[jira] [Created] (ZEPPELIN-3622) Zeppelin does not Logout in IE with authc
venkata praveen created ZEPPELIN-3622: - Summary: Zeppelin does not Logout in IE with authc Key: ZEPPELIN-3622 URL: https://issues.apache.org/jira/browse/ZEPPELIN-3622 Project: Zeppelin Issue Type: Bug Components: security Affects Versions: 0.8.0 Environment: IE - 11.0 Reporter: venkata praveen Logout from Zeppelin in IE is not working.On Logout, "Logout Success" popup is shown and then page redirected to user home page. Sometimes logout works, but following message appears on login popup 'Your ticket is invalid possibly due to server restart. Please login again.' Working fine in Chrome. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (ZEPPELIN-3621) Add method getInterpreterInTheSameSession to Interpreter
Jeff Zhang created ZEPPELIN-3621: Summary: Add method getInterpreterInTheSameSession to Interpreter Key: ZEPPELIN-3621 URL: https://issues.apache.org/jira/browse/ZEPPELIN-3621 Project: Zeppelin Issue Type: Improvement Reporter: Jeff Zhang -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] zeppelin pull request #3067: [ZEPPELIN-3609] Refactor ZeppelinServer class
GitHub user jongyoul opened a pull request: https://github.com/apache/zeppelin/pull/3067 [ZEPPELIN-3609] Refactor ZeppelinServer class ### What is this PR for? Refactoring ZeppelinServer to add new feature easily and understand more clearly. And I'd like to refactor with several commits not to keep apart from the current master. ### What type of PR is it? [Refactoring] ### Todos * [x] - Intorduce @Inject annotation for server component ### What is the Jira issue? * https://issues.apache.org/jira/browse/ZEPPELIN-3609 ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No You can merge this pull request into a Git repository by running: $ git pull https://github.com/jongyoul/zeppelin ZEPPELIN-3609 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/zeppelin/pull/3067.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #3067 commit 6323d3760c4d4e6a7569af62437e66f0c7858410 Author: Jongyoul Lee Date: 2018-07-12T04:34:58Z Add @Inject annotation ---
[jira] [Created] (ZEPPELIN-3620) zeppelin process died when using kubernetes containers
george created ZEPPELIN-3620:
Summary: zeppelin process died when using kubernetes containers
Key: ZEPPELIN-3620
URL: https://issues.apache.org/jira/browse/ZEPPELIN-3620
Project: Zeppelin
Issue Type: Bug
Components: zeppelin-server
Affects Versions: 0.7.0
Environment: Host OS: Ubuntu 16.04
k8s: Rancher 2.0
docker image:
cthiebault/zeppelin-mongodb:latest
zeppelin version: 0.7.0
[^zeppelin--zeppelin-759765f857-4ndjv.log]
Reporter: george
Fix For: 0.7.0
Attachments: zeppelin--zeppelin-759765f857-4ndjv.log,
zeppelin--zeppelin-759765f857-4ndjv.out,
zeppelin--zeppelin-c878d88b9-26qnc.log, zeppelin--zeppelin-c878d88b9-26qnc.out
when I deploy a kubernetes service using this docker image:
https://hub.docker.com/r/cthiebault/zeppelin-mongodb/
the container failed, showing up this message:
{code:java}
Zeppelin start [ OK ] Zeppelin process died [FAILED]{code}
I found zeppelin/logs here:
{code:java}
ZEPPELIN_CLASSPATH:
::/opt/zeppelin/lib/interpreter/*:/opt/zeppelin/lib/*:/opt/zeppelin/*::/opt/zeppelin/conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in
[jar:file:/opt/zeppelin/lib/interpreter/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in
[jar:file:/opt/zeppelin/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Exception in thread "main" java.lang.NumberFormatException: For input string:
"tcp://10.43.25.163:8080"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:492)
at java.lang.Integer.parseInt(Integer.java:527)
at
org.apache.zeppelin.conf.ZeppelinConfiguration.getInt(ZeppelinConfiguration.java:213)
at
org.apache.zeppelin.conf.ZeppelinConfiguration.getInt(ZeppelinConfiguration.java:208)
at
org.apache.zeppelin.conf.ZeppelinConfiguration.getServerPort(ZeppelinConfiguration.java:283)
at
org.apache.zeppelin.conf.ZeppelinConfiguration.create(ZeppelinConfiguration.java:111)
at org.apache.zeppelin.server.ZeppelinServer.main(ZeppelinServer.java:156)
{code}
but if I just use docker CLI to run this image, everything is OK.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
Re: [DISCUSS] Share Data in Zeppelin
Thanks Sanjay, I have fixed the example note.
*Folks, to be noticed,* the example note is just a fake note, it won't work
for now.
Jongyoul Lee 于2018年7月13日周五 上午10:54写道:
> BTW, we need to consider the case where the result is large in a design
> time. In my experience, If we implement this feature, users could use it
> with large data.
>
> On Fri, Jul 13, 2018 at 11:51 AM, Sanjay Dasgupta <
> sanjay.dasgu...@gmail.com> wrote:
>
>> I prefer 2.b also. Could we use (save*Result*AsTable=people) instead?
>>
>> There are a few typos in the example note shared:
>>
>> 1) The line val peopleDF = spark.read.format("zeppelin").load() should
>> mention the table name (possibly as argument to load?)
>> 2) The python line val peopleDF = z.getTable("people").toPandas() should
>> not have the val
>>
>>
>> The z.getTable() method could be a very good tool to judge
>> which use-cases are important in the community. It is easy to implement for
>> the in-memory data case, and could be very useful for many situations where
>> a small amount of data is being transferred across interpreters (like the
>> jdbc -> matplotlib case mentioned).
>>
>> Thanks,
>> Sanjay
>>
>> On Fri, Jul 13, 2018 at 8:07 AM, Jongyoul Lee wrote:
>>
>>> Yes, it's similar to 2.b.
>>>
>>> Basically, my concern is to handle all kinds of data. But in your case,
>>> it looks like focusing on table data. It's also useful but it would be
>>> better to handle all of the data including table or plain text as well.
>>> WDYT?
>>>
>>> About storage, we could discuss it later.
>>>
>>> On Fri, Jul 13, 2018 at 11:25 AM, Jeff Zhang wrote:
>>>
I think your use case is the same of 2.b. Personally I don't recommend
to use z.get(noteId, paragraphId) to get the shared data for 2 reasons
1. noteId, paragraphId is meaningless, which is not readable
2. The note will break if we clone it as the noteId is changed.
That's why I suggest to use paragraph property to save paragraph's
result
Regarding the intermediate storage, I also though about it and agree
that in the long term we should provide such layer to support large data,
currently we put the shared data in memory which is not a scalable
solution. One candidate in my mind is alluxio [1], and regarding the data
format I think apache arrow [2] is another good option for zeppelin to
share table data across interpreter processes and different languages. But
these are all implementation details, I think we can talk about them in
another thread. In this thread, I think we should focus on the user facing
api.
[1] http://www.alluxio.org/
[2] https://arrow.apache.org/
Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
> I have a bit different idea to share data.
>
> In my case,
>
> It would be very useful to get a paragraph's result as an input of
> other paragraphs.
>
> e.g.
>
> -- Paragrph 1
> %jdbc
> select * from some_table;
>
> -- Paragraph 2
> %spark
> val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
> spark.read(table).select
>
> If paragraph 1's result is too big to show on FE, it would be saved in
> Zeppelin Server with proper way and pass to SparkInterpreter when
> Paragraph
> 2 is executed.
>
> Basically, I think we need to intermediate storage to store
> paragraph's results to share them. We can introduce another layer or
> extend
> NotebootRepo. In some cases, we might change notebook repos as well.
>
> JL
>
>
>
> On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
>
>> Hi Folks,
>>
>> Recently, there's several tickets [1][2][3] about sharing data in
>> zeppelin.
>> Zeppelin's goal is to be an unified data analyst platform which could
>> integrate most of the big data tools and help user to switch between
>> tools
>> and share data between tools easily. So sharing data is a very
>> critical and
>> killer feature of Zeppelin IMHO.
>>
>> I raise this ticket to discuss about the scenario of sharing data and
>> how
>> to do that. Although zeppelin already provides tools and api to share
>> data,
>> I don't think it is mature and stable enough. After seeing these
>> tickets, I
>> think it might be a good time to talk about it in community and
>> gather more
>> feedback, so that we could provide a more stable and mature approach
>> for
>> it.
>>
>> Currently, there're 3 approaches to share data between interpreters
>> and
>> interpreter processes.
>> 1. Sharing data across interpreter in the same interpreter process.
>> Like
>> sharing data via the same SparkContext in %spark, %spark.pyspark and
>> %spark.r.
>> 2. Sharing data between frontend and backend via angularObject
>> 3. Sharing data across interpreter processes via
Re: [DISCUSS] Share Data in Zeppelin
BTW, we need to consider the case where the result is large in a design
time. In my experience, If we implement this feature, users could use it
with large data.
On Fri, Jul 13, 2018 at 11:51 AM, Sanjay Dasgupta wrote:
> I prefer 2.b also. Could we use (save*Result*AsTable=people) instead?
>
> There are a few typos in the example note shared:
>
> 1) The line val peopleDF = spark.read.format("zeppelin").load() should
> mention the table name (possibly as argument to load?)
> 2) The python line val peopleDF = z.getTable("people").toPandas() should
> not have the val
>
>
> The z.getTable() method could be a very good tool to judge
> which use-cases are important in the community. It is easy to implement for
> the in-memory data case, and could be very useful for many situations where
> a small amount of data is being transferred across interpreters (like the
> jdbc -> matplotlib case mentioned).
>
> Thanks,
> Sanjay
>
> On Fri, Jul 13, 2018 at 8:07 AM, Jongyoul Lee wrote:
>
>> Yes, it's similar to 2.b.
>>
>> Basically, my concern is to handle all kinds of data. But in your case,
>> it looks like focusing on table data. It's also useful but it would be
>> better to handle all of the data including table or plain text as well.
>> WDYT?
>>
>> About storage, we could discuss it later.
>>
>> On Fri, Jul 13, 2018 at 11:25 AM, Jeff Zhang wrote:
>>
>>>
>>> I think your use case is the same of 2.b. Personally I don't recommend
>>> to use z.get(noteId, paragraphId) to get the shared data for 2 reasons
>>> 1. noteId, paragraphId is meaningless, which is not readable
>>> 2. The note will break if we clone it as the noteId is changed.
>>> That's why I suggest to use paragraph property to save paragraph's result
>>>
>>> Regarding the intermediate storage, I also though about it and agree
>>> that in the long term we should provide such layer to support large data,
>>> currently we put the shared data in memory which is not a scalable
>>> solution. One candidate in my mind is alluxio [1], and regarding the data
>>> format I think apache arrow [2] is another good option for zeppelin to
>>> share table data across interpreter processes and different languages. But
>>> these are all implementation details, I think we can talk about them in
>>> another thread. In this thread, I think we should focus on the user facing
>>> api.
>>>
>>>
>>> [1] http://www.alluxio.org/
>>> [2] https://arrow.apache.org/
>>>
>>>
>>>
>>> Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
>>>
I have a bit different idea to share data.
In my case,
It would be very useful to get a paragraph's result as an input of
other paragraphs.
e.g.
-- Paragrph 1
%jdbc
select * from some_table;
-- Paragraph 2
%spark
val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
spark.read(table).select
If paragraph 1's result is too big to show on FE, it would be saved in
Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
2 is executed.
Basically, I think we need to intermediate storage to store paragraph's
results to share them. We can introduce another layer or extend
NotebootRepo. In some cases, we might change notebook repos as well.
JL
On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
> Hi Folks,
>
> Recently, there's several tickets [1][2][3] about sharing data in
> zeppelin.
> Zeppelin's goal is to be an unified data analyst platform which could
> integrate most of the big data tools and help user to switch between
> tools
> and share data between tools easily. So sharing data is a very
> critical and
> killer feature of Zeppelin IMHO.
>
> I raise this ticket to discuss about the scenario of sharing data and
> how
> to do that. Although zeppelin already provides tools and api to share
> data,
> I don't think it is mature and stable enough. After seeing these
> tickets, I
> think it might be a good time to talk about it in community and gather
> more
> feedback, so that we could provide a more stable and mature approach
> for
> it.
>
> Currently, there're 3 approaches to share data between interpreters and
> interpreter processes.
> 1. Sharing data across interpreter in the same interpreter process.
> Like
> sharing data via the same SparkContext in %spark, %spark.pyspark and
> %spark.r.
> 2. Sharing data between frontend and backend via angularObject
> 3. Sharing data across interpreter processes via Zeppelin's
> ResourcePool
>
> For this thread, I would like to talk about the approach 3 (Sharing
> data
> via Zeppelin's ResourcePool)
>
> Here's my current thinking of sharing data.
> 1. What kind of data would be shared ?
>IMHO, users would share 2 kinds of data: primitive data (string,
> number)
> and
Re: [DISCUSS] Share Data in Zeppelin
That would be great.
BTW, does ZEPL's example work for now?
On Fri, Jul 13, 2018 at 11:43 AM, Jeff Zhang wrote:
>
> Sure, we can support plain text as well.
>
> Jongyoul Lee 于2018年7月13日周五 上午10:37写道:
>
>> Yes, it's similar to 2.b.
>>
>> Basically, my concern is to handle all kinds of data. But in your case,
>> it looks like focusing on table data. It's also useful but it would be
>> better to handle all of the data including table or plain text as well.
>> WDYT?
>>
>> About storage, we could discuss it later.
>>
>> On Fri, Jul 13, 2018 at 11:25 AM, Jeff Zhang wrote:
>>
>>>
>>> I think your use case is the same of 2.b. Personally I don't recommend
>>> to use z.get(noteId, paragraphId) to get the shared data for 2 reasons
>>> 1. noteId, paragraphId is meaningless, which is not readable
>>> 2. The note will break if we clone it as the noteId is changed.
>>> That's why I suggest to use paragraph property to save paragraph's result
>>>
>>> Regarding the intermediate storage, I also though about it and agree
>>> that in the long term we should provide such layer to support large data,
>>> currently we put the shared data in memory which is not a scalable
>>> solution. One candidate in my mind is alluxio [1], and regarding the data
>>> format I think apache arrow [2] is another good option for zeppelin to
>>> share table data across interpreter processes and different languages. But
>>> these are all implementation details, I think we can talk about them in
>>> another thread. In this thread, I think we should focus on the user facing
>>> api.
>>>
>>>
>>> [1] http://www.alluxio.org/
>>> [2] https://arrow.apache.org/
>>>
>>>
>>>
>>> Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
>>>
I have a bit different idea to share data.
In my case,
It would be very useful to get a paragraph's result as an input of
other paragraphs.
e.g.
-- Paragrph 1
%jdbc
select * from some_table;
-- Paragraph 2
%spark
val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
spark.read(table).select
If paragraph 1's result is too big to show on FE, it would be saved in
Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
2 is executed.
Basically, I think we need to intermediate storage to store paragraph's
results to share them. We can introduce another layer or extend
NotebootRepo. In some cases, we might change notebook repos as well.
JL
On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
> Hi Folks,
>
> Recently, there's several tickets [1][2][3] about sharing data in
> zeppelin.
> Zeppelin's goal is to be an unified data analyst platform which could
> integrate most of the big data tools and help user to switch between
> tools
> and share data between tools easily. So sharing data is a very
> critical and
> killer feature of Zeppelin IMHO.
>
> I raise this ticket to discuss about the scenario of sharing data and
> how
> to do that. Although zeppelin already provides tools and api to share
> data,
> I don't think it is mature and stable enough. After seeing these
> tickets, I
> think it might be a good time to talk about it in community and gather
> more
> feedback, so that we could provide a more stable and mature approach
> for
> it.
>
> Currently, there're 3 approaches to share data between interpreters and
> interpreter processes.
> 1. Sharing data across interpreter in the same interpreter process.
> Like
> sharing data via the same SparkContext in %spark, %spark.pyspark and
> %spark.r.
> 2. Sharing data between frontend and backend via angularObject
> 3. Sharing data across interpreter processes via Zeppelin's
> ResourcePool
>
> For this thread, I would like to talk about the approach 3 (Sharing
> data
> via Zeppelin's ResourcePool)
>
> Here's my current thinking of sharing data.
> 1. What kind of data would be shared ?
>IMHO, users would share 2 kinds of data: primitive data (string,
> number)
> and table data.
>
> 2. How to write shared data ?
> User may want to share data via 2 approches
> a. Use ZeppelinContext (e.g. z.put).
> b. Share the paragraph result via paragraph properties. e.g. user
> may
> want to read data from oracle database via jdbc interpreter and then do
> plotting in python interpreter. In such scenario. he can save the jdbc
> result in ResourcePool via paragraph property and then read it it via
> z.get. Here's one simple example (Not implemented yet)
>
> %jdbc(saveAsTable=people)
> select * from oracle_table
>
> %python
> z.getTable("people).toPandas()
>
> 3. How to read shared data ?
> User can also have 2 approaches to read
Re: [DISCUSS] Share Data in Zeppelin
I prefer 2.b also. Could we use (save*Result*AsTable=people) instead?
There are a few typos in the example note shared:
1) The line val peopleDF = spark.read.format("zeppelin").load() should
mention the table name (possibly as argument to load?)
2) The python line val peopleDF = z.getTable("people").toPandas() should
not have the val
The z.getTable() method could be a very good tool to judge
which use-cases are important in the community. It is easy to implement for
the in-memory data case, and could be very useful for many situations where
a small amount of data is being transferred across interpreters (like the
jdbc -> matplotlib case mentioned).
Thanks,
Sanjay
On Fri, Jul 13, 2018 at 8:07 AM, Jongyoul Lee wrote:
> Yes, it's similar to 2.b.
>
> Basically, my concern is to handle all kinds of data. But in your case, it
> looks like focusing on table data. It's also useful but it would be better
> to handle all of the data including table or plain text as well. WDYT?
>
> About storage, we could discuss it later.
>
> On Fri, Jul 13, 2018 at 11:25 AM, Jeff Zhang wrote:
>
>>
>> I think your use case is the same of 2.b. Personally I don't recommend
>> to use z.get(noteId, paragraphId) to get the shared data for 2 reasons
>> 1. noteId, paragraphId is meaningless, which is not readable
>> 2. The note will break if we clone it as the noteId is changed.
>> That's why I suggest to use paragraph property to save paragraph's result
>>
>> Regarding the intermediate storage, I also though about it and agree that
>> in the long term we should provide such layer to support large data,
>> currently we put the shared data in memory which is not a scalable
>> solution. One candidate in my mind is alluxio [1], and regarding the data
>> format I think apache arrow [2] is another good option for zeppelin to
>> share table data across interpreter processes and different languages. But
>> these are all implementation details, I think we can talk about them in
>> another thread. In this thread, I think we should focus on the user facing
>> api.
>>
>>
>> [1] http://www.alluxio.org/
>> [2] https://arrow.apache.org/
>>
>>
>>
>> Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
>>
>>> I have a bit different idea to share data.
>>>
>>> In my case,
>>>
>>> It would be very useful to get a paragraph's result as an input of other
>>> paragraphs.
>>>
>>> e.g.
>>>
>>> -- Paragrph 1
>>> %jdbc
>>> select * from some_table;
>>>
>>> -- Paragraph 2
>>> %spark
>>> val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
>>> spark.read(table).select
>>>
>>> If paragraph 1's result is too big to show on FE, it would be saved in
>>> Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
>>> 2 is executed.
>>>
>>> Basically, I think we need to intermediate storage to store paragraph's
>>> results to share them. We can introduce another layer or extend
>>> NotebootRepo. In some cases, we might change notebook repos as well.
>>>
>>> JL
>>>
>>>
>>>
>>> On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
>>>
Hi Folks,
Recently, there's several tickets [1][2][3] about sharing data in
zeppelin.
Zeppelin's goal is to be an unified data analyst platform which could
integrate most of the big data tools and help user to switch between
tools
and share data between tools easily. So sharing data is a very critical
and
killer feature of Zeppelin IMHO.
I raise this ticket to discuss about the scenario of sharing data and
how
to do that. Although zeppelin already provides tools and api to share
data,
I don't think it is mature and stable enough. After seeing these
tickets, I
think it might be a good time to talk about it in community and gather
more
feedback, so that we could provide a more stable and mature approach for
it.
Currently, there're 3 approaches to share data between interpreters and
interpreter processes.
1. Sharing data across interpreter in the same interpreter process. Like
sharing data via the same SparkContext in %spark, %spark.pyspark and
%spark.r.
2. Sharing data between frontend and backend via angularObject
3. Sharing data across interpreter processes via Zeppelin's ResourcePool
For this thread, I would like to talk about the approach 3 (Sharing data
via Zeppelin's ResourcePool)
Here's my current thinking of sharing data.
1. What kind of data would be shared ?
IMHO, users would share 2 kinds of data: primitive data (string,
number)
and table data.
2. How to write shared data ?
User may want to share data via 2 approches
a. Use ZeppelinContext (e.g. z.put).
b. Share the paragraph result via paragraph properties. e.g. user
may
want to read data from oracle database via jdbc interpreter and then do
plotting in python interpreter. In such scenario. he can save the jdbc
Re: [DISCUSS] Share Data in Zeppelin
Sure, we can support plain text as well.
Jongyoul Lee 于2018年7月13日周五 上午10:37写道:
> Yes, it's similar to 2.b.
>
> Basically, my concern is to handle all kinds of data. But in your case, it
> looks like focusing on table data. It's also useful but it would be better
> to handle all of the data including table or plain text as well. WDYT?
>
> About storage, we could discuss it later.
>
> On Fri, Jul 13, 2018 at 11:25 AM, Jeff Zhang wrote:
>
>>
>> I think your use case is the same of 2.b. Personally I don't recommend
>> to use z.get(noteId, paragraphId) to get the shared data for 2 reasons
>> 1. noteId, paragraphId is meaningless, which is not readable
>> 2. The note will break if we clone it as the noteId is changed.
>> That's why I suggest to use paragraph property to save paragraph's result
>>
>> Regarding the intermediate storage, I also though about it and agree that
>> in the long term we should provide such layer to support large data,
>> currently we put the shared data in memory which is not a scalable
>> solution. One candidate in my mind is alluxio [1], and regarding the data
>> format I think apache arrow [2] is another good option for zeppelin to
>> share table data across interpreter processes and different languages. But
>> these are all implementation details, I think we can talk about them in
>> another thread. In this thread, I think we should focus on the user facing
>> api.
>>
>>
>> [1] http://www.alluxio.org/
>> [2] https://arrow.apache.org/
>>
>>
>>
>> Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
>>
>>> I have a bit different idea to share data.
>>>
>>> In my case,
>>>
>>> It would be very useful to get a paragraph's result as an input of other
>>> paragraphs.
>>>
>>> e.g.
>>>
>>> -- Paragrph 1
>>> %jdbc
>>> select * from some_table;
>>>
>>> -- Paragraph 2
>>> %spark
>>> val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
>>> spark.read(table).select
>>>
>>> If paragraph 1's result is too big to show on FE, it would be saved in
>>> Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
>>> 2 is executed.
>>>
>>> Basically, I think we need to intermediate storage to store paragraph's
>>> results to share them. We can introduce another layer or extend
>>> NotebootRepo. In some cases, we might change notebook repos as well.
>>>
>>> JL
>>>
>>>
>>>
>>> On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
>>>
Hi Folks,
Recently, there's several tickets [1][2][3] about sharing data in
zeppelin.
Zeppelin's goal is to be an unified data analyst platform which could
integrate most of the big data tools and help user to switch between
tools
and share data between tools easily. So sharing data is a very critical
and
killer feature of Zeppelin IMHO.
I raise this ticket to discuss about the scenario of sharing data and
how
to do that. Although zeppelin already provides tools and api to share
data,
I don't think it is mature and stable enough. After seeing these
tickets, I
think it might be a good time to talk about it in community and gather
more
feedback, so that we could provide a more stable and mature approach for
it.
Currently, there're 3 approaches to share data between interpreters and
interpreter processes.
1. Sharing data across interpreter in the same interpreter process. Like
sharing data via the same SparkContext in %spark, %spark.pyspark and
%spark.r.
2. Sharing data between frontend and backend via angularObject
3. Sharing data across interpreter processes via Zeppelin's ResourcePool
For this thread, I would like to talk about the approach 3 (Sharing data
via Zeppelin's ResourcePool)
Here's my current thinking of sharing data.
1. What kind of data would be shared ?
IMHO, users would share 2 kinds of data: primitive data (string,
number)
and table data.
2. How to write shared data ?
User may want to share data via 2 approches
a. Use ZeppelinContext (e.g. z.put).
b. Share the paragraph result via paragraph properties. e.g. user
may
want to read data from oracle database via jdbc interpreter and then do
plotting in python interpreter. In such scenario. he can save the jdbc
result in ResourcePool via paragraph property and then read it it via
z.get. Here's one simple example (Not implemented yet)
%jdbc(saveAsTable=people)
select * from oracle_table
%python
z.getTable("people).toPandas()
3. How to read shared data ?
User can also have 2 approaches to read the shared data.
a. Via ZeppelinContext. (e.g. z.get, z.getTable)
b. Via variable substitution [1]
Here's one sample note which illustrate the scenario of sharing data.
Re: [DISCUSS] Share Data in Zeppelin
Yes, it's similar to 2.b.
Basically, my concern is to handle all kinds of data. But in your case, it
looks like focusing on table data. It's also useful but it would be better
to handle all of the data including table or plain text as well. WDYT?
About storage, we could discuss it later.
On Fri, Jul 13, 2018 at 11:25 AM, Jeff Zhang wrote:
>
> I think your use case is the same of 2.b. Personally I don't recommend to
> use z.get(noteId, paragraphId) to get the shared data for 2 reasons
> 1. noteId, paragraphId is meaningless, which is not readable
> 2. The note will break if we clone it as the noteId is changed.
> That's why I suggest to use paragraph property to save paragraph's result
>
> Regarding the intermediate storage, I also though about it and agree that
> in the long term we should provide such layer to support large data,
> currently we put the shared data in memory which is not a scalable
> solution. One candidate in my mind is alluxio [1], and regarding the data
> format I think apache arrow [2] is another good option for zeppelin to
> share table data across interpreter processes and different languages. But
> these are all implementation details, I think we can talk about them in
> another thread. In this thread, I think we should focus on the user facing
> api.
>
>
> [1] http://www.alluxio.org/
> [2] https://arrow.apache.org/
>
>
>
> Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
>
>> I have a bit different idea to share data.
>>
>> In my case,
>>
>> It would be very useful to get a paragraph's result as an input of other
>> paragraphs.
>>
>> e.g.
>>
>> -- Paragrph 1
>> %jdbc
>> select * from some_table;
>>
>> -- Paragraph 2
>> %spark
>> val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
>> spark.read(table).select
>>
>> If paragraph 1's result is too big to show on FE, it would be saved in
>> Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
>> 2 is executed.
>>
>> Basically, I think we need to intermediate storage to store paragraph's
>> results to share them. We can introduce another layer or extend
>> NotebootRepo. In some cases, we might change notebook repos as well.
>>
>> JL
>>
>>
>>
>> On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
>>
>>> Hi Folks,
>>>
>>> Recently, there's several tickets [1][2][3] about sharing data in
>>> zeppelin.
>>> Zeppelin's goal is to be an unified data analyst platform which could
>>> integrate most of the big data tools and help user to switch between
>>> tools
>>> and share data between tools easily. So sharing data is a very critical
>>> and
>>> killer feature of Zeppelin IMHO.
>>>
>>> I raise this ticket to discuss about the scenario of sharing data and how
>>> to do that. Although zeppelin already provides tools and api to share
>>> data,
>>> I don't think it is mature and stable enough. After seeing these
>>> tickets, I
>>> think it might be a good time to talk about it in community and gather
>>> more
>>> feedback, so that we could provide a more stable and mature approach for
>>> it.
>>>
>>> Currently, there're 3 approaches to share data between interpreters and
>>> interpreter processes.
>>> 1. Sharing data across interpreter in the same interpreter process. Like
>>> sharing data via the same SparkContext in %spark, %spark.pyspark and
>>> %spark.r.
>>> 2. Sharing data between frontend and backend via angularObject
>>> 3. Sharing data across interpreter processes via Zeppelin's ResourcePool
>>>
>>> For this thread, I would like to talk about the approach 3 (Sharing data
>>> via Zeppelin's ResourcePool)
>>>
>>> Here's my current thinking of sharing data.
>>> 1. What kind of data would be shared ?
>>>IMHO, users would share 2 kinds of data: primitive data (string,
>>> number)
>>> and table data.
>>>
>>> 2. How to write shared data ?
>>> User may want to share data via 2 approches
>>> a. Use ZeppelinContext (e.g. z.put).
>>> b. Share the paragraph result via paragraph properties. e.g. user may
>>> want to read data from oracle database via jdbc interpreter and then do
>>> plotting in python interpreter. In such scenario. he can save the jdbc
>>> result in ResourcePool via paragraph property and then read it it via
>>> z.get. Here's one simple example (Not implemented yet)
>>>
>>> %jdbc(saveAsTable=people)
>>> select * from oracle_table
>>>
>>> %python
>>> z.getTable("people).toPandas()
>>>
>>> 3. How to read shared data ?
>>> User can also have 2 approaches to read the shared data.
>>> a. Via ZeppelinContext. (e.g. z.get, z.getTable)
>>> b. Via variable substitution [1]
>>>
>>> Here's one sample note which illustrate the scenario of sharing data.
>>> https://www.zepl.com/viewer/notebooks/bm90ZTovL3pqZmZkdS8zMzkxZjg3Ym
>>> FhMjg0MDY3OGM1ZmYzODAwODAxMGJhNy9ub3RlLmpzb24
>>>
>>> This is just my current thinking of sharing data in zeppelin, it
>>> definitely
>>> doesn't cover all the scenarios, so I raise this thread to discuss about
>>> in
>>>
[GitHub] zeppelin pull request #3058: [ZEPPELIN-3593] Change LuceneSearch's directory...
Github user asfgit closed the pull request at: https://github.com/apache/zeppelin/pull/3058 ---
Re: [DISCUSS] Share Data in Zeppelin
I think your use case is the same of 2.b. Personally I don't recommend to
use z.get(noteId, paragraphId) to get the shared data for 2 reasons
1. noteId, paragraphId is meaningless, which is not readable
2. The note will break if we clone it as the noteId is changed.
That's why I suggest to use paragraph property to save paragraph's result
Regarding the intermediate storage, I also though about it and agree that
in the long term we should provide such layer to support large data,
currently we put the shared data in memory which is not a scalable
solution. One candidate in my mind is alluxio [1], and regarding the data
format I think apache arrow [2] is another good option for zeppelin to
share table data across interpreter processes and different languages. But
these are all implementation details, I think we can talk about them in
another thread. In this thread, I think we should focus on the user facing
api.
[1] http://www.alluxio.org/
[2] https://arrow.apache.org/
Jongyoul Lee 于2018年7月13日周五 上午10:11写道:
> I have a bit different idea to share data.
>
> In my case,
>
> It would be very useful to get a paragraph's result as an input of other
> paragraphs.
>
> e.g.
>
> -- Paragrph 1
> %jdbc
> select * from some_table;
>
> -- Paragraph 2
> %spark
> val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
> spark.read(table).select
>
> If paragraph 1's result is too big to show on FE, it would be saved in
> Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
> 2 is executed.
>
> Basically, I think we need to intermediate storage to store paragraph's
> results to share them. We can introduce another layer or extend
> NotebootRepo. In some cases, we might change notebook repos as well.
>
> JL
>
>
>
> On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
>
>> Hi Folks,
>>
>> Recently, there's several tickets [1][2][3] about sharing data in
>> zeppelin.
>> Zeppelin's goal is to be an unified data analyst platform which could
>> integrate most of the big data tools and help user to switch between tools
>> and share data between tools easily. So sharing data is a very critical
>> and
>> killer feature of Zeppelin IMHO.
>>
>> I raise this ticket to discuss about the scenario of sharing data and how
>> to do that. Although zeppelin already provides tools and api to share
>> data,
>> I don't think it is mature and stable enough. After seeing these tickets,
>> I
>> think it might be a good time to talk about it in community and gather
>> more
>> feedback, so that we could provide a more stable and mature approach for
>> it.
>>
>> Currently, there're 3 approaches to share data between interpreters and
>> interpreter processes.
>> 1. Sharing data across interpreter in the same interpreter process. Like
>> sharing data via the same SparkContext in %spark, %spark.pyspark and
>> %spark.r.
>> 2. Sharing data between frontend and backend via angularObject
>> 3. Sharing data across interpreter processes via Zeppelin's ResourcePool
>>
>> For this thread, I would like to talk about the approach 3 (Sharing data
>> via Zeppelin's ResourcePool)
>>
>> Here's my current thinking of sharing data.
>> 1. What kind of data would be shared ?
>>IMHO, users would share 2 kinds of data: primitive data (string,
>> number)
>> and table data.
>>
>> 2. How to write shared data ?
>> User may want to share data via 2 approches
>> a. Use ZeppelinContext (e.g. z.put).
>> b. Share the paragraph result via paragraph properties. e.g. user may
>> want to read data from oracle database via jdbc interpreter and then do
>> plotting in python interpreter. In such scenario. he can save the jdbc
>> result in ResourcePool via paragraph property and then read it it via
>> z.get. Here's one simple example (Not implemented yet)
>>
>> %jdbc(saveAsTable=people)
>> select * from oracle_table
>>
>> %python
>> z.getTable("people).toPandas()
>>
>> 3. How to read shared data ?
>> User can also have 2 approaches to read the shared data.
>> a. Via ZeppelinContext. (e.g. z.get, z.getTable)
>> b. Via variable substitution [1]
>>
>> Here's one sample note which illustrate the scenario of sharing data.
>>
>> https://www.zepl.com/viewer/notebooks/bm90ZTovL3pqZmZkdS8zMzkxZjg3YmFhMjg0MDY3OGM1ZmYzODAwODAxMGJhNy9ub3RlLmpzb24
>>
>> This is just my current thinking of sharing data in zeppelin, it
>> definitely
>> doesn't cover all the scenarios, so I raise this thread to discuss about
>> in
>> community, welcome any feedback and comments.
>>
>>
>> [1]. https://issues.apache.org/jira/browse/ZEPPELIN-3377
>> [2]. https://issues.apache.org/jira/browse/ZEPPELIN-3596
>> [3]. https://issues.apache.org/jira/browse/ZEPPELIN-3617
>>
>
>
>
> --
> 이종열, Jongyoul Lee, 李宗烈
> http://madeng.net
>
Re: [DISCUSS] Share Data in Zeppelin
I have a bit different idea to share data.
In my case,
It would be very useful to get a paragraph's result as an input of other
paragraphs.
e.g.
-- Paragrph 1
%jdbc
select * from some_table;
-- Paragraph 2
%spark
val rdd = z.get("noteId", "paragraphId").parse.makeRddByMyself
spark.read(table).select
If paragraph 1's result is too big to show on FE, it would be saved in
Zeppelin Server with proper way and pass to SparkInterpreter when Paragraph
2 is executed.
Basically, I think we need to intermediate storage to store paragraph's
results to share them. We can introduce another layer or extend
NotebootRepo. In some cases, we might change notebook repos as well.
JL
On Fri, Jul 13, 2018 at 10:39 AM, Jeff Zhang wrote:
> Hi Folks,
>
> Recently, there's several tickets [1][2][3] about sharing data in zeppelin.
> Zeppelin's goal is to be an unified data analyst platform which could
> integrate most of the big data tools and help user to switch between tools
> and share data between tools easily. So sharing data is a very critical and
> killer feature of Zeppelin IMHO.
>
> I raise this ticket to discuss about the scenario of sharing data and how
> to do that. Although zeppelin already provides tools and api to share data,
> I don't think it is mature and stable enough. After seeing these tickets, I
> think it might be a good time to talk about it in community and gather more
> feedback, so that we could provide a more stable and mature approach for
> it.
>
> Currently, there're 3 approaches to share data between interpreters and
> interpreter processes.
> 1. Sharing data across interpreter in the same interpreter process. Like
> sharing data via the same SparkContext in %spark, %spark.pyspark and
> %spark.r.
> 2. Sharing data between frontend and backend via angularObject
> 3. Sharing data across interpreter processes via Zeppelin's ResourcePool
>
> For this thread, I would like to talk about the approach 3 (Sharing data
> via Zeppelin's ResourcePool)
>
> Here's my current thinking of sharing data.
> 1. What kind of data would be shared ?
>IMHO, users would share 2 kinds of data: primitive data (string, number)
> and table data.
>
> 2. How to write shared data ?
> User may want to share data via 2 approches
> a. Use ZeppelinContext (e.g. z.put).
> b. Share the paragraph result via paragraph properties. e.g. user may
> want to read data from oracle database via jdbc interpreter and then do
> plotting in python interpreter. In such scenario. he can save the jdbc
> result in ResourcePool via paragraph property and then read it it via
> z.get. Here's one simple example (Not implemented yet)
>
> %jdbc(saveAsTable=people)
> select * from oracle_table
>
> %python
> z.getTable("people).toPandas()
>
> 3. How to read shared data ?
> User can also have 2 approaches to read the shared data.
> a. Via ZeppelinContext. (e.g. z.get, z.getTable)
> b. Via variable substitution [1]
>
> Here's one sample note which illustrate the scenario of sharing data.
> https://www.zepl.com/viewer/notebooks/bm90ZTovL3pqZmZkdS8zMzkxZjg3Ym
> FhMjg0MDY3OGM1ZmYzODAwODAxMGJhNy9ub3RlLmpzb24
>
> This is just my current thinking of sharing data in zeppelin, it definitely
> doesn't cover all the scenarios, so I raise this thread to discuss about in
> community, welcome any feedback and comments.
>
>
> [1]. https://issues.apache.org/jira/browse/ZEPPELIN-3377
> [2]. https://issues.apache.org/jira/browse/ZEPPELIN-3596
> [3]. https://issues.apache.org/jira/browse/ZEPPELIN-3617
>
--
이종열, Jongyoul Lee, 李宗烈
http://madeng.net
[GitHub] zeppelin issue #3064: [ZEPPELIN-3596] Saving resources from pool to SQL
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3064 @oxygen311 I am not sure how much useful and important this senior is for users. It looks like a little weird to me that you have to insert the paragraph result into database and then execute the query. Can you share more details about your scenario ? BTW, I raise one thread in mail list to discuss about sharing data in zeppelin, welcome any comments on that. https://lists.apache.org/thread.html/36d5c74bc946df2ed2ab456227251e94c1d88635c6acbc69d9a8c4f1@%3Cdev.zeppelin.apache.org%3E ---
[DISCUSS] Share Data in Zeppelin
Hi Folks,
Recently, there's several tickets [1][2][3] about sharing data in zeppelin.
Zeppelin's goal is to be an unified data analyst platform which could
integrate most of the big data tools and help user to switch between tools
and share data between tools easily. So sharing data is a very critical and
killer feature of Zeppelin IMHO.
I raise this ticket to discuss about the scenario of sharing data and how
to do that. Although zeppelin already provides tools and api to share data,
I don't think it is mature and stable enough. After seeing these tickets, I
think it might be a good time to talk about it in community and gather more
feedback, so that we could provide a more stable and mature approach for
it.
Currently, there're 3 approaches to share data between interpreters and
interpreter processes.
1. Sharing data across interpreter in the same interpreter process. Like
sharing data via the same SparkContext in %spark, %spark.pyspark and
%spark.r.
2. Sharing data between frontend and backend via angularObject
3. Sharing data across interpreter processes via Zeppelin's ResourcePool
For this thread, I would like to talk about the approach 3 (Sharing data
via Zeppelin's ResourcePool)
Here's my current thinking of sharing data.
1. What kind of data would be shared ?
IMHO, users would share 2 kinds of data: primitive data (string, number)
and table data.
2. How to write shared data ?
User may want to share data via 2 approches
a. Use ZeppelinContext (e.g. z.put).
b. Share the paragraph result via paragraph properties. e.g. user may
want to read data from oracle database via jdbc interpreter and then do
plotting in python interpreter. In such scenario. he can save the jdbc
result in ResourcePool via paragraph property and then read it it via
z.get. Here's one simple example (Not implemented yet)
%jdbc(saveAsTable=people)
select * from oracle_table
%python
z.getTable("people).toPandas()
3. How to read shared data ?
User can also have 2 approaches to read the shared data.
a. Via ZeppelinContext. (e.g. z.get, z.getTable)
b. Via variable substitution [1]
Here's one sample note which illustrate the scenario of sharing data.
https://www.zepl.com/viewer/notebooks/bm90ZTovL3pqZmZkdS8zMzkxZjg3YmFhMjg0MDY3OGM1ZmYzODAwODAxMGJhNy9ub3RlLmpzb24
This is just my current thinking of sharing data in zeppelin, it definitely
doesn't cover all the scenarios, so I raise this thread to discuss about in
community, welcome any feedback and comments.
[1]. https://issues.apache.org/jira/browse/ZEPPELIN-3377
[2]. https://issues.apache.org/jira/browse/ZEPPELIN-3596
[3]. https://issues.apache.org/jira/browse/ZEPPELIN-3617
[GitHub] zeppelin issue #3066: [ZEPPELIN-3618] ZeppelinContext methods z.run and z.ru...
Github user egorklimov commented on the issue: https://github.com/apache/zeppelin/pull/3066 I didn't find out how to send error message in paragraph result, my best try also removed other output in that paragraph, It would be nice if you could suggest an easy way to make it. ---
[GitHub] zeppelin pull request #3066: [Zeppelin-3618] ZeppelinContext methods z.run a...
GitHub user egorklimov opened a pull request:
https://github.com/apache/zeppelin/pull/3066
[Zeppelin-3618] ZeppelinContext methods z.run and z.runNote fall after
passing wrong argument
### What is this PR for?
Passing wrong argument to z.run() or z.runNote() causes error:
* Zeppelin log:
```
ERROR [2018-07-12 18:19:05,110] ({pool-5-thread-1}
TThreadPoolServer.java[run]:297) - Error occurred during processing of message.
java.lang.RuntimeException: Not existed noteId: WrongNoteId
at
org.apache.zeppelin.interpreter.RemoteInterpreterEventServer.runParagraphs(RemoteInterpreterEventServer.java:250)
...
```
* Interpreter log:
```
WARN [2018-07-12 18:19:05,113] ({pool-2-thread-5}
RemoteInterpreterEventClient.java[runParagraphs]:259) - Fail to runParagraphs:
RunParagraphsEvent(noteId:broadcast, paragraphIds:[], paragraphIndices:[],
curParagraphId:20180709-113817_1103600568)
org.apache.thrift.transport.TTransportException
...
INFO [2018-07-12 18:19:05,223] ({pool-2-thread-5}
SchedulerFactory.java[jobFinished]:115) - Job 20180709-113817_1103600568
finished by scheduler interpreter_434750169
WARN [2018-07-12 18:20:10,756] ({pool-1-thread-1}
RemoteInterpreterEventClient.java[onInterpreterOutputUpdateAll]:234) - Fail to
updateAllOutput
org.apache.thrift.transport.TTransportException
...
```
After that user couldn't use z.run() and z.runNote() until interpreter
restart.
### What type of PR is it?
Bug Fix
### What is the Jira issue?
Issue on Jira https://issues.apache.org/jira/browse/ZEPPELIN-3618
### How should this be tested?
* CI pass
* Zeppelin log for `z.run("WrongParagraphId")` and
`z.runNote("WrongNoteId")`:
```
ERROR [2018-07-12 19:32:49,125] ({pool-5-thread-1}
RemoteInterpreterEventServer.java[runParagraphs]:250) - Not existed
paragraphId: WrongParagraphId
ERROR [2018-07-12 19:31:45,746] ({pool-5-thread-1}
RemoteInterpreterEventServer.java[runParagraphs]:250) - Not existed noteId:
WrongNoteId
```
* No error messages in interpreter log
### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/TinkoffCreditSystems/zeppelin ZEPPELIN-3618
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/zeppelin/pull/3066.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #3066
commit a336b8c41d8d43868486449a5b6ec726989d0bfd
Author: egorklimov
Date: 2018-07-12T18:05:13Z
Fix failing runParagraphs
---
[jira] [Created] (ZEPPELIN-3619) Multi-line code is not allowed: illegal start of definition
Maziyar PANAHI created ZEPPELIN-3619:
Summary: Multi-line code is not allowed: illegal start of
definition
Key: ZEPPELIN-3619
URL: https://issues.apache.org/jira/browse/ZEPPELIN-3619
Project: Zeppelin
Issue Type: Bug
Affects Versions: 0.8.0
Reporter: Maziyar PANAHI
Hi,
Previously I was able to have code like this in my 0.7.3 Spark Interpreter
(YARN cluster):
{code:java}
val word2Vec = new Word2Vec()
.setInputCol("filtered")
.setOutputCol("word2vec")
.setVectorSize(100)
.setMinCount(10)
.setMaxIter(20){code}
But the same code in Zeppelin 0.8 on my local machine gives me this error (I am
testing the new release before I upgrade the one on the cluster)
{code:java}
:1: error: illegal start of definition{code}
Many thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (ZEPPELIN-3618) ZeppelinContext methods z.run and z.runNote fall after passing wrong argument.
George Klimov created ZEPPELIN-3618:
---
Summary: ZeppelinContext methods z.run and z.runNote fall after
passing wrong argument.
Key: ZEPPELIN-3618
URL: https://issues.apache.org/jira/browse/ZEPPELIN-3618
Project: Zeppelin
Issue Type: Bug
Components: zeppelin-zengine
Affects Versions: 0.8.0
Environment:
Reporter: George Klimov
Assignee: George Klimov
Passing wrong argument to z.run() or z.runNote() causes error:
* Zeppelin log:
```
ERROR [2018-07-12 18:19:05,110] (\{pool-5-thread-1}
TThreadPoolServer.java[run]:297) - Error occurred during processing of message.
java.lang.RuntimeException: Not existed noteId: broadcast
at
org.apache.zeppelin.interpreter.RemoteInterpreterEventServer.runParagraphs(RemoteInterpreterEventServer.java:250)
at
org.apache.zeppelin.interpreter.thrift.RemoteInterpreterEventService$Processor$runParagraphs.getResult(RemoteInterpreterEventService.java:1166)
...
```
* Interpreter log:
```
WARN [2018-07-12 18:19:05,113] (\{pool-2-thread-5}
RemoteInterpreterEventClient.java[runParagraphs]:259) - Fail to runParagraphs:
RunParagraphsEvent(noteId:broadcast, paragraphIds:[], paragraphIndices:[],
curParagraphId:20180709-113817_1103600568)
org.apache.thrift.transport.TTransportException
...
INFO [2018-07-12 18:19:05,223] (\{pool-2-thread-5}
SchedulerFactory.java[jobFinished]:115) - Job 20180709-113817_1103600568
finished by scheduler interpreter_434750169
WARN [2018-07-12 18:20:10,756] (\{pool-1-thread-1}
RemoteInterpreterEventClient.java[onInterpreterOutputUpdateAll]:234) - Fail to
updateAllOutput
org.apache.thrift.transport.TTransportException
...
```
After that user couldn't use z.run() and z.runNote() until interpreter restart.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] zeppelin issue #3065: ZEPPELIN-3617. Allow to specify saving resourceName as...
Github user sanjaydasgupta commented on the issue:
https://github.com/apache/zeppelin/pull/3065
This will also make it possible to access paragraph results easily using
the z-variable interpolation feature of various interpreters. So a simple
command like `%sh echo {population-table}` will retrieve and display a
previously saved (population-table) result (if interpolation is enabled for
shell).
But a crafty user will be able to disrupt
https://issues.apache.org/jira/browse/ZEPPELIN-3596 by using a resourceName
compatible with ZEPPELIN-3596's syntax for {...}
---
[GitHub] zeppelin pull request #3064: [ZEPPELIN-3596] Saving resources from pool to S...
GitHub user oxygen311 reopened a pull request:
https://github.com/apache/zeppelin/pull/3064
[ZEPPELIN-3596] Saving resources from pool to SQL
### What is this PR for?
> It's information in resourcePool, but it is only available for viewing.
It would be nice if we can save this data to SQL via JDBC Driver.
Now you can access to `ResourcePool` data from SQL query. For example, if
you write `SELECT * FROM
{ResourcePool.note_id=SOME_NOTE_ID.paragraph_id=SOME_PARAGRAPH_ID};` and it
will be correct SQL query.
How it works:
1. Creates and fills a table named like a `PARAGRAPH_ID`;
2. Expression `{*}` replaces with actual table name;
3. Updated SQL query is running.
Also, you can not specify the note_id, then the note_id of the current
notebook will be used. For example, `SELECT * FROM
{ResourcePool.paragraph_id=SOME_PARAGRAPH_ID};`.
### What type of PR is it?
Improvement
### What is the Jira issue?
[Zeppelin
3596](https://issues.apache.org/jira/projects/ZEPPELIN/issues/ZEPPELIN-3596?filter=allopenissues)
### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/TinkoffCreditSystems/zeppelin ZEPPELIN-3596
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/zeppelin/pull/3064.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #3064
commit 6033d8fddb4b7f21f268a79143baa5903bf6c759
Author: oxygen311
Date: 2018-07-10T10:18:37Z
Add `preparePoolData` function
commit 882a4ee9aa128d2d06d85841a4ea50e4d01f4aaa
Author: oxygen311
Date: 2018-07-10T16:06:45Z
Code refactoring
commit af8747b6c19e7ab94e23352ab8162d72c9a19fe0
Author: oxygen311
Date: 2018-07-11T09:41:28Z
Refactoring
commit 1a32689b101d5974f5e31d1d883befe9d0142eec
Author: oxygen311
Date: 2018-07-11T11:41:03Z
Add tests
commit d5e57ad5cc5e19b77aded00efcc2a567283f1b1b
Author: oxygen311
Date: 2018-07-11T11:55:47Z
Remove assignment operation from cycle
---
[GitHub] zeppelin pull request #3064: [ZEPPELIN-3596] Saving resources from pool to S...
Github user oxygen311 closed the pull request at: https://github.com/apache/zeppelin/pull/3064 ---
[GitHub] zeppelin pull request #3057: [ZEPPELIN 3582] Add type data to result of quer...
Github user oxygen311 closed the pull request at: https://github.com/apache/zeppelin/pull/3057 ---
[GitHub] zeppelin pull request #3057: [ZEPPELIN 3582] Add type data to result of quer...
GitHub user oxygen311 reopened a pull request: https://github.com/apache/zeppelin/pull/3057 [ZEPPELIN 3582] Add type data to result of query from SQL ### What is this PR for? JDBCInterpreter knows type information for every SQL Query. We could save this info to pool and use it. There are three types of table column: - Number; - String; - Date. ### What type of PR is it? Improvement ### What is the Jira issue? [Zeppelin 3582](https://issues.apache.org/jira/projects/ZEPPELIN/issues/ZEPPELIN-3582) ### Screenshots 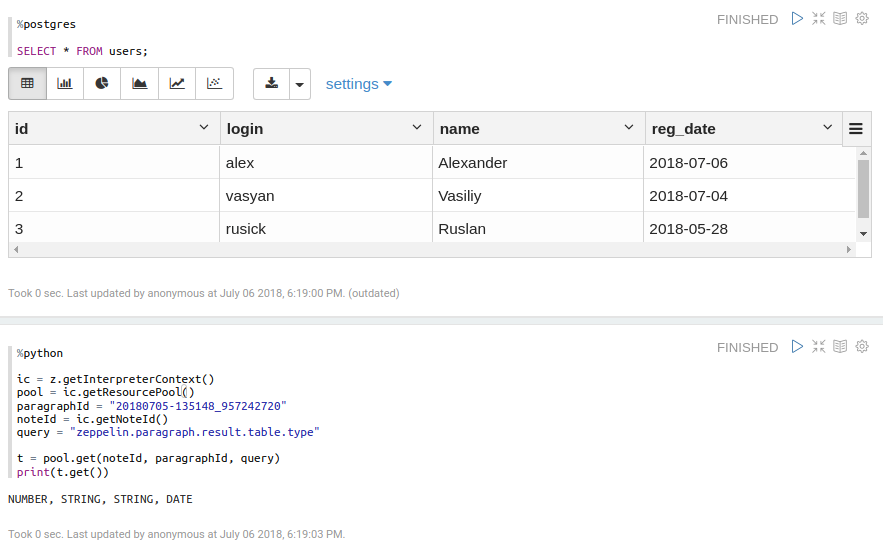 ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No You can merge this pull request into a Git repository by running: $ git pull https://github.com/TinkoffCreditSystems/zeppelin ZEPPELIN-3582 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/zeppelin/pull/3057.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #3057 commit 5cd8d6d2b1bb2ea795824b0706b3b9bb4af1868f Author: oxygen311 Date: 2018-07-05T08:11:48Z Extend InterpreterResultMessage for holds it's results type information commit 86c76a9b76ffabb3874c365929fb1df88c92de4b Author: oxygen311 Date: 2018-07-05T09:18:12Z Added the ability for JDBCInterpreter to export types of it's data commit 235b27a3360060ea44485c6135b53dad459dc6a0 Author: oxygen311 Date: 2018-07-05T09:45:53Z Fix %table issue for passing tests (%table don't actually exists in result msg string and must be dropped) commit 50141d2f2af20bea8d33ee6b5b6eec7996a394ae Author: oxygen311 Date: 2018-07-05T10:39:02Z Add tests for column type information commit 15212e811177b0679157b3a0bca48622911dfef4 Author: oxygen311 Date: 2018-07-05T11:25:18Z Add type info information to resource pool commit 1f055f35740d83325ed788698881aed010458caf Author: oxygen311 Date: 2018-07-06T10:12:51Z Add class for message column type information. commit def58011c9b76425244b0b6251c694902d82ac7c Author: oxygen311 Date: 2018-07-06T11:33:47Z Add new class JDBCUtils with JDBCInterpreter's static methods commit 018c3319ec5c6c60afe14dfb3d92a44689aa9af0 Author: oxygen311 Date: 2018-07-06T12:12:31Z Fix tests commit b1511214d638630b71ce7dc816c13a534b8e27c5 Author: oxygen311 Date: 2018-07-09T08:47:43Z Add new class JDBCUtils with JDBCInterpreter's static methods commit fe75ae677e0f63e51d2340fcacb3f40d17371bf1 Author: oxygen311 Date: 2018-07-09T08:47:43Z Fix `InterpreterResultMessage` constructor commit 36632cb0af29e08a44804c5187109a8c35f5a776 Author: oxygen311 Date: 2018-07-09T08:54:12Z Merge remote-tracking branch 'tinkoff/ZEPPELIN-3582' into ZEPPELIN-3582 commit 12f86927ff2e38da76b3533db0f0ac24d17cfede Author: oxygen311 Date: 2018-07-09T09:07:20Z Store only `List` in `InterpreterResultMessage` ---
[GitHub] zeppelin issue #3064: [ZEPPELIN-3596] Saving resources from pool to SQL
Github user sanjaydasgupta commented on the issue:
https://github.com/apache/zeppelin/pull/3064
There are similarities between the two features that all users will notice,
and think about for some time. There needs to be good documentation to avoid
any confusion. The substitution syntax {...} used in this feature is the same
as in ZEPPELIN-3377, but there is almost 0 possibility that the wrong features
will be invoked. More specifically, even if z-variable interpolation is enabled
(zeppelin.jdbc.interpolation = true), the contents of {...} will be safely
passed through since it is virtually impossible for a user to produce the
correct string to use to activate ZEPPELIN-3377's code.
---
[GitHub] zeppelin issue #3065: ZEPPELIN-3617. Allow to specify saving resourceName as...
Github user mebelousov commented on the issue: https://github.com/apache/zeppelin/pull/3065 @zjffdu Nice! How about adding to ResourcePool only if resourceName specified in paragraph properties? ---
[GitHub] zeppelin issue #3055: ZEPPELIN-3587. Interpret paragarph text as whole code ...
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3055 Actually we already import this when initialize spark interpreter. https://github.com/apache/zeppelin/blob/master/spark/spark-scala-parent/src/main/scala/org/apache/zeppelin/spark/BaseSparkScalaInterpreter.scala#L171 The problem is that we would still hit this kind of error when run the tutorial note of bank data. This is due to an issue scala 2.10 (SI-6649)[https://issues.scala-lang.org/browse/SI-6649]. This error doesn't' happen before just because we split code into lines and interpret it line by line. But as I mentioned before, interpret it line by line is not a correct approach. The good news is that it only affect scala 2.10. ---
[GitHub] zeppelin issue #3064: [ZEPPELIN-3596] Saving resources from pool to SQL
Github user oxygen311 commented on the issue: https://github.com/apache/zeppelin/pull/3064 @zjffdu variable interpolation is about just using text variable. But with this feature you can transform `%table` text from ResourcePool to SQL table. ---
[GitHub] zeppelin issue #3065: ZEPPELIN-3617. Allow to specify saving resourceName as...
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3065 @mebelousov This is related with ZEPPELIN-3545, feel free to try this PR and provide comments. ---
[GitHub] zeppelin pull request #3065: ZEPPELIN-3617. Allow to specify saving resource...
GitHub user zjffdu opened a pull request: https://github.com/apache/zeppelin/pull/3065 ZEPPELIN-3617. Allow to specify saving resourceName as paragraph property ### What is this PR for? This is allow user to specify resourceName when they want to save the paragraph result into ResourcePool. Before this PR, user don't have control on what name of the saving resource name. It is associated with noteId and paragraphId, but this is not a good solution. Because when you clone the note, noteId will be changed, and you have to change the noteId in code as well. This PR is trying to allow user to set resource Name for the saving paragraph result. ### What type of PR is it? [ Feature |g] ### Todos * [ ] - Task ### What is the Jira issue? * https://issues.apache.org/jira/browse/ZEPPELIN-3617 ### How should this be tested? * CI pass ### Screenshots (if appropriate) ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No You can merge this pull request into a Git repository by running: $ git pull https://github.com/zjffdu/zeppelin ZEPPELIN-3617 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/zeppelin/pull/3065.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #3065 commit 4bbff1ff2adbc2a3fce299b4d5143fa0f1213471 Author: Jeff Zhang Date: 2018-07-12T06:28:02Z ZEPPELIN-3617. Allow to specify saving resourceName as paragraph property ---