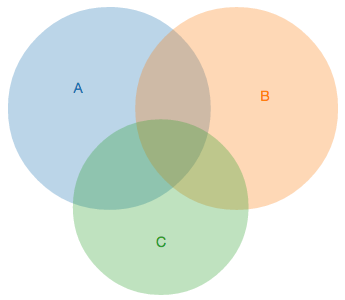
Sorry if I wasn't clear, I mean in the sense that A is neither the intersection nor union of B and C in the venn diagram below. As Max says, what really matters is the set of features you care about.
[image: venn.png] https://www.benfrederickson.com/images/venn.png On Thu, May 2, 2019 at 11:04 AM kant kodali <[email protected]> wrote: > > I don't understand the following statement. > > "Beam's feature set is neither the intersection nor union of the feature sets of those runners it has available as execution engines." > > If Beam is neither intersection nor union how can Beam abstract anything? Generally speaking, if there is nothing in common what is there to abstract? Sounds like the 101 principles I had learned are broken or I must have completely misunderstood. > > > > > > On Thu, May 2, 2019 at 12:46 AM Robert Bradshaw <[email protected]> wrote: >> >> On Thu, May 2, 2019 at 12:13 AM Pankaj Chand <[email protected]> wrote: >> > >> > I thought by choosing Beam, I would get the benefits of both (Spark and Flink), one at a time. Now, I'm understanding that I might not get the full potential from either of the two. >> >> You get the benefit of being able to choose, without rewriting your >> pipeline, whether to run on Spark or Flink. Or the next new runner >> that comes around. As well as the Beam model, API, etc. >> >> > Example: If I use Beam with Flink, and then a new feature is added to Flink but I cannot access it via Beam, and that feature is not important to the Beam community, then what is the suggested workaround? If I really need that feature, I would not want to re-write my pipeline in Flink from scratch. >> >> How is this different from "If I used Spark, and a new feature is >> added to Flink, I cannot access it from Spark. If that feature is not >> important to the Spark community, then what is the suggested >> workaround? If I really need that feature, I would not want to >> re-write my pipeline in Flink from scratch." Or vice-versa. Or when a >> new feature added to Beam itself (that may not be not present in any >> of the underlying systems). Beam's feature set is neither the >> intersection nor union of the feature sets of those runners it has >> available as execution engines. (Even the notion of what is meant by >> "feature" is nebulous enough that it's hard to make this discussion >> concrete.) >> >> > Is it possible that in the near future, most of Beam's capabilities would favor Google's Dataflow API? That way, Beam could be used to lure developers and organizations who would typically use Spark/Flink, with the promise of portability. After they get dependent on Beam and cannot afford to re-write their pipelines in Spark/Flink from scratch, they would realize that Beam does not give access to some of the capabilities of the free engines that they may require. Then, they would be told that if they want all possible capabilities and would want to use their code in Beam, they could pay for the Dataflow engine instead. >> >> Google is very upfront about the fact that they are selling a service >> to run Beam pipelines in a completely managed way. But Google has >> *also* invested very heavily in making sure that the portability story >> is not just talk, for those who need or want to run their jobs on >> premise or elsewhere (now or in the future). It is our goal that all >> runners be able to run all pipelines, and this is a community effort. >> >> > Pankaj >> > >> > On Tue, Apr 30, 2019 at 6:15 PM Kenneth Knowles <[email protected]> wrote: >> >> >> >> It is worth noting that Beam isn't solely a portability layer that exposes underlying API features, but a feature-rich layer in its own right, with carefully coherent abstractions. For example, quite early on the SparkRunner supported streaming aspects of the Beam model - watermarks, windowing, triggers - that were not really available any other way. Beam's various features sometimes requires just a pass-through API and sometimes requires clever new implementation. And everything is moving constantly. I don't see Beam as following the features of any engine, but rather coming up with new needed data processing abstractions and figuring out how to efficiently implement them on top of various architectures. >> >> >> >> Kenn >> >> >> >> On Tue, Apr 30, 2019 at 8:37 AM kant kodali <[email protected]> wrote: >> >>> >> >>> Staying behind doesn't imply one is better than the other and I didn't mean that in any way but I fail to see how an abstraction framework like Beam can stay ahead of the underlying execution engines? >> >>> >> >>> For example, If a new feature is added into the underlying execution engine that doesn't fit the interface of Beam or breaks then I would think the interface would need to be changed. Another example would say the underlying execution engines take different kind's of parameters for the same feature then it isn't so straight forward to come up with an interface since there might be very little in common in the first place so, in that sense, I fail to see how Beam can stay ahead. >> >>> >> >>> "Of course the API itself is Spark-specific, but it borrows heavily (among other things) on ideas that Beam itself pioneered long before Spark 2.0" Good to know. >> >>> >> >>> "one of the things Beam has focused on was a language portability framework" Sure but how important is this for a typical user? Do people stop using a particular tool because it is in an X language? I personally would put features first over language portability and it's completely fine that may not be in line with Beam's priorities. All said I can agree Beam focus on language portability is great. >> >>> >> >>> On Tue, Apr 30, 2019 at 2:48 AM Maximilian Michels <[email protected]> wrote: >> >>>> >> >>>> > I wouldn't say one is, or will always be, in front of or behind another. >> >>>> >> >>>> That's a great way to phrase it. I think it is very common to jump to >> >>>> the conclusion that one system is better than the other. In reality it's >> >>>> often much more complicated. >> >>>> >> >>>> For example, one of the things Beam has focused on was a language >> >>>> portability framework. Do I get this with Flink? No. Does that mean Beam >> >>>> is better than Flink? No. Maybe a better question would be, do I want to >> >>>> be able to run Python pipelines? >> >>>> >> >>>> This is just an example, there are many more factors to consider. >> >>>> >> >>>> Cheers, >> >>>> Max >> >>>> >> >>>> On 30.04.19 10:59, Robert Bradshaw wrote: >> >>>> > Though we all certainly have our biases, I think it's fair to say that >> >>>> > all of these systems are constantly innovating, borrowing ideas from >> >>>> > one another, and have their strengths and weaknesses. I wouldn't say >> >>>> > one is, or will always be, in front of or behind another. >> >>>> > >> >>>> > Take, as the given example Spark Structured Streaming. Of course the >> >>>> > API itself is spark-specific, but it borrows heavily (among other >> >>>> > things) on ideas that Beam itself pioneered long before Spark 2.0, >> >>>> > specifically the unification of batch and streaming processing into a >> >>>> > single API, and the event-time based windowing (triggering) model for >> >>>> > consistently and correctly handling distributed, out-of-order data >> >>>> > streams. >> >>>> > >> >>>> > Of course there are also operational differences. Spark, for example, >> >>>> > is very tied to the micro-batch style of execution whereas Flink is >> >>>> > fundamentally very continuous, and Beam delegates to the underlying >> >>>> > runner. >> >>>> > >> >>>> > It is certainly Beam's goal to keep overhead minimal, and one of the >> >>>> > primary selling points is the flexibility of portability (of both the >> >>>> > execution runtime and the SDK) as your needs change. >> >>>> > >> >>>> > - Robert >> >>>> > >> >>>> > >> >>>> > On Tue, Apr 30, 2019 at 5:29 AM <[email protected]> wrote: >> >>>> >> >> >>>> >> Ofcourse! I suspect beam will always be one or two step backwards to the new functionality that is available or yet to come. >> >>>> >> >> >>>> >> For example: Spark Structured Streaming is still not available, no CEP apis yet and much more. >> >>>> >> >> >>>> >> Sent from my iPhone >> >>>> >> >> >>>> >> On Apr 30, 2019, at 12:11 AM, Pankaj Chand < [email protected]> wrote: >> >>>> >> >> >>>> >> Will Beam add any overhead or lack certain API/functions available in Spark/Flink?
{kind=link}