[GitHub] [spark] SparkQA commented on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING
SparkQA commented on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING URL: https://github.com/apache/spark/pull/25651#issuecomment-527314270 **[Test build #110027 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110027/testReport)** for PR 25651 at commit [`0da5453`](https://github.com/apache/spark/commit/0da5453549a53cab720533b212b24cdd83e4640b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING
AmplabJenkins removed a comment on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING URL: https://github.com/apache/spark/pull/25651#issuecomment-527313252 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING
AmplabJenkins removed a comment on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING URL: https://github.com/apache/spark/pull/25651#issuecomment-527313256 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/15045/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING
AmplabJenkins commented on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING URL: https://github.com/apache/spark/pull/25651#issuecomment-527313256 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/15045/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING
AmplabJenkins commented on issue #25651: [SPARK-28948][SQL] support data source v2 in CREATE TABLE USING URL: https://github.com/apache/spark/pull/25651#issuecomment-527313252 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #25306: [SPARK-28573][SQL] Convert InsertIntoTable(HiveTableRelation) to DataSource inserting for partitioned table
cloud-fan closed pull request #25306: [SPARK-28573][SQL] Convert InsertIntoTable(HiveTableRelation) to DataSource inserting for partitioned table URL: https://github.com/apache/spark/pull/25306 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25306: [SPARK-28573][SQL] Convert InsertIntoTable(HiveTableRelation) to DataSource inserting for partitioned table
cloud-fan commented on issue #25306: [SPARK-28573][SQL] Convert InsertIntoTable(HiveTableRelation) to DataSource inserting for partitioned table URL: https://github.com/apache/spark/pull/25306#issuecomment-527312070 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2 URL: https://github.com/apache/spark/pull/25626#discussion_r320095937 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -574,6 +574,15 @@ case class DeleteFromTable( override def children: Seq[LogicalPlan] = child :: Nil } +case class UpdateTable( +child: LogicalPlan, +attrs: Seq[Attribute], Review comment: can we really use `Seq[Attribute]`? When Spark resolves it to nested field, it will be `Alias` which is not an `Attribute`, and we will get weird errors. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25653: [SPARK-28954][SQL] In SparkSQL CLI, pass extra jar through hive hive conf HIVEAUXJARS, we just use SessionResourceLoader API to cover
AmplabJenkins removed a comment on issue #25653: [SPARK-28954][SQL] In SparkSQL CLI, pass extra jar through hive hive conf HIVEAUXJARS, we just use SessionResourceLoader API to cover multi-version problem URL: https://github.com/apache/spark/pull/25653#issuecomment-527197196 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25653: [SPARK-28954][SQL] In SparkSQL CLI, pass extra jar through hive hive conf HIVEAUXJARS, we just use SessionResourceLoader API to cover multi-version
wangyum commented on issue #25653: [SPARK-28954][SQL] In SparkSQL CLI, pass extra jar through hive hive conf HIVEAUXJARS, we just use SessionResourceLoader API to cover multi-version problem URL: https://github.com/apache/spark/pull/25653#issuecomment-527310354 ok to test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add
UPDATE support for DataSource V2
URL: https://github.com/apache/spark/pull/25626#discussion_r320095359
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/sources/v2/DataSourceV2SQLSuite.scala
##
@@ -1767,6 +1767,125 @@ class DataSourceV2SQLSuite
}
}
+ test("Update: basic") {
+val t = "testcat.ns1.ns2.tbl"
+withTable(t) {
+ sql(s"CREATE TABLE $t (id bigint, name string, age int, p int)" +
Review comment:
nit: we can use multiline string, e.g.
```
sql(
s"""
|xxx
""".stripMargin)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add
UPDATE support for DataSource V2
URL: https://github.com/apache/spark/pull/25626#discussion_r320095086
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Strategy.scala
##
@@ -245,6 +246,28 @@ object DataSourceV2Strategy extends Strategy with
PredicateHelper {
}.toArray
DeleteFromTableExec(r.table.asDeletable, filters) :: Nil
+case UpdateTable(r: DataSourceV2Relation, attrs, values, condition) =>
+ val nested =
attrs.asInstanceOf[Seq[Any]].filterNot(_.isInstanceOf[AttributeReference])
Review comment:
why do we need the `.asInstanceOf[Seq[Any]]`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r320095042
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -249,32 +253,42 @@ private[hive] class SparkExecuteStatementOperation(
}
dataTypes = result.queryExecution.analyzed.output.map(_.dataType).toArray
} catch {
- case e: HiveSQLException =>
-if (getStatus().getState() == OperationState.CANCELED) {
+ // Actually do need to catch Throwable as some failures don't inherit
from Exception and
+ // HiveServer will silently swallow them.
+ case e: Throwable =>
+val currentState = getStatus().getState()
+if (currentState.isTerminal) {
Review comment:
> ocd nit: `if (getStatus.getState.isTerminal)` would make it consistent
with other places in the file, and adding the `val currentState` now is not
needed, as it's accessed only once anyway.
We should show currentState in
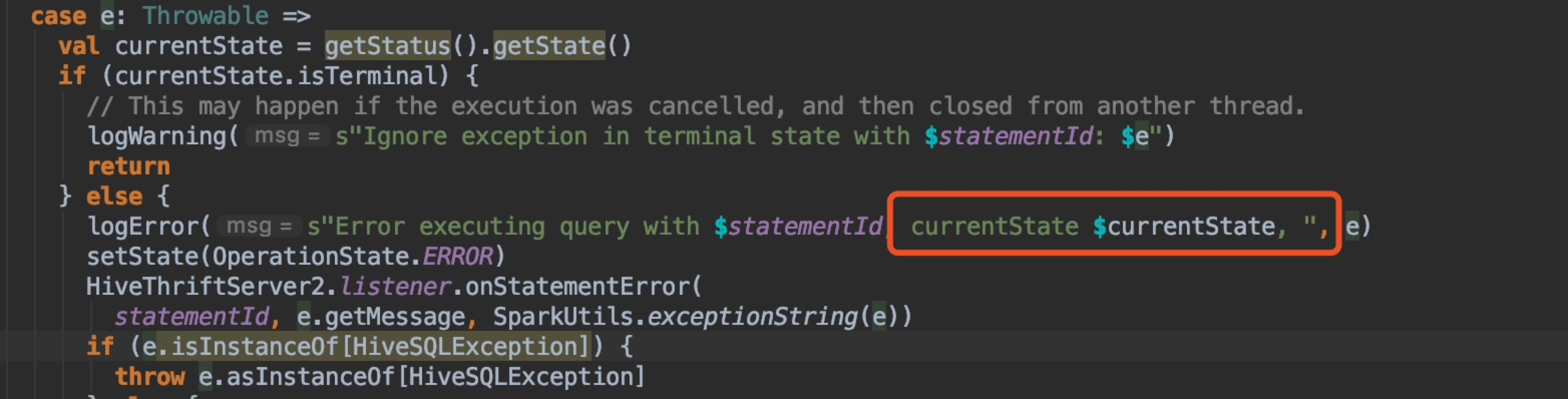
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add
UPDATE support for DataSource V2
URL: https://github.com/apache/spark/pull/25626#discussion_r320095143
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Strategy.scala
##
@@ -245,6 +246,28 @@ object DataSourceV2Strategy extends Strategy with
PredicateHelper {
}.toArray
DeleteFromTableExec(r.table.asDeletable, filters) :: Nil
+case UpdateTable(r: DataSourceV2Relation, attrs, values, condition) =>
+ val nested =
attrs.asInstanceOf[Seq[Any]].filterNot(_.isInstanceOf[AttributeReference])
+ if (nested.nonEmpty) {
+throw new RuntimeException(s"Update only support non-nested fields.
Nested: $nested")
Review comment:
I'd prefer AnalysisException
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r320094261
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -249,32 +253,42 @@ private[hive] class SparkExecuteStatementOperation(
}
dataTypes = result.queryExecution.analyzed.output.map(_.dataType).toArray
} catch {
- case e: HiveSQLException =>
-if (getStatus().getState() == OperationState.CANCELED) {
+ // Actually do need to catch Throwable as some failures don't inherit
from Exception and
+ // HiveServer will silently swallow them.
+ case e: Throwable =>
+val currentState = getStatus().getState()
+if (currentState.isTerminal) {
+ // This may happen if the execution was cancelled, and then closed
from another thread.
+ logWarning(s"Ignore exception in terminal state with $statementId:
$e")
return
} else {
+ logError(s"Error executing query, currentState $currentState, ", e)
setState(OperationState.ERROR)
HiveThriftServer2.listener.onStatementError(
statementId, e.getMessage, SparkUtils.exceptionString(e))
- throw e
+ if (e.isInstanceOf[HiveSQLException]) {
+throw e.asInstanceOf[HiveSQLException]
+ } else {
+throw new HiveSQLException("Error running query: " + e.toString, e)
+ }
}
- // Actually do need to catch Throwable as some failures don't inherit
from Exception and
- // HiveServer will silently swallow them.
- case e: Throwable =>
-val currentState = getStatus().getState()
-logError(s"Error executing query, currentState $currentState, ", e)
-setState(OperationState.ERROR)
-HiveThriftServer2.listener.onStatementError(
- statementId, e.getMessage, SparkUtils.exceptionString(e))
-throw new HiveSQLException(e.toString)
}
-setState(OperationState.FINISHED)
-HiveThriftServer2.listener.onStatementFinish(statementId)
+synchronized {
+ if (!getStatus.getState.isTerminal) {
+setState(OperationState.FINISHED)
+HiveThriftServer2.listener.onStatementFinish(statementId)
+ }
+}
}
override def cancel(): Unit = {
-logInfo(s"Cancel '$statement' with $statementId")
-cleanup(OperationState.CANCELED)
+synchronized {
+ if (!getStatus.getState.isTerminal) {
+logInfo(s"Cancel '$statement' with $statementId")
Review comment:
> Could you do `logInfo(s"Cancel query with $statementId")`? I think it's
enough to log the full statement at submission time.
In my experience, more detail SQL information here makes it easier to
troubleshoot problems
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r320094261
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -249,32 +253,42 @@ private[hive] class SparkExecuteStatementOperation(
}
dataTypes = result.queryExecution.analyzed.output.map(_.dataType).toArray
} catch {
- case e: HiveSQLException =>
-if (getStatus().getState() == OperationState.CANCELED) {
+ // Actually do need to catch Throwable as some failures don't inherit
from Exception and
+ // HiveServer will silently swallow them.
+ case e: Throwable =>
+val currentState = getStatus().getState()
+if (currentState.isTerminal) {
+ // This may happen if the execution was cancelled, and then closed
from another thread.
+ logWarning(s"Ignore exception in terminal state with $statementId:
$e")
return
} else {
+ logError(s"Error executing query, currentState $currentState, ", e)
setState(OperationState.ERROR)
HiveThriftServer2.listener.onStatementError(
statementId, e.getMessage, SparkUtils.exceptionString(e))
- throw e
+ if (e.isInstanceOf[HiveSQLException]) {
+throw e.asInstanceOf[HiveSQLException]
+ } else {
+throw new HiveSQLException("Error running query: " + e.toString, e)
+ }
}
- // Actually do need to catch Throwable as some failures don't inherit
from Exception and
- // HiveServer will silently swallow them.
- case e: Throwable =>
-val currentState = getStatus().getState()
-logError(s"Error executing query, currentState $currentState, ", e)
-setState(OperationState.ERROR)
-HiveThriftServer2.listener.onStatementError(
- statementId, e.getMessage, SparkUtils.exceptionString(e))
-throw new HiveSQLException(e.toString)
}
-setState(OperationState.FINISHED)
-HiveThriftServer2.listener.onStatementFinish(statementId)
+synchronized {
+ if (!getStatus.getState.isTerminal) {
+setState(OperationState.FINISHED)
+HiveThriftServer2.listener.onStatementFinish(statementId)
+ }
+}
}
override def cancel(): Unit = {
-logInfo(s"Cancel '$statement' with $statementId")
-cleanup(OperationState.CANCELED)
+synchronized {
+ if (!getStatus.getState.isTerminal) {
+logInfo(s"Cancel '$statement' with $statementId")
Review comment:
> Could you do `logInfo(s"Cancel query with $statementId")`? I think it's
enough to log the full statement at submission time.
In my experience, more detail SQL information here makes it easier to
troubleshoot problems
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r320094276
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -249,32 +253,42 @@ private[hive] class SparkExecuteStatementOperation(
}
dataTypes = result.queryExecution.analyzed.output.map(_.dataType).toArray
} catch {
- case e: HiveSQLException =>
-if (getStatus().getState() == OperationState.CANCELED) {
+ // Actually do need to catch Throwable as some failures don't inherit
from Exception and
+ // HiveServer will silently swallow them.
+ case e: Throwable =>
+val currentState = getStatus().getState()
+if (currentState.isTerminal) {
+ // This may happen if the execution was cancelled, and then closed
from another thread.
+ logWarning(s"Ignore exception in terminal state with $statementId:
$e")
return
} else {
+ logError(s"Error executing query, currentState $currentState, ", e)
setState(OperationState.ERROR)
HiveThriftServer2.listener.onStatementError(
statementId, e.getMessage, SparkUtils.exceptionString(e))
- throw e
+ if (e.isInstanceOf[HiveSQLException]) {
+throw e.asInstanceOf[HiveSQLException]
+ } else {
+throw new HiveSQLException("Error running query: " + e.toString, e)
+ }
}
- // Actually do need to catch Throwable as some failures don't inherit
from Exception and
- // HiveServer will silently swallow them.
- case e: Throwable =>
-val currentState = getStatus().getState()
-logError(s"Error executing query, currentState $currentState, ", e)
-setState(OperationState.ERROR)
-HiveThriftServer2.listener.onStatementError(
- statementId, e.getMessage, SparkUtils.exceptionString(e))
-throw new HiveSQLException(e.toString)
}
-setState(OperationState.FINISHED)
-HiveThriftServer2.listener.onStatementFinish(statementId)
+synchronized {
+ if (!getStatus.getState.isTerminal) {
+setState(OperationState.FINISHED)
+HiveThriftServer2.listener.onStatementFinish(statementId)
+ }
Review comment:
> nit: I think this could become a `finally { synchronized {` block; the if
check will make sure that it doesn't go to finished after another state.
Reasonable, I add too much control.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add
UPDATE support for DataSource V2
URL: https://github.com/apache/spark/pull/25626#discussion_r320093967
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -352,6 +352,31 @@ class AstBuilder(conf: SQLConf) extends
SqlBaseBaseVisitor[AnyRef] with Logging
DeleteFromStatement(tableId, tableAlias,
expression(ctx.whereClause().booleanExpression()))
}
+ override def visitUpdateTable(ctx: UpdateTableContext): LogicalPlan =
withOrigin(ctx) {
+val tableId = visitMultipartIdentifier(ctx.multipartIdentifier)
+val tableAlias = if (ctx.tableAlias() != null) {
+ val ident = ctx.tableAlias().strictIdentifier()
+ if (ident != null) { Some(ident.getText) } else { None }
+} else {
+ None
+}
+val sets = ctx.setClause().assign().asScala.map {
+ kv => visitMultipartIdentifier(kv.key) -> expression(kv.value)
+}.toMap
Review comment:
instead of `toMap` here and get keys/values later, how about
```
val (attrs, values) = ctx.setClause().unzip()
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25654: [SPARK-28912][STREAMING] Fixed MatchError in getCheckpointFiles()
HyukjinKwon commented on a change in pull request #25654:
[SPARK-28912][STREAMING] Fixed MatchError in getCheckpointFiles()
URL: https://github.com/apache/spark/pull/25654#discussion_r320091518
##
File path: streaming/src/main/scala/org/apache/spark/streaming/Checkpoint.scala
##
@@ -102,7 +102,7 @@ class Checkpoint(ssc: StreamingContext, val
checkpointTime: Time)
private[streaming]
object Checkpoint extends Logging {
val PREFIX = "checkpoint-"
- val REGEX = (PREFIX + """([\d]+)([\w\.]*)""").r
+ val REGEX = (PREFIX + """([\d]{9,})([\w\.]*)""").r
Review comment:
I think it will technically introduce a behaviour change since it targets to
support the `checkpoint-` name with numbers. Let's clarify it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill
HyukjinKwon commented on issue #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill URL: https://github.com/apache/spark/pull/25628#issuecomment-527302709 That works because you backquoted but the change seems removing the backquotes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
cloud-fan commented on a change in pull request #25512: [SPARK-28782][SQL]
Generator support in aggregate expressions
URL: https://github.com/apache/spark/pull/25512#discussion_r320089158
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -2018,6 +2018,62 @@ class Analyzer(
throw new AnalysisException("Only one generator allowed per select
clause but found " +
generators.size + ": " + generators.map(toPrettySQL).mkString(", "))
+ case Aggregate(_, aggList, _) if aggList.exists(hasNestedGenerator) =>
+val nestedGenerator = aggList.find(hasNestedGenerator).get
+throw new AnalysisException("Generators are not supported when it's
nested in " +
+ "expressions, but got: " + toPrettySQL(trimAlias(nestedGenerator)))
+
+ case Aggregate(_, aggList, _) if aggList.count(hasGenerator) > 1 =>
+val generators = aggList.filter(hasGenerator).map(trimAlias)
+throw new AnalysisException("Only one generator allowed per aggregate
clause but found " +
+ generators.size + ": " + generators.map(toPrettySQL).mkString(", "))
+
+ case agg @ Aggregate(groupList, aggList, child) if aggList.forall {
+ case AliasedGenerator(generator, _, _) => generator.childrenResolved
Review comment:
please take a look at the object `AliasedGenerator`. There is no
`AliasedGenerator` instance. It's just an `unapply` method. And we can use
`hasGenerator` here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] PavithraRamachandran commented on issue #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill
PavithraRamachandran commented on issue #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill URL: https://github.com/apache/spark/pull/25628#issuecomment-527300788 @HyukjinKwon i tested this case too.. It works fine. 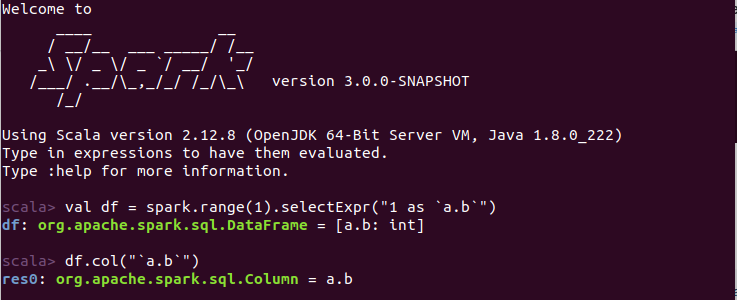 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527288814 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527288818 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110026/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527288814 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527288818 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110026/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527266434 **[Test build #110026 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110026/testReport)** for PR 22138 at commit [`fa12a0a`](https://github.com/apache/spark/commit/fa12a0a6ee023d52a9257d76415556d5d49902de). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527288424 **[Test build #110026 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110026/testReport)** for PR 22138 at commit [`fa12a0a`](https://github.com/apache/spark/commit/fa12a0a6ee023d52a9257d76415556d5d49902de). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on issue #24881: [SPARK-23160][SQL][TEST] Port window.sql
gatorsmile commented on issue #24881: [SPARK-23160][SQL][TEST] Port window.sql URL: https://github.com/apache/spark/pull/24881#issuecomment-527287290 @DylanGuedes any update? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sharangk commented on issue #25595: [SPARK-28792][SQL][DOC] Document CREATE DATABASE statement in SQL Reference.
sharangk commented on issue #25595: [SPARK-28792][SQL][DOC] Document CREATE DATABASE statement in SQL Reference. URL: https://github.com/apache/spark/pull/25595#issuecomment-527286839 Thanks for the timely review. I will work the comments and resubmit the PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25363: [SPARK-28628][SQL] Implement SupportsNamespaces in V2SessionCatalog
cloud-fan commented on a change in pull request #25363: [SPARK-28628][SQL]
Implement SupportsNamespaces in V2SessionCatalog
URL: https://github.com/apache/spark/pull/25363#discussion_r320075731
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalogSuite.scala
##
@@ -22,41 +22,56 @@ import java.util.Collections
import scala.collection.JavaConverters._
-import org.scalatest.{BeforeAndAfter, BeforeAndAfterAll}
+import org.scalatest.BeforeAndAfter
import org.apache.spark.SparkFunSuite
import org.apache.spark.sql.AnalysisException
-import org.apache.spark.sql.catalog.v2.{Catalogs, Identifier, TableCatalog,
TableChange}
-import org.apache.spark.sql.catalyst.analysis.{NoSuchTableException,
TableAlreadyExistsException}
+import org.apache.spark.sql.catalog.v2.{Catalogs, Identifier, NamespaceChange,
TableChange}
+import
org.apache.spark.sql.catalyst.analysis.{NamespaceAlreadyExistsException,
NoSuchNamespaceException, NoSuchTableException, TableAlreadyExistsException}
import org.apache.spark.sql.catalyst.parser.CatalystSqlParser
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.test.SharedSparkSession
import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType,
StringType, StructField, StructType, TimestampType}
import org.apache.spark.sql.util.CaseInsensitiveStringMap
-class V2SessionCatalogSuite
-extends SparkFunSuite with SharedSparkSession with BeforeAndAfter {
- import org.apache.spark.sql.catalog.v2.CatalogV2Implicits._
+class V2SessionCatalogBaseSuite extends SparkFunSuite with SharedSparkSession
with BeforeAndAfter {
Review comment:
The session catalog has 2 implementations: in-memory and hive. Shall we
follow `ExternalCatalogSuite` and run the tests in both sql/core and sql/hive?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25363: [SPARK-28628][SQL] Implement SupportsNamespaces in V2SessionCatalog
cloud-fan commented on a change in pull request #25363: [SPARK-28628][SQL]
Implement SupportsNamespaces in V2SessionCatalog
URL: https://github.com/apache/spark/pull/25363#discussion_r320074529
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalog.scala
##
@@ -177,10 +184,97 @@ class V2SessionCatalog(sessionState: SessionState)
extends TableCatalog {
}
}
+ override def namespaceExists(namespace: Array[String]): Boolean = namespace
match {
+case Array(db) =>
+ catalog.databaseExists(db)
+case _ =>
+ false
+ }
+
+ override def listNamespaces(): Array[Array[String]] = {
+catalog.listDatabases().map(Array(_)).toArray
+ }
+
+ override def listNamespaces(namespace: Array[String]): Array[Array[String]]
= {
+namespace match {
+ case Array() =>
+listNamespaces()
+ case Array(db) if catalog.databaseExists(db) =>
+Array()
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def loadNamespaceMetadata(namespace: Array[String]):
util.Map[String, String] = {
+namespace match {
+ case Array(db) =>
+catalog.getDatabaseMetadata(db).toMetadata
+
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def createNamespace(
+ namespace: Array[String],
+ metadata: util.Map[String, String]): Unit = namespace match {
+case Array(db) if !catalog.databaseExists(db) =>
+ catalog.createDatabase(
+toCatalogDatabase(db, metadata, defaultLocation =
Some(catalog.getDefaultDBPath(db))),
+ignoreIfExists = false)
+
+case Array(_) =>
+ throw new NamespaceAlreadyExistsException(namespace)
+
+case _ =>
+ throw new IllegalArgumentException(s"Invalid namespace name:
${namespace.quoted}")
+ }
+
+ override def alterNamespace(namespace: Array[String], changes:
NamespaceChange*): Unit = {
+namespace match {
+ case Array(db) =>
+// validate that this catalog's reserved properties are not removed
+changes.foreach {
+ case remove: RemoveProperty if
RESERVED_PROPERTIES.contains(remove.property) =>
+throw new UnsupportedOperationException(
+ s"Cannot remove reserved property: ${remove.property}")
+ case _ =>
+}
+
+val metadata = catalog.getDatabaseMetadata(db).toMetadata
+catalog.alterDatabase(
+ toCatalogDatabase(db, CatalogV2Util.applyNamespaceChanges(metadata,
changes)))
+
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def dropNamespace(namespace: Array[String]): Boolean = namespace
match {
+case Array(db) if catalog.databaseExists(db) =>
+ if (catalog.listTables(db).nonEmpty) {
+throw new IllegalStateException(s"Namespace ${namespace.quoted} is not
empty")
+ }
+ catalog.dropDatabase(db, ignoreIfNotExists = false, cascade = false)
+ true
+
+case Array(_) =>
+ // exists returned false
Review comment:
ah i see
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
AmplabJenkins removed a comment on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25657#issuecomment-527277300 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
AmplabJenkins commented on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25657#issuecomment-527277648 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
AmplabJenkins removed a comment on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25657#issuecomment-527277202 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
AmplabJenkins commented on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25657#issuecomment-527277300 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
AmplabJenkins commented on issue #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25657#issuecomment-527277202 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MrDLontheway closed pull request #25650: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
MrDLontheway closed pull request #25650: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25650 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MrDLontheway opened a new pull request #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
MrDLontheway opened a new pull request #25657: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25657 ### What changes were proposed in this pull request? support insertInto a specific table partition ### Why are the changes needed? make the api more kind ### Does this PR introduce any user-facing change? no ### How was this patch tested? use api write data to partioned hive table df.write.insertInto(ptTableName, "pt1='2018',pt2='0601'") This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MrDLontheway commented on issue #25650: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition
MrDLontheway commented on issue #25650: [SPARK-28050][SQL]DataFrameWriter support insertInto a specific table partition URL: https://github.com/apache/spark/pull/25650#issuecomment-527276503 @dongjoon-hyun i create a new branch to make PR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kiszk commented on a change in pull request #25655: [SPARK-28906][Build] Fix incorrect information in bin/spark-submit --version
kiszk commented on a change in pull request #25655: [SPARK-28906][Build] Fix incorrect information in bin/spark-submit --version URL: https://github.com/apache/spark/pull/25655#discussion_r320066049 ## File path: dev/create-release/release-build.sh ## @@ -164,7 +164,6 @@ DEST_DIR_NAME="$SPARK_PACKAGE_VERSION" git clean -d -f -x rm .gitignore -rm -rf .git Review comment: @felixcheung Without this PR, then tarballs is created by `dev/create-release/do-release-docker.sh`, the version information related to output by `git` command is missing. This is because `git` command executed without `.git directory`. As a result, `git` command (e.g. `git git rev-parse HEAD`) returns empty. Then, version information is missing. This change tries to keep `.git` directory to correctly execute `.git` command in `build/spark-build-info`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hddong commented on a change in pull request #25649: [SPARK-28694][EXAMPLES]Add Java/Scala StructuredKerberizedKafkaWordCount examples
hddong commented on a change in pull request #25649: [SPARK-28694][EXAMPLES]Add
Java/Scala StructuredKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25649#discussion_r320065744
##
File path:
examples/src/main/java/org/apache/spark/examples/sql/streaming/JavaStructuredKerberiedKafkaWordCount.java
##
@@ -0,0 +1,129 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.sql.streaming;
+
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.spark.api.java.function.FlatMapFunction;
+import org.apache.spark.sql.Dataset;
+import org.apache.spark.sql.Encoders;
+import org.apache.spark.sql.Row;
+import org.apache.spark.sql.SparkSession;
+import org.apache.spark.sql.streaming.StreamingQuery;
+
+import java.util.Arrays;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaStructuredKerberiedKafkaWordCount
+ *The Kafka "bootstrap.servers" configuration. A
+ * comma-separated list of host:port.
+ *There are three kinds of type, i.e. 'assign',
'subscribe',
+ * 'subscribePattern'.
+ * |- Specific TopicPartitions to consume. Json string
+ * | {"topicA":[0,1],"topicB":[2,4]}.
+ * |- The topic list to subscribe. A comma-separated list of
+ * | topics.
+ * |- The pattern used to subscribe to topic(s).
+ * | Java regex string.
+ * |- Only one of "assign, "subscribe" or "subscribePattern" options can be
+ * | specified for Kafka source.
+ *Different value format depends on the value of 'subscribe-type'.
+ *
+ * Example:
+ * Yarn client:
+ *$ bin/run-example --files
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_driver_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * --master yarn
+ * sql.streaming.JavaStructuredKerberiedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * subscribe topic1,topic2
+ * Yarn cluster:
+ *$ bin/run-example --files \
+ *
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab,${krb5_path}/krb5.conf
\
+ * --driver-java-options \
+ * "-Djava.security.auth.login.config=./kafka_jaas.conf \
+ * -Djava.security.krb5.conf=./krb5.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * --master yarn --deploy-mode cluster \
+ * sql.streaming.JavaStructuredKerberiedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * subscribe topic1,topic2
+ *
+ * kafka_jaas.conf can manually create, template as:
+ * KafkaClient {
+ * com.sun.security.auth.module.Krb5LoginModule required
+ * keyTab="./kafka.service.keytab"
+ * useKeyTab=true
+ * storeKey=true
+ * useTicketCache=false
+ * serviceName="kafka"
+ * principal="kafka/h...@example.com";
+ * };
+ * kafka_driver_jaas.conf (used by yarn client) and kafka_jaas.conf are
basically the same
+ * except for some differences at 'keyTab'. In kafka_driver_jaas.conf,
'keyTab' should be
+ * "${keytab_path}/kafka.service.keytab".
+ * In addition, for IBM JVMs, please use
'com.ibm.security.auth.module.Krb5LoginModule'
+ * instead of 'com.sun.security.auth.module.Krb5LoginModule'.
+ *
+ * Note that this example uses SASL_PLAINTEXT for simplicity; however,
+ * SASL_PLAINTEXT has no SSL encryption and likely be less secure. Please
consider
+ * using SASL_SSL in production.
+ */
+public class JavaStructuredKerberiedKafkaWordCount {
+ public static void main(String[] args) throws Exception {
+if (args.length < 3) {
+ System.err.println("Usage: JavaStructuredKerberiedKafkaWordCount
" +
+" ");
+ System.exit(1);
+}
+
+String bootstrapServers = args[0];
+String subscribeType = args[1];
+String topics = args[2];
+
+SparkSession spark = SparkSession
+ .builder()
+ .appName("JavaStructuredKerberiedKafkaWordCount")
+ .getOrCreate();
+
+// Create DataSet representing the stream of input lines from kafka
+
[GitHub] [spark] kiszk commented on a change in pull request #25655: [SPARK-28906][Build] Fix incorrect information in bin/spark-submit --version
kiszk commented on a change in pull request #25655: [SPARK-28906][Build] Fix incorrect information in bin/spark-submit --version URL: https://github.com/apache/spark/pull/25655#discussion_r320065272 ## File path: dev/create-release/release-build.sh ## @@ -164,7 +164,6 @@ DEST_DIR_NAME="$SPARK_PACKAGE_VERSION" git clean -d -f -x rm .gitignore -rm -rf .git Review comment: @dongjoon-hyun Here is the result. I confirmed that release tarballs do not have `.git` directory. ``` $ tar xf spark-2.3.4-bin-hadoop2.6.tgz $ cd spark-2.3.4-bin-hadoop2.6/ $ bin/spark-submit --version Welcome to __ / __/__ ___ _/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.4 /_/ Using Scala version 2.11.8, OpenJDK 64-Bit Server VM, 1.8.0_212 Branch HEAD Compiled by user ishizaki on 2019-09-02T19:30:42Z Revision 8c6f8150f3c6298ff4e1c7e06028f12d7eaf0210 Url https://gitbox.apache.org/repos/asf/spark.git Type --help for more information. $ ls -al total 120 drwxr-xr-x 13 ishizaki ishizaki 4096 Sep 3 04:43 . drwxrwxr-x 5 ishizaki ishizaki 4096 Sep 3 10:31 .. -rw-r--r-- 1 ishizaki ishizaki 18045 Sep 3 04:43 LICENSE -rw-r--r-- 1 ishizaki ishizaki 26366 Sep 3 04:43 NOTICE drwxr-xr-x 3 ishizaki ishizaki 4096 Sep 3 04:43 R -rw-r--r-- 1 ishizaki ishizaki 3809 Sep 3 04:43 README.md -rw-r--r-- 1 ishizaki ishizaki 203 Sep 3 04:43 RELEASE drwxr-xr-x 2 ishizaki ishizaki 4096 Sep 3 04:43 bin drwxr-xr-x 2 ishizaki ishizaki 4096 Sep 3 04:43 conf drwxr-xr-x 5 ishizaki ishizaki 4096 Sep 3 04:43 data drwxr-xr-x 4 ishizaki ishizaki 4096 Sep 3 04:43 examples drwxr-xr-x 2 ishizaki ishizaki 16384 Sep 3 04:43 jars drwxr-xr-x 3 ishizaki ishizaki 4096 Sep 3 04:43 kubernetes drwxr-xr-x 2 ishizaki ishizaki 4096 Sep 3 04:43 licenses drwxr-xr-x 6 ishizaki ishizaki 4096 Sep 3 04:43 python drwxr-xr-x 2 ishizaki ishizaki 4096 Sep 3 04:43 sbin drwxr-xr-x 2 ishizaki ishizaki 4096 Sep 3 04:43 yarn $ cd .. $ tar tvf spark-2.3.4-bin-hadoop2.6.tgz | grep "spark-2.3.4-bin-hadoop2.6/.git" $ ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zzcclp commented on issue #25439: [SPARK-28709][DSTREAMS] Fix StreamingContext leak through Streaming
zzcclp commented on issue #25439: [SPARK-28709][DSTREAMS] Fix StreamingContext leak through Streaming URL: https://github.com/apache/spark/pull/25439#issuecomment-527269181 @choojoyq @srowen @dongjoon-hyun 2.4.4 was released, do you plan to merge this pr into branch-2.4? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zzcclp commented on issue #25511: [SPARK-22955][DSTREAMS] - graceful shutdown shouldn't lead to job gen…
zzcclp commented on issue #25511: [SPARK-22955][DSTREAMS] - graceful shutdown shouldn't lead to job gen… URL: https://github.com/apache/spark/pull/25511#issuecomment-527269151 @choojoyq @srowen 2.4.4 was released, do you plan to merge this pr into branch-2.4? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hddong commented on issue #23952: [SPARK-26929][SQL]fix table owner use user instead of principal when create table through spark-sql or beeline
hddong commented on issue #23952: [SPARK-26929][SQL]fix table owner use user instead of principal when create table through spark-sql or beeline URL: https://github.com/apache/spark/pull/23952#issuecomment-527268064 > I'm not sure whether it's easy or challenging, but if possible could we have UT for this? You already know it has been back-and-forth, principal -> username -> principal, and you're fixing it again to username. Ideally we need to try our best to avoid regression. I think it's should be username, and user's name is better than principal here. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527266434 **[Test build #110026 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110026/testReport)** for PR 22138 at commit [`fa12a0a`](https://github.com/apache/spark/commit/fa12a0a6ee023d52a9257d76415556d5d49902de). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527265942 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527265922 ``` Running build tests exec: curl -s -L https://downloads.lightbend.com/zinc/0.3.15/zinc-0.3.15.tgz exec: curl -s -L https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz exec: curl -s -L https://www.apache.org/dyn/closer.lua?action=download=/maven/maven-3/3.6.1/binaries/apache-maven-3.6.1-bin.tar.gz gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now Using `mvn` from path: /home/jenkins/workspace/SparkPullRequestBuilder/build/apache-maven-3.6.1/bin/mvn build/mvn: line 163: /home/jenkins/workspace/SparkPullRequestBuilder/build/apache-maven-3.6.1/bin/mvn: No such file or directory Error while getting version string from Maven: ``` Looks like intermittent failure. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264737 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110025/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527264678 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264540 **[Test build #110025 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110025/testReport)** for PR 22138 at commit [`297f47a`](https://github.com/apache/spark/commit/297f47a1c780898435785f1c2b0cb033408673f6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
SparkQA removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527261203 **[Test build #110024 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110024/testReport)** for PR 25647 at commit [`3c0f92c`](https://github.com/apache/spark/commit/3c0f92cf71d49ebb6f4060453a38e8bb768b82c2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527264680 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110024/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264734 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264730 **[Test build #110025 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110025/testReport)** for PR 22138 at commit [`297f47a`](https://github.com/apache/spark/commit/297f47a1c780898435785f1c2b0cb033408673f6). * This patch **fails build dependency tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264734 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264737 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110025/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527264680 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110024/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
SparkQA commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527264649 **[Test build #110024 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110024/testReport)** for PR 25647 at commit [`3c0f92c`](https://github.com/apache/spark/commit/3c0f92cf71d49ebb6f4060453a38e8bb768b82c2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527264678 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-527264540 **[Test build #110025 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110025/testReport)** for PR 22138 at commit [`297f47a`](https://github.com/apache/spark/commit/297f47a1c780898435785f1c2b0cb033408673f6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25641: [SPARK-28921][BUILD][K8S][2.4] Update kubernetes client to 4.4.2
dongjoon-hyun closed pull request #25641: [SPARK-28921][BUILD][K8S][2.4] Update kubernetes client to 4.4.2 URL: https://github.com/apache/spark/pull/25641 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25641: [SPARK-28921][BUILD][K8S][2.4] Update kubernetes client to 4.4.2
dongjoon-hyun edited a comment on issue #25641: [SPARK-28921][BUILD][K8S][2.4]
Update kubernetes client to 4.4.2
URL: https://github.com/apache/spark/pull/25641#issuecomment-527262891
This PR is tested with `EKS`. Thank you, @andygrove .
Merged to `branch-2.4`.
```
$ kubectl version --short
Client Version: v1.15.3
Server Version: v1.13.10-eks-5ac0f1
```
```
$ aws ecr list-images --repository-name spark
{
"imageIds": [
{
"imageDigest":
"sha256:c92d634507aa8336c79cb094ba69083d9cb50f4a6f09259e3b0cb4b6bf1c5214",
"imageTag": "PR-25640"
},
{
"imageDigest":
"sha256:0a57b8479a54b371621fee90a84126aa259a13edfc73a28c139046475ab604d1",
"imageTag": "PR-25641"
},
{
"imageDigest":
"sha256:5318c3b9a2f1c85bae5d913c799d35a732b0b658f7500dbf733a94b5d8981552",
"imageTag": "2.4.5-SNAPSHOT"
},
{
"imageDigest":
"sha256:a2a48304453c147ec2f049ea0b6c4dbadb625a0c8d76d4c1eb4f7cb3f134890c",
"imageTag": "latest"
}
]
}
```
```
$ echo $K8S_MASTER
https://9310EC45A37C51BCCF6BC12CDBFCBB61.sk1.us-west-2.eks.amazonaws.com
$ echo $IMAGE
095589911305.dkr.ecr.us-west-2.amazonaws.com/spark:PR-25641
$ bin/spark-submit \
--master k8s://$K8S_MASTER \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.container.image=$IMAGE \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.5-SNAPSHOT.jar
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25641: [SPARK-28921][BUILD][K8S][2.4] Update kubernetes client to 4.4.2
dongjoon-hyun commented on issue #25641: [SPARK-28921][BUILD][K8S][2.4] Update kubernetes client to 4.4.2 URL: https://github.com/apache/spark/pull/25641#issuecomment-527262891 This PR is tested with `EKS`. Thank you, @andygrove . Merged to `branch-2.4`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
SparkQA commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527261203 **[Test build #110024 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110024/testReport)** for PR 25647 at commit [`3c0f92c`](https://github.com/apache/spark/commit/3c0f92cf71d49ebb6f4060453a38e8bb768b82c2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527260708 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins removed a comment on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527260709 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/15044/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527260708 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
AmplabJenkins commented on issue #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#issuecomment-527260709 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/15044/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
HyukjinKwon commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320057121 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). + +2. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to include Rtools and R in `PATH`. Note that support for R prior to version 3.4 is deprecated as of Spark 3.0.0. -2. Install -[JDK8](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) and set +3. Install [JDK](https://www.oracle.com/technetwork/java/javase/downloads) that SparkR supports - see `R/pkg/DESCRIPTION`, and set `JAVA_HOME` in the system environment variables. -3. Download and install [Maven](https://maven.apache.org/download.html). Also include the `bin` +4. Download and install [Maven](https://maven.apache.org/download.html). Also include the `bin` Review comment: Windows cannot use `./build/mvn` but it should use just regular `mvn` .. so we can't deduplicate it for now. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
HyukjinKwon commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320056846 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). + +2. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to include Rtools and R in `PATH`. Note that support for R prior to version 3.4 is deprecated as of Spark 3.0.0. -2. Install -[JDK8](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) and set +3. Install [JDK](https://www.oracle.com/technetwork/java/javase/downloads) that SparkR supports - see `R/pkg/DESCRIPTION`, and set Review comment: let me just remove the link This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
HyukjinKwon commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320056811 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). Review comment: At least it works on my laptop - I have one Windows laptop that has Spark dev setup. Not sure if it still works on latest Windows though. Seem still being actively developed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25640: [SPARK-28921][BUILD][K8S] Upgrade kubernetes client to 4.4.2
dongjoon-hyun closed pull request #25640: [SPARK-28921][BUILD][K8S] Upgrade kubernetes client to 4.4.2 URL: https://github.com/apache/spark/pull/25640 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25640: [SPARK-28921][BUILD][K8S] Upgrade kubernetes client to 4.4.2
dongjoon-hyun commented on issue #25640: [SPARK-28921][BUILD][K8S] Upgrade
kubernetes client to 4.4.2
URL: https://github.com/apache/spark/pull/25640#issuecomment-527259020
This PR is tested with `EKS`.
```
$ kubectl version --short
Client Version: v1.15.3
Server Version: v1.13.10-eks-5ac0f1
```
```
$ aws ecr list-images --repository-name spark
{
"imageIds": [
{
"imageDigest":
"sha256:c92d634507aa8336c79cb094ba69083d9cb50f4a6f09259e3b0cb4b6bf1c5214",
"imageTag": "PR-25640"
},
{
"imageDigest":
"sha256:a2a48304453c147ec2f049ea0b6c4dbadb625a0c8d76d4c1eb4f7cb3f134890c",
"imageTag": "latest"
}
]
}
```
```
$ echo $K8S_MASTER
https://9310EC45A37C51BCCF6BC12CDBFCBB61.sk1.us-west-2.eks.amazonaws.com
$ echo $IMAGE
095589911305.dkr.ecr.us-west-2.amazonaws.com/spark:PR-25640
```
```
bin/spark-submit \
--master k8s://$K8S_MASTER \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.container.image=$IMAGE \
local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0-SNAPSHOT.jar
```
Thank you, @andygrove , @srowen , @felixcheung .
Merged to `master`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r320055695
##
File path:
mllib/src/main/scala/org/apache/spark/ml/feature/RFormulaParser.scala
##
@@ -247,9 +273,24 @@ private[ml] case class Terms(terms: Seq[Term]) extends
Term {
/**
* Limited implementation of R formula parsing. Currently supports: '~', '+',
'-', '.', ':',
- * '*', '^'.
+ * '*', '^', 'I()'.
*/
-private[ml] object RFormulaParser extends RegexParsers {
+private[ml] object RFormulaParser extends RegexParsers with EvalExprParser {
+
+ /**
+ * Whether to skip whitespace in literals and regex is currently only
achived with
+ * a global switch, and by default it's skipped. We'd like it to be skipped
for most parsers,
Review comment:
when you refer to a switch.. is it supposed to be configurable?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r320055209
##
File path: mllib/src/main/scala/org/apache/spark/ml/feature/RFormula.scala
##
@@ -404,6 +429,30 @@ class RFormulaModel private[feature](
s"Label column already exists and is not of type
${NumericType.simpleString}.")
}
+ private def foldExprs(dataframe: DataFrame)(f: (DataFrame, String) =>
DataFrame): DataFrame =
+resolvedFormula.evalExprs.foldLeft(dataframe)(f)
Review comment:
this is very minor - perhaps save
`resolvedFormula.evalExprs.foldLeft(dataframe)(f)` in a field, next to
resolvedFormula which already is
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r319810555
##
File path:
mllib/src/test/scala/org/apache/spark/ml/feature/RFormulaParserSuite.scala
##
@@ -198,4 +198,31 @@ class RFormulaParserSuite extends SparkFunSuite {
"Petal.Length:Petal.Width"),
schema)
}
+
+ test("parse skip whitespace") {
+val schema = (new StructType)
+ .add("a", "int", true)
+ .add("b", "long", false)
+ .add("c", "string", true)
+checkParse(" ~a+ b : c ", "", Seq("a", "b:c"))
+checkParse(" ~ a * b", "", Seq("a", "b", "a:b"))
+checkParse("~ ( a +b )^ 2", "", Seq("a", "b", "a:b"))
+checkParse("~ . ^ 2 - a-b - c", "", Seq("a:b", "a:c", "b:c"), schema)
+checkParse("~ ( a) * ( ( (b ) : c ) )", "", Seq("a", "b:c", "a:b:c"))
+ }
+
+ test("parse functions") {
+checkParse("y ~ I(a+b) + c", "y", Seq("a+b", "c"))
+checkParse("y ~ I(a+b)*c", "y", Seq("a+b", "c", "a+b:c"))
+checkParse("y ~ (I((a+b)) + c)^2", "y", Seq("(a+b)", "c", "(a+b):c"))
+checkParse("y ~ I(log(a)*(log(a)*2)) + b", "y", Seq("log(a)*(log(a)*2)",
"b"))
+checkParse("y ~ exp(a) + (b + c)", "y", Seq("exp(a)", "b", "c"))
+checkParse("log(y) ~ a + log(b)", "log(y)", Seq("a", "log(b)"))
+checkParse("I(c+d) ~ a + log(b)", "c+d", Seq("a", "log(b)"))
Review comment:
add some tests for func `percentile_approx` or `map_from_arrays` or `base64`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r320055670
##
File path:
mllib/src/main/scala/org/apache/spark/ml/feature/RFormulaParser.scala
##
@@ -247,9 +273,24 @@ private[ml] case class Terms(terms: Seq[Term]) extends
Term {
/**
* Limited implementation of R formula parsing. Currently supports: '~', '+',
'-', '.', ':',
- * '*', '^'.
+ * '*', '^', 'I()'.
*/
-private[ml] object RFormulaParser extends RegexParsers {
+private[ml] object RFormulaParser extends RegexParsers with EvalExprParser {
+
+ /**
+ * Whether to skip whitespace in literals and regex is currently only
achived with
Review comment:
`achieved`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r320054935
##
File path: mllib/src/main/scala/org/apache/spark/ml/feature/RFormula.scala
##
@@ -404,6 +429,30 @@ class RFormulaModel private[feature](
s"Label column already exists and is not of type
${NumericType.simpleString}.")
}
+ private def foldExprs(dataframe: DataFrame)(f: (DataFrame, String) =>
DataFrame): DataFrame =
+resolvedFormula.evalExprs.foldLeft(dataframe)(f)
+
+ private def transformSelectExprs(dataframe: DataFrame): DataFrame =
foldExprs(dataframe) {
+case(df, colname) => df.withColumn(colname, expr(colname))
+ }
+
+ private def transformDropExprs(dataframe: DataFrame): DataFrame =
foldExprs(dataframe) {
+case(df, colname) => df.drop(col(s"`$colname`"))
+ }
+
+ private def transformSelectExprsSchema(schema: StructType): StructType = {
+val spark = SparkSession.builder().getOrCreate()
+val dummyRDD = spark.sparkContext.parallelize(Seq(Row.empty))
Review comment:
should it use
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.SparkContext@emptyRDD[T](implicitevidence$8:scala.reflect.ClassTag[T]):org.apache.spark.rdd.RDD[T]
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r319800969
##
File path: mllib/src/main/scala/org/apache/spark/ml/feature/RFormula.scala
##
@@ -216,9 +226,14 @@ class RFormula @Since("1.5.0") (@Since("1.5.0") override
val uid: String)
col
}
-// First we index each string column referenced by the input terms.
+// Add evaluated expressions to the dataset
+val selectedCols = resolvedFormula.evalExprs
+ .map(col => expr(col).alias(col)) ++ dataset.columns.map(col(_))
Review comment:
`.alias(col)` - why is this needed? I think that's the alias by default
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions URL: https://github.com/apache/spark/pull/24939#discussion_r319799511 ## File path: mllib/src/main/scala/org/apache/spark/ml/feature/RFormula.scala ## @@ -126,7 +127,13 @@ private[feature] trait RFormulaBase extends HasFeaturesCol with HasLabelCol with /** * :: Experimental :: * Implements the transforms required for fitting a dataset against an R model formula. Currently - * we support a limited subset of the R operators, including '~', '.', ':', '+', '-', '*' and '^'. + * we support a limited subset of the R operators, including '~', '.', ':', '+', '-', '*', '^' + * and 'I()'. Arithmetic expressions which use spark functions or registered UDFs are Review comment: `spark functions` should be `Spark SQL functions` or `Spark SQL built-in functions`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r319809995
##
File path:
mllib/src/test/scala/org/apache/spark/ml/feature/RFormulaParserSuite.scala
##
@@ -198,4 +198,31 @@ class RFormulaParserSuite extends SparkFunSuite {
"Petal.Length:Petal.Width"),
schema)
}
+
+ test("parse skip whitespace") {
+val schema = (new StructType)
+ .add("a", "int", true)
+ .add("b", "long", false)
+ .add("c", "string", true)
+checkParse(" ~a+ b : c ", "", Seq("a", "b:c"))
+checkParse(" ~ a * b", "", Seq("a", "b", "a:b"))
+checkParse("~ ( a +b )^ 2", "", Seq("a", "b", "a:b"))
+checkParse("~ . ^ 2 - a-b - c", "", Seq("a:b", "a:c", "b:c"), schema)
+checkParse("~ ( a) * ( ( (b ) : c ) )", "", Seq("a", "b:c", "a:b:c"))
+ }
+
+ test("parse functions") {
+checkParse("y ~ I(a+b) + c", "y", Seq("a+b", "c"))
+checkParse("y ~ I(a+b)*c", "y", Seq("a+b", "c", "a+b:c"))
+checkParse("y ~ (I((a+b)) + c)^2", "y", Seq("(a+b)", "c", "(a+b):c"))
Review comment:
Can you please add some test with whitespace eg. `( I(` or `I( a` or `I ( a`
and then `c )`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on a change in pull request #24939: [SPARK-18569][ML][R]
Support RFormula arithmetic, I() and spark functions
URL: https://github.com/apache/spark/pull/24939#discussion_r320055902
##
File path:
mllib/src/main/scala/org/apache/spark/ml/feature/RFormulaParser.scala
##
@@ -269,40 +310,78 @@ private[ml] object RFormulaParser extends RegexParsers {
}
private val intercept: Parser[Term] =
-"([01])".r ^^ { case a => Intercept(a == "1") }
+skipSpace("([01])".r) ^^ { case a => Intercept(a == "1") }
private val columnRef: Parser[ColumnRef] =
-"([a-zA-Z]|\\.[a-zA-Z_])[a-zA-Z0-9._]*".r ^^ { case a => ColumnRef(a) }
+skipSpace("([a-zA-Z]|\\.[a-zA-Z_])[a-zA-Z0-9._]*".r) ^^ { case a =>
ColumnRef(a) }
- private val empty: Parser[ColumnRef] = "" ^^ { case a => ColumnRef("") }
+ private val empty: Parser[ColumnRef] = skipSpace("".r) ^^ { case a =>
ColumnRef("") }
- private val label: Parser[ColumnRef] = columnRef | empty
+ private val label: Parser[Label] = evalExpr | columnRef | empty
- private val dot: Parser[Term] = "\\.".r ^^ { case _ => Dot }
+ private val dot: Parser[Term] = skipSpace("\\.".r) ^^ { case _ => Dot }
- private val parens: Parser[Term] = "(" ~> expr <~ ")"
+ private val parens: Parser[Term] = skipSpace("\\(".r) ~> expr <~
skipSpace("\\)".r)
- private val term: Parser[Term] = parens | intercept | columnRef | dot
+ private val term: Parser[Term] = evalExpr | parens | intercept | columnRef |
dot
- private val pow: Parser[Term] = term ~ "^" ~ "^[1-9]\\d*".r ^^ {
+ private val pow: Parser[Term] = term ~ "^" ~ skipSpace("^[1-9]\\d*".r) ^^ {
case base ~ "^" ~ degree => power(base, degree.toInt)
} | term
- private val interaction: Parser[Term] = pow * (":" ^^^ { interact _ })
+ private val interaction: Parser[Term] = pow * (skipSpace("\\:".r) ^^^ {
interact _ })
- private val factor = interaction * ("*" ^^^ { cross _ })
+ private val factor = interaction * (skipSpace("\\*".r) ^^^ { cross _ })
- private val sum = factor * ("+" ^^^ { add _ } |
-"-" ^^^ { subtract _ })
+ private val sum = factor * (skipSpace("\\+".r) ^^^ { add _ } |
+skipSpace("\\-".r) ^^^ { subtract _ })
private val expr = (sum | term)
- private val formula: Parser[ParsedRFormula] =
-(label ~ "~" ~ expr) ^^ { case r ~ "~" ~ t => ParsedRFormula(r,
t.asTerms.terms) }
+ private val formula: Parser[ParsedRFormula] = (label ~ skipSpace("\\~".r) ~
expr) ^^ {
+case r ~ "~" ~ t => ParsedRFormula(r, t.asTerms.terms) }
def parse(value: String): ParsedRFormula = parseAll(formula, value) match {
case Success(result, _) => result
case failure: NoSuccess => throw new IllegalArgumentException(
"Could not parse formula: " + value)
}
}
+
+/**
+ * Parser for evaluated expressions in a formula. An evaluated expression is
+ * any alphanumeric identifiers followed by (), e.g. `func123(a+b, func())`,
+ * or anything inside `I()`. A valid expression is any string-parentheses
product,
+ * such that if there are any parentheses ('(' or ')') they're all balanced.
+ */
+private[ml] trait EvalExprParser extends RegexParsers {
Review comment:
is there a reason this isn't doing skipSpace here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320053768 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). Review comment: btw, do we know Cygwin still work? or should we tell ppl to use https://docs.microsoft.com/en-us/windows/wsl/install-win10 ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320053788 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). + +2. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to include Rtools and R in `PATH`. Note that support for R prior to version 3.4 is deprecated as of Spark 3.0.0. -2. Install -[JDK8](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) and set +3. Install [JDK](https://www.oracle.com/technetwork/java/javase/downloads) that SparkR supports - see `R/pkg/DESCRIPTION`, and set Review comment: could be both... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320053858 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). + +2. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to include Rtools and R in `PATH`. Note that support for R prior to version 3.4 is deprecated as of Spark 3.0.0. -2. Install -[JDK8](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) and set +3. Install [JDK](https://www.oracle.com/technetwork/java/javase/downloads) that SparkR supports - see `R/pkg/DESCRIPTION`, and set `JAVA_HOME` in the system environment variables. -3. Download and install [Maven](https://maven.apache.org/download.html). Also include the `bin` +4. Download and install [Maven](https://maven.apache.org/download.html). Also include the `bin` Review comment: I think we should avoid duplicating here vs the main doc - why we don't link to spark.apache.org or some other places for all version numbers? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows
felixcheung commented on a change in pull request #25647: [SPARK-28946][R][DOCS] Add some more information about building SparkR on Windows URL: https://github.com/apache/spark/pull/25647#discussion_r320053923 ## File path: R/WINDOWS.md ## @@ -20,25 +20,28 @@ license: | To build SparkR on Windows, the following steps are required -1. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to +1. Make sure `bash` is available and in `PATH` if you already have a built-in `bash` on Windows. If you do not have, install [Cygwin](https://www.cygwin.com/). + +2. Install R (>= 3.1) and [Rtools](https://cloud.r-project.org/bin/windows/Rtools/). Make sure to include Rtools and R in `PATH`. Note that support for R prior to version 3.4 is deprecated as of Spark 3.0.0. -2. Install -[JDK8](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) and set +3. Install [JDK](https://www.oracle.com/technetwork/java/javase/downloads) that SparkR supports - see `R/pkg/DESCRIPTION`, and set `JAVA_HOME` in the system environment variables. -3. Download and install [Maven](https://maven.apache.org/download.html). Also include the `bin` +4. Download and install [Maven](https://maven.apache.org/download.html). Also include the `bin` directory in Maven in `PATH`. -4. Set `MAVEN_OPTS` as described in [Building Spark](https://spark.apache.org/docs/latest/building-spark.html). +5. Set `MAVEN_OPTS` as described in [Building Spark](https://spark.apache.org/docs/latest/building-spark.html). -5. Open a command shell (`cmd`) in the Spark directory and build Spark with [Maven](https://spark.apache.org/docs/latest/building-spark.html#buildmvn) and include the `-Psparkr` profile to build the R package. For example to use the default Hadoop versions you can run +6. Open a command shell (`cmd`) in the Spark directory and build Spark with [Maven](https://spark.apache.org/docs/latest/building-spark.html#buildmvn) and include the `-Psparkr` profile to build the R package. For example to use the default Hadoop versions you can run ```bash mvn.cmd -DskipTests -Psparkr package ``` -`.\build\mvn` is a shell script so `mvn.cmd` should be used directly on Windows. +Note that `.\build\mvn` is a shell script so `mvn.cmd` on the system should be used directly on Windows. + +Note that it is a workaround for SparkR developers on Windows. Apache Spark does not officially support to _build_ on Windows yet whereas it supports to _run_ on Windows. Review comment: ok for me This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on issue #25648: [SPARK-28947][K8S] Status logging not happens at an interval for liveness
felixcheung commented on issue #25648: [SPARK-28947][K8S] Status logging not happens at an interval for liveness URL: https://github.com/apache/spark/pull/25648#issuecomment-527255031 @mccheah This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #25655: [SPARK-28906][Build] Fix incorrect information in bin/spark-submit --version
felixcheung commented on a change in pull request #25655: [SPARK-28906][Build] Fix incorrect information in bin/spark-submit --version URL: https://github.com/apache/spark/pull/25655#discussion_r320053301 ## File path: dev/create-release/release-build.sh ## @@ -164,7 +164,6 @@ DEST_DIR_NAME="$SPARK_PACKAGE_VERSION" git clean -d -f -x rm .gitignore -rm -rf .git Review comment: why change this? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25656: [SPARK-28951][INFRA] Add release announce template
dongjoon-hyun closed pull request #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25656: [SPARK-28951][INFRA] Add release announce template
dongjoon-hyun commented on issue #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656#issuecomment-527248748 Thank you, @srowen . Merged to master/2.4. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #25363: [SPARK-28628][SQL] Implement SupportsNamespaces in V2SessionCatalog
rdblue commented on a change in pull request #25363: [SPARK-28628][SQL]
Implement SupportsNamespaces in V2SessionCatalog
URL: https://github.com/apache/spark/pull/25363#discussion_r320048370
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalog.scala
##
@@ -177,10 +184,97 @@ class V2SessionCatalog(sessionState: SessionState)
extends TableCatalog {
}
}
+ override def namespaceExists(namespace: Array[String]): Boolean = namespace
match {
+case Array(db) =>
+ catalog.databaseExists(db)
+case _ =>
+ false
+ }
+
+ override def listNamespaces(): Array[Array[String]] = {
+catalog.listDatabases().map(Array(_)).toArray
+ }
+
+ override def listNamespaces(namespace: Array[String]): Array[Array[String]]
= {
+namespace match {
+ case Array() =>
+listNamespaces()
+ case Array(db) if catalog.databaseExists(db) =>
+Array()
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def loadNamespaceMetadata(namespace: Array[String]):
util.Map[String, String] = {
+namespace match {
+ case Array(db) =>
+catalog.getDatabaseMetadata(db).toMetadata
+
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def createNamespace(
+ namespace: Array[String],
+ metadata: util.Map[String, String]): Unit = namespace match {
+case Array(db) if !catalog.databaseExists(db) =>
+ catalog.createDatabase(
+toCatalogDatabase(db, metadata, defaultLocation =
Some(catalog.getDefaultDBPath(db))),
+ignoreIfExists = false)
+
+case Array(_) =>
+ throw new NamespaceAlreadyExistsException(namespace)
+
+case _ =>
+ throw new IllegalArgumentException(s"Invalid namespace name:
${namespace.quoted}")
+ }
+
+ override def alterNamespace(namespace: Array[String], changes:
NamespaceChange*): Unit = {
+namespace match {
+ case Array(db) =>
+// validate that this catalog's reserved properties are not removed
+changes.foreach {
+ case remove: RemoveProperty if
RESERVED_PROPERTIES.contains(remove.property) =>
+throw new UnsupportedOperationException(
+ s"Cannot remove reserved property: ${remove.property}")
+ case _ =>
+}
+
+val metadata = catalog.getDatabaseMetadata(db).toMetadata
+catalog.alterDatabase(
+ toCatalogDatabase(db, CatalogV2Util.applyNamespaceChanges(metadata,
changes)))
+
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def dropNamespace(namespace: Array[String]): Boolean = namespace
match {
+case Array(db) if catalog.databaseExists(db) =>
+ if (catalog.listTables(db).nonEmpty) {
+throw new IllegalStateException(s"Namespace ${namespace.quoted} is not
empty")
+ }
+ catalog.dropDatabase(db, ignoreIfNotExists = false, cascade = false)
+ true
+
+case Array(_) =>
+ // exists returned false
Review comment:
Correct. This is the case where the database does not exist. We know that
because the above existence check returned false. This comment clarifies the
Array case because it appears that an Array of one item always matches. So we
need to note the context from the previous case.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #25363: [SPARK-28628][SQL] Implement SupportsNamespaces in V2SessionCatalog
rdblue commented on a change in pull request #25363: [SPARK-28628][SQL]
Implement SupportsNamespaces in V2SessionCatalog
URL: https://github.com/apache/spark/pull/25363#discussion_r320048370
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalog.scala
##
@@ -177,10 +184,97 @@ class V2SessionCatalog(sessionState: SessionState)
extends TableCatalog {
}
}
+ override def namespaceExists(namespace: Array[String]): Boolean = namespace
match {
+case Array(db) =>
+ catalog.databaseExists(db)
+case _ =>
+ false
+ }
+
+ override def listNamespaces(): Array[Array[String]] = {
+catalog.listDatabases().map(Array(_)).toArray
+ }
+
+ override def listNamespaces(namespace: Array[String]): Array[Array[String]]
= {
+namespace match {
+ case Array() =>
+listNamespaces()
+ case Array(db) if catalog.databaseExists(db) =>
+Array()
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def loadNamespaceMetadata(namespace: Array[String]):
util.Map[String, String] = {
+namespace match {
+ case Array(db) =>
+catalog.getDatabaseMetadata(db).toMetadata
+
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def createNamespace(
+ namespace: Array[String],
+ metadata: util.Map[String, String]): Unit = namespace match {
+case Array(db) if !catalog.databaseExists(db) =>
+ catalog.createDatabase(
+toCatalogDatabase(db, metadata, defaultLocation =
Some(catalog.getDefaultDBPath(db))),
+ignoreIfExists = false)
+
+case Array(_) =>
+ throw new NamespaceAlreadyExistsException(namespace)
+
+case _ =>
+ throw new IllegalArgumentException(s"Invalid namespace name:
${namespace.quoted}")
+ }
+
+ override def alterNamespace(namespace: Array[String], changes:
NamespaceChange*): Unit = {
+namespace match {
+ case Array(db) =>
+// validate that this catalog's reserved properties are not removed
+changes.foreach {
+ case remove: RemoveProperty if
RESERVED_PROPERTIES.contains(remove.property) =>
+throw new UnsupportedOperationException(
+ s"Cannot remove reserved property: ${remove.property}")
+ case _ =>
+}
+
+val metadata = catalog.getDatabaseMetadata(db).toMetadata
+catalog.alterDatabase(
+ toCatalogDatabase(db, CatalogV2Util.applyNamespaceChanges(metadata,
changes)))
+
+ case _ =>
+throw new NoSuchNamespaceException(namespace)
+}
+ }
+
+ override def dropNamespace(namespace: Array[String]): Boolean = namespace
match {
+case Array(db) if catalog.databaseExists(db) =>
+ if (catalog.listTables(db).nonEmpty) {
+throw new IllegalStateException(s"Namespace ${namespace.quoted} is not
empty")
+ }
+ catalog.dropDatabase(db, ignoreIfNotExists = false, cascade = false)
+ true
+
+case Array(_) =>
+ // exists returned false
Review comment:
Correct. This is the case where the database does not exist. We know that
because the above existence check returned false. This comment clarifies the
Array case because it appears that an Array of one item always matches. So we
need to note the context.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #25363: [SPARK-28628][SQL] Implement SupportsNamespaces in V2SessionCatalog
rdblue commented on a change in pull request #25363: [SPARK-28628][SQL]
Implement SupportsNamespaces in V2SessionCatalog
URL: https://github.com/apache/spark/pull/25363#discussion_r320048205
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/v2/V2SessionCatalogSuite.scala
##
@@ -753,3 +760,293 @@ class V2SessionCatalogSuite
assert(exc.message.contains("RENAME TABLE source and destination databases
do not match"))
}
}
+
+class V2SessionCatalogNamespaceSuite extends V2SessionCatalogBaseSuite {
+
+ import org.apache.spark.sql.catalog.v2.CatalogV2Implicits._
+
+ def checkMetadata(
+ expected: scala.collection.Map[String, String],
+ actual: scala.collection.Map[String, String]): Unit = {
+// remove location and comment that are automatically added by HMS unless
they are expected
+val toRemove =
V2SessionCatalog.RESERVED_PROPERTIES.filter(expected.contains)
+assert(expected -- toRemove === actual)
+ }
+
+ test("listNamespaces: basic behavior") {
+val catalog = newCatalog()
+catalog.createNamespace(testNs, Map("property" -> "value").asJava)
+
+assert(catalog.listNamespaces() === Array(testNs, defaultNs))
+assert(catalog.listNamespaces(Array()) === Array(testNs, defaultNs))
+assert(catalog.listNamespaces(testNs) === Array())
+
+catalog.dropNamespace(testNs)
+ }
+
+ test("listNamespaces: fail if missing namespace") {
+val catalog = newCatalog()
+
+assert(catalog.namespaceExists(testNs) === false)
+
+val exc = intercept[NoSuchNamespaceException] {
+ assert(catalog.listNamespaces(testNs) === Array())
+}
+
+assert(exc.getMessage.contains(testNs.quoted))
+assert(catalog.namespaceExists(testNs) === false)
+ }
+
+ test("loadNamespaceMetadata: fail missing namespace") {
+val catalog = newCatalog()
+
+val exc = intercept[NoSuchNamespaceException] {
+ catalog.loadNamespaceMetadata(testNs)
+}
+
+assert(exc.getMessage.contains(testNs.quoted))
+ }
+
+ test("loadNamespaceMetadata: non-empty metadata") {
+val catalog = newCatalog()
+
+assert(catalog.namespaceExists(testNs) === false)
+
+catalog.createNamespace(testNs, Map("property" -> "value").asJava)
+
+val metadata = catalog.loadNamespaceMetadata(testNs)
+
+assert(catalog.namespaceExists(testNs) === true)
+checkMetadata(metadata.asScala, Map("property" -> "value"))
+
+catalog.dropNamespace(testNs)
+ }
+
+ test("loadNamespaceMetadata: empty metadata") {
+val catalog = newCatalog()
+
+assert(catalog.namespaceExists(testNs) === false)
+
+catalog.createNamespace(testNs, emptyProps)
+
+val metadata = catalog.loadNamespaceMetadata(testNs)
+
+assert(catalog.namespaceExists(testNs) === true)
+checkMetadata(metadata.asScala, emptyProps.asScala)
+
+catalog.dropNamespace(testNs)
+ }
+
+ test("createNamespace: basic behavior") {
+val catalog = newCatalog()
+val expectedPath =
sqlContext.sessionState.catalog.getDefaultDBPath(testNs(0)).toString
+
+catalog.createNamespace(testNs, Map("property" -> "value").asJava)
+
+assert(expectedPath ===
spark.catalog.getDatabase(testNs(0)).locationUri.toString)
+
+assert(catalog.namespaceExists(testNs) === true)
+val metadata = catalog.loadNamespaceMetadata(testNs).asScala
+checkMetadata(metadata, Map("property" -> "value"))
+assert(expectedPath === metadata("location"))
+
+catalog.dropNamespace(testNs)
+ }
+
+ test("createNamespace: initialize location") {
+val catalog = newCatalog()
+val expectedPath = "file:/tmp/db.db"
+
+catalog.createNamespace(testNs, Map("location" -> expectedPath).asJava)
+
+assert(expectedPath ===
spark.catalog.getDatabase(testNs(0)).locationUri.toString)
+
+assert(catalog.namespaceExists(testNs) === true)
+val metadata = catalog.loadNamespaceMetadata(testNs).asScala
+checkMetadata(metadata, Map.empty)
+assert(expectedPath === metadata("location"))
+
+catalog.dropNamespace(testNs)
+ }
+
+ test("createNamespace: fail if namespace already exists") {
+val catalog = newCatalog()
+
+catalog.createNamespace(testNs, Map("property" -> "value").asJava)
+
+val exc = intercept[NamespaceAlreadyExistsException] {
+ catalog.createNamespace(testNs, Map("property" -> "value2").asJava)
+}
+
+assert(exc.getMessage.contains(testNs.quoted))
+assert(catalog.namespaceExists(testNs) === true)
+checkMetadata(catalog.loadNamespaceMetadata(testNs).asScala,
Map("property" -> "value"))
+
+catalog.dropNamespace(testNs)
+ }
+
+ test("createNamespace: fail nested namespace") {
+val catalog = newCatalog()
+
+// ensure the parent exists
+catalog.createNamespace(Array("db"), emptyProps)
+
+val exc = intercept[IllegalArgumentException] {
+ catalog.createNamespace(Array("db", "nested"), emptyProps)
+}
+
+assert(exc.getMessage.contains("Invalid namespace name: db.nested"))
+
+
[GitHub] [spark] AmplabJenkins removed a comment on issue #25656: [SPARK-28951][INFRA] Add release announce template
AmplabJenkins removed a comment on issue #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656#issuecomment-527242000 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110023/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25656: [SPARK-28951][INFRA] Add release announce template
AmplabJenkins removed a comment on issue #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656#issuecomment-527241997 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25656: [SPARK-28951][INFRA] Add release announce template
AmplabJenkins commented on issue #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656#issuecomment-527241997 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25656: [SPARK-28951][INFRA] Add release announce template
AmplabJenkins commented on issue #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656#issuecomment-527242000 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110023/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25656: [SPARK-28951][INFRA] Add release announce template
SparkQA removed a comment on issue #25656: [SPARK-28951][INFRA] Add release announce template URL: https://github.com/apache/spark/pull/25656#issuecomment-527222088 **[Test build #110023 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110023/testReport)** for PR 25656 at commit [`4bfa00e`](https://github.com/apache/spark/commit/4bfa00e88802ed6a81f3cfe22524f715735d02e6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org