[GitHub] carbondata issue #2969: [CARBONDATA-3127]Fix the TestCarbonSerde exception
Github user SteNicholas commented on the issue: https://github.com/apache/carbondata/pull/2969 @zzcclp Please review this update. ---
[GitHub] carbondata issue #2975: [WIP][CARBONDATA-3145] Read improvement for complex ...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2975 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1642/ ---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1641/ ---
[GitHub] carbondata pull request #2975: [WIP][CARBONDATA-3145] Read improvement for c...
GitHub user dhatchayani opened a pull request: https://github.com/apache/carbondata/pull/2975 [WIP][CARBONDATA-3145] Read improvement for complex column pages while querying **Problem:** Column page is decoded for getting each row of a complex primitive column. **Solution:** Decode a page it once then use the same. - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [x] Testing done Existing UT - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/dhatchayani/carbondata CARBONDATA-3145 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2975.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2975 commit 2f1f8b0081f3229ef151f8171b19fa76006065fb Author: dhatchayani Date: 2018-12-05T07:10:56Z [CARBONDATA-3145] Read improvement for complex column pages while querying ---
[GitHub] carbondata issue #2969: [CARBONDATA-3127]Fix the TestCarbonSerde exception
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2969 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1851/ ---
[GitHub] carbondata issue #2969: [CARBONDATA-3127]Fix the TestCarbonSerde exception
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2969 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9900/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9899/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1850/ ---
[GitHub] carbondata issue #2969: [CARBONDATA-3127]Fix the TestCarbonSerde exception
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2969 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1640/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1639/ ---
[GitHub] carbondata pull request #2969: [CARBONDATA-3127]Fix the TestCarbonSerde exce...
Github user SteNicholas commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2969#discussion_r238936639
--- Diff:
integration/hive/src/test/java/org/apache/carbondata/hive/TestCarbonSerDe.java
---
@@ -0,0 +1,133 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.hive;
+
+import junit.framework.TestCase;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.hive.common.type.HiveDecimal;
+import org.apache.hadoop.hive.serde2.SerDeException;
+import org.apache.hadoop.hive.serde2.SerDeUtils;
+import org.apache.hadoop.hive.serde2.io.DoubleWritable;
+import org.apache.hadoop.hive.serde2.io.HiveDecimalWritable;
+import org.apache.hadoop.hive.serde2.io.ShortWritable;
+import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
+import org.apache.hadoop.io.*;
+import org.junit.Test;
+
+import java.util.Properties;
+
+public class TestCarbonSerDe extends TestCase {
+@Test
+public void testCarbonHiveSerDe() throws Throwable {
+try {
+// Create the SerDe
+System.out.println("test: testCarbonHiveSerDe");
+
+final CarbonHiveSerDe serDe = new CarbonHiveSerDe();
+final Configuration conf = new Configuration();
+final Properties tbl = createProperties();
+SerDeUtils.initializeSerDe(serDe, conf, tbl, null);
+
+// Data
+final Writable[] arr = new Writable[7];
+
+//primitive types
+arr[0] = new ShortWritable((short) 456);
+arr[1] = new IntWritable(789);
+arr[2] = new LongWritable(1000l);
+arr[3] = new DoubleWritable(5.3);
+arr[4] = new HiveDecimalWritable(HiveDecimal.create(1));
+arr[5] = new Text("carbonSerde binary".getBytes("UTF-8"));
--- End diff --
@xubo245 Sorry to forget string spell format,please review it.Sorry for the
inconvenience.
---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9898/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1638/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1849/ ---
[GitHub] carbondata pull request #2974: [CARBONDATA-2563][CATALYST] Explain query wit...
Github user qiuchenjian commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2974#discussion_r238906069 --- Diff: integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/table/CarbonExplainCommand.scala --- @@ -51,8 +51,8 @@ case class CarbonExplainCommand( sparkSession.sessionState.executePlan(child.asInstanceOf[ExplainCommand].logicalPlan) --- End diff -- Whether this code (line 50 and 51) is not executed , if isQueryStatisticsEnabled is false ---
[GitHub] carbondata issue #2966: [WIP] test and check no sort by default
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2966 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1848/ ---
[GitHub] carbondata issue #2966: [WIP] test and check no sort by default
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2966 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9897/ ---
[GitHub] carbondata issue #2966: [WIP] test and check no sort by default
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2966 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1637/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1847/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9896/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1636/ ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2974 @ravipesala @kumarvishal09 Please review and let me know for suggestions. ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2974 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1635/ ---
[GitHub] carbondata pull request #2974: [CARBONDATA-2563][CATALYST] Explain query wit...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2974 [CARBONDATA-2563][CATALYST] Explain query with Order by operator is fired Spark Job which is increase explain query time even though isQueryStatisticsEnabled is false ## What changes were proposed in this pull request? Even though isQueryStatisticsEnabled is false which means user doesnt wants to see statistics for explain command, still the engine tries to fetch the paritions information which causes a job execution in case of order by query, this is mainly because spark engine does sampling for defifning certain range within paritions for sorting process. As part of solution the explain command process shall fetch the parition info only if isQueryStatisticsEnabled true. ## How was this patch tested? Manual testing. Before fix 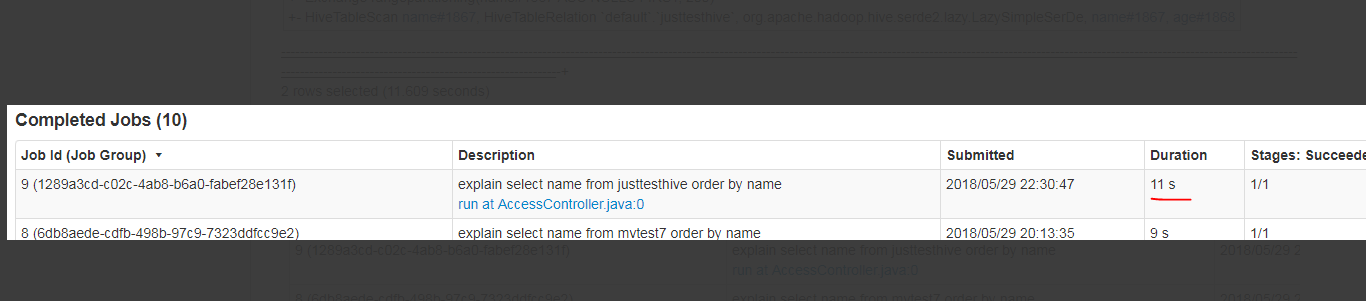 After fix 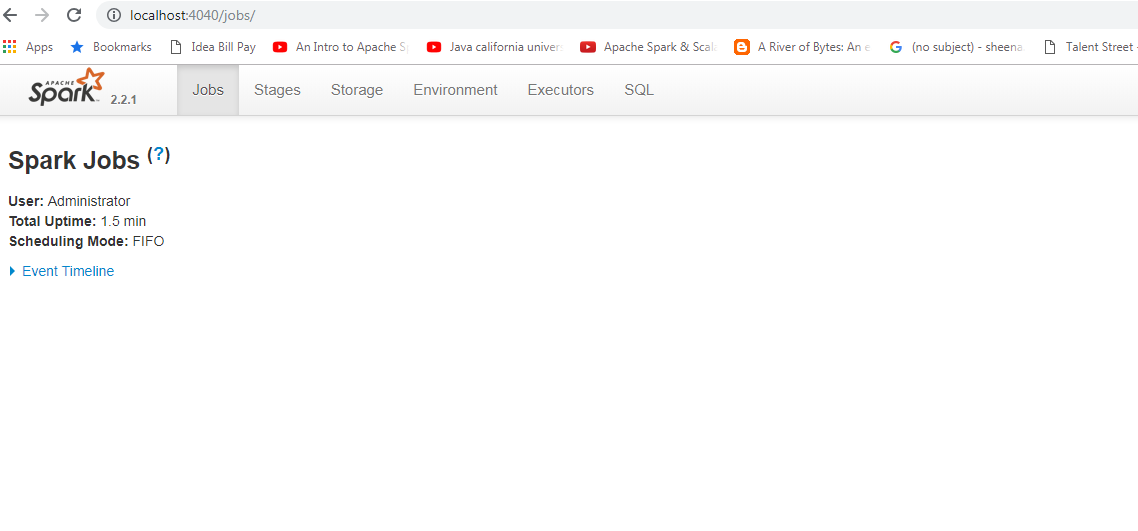 You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata master_explin Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2974.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2974 commit b20005d3cfbfbadd316ef9d8f7749c9236fe8bc8 Author: s71955 Date: 2018-12-04T15:18:55Z [CARBONDATA-2563][CATALYST] Explain query with Order by operator is fired Spark Job which is increase explain query time even though isQueryStatisticsEnabled is false ## What changes were proposed in this pull request? Even though isQueryStatisticsEnabled is false which means user doesnt wants to see statistics for explain command, still the engine tries to fetch the paritions information which causes a job execution in case of order by query, this is mainly because spark engine does sampling for defifning certain range within paritions for sorting process. As part of solution the explain command process shall fetch the parition info only if isQueryStatisticsEnabled true. ## How was this patch tested? Manual testing. ---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9894/ ---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1845/ ---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1634/ ---
[GitHub] carbondata pull request #2847: [WIP]Support Gzip as column compressor
Github user akashrn5 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2847#discussion_r238658593
--- Diff:
core/src/main/java/org/apache/carbondata/core/datastore/compression/GzipCompressor.java
---
@@ -0,0 +1,203 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.core.datastore.compression;
+
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import java.nio.ByteBuffer;
+import java.nio.DoubleBuffer;
+import java.nio.FloatBuffer;
+import java.nio.IntBuffer;
+import java.nio.LongBuffer;
+import java.nio.ShortBuffer;
+
+import org.apache.carbondata.core.util.ByteUtil;
+
+import
org.apache.commons.compress.compressors.gzip.GzipCompressorInputStream;
+import
org.apache.commons.compress.compressors.gzip.GzipCompressorOutputStream;
+
+public class GzipCompressor implements Compressor {
+
+ public GzipCompressor() {
+ }
+
+ @Override public String getName() {
+return "gzip";
+ }
+
+ /*
+ * Method called for compressing the data and
--- End diff --
change the comment as starndard doc
---
[GitHub] carbondata pull request #2847: [WIP]Support Gzip as column compressor
Github user akashrn5 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2847#discussion_r238657955
--- Diff:
core/src/main/java/org/apache/carbondata/core/datastore/compression/GzipCompressor.java
---
@@ -0,0 +1,203 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.core.datastore.compression;
+
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import java.nio.ByteBuffer;
+import java.nio.DoubleBuffer;
+import java.nio.FloatBuffer;
+import java.nio.IntBuffer;
+import java.nio.LongBuffer;
+import java.nio.ShortBuffer;
+
+import org.apache.carbondata.core.util.ByteUtil;
+
+import
org.apache.commons.compress.compressors.gzip.GzipCompressorInputStream;
+import
org.apache.commons.compress.compressors.gzip.GzipCompressorOutputStream;
+
+public class GzipCompressor implements Compressor {
+
+ public GzipCompressor() {
+ }
+
+ @Override public String getName() {
+return "gzip";
+ }
+
+ /*
+ * Method called for compressing the data and
+ * return a byte array
+ */
+ private byte[] compressData(byte[] data) {
+
+ByteArrayOutputStream byteArrayOutputStream = new
ByteArrayOutputStream();
+try {
+ GzipCompressorOutputStream gzipCompressorOutputStream =
+ new GzipCompressorOutputStream(byteArrayOutputStream);
+ try {
+gzipCompressorOutputStream.write(data);
+ } catch (IOException e) {
+throw new RuntimeException("Error during Compression step " +
e.getMessage());
+ } finally {
+gzipCompressorOutputStream.close();
+ }
+} catch (IOException e) {
+ throw new RuntimeException("Error during Compression step " +
e.getMessage());
+}
+
+return byteArrayOutputStream.toByteArray();
+ }
+
+ /*
+ * Method called for decompressing the data and
+ * return a byte array
+ */
+ private byte[] decompressData(byte[] data) {
+
+ByteArrayInputStream byteArrayOutputStream = new
ByteArrayInputStream(data);
+ByteArrayOutputStream byteOutputStream = new ByteArrayOutputStream();
+
--- End diff --
remove empty line
---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1844/ ---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9893/ ---
[GitHub] carbondata issue #2847: [WIP]Support Gzip as column compressor
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2847 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1633/ ---
[GitHub] carbondata issue #2972: [CARBONDATA-3143] Fixed local dictionary in presto
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2972 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1843/ ---
[GitHub] carbondata issue #2972: [CARBONDATA-3143] Fixed local dictionary in presto
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2972 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9892/ ---
[GitHub] carbondata issue #2972: [CARBONDATA-3143] Fixed local dictionary in presto
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2972 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1632/ ---
[GitHub] carbondata issue #2968: [CARBONDATA-3141] Removed Carbon Table Detail Comman...
Github user manishgupta88 commented on the issue: https://github.com/apache/carbondata/pull/2968 LGTM ---
[GitHub] carbondata issue #2973: [WIP][CARBONDATA-3144] CarbonData support spark-2.4....
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2973 Build Failed with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9891/ ---
[GitHub] carbondata issue #2973: [WIP][CARBONDATA-3144] CarbonData support spark-2.4....
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2973 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1842/ ---
[GitHub] carbondata issue #2973: [WIP][CARBONDATA-3144] CarbonData support spark-2.4....
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2973 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1631/ ---
[GitHub] carbondata issue #2951: [SDV] Add datasource testcases for Spark File Format
Github user shivamasn commented on the issue: https://github.com/apache/carbondata/pull/2951 > @shivamasn Please add description for the PR. Also attach test report in the description. Done ---
[GitHub] carbondata pull request #2973: [WIP][CARBONDATA-3144] CarbonData support spa...
GitHub user xubo245 opened a pull request: https://github.com/apache/carbondata/pull/2973 [WIP][CARBONDATA-3144] CarbonData support spark-2.4.0 Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xubo245/carbondata CARBONDATA-3144_supportSpark2_4 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2973.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2973 commit a9aa1058c67e76a9120f0d7794b961e6eac2afa4 Author: xubo245 Date: 2018-12-04T10:08:01Z [CARBONDATA-3144] CarbonData support spark-2.4.0 commit b344a8930b4cdde1aab3ccd132a895a880b41b92 Author: xubo245 Date: 2018-12-04T10:10:19Z add ---
[GitHub] carbondata issue #2971: [TEST] Test loading performance of range_sort
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2971 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/1841/ ---
[GitHub] carbondata issue #2971: [TEST] Test loading performance of range_sort
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2971 Build Success with Spark 2.3.1, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/9890/ ---
[GitHub] carbondata issue #2971: [TEST] Test loading performance of range_sort
Github user CarbonDataQA commented on the issue: https://github.com/apache/carbondata/pull/2971 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/1630/ ---