[jira] [Created] (DRILL-7013) Hash-Join and Hash-Aggr to handle incoming with selection vectors
Boaz Ben-Zvi created DRILL-7013:
---
Summary: Hash-Join and Hash-Aggr to handle incoming with selection
vectors
Key: DRILL-7013
URL: https://issues.apache.org/jira/browse/DRILL-7013
Project: Apache Drill
Issue Type: Improvement
Components: Execution - Relational Operators, Query Planning
Optimization
Affects Versions: 1.15.0
Reporter: Boaz Ben-Zvi
The Hash-Join and Hash-Aggr operators copy each incoming row separately. When
the incoming data has a selection vector (e.g., outgoing from a Filter), a
_SelectionVectorRemover_ is added before the Hash operator, as the latter
cannot handle the selection vector.
Thus every row is needlessly being copied twice!
+Suggestion+: Enhance the Hash operators to handle potential incoming selection
vectors, thus eliminating the need for the extra copy. The planner needs to be
changed not to add that SelectionVectorRemover.
For example:
{code:sql}
select * from cp.`tpch/lineitem.parquet` L, cp.`tpch/orders.parquet` O where
O.o_custkey > 1498 and L.l_orderkey > 58999 and O.o_orderkey = L.l_orderkey
{code}
And the plan:
{panel}
00-00 Screen : rowType = RecordType(DYNAMIC_STAR **, DYNAMIC_STAR **0):
00-01 ProjectAllowDup(**=[$0], **0=[$1]) : rowType = RecordType(DYNAMIC_STAR
**, DYNAMIC_STAR **0):
00-02 Project(T44¦¦**=[$0], T45¦¦**=[$2]) : rowType = RecordType(DYNAMIC_STAR
T44¦¦**, DYNAMIC_STAR T45¦¦**):
00-03 HashJoin(condition=[=($1, $4)], joinType=[inner], semi-join: =[false]) :
rowType = RecordType(DYNAMIC_STAR T44¦¦**, ANY l_orderkey, DYNAMIC_STAR
T45¦¦**, ANY o_custkey, ANY o_orderkey):
00-05 *SelectionVectorRemover* : rowType = RecordType(DYNAMIC_STAR T44¦¦**,
ANY l_orderkey):
00-07 Filter(condition=[>($1, 58999)]) : rowType = RecordType(DYNAMIC_STAR
T44¦¦**, ANY l_orderkey):
00-09 Project(T44¦¦**=[$0], l_orderkey=[$1]) : rowType =
RecordType(DYNAMIC_STAR T44¦¦**, ANY l_orderkey):
00-11 Scan(table=[[cp, tpch/lineitem.parquet]], groupscan=[ParquetGroupScan
[entries=[ReadEntryWithPath [path=classpath:/tpch/lineitem.parquet]],
00-04 *SelectionVectorRemover* : rowType = RecordType(DYNAMIC_STAR T45¦¦**,
ANY o_custkey, ANY o_orderkey):
00-06 Filter(condition=[AND(>($1, 1498), >($2, 58999))]) : rowType =
RecordType(DYNAMIC_STAR T45¦¦**, ANY o_custkey, ANY o_orderkey):
00-08 Project(T45¦¦**=[$0], o_custkey=[$1], o_orderkey=[$2]) : rowType =
RecordType(DYNAMIC_STAR T45¦¦**, ANY o_custkey, ANY o_orderkey):
00-10 Scan(table=[[cp, tpch/orders.parquet]],
{panel}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (DRILL-7012) Make SelectionVectorRemover project only the needed columns
Boaz Ben-Zvi created DRILL-7012:
---
Summary: Make SelectionVectorRemover project only the needed
columns
Key: DRILL-7012
URL: https://issues.apache.org/jira/browse/DRILL-7012
Project: Apache Drill
Issue Type: Improvement
Components: Execution - Relational Operators, Query Planning
Optimization
Affects Versions: 1.15.0
Reporter: Boaz Ben-Zvi
A SelectionVectorRemover is often used after a filter, to copy into a newly
allocated new batch only the "filtered out" rows. In some cases the columns
used by the filter are not needed downstream; currently these columns are being
needlessly allocated and copied, and later removed by a Project.
_+Suggested improvement+_: The planner can pass the information about these
columns to the SelectionVectorRemover, which would avoid this useless
allocation and copy. The Planner would also eliminate that Project from the
plan.
Here is an example, the query:
{code:java}
select max(l_quantity) from cp.`tpch/lineitem.parquet` L where L.l_orderkey >
58999 and L.l_shipmode = 'TRUCK' group by l_linenumber ;
{code}
And the result plan (trimmed for readability), where "l_orderkey" and
"l_shipmode" are removed by the Project:
{noformat}
00-00 Screen : rowType = RecordType(ANY EXPR$0):
00-01 Project(EXPR$0=[$0]) : rowType = RecordType(ANY EXPR$0):
00-02 Project(EXPR$0=[$1]) : rowType = RecordType(ANY EXPR$0):
00-03 HashAgg(group=[\{0}], EXPR$0=[MAX($1)]) : rowType = RecordType(ANY
l_linenumber, ANY EXPR$0):
00-04 *Project*(l_linenumber=[$2], l_quantity=[$3]) : rowType = RecordType(ANY
l_linenumber, ANY l_quantity):
00-05 *SelectionVectorRemover* : rowType = RecordType(ANY *l_orderkey*, ANY
*l_shipmode*, ANY l_linenumber, ANY l_quantity):
00-06 *Filter*(condition=[AND(>($0, 58999), =($1, 'TRUCK'))]) : rowType =
RecordType(ANY l_orderkey, ANY l_shipmode, ANY l_linenumber, ANY l_quantity):
00-07 Scan(table=[[cp, tpch/lineitem.parquet]], groupscan=[ParquetGroupScan
[entries=[ReadEntryWithPath [path=classpath:/tpch/lineitem.parquet]],
selectionRoot=classpath:/tpch/lineitem.parquet, numFiles=1, numRowGroups=1,
usedMetadataFile=false, columns=[`l_orderkey`, `l_shipmode`, `l_linenumber`,
`l_quantity`]]]) : rowType = RecordType(ANY l_orderkey, ANY l_shipmode, ANY
l_linenumber, ANY l_quantity):
{noformat}
The implementation will not be simple, as the relevant code (e.g.,
GenericSV2Copier) has no idea of specific columns.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Resolved] (DRILL-7002) RuntimeFilter produce wrong results while setting exec.hashjoin.num_partitions=1
[ https://issues.apache.org/jira/browse/DRILL-7002?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] weijie.tong resolved DRILL-7002. Resolution: Fixed > RuntimeFilter produce wrong results while setting > exec.hashjoin.num_partitions=1 > > > Key: DRILL-7002 > URL: https://issues.apache.org/jira/browse/DRILL-7002 > Project: Apache Drill > Issue Type: Bug > Components: Execution - Relational Operators >Affects Versions: 1.16.0 >Reporter: weijie.tong >Assignee: weijie.tong >Priority: Major > Labels: reviewable > Fix For: 1.16.0 > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
Re: "Crude-but-effective" Arrow integration
Hey Paul, I’m curious as to what, if anything ever came of this thread? IMHO, you’re on to something here. We could get the benefit of Arrow—specifically the interoperability with other big data tools—without the pain of having to completely re-work Drill. This seems like a real win-win to me. — C > On Aug 20, 2018, at 13:51, Paul Rogers wrote: > > Hi Ted, > > We may be confusing two very different ideas. The one is a Drill-to-Arrow > adapter on Drill's periphery, this is the "crude-but-effective" integration > suggestion. On the periphery we are not changing existing code, we're just > building an adapter to read Arrow data into Drill, or convert Drill output to > Arrow. > > The other idea, being discussed in a parallel thread, is to convert Drill's > runtime engine to use Arrow. That is a whole other beast. > > When changing Drill internals, code must change. There is a cost associated > with that. Whether the Arrow code is better or not is not the key question. > Rather, the key question is simply the volume of changes. > > Drill divides into roughly two main layers: plan-time and run-time. Plan-time > is not much affected by Arrow. But, run-time code is all about manipulating > vectors and their metadata, often in quite detailed ways with APIs unique to > Drill. While swapping Arrow vectors for Drill vectors is conceptually simple, > those of us who've looked at the details have noted that the sheer volume of > the lines of code that must change is daunting. > > Would be good to get second options. That PR I mentioned will show the volume > of code that changed at that time (but Drill has grown since then.) Parth is > another good resource as he reviewed the original PR and has kept a close eye > on Arrow. > > When considering Arrow in the Drill execution engine, we must realistically > understand the cost then ask, do the benefits we gain justify those costs? > Would Arrow be the highest-priority investment? Frankly, would Arrow > integration increase Drill adoption more than the many other topics discussed > recently on these mail lists? > > Charles and others make a strong case for Arrow for integration. What is the > strong case for Drill's internals? That's really the question the group will > want to answer. > > More details below. > > Thanks, > - Paul > > > >On Monday, August 20, 2018, 9:41:49 AM PDT, Ted Dunning > wrote: > > Inline. > > > On Mon, Aug 20, 2018 at 9:20 AM Paul Rogers > wrote: > >> ... >> By contrast, migrating Drill internals to Arrow has always been seen as >> the bulk of the cost; costs which the "crude-but-effective" suggestion >> seeks to avoid. Some of the full-integration costs include: >> >> * Reworking Drill's direct memory model to work with Arrow's. >> > > > Ted: This should be relatively isolated to the allocation/deallocation code. > The > deallocation should become a no-op. The allocation becomes simpler and > safer. > > Paul: If only that were true. Drill has an ingenious integration of vector > allocation and Netty. Arrow may have done the same. (Probably did, since such > integration is key to avoiding copies on send/receive.). That code is highly > complex. Clearly, the swap can be done; it will simply take some work to get > right. > > >> * Changing all low-level runtime code that works with vectors to instead >> work with Arrow vectors. >> > > > Ted: Why? You already said that most code doesn't have to change since the > format is the same. > > Paul: My comment about the format being the same was that the direct memory > layout is the same, allowing conversion of a Drill vector to an Arrow vector > by relabeling the direct memory that holds the data. > > Paul: But, in the Drill runtime engine, we don't work with the memory > directly, we use the vector APIs, mutator APIs and so on. These all changed > in Arrow. Granted, the Arrow versions are cleaner. But, that does mean that > every vector reference (of which there are thousands) must be revised to use > the Arrow APIs. That is the cost that has put us off a bit. > > >> * Change all Drill's vector metadata, and code that uses that metadata, to >> use Arrow's metadata instead. >> > > > Ted: Why? You said that converting Arrow metadata to Drill's metadata would be > simple. Why not just continue with that? > > Paul: In an API, we can convert one data structure to the other by writing > code to copy data. But, if we change Drill's internals, we must rewrite code > in every operator that uses Drill's metadata to instead use Arrows. That is a > much more extensive undertaking than simply converting metadata on input or > output. > > >> * Since generated code works directly with vectors, change all the code >> generation. >> > > Ted: Why? You said the UDFs would just work. > > Paul: Again, I fear we are confusing two issues. If we don't change Drill's > internals, then UDFs will work as today. If we do change Drill to
[GitHub] paul-rogers commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers
paul-rogers commented on a change in pull request #1623: DRILL-7006: Add type
conversion to row writers
URL: https://github.com/apache/drill/pull/1623#discussion_r251661749
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/PrimitiveColumnMetadata.java
##
@@ -23,16 +23,53 @@
import org.apache.drill.common.types.Types;
import org.apache.drill.exec.expr.TypeHelper;
import org.apache.drill.exec.record.MaterializedField;
+import org.apache.drill.exec.vector.accessor.ColumnConversionFactory;
/**
* Primitive (non-map) column. Describes non-nullable, nullable and
* array types (which differ only in mode, but not in metadata structure.)
+ *
+ * Metadata is of two types:
+ *
+ * Storage metadata that describes how the is materialized in a
+ * vector. Storage metadata is immutable because revising an existing
+ * vector is a complex operation.
+ * Supplemental metadata used when reading or writing the column.
+ * Supplemental metadata can be changed after the column is created,
+ * though it should generally be set before invoking code that uses
+ * the metadata.
+ *
*/
public class PrimitiveColumnMetadata extends AbstractColumnMetadata {
+ /**
+ * Expected (average) width for variable-width columns.
+ */
+
private int expectedWidth;
+ /**
+ * Default value to use for filling a vector when no real data is
+ * available, such as for columns added in new files but which does not
+ * exist in existing files. The "default default" is null, which works
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] paul-rogers commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers
paul-rogers commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers URL: https://github.com/apache/drill/pull/1623#discussion_r251661723 ## File path: exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/PrimitiveColumnMetadata.java ## @@ -23,16 +23,53 @@ import org.apache.drill.common.types.Types; import org.apache.drill.exec.expr.TypeHelper; import org.apache.drill.exec.record.MaterializedField; +import org.apache.drill.exec.vector.accessor.ColumnConversionFactory; /** * Primitive (non-map) column. Describes non-nullable, nullable and * array types (which differ only in mode, but not in metadata structure.) + * + * Metadata is of two types: + * + * Storage metadata that describes how the is materialized in a Review comment: Done This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] paul-rogers commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers
paul-rogers commented on a change in pull request #1623: DRILL-7006: Add type
conversion to row writers
URL: https://github.com/apache/drill/pull/1623#discussion_r251662211
##
File path:
exec/vector/src/main/java/org/apache/drill/exec/vector/accessor/writer/ScalarArrayWriter.java
##
@@ -60,13 +60,17 @@
public final void nextElement() { next(); }
}
- private final BaseScalarWriter elementWriter;
+ private final ConcreteWriter elementWriter;
public ScalarArrayWriter(ColumnMetadata schema,
RepeatedValueVector vector, BaseScalarWriter elementWriter) {
super(schema, vector.getOffsetVector(),
new ScalarObjectWriter(elementWriter));
-this.elementWriter = elementWriter;
+
+// Save the writer from the scalar object writer created above
+// which may have wrapped the element writer in a type convertor.
+
+this.elementWriter = (ConcreteWriter) elementObjWriter.scalar();
Review comment:
Yes. The plumbing ensures that the actual implementation is always of this
class. This is, however, part of the messiness described in a comment
elsewhere. I'm think about how to refactor this to avoid the need for these
casts, for the clunky pass-through methods in the type converter, and to make
the change fit into the result set loader. This is a first step.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] sohami commented on a change in pull request #1626: DRILL-6855: Query from non-existent proxy user fails with "No default schema selected" when impersonation is enabled
sohami commented on a change in pull request #1626: DRILL-6855: Query from
non-existent proxy user fails with "No default schema selected" when
impersonation is enabled
URL: https://github.com/apache/drill/pull/1626#discussion_r251604318
##
File path:
exec/java-exec/src/main/java/org/apache/calcite/jdbc/DynamicRootSchema.java
##
@@ -115,8 +116,25 @@ public void loadSchemaFactory(String schemaName, boolean
caseSensitive) {
schemaPlus.add(wrapper.getName(), wrapper);
}
}
-} catch(ExecutionSetupException | IOException ex) {
+} catch(ExecutionSetupException ex) {
logger.warn("Failed to load schema for \"" + schemaName + "\"!", ex);
+} catch (IOException iex) {
+ // We can't proceed further without a schema, throw a runtime exception.
+ UserException.Builder exceptBuilder =
+ UserException
+ .resourceError(iex)
+ .message("Failed to create schema tree.")
+ .addContext("IOException: ", iex.getMessage());
+
+ // Improve the error message for client side.
+ final String errorMsg = "Error getting user info for current user";
+ if (iex.getMessage().startsWith(errorMsg)) {
+final String contextString = "[Hint: Username is absent in connection
URL or doesn't " +
+ "exist on Drillbit node. Please
specify a username in connection " +
+ "URL which is present on Drillbit
node.]";
+exceptBuilder.addContext(contextString);
+ }
+ throw exceptBuilder.build(logger);
Review comment:
I am not sure if there is any use case because of which the exceptions were
originally consumed and not thrown from here. If not and throwing exception is
fine then why not throw `UserException` for all the exceptions caught here ?
Also my preference will be that this errorMsg check and adding hint message
should be put as close to the original thrower of the IOException as possible.
Like in this case it will be
[here](https://github.com/apache/drill/blob/master/exec/java-exec/src/main/java/org/apache/drill/exec/store/dfs/FileSystemSchemaFactory.java#L86).
Reason being then if we want to provide Hints for IOException from different
storage plugin then it can be done in each storage plugin rather than having
that logic here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] kkhatua commented on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query
kkhatua commented on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query URL: https://github.com/apache/drill/pull/1608#issuecomment-458290352 Thanks @ihuzenko . I think i see the issue here being that the internal value didn't update after the field was changed. I'll fix that. But apart from that, I would think that `1,000` should not be considered as valid, considering that in Europe that is a decimal separator unlike the dot in the United States. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] arina-ielchiieva commented on a change in pull request #1618: DRILL-6950: Row set-based scan framework
arina-ielchiieva commented on a change in pull request #1618: DRILL-6950: Row
set-based scan framework
URL: https://github.com/apache/drill/pull/1618#discussion_r251458228
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/scan/file/FileMetadataManager.java
##
@@ -0,0 +1,239 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.drill.exec.physical.impl.scan.file;
+
+import java.util.ArrayList;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.directory.api.util.Strings;
+import org.apache.drill.common.map.CaseInsensitiveMap;
+import org.apache.drill.exec.ExecConstants;
+import org.apache.drill.exec.physical.impl.scan.project.ColumnProjection;
+import org.apache.drill.exec.physical.impl.scan.project.ConstantColumnLoader;
+import org.apache.drill.exec.physical.impl.scan.project.MetadataManager;
+import org.apache.drill.exec.physical.impl.scan.project.ResolvedTuple;
+import
org.apache.drill.exec.physical.impl.scan.project.ScanLevelProjection.ScanProjectionParser;
+import
org.apache.drill.exec.physical.impl.scan.project.SchemaLevelProjection.SchemaProjectionResolver;
+import org.apache.drill.exec.physical.impl.scan.project.VectorSource;
+import org.apache.drill.exec.physical.rowSet.ResultVectorCache;
+import org.apache.drill.exec.record.VectorContainer;
+import org.apache.drill.exec.record.metadata.TupleMetadata;
+import org.apache.drill.exec.server.options.OptionSet;
+import org.apache.drill.exec.store.ColumnExplorer.ImplicitFileColumns;
+import org.apache.drill.exec.vector.ValueVector;
+import org.apache.hadoop.fs.Path;
+
+import
org.apache.drill.shaded.guava.com.google.common.annotations.VisibleForTesting;
+
+public class FileMetadataManager implements MetadataManager,
SchemaProjectionResolver, VectorSource {
+
+ // Input
+
+ private Path scanRootDir;
+ private FileMetadata currentFile;
+
+ // Config
+
+ protected final String partitionDesignator;
+ protected List implicitColDefns = new ArrayList<>();
+ protected Map fileMetadataColIndex =
CaseInsensitiveMap.newHashMap();
+ protected boolean useLegacyWildcardExpansion = true;
Review comment:
Looked at `org.apache.drill.exec.physical.impl.ScanBatch` class, when table
has partition columns they are added before the table columns, implicit file
columns are added only if they are present in the select. If they are, they are
added before partition columns.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (DRILL-7011) Allow hybrid model in the Row set-based scan framework
Arina Ielchiieva created DRILL-7011: --- Summary: Allow hybrid model in the Row set-based scan framework Key: DRILL-7011 URL: https://issues.apache.org/jira/browse/DRILL-7011 Project: Apache Drill Issue Type: Improvement Affects Versions: 1.15.0 Reporter: Arina Ielchiieva Assignee: Paul Rogers Fix For: 1.16.0 As part of schema provisioning project we want to allow hybrid model for Row set-based scan framework, namely to allow to pass custom schema metadata which can be partial. Currently schema provisioning has TableSchema class that contains the following information (can be obtained from metastore, schema file, table function): 1. table schema represented by org.apache.drill.exec.record.metadata.TupleMetadata 2. table properties represented by Map, can contain information if schema is strict or partial (default is partial) etc. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] arina-ielchiieva commented on a change in pull request #1618: DRILL-6950: Row set-based scan framework
arina-ielchiieva commented on a change in pull request #1618: DRILL-6950: Row
set-based scan framework
URL: https://github.com/apache/drill/pull/1618#discussion_r251437978
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/scan/file/FileMetadataColumnsParser.java
##
@@ -0,0 +1,166 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.drill.exec.physical.impl.scan.file;
+
+import java.util.regex.Matcher;
+import java.util.regex.Pattern;
+
+import org.apache.drill.exec.physical.impl.scan.project.ColumnProjection;
+import org.apache.drill.exec.physical.impl.scan.project.ScanLevelProjection;
+import
org.apache.drill.exec.physical.impl.scan.project.ScanLevelProjection.ScanProjectionParser;
+import
org.apache.drill.exec.physical.rowSet.project.RequestedTuple.RequestedColumn;
+
+public class FileMetadataColumnsParser implements ScanProjectionParser {
+
+ static final org.slf4j.Logger logger =
org.slf4j.LoggerFactory.getLogger(FileMetadataColumnsParser.class);
+
+ // Internal
+
+ private final FileMetadataManager metadataManager;
+ private final Pattern partitionPattern;
+ private ScanLevelProjection builder;
+
+ // Output
+
+ boolean hasMetadata;
+
+ public FileMetadataColumnsParser(FileMetadataManager metadataManager) {
+this.metadataManager = metadataManager;
+partitionPattern = Pattern.compile(metadataManager.partitionDesignator +
"(\\d+)", Pattern.CASE_INSENSITIVE);
+ }
+
+ @Override
+ public void bind(ScanLevelProjection builder) {
+this.builder = builder;
+ }
+
+ @Override
+ public boolean parse(RequestedColumn inCol) {
+Matcher m = partitionPattern.matcher(inCol.name());
+if (m.matches()) {
+ return buildPartitionColumn(m, inCol);
+}
+
+FileMetadataColumnDefn defn =
metadataManager.fileMetadataColIndex.get(inCol.name());
+if (defn != null) {
+ return buildMetadataColumn(defn, inCol);
+}
+if (inCol.isWildcard()) {
+ buildWildcard();
+
+ // Don't consider this a match.
+}
+return false;
+ }
+
+ private boolean buildPartitionColumn(Matcher m, RequestedColumn inCol) {
+
+// If the projected column is a map or array, then it shadows the
+// partition column. Example: dir0.x, dir0[2].
+
+if (! inCol.isSimple()) {
+ logger.warn("Partition column {} is shadowed by a projected {}",
+ inCol.name(), inCol.summary());
+ return false;
+}
+if (builder.hasWildcard()) {
+ wildcardAndMetadataError();
+}
+
+// Partition column
+
+builder.addMetadataColumn(
+new PartitionColumn(
+ inCol.name(),
+ Integer.parseInt(m.group(1;
+hasMetadata = true;
+return true;
+ }
+
+ private boolean buildMetadataColumn(FileMetadataColumnDefn defn,
+ RequestedColumn inCol) {
+
+// If the projected column is a map or array, then it shadows the
+// metadata column. Example: filename.x, filename[2].
+
+if (! inCol.isSimple()) {
+ logger.warn("File metadata column {} is shadowed by a projected {}",
+ inCol.name(), inCol.summary());
+ return false;
+}
+if (builder.hasWildcard()) {
+ wildcardAndMetadataError();
+}
+
+// File metadata (implicit) column
+
+builder.addMetadataColumn(new FileMetadataColumn(inCol.name(), defn));
+hasMetadata = true;
+return true;
+ }
+
+ private void buildWildcard() {
+if (hasMetadata) {
+ wildcardAndMetadataError();
+}
+if (metadataManager.useLegacyWildcardExpansion) {
+
+ // Star column: this is a SELECT * query.
+
+ // Old-style wildcard handling inserts all metadata columns in
+ // the scanner, removes them in Project.
+ // Fill in the file metadata columns. Can do here because the
+ // set is constant across all files.
+
+ expandWildcard();
+ hasMetadata = true;
+}
+ }
+
+ protected void expandWildcard() {
+
+// Legacy wildcard expansion: include the file metadata and
+// file partitions for this file.
+// This is a disadvantage for a * query: files at different directory
+// levels will have different numbers of columns. Would be better to
+// return this data
[GitHub] arina-ielchiieva commented on a change in pull request #1618: DRILL-6950: Row set-based scan framework
arina-ielchiieva commented on a change in pull request #1618: DRILL-6950: Row
set-based scan framework
URL: https://github.com/apache/drill/pull/1618#discussion_r251437169
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/scan/ScanOperatorExec.java
##
@@ -0,0 +1,278 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.drill.exec.physical.impl.scan;
+
+import org.apache.drill.common.exceptions.ExecutionSetupException;
+import org.apache.drill.common.exceptions.UserException;
+import org.apache.drill.exec.ops.OperatorContext;
+import org.apache.drill.exec.physical.impl.protocol.BatchAccessor;
+import org.apache.drill.exec.physical.impl.protocol.OperatorExec;
+import org.apache.drill.exec.physical.impl.protocol.VectorContainerAccessor;
+
+import
org.apache.drill.shaded.guava.com.google.common.annotations.VisibleForTesting;
+
+/**
+ * Implementation of the revised scan operator that uses a mutator aware of
+ * batch sizes. This is the successor to {@link ScanBatch} and should be used
+ * by all new scan implementations.
+ *
+ * Scanner Framework
+ *
+ * Acts as an adapter between the operator protocol and the row reader
+ * protocol.
+ *
+ * The scan operator itself is simply a framework for handling a set of
readers;
+ * it knows nothing other than the interfaces of the components it works with;
+ * delegating all knowledge of schemas, projection, reading and the like to
+ * implementations of those interfaces. Because that work is complex, a set
+ * of frameworks exist to handle most common use cases, but a specialized
reader
+ * can create a framework or reader from scratch.
+ *
+ * Error handling in this class is minimal: the enclosing record batch iterator
+ * is responsible for handling exceptions. Error handling relies on the fact
+ * that the iterator will call close() regardless of which exceptions
+ * are thrown.
+ *
+ * Protocol
+ *
+ * The scanner works directly with two other interfaces
+ *
+ * The {@link ScanOperatorEvents} implementation provides the set of readers to
+ * use. This class can simply maintain a list, or can create the reader on
+ * demand.
+ *
+ * More subtly, the factory also handles projection issues and manages vectors
+ * across subsequent readers. A number of factories are available for the most
+ * common cases. Extend these to implement a version specific to a data source.
+ *
+ * The {@link RowBatchReader} is a surprisingly minimal interface that
+ * nonetheless captures the essence of reading a result set as a set of
batches.
+ * The factory implementations mentioned above implement this interface to
provide
+ * commonly-used services, the most important of which is access to a
+ * {#link ResultSetLoader} to write values into value vectors.
+ *
+ * Schema Versions
+ * Readers may change schemas from time to time. To track such changes,
+ * this implementation tracks a batch schema version, maintained by comparing
+ * one schema with the next.
+ *
+ * Readers can discover columns as they read data, such as with any JSON-based
+ * format. In this case, the row set mutator also provides a schema version,
+ * but a fine-grained one that changes each time a column is added.
+ *
+ * The two schema versions serve different purposes and are not
interchangeable.
+ * For example, if a scan reads two files, both will build up their own
schemas,
+ * each increasing its internal version number as work proceeds. But, at the
+ * end of each batch, the schemas may (and, in fact, should) be identical,
+ * which is the schema version downstream operators care about.
+ */
+
+public class ScanOperatorExec implements OperatorExec {
+
+ private enum State { START, READER, END, FAILED, CLOSED }
+
+ static final org.slf4j.Logger logger =
org.slf4j.LoggerFactory.getLogger(ScanOperatorExec.class);
+
+ private final ScanOperatorEvents factory;
+ protected final VectorContainerAccessor containerAccessor = new
VectorContainerAccessor();
+ private State state = State.START;
+ protected OperatorContext context;
+ private int readerCount;
+ private ReaderState readerState;
+
+ public ScanOperatorExec(ScanOperatorEvents factory) {
+this.factory =
[jira] [Created] (DRILL-7010) Wrong result is returned if filtering by a decimal column using old parquet data with old metadata file.
Anton Gozhiy created DRILL-7010:
---
Summary: Wrong result is returned if filtering by a decimal column
using old parquet data with old metadata file.
Key: DRILL-7010
URL: https://issues.apache.org/jira/browse/DRILL-7010
Project: Apache Drill
Issue Type: Bug
Affects Versions: 1.15.0
Reporter: Anton Gozhiy
Attachments: partsupp_old.zip, supplier_old.zip
*Prerequisites:*
- The data was generated by Drill 1.14.0-SNAPSHOT (commit
4c4953bcab4886be14fc9b7f95a77caa86a7629f). See attachment.
- set store.parquet.reader.strings_signed_min_max = "true"
*Query #1:*
{code:sql}
select *
from dfs.tmp.`supplier_old`
where not s_acctbal > -900
{code}
*Expected result:*
{noformat}
65 Supplier#00065 BsAnHUmSFArppKrM22 32-444-835-2434
-963.79 l ideas wake carefully around the regular packages. furiously ruthless
pinto bea
65 Supplier#00065 BsAnHUmSFArppKrM22 32-444-835-2434
-963.79 l ideas wake carefully around the regular packages. furiously ruthless
pinto bea
65 Supplier#00065 BsAnHUmSFArppKrM22 32-444-835-2434
-963.79 l ideas wake carefully around the regular packages. furiously ruthless
pinto bea
22 Supplier#00022 okiiQFk 8lm6EVX6Q0,bEcO 4 14-144-830-2814
-966.20 ironically among the deposits. closely expre
22 Supplier#00022 okiiQFk 8lm6EVX6Q0,bEcO 4 14-144-830-2814
-966.20 ironically among the deposits. closely expre
22 Supplier#00022 okiiQFk 8lm6EVX6Q0,bEcO 4 14-144-830-2814
-966.20 ironically among the deposits. closely expre
{noformat}
*Actual result:*
{noformat}
65 Supplier#00065 BsAnHUmSFArppKrM22 32-444-835-2434
-963.79 l ideas wake carefully around the regular packages. furiously ruthless
pinto bea
65 Supplier#00065 BsAnHUmSFArppKrM22 32-444-835-2434
-963.79 l ideas wake carefully around the regular packages. furiously ruthless
pinto bea
65 Supplier#00065 BsAnHUmSFArppKrM22 32-444-835-2434
-963.79 l ideas wake carefully around the regular packages. furiously ruthless
pinto bea
{noformat}
*Query #2*
{code:sql}
select ps_availqty, ps_supplycost, ps_comment
from dfs.tmp.`partsupp_old`
where ps_supplycost > 999.9
{code}
*Expected result:*
{noformat}
5136999.92 lets grow carefully. slyly silent ideas about the foxes nag
blithely ironi
8324999.93 ly final instructions. closely final deposits nag furiously
alongside of the furiously dogged theodolites. blithely unusual theodolites are
furi
5070999.99 ironic, special deposits. carefully final deposits haggle
fluffily. furiously final foxes use furiously furiously ironic accounts. package
6915999.95 fluffily unusual packages doubt even, regular requests. ironic
requests detect carefully blithely silen
1761999.95 lyly about the permanently ironic instructions. carefully
ironic pinto beans
2120999.97 ts haggle blithely about the pending, regular ideas! e
1615999.92 riously ironic foxes detect fluffily across the regular packages
{noformat}
*Actual result:*
No data is returned.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] ihuzenko commented on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query
ihuzenko commented on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query URL: https://github.com/apache/drill/pull/1608#issuecomment-458137436 Hello @kkhatua , sorry for the late answer. I wanted to start review from check that fix works fine, but suddenly bumped into an issue. I wasn't able to submit query with my current locale, because it affects number formatting. 1. Tried to use default number: 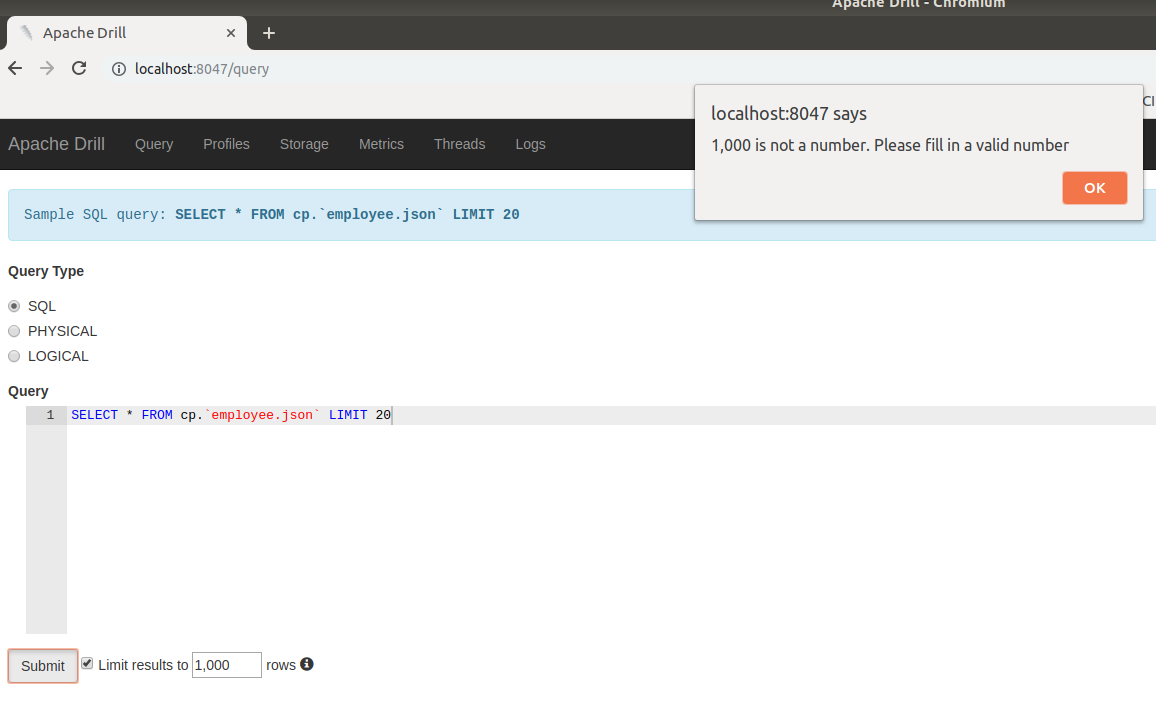 2. Tried to remove comma from default number: 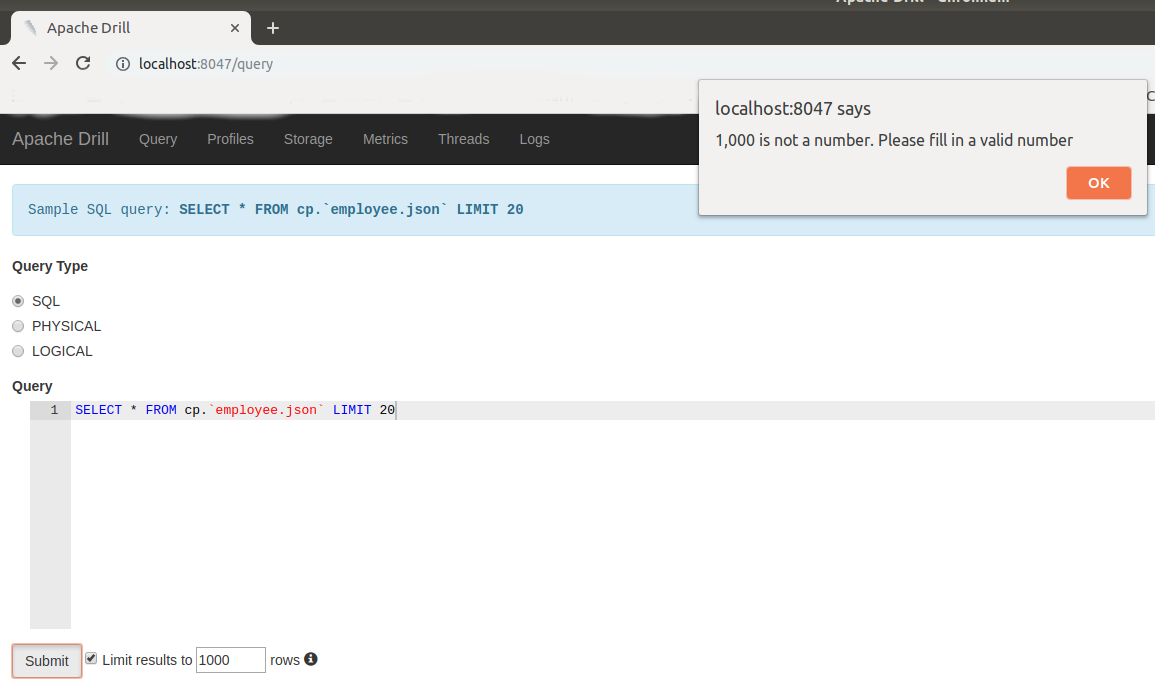 3. Tried to use own auto limit 50 : 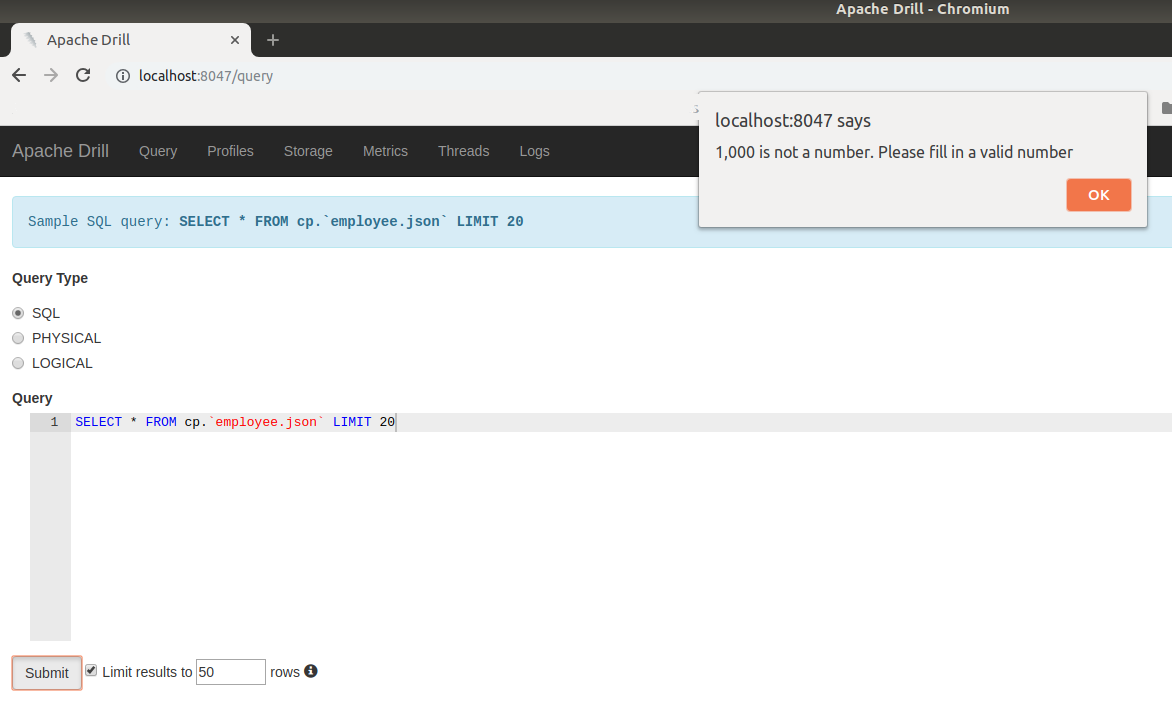 After those failed attempts I executed the line ```console.log(window.navigator.userLanguage || window.navigator.language)``` in JS console and got locale ```en-US``` in my chromium-browser. @kkhatua, can you please fix the blocking issue in order to unlock further review ? Thank you in advance, Igor. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] arina-ielchiieva commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers
arina-ielchiieva commented on a change in pull request #1623: DRILL-7006: Add
type conversion to row writers
URL: https://github.com/apache/drill/pull/1623#discussion_r251408134
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/PrimitiveColumnMetadata.java
##
@@ -23,16 +23,53 @@
import org.apache.drill.common.types.Types;
import org.apache.drill.exec.expr.TypeHelper;
import org.apache.drill.exec.record.MaterializedField;
+import org.apache.drill.exec.vector.accessor.ColumnConversionFactory;
/**
* Primitive (non-map) column. Describes non-nullable, nullable and
* array types (which differ only in mode, but not in metadata structure.)
+ *
+ * Metadata is of two types:
+ *
+ * Storage metadata that describes how the is materialized in a
+ * vector. Storage metadata is immutable because revising an existing
+ * vector is a complex operation.
+ * Supplemental metadata used when reading or writing the column.
+ * Supplemental metadata can be changed after the column is created,
+ * though it should generally be set before invoking code that uses
+ * the metadata.
+ *
*/
public class PrimitiveColumnMetadata extends AbstractColumnMetadata {
+ /**
+ * Expected (average) width for variable-width columns.
+ */
+
private int expectedWidth;
+ /**
+ * Default value to use for filling a vector when no real data is
+ * available, such as for columns added in new files but which does not
+ * exist in existing files. The "default default" is null, which works
Review comment:
`"default default"` -> `"default value"`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] arina-ielchiieva commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers
arina-ielchiieva commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers URL: https://github.com/apache/drill/pull/1623#discussion_r251409042 ## File path: exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/PrimitiveColumnMetadata.java ## @@ -23,16 +23,53 @@ import org.apache.drill.common.types.Types; import org.apache.drill.exec.expr.TypeHelper; import org.apache.drill.exec.record.MaterializedField; +import org.apache.drill.exec.vector.accessor.ColumnConversionFactory; /** * Primitive (non-map) column. Describes non-nullable, nullable and * array types (which differ only in mode, but not in metadata structure.) + * + * Metadata is of two types: + * + * Storage metadata that describes how the is materialized in a Review comment: `describes how the is materialized` -> column? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] arina-ielchiieva commented on a change in pull request #1623: DRILL-7006: Add type conversion to row writers
arina-ielchiieva commented on a change in pull request #1623: DRILL-7006: Add
type conversion to row writers
URL: https://github.com/apache/drill/pull/1623#discussion_r251413842
##
File path:
exec/vector/src/main/java/org/apache/drill/exec/vector/accessor/writer/ScalarArrayWriter.java
##
@@ -60,13 +60,17 @@
public final void nextElement() { next(); }
}
- private final BaseScalarWriter elementWriter;
+ private final ConcreteWriter elementWriter;
public ScalarArrayWriter(ColumnMetadata schema,
RepeatedValueVector vector, BaseScalarWriter elementWriter) {
super(schema, vector.getOffsetVector(),
new ScalarObjectWriter(elementWriter));
-this.elementWriter = elementWriter;
+
+// Save the writer from the scalar object writer created above
+// which may have wrapped the element writer in a type convertor.
+
+this.elementWriter = (ConcreteWriter) elementObjWriter.scalar();
Review comment:
Is it ok to do the cast here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] ihuzenko removed a comment on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query
ihuzenko removed a comment on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query URL: https://github.com/apache/drill/pull/1608#issuecomment-458127161 Hello @kkhatua , sorry for the late answer. I wanted to start review from check that fix works fine, but suddenly bumped into an issue. I wasn't able to submit query with my current locale, because it affects number formatting. 1. Tried to use default number: 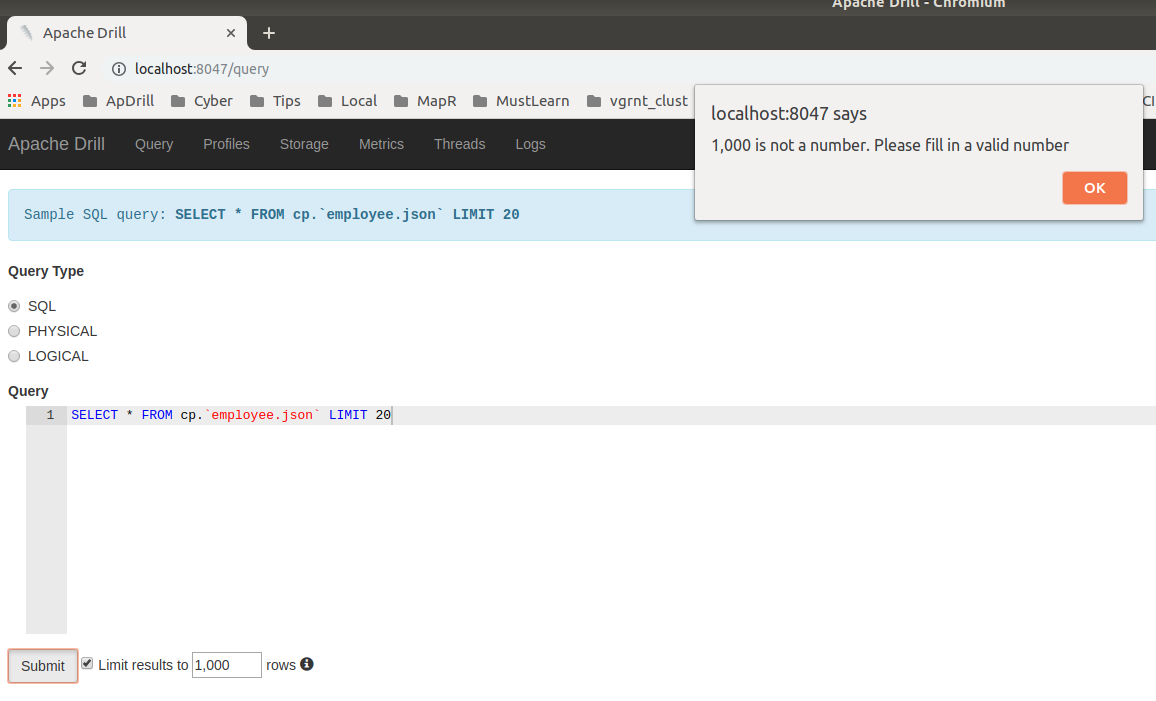 2. Tried to remove comma from default number: 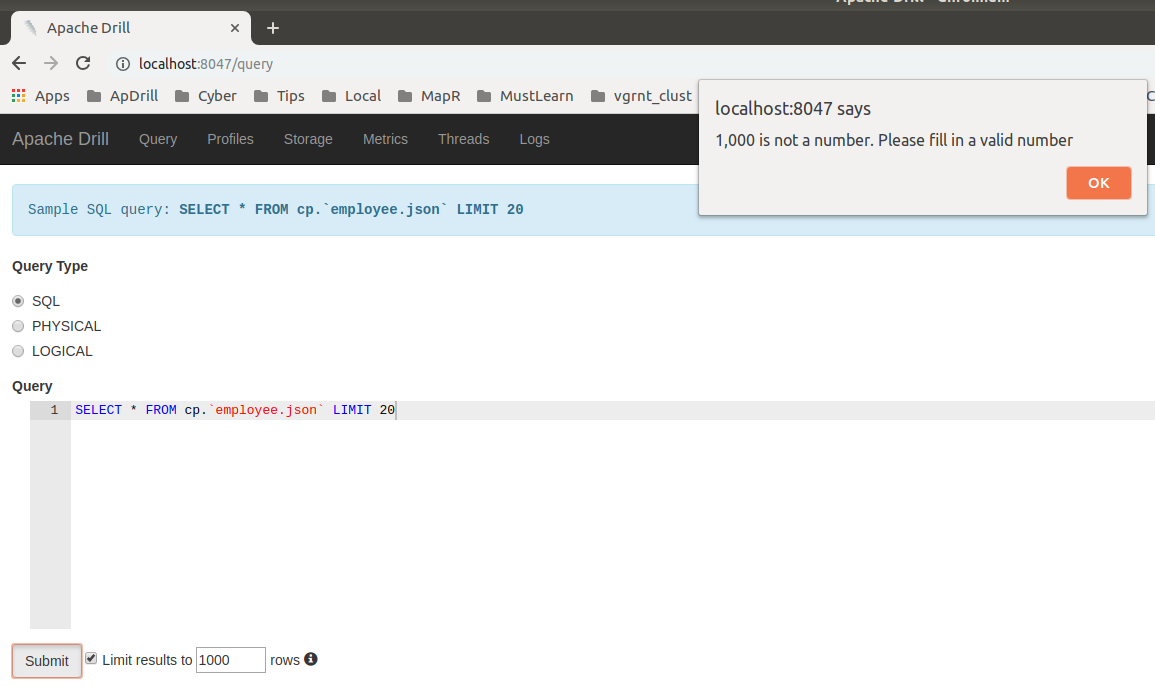 3. Tried to use own auto limit 50 : 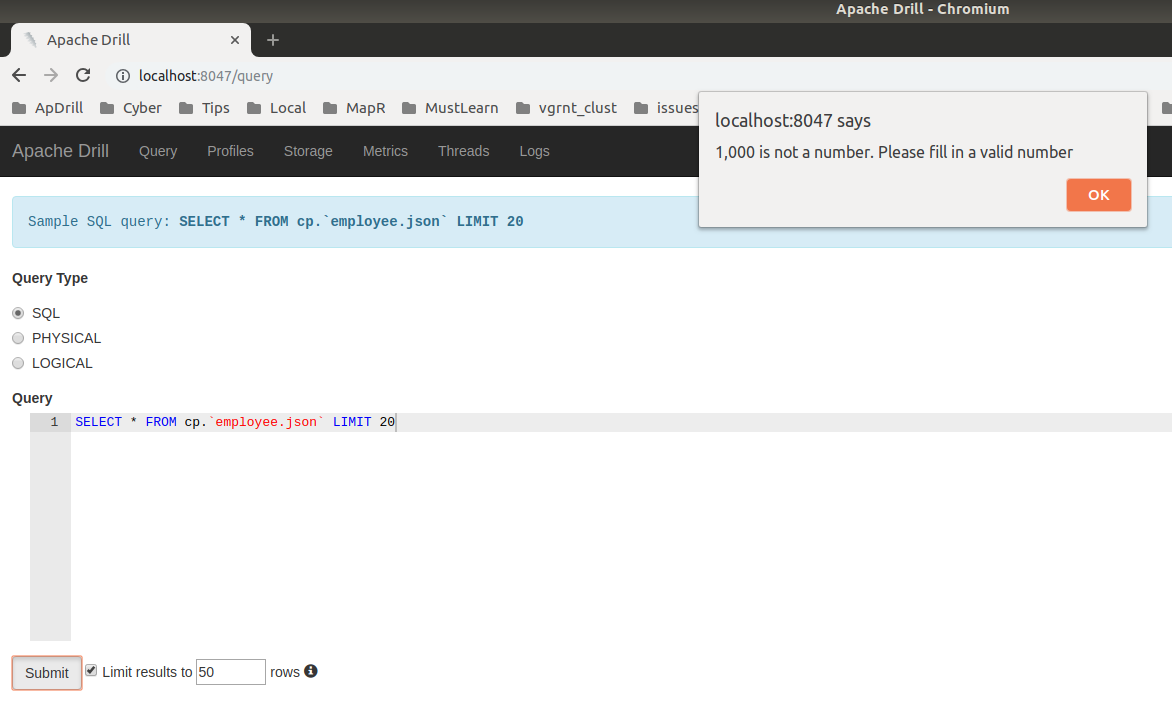 After those failed attempts I executed the line ```console.log(window.navigator.userLanguage || window.navigator.language)``` in JS console and got locale ```en-US``` in my chromium-browser. @kkhatua, can you please fix the blocking issue in order to unlock further review ? Thank you in advance, Igor. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] ihuzenko commented on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query
ihuzenko commented on issue #1608: DRILL-6960: Auto Limit Wrapping should not apply to non-select query URL: https://github.com/apache/drill/pull/1608#issuecomment-458127161 Hello @kkhatua , sorry for the late answer. I wanted to start review from check that fix works fine, but suddenly bumped into an issue. I wasn't able to submit query with my current locale, because it affects number formatting. 1. Tried to use default number:  2. Tried to remove comma from default number:  3. Tried to use own auto limit 50 :  After those failed attempts I executed the line ```console.log(window.navigator.userLanguage || window.navigator.language)``` in JS console and got locale ```en-US``` in my chromium-browser. @kkhatua, can you please fix the blocking issue in order to unlock further review ? Thank you in advance, Igor. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] arina-ielchiieva commented on issue #1625: DRILL-7008: Drillbits: clear stale shutdown hooks
arina-ielchiieva commented on issue #1625: DRILL-7008: Drillbits: clear stale shutdown hooks URL: https://github.com/apache/drill/pull/1625#issuecomment-458100912 +1, @vlsi thanks for making the changes and the fact that tests run much faster is awesome. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] vlsi commented on a change in pull request #1625: DRILL-7008: Drillbits: clear stale shutdown hooks
vlsi commented on a change in pull request #1625: DRILL-7008: Drillbits: clear
stale shutdown hooks
URL: https://github.com/apache/drill/pull/1625#discussion_r251380421
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/server/Drillbit.java
##
@@ -258,6 +260,13 @@ public synchronized void close() {
}
final Stopwatch w = Stopwatch.createStarted();
logger.debug("Shutdown begun.");
+// We don't really want for Drillbits to pile up in memory, so the hook
should be removed
+// It might be better to use PhantomReferences to cleanup as soon as
Drillbit becomes
+// unreachable, however current approach seems to be good enough.
+Thread shutdownHook = this.shutdownHook;
+if (shutdownHook != null && Thread.currentThread() != shutdownHook) {
+ Runtime.getRuntime().removeShutdownHook(shutdownHook);
Review comment:
@arina-ielchiieva , I've added try-catch
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] arina-ielchiieva commented on a change in pull request #1625: DRILL-7008: Drillbits: clear stale shutdown hooks
arina-ielchiieva commented on a change in pull request #1625: DRILL-7008:
Drillbits: clear stale shutdown hooks
URL: https://github.com/apache/drill/pull/1625#discussion_r251376457
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/server/Drillbit.java
##
@@ -258,6 +260,13 @@ public synchronized void close() {
}
final Stopwatch w = Stopwatch.createStarted();
logger.debug("Shutdown begun.");
+// We don't really want for Drillbits to pile up in memory, so the hook
should be removed
+// It might be better to use PhantomReferences to cleanup as soon as
Drillbit becomes
+// unreachable, however current approach seems to be good enough.
+Thread shutdownHook = this.shutdownHook;
+if (shutdownHook != null && Thread.currentThread() != shutdownHook) {
+ Runtime.getRuntime().removeShutdownHook(shutdownHook);
Review comment:
Frankly saying, I am not sure. Can you please point to the reference that
says that thread check is enough?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] vlsi commented on a change in pull request #1625: DRILL-7008: Drillbits: clear stale shutdown hooks
vlsi commented on a change in pull request #1625: DRILL-7008: Drillbits: clear
stale shutdown hooks
URL: https://github.com/apache/drill/pull/1625#discussion_r251374378
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/server/Drillbit.java
##
@@ -258,6 +260,13 @@ public synchronized void close() {
}
final Stopwatch w = Stopwatch.createStarted();
logger.debug("Shutdown begun.");
+// We don't really want for Drillbits to pile up in memory, so the hook
should be removed
+// It might be better to use PhantomReferences to cleanup as soon as
Drillbit becomes
+// unreachable, however current approach seems to be good enough.
+Thread shutdownHook = this.shutdownHook;
+if (shutdownHook != null && Thread.currentThread() != shutdownHook) {
+ Runtime.getRuntime().removeShutdownHook(shutdownHook);
Review comment:
\@arina-ielchiieva , it is handled by `Thread.currentThread() !=
shutdownHook`, isn't it?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] arina-ielchiieva commented on a change in pull request #1625: DRILL-7008: Drillbits: clear stale shutdown hooks
arina-ielchiieva commented on a change in pull request #1625: DRILL-7008:
Drillbits: clear stale shutdown hooks
URL: https://github.com/apache/drill/pull/1625#discussion_r251373908
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/server/Drillbit.java
##
@@ -258,6 +260,13 @@ public synchronized void close() {
}
final Stopwatch w = Stopwatch.createStarted();
logger.debug("Shutdown begun.");
+// We don't really want for Drillbits to pile up in memory, so the hook
should be removed
+// It might be better to use PhantomReferences to cleanup as soon as
Drillbit becomes
+// unreachable, however current approach seems to be good enough.
+Thread shutdownHook = this.shutdownHook;
+if (shutdownHook != null && Thread.currentThread() != shutdownHook) {
+ Runtime.getRuntime().removeShutdownHook(shutdownHook);
Review comment:
@vlsi `removeShutdownHook` can throw `IllegalStateException` if the virtual
machine is already in the process of shutting down. Maybe we should add try /
catch block to ignore such exception?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (DRILL-7009) Lots of tests are locale-specific. Enforce en_US locale for now.
Vladimir Sitnikov created DRILL-7009:
Summary: Lots of tests are locale-specific. Enforce en_US locale
for now.
Key: DRILL-7009
URL: https://issues.apache.org/jira/browse/DRILL-7009
Project: Apache Drill
Issue Type: Bug
Components: Server, Tools, Build Test
Affects Versions: 1.15.0
Reporter: Vladimir Sitnikov
Lots of tests fail for locale reasons when running {{mvn test}} in ru_RU locale.
I suggest to enforce en_US for now so {{mvn test}} works at least
For instance:
{noformat}
[ERROR] Failures:
[ERROR] TestDurationFormat.testCompactSecMillis:58->validateDurationFormat:43
expected:<4[,]545s> but was:<4[.]545s>
[ERROR]
TestDurationFormat.testCompactTwoDigitMilliSec:48->validateDurationFormat:43
expected:<0[,]045s> but was:<0[.]045s>
[ERROR]
TestValueVectorElementFormatter.testFormatValueVectorElementAllDateTimeFormats:142
expected:<[Mon, Nov] 5, 2012> but was:<[Пн, ноя] 5, 2012>
[ERROR]
TestValueVectorElementFormatter.testFormatValueVectorElementDateValidPattern:83
expected:<[Mon, Nov] 5, 2012> but was:<[Пн, ноя] 5, 2012>
[ERROR] Errors:
[ERROR] TestFunctionsQuery.testToCharFunction:567 » After matching 0
records, did not...
[ERROR] TestSelectivity.testFilterSelectivityOptions » UserRemote PARSE
ERROR: Encount...
[ERROR]
TestVarDecimalFunctions.testCastDecimalDouble:724->BaseTestQuery.testRunAndReturn:341
» Rpc
[ERROR]
TestVarDecimalFunctions.testCastDoubleDecimal:694->BaseTestQuery.testRunAndReturn:341
» Rpc
[ERROR] TestVarDecimalFunctions.testDecimalToChar:775 » at position 0 column
'`s1`' m...
[ERROR] TestTopNSchemaChanges.testMissingColumn:192 »
org.apache.drill.common.excepti...
[ERROR] TestTopNSchemaChanges.testNumericTypes:82 »
org.apache.drill.common.exception...
[ERROR] TestTopNSchemaChanges.testUnionTypes:162 »
org.apache.drill.common.exceptions...
[ERROR]
TestMergeJoinWithSchemaChanges.testNumericStringTypes:192->BaseTestQuery.testRunAndReturn:341
» Rpc
[ERROR]
TestMergeJoinWithSchemaChanges.testNumericTypes:114->BaseTestQuery.testRunAndReturn:341
» Rpc
[ERROR]
TestMergeJoinWithSchemaChanges.testOneSideSchemaChanges:348->BaseTestQuery.testRunAndReturn:341
» Rpc
[ERROR] TestExternalSort.testNumericTypesLegacy:49->testNumericTypes:113 »
org.apache...
[ERROR] TestExternalSort.testNumericTypesManaged:44->testNumericTypes:113 »
org.apach...
[ERROR] TestImageRecordReader.testAviImage:101->createAndQuery:50 » at
position 0 col...
[ERROR] TestImageRecordReader.testBmpImage:56->createAndQuery:50 » at
position 0 colu...
[ERROR] TestImageRecordReader.testEpsImage:121->createAndQuery:50 » at
position 0 col...
[ERROR] TestImageRecordReader.testJpegImage:71->createAndQuery:50 » at
position 0 col...
[ERROR] TestImageRecordReader.testMovImage:111->createAndQuery:50 » at
position 0 col...
[ERROR] TestImageRecordReader.testPngImage:81->createAndQuery:50 » at
position 0 colu...
[ERROR] TestImageRecordReader.testPsdImage:86->createAndQuery:50 » at
position 0 colu...
[INFO]
[ERROR] Tests run: 3723, Failures: 4, Errors: 20, Skipped: 157
[INFO]
[INFO]
[INFO] Reactor Summary:
[INFO]
[INFO] Apache Drill Root POM 1.16.0-SNAPSHOT .. SUCCESS [ 6.470 s]
[INFO] tools/Parent Pom ... SUCCESS [ 0.928 s]
[INFO] tools/freemarker codegen tooling ... SUCCESS [ 6.004 s]
[INFO] Drill Protocol . SUCCESS [ 5.090 s]
[INFO] Common (Logical Plan, Base expressions) SUCCESS [ 5.898 s]
[INFO] Logical Plan, Base expressions . SUCCESS [ 5.662 s]
[INFO] exec/Parent Pom SUCCESS [ 0.696 s]
[INFO] exec/memory/Parent Pom . SUCCESS [ 0.569 s]
[INFO] exec/memory/base ... SUCCESS [ 3.380 s]
[INFO] exec/rpc ... SUCCESS [ 1.782 s]
[INFO] exec/Vectors ... SUCCESS [ 6.364 s]
[INFO] contrib/Parent Pom . SUCCESS [ 0.487 s]
[INFO] contrib/data/Parent Pom SUCCESS [ 0.604 s]
[INFO] contrib/data/tpch-sample-data .. SUCCESS [ 2.891 s]
[INFO] exec/Java Execution Engine . FAILURE [26:24 min]
[INFO] exec/JDBC Driver using dependencies SKIPPED{noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] vlsi commented on issue #1625: DRILL-7008: Drillbits: clear stale shutdown hooks
vlsi commented on issue #1625: DRILL-7008: Drillbits: clear stale shutdown hooks URL: https://github.com/apache/drill/pull/1625#issuecomment-458081466 @arina-ielchiieva , done This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (DRILL-7008) Drillbits: clear stale shutdown hook on close
Vladimir Sitnikov created DRILL-7008: Summary: Drillbits: clear stale shutdown hook on close Key: DRILL-7008 URL: https://issues.apache.org/jira/browse/DRILL-7008 Project: Apache Drill Issue Type: Bug Components: Server Affects Versions: 1.15.0 Reporter: Vladimir Sitnikov Drillbits#close should clear shutdown hook if one was installed. Stale shutdown hooks cause memory leak. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] arina-ielchiieva commented on issue #1624: DRILL-7007: Use verify method in row set tests
arina-ielchiieva commented on issue #1624: DRILL-7007: Use verify method in row set tests URL: https://github.com/apache/drill/pull/1624#issuecomment-458035037 +1 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] arina-ielchiieva edited a comment on issue #1625: Drillbits: clear stale shutdown hooks
arina-ielchiieva edited a comment on issue #1625: Drillbits: clear stale shutdown hooks URL: https://github.com/apache/drill/pull/1625#issuecomment-458033960 @vlsi thanks for the PR. Could you please create Apache Jira and add its number in the commit message and PR title? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] arina-ielchiieva commented on issue #1625: Drillbits: clear stale shutdown hooks
arina-ielchiieva commented on issue #1625: Drillbits: clear stale shutdown hooks URL: https://github.com/apache/drill/pull/1625#issuecomment-458033960 @vlsi thanks for the PR. Could you please create Apache Jira and add it's number in commit message and PR title? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services