedColumnReader
## How was this patch tested?
Existing test suite
Author: James Thompson
Closes #20580 from jamesthomp/jt/add-back-binary-decimal.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/5bb11411
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/5bb11411
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/5bb11411
Branch: refs/heads/master
Commit: 5bb11411aec18b8d623e54caba5397d7cb8e89f0
Parents: 4a4dd4f
Author: James Thompson
Authored: Mon Feb 12 11:34:56 2018 -0800
Committer: gatorsmile
Committed: Mon Feb 12 11:34:56 2018 -0800
--
.../sql/execution/datasources/parquet/VectorizedColumnReader.java | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/5bb11411/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
index c120863..47dd625 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java
@@ -444,7 +444,8 @@ public class VectorizedColumnReader {
// This is where we implement support for the valid type conversions.
// TODO: implement remaining type conversions
VectorizedValuesReader data = (VectorizedValuesReader) dataColumn;
-if (column.dataType() == DataTypes.StringType || column.dataType() ==
DataTypes.BinaryType) {
+if (column.dataType() == DataTypes.StringType || column.dataType() ==
DataTypes.BinaryType
+|| DecimalType.isByteArrayDecimalType(column.dataType())) {
defColumn.readBinarys(num, column, rowId, maxDefLevel, data);
} else if (column.dataType() == DataTypes.TimestampType) {
if (!shouldConvertTimestamps()) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[2/2] spark git commit: Preparing development version 2.3.1-SNAPSHOT
Preparing development version 2.3.1-SNAPSHOT
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/70be6038
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/70be6038
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/70be6038
Branch: refs/heads/branch-2.3
Commit: 70be6038df38d5e80af8565120eedd8242c5a7c5
Parents: 89f6fcb
Author: Sameer Agarwal
Authored: Mon Feb 12 11:08:34 2018 -0800
Committer: Sameer Agarwal
Committed: Mon Feb 12 11:08:34 2018 -0800
--
R/pkg/DESCRIPTION | 2 +-
assembly/pom.xml | 2 +-
common/kvstore/pom.xml| 2 +-
common/network-common/pom.xml | 2 +-
common/network-shuffle/pom.xml| 2 +-
common/network-yarn/pom.xml | 2 +-
common/sketch/pom.xml | 2 +-
common/tags/pom.xml | 2 +-
common/unsafe/pom.xml | 2 +-
core/pom.xml | 2 +-
docs/_config.yml | 4 ++--
examples/pom.xml | 2 +-
external/docker-integration-tests/pom.xml | 2 +-
external/flume-assembly/pom.xml | 2 +-
external/flume-sink/pom.xml | 2 +-
external/flume/pom.xml| 2 +-
external/kafka-0-10-assembly/pom.xml | 2 +-
external/kafka-0-10-sql/pom.xml | 2 +-
external/kafka-0-10/pom.xml | 2 +-
external/kafka-0-8-assembly/pom.xml | 2 +-
external/kafka-0-8/pom.xml| 2 +-
external/kinesis-asl-assembly/pom.xml | 2 +-
external/kinesis-asl/pom.xml | 2 +-
external/spark-ganglia-lgpl/pom.xml | 2 +-
graphx/pom.xml| 2 +-
hadoop-cloud/pom.xml | 2 +-
launcher/pom.xml | 2 +-
mllib-local/pom.xml | 2 +-
mllib/pom.xml | 2 +-
pom.xml | 2 +-
python/pyspark/version.py | 2 +-
repl/pom.xml | 2 +-
resource-managers/kubernetes/core/pom.xml | 2 +-
resource-managers/mesos/pom.xml | 2 +-
resource-managers/yarn/pom.xml| 2 +-
sql/catalyst/pom.xml | 2 +-
sql/core/pom.xml | 2 +-
sql/hive-thriftserver/pom.xml | 2 +-
sql/hive/pom.xml | 2 +-
streaming/pom.xml | 2 +-
tools/pom.xml | 2 +-
41 files changed, 42 insertions(+), 42 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/70be6038/R/pkg/DESCRIPTION
--
diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION
index 6d46c31..29a8a00 100644
--- a/R/pkg/DESCRIPTION
+++ b/R/pkg/DESCRIPTION
@@ -1,6 +1,6 @@
Package: SparkR
Type: Package
-Version: 2.3.0
+Version: 2.3.1
Title: R Frontend for Apache Spark
Description: Provides an R Frontend for Apache Spark.
Authors@R: c(person("Shivaram", "Venkataraman", role = c("aut", "cre"),
http://git-wip-us.apache.org/repos/asf/spark/blob/70be6038/assembly/pom.xml
--
diff --git a/assembly/pom.xml b/assembly/pom.xml
index 2ca9ab6..5c5a8e9 100644
--- a/assembly/pom.xml
+++ b/assembly/pom.xml
@@ -21,7 +21,7 @@
org.apache.spark
spark-parent_2.11
-2.3.0
+2.3.1-SNAPSHOT
../pom.xml
http://git-wip-us.apache.org/repos/asf/spark/blob/70be6038/common/kvstore/pom.xml
--
diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml
index 404c744..2a625da 100644
--- a/common/kvstore/pom.xml
+++ b/common/kvstore/pom.xml
@@ -22,7 +22,7 @@
org.apache.spark
spark-parent_2.11
-2.3.0
+2.3.1-SNAPSHOT
../../pom.xml
http://git-wip-us.apache.org/repos/asf/spark/blob/70be6038/common/network-common/pom.xml
--
diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml
index 3c0b528..adb1890 100644
--- a/common/network-common/pom.xml
+++ b/common/network-common/pom.xml
@@ -22,7 +22,7 @@
org.apache.spark
spark-parent_2.11
-2.3.0
+2.3.1-SNAPSHOT
../../pom.xml
http://git-wip-us.apache.org/repos/asf/spark/blob/70be6038/common/network-shuffle/pom.xml
--
diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml
index fe3bcfd..4cdcfa2 100644
--- a/common/network-shuffle/pom.xml
+++ b/common/network-shuffle/pom.xml
@@ -22,7 +22,7 @@
org.apache.spark
spark-parent_2.11
-
[1/2] spark git commit: Preparing Spark release v2.3.0-rc3
Repository: spark
Updated Branches:
refs/heads/branch-2.3 d31c4ae7b -> 70be6038d
Preparing Spark release v2.3.0-rc3
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/89f6fcba
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/89f6fcba
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/89f6fcba
Branch: refs/heads/branch-2.3
Commit: 89f6fcbafcfb0a7aeb897fba6036cb085bd35121
Parents: d31c4ae
Author: Sameer Agarwal
Authored: Mon Feb 12 11:08:28 2018 -0800
Committer: Sameer Agarwal
Committed: Mon Feb 12 11:08:28 2018 -0800
--
R/pkg/DESCRIPTION | 2 +-
assembly/pom.xml | 2 +-
common/kvstore/pom.xml| 2 +-
common/network-common/pom.xml | 2 +-
common/network-shuffle/pom.xml| 2 +-
common/network-yarn/pom.xml | 2 +-
common/sketch/pom.xml | 2 +-
common/tags/pom.xml | 2 +-
common/unsafe/pom.xml | 2 +-
core/pom.xml | 2 +-
docs/_config.yml | 4 ++--
examples/pom.xml | 2 +-
external/docker-integration-tests/pom.xml | 2 +-
external/flume-assembly/pom.xml | 2 +-
external/flume-sink/pom.xml | 2 +-
external/flume/pom.xml| 2 +-
external/kafka-0-10-assembly/pom.xml | 2 +-
external/kafka-0-10-sql/pom.xml | 2 +-
external/kafka-0-10/pom.xml | 2 +-
external/kafka-0-8-assembly/pom.xml | 2 +-
external/kafka-0-8/pom.xml| 2 +-
external/kinesis-asl-assembly/pom.xml | 2 +-
external/kinesis-asl/pom.xml | 2 +-
external/spark-ganglia-lgpl/pom.xml | 2 +-
graphx/pom.xml| 2 +-
hadoop-cloud/pom.xml | 2 +-
launcher/pom.xml | 2 +-
mllib-local/pom.xml | 2 +-
mllib/pom.xml | 2 +-
pom.xml | 2 +-
python/pyspark/version.py | 2 +-
repl/pom.xml | 2 +-
resource-managers/kubernetes/core/pom.xml | 2 +-
resource-managers/mesos/pom.xml | 2 +-
resource-managers/yarn/pom.xml| 2 +-
sql/catalyst/pom.xml | 2 +-
sql/core/pom.xml | 2 +-
sql/hive-thriftserver/pom.xml | 2 +-
sql/hive/pom.xml | 2 +-
streaming/pom.xml | 2 +-
tools/pom.xml | 2 +-
41 files changed, 42 insertions(+), 42 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/89f6fcba/R/pkg/DESCRIPTION
--
diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION
index 29a8a00..6d46c31 100644
--- a/R/pkg/DESCRIPTION
+++ b/R/pkg/DESCRIPTION
@@ -1,6 +1,6 @@
Package: SparkR
Type: Package
-Version: 2.3.1
+Version: 2.3.0
Title: R Frontend for Apache Spark
Description: Provides an R Frontend for Apache Spark.
Authors@R: c(person("Shivaram", "Venkataraman", role = c("aut", "cre"),
http://git-wip-us.apache.org/repos/asf/spark/blob/89f6fcba/assembly/pom.xml
--
diff --git a/assembly/pom.xml b/assembly/pom.xml
index 5c5a8e9..2ca9ab6 100644
--- a/assembly/pom.xml
+++ b/assembly/pom.xml
@@ -21,7 +21,7 @@
org.apache.spark
spark-parent_2.11
-2.3.1-SNAPSHOT
+2.3.0
../pom.xml
http://git-wip-us.apache.org/repos/asf/spark/blob/89f6fcba/common/kvstore/pom.xml
--
diff --git a/common/kvstore/pom.xml b/common/kvstore/pom.xml
index 2a625da..404c744 100644
--- a/common/kvstore/pom.xml
+++ b/common/kvstore/pom.xml
@@ -22,7 +22,7 @@
org.apache.spark
spark-parent_2.11
-2.3.1-SNAPSHOT
+2.3.0
../../pom.xml
http://git-wip-us.apache.org/repos/asf/spark/blob/89f6fcba/common/network-common/pom.xml
--
diff --git a/common/network-common/pom.xml b/common/network-common/pom.xml
index adb1890..3c0b528 100644
--- a/common/network-common/pom.xml
+++ b/common/network-common/pom.xml
@@ -22,7 +22,7 @@
org.apache.spark
spark-parent_2.11
-2.3.1-SNAPSHOT
+2.3.0
../../pom.xml
http://git-wip-us.apache.org/repos/asf/spark/blob/89f6fcba/common/network-shuffle/pom.xml
--
diff --git a/common/network-shuffle/pom.xml b/common/network-shuffle/pom.xml
index 4cdcfa2..fe3bcfd 100644
--- a/common/network-shuffle/pom.xml
+++ b/common/network-shuffle/po
[spark] Git Push Summary
Repository: spark Updated Tags: refs/tags/v2.3.0-rc3 [created] 89f6fcbaf - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24961 - in /dev/spark/2.3.1-SNAPSHOT-2018_02_12_10_01-d31c4ae-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 18:15:26 2018 New Revision: 24961 Log: Apache Spark 2.3.1-SNAPSHOT-2018_02_12_10_01-d31c4ae docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24954 - in /dev/spark/2.4.0-SNAPSHOT-2018_02_12_08_02-4a4dd4f-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 16:21:15 2018 New Revision: 24954 Log: Apache Spark 2.4.0-SNAPSHOT-2018_02_12_08_02-4a4dd4f docs [This commit notification would consist of 1444 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23391][CORE] It may lead to overflow for some integer multiplication
Repository: spark
Updated Branches:
refs/heads/branch-2.2 169483455 -> 14b5dbfa9
[SPARK-23391][CORE] It may lead to overflow for some integer multiplication
In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater
than 2^28, `blockId.reduceId*8` will overflow
In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize`
may lead to overflow
N/A
Author: liuxian
Closes #20581 from 10110346/overflow2.
(cherry picked from commit 4a4dd4f36f65410ef5c87f7b61a960373f044e61)
Signed-off-by: Sean Owen
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/14b5dbfa
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/14b5dbfa
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/14b5dbfa
Branch: refs/heads/branch-2.2
Commit: 14b5dbfa9a5ef9555ef9072ff0639985fcf57118
Parents: 1694834
Author: liuxian
Authored: Mon Feb 12 08:49:45 2018 -0600
Committer: Sean Owen
Committed: Mon Feb 12 08:52:39 2018 -0600
--
.../org/apache/spark/shuffle/IndexShuffleBlockResolver.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/14b5dbfa/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
b/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
index 2414b94..449f602 100644
---
a/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
+++
b/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
@@ -203,13 +203,13 @@ private[spark] class IndexShuffleBlockResolver(
// class of issue from re-occurring in the future which is why they are
left here even though
// SPARK-22982 is fixed.
val channel = Files.newByteChannel(indexFile.toPath)
-channel.position(blockId.reduceId * 8)
+channel.position(blockId.reduceId * 8L)
val in = new DataInputStream(Channels.newInputStream(channel))
try {
val offset = in.readLong()
val nextOffset = in.readLong()
val actualPosition = channel.position()
- val expectedPosition = blockId.reduceId * 8 + 16
+ val expectedPosition = blockId.reduceId * 8L + 16
if (actualPosition != expectedPosition) {
throw new Exception(s"SPARK-22982: Incorrect channel position after
index file reads: " +
s"expected $expectedPosition but actual position was
$actualPosition.")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23391][CORE] It may lead to overflow for some integer multiplication
Repository: spark
Updated Branches:
refs/heads/branch-2.3 1e3118c2e -> d31c4ae7b
[SPARK-23391][CORE] It may lead to overflow for some integer multiplication
## What changes were proposed in this pull request?
In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater
than 2^28, `blockId.reduceId*8` will overflow
In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize`
may lead to overflow
## How was this patch tested?
N/A
Author: liuxian
Closes #20581 from 10110346/overflow2.
(cherry picked from commit 4a4dd4f36f65410ef5c87f7b61a960373f044e61)
Signed-off-by: Sean Owen
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/d31c4ae7
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/d31c4ae7
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/d31c4ae7
Branch: refs/heads/branch-2.3
Commit: d31c4ae7ba734356c849347b9a7b448da9a5a9a1
Parents: 1e3118c
Author: liuxian
Authored: Mon Feb 12 08:49:45 2018 -0600
Committer: Sean Owen
Committed: Mon Feb 12 08:49:52 2018 -0600
--
.../org/apache/spark/shuffle/IndexShuffleBlockResolver.scala | 4 ++--
.../sql/execution/columnar/compression/compressionSchemes.scala | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/d31c4ae7/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
b/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
index 2414b94..449f602 100644
---
a/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
+++
b/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
@@ -203,13 +203,13 @@ private[spark] class IndexShuffleBlockResolver(
// class of issue from re-occurring in the future which is why they are
left here even though
// SPARK-22982 is fixed.
val channel = Files.newByteChannel(indexFile.toPath)
-channel.position(blockId.reduceId * 8)
+channel.position(blockId.reduceId * 8L)
val in = new DataInputStream(Channels.newInputStream(channel))
try {
val offset = in.readLong()
val nextOffset = in.readLong()
val actualPosition = channel.position()
- val expectedPosition = blockId.reduceId * 8 + 16
+ val expectedPosition = blockId.reduceId * 8L + 16
if (actualPosition != expectedPosition) {
throw new Exception(s"SPARK-22982: Incorrect channel position after
index file reads: " +
s"expected $expectedPosition but actual position was
$actualPosition.")
http://git-wip-us.apache.org/repos/asf/spark/blob/d31c4ae7/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
index 79dcf3a..00a1d54 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
@@ -116,7 +116,7 @@ private[columnar] case object PassThrough extends
CompressionScheme {
while (pos < capacity) {
if (pos != nextNullIndex) {
val len = nextNullIndex - pos
- assert(len * unitSize < Int.MaxValue)
+ assert(len * unitSize.toLong < Int.MaxValue)
putFunction(columnVector, pos, bufferPos, len)
bufferPos += len * unitSize
pos += len
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23391][CORE] It may lead to overflow for some integer multiplication
Repository: spark
Updated Branches:
refs/heads/master 0e2c266de -> 4a4dd4f36
[SPARK-23391][CORE] It may lead to overflow for some integer multiplication
## What changes were proposed in this pull request?
In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater
than 2^28, `blockId.reduceId*8` will overflow
In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize`
may lead to overflow
## How was this patch tested?
N/A
Author: liuxian
Closes #20581 from 10110346/overflow2.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/4a4dd4f3
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/4a4dd4f3
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/4a4dd4f3
Branch: refs/heads/master
Commit: 4a4dd4f36f65410ef5c87f7b61a960373f044e61
Parents: 0e2c266
Author: liuxian
Authored: Mon Feb 12 08:49:45 2018 -0600
Committer: Sean Owen
Committed: Mon Feb 12 08:49:45 2018 -0600
--
.../org/apache/spark/shuffle/IndexShuffleBlockResolver.scala | 4 ++--
.../sql/execution/columnar/compression/compressionSchemes.scala | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/4a4dd4f3/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
b/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
index d88b25c..d3f1c7e 100644
---
a/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
+++
b/core/src/main/scala/org/apache/spark/shuffle/IndexShuffleBlockResolver.scala
@@ -202,13 +202,13 @@ private[spark] class IndexShuffleBlockResolver(
// class of issue from re-occurring in the future which is why they are
left here even though
// SPARK-22982 is fixed.
val channel = Files.newByteChannel(indexFile.toPath)
-channel.position(blockId.reduceId * 8)
+channel.position(blockId.reduceId * 8L)
val in = new DataInputStream(Channels.newInputStream(channel))
try {
val offset = in.readLong()
val nextOffset = in.readLong()
val actualPosition = channel.position()
- val expectedPosition = blockId.reduceId * 8 + 16
+ val expectedPosition = blockId.reduceId * 8L + 16
if (actualPosition != expectedPosition) {
throw new Exception(s"SPARK-22982: Incorrect channel position after
index file reads: " +
s"expected $expectedPosition but actual position was
$actualPosition.")
http://git-wip-us.apache.org/repos/asf/spark/blob/4a4dd4f3/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
index 79dcf3a..00a1d54 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/compression/compressionSchemes.scala
@@ -116,7 +116,7 @@ private[columnar] case object PassThrough extends
CompressionScheme {
while (pos < capacity) {
if (pos != nextNullIndex) {
val len = nextNullIndex - pos
- assert(len * unitSize < Int.MaxValue)
+ assert(len * unitSize.toLong < Int.MaxValue)
putFunction(columnVector, pos, bufferPos, len)
bufferPos += len * unitSize
pos += len
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-22977][SQL] fix web UI SQL tab for CTAS
Repository: spark
Updated Branches:
refs/heads/branch-2.3 79e8650cc -> 1e3118c2e
[SPARK-22977][SQL] fix web UI SQL tab for CTAS
## What changes were proposed in this pull request?
This is a regression in Spark 2.3.
In Spark 2.2, we have a fragile UI support for SQL data writing commands. We
only track the input query plan of `FileFormatWriter` and display its metrics.
This is not ideal because we don't know who triggered the writing(can be table
insertion, CTAS, etc.), but it's still useful to see the metrics of the input
query.
In Spark 2.3, we introduced a new mechanism: `DataWritigCommand`, to fix the UI
issue entirely. Now these writing commands have real children, and we don't
need to hack into the `FileFormatWriter` for the UI. This also helps with
`explain`, now `explain` can show the physical plan of the input query, while
in 2.2 the physical writing plan is simply `ExecutedCommandExec` and it has no
child.
However there is a regression in CTAS. CTAS commands don't extend
`DataWritigCommand`, and we don't have the UI hack in `FileFormatWriter`
anymore, so the UI for CTAS is just an empty node. See
https://issues.apache.org/jira/browse/SPARK-22977 for more information about
this UI issue.
To fix it, we should apply the `DataWritigCommand` mechanism to CTAS commands.
TODO: In the future, we should refactor this part and create some physical
layer code pieces for data writing, and reuse them in different writing
commands. We should have different logical nodes for different operators, even
some of them share some same logic, e.g. CTAS, CREATE TABLE, INSERT TABLE.
Internally we can share the same physical logic.
## How was this patch tested?
manually tested.
For data source table
https://user-images.githubusercontent.com/3182036/35874155-bdffab28-0ba6-11e8-94a8-e32e106ba069.png";>
For hive table
https://user-images.githubusercontent.com/3182036/35874161-c437e2a8-0ba6-11e8-98ed-7930f01432c5.png";>
Author: Wenchen Fan
Closes #20521 from cloud-fan/UI.
(cherry picked from commit 0e2c266de7189473177f45aa68ea6a45c7e47ec3)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/1e3118c2
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/1e3118c2
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/1e3118c2
Branch: refs/heads/branch-2.3
Commit: 1e3118c2ee0fe7d2c59cb3e2055709bb2809a6db
Parents: 79e8650
Author: Wenchen Fan
Authored: Mon Feb 12 22:07:59 2018 +0800
Committer: Wenchen Fan
Committed: Mon Feb 12 22:08:16 2018 +0800
--
.../command/createDataSourceTables.scala| 21
.../sql/execution/datasources/DataSource.scala | 44 +---
.../datasources/DataSourceStrategy.scala| 2 +-
.../apache/spark/sql/hive/HiveStrategies.scala | 2 +-
.../CreateHiveTableAsSelectCommand.scala| 55 +++-
.../sql/hive/execution/HiveExplainSuite.scala | 26 -
6 files changed, 80 insertions(+), 70 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/1e3118c2/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
index 306f43d..e974776 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
@@ -21,7 +21,9 @@ import java.net.URI
import org.apache.spark.sql._
import org.apache.spark.sql.catalyst.catalog._
+import org.apache.spark.sql.catalyst.expressions.Attribute
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
import org.apache.spark.sql.execution.datasources._
import org.apache.spark.sql.sources.BaseRelation
import org.apache.spark.sql.types.StructType
@@ -136,12 +138,11 @@ case class CreateDataSourceTableCommand(table:
CatalogTable, ignoreIfExists: Boo
case class CreateDataSourceTableAsSelectCommand(
table: CatalogTable,
mode: SaveMode,
-query: LogicalPlan)
- extends RunnableCommand {
-
- override protected def innerChildren: Seq[LogicalPlan] = Seq(query)
+query: LogicalPlan,
+outputColumns: Seq[Attribute])
+ extends DataWritingCommand {
- override def run(sparkSession: SparkSession): Seq[Row] = {
+ override def run(sparkSession: SparkSession, child: SparkPlan): Seq[Row] = {
assert(table.tableType != CatalogTableType.VIEW)
assert(table.provider.isDefined)
@@ -163,7 +164,7 @@ case class CreateDataSourceTableAsSelect
spark git commit: [SPARK-22977][SQL] fix web UI SQL tab for CTAS
Repository: spark
Updated Branches:
refs/heads/master caeb108e2 -> 0e2c266de
[SPARK-22977][SQL] fix web UI SQL tab for CTAS
## What changes were proposed in this pull request?
This is a regression in Spark 2.3.
In Spark 2.2, we have a fragile UI support for SQL data writing commands. We
only track the input query plan of `FileFormatWriter` and display its metrics.
This is not ideal because we don't know who triggered the writing(can be table
insertion, CTAS, etc.), but it's still useful to see the metrics of the input
query.
In Spark 2.3, we introduced a new mechanism: `DataWritigCommand`, to fix the UI
issue entirely. Now these writing commands have real children, and we don't
need to hack into the `FileFormatWriter` for the UI. This also helps with
`explain`, now `explain` can show the physical plan of the input query, while
in 2.2 the physical writing plan is simply `ExecutedCommandExec` and it has no
child.
However there is a regression in CTAS. CTAS commands don't extend
`DataWritigCommand`, and we don't have the UI hack in `FileFormatWriter`
anymore, so the UI for CTAS is just an empty node. See
https://issues.apache.org/jira/browse/SPARK-22977 for more information about
this UI issue.
To fix it, we should apply the `DataWritigCommand` mechanism to CTAS commands.
TODO: In the future, we should refactor this part and create some physical
layer code pieces for data writing, and reuse them in different writing
commands. We should have different logical nodes for different operators, even
some of them share some same logic, e.g. CTAS, CREATE TABLE, INSERT TABLE.
Internally we can share the same physical logic.
## How was this patch tested?
manually tested.
For data source table
https://user-images.githubusercontent.com/3182036/35874155-bdffab28-0ba6-11e8-94a8-e32e106ba069.png";>
For hive table
https://user-images.githubusercontent.com/3182036/35874161-c437e2a8-0ba6-11e8-98ed-7930f01432c5.png";>
Author: Wenchen Fan
Closes #20521 from cloud-fan/UI.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/0e2c266d
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/0e2c266d
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/0e2c266d
Branch: refs/heads/master
Commit: 0e2c266de7189473177f45aa68ea6a45c7e47ec3
Parents: caeb108
Author: Wenchen Fan
Authored: Mon Feb 12 22:07:59 2018 +0800
Committer: Wenchen Fan
Committed: Mon Feb 12 22:07:59 2018 +0800
--
.../command/createDataSourceTables.scala| 21
.../sql/execution/datasources/DataSource.scala | 44 +---
.../datasources/DataSourceStrategy.scala| 2 +-
.../apache/spark/sql/hive/HiveStrategies.scala | 2 +-
.../CreateHiveTableAsSelectCommand.scala| 55 +++-
.../sql/hive/execution/HiveExplainSuite.scala | 26 -
6 files changed, 80 insertions(+), 70 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/0e2c266d/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
index 306f43d..e974776 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
@@ -21,7 +21,9 @@ import java.net.URI
import org.apache.spark.sql._
import org.apache.spark.sql.catalyst.catalog._
+import org.apache.spark.sql.catalyst.expressions.Attribute
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
import org.apache.spark.sql.execution.datasources._
import org.apache.spark.sql.sources.BaseRelation
import org.apache.spark.sql.types.StructType
@@ -136,12 +138,11 @@ case class CreateDataSourceTableCommand(table:
CatalogTable, ignoreIfExists: Boo
case class CreateDataSourceTableAsSelectCommand(
table: CatalogTable,
mode: SaveMode,
-query: LogicalPlan)
- extends RunnableCommand {
-
- override protected def innerChildren: Seq[LogicalPlan] = Seq(query)
+query: LogicalPlan,
+outputColumns: Seq[Attribute])
+ extends DataWritingCommand {
- override def run(sparkSession: SparkSession): Seq[Row] = {
+ override def run(sparkSession: SparkSession, child: SparkPlan): Seq[Row] = {
assert(table.tableType != CatalogTableType.VIEW)
assert(table.provider.isDefined)
@@ -163,7 +164,7 @@ case class CreateDataSourceTableAsSelectCommand(
}
saveDataIntoTable(
-sparkSession, table, table.storage.locationUri, que
spark git commit: [MINOR][TEST] spark.testing` No effect on the SparkFunSuite unit test
Repository: spark
Updated Branches:
refs/heads/master c338c8cf8 -> caeb108e2
[MINOR][TEST] spark.testing` No effect on the SparkFunSuite unit test
## What changes were proposed in this pull request?
Currently, we use SBT and MAVN to spark unit test, are affected by the
parameters of `spark.testing`. However, when using the IDE test tool,
`spark.testing` support is not very good, sometimes need to be manually added
to the beforeEach. example: HiveSparkSubmitSuite RPackageUtilsSuite
SparkSubmitSuite. The PR unified `spark.testing` parameter extraction to
SparkFunSuite, support IDE test tool, and the test code is more compact.
## How was this patch tested?
the existed test cases.
Author: caoxuewen
Closes #20582 from heary-cao/sparktesting.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/caeb108e
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/caeb108e
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/caeb108e
Branch: refs/heads/master
Commit: caeb108e25e5bfb7cffcf09ef9abbb1abcfa355d
Parents: c338c8c
Author: caoxuewen
Authored: Mon Feb 12 22:05:27 2018 +0800
Committer: Wenchen Fan
Committed: Mon Feb 12 22:05:27 2018 +0800
--
core/src/test/scala/org/apache/spark/SparkFunSuite.scala| 1 +
.../src/test/scala/org/apache/spark/deploy/RPackageUtilsSuite.scala | 1 -
core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala | 1 -
.../apache/spark/network/netty/NettyBlockTransferServiceSuite.scala | 1 +
.../test/scala/org/apache/spark/sql/hive/HiveSparkSubmitSuite.scala | 1 -
5 files changed, 2 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/caeb108e/core/src/test/scala/org/apache/spark/SparkFunSuite.scala
--
diff --git a/core/src/test/scala/org/apache/spark/SparkFunSuite.scala
b/core/src/test/scala/org/apache/spark/SparkFunSuite.scala
index 3af9d82..3128902 100644
--- a/core/src/test/scala/org/apache/spark/SparkFunSuite.scala
+++ b/core/src/test/scala/org/apache/spark/SparkFunSuite.scala
@@ -59,6 +59,7 @@ abstract class SparkFunSuite
protected val enableAutoThreadAudit = true
protected override def beforeAll(): Unit = {
+System.setProperty("spark.testing", "true")
if (enableAutoThreadAudit) {
doThreadPreAudit()
}
http://git-wip-us.apache.org/repos/asf/spark/blob/caeb108e/core/src/test/scala/org/apache/spark/deploy/RPackageUtilsSuite.scala
--
diff --git
a/core/src/test/scala/org/apache/spark/deploy/RPackageUtilsSuite.scala
b/core/src/test/scala/org/apache/spark/deploy/RPackageUtilsSuite.scala
index 32dd3ec..ef947eb 100644
--- a/core/src/test/scala/org/apache/spark/deploy/RPackageUtilsSuite.scala
+++ b/core/src/test/scala/org/apache/spark/deploy/RPackageUtilsSuite.scala
@@ -66,7 +66,6 @@ class RPackageUtilsSuite
override def beforeEach(): Unit = {
super.beforeEach()
-System.setProperty("spark.testing", "true")
lineBuffer.clear()
}
http://git-wip-us.apache.org/repos/asf/spark/blob/caeb108e/core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
--
diff --git a/core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
b/core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
index 27dd435..803a38d 100644
--- a/core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
+++ b/core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
@@ -107,7 +107,6 @@ class SparkSubmitSuite
override def beforeEach() {
super.beforeEach()
-System.setProperty("spark.testing", "true")
}
// scalastyle:off println
http://git-wip-us.apache.org/repos/asf/spark/blob/caeb108e/core/src/test/scala/org/apache/spark/network/netty/NettyBlockTransferServiceSuite.scala
--
diff --git
a/core/src/test/scala/org/apache/spark/network/netty/NettyBlockTransferServiceSuite.scala
b/core/src/test/scala/org/apache/spark/network/netty/NettyBlockTransferServiceSuite.scala
index f7bc372..78423ee 100644
---
a/core/src/test/scala/org/apache/spark/network/netty/NettyBlockTransferServiceSuite.scala
+++
b/core/src/test/scala/org/apache/spark/network/netty/NettyBlockTransferServiceSuite.scala
@@ -80,6 +80,7 @@ class NettyBlockTransferServiceSuite
private def verifyServicePort(expectedPort: Int, actualPort: Int): Unit = {
actualPort should be >= expectedPort
// avoid testing equality in case of simultaneous tests
+// if `spark.testing` is true,
// the default value for `spark.port.maxRetries` is 100 under test
actualPort should be <= (expectedPort +
svn commit: r24948 - in /dev/spark/2.4.0-SNAPSHOT-2018_02_12_04_35-c338c8c-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 12:49:35 2018 New Revision: 24948 Log: Apache Spark 2.4.0-SNAPSHOT-2018_02_12_04_35-c338c8c docs [This commit notification would consist of 1444 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23352][PYTHON] Explicitly specify supported types in Pandas UDFs
Repository: spark
Updated Branches:
refs/heads/master 6efd5d117 -> c338c8cf8
[SPARK-23352][PYTHON] Explicitly specify supported types in Pandas UDFs
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in
`returnType` ahead with documenting this; however, it happened to fix multiple
things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems
we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array',
PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported
with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual
execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon
Closes #20531 from HyukjinKwon/pudf-cleanup.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/c338c8cf
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/c338c8cf
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/c338c8cf
Branch: refs/heads/master
Commit: c338c8cf8253c037ecd4f39bbd58ed5a86581b37
Parents: 6efd5d1
Author: hyukjinkwon
Authored: Mon Feb 12 20:49:36 2018 +0900
Committer: hyukjinkwon
Committed: Mon Feb 12 20:49:36 2018 +0900
--
docs/sql-programming-guide.md | 4 +-
python/pyspark/sql/tests.py | 130 +++
python/pyspark/sql/types.py | 4 +
python/pyspark/sql/udf.py | 36 +++--
python/pyspark/worker.py| 2 +-
.../org/apache/spark/sql/internal/SQLConf.scala | 2 +-
6 files changed, 111 insertions(+), 67 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/c338c8cf/docs/sql-programming-guide.md
--
diff --git a/docs/sql-programming-guide.md b/docs/sql-programming-guide.md
index eab4030..6174a93 100644
--- a/docs/sql-programming-guide.md
+++ b/docs/sql-programming-guide.md
@@ -1676,7 +1676,7 @@ Using the above optimizations with Arrow will produce the
same results as when A
enabled. Note that even with Arrow, `toPandas()` results in the collection of
all records in the
DataFrame to the driver program and should be done on a small subset of the
data. Not all Spark
data types are currently supported and an error can be raised if a column has
an unsupported type,
-see [Supported Types](#supported-sql-arrow-types). If an error occurs during
`createDataFrame()`,
+see [Supported SQL Types](#supported-sql-arrow-types). If an error occurs
during `createDataFrame()`,
Spark will fall back to create the DataFrame without Arrow.
## Pandas UDFs (a.k.a. Vectorized UDFs)
@@ -1734,7 +1734,7 @@ For detailed usage, please see
[`pyspark.sql.functions.pandas_udf`](api/python/p
### Supported SQL Types
-Currently, all Spark SQL data types are supported by Arrow-based conversion
except `MapType`,
+Currently, all Spark SQL data types are supported by Arrow-based conversion
except `BinaryType`, `MapType`,
`ArrayType` of `TimestampType`, and nested `StructType`.
### Setting Arrow Batch Size
http://git-wip-us.apache.org/repos/asf/spark/blob/c338c8cf/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index fe89bd0..2af218a 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -3790,10 +3790,10 @@ class PandasUDFTests(ReusedSQLTestCase):
self.assertEqual(foo.returnType, schema)
self.assertEqual(foo.evalType,
PythonEvalType.SQL_GROUPED_MAP_PANDAS_UDF)
-@pandas_udf(returnType='v double', functionType=PandasUDFType.SCALAR)
+@pandas_udf(returnType='double', functionType=PandasUDFType.SCALAR)
svn commit: r24943 - in /dev/spark/2.3.1-SNAPSHOT-2018_02_12_02_01-79e8650-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 10:15:46 2018 New Revision: 24943 Log: Apache Spark 2.3.1-SNAPSHOT-2018_02_12_02_01-79e8650 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24942 - in /dev/spark/2.4.0-SNAPSHOT-2018_02_12_00_01-6efd5d1-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Mon Feb 12 08:16:24 2018 New Revision: 24942 Log: Apache Spark 2.4.0-SNAPSHOT-2018_02_12_00_01-6efd5d1 docs [This commit notification would consist of 1444 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org