[GitHub] [flink-kubernetes-operator] gyfora commented on a diff in pull request #305: [FLINK-28447] GitHub Pull Request template
gyfora commented on code in PR #305: URL: https://github.com/apache/flink-kubernetes-operator/pull/305#discussion_r917226385 ## .github/PULL_REQUEST_TEMPLATE.md: ## @@ -0,0 +1,68 @@ + + +## What is the purpose of the change + +*(For example: This pull request adds a new feature to periodically create and maintain savepoints through the `FlinkDeployment` custom resource.)* + + +## Brief change log + +*(for example:)* + - *Periodic savepoint trigger is introduced to the custom resource* + - *The operator checks on reconciliation whether the required time has passed* + - *The JobManager's dispose savepoint API is used to clean up obsolete savepoints* + +## Verifying this change + +Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing + +*(Please pick either of the following options)* + +This change is a trivial rework / code cleanup without any test coverage. + +*(or)* + +This change is already covered by existing tests, such as *(please describe tests)*. + +*(or)* + +This change added tests and can be verified as follows: + +*(example:)* + - *Added integration tests for end-to-end deployment with large payloads (100MB)* + - *Extended integration test for recovery after master (JobManager) failure* + - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* + +## Does this pull request potentially affect one of the following parts: + + - Dependencies (does it add or upgrade a dependency): (yes / no) + - The public API, i.e., is any changes to the `CustomResourceDescriptors`: (yes / no) + Review Comment: Here we could also add: Core observe/reconcile logic -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-docker] Myasuka commented on a diff in pull request #117: [FLINK-28057] Fix LD_PRELOAD on ARM images
Myasuka commented on code in PR #117:
URL: https://github.com/apache/flink-docker/pull/117#discussion_r917225904
##
1.15/scala_2.12-java11-debian/docker-entrypoint.sh:
##
@@ -91,7 +91,12 @@ prepare_configuration() {
maybe_enable_jemalloc() {
if [ "${DISABLE_JEMALLOC:-false}" == "false" ]; then
-export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
+# Maybe use export LD_PRELOAD=$LD_PRELOAD:/usr/lib/$(uname
-i)-linux-gnu/libjemalloc.so
+if [[ `uname -i` == 'aarch64' ]]; then
+export
LD_PRELOAD=$LD_PRELOAD:/usr/lib/aarch64-linux-gnu/libjemalloc.so
Review Comment:
> It already is a very low level thing that you won't be able to notice
unless you specifically look for it, because there's no way to know that
Jemalloc isn't being used (it took months for us to realize).
Actually, you can use `pmap ` to check whether the process has attached
the required library.
I think this PR looks good without unit test as the logic is quite easy, and
it's a bit complex to verify this behavior.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] zhuzhurk commented on a diff in pull request #20153: [FLINK-28144][runtime] Let JobMaster support blocklist.
zhuzhurk commented on code in PR #20153:
URL: https://github.com/apache/flink/pull/20153#discussion_r917217609
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1384,8 +1374,9 @@ public void testRequestPartitionState() throws Exception {
fail("Expected failure.");
Review Comment:
Let's replace the try-catch block with a `assertThatThrownBy`
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -959,20 +951,20 @@ public void testReconnectionAfterDisconnect() throws
Exception {
// wait for first registration attempt
final JobMasterId firstRegistrationAttempt =
registrationsQueue.take();
-assertThat(firstRegistrationAttempt, equalTo(jobMasterId));
+assertThat(firstRegistrationAttempt).isEqualTo(jobMasterId);
-assertThat(registrationsQueue.isEmpty(), is(true));
+assertThat(registrationsQueue.isEmpty()).isTrue();
Review Comment:
can be `assertThat(registrationsQueue).isEmpty();`
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1384,8 +1374,9 @@ public void testRequestPartitionState() throws Exception {
fail("Expected failure.");
} catch (ExecutionException e) {
assertThat(
-ExceptionUtils.findThrowable(e,
IllegalArgumentException.class).isPresent(),
-is(true));
+ExceptionUtils.findThrowable(e,
IllegalArgumentException.class)
Review Comment:
Would `hasRootCauseInstanceOf(IllegalArgumentException.class)` work here?
If not, we can still simplify it to be
`assertThat(ExceptionUtils.findThrowable(e,
IllegalArgumentException.class)).isPresent()`.
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1462,19 +1455,19 @@ public void testTriggerSavepointTimeout() throws
Exception {
try {
savepointFutureLowTimeout.get(testingTimeout.getSize(),
testingTimeout.getUnit());
-fail();
+fail("Expected TimeoutException");
} catch (final ExecutionException e) {
final Throwable cause =
ExceptionUtils.stripExecutionException(e);
-assertThat(cause, instanceOf(TimeoutException.class));
+assertThat(cause).isInstanceOf(TimeoutException.class);
}
-assertThat(savepointFutureHighTimeout.isDone(),
is(equalTo(false)));
+assertThat(savepointFutureHighTimeout.isDone()).isFalse();
Review Comment:
can be `assertThat(savepointFutureHighTimeout).isNotDone();`
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1414,9 +1406,10 @@ public void testRequestPartitionState() throws Exception
{
fail("Expected failure.");
} catch (ExecutionException e) {
assertThat(
-ExceptionUtils.findThrowable(e,
PartitionProducerDisposedException.class)
-.isPresent(),
-is(true));
Review Comment:
See above comment.
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1398,8 +1389,9 @@ public void testRequestPartitionState() throws Exception {
fail("Expected failure.");
} catch (ExecutionException e) {
assertThat(
Review Comment:
See above 2 comments.
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1593,18 +1585,18 @@ public void
testTaskExecutorNotReleasedOnFailedAllocationIfPartitionIsAllocated(
// we should free the slot, but not disconnect from the
TaskExecutor as we still have an
// allocated partition
-assertThat(freedSlotFuture.get(), equalTo(allocationId));
+assertThat(freedSlotFuture.get()).isEqualTo(allocationId);
// trigger some request to guarantee ensure the
slotAllocationFailure processing if
// complete
jobMasterGateway.requestJobStatus(Time.seconds(5)).get();
-assertThat(disconnectTaskExecutorFuture.isDone(), is(false));
+assertThat(disconnectTaskExecutorFuture.isDone()).isFalse();
Review Comment:
can be `assertThat(disconnectTaskExecutorFuture).isNotDone();`
##
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/JobMasterTest.java:
##
@@ -1462,19 +1455,19 @@ public void testTriggerSavepointTimeout() throws
Exception {
try {
savepointFutureLowTimeout.get(testingTimeout.getSize(),
testingTimeout.getUnit());
-fail();
+fail("Expected
[jira] [Commented] (FLINK-28364) Python Job support for Kubernetes Operator
[ https://issues.apache.org/jira/browse/FLINK-28364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564511#comment-17564511 ] wu3396 commented on FLINK-28364: My thought is that it is easy for users to use, and there are documentation examples to demonstrate. It would be great to have an official pyflink image. > Python Job support for Kubernetes Operator > -- > > Key: FLINK-28364 > URL: https://issues.apache.org/jira/browse/FLINK-28364 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: wu3396 >Priority: Major > > *Describe the solution* > Job types that I want to support pyflink for > *Describe alternatives* > like [here|https://github.com/spotify/flink-on-k8s-operator/pull/165] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] zhuzhurk commented on a diff in pull request #20222: [FLINK-28137] Introduce SpeculativeScheduler
zhuzhurk commented on code in PR #20222:
URL: https://github.com/apache/flink/pull/20222#discussion_r917214684
##
flink-runtime/src/test/java/org/apache/flink/runtime/executiongraph/failover/flip1/ExecutionFailureHandlerTest.java:
##
@@ -71,122 +74,125 @@ public void setUp() {
/** Tests the case that task restarting is accepted. */
@Test
-public void testNormalFailureHandling() {
+void testNormalFailureHandling() throws Exception {
final Set tasksToRestart =
Collections.singleton(new ExecutionVertexID(new JobVertexID(),
0));
failoverStrategy.setTasksToRestart(tasksToRestart);
+Execution execution = createExecution(EXECUTOR_RESOURCE.getExecutor());
Exception cause = new Exception("test failure");
long timestamp = System.currentTimeMillis();
// trigger a task failure
final FailureHandlingResult result =
-executionFailureHandler.getFailureHandlingResult(
-new ExecutionVertexID(new JobVertexID(), 0), cause,
timestamp);
+executionFailureHandler.getFailureHandlingResult(execution,
cause, timestamp);
// verify results
-assertTrue(result.canRestart());
-assertEquals(RESTART_DELAY_MS, result.getRestartDelayMS());
-assertEquals(tasksToRestart, result.getVerticesToRestart());
-assertThat(result.getError(), is(cause));
-assertThat(result.getTimestamp(), is(timestamp));
-assertEquals(1, executionFailureHandler.getNumberOfRestarts());
+assertThat(result.canRestart()).isTrue();
+assertThat(result.getFailedExecution().isPresent()).isTrue();
+assertThat(result.getFailedExecution().get()).isSameAs(execution);
+assertThat(result.getRestartDelayMS()).isEqualTo(RESTART_DELAY_MS);
+assertThat(result.getVerticesToRestart()).isEqualTo(tasksToRestart);
+assertThat(result.getError()).isSameAs(cause);
+assertThat(result.getTimestamp()).isEqualTo(timestamp);
+assertThat(executionFailureHandler.getNumberOfRestarts()).isEqualTo(1);
}
/** Tests the case that task restarting is suppressed. */
@Test
-public void testRestartingSuppressedFailureHandlingResult() {
+void testRestartingSuppressedFailureHandlingResult() throws Exception {
// restart strategy suppresses restarting
backoffTimeStrategy.setCanRestart(false);
// trigger a task failure
+Execution execution = createExecution(EXECUTOR_RESOURCE.getExecutor());
final Throwable error = new Exception("expected test failure");
final long timestamp = System.currentTimeMillis();
final FailureHandlingResult result =
-executionFailureHandler.getFailureHandlingResult(
-new ExecutionVertexID(new JobVertexID(), 0), error,
timestamp);
+executionFailureHandler.getFailureHandlingResult(execution,
error, timestamp);
// verify results
-assertFalse(result.canRestart());
-assertThat(result.getError(), containsCause(error));
-assertThat(result.getTimestamp(), is(timestamp));
-
assertFalse(ExecutionFailureHandler.isUnrecoverableError(result.getError()));
-try {
-result.getVerticesToRestart();
-fail("get tasks to restart is not allowed when restarting is
suppressed");
-} catch (IllegalStateException ex) {
-// expected
-}
-try {
-result.getRestartDelayMS();
-fail("get restart delay is not allowed when restarting is
suppressed");
-} catch (IllegalStateException ex) {
-// expected
-}
-assertEquals(0, executionFailureHandler.getNumberOfRestarts());
+assertThat(result.canRestart()).isFalse();
+assertThat(result.getFailedExecution().isPresent()).isTrue();
+assertThat(result.getFailedExecution().get()).isSameAs(execution);
+assertThat(result.getError()).hasCause(error);
+assertThat(result.getTimestamp()).isEqualTo(timestamp);
+
assertThat(ExecutionFailureHandler.isUnrecoverableError(result.getError())).isFalse();
+
+assertThatThrownBy(() -> result.getVerticesToRestart())
Review Comment:
Ok. However, I believe this should be a comment to #20221.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] zhuzhurk commented on pull request #20221: [FLINK-28402] Create FailureHandlingResultSnapshot with the truly failed execution
zhuzhurk commented on PR #20221: URL: https://github.com/apache/flink/pull/20221#issuecomment-1179457223 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] mas-chen commented on pull request #19366: [FLINK-24660][Connectors / Kafka] allow setting KafkaSubscriber in KafkaSourceBuilder
mas-chen commented on PR #19366: URL: https://github.com/apache/flink/pull/19366#issuecomment-1179434006 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20230: [FLINK-28449][tests][JUnit5 migration] flink-parquet
flinkbot commented on PR #20230: URL: https://github.com/apache/flink/pull/20230#issuecomment-1179419344 ## CI report: * baaa6afb49ee84320d422273ce57611302e29f78 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-28449) [JUnit5 Migration] Module: flink-parquet
[ https://issues.apache.org/jira/browse/FLINK-28449?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-28449: --- Labels: pull-request-available (was: ) > [JUnit5 Migration] Module: flink-parquet > > > Key: FLINK-28449 > URL: https://issues.apache.org/jira/browse/FLINK-28449 > Project: Flink > Issue Type: Sub-task > Components: Connectors / FileSystem >Reporter: Ryan Skraba >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] RyanSkraba opened a new pull request, #20230: [FLINK-28449][tests][JUnit5 migration] flink-parquet
RyanSkraba opened a new pull request, #20230: URL: https://github.com/apache/flink/pull/20230 ## What is the purpose of the change Update the `flink-formats/flink-parquet` module to AssertJ and JUnit 5 following the [JUnit 5 Migration Guide](https://docs.google.com/document/d/1514Wa_aNB9bJUen4xm5uiuXOooOJTtXqS_Jqk9KJitU/edit) ## Brief change log * Removed dependences on JUnit 4, JUnit 5 Assertions and Hamcrest where possible. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. I've verified that there are 94 tests run in this module before and after the refactoring. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive):no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature?no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-26366) Support "insert directory"
[
https://issues.apache.org/jira/browse/FLINK-26366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26366:
---
Labels: pull-request-available stale-assigned (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issue is assigned but has not
received an update in 30 days, so it has been labeled "stale-assigned".
If you are still working on the issue, please remove the label and add a
comment updating the community on your progress. If this issue is waiting on
feedback, please consider this a reminder to the committer/reviewer. Flink is a
very active project, and so we appreciate your patience.
If you are no longer working on the issue, please unassign yourself so someone
else may work on it.
> Support "insert directory"
> --
>
> Key: FLINK-26366
> URL: https://issues.apache.org/jira/browse/FLINK-26366
> Project: Flink
> Issue Type: Sub-task
>Reporter: luoyuxia
>Assignee: luoyuxia
>Priority: Major
> Labels: pull-request-available, stale-assigned
>
> In hive, it allow to write data into the filesystem from queries using the
> following sql
> {code:java}
> INSERT OVERWRITE [LOCAL] DIRECTORY directory1
> [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available
> starting with Hive 0.11.0)
> SELECT ... FROM ...
> {code}
> See more detail in
> [Writingdataintothefilesystemfromqueries|https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=82903069#LanguageManualDML-Writingdataintothefilesystemfromqueries].
> As it's quite often used in production environment. We also need to support
> such usage in hive dialect.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-26202) Support Table API in Pulsar Source Connector
[ https://issues.apache.org/jira/browse/FLINK-26202?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-26202: --- Labels: Pulsar auto-deprioritized-major (was: Pulsar stale-major) Priority: Minor (was: Major) This issue was labeled "stale-major" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Major, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Support Table API in Pulsar Source Connector > > > Key: FLINK-26202 > URL: https://issues.apache.org/jira/browse/FLINK-26202 > Project: Flink > Issue Type: New Feature > Components: Connectors / Pulsar >Affects Versions: 1.15.0 >Reporter: Yufei Zhang >Priority: Minor > Labels: Pulsar, auto-deprioritized-major > > Currently pulsar connector only supports DataStream API, we plan to support > Table API. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-26238) PulsarSinkITCase.writeRecordsToPulsar failed on azure
[
https://issues.apache.org/jira/browse/FLINK-26238?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26238:
---
Labels: auto-deprioritized-major test-stability (was: stale-major
test-stability)
Priority: Minor (was: Major)
This issue was labeled "stale-major" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Major, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> PulsarSinkITCase.writeRecordsToPulsar failed on azure
> -
>
> Key: FLINK-26238
> URL: https://issues.apache.org/jira/browse/FLINK-26238
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Pulsar
>Affects Versions: 1.15.0
>Reporter: Yun Gao
>Priority: Minor
> Labels: auto-deprioritized-major, test-stability
>
> {code:java}
> Feb 17 12:19:44 [ERROR] Tests run: 3, Failures: 1, Errors: 0, Skipped: 0,
> Time elapsed: 342.177 s <<< FAILURE! - in
> org.apache.flink.connector.pulsar.sink.PulsarSinkITCase
> Feb 17 12:19:44 [ERROR]
> org.apache.flink.connector.pulsar.sink.PulsarSinkITCase.writeRecordsToPulsar(DeliveryGuarantee)[3]
> Time elapsed: 302.4 s <<< FAILURE!
> Feb 17 12:19:44 java.lang.AssertionError:
> Feb 17 12:19:44
> Feb 17 12:19:44 Actual and expected should have same size but actual size is:
> Feb 17 12:19:44 0
> Feb 17 12:19:44 while expected size is:
> Feb 17 12:19:44 179
> Feb 17 12:19:44 Actual was:
> Feb 17 12:19:44 []
> Feb 17 12:19:44 Expected was:
> Feb 17 12:19:44 ["NONE-CzYEIFDd-0-eELBphcHiu",
> Feb 17 12:19:44 "NONE-CzYEIFDd-1-odr3NpH6pg",
> Feb 17 12:19:44 "NONE-CzYEIFDd-2-HfIphNFXoM",
> Feb 17 12:19:44 "NONE-CzYEIFDd-3-iaZ9v2HCnw",
> Feb 17 12:19:44 "NONE-CzYEIFDd-4-6KkXK34GZl",
> Feb 17 12:19:44 "NONE-CzYEIFDd-5-jK9UxXSQcX",
> Feb 17 12:19:44 "NONE-CzYEIFDd-6-HipVPVNqZA",
> Feb 17 12:19:44 "NONE-CzYEIFDd-7-lT4lVH3CzX",
> Feb 17 12:19:44 "NONE-CzYEIFDd-8-4jShEBuQaS",
> Feb 17 12:19:44 "NONE-CzYEIFDd-9-fInSd97msu",
> Feb 17 12:19:44 "NONE-CzYEIFDd-10-dGBm5e92os",
> Feb 17 12:19:44 "NONE-CzYEIFDd-11-GkINb6Dipx",
> Feb 17 12:19:44 "NONE-CzYEIFDd-12-M7Q8atHhNQ",
> Feb 17 12:19:44 "NONE-CzYEIFDd-13-EG2FpyziCL",
> Feb 17 12:19:44 "NONE-CzYEIFDd-14-4HwGJSOkTk",
> Feb 17 12:19:44 "NONE-CzYEIFDd-15-UC0IwwKN0O",
> Feb 17 12:19:44 "NONE-CzYEIFDd-16-D9FOV8hKBq",
> Feb 17 12:19:44 "NONE-CzYEIFDd-17-J2Zb6pNmOO",
> Feb 17 12:19:44 "NONE-CzYEIFDd-18-abo3YgkYKP",
> Feb 17 12:19:44 "NONE-CzYEIFDd-19-4Q5GbBRSc6",
> Feb 17 12:19:44 "NONE-CzYEIFDd-20-WxSP9oExJP",
> Feb 17 12:19:44 "NONE-CzYEIFDd-21-0wiqq21CY1",
> Feb 17 12:19:44 "NONE-CzYEIFDd-22-3iJQiFjgQu",
> Feb 17 12:19:44 "NONE-CzYEIFDd-23-78je74YwU6",
> Feb 17 12:19:44 "NONE-CzYEIFDd-24-tEkEaF9IuD",
> Feb 17 12:19:44 "NONE-CzYEIFDd-25-vDi5h44tjJ",
> Feb 17 12:19:44 "NONE-CzYEIFDd-26-GzIh4FLlvP",
> {code}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=31739=logs=fc5181b0-e452-5c8f-68de-1097947f6483=995c650b-6573-581c-9ce6-7ad4cc038461=27095
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-26237) PulsarSourceOrderedE2ECase failed on azure due to timeout
[
https://issues.apache.org/jira/browse/FLINK-26237?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26237:
---
Labels: auto-deprioritized-major test-stability (was: stale-major
test-stability)
Priority: Minor (was: Major)
This issue was labeled "stale-major" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Major, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> PulsarSourceOrderedE2ECase failed on azure due to timeout
> -
>
> Key: FLINK-26237
> URL: https://issues.apache.org/jira/browse/FLINK-26237
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Pulsar
>Affects Versions: 1.15.0
>Reporter: Yun Gao
>Priority: Minor
> Labels: auto-deprioritized-major, test-stability
>
> {code:java}
> Feb 17 10:43:42 [ERROR] Tests run: 16, Failures: 1, Errors: 0, Skipped: 0,
> Time elapsed: 636.317 s <<< FAILURE! - in
> org.apache.flink.tests.util.pulsar.PulsarSourceOrderedE2ECase
> Feb 17 10:43:42 [ERROR]
> org.apache.flink.tests.util.pulsar.PulsarSourceOrderedE2ECase.testScaleDown(TestEnvironment,
> DataStreamSourceExternalContext, CheckpointingMode)[2] Time elapsed:
> 155.986 s <<< FAILURE!
> Feb 17 10:43:42 java.lang.AssertionError:
> Feb 17 10:43:42
> Feb 17 10:43:42 Expecting
> Feb 17 10:43:42
> Feb 17 10:43:42 to be completed within 2M.
> Feb 17 10:43:42
> Feb 17 10:43:42 exception caught while trying to get the future result:
> java.util.concurrent.TimeoutException
> Feb 17 10:43:42 at
> java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1784)
> Feb 17 10:43:42 at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1928)
> Feb 17 10:43:42 at
> org.assertj.core.internal.Futures.assertSucceededWithin(Futures.java:109)
> Feb 17 10:43:42 at
> org.assertj.core.api.AbstractCompletableFutureAssert.internalSucceedsWithin(AbstractCompletableFutureAssert.java:400)
> Feb 17 10:43:42 at
> org.assertj.core.api.AbstractCompletableFutureAssert.succeedsWithin(AbstractCompletableFutureAssert.java:396)
> Feb 17 10:43:42 at
> org.apache.flink.connector.testframe.testsuites.SourceTestSuiteBase.checkResultWithSemantic(SourceTestSuiteBase.java:766)
> Feb 17 10:43:42 at
> org.apache.flink.connector.testframe.testsuites.SourceTestSuiteBase.restartFromSavepoint(SourceTestSuiteBase.java:399)
> Feb 17 10:43:42 at
> org.apache.flink.connector.testframe.testsuites.SourceTestSuiteBase.testScaleDown(SourceTestSuiteBase.java:285)
> Feb 17 10:43:42 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> Feb 17 10:43:42 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> Feb 17 10:43:42 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> Feb 17 10:43:42 at java.lang.reflect.Method.invoke(Method.java:498)
> Feb 17 10:43:42 at
> org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:725)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestTemplateMethod(TimeoutExtension.java:92)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain.proceed(InvocationInterceptorChain.java:64)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain.chainAndInvoke(InvocationInterceptorChain.java:45)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain.invoke(InvocationInterceptorChain.java:37)
> Feb 17 10:43:42 at
> org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:104)
> Feb 17 10:43:42
[jira] [Updated] (FLINK-26203) Support Table API in Pulsar Sink Connector
[ https://issues.apache.org/jira/browse/FLINK-26203?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-26203: --- Labels: Pulsar auto-deprioritized-major (was: Pulsar stale-major) Priority: Minor (was: Major) This issue was labeled "stale-major" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Major, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Support Table API in Pulsar Sink Connector > -- > > Key: FLINK-26203 > URL: https://issues.apache.org/jira/browse/FLINK-26203 > Project: Flink > Issue Type: New Feature > Components: Connectors / Pulsar >Reporter: Yufei Zhang >Priority: Minor > Labels: Pulsar, auto-deprioritized-major > > Currently Pulsar connector only supports DataStream API. We plan to support > Table API as well. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-27529) HybridSourceSplitEnumerator sourceIndex using error Integer check
[
https://issues.apache.org/jira/browse/FLINK-27529?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-27529:
---
Labels: pull-request-available stale-assigned (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issue is assigned but has not
received an update in 30 days, so it has been labeled "stale-assigned".
If you are still working on the issue, please remove the label and add a
comment updating the community on your progress. If this issue is waiting on
feedback, please consider this a reminder to the committer/reviewer. Flink is a
very active project, and so we appreciate your patience.
If you are no longer working on the issue, please unassign yourself so someone
else may work on it.
> HybridSourceSplitEnumerator sourceIndex using error Integer check
> -
>
> Key: FLINK-27529
> URL: https://issues.apache.org/jira/browse/FLINK-27529
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Common
>Affects Versions: 1.14.4, 1.15.0, 1.15.1
>Reporter: Ran Tao
>Assignee: Ran Tao
>Priority: Major
> Labels: pull-request-available, stale-assigned
>
> Currently HybridSourceSplitEnumerator check readerSourceIndex using Integer
> type but == operator.
> As hybrid source definition, it can concat with more than 2 child sources. so
> currently works just because Integer cache(only works <=127), if we have more
> sources will fail on error. In a word, we can't use == to compare Integer
> index unless we limit hybrid sources only works <=127.
> e.g.
> {code:java}
> Integer i1 = 128;
> Integer i2 = 128;
> System.out.println(i1 == i2);
> int i3 = 128;
> int i4 = 128;
> System.out.println((Integer) i3 == (Integer) i4);
> {code}
> It will show false, false.
> HybridSource Integer index comparison is below:
> {code:java}
> @Override
> public Map registeredReaders() {
>
> Integer lastIndex = null;
> for (Integer sourceIndex : readerSourceIndex.values()) {
> if (lastIndex != null && lastIndex != sourceIndex) {
> return filterRegisteredReaders(readers);
> }
> lastIndex = sourceIndex;
> }
> return readers;
> }
> private Map filterRegisteredReaders(Map ReaderInfo> readers) {
> Map readersForSource = new
> HashMap<>(readers.size());
> for (Map.Entry e : readers.entrySet()) {
> if (readerSourceIndex.get(e.getKey()) == (Integer)
> sourceIndex) {
> readersForSource.put(e.getKey(), e.getValue());
> }
> }
> return readersForSource;
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-27710) Improve logs to better display Execution
[
https://issues.apache.org/jira/browse/FLINK-27710?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-27710:
---
Labels: pull-request-available stale-assigned (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issue is assigned but has not
received an update in 30 days, so it has been labeled "stale-assigned".
If you are still working on the issue, please remove the label and add a
comment updating the community on your progress. If this issue is waiting on
feedback, please consider this a reminder to the committer/reviewer. Flink is a
very active project, and so we appreciate your patience.
If you are no longer working on the issue, please unassign yourself so someone
else may work on it.
> Improve logs to better display Execution
>
>
> Key: FLINK-27710
> URL: https://issues.apache.org/jira/browse/FLINK-27710
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Coordination, Runtime / Task
>Affects Versions: 1.16.0
>Reporter: Zhu Zhu
>Assignee: Zhu Zhu
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> Currently, an execution is usually represented as "{{{}job vertex name{}}}
> ({{{}subtaskIndex+1{}}}/{{{}vertex parallelism{}}}) ({{{}attemptId{}}})" in
> logs, which may be redundant after this refactoring work. With the change of
> FLINK-17295, the representation of Execution in logs will be redundant. e.g.
> the subtask index is displayed 2 times.
> Therefore, I'm proposing to change the format to be "<{{{}job vertex name>
> {{(<{{{}subtaskIndex>+1{}}}/<{{{}vertex parallelism>{}}})
> {{#}} (graph: <{{{}short ExecutionGraphID>, vertex:
> <{}}}{{{}JobVertexID>{}}}) " and avoid directly display the
> {{{}ExecutionAttemptID{}}}. This can increase the log readability.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-25784) SerializedThrowable(De)Serializer out of sync
[ https://issues.apache.org/jira/browse/FLINK-25784?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564456#comment-17564456 ] Weijie Guo commented on FLINK-25784: In `SerializedThrowableSerializer`, the other two fields have already been serialized during write serialized-throwable field. The deserialized object should be able to get `originalerrorClassName` and `fullStringifiedStacktrace` directly. I think the serialization of these two fields should be removed as you said.If you think it reasonable, I can prepare a PR for this simple work. > SerializedThrowable(De)Serializer out of sync > - > > Key: FLINK-25784 > URL: https://issues.apache.org/jira/browse/FLINK-25784 > Project: Flink > Issue Type: Technical Debt > Components: Runtime / REST >Affects Versions: 1.15.0 >Reporter: Chesnay Schepler >Priority: Major > > The serializers writes 3 fields, but we only deserialize one of them. > If the latter is sufficient, then we could skip the serialization of 2 fields. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-28399) Refactor CheckedThread to accept runnable via constructor
[ https://issues.apache.org/jira/browse/FLINK-28399?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564448#comment-17564448 ] Weijie Guo commented on FLINK-28399: Hi [~chesnay] Thanks for open this ticket, I think this idea is very reasonable. We should use `CheckedThread` just like java's `Thread`. The only difference is that it will help us take care of exceptions. I have prepared a PR for this ticket, can you help assign this ticket to me and take a look. > Refactor CheckedThread to accept runnable via constructor > - > > Key: FLINK-28399 > URL: https://issues.apache.org/jira/browse/FLINK-28399 > Project: Flink > Issue Type: Technical Debt > Components: API / Core >Reporter: Chesnay Schepler >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > Make the CheckedThread an easier drop-in replacements for threads by passing > the runnable via the constructor. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-28399) Refactor CheckedThread to accept runnable via constructor
[ https://issues.apache.org/jira/browse/FLINK-28399?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564448#comment-17564448 ] Weijie Guo edited comment on FLINK-28399 at 7/8/22 8:07 PM: Hi [~chesnay] Thanks for open this ticket, I think this idea is very reasonable. We should use `CheckedThread` just like java's `Thread`. The only difference is that `CheckedThread` will help us take care of exceptions. I have prepared a PR for this ticket, can you help assign this ticket to me and take a look. was (Author: weijie guo): Hi [~chesnay] Thanks for open this ticket, I think this idea is very reasonable. We should use `CheckedThread` just like java's `Thread`. The only difference is that it will help us take care of exceptions. I have prepared a PR for this ticket, can you help assign this ticket to me and take a look. > Refactor CheckedThread to accept runnable via constructor > - > > Key: FLINK-28399 > URL: https://issues.apache.org/jira/browse/FLINK-28399 > Project: Flink > Issue Type: Technical Debt > Components: API / Core >Reporter: Chesnay Schepler >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > Make the CheckedThread an easier drop-in replacements for threads by passing > the runnable via the constructor. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #20229: [FLINK-28399] Refactor CheckedThread to accept runnable via constructor
flinkbot commented on PR #20229: URL: https://github.com/apache/flink/pull/20229#issuecomment-1179323284 ## CI report: * bfb8415d3cf9b0d09e49e671ab6e8c93c815bd7c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20228: [hotfix] [docs] Fix small typo in flink-conf.yaml file
flinkbot commented on PR #20228: URL: https://github.com/apache/flink/pull/20228#issuecomment-1179322795 ## CI report: * 6bfd8fc35b77283bc0adb06a8c3e1d595c09b302 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-28399) Refactor CheckedThread to accept runnable via constructor
[ https://issues.apache.org/jira/browse/FLINK-28399?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-28399: --- Labels: pull-request-available (was: ) > Refactor CheckedThread to accept runnable via constructor > - > > Key: FLINK-28399 > URL: https://issues.apache.org/jira/browse/FLINK-28399 > Project: Flink > Issue Type: Technical Debt > Components: API / Core >Reporter: Chesnay Schepler >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > Make the CheckedThread an easier drop-in replacements for threads by passing > the runnable via the constructor. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] reswqa opened a new pull request, #20229: [FLINK-28399] Refactor CheckedThread to accept runnable via constructor
reswqa opened a new pull request, #20229: URL: https://github.com/apache/flink/pull/20229 ## What is the purpose of the change Let `CheckedThread` supports pass a `RunnableWithException` to constructor, this will make it behave more like a thread. After this pr, we can use `CheckedThread` as the same way of using `Thread` like: `new Thread(Runnable runnable)` or `new Thread()` and then override `Thread.run()` method. Just change it to `CheckedThread(RunnableWithException runnableWithException)` or `new CheckedThread()` and then override `CheckedThread.go()` method. ## Brief change log - *Let `CheckedThread` supports pass a `RunnableWithException` to constructor* - *All anonymous inner class based on it are replaced by lambda expressions constructor* - *Add test for CheckedThread* ## Verifying this change This change added tests and can be verified by `CheckedThreadTest` ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lkokhreidze opened a new pull request, #20228: [hotfix] [docs] Fix small typo in flink-conf.yaml file
lkokhreidze opened a new pull request, #20228: URL: https://github.com/apache/flink/pull/20228 Fixes small typo in flink-conf.yaml. file. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] sunshineJK commented on pull request #20127: [FLINK-26270] Flink SQL write data to kafka by CSV format , whether d…
sunshineJK commented on PR #20127: URL: https://github.com/apache/flink/pull/20127#issuecomment-1179279118 hi @afedulov , Parameter name has been modified, thank you for your suggestion -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27893) Add additionalPrinterColumns for Job Status and Reconciliation Status in CRDs
[
https://issues.apache.org/jira/browse/FLINK-27893?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564401#comment-17564401
]
Gyula Fora commented on FLINK-27893:
Thank you for the input [~maddisondavid] , I see the value but I am going to
play the devils advocate here a little :)
What you expect to see when you list FlinkDeployments is not necessarily the
state of the job, but the state of the resource. Arguable the job state is part
of it so I am not against showing it but I suggest we show something like:
{noformat}
enum ResourceLifecycleState {
SUSPENDED, UPGRADING, DEPLOYED, STABLE, ROLLING_BACK, ROLLED_BACK, FAILED
}{noformat}
I am working on something like this for tracking detailed metrics about the
operator (measure time in applicaiton lifecycle state transictions).
Not sure UpgradeMode/Savepoint should be shown here, I think thats not really
important as long as it works correctly. Flink version makes sense
> Add additionalPrinterColumns for Job Status and Reconciliation Status in CRDs
> -
>
> Key: FLINK-27893
> URL: https://issues.apache.org/jira/browse/FLINK-27893
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: Jeesmon Jacob
>Assignee: Jeesmon Jacob
>Priority: Major
>
> Right now only columns available when you run "kubectl get flinkdeployment"
> is NAME and AGE. It is beneficial to see the .status.jobStatus.State and
> .status.ReconciliationStatus.State as additionalPrintColumns in CRD. It will
> be beneficial for automation to use those columns for status reporting.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #20227: [FLINK-28471]Translate hive_read_write.md into Chinese
flinkbot commented on PR #20227: URL: https://github.com/apache/flink/pull/20227#issuecomment-1179249576 ## CI report: * f3b579432a52ce7b3dae5c81fde4a2e833be261c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-28471) Translate hive_read_write.md into Chinese
[ https://issues.apache.org/jira/browse/FLINK-28471?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-28471: --- Labels: pull-request-available (was: ) > Translate hive_read_write.md into Chinese > - > > Key: FLINK-28471 > URL: https://issues.apache.org/jira/browse/FLINK-28471 > Project: Flink > Issue Type: Improvement > Components: Documentation >Reporter: eyys >Priority: Minor > Labels: pull-request-available > > Translate hive_read_write.md into Chinese > 将 hive_read_write.md翻译成中文 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] eyys opened a new pull request, #20227: [FLINK-28471]Translate hive_read_write.md into Chinese
eyys opened a new pull request, #20227: URL: https://github.com/apache/flink/pull/20227 https://issues.apache.org/jira/browse/FLINK-28471 Hello, I have translated the hive_read_write.md into Chinese. It is my first attempt to translate it. I hope to get your correction for the shortcomings . Thank You . ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) no - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] snuyanzin commented on pull request #20224: [FLINK-28466][Tests] Bump assertj to 3.23.1
snuyanzin commented on PR #20224: URL: https://github.com/apache/flink/pull/20224#issuecomment-1179245404 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-28471) Translate hive_read_write.md into Chinese
eyys created FLINK-28471: Summary: Translate hive_read_write.md into Chinese Key: FLINK-28471 URL: https://issues.apache.org/jira/browse/FLINK-28471 Project: Flink Issue Type: Improvement Components: Documentation Reporter: eyys Translate hive_read_write.md into Chinese 将 hive_read_write.md翻译成中文 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-27893) Add additionalPrinterColumns for Job Status and Reconciliation Status in CRDs
[
https://issues.apache.org/jira/browse/FLINK-27893?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564362#comment-17564362
]
David Maddison commented on FLINK-27893:
I do agree that the JobState reflects a point in time value and therefore may
miss state changes that happen in between the reconcile schedule (i.e. a Job
changing RUNNING -> RESTARTING -> RUNNING) however, it's still potentially
useful information that is not reflected elsewhere.
Other useful information would be the Flink Version, Upgrade Mode and Savepoint
the job last started from, i.e.
{code:java}
NAME STATE FLINK MODE SAVEPOINT
basic-checkpoint-ha-example RUNNING 1.15.0 savepoint
file:/mnt/flink/savepoints/savepoint-00-081fd2030040
basic-example RUNNING 1.15.0 stateless{code}
> Add additionalPrinterColumns for Job Status and Reconciliation Status in CRDs
> -
>
> Key: FLINK-27893
> URL: https://issues.apache.org/jira/browse/FLINK-27893
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: Jeesmon Jacob
>Assignee: Jeesmon Jacob
>Priority: Major
>
> Right now only columns available when you run "kubectl get flinkdeployment"
> is NAME and AGE. It is beneficial to see the .status.jobStatus.State and
> .status.ReconciliationStatus.State as additionalPrintColumns in CRD. It will
> be beneficial for automation to use those columns for status reporting.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-28250) exactly-once sink kafka cause out of memory
[
https://issues.apache.org/jira/browse/FLINK-28250?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564358#comment-17564358
]
Chalres Tan commented on FLINK-28250:
-
Hi all, I've gone ahead and opened a PR with [~jinshuangxian]'s suggested
patch, as I'm running into the same issues with my application ([mailing list
thread|https://lists.apache.org/thread/c86cd8qyqb6qxy639hkzbozkwv2qxk84]).
Would appreciate feedback on the
[PR|https://github.com/apache/flink/pull/20205], thanks!
> exactly-once sink kafka cause out of memory
> ---
>
> Key: FLINK-28250
> URL: https://issues.apache.org/jira/browse/FLINK-28250
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.15.0
> Environment: *flink version: flink-1.15.0*
> *tm: 8* parallelism, 1 slot, 2g
> centos7
>Reporter: jinshuangxian
>Priority: Critical
> Labels: pull-request-available
> Attachments: image-2022-06-25-22-07-35-686.png,
> image-2022-06-25-22-07-54-649.png, image-2022-06-25-22-08-04-891.png,
> image-2022-06-25-22-08-15-024.png
>
>
> *my sql code:*
> CREATE TABLE sourceTable (
> data bytes
> )WITH(
> 'connector'='kafka',
> 'topic'='topic1',
> 'properties.bootstrap.servers'='host1',
> 'properties.group.id'='gorup1',
> 'scan.startup.mode'='latest-offset',
> 'format'='raw'
> );
>
> CREATE TABLE sinkTable (
> data bytes
> )
> WITH (
> 'connector'='kafka',
> 'topic'='topic2',
> 'properties.bootstrap.servers'='host2',
> 'properties.transaction.timeout.ms'='3',
> 'sink.semantic'='exactly-once',
> 'sink.transactional-id-prefix'='xx-kafka-sink-a',
> 'format'='raw'
> );
> insert into sinkTable
> select data
> from sourceTable;
>
> *problem:*
> After the program runs online for about half an hour, full gc frequently
> appears
>
> {*}Troubleshoot{*}:
> I use command 'jmap -dump:live,format=b,file=/tmp/dump2.hprof' dump the
> problem tm memory. It is found that there are 115
> FlinkKafkaInternalProducers, which is not normal.
> !image-2022-06-25-22-07-54-649.png!!image-2022-06-25-22-07-35-686.png!
> After reading the code of KafkaCommitter, it is found that after the commit
> is successful, the producer is not recycled, only abnormal situations are
> recycled.
> !image-2022-06-25-22-08-04-891.png!
> I added a few lines of code. After the online test, the program works
> normally, and the problem of oom memory is solved.
> !image-2022-06-25-22-08-15-024.png!
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] HuangZhenQiu commented on pull request #20176: [FLINK-27660][table] add table api for registering function with resource
HuangZhenQiu commented on PR #20176: URL: https://github.com/apache/flink/pull/20176#issuecomment-1179171635 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-27357) In Flink HA Service on K8S, Web UI External Service should point to elected Job Manager leader's IP
[ https://issues.apache.org/jira/browse/FLINK-27357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564348#comment-17564348 ] Jesus H Christ edited comment on FLINK-27357 at 7/8/22 4:14 PM: [~wangyang0918] Yes, that would be the correct solution so that we can point to leader from Kubernetes Service. I will demonstrate in PR if I can find the time. was (Author: JIRAUSER288497): Yes, that would be the correct solution. I will demonstrate in PR if I can find the time. > In Flink HA Service on K8S, Web UI External Service should point to elected > Job Manager leader's IP > --- > > Key: FLINK-27357 > URL: https://issues.apache.org/jira/browse/FLINK-27357 > Project: Flink > Issue Type: Improvement >Reporter: Jesus H Christ >Priority: Minor > > Flink on Kubernetes has High Availability services which build an external > service for the rest api access. > [https://sourcegraph.com/github.com/apache/flink@master/-/blob/flink-kubernetes/src/main/java/org/apache/flink/kubernetes/kubeclient/decorators/ExternalServiceDecorator.java] > In the case of multiple job managers in reactive mode or to avoid 15s or so > between job manager restarts in K8S High Availability services, a new job > manager leader can be elected. In this case I think the external service we > create for the web ui, and possibly even the REST API service, no longer > points to the correct job manager as any of the job manager pods can have the > jobmanager label. Is this correct? > If so, it might help to use the endpoint containing the elected leader IP in > the ConfigMap of one specific pod of the JobManager for the external service > web ui, similar to how TaskManagers use JobManager IPs for High Availabiilty. > > It might also help to update the service or endpoint with the new IP to > point to when updating the ConfigMap for JobManager leader election: > [https://sourcegraph.com/github.com/apache/flink/-/blob/flink-kubernetes/src/main/java/org/apache/flink/kubernetes/highavailability/KubernetesLeaderRetrievalDriverFactory.java] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-27357) In Flink HA Service on K8S, Web UI External Service should point to elected Job Manager leader's IP
[ https://issues.apache.org/jira/browse/FLINK-27357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564348#comment-17564348 ] Jesus H Christ commented on FLINK-27357: Yes, that would be the correct solution. I will demonstrate in PR if I can find the time. > In Flink HA Service on K8S, Web UI External Service should point to elected > Job Manager leader's IP > --- > > Key: FLINK-27357 > URL: https://issues.apache.org/jira/browse/FLINK-27357 > Project: Flink > Issue Type: Improvement >Reporter: Jesus H Christ >Priority: Minor > > Flink on Kubernetes has High Availability services which build an external > service for the rest api access. > [https://sourcegraph.com/github.com/apache/flink@master/-/blob/flink-kubernetes/src/main/java/org/apache/flink/kubernetes/kubeclient/decorators/ExternalServiceDecorator.java] > In the case of multiple job managers in reactive mode or to avoid 15s or so > between job manager restarts in K8S High Availability services, a new job > manager leader can be elected. In this case I think the external service we > create for the web ui, and possibly even the REST API service, no longer > points to the correct job manager as any of the job manager pods can have the > jobmanager label. Is this correct? > If so, it might help to use the endpoint containing the elected leader IP in > the ConfigMap of one specific pod of the JobManager for the external service > web ui, similar to how TaskManagers use JobManager IPs for High Availabiilty. > > It might also help to update the service or endpoint with the new IP to > point to when updating the ConfigMap for JobManager leader election: > [https://sourcegraph.com/github.com/apache/flink/-/blob/flink-kubernetes/src/main/java/org/apache/flink/kubernetes/highavailability/KubernetesLeaderRetrievalDriverFactory.java] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-28470) Show source watermarks on dashboard
James created FLINK-28470: - Summary: Show source watermarks on dashboard Key: FLINK-28470 URL: https://issues.apache.org/jira/browse/FLINK-28470 Project: Flink Issue Type: Improvement Components: Runtime / Web Frontend Reporter: James All the operators on the dashboard show the low-watermark which is useful to see at a glance where a blockage might be. Can the same be added to sources (or at least legacy sources)? Currently I have to click on the node and add the "output watermark" metric. Would be useful to see source watermarks at a glance too. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-28469) Setting a timer within broadcast applyToKeyedState()
James created FLINK-28469: - Summary: Setting a timer within broadcast applyToKeyedState() Key: FLINK-28469 URL: https://issues.apache.org/jira/browse/FLINK-28469 Project: Flink Issue Type: Improvement Components: API / DataStream Affects Versions: 1.16.0 Reporter: James I know we can’t set a timer in the processBroadcastElement() of the KeyedBroadcastProcessFunction as there is no key. However, there is a context.applyToKeyedState() method which allows us to iterate over the keyed state in the scope of a key. So it is possible to add access to the TimerService onto the Context parameter passed into that delegate? Since the code running in the applyToKeyedState() method is scoped to a key we should be able to set up timers for that key too. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-28357) Watermark issue when recovering Finished sources
[ https://issues.apache.org/jira/browse/FLINK-28357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564346#comment-17564346 ] James commented on FLINK-28357: --- Hello - sorry been busy and just got round to rechecking my test program. If I comment out the line "env.disableOperatorChaining();" to allow operator chaining the issue also occurs. The screenshot of the dashboard after a recovery and the watermark not working properly is shown below: !image-2022-07-08-17-06-01-256.png! As you can see input2 for the join is saying Long.MIN_VALUE meaning the framework didn't trasnmit the watermark on behalf of my finished source (I didn't see the console message as you describe because it is finished). If you're having trouble reproducing on 1.15.0 before your fix, try changing the checkpointing frequency to 5 * 1000 instead of 70 as per my comments. For me that cause the issue immediately after the first recovery. BTW, I can't re-open this issue as you describe - not sure if I have perms etc. > Watermark issue when recovering Finished sources > > > Key: FLINK-28357 > URL: https://issues.apache.org/jira/browse/FLINK-28357 > Project: Flink > Issue Type: Bug > Components: Runtime / Checkpointing >Affects Versions: 1.15.0 > Environment: This can be reproduced in an IDE with the attached > sample program. >Reporter: James >Assignee: Piotr Nowojski >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0, 1.15.2, 1.14.6 > > Attachments: WatermarkDemoMain.java, > image-2022-07-01-16-18-14-768.png, image-2022-07-08-17-06-01-256.png, > longExample.txt > > > Copied mostly from email trail on the flink user mailing list: > I done a lot of experimentation and I’m convinced there is a problem with > Flink handling Finished sources and recovery. > The program consists of: > * Two sources: > ** One “Long Running Source” – stays alive and emits a watermark of > DateTime.now() every 10 seconds. > *** Prints the console a message saying the watermark has been emitted. > *** *Throws an exception every 5 or 10 iterations to force a recovery.* > ** One “Short Lived Source” – emits a Long.MAX_VALUE watermark, prints a > message to the console and returns. > * The “Short Live Source” feeds into a map() and then it joins with the > “Long Running Source” with a KeyedCoProcessFunction. Moves to “FINISHED” > state by Flink. > The problem here is that the “Join” receives no Long.MAX_VALUE watermark from > the map() in some situations after a recovery. The dashboard goes from > showing this: > !https://attachment.outlook.live.net/owa/MSA%3Ajas_sl%40hotmail.com/service.svc/s/GetAttachmentThumbnail?id=AQMkADAwATEyMTk3LTZiMDQtODBkMi0wMAItMDAKAEYAAAOeUdiydD9QS6CQDK1Dg0olBwACkmHn2W1HRKQHhbPYmGe%2BAASF%2B488ApJh59ltR0SkB4Wz2JhnvgAFXJ9puQESABAAyemY6ar4b0GAFLHn3hpyCw%3D%3D=2=1=eyJhbGciOiJSUzI1NiIsImtpZCI6IkZBRDY1NDI2MkM2QUYyOTYxQUExRThDQUI3OEZGMUIyNzBFNzA3RTkiLCJ0eXAiOiJKV1QiLCJ4NXQiOiItdFpVSml4cThwWWFvZWpLdDRfeHNuRG5CLWsifQ.eyJvcmlnaW4iOiJodHRwczovL291dGxvb2subGl2ZS5jb20iLCJ1YyI6IjMwMDU4MTIzODAzMzRlMmZhNzE5ZGUxOTNjNjA4NjQ3IiwidmVyIjoiRXhjaGFuZ2UuQ2FsbGJhY2suVjEiLCJhcHBjdHhzZW5kZXIiOiJPd2FEb3dubG9hZEA4NGRmOWU3Zi1lOWY2LTQwYWYtYjQzNS1hYWFhYWFhYWFhYWEiLCJpc3NyaW5nIjoiV1ciLCJhcHBjdHgiOiJ7XCJtc2V4Y2hwcm90XCI6XCJvd2FcIixcInB1aWRcIjpcIjMxODQwOTE5NTk0NjE5NFwiLFwic2NvcGVcIjpcIk93YURvd25sb2FkXCIsXCJvaWRcIjpcIjAwMDEyMTk3LTZiMDQtODBkMi0wMDAwLTAwMDAwMDAwMDAwMFwiLFwicHJpbWFyeXNpZFwiOlwiUy0xLTI4MjctNzQxMzUtMTc5NTQ1NzIzNFwifSIsIm5iZiI6MTY1NjY4ODI3OCwiZXhwIjoxNjU2Njg4ODc4LCJpc3MiOiIwMDAwMDAwMi0wMDAwLTBmZjEtY2UwMC0wMDAwMDAwMDAwMDBAODRkZjllN2YtZTlmNi00MGFmLWI0MzUtYWFhYWFhYWFhYWFhIiwiYXVkIjoiMDAwMDAwMDItMDAwMC0wZmYxLWNlMDAtMDAwMDAwMDAwMDAwL2F0dGFjaG1lbnQub3V0bG9vay5saXZlLm5ldEA4NGRmOWU3Zi1lOWY2LTQwYWYtYjQzNS1hYWFhYWFhYWFhYWEiLCJoYXBwIjoib3dhIn0.KI4I55ycdP1duIwxyYZstLCtnNOwEkyTxfEwK_5a35-ZLMrKd8zHCB5Elw-9-A9UHIxFGSYOlwnHXRvDT0xa6FqFIlO8cnebBRLKv9DhxHwfZqdKWIeF2EcUqwH0ejeA3RvD3-dR95iHPTf52-tuKi27nclPUUEJgbfRWQY3wHMDAFLLaLvKM6AV5S1IhGjBmy3MF_1oulTXbqRZx0ar3L8YQiHEGnfKGjFO2zSxQcTZXAp_rch4HIrVv9GSEcQnD7nBhWPBuuzuvXOvJiUzg0u_e9CUuf1-OcQwhUV3cf7cvme8JadfliY6ywkOne1OZsclQeDFc8EnGZke3l2V_Q=Es9QgEoDXEyksG3kZxXeMGC1LvlzW9oYJ-lyWNl-xblWQjmqz5FH_a2-eHuR6Zr51XNjigQpQDs.=outlook.live.com=20220617005.11=true! > To the below after a recovery (with the currentInput1/2Watermark metrics > showing input 2 having not received a watermark from the map, saying > –Long.MAX_VALUE): > !image-2022-07-01-16-18-14-768.png! > The program is currently set to checkpoint every 5 seconds. By experimenting > with 70 seconds, it seems that if only one checkpoint has been taken with the > “Short Lived Source” in a FINISHED state since the last recovery then > everything works fine and the restarted
[jira] [Updated] (FLINK-28357) Watermark issue when recovering Finished sources
[ https://issues.apache.org/jira/browse/FLINK-28357?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] James updated FLINK-28357: -- Attachment: image-2022-07-08-17-06-01-256.png > Watermark issue when recovering Finished sources > > > Key: FLINK-28357 > URL: https://issues.apache.org/jira/browse/FLINK-28357 > Project: Flink > Issue Type: Bug > Components: Runtime / Checkpointing >Affects Versions: 1.15.0 > Environment: This can be reproduced in an IDE with the attached > sample program. >Reporter: James >Assignee: Piotr Nowojski >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0, 1.15.2, 1.14.6 > > Attachments: WatermarkDemoMain.java, > image-2022-07-01-16-18-14-768.png, image-2022-07-08-17-06-01-256.png, > longExample.txt > > > Copied mostly from email trail on the flink user mailing list: > I done a lot of experimentation and I’m convinced there is a problem with > Flink handling Finished sources and recovery. > The program consists of: > * Two sources: > ** One “Long Running Source” – stays alive and emits a watermark of > DateTime.now() every 10 seconds. > *** Prints the console a message saying the watermark has been emitted. > *** *Throws an exception every 5 or 10 iterations to force a recovery.* > ** One “Short Lived Source” – emits a Long.MAX_VALUE watermark, prints a > message to the console and returns. > * The “Short Live Source” feeds into a map() and then it joins with the > “Long Running Source” with a KeyedCoProcessFunction. Moves to “FINISHED” > state by Flink. > The problem here is that the “Join” receives no Long.MAX_VALUE watermark from > the map() in some situations after a recovery. The dashboard goes from > showing this: > !https://attachment.outlook.live.net/owa/MSA%3Ajas_sl%40hotmail.com/service.svc/s/GetAttachmentThumbnail?id=AQMkADAwATEyMTk3LTZiMDQtODBkMi0wMAItMDAKAEYAAAOeUdiydD9QS6CQDK1Dg0olBwACkmHn2W1HRKQHhbPYmGe%2BAASF%2B488ApJh59ltR0SkB4Wz2JhnvgAFXJ9puQESABAAyemY6ar4b0GAFLHn3hpyCw%3D%3D=2=1=eyJhbGciOiJSUzI1NiIsImtpZCI6IkZBRDY1NDI2MkM2QUYyOTYxQUExRThDQUI3OEZGMUIyNzBFNzA3RTkiLCJ0eXAiOiJKV1QiLCJ4NXQiOiItdFpVSml4cThwWWFvZWpLdDRfeHNuRG5CLWsifQ.eyJvcmlnaW4iOiJodHRwczovL291dGxvb2subGl2ZS5jb20iLCJ1YyI6IjMwMDU4MTIzODAzMzRlMmZhNzE5ZGUxOTNjNjA4NjQ3IiwidmVyIjoiRXhjaGFuZ2UuQ2FsbGJhY2suVjEiLCJhcHBjdHhzZW5kZXIiOiJPd2FEb3dubG9hZEA4NGRmOWU3Zi1lOWY2LTQwYWYtYjQzNS1hYWFhYWFhYWFhYWEiLCJpc3NyaW5nIjoiV1ciLCJhcHBjdHgiOiJ7XCJtc2V4Y2hwcm90XCI6XCJvd2FcIixcInB1aWRcIjpcIjMxODQwOTE5NTk0NjE5NFwiLFwic2NvcGVcIjpcIk93YURvd25sb2FkXCIsXCJvaWRcIjpcIjAwMDEyMTk3LTZiMDQtODBkMi0wMDAwLTAwMDAwMDAwMDAwMFwiLFwicHJpbWFyeXNpZFwiOlwiUy0xLTI4MjctNzQxMzUtMTc5NTQ1NzIzNFwifSIsIm5iZiI6MTY1NjY4ODI3OCwiZXhwIjoxNjU2Njg4ODc4LCJpc3MiOiIwMDAwMDAwMi0wMDAwLTBmZjEtY2UwMC0wMDAwMDAwMDAwMDBAODRkZjllN2YtZTlmNi00MGFmLWI0MzUtYWFhYWFhYWFhYWFhIiwiYXVkIjoiMDAwMDAwMDItMDAwMC0wZmYxLWNlMDAtMDAwMDAwMDAwMDAwL2F0dGFjaG1lbnQub3V0bG9vay5saXZlLm5ldEA4NGRmOWU3Zi1lOWY2LTQwYWYtYjQzNS1hYWFhYWFhYWFhYWEiLCJoYXBwIjoib3dhIn0.KI4I55ycdP1duIwxyYZstLCtnNOwEkyTxfEwK_5a35-ZLMrKd8zHCB5Elw-9-A9UHIxFGSYOlwnHXRvDT0xa6FqFIlO8cnebBRLKv9DhxHwfZqdKWIeF2EcUqwH0ejeA3RvD3-dR95iHPTf52-tuKi27nclPUUEJgbfRWQY3wHMDAFLLaLvKM6AV5S1IhGjBmy3MF_1oulTXbqRZx0ar3L8YQiHEGnfKGjFO2zSxQcTZXAp_rch4HIrVv9GSEcQnD7nBhWPBuuzuvXOvJiUzg0u_e9CUuf1-OcQwhUV3cf7cvme8JadfliY6ywkOne1OZsclQeDFc8EnGZke3l2V_Q=Es9QgEoDXEyksG3kZxXeMGC1LvlzW9oYJ-lyWNl-xblWQjmqz5FH_a2-eHuR6Zr51XNjigQpQDs.=outlook.live.com=20220617005.11=true! > To the below after a recovery (with the currentInput1/2Watermark metrics > showing input 2 having not received a watermark from the map, saying > –Long.MAX_VALUE): > !image-2022-07-01-16-18-14-768.png! > The program is currently set to checkpoint every 5 seconds. By experimenting > with 70 seconds, it seems that if only one checkpoint has been taken with the > “Short Lived Source” in a FINISHED state since the last recovery then > everything works fine and the restarted “Short Lived Source” emits its > watermark and I see the “ShortedLivedEmptySource emitting Long.MAX_VALUE > watermark” message on the console meaning the run() definitely executed. > However, I found that if 2 or more checkpoints are taken since the last > recovery with the source in a FINISHED state then the console message does > not appear and the watermark is not emitted. > To repeat – the Join does not get a Long.MAX_VALUE watermark from my source > or Flink if I see two or more checkpoints logged in between recoveries. If > zero or checkpoints are made, everything is fine – the join gets the > watermark and I see my console message. You can play with the checkpointing > frequency as per the code comments: > // Useful checkpoint interval options: > // 5 - see the problem after the first recovery >
[jira] [Commented] (FLINK-23528) stop-with-savepoint can fail with FlinkKinesisConsumer
[
https://issues.apache.org/jira/browse/FLINK-23528?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564343#comment-17564343
]
Arvid Heise commented on FLINK-23528:
-
As far as I remember, I needed to fix this for the tests to succeed reliably.
> stop-with-savepoint can fail with FlinkKinesisConsumer
> --
>
> Key: FLINK-23528
> URL: https://issues.apache.org/jira/browse/FLINK-23528
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kinesis
>Affects Versions: 1.11.3, 1.13.1, 1.12.4, 1.14.3, 1.15.0
>Reporter: Piotr Nowojski
>Assignee: Krzysztof Dziolak
>Priority: Critical
> Labels: pull-request-available, stale-assigned
> Fix For: 1.15.2
>
>
> {{FlinkKinesisConsumer#cancel()}} (inside
> {{KinesisDataFetcher#shutdownFetcher()}}) shouldn't be interrupting source
> thread. Otherwise, as described in FLINK-23527, network stack can be left in
> an invalid state and downstream tasks can encounter deserialisation errors.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564342#comment-17564342
]
Danny Cranmer commented on FLINK-24229:
---
[~Gusev] I think we certainly need to hide the {{ElementConverter}}, since the
DDB sink needs to serialise and deserialise records for checkpointing. If you
expose the {{ElementConverter}} this would allow users to create objects that
are incompatible with the checkpoint serde. But generally speaking, yes let's
move discussion to the new repo
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-27438) SQL validation failed when constructing a map array
[
https://issues.apache.org/jira/browse/FLINK-27438?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564339#comment-17564339
]
Roman Boyko commented on FLINK-27438:
-
Hi [~twalthr] !
Could you please check the changed fix -
[https://github.com/apache/flink/pull/19648] ?
> SQL validation failed when constructing a map array
> ---
>
> Key: FLINK-27438
> URL: https://issues.apache.org/jira/browse/FLINK-27438
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.14.4, 1.15.0
>Reporter: Wei Zhong
>Assignee: Roman Boyko
>Priority: Major
> Labels: pull-request-available, stale-assigned
>
> Exception:
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> SQL validation failed. Unsupported type when convertTypeToSpec: MAP
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$validate(FlinkPlannerImpl.scala:185)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.validate(FlinkPlannerImpl.scala:110)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:237)
> at
> org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:105)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:695)
> at
> org.apache.flink.table.planner.plan.stream.sql.LegacyTableFactoryTest.(LegacyTableFactoryTest.java:35)
> at
> org.apache.flink.table.planner.plan.stream.sql.LegacyTableFactoryTest.main(LegacyTableFactoryTest.java:49)
> Caused by: java.lang.UnsupportedOperationException: Unsupported type when
> convertTypeToSpec: MAP
> at
> org.apache.calcite.sql.type.SqlTypeUtil.convertTypeToSpec(SqlTypeUtil.java:1059)
> at
> org.apache.calcite.sql.type.SqlTypeUtil.convertTypeToSpec(SqlTypeUtil.java:1081)
> at
> org.apache.flink.table.planner.functions.utils.SqlValidatorUtils.castTo(SqlValidatorUtils.java:82)
> at
> org.apache.flink.table.planner.functions.utils.SqlValidatorUtils.adjustTypeForMultisetConstructor(SqlValidatorUtils.java:74)
> at
> org.apache.flink.table.planner.functions.utils.SqlValidatorUtils.adjustTypeForArrayConstructor(SqlValidatorUtils.java:39)
> at
> org.apache.flink.table.planner.functions.sql.SqlArrayConstructor.inferReturnType(SqlArrayConstructor.java:44)
> at
> org.apache.calcite.sql.SqlOperator.validateOperands(SqlOperator.java:449)
> at org.apache.calcite.sql.SqlOperator.deriveType(SqlOperator.java:531)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl$DeriveTypeVisitor.visit(SqlValidatorImpl.java:5716)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl$DeriveTypeVisitor.visit(SqlValidatorImpl.java:5703)
> at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:139)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.deriveTypeImpl(SqlValidatorImpl.java:1736)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.deriveType(SqlValidatorImpl.java:1727)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.expandSelectItem(SqlValidatorImpl.java:421)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelectList(SqlValidatorImpl.java:4061)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelect(SqlValidatorImpl.java:3347)
> at
> org.apache.calcite.sql.validate.SelectNamespace.validateImpl(SelectNamespace.java:60)
> at
> org.apache.calcite.sql.validate.AbstractNamespace.validate(AbstractNamespace.java:84)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateNamespace(SqlValidatorImpl.java:997)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateQuery(SqlValidatorImpl.java:975)
> at org.apache.calcite.sql.SqlSelect.validate(SqlSelect.java:232)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateScopedExpression(SqlValidatorImpl.java:952)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validate(SqlValidatorImpl.java:704)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$validate(FlinkPlannerImpl.scala:180)
> ... 6 more {code}
> How to reproduce:
> {code:java}
> tableEnv.executeSql("select array[map['A', 'AA'], map['B', 'BB'], map['C',
> CAST(NULL AS STRING)]] from (VALUES ('a'))").print(); {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] rkhachatryan commented on a diff in pull request #19309: [FLINK-26964][state/heap] Notify CheckpointStrategy about checkpoint completion/abortion
rkhachatryan commented on code in PR #19309:
URL: https://github.com/apache/flink/pull/19309#discussion_r916946400
##
flink-runtime/src/main/java/org/apache/flink/runtime/state/heap/HeapKeyedStateBackend.java:
##
@@ -333,13 +334,17 @@ public SavepointResources savepoint() {
}
@Override
-public void notifyCheckpointComplete(long checkpointId) {
-// Nothing to do
+public void notifyCheckpointComplete(long checkpointId) throws Exception {
+if (checkpointStrategy instanceof CheckpointListener) {
+((CheckpointListener)
checkpointStrategy).notifyCheckpointComplete(checkpointId);
+}
}
@Override
-public void notifyCheckpointAborted(long checkpointId) {
-// nothing to do
+public void notifyCheckpointAborted(long checkpointId) throws Exception {
Review Comment:
You're right, it's not implemented by the strategy. But I think it would be
more consistent to have it implemented here the same way as
`notifyCheckpointComplete`.
WDYT?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-28325) DataOutputSerializer#writeBytes increase position twice
[ https://issues.apache.org/jira/browse/FLINK-28325?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564338#comment-17564338 ] Weijie Guo commented on FLINK-28325: duplicate as FLINK-23598 > DataOutputSerializer#writeBytes increase position twice > --- > > Key: FLINK-28325 > URL: https://issues.apache.org/jira/browse/FLINK-28325 > Project: Flink > Issue Type: Bug > Components: Runtime / Task >Reporter: huweihua >Priority: Minor > Attachments: image-2022-06-30-18-14-50-827.png, > image-2022-06-30-18-15-18-590.png, image.png > > > Hi, I was looking at the code and found that DataOutputSerializer.writeBytes > increases the position twice, I feel it is a problem, please let me know if > it is for a special purpose > org.apache.flink.core.memory.DataOutputSerializer#writeBytes > > !image-2022-06-30-18-14-50-827.png!!image-2022-06-30-18-15-18-590.png! -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] reswqa commented on pull request #20157: [FLINK-28326][runtime] fix unstable test ResultPartitionTest.testIdleAndBackPressuredTime.
reswqa commented on PR #20157: URL: https://github.com/apache/flink/pull/20157#issuecomment-1179124729 Hi @zentol, I have update this pull request by your suggestion, PTAL~ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-28172) Scatter dstl files into separate directories by job id
[
https://issues.apache.org/jira/browse/FLINK-28172?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Roman Khachatryan closed FLINK-28172.
-
Fix Version/s: 1.16.0
Resolution: Fixed
Merged as 135130379e592d9ae752bc4eea20b6fb222f8c15 into master (1.16).
Thanks [~Feifan Wang] for the contribution!
> Scatter dstl files into separate directories by job id
> --
>
> Key: FLINK-28172
> URL: https://issues.apache.org/jira/browse/FLINK-28172
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / State Backends
>Affects Versions: 1.15.0
>Reporter: Feifan Wang
>Assignee: Feifan Wang
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.16.0
>
>
> In the current implementation of {_}FsStateChangelogStorage{_}, dstl files
> from all jobs are put into the same directory (configured via
> {_}dstl.dfs.base-path{_}). Everything is fine if it's a filesystem like
> S3.But if it is a file system like hadoop, there will be some problems.
> First, there may be an upper limit to the number of files in a single
> directory. Increasing this threshold will greatly reduce the performance of
> the distributed file system.
> Second, dstl file management becomes difficult because the user cannot tell
> which job the dstl file belongs to, especially when the retained checkpoint
> is turned on.
> h3. Propose
> # create a subdirectory named with the job id under the _dstl.dfs.base-path_
> directory when the job starts
> # all dstl files upload to the subdirectory
> ( Going a step further, we can even create two levels of subdirectories under
> the _dstl.dfs.base-path_ directory, like _base-path/\{jobId}/dstl ._ This
> way, if the user configures the same dstl.dfs.base-path as
> state.checkpoints.dir, all files needed for job recovery will be in the same
> directory and well organized. )
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Comment Edited] (FLINK-28364) Python Job support for Kubernetes Operator
[ https://issues.apache.org/jira/browse/FLINK-28364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564329#comment-17564329 ] Nicholas Jiang edited comment on FLINK-28364 at 7/8/22 3:35 PM: [~bgeng777], the users build a custom image which has Python and PyFlink prepared by following the document [using-flink-python-on-docker|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/resource-providers/standalone/docker/#using-flink-python-on-docker], no need to more document about building PyFlink image. Hence you could firstly publish the official PyFlink image, then provide the PyFlink example. [~wu3396], WDYT? was (Author: nicholasjiang): [~bgeng777], the users build a custom image which has Python and PyFlink prepared by following the document [using-flink-python-on-docker|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/resource-providers/standalone/docker/#using-flink-python-on-docker], no need to more document about building PyFlink image. Hence you could firstly publish the official PyFlink image, then provide the PyFlink example. > Python Job support for Kubernetes Operator > -- > > Key: FLINK-28364 > URL: https://issues.apache.org/jira/browse/FLINK-28364 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: wu3396 >Priority: Major > > *Describe the solution* > Job types that I want to support pyflink for > *Describe alternatives* > like [here|https://github.com/spotify/flink-on-k8s-operator/pull/165] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] rkhachatryan merged pull request #20093: [FLINK-28172][changelog] Scatter dstl files into separate directories…
rkhachatryan merged PR #20093: URL: https://github.com/apache/flink/pull/20093 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] mas-chen commented on pull request #19366: [FLINK-24660][Connectors / Kafka] allow setting KafkaSubscriber in KafkaSourceBuilder
mas-chen commented on PR #19366: URL: https://github.com/apache/flink/pull/19366#issuecomment-1179122465 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-28364) Python Job support for Kubernetes Operator
[ https://issues.apache.org/jira/browse/FLINK-28364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564329#comment-17564329 ] Nicholas Jiang commented on FLINK-28364: [~bgeng777], the users build a custom image which has Python and PyFlink prepared by following the document [using-flink-python-on-docker|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/resource-providers/standalone/docker/#using-flink-python-on-docker], no need to more document about building PyFlink image. Hence you could firstly publish the official PyFlink image, then provide the PyFlink example. > Python Job support for Kubernetes Operator > -- > > Key: FLINK-28364 > URL: https://issues.apache.org/jira/browse/FLINK-28364 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: wu3396 >Priority: Major > > *Describe the solution* > Job types that I want to support pyflink for > *Describe alternatives* > like [here|https://github.com/spotify/flink-on-k8s-operator/pull/165] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] reswqa commented on a diff in pull request #20222: [FLINK-28137] Introduce SpeculativeScheduler
reswqa commented on code in PR #20222:
URL: https://github.com/apache/flink/pull/20222#discussion_r916889626
##
flink-runtime/src/test/java/org/apache/flink/runtime/executiongraph/failover/flip1/ExecutionFailureHandlerTest.java:
##
@@ -71,122 +74,125 @@ public void setUp() {
/** Tests the case that task restarting is accepted. */
@Test
-public void testNormalFailureHandling() {
+void testNormalFailureHandling() throws Exception {
final Set tasksToRestart =
Collections.singleton(new ExecutionVertexID(new JobVertexID(),
0));
failoverStrategy.setTasksToRestart(tasksToRestart);
+Execution execution = createExecution(EXECUTOR_RESOURCE.getExecutor());
Exception cause = new Exception("test failure");
long timestamp = System.currentTimeMillis();
// trigger a task failure
final FailureHandlingResult result =
-executionFailureHandler.getFailureHandlingResult(
-new ExecutionVertexID(new JobVertexID(), 0), cause,
timestamp);
+executionFailureHandler.getFailureHandlingResult(execution,
cause, timestamp);
// verify results
-assertTrue(result.canRestart());
-assertEquals(RESTART_DELAY_MS, result.getRestartDelayMS());
-assertEquals(tasksToRestart, result.getVerticesToRestart());
-assertThat(result.getError(), is(cause));
-assertThat(result.getTimestamp(), is(timestamp));
-assertEquals(1, executionFailureHandler.getNumberOfRestarts());
+assertThat(result.canRestart()).isTrue();
+assertThat(result.getFailedExecution().isPresent()).isTrue();
+assertThat(result.getFailedExecution().get()).isSameAs(execution);
+assertThat(result.getRestartDelayMS()).isEqualTo(RESTART_DELAY_MS);
+assertThat(result.getVerticesToRestart()).isEqualTo(tasksToRestart);
+assertThat(result.getError()).isSameAs(cause);
+assertThat(result.getTimestamp()).isEqualTo(timestamp);
+assertThat(executionFailureHandler.getNumberOfRestarts()).isEqualTo(1);
}
/** Tests the case that task restarting is suppressed. */
@Test
-public void testRestartingSuppressedFailureHandlingResult() {
+void testRestartingSuppressedFailureHandlingResult() throws Exception {
// restart strategy suppresses restarting
backoffTimeStrategy.setCanRestart(false);
// trigger a task failure
+Execution execution = createExecution(EXECUTOR_RESOURCE.getExecutor());
final Throwable error = new Exception("expected test failure");
final long timestamp = System.currentTimeMillis();
final FailureHandlingResult result =
-executionFailureHandler.getFailureHandlingResult(
-new ExecutionVertexID(new JobVertexID(), 0), error,
timestamp);
+executionFailureHandler.getFailureHandlingResult(execution,
error, timestamp);
// verify results
-assertFalse(result.canRestart());
-assertThat(result.getError(), containsCause(error));
-assertThat(result.getTimestamp(), is(timestamp));
-
assertFalse(ExecutionFailureHandler.isUnrecoverableError(result.getError()));
-try {
-result.getVerticesToRestart();
-fail("get tasks to restart is not allowed when restarting is
suppressed");
-} catch (IllegalStateException ex) {
-// expected
-}
-try {
-result.getRestartDelayMS();
-fail("get restart delay is not allowed when restarting is
suppressed");
-} catch (IllegalStateException ex) {
-// expected
-}
-assertEquals(0, executionFailureHandler.getNumberOfRestarts());
+assertThat(result.canRestart()).isFalse();
+assertThat(result.getFailedExecution().isPresent()).isTrue();
+assertThat(result.getFailedExecution().get()).isSameAs(execution);
+assertThat(result.getError()).hasCause(error);
+assertThat(result.getTimestamp()).isEqualTo(timestamp);
+
assertThat(ExecutionFailureHandler.isUnrecoverableError(result.getError())).isFalse();
+
+assertThatThrownBy(() -> result.getVerticesToRestart())
+.as("getVerticesToRestart is not allowed when restarting is
suppressed")
+.isInstanceOf(IllegalStateException.class);
+
+assertThatThrownBy(() -> result.getRestartDelayMS())
+.as("getRestartDelayMS is not allowed when restarting is
suppressed")
+.isInstanceOf(IllegalStateException.class);
+
+assertThat(executionFailureHandler.getNumberOfRestarts()).isZero();
}
/** Tests the case that the failure is non-recoverable type. */
@Test
-public void testNonRecoverableFailureHandlingResult() {
+void testNonRecoverableFailureHandlingResult() throws Exception {
+
// trigger an
[jira] [Commented] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564322#comment-17564322
]
Yuri Gusev commented on FLINK-24229:
Ok thanks, we had few open questions in progress (like hiding or not
ElementConverter). But it may be better to start fresh on a new PR
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Comment Edited] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564322#comment-17564322
]
Yuri Gusev edited comment on FLINK-24229 at 7/8/22 3:08 PM:
Ok thanks, we had few open questions in progress (like hiding or not
ElementConverter). But it may be better to start fresh on a new PR
[~dannycranmer]
was (Author: gusev):
Ok thanks, we had few open questions in progress (like hiding or not
ElementConverter). But it may be better to start fresh on a new PR
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] afedulov commented on a diff in pull request #20204: [hotfix][docs] Update code formatting instructions for newer IntelliJ versions.
afedulov commented on code in PR #20204: URL: https://github.com/apache/flink/pull/20204#discussion_r916905260 ## docs/content/docs/flinkDev/ide_setup.md: ## @@ -149,6 +149,12 @@ It is recommended to automatically format your code by applying the following se 8. Under "Formatting Actions", select "Optimize imports" and "Reformat file". 9. Under "File Path Inclusions", add an entry for `.*\.java` and `.*\.scala` to avoid formatting other file types. +For IntelliJ IDEA version > 2021.2: + +6. Go to "Settings" → "Tools" → "Actions on Save". +7. Under "Formatting Actions", select "Optimize imports" and "Reformat file". +8. From the "All file types list" next to "Reformat code", select Java and Scala. Review Comment: I had a copy of 2021.2 CE on my machine, the Copyright is there :thinking: Checked 2022.1.3 CE - also available. :man_shrugging: Maybe it is a Windows-specific issue? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on pull request #20214: [FLINK-28454][kafka][docs] Fix the wrong timestamp unit of KafkaSource
1996fanrui commented on PR #20214: URL: https://github.com/apache/flink/pull/20214#issuecomment-1179089090 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-27556) Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022
[ https://issues.apache.org/jira/browse/FLINK-27556?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Roman Khachatryan reassigned FLINK-27556: - Assignee: Roman Khachatryan > Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022 > --- > > Key: FLINK-27556 > URL: https://issues.apache.org/jira/browse/FLINK-27556 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Checkpointing >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Assignee: Roman Khachatryan >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > Attachments: Screenshot_2022-05-09_10-35-57.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=1=checkpointSingleInput.UNALIGNED=on=on=off=2=200 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-27556) Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022
[ https://issues.apache.org/jira/browse/FLINK-27556?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Roman Khachatryan closed FLINK-27556. - Fix Version/s: 1.16.0 Resolution: Fixed Merged into master as 231e96b205edadcf9cbccf19d5cd1b414c2eadea. > Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022 > --- > > Key: FLINK-27556 > URL: https://issues.apache.org/jira/browse/FLINK-27556 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Checkpointing >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > Attachments: Screenshot_2022-05-09_10-35-57.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=1=checkpointSingleInput.UNALIGNED=on=on=off=2=200 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] rkhachatryan merged pull request #20173: [FLINK-27556][state] Inline state handle id generation
rkhachatryan merged PR #20173: URL: https://github.com/apache/flink/pull/20173 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-26721) PulsarSourceITCase.testSavepoint failed on azure pipeline
[
https://issues.apache.org/jira/browse/FLINK-26721?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564317#comment-17564317
]
Yufan Sheng commented on FLINK-26721:
-
[~martijnvisser] Pulsar 2.10.0 fixes the unstable tests on Transaction. I'm
working on https://issues.apache.org/jira/browse/FLINK-27399. The new start
position setting logic seems fixed the failure on connector testing tools.
> PulsarSourceITCase.testSavepoint failed on azure pipeline
> -
>
> Key: FLINK-26721
> URL: https://issues.apache.org/jira/browse/FLINK-26721
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Pulsar
>Affects Versions: 1.16.0
>Reporter: Yun Gao
>Assignee: Yufan Sheng
>Priority: Blocker
> Labels: build-stability, test-stability
> Fix For: 1.16.0
>
>
> {code:java}
> Mar 18 05:49:52 [ERROR] Tests run: 12, Failures: 1, Errors: 0, Skipped: 0,
> Time elapsed: 315.581 s <<< FAILURE! - in
> org.apache.flink.connector.pulsar.source.PulsarSourceITCase
> Mar 18 05:49:52 [ERROR]
> org.apache.flink.connector.pulsar.source.PulsarSourceITCase.testSavepoint(TestEnvironment,
> DataStreamSourceExternalContext, CheckpointingMode)[1] Time elapsed:
> 140.803 s <<< FAILURE!
> Mar 18 05:49:52 java.lang.AssertionError:
> Mar 18 05:49:52
> Mar 18 05:49:52 Expecting
> Mar 18 05:49:52
> Mar 18 05:49:52 to be completed within 2M.
> Mar 18 05:49:52
> Mar 18 05:49:52 exception caught while trying to get the future result:
> java.util.concurrent.TimeoutException
> Mar 18 05:49:52 at
> java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1784)
> Mar 18 05:49:52 at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1928)
> Mar 18 05:49:52 at
> org.assertj.core.internal.Futures.assertSucceededWithin(Futures.java:109)
> Mar 18 05:49:52 at
> org.assertj.core.api.AbstractCompletableFutureAssert.internalSucceedsWithin(AbstractCompletableFutureAssert.java:400)
> Mar 18 05:49:52 at
> org.assertj.core.api.AbstractCompletableFutureAssert.succeedsWithin(AbstractCompletableFutureAssert.java:396)
> Mar 18 05:49:52 at
> org.apache.flink.connector.testframe.testsuites.SourceTestSuiteBase.checkResultWithSemantic(SourceTestSuiteBase.java:766)
> Mar 18 05:49:52 at
> org.apache.flink.connector.testframe.testsuites.SourceTestSuiteBase.restartFromSavepoint(SourceTestSuiteBase.java:399)
> Mar 18 05:49:52 at
> org.apache.flink.connector.testframe.testsuites.SourceTestSuiteBase.testSavepoint(SourceTestSuiteBase.java:241)
> Mar 18 05:49:52 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> Mar 18 05:49:52 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> Mar 18 05:49:52 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> Mar 18 05:49:52 at java.lang.reflect.Method.invoke(Method.java:498)
> Mar 18 05:49:52 at
> org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:725)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestTemplateMethod(TimeoutExtension.java:92)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain.proceed(InvocationInterceptorChain.java:64)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain.chainAndInvoke(InvocationInterceptorChain.java:45)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain.invoke(InvocationInterceptorChain.java:37)
> Mar 18 05:49:52 at
> org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:104)
> Mar 18 05:49:52 at
>
[GitHub] [flink] rkhachatryan commented on pull request #20173: [FLINK-27556][state] Inline state handle id generation
rkhachatryan commented on PR #20173: URL: https://github.com/apache/flink/pull/20173#issuecomment-1179085624 Thanks for the review @akalash, the failure is unrelated (FLINK-28391) and did not happen in my private [branch](https://dev.azure.com/khachatryanroman/flink/_build/results?buildId=1578=logs=5e593fe1-85ee-5bfc-9301-17805ac8025b). Merging. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27831) Provide example of Beam on the k8s operator
[ https://issues.apache.org/jira/browse/FLINK-27831?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564309#comment-17564309 ] Márton Balassi commented on FLINK-27831: I am creating an example within the flink-kubernetes-operator project following the structure of this example for now: https://github.com/apache/flink-kubernetes-operator/tree/main/examples/flink-sql-runner-example > Provide example of Beam on the k8s operator > --- > > Key: FLINK-27831 > URL: https://issues.apache.org/jira/browse/FLINK-27831 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Márton Balassi >Assignee: Márton Balassi >Priority: Minor > Fix For: kubernetes-operator-1.1.0 > > > Multiple users have asked for whether the operator supports Beam jobs in > different shapes. I assume that running a Beam job ultimately with the > current operator ultimately comes down to having the right jars on the > classpath / packaged into the user's fatjar. > At this stage I suggest adding one such example, providing it might attract > new users. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-28468) Creating benchmark channel in Apache Flink slack
[ https://issues.apache.org/jira/browse/FLINK-28468?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Anton Kalashnikov reassigned FLINK-28468: - Assignee: Anton Kalashnikov > Creating benchmark channel in Apache Flink slack > > > Key: FLINK-28468 > URL: https://issues.apache.org/jira/browse/FLINK-28468 > Project: Flink > Issue Type: Improvement >Reporter: Anton Kalashnikov >Assignee: Anton Kalashnikov >Priority: Major > > It needs to create slack channel to which the result of benchmarks will be > sent. > Steps: > * Create `dev-benchmarks` channel(with the help of admin of Apache Flink > slack needed) > * Create `Slack app` for sending benchmark results to slack(admin help as > well). > * Configure existing Jenkins with the new `Slack app`'s token to send the > result of benchmarks to this new channel. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-28468) Creating benchmark channel in Apache Flink slack
Anton Kalashnikov created FLINK-28468: - Summary: Creating benchmark channel in Apache Flink slack Key: FLINK-28468 URL: https://issues.apache.org/jira/browse/FLINK-28468 Project: Flink Issue Type: Improvement Reporter: Anton Kalashnikov It needs to create slack channel to which the result of benchmarks will be sent. Steps: * Create `dev-benchmarks` channel(with the help of admin of Apache Flink slack needed) * Create `Slack app` for sending benchmark results to slack(admin help as well). * Configure existing Jenkins with the new `Slack app`'s token to send the result of benchmarks to this new channel. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-28447) Create Kubernetes Operator PR template
[ https://issues.apache.org/jira/browse/FLINK-28447?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-28447: --- Labels: pull-request-available (was: ) > Create Kubernetes Operator PR template > -- > > Key: FLINK-28447 > URL: https://issues.apache.org/jira/browse/FLINK-28447 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Márton Balassi >Priority: Major > Labels: pull-request-available > > We should create a sensible PR template similar (but simpler) to Flink > itself. This should help avoid PRs with poor description that are hard to > review. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] mbalassi opened a new pull request, #305: [FLINK-28447] GitHub Pull Request template
mbalassi opened a new pull request, #305: URL: https://github.com/apache/flink-kubernetes-operator/pull/305 I have started from the template in the main Flink repo and made some simplification given the smaller scope of the project. Let me know if you prefer to make the guide more concise. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #20226: Fix Chinese document format errors.
flinkbot commented on PR #20226: URL: https://github.com/apache/flink/pull/20226#issuecomment-1179066625 ## CI report: * c0c5037390b98b4de97c33195d434cc25f2e1143 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 opened a new pull request, #20226: Fix Chinese document format errors.
liuzhuang2017 opened a new pull request, #20226: URL: https://github.com/apache/flink/pull/20226 ## What is the purpose of the change - **In english document:** 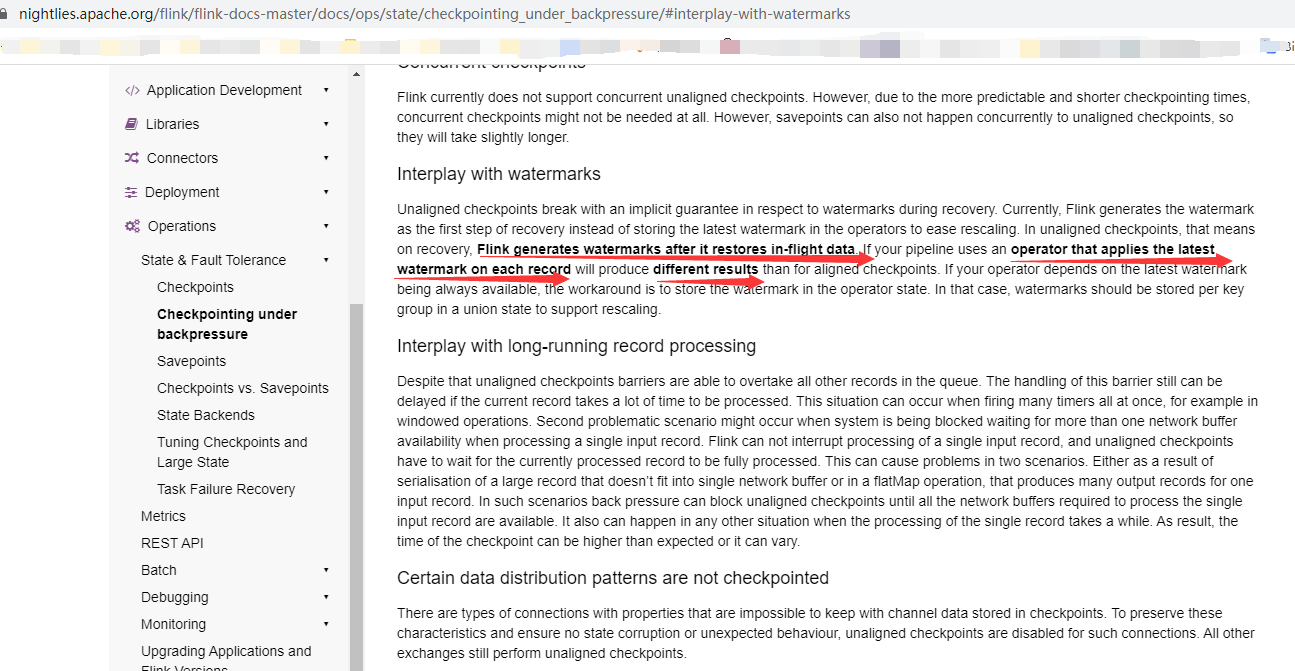 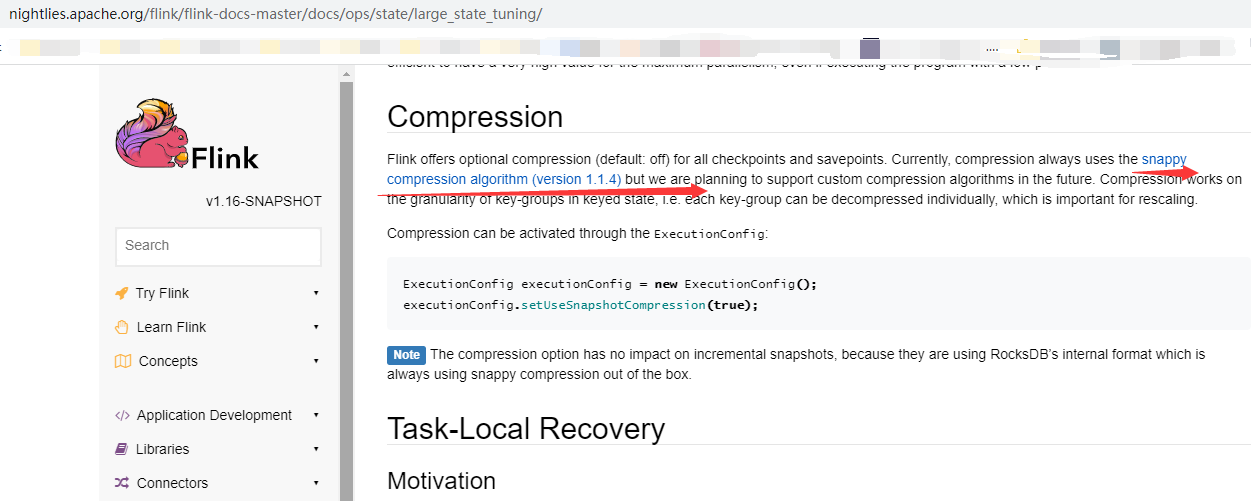 - **In chinese document:** 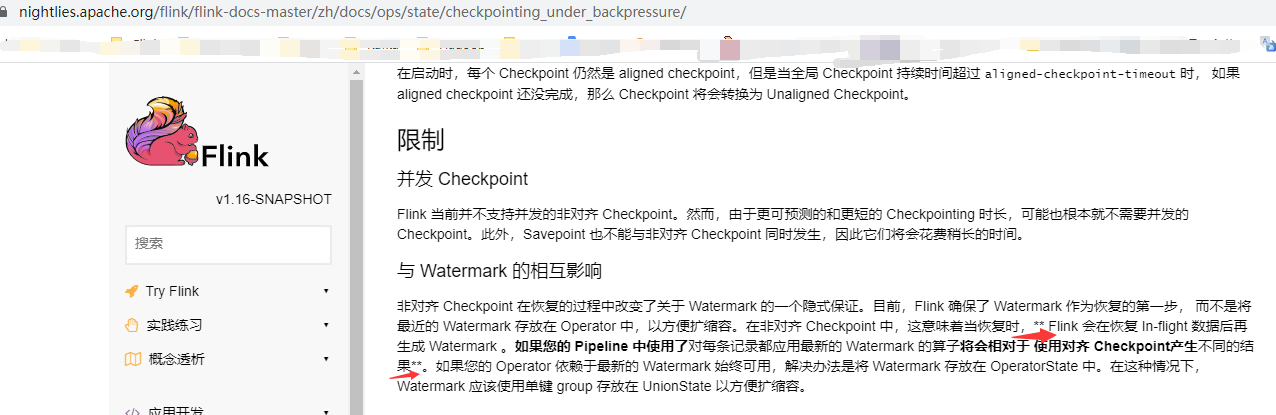 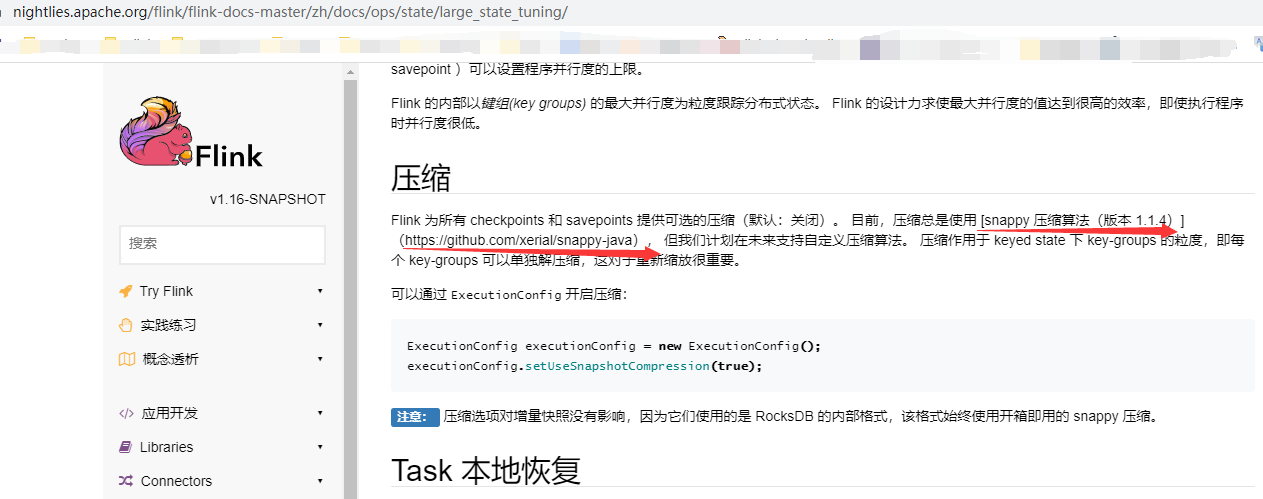 ## Brief change log - **The modified result looks like this:** 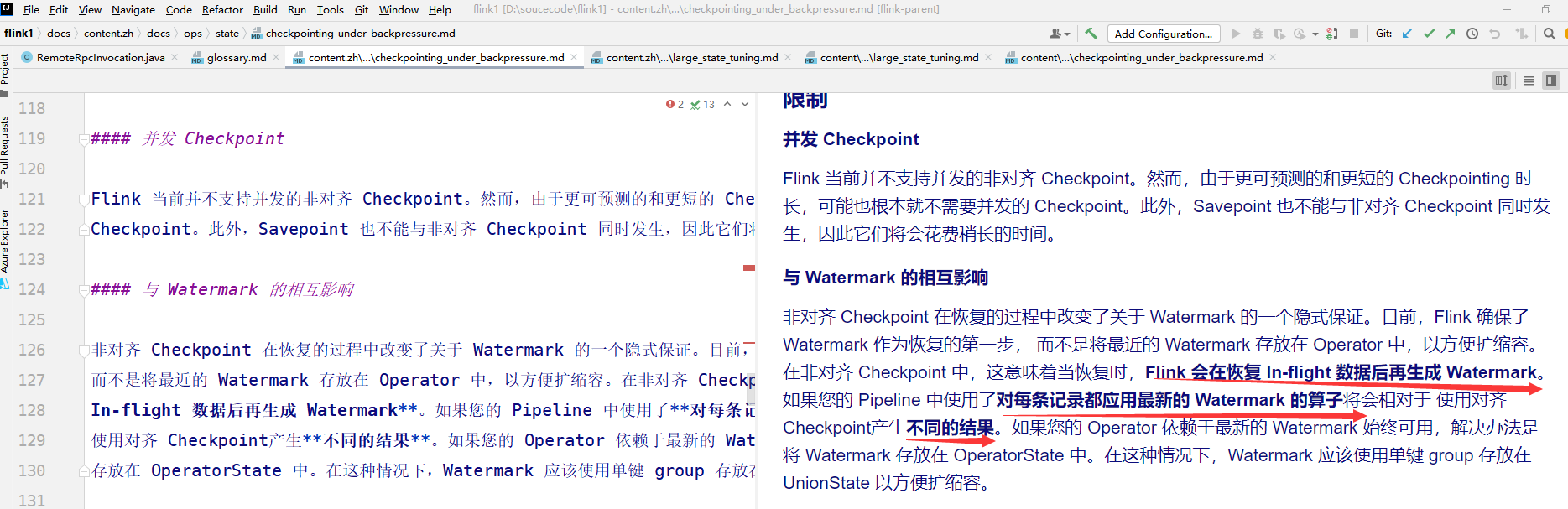 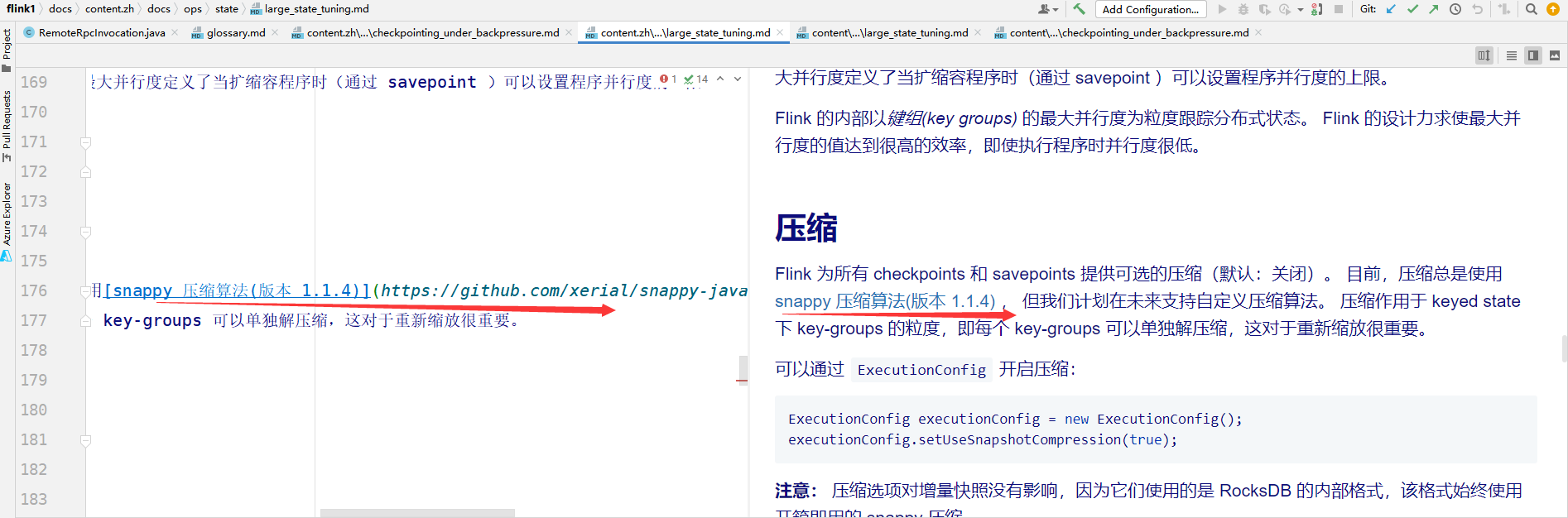 ## Verifying this change - No need to test. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #20204: [hotfix][docs] Update code formatting instructions for newer IntelliJ versions.
zentol commented on code in PR #20204: URL: https://github.com/apache/flink/pull/20204#discussion_r916868414 ## docs/content/docs/flinkDev/ide_setup.md: ## @@ -149,6 +149,12 @@ It is recommended to automatically format your code by applying the following se 8. Under "Formatting Actions", select "Optimize imports" and "Reformat file". 9. Under "File Path Inclusions", add an entry for `.*\.java` and `.*\.scala` to avoid formatting other file types. +For IntelliJ IDEA version > 2021.2: + +6. Go to "Settings" → "Tools" → "Actions on Save". +7. Under "Formatting Actions", select "Optimize imports" and "Reformat file". +8. From the "All file types list" next to "Reformat code", select Java and Scala. Review Comment: Not there for me in 2022.1.3 CE. So the guide may work as-is for later Ultimate versions. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] echauchot commented on pull request #19935: [FLINK-27884] Move OutputFormatBase to flink-core to offer flush mechanism to all output formats
echauchot commented on PR #19935: URL: https://github.com/apache/flink/pull/19935#issuecomment-1179030111 @zentol All discussions are resolved and CI passes. Is this PR ready for merging ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #20204: [hotfix][docs] Update code formatting instructions for newer IntelliJ versions.
zentol commented on code in PR #20204: URL: https://github.com/apache/flink/pull/20204#discussion_r916837239 ## docs/content/docs/flinkDev/ide_setup.md: ## @@ -149,6 +149,12 @@ It is recommended to automatically format your code by applying the following se 8. Under "Formatting Actions", select "Optimize imports" and "Reformat file". 9. Under "File Path Inclusions", add an entry for `.*\.java` and `.*\.scala` to avoid formatting other file types. +For IntelliJ IDEA version > 2021.2: + +6. Go to "Settings" → "Tools" → "Actions on Save". +7. Under "Formatting Actions", select "Optimize imports" and "Reformat file". +8. From the "All file types list" next to "Reformat code", select Java and Scala. Review Comment: In my 2021.3 it was missing. Let me update my IDE. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] reswqa commented on a diff in pull request #20223: [FLINK-28457][runtime] Introduce JobStatusHook
reswqa commented on code in PR #20223:
URL: https://github.com/apache/flink/pull/20223#discussion_r916800623
##
flink-runtime/src/test/java/org/apache/flink/runtime/executiongraph/TestingJobStatusHook.java:
##
@@ -0,0 +1,54 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.executiongraph;
+
+import org.apache.flink.api.common.JobID;
+
+import java.util.List;
+
+/** {@link JobStatusHook} implementation for testing purposes. */
+public class TestingJobStatusHook implements JobStatusHook {
+
+// Record job status changes.
+private final List jobStatus;
+
+public TestingJobStatusHook(List jobStatus) {
+this.jobStatus = jobStatus;
+}
+
+@Override
+public void onCreated(JobID jobId) {
+jobStatus.add("Created");
Review Comment:
Because this is a public testing mock class and not an internal class, we
should consider making it more flexible. I suggest the following pattern for
all onXXX method:
```
private Consumer onCreatedConsumer = (jobID) -> {};
```
and set it by `setOnCreatedConsumer(Consumer onCreatedConsumer)`
the callback method will looks like here:
```
public void onCreated(JobID jobId) {
onCreatedConsumer.accept(jobId);
}
```
This will make the testing mock class more flexible and easy to expand.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] reswqa commented on a diff in pull request #20223: [FLINK-28457][runtime] Introduce JobStatusHook
reswqa commented on code in PR #20223:
URL: https://github.com/apache/flink/pull/20223#discussion_r916804257
##
flink-runtime/src/test/java/org/apache/flink/runtime/scheduler/DefaultSchedulerTest.java:
##
@@ -1618,6 +1622,99 @@ public void
testCheckpointCleanerIsClosedAfterCheckpointServices() throws Except
}
}
+@Test
+public void testJobStatusHookWithJobFailed() throws Exception {
+final JobGraph jobGraph = singleNonParallelJobVertexJobGraph();
+List jobStatusHooks = new ArrayList<>();
+List jobStatusList = new LinkedList<>();
+jobStatusHooks.add(new TestingJobStatusHook(jobStatusList));
+jobGraph.setJobStatusHooks(jobStatusHooks);
+
+testRestartBackoffTimeStrategy.setCanRestart(false);
+
+final DefaultScheduler scheduler =
createSchedulerAndStartScheduling(jobGraph);
+
+final ArchivedExecutionVertex onlyExecutionVertex =
+Iterables.getOnlyElement(
+scheduler
+.requestJob()
+.getArchivedExecutionGraph()
+.getAllExecutionVertices());
+final ExecutionAttemptID attemptId =
+
onlyExecutionVertex.getCurrentExecutionAttempt().getAttemptId();
+
+
scheduler.updateTaskExecutionState(createFailedTaskExecutionState(attemptId));
+
+taskRestartExecutor.triggerScheduledTasks();
+
+waitForTermination(scheduler);
+final JobStatus jobStatus = scheduler.requestJobStatus();
+assertThat(jobStatus, is(equalTo(JobStatus.FAILED)));
Review Comment:
New test method should avoid using hamcrest
##
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/DefaultExecutionGraph.java:
##
@@ -1544,6 +1552,30 @@ private void notifyJobStatusChange(JobStatus newState) {
}
}
+private void notifyJobStatusHooks(JobStatus newState, Throwable cause) {
Review Comment:
```suggestion
private void notifyJobStatusHooks(JobStatus newState, @Nullable
Throwable cause) {
```
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/graph/StreamGraph.java:
##
@@ -1034,4 +1037,18 @@ public void setVertexNameIncludeIndexPrefix(boolean
includePrefix) {
public boolean isVertexNameIncludeIndexPrefix() {
return this.vertexNameIncludeIndexPrefix;
}
+
+/** Registers the JobStatusHook. */
+public void registerJobStatusHook(JobStatusHook hook) {
+if (hook == null) {
+throw new IllegalArgumentException();
+}
Review Comment:
```suggestion
checkNotNull(hook, "Registering a null JobStatusHook is not allowed.
")
```
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/graph/StreamingJobGraphGenerator.java:
##
@@ -225,6 +225,8 @@ private JobGraph createJobGraph() {
setVertexDescription();
+jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
Review Comment:
+1
##
flink-runtime/src/test/java/org/apache/flink/runtime/scheduler/DefaultSchedulerTest.java:
##
@@ -97,6 +99,7 @@
import org.apache.flink.shaded.guava30.com.google.common.collect.Iterables;
+import org.assertj.core.util.Lists;
Review Comment:
Why use assertj's Lists, but don't use assertj as assertion. In addition,
it's best to use assertj for all newly introduced tests.
##
flink-runtime/src/test/java/org/apache/flink/runtime/executiongraph/TestingJobStatusHook.java:
##
@@ -0,0 +1,54 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.executiongraph;
+
+import org.apache.flink.api.common.JobID;
+
+import java.util.List;
+
+/** {@link JobStatusHook} implementation for testing purposes. */
+public class TestingJobStatusHook implements JobStatusHook {
+
+// Record job status changes.
+private final List jobStatus;
+
+public TestingJobStatusHook(List jobStatus) {
+this.jobStatus = jobStatus;
+}
+
+@Override
+public void onCreated(JobID jobId) {
+jobStatus.add("Created");
Review Comment:
[jira] [Commented] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564293#comment-17564293
]
Danny Cranmer commented on FLINK-24229:
---
[~Gusev] we will need to move the PR since it will be a different repository
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564286#comment-17564286
]
Yuri Gusev commented on FLINK-24229:
Hi [~dannycranmer],
Sure happy to do this once new repo is available. Would the review discussion
in the current PR or shall we take a fresh look in the new repo already?
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-28388) Python doc build breaking nightly docs
[
https://issues.apache.org/jira/browse/FLINK-28388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564285#comment-17564285
]
Márton Balassi commented on FLINK-28388:
Thanks [~dianfu]!
> Python doc build breaking nightly docs
> --
>
> Key: FLINK-28388
> URL: https://issues.apache.org/jira/browse/FLINK-28388
> Project: Flink
> Issue Type: Bug
> Components: API / Python, Documentation
>Affects Versions: 1.16.0
>Reporter: Márton Balassi
>Assignee: Dian Fu
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 1.16.0
>
>
> For the past 5 days the nightly doc builds via GHA are broken:
> https://github.com/apache/flink/actions/workflows/docs.yml
> {noformat}
> Exception occurred:
> File "/root/flink/flink-python/pyflink/java_gateway.py", line 86, in
> launch_gateway
> raise Exception("It's launching the PythonGatewayServer during Python UDF
> execution "
> Exception: It's launching the PythonGatewayServer during Python UDF execution
> which is unexpected. It usually happens when the job codes are in the top
> level of the Python script file and are not enclosed in a `if name == 'main'`
> statement.
> The full traceback has been saved in /tmp/sphinx-err-3thh_wi2.log, if you
> want to report the issue to the developers.
> Please also report this if it was a user error, so that a better error
> message can be provided next time.
> A bug report can be filed in the tracker at
> . Thanks!
> Makefile:76: recipe for target 'html' failed
> make: *** [html] Error 2
> ==sphinx checks... [FAILED]===
> Error: Process completed with exit code 1.
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564283#comment-17564283
]
Danny Cranmer commented on FLINK-24229:
---
Hey [~Gusev], I have the FLIP ready and currently under internal review. I hope
to publish it soon. Since we will be creating a new connector repository for
this, once it is approved and created we will need to port your code to the new
repository. Will you be able to do this?
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-24229) [FLIP-171] DynamoDB implementation of Async Sink
[
https://issues.apache.org/jira/browse/FLINK-24229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564281#comment-17564281
]
Yuri Gusev commented on FLINK-24229:
Hi [~dannycranmer] & Team any updates on when this could be moved forward. I'll
move on with merging functionality to hide element converter for now.
> [FLIP-171] DynamoDB implementation of Async Sink
>
>
> Key: FLINK-24229
> URL: https://issues.apache.org/jira/browse/FLINK-24229
> Project: Flink
> Issue Type: New Feature
> Components: Connectors / Common
>Reporter: Zichen Liu
>Assignee: Yuri Gusev
>Priority: Major
> Labels: pull-request-available, stale-assigned
> Fix For: 1.16.0
>
>
> h2. Motivation
> *User stories:*
> As a Flink user, I’d like to use DynamoDB as sink for my data pipeline.
> *Scope:*
> * Implement an asynchronous sink for DynamoDB by inheriting the
> AsyncSinkBase class. The implementation can for now reside in its own module
> in flink-connectors.
> * Implement an asynchornous sink writer for DynamoDB by extending the
> AsyncSinkWriter. The implementation must deal with failed requests and retry
> them using the {{requeueFailedRequestEntry}} method. If possible, the
> implementation should batch multiple requests (PutRecordsRequestEntry
> objects) to Firehose for increased throughput. The implemented Sink Writer
> will be used by the Sink class that will be created as part of this story.
> * Java / code-level docs.
> * End to end testing: add tests that hits a real AWS instance. (How to best
> donate resources to the Flink project to allow this to happen?)
> h2. References
> More details to be found
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-171%3A+Async+Sink]
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] reswqa commented on a diff in pull request #20223: [FLINK-28457][runtime] Introduce JobStatusHook
reswqa commented on code in PR #20223:
URL: https://github.com/apache/flink/pull/20223#discussion_r916792016
##
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/JobStatusHook.java:
##
@@ -0,0 +1,41 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.executiongraph;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.JobID;
+
+import java.io.Serializable;
+
+/** Hooks provided by users on job status changing. */
+@Internal
+public interface JobStatusHook extends Serializable {
+
+/** When Job become CREATED status. It would only be called one time. */
Review Comment:
```suggestion
/** When Job become {@link JobStatus#CREATED} status. It would only be
called one time. */
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] afedulov commented on a diff in pull request #20204: [hotfix][docs] Update code formatting instructions for newer IntelliJ versions.
afedulov commented on code in PR #20204: URL: https://github.com/apache/flink/pull/20204#discussion_r916787296 ## docs/content/docs/flinkDev/ide_setup.md: ## @@ -149,6 +149,12 @@ It is recommended to automatically format your code by applying the following se 8. Under "Formatting Actions", select "Optimize imports" and "Reformat file". 9. Under "File Path Inclusions", add an entry for `.*\.java` and `.*\.scala` to avoid formatting other file types. +For IntelliJ IDEA version > 2021.2: + +6. Go to "Settings" → "Tools" → "Actions on Save". +7. Under "Formatting Actions", select "Optimize imports" and "Reformat file". +8. From the "All file types list" next to "Reformat code", select Java and Scala. Review Comment: Hmm...I am on 2022.1.3 and the Copyright works fine.  I am on Ultimate, but [this](https://www.jetbrains.com/help/idea/2022.1/copyright.html) page in the docs does not have the "Ultimate" tag, so it still must be available in the CE. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-28364) Python Job support for Kubernetes Operator
[ https://issues.apache.org/jira/browse/FLINK-28364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564277#comment-17564277 ] Biao Geng commented on FLINK-28364: --- Following the pattern we have adopted for sql job example, I have created a simple [example|https://github.com/bgeng777/flink-kubernetes-operator/blob/python_example/examples/flink-python-example/python-example.yaml] to run pyflink jobs. As [~nicholasjiang] said, the python demo is trival but we may need more document about building pyflink image in the operator repo. [~gyfora] [~dianfu] I can take this ticket to add the pyflink example. > Python Job support for Kubernetes Operator > -- > > Key: FLINK-28364 > URL: https://issues.apache.org/jira/browse/FLINK-28364 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: wu3396 >Priority: Major > > *Describe the solution* > Job types that I want to support pyflink for > *Describe alternatives* > like [here|https://github.com/spotify/flink-on-k8s-operator/pull/165] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-28297) Incorrect metric group order for namespaced operator metrics
[
https://issues.apache.org/jira/browse/FLINK-28297?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Gyula Fora closed FLINK-28297.
--
Resolution: Fixed
merged to main 1b3acc23868f9ad09ea73e7556a7b31176496783
> Incorrect metric group order for namespaced operator metrics
>
>
> Key: FLINK-28297
> URL: https://issues.apache.org/jira/browse/FLINK-28297
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: Gyula Fora
>Assignee: Gyula Fora
>Priority: Major
> Labels: pull-request-available
> Fix For: kubernetes-operator-1.1.0
>
>
> The metric group for the resource namespace should follow the main metric
> group for the metric itself.
> So instead of
> {noformat}
> flink-kubernetes-operator-64d8cc77c4-w49nj.k8soperator.default.flink-kubernetes-operator.resourcens.default.FlinkDeployment.READY.Count:
> 1
> {noformat}
> we should have
> {noformat}
> flink-kubernetes-operator-64d8cc77c4-w49nj.k8soperator.default.flink-kubernetes-operator.FlinkDeployment.READY.resourcens.default.Count:
> 1{noformat}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Closed] (FLINK-27914) Integrate JOSDK metrics with Flink Metrics reporter
[ https://issues.apache.org/jira/browse/FLINK-27914?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gyula Fora closed FLINK-27914. -- Resolution: Fixed merged to main 308f8add74165febaa2f80c61a2a9d242d8b0629 > Integrate JOSDK metrics with Flink Metrics reporter > --- > > Key: FLINK-27914 > URL: https://issues.apache.org/jira/browse/FLINK-27914 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Minor > Labels: Starter, pull-request-available > Fix For: kubernetes-operator-1.1.0 > > > The Java Operator SDK comes with an internal metric interface that could be > implemented to forward metrics/measurements to the Flink metric registries. > We should investigate and implement this if possible. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] gyfora merged pull request #302: [FLINK-28297][FLINK-27914] Improve operator metric groups + Add JOSDK metric integration
gyfora merged PR #302: URL: https://github.com/apache/flink-kubernetes-operator/pull/302 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lsyldliu commented on a diff in pull request #20223: [FLINK-28457][runtime] Introduce JobStatusHook
lsyldliu commented on code in PR #20223:
URL: https://github.com/apache/flink/pull/20223#discussion_r916762924
##
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/DefaultExecutionGraph.java:
##
@@ -1544,6 +1552,30 @@ private void notifyJobStatusChange(JobStatus newState) {
}
}
+private void notifyJobStatusHooks(JobStatus newState, Throwable cause) {
+JobID jobID = jobInformation.getJobId();
+for (JobStatusHook hook : jobStatusHooks) {
+try {
+switch (newState) {
+case CREATED:
+hook.onCreated(jobID);
+break;
+case CANCELED:
+hook.onCanceled(jobID);
+break;
+case FAILED:
+hook.onFailed(jobID, cause);
+break;
+case FINISHED:
+hook.onFinished(jobID);
+break;
+}
+} catch (Throwable ignore) {
+LOG.warn("Error while notifying JobStatusHook[{}]",
hook.getClass(), ignore);
Review Comment:
I think this exception should not be ignored, if the hook execute failed,
the job execution will occur other exception which will confuse the user, so I
think we should throw this exception early.
##
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/JobStatusHook.java:
##
@@ -0,0 +1,41 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.executiongraph;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.JobID;
+
+import java.io.Serializable;
+
+/** Hooks provided by users on job status changing. */
Review Comment:
I suggest add more annotation about this hook, let user know its function
and how to use it.
##
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/JobStatusHook.java:
##
@@ -0,0 +1,41 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.executiongraph;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.JobID;
+
+import java.io.Serializable;
+
+/** Hooks provided by users on job status changing. */
+@Internal
+public interface JobStatusHook extends Serializable {
+
+/** When Job become CREATED status. It would only be called one time. */
Review Comment:
```suggestion
/** When Job become CREATED status, it would only be called one time. */
```
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/graph/StreamingJobGraphGenerator.java:
##
@@ -225,6 +225,8 @@ private JobGraph createJobGraph() {
setVertexDescription();
+jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
Review Comment:
I think it would be better to set hooks when hooks > 0.
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/graph/StreamGraph.java:
##
@@ -1034,4 +1037,18 @@ public void setVertexNameIncludeIndexPrefix(boolean
includePrefix) {
public boolean isVertexNameIncludeIndexPrefix() {
return this.vertexNameIncludeIndexPrefix;
}
+
+/** Registers the JobStatusHook. */
+public void registerJobStatusHook(JobStatusHook hook) {
+if (hook == null) {
+
[jira] [Updated] (FLINK-28467) Flink Table API Avro format fails during schema evolution
[
https://issues.apache.org/jira/browse/FLINK-28467?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jaya Ananthram updated FLINK-28467:
---
Summary: Flink Table API Avro format fails during schema evolution (was:
AVRO Table API fails during schema evolution)
> Flink Table API Avro format fails during schema evolution
> -
>
> Key: FLINK-28467
> URL: https://issues.apache.org/jira/browse/FLINK-28467
> Project: Flink
> Issue Type: Bug
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.14.4
>Reporter: Jaya Ananthram
>Priority: Major
> Attachments: image-2022-07-08-15-01-49-648.png
>
>
> It looks like the Flink Table API fails during the schema evolution. ie -
> when we add a new optional field in the producer side, the consumer (Flink
> table API) fails to parse the message with the old schema. Following are the
> exact scenario to reproduce,
> # Create a schema X with two field
> # Send five messages to Kafka using schema X
> # Update the schema X to add one new optional field with default NULL (at
> last position)
> # Send five messages to Kafka using schema Y
> # Create a Flink SQL job to consume all the 10 messages using schema X (with
> two fields)
> # Exactly it will fail at the 7th message to get the exception *_Malformed
> data. Length is negative: -xx_* (the 6th message will pass successfully
> though).
> The complete stack trace is available below,
> {code:java}
> Caused by: org.apache.avro.AvroRuntimeException: Malformed data. Length is
> negative: -56 at
> org.apache.avro.io.BinaryDecoder.readString(BinaryDecoder.java:285) at
> org.apache.avro.io.ResolvingDecoder.readString(ResolvingDecoder.java:208)
> at
> org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:469)
>at
> org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:459)
>at
> org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:191)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
> at
> org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:259)
> at
> org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:247)
>at
> org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:179)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:153)
> at
> org.apache.flink.formats.avro.AvroDeserializationSchema.deserialize(AvroDeserializationSchema.java:142)
> at
> org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:103)
> ... 19 more {code}
>
> From [Avro specification|https://avro.apache.org/docs/1.10.0/spec.html]
> (refer to the section "Single object Encoding" or the attached image), it
> looks by default Avro provides the schema evolution support, so, as an
> end-user I expect the Flink table API to provide the same functionalities. I
> can also confirm that the old schema is able to decode all the 10 messages
> outside of Flink (ie - using simple hello world AvroDeserializer)
> I am adding the root cause as a comment, as I am exactly sure whether my
> finding is correct.
> *Note:* I am marking this as a Major ticket as we have another open ticket
> ([here|https://issues.apache.org/jira/browse/FLINK-20091]) which lacks the
> functionalities to ignore failures. This means that, even if the user is
> ready to miss some message (when a batch contains two types of messages),
> still we can't specify the property to ignore it (to update the DDL once it
> crosses the switch over messages). So it looks like the Avro table API can't
> be used in PROD when we expect to change the schema. I assume most of the
> cases, we are expected to change schema. If the severity is not correct
> please feel free to reduce the priority.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-26621) ChangelogPeriodicMaterializationITCase crashes JVM on CI in RocksDB cleanup
[
https://issues.apache.org/jira/browse/FLINK-26621?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564270#comment-17564270
]
Chesnay Schepler commented on FLINK-26621:
--
Currently looping the test on CI.
One of the runs failed with this error after the test finished:
{code:java}
Jul 08 12:24:21 pure virtual method called
Jul 08 12:24:21 terminate called without an active exception {code}
> ChangelogPeriodicMaterializationITCase crashes JVM on CI in RocksDB cleanup
> ---
>
> Key: FLINK-26621
> URL: https://issues.apache.org/jira/browse/FLINK-26621
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing, Tests
>Affects Versions: 1.14.4, 1.16.0, 1.15.2
>Reporter: Yun Gao
>Assignee: Chesnay Schepler
>Priority: Critical
> Labels: test-stability
> Fix For: 1.16.0
>
>
> {code:java}
> 2022-03-11T16:20:12.6929558Z Mar 11 16:20:12 [WARNING] The requested profile
> "skip-webui-build" could not be activated because it does not exist.
> 2022-03-11T16:20:12.6939269Z Mar 11 16:20:12 [ERROR] Failed to execute goal
> org.apache.maven.plugins:maven-surefire-plugin:3.0.0-M5:test
> (integration-tests) on project flink-tests: There are test failures.
> 2022-03-11T16:20:12.6940062Z Mar 11 16:20:12 [ERROR]
> 2022-03-11T16:20:12.6940954Z Mar 11 16:20:12 [ERROR] Please refer to
> /__w/2/s/flink-tests/target/surefire-reports for the individual test results.
> 2022-03-11T16:20:12.6941875Z Mar 11 16:20:12 [ERROR] Please refer to dump
> files (if any exist) [date].dump, [date]-jvmRun[N].dump and [date].dumpstream.
> 2022-03-11T16:20:12.6942966Z Mar 11 16:20:12 [ERROR] ExecutionException Error
> occurred in starting fork, check output in log
> 2022-03-11T16:20:12.6943919Z Mar 11 16:20:12 [ERROR]
> org.apache.maven.surefire.booter.SurefireBooterForkException:
> ExecutionException Error occurred in starting fork, check output in log
> 2022-03-11T16:20:12.6945023Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.awaitResultsDone(ForkStarter.java:532)
> 2022-03-11T16:20:12.6945878Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.runSuitesForkPerTestSet(ForkStarter.java:479)
> 2022-03-11T16:20:12.6946761Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.run(ForkStarter.java:322)
> 2022-03-11T16:20:12.6947532Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.run(ForkStarter.java:266)
> 2022-03-11T16:20:12.6953051Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.AbstractSurefireMojo.executeProvider(AbstractSurefireMojo.java:1314)
> 2022-03-11T16:20:12.6954035Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.AbstractSurefireMojo.executeAfterPreconditionsChecked(AbstractSurefireMojo.java:1159)
> 2022-03-11T16:20:12.6954917Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.AbstractSurefireMojo.execute(AbstractSurefireMojo.java:932)
> 2022-03-11T16:20:12.6955749Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo(DefaultBuildPluginManager.java:132)
> 2022-03-11T16:20:12.6956542Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:208)
> 2022-03-11T16:20:12.6957456Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:153)
> 2022-03-11T16:20:12.6958232Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:145)
> 2022-03-11T16:20:12.6959038Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject(LifecycleModuleBuilder.java:116)
> 2022-03-11T16:20:12.6960553Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject(LifecycleModuleBuilder.java:80)
> 2022-03-11T16:20:12.6962116Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build(SingleThreadedBuilder.java:51)
> 2022-03-11T16:20:12.6963009Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.LifecycleStarter.execute(LifecycleStarter.java:120)
> 2022-03-11T16:20:12.6963737Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.DefaultMaven.doExecute(DefaultMaven.java:355)
> 2022-03-11T16:20:12.6964644Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.DefaultMaven.execute(DefaultMaven.java:155)
> 2022-03-11T16:20:12.6965647Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.cli.MavenCli.execute(MavenCli.java:584)
> 2022-03-11T16:20:12.6966732Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.cli.MavenCli.doMain(MavenCli.java:216)
>
[jira] [Comment Edited] (FLINK-26621) ChangelogPeriodicMaterializationITCase crashes JVM on CI in RocksDB cleanup
[
https://issues.apache.org/jira/browse/FLINK-26621?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564270#comment-17564270
]
Chesnay Schepler edited comment on FLINK-26621 at 7/8/22 12:34 PM:
---
Currently looping the test on CI.
One of the runs failed with this error after the test finished:
{code:java}
Jul 08 12:24:21 pure virtual method called
Jul 08 12:24:21 terminate called without an active exception{code}
was (Author: zentol):
Currently looping the test on CI.
One of the runs failed with this error after the test finished:
{code:java}
Jul 08 12:24:21 pure virtual method called
Jul 08 12:24:21 terminate called without an active exception {code}
> ChangelogPeriodicMaterializationITCase crashes JVM on CI in RocksDB cleanup
> ---
>
> Key: FLINK-26621
> URL: https://issues.apache.org/jira/browse/FLINK-26621
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing, Tests
>Affects Versions: 1.14.4, 1.16.0, 1.15.2
>Reporter: Yun Gao
>Assignee: Chesnay Schepler
>Priority: Critical
> Labels: test-stability
> Fix For: 1.16.0
>
>
> {code:java}
> 2022-03-11T16:20:12.6929558Z Mar 11 16:20:12 [WARNING] The requested profile
> "skip-webui-build" could not be activated because it does not exist.
> 2022-03-11T16:20:12.6939269Z Mar 11 16:20:12 [ERROR] Failed to execute goal
> org.apache.maven.plugins:maven-surefire-plugin:3.0.0-M5:test
> (integration-tests) on project flink-tests: There are test failures.
> 2022-03-11T16:20:12.6940062Z Mar 11 16:20:12 [ERROR]
> 2022-03-11T16:20:12.6940954Z Mar 11 16:20:12 [ERROR] Please refer to
> /__w/2/s/flink-tests/target/surefire-reports for the individual test results.
> 2022-03-11T16:20:12.6941875Z Mar 11 16:20:12 [ERROR] Please refer to dump
> files (if any exist) [date].dump, [date]-jvmRun[N].dump and [date].dumpstream.
> 2022-03-11T16:20:12.6942966Z Mar 11 16:20:12 [ERROR] ExecutionException Error
> occurred in starting fork, check output in log
> 2022-03-11T16:20:12.6943919Z Mar 11 16:20:12 [ERROR]
> org.apache.maven.surefire.booter.SurefireBooterForkException:
> ExecutionException Error occurred in starting fork, check output in log
> 2022-03-11T16:20:12.6945023Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.awaitResultsDone(ForkStarter.java:532)
> 2022-03-11T16:20:12.6945878Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.runSuitesForkPerTestSet(ForkStarter.java:479)
> 2022-03-11T16:20:12.6946761Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.run(ForkStarter.java:322)
> 2022-03-11T16:20:12.6947532Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.booterclient.ForkStarter.run(ForkStarter.java:266)
> 2022-03-11T16:20:12.6953051Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.AbstractSurefireMojo.executeProvider(AbstractSurefireMojo.java:1314)
> 2022-03-11T16:20:12.6954035Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.AbstractSurefireMojo.executeAfterPreconditionsChecked(AbstractSurefireMojo.java:1159)
> 2022-03-11T16:20:12.6954917Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.surefire.AbstractSurefireMojo.execute(AbstractSurefireMojo.java:932)
> 2022-03-11T16:20:12.6955749Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo(DefaultBuildPluginManager.java:132)
> 2022-03-11T16:20:12.6956542Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:208)
> 2022-03-11T16:20:12.6957456Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:153)
> 2022-03-11T16:20:12.6958232Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:145)
> 2022-03-11T16:20:12.6959038Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject(LifecycleModuleBuilder.java:116)
> 2022-03-11T16:20:12.6960553Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject(LifecycleModuleBuilder.java:80)
> 2022-03-11T16:20:12.6962116Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build(SingleThreadedBuilder.java:51)
> 2022-03-11T16:20:12.6963009Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.lifecycle.internal.LifecycleStarter.execute(LifecycleStarter.java:120)
> 2022-03-11T16:20:12.6963737Z Mar 11 16:20:12 [ERROR] at
> org.apache.maven.DefaultMaven.doExecute(DefaultMaven.java:355)
> 2022-03-11T16:20:12.6964644Z Mar 11 16:20:12 [ERROR] at
>
[jira] [Comment Edited] (FLINK-28467) AVRO Table API fails during schema evolution
[
https://issues.apache.org/jira/browse/FLINK-28467?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564268#comment-17564268
]
Jaya Ananthram edited comment on FLINK-28467 at 7/8/22 12:33 PM:
-
*Root cause:* It looks like the byte buffer is not cleared properly when the
message contains a new field that is not in the schema. So, as a result, the
7th message contains a partial 6th message (technically the new field) + a
partial 7th message. This happens due to resuing the object
[binaryDecoder|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/AvroDeserializationSchema.java#L165].
If I create a new binaryDecoder object for each message, then it works fine in
my local. Not 100% sure though, hence marking it as a comment.
*Note:* For the test case, we need to make sure to add at least two messages
parsed successfully during schema evolution as one message is parsed
successfully after a schema change.
was (Author: jaya.ananthram):
*Root cause:* It looks like the byte buffer is not cleared properly when the
message contains a new field that is not in the schema. So, as a result, the
7th message contains a partial 6th message (technically the new field) + a
partial 7th message. This happens due to resuing the object
[binaryDecoder|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/AvroDeserializationSchema.java#L165].
If I create a new binaryDecoder object for each message, then it works fine in
my local. Not 100% sure though, hence marking it as a comment.
*Note:* For the test case, we need to make sure to add at least two messages
parsed successfully during schema evolution.
> AVRO Table API fails during schema evolution
>
>
> Key: FLINK-28467
> URL: https://issues.apache.org/jira/browse/FLINK-28467
> Project: Flink
> Issue Type: Bug
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.14.4
>Reporter: Jaya Ananthram
>Priority: Major
> Attachments: image-2022-07-08-15-01-49-648.png
>
>
> It looks like the Flink Table API fails during the schema evolution. ie -
> when we add a new optional field in the producer side, the consumer (Flink
> table API) fails to parse the message with the old schema. Following are the
> exact scenario to reproduce,
> # Create a schema X with two field
> # Send five messages to Kafka using schema X
> # Update the schema X to add one new optional field with default NULL (at
> last position)
> # Send five messages to Kafka using schema Y
> # Create a Flink SQL job to consume all the 10 messages using schema X (with
> two fields)
> # Exactly it will fail at the 7th message to get the exception *_Malformed
> data. Length is negative: -xx_* (the 6th message will pass successfully
> though).
> The complete stack trace is available below,
> {code:java}
> Caused by: org.apache.avro.AvroRuntimeException: Malformed data. Length is
> negative: -56 at
> org.apache.avro.io.BinaryDecoder.readString(BinaryDecoder.java:285) at
> org.apache.avro.io.ResolvingDecoder.readString(ResolvingDecoder.java:208)
> at
> org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:469)
>at
> org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:459)
>at
> org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:191)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
> at
> org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:259)
> at
> org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:247)
>at
> org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:179)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:153)
> at
> org.apache.flink.formats.avro.AvroDeserializationSchema.deserialize(AvroDeserializationSchema.java:142)
> at
> org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:103)
> ... 19 more {code}
>
> From [Avro specification|https://avro.apache.org/docs/1.10.0/spec.html]
> (refer to the section "Single object Encoding" or the attached image), it
> looks by default Avro provides the schema evolution support, so, as an
> end-user I expect the Flink table API to provide the same functionalities. I
> can also confirm that the old schema is able to decode all the 10 messages
> outside of Flink (ie - using simple hello world AvroDeserializer)
> I
[jira] [Commented] (FLINK-28467) AVRO Table API fails during schema evolution
[
https://issues.apache.org/jira/browse/FLINK-28467?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564268#comment-17564268
]
Jaya Ananthram commented on FLINK-28467:
*Root cause:* It looks like the byte buffer is not cleared properly when the
message contains a new field that is not in the schema. So, as a result, the
7th message contains a partial 6th message (technically the new field) + a
partial 7th message. This happens due to resuing the object
[binaryDecoder|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/AvroDeserializationSchema.java#L165].
If I create a new binaryDecoder object for each message, then it works fine in
my local. Not 100% sure though, hence marking it as a comment.
*Note:* For the test case, we need to make sure to add at least two messages
parsed successfully during schema evolution.
> AVRO Table API fails during schema evolution
>
>
> Key: FLINK-28467
> URL: https://issues.apache.org/jira/browse/FLINK-28467
> Project: Flink
> Issue Type: Bug
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.14.4
>Reporter: Jaya Ananthram
>Priority: Major
> Attachments: image-2022-07-08-15-01-49-648.png
>
>
> It looks like the Flink Table API fails during the schema evolution. ie -
> when we add a new optional field in the producer side, the consumer (Flink
> table API) fails to parse the message with the old schema. Following are the
> exact scenario to reproduce,
> # Create a schema X with two field
> # Send five messages to Kafka using schema X
> # Update the schema X to add one new optional field with default NULL (at
> last position)
> # Send five messages to Kafka using schema Y
> # Create a Flink SQL job to consume all the 10 messages using schema X (with
> two fields)
> # Exactly it will fail at the 7th message to get the exception *_Malformed
> data. Length is negative: -xx_* (the 6th message will pass successfully
> though).
> The complete stack trace is available below,
> {code:java}
> Caused by: org.apache.avro.AvroRuntimeException: Malformed data. Length is
> negative: -56 at
> org.apache.avro.io.BinaryDecoder.readString(BinaryDecoder.java:285) at
> org.apache.avro.io.ResolvingDecoder.readString(ResolvingDecoder.java:208)
> at
> org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:469)
>at
> org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:459)
>at
> org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:191)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
> at
> org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:259)
> at
> org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:247)
>at
> org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:179)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
> at
> org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:153)
> at
> org.apache.flink.formats.avro.AvroDeserializationSchema.deserialize(AvroDeserializationSchema.java:142)
> at
> org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:103)
> ... 19 more {code}
>
> From [Avro specification|https://avro.apache.org/docs/1.10.0/spec.html]
> (refer to the section "Single object Encoding" or the attached image), it
> looks by default Avro provides the schema evolution support, so, as an
> end-user I expect the Flink table API to provide the same functionalities. I
> can also confirm that the old schema is able to decode all the 10 messages
> outside of Flink (ie - using simple hello world AvroDeserializer)
> I am adding the root cause as a comment, as I am exactly sure whether my
> finding is correct.
> *Note:* I am marking this as a Major ticket as we have another open ticket
> ([here|https://issues.apache.org/jira/browse/FLINK-20091]) which lacks the
> functionalities to ignore failures. This means that, even if the user is
> ready to miss some message (when a batch contains two types of messages),
> still we can't specify the property to ignore it (to update the DDL once it
> crosses the switch over messages). So it looks like the Avro table API can't
> be used in PROD when we expect to change the schema. I assume most of the
> cases, we are expected to change schema. If the severity is not correct
> please feel free to reduce the priority.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Assigned] (FLINK-28408) FAQ / best practices page for Kubernetes Operator
[ https://issues.apache.org/jira/browse/FLINK-28408?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gyula Fora reassigned FLINK-28408: -- Assignee: Matyas Orhidi > FAQ / best practices page for Kubernetes Operator > - > > Key: FLINK-28408 > URL: https://issues.apache.org/jira/browse/FLINK-28408 > Project: Flink > Issue Type: Improvement > Components: Documentation, Kubernetes Operator >Affects Versions: kubernetes-operator-1.1.0 >Reporter: Márton Balassi >Assignee: Matyas Orhidi >Priority: Major > > Based on our recent interactions with the users we should gather some > frequently recurring topics in the docs. The following initial ones come to > my mind: > # Enabling plugins,[especially built-in > ones|https://stackoverflow.com/questions/72826712/apache-flink-operator-enable-azure-fs-hadoop/72844654] > # Running SQL jobs on the operator > # Templating FlinkDeployment CRs for multiple environments (kustomize) > # Packaging the user jar into a custom container based on the flink base image > # Logging / metrics integration -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-28467) AVRO Table API fails during schema evolution
Jaya Ananthram created FLINK-28467:
--
Summary: AVRO Table API fails during schema evolution
Key: FLINK-28467
URL: https://issues.apache.org/jira/browse/FLINK-28467
Project: Flink
Issue Type: Bug
Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
Affects Versions: 1.14.4
Reporter: Jaya Ananthram
Attachments: image-2022-07-08-15-01-49-648.png
It looks like the Flink Table API fails during the schema evolution. ie - when
we add a new optional field in the producer side, the consumer (Flink table
API) fails to parse the message with the old schema. Following are the exact
scenario to reproduce,
# Create a schema X with two field
# Send five messages to Kafka using schema X
# Update the schema X to add one new optional field with default NULL (at last
position)
# Send five messages to Kafka using schema Y
# Create a Flink SQL job to consume all the 10 messages using schema X (with
two fields)
# Exactly it will fail at the 7th message to get the exception *_Malformed
data. Length is negative: -xx_* (the 6th message will pass successfully though).
The complete stack trace is available below,
{code:java}
Caused by: org.apache.avro.AvroRuntimeException: Malformed data. Length is
negative: -56at
org.apache.avro.io.BinaryDecoder.readString(BinaryDecoder.java:285) at
org.apache.avro.io.ResolvingDecoder.readString(ResolvingDecoder.java:208)at
org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:469)
at
org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:459)
at
org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:191)
at
org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160) at
org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:259)
at
org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:247)
at
org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:179)
at
org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160) at
org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:153) at
org.apache.flink.formats.avro.AvroDeserializationSchema.deserialize(AvroDeserializationSchema.java:142)
at
org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:103)
... 19 more {code}
>From [Avro specification|https://avro.apache.org/docs/1.10.0/spec.html] (refer
>to the section "Single object Encoding" or the attached image), it looks by
>default Avro provides the schema evolution support, so, as an end-user I
>expect the Flink table API to provide the same functionalities. I can also
>confirm that the old schema is able to decode all the 10 messages outside of
>Flink (ie - using simple hello world AvroDeserializer)
I am adding the root cause as a comment, as I am exactly sure whether my
finding is correct.
*Note:* I am marking this as a Major ticket as we have another open ticket
([here|https://issues.apache.org/jira/browse/FLINK-20091]) which lacks the
functionalities to ignore failures. This means that, even if the user is ready
to miss some message (when a batch contains two types of messages), still we
can't specify the property to ignore it (to update the DDL once it crosses the
switch over messages). So it looks like the Avro table API can't be used in
PROD when we expect to change the schema. I assume most of the cases, we are
expected to change schema. If the severity is not correct please feel free to
reduce the priority.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #20225: Update japicmp configuration for 1.15.1
flinkbot commented on PR #20225: URL: https://github.com/apache/flink/pull/20225#issuecomment-1178922684 ## CI report: * 98fcd31b3503521db7d134d9076939068ebc UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-28187) Duplicate job submission for FlinkSessionJob
[ https://issues.apache.org/jira/browse/FLINK-28187?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17564261#comment-17564261 ] Gyula Fora commented on FLINK-28187: [~aitozi] we have similar logic now in Flink for Applications: [https://github.com/apache/flink/commit/e70fe68dea764606180ca3728184c00fc63ea0ff] > Duplicate job submission for FlinkSessionJob > > > Key: FLINK-28187 > URL: https://issues.apache.org/jira/browse/FLINK-28187 > Project: Flink > Issue Type: Bug > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.0.0 >Reporter: Jeesmon Jacob >Assignee: Aitozi >Priority: Critical > Attachments: flink-operator-log.txt > > > During a session job submission if a deployment error (ex: > concurrent.TimeoutException) is hit, operator will submit the job again. But > first submission could have succeeded in jobManager side and second > submission could result in duplicate job. Operator log attached. > Per [~gyfora]: > The problem is that in case a deployment error was hit, the > SessionJobObserver will not be able to tell whether it has submitted the job > or not. So it will simply try to submit it again. We have to find a mechanism > to correlate Jobs on the cluster with the SessionJob CR itself. Maybe we > could override the job name itself for this purpose or something like that. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-28445) Support operator configuration from multiple configmaps
[ https://issues.apache.org/jira/browse/FLINK-28445?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gyula Fora closed FLINK-28445. -- Resolution: Fixed Merged to main 56381ecf4515ff12d72fe6b1a245160580aacb72 > Support operator configuration from multiple configmaps > --- > > Key: FLINK-28445 > URL: https://issues.apache.org/jira/browse/FLINK-28445 > Project: Flink > Issue Type: New Feature >Reporter: Matyas Orhidi >Assignee: Matyas Orhidi >Priority: Major > Labels: pull-request-available > Fix For: kubernetes-operator-1.1.0 > > > It is beneficial in certain scenarios to load operator configurations from > multiple ConfigMaps. For example the `kubernetes.operator.watched.namespaces` > is a typical property maintained by control planes and the rest is by the > Operator. By allowing loading the configuration from multiple ConfigMaps the > default configuration can be owned by the Operator and other environment > specific overrides by a control plane. This also allows upgrading the > Operator independently from control planes. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] gyfora merged pull request #304: [FLINK-28445] Support operator configuration from multiple configmaps
gyfora merged PR #304: URL: https://github.com/apache/flink-kubernetes-operator/pull/304 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #20204: [hotfix][docs] Update code formatting instructions for newer IntelliJ versions.
zentol commented on code in PR #20204: URL: https://github.com/apache/flink/pull/20204#discussion_r916758185 ## docs/content/docs/flinkDev/ide_setup.md: ## @@ -149,6 +149,12 @@ It is recommended to automatically format your code by applying the following se 8. Under "Formatting Actions", select "Optimize imports" and "Reformat file". 9. Under "File Path Inclusions", add an entry for `.*\.java` and `.*\.scala` to avoid formatting other file types. +For IntelliJ IDEA version > 2021.2: + +6. Go to "Settings" → "Tools" → "Actions on Save". +7. Under "Formatting Actions", select "Optimize imports" and "Reformat file". +8. From the "All file types list" next to "Reformat code", select Java and Scala. Review Comment: AFAICT the `Copyright Profile` doesn't work anymore; doesn't look like it was moved, maybe it was just superceded by file templates (which is what I use). For scala spotless takes care of license headers, which we could also enabled for java. The rest should be fine I think. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] afedulov commented on a diff in pull request #20204: [hotfix][docs] Update code formatting instructions for newer IntelliJ versions.
afedulov commented on code in PR #20204: URL: https://github.com/apache/flink/pull/20204#discussion_r916748524 ## docs/content/docs/flinkDev/ide_setup.md: ## @@ -149,6 +149,12 @@ It is recommended to automatically format your code by applying the following se 8. Under "Formatting Actions", select "Optimize imports" and "Reformat file". 9. Under "File Path Inclusions", add an entry for `.*\.java` and `.*\.scala` to avoid formatting other file types. +For IntelliJ IDEA version > 2021.2: + +6. Go to "Settings" → "Tools" → "Actions on Save". +7. Under "Formatting Actions", select "Optimize imports" and "Reformat file". +8. From the "All file types list" next to "Reformat code", select Java and Scala. Review Comment: I thought about doing it that way but there is an "umbrella" statement that the whole section is applicable to 2020.3. https://github.com/afedulov/flink/blob/hotfix-intellij/docs/content/docs/flinkDev/ide_setup.md?plain=1#L65 Do you know if the rest is applicable verbatim in the newer versions? Then we can bump that statement to 2021.2, move the new section up and the existing under the "For older IntelliJ version:" paragraph. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-docker] nferrario commented on a diff in pull request #117: [FLINK-28057] Fix LD_PRELOAD on ARM images
nferrario commented on code in PR #117:
URL: https://github.com/apache/flink-docker/pull/117#discussion_r916746986
##
1.15/scala_2.12-java11-debian/docker-entrypoint.sh:
##
@@ -91,7 +91,12 @@ prepare_configuration() {
maybe_enable_jemalloc() {
if [ "${DISABLE_JEMALLOC:-false}" == "false" ]; then
-export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
+# Maybe use export LD_PRELOAD=$LD_PRELOAD:/usr/lib/$(uname
-i)-linux-gnu/libjemalloc.so
+if [[ `uname -i` == 'aarch64' ]]; then
+export
LD_PRELOAD=$LD_PRELOAD:/usr/lib/aarch64-linux-gnu/libjemalloc.so
Review Comment:
@Myasuka I don't think there's a good way to have the tests actually check
if LD_PRELOAD is set. I'm not sure if you'd want me to `touch`, which might be
fine on Github Actions but might be annoying when testing locally, or just
ignore the test entirely.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org