This is an automated email from the ASF dual-hosted git repository.
wusheng pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/skywalking-banyandb.git
The following commit(s) were added to refs/heads/main by this push:
new b8bcf96d Add document for column-based storage (#435)
b8bcf96d is described below
commit b8bcf96d38b68068b014a894ecf68f22e046820e
Author: Huang Youliang <52878305+butterbri...@users.noreply.github.com>
AuthorDate: Wed Apr 24 06:22:41 2024 -0700
Add document for column-based storage (#435)
---
CONTRIBUTING.md | 2 +-
docs/concept/tsdb.md | 51 ++++++++++++++++++++++++++++++-------------
docs/installation.md | 2 +-
docs/installation/binaries.md | 2 +-
4 files changed, 39 insertions(+), 18 deletions(-)
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index fcae5d0b..026ebc2a 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -49,7 +49,7 @@ Users who want to build a binary from sources have to set up:
### Windows
-BanyanDB is built on Linux and macOS that introduced several platform-specific
characters to the building system. Therefore, we highly recommend you use
[WSL2+Ubuntu](https://ubuntu.com/wsl) to execute tasks of the Makefile.
+BanyanDB is built on Linux and macOS that introduced several platform-specific
characters to the building system. Therefore, we highly recommend you use
[WSL2+Ubuntu](https://ubuntu.com/desktop/wsl) to execute tasks of the Makefile.
#### End of line sequence
diff --git a/docs/concept/tsdb.md b/docs/concept/tsdb.md
index c1422ece..331afa4a 100644
--- a/docs/concept/tsdb.md
+++ b/docs/concept/tsdb.md
@@ -2,37 +2,58 @@
TSDB is a time-series storage engine designed to store and query large volumes
of time-series data. One of the key features of TSDB is its ability to
automatically manage data storage over time, optimize performance and ensure
that the system can scale to handle large workloads. TSDB empowers `Measure`
and `Stream` relevant data.
-
## Shard
In TSDB, the data in a group is partitioned into shards based on a
configurable sharding scheme. Each shard is assigned to a specific set of
storage nodes, and those nodes store and process the data within that shard.
This allows BanyanDB to scale horizontally by adding more storage nodes to the
cluster as needed.
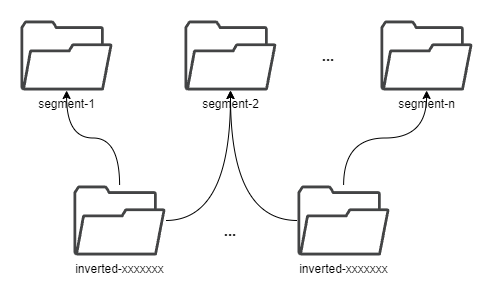
+Within each shard, data is stored in different [segments](#Segment) based on
time ranges. The series indexes are generated based on entities, and the
indexes generated based on indexing rules of the `Measure` types are also
stored under the shard.
+
+
+
+## Segment
+
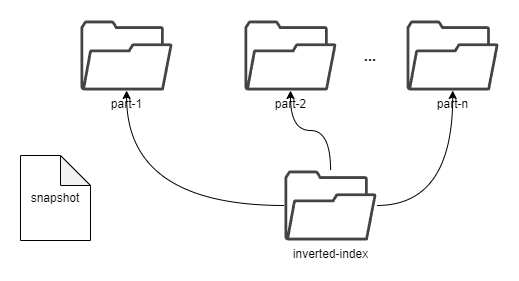
+Each segment is composed of multiple [parts](#Part). Whenever SkyWalking sends
a batch of data, BanyanDB writes this batch of data into a new part. For data
of the `Stream` type, the inverted indexes generated based on the indexing
rules are also stored in the segment. Since BanyanDB adopts a snapshot approach
for data read and write operations, the segment also needs to maintain
additional snapshot information to record the validity of the parts.
+
+
+
+## Part
+
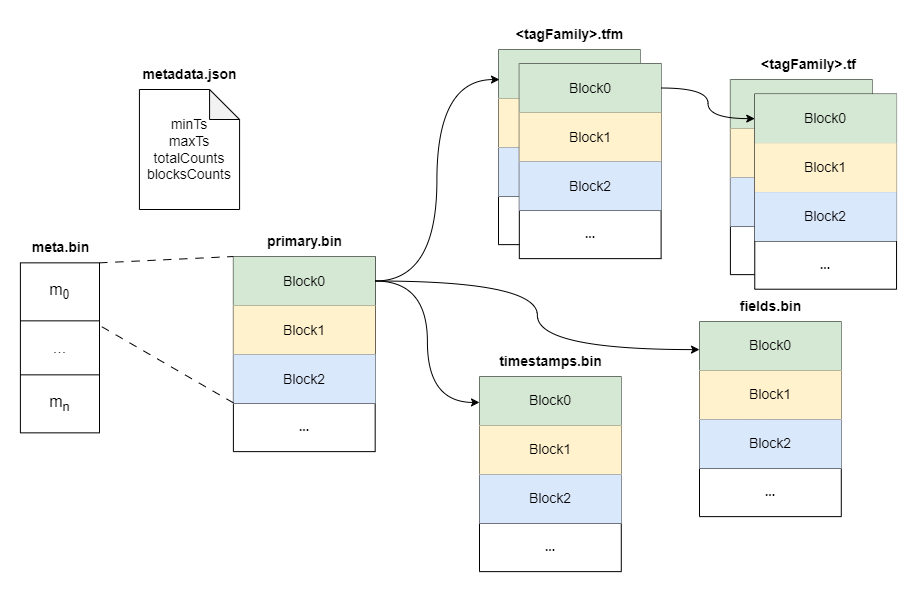
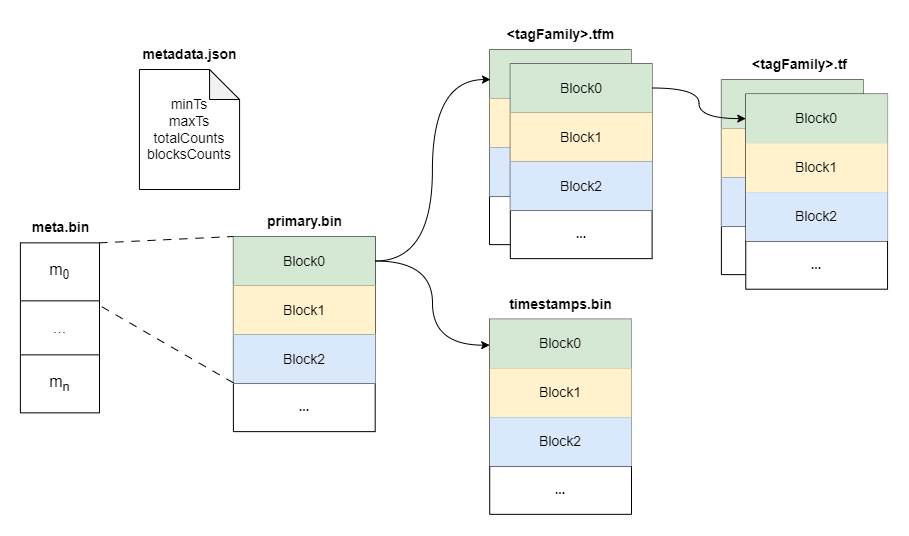
+Within a part, data is split into multiple files in a columnar manner. The
timestamps are stored in the `timestamps.bin` file, tags are organized in
persistent tag families as various files with the `.tf` suffix, and fields are
stored separately in the `fields.bin` file.
-[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.4.0/tsdb-shard.png)
+In addition, each part maintains several metadata files. Among them,
`metadata.json` is the metadata file for the part, storing descriptive
information, such as start and end times, part size, etc.
-* Buffer: It is typically implemented as an in-memory queue managed by a
shard. When new time-series data is ingested into the system, it is added to
the end of the queue, and when the buffer reaches a specific size, the data is
flushed to disk in batches.
-* SST: When a bucket of buffer becomes full or reaches a certain size
threshold, it is flushed to disk as a new Sorted String Table (SST) file. This
process is known as compaction.
-* Segments and Blocks: Time-series data is stored in data segments/blocks
within each shard. Blocks contain a fixed number of data points and are
organized into time windows. Each data segment includes an index that
efficiently retrieves data within the block.
-* Block Cache: It manages the in-memory cache of data blocks, improving query
performance by caching frequently accessed data blocks in memory.
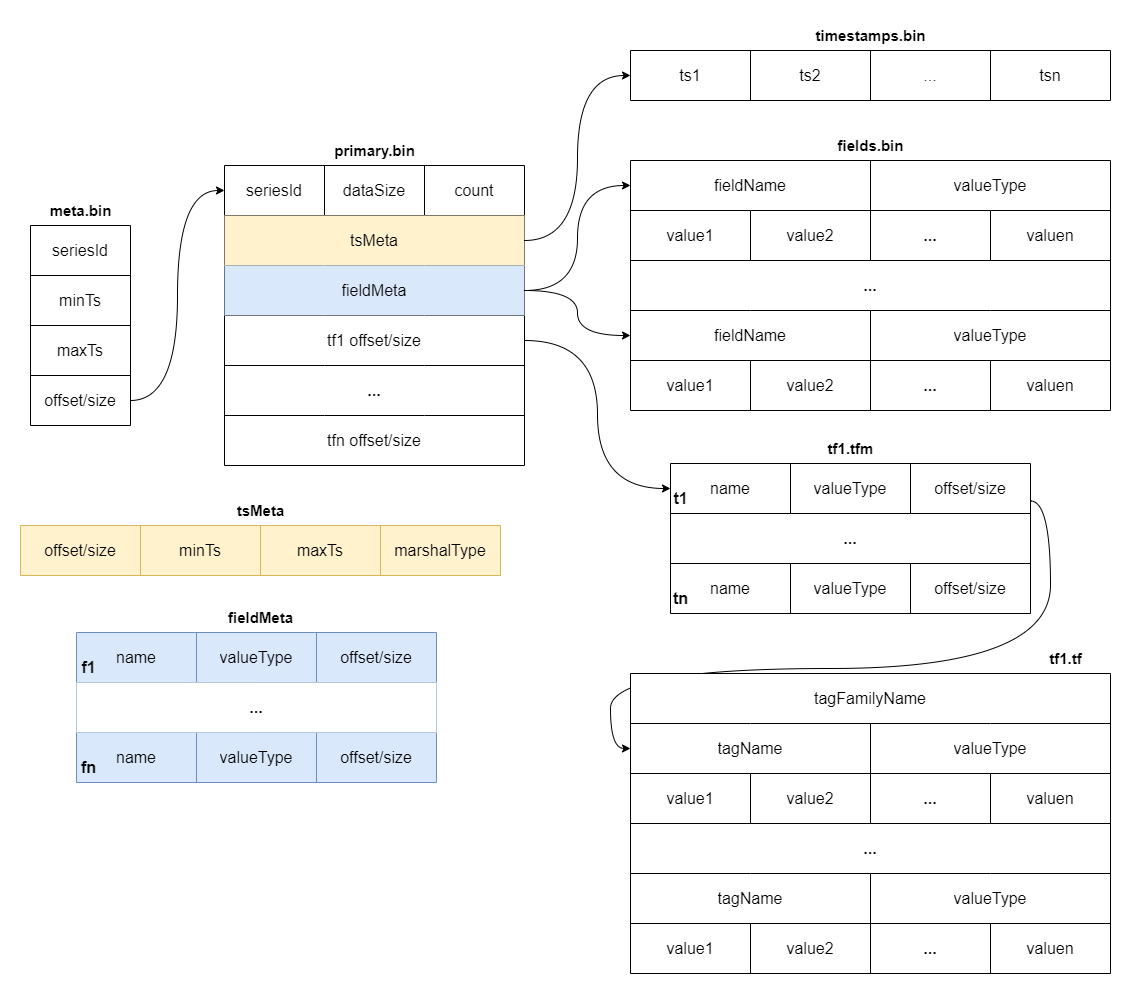
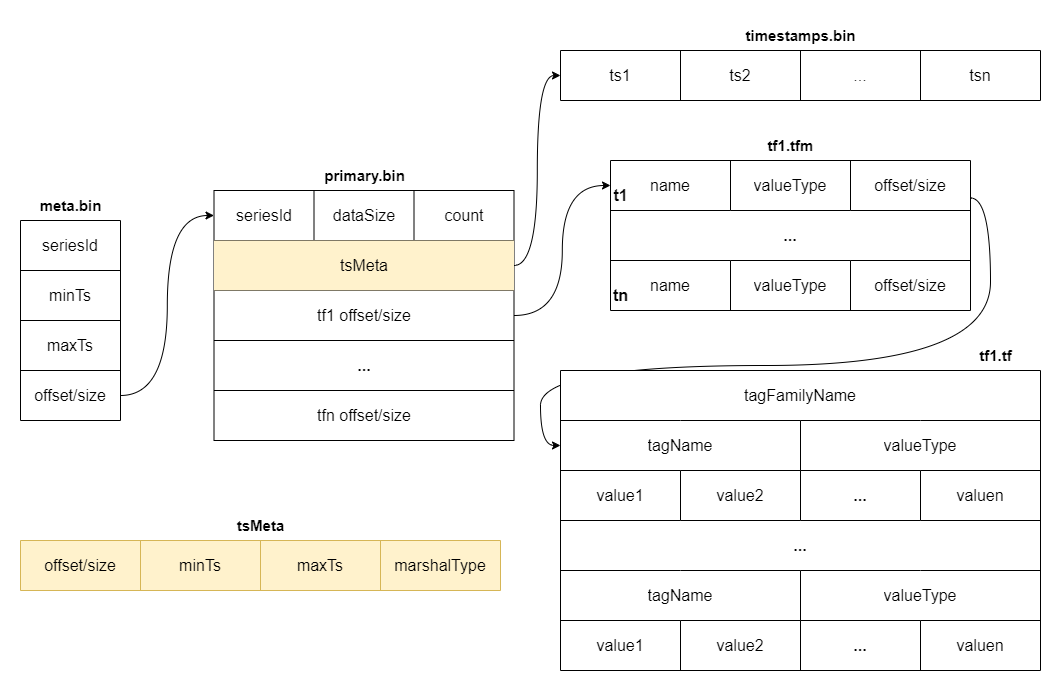
+The `meta.bin` is a skipping index file serves as the entry file for the
entire part, helping to index the `primary.bin` file.
+
+The `primary.bin` file contains the index of each [block](#Block). Through it,
the actual data files or the tagFamily metadata files ending with `.tfm` can be
indexed, which in turn helps to locate the data in blocks.
+
+Notably, for data of the `Stream` type, since there are no field columns, the
`fields.bin` file does not exist, while the rest of the structure is entirely
consistent with the `Measure` type.
+
+
+
+
+## Block
+
+The diagram below shows the detailed fields within each block. The block is
the minimal unit of tsdb, which contains several rows of data. Due to the
column-based design, each block is spread over several files.
+
+
+
## Write Path
The write path of TSDB begins when time-series data is ingested into the
system. TSDB will consult the schema repository to check if the group exists,
and if it does, then it will hash the SeriesID to determine which shard it
belongs to.
-Each shard in TSDB is responsible for storing a subset of the time-series
data, and it uses a write-ahead log to record incoming writes in a durable and
fault-tolerant manner. The shard also holds an in-memory index allowing fast
lookups of time-series data.
+Each shard in TSDB is responsible for storing a subset of the time-series
data. The shard also holds an in-memory index allowing fast lookups of
time-series data.
-When a shard receives a write request, the data is written to the buffer as a
series of buckets. Each bucket is a fixed-size chunk of time-series data
typically configured to be several minutes or hours long. As new data is
written to the buffer, it is appended to the current bucket until it is full.
Once the bucket is full, it is closed, and a new bucket is created to continue
buffering writes.
+When a shard receives a write request, the data is written to the buffer as a
memory part. Meanwhile, the series index and inverted index will also be
updated. The worker in the background periodically flushes data, writing the
memory part to the disk. After the flush operation is completed, it triggers a
merge operation to combine the parts and remove invalid data.
-Once a bucket is closed, it is stored as a single SST in a shard. The file is
indexed and added to the index for the corresponding time range and resolution.
+Whenever a new memory part is generated, or when a flush or merge operation is
triggered, they initiate an update of the snapshot and delete outdated
snapshots. The parts in a persistent snapshot could be accessible to the reader.
## Read Path
-The read path in TSDB retrieves time-series data from disk or memory and
returns it to the query engine. The read path comprises several components: the
buffer, cache, and SST file. The following is a high-level overview of how
these components work together to retrieve time-series data in TSDB.
-
-The first step in the read path is to perform an index lookup to determine
which blocks contain the desired time range. The index contains metadata about
each data block, including its start and end time and its location on disk.
+The read path in TSDB retrieves time-series data from disk or memory, and
returns it to the query engine. The read path comprises several components: the
buffer and parts. The following is a high-level overview of how these
components work together to retrieve time-series data in TSDB.
-If the requested data is present in the buffer (i.e., it has been recently
written but not yet persisted to disk), the buffer is checked to see if the
data can be returned directly from memory. The read path determines which
bucket(s) contain the requested time range. If the data is not present in the
buffer, the read path proceeds to the next step.
+The first step in the read path is to perform an index lookup to determine
which parts contain the desired time range. The index contains metadata about
each data part, including its start and end time.
-If the requested data is present in the cache (i.e., it has been recently read
from disk and is still in memory), it is checked to see if the data can be
returned directly from memory. The read path proceeds to the next step if the
data is not in the cache.
+If the requested data is present in the buffer (i.e., it has been recently
written but not yet persisted to disk), the buffer is checked to see if the
data can be returned directly from memory. The read path determines which
memory part(s) contain the requested time range. If the data is not present in
the buffer, the read path proceeds to the next step.
-The final step in the read path is to look up the appropriate SST file on
disk. Files are the on-disk representation of data blocks and are organized by
shard and time range. The read path determines which SST files contain the
requested time range and reads the appropriate data blocks from the disk.
+The next step in the read path is to look up the appropriate parts on disk.
Files are the on-disk representation of blocks and are organized by shard and
time range. The read path determines which parts contain the requested time
range and reads the appropriate blocks from the disk. Due to the column-based
storage design, it may be necessary to read multiple data files.
diff --git a/docs/installation.md b/docs/installation.md
index 8799cc68..c62d9b7c 100644
--- a/docs/installation.md
+++ b/docs/installation.md
@@ -23,7 +23,7 @@ Users who want to build a binary from sources have to set up:
#### Windows
-BanyanDB is built on Linux and macOS that introduced several platform-specific
characters to the building system. Therefore, we highly recommend you use
[WSL2+Ubuntu](https://ubuntu.com/wsl) to execute tasks of the Makefile.
+BanyanDB is built on Linux and macOS that introduced several platform-specific
characters to the building system. Therefore, we highly recommend you use
[WSL2+Ubuntu](https://ubuntu.com/desktop/wsl) to execute tasks of the Makefile.
#### Build Binaries
diff --git a/docs/installation/binaries.md b/docs/installation/binaries.md
index f0d4a95a..f5346011 100644
--- a/docs/installation/binaries.md
+++ b/docs/installation/binaries.md
@@ -20,7 +20,7 @@ Users who want to build a binary from sources have to set up:
### Windows
-BanyanDB is built on Linux and macOS that introduced several platform-specific
characters to the building system. Therefore, we highly recommend you use
[WSL2+Ubuntu](https://ubuntu.com/wsl) to execute tasks of the Makefile.
+BanyanDB is built on Linux and macOS that introduced several platform-specific
characters to the building system. Therefore, we highly recommend you use
[WSL2+Ubuntu](https://ubuntu.com/desktop/wsl) to execute tasks of the Makefile.
### Build Binaries
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}