[GitHub] [arrow] liyafan82 commented on pull request #7543: ARROW-9221: [Java] account for big-endian buffers in ArrowBuf.setBytes
liyafan82 commented on pull request #7543: URL: https://github.com/apache/arrow/pull/7543#issuecomment-652211147 @lidavidm Thanks for reporting the problem. I am curious how this problem has ever arised. The default byte order is platform dependent. For a big endian machine, the program should crash at the stage of class loading, as our current implementation does not support big endian platforms. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7603: ARROW-9206: [C++][Flight] Add latency benchmark
github-actions[bot] commented on pull request #7603: URL: https://github.com/apache/arrow/pull/7603#issuecomment-652201778 https://issues.apache.org/jira/browse/ARROW-9206 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] cyb70289 opened a new pull request #7603: ARROW-9206: [C++][Flight] Add latency benchmark
cyb70289 opened a new pull request #7603: URL: https://github.com/apache/arrow/pull/7603 Calculate latency by accumulating processing time of all threads then divides total batches transferred. It only works for synchronous RPC. This patch also adds throughput(IOPS) metric. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
xhochy commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652195053 I think prefixes make sense. We will have sometime similar kernel names that act quite different depending on the types they work on. I would differentiate in the string/binary case the kernels between the categories: * `binary_`: works on any binary data * `ascii_`: works on string data but is limited ASCII-only characters * `utf8_`: works on string data and respects UTF8-encoding or even makes use of an UTF8-symbol table (i.e. `utf8proc`). With that, I would rename the kernel here to `binary_contains_exact`. The `exact` suffix is important for me as I intent to implement also `ut8_contains_case_insensitve`, `binary_contains_regex` (or should this be string/utf8?), `utf8_contains_regex_case_insensitve`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] liyafan82 commented on pull request #7287: ARROW-8771: [C++] Add boost/process library to build support
liyafan82 commented on pull request #7287: URL: https://github.com/apache/arrow/pull/7287#issuecomment-652145927 > Could this be picked up again? Maybe we can pick it up after upgrading to Thrift 0.13. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm closed pull request #7584: ARROW-9272: [C++][Python] Reduce complexity in python to arrow conversion
wesm closed pull request #7584: URL: https://github.com/apache/arrow/pull/7584 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7287: ARROW-8771: [C++] Add boost/process library to build support
wesm commented on pull request #7287: URL: https://github.com/apache/arrow/pull/7287#issuecomment-652142725 Could this be picked up again? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7507: ARROW-8797: [C++] Create test to receive RecordBatch for different endian
wesm commented on pull request #7507: URL: https://github.com/apache/arrow/pull/7507#issuecomment-652142541 @kiszk I would suggest creating a LE and BE example corpus in apache/arrow-testing. You can use the integration test command line tools to create point-of-truth JSON files and then use the JSON_TO_ARROW mode of the integration test executable to create IPC binary files that can be checked in This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm closed pull request #7478: ARROW-9055: [C++] Add sum/mean/minmax kernels for Boolean type
wesm closed pull request #7478: URL: https://github.com/apache/arrow/pull/7478 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7584: ARROW-9272: [C++][Python] Reduce complexity in python to arrow conversion
wesm commented on a change in pull request #7584:
URL: https://github.com/apache/arrow/pull/7584#discussion_r448064117
##
File path: cpp/src/arrow/python/python_to_arrow.cc
##
@@ -53,6 +53,335 @@ using internal::checked_pointer_cast;
namespace py {
+// --
+// NullCoding
+
+enum class NullCoding : char { NONE_ONLY, PANDAS_SENTINELS };
+
+template
+struct NullChecker {};
+
+template <>
+struct NullChecker {
+ static inline bool Check(PyObject* obj) { return obj == Py_None; }
+};
+
+template <>
+struct NullChecker {
+ static inline bool Check(PyObject* obj) { return
internal::PandasObjectIsNull(obj); }
+};
+
+// --
+// ValueConverters
+//
+// Typed conversion logic for single python objects are encapsulated in
+// ValueConverter structs using SFINAE for specialization.
+//
+// The FromPython medthod is responsible to convert the python object to the
+// C++ value counterpart which can be directly appended to the ArrayBuilder or
+// Scalar can be constructed from.
+
+template
+struct ValueConverter {};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj) {
+if (obj == Py_True) {
+ return true;
+} else if (obj == Py_False) {
+ return false;
+} else {
+ return internal::InvalidValue(obj, "tried to convert to boolean");
+}
+ }
+};
+
+template
+struct ValueConverter> {
+ using ValueType = typename Type::c_type;
+
+ static inline Result FromPython(PyObject* obj) {
+ValueType value;
+RETURN_NOT_OK(internal::CIntFromPython(obj, &value));
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ using ValueType = typename HalfFloatType::c_type;
+
+ static inline Result FromPython(PyObject* obj) {
+ValueType value;
+RETURN_NOT_OK(PyFloat_AsHalf(obj, &value));
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj) {
+float value;
+if (internal::PyFloatScalar_Check(obj)) {
+ value = static_cast(PyFloat_AsDouble(obj));
+ RETURN_IF_PYERROR();
+} else if (internal::PyIntScalar_Check(obj)) {
+ RETURN_NOT_OK(internal::IntegerScalarToFloat32Safe(obj, &value));
+} else {
+ return internal::InvalidValue(obj, "tried to convert to float32");
+}
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj) {
+double value;
+if (PyFloat_Check(obj)) {
+ value = PyFloat_AS_DOUBLE(obj);
+} else if (internal::PyFloatScalar_Check(obj)) {
+ // Other kinds of float-y things
+ value = PyFloat_AsDouble(obj);
+ RETURN_IF_PYERROR();
+} else if (internal::PyIntScalar_Check(obj)) {
+ RETURN_NOT_OK(internal::IntegerScalarToDoubleSafe(obj, &value));
+} else {
+ return internal::InvalidValue(obj, "tried to convert to double");
+}
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj) {
+int32_t value;
+if (PyDate_Check(obj)) {
+ auto pydate = reinterpret_cast(obj);
+ value = static_cast(internal::PyDate_to_days(pydate));
+} else {
+ RETURN_NOT_OK(
+ internal::CIntFromPython(obj, &value, "Integer too large for
date32"));
+}
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj) {
+int64_t value;
+if (PyDateTime_Check(obj)) {
+ auto pydate = reinterpret_cast(obj);
+ value = internal::PyDateTime_to_ms(pydate);
+ // Truncate any intraday milliseconds
+ value -= value % 8640LL;
+} else if (PyDate_Check(obj)) {
+ auto pydate = reinterpret_cast(obj);
+ value = internal::PyDate_to_ms(pydate);
+} else {
+ RETURN_NOT_OK(
+ internal::CIntFromPython(obj, &value, "Integer too large for
date64"));
+}
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj, TimeUnit::type unit)
{
+int32_t value;
+if (PyTime_Check(obj)) {
+ // datetime.time stores microsecond resolution
+ switch (unit) {
+case TimeUnit::SECOND:
+ value = static_cast(internal::PyTime_to_s(obj));
+ break;
+case TimeUnit::MILLI:
+ value = static_cast(internal::PyTime_to_ms(obj));
+ break;
+default:
+ return Status::UnknownError("Invalid time unit");
+ }
+} else {
+ RETURN_NOT_OK(internal::CIntFromPython(obj, &value, "Integer too large
for int32"));
+}
+return value;
+ }
+};
+
+template <>
+struct ValueConverter {
+ static inline Result FromPython(PyObject* obj, TimeUnit::type unit)
{
+int64_t value;
+if (PyTime_Check(obj)) {
+ // datetime.time stores microsecond resolution
+ switch (unit) {
+case Ti
[GitHub] [arrow] wesm closed pull request #7578: ARROW-9264: [C++][Parquet] Refactor and modernize schema conversion code
wesm closed pull request #7578: URL: https://github.com/apache/arrow/pull/7578 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm closed pull request #7556: ARROW-9188: [C++] Use Brotli shared libraries if they are available
wesm closed pull request #7556: URL: https://github.com/apache/arrow/pull/7556 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] mrkn commented on pull request #7477: ARROW-4221: [C++][Python] Add canonical flag in COO sparse index
mrkn commented on pull request #7477: URL: https://github.com/apache/arrow/pull/7477#issuecomment-652124757 @pitrou In summary, the constraint of the indices order of SparseCOOIndex was removed, but the new flag field is introduced to state whether or not the indices tensor is ordered in a row-major manner. By this new flag, we can preserve the canonicality or noncanonicality of the sparse tensor before and after serialization. Preserving this property can avoid needless scanning of the indices tensor after deserialization. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] BryanCutler commented on a change in pull request #7275: ARROW-6110: [Java][Integration] Support LargeList Type and add integration test with C++
BryanCutler commented on a change in pull request #7275:
URL: https://github.com/apache/arrow/pull/7275#discussion_r448032771
##
File path:
java/vector/src/main/java/org/apache/arrow/vector/complex/LargeListVector.java
##
@@ -0,0 +1,991 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.arrow.vector.complex;
+
+import static java.util.Collections.singletonList;
+import static org.apache.arrow.memory.util.LargeMemoryUtil.capAtMaxInt;
+import static org.apache.arrow.memory.util.LargeMemoryUtil.checkedCastToInt;
+import static org.apache.arrow.util.Preconditions.checkNotNull;
+
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+
+import org.apache.arrow.memory.ArrowBuf;
+import org.apache.arrow.memory.BufferAllocator;
+import org.apache.arrow.memory.OutOfMemoryException;
+import org.apache.arrow.memory.util.ArrowBufPointer;
+import org.apache.arrow.memory.util.ByteFunctionHelpers;
+import org.apache.arrow.memory.util.CommonUtil;
+import org.apache.arrow.memory.util.hash.ArrowBufHasher;
+import org.apache.arrow.util.Preconditions;
+import org.apache.arrow.vector.AddOrGetResult;
+import org.apache.arrow.vector.BaseFixedWidthVector;
+import org.apache.arrow.vector.BaseValueVector;
+import org.apache.arrow.vector.BaseVariableWidthVector;
+import org.apache.arrow.vector.BitVectorHelper;
+import org.apache.arrow.vector.BufferBacked;
+import org.apache.arrow.vector.DensityAwareVector;
+import org.apache.arrow.vector.FieldVector;
+import org.apache.arrow.vector.NullVector;
+import org.apache.arrow.vector.UInt4Vector;
+import org.apache.arrow.vector.ValueVector;
+import org.apache.arrow.vector.ZeroVector;
+import org.apache.arrow.vector.compare.VectorVisitor;
+import org.apache.arrow.vector.complex.impl.ComplexCopier;
+import org.apache.arrow.vector.complex.impl.UnionLargeListReader;
+import org.apache.arrow.vector.complex.impl.UnionLargeListWriter;
+import org.apache.arrow.vector.complex.reader.FieldReader;
+import org.apache.arrow.vector.ipc.message.ArrowFieldNode;
+import org.apache.arrow.vector.types.Types.MinorType;
+import org.apache.arrow.vector.types.pojo.ArrowType;
+import org.apache.arrow.vector.types.pojo.Field;
+import org.apache.arrow.vector.types.pojo.FieldType;
+import org.apache.arrow.vector.util.CallBack;
+import org.apache.arrow.vector.util.JsonStringArrayList;
+import org.apache.arrow.vector.util.OversizedAllocationException;
+import org.apache.arrow.vector.util.SchemaChangeRuntimeException;
+import org.apache.arrow.vector.util.TransferPair;
+
+/**
+ * A list vector contains lists of a specific type of elements. Its structure
contains 3 elements.
+ *
+ * A validity buffer.
+ * An offset buffer, that denotes lists boundaries.
+ * A child data vector that contains the elements of lists.
+ *
+ *
+ * This is the LargeList variant of list, it has a 64-bit wide offset
+ *
+ *
+ * todo review checkedCastToInt usage in this class.
+ * Once int64 indexed vectors are supported these checks aren't needed.
+ *
+ */
+public class LargeListVector extends BaseValueVector implements
RepeatedValueVector, BaseListVector, PromotableVector {
+
+ public static LargeListVector empty(String name, BufferAllocator allocator) {
+return new LargeListVector(name, allocator,
FieldType.nullable(ArrowType.LargeList.INSTANCE), null);
+ }
+
+ public static final FieldVector DEFAULT_DATA_VECTOR = ZeroVector.INSTANCE;
+ public static final String DATA_VECTOR_NAME = "$data$";
+
+ public static final byte OFFSET_WIDTH = 8;
+ protected ArrowBuf offsetBuffer;
+ protected FieldVector vector;
+ protected final CallBack callBack;
+ protected int valueCount;
+ protected long offsetAllocationSizeInBytes = INITIAL_VALUE_ALLOCATION *
OFFSET_WIDTH;
+ private final String name;
+
+ protected String defaultDataVectorName = DATA_VECTOR_NAME;
+ protected ArrowBuf validityBuffer;
+ protected UnionLargeListReader reader;
+ private final FieldType fieldType;
+ private int validityAllocationSizeInBytes;
+
+ /**
+ * The maximum index that is actually set.
+ */
+ private long lastSet;
+
+ /**
+ * Constructs a new instance.
+ *
+ * @param name The nam
[GitHub] [arrow] wesm commented on a change in pull request #7602: ARROW-9083: [R] collect int64, uint32, uint64 as R integer type if not out of bounds
wesm commented on a change in pull request #7602:
URL: https://github.com/apache/arrow/pull/7602#discussion_r448028250
##
File path: r/src/array_to_vector.cpp
##
@@ -673,6 +676,17 @@ class Converter_Null : public Converter {
}
};
+bool arrays_can_fit_integer(ArrayVector arrays) {
Review comment:
nit: not sure if it's worth the effort of following the C++ guide
viz-a-viz function naming
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7602: ARROW-9083: [R] collect int64, uint32, uint64 as R integer type if not out of bounds
github-actions[bot] commented on pull request #7602: URL: https://github.com/apache/arrow/pull/7602#issuecomment-652080559 https://issues.apache.org/jira/browse/ARROW-9083 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] sunchao commented on a change in pull request #7586: ARROW-9280: [Rust] [Parquet] Calculate page and column statistics
sunchao commented on a change in pull request #7586:
URL: https://github.com/apache/arrow/pull/7586#discussion_r448014374
##
File path: rust/parquet/src/column/writer.rs
##
@@ -387,15 +538,28 @@ impl ColumnWriterImpl {
));
}
-// TODO: update page statistics
+if calculate_page_stats {
+for val in &values[0..values_to_write] {
+if self.min_page_value.is_none()
Review comment:
maybe we should extract this into a util function `update_page_min_max`
and similarly for column min/max value.
##
File path: rust/parquet/src/column/writer.rs
##
@@ -276,12 +372,60 @@ impl ColumnWriterImpl {
&values[values_offset..],
def_levels.map(|lv| &lv[levels_offset..]),
rep_levels.map(|lv| &lv[levels_offset..]),
+calculate_page_stats,
)?;
// Return total number of values processed.
Ok(values_offset)
}
+/// Writes batch of values, definition levels and repetition levels.
+/// Returns number of values processed (written).
+///
+/// If definition and repetition levels are provided, we write fully those
levels and
+/// select how many values to write (this number will be returned), since
number of
+/// actual written values may be smaller than provided values.
+///
+/// If only values are provided, then all values are written and the
length of
+/// of the values buffer is returned.
+///
+/// Definition and/or repetition levels can be omitted, if values are
+/// non-nullable and/or non-repeated.
+pub fn write_batch(
+&mut self,
+values: &[T::T],
+def_levels: Option<&[i16]>,
+rep_levels: Option<&[i16]>,
+) -> Result {
+self.write_batch_internal(
+values, def_levels, rep_levels, &None, &None, None, None,
+)
+}
+
+/// Writer may optionally provide pre-calculated statistics for this
batch, in which case we do
+/// not calculate page level statistics as this will defeat the purpose of
speeding up the write
+/// process with pre-calculated statistics.
+pub fn write_batch_with_statistics(
+&mut self,
+values: &[T::T],
+def_levels: Option<&[i16]>,
+rep_levels: Option<&[i16]>,
+min: &Option,
Review comment:
Is it possible that among these 4 parameters, ppl only provide, say,
`nulls_count` but leave the rest as `None`? will this result to partial stats
and yield to issues when compute engines want to rely on them? If so do we want
to enforce that either all of these 4 are `None` OR all of these are `Some`?
##
File path: rust/parquet/src/column/writer.rs
##
@@ -216,26 +278,26 @@ impl ColumnWriterImpl {
def_levels_sink: vec![],
rep_levels_sink: vec![],
data_pages: VecDeque::new(),
+min_page_value: None,
+max_page_value: None,
+num_page_nulls: 0,
+page_distinct_count: None,
Review comment:
Seems this is not used at all?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] nealrichardson opened a new pull request #7602: ARROW-9083: [R] collect int64, uint32, uint64 as R integer type if not out of bounds
nealrichardson opened a new pull request #7602: URL: https://github.com/apache/arrow/pull/7602 Still to do: - [ ] Update test expectations since the output types have changed - [ ] Add tests that exercise the case where the data doesn't fit into int32 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kou commented on a change in pull request #7556: ARROW-9188: [C++] Use Brotli shared libraries if they are available
kou commented on a change in pull request #7556:
URL: https://github.com/apache/arrow/pull/7556#discussion_r448003034
##
File path: python/manylinux201x/build_arrow.sh
##
@@ -120,6 +120,7 @@ PATH="${CPYTHON_PATH}/bin:${PATH}" cmake \
-DARROW_WITH_SNAPPY=ON \
-DARROW_WITH_ZLIB=ON \
-DARROW_WITH_ZSTD=ON \
+-DARROW_BROTLI_USE_SHARED=OFF \
Review comment:
Ditto.
##
File path: python/manylinux1/build_arrow.sh
##
@@ -122,6 +122,7 @@ cmake \
-DARROW_WITH_SNAPPY=ON \
-DARROW_WITH_ZLIB=ON \
-DARROW_WITH_ZSTD=ON \
+-DARROW_BROTLI_USE_SHARED=OFF \
Review comment:
Could you keep this option list in alphabetical order?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7556: ARROW-9188: [C++] Use Brotli shared libraries if they are available
wesm commented on pull request #7556: URL: https://github.com/apache/arrow/pull/7556#issuecomment-652058759 If there's no further feedback I will merge this in the next 24h and I assume that any packaging issues will come up in nightlies as we push toward the next release. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7601: ARROW-8867: [R] Support converting POSIXlt type
github-actions[bot] commented on pull request #7601: URL: https://github.com/apache/arrow/pull/7601#issuecomment-652056875 https://issues.apache.org/jira/browse/ARROW-8867 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nealrichardson opened a new pull request #7601: ARROW-8867: [R] Support converting POSIXlt type
nealrichardson opened a new pull request #7601: URL: https://github.com/apache/arrow/pull/7601 Also contains some test refactor, documentation, and slight tweaks as followup to ARROW-8899. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652053744 I also propose to rename the function from "contains_exact" to "utf8_contains". ~~I'm pushing that change here shortly~~. Or should we call it "binary_contains" / "string_contains" since it will work with any base binary types? I'll hold off on making any changes until there is consensus about the name. I think it would be useful to put string functions in a "pseudo-namespace" so they appear next to each other when sorted alphabetically. Ideas: - string_contains - string_lower_utf8 - string_lower_ascii - ... @maartenbreddels @pitrou any opinions about this? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652053744 I also propose to rename the function from "contains_exact" to "utf8_contains". ~~I'm pushing that change here shortly~~. Or should we call it "binary_contains" / "string_contains" since it will work with any base binary types? I'll hold off on making any changes until there is consensus about the name. I think it would be useful to put string functions in a "pseudo-namespace" so they appear next to each other when sorted alphabetically. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652053744 I also propose to rename the function from "contains_exact" to "utf8_contains". ~~I'm pushing that change here shortly~~. Or should we call it "binary_contains" / "string_contains" since it will work with any base binary types? I'll hold off on making any changes until there is consensus about the name. I think it would be useful to put string functions in a "pseudo-namespace" so they appear next to each other when sorted alphabetically. Ideas: - string_contains - string_utf8_lower - string_ascii_lower - ... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652053744 I also propose to rename the function from "contains_exact" to "utf8_contains". I'm pushing that change here shortly. Or should we call it "BinaryContains" since it will work with any base binary types? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652053744 I also propose to rename the function from "contains_exact" to "utf8_contains". I'm pushing that change here shortly. Or should we call it "binary_contains" / "string_contains" since it will work with any base binary types? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652053744 I also propose to rename the function from "contains_exact" to "utf8_contains". I'm pushing that change here shortly This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652048000 I just opened https://issues.apache.org/jira/browse/ARROW-9285 -- it should be easy to check if a kernel has mistakenly replaced a preallocated data buffer (which may be a slice of a larger output that is being populated) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm commented on a change in pull request #7593:
URL: https://github.com/apache/arrow/pull/7593#discussion_r447982219
##
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##
@@ -387,16 +380,20 @@ using ContainsExactState =
OptionsWrapper;
template
struct ContainsExact {
+ using offset_type = typename Type::offset_type;
static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
-ContainsExactOptions arg =
-checked_cast(*ctx->state()).options;
-auto transform_func =
-std::bind(TransformContainsExact,
- reinterpret_cast(arg.pattern.c_str()),
- arg.pattern.length(), std::placeholders::_1,
std::placeholders::_2,
- std::placeholders::_3, std::placeholders::_4);
-
-StringBoolTransform(ctx, batch, transform_func, out);
+ContainsExactOptions arg = ContainsExactState::Get(ctx);
+const uint8_t* pat = reinterpret_cast(arg.pattern.c_str());
+const int64_t pat_size = arg.pattern.length();
+StringBoolTransform(
+ctx, batch,
+[pat, pat_size](const void* offsets, const uint8_t* data, int64_t
length,
+int64_t output_offset, uint8_t* output) {
+ TransformContainsExact(
+ pat, pat_size, reinterpret_cast(offsets),
data, length,
+ output_offset, output);
+},
Review comment:
I hope you don't mind, this seemed simpler to me
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-652045953 @xhochy I'm fixing a couple issues with the implementation: * The function executor allocates memory for you unless you explicitly disable it. The idea is that you don't want to do allocations in-kernel unless it is necessary. The preallocation settings affect how execution with chunked arrays work * The slice offset of the `Datum* out` parameter must be respected (it may be non-zero -- the executor does not preserve the chunk layout of ChunkedArrays and will merge chunks to make larger output arrays -- this can be configured in `ExecContext`) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7315: ARROW-7605: [C++] Bundle jemalloc into static libarrow
wesm edited a comment on pull request #7315: URL: https://github.com/apache/arrow/pull/7315#issuecomment-652020060 We're running out of time to get this completed for the release, so if a working solution can be demonstrated to have been reached on all 3 platforms that works for both jemalloc (for Linux and macOS) and mimalloc (for Windows), then I will accept it. But there are single digits days remaining to complete this work now. CMake 3.9 is a bit problematic since we've tried to support CMake >= 3.2 and definitely >= 3.7 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7315: ARROW-7605: [C++] Bundle jemalloc into static libarrow
wesm commented on pull request #7315: URL: https://github.com/apache/arrow/pull/7315#issuecomment-652020060 We're running out of time to get this completed for the release, so if a working solution can be demonstrated to have been reached on all 3 platforms that works for both jemalloc (for Linux and macOS) and mimalloc (for Windows), then I will accept it. But there are single digits days remaining to complete this work now This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nealrichardson closed pull request #7597: ARROW-9282: [R] Remove usage of _EXTPTR_PTR
nealrichardson closed pull request #7597: URL: https://github.com/apache/arrow/pull/7597 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] tobim commented on pull request #7315: ARROW-7605: [C++] Bundle jemalloc into static libarrow
tobim commented on pull request #7315: URL: https://github.com/apache/arrow/pull/7315#issuecomment-652001357 @wesm I still believe this approach is the sanest, but seeing that it requires CMake 3.9 I guess that makes it a non-starter? I would not expect problems with this on windows, but that is not my turf, so don't take my word for it. Which other bundled dependencies were you thinking of? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nealrichardson closed pull request #7595: ARROW-9281: [R] Turn off utf8proc in R builds
nealrichardson closed pull request #7595: URL: https://github.com/apache/arrow/pull/7595 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] BryanCutler commented on pull request #7275: ARROW-6110: [Java][Integration] Support LargeList Type and add integration test with C++
BryanCutler commented on pull request #7275: URL: https://github.com/apache/arrow/pull/7275#issuecomment-651984931 > Is this good to merge now? @BryanCutler are you still planning to review this? Would like to get this in 1.0. I'm taking a look now, I'd like to get it in for 1.0 too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nealrichardson closed pull request #7600: ARROW-4390: [R] Serialize "labeled" metadata in Feather files, IPC messages
nealrichardson closed pull request #7600: URL: https://github.com/apache/arrow/pull/7600 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] lmsanch commented on issue #6841: AttributeError: module 'pyarrow' has no attribute 'filesystem'
lmsanch commented on issue #6841: URL: https://github.com/apache/arrow/issues/6841#issuecomment-651976303 I am experiencing the same problem. I don't know what the solution is This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] sunchao commented on a change in pull request #7319: ARROW-8289: [Rust] Parquet Arrow writer with nested support
sunchao commented on a change in pull request #7319:
URL: https://github.com/apache/arrow/pull/7319#discussion_r447898772
##
File path: rust/parquet/src/arrow/arrow_writer.rs
##
@@ -0,0 +1,348 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing,
+// software distributed under the License is distributed on an
+// "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+// KIND, either express or implied. See the License for the
+// specific language governing permissions and limitations
+// under the License.
+
+//! Contains writer which writes arrow data into parquet data.
+
+use std::fs::File;
+use std::rc::Rc;
+
+use array::Array;
+use arrow::array;
+use arrow::datatypes::{DataType as ArrowDataType, Field, Schema};
+use arrow::record_batch::RecordBatch;
+
+use crate::column::writer::ColumnWriter;
+use crate::errors::Result;
+use crate::file::properties::WriterProperties;
+use crate::{
+data_type::*,
+file::writer::{FileWriter, RowGroupWriter, SerializedFileWriter},
+};
+
+struct ArrowWriter {
+writer: SerializedFileWriter,
+rows: i64,
+}
+
+impl ArrowWriter {
+pub fn try_new(file: File, arrow_schema: &Schema) -> Result {
+let schema = crate::arrow::arrow_to_parquet_schema(arrow_schema)?;
+let props = Rc::new(WriterProperties::builder().build());
+let file_writer = SerializedFileWriter::new(
+file.try_clone()?,
+schema.root_schema_ptr(),
+props,
+)?;
+
+Ok(Self {
+writer: file_writer,
+rows: 0,
+})
+}
+
+pub fn write(&mut self, batch: &RecordBatch) -> Result<()> {
+let mut row_group_writer = self.writer.next_row_group()?;
+self.rows += unnest_arrays_to_leaves(
+&mut row_group_writer,
+batch.schema().fields(),
+batch.columns(),
+&vec![1i16; batch.num_rows()][..],
+0,
+)?;
+self.writer.close_row_group(row_group_writer)
+}
+
+pub fn close(&mut self) -> Result<()> {
+self.writer.close()
+}
+}
+
+/// Write nested arrays by traversing into structs and lists until primitive
+/// arrays are found.
+fn unnest_arrays_to_leaves(
+row_group_writer: &mut Box,
+// The fields from the record batch or struct
+fields: &Vec,
+// The columns from record batch or struct, must have same length as fields
+columns: &[array::ArrayRef],
+// The parent mask, in the case of a struct, this represents which values
+// of the struct are true (1) or false(0).
+// This is useful to respect the definition level of structs where all
values are null in a row
+parent_mask: &[i16],
+// The current level that is being read at
+level: i16,
+) -> Result {
+let mut rows_written = 0;
+for (field, column) in fields.iter().zip(columns) {
+match field.data_type() {
+ArrowDataType::List(_dtype) => unimplemented!("list not yet
implemented"),
+ArrowDataType::FixedSizeList(_, _) => {
+unimplemented!("fsl not yet implemented")
+}
+ArrowDataType::Struct(fields) => {
+// fields in a struct should recursively be written out
+let array = column
+.as_any()
+.downcast_ref::()
+.expect("Unable to get struct array");
+let mut null_mask = Vec::with_capacity(array.len());
+for i in 0..array.len() {
+null_mask.push(array.is_valid(i) as i16);
+}
+rows_written += unnest_arrays_to_leaves(
+row_group_writer,
+fields,
+&array.columns_ref()[..],
+&null_mask[..],
+// if the field is nullable, we have to increment level
+level + field.is_nullable() as i16,
+)?;
+}
+ArrowDataType::Null => unimplemented!(),
+ArrowDataType::Boolean
+| ArrowDataType::Int8
+| ArrowDataType::Int16
+| ArrowDataType::Int32
+| ArrowDataType::Int64
+| ArrowDataType::UInt8
+| ArrowDataType::UInt16
+| ArrowDataType::UInt32
+| ArrowDataType::UInt64
+| ArrowDataType::Float16
+| ArrowDataType::Float32
+| ArrowDataType::Float64
+| ArrowDataType::
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447758318
##
File path: python/pyarrow/tests/test_scalars.py
##
@@ -16,427 +16,443 @@
# under the License.
import datetime
+import decimal
import pytest
-import unittest
import numpy as np
import pyarrow as pa
-class TestScalars(unittest.TestCase):
-
-def test_null_singleton(self):
-with pytest.raises(Exception):
-pa.NAType()
+@pytest.mark.parametrize(['value', 'ty', 'klass', 'deprecated'], [
+(False, None, pa.BooleanScalar, pa.BooleanValue),
+(True, None, pa.BooleanScalar, pa.BooleanValue),
+(1, None, pa.Int64Scalar, pa.Int64Value),
+(-1, None, pa.Int64Scalar, pa.Int64Value),
+(1, pa.int8(), pa.Int8Scalar, pa.Int8Value),
+(1, pa.uint8(), pa.UInt8Scalar, pa.UInt8Value),
+(1, pa.int16(), pa.Int16Scalar, pa.Int16Value),
+(1, pa.uint16(), pa.UInt16Scalar, pa.UInt16Value),
+(1, pa.int32(), pa.Int32Scalar, pa.Int32Value),
+(1, pa.uint32(), pa.UInt32Scalar, pa.UInt32Value),
+(1, pa.int64(), pa.Int64Scalar, pa.Int64Value),
+(1, pa.uint64(), pa.UInt64Scalar, pa.UInt64Value),
+(1.0, None, pa.DoubleScalar, pa.DoubleValue),
+(np.float16(1.0), pa.float16(), pa.HalfFloatScalar, pa.HalfFloatValue),
+(1.0, pa.float32(), pa.FloatScalar, pa.FloatValue),
+("string", None, pa.StringScalar, pa.StringValue),
+(b"bytes", None, pa.BinaryScalar, pa.BinaryValue),
+([1, 2, 3], None, pa.ListScalar, pa.ListValue),
+([1, 2, 3, 4], pa.large_list(pa.int8()), pa.LargeListScalar,
+ pa.LargeListValue),
+(datetime.date.today(), None, pa.Date32Scalar, pa.Date64Value),
+(datetime.datetime.now(), None, pa.TimestampScalar, pa.TimestampValue),
+({'a': 1, 'b': [1, 2]}, None, pa.StructScalar, pa.StructValue)
+])
+def test_basics(value, ty, klass, deprecated):
+s = pa.scalar(value, type=ty)
+assert isinstance(s, klass)
+assert s == value
+assert s == s
+assert s != "else"
+assert hash(s) == hash(s)
Review comment:
It tests that different calls of the c++ hashing mechanism produces the
same hash values.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7586: ARROW-9280: [Rust] [Parquet] Calculate page and column statistics
github-actions[bot] commented on pull request #7586: URL: https://github.com/apache/arrow/pull/7586#issuecomment-651852823 https://issues.apache.org/jira/browse/ARROW-9280 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-651849432 @xhochy chunked arrays should be handled automatically by the function executors. I will take a look. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
wesm commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-651849432 @xhochy chunked array should be handled automatically by the function executors. I will take a look. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
pitrou commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447751371
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+return self.wrapped
+
+@property
+def type(self):
+return pyarrow_wrap_data_type(self.wrapped.get().type)
-self.type = null()
+@property
+def is_valid(self):
+return self.wrapped.get().is_valid
def __repr__(self):
-return 'NULL'
+return ''.format(
+self.__class__.__name__, self.as_py()
+)
-def as_py(self):
-"""
-Return None
-"""
-return None
+def __str__(self):
+return str(self.as_py())
+
+def equals(self, Scalar other):
+return self.wrapped.get().Equals(other.unwrap().get()[0])
def __eq__(self, other):
-return NA
+try:
+if not isinstance(other, Scalar):
+other = scalar(other, type=self.type)
+return self.equals(other)
+except (TypeError, ValueError, ArrowInvalid):
+return NotImplemented
+
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
+
+def as_py(self):
+raise NotImplementedError()
-_NULL = NA = NullType()
+_NULL = NA = None
-cdef class ArrayValue(Scalar):
+cdef class NullScalar(Scalar):
"""
-The base class for non-null array elements.
+Concrete class for null scalars.
"""
-def __init__(self):
-raise TypeError("Do not call {}'s constructor directly, use array "
-"subscription instead."
-.format(self.__class__.__name__))
+def __cinit__(self):
+global NA
+if NA is not None:
+raise Exception('Cannot create multiple NAType instances')
+self.init(shared_ptr[CScalar](new CNullScalar()))
-cdef void init(self, DataType type, const shared_ptr[CArray]& sp_array,
- int64_t index):
-self.type = type
-self.index = index
-self._set_array(sp_array)
+def __init__(self):
+pass
-cdef void _set_array(self, const shared_ptr[CArray]& sp_array):
-self.sp_array = sp_array
+def __eq__(self, other):
+return NA
-def __repr__(self):
-if hasattr(self, 'as_py'):
-return repr(self.as_py())
-else:
-return super(Scalar, self).__repr__()
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
-def __str__(self):
-if hasattr(self, 'as_py'):
-return str(self.as_py())
-else:
-return super(Scalar, self).__str__()
+def as_py(self):
+"""
+Return this value as a Python None.
+"""
+return None
-def __eq__(self, other):
-if hasattr(self, 'as_py'):
-if isinstance(other, ArrayValue):
-other = other.as_py()
-return self.as_py() == other
-else:
-raise NotImplementedError(
-"Cannot compare Arrow values that don't support as_py()")
-def __hash__(self):
-return hash(self.as_py())
+_NULL = NA = NullScalar()
-cdef class BooleanValue(ArrayValue):
+cdef class BooleanScalar(Scalar):
"""
-Concrete class for boolean array elements.
+Concrete class for boolean scalars.
"""
def as_py(self):
"""
Return this value as a Python bool.
"""
-cdef CBooleanArray* ap = self.sp_array.get()
-return ap.Value(self.index)
+cdef CBooleanScalar* sp = self.wrapped.get()
+return sp.value if sp.is_valid else None
-cdef class Int8Value(ArrayValue):
+cdef class UInt8Scalar(Scalar):
"""
-
[GitHub] [arrow] wesm commented on pull request #7556: ARROW-9188: [C++] Use Brotli shared libraries if they are available
wesm commented on pull request #7556: URL: https://github.com/apache/arrow/pull/7556#issuecomment-651847404 This looks good to me, @kszucs @kou @nealrichardson anything else you would want to check? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] crcrpar commented on pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
crcrpar commented on pull request #7590: URL: https://github.com/apache/arrow/pull/7590#issuecomment-651844844 I'm so impressed by your quick response! Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou closed pull request #7549: ARROW-9230: [FlightRPC][Python] pass through all options in flight.connect
pitrou closed pull request #7549: URL: https://github.com/apache/arrow/pull/7549 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7589: ARROW-9276: [Release] Enforce CUDA device for updating the api documentations
pitrou commented on a change in pull request #7589:
URL: https://github.com/apache/arrow/pull/7589#discussion_r447741353
##
File path: dev/release/post-09-docs.sh
##
@@ -42,20 +47,20 @@ popd
pushd "${ARROW_DIR}"
git checkout "${release_tag}"
Review comment:
@kszucs Is a CUDA machine needed? Do you want me to try?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447738979
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+return self.wrapped
+
+@property
+def type(self):
+return pyarrow_wrap_data_type(self.wrapped.get().type)
-self.type = null()
+@property
+def is_valid(self):
+return self.wrapped.get().is_valid
def __repr__(self):
-return 'NULL'
+return ''.format(
+self.__class__.__name__, self.as_py()
+)
-def as_py(self):
-"""
-Return None
-"""
-return None
+def __str__(self):
+return str(self.as_py())
+
+def equals(self, Scalar other):
+return self.wrapped.get().Equals(other.unwrap().get()[0])
def __eq__(self, other):
-return NA
+try:
+if not isinstance(other, Scalar):
+other = scalar(other, type=self.type)
+return self.equals(other)
+except (TypeError, ValueError, ArrowInvalid):
+return NotImplemented
+
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
+
+def as_py(self):
+raise NotImplementedError()
-_NULL = NA = NullType()
+_NULL = NA = None
-cdef class ArrayValue(Scalar):
+cdef class NullScalar(Scalar):
"""
-The base class for non-null array elements.
+Concrete class for null scalars.
"""
-def __init__(self):
-raise TypeError("Do not call {}'s constructor directly, use array "
-"subscription instead."
-.format(self.__class__.__name__))
+def __cinit__(self):
+global NA
+if NA is not None:
+raise Exception('Cannot create multiple NAType instances')
+self.init(shared_ptr[CScalar](new CNullScalar()))
-cdef void init(self, DataType type, const shared_ptr[CArray]& sp_array,
- int64_t index):
-self.type = type
-self.index = index
-self._set_array(sp_array)
+def __init__(self):
+pass
-cdef void _set_array(self, const shared_ptr[CArray]& sp_array):
-self.sp_array = sp_array
+def __eq__(self, other):
+return NA
-def __repr__(self):
-if hasattr(self, 'as_py'):
-return repr(self.as_py())
-else:
-return super(Scalar, self).__repr__()
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
-def __str__(self):
-if hasattr(self, 'as_py'):
-return str(self.as_py())
-else:
-return super(Scalar, self).__str__()
+def as_py(self):
+"""
+Return this value as a Python None.
+"""
+return None
-def __eq__(self, other):
-if hasattr(self, 'as_py'):
-if isinstance(other, ArrayValue):
-other = other.as_py()
-return self.as_py() == other
-else:
-raise NotImplementedError(
-"Cannot compare Arrow values that don't support as_py()")
-def __hash__(self):
-return hash(self.as_py())
+_NULL = NA = NullScalar()
-cdef class BooleanValue(ArrayValue):
+cdef class BooleanScalar(Scalar):
"""
-Concrete class for boolean array elements.
+Concrete class for boolean scalars.
"""
def as_py(self):
"""
Return this value as a Python bool.
"""
-cdef CBooleanArray* ap = self.sp_array.get()
-return ap.Value(self.index)
+cdef CBooleanScalar* sp = self.wrapped.get()
+return sp.value if sp.is_valid else None
-cdef class Int8Value(ArrayValue):
+cdef class UInt8Scalar(Scalar):
"""
-
[GitHub] [arrow] nevi-me commented on pull request #7591: ARROW-8535: [Rust] Specify arrow-flight version
nevi-me commented on pull request #7591: URL: https://github.com/apache/arrow/pull/7591#issuecomment-651837534 @kszucs may you please have a look at this when you get a chance. There's a change to the prepare-test Ruby script This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
pitrou commented on pull request #7590: URL: https://github.com/apache/arrow/pull/7590#issuecomment-651836379 Thank you for your contribution. Please don't hesitate to report other doc problems. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou closed pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
pitrou closed pull request #7590: URL: https://github.com/apache/arrow/pull/7590 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447734944
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+return self.wrapped
+
+@property
+def type(self):
+return pyarrow_wrap_data_type(self.wrapped.get().type)
-self.type = null()
+@property
+def is_valid(self):
+return self.wrapped.get().is_valid
def __repr__(self):
-return 'NULL'
+return ''.format(
+self.__class__.__name__, self.as_py()
+)
-def as_py(self):
-"""
-Return None
-"""
-return None
+def __str__(self):
+return str(self.as_py())
+
+def equals(self, Scalar other):
+return self.wrapped.get().Equals(other.unwrap().get()[0])
def __eq__(self, other):
-return NA
+try:
+if not isinstance(other, Scalar):
+other = scalar(other, type=self.type)
+return self.equals(other)
+except (TypeError, ValueError, ArrowInvalid):
+return NotImplemented
+
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
+
+def as_py(self):
+raise NotImplementedError()
-_NULL = NA = NullType()
+_NULL = NA = None
-cdef class ArrayValue(Scalar):
+cdef class NullScalar(Scalar):
"""
-The base class for non-null array elements.
+Concrete class for null scalars.
"""
-def __init__(self):
-raise TypeError("Do not call {}'s constructor directly, use array "
-"subscription instead."
-.format(self.__class__.__name__))
+def __cinit__(self):
+global NA
+if NA is not None:
+raise Exception('Cannot create multiple NAType instances')
+self.init(shared_ptr[CScalar](new CNullScalar()))
-cdef void init(self, DataType type, const shared_ptr[CArray]& sp_array,
- int64_t index):
-self.type = type
-self.index = index
-self._set_array(sp_array)
+def __init__(self):
+pass
-cdef void _set_array(self, const shared_ptr[CArray]& sp_array):
-self.sp_array = sp_array
+def __eq__(self, other):
+return NA
-def __repr__(self):
-if hasattr(self, 'as_py'):
-return repr(self.as_py())
-else:
-return super(Scalar, self).__repr__()
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
-def __str__(self):
-if hasattr(self, 'as_py'):
-return str(self.as_py())
-else:
-return super(Scalar, self).__str__()
+def as_py(self):
+"""
+Return this value as a Python None.
+"""
+return None
-def __eq__(self, other):
-if hasattr(self, 'as_py'):
-if isinstance(other, ArrayValue):
-other = other.as_py()
-return self.as_py() == other
-else:
-raise NotImplementedError(
-"Cannot compare Arrow values that don't support as_py()")
-def __hash__(self):
-return hash(self.as_py())
+_NULL = NA = NullScalar()
-cdef class BooleanValue(ArrayValue):
+cdef class BooleanScalar(Scalar):
"""
-Concrete class for boolean array elements.
+Concrete class for boolean scalars.
"""
def as_py(self):
"""
Return this value as a Python bool.
"""
-cdef CBooleanArray* ap = self.sp_array.get()
-return ap.Value(self.index)
+cdef CBooleanScalar* sp = self.wrapped.get()
+return sp.value if sp.is_valid else None
-cdef class Int8Value(ArrayValue):
+cdef class UInt8Scalar(Scalar):
"""
-
[GitHub] [arrow] crcrpar commented on pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
crcrpar commented on pull request #7590: URL: https://github.com/apache/arrow/pull/7590#issuecomment-651835046 @pitrou My pleasure :smiley: Yes, I think so as the use of `arrow::Result` in my commits might be confusing. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447733611
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+return self.wrapped
+
+@property
+def type(self):
+return pyarrow_wrap_data_type(self.wrapped.get().type)
-self.type = null()
+@property
+def is_valid(self):
+return self.wrapped.get().is_valid
def __repr__(self):
-return 'NULL'
+return ''.format(
+self.__class__.__name__, self.as_py()
+)
-def as_py(self):
-"""
-Return None
-"""
-return None
+def __str__(self):
+return str(self.as_py())
+
+def equals(self, Scalar other):
+return self.wrapped.get().Equals(other.unwrap().get()[0])
def __eq__(self, other):
-return NA
+try:
+if not isinstance(other, Scalar):
+other = scalar(other, type=self.type)
+return self.equals(other)
+except (TypeError, ValueError, ArrowInvalid):
+return NotImplemented
+
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
+
+def as_py(self):
+raise NotImplementedError()
-_NULL = NA = NullType()
+_NULL = NA = None
-cdef class ArrayValue(Scalar):
+cdef class NullScalar(Scalar):
"""
-The base class for non-null array elements.
+Concrete class for null scalars.
"""
-def __init__(self):
-raise TypeError("Do not call {}'s constructor directly, use array "
-"subscription instead."
-.format(self.__class__.__name__))
+def __cinit__(self):
+global NA
+if NA is not None:
+raise Exception('Cannot create multiple NAType instances')
+self.init(shared_ptr[CScalar](new CNullScalar()))
-cdef void init(self, DataType type, const shared_ptr[CArray]& sp_array,
- int64_t index):
-self.type = type
-self.index = index
-self._set_array(sp_array)
+def __init__(self):
+pass
-cdef void _set_array(self, const shared_ptr[CArray]& sp_array):
-self.sp_array = sp_array
+def __eq__(self, other):
+return NA
-def __repr__(self):
-if hasattr(self, 'as_py'):
-return repr(self.as_py())
-else:
-return super(Scalar, self).__repr__()
+def __hash__(self):
Review comment:
Once I override `__eq__` the inherited `__hash__` gets removed.
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+
[GitHub] [arrow] pitrou commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
pitrou commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447732301
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+return self.wrapped
+
+@property
+def type(self):
+return pyarrow_wrap_data_type(self.wrapped.get().type)
-self.type = null()
+@property
+def is_valid(self):
+return self.wrapped.get().is_valid
def __repr__(self):
-return 'NULL'
+return ''.format(
+self.__class__.__name__, self.as_py()
+)
-def as_py(self):
-"""
-Return None
-"""
-return None
+def __str__(self):
+return str(self.as_py())
+
+def equals(self, Scalar other):
+return self.wrapped.get().Equals(other.unwrap().get()[0])
def __eq__(self, other):
-return NA
+try:
+if not isinstance(other, Scalar):
+other = scalar(other, type=self.type)
+return self.equals(other)
+except (TypeError, ValueError, ArrowInvalid):
+return NotImplemented
+
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
+
+def as_py(self):
+raise NotImplementedError()
-_NULL = NA = NullType()
+_NULL = NA = None
-cdef class ArrayValue(Scalar):
+cdef class NullScalar(Scalar):
"""
-The base class for non-null array elements.
+Concrete class for null scalars.
"""
-def __init__(self):
-raise TypeError("Do not call {}'s constructor directly, use array "
-"subscription instead."
-.format(self.__class__.__name__))
+def __cinit__(self):
+global NA
+if NA is not None:
+raise Exception('Cannot create multiple NAType instances')
+self.init(shared_ptr[CScalar](new CNullScalar()))
-cdef void init(self, DataType type, const shared_ptr[CArray]& sp_array,
- int64_t index):
-self.type = type
-self.index = index
-self._set_array(sp_array)
+def __init__(self):
+pass
-cdef void _set_array(self, const shared_ptr[CArray]& sp_array):
-self.sp_array = sp_array
+def __eq__(self, other):
+return NA
Review comment:
Well, it should probably return `False` for non-nulls?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] pitrou closed pull request #7592: ARROW-9220: [C++] Make utf8proc optional even with ARROW_COMPUTE=ON
pitrou closed pull request #7592: URL: https://github.com/apache/arrow/pull/7592 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#discussion_r447731034
##
File path: python/pyarrow/scalar.pxi
##
@@ -16,1198 +16,745 @@
# under the License.
-_NULL = NA = None
+import collections
cdef class Scalar:
"""
-The base class for all array elements.
+The base class for scalars.
"""
+def __init__(self):
+raise TypeError("Do not call {}'s constructor directly, use "
+"pa.scalar() instead.".format(self.__class__.__name__))
-cdef class NullType(Scalar):
-"""
-Singleton for null array elements.
-"""
-# TODO rename this NullValue?
+cdef void init(self, const shared_ptr[CScalar]& wrapped):
+self.wrapped = wrapped
-def __cinit__(self):
-global NA
-if NA is not None:
-raise Exception('Cannot create multiple NAType instances')
+@staticmethod
+cdef wrap(const shared_ptr[CScalar]& wrapped):
+cdef:
+Scalar self
+Type type_id = wrapped.get().type.get().id()
+
+if type_id == _Type_NA:
+return _NULL
+
+typ = _scalar_classes[type_id]
+self = typ.__new__(typ)
+self.init(wrapped)
+
+return self
+
+cdef inline shared_ptr[CScalar] unwrap(self) nogil:
+return self.wrapped
+
+@property
+def type(self):
+return pyarrow_wrap_data_type(self.wrapped.get().type)
-self.type = null()
+@property
+def is_valid(self):
+return self.wrapped.get().is_valid
def __repr__(self):
-return 'NULL'
+return ''.format(
+self.__class__.__name__, self.as_py()
+)
-def as_py(self):
-"""
-Return None
-"""
-return None
+def __str__(self):
+return str(self.as_py())
+
+def equals(self, Scalar other):
+return self.wrapped.get().Equals(other.unwrap().get()[0])
def __eq__(self, other):
-return NA
+try:
+if not isinstance(other, Scalar):
+other = scalar(other, type=self.type)
+return self.equals(other)
+except (TypeError, ValueError, ArrowInvalid):
+return NotImplemented
+
+def __hash__(self):
+cdef CScalarHash hasher
+return hasher(self.wrapped)
+
+def as_py(self):
+raise NotImplementedError()
-_NULL = NA = NullType()
+_NULL = NA = None
-cdef class ArrayValue(Scalar):
+cdef class NullScalar(Scalar):
"""
-The base class for non-null array elements.
+Concrete class for null scalars.
"""
-def __init__(self):
-raise TypeError("Do not call {}'s constructor directly, use array "
-"subscription instead."
-.format(self.__class__.__name__))
+def __cinit__(self):
+global NA
+if NA is not None:
+raise Exception('Cannot create multiple NAType instances')
+self.init(shared_ptr[CScalar](new CNullScalar()))
-cdef void init(self, DataType type, const shared_ptr[CArray]& sp_array,
- int64_t index):
-self.type = type
-self.index = index
-self._set_array(sp_array)
+def __init__(self):
+pass
-cdef void _set_array(self, const shared_ptr[CArray]& sp_array):
-self.sp_array = sp_array
+def __eq__(self, other):
+return NA
Review comment:
Well, it was the behavior before the refactor. Shall we check proper
equality with NullScalar instead?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7544: ARROW-7285: [C++] ensure C++ implementation meets clarified dictionary spec
pitrou commented on a change in pull request #7544:
URL: https://github.com/apache/arrow/pull/7544#discussion_r447729043
##
File path: cpp/src/arrow/ipc/read_write_test.cc
##
@@ -1228,6 +1228,152 @@ TEST_P(TestFileFormat, RoundTrip) {
TestZeroLengthRoundTrip(*GetParam(), options);
}
+Status MakeDictionaryBatch(std::shared_ptr* out) {
+ const int64_t length = 6;
+
+ std::vector is_valid = {true, true, false, true, true, true};
+
+ auto dict_ty = utf8();
+
+ auto dict = ArrayFromJSON(dict_ty, "[\"foo\", \"bar\", \"baz\"]");
+
+ auto f0_type = arrow::dictionary(arrow::int32(), dict_ty);
+ auto f1_type = arrow::dictionary(arrow::int8(), dict_ty);
+
+ std::shared_ptr indices0, indices1;
+ std::vector indices0_values = {1, 2, -1, 0, 2, 0};
+ std::vector indices1_values = {0, 0, 2, 2, 1, 1};
+
+ ArrayFromVector(is_valid, indices0_values, &indices0);
+ ArrayFromVector(is_valid, indices1_values, &indices1);
Review comment:
You can create the indices arrays with `ArrayFromJSON` too, it will
probably make the code simpler to read and maintain.
##
File path: cpp/src/arrow/ipc/metadata_internal.h
##
@@ -198,7 +198,7 @@ Status WriteDictionaryMessage(
const int64_t id, const int64_t length, const int64_t body_length,
const std::shared_ptr& custom_metadata,
const std::vector& nodes, const
std::vector& buffers,
-const IpcWriteOptions& options, std::shared_ptr* out);
+const IpcWriteOptions& options, std::shared_ptr* out, bool
isDelta);
Review comment:
We should keep `std::shared* out` at the end of the arguments.
##
File path: cpp/src/arrow/ipc/reader.cc
##
@@ -684,7 +685,19 @@ Status ReadDictionary(const Buffer& metadata,
DictionaryMemo* dictionary_memo,
return Status::Invalid("Dictionary record batch must only contain one
field");
}
auto dictionary = batch->column(0);
- return dictionary_memo->AddDictionary(id, dictionary);
+ if (dictionary_batch->isDelta()) {
+std::shared_ptr originalDict, combinedDict;
+RETURN_NOT_OK(dictionary_memo->GetDictionary(id, &originalDict));
+ArrayVector dictsToCombine{originalDict, dictionary};
+ARROW_ASSIGN_OR_RAISE(combinedDict, Concatenate(dictsToCombine,
options.memory_pool));
Review comment:
How about folding this logic, e.g. add a `AddDirectoryDelta` method to
`DictionaryMemo`?
##
File path: cpp/src/arrow/ipc/writer.h
##
@@ -341,6 +343,29 @@ class ARROW_EXPORT IpcPayloadWriter {
virtual Status Close() = 0;
};
+/// Create a new IPC payload stream writer from stream sink. User is
+/// responsible for closing the actual OutputStream.
+///
+/// \param[in] sink output stream to write to
+/// \param[in] options options for serialization
+/// \return Result>
+ARROW_EXPORT
+Result> NewPayloadStreamWriter(
Review comment:
Nit: call this `MakePayloadStreamWriter`
##
File path: cpp/src/arrow/ipc/writer.h
##
@@ -341,6 +343,29 @@ class ARROW_EXPORT IpcPayloadWriter {
virtual Status Close() = 0;
};
+/// Create a new IPC payload stream writer from stream sink. User is
+/// responsible for closing the actual OutputStream.
+///
+/// \param[in] sink output stream to write to
+/// \param[in] options options for serialization
+/// \return Result>
+ARROW_EXPORT
+Result> NewPayloadStreamWriter(
+io::OutputStream* sink, const IpcWriteOptions& options =
IpcWriteOptions::Defaults());
+
+/// Create a new IPC payload file writer from stream sink.
+///
+/// \param[in] sink output stream to write to
+/// \param[in] schema the schema of the record batches to be written
+/// \param[in] options options for serialization, optional
+/// \param[in] metadata custom metadata for File Footer, optional
+/// \return Status
+ARROW_EXPORT
+Result> NewPayloadFileWriter(
Review comment:
Nit: call this `MakePayloadFileWriter`
##
File path: cpp/src/arrow/ipc/read_write_test.cc
##
@@ -1228,6 +1228,152 @@ TEST_P(TestFileFormat, RoundTrip) {
TestZeroLengthRoundTrip(*GetParam(), options);
}
+Status MakeDictionaryBatch(std::shared_ptr* out) {
+ const int64_t length = 6;
+
+ std::vector is_valid = {true, true, false, true, true, true};
+
+ auto dict_ty = utf8();
+
+ auto dict = ArrayFromJSON(dict_ty, "[\"foo\", \"bar\", \"baz\"]");
+
+ auto f0_type = arrow::dictionary(arrow::int32(), dict_ty);
+ auto f1_type = arrow::dictionary(arrow::int8(), dict_ty);
+
+ std::shared_ptr indices0, indices1;
+ std::vector indices0_values = {1, 2, -1, 0, 2, 0};
+ std::vector indices1_values = {0, 0, 2, 2, 1, 1};
+
+ ArrayFromVector(is_valid, indices0_values, &indices0);
+ ArrayFromVector(is_valid, indices1_values, &indices1);
+
+ auto a0 = std::make_shared(f0_type, indices0, dict);
+ auto a1 = std::make_shared(f1_type, indices1, dict);
+
+ // construct batch
+ auto schema = ::arrow::schema({field("dict1", f0_type), field("dict2",
f1_type)});
+
+ *out = RecordBatch::Make(schema, length, {a0, a1});
+
[GitHub] [arrow] github-actions[bot] commented on pull request #7594: ARROW-7654: [Python] Ability to set column_types to a Schema in csv.ConvertOptions is undocumented
github-actions[bot] commented on pull request #7594: URL: https://github.com/apache/arrow/pull/7594#issuecomment-651831683 https://issues.apache.org/jira/browse/ARROW-7654 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519: URL: https://github.com/apache/arrow/pull/7519#discussion_r447725569 ## File path: python/pyarrow/lib.pxd ## @@ -179,101 +179,18 @@ cdef class Schema: cdef class Scalar: -cdef readonly: -DataType type - - -cdef class NAType(Scalar): -pass - - -cdef class ArrayValue(Scalar): cdef: -shared_ptr[CArray] sp_array -int64_t index - -cdef void init(self, DataType type, - const shared_ptr[CArray]& sp_array, int64_t index) - -cdef void _set_array(self, const shared_ptr[CArray]& sp_array) - -cdef class ScalarValue(Scalar): -cdef: -shared_ptr[CScalar] sp_scalar - -cdef void init(self, const shared_ptr[CScalar]& sp_scalar) - -cdef class Int8Value(ArrayValue): -pass +shared_ptr[CScalar] wrapped +cdef void init(self, const shared_ptr[CScalar]& wrapped) -cdef class Int64Value(ArrayValue): -pass - - -cdef class ListValue(ArrayValue): -cdef readonly: -DataType value_type - -cdef: -CListArray* ap - -cdef getitem(self, int64_t i) -cdef int64_t length(self) - - -cdef class LargeListValue(ArrayValue): -cdef readonly: -DataType value_type - -cdef: -CLargeListArray* ap - -cdef getitem(self, int64_t i) -cdef int64_t length(self) - - -cdef class MapValue(ArrayValue): -cdef readonly: -DataType key_type -DataType item_type - -cdef: -CMapArray* ap - -cdef getitem(self, int64_t i) -cdef int64_t length(self) - - -cdef class FixedSizeListValue(ArrayValue): -cdef readonly: -DataType value_type - -cdef: -CFixedSizeListArray* ap - -cdef getitem(self, int64_t i) -cdef int64_t length(self) - - -cdef class StructValue(ArrayValue): -cdef: -CStructArray* ap - - -cdef class UnionValue(ArrayValue): -cdef: -CUnionArray* ap -list value_types - -cdef getitem(self, int64_t i) - +@staticmethod +cdef wrap(const shared_ptr[CScalar]& wrapped) -cdef class StringValue(ArrayValue): -pass +cdef inline shared_ptr[CScalar] unwrap(self) nogil -cdef class FixedSizeBinaryValue(ArrayValue): +cdef class NAType(Scalar): Review comment: Forgot to rename it in the `.pxd` file. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
kszucs commented on a change in pull request #7519: URL: https://github.com/apache/arrow/pull/7519#discussion_r447725217 ## File path: python/pyarrow/includes/libarrow.pxd ## @@ -44,6 +44,11 @@ cdef extern from "arrow/util/key_value_metadata.h" namespace "arrow" nogil: c_bool Contains(const c_string& key) const +cdef extern from "arrow/util/decimal.h" namespace "arrow" nogil: +cdef cppclass CDecimal128" arrow::Decimal128": +c_string ToString(int32_t scale) const Review comment: Created jira https://issues.apache.org/jira/browse/ARROW-9279 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7594: ARROW-7654: [Python] Ability to set column_types to a Schema in csv.ConvertOptions is undocumented
pitrou commented on a change in pull request #7594: URL: https://github.com/apache/arrow/pull/7594#discussion_r447724372 ## File path: python/pyarrow/_csv.pyx ## @@ -342,9 +342,9 @@ cdef class ConvertOptions: -- check_utf8 : bool, optional (default True) Whether to check UTF8 validity of string columns. -column_types: dict, optional -Map column names to column types -(disabling type inference on those columns). +column_types: pa.Schema or dict, optional +Explicitly map column names to column types. Passing this argument Review comment: I'm surprised: was the original spelling not clear? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs opened a new pull request #7594: ARROW-7654: [Python] Ability to set column_types to a Schema in csv.ConvertOptions is undocumented
kszucs opened a new pull request #7594: URL: https://github.com/apache/arrow/pull/7594 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7594: ARROW-7654: [Python] Ability to set column_types to a Schema in csv.ConvertOptions is undocumented
kszucs commented on a change in pull request #7594: URL: https://github.com/apache/arrow/pull/7594#discussion_r447723473 ## File path: python/pyarrow/_csv.pyx ## @@ -342,9 +342,9 @@ cdef class ConvertOptions: -- check_utf8 : bool, optional (default True) Whether to check UTF8 validity of string columns. -column_types: dict, optional -Map column names to column types -(disabling type inference on those columns). +column_types: pa.Schema or dict, optional +Explicitly map column names to column types. Passing this argument Review comment: I'm not sure how to clarify it better. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] lidavidm commented on pull request #7582: ARROW-8190: [FlightRPC][C++] Expose IPC options
lidavidm commented on pull request #7582: URL: https://github.com/apache/arrow/pull/7582#issuecomment-651813343 Thanks for the review! I've fixed the comment/test names. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nevi-me commented on pull request #7586: Calculate page and column statistics
nevi-me commented on pull request #7586: URL: https://github.com/apache/arrow/pull/7586#issuecomment-651810251 Hi @zeevm, may you please kindly rebase (to fix the Rust failures) and open a JIRA for this PR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] fsaintjacques closed pull request #7536: ARROW-8647: [C++][Python][Dataset] Allow partitioning fields to be inferred with dictionary type
fsaintjacques closed pull request #7536: URL: https://github.com/apache/arrow/pull/7536 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7519: ARROW-9017: [C++][Python] Refactor scalar bindings
pitrou commented on pull request #7519:
URL: https://github.com/apache/arrow/pull/7519#issuecomment-651806049
Ok, at a quick glance, it seems that null container tests work properly
regardless:
```python
>>> s = set()
>>> s.add(pa.scalar(None))
>>> s
{}
>>> pa.scalar(None) in s
True
>>> s.add(pa.scalar(None, pa.int64()))
>>> s.add(pa.scalar(12, pa.int64()))
>>> s
{,
,
}
>>> pa.scalar(None, pa.int64()) in s
True
>>> pa.scalar(None, pa.int32()) in s
False
```
```python
>>> l = [pa.scalar(None)]
>>> pa.scalar(None) in l
True
>>> pa.scalar(None, pa.int64()) in l
False
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7535: ARROW-9222: [Format][DONOTMERGE] Columnar.rst changes for removing validity bitmap from union types
wesm commented on a change in pull request #7535: URL: https://github.com/apache/arrow/pull/7535#discussion_r447692444 ## File path: docs/source/format/Columnar.rst ## @@ -688,11 +687,10 @@ will have the following layout: :: ||---| | joemark| unspecified (padding) | -Similar to structs, a particular child array may have a non-null slot -even if the validity bitmap of the parent union array indicates the -slot is null. Additionally, a child array may have a non-null slot -even if the types array indicates that a slot contains a different -type at the index. +Note that a child array may have a non-null slot even if the types array +indicates that a slot contains a different type at the index, so the Review comment: OK This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7535: ARROW-9222: [Format][DONOTMERGE] Columnar.rst changes for removing validity bitmap from union types
wesm commented on a change in pull request #7535:
URL: https://github.com/apache/arrow/pull/7535#discussion_r447691975
##
File path: docs/source/format/Columnar.rst
##
@@ -566,33 +572,28 @@ having the values: ``[{f=1.2}, null, {f=3.4}, {i=5}]``
::
* Length: 4, Null count: 1
-* Validity bitmap buffer:
- |Byte 0 (validity bitmap) | Bytes 1-63|
- |-|---|
- |1101 | 0 (padding) |
-
* Types buffer:
|Byte 0 | Byte 1 | Byte 2 | Byte 3 | Bytes 4-63 |
|-|-|--|--|-|
- | 0 | unspecified | 0| 1| unspecified |
+ | 0 | 0 | 0| 1| unspecified |
* Offset buffer:
|Bytes 0-3 | Bytes 4-7 | Bytes 8-11 | Bytes 12-15 | Bytes 16-63 |
|--|-||-|-|
- | 0| unspecified | 1 | 0 | unspecified |
+ | 0| 1 | 2 | 0 | unspecified |
* Children arrays:
* Field-0 array (f: float):
* Length: 2, nulls: 0
Review comment:
Yes
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
maartenbreddels commented on pull request #7449: URL: https://github.com/apache/arrow/pull/7449#issuecomment-651796902 You're welcome. Thanks all for your help. Impressed by the project, setup (CI/CMake), and people, and happy with the results: 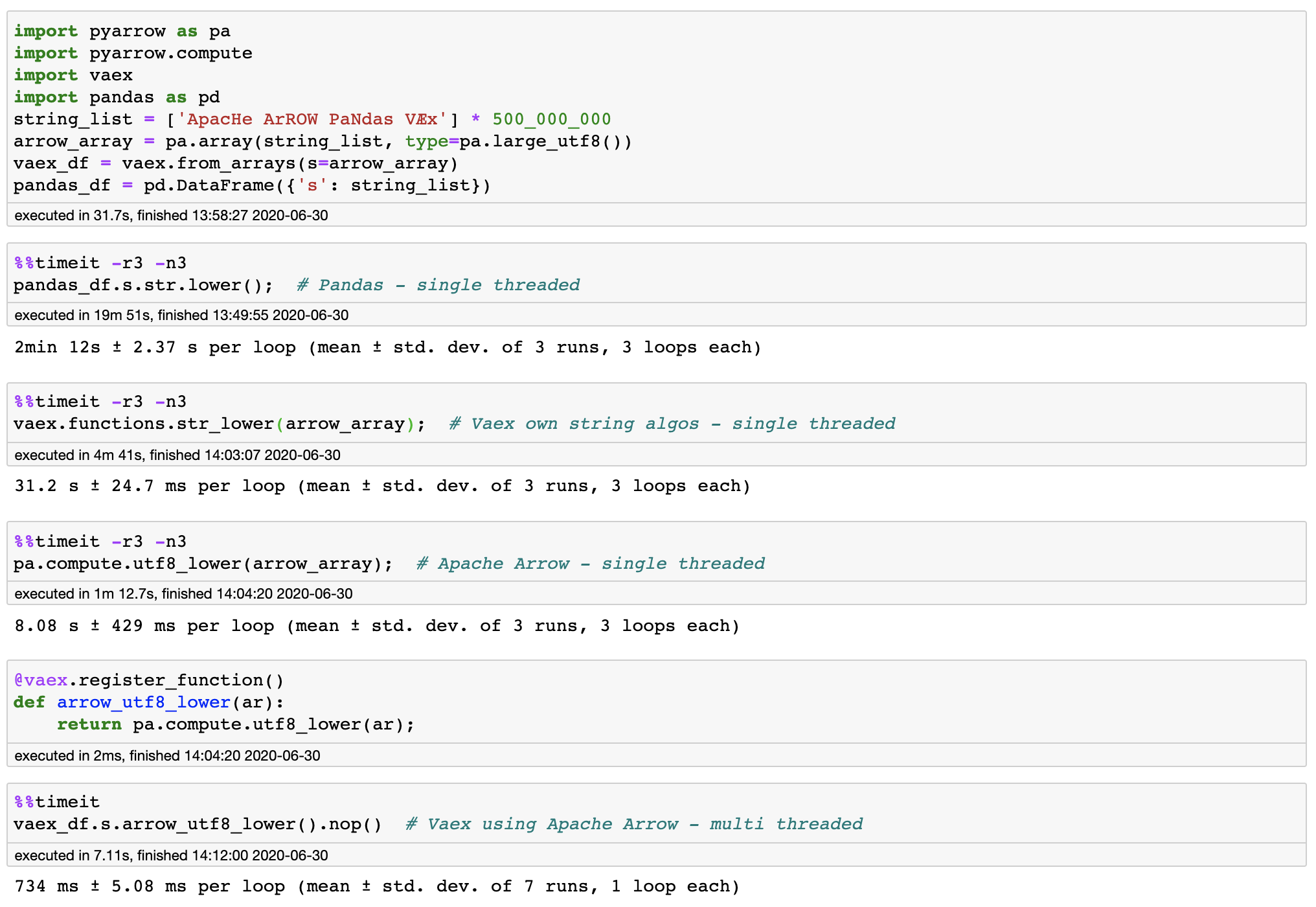 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
wesm commented on pull request #7449: URL: https://github.com/apache/arrow/pull/7449#issuecomment-651793397 thanks @maartenbreddels! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7592: ARROW-9220: [C++] Make utf8proc optional even with ARROW_COMPUTE=ON
github-actions[bot] commented on pull request #7592: URL: https://github.com/apache/arrow/pull/7592#issuecomment-651787096 https://issues.apache.org/jira/browse/ARROW-9220 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
github-actions[bot] commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-651787097 https://issues.apache.org/jira/browse/ARROW-9160 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] xhochy edited a comment on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
xhochy edited a comment on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-651779867 This currently fails for chunked arrays. I thought that they should be handled by the kernel framework automatically but it seems, they aren't. ``` [--] 1 test from TestStringKernels/1, where TypeParam = arrow::LargeStringType [ RUN ] TestStringKernels/1.ContainsExact ../src/arrow/testing/gtest_util.cc:149: Failure Failed Got: [ [ false, null, false ] ] Expected: [ [ true, null ], [ false ] ] ../src/arrow/testing/gtest_util.cc:149: Failure Failed Got: [ [ false, false, false, null, false ] ] Expected: [ [ true, false ], [ true, null, false ] ] [ FAILED ] TestStringKernels/1.ContainsExact, where TypeParam = arrow::LargeStringType (2 ms) ``` @wesm @pitrou Any pointers what I'm missing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7582: ARROW-8190: [FlightRPC][C++] Expose IPC options
pitrou commented on a change in pull request #7582:
URL: https://github.com/apache/arrow/pull/7582#discussion_r447665599
##
File path: cpp/src/arrow/flight/flight_test.cc
##
@@ -1808,6 +1880,90 @@ TEST_F(TestMetadata, DoPutReadMetadata) {
ASSERT_OK(writer->Close());
}
+TEST_F(TestOptions, DoGetReadOptions) {
+ // Call DoGet, but with a very low read nesting depth set to fail the call.
+ Ticket ticket{""};
+ auto options = FlightCallOptions();
+ options.read_options.max_recursion_depth = 1;
+ std::unique_ptr stream;
+ ASSERT_OK(client_->DoGet(options, ticket, &stream));
+ FlightStreamChunk chunk;
+ ASSERT_RAISES(Invalid, stream->Next(&chunk));
+}
+
+TEST_F(TestOptions, DoPutWriteOptions) {
+ // Call DoPut, but with a very low write nesting depth set to fail the call.
+ std::unique_ptr writer;
+ std::unique_ptr reader;
+ BatchVector expected_batches;
+ ASSERT_OK(ExampleNestedBatches(&expected_batches));
+
+ auto options = FlightCallOptions();
+ options.write_options.max_recursion_depth = 1;
+ ASSERT_OK(client_->DoPut(options, FlightDescriptor{},
expected_batches[0]->schema(),
+ &writer, &reader));
+ for (const auto& batch : expected_batches) {
+ASSERT_RAISES(Invalid, writer->WriteRecordBatch(*batch));
+ }
+}
+
+TEST_F(TestOptions, DoExchangeReadOptions) {
+ // Call DoExchange and write nested data, but read with a very low nesting
depth set to
+ // fail the call.
+ auto options = FlightCallOptions();
+ options.write_options.max_recursion_depth = 1;
+ auto descr = FlightDescriptor::Command("");
+ std::unique_ptr reader;
+ std::unique_ptr writer;
+ ASSERT_OK(client_->DoExchange(options, descr, &writer, &reader));
+ BatchVector batches;
+ ASSERT_OK(ExampleNestedBatches(&batches));
+ ASSERT_OK(writer->Begin(batches[0]->schema()));
+ for (const auto& batch : batches) {
+ASSERT_RAISES(Invalid, writer->WriteRecordBatch(*batch));
+ }
+ ASSERT_OK(writer->DoneWriting());
+ ASSERT_OK(writer->Close());
+}
+
+TEST_F(TestOptions, DoExchangeReadOptionsBegin) {
+ // Call DoExchange and write nested data, but read with a very low nesting
depth set to
+ // fail the call. Here the options are set explicitly when we write data and
not in the
+ // call options.
+ auto descr = FlightDescriptor::Command("");
+ std::unique_ptr reader;
+ std::unique_ptr writer;
+ ASSERT_OK(client_->DoExchange(descr, &writer, &reader));
+ BatchVector batches;
+ ASSERT_OK(ExampleNestedBatches(&batches));
+ auto options = ipc::IpcWriteOptions::Defaults();
+ options.max_recursion_depth = 1;
+ ASSERT_OK(writer->Begin(batches[0]->schema(), options));
+ for (const auto& batch : batches) {
+ASSERT_RAISES(Invalid, writer->WriteRecordBatch(*batch));
+ }
+ ASSERT_OK(writer->DoneWriting());
+ ASSERT_OK(writer->Close());
+}
+
+TEST_F(TestOptions, DoExchangeWriteOptions) {
+ // Call DoExchange and write nested data, but with a very low nesting depth
set to fail
+ // the call. (The low nesting depth is set on the server side.)
+ auto options = FlightCallOptions();
+ options.read_options.max_recursion_depth = 1;
Review comment:
Why do you set the read options here? AFAICT, this test raises its error
on the server side.
##
File path: cpp/src/arrow/flight/flight_test.cc
##
@@ -1808,6 +1880,90 @@ TEST_F(TestMetadata, DoPutReadMetadata) {
ASSERT_OK(writer->Close());
}
+TEST_F(TestOptions, DoGetReadOptions) {
+ // Call DoGet, but with a very low read nesting depth set to fail the call.
+ Ticket ticket{""};
+ auto options = FlightCallOptions();
+ options.read_options.max_recursion_depth = 1;
+ std::unique_ptr stream;
+ ASSERT_OK(client_->DoGet(options, ticket, &stream));
+ FlightStreamChunk chunk;
+ ASSERT_RAISES(Invalid, stream->Next(&chunk));
+}
+
+TEST_F(TestOptions, DoPutWriteOptions) {
+ // Call DoPut, but with a very low write nesting depth set to fail the call.
+ std::unique_ptr writer;
+ std::unique_ptr reader;
+ BatchVector expected_batches;
+ ASSERT_OK(ExampleNestedBatches(&expected_batches));
+
+ auto options = FlightCallOptions();
+ options.write_options.max_recursion_depth = 1;
+ ASSERT_OK(client_->DoPut(options, FlightDescriptor{},
expected_batches[0]->schema(),
+ &writer, &reader));
+ for (const auto& batch : expected_batches) {
+ASSERT_RAISES(Invalid, writer->WriteRecordBatch(*batch));
+ }
+}
+
+TEST_F(TestOptions, DoExchangeReadOptions) {
+ // Call DoExchange and write nested data, but read with a very low nesting
depth set to
Review comment:
Comment seems off, it's the write options that are being set (and it's
the `WriteRecordBatch` call that fails).
##
File path: cpp/src/arrow/flight/flight_test.cc
##
@@ -1808,6 +1880,90 @@ TEST_F(TestMetadata, DoPutReadMetadata) {
ASSERT_OK(writer->Close());
}
+TEST_F(TestOptions, DoGetReadOptions) {
+ // Call DoGet, but with a very low read nesting depth set to fail the call.
+
[GitHub] [arrow] xhochy commented on pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
xhochy commented on pull request #7593: URL: https://github.com/apache/arrow/pull/7593#issuecomment-651779867 This currently fails for chunked arrays. I though that they should be handled by the kernel framework automatically but it seems, they aren't. ``` [--] 1 test from TestStringKernels/1, where TypeParam = arrow::LargeStringType [ RUN ] TestStringKernels/1.ContainsExact ../src/arrow/testing/gtest_util.cc:149: Failure Failed Got: [ [ false, null, false ] ] Expected: [ [ true, null ], [ false ] ] ../src/arrow/testing/gtest_util.cc:149: Failure Failed Got: [ [ false, false, false, null, false ] ] Expected: [ [ true, false ], [ true, null, false ] ] [ FAILED ] TestStringKernels/1.ContainsExact, where TypeParam = arrow::LargeStringType (2 ms) ``` @wesm @pitrou Any pointers what I'm missing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] lidavidm commented on pull request #7543: ARROW-9221: [Java] account for big-endian buffers in ArrowBuf.setBytes
lidavidm commented on pull request #7543: URL: https://github.com/apache/arrow/pull/7543#issuecomment-651777225 Would a Java maintainer be able to look at this? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
pitrou commented on pull request #7590: URL: https://github.com/apache/arrow/pull/7590#issuecomment-651773473 @crcrpar Do you think the version I pushed is ok and clear enough? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] xhochy opened a new pull request #7593: ARROW-9160: [C++] Implement contains for exact matches
xhochy opened a new pull request #7593: URL: https://github.com/apache/arrow/pull/7593 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nevi-me closed pull request #7588: ARROW-9274: [Rust] Parse 64bit numbers from integration files as strings
nevi-me closed pull request #7588: URL: https://github.com/apache/arrow/pull/7588 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
pitrou commented on pull request #7590: URL: https://github.com/apache/arrow/pull/7590#issuecomment-651769268 Thank you for spotting this and suggesting a fix! I will make a couple changes to your suggestion. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou opened a new pull request #7592: ARROW-9220: [C++] Make utf8proc optional even with ARROW_COMPUTE=ON
pitrou opened a new pull request #7592: URL: https://github.com/apache/arrow/pull/7592 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7591: ARROW-8535: [Rust] Specify arrow-flight version
github-actions[bot] commented on pull request #7591: URL: https://github.com/apache/arrow/pull/7591#issuecomment-651768213 https://issues.apache.org/jira/browse/ARROW-8535 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7590: ARROW-9277: [C++] Fix docs of reading CSV files
github-actions[bot] commented on pull request #7590: URL: https://github.com/apache/arrow/pull/7590#issuecomment-651768214 https://issues.apache.org/jira/browse/ARROW-9277 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nevi-me opened a new pull request #7591: ARROW-8535: [Rust] Specify arrow-flight version
nevi-me opened a new pull request #7591: URL: https://github.com/apache/arrow/pull/7591 This is to ensure that Rust users who include the arrow crate from crates.io do not get errors as they would not have the arrow-flight directory This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7589: ARROW-9276: [Release] Enforce CUDA device for updating the api documentations
github-actions[bot] commented on pull request #7589: URL: https://github.com/apache/arrow/pull/7589#issuecomment-651761179 https://issues.apache.org/jira/browse/ARROW-9276 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7590: [C++] Fix docs of reading CSV files
github-actions[bot] commented on pull request #7590:
URL: https://github.com/apache/arrow/pull/7590#issuecomment-651761199
Thanks for opening a pull request!
Could you open an issue for this pull request on JIRA?
https://issues.apache.org/jira/browse/ARROW
Then could you also rename pull request title in the following format?
ARROW-${JIRA_ID}: [${COMPONENT}] ${SUMMARY}
See also:
* [Other pull requests](https://github.com/apache/arrow/pulls/)
* [Contribution Guidelines - How to contribute
patches](https://arrow.apache.org/docs/developers/contributing.html#how-to-contribute-patches)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] crcrpar opened a new pull request #7590: [C++] Fix docs of reading CSV files
crcrpar opened a new pull request #7590: URL: https://github.com/apache/arrow/pull/7590 Hi, This is my first PR for this awesome project. So if I do not follow the workflow, could you tell me, please? In this PR, I aim at fixing https://arrow.apache.org/docs/cpp/csv.html?highlight=csv%20c#basic-usage as I found the example not working in my environment (arrow v0.17.1). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] kszucs commented on a change in pull request #7589: ARROW-9276: [Release] Enforce CUDA device for updating the api documentations
kszucs commented on a change in pull request #7589:
URL: https://github.com/apache/arrow/pull/7589#discussion_r447643080
##
File path: dev/release/post-09-docs.sh
##
@@ -42,20 +47,20 @@ popd
pushd "${ARROW_DIR}"
git checkout "${release_tag}"
Review comment:
@wesm could you try running it after commenting the checkout line above
(unless you have the tag locally):
```bash
PUSH=0 dev/release/post-09-docs.sh 0.17.1
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [arrow] kszucs opened a new pull request #7589: ARROW-9276: [Release] Enforce CUDA device for updating the api documentations
kszucs opened a new pull request #7589: URL: https://github.com/apache/arrow/pull/7589 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nevi-me commented on pull request #7588: ARROW-9274: [Rust] Parse 64bit numbers from integration files as strings
nevi-me commented on pull request #7588: URL: https://github.com/apache/arrow/pull/7588#issuecomment-651720277 @wesm may I merge this? The Travis CI often takes long to start running This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
pitrou commented on pull request #7449: URL: https://github.com/apache/arrow/pull/7449#issuecomment-651717472 Phew. It worked. RTools 4.0 is still broken, but there doesn't seem to be anything we can do, except perhaps disable that job. I'm gonna merge and leave the R cleanup to someone else. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou closed pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
pitrou closed pull request #7449: URL: https://github.com/apache/arrow/pull/7449 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7588: ARROW-9274: [Rust] Parse 64bit numbers from integration files as strings
github-actions[bot] commented on pull request #7588: URL: https://github.com/apache/arrow/pull/7588#issuecomment-651709041 https://issues.apache.org/jira/browse/ARROW-9274 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] tianchen92 commented on pull request #6156: ARROW-7539: [Java] FieldVector getFieldBuffers API should not set reader/writer indices
tianchen92 commented on pull request #6156: URL: https://github.com/apache/arrow/pull/6156#issuecomment-651706326 > Can we leave the old method in place and mark it as deprecated and remove in a later release? I am afraid it's not reasonable. since we need the right order in IPC and Dremio need the old wrong order in getBuffers to avoid test failure, unless we correct the behavior in getBuffers and rename the old method like getBuffers2 which seems ugly . @projjal Any thought? :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] nevi-me opened a new pull request #7588: ARROW-9274: [Rust] Parse 64bit numbers from integration files as strings
nevi-me opened a new pull request #7588: URL: https://github.com/apache/arrow/pull/7588 This fixes Rust build failures This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [arrow] pitrou closed pull request #7580: ARROW-9261: [Python] Fix CA certificate lookup with S3 filesystem on manylinux
pitrou closed pull request #7580: URL: https://github.com/apache/arrow/pull/7580 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org