[GitHub] [carbondata] zhangboren93 opened a new issue, #4281: [SDK Optimization] Multiple SimpleDateFormat initialization in CarbonReader
zhangboren93 opened a new issue, #4281: URL: https://github.com/apache/carbondata/issues/4281 I found that reading carbon files from CarbonReader takes long time in "SimpleDateFormat.", see attached file for output of profiling. https://github.com/apache/carbondata/blob/4b8846d1e6737e7db8a96014818c067c8c253d1f/sdk/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonReader.java#L207 I wonder if it is OK if we add some lazy initialization to SimpleDateFormat in the class, and if so should it support multi-threading. [profile.zip](https://github.com/apache/carbondata/files/8954954/profile.zip) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Black-max12138 opened a new issue, #4275: carbonReader read incomplete data
Black-max12138 opened a new issue, #4275:
URL: https://github.com/apache/carbondata/issues/4275
Look at this line of code. `boolean hasNext = currentReader.nextKeyValue();`
If hasNext returns false and currentReader is not the last one, it indicates
that the iterator exits and subsequent data is not parsed. How to solve this
problem?
```
/**
* Return true if has next row
*/
public boolean hasNext() throws IOException, InterruptedException {
if (0 == readers.size() || currentReader == null) {
return false;
}
validateReader();
if (currentReader.nextKeyValue()) {
return true;
} else {
if (index == readers.size() - 1) {
// no more readers
return false;
} else {
// current reader is closed
currentReader.close();
// no need to keep a reference to CarbonVectorizedRecordReader,
// until all the readers are processed.
// If readers count is very high,
// we get OOM as GC not happened for any of the content in
CarbonVectorizedRecordReader
readers.set(index, null);
index++;
currentReader = readers.get(index);
boolean hasNext = currentReader.nextKeyValue();
if (hasNext) {
return true;
}
}
}
return false;
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] liutaobigdata opened a new issue #4249: Failed to execute goal org.codehaus.mojo:findbugs-maven-plugin:3.0.4:check
liutaobigdata opened a new issue #4249: URL: https://github.com/apache/carbondata/issues/4249 when I change hadoop version from 2.7.2 to 3.0.0 while compileing the source the error is coming : Failed to execute goal org.codehaus.mojo:findbugs-maven-plugin:3.0.4:check (analyze-compile) on project carbondata-core: failed with 1 bugs and 0 errors -> [Help 1] [ERROR] has anyone encountered ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] XinyuZeng opened a new issue #4247: All figures in cwiki are broken
XinyuZeng opened a new issue #4247: URL: https://github.com/apache/carbondata/issues/4247 For example, figures in https://cwiki.apache.org/confluence/display/CARBONDATA/Unique+Data+Organization are broken. Could you fix the issue? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] chenliang613 commented on issue #4236: 【字节跳动】招聘意向沟通
chenliang613 commented on issue #4236: URL: https://github.com/apache/carbondata/issues/4236#issuecomment-972810564 Will close this issue. Please don't create recruitment advertisement issue. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] yoooouth opened a new issue #4236: 【字节跳动】招聘意向沟通
yuth opened a new issue #4236: URL: https://github.com/apache/carbondata/issues/4236 你好, 我是字节跳动Data&搜索的HR,负责大数据方向的岗位招聘。目前我们正在招募组建Flink/Presto/Spark/Hudi/Iceberg等这几个方向的大数据引擎团队,负责人和工程师的需求都有,北/上/杭base地点灵活。请问您有兴趣聊聊吗? 期待回复,谢谢! 联系人:陈凌薇 +86-15268606705 Hello, my name is Lisa Chen. I am the HR of ByteDance Data, responsible for job recruitment in the direction of big data. At present, we are recruiting and forming big data engine teams in Flink/Presto/Spark/Hudi/Iceberg, etc. The positions required are: team leader and engineer,also the base is flexible(Beijing /Hangzhou/Shanghai)Are you interested in chatting? Looking forward to reply, thank you! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] maheshrajus edited a comment on issue #4181: it does not support merge into ,please modify the document.
maheshrajus edited a comment on issue #4181: URL: https://github.com/apache/carbondata/issues/4181#issuecomment-939908981 Hi, Merge into support is added as part of below PR(1). Please check the below guide(2) about merge into operations. You can refer below test cases(3). Carbondata supports ACID. you can refer(4) for more details. 1 https://github.com/apache/carbondata/pull/4032 2 https://github.com/apache/carbondata/blob/master/docs/scd-and-cdc-guide.md 3 https://github.com/apache/carbondata/blob/master/integration/spark/src/test/scala/org/apache/carbondata/spark/testsuite/iud/MergeIntoCarbonTableTestCase.scala 4 https://brijoobopanna.medium.com/making-apache-spark-better-with-carbondata-d37f98d235de Thanks & Regards -Mahesh Raju S (githubid: maheshrajus) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] maheshrajus commented on issue #4181: it does not support merge into ,please modify the document.
maheshrajus commented on issue #4181: URL: https://github.com/apache/carbondata/issues/4181#issuecomment-939908981 Hi, Merge into support is added as part of below PR(#1). Please check the below guide(#2) about merge into operations. You can refer below test cases(#3). Carbondata supports ACID. you can refer(#4) for more details. #1 https://github.com/apache/carbondata/pull/4032 #2 https://github.com/apache/carbondata/blob/master/docs/scd-and-cdc-guide.md #3 https://github.com/apache/carbondata/blob/master/integration/spark/src/test/scala/org/apache/carbondata/spark/testsuite/iud/MergeIntoCarbonTableTestCase.scala #4 https://brijoobopanna.medium.com/making-apache-spark-better-with-carbondata-d37f98d235de Thanks & Regards -Mahesh Raju S (githubid: maheshrajus) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Lior-AI commented on issue #4212: Cannot Insert data to table with a partitions in Spark in EMR
Lior-AI commented on issue #4212: URL: https://github.com/apache/carbondata/issues/4212#issuecomment-939502383 1.No, This are the logs: ``` SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/mnt/yarn/usercache/livy/filecache/48/__spark_libs__3665716770347383703.zip/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 21/09/29 15:44:36 INFO CoarseGrainedExecutorBackend: Started daemon with process name: 18902@ip-10-4-181-156 21/09/29 15:44:37 INFO SignalUtils: Registered signal handler for TERM 21/09/29 15:44:37 INFO SignalUtils: Registered signal handler for HUP 21/09/29 15:44:37 INFO SignalUtils: Registered signal handler for INT 21/09/29 15:44:37 INFO SecurityManager: Changing view acls to: yarn,livy 21/09/29 15:44:37 INFO SecurityManager: Changing modify acls to: yarn,livy 21/09/29 15:44:37 INFO SecurityManager: Changing view acls groups to: 21/09/29 15:44:37 INFO SecurityManager: Changing modify acls groups to: 21/09/29 15:44:37 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(yarn, livy); groups with view permissions: Set(); users with modify permissions: Set(yarn, livy); groups with modify permissions: Set() 21/09/29 15:44:38 INFO TransportClientFactory: Successfully created connection to ip-10-4-137-125.eu-west-1.compute.internal/10.4.137.125:34545 after 78 ms (0 ms spent in bootstraps) 21/09/29 15:44:38 INFO SecurityManager: Changing view acls to: yarn,livy 21/09/29 15:44:38 INFO SecurityManager: Changing modify acls to: yarn,livy 21/09/29 15:44:38 INFO SecurityManager: Changing view acls groups to: 21/09/29 15:44:38 INFO SecurityManager: Changing modify acls groups to: 21/09/29 15:44:38 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(yarn, livy); groups with view permissions: Set(); users with modify permissions: Set(yarn, livy); groups with modify permissions: Set() 21/09/29 15:44:38 INFO TransportClientFactory: Successfully created connection to ip-10-4-137-125.eu-west-1.compute.internal/10.4.137.125:34545 after 1 ms (0 ms spent in bootstraps) 21/09/29 15:44:38 INFO DiskBlockManager: Created local directory at /mnt2/yarn/usercache/livy/appcache/application_1632902169938_0005/blockmgr-5aa03748-2d6d-4c78-9da5-1ef0e23cc506 21/09/29 15:44:38 INFO DiskBlockManager: Created local directory at /mnt1/yarn/usercache/livy/appcache/application_1632902169938_0005/blockmgr-2dba9cef-1782-4baa-a13f-fe379e090118 21/09/29 15:44:38 INFO DiskBlockManager: Created local directory at /mnt/yarn/usercache/livy/appcache/application_1632902169938_0005/blockmgr-d279178b-8dc9-4319-a64c-1e5bad11fe29 21/09/29 15:44:38 INFO MemoryStore: MemoryStore started with capacity 4.0 GB 21/09/29 15:44:38 INFO CoarseGrainedExecutorBackend: Connecting to driver: spark://coarsegrainedschedu...@ip-10-4-137-125.eu-west-1.compute.internal:34545 21/09/29 15:44:38 INFO CoarseGrainedExecutorBackend: Successfully registered with driver 21/09/29 15:44:38 INFO Executor: Starting executor ID 4 on host ip-10-4-181-156.eu-west-1.compute.internal 21/09/29 15:44:38 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 38947. 21/09/29 15:44:38 INFO NettyBlockTransferService: Server created on ip-10-4-181-156.eu-west-1.compute.internal:38947 21/09/29 15:44:38 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 21/09/29 15:44:38 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(4, ip-10-4-181-156.eu-west-1.compute.internal, 38947, None) 21/09/29 15:44:38 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(4, ip-10-4-181-156.eu-west-1.compute.internal, 38947, None) 21/09/29 15:44:38 INFO BlockManager: external shuffle service port = 7337 21/09/29 15:44:38 INFO BlockManager: Registering executor with local external shuffle service. 21/09/29 15:44:38 INFO TransportClientFactory: Successfully created connection to ip-10-4-181-156.eu-west-1.compute.internal/10.4.181.156:7337 after 2 ms (0 ms spent in bootstraps) 21/09/29 15:44:38 INFO BlockManager: Initialized BlockManager: BlockManagerId(4, ip-10-4-181-156.eu-west-1.compute.internal, 38947, None) 21/09/29 15:44:38 INFO Executor: Using REPL class URI: spark://ip-10-4-137-125.eu-west-1.compute.internal:34545/classes 21/09/29 15:44:38 INFO CoarseGrainedExecutorBackend: Got assigned task 1 21/09/29 15:44:38 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
[GitHub] [carbondata] maheshrajus commented on issue #4223: Question about lucene index and presto integration.
maheshrajus commented on issue #4223: URL: https://github.com/apache/carbondata/issues/4223#issuecomment-928846480 @tsinan 1)Create lucene index is not support from presto 2) Read lucene index support is there [You need to create lucene index from spark] -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] maheshrajus commented on issue #4223: Question about lucene index and presto integration.
maheshrajus commented on issue #4223: URL: https://github.com/apache/carbondata/issues/4223#issuecomment-928846480 @tsinan 1)Create lucene index is not support from presto 2) Read lucene index support is there [You need to create lucene index from spark] -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Indhumathi27 commented on issue #4212: Cannot Insert data to table with a partitions in Spark in EMR
Indhumathi27 commented on issue #4212: URL: https://github.com/apache/carbondata/issues/4212#issuecomment-927895361 Hi, Please check the following. If any exception occurred during insert ? because the segment here is Marked for Delete If scenario works fine with non-partition table ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] tsinan opened a new issue #4223: Question about lucene index and presto integration.
tsinan opened a new issue #4223: URL: https://github.com/apache/carbondata/issues/4223 When use prestosql to query carbondata, the lucene index can be used to prune blocklet? (Like 'TEXT_MATCH') Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Lior-AI commented on issue #4206: Cannot create table with partitions in Spark in EMR
Lior-AI commented on issue #4206: URL: https://github.com/apache/carbondata/issues/4206#issuecomment-911815814 Solved in https://github.com/apache/carbondata/commit/42f69827e0a577b6128417104c0a49cd5bf21ad7 but now there is a different problem : https://github.com/apache/carbondata/issues/4212 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Lior-AI closed issue #4206: Cannot create table with partitions in Spark in EMR
Lior-AI closed issue #4206: URL: https://github.com/apache/carbondata/issues/4206 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Lior-AI opened a new issue #4212: Cannot Insert data to table with a partitions
Lior-AI opened a new issue #4212: URL: https://github.com/apache/carbondata/issues/4212 After https://github.com/apache/carbondata/commit/42f69827e0a577b6128417104c0a49cd5bf21ad7 I have successfully created a table with partitions, but when I trying insert data the job end with a success but the segment is marked as "Marked for Delete" I running ```sql CREATE TABLE lior_carbon_tests.mark_for_del_bug( timestamp string, name string ) STORED AS carbondata PARTITIONED BY (dt string, hr string) ``` ```sql INSERT INTO lior_carbon_tests.mark_for_del_bug select '2021-07-07T13:23:56.012+00:00','spark','2021-07-07','13' ``` ```sql select * from lior_carbon_tests.mark_for_del_bug ``` gives ``` +-++---+---+ |timestamp|name| dt| hr| +-++---+---+ +-++---+---+ ``` ```sql show segments for TABLE lior_carbon_tests.mark_for_del_bug ``` gives ``` +---+-+---+---+-+-+--+---+ |ID |Status |Load Start Time|Load Time Taken|Partition|Data Size|Index Size|File Format| +---+-+---+---+-+-+--+---+ |0 |Marked for Delete|2021-09-02 15:24:21.022|11.798S|NA |NA |NA|columnar_v3| +---+-+---+---+-+-+--+---+ ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4206: Cannot create table with partitions in Spark in EMR
nihal0107 commented on issue #4206: URL: https://github.com/apache/carbondata/issues/4206#issuecomment-903767216 Hi, As you can see the error message is `partition is not supported for external table`. Whenever you create a table with location then it will be an external table and we are not supporting partition for the external table. Partition is only supported for the transactional table. please go through other details about partitions https://github.com/apache/carbondata/blob/master/docs/ddl-of-carbondata.md#partition -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] Lior-AI opened a new issue #4206: Cannot create table with partitions in Spark in EMR
Lior-AI opened a new issue #4206: URL: https://github.com/apache/carbondata/issues/4206 I am running spark in EMR > Release label:emr-5.24.1 Hadoop distribution:Amazon 2.8.5 Applications: Hive 2.3.4, Pig 0.17.0, Hue 4.4.0, Flink 1.8.0, Spark 2.4.2, Presto 0.219, JupyterHub 0.9.6 Jar complied with: >apache-carbondata:2.2.0 spark:2.4.5 hadoop:2.8.3 When trying to create a table like this: ``` CREATE TABLE IF NOT EXISTS will_not_work( timestamp string, name string ) PARTITIONED BY (dt string, hr string) STORED AS carbondata LOCATION 's3a://my-bucket/CarbonDataTests/will_not_work ``` I get the following error: ``` org.apache.carbondata.common.exceptions.sql.MalformedCarbonCommandException: Partition is not supported for external table at org.apache.spark.sql.parser.CarbonSparkSqlParserUtil$.buildTableInfoFromCatalogTable(CarbonSparkSqlParserUtil.scala:219) at org.apache.spark.sql.CarbonSource$.createTableInfo(CarbonSource.scala:235) at org.apache.spark.sql.CarbonSource$.createTableMeta(CarbonSource.scala:394) at org.apache.spark.sql.execution.command.table.CarbonCreateDataSourceTableCommand.processMetadata(CarbonCreateDataSourceTableCommand.scala:69) at org.apache.spark.sql.execution.command.MetadataCommand$$anonfun$run$1.apply(package.scala:137) at org.apache.spark.sql.execution.command.MetadataCommand$$anonfun$run$1.apply(package.scala:137) at org.apache.spark.sql.execution.command.Auditable$class.runWithAudit(package.scala:118) at org.apache.spark.sql.execution.command.MetadataCommand.runWithAudit(package.scala:134) at org.apache.spark.sql.execution.command.MetadataCommand.run(package.scala:137) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79) at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194) at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194) at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3364) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3363) at org.apache.spark.sql.Dataset.(Dataset.scala:194) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:643) ... 64 elided ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] brijoobopanna commented on issue #4178: how to use MERGE INTO
brijoobopanna commented on issue #4178: URL: https://github.com/apache/carbondata/issues/4178#issuecomment-892560119 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4178: how to use MERGE INTO
study-day commented on issue #4178: URL: https://github.com/apache/carbondata/issues/4178#issuecomment-893095394 thanks ,Can I use sql to write merge into syntax? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] brijoobopanna commented on issue #4178: how to use MERGE INTO
brijoobopanna commented on issue #4178: URL: https://github.com/apache/carbondata/issues/4178#issuecomment-893295027 yes plz check examples here examples/spark/src/main/scala/org/apache/carbondata/examples/DataMergeIntoExample.scala -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4178: how to use MERGE INTO
study-day commented on issue #4178: URL: https://github.com/apache/carbondata/issues/4178#issuecomment-893095394 thanks ,Can I use sql to write merge into syntax? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] brijoobopanna commented on issue #4178: how to use MERGE INTO
brijoobopanna commented on issue #4178: URL: https://github.com/apache/carbondata/issues/4178#issuecomment-892560119 please check if below can help https://github.com/apache/carbondata/blob/master/examples/spark/src/main/scala/org/apache/carbondata/examples/CDCExample.scala -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] didiaode18 commented on issue #4182: FusionInsightHD 6518 spark2.3.2 carbon-2.0.0 skewedJoin adaptive execution no use.
didiaode18 commented on issue #4182: URL: https://github.com/apache/carbondata/issues/4182#issuecomment-889001315 +1 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] czy006 closed issue #4184: How to build successful of presto 333 version ?
czy006 closed issue #4184: URL: https://github.com/apache/carbondata/issues/4184 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] ajantha-bhat commented on issue #4184: How to build successful of presto 333 version ?
ajantha-bhat commented on issue #4184: URL: https://github.com/apache/carbondata/issues/4184#issuecomment-887262090 @czy006 : Hi, can you use spark2.3 profile instead of 2.4 ? 2.4 brings hadoop3 dependencies which doesn't work well with presto333. Also remove Dhadoop, Dhive version and try -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] czy006 opened a new issue #4184: How to build successful of presto 333 version ?
czy006 opened a new issue #4184: URL: https://github.com/apache/carbondata/issues/4184 @ajantha-bhat hello,I always build fail for your presto version about 333,I don't know what's problem,it must be use jdk11 to build it ? My mvn build command is my build command is mvn -DskipTests -Pspark-2.4 -Pprestosql -Dspark.version=2.4.5 -Dhadoop.version=2.7.7 -Dhive.version=3.1.0 ,but it say error is: has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0 . This is mean not support jdk8 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-886418870 thanks thanks thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day closed issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day closed issue #4173: URL: https://github.com/apache/carbondata/issues/4173 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-886379874 There is some ten valid segment status. You can refer to the file `SegmentStatus.java`. Once we trigger the load and if the load will be success then segment status will be success. And when we trigger compaction, all the segments that will participate in compaction will be marked as `compacted`, and new segments after compaction will be marked as success. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4182: FusionInsightHD 6518 spark2.3.2 carbon-2.0.0 skewedJoin adaptive execution no use.
study-day commented on issue #4182: URL: https://github.com/apache/carbondata/issues/4182#issuecomment-886306886 hi ,kongxianghe, We have also found a similar problem. If two tables are join, it will be very time-consuming if there is no de-duplication. And spark only uses a few executors.. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kongxianghe1234 commented on issue #4182: FusionInsightHD 6518 spark2.3.2 carbon-2.0.0 skewedJoin adaptive execution no use.
kongxianghe1234 commented on issue #4182: URL: https://github.com/apache/carbondata/issues/4182#issuecomment-885997419 also add "spark.shuffle.statistics.verbose=true",still no use for skewed join -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kongxianghe1234 opened a new issue #4182: FusionInsightHD 6518 spark2.3.2 carbon-2.0.0 skewedJoin adaptive execution no use.
kongxianghe1234 opened a new issue #4182: URL: https://github.com/apache/carbondata/issues/4182 spark.sql.adaptive.enabled=true spark.sql.adaptive.skewedJoin.enabled=true spark.sql.adaptive.skewedPartitionMaxSplits=5 spark.sql.adaptive.skewedPartitionRowCountThreshold=1000 spark.sql.adaptive.skewedPartitionSizeThreshold=67108864 spark.sql.adaptive.skewedPartitionFactor : 5 --- In Spark2x JDBC no use for it. t1 left join t2 on t1.id = t2.id column id has one key, for example -00-00 ,has 100,000 records t2 has same key in column id also has 100,000 records ,this will generate 10*10 = 10B records!! for only one reducer. carbon solution no use for it,please check it. -- call hw. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day removed a comment on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day removed a comment on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-885533091 thanks . what does it mean about 'Compacted' 'Success', the Status has how many types ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-885533091 thanks . what does it mean about 'Compacted' 'Success', the Status has how many types ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-885531971 thanks . what does it mean about 'Compacted' 'Success', the Status has how many types ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 edited a comment on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 edited a comment on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-885396320 That won't be deleted automatically. Once the retention time will expire then subsequent clean file command will delete the directory. 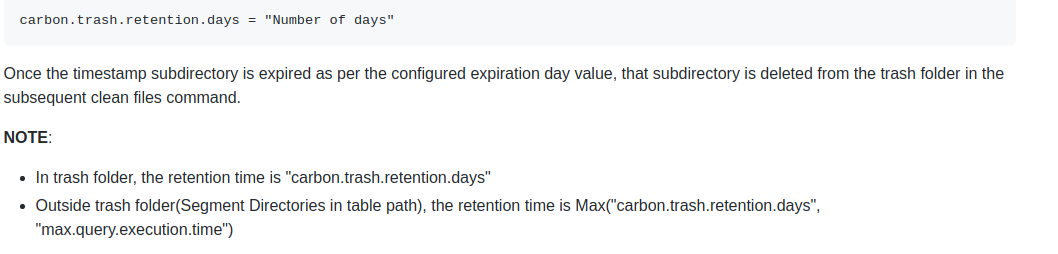 This is as per design. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-885396320 That won't be deleted automatically. Once the retention time will expire the subsequent clean file command will delete the directory. 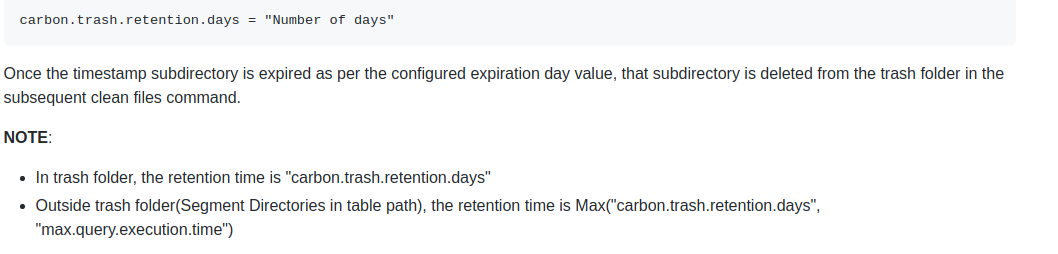 This is as per design. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day opened a new issue #4181: it does not support merge into ,please modify the document.
study-day opened a new issue #4181: URL: https://github.com/apache/carbondata/issues/4181 https://cwiki.apache.org/confluence/display/CARBONDATA/Apache+CarbonData+2.1.1+Release it does not support merge into ,please modify the document. ``` hive --version Hive 1.2.1000.2.6.5.0-292 [hdfs@hadoop-node-1 spark-2.3.4-bin-hadoop2.7]$ bin/beeline Beeline version 1.2.1.spark2 by Apache Hive beeline> !connect jdbc:hive2://hadoop-node-1:1 Connecting to jdbc:hive2://hadoop-node-1:1 Enter username for jdbc:hive2://hadoop-node-1:1: abcdsesss Enter password for jdbc:hive2://hadoop-node-1:1: ** Connected to: Spark SQL (version 2.3.4) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://hadoop-node-1:1> merge into test_table t using ( select t1.name name,t1.id age, t1.age id, t1.city city from test_table t1 )s on (t.id=s.id) when matched then update set t.age=s.age ; Error: org.apache.carbondata.common.exceptions.sql.MalformedCarbonCommandException: Parse failed! (state=,code=0) 0: jdbc:hive2://hadoop-node-1:1> ``` finally,MERGE is available starting in Hive 2.2. and carbondata table is the table that support ACID ? ``` Merge Version Information MERGE is available starting in Hive 2.2. Merge can only be performed on tables that support ACID. See Hive Transactions for details. ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-885358237 Thank you very much for your help, let me know more about carbondata! I have a questions . in the https://github.com/apache/carbondata/blob/master/docs/clean-files.md ``` Carbondata supports a Trash Folder which is used as a redundant folder where all stale(segments whose entry is not in tablestatus file) carbondata segments are moved to during clean files operation. This trash folder is mantained inside the table path and is a hidden folder(.Trash). The segments that are moved to the trash folder are mantained under a timestamp subfolder(each clean files operation is represented by a timestamp). This helps the user to list down segments in the trash folder by timestamp. By default all the timestamp sub-directory have an expiration time of 7 days(since the timestamp it was created) and it can be configured by the user using the following carbon property. The supported values are between 0 and 365(both included.) ``` but, Not automatically deleted after the default time.This is why? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883917592 As I can see in the output of the show segment => segment status with id 0 and 1 is marked for delete. It means these segments are not valid. You can execute once `clean file command` to remove these unnecessary segments. In the delete command, you can give the segment id which status is either success. Something similar to `DELETE FROM table test_table WHERE SEGMENT.ID IN (2.3)` After executing this query your segment status will be `marked for delete`. You can remove all these(marked for delete, compacted) segments with clean files. Refer to this: https://github.com/apache/carbondata/blob/master/docs/clean-files.md you can use force option for clean or based on your requirement. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883819350 hi, when the spark beeline ,it also happen error ``` [hdfs@hadoop-node-1 spark-2.3.4-bin-hadoop2.7]$ bin/beeline Beeline version 1.2.1.spark2 by Apache Hive beeline> !connecot jdbc:hive2://hadoop-node-1:1 Unknown command: connecot jdbc:hive2://hadoop-node-1:1 beeline> !connect jdbc:hive2://hadoop-node-1:1 Connecting to jdbc:hive2://hadoop-node-1:1 Enter username for jdbc:hive2://hadoop-node-1:1: hd123 Enter password for jdbc:hive2://hadoop-node-1:1: ** Connected to: Spark SQL (version 2.3.4) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://hadoop-node-1:1> show segments for table test_table; +---++--+--+++-+--+--+ | ID | Status | Load Start Time | Load Time Taken | Partition | Data Size | Index Size | File Format | +---++--+--+++-+--+--+ | 21| Compacted | 2021-07-09 09:22:41.538 | 7.399S | NA | 619.53KB | 54.21KB | columnar_v3 | | 20| Compacted | 2021-07-08 18:15:33.536 | 1.454S | NA | 411.54KB | 54.02KB | columnar_v3 | | 19| Compacted | 2021-07-08 18:14:44.265 | 8.104S | NA | 259.04KB | 53.96KB | columnar_v3 | | 18| Compacted | 2021-07-08 18:09:25.752 | 7.792S | NA | 178.86KB | 53.90KB | columnar_v3 | | 17| Compacted | 2021-07-08 18:09:02.815 | 5.136S | NA | 88.90KB| 26.86KB | columnar_v3 | | 16.1 | Compacted | 2021-07-12 13:51:47.44 | 2.452S | NA | 390.78KB | 54.30KB | columnar_v3 | | 16| Compacted | 2021-07-08 18:03:54.558 | 7.348S | NA | 44.62KB| 13.42KB | columnar_v3 | | 15| Compacted | 2021-07-08 15:03:17.527 | 1.354S | NA | 12.61KB| 1.29KB | columnar_v3 | | 14| Compacted | 2021-07-08 14:32:53.337 | 0.485S | NA | 7.48KB | 1.29KB | columnar_v3 | | 13| Compacted | 2021-07-08 14:32:36.673 | 0.44S| NA | 4.83KB | 1.28KB | columnar_v3 | | 12.1 | Compacted | 2021-07-12 13:51:47.44 | 1.122S | NA | 22.06KB| 1.30KB | columnar_v3 | | 12| Compacted | 2021-07-08 14:30:41.506 | 0.43S| NA | 3.59KB | 1.28KB | columnar_v3 | | 11| Compacted | 2021-07-08 14:29:57.866 | 0.436S | NA | 2.95KB | 1.27KB | columnar_v3 | | 10| Compacted | 2021-07-08 14:29:45.201 | 0.445S | NA | 2.57KB | 1.27KB | columnar_v3 | | 9 | Compacted | 2021-07-08 14:28:36.513 | 0.438S | NA | 2.38KB | 1.27KB | columnar_v3 | | 8.1 | Compacted | 2021-07-12 13:51:47.44 | 0.837S | NA | 3.52KB | 1.28KB | columnar_v3 | | 8 | Compacted | 2021-07-08 14:27:50.502 | 0.541S | NA | 2.28KB | 1.26KB | columnar_v3 | | 7 | Compacted | 2021-07-08 14:27:08.431 | 0.49S| NA | 2.20KB | 1.26KB | columnar_v3 | | 6 | Marked for Delete | 2021-07-08 10:48:47.684 | 0.386S | NA | 1.08KB | 656.0B | columnar_v3 | | 5 | Compacted | 2021-07-08 10:44:38.283 | 14.552S | NA | 1.06KB | 646.0B | columnar_v3 | | 4 | Compacted | 2021-07-08 10:43:51.58 | 14.259S | NA | 1.05KB | 644.0B | columnar_v3 | | 3 | Marked for Delete | 2021-07-08 10:43:19.104 | 16.868S | NA | 1.05KB | 644.0B | columnar_v3 | | 2.3 | Success| 2021-07-12 13:52:15.043 | 1.342S | NA | 1.14MB | 54.60KB | columnar_v3 | | 2.2 | Compacted | 2021-07-12 13:51:47.44 | 1.389S | NA | 23.36KB| 1.30KB | columnar_v3 | | 2.1 | Compacted | 2021-07-12 13:51:47.44 | 0.56S| NA | 2.28KB | 1.27KB | columnar_v3 | | 2 | Compacted | 2021-07-08 10:27:01.657 | 0.487S | NA | 1.14KB | 659.0B | columnar_v3 | | 1 | Marked for Delete | 2021-07-08 10:21:01.823 | 0.45S| NA | 1.06KB | 646.0B | columnar_v3 | | 0 | Marked for Delete | 2021-07-08 10:20:36.083
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883815940 1. it is hive beeline ``` 0: jdbc:hive2://hadoop-node-1:1> show create table test_table; ++--+ | createtab_stmt | ++--+ | CREATE TABLE `test_table` (`id` STRING, `name` STRING, `city` STRING, `age` INT) USING carbondata OPTIONS ( `indexInfo` '[]' ) | ++--+ 1 row selected (0.493 seconds) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 edited a comment on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 edited a comment on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883222462 Can you please share the details of where you are running these queries? Either it is hive-beeline or spark sql/beeline, etc. As these queries should not fail. Because in the case of spark we have many test cases where we run this query. Ideally, it should not be an issue. Also, please share the create table command. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4172: tez will report an error
study-day commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-883224506 hi ,thank you for your suggestion。 you can try it in the hive client (tez engine) the error will happen . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883222462 Can you please share the details of where you are running these queries? Either it is hive-beeline or spark sql/beeline, etc. As these queries should not fail. Because in the case of spark we have many test cases where we run this query. Ideally, it should not be an issue. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882976676 Hi, DELETE FROM default.test_table WHERE SEGMENT.ID IN (0,1); also reported an error. error info : Error: org.apache.spark.sql.AnalysisException: cannot resolve '`SEGMENT.ID`' given input columns: .line 1 pos 45; 'Project ['tupleId] +- 'Filter 'SEGMENT.ID IN (0) ... 39 more fields] +- SubqueryAlias 38 more fields] CarbonDatasourceHadoopRelation (state=,code=0) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4172: tez will report an error
study-day commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-883224506 hi ,thank you for your suggestion。 you can try it in the hive client (tez engine) the error will happen . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 edited a comment on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 edited a comment on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882401423 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4172: tez will report an error
nihal0107 commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-882402060 If you are not sure about the issue then can you please close it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882401423 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882976676 Hi, DELETE FROM default.test_table WHERE SEGMENT.ID IN (0,1); also reported an error. error info : Error: org.apache.spark.sql.AnalysisException: cannot resolve '`SEGMENT.ID`' given input columns: .line 1 pos 45; 'Project ['tupleId] +- 'Filter 'SEGMENT.ID IN (0) ... 39 more fields] +- SubqueryAlias 38 more fields] CarbonDatasourceHadoopRelation (state=,code=0) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4172: tez will report an error
study-day commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-883224506 hi ,thank you for your suggestion。 you can try it in the hive client (tez engine) the error will happen . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day opened a new issue #4178: how to use MERGE INTO
study-day opened a new issue #4178: URL: https://github.com/apache/carbondata/issues/4178 Support MERGE INTO SQL Syntax CarbonData now supports MERGE INTO SQL syntax along with the API support. This will help the users to write CDC job and merge job using SQL also now. how to use MERGE INTO ? Please add in the use document -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 edited a comment on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 edited a comment on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883222462 Can you please share the details of where you are running these queries? Either it is hive-beeline or spark sql/beeline, etc. As these queries should not fail. Because in the case of spark we have many test cases where we run this query. Ideally, it should not be an issue. Also, please share the create table command. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-883222462 Can you please share the details of where you are running these queries? Either it is hive-beeline or spark sql/beeline, etc. As these queries should not fail. Because in the case of spark we have many test cases where we run this query. Ideally, it should not be an issue. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882976676 Hi, DELETE FROM default.test_table WHERE SEGMENT.ID IN (0,1); also reported an error. error info : Error: org.apache.spark.sql.AnalysisException: cannot resolve '`SEGMENT.ID`' given input columns: .line 1 pos 45; 'Project ['tupleId] +- 'Filter 'SEGMENT.ID IN (0) ... 39 more fields] +- SubqueryAlias 38 more fields] CarbonDatasourceHadoopRelation (state=,code=0) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4172: tez will report an error
nihal0107 commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-882402060 If you are not sure about the issue then can you please close it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 edited a comment on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 edited a comment on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882401423 Hi, please remove the keyword `table` from the query. New query would be something like: `DELETE FROM default.test_table WHERE SEGMENT.ID IN (0,1);` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
nihal0107 commented on issue #4173: URL: https://github.com/apache/carbondata/issues/4173#issuecomment-882401423 Hi, please remove the keyword `table` from the query. New query would be something like: `DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN (0,1);` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day closed issue #4170: Official documents omit too much
study-day closed issue #4170: URL: https://github.com/apache/carbondata/issues/4170 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day commented on issue #4172: tez will report an error
study-day commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-878016650 I guess it has something to do with tez. But I don't know how to solve it, I switched to spark sql. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day opened a new issue #4173: DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an error in benline
study-day opened a new issue #4173:
URL: https://github.com/apache/carbondata/issues/4173
carbondata 2.1.1
DELETE FROM TABLE default.test_table WHERE SEGMENT.ID IN reported an
error in benline
```
0: jdbc:hive2://hadoop-node-1:10016> show segments for table test_table;
+---++--+--+++-+--+--+
| ID | Status | Load Start Time | Load Time Taken |
Partition | Data Size | Index Size | File Format |
+---++--+--+++-+--+--+
| 21| Compacted | 2021-07-09 09:22:41.538 | 7.399S |
NA | 619.53KB | 54.21KB | columnar_v3 |
| 20| Compacted | 2021-07-08 18:15:33.536 | 1.454S |
NA | 411.54KB | 54.02KB | columnar_v3 |
| 19| Compacted | 2021-07-08 18:14:44.265 | 8.104S |
NA | 259.04KB | 53.96KB | columnar_v3 |
| 18| Compacted | 2021-07-08 18:09:25.752 | 7.792S |
NA | 178.86KB | 53.90KB | columnar_v3 |
| 17| Compacted | 2021-07-08 18:09:02.815 | 5.136S |
NA | 88.90KB| 26.86KB | columnar_v3 |
| 16.1 | Compacted | 2021-07-12 13:51:47.44 | 2.452S |
NA | 390.78KB | 54.30KB | columnar_v3 |
| 16| Compacted | 2021-07-08 18:03:54.558 | 7.348S |
NA | 44.62KB| 13.42KB | columnar_v3 |
| 15| Compacted | 2021-07-08 15:03:17.527 | 1.354S |
NA | 12.61KB| 1.29KB | columnar_v3 |
| 14| Compacted | 2021-07-08 14:32:53.337 | 0.485S |
NA | 7.48KB | 1.29KB | columnar_v3 |
| 13| Compacted | 2021-07-08 14:32:36.673 | 0.44S|
NA | 4.83KB | 1.28KB | columnar_v3 |
| 12.1 | Compacted | 2021-07-12 13:51:47.44 | 1.122S |
NA | 22.06KB| 1.30KB | columnar_v3 |
| 12| Compacted | 2021-07-08 14:30:41.506 | 0.43S|
NA | 3.59KB | 1.28KB | columnar_v3 |
| 11| Compacted | 2021-07-08 14:29:57.866 | 0.436S |
NA | 2.95KB | 1.27KB | columnar_v3 |
| 10| Compacted | 2021-07-08 14:29:45.201 | 0.445S |
NA | 2.57KB | 1.27KB | columnar_v3 |
| 9 | Compacted | 2021-07-08 14:28:36.513 | 0.438S |
NA | 2.38KB | 1.27KB | columnar_v3 |
| 8.1 | Compacted | 2021-07-12 13:51:47.44 | 0.837S |
NA | 3.52KB | 1.28KB | columnar_v3 |
| 8 | Compacted | 2021-07-08 14:27:50.502 | 0.541S |
NA | 2.28KB | 1.26KB | columnar_v3 |
| 7 | Compacted | 2021-07-08 14:27:08.431 | 0.49S|
NA | 2.20KB | 1.26KB | columnar_v3 |
| 6 | Marked for Delete | 2021-07-08 10:48:47.684 | 0.386S |
NA | 1.08KB | 656.0B | columnar_v3 |
| 5 | Compacted | 2021-07-08 10:44:38.283 | 14.552S |
NA | 1.06KB | 646.0B | columnar_v3 |
| 4 | Compacted | 2021-07-08 10:43:51.58 | 14.259S |
NA | 1.05KB | 644.0B | columnar_v3 |
| 3 | Marked for Delete | 2021-07-08 10:43:19.104 | 16.868S |
NA | 1.05KB | 644.0B | columnar_v3 |
| 2.3 | Success| 2021-07-12 13:52:15.043 | 1.342S |
NA | 1.14MB | 54.60KB | columnar_v3 |
| 2.2 | Compacted | 2021-07-12 13:51:47.44 | 1.389S |
NA | 23.36KB| 1.30KB | columnar_v3 |
| 2.1 | Compacted | 2021-07-12 13:51:47.44 | 0.56S|
NA | 2.28KB | 1.27KB | columnar_v3 |
| 2 | Compacted | 2021-07-08 10:27:01.657 | 0.487S |
NA | 1.14KB | 659.0B | columnar_v3 |
| 1 | Marked for Delete | 2021-07-08 10:21:01.823 | 0.45S|
NA | 1.06KB | 646.0B | columnar_v3 |
| 0 | Marked for Delete | 2021-07-08 10:20:36.083 | 0.738S |
NA | 1.05KB | 644.0B | columnar_v3 |
+---++--+--+++-+--+--+
28 rows selected (0.063 seconds)
0: jdbc:hive2://hadoop-node-1:10016> DELETE FROM TABLE default.test_table
WHERE SEGMENT.ID IN ("0","1");
Error: org.apache.spark.sql.catalyst.analysis.NoSuchTableException: Table or
view 'table' not found in database 'default'; (state=,code=0)
0: jdbc:hive2://hadoop-node-1:10016>
```
[GitHub] [carbondata] vikramahuja1001 commented on issue #4168: use java 11 build spark 3.1 failed
vikramahuja1001 commented on issue #4168: URL: https://github.com/apache/carbondata/issues/4168#issuecomment-877129631 hi @LiuLarry , you can try using the Oracle Java as given in the [build page](https://github.com/apache/carbondata/tree/master/build) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] ydvpankaj99 edited a comment on issue #4168: use java 11 build spark 3.1 failed
ydvpankaj99 edited a comment on issue #4168: URL: https://github.com/apache/carbondata/issues/4168#issuecomment-876491512 hi please use below maven command to compile with spark 3.1 :- clean install -U -Pbuild-with-format scalastyle:check checkstyle:check -Pspark-3.1 -Dspark.version=3.1.1 -Djacoco.skip=true -DskipTests java -version :- java version "1.8.0_221" Java(TM) SE Runtime Environment (build 1.8.0_221-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode) First try with above maven command then you can check for java version . Spark runs on Java 8/11, Scala 2.12, Python 3.6+ and R 3.5+. Java 8 prior to version 8u92 support is deprecated as of Spark 3.0.0. Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] ydvpankaj99 commented on issue #4168: use java 11 build spark 3.1 failed
ydvpankaj99 commented on issue #4168: URL: https://github.com/apache/carbondata/issues/4168#issuecomment-876491512 hi please use below maven command to compile with spark 3.1 :- clean install -U -Pbuild-with-format scalastyle:check checkstyle:check -Pspark-3.1 -Dspark.version=3.1.1 -Djacoco.skip=true -DskipTests java -version :- java version "1.8.0_221" Java(TM) SE Runtime Environment (build 1.8.0_221-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode) First try with above maven command then you can check for java version . For spark 3.0 java version 8 and 11 supported . Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4172: tez will report an error
nihal0107 commented on issue #4172: URL: https://github.com/apache/carbondata/issues/4172#issuecomment-876470349 Hi, can you please provide the detailed query which you are trying to execute: Like either you are facing the issue at the time of creating table or insert query. Although from your error message it seems some problem with replacing the carbon jars. But before coming to conclusion we first need to check the query. Please go through the documentation link https://github.com/apache/carbondata/blob/master/docs/hive-guide.md Here you will find the details about replacing the jars and write support with hive. Please note that Only non-transactional tables are supported when created through hive. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] brijoobopanna commented on issue #4170: Official documents omit too much
brijoobopanna commented on issue #4170: URL: https://github.com/apache/carbondata/issues/4170#issuecomment-876457406 please share the issue you faced -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day opened a new issue #4172: tez will report an error
study-day opened a new issue #4172: URL: https://github.com/apache/carbondata/issues/4172 Data can only be read through hive. If you use hive to write input, tez will report an error. ``` Caused by: java.lang.RuntimeException: Failed to load plan: hdfs://hadoop-node-1:8020/tmp/hive/hdfs/010e1336-6251-4157-9499-e15efce79293/hive_2021-07-07_16-38-01_759_6301054491957594370-1/40e54cbd-439d-4e35-979a-fdc38dfa680f/map.xml: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: org.apache.carbondata.hive.MapredCarbonInputFormat ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day opened a new issue #4170: Official documents omit too much
study-day opened a new issue #4170: URL: https://github.com/apache/carbondata/issues/4170 Operate according to the official document Quick Start, no success, the document omits too many details, which is unfriendly。 https://carbondata.apache.org/quick-start-guide.html -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] study-day opened a new issue #4169: ANTLR Tool Incompatible version
study-day opened a new issue #4169: URL: https://github.com/apache/carbondata/issues/4169 spark version 2.3.4 use ANTLR Tool version 4.7 ,but carbondata use ANTLR 4.8 An error occurred in the spark sql , please use version 4.7 error log ANTLR Tool version 4.7 used for code generation does not match the current runtime version 4.8ANTLR Runtime version 4.7 used for parser compilation does not match the current runtime version 4.8ANTLR Tool version 4.7 used for code generation does not match the current runtime version 4.8ANTLR Runtime version 4.7 used for parser compilation does not match the current runtime version 4.8Error in query: Operation not allowed: STORED AS with file format 'carbondata'(line 6, pos 10) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] LiuLarry opened a new issue #4168: use java 11 build spark 3.1 failed
LiuLarry opened a new issue #4168: URL: https://github.com/apache/carbondata/issues/4168 use the follow command to build carbondata, got error message as attachment show. mvn -DskipTests -Dfindbugs.skip=true -Dcheckstyle.skip=true -Pspark-3.1 -Pbuild-with-format clean package install java version: openjdk version "11.0.2" 2019-01-15 OpenJDK Runtime Environment 18.9 (build 11.0.2+9) OpenJDK 64-Bit Server VM 18.9 (build 11.0.2+9, mixed mode) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on issue #4146: Multi hosts write to one hdfs file?
QiangCai commented on issue #4146: URL: https://github.com/apache/carbondata/issues/4146#issuecomment-869277674 I suggest using SDK to write data into the stage area and using insert into the stage to add it to the table. https://github.com/apache/carbondata/blob/master/docs/flink-integration-guide.md Another way is using add segment function to support multiple formats in a table, but it has many limitations. https://github.com/apache/carbondata/blob/8740016917168777f1514ef4de0615f83b13c6d3/docs/addsegment-guide.md -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on issue #4160: Why opened task less than available executors in case of insert into/load data
QiangCai commented on issue #4160: URL: https://github.com/apache/carbondata/issues/4160#issuecomment-869274861 It only works for the local_sort loading. It can help to avoid data shuffle during executors. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@carbondata.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] 01lin opened a new issue #4160: Why opened task less than available executors in case of insert into/load data
01lin opened a new issue #4160:
URL: https://github.com/apache/carbondata/issues/4160
In case of insert into or load data, the total number of tasks in the stage
is almost equal to the number of hosts, and in general it is much smaller than
the available executors. The low parallelism of the stage results in slower
execution. Why must the parallelism be constrained on the distinct host? Can
start more tasks to increase parallelism and improve resource utilization?
Thanks
org/apache/carbondata/spark/rdd/CarbonDataRDDFactory.scala: loadDataFrame
```
/**
* Execute load process to load from input dataframe
*/
private def loadDataFrame(
sqlContext: SQLContext,
dataFrame: Option[DataFrame],
carbonLoadModel: CarbonLoadModel
): Array[(String, (LoadMetadataDetails, ExecutionErrors))] = {
try {
val rdd = dataFrame.get.rdd
// 基于getPreferredLocs获取优化位置,取distinct值:获取host list
val nodeNumOfData = rdd.partitions.flatMap[String, Array[String]] { p
=>
DataLoadPartitionCoalescer.getPreferredLocs(rdd, p).map(_.host)
}.distinct.length
val nodes = DistributionUtil.ensureExecutorsByNumberAndGetNodeList(
nodeNumOfData,
sqlContext.sparkContext) // 确保executor数量要和数据的节点数一样多
val newRdd = new DataLoadCoalescedRDD[Row](sqlContext.sparkSession,
rdd, nodes.toArray
.distinct)
new NewDataFrameLoaderRDD(
sqlContext.sparkSession,
new DataLoadResultImpl(),
carbonLoadModel,
newRdd
).collect()
} catch {
case ex: Exception =>
LOGGER.error("load data frame failed", ex)
throw ex
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] BestP2P commented on issue #4144: carbon-sdk support hdfs ?
BestP2P commented on issue #4144: URL: https://github.com/apache/carbondata/issues/4144#issuecomment-853599764 thank you very much from china! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] BestP2P closed issue #4144: carbon-sdk support hdfs ?
BestP2P closed issue #4144: URL: https://github.com/apache/carbondata/issues/4144 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4144: carbon-sdk support hdfs ?
nihal0107 commented on issue #4144: URL: https://github.com/apache/carbondata/issues/4144#issuecomment-853580601 Hi, Yes, carbon-SDK supports hdfs configuration. When building a carbon writer, you can use API named `withHadoopConf(Configuration conf)` to pass the detailed configuration of HDFS. You can find an example for S3 given in SDKS3Example.java. In similar way you can use for HDFS. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] BestP2P opened a new issue #4146: Multi hosts write to one hdfs file?
BestP2P opened a new issue #4146: URL: https://github.com/apache/carbondata/issues/4146 if I use hdfs system, and the using sdk program running on multi hosts, how can i let them write to one hdfs file? thank you -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] BestP2P closed issue #4144: carbon-sdk support hdfs ?
BestP2P closed issue #4144: URL: https://github.com/apache/carbondata/issues/4144 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] BestP2P commented on issue #4144: carbon-sdk support hdfs ?
BestP2P commented on issue #4144: URL: https://github.com/apache/carbondata/issues/4144#issuecomment-853599764 thank you very much from china! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] nihal0107 commented on issue #4144: carbon-sdk support hdfs ?
nihal0107 commented on issue #4144: URL: https://github.com/apache/carbondata/issues/4144#issuecomment-853580601 Hi, Yes, carbon-SDK supports hdfs configuration. When building a carbon writer, you can use API named `withHadoopConf(Configuration conf)` to pass the detailed configuration of HDFS. You can find an example for S3 given in SDKS3Example.java. In similar way you can use for HDFS. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] BestP2P opened a new issue #4144: carbon-sdk support hdfs ?
BestP2P opened a new issue #4144: URL: https://github.com/apache/carbondata/issues/4144 Writing carbondata files from other application which does not use Spark,it is support hdfs configure? how can i write the carbondata to hdfs system? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] chenliang613 opened a new issue #4114: Join community
chenliang613 opened a new issue #4114: URL: https://github.com/apache/carbondata/issues/4114 Join community by emailing to dev-subscr...@carbondata.apache.org, then you can discuss issues by emailing to d...@carbondata.apache.org or visit http://apache-carbondata-mailing-list-archive.1130556.n5.nabble.com -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4110: [WIP]Secondary Index as a coarse grain datamap
CarbonDataQA2 commented on pull request #4110: URL: https://github.com/apache/carbondata/pull/4110#issuecomment-808462627 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12602/job/ApacheCarbonPRBuilder2.3/5098/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4110: [WIP]Secondary Index as a coarse grain datamap
CarbonDataQA2 commented on pull request #4110: URL: https://github.com/apache/carbondata/pull/4110#issuecomment-808462123 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12602/job/ApacheCarbon_PR_Builder_2.4.5/3347/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] VenuReddy2103 commented on pull request #4110: [WIP]Secondary Index as a coarse grain datamap
VenuReddy2103 commented on pull request #4110: URL: https://github.com/apache/carbondata/pull/4110#issuecomment-808456818 retest this please -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4110: [WIP]Secondary Index as a coarse grain datamap
CarbonDataQA2 commented on pull request #4110: URL: https://github.com/apache/carbondata/pull/4110#issuecomment-808449842 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12602/job/ApacheCarbonPRBuilder2.3/5097/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4110: [WIP]Secondary Index as a coarse grain datamap
CarbonDataQA2 commented on pull request #4110: URL: https://github.com/apache/carbondata/pull/4110#issuecomment-808449555 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12602/job/ApacheCarbon_PR_Builder_2.4.5/3346/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] asfgit closed pull request #4109: [CARBONDATA-4154] Fix various concurrent issues with clean files
asfgit closed pull request #4109: URL: https://github.com/apache/carbondata/pull/4109 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] ajantha-bhat commented on pull request #4109: [CARBONDATA-4154] Fix various concurrent issues with clean files
ajantha-bhat commented on pull request #4109: URL: https://github.com/apache/carbondata/pull/4109#issuecomment-807946403 LGTM. Just done high level review. Merging PR for RC2 cut. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4109: [CARBONDATA-4154] Fix various concurrent issues with clean files
CarbonDataQA2 commented on pull request #4109: URL: https://github.com/apache/carbondata/pull/4109#issuecomment-807077748 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12602/job/ApacheCarbon_PR_Builder_2.4.5/3343/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4109: [CARBONDATA-4154] Fix various concurrent issues with clean files
CarbonDataQA2 commented on pull request #4109: URL: https://github.com/apache/carbondata/pull/4109#issuecomment-807077185 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12602/job/ApacheCarbonPRBuilder2.3/5095/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kunal642 commented on pull request #4109: [CARBONDATA-4154] Fix various concurrent issues with clean files
kunal642 commented on pull request #4109: URL: https://github.com/apache/carbondata/pull/4109#issuecomment-806920029 retest this please -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] asfgit closed pull request #4101: [CARBONDATA-4156] Fix Writing Segment Min max with all blocks of a segment
asfgit closed pull request #4101: URL: https://github.com/apache/carbondata/pull/4101 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kunal642 commented on pull request #4101: [CARBONDATA-4156] Fix Writing Segment Min max with all blocks of a segment
kunal642 commented on pull request #4101: URL: https://github.com/apache/carbondata/pull/4101#issuecomment-806904148 LGTM -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4100: [CARBONDATA-4138] Reordering Carbon Expression instead of Spark Filter
CarbonDataQA2 commented on pull request #4100: URL: https://github.com/apache/carbondata/pull/4100#issuecomment-806464050 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12602/job/ApacheCarbonPRBuilder2.3/5094/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #4100: [CARBONDATA-4138] Reordering Carbon Expression instead of Spark Filter
CarbonDataQA2 commented on pull request #4100: URL: https://github.com/apache/carbondata/pull/4100#issuecomment-806463869 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12602/job/ApacheCarbon_PR_Builder_2.4.5/3342/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on pull request #4100: [CARBONDATA-4138] Reordering Carbon Expression instead of Spark Filter
QiangCai commented on pull request #4100: URL: https://github.com/apache/carbondata/pull/4100#issuecomment-806410550 retest this please -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA2 commented on pull request #3988: [CARBONDATA-4037] Improve the table status and segment file writing
CarbonDataQA2 commented on pull request #3988: URL: https://github.com/apache/carbondata/pull/3988#issuecomment-805753259 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12602/job/ApacheCarbon_PR_Builder_2.4.5/3341/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org