Hi, Running the topology in cluster mode, on a 40 core machine. The topology is simple KafkaSpout -> Bolt. Data load is 50k records at approx 2000 tuples/sec. Kafka parallelism is 4= number of partitions and bolt parallelism is 4. The storm version is 1.2.1.
The CPU utilization is high around 400-600%.
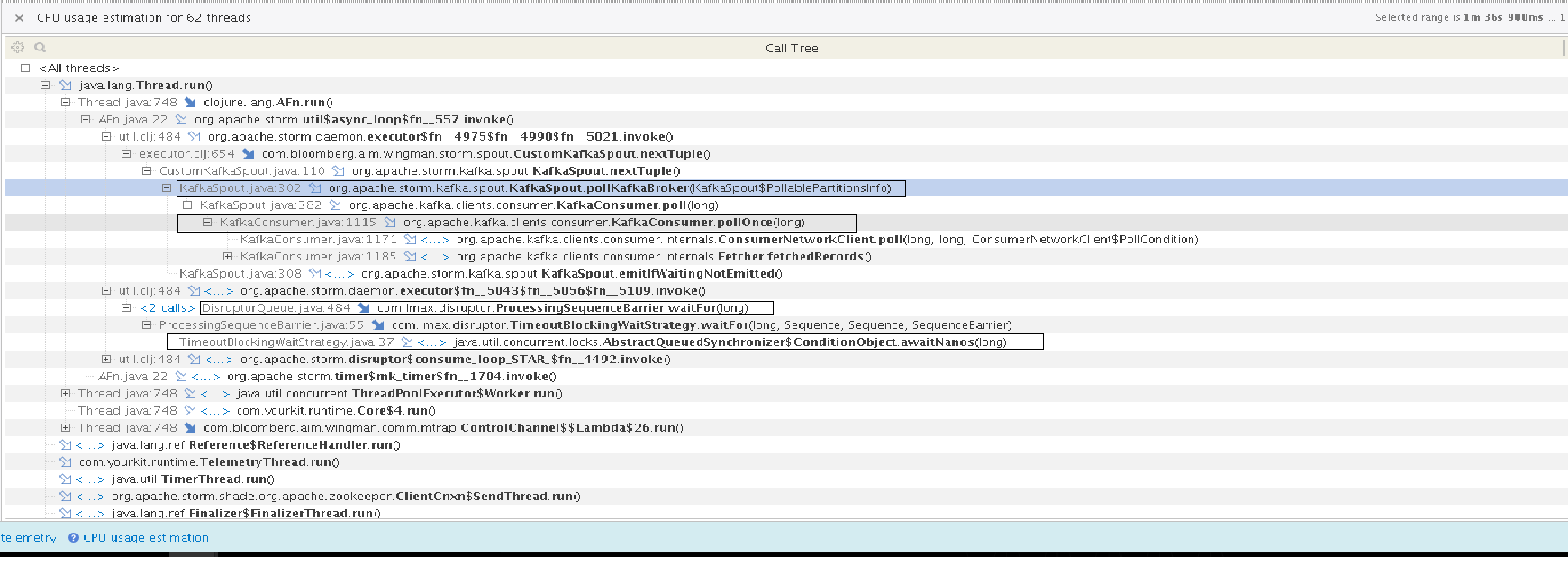
Following are my observations and questions (made when the data is being read
from kafka), CPU utilization is more in the following methods (PFA the screen
shot):
1) KafkaSpout.pollKafkaBroker() // which calls KafkaConsumer.poll() which is
dependent on poll.timeout.ms but this comes into play only when there is no
data right?
2) TimeoutBlockingWaitStrategy -> awaitNanos() which takes timeout passed as
constructor to TimeoutBlockingWaitStrategy instance which is created in
DisruptorQueue.java to which is passed in constructor as readTimeout.
2.1 What is this DisruptorQueue.java and where is it used. It says a
single consumer that uses Lmax Disruptor? And how does it have an effect on the
CPU utilization/latency.
2.2 What is the value readTimeout in DisruptorQueue.java set and how does
it effect the CPU utilization?
Some of the properties are as follows:
<property><name>poll.timeout.ms</name><value>200</value></property>
<property><name>offset.commit.period.ms</name><value>30000</value></property>
<property><name>max.uncommitted.offsets</name><value>10000000</value></property>
<property><name>topology.disruptor.batch.timeout.millis</name><value>1000</value></property>
<property><name>topology.disruptor.batch.size</name><value>100</value></property>
<property><name>topology.max.spout.pending</name><value>1000000</value></property>
<property><name>topology.disruptor.wait.timeout.millis</name><value>1000</value></property>
![]() PerformanceTuning.png
PerformanceTuning.png
Description: Binary data
{kind=link}