26 июля 2011, 16:42 от [email protected]: > Think about the distribution of your Data. > > select count(*) as cnt,kind,computer > from log > group by kind,computer > order by cnt desc > > what happens here? > > SELECT * > FROM log INDEXED BY idxlog_kind_computer > WHERE kind = 'info' AND computer=1 and id > 7070636 > LIMIT 100; > > there are 3_022_148 identical entries 'info,1' in your index
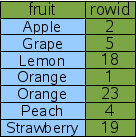
If there wasn't id condition in WHERE I would agree. But in my opinion this is not that simple. Each index record includes ROWID. At the end. http://www.sqlite.org/queryplanner.html "An index is another table similar to the original "fruitsforsale" table but with the content (the fruit column in this case) stored in front of the rowid and with all rows in content order." http://www.sqlite.org/images/qp/idx1.gif "The "fruit" column is the primary key used to order the elements of the table and the "rowid" is the secondary key used to break the tie when two or more rows have the same "fruit". In the example, the rowid has to be used as a tie-breaker for the "Orange" rows. Notice that since the rowid is always unique over all elements of the original table, the composite key of "fruit" followed by "rowid" will be unique over all elements of the index." And this makes each index record different. WHERE condition is providing query planner with 3 nice values to match exact index record. And SQLITE ignores this knowledge and uses only first 2 values to search index. Why? _______________________________________________ sqlite-users mailing list [email protected] http://sqlite.org:8080/cgi-bin/mailman/listinfo/sqlite-users
{kind=link}