Hi Konstantin, if you do not need a deterministic grouping of elements you should not use a keyed stream or window. Instead you can do the lookups in a parallel flatMap function. The function would collect arriving elements and perform a lookup query after a certain number of elements arrived (can cause high latency if the arrival rate of elements is low or varies). The flatmap function can be executed in parallel and does not require a keyed stream.
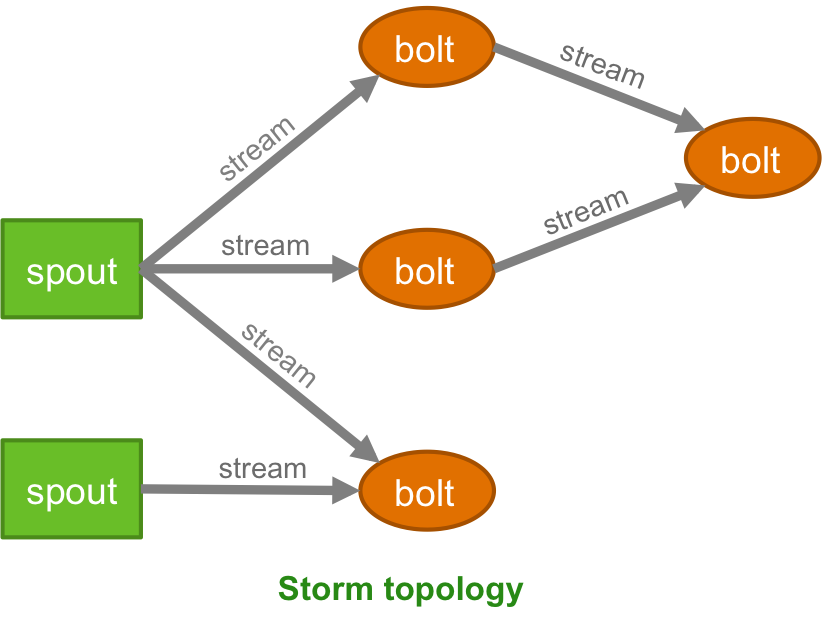
Best, Fabian 2016-04-25 18:58 GMT+02:00 Konstantin Kulagin <kkula...@gmail.com>: > As usual - thanks for answers, Aljoscha! > > I think I understood what I want to know. > > 1) To add few comments: about streams I was thinking about something > similar to Storm where you can have one Source and 'duplicate' the same > entry going through different 'path's. > Something like this: > https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.3.4/bk_storm-user-guide/content/figures/1/figures/SpoutsAndBolts.png > And later you can 'join' these separate streams back. > And actually I think this is what I meant: > https://ci.apache.org/projects/flink/flink-docs-master/api/java/org/apache/flink/streaming/api/datastream/JoinedStreams.html > - this one actually 'joins' by window. > > As for 'exact-once-guarantee' I've got the difference from this paper: > http://data-artisans.com/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink > - Thanks! > > 2) understood, thank you very much > > > > > > > I'll probably bother you one more time with another question: > > 3) Lets say I have a Source which provides raw (i.e. non-keyed) data. And > lets say I need to 'enhance' each entry with some fields which I can take > from a database. > So I define some DbEnhanceOperation > > Database query might be expensive - so I would want to > a) batch entries to perform queries > b) be able to have several parallel DbEnhaceOperations so those will not > slow down my whole processing. > > > I do not see a way to do that? > > > Problems: > > I cannot go with countWindowAll because of b) - that thing does not > support several streams (correct?) > > So I need to create a windowed stream and for that I need to have some key > - Correct? I.e cannot create windows on a stream of general object just > using number of objects. > > I probably can 'emulate' keyed stream by providing some 'fake' key. But in > this case I can parallelize only on different keys. Again - it is probably > doable by introducing some AtomicLong key generator at the first place ( > this part probably hard to understand - I can share details if necessary) > but still looks like a bit of hack :) > > But the general question - if I can implement 3) 'normally' in a flink-way? > > Thanks! > Konstantin. > > > > > > > > > > > > On Mon, Apr 25, 2016 at 10:53 AM, Aljoscha Krettek <aljos...@apache.org> > wrote: > >> Hi, >> I'll try and answer your questions separately. First, a general remark, >> although Flink has the DataSet API for batch processing and the DataStream >> API for stream processing we only have one underlying streaming execution >> engine that is used for both. Now, regarding the questions: >> >> 1) What do you mean by "parallel into 2 streams"? Maybe that could >> influence my answer but I'll just give a general answer: Flink does not >> give any guarantees about the ordering of elements in a Stream or in a >> DataSet. This means that merging or unioning two streams/data sets will >> just mean that operations see all elements in the two merged streams but >> the order in which we see them is arbitrary. This means that we don't keep >> buffers based on time or size or anything. >> >> 2) The elements that flow through the topology are not tracked >> individually, each operation just receives elements, updates state and >> sends elements to downstream operation. In essence this means that elements >> themselves don't block any resources except if they alter some kept state >> in operations. If you have a stateless pipeline that only has >> filters/maps/flatMaps then the amount of required resources is very low. >> >> For a finite data set, elements are also streamed through the topology. >> Only if you use operations that require grouping or sorting (such as >> groupBy/reduce and join) will elements be buffered in memory or on disk >> before they are processed. >> >> Two answer your last question. If you only do stateless >> transformations/filters then you are fine to use either API and the >> performance should be similar. >> >> Cheers, >> Aljoscha >> >> On Sun, 24 Apr 2016 at 15:54 Konstantin Kulagin <kkula...@gmail.com> >> wrote: >> >>> Hi guys, >>> >>> I have some kind of general question in order to get more understanding >>> of stream vs final data transformation. More specific - I am trying to >>> understand 'entities' lifecycle during processing. >>> >>> 1) For example in a case of streams: suppose we start with some >>> key-value source, parallel it into 2 streams by key. Each stream modifies >>> entry's values, lets say adds some fields. And we want to merge it back >>> later. How does it happen? >>> Merging point will keep some finite buffer of entries? Basing on time or >>> size? >>> >>> I understand that probably right solution in this case would be having >>> one stream and achieve more more performance by increasing parallelism, but >>> what if I have 2 sources from the beginning? >>> >>> >>> 2) Also I assume that in a case of streaming each entry considered as >>> 'processed' once it passes whole chain and emitted into some sink, so after >>> it will not consume resources. Basically similar to what Storm is doing. >>> But in a case of finite data (data sets): how big amount of data system >>> will keep in memory? The whole set? >>> >>> I probably have some example of dataset vs stream 'mix': I need to >>> *transform* big but finite chunk of data, I don't really need to do any >>> 'joins', grouping or smth like that so I never need to store whole dataset >>> in memory/storage. What my choice would be in this case? >>> >>> Thanks! >>> Konstantin >>> >>> >>> >
{kind=link}