是不是作业是一个批作业呀? Yichao Yang <[email protected]> 于2020年6月29日周一 下午6:58写道:
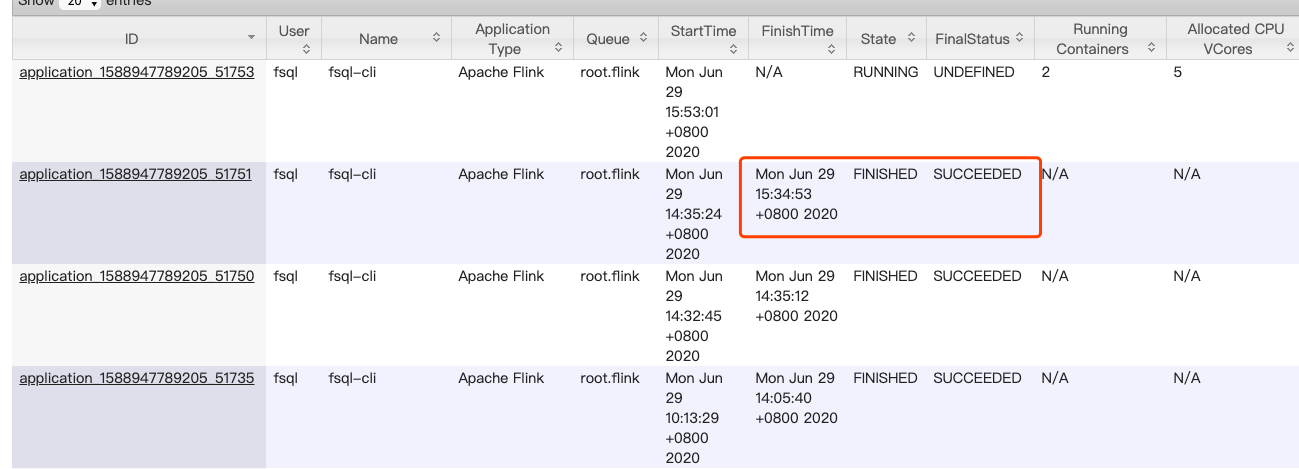
> Hi > > > 看你的日志你的数据源是hive table?可以看下是否是批作业模式而不是流作业模式。 > > > Best, > Yichao Yang > > > > > ------------------ 原始邮件 ------------------ > 发件人: "MuChen"<[email protected]>; > 发送时间: 2020年6月29日(星期一) 下午4:53 > 收件人: "user-zh"<[email protected]>; > > 主题: flinksql流计算任务非正常结束 > > > > hi,大家好: > > 我启动了yarn-session:bin/yarn-session.sh -jm 1g -tm 4g -s 4 -qu root.flink -nm > fsql-cli&nbsp; 2&gt;&amp;1 &amp; > > 然后通过sql-client,提交了一个sql: > > 主要逻辑是将一个kafka表和一个hive维表做join,然后将聚合结果写到mysql中。&nbsp; > > 运行过程中,经常出现短则几个小时,长则几十个小时后,任务状态变为succeeded的情况,如图: > https://s1.ax1x.com/2020/06/29/Nf2dIA.png > > 日志中能看到INFO级别的异常,15:34任务结束时的日志如下: > 2020-06-29 14:53:20,260 INFO > org.apache.flink.api.common.io.LocatableInputSplitAssigner > - Assigning remote split to host uhadoop-op3raf-core12 2020-06-29 > 14:53:22,845 INFO > org.apache.flink.runtime.executiongraph.ExecutionGraph > - Source: HiveTableSource(vid, q70) TablePath: dw.video_pic_title_q70, > PartitionPruned: false, PartitionNums: null (1/1) (68c24aa5 > 9c898cefbb20fbc929ddbafd) switched from RUNNING to FINISHED. 2020-06-29 > 15:34:52,982 INFO > org.apache.flink.runtime.entrypoint.ClusterEntrypoint > - Shutting YarnSessionClusterEntrypoint down with application status > SUCCEEDED. Diagnostics null. 2020-06-29 15:34:52,984 INFO > org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint > - Shutting down rest endpoint. 2020-06-29 15:34:53,072 INFO > org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint > - Removing cache directory > /tmp/flink-web-cdb67193-05ee-4a83-b957-9b7a9d85c23f/flink-web-ui 2020-06-29 > 15:34:53,073 INFO > org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint > - http://uhadoop-op3raf-core1:44664 lost leadership 2020-06-29 > 15:34:53,074 INFO > org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint > - Shut down complete. 2020-06-29 15:34:53,074 INFO > org.apache.flink.yarn.YarnResourceManager > - Shut down cluster because application is in SUCCEEDED, diagnostics null. > 2020-06-29 15:34:53,076 INFO > org.apache.flink.yarn.YarnResourceManager > - Unregister application from the YARN Resource Manager with final status > SUCCEEDED. 2020-06-29 15:34:53,088 INFO > org.apache.hadoop.yarn.client.api.impl.AMRMClientImpl > - Waiting for application to be successfully unregistered. 2020-06-29 > 15:34:53,306 INFO > org.apache.flink.runtime.entrypoint.component.DispatcherResourceManagerComponent > - Closing components. 2020-06-29 15:34:53,308 INFO > org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess > - Stopping SessionDispatcherLeaderProcess. 2020-06-29 15:34:53,309 > INFO > org.apache.flink.runtime.dispatcher.StandaloneDispatcher > - Stopping dispatcher > akka.tcp://flink@uhadoop-op3raf-core1:38817/user/dispatcher. > 2020-06-29 15:34:53,310 INFO > org.apache.flink.runtime.dispatcher.StandaloneDispatcher > - Stopping all currently running jobs of dispatcher > akka.tcp://flink@uhadoop-op3raf-core1:38817/user/dispatcher. 2020-06-29 > 15:34:53,311 INFO > org.apache.flink.runtime.jobmaster.JobMaster > - Stopping the JobMaster for job default: insert into > rt_app.app_video_cover_abtest_test ... 2020-06-29 15:34:53,322 INFO > org.apache.hadoop.yarn.client.api.async.impl.AMRMClientAsyncImpl - > Interrupted while waiting for queue > java.lang.InterruptedException > at > java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.reportInterruptAfterWait(AbstractQueuedSynchronizer.java:2014) > at > java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2048) > at > java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442) > at > org.apache.hadoop.yarn.client.api.async.impl.AMRMClientAsyncImpl$CallbackHandlerThread.run(AMRMClientAsyncImpl.java:287) > 2020-06-29 15:34:53,324 INFO > org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy > - Opening proxy : uhadoop-op3raf-core12:23333 > > > ps:&nbsp; > > 1. kafka中一直有数据在写入的 > 2. flink版本1.10.0 > 请问,任务状态为什么会变为SUCCEEDED呢? > > 谢谢大家! > > > > > 逻辑稍微有些复杂,可以忽略下面的sql代码: > # -- 提供:5分钟起始时间、vid、vid_group、曝光次数、点击次数、播放次数、有效播放次数 -- > 每5分钟将近5分钟统计结果写入mysql insert into rt_app.app_video_cover_abtest_test > select begin_time, vid, vid_group, max(dv), > max(click), max(vv), max(effectivevv) from( > select t1.begin_time begin_time, t1.u_vid > vid, t1.u_vid_group vid_group, dv, > click, vv, if(effectivevv is null,0,effectivevv) > effectivevv from ( -- dv、click、vv > select CAST(TUMBLE_START(bjdt,INTERVAL '5' MINUTE) > AS STRING) begin_time, cast(u_vid as bigint) > u_vid, u_vid_group, > sum(if(concat(u_mod,'-',u_ac)='emptylog-video_display' and > u_c_module='M011',1,0)) dv, > sum(if(concat(u_mod,'-',u_ac)='emptylog-video_click' and > u_c_module='M011',1,0)) click, > sum(if(concat(u_mod,'-',u_ac)='top-hits' and u_f_module='M011',1,0)) > vv FROM rt_ods.ods_applog_vidsplit where u_vid is > not null and trim(u_vid)<&gt;'' and u_vid_group is > not null and trim(u_vid_group) not in ('','-1') and > ( (concat(u_mod,'-',u_ac) in > ('emptylog-video_display','emptylog-video_click') and > u_c_module='M011') or (concat(u_mod,'-',u_ac)='top-hits' and > u_f_module='M011') ) group > by TUMBLE(bjdt, INTERVAL '5' > MINUTE), cast(u_vid as bigint), > u_vid_group ) t1 left join ( -- > effectivevv select > begin_time, u_vid, > u_vid_group, count(1) effectivevv > from ( select begin_time, > u_vid, u_vid_group, u_diu, u_playid, m_pt, > q70 from dw.video_pic_title_q70 > a join ( > select CAST(TUMBLE_START(bjdt,INTERVAL '5' MINUTE) AS STRING) > begin_time, cast(u_vid as bigint) u_vid, u_vid_group, > u_diu, u_playid, max(u_playtime) m_pt > FROM rt_ods.ods_applog_vidsplit where u_vid is not > null and trim(u_vid)<&gt;'' and u_vid_group is not null and > trim(u_vid_group) not in ('','-1') and > concat(u_mod,'-',u_ac)='emptylog-video_play_speed' and > u_f_module='M011' and u_playtime&gt;0 > group by TUMBLE(bjdt, INTERVAL '5' MINUTE), cast(u_vid as > bigint), u_vid_group, u_diu, u_playid ) > b on a.vid=b.u_vid group by > begin_time, u_vid, u_vid_group, u_diu, > u_playid, m_pt, q70 ) temp where > m_pt&gt;=q70 group by > begin_time, u_vid, u_vid_group ) > t2 on t1.begin_time=t2.begin_time and > t1.u_vid=t2.u_vid and t1.u_vid_group=t2.u_vid_group > )t3 group by begin_time, vid, vid_group ;
{kind=link}